
Pre-SIG Genome Annotation Database Operations
51
Pre-SIG Genome Annotation Database Operations Suzanna Lewis FlyBase/Berkeley Drosophila Genome Project Gene Ontology Consortium
-
Upload
hilary-shannon -
Category
Documents
-
view
21 -
download
0
description
Pre-SIG Genome Annotation Database Operations. Suzanna Lewis. FlyBase/Berkeley Drosophila Genome Project. Gene Ontology Consortium. Having it all. Complete: every occurrence is found Precise: every occurrence is accurate Comprehensive: all types of features - PowerPoint PPT Presentation
Transcript of Pre-SIG Genome Annotation Database Operations

Pre-SIG Genome AnnotationDatabase Operations
Suzanna Lewis
FlyBase/Berkeley Drosophila Genome ProjectGene Ontology Consortium

Having it all
Complete: every occurrence is found
Precise: every occurrence is accurate
Comprehensive: all types of features
Richly described: biological functional data

Having it all
Complete: every occurrence is found
Precise: every occurrence is accurate
Comprehensive: all types of features
Richly described: biological functional data

Contradictions and Complications
Assembly errors Missed gene merges Missed gene splits Complex adjustments Dicistronic genes Overlaps and intersections

Assembly dependencies
Missed merges

Missed Splits

Splerges

Dicistronic Genes

Shared 5’ UTR

Shared 3’ - 5’ UTRs

Having it all
Complete: every occurrence is found
Precise: every occurrence is accurate
Comprehensive: all types of features
Richly described: biological functional data
deleted: 41new: 179merges: 31splits: 26reinstated: 32

Broad Institute
TIGR
JGI
Baylor College of Medicine
Washington University
FlyBase
Ensembl
GMOD contributors meeting March 2004

The Essentials
Visualization and manual editors

The Essentials
Visualization and manual editors Combiners

The Essentials
Visualization and manual editors Combiners Full-length cDNA sequences

The Essentials
Visualization and manual editors Combiners Full-length cDNA sequences High-quality assemblies

The Essentials
Visualization and manual editors Combiners Full-length cDNA sequences High-quality assemblies Annotation standards and
verification

The Essentials
Visualization and manual editors Combiners Full-length cDNA sequences High-quality assemblies Annotation standards and
verification Evidence tracking and versioning

The Essentials
Visualization and manual editors Combiners Full-length cDNA sequences High-quality assemblies Annotation standards and
verification Evidence tracking and versioning Open source software components
and standards are critical to long term success

The Essentials
Visualization and manual editors Combiners Full-length cDNA sequences High-quality assemblies Annotation standards and
verification Evidence tracking and versioning Open source software components
and standards are critical to long term success

Annotation verification
Community input On-line error reporting Curation of the literature
Confirmation by comparison to cDNA sequences

SWISSPROT Comparison
Perfect match 100% identity over 100% of lengths
Single AA substitutions 99% identity over 100% of lengths
The above account for 75% of all genes with a SWISSPROT cognate (2,771 out of 3,687).

SWISSPROT Comparison
Significant mismatch spans of 40 residues or 20% peptide
length, with at least 97% sequence identity
No match poor or empty matches
These remaining differences were due to lingering annotation errors or errors in the reported DNA sequence from SWISSPROT
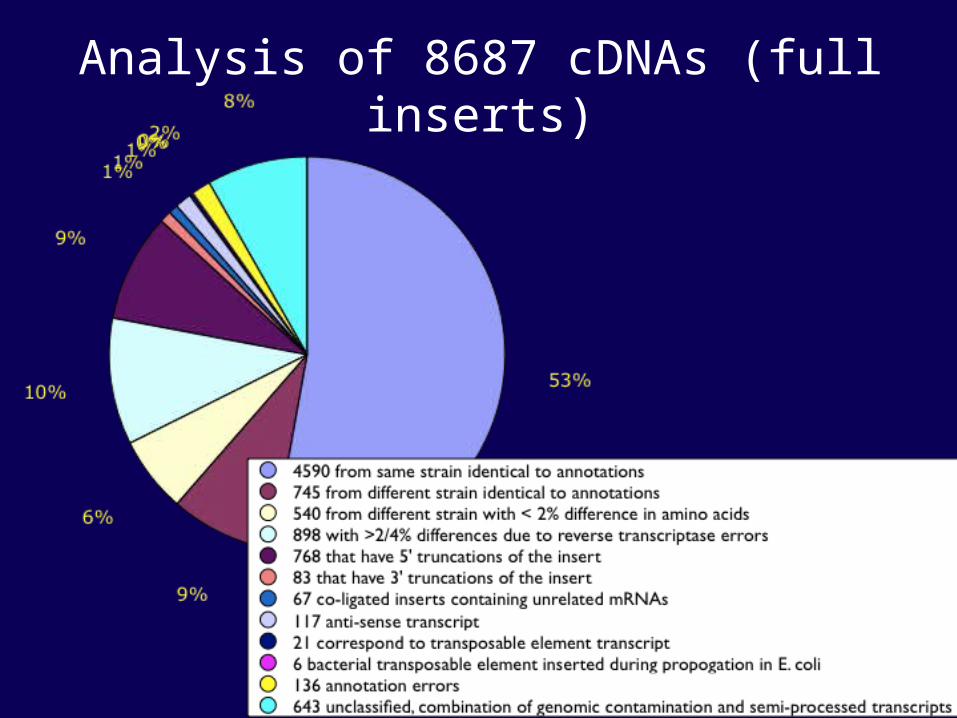
Analysis of 8687 cDNAs (full inserts)

Having it all
Complete: every occurrence is found
Precise: every occurrence is accurate
Comprehensive: all types of features
Richly described: biological functional data

Annotation of all types of features
Protein-coding 13,410
tRNA 291
microRNA 23
snRNA 32
snoRNA 29
Pseudogenes 19
Non-coding RNA 36
Transposons 1,572
Promoters (thousands)
TSS (thousands)
P element Insertions (thousands)
Total 15,412

Having it all
Complete: every occurrence is found
Precise: every occurrence is accurate
Comprehensive: all types of features
Richly described: biological functional data

How to find what you need
FlyBase MGISGD
Cappuccino BNI1 Formin 2
By name?By database ID?
Actin binding Actin binding Actin binding
FBgn0000256
S0005215 MGI:1859252
By function?

But in 1998 there was a problem…
None of the organism databases used standard terminology to describe biological function.

For example
It will be difficult for you—and even harder for a
computer—to find functionally equivalent gene
products.
translation Proteinsynthesis
You want all gene products that are involved in bacterial protein synthesis, But the sequences are significantly different from those in humans.

How to best describe biology?
Natural language Highly expressive Ambiguous in meaning Hard to compute on
Structured
representation Limited in expressivity Precise May be computed on
We needed to find a middle ground,
that supports and enables both.

The aims of GO
1.To develop comprehensive shared vocabularies.
2.Use the vocabularies to describe the gene products held in different databases.
3.To provide access to the vocabularies, the annotations, and associated data.
4.To provide software tools to assist biological researchers.

The early key decisions
The vocabulary itself requires a serious and ongoing effort.
Carefully define every concept Initially keep things as simple as
possible and only use a minimally sufficient data representation.
Focus initially on molecular aspects that are shared between many organisms.

A sequence is not equal to a gene
Physically a gene is composed of sequences.
DNA, RNA, and protein Different strains, ESTs, cDNAs,
alleles… A fully characterized gene has
multiple sequence references

GO is NOT a gene nomenclature system
Communities decide upon the ‘official’ gene name or symbol and their community databases maintain these data.
Sequence repositories (I.e. Genbank/EMBL/DDBJ/SwissProt) provide sequence identifiers and protein names
Proteins may be named differently than genes e.g. HUGO and UniProt IDs

GO encompasses descriptions for
all functional molecular entities A gene product may be either a
functional RNA or a protein Protein tRNA miRNA snRNA rRNA …

The breakdown of work
Task 1 Building the ontology: a computable
description of the biological world
Task 2 Describing your gene—annotation
Protein structure Phenotype Expression data Function, process, localization…

Vocabulary and relationships
Look up concept to accurately
express biology Your gene product
Refer to representative
sequences
Gene nomenclaturedecisions
SequenceDB
Choose approved name and synonyms
Collect what is known from the literature

GO databases: distributed and centralized
Support cross-database queries By having a mutual understanding of the
definition and meaning of any word used to describe a gene product
Provide database access to a common repository of annotations By submitting a summary of gene products
that have been annotated

If we build it…
What is a term? Definition of term concepts How to represent and manage the
concepts Biological scope Annotation

What is a ‘term’?
Must have a stable ID
May have synonyms
Have relationships to other terms
Can be made obsolete
Can be split or merged
Must have a definition

Definitions
Purpose is to remove ambiguity of interpretation and alternate meanings
All definitions are supported by cross-references to the source(s)

Annotating gene products Expert curation accepted from any group
that can provide an ID and evidence Each annotation must be supported by
evidence, including a cross-reference http://www.geneontology.org/GO.evidence.html
Gene can be annotated with multiple terms Annotation is at finest possible granularity Guidelines
http://www.geneontology.org/doc/GO.usage.html

GO functional analysis
Sequence similarity Literature harvesting Motif analysis Expression studies Interaction studies

Current work
Low coverage genome sequencing Multiple species genome
comparisons SO—the Sequence Ontology

e.g. What is a pseudogene?
Human Sequence similar to known protein but
contains frameshift(s) and/or stop codons which disrupts the ORF.
Neisseria A gene that is inactive - but may be
activated by translocation (e.g. by gene conversion) to a new chromosome site.
- note some would call such a gene a “cassette” in yeast.

SO is useful if you want to:
Annotate sequence using consistent terminology for the same features across genomes.
Enable practical querying and comparisons between sequence databases.
Describe and propagate features at all levels of the sequence from genomic to mature protein.

Thank You to…www.flybase.org
Curators-Berkeley Sima Misra, Josh
Kaminker, Simon Prochnik, Chris Smith, Jon Tupy
Curators-Harvard Lynn Crosby, Bev
Matthews, Kathy Campbell, Pavel Hradecky, Yanmei Huang, Leyla Bayraktaroglu
Curators-Cambridge Gillian Millburn, Rachel
Drysdale, Chihiro Yamada
Curators-SWISSPROT Eleanor Whitfield
Software-Berkeley Chris Mungall, Ben Berman,
Joe Carlson, Mark Gibson, Nomi Harris, George Hartzell, Brad Marshall, John Richter, ShengQiang Shu
Software-Harvard David Emmert
Software-Cambridge Aubrey de Grey
Software-Ensembl Michelle Clamp, Vivek Iyer,
Steve Searle

and Thanks to…
www.geneontology.org Christopher Mungall
John Day-Richter
Brad Marshall Karen Eilbeck Mark Yandell George Hartzell
David Hill Joel Richardson GO Curators Michael Ashburner Judith Blake J. Michael Cherry

We want and depend on you!
Corrections to the peptides Functional annotation Corrections and additions to GO


















