
Endommagement par fatigue et prédiction de la durée de vie ...

RÉPUBLIQUE DU BÉNIN
MINISTÈRE DE L’ENSEIGNEMENT SUPÉRIEURET DE LA RECHERCHE SCIENTIFIQUE
UNIVERSITÉ D’ABOMEY-CALAVI
ECOLE POLYTECHNIQUED’ABOMEY-CALAVI
DEPARTEMENT DE GENIE INFORMATIQUE ETTELECOMMUNICATIONS
Option: Réseaux Informatique et Internet
MEMOIRE DE FIN DE FORMATIONPOUR L’OBTENTION DU
DIPLOME D’INGENIEUR DE CONCEPTION
Thème :
Prédiction des performances d’une architecture 2DSOME-Bus avec le Deep Learning
Harold [email protected]
Sous la supervision de :Dr Ing. Vinasétan Ratheil HOUNDJI
Année Académique : 2017-2018
11e Promotion

Table des matières
Dédicaces iii
Remerciements iv
Liste des figures v
Liste des tableaux vii
Liste des sigles et abréviations viii
Résumé 1
Abstract 2
Introduction 3
1 Revue de littérature 71.1 Les architectures SOME-Bus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.1.1 Les architectures multiprocesseur . . . . . . . . . . . . . . . . . . . . . . . . 71.1.2 L’architecture 1D SOME-Bus . . . . . . . . . . . . . . . . . . . . . . . . . . 111.1.3 L’architecture 2D SOME-Bus . . . . . . . . . . . . . . . . . . . . . . . . . . 131.1.4 Etat de l’art sur la prédiction des mesures de performances des architec-
tures multiprocesseurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161.2 Deep Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
1.2.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181.2.2 Le neurone . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191.2.3 Réseau de neurones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 271.2.4 Apprentissage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2 Matériel et choix techniques 302.1 Matériel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.1.1 L’ensemble de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.1.2 Hardware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.2 Choix techniques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
i

TABLE DES MATIÈRES TABLE DES MATIÈRES
2.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3 Solution proposée 383.1 Division et normalisation de l’ensemble de données . . . . . . . . . . . . . . . . . 393.2 Entrainement du réseau de neurones . . . . . . . . . . . . . . . . . . . . . . . . . . 403.3 Validation Croisée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403.4 Architecture des réseaux de neurones . . . . . . . . . . . . . . . . . . . . . . . . . 413.5 Evaluation des réseaux de neurones . . . . . . . . . . . . . . . . . . . . . . . . . . 423.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4 Résultats et discussions 454.1 Résultats obtenus pour quatre neurones dans les couches cachées . . . . . . . . . 454.2 Résultats obtenus pour six neurones dans les couches cachées . . . . . . . . . . . 504.3 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 544.4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
Conclusion et perspectives 59
English Part 604.5 The SOME-bus architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
4.5.1 The 1D SOME-bus architecture . . . . . . . . . . . . . . . . . . . . . . . . . 614.5.2 The 2D SOME-bus architecture . . . . . . . . . . . . . . . . . . . . . . . . . 62
4.6 Related Works . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 634.7 Primer on Artificial Neural Network . . . . . . . . . . . . . . . . . . . . . . . . . . 644.8 Technical choices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 644.9 Our solution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 654.10 Result and discussions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
Bibliographie 73
Webographie 75
ii

Dédicaces
À• Mon père Roger KIOSSOU, pour avoir soutenu mes études et assuré mon éducation.
Reçois ici les fruits de tes efforts.
• Ma mère Monique HAZOUME, pour les sacrifices consentis. Que ce travail soit le cou-ronnement de tes sacrifices.
• Mes sœurs, Mélaine KIOSSOU et Hermine KIOSSOU pour leur soutien.
iii

Remerciements
Mes remerciements vont à l’endroit de tous ceux qui de près ou de loin ont participé à laréalisation de ce travail. Je remercie particulièrement :
• au Dr Ing. Vinasétan Ratheil HOUNDJI, mon superviseur pour ses conseils, ses direc-tives et tout ce qu’il a apporté dans la concrétisation de ce travail ;
• au Dr. Léopold DJOGBE, chef du Département de Génie Informatique et Télécommuni-cations (GIT) et à tous les enseignants dudit département ;
• à toute ma famille pour leur soutien indéfectible ;
• à mes amis Faïzath ZOUMAROU WALIS, Jean-Baptiste SOSSOU, Erick ADJE, JacquesAKOUEIKOU, Géraldine ATCHADE, Daryl GOGAN et à tous ceux que je ne pourraisciter ici.
iv

Table des figures
1.1 Multiprocesseur à mémoire distribuée . . . . . . . . . . . . . . . . . . . . . . . . . 81.2 Multiprocesseur à mémoire partagée(a) . . . . . . . . . . . . . . . . . . . . . . . . 91.3 Multiprocesseur à mémoire partagée(b) . . . . . . . . . . . . . . . . . . . . . . . . 101.4 Interface Optique [3] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111.5 Interface Processeur [3] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121.6 Récepteur parallèle [3] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131.7 2D SOME-Bus [3] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.8 Diagramme d’un nœud [3] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151.9 Neurone biologique [14] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191.10 Perceptron [15] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211.11 Perceptron [15] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211.12 Fonction linéaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231.13 Fonction sigmoïde . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 241.14 Fonction tangente hyperbolique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 251.15 Fonction linéaire rectifiée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261.16 Fonction softmax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 271.17 Réseau de neurones artificiels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.1 KDnuggets Analytics / Data Science 2018. Sondage sur les logiciels : les princi-paux outils en 2018 et leur part dans les sondages 2016-7 [28] . . . . . . . . . . . . 36
3.1 Diagramme des étapes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.1 Courbes d’entraînement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 554.2 Example of two dimensional SOME-Bus with 16 Nodes [11] . . . . . . . . . . . . 624.3 Courbes d’entraînement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
v

Liste des tableaux
2.1 Statistiques descriptives des variables prédictives . . . . . . . . . . . . . . . . . . 312.2 Statistiques descriptives des variables prédictives . . . . . . . . . . . . . . . . . . 322.3 Statistiques descriptives des mesures de performances . . . . . . . . . . . . . . . . 32
4.1 Résultats pour quatre neurones dans les couches cachées - Epoques = 50 & Tailledu lot = 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.2 Résultats pour quatre neurones dans les couches cachées - Epoques = 50 & Tailledu lot = 5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.3 Résultats pour quatre neurones dans les couches cachées - Epoques = 50 & Tailledu lot = 6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.4 Résultats pour quatre neurones dans les couches cachées - Epoques = 100 & Tailledu lot = 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.5 Résultats pour quatre neurones dans les couches cachées - Epoques = 100 & Tailledu lot = 5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.6 Résultats pour quatre neurones dans les couches cachées - Epoques = 100 & Tailledu lot = 6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.7 Résultats pour quatre neurones dans les couches cachées - Epoques = 200 & Tailledu lot = 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.8 Résultats pour quatre neurones dans les couches cachées - Epoques = 200 & Tailledu lot = 5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.9 Résultats pour quatre neurones dans les couches cachées - Epoques = 200 & Tailledu lot = 6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.10 Résultats pour quatre neurones dans les couches cachées - Epoques = 500 & Tailledu lot = 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.11 Résultats pour quatre neurones dans les couches cachées - Epoques = 500 & Tailledu lot = 5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.12 Résultats pour quatre neurones dans les couches cachées - Epoques = 500 & Tailledu lot = 6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.13 Résultats pour six neurones dans les couches cachées - Epoques = 50 & Taille dulot = 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.14 Résultats pour six neurones dans les couches cachées - Epoques = 50 & Taille dulot = 5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
vi

LISTE DES TABLEAUX LISTE DES TABLEAUX
4.15 Résultats pour six neurones dans les couches cachées - Epoques = 50 & Taille dulot = 6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.16 Résultats pour six neurones dans les couches cachées - Epoques = 100 & Taille dulot = 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.17 Résultats pour six neurones dans les couches cachées - Epoques = 100 & Taille dulot = 5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.18 Résultats pour six neurones dans les couches cachées - Epoques = 100 & Taille dulot = 6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.19 Résultats pour six neurones dans les couches cachées - Epoques = 200 & Taille dulot = 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.20 Résultats pour six neurones dans les couches cachées - Epoques = 200 & Taille dulot = 5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.21 Résultats pour six neurones dans les couches cachées - Epoques = 200 & Taille dulot = 6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.22 Résultats pour six neurones dans les couches cachées - Epoques = 500 & Taille dulot = 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.23 Résultats pour six neurones dans les couches cachées - Epoques = 500 & Taille dulot = 5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.24 Résultats pour six neurones dans les couches cachées - Epoques = 500 & Taille dulot = 6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.25 Résultat pour la prédiction de l’utilisation moyenne du canal. . . . . . . . . . . . 564.26 Résultats pour la prédiction du temps d’attente moyen du canal. . . . . . . . . . . 564.27 Résultats pour la prédiction de la latence moyenne du réseau. . . . . . . . . . . . 564.28 Résultats pour la prédiction de l’utilisation moyenne du processeur. . . . . . . . . 574.29 Résultats pour la prédiction du temps d’attente moyen des entrées. . . . . . . . . 574.30 Results for prediction of average channel utilization. . . . . . . . . . . . . . . . . . 694.31 Results for prediction of average channel waiting time. . . . . . . . . . . . . . . . 694.32 Results for prediction of average network latency. . . . . . . . . . . . . . . . . . . 694.33 Results for prediction of average processor utilization. . . . . . . . . . . . . . . . . 704.34 Results for prediction of average input waiting time. . . . . . . . . . . . . . . . . . 70
vii

Liste des sigles et abréviations
1D SOME-Bus : 1-dimensional Simultaneous Optical Multiprocessor Exchange Bus
2D SOME-Bus : 2-dimensional Simultaneous Optical Multiprocessor Exchange Bus
IOP : Input Output Processor
MAE : Mean Absolute Error
MFANN : Multi-layer Feed Forward Neural Networks
NUMA : Nonuniform Memory Access
R : Multiple correlation coefficients
RAE : Root Absolute Error
RMSE : Root Mean Square Error
RRSE : Relative Root Square Error
SGD : Stochastic gradient descent
SOME-Bus : Simultaneous Optical Multiprocessor Exchange Bus
SVR : Support Vector Regression
UCT : unité Centrale de Traitement
UMA : Uniform Memory Access
viii

Résumé. Les performances d’un système multiprocesseur dépendent fortement del’efficacité de son architecture de bus. Le 2-dimensional Simultaneous Optical Mul-tiprocessor Exchange Bus (2D SOME-Bus) est un réseau d’interconnexion optiquecaractérisé par une faible latence. C’est une implémentation robuste d’architecturesinformatiques performantes en pétaflops. Dans ce travail, nous proposons des mo-dèles de réseaux de neurones artificiels pour prédire les mesures de performance(notamment l’utilisation moyenne du canal, le temps moyen d’attente du canal, lalatence moyenne du réseau, l’utilisation moyenne du processeur et le temps moyend’attente des entrées) d’une architecture de passage de message interconnectée parle 2D SOME-Bus. En utilisant la validation croisée par 10, nous évaluons les perfor-mances des modèles de prédiction à l’aide de plusieurs métriques de performance.Les expériences démontrent que nos modèles de réseaux de neurones sont plus per-formants que les modèles d’apprentissage automatique de l’état de l’art pour ceproblème pour la plupart des prédictions.
Mots clés : 2D SOME-Bus, multiprocesseurs, deep learning, mesures de performance.
1

Abstract. The performance of a multiprocessor system, is highly dependent on theefficiency of its bus architecture. The 2-dimensional Simultaneous Optical Multi-processor Exchange Bus (2D SOME-Bus) is an optical interconnect network charac-terized by its low latency. It is a robust implementation of petaflops-performancecomputer architectures. In this work, we propose some artificial neural networkmodels to predict the performance measures (namely average channel utilization,average channel waiting time, average network latency, average processor utiliza-tion and average input waiting time) of a passing message architecture intercon-nected by the 2D SOME-Bus. By using 10-fold cross validation, we evaluate the per-formance of the predictions models using several performance metrics. The experi-ments demonstrate that our neural networks models outperform the state-of-the-artmachine learning models for this problem on most of the predictions.
Keys words: 2D SOME-Bus, multiprocessors, deep learning, performance measurements.
2

Introduction
Grâce à la puissance de calcul élevée des ordinateurs parallèles, il est désormais possibled’aborder de nombreuses applications qui, jusqu’à récemment, dépassaient les possibilités destechniques informatiques classiques. Les environnements de passage de messages sont consi-dérés comme les méthodes de programmation les plus populaires pour les ordinateurs paral-lèles. Leur flexibilité permet de paralléliser tous les types d’application (systèmes client-serveur,parallèles de données, embarqués et en temps réel, etc.). Ces ordinateurs sont constitués de sys-tèmes multiprocesseurs présentant différentes caractéristiques qui influencent leur utilisation.Cependant, afin que le public dispose des meilleurs équipements, beaucoup de tests sont faitsen usine et ces tests s’avèrent coûteux en temps. A l’heure où l’intelligence artificielle présentede nombreuses applications et des résultats encourageants, il serait intéressant d’analyser sonutilité dans la prédiction des mesures de performances des systèmes multiprocesseurs. Nousnous intéressons dans le cadre de ce travail, à l’application du deep learning dans la prédic-tion des performances d’une architecture 2-dimensional Simultaneous Optical MultiprocessorExchange Bus (2D SOME-Bus).
Contexte
Des performances élevées de calcul sont nécessaires pour de nombreuses applications, y com-pris la simulation de phénomènes physiques, la simulation de circuits intégrés et des réseauxneuronaux, la modélisation météorologique, l’aérodynamique et le traitement d’images. Cesperformances sont de plus en plus difficilement obtenues avec des ordinateurs monoproces-seurs car la vitesse de traitement qui est liée à l’augmentation de la fréquence des processeursconnait des limites. C’est donc pour y pallier que le parallélisme intervient. Il consiste à mettreen œuvre des architectures permettant de traiter des informations de manière simultanée àl’aide de plusieurs processeurs en communication, ainsi que les algorithmes spécialisés pourcelles-ci [2]. Ces techniques ont pour but de réaliser le plus grand nombre d’opérations pos-sibles en un temps limité et réduit.
3

Glossary Glossary
Les systèmes multiprocesseurs peuvent être classés suivant que la mémoire entre les pro-cesseurs est partagée ou distribuée. Dans le cas d’une architecture à mémoire partagée, tousles processeurs ont accès aux mêmes données, l’espace mémoire est global et uniforme. Maisavec cette méthode, il y a un problème au niveau matériel : les processeurs ne peuvent pas tousavoir accès à la mémoire en même temps. Par contre, dans le cas d’une architecture à mémoiredistribuée, chaque processeur a sa propre mémoire et ses propres données. L’espace mémoireest fragmenté. Une autre composante des systèmes multiprocesseurs hormis les processeurs etla mémoire est le réseau d’interconnexion qui relie les processeurs entres eux (dans le cas de lamémoire distribuée) ou qui relie les processeurs avec les bancs mémoire (dans le cas de la mé-moire partagée). Le réseau d’interconnexion doit permettre l’échange d’informations entre lesprocesseurs. Ses performances sont critiques et il faut donc y accorder une importance capitaleà la conception. Il existe plusieurs façons d’interconnecter les processeurs dans ces systèmeset ces différentes façons influent sur les performances du système en entier. Une architectureest le 2D SOME-Bus [3, 7, 10, 11]. De façon générale, le Simultaneous Optical MultiprocessorExchange Bus (SOME-Bus) incorpore des dispositifs optoélectroniques dans une architecturede traitement très performante. Il s’agit d’un réseau d’interconnexion à fibre optique à faible la-tence et à large bande passante qui connecte directement chaque nœud à tous les autres nœudssans contention [7]. Le 2D SOME-Bus est une implémentation fiable et robuste de cette archi-tecture pour atteindre des puissances de calcul de l’ordre du pétaFLOPS1. Le 2D SOME-Bus secompose de N réseaux horizontaux et N verticaux 1-dimensional Simultaneous Optical Mul-tiprocessor Exchange Bus (1D SOME-Bus) et N2 nœuds. Chacun des N nœuds connectés à un1D SOME-Bus possède un canal de diffusion dédié et une interface de canal d’entrée baséesur un réseau de N récepteurs surveillant tous les N canaux et permettant plusieurs diffusionssimultanées. A chaque nœud, un convertisseur électro-optique composé d’une paire doublerécepteur-émetteur permet de transmettre et de diffuser les messages diffusés sur un bus dansl’autre dimension [3, 10]. Des simulations suivant des modèles analytiques ou des simulationsstatistiques sont faites en usine afin d’évaluer les performances du réseau et du système globa-lement. Nous nous intéressons à la prédiction de ces performances en utilisant les techniquesd’apprentissage profond pour une architecture 2D SOME-Bus.
Problématique
Deux méthodes sont généralement utilisées pour les études des multiprocesseurs : la modéli-sation analytique et la simulation. Les modèles analytiques deviennent intraitables lorsque ladynamique des multiprocesseurs est prise en compte et ne sont pas pratiques pour les étudesdépendantes de l’application [4, 5, 6]. La simulation, avec les hypothèses correctes, est une ap-proche réalisable qui peut produire une image précise du comportement dynamique des mul-
1petaFLOPS = 1015FLOPS où FLOPS (floating-point operations per second) est le Le nombre d’opérationsen virgule flottante par seconde. Il s’agit d’une unité de mesure de la performance d’un système informatique.
4

Glossary Glossary
tiprocesseurs. La simulation statistique est une méthode qui caractérise le comportement duprogramme et de l’architecture avec certaines distributions de probabilités. L’idée de la simu-lation statistique est de mesurer un certain nombre de caractéristiques importantes d’exécutiondu programme, de générer une trace synthétique qui montre les références mémoire d’unecharge de travail et de simuler cette trace synthétique [4]. L’avantage important est qu’unetrace synthétique est très petite par rapport aux traces de programme réelles. Une simulationstatistique est un outil robuste, flexible et adapté à la conception multiprocesseur, mais cela peutprendre beaucoup de temps, surtout lorsque les systèmes multiprocesseurs à simuler possèdentde nombreux paramètres et que ces paramètres doivent être testés avec différentes distributionsde probabilités [4, 5, 6]. Il existe des études dans la littérature qui prouvent que des méthodesd’intelligence artificielle pourraient être appliquées pour prédire les mesures de performanced’une architecture multiprocesseur. Par exemple, AKAY et ABASIKELES [10] ont proposé uneprédiction de performances des systèmes optiques multiprocesseurs à mémoire partagée baséesur le Support Vector Regression (SVR). Plus récemment, AKAY et ZAYID ont proposé un mo-dèle de prédiction des mesures de performances des architectures multiprocesseurs basé sur lepassage de messages en utilisant les réseaux de neurones artificiels [9]. C’est dans ce cadre ques’inscrit le présent travail qui a pour intitulé : Prédiction des performances d’une architecture2D SOME-Bus avec le Deep Learning.
Objectifs
L’objectif de ce travail est d’utiliser les méthodes d’apprentissage profond pour la prédic-tion des performances des systèmes multiprocesseurs dans les architectures 2D SOME-Bus. Defaçon spécifique, il s’agira :
• d’étudier et d’implémenter différents modèles de réseau de neurones d’apprentissageprofond capables de prédire les mesures de performances d’un système multiprocesseurà partir de données statistiques ;
• de faire une étude comparative et de déduire le meilleur modèle après une étude théo-rique et empirique ;
• de comparer ces résultats à l’état de l’art.
Organisation du travail
La suite de ce document est organisée comme suit : le chapitre 1 fait l’état de l’art des re-cherches effectuées dans le cadre du 2D SOME-Bus et de la prédiction des mesures de perfor-mance en introduisant ce qu’est le deep learning ; le chapitre 2 présente le matériel ainsi queles choix techniques effectués que nous utilisons pour l’élaboration des modèles de prédiction ;
5

Glossary Glossary
ensuite le chapitre 3, présente notre solution et les modèles mis en place et enfin, dans le cha-pitre 4, nous présentons les résultats obtenus après les différents tests ainsi que l’analyse de cesrésultats.
6

Chapitre 1Revue de littérature
Résumé. Le 2-dimensional Simultaneaous Optical Multiprocessor Exchange Bus (2DSOME-Bus) est une architecture qui s’avère intéressante pour atteindre des perfor-mances de calcul toujours plus élevées. Comme pour toute architecture multiproces-seur, il est important dans la construction d’évaluer les performances du 2D SOME-Bus. Les méthodes classiques d’évaluation des performances sont celles analytiqueset classiques mais elles requièrent du temps. Une alternative est l’intelligence arti-ficielle et la conception de modèles de prédiction pour pallier aux insuffisances desautres méthodes.
Introduction
Ce chapitre fait un tour d’horizon sur les architectures multiprocesseurs en mettant l’accentsur ce qu’est le 2D SOME-Bus. Nous y présentons les différentes méthodes de prédiction desperformances existantes, l’implication de l’intelligence artificielle dans ce domaine ainsi que cequ’est l’apprentissage profond (deep learning).
1.1 Les architectures SOME-Bus
1.1.1 Les architectures multiprocesseur
Le multitraitement (Multiprocessing) consiste à utiliser deux ou plusieurs unités centralesde traitement (processeurs) dans un même système informatique. Le terme fait également réfé-rence à la capacité d’un système à prendre en charge plusieurs processeurs et/ou à la capacitéd’attribuer des tâches entre eux. Le terme « processeur » dans le multiprocesseur peut signi-fier une unité Centrale de Traitement (UCT) ou un processeur d’entrée-sortie en anglais Input
7

Chapitre 1. Revue de littérature 1.1. Les architectures SOME-Bus
Output Processor (IOP). Les multiprocesseurs sont classés en fonction de l’organisation de leurmémoire. Il existe deux principaux types de système multiprocesseur : multiprocesseur à mé-moire distribuée et multiprocesseur à mémoire partagée.
1.1.1.1 Multiprocesseur à mémoire distribuée
Dans un multiprocesseur à mémoire distribuée, chaque module de mémoire est associé àun processeur, comme indiqué sur la figure 1.1. Tout processeur peut accéder directement à sapropre mémoire. Un mécanisme de passage de message est utilisé afin de permettre à un pro-cesseur d’accéder à d’autres modules de mémoire associés à d’autres processeurs (NonuniformMemory Access (NUMA)). L’interface de passage de message est un protocole de communica-tion indépendant du langage utilisé [2].
En ce sens, l’accès à la mémoire par un processeur n’est pas uniforme car cela dépend dumodule de mémoire auquel le processeur tente d’accéder. C’est ce qu’on appelle un systèmemultiprocesseur NUMA. Si le multiprocesseur à mémoire distribuée est composé de proces-seurs identiques, on dit qu’il s’agit d’un multiprocesseur symétrique. Si le multiprocesseur àmémoire distribuée est composé de processeurs hétérogènes, on dit qu’il s’agit d’un multipro-cesseur asymétrique [2].
FIGURE 1.1 – Multiprocesseur à mémoire distribuée
1.1.1.2 Multiprocesseur à mémoire partagée
Les processeurs à mémoire partagée sont populaires en raison de leur modèle de program-mation simple et général, qui permet un développement simple de logiciels parallèles prenanten charge le partage de codes et de données. Un autre nom pour les processeurs de mémoirepartagée est : machine à accès parallèle. La mémoire partagée ou l’espace d’adressage partagéest utilisé comme moyen de communication entre les processeurs (Uniform Memory Access(UMA)). Tous les processeurs d’une architecture à mémoire partagée peuvent accéder au mêmeespace adresse d’une mémoire commune via un réseau d’interconnexion, comme indiqué surla figure 1.2. Ce réseau d’interconnexion est généralement un bus, mais pour les systèmes plus
8

Chapitre 1. Revue de littérature 1.1. Les architectures SOME-Bus
importants, un réseau le remplace pour améliorer les performances [2].La bande passante de la mémoire devient un problème du système puisqu’un seul proces-
seur peut accéder à la mémoire à un moment donné. Pour résoudre ce problème, la configu-ration de la figure 1.3 remplace le bus par un réseau d’interconnexion permettant à plusieursprocesseurs d’accéder simultanément au réseau. La configuration remplace également le mo-dule de mémoire unique par une banque de mémoires. Cela permet à plusieurs opérationsde lecture / écriture en mémoire d’avoir lieu simultanément[2]. Dans un multiprocesseur àmémoire partagée, tout processeur peut accéder à n’importe quel module de mémoire. La fi-gure 1.3 illustre l’architecture multiprocesseur à mémoire partagée. Le fait d’avoir plusieursmodules de mémoire permet à plusieurs processeurs d’accéder simultanément à plusieurs mo-dules de mémoire. Cela augmente évidemment la bande passante de la mémoire en fonctiondes limitations du réseau d’interconnexion et des collisions de la mémoire. Une collision demémoire se produit lorsque plusieurs processeurs tentent d’accéder au même module de mé-moire.
FIGURE 1.2 – Multiprocesseur à mémoire partagée(a)
9

Chapitre 1. Revue de littérature 1.1. Les architectures SOME-Bus
FIGURE 1.3 – Multiprocesseur à mémoire partagée(b)
1.1.1.3 Réseaux d’interconnexion
Les processeurs doivent communiquer entre eux à l’aide d’un réseau d’interconnexion. Ceréseau peut constituer un problème s’il ne peut pas prendre en charge la communication simul-tanée entre des paires de processeurs arbitraires [2].
Fournir les liens entre les processeurs revient à fournir des canaux physiques dans les té-lécommunications. La manière dont les données sont échangées doit être spécifiée. Un bus estla forme la plus simple de réseau d’interconnexion. Les données sont échangées sous forme demots et une horloge système informe les processeurs lorsque les données sont valides. Danscette architecture, les données sont échangées sur la puce sous forme de paquets et sont ache-minées entre les modules de la puce à l’aide de routeurs.
Les principaux facteurs qui affectent les performances du réseau d’interconnexion sont lessuivants :
• les liens de réseau, qui peuvent être des câbles, des réseaux sans fil, voire des canauxoptiques ou des supports ;
• des commutateurs qui relient les liens entre eux ;
• le logiciel / micrologiciel de protocole utilisé pour acheminer les paquets ou les messagesentre les processeurs via les commutateurs et les liaisons ;
• la topologie du réseau, qui correspond au mode de connexion des commutateurs.
Il existe plusieurs types d’architecture pour les réseaux d’interconnexion tels que ceux enbus, ceux en étoile, le crossbar, et les architectures SOME-Bus qui font l’objet de notre étude.
10

Chapitre 1. Revue de littérature 1.1. Les architectures SOME-Bus
1.1.2 L’architecture 1D SOME-Bus
Le bus d’échange multiprocesseur optique simultané (en anglais Simultaneous OpticalMultiprocessor Exchange SOME-Bus) incorpore des dispositifs opto-électroniques dans unearchitecture de traitement très performante. Il s’agit d’un réseau d’interconnexion à fibre op-tique à faible latence et à large bande passante qui connecte directement chaque nœud à tousles autres nœuds sans contention. Ses propriétés le distinguent des autres réseaux d’intercon-nexion optique examinés par le passé.
L’une de ses principales caractéristiques est que chacun des N nœuds possède un canal dediffusion dédié fonctionnant à 20-30 Go/s, réalisé par un groupe de longueurs d’ondes dansune fibre spécifique, et une interface de canal d’entrée basée sur un réseau de récepteurs quisurveille simultanément tous les N canaux, résultant en un réseau pleinement connecté [3]. Leréseau de récepteurs n’a pas besoin d’effectuer de routage et, par conséquent, sa complexitématérielle (y compris le stockage du détecteur, de la logique et de la mémoire de paquets)est faible. Cette organisation élimine la nécessité d’un arbitrage global et fournit une bandepassante qui évolue directement avec le nombre de nœuds du système. Aucun nœud n’estjamais empêché de transmettre par un autre émetteur ou en raison d’un conflit de logique decommutation partagée.
FIGURE 1.4 – Interface Optique [3]
Le SOME-Bus évite la latence de l’arbitrage, la configuration de la commutation et l’infor-mation du nœud expéditeur que la connexion est terminée. La possibilité de prendre en charge
11

Chapitre 1. Revue de littérature 1.1. Les architectures SOME-Bus
plusieurs diffusions simultanées est une caractéristique unique de SOME-Bus qui prend effica-cement en charge les mécanismes de synchronisation de la barrière distribuée à grande vitesseet les protocoles de cohérence du cache et permet le partitionnement des groupes de processusau sein du tableau récepteur.
Les messages échangés entre les nœuds contiennent un champ d’en-tête avec des informa-tions sur le type de message (données ou synchronisation), la longueur et l’adresse de destina-tion. Une fois que le signal de niveau logique est restauré à partir des données optiques, il estdirigé vers l’interface de canal d’entrée composée de deux parties : l’interface optique illustréeà la figure 1.4, qui comprend la signalisation physique, le filtrage d’adresses, le traitement desbarrières, la surveillance de la longueur et le décodage de type, ainsi que l’interface du proces-seur, représentée sur la figure 1.5, qui comprend un réseau de routage et un système de miseen file d’attente. Une file d’attente est associée à chaque canal d’entrée, permettant aux mes-sages provenant d’un nombre quelconque de processeurs d’arriver et d’être mis en mémoiretampon simultanément, jusqu’à ce que le processeur local soit prêt à les supprimer. Les mes-sages de synchronisation sont collectés et traités au niveau du récepteur. L’arbitrage peut êtrerequis uniquement localement dans un tableau de récepteurs lorsque plusieurs files d’attenteen entrée contiennent des messages.
FIGURE 1.5 – Interface Processeur [3]
Chaque détecteur génère un flux de bits qui est examiné pour détecter le début du paquetet l’en-tête du paquet. Le circuit de décodage d’en-tête examine le champ d’en-tête, qui com-prend des informations sur le type de message, l’adresse de destination et la longueur, afin de
12

Chapitre 1. Revue de littérature 1.1. Les architectures SOME-Bus
déterminer si le message est un message de synchronisation ou un message de données. Si lemessage est un message de synchronisation, il est géré par le circuit de barrière, sinon, il s’agitd’un message de données et l’adresse de destination est comparée à l’ensemble des adresses va-lides contenues dans le circuit de décodage d’adresse. En plus de reconnaître sa propre adresseindividuelle, un processeur peut reconnaître des adresses de groupe de multidiffusion ainsi quedes adresses de diffusion. Une fois qu’une adresse valide a été identifiée, les données sont misesen mémoire tampon et placées dans la file d’attente appropriée. Si l’adresse ne correspond pas,le message est ignoré.
FIGURE 1.6 – Récepteur parallèle [3]
1.1.3 L’architecture 2D SOME-Bus
Le 2D SOME-Bus est constitué de N réseaux horizontaux et N verticaux 1D SOME-Bus etde N2 nœuds. Chaque nœud est connecté à un SOME-Bus horizontal et un SOME-Bus verti-cal. À chaque nœud, un convertisseur électro-optique composé d’une paire double récepteur etémetteur permet de transmettre et diffuser (de manière traversante) les messages diffusés surun bus dans l’autre dimension. La figure 1.7 montre l’organisation d’un réseau à petite échelle(4 par 4). Chaque bus a un ensemble de longueurs d’onde qui forment les canaux de commu-nication des nœuds attachés à ce bus. Tous les bus utilisent les mêmes longueurs d’onde. Poursimplifier, la figure 1.7 montre une longueur d’onde par canal (marquée α, β, γ, δ).
13

Chapitre 1. Revue de littérature 1.1. Les architectures SOME-Bus
FIGURE 1.7 – 2D SOME-Bus [3]
Si un nœud Nij (connecté au bus vertical Vi et au bus horizontal Hj) envoie un message aunœud Nmn et que i = m ou j = n, alors un seul bus (respectivement vertical ou horizontal) estutilisé. L’en-tête du message comprend l’identification du nœud de destination et le messageest diffusé sur le bus approprié. Si à la fois i 6= m et j 6= n, alors le message est d’abord diffusésur le bus horizontal Hj vers le nœud Nmj avec l’en-tête contenant une indication que le nœudmj diffuse le message sur le bus vertical Vm afin qu’il puisse être livré à sa destination finale,
14

Chapitre 1. Revue de littérature 1.1. Les architectures SOME-Bus
nœud Nmn. Par symétrie, le nœud source peut choisir de diffuser d’abord le message sur le busvertical Vi au nœud intermédiaire Nin pour la rediffusion sur le bus horizontal Hn.
La conception de l’en-tête permet de spécifier plusieurs destinations, de sorte que toutes lesfonctionnalités de l’architecture puissent être exploitées. Dans la configuration la plus simple,l’en-tête du message contient une liste de destinations finales. Le message est d’abord diffusésur le bus horizontal au niveau du nœud source et transmis à tous les nœuds requis sur cebus horizontal. Chacun de ces nœuds examine l’en-tête pour déterminer s’il est spécifié commedestination du message et / ou s’il doit rediffuser le message sur son propre bus vertical.
FIGURE 1.8 – Diagramme d’un nœud [3]
Si aucune rediffusion d’une dimension à l’autre n’est nécessaire, le fonctionnement du sys-tème est équivalent au fonctionnement du 1D SOME-Bus. Lorsqu’un message doit être redif-fusé d’une dimension à l’autre, l’architecture offre deux manières d’effectuer cette opération.Au plus simple, un message est mis en file d’attente localement au niveau du nœud inter-médiaire. Plus tard, le message est diffusé sur l’autre dimension de la même manière que lesmessages générés localement sont transmis. L’inconvénient de cette méthode est que la latenceest considérablement accrue en raison de la mise en file d’attente au niveau du nœud intermé-
15

Chapitre 1. Revue de littérature 1.1. Les architectures SOME-Bus
diaire et de la retransmission. Les simulations montrent qu’il existe une forte probabilité qu’unmessage qui arrive à un nœud intermédiaire à partir d’une dimension trouve le transmetteurdans l’autre dimension inactif et que, par conséquent, la transmission directe du message estbénéfique [3].
Comme le montre la figure 1.7, chaque nœud a un circuit électro-optique qui permet aunœud de déterminer si un message entrant doit être contourné vers l’autre bus et le retrans-met, bloquant l’émetteur local pendant la durée du transfert du message entrant. La figure 1.8montre le diagramme d’un nœud. Il existe deux ensembles de récepteurs et d’émetteurs, l’unassocié à un bus vertical et l’autre à un bus horizontal. Un routeur connecte les paires récepteur/ émetteur et le processeur local. Le routeur permet au processeur d’accéder à la file d’attentedans chaque émetteur et à une file d’attente dans chaque récepteur.
1.1.4 Etat de l’art sur la prédiction des mesures de performances des archi-tectures multiprocesseurs
La performance est une considération essentielle à la fois dans la conception de nouveauxsystèmes et dans le déploiement de systèmes existants. Les utilisateurs d’ordinateurs souhaitentutiliser leurs systèmes matériels et logiciels le plus efficacement possible. Au fil des ans, undomaine connu sous le nom d’évaluation des performances des ordinateurs est apparu pourrésoudre le problème de la quantification et de la prévision des performances des ordinateurs.Il existe des méthodes permettant de déterminer l’efficacité avec laquelle les ressources du sys-tème sont utilisées. Ceux-ci peuvent aider à localiser les causes probables de problèmes deperformances.
Il existe de nombreux ouvrages sur l’évaluation des performances des ordinateurs en géné-ral. La plupart des traitements sur le terrain s’accordent pour dire que le travail peut être classéen deux grandes catégories : la modélisation analytique des performances et la modélisationdes performances par simulation.
La modélisation analytique des performances consiste à utiliser des techniques mathéma-tiques pour résoudre des systèmes d’équations exprimant le comportement en régime per-manent de systèmes informatiques. Le modèle analytique a l’inconvénient de devenir inutilelorsque l’on prend en compte la dynamique du multiprocesseur. La modélisation par simu-lation utilise des programmes appelés simulateurs qui reflètent le comportement du systèmemodélisé. Il est plus souple que la modélisation analytique car le modèle est représenté parun programme informatique plutôt que par un système d’équations mais présente l’inconvé-nient de prendre beaucoup de temps [4]. La réduction de ce temps constituerait un avantageimportant lors de la conception d’architectures multiprocesseurs.
La modélisation par simulation malgré son coût en temps est plus utilisée dans l’évaluationdes performances. Pour réduire ce coût en temps, certaines études font appel à l’intelligenceartificielle pour évaluer les performances des architectures multiprocesseur.
16

Chapitre 1. Revue de littérature 1.1. Les architectures SOME-Bus
Ainsi, il existe des études dans la littérature [9, 8], qui prouvent le fait que des méthodesd’intelligence artificielle pourraient être appliquées pour prédire les mesures de performanced’une architecture multiprocesseur. Akay et Abasikeles[10], ont prédit les mesures de perfor-mance d’une architecture multiprocesseur utilisant le modèle de programmation à mémoirepartagée répartie sur l’architecture 1D SOME-Bus. Dans cette étude, une simulation statistiquede l’architecture a été réalisée pour générer l’ensemble de données. L’ensemble de donnéescontenait les variables d’entrée suivantes : rapport du temps moyen de transfert du canal demessage au temps moyen de traitement du thread (T / R), probabilité qu’un bloc puisse êtretrouvé dans l’état modifié, probabilité qu’un message de données soit dû à une écriture miss,probabilité qu’un cache soit plein et probabilité d’avoir une demande de propriété de mise àniveau. La SVR a été utilisée pour créer des modèles de prédiction permettant de prédire lalatence moyenne du réseau, le temps d’attente moyen des canaux et l’utilisation moyenne duprocesseur. Il a été conclu que le modèle SVR est un outil prometteur pour la prévision desmesures de performance d’un multiprocesseur à mémoire partagée distribuée.
Dans un travail ultérieur Zayid et al. [9] ont, avec un réseau de neurones artificiels à ré-troaction en anglais Multi-layer Feed Forward Neural Networks (MFANN) prédit les mesuresde performance de l’architecture 1D SOME-Bus utilisant le modèle de programmation de pas-sage de messages. OPNET Modeler [20] a été utilisé pour simuler statistiquement le messageen passant par l’architecture 1D SOME-Bus. Les variables d’entrée du modèle de prédictioncomprenaient T / R, le numéro de nœud, le numéro de fil et le modèle de trafic. Les variablesde sortie du modèle de prévision comprenaient le temps d’attente moyen des canaux, l’utilisa-tion moyenne des canaux, la latence moyenne du réseau, l’utilisation moyenne du processeuret le temps d’attente moyen des entrées. Il a été conclu que le modèle de prévision basé surMFANN était le meilleur pour prévoir les mesures de performance de l’architecture SOME-Busà passage de messages.
De la même manière, Akay et al. [11] utilisent SVR, MFANN et la régression linéaire multiplepour prédire les mesures de performance de l’architecture multiprocesseur 2D SOME-Bus àl’aide du modèle de programmation de passage de messages. OPNET Modeler a été utilisé poursimuler le message en passant l’architecture multiprocesseur 2D SOME-Bus et pour créer lesjeux de données de formation et de test. L’ensemble de données obtenu comporte cinq variablesd’entrée (T/R, numéro de nœud, nombre de threads, distribution spatiale du trafic et mode detrafic) et cinq variables de sortie (utilisation moyenne du canal, temps d’attente moyen du canal,latence moyenne du réseau, utilisation moyenne du processeur et temps d’attente moyen desentrées).
Dans ce document, des réseaux de neurones issus de l’apprentissage profond (deep lear-ning) ont été utilisés pour prédire les mesures de performance de l’architecture multiprocesseur2D SOME-Bus à l’aide du modèle de programmation par transmission de messages. Nous uti-lisons le même ensemble de données que [11] dans leur étude. En utilisant la validation croiséepar 10, les performances des modèles de prédiction comme dans [11] sont évaluées en calculant
17

Chapitre 1. Revue de littérature 1.2. Deep Learning
leurs coefficients de corrélation multiples (Multiple correlation coefficients (R)), leurs erreursmoyennes quadratiques (Root Mean Square Error (RMSE)), leurs erreurs absolues moyennes(Mean Absolute Error (MAE)), leurs erreurs absolues relatives (Root Absolute Error (RAE)) etles erreurs relatives de racine carré (Relative Root Square Error (RRSE)). Les résultats montrentque notre modèle présente l’erreur de prédiction la plus faible.
1.2 Deep Learning
1.2.1 Généralités
L’apprentissage automatique (machine learning) est l’intersection entre l’informatique théo-rique et des données brutes. En gros, il s’agit de donner du sens aux données des machines, dela même manière que les humains le font[15]. L’apprentissage automatique est un type d’in-telligence artificielle par lequel un algorithme ou une méthode extrait des motifs à partir dedonnées. L’apprentissage automatique résout quelques problèmes généraux :
• Apprentissage supervisé : ici, on dispose d’un ensemble d’objets et pour chaque objet unevaleur cible associée ; le modèle doit être capable de prédire la bonne valeur cible pour unnouvel objet. On distingue les problèmes de régression des problèmes de classification.Ainsi, on considère que les problèmes de prédiction d’une variable quantitative sont desproblèmes de régression (dont relève notre travail) tandis que les problèmes de prédictiond’une variable qualitative sont des problèmes de classification ;
• Apprentissage non supervisé : ici, on dispose d’un ensemble d’objets sans aucune valeurcible associée ; le modèle doit être capable d’extraire les régularités présentes au sein desobjets pour mieux visualiser ou appréhender la structure de l’ensemble des données ;
• Apprentissage par renforcement : ici, on dispose d’un ensemble de séquences de déci-sions dans un environnement dynamique, et pour chaque action de chaque séquence unevaleur de récompense (la valeur de récompense de la séquence est alors la somme desvaleurs des récompenses des actions qu’elle met en œuvre) ; il faut apprendre un modélecapable de prédire la meilleure décision à prendre étant donné un état de l’environne-ment.
Le Deep Learning ou apprentissage profond est un sous-domaine de l’apprentissage au-tomatique qui concerne les algorithmes inspirés de la structure et de la fonction du cerveau,appelés réseaux de neurones artificiels.
Les réseaux de neurones constituent donc un type de modèle d’apprentissage automatique ;ils existent depuis au moins 50 ans. L’unité fondamentale d’un réseau de neurones est unnœud (neurone), basé vaguement sur le neurone biologique du cerveau des mammifères. Lesconnexions entre neurones sont également modélisées sur le cerveau biologique, de même quela manière dont ces connexions se développent dans le temps (avec « entraînement »).
18

Chapitre 1. Revue de littérature 1.2. Deep Learning
1.2.2 Le neurone
1.2.2.1 Le neurone biologique
Le neurone biologique (voir figure 1.9) est une cellule nerveuse qui constitue l’unité fonc-tionnelle fondamentale du système nerveux de tous les animaux. Les neurones existent pourcommuniquer les uns avec les autres et transmettre des impulsions électrochimiques à traversles synapses, d’une cellule à l’autre, à condition que l’impulsion soit suffisamment puissantepour activer la libération de produits chimiques à travers une fente synaptique. La force del’impulsion doit dépasser un seuil minimal, sinon les produits chimiques ne seront pas libé-rés. La figure présente les principales parties de la cellule nerveuse : le soma, les dendrites, lesaxones et les synapses.
FIGURE 1.9 – Neurone biologique [14]
Le neurone est constitué d’une cellule nerveuse constituée d’un soma (corps cellulaire) etde plusieurs dendrites mais un seul axone. L’axone unique peut cependant se ramifier des cen-taines de fois. Les dendrites sont des structures minces issues du corps cellulaire principal. Lesaxones sont des fibres nerveuses ayant une extension cellulaire particulière qui provient ducorps de la cellule.
Les synapses
Les synapses sont la jonction de connexion entre axone et dendrites. La majorité des sy-napses envoient des signaux de l’axone d’un neurone à la dendrite d’un autre neurone.
Les dendrites
19

Chapitre 1. Revue de littérature 1.2. Deep Learning
Les dendrites ont des fibres qui sortent du soma dans un réseau touffu autour de la cellulenerveuse. Les dendrites permettent à la cellule de recevoir des signaux de neurones voisinsconnectés et chaque dendrite peut effectuer une multiplication par la valeur du poids de cettedendrite. Par multiplication, on entend une augmentation ou une diminution du rapport neu-rotransmetteur synaptique aux signaux chimiques introduits dans la dendrite.
Les axones
Les axones sont les fibres simples et longues qui s’étendent du soma principal. Ils s’étendentsur des distances plus longues que les dendrites et mesurent généralement 1 centimètre de long(100 fois le diamètre du soma). Finalement, l’axone se ramifiera et se connectera à d’autres den-drites. Les neurones sont capables d’envoyer des impulsions électrochimiques par le biais dechangements de tension inter-membrane générant un potentiel d’action. Ce signal se déplacele long de l’axone de la cellule et active les connexions synaptiques avec d’autres neurones.
Flux d’informations à travers le neurone biologique
Les synapses qui augmentent le potentiel sont considérées comme excitatrices, et celles quile diminuent sont considérées comme inhibitrices. La plasticité fait référence aux changementsà long terme de la force des connexions en réponse au stimulus d’entrée. Les neurones se sontégalement avérés former de nouvelles connexions au fil du temps et même migrer. Ces méca-nismes combinés au changement de connexion dirigent le processus d’apprentissage dans lecerveau biologique.
De biologique à artificiel
Il a été démontré que le cerveau de l’animal est responsable des composants fondamentauxde l’esprit. Nous pouvons étudier les composants de base du cerveau et les comprendre. Larecherche a montré des moyens de cartographier les fonctionnalités du cerveau et de suivre lessignaux lorsqu’ils se déplacent dans les neurones.
1.2.2.2 Le perceptron
Le perceptron a été inventé en 1957 par le laboratoire aéronautique Cornell de Frank Rosen-blatt.Le perceptron est un classificateur binaire à modèle linéaire avec une simple relation entrée /sortie, comme illustré à la figure 1.10, qui montre que nous additionnons n nombre d’entréesfois leurs poids associés, puis que nous envoyons cette «entrée nette» à une fonction d’activa-tion avec un seuil défini. Généralement avec les perceptrons, il s’agit d’une fonction échelonunité (Heaviside) avec une valeur seuil de 0,5. Cette fonction génère une valeur binaire unique
20

Chapitre 1. Revue de littérature 1.2. Deep Learning
à valeur réelle (0 ou 1), en fonction de l’entrée.
FIGURE 1.10 – Perceptron [15]
La sortie de la fonction échelon unité (fonction d’activation) est la sortie du perceptron etnous donne une classification des valeurs d’entrée. Si la valeur du biais est négative, la sommedes poids appris devient une valeur beaucoup plus grande pour obtenir une sortie de classifi-cation de 1.
1.2.2.3 Neurone artificielle
Le neurone artificiel est similaire à son prédécesseur, le perceptron, mais il ajoute de la flexi-bilité dans le type de couche d’activation qui peut être utilisé. La figure 1.11 présente un dia-gramme mis à jour du neurone artificiel basé sur le perceptron.
FIGURE 1.11 – Perceptron [15]
Ce diagramme est similaire à la figure 1.10 pour le perceptron monocouche, mais nous re-marquons une fonction d’activation plus généralisée.
21

Chapitre 1. Revue de littérature 1.2. Deep Learning
L’entrée nette dans la fonction d’activation reste le produit scalaire des poids et des caracté-ristiques d’entrée, mais la fonction d’activation flexible nous permet de créer différents typesà partir de valeurs de sortie. C’est un contraste majeur avec la conception antérieure du per-ceptron qui utilisait une fonction échelon (Heaviside) linéaire par morceaux, cette améliorationpermettant désormais au neurone artificiel d’exprimer une sortie d’activation plus complexe.Les neurones artificiels peuvent être définis par le type d’entrée qu’ils sont capables de recevoir(binaire ou continue) et par le type de transformation (fonction d’activation) qu’ils utilisentpour produire une sortie.Différents éléments caractéristiques importantes de ces neurones sont :
Poids de connexion
Les poids sur les connexions dans un réseau de neurones sont des cœfficients qui modifient(amplifient ou minimisent) le signal entrant dans un neurone donné du réseau. Dans les repré-sentations communes des réseaux de neurones, il s’agit des lignes / flèches allant d’un pointà l’autre, des arêtes du graphe mathématique. Souvent, les connexions sont notées comme wdans les représentations mathématiques des réseaux de neurones.
Les biais
Les biais sont des valeurs scalaires ajoutées à l’entrée pour garantir qu’au moins quelquesnœuds par couche sont activés, quelle que soit la puissance du signal. Les biais permettent l’ap-prentissage en donnant au réseau une action en cas de faible signal. Ils permettent au réseaud’essayer de nouvelles interprétations ou comportements. Les biais sont généralement notés bet, comme les poids, ils sont modifiés tout au long du processus d’apprentissage.
Fonctions d’activation
Les fonctions qui régissent le comportement du neurone artificiel sont appelées fonctionsd’activation. La transmission de cette entrée est appelée propagation en avant. Les fonctionsd’activation transforment la combinaison des entrées, des poids et des biais. Les produits deces transformations sont entrés pour la couche de nœuds suivante. De nombreuses transfor-mations non linéaires (mais pas toutes) utilisées dans les réseaux de neurones transforment lesdonnées en une plage appropriée, telle que 0 à 1 ou -1 à 1. Lorsqu’un neurone artificiel transmetune valeur non nulle à un autre neurone artificiel, on dit qu’il activé. Voici quelques fonctionsd’activation :
• Linéaire : Une transformation linéaire (voir la figure 1.12) qui est fondamentalement lafonction identité ou la fonction :
f(x) = Wx (1.1)
22

Chapitre 1. Revue de littérature 1.2. Deep Learning
où la variable dépendante a une relation proportionnelle directe avec la variable indépen-dante.
FIGURE 1.12 – Fonction linéaire
• Sigmoïde : Une fonction sigmoïde est une machine qui convertit des variables indépen-dantes d’une étendue quasi infinie en probabilités simples comprises entre 0 et 1, et laplupart de ses sorties seront très proches de 0 ou 1. Sa formule est :
g(x) = σ(x) =1
1 + e−x(1.2)
et une représentation est donnée à la figure 1.13
23

Chapitre 1. Revue de littérature 1.2. Deep Learning
FIGURE 1.13 – Fonction sigmoïde
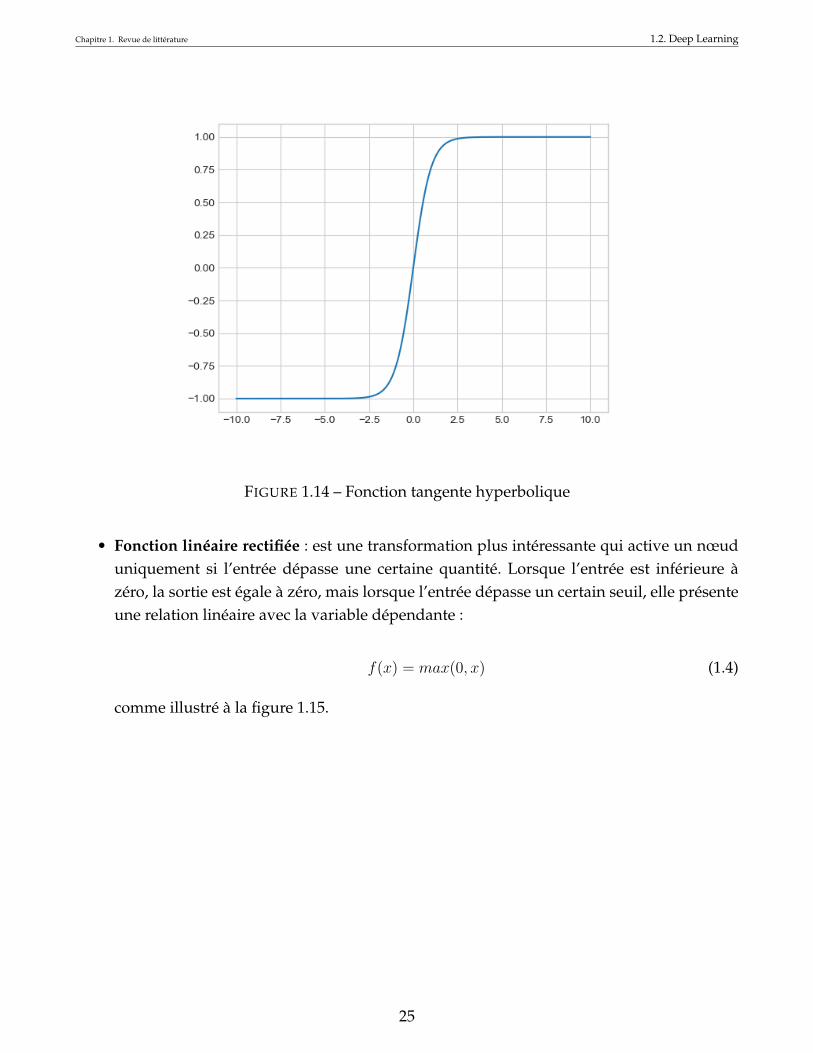
• Tanh : est une fonction trigonométrique hyperbolique (voir figure 1.14). Tout comme latangente représente un rapport entre les côtés opposés et adjacents d’un triangle rectangle,tanh représente le rapport entre le sinus hyperbolique et le cosinus hyperbolique :
tanh(x) =sinh(x)
cosh(x)(1.3)
Contrairement à la fonction Sigmoïde, la plage normalisée de tanh est comprise entre -1et 1. L’avantage de tanh est qu’il peut traiter plus facilement les nombres négatifs.
24
Chapitre 1. Revue de littérature 1.2. Deep Learning
FIGURE 1.14 – Fonction tangente hyperbolique
• Fonction linéaire rectifiée : est une transformation plus intéressante qui active un nœuduniquement si l’entrée dépasse une certaine quantité. Lorsque l’entrée est inférieure àzéro, la sortie est égale à zéro, mais lorsque l’entrée dépasse un certain seuil, elle présenteune relation linéaire avec la variable dépendante :
f(x) = max(0, x) (1.4)
comme illustré à la figure 1.15.
25

Chapitre 1. Revue de littérature 1.2. Deep Learning
FIGURE 1.15 – Fonction linéaire rectifiée
• Softmax : est une généralisation de la régression logistique dans la mesure où il peutêtre appliqué à des données continues et peut contenir plusieurs limites de décision. Unereprésentation de sa sortie est donnée à la figure 1.16
26

Chapitre 1. Revue de littérature 1.2. Deep Learning
FIGURE 1.16 – Fonction softmax
1.2.3 Réseau de neurones
Un réseau de neurones artificiels est une tentative de simulation du réseau de neuronesconstituant le cerveau humain, de sorte que l’ordinateur puisse apprendre des choses et prendredes décisions de manière humaine. Les réseaux de neurones artificiels sont créés en program-mant des ordinateurs ordinaires pour qu’ils se comportent comme des cellules cérébrales inter-connectées. Dans un réseau de neurones artificiels, nous avons des neurones artificiels disposésen groupes appelés couches comme suit :
• une couche d’entrée ;
• une ou plusieurs couches cachées, entièrement connectées ;
• une seule couche de sortie
Comme le montre la figure 1.17, les neurones de chaque couche (représentés par les cercles)sont entièrement connectés à tous les neurones de toutes les couches adjacentes. Les neuronesde chaque couche utilisent tous le même type de fonction d’activation (la plupart du temps).Pour la couche d’entrée, l’entrée est l’entrée vectorielle brute. L’entrée des neurones des autrescouches est la sortie (activation) des neurones de la couche précédente.
27

Chapitre 1. Revue de littérature 1.2. Deep Learning
Input #1
Input #2
Input #3
Input #4
Output
Hiddenlayer
Inputlayer
Outputlayer
FIGURE 1.17 – Réseau de neurones artificiels
Couche d’entrée
Cette couche réceptionne les données d’entrée (vecteurs) introduites dans notre réseau. Lenombre de neurones dans une couche d’entrée est généralement le même nombre que l’entitéd’entrée sur le réseau. Les couches en entrée sont suivies d’une ou de plusieurs couches cachées.
Couche cachée
Il existe une ou plusieurs couches cachées dans un réseau de neurones. Les valeurs de poidssur les connexions entre les couches indiquent comment les réseaux de neurones codent les in-formations acquises et extraites des données brutes d’apprentissage. Les couches cachées sontla clé pour permettre aux réseaux de neurones de modéliser des fonctions non linéaires.
Couche de sortie
Nous obtenons la réponse ou la prédiction de notre modèle à partir de la couche de sortie.Étant donné que nous mappons un espace d’entrée vers un espace de sortie avec le modèlede réseau neuronal, la couche de sortie nous fournit une sortie basée sur l’entrée de la couched’entrée. Selon la configuration du réseau de neurones, la sortie finale peut être une sortie àvaleur réelle (régression) ou un ensemble de probabilités (classification). Ceci est contrôlé parle type de fonction d’activation que nous utilisons sur les neurones de la couche de sortie. Lacouche de sortie utilise généralement une fonction d’activation sigmoïde pour la classification.
Connexions entre les couches
Dans un réseau entièrement connecté, les connexions entre les couches sont les connexions
28

Chapitre 1. Revue de littérature 1.2. Deep Learning
sortantes de tous les neurones de la couche précédente à tous les neurones de la couche sui-vante. Nous modifions ces poids progressivement au fur et à mesure que notre algorithmetrouve la meilleure solution possible avec l’algorithme d’apprentissage de la rétro-propagation.Les poids peuvent être compris mathématiquement en les considérant comme le vecteur de pa-ramètre dans la section précédente sur l’algèbre linéaire, décrivant le processus d’apprentissageautomatique comme une optimisation du vecteur de paramètre (par exemple, les «pondéra-tions» ici) afin de minimiser les erreurs.
1.2.4 Apprentissage
Un réseau neuronal artificiel bien entraîné a des poids qui amplifient le signal et atténuent lebruit. Un poids plus important signifie une corrélation plus étroite entre un signal et le résultatdu réseau. Les entrées associées à des poids élevés affecteront davantage l’interprétation desdonnées par le réseau que les entrées associées à des poids plus faibles.
Le processus d’apprentissage pour tout algorithme d’apprentissage utilisant des poids est leprocessus de réajustement des poids et des biais, en rendant certains plus petits et d’autres plusgrands, attribuant ainsi une signification à certaines informations et en minimisant d’autres.Cela aide notre modèle à déterminer quelles variables de prédiction (ou caractéristiques) sontliés à quels résultats et ajuste les poids et les biais en conséquence.
Dans la plupart des ensembles de données, certaines caractéristiques sont fortement corré-lées avec certaines étiquettes (par exemple, la superficie en pieds carrés correspond au prix devente d’une maison). Les réseaux de neurones apprennent aveuglément ces relations en faisantune supposition basée sur les entrées et les poids, puis en mesurant la précision des résultats.Les fonctions de perte dans les algorithmes d’optimisation, tels que la descente de gradientstochastique (Stochastic gradient descent (SGD)), récompensent le réseau pour les bonnes sup-positions et le pénalisent pour les mauvaises. SGD déplace les paramètres du réseau vers debonnes prévisions et s’éloigne des mauvaises.
Conclusion
Tout au long de ce chapitre nous avons abordé les notions liée aux architectures multiproces-seur ainsi qu’au 2D SOME-Bus. Nous avons exposé les différentes méthodes utilisées générale-ment pour prédire les performances des architectures multiprocesseurs ainsi que celles baséessur l’intelligence artificielle qui peuvent présenter un avantage par rapport aux autres du faitde leur faible coût en temps. Pour finir, nous avons présenté ce que c’est que l’apprentissageprofond avec les techniques qui lui sont relatives.
29

Chapitre 2Matériel et choix techniques
Résumé. Pour concevoir les modèles de prédictions des mesures de performancedu 2D SOME-Bus il est nécessaire de disposer de données. Les différentes variablesde prédictions de l’ensemble de données sont importantes dans la conception desmodèles aussi, faut il choisir efficacement les outils pour les exploiter.
Introduction
Ce chapitre fait la synthèse des différents outils aussi bien matériels que logiciels que nousavons eu a utilisés tout au long de notre étude. Nous y présentons aussi les différents choixtechniques que nous avons eu à faire pour mener à bien ce travail.
2.1 Matériel
Pour mener à bien les expérimentations, nous avons eu à utiliser des éléments aussi bienmatériel que logiciel que nous détaillons dans la suite.
2.1.1 L’ensemble de données
Pour nos expérimentations nous utilisons l’ensemble de données Optical Interconnection Net-work Data Set. Disponible depuis l’UCI Machine Learning Repository [21] c’est aussi celui uti-lisé par Akay et al. [11] dans leurs travaux. Cet ensemble a été généré avec OPNET Modelercomme environnement de simulation et contient 640 échantillons de données. Il contient desinformations comme la distribution temporelle et la distribution spatiale du trafic dans le bus.La conception des architectures de réseau nécessite des mécanismes permettant de prédire avecprécision l’utilisation du réseau à l’avance, au lieu de concevoir ou de fabriquer le réseau et
30

Chapitre 2. Matériel et choix techniques 2.1. Matériel
d’évaluer ensuite ses performances. Afin de répondre à cette exigence, les architectes utilisentdivers modèles de trafic pour déterminer et quantifier l’impact des paramètres critiques sur leréseau sous-jacent. Plus précisément, un modèle de trafic est un graphe décrivant à la fois ladistribution spatiale et temporelle du trafic réseau (communication de données et de signauxentre les nœuds).
Une distribution temporelle détermine comment un nœud individuel génère du trafic dansle temps et comment ce trafic se propage dans le réseau. Cette distribution inclut une liste depropriétés de trafic, comme la période (ou le taux) de génération des messages, tandis queles valeurs typiques de ce paramètre sont constantes (périodiques), aléatoires, normales, etc.Dans la simulation faite pour obtenir l’ensemble de données, les modes de trafic client-serveur(c’est-à-dire un nœud serveur envoie des paquets pour répondre à la réception des paquets desclients) et asynchrone ont été utilisés.
La distribution spatiale du trafic est le modèle selon lequel la destination est sélectionnée[16, 17, 18]. Dans les simulations, un ensemble de distributions spatiales bien connues a étéutilisé : bits inversés (BR), mélange parfait (PS), région uniforme (UN) et région chaude (HR).Les permutations de bits telles que les bits inverses et les mélanges parfaits sont celles danslesquelles chaque bit di de l’adresse de destination b-bit est fonction du bit de l’adresse source[18]. Un modèle de trafic uniforme peut être représenté par une matrice de trafic, où chaqueélément de la matrice λs,d donne la fraction de trafic envoyée par le nœud s en destination dunœud d. Dans le trafic uniforme, le nœud de destination est sélectionné à l’aide d’une distribu-tion uniforme dont la moyenne est comprise entre 1 et N . Dans le modèle de région chaude,les destinations des 25% de paquets sont choisies de manière aléatoire dans une petite régionchaude constituée de 12,5% des nœuds[18, 19].
Le tableau 2.1 liste donc la sélection du nœud de destination pour ces modèles de trafic :
TABLEAU 2.1 – Statistiques descriptives des variables prédictives
Nom ModèleUniforme λs,d =
1N
Inversion de bits di = bi+1
Mélange parfait di = si−1 mod bRégion chaude Les 25% des paquets sont envoyés à 12,5% du groupe de nœuds
D’autres variables de prédictions sont le rapport T/R du temps de traitement par le tempsde transfert. Le temps de traitement (R) est supposé être distribué de manière exponentielleavec une moyenne de 100 cycles d’horloge. Le temps de transfert de message (T) est supposéêtre uniformément réparti avec une moyenne comprise entre 5 et 100 cycles d’horloge. Lesautres paramètres de la simulation sont le nombre de nœuds dans le système (16 et 64) et le
31
Chapitre 2. Matériel et choix techniques 2.1. Matériel
nombre initial de threads exécutés par chaque processeur (4, 6, 8 et 10).
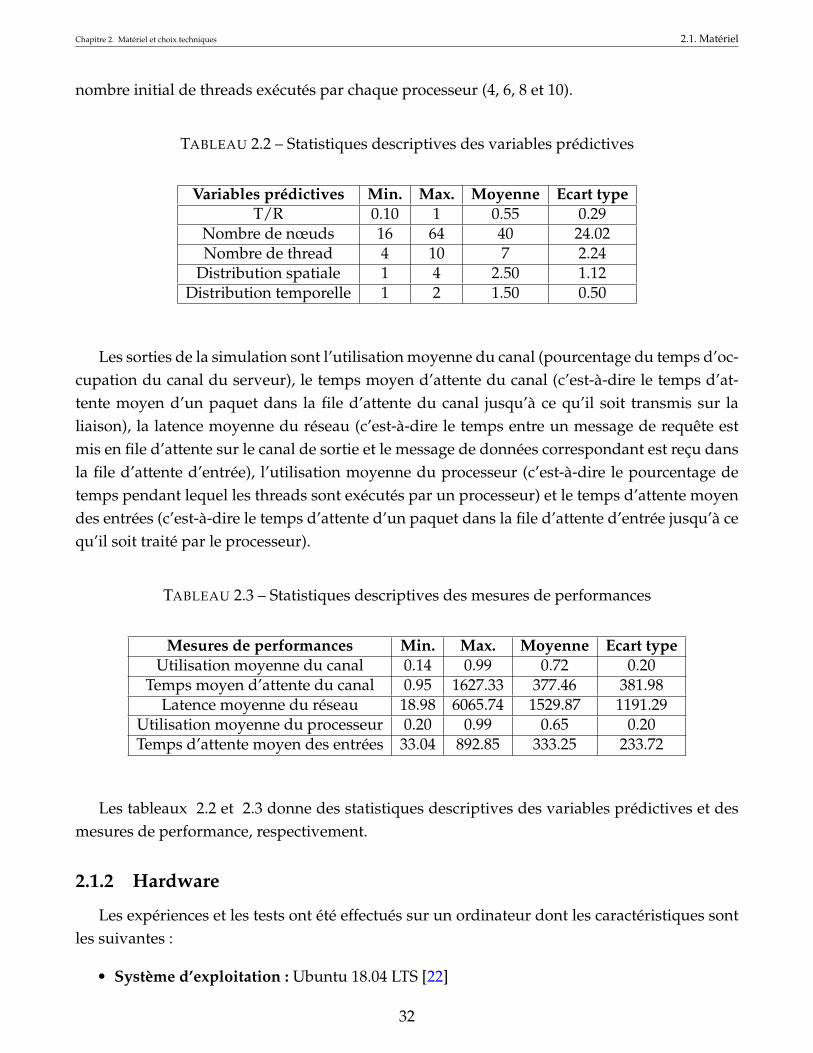
TABLEAU 2.2 – Statistiques descriptives des variables prédictives
Variables prédictives Min. Max. Moyenne Ecart typeT/R 0.10 1 0.55 0.29
Nombre de nœuds 16 64 40 24.02Nombre de thread 4 10 7 2.24
Distribution spatiale 1 4 2.50 1.12Distribution temporelle 1 2 1.50 0.50
Les sorties de la simulation sont l’utilisation moyenne du canal (pourcentage du temps d’oc-cupation du canal du serveur), le temps moyen d’attente du canal (c’est-à-dire le temps d’at-tente moyen d’un paquet dans la file d’attente du canal jusqu’à ce qu’il soit transmis sur laliaison), la latence moyenne du réseau (c’est-à-dire le temps entre un message de requête estmis en file d’attente sur le canal de sortie et le message de données correspondant est reçu dansla file d’attente d’entrée), l’utilisation moyenne du processeur (c’est-à-dire le pourcentage detemps pendant lequel les threads sont exécutés par un processeur) et le temps d’attente moyendes entrées (c’est-à-dire le temps d’attente d’un paquet dans la file d’attente d’entrée jusqu’à cequ’il soit traité par le processeur).
TABLEAU 2.3 – Statistiques descriptives des mesures de performances
Mesures de performances Min. Max. Moyenne Ecart typeUtilisation moyenne du canal 0.14 0.99 0.72 0.20
Temps moyen d’attente du canal 0.95 1627.33 377.46 381.98Latence moyenne du réseau 18.98 6065.74 1529.87 1191.29
Utilisation moyenne du processeur 0.20 0.99 0.65 0.20Temps d’attente moyen des entrées 33.04 892.85 333.25 233.72
Les tableaux 2.2 et 2.3 donne des statistiques descriptives des variables prédictives et desmesures de performance, respectivement.
2.1.2 Hardware
Les expériences et les tests ont été effectués sur un ordinateur dont les caractéristiques sontles suivantes :
• Système d’exploitation : Ubuntu 18.04 LTS [22]
32

Chapitre 2. Matériel et choix techniques 2.2. Choix techniques
• Architecture : 64 bits
• Processeur : Intel® Core™ i7-7700HQ CPU @ 2.80GHz x 8
• Mémoire RAM : 8.00 Go
2.2 Choix techniques
Pour notre étude, nous avons été confrontés à des choix quant au langage de programma-tion et aux différentes librairies à utiliser. En effet il existe plusieurs langages de programmationet bon nombre d’entre eux sont mis à jour avec l’ajout des supports sur l’apprentissage auto-matique. Il est donc important de choisir judicieusement le langage à utiliser.
Parmi cette multitude de langages, il existe quatre qui se démarquent de par leur nombred’utilisateurs, leur efficacité et les différentes fonctionnalités qu’ils offrent :
1. MATLAB (matrix laboratory) : est un environnement informatique numérique multi-paradigmes. MATLAB, langage de programmation propriétaire développé par MathWorks,permet des manipulations matricielles, le traçage de fonctions et de données, la miseen œuvre d’algorithmes, la création d’interfaces utilisateur et l’interfaçage avec des pro-grammes écrits dans d’autres langages, notamment C, C ++, C#, Java, Fortran et Python.
Avantages :
• plate-forme mathématique et informatique la plus rapide, en particulier pour les opé-rations vectorisées / algèbre à matrice linéaire ;
• très courts scripts en considérant la forte intégration de tous les paquets ;
• meilleure visualisation des figures et des graphiques interactifs ;
• bien testé et supporté car c’est un produit commercial.
Inconvénients :
• impossible d’exécuter les scripts de façon autonome - ils doivent être traduits dansun autre langage ;
• prix d’acquisition de licence élevé ;
• mauvaise intégration avec d’autres langages ;
• mauvaise performance pour les boucles itératives.
2. Python : est un langage de programmation de haut niveau, interprété et utilisé pour laprogrammation à usage général. Créé par Guido van Rossum et publié pour la première
33

Chapitre 2. Matériel et choix techniques 2.2. Choix techniques
fois en 1991, Python repose sur une philosophie de conception qui met l’accent sur la lisi-bilité du code, en utilisant notamment des espaces significatifs. Il fournit des constructionspermettant une programmation claire à petite et grande échelle.
Avantages :
• idéal pour la programmation générale et le développement d’applications ;
• beaucoup de paquets Open Source (Pandas, Numpy, Scipy) ;
• peut être un langage utilisé pour connecter d’autres langages : R, C ++ et autres(python) ;
• La vitesse générale la plus élevée, en particulier dans les boucles itératives.
Inconvénients :
• erreurs silencieuses pouvant être très longues à retrouver (même avec les débogueursvisuels / IDE) ;
• plus de code requis pour les mêmes opérations que R ou MATLAB;
• certains paquets ne sont pas compatibles avec d’autres ou contiennent des chevau-chements.
3. R : est un langage et un environnement pour l’informatique statistique et les graphiques.Il s’agit d’un projet GNU similaire au langage et environnement S développé par JohnChambers et ses collègues aux laboratoires Bell (anciennement AT&T, maintenant LucentTechnologies). R peut être considéré comme une implémentation différente de S. Il existequelques différences importantes, mais une grande partie du code écrit pour S fonctionnesans modification sous R.
Avantages :
• vitesse de développement rapide (60% de lignes en moins par rapport au python,environ 500% de moins que C) ;
• beaucoup de paquets Open Source ;
• peut s’intégrer dans du C++/C avec rcpp ;
• plus grande communauté.
Inconvénients :
• lent par rapport à Python en particulier dans les boucles itératives et les fonctionsnon vectorisées ;
• mauvais tracé de figure par rapport à Python et assez difficultés à mettre en œuvredes graphiques interactifs ;
34

Chapitre 2. Matériel et choix techniques 2.2. Choix techniques
• capacités limitées pour créer des applications autonomes.
4. Octave : Octave est en quelque sorte la réponse de GNU au langage commercial MATLAB.C’est-à-dire qu’il s’agit d’un langage de manipulation de matrice et sa syntaxe est compa-tible à environ 95% avec MATLAB. C’est un langage conçu par les ingénieurs, et donc trèschargé en routines couramment utilisées par les ingénieurs. Il comporte de nombreusesroutines d’analyse de séries chronologiques, de statistiques, de commandes de fichiers etde commandes de traçage du langage MATLAB.
Avantages :
• beaucoup de paquets et tant qu’un programme ne nécessite pas de sortie graphique,il y a de bonnes chances qu’il s’exécute sous Octave comme sous Matlab sans deconsidérables modifications ;
• Octave utilise GNU Plot ou JHandles en tant que progiciels graphiques, ce dernierétant en quelque sorte plus proche de ce que fournit Matlab.
Inconvénients :
• juste une version libre et gratuite de MATLAB qui n’apporte rien de nouveau ;
De même une étude menée par KDNuggets [28] auprès de ces utilisateurs sur les outils lesplus utilisés dans les sciences de données entre 2016 et 2018 a donné les résultats présents dansla figure 2.1 :
35

Chapitre 2. Matériel et choix techniques 2.2. Choix techniques
FIGURE 2.1 – KDnuggets Analytics / Data Science 2018. Sondage sur les logiciels : les principauxoutils en 2018 et leur part dans les sondages 2016-7 [28]
La figure 2.1 nous montre ainsi que depuis 2017, Python avec ses différents avantages estl’outil le plus utilisé pour le Machine Learning à la vue des différentes possibilités qu’il offre.Notre choix après ces différentes analyses s’est donc porté sur lui en tant qu’outil principal pourmener à bien notre étude.
En outre, il existe plusieurs distributions, paquets et modules conçus pour Python facilitantl’utilisation des concepts clés de l’apprentissage automatique. Listés sur la figure 2.1, ils se sontavérés important dans notre étude et sont :
Anaconda[24] : est une distribution libre et gratuite des langages de programmation Pythonet R ainsi que de nombreux autres outils tel que spyder (un environnement de développementintégré abrégé EDI en français pour écrire du code en python), matplotlib (pour visualiser desdonnées à travers les courbes) pour les applications liées à la science des données et à l’ap-prentissage automatique (traitement de données à grande échelle, analyse prédictive, calculscientifique), qui vise à simplifier la gestion et le déploiement d’applications relatives à cettedernière.
Tensorflow[25] : est un framework de programmation pour le calcul numérique qui a étérendu Open Source par Google en Novembre 2015. TensorFlow n’a cessé de gagner en popula-
36

Chapitre 2. Matériel et choix techniques 2.3. Conclusion
rité, pour devenir très rapidement l’un des frameworks les plus utilisés pour le Deep Learninget donc les réseaux de neurones. Son nom est notamment inspiré du fait que les opérationscourantes sur des réseaux de neurones sont principalement faites via des tables de donnéesmulti-dimensionnelles, appelées Tenseurs (Tensor). Un Tenseur à deux dimensions est l’équi-valent d’une matrice. Aujourd’hui, les principaux produits de Google sont basés sur Tensor-Flow : Gmail, Google Photos, Reconnaissance de voix, ainsi sa documentation très riche faitd’elle une bibliothèque facile à utiliser.
Keras[26] : est une API de réseaux de neurones de haut niveau, écrite en Python et capablede fonctionner sur TensorFlow ou Theano. Il a été développé en mettant l’accent sur l’expéri-mentation rapide. Être capable d’aller de l’idée à un résultat avec le moins de délai possible estla clé pour faire de bonnes recherches. Il a été développé dans le cadre de l’effort de recherchedu projet ONEIROS (Open-ended Neuro-Electronic Intelligent Robot Operating System), et sonprincipal auteur et mainteneur est François Chollet, un ingénieur Google. En 2017, l’équipe Ten-sorFlow de Google a décidé de soutenir Keras dans la bibliothèque principale de TensorFlow.Chollet a expliqué que Keras a été conçue comme une interface plutôt que comme un cadred’apprentissage end-to-end. Il présente un ensemble d’abstractions de niveau supérieur et plusintuitif qui facilitent la configuration des réseaux neuronaux.
Scikit-learn[27] : est une bibliothèque libre Python dédiée à l’apprentissage automatique.Elle est développée par de nombreux contributeurs notamment dans le monde académique pardes instituts français d’enseignement supérieur et de recherche comme Inria et Télécom Paris-Tech. Elle comprend notamment des fonctions pour estimer des forêts aléatoires, des régres-sions logistiques, des algorithmes de classification, et les machines à vecteur de support. Elleest conçue pour s’harmoniser avec d’autres bibliothèques libre Python, notamment NumPy etSciPy.
2.3 Conclusion
L’étude que nous avons menée a nécessité différents outils matériel et logiciel pour sa bonnemarche. Ce chapitre en a ainsi fait le point en justifiant les différents choix opérés.
37

Chapitre 3Solution proposée
Résumé. Pour avoir les meilleurs modèles possibles avec les données à notre dis-position, une méthodologie stricte est suivie. Elle revient essentiellement, en plusde bien définir l’architecture des réseaux de neurones et les fonctions d’activation,à bien choisir les différents paramètres pour l’entraînement ainsi que les métriquesd’évaluation des réseaux.
Introduction
Dans ce chapitre nous décrivons les configurations expérimentales mises en place pour l’ob-tention des modèles de prédiction. Nous y détaillons aussi les différents paramètres en causedans l’entraînement et la construction de ces modèles. Mener à bien les différentes expérimen-tations afin d’obtenir le meilleur modèle de prédiction requiert l’utilisation optimale de l’en-semble de données et de suivre la meilleure méthode afin d’obtenir un modèle efficace. Pour cefaire, avec l’ensemble de données à notre disposition nous suivons les étapes résumées dans ledigramme à la figure 3.1.
38

Chapitre 3. Solution proposée 3.1. Division et normalisation de l’ensemble de données
FIGURE 3.1 – Diagramme des étapes
3.1 Division et normalisation de l’ensemble de données
Dans le processus d’obtention du modèle de prédiction, il y a l’étape de d’entraînement.Pour faire l’entraînement, nous utilisons des données présentes dans l’ensemble de données ànotre disposition. Ainsi pour l’entrainement du modèle nous utilisons 80% des données et 20%
39

Chapitre 3. Solution proposée 3.2. Entrainement du réseau de neurones
pour la validation.Ensuite les données disponibles étant sous différents formats il faut faire une normalisation.
Il s’agit simplement d’obtenir toutes les données à la même échelle : si les échelles des diffé-rentes variables de l’ensemble de données sont très différentes, cela peut avoir un effet néfastesur l’entraînement. S’assurer que les variables de l’ensemble de données sont normalisées per-met implicitement au réseau de neurones de les considérer de façon égale. Leur représentationest la même. Au cours de cette normalisation, nous attribuons des valeurs numériques aux don-nées qualitatives. Ainsi, toutes les valeurs de l’ensemble de données se retrouvent comprisesentre 0 et 1 pour atteindre plus vite et au mieux la convergence.
3.2 Entrainement du réseau de neurones
Au cours de cette phase, nous procédons à l’entraînement du réseau. Entrainement au coursduquel les différents paramètres tels que les poids de neurones et le biais sont variés afin d’ob-tenir un modèle efficace sur l’ensemble d’entraînement. Mais afin d’obtenir les meilleurs pa-ramètres possibles, il nous faut choisir efficacement les hyperparamètres (c’est-à-dire les para-mètres que nous pouvons modifier à savoir : le nombre d’époques, la taille des lots, les fonctionsd’activation, les algorithmes d’optimisation). Tester plusieurs hyperparamètres pour trouver laparfaite combinaison est coûteux en temps et en puissance de calcul. Il existe différents algo-rithmes parmi lesquels le Grid Search, le Random Search... Nous avons utilisé ici dans le cadrede notre travail le Grid Search car c’est une méthode simple et qui permet de tester toutes lescombinaisons d’hyperparamètres ajoutés. Il consiste à mettre en place une grille de valeurs deces hyperparamètres et, pour chaque combinaison, de former un modèle et de tester le modèlesur les données de l’ensemble de validation.
Les hyperparamètres ne peuvent pas être testés sur les données de test. Nous ne pouvonsutiliser les données de test qu’une seule fois lorsque nous évaluons le modèle final. Les donnéesde test sont censées servir pour l’estimation de la performance du modèle lorsqu’il est déployésur des données réelles. Par conséquent, nous ne voulons pas optimiser notre modèle par rap-port aux données de test car cela ne nous donnera pas une estimation juste des performancesréelles. La bonne approche consiste donc à utiliser un ensemble de validation. Cependant, aulieu de scinder les données d’entraînement en un ensemble distinct d’entraînement et de vali-dation, nous utilisons la validation croisée k-fold. En plus de préserver les données d’entraîne-ment, cela devrait nous donner une meilleure estimation de la performance de généralisationsur l’ensemble de tests que d’utiliser un seul ensemble de validation.
3.3 Validation Croisée
Soit un modèle avec un ou plusieurs paramètres inconnus, et un ensemble de données d’ap-prentissage sur lequel on peut entraîner le modèle. Le processus d’apprentissage optimise les
40

Chapitre 3. Solution proposée 3.4. Architecture des réseaux de neurones
paramètres du modèle afin que celui-ci corresponde aux données le plus possible. Si on prendensuite un échantillon de validation indépendant issu de la même population d’entraînement,il constatera en général que le modèle ne réagit pas aussi bien à la validation que durant l’entraî-nement : on parle parfois de sur-apprentissage. La validation croisée est un moyen de prédirel’efficacité d’un modèle sur un ensemble hypothétique de validation lorsqu’un ensemble devalidation indépendant et explicite n’est pas disponible.
En k − fold cross validation, on divise l’échantillon original en k échantillons, puis on sé-lectionne un des k échantillons comme ensemble de validation et les k − 1 autres échantillonsconstitueront l’ensemble d’apprentissage. On calcule le score de performance, puis on répètel’opération en sélectionnant un autre échantillon de validation parmi les k − 1 échantillons quin’ont pas encore été utilisées pour la validation du modèle. L’opération se répète ainsi k foispour qu’en fin de compte chaque sous-échantillon ait été utilisé exactement une fois comme en-semble de validation. La moyenne de k erreurs quadratiques moyennes est enfin calculée pourestimer l’erreur de prédiction.
Ainsi, avec l’aide du Grid Search et de la validation croisée k-fold avec k = 10, nous testonsplusieurs hyperparamètres afin de faire ressortir les meilleurs modèles de prédiction.
3.4 Architecture des réseaux de neurones
Le réseau de neurones final ainsi que les différents paramètres qui lui sont liés a été ob-tenu avec la méthode d’essais et corrections. Nous avons donc essayé différents modèles deréseaux de neurones en changeant le nombre de couches ou de neurones en fonction des résul-tats obtenus. Dans cette optique d’essais et corrections, nous modifions les hyperparamètres etla structure du réseau à chaque essai mais certains détails sont restés inchangés à savoir :
• Nombre de neurones dans la couche d’entrée : notre ensemble de données possèdesix variables de prédiction (une par entrée) mais notre réseau 7. En effet, après le pré-traitement et une normalisation des variables le nombre passe de 6 à 7. Ce changementest dû au fait que les variables de prédiction telles que la distribution spatiale et la dis-tribution temporelle sont des variables qualitatives et contiennent respectivement 4 et 2catégories. Ces catégories sont converties sous forme numérique lors de la normalisationoù on évite d’énumérer les catégories de façon ordinale (1, 2, 3) pour éviter que le modèlen’accorde plus de valeur à une catégorie. C’est là qu’intervient le concept de variablesbidons utilisant l’encodage One-hot.
L’encodage One-hot est une méthode de représentation qui prend chaque valeur de caté-gorie et la convertit en un vecteur binaire de taille | i | (nombre de valeurs de la catégoriei) où toutes les colonnes sont égales à zéro en plus de la colonne de catégorie. Lorsqu’onutilise cet encodage dans notre cas, on obtient pour la distribution spatiale 4 et la distri-bution temporelle 2. Mais les premières variables dans cet encodage sont des références à
41

Chapitre 3. Solution proposée 3.5. Evaluation des réseaux de neurones
la catégorie donc nous les éliminons et on passe donc respectivement à 3 et 1. Ce qui nousrevient à un total de 7 variables ;
• Nombre de neurones dans la couche de sortie : un seul neurone correspondant à la me-sure de performance à prédire ;
• Nombre de couches cachées : ici après plusieurs essais, les résultats les plus intéressantsont étés atteints avec deux couches cachées dont nous faisons varier le nombre de neu-rones ;
• les fonctions d’activation : étant dans un cas de régression car prédisant des valeurs nu-mériques dans la couche de sortie, nous utilisons la fonction d’activation linéaire. Dansles couches cachées, nous avons effectué des tests en utilisant la fonction d’activationsoftmax et relu ;
• Fonction d’entraînement : pour la fonction d’entraînement, nous en avons testé plusieurstels que sgd, rmsprop et adam qui sont tous des variantes de l’algorithme de la descente dugradient. Nous retenons après tous les tests adam.
Nous présentons les résultats de deux différents modèles de réseau de neurones. L’un com-portant 4 neurones par couche cachée et l’autre 6. Les résultats sont présentés en fonction dunombre d’époques et de la taille des lots dans l’ensemble de données. Ainsi nous faisons varier :
• le nombre d’époques entre 50 et 500 avec une époque qui correspond au passage de l’en-semble de données entier à travers le réseau de neurones une seule fois ;
• la taille de lot (3, 4, 5) : au cours de l’entraînement, des poids sont affectés aux neuroneset on calcule une perte ou une précision. L’ensemble de données entier est divisé en lots.Ainsi, afin de minimiser la perte ou augmenter la précision après une évaluation, le réseaude neurones modifie en conséquence les poids à chaque lot.
3.5 Evaluation des réseaux de neurones
Après l’entraînement du réseau, nous lui passons les données de l’ensemble de validationafin de juger de son efficacité. Ainsi, il fait des prédictions sur cet ensemble que nous comparonsaux informations réelles. Nous évaluons le modèle en calculant différentes métriques tellesque le cœfficient de corrélation multiple (R, 3.1) , l’erreur moyenne quadratique (RMSE, 3.2),l’erreur moyenne absolue (MAE, 3.3), l’erreur relative absolue (RAE, 3.4), l’erreur quadratiquerelative (RRSE, 3.5) dont les formules sont données ci dessous.
R =
√√√√√√1−
∑ni=1
(Y − Y ′
)2∑n
i=1
(Y − Y
)2 (3.1)
42

Chapitre 3. Solution proposée 3.5. Evaluation des réseaux de neurones
RMSE =
√√√√ 1
n
n∑i=1
(Y − Y ′
)2(3.2)
MAE =1
n
n∑i=1
| Y − Y ′ | (3.3)
RAE =
∑ni=1 | Y − Y ′ |∑ni=1 | Y − Y |
(3.4)
RRSE =
√√√√√√∑n
i=1
(Y − Y ′
)2∑n
i=1
(Y − Y
)2 (3.5)
Dans les équations 3.1 à 3.5, Y représente la valeur actuelle à prédire, Y ′ la valeur prédite,Y la moyenne des valeurs actuelles et n la taille de l’ensemble de test.
Le cœfficient de corrélation multiple (R, 3.1) est une métrique que nous pouvons utiliserpour évaluer un modèle et qui est étroitement liée à la RMSE, mais qui a l’avantage d’êtreexempte d’échelle. Un bon modèle aura un R proche de 1.
Le RMSE 3.2 mesure l’erreur quadratique moyenne de nos prédictions. Pour calculer l’er-reur quadratique moyenne, pour chaque point, on calcule le carrée de la différence carrée entreles prédictions et la cible, puis on calcule la racine carré de la moyenne de ces valeurs. Pluscette valeur est élevée, plus le modèle est mauvais. L’erreur n’est jamais négative, puisque nouscalculons les erreurs de prévision individuelles avant de les additionner, mais serait nulle pourun modèle parfait.
L’erreur moyenne absolue (MAE, 3.3) est calculée en tant que moyenne des différences ab-solues entre les valeurs cibles et les prédictions. Le MAE est un score linéaire, ce qui signifieque toutes les différences individuelles sont pondérées de manière égale dans la moyenne. Parexemple, la différence entre 10 et 0 sera le double de la différence entre 5 et 0.
L’erreur relative absolue (RAE, 3.4) est relative à un prédicteur, qui n’est que la moyennedes valeurs réelles Y . Dans ce cas, cependant, l’erreur correspond uniquement à l’erreur ab-solue totale. Ainsi, l’erreur absolue relative prend l’erreur absolue totale et la normalise en ladivisant par l’erreur absolue totale du prédicteur simple. Pour un modèle parfait, l’erreur estnulle.
L’erreur quadratique relative (RRSE, 3.5) est relative à ce qu’elle aurait été si un simple pré-dicteur avait été utilisé. Plus précisément, ce simple prédicteur est simplement la moyenne des
43

Chapitre 3. Solution proposée 3.6. Conclusion
valeurs réelles. Ainsi, l’erreur quadratique relative prend l’erreur au carré totale et la normaliseen la divisant par l’erreur quadratique totale du prédicteur simple. Pour un modèle parfait,l’erreur est nulle.
3.6 Conclusion
Ce chapitre fait la synthèse sur la méthodologie utilisée dans l’élaboration des modèles deprédiction en décrivant les différentes étapes qui ont permis d’aboutir aux modèles finaux.Ensuite, il fait le point sur la configuration expérimentale ainsi que les différents paramètresutilisés.
44

Chapitre 4Résultats et discussions
Résumé. Les modèles proposés ont été testés et évalués suivant plusieurs métriquesdont le cœfficient de corrélation multiple et l’erreur quadratique moyenne. Ils pro-duisent généralement de meilleurs résultats que les modèles de l’état de l’art.
Introduction
Afin de déterminer le meilleur modèle et les hyperparamètres optimaux, nous utilisons l’al-gorithme du Grid Search et évaluons le modèle en calculant le R et le RMSE. Plusieurs testsont été effectués sur plusieurs architectures de réseaux de neurones, mais nous présentons iciceux ayant donné les meilleurs résultats.
4.1 Résultats obtenus pour quatre neurones dans les couchescachées
Les tableaux 4.1 à 4.12 présentent les résultats obtenus en calculant les différentes mé-triques entre les valeurs exactes et les valeurs prédites sur l’ensemble de validation en utilisantle modèle de réseau de neurones avec quatre neurones par couche cachée :
45
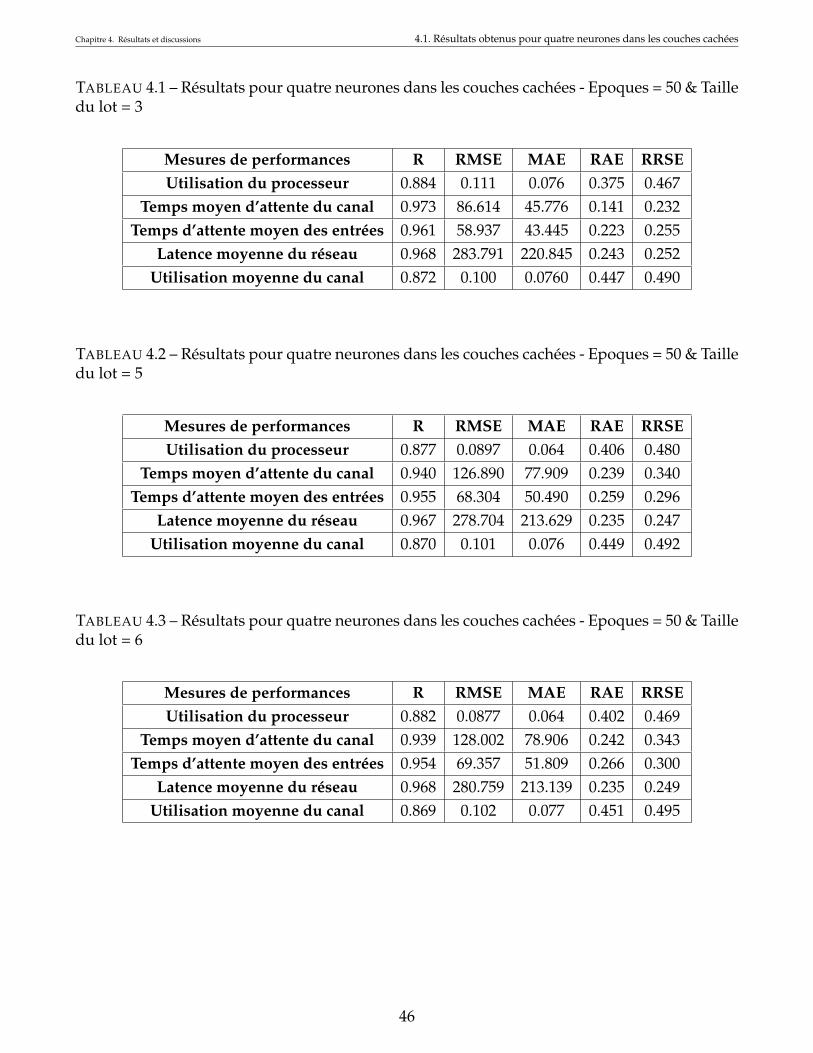
Chapitre 4. Résultats et discussions 4.1. Résultats obtenus pour quatre neurones dans les couches cachées
TABLEAU 4.1 – Résultats pour quatre neurones dans les couches cachées - Epoques = 50 & Tailledu lot = 3
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.884 0.111 0.076 0.375 0.467
Temps moyen d’attente du canal 0.973 86.614 45.776 0.141 0.232Temps d’attente moyen des entrées 0.961 58.937 43.445 0.223 0.255
Latence moyenne du réseau 0.968 283.791 220.845 0.243 0.252Utilisation moyenne du canal 0.872 0.100 0.0760 0.447 0.490
TABLEAU 4.2 – Résultats pour quatre neurones dans les couches cachées - Epoques = 50 & Tailledu lot = 5
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.877 0.0897 0.064 0.406 0.480
Temps moyen d’attente du canal 0.940 126.890 77.909 0.239 0.340Temps d’attente moyen des entrées 0.955 68.304 50.490 0.259 0.296
Latence moyenne du réseau 0.967 278.704 213.629 0.235 0.247Utilisation moyenne du canal 0.870 0.101 0.076 0.449 0.492
TABLEAU 4.3 – Résultats pour quatre neurones dans les couches cachées - Epoques = 50 & Tailledu lot = 6
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.882 0.0877 0.064 0.402 0.469
Temps moyen d’attente du canal 0.939 128.002 78.906 0.242 0.343Temps d’attente moyen des entrées 0.954 69.357 51.809 0.266 0.300
Latence moyenne du réseau 0.968 280.759 213.139 0.235 0.249Utilisation moyenne du canal 0.869 0.102 0.077 0.451 0.495
46

Chapitre 4. Résultats et discussions 4.1. Résultats obtenus pour quatre neurones dans les couches cachées
TABLEAU 4.4 – Résultats pour quatre neurones dans les couches cachées - Epoques = 100 &Taille du lot = 3
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.896 0.0828 0.057 0.360 0.443
Temps moyen d’attente du canal 0.961 102.669 60.902 0.187 0.275Temps d’attente moyen des entrées 0.982 43.728 30.855 0.158 0.189
Latence moyenne du réseau 0.970 274.172 207.831 0.229 0.243Utilisation moyenne du canal 0.919 0.081 0.0618 0.363 0.395
TABLEAU 4.5 – Résultats pour quatre neurones dans les couches cachées - Epoques = 100 &Taille du lot = 5
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.882 0.088 0.0619 0.390 0.472
Temps moyen d’attente du canal 0.977 80.271 36.973 0.113 0.215Temps d’attente moyen des entrées 0.978 48.304 34.297 0.176 0.209
Latence moyenne du réseau 0.969 278.883 216.632 0.238 0.248Utilisation moyenne du canal 0.885 0.0955 0.0725 0.426 0.465
TABLEAU 4.6 – Résultats pour quatre neurones dans les couches cachées - Epoques = 100 &Taille du lot = 6
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.885 0.111 0.078 0.387 0.466
Temps moyen d’attente du canal 0.947 119.221 72.041 0.221 0.320Temps d’attente moyen des entrées 0.975 51.565 36.654 0.188 0.223
Latence moyenne du réseau 0.969 279.119 216.937 0.239 0.249Utilisation moyenne du canal 0.879 0.098 0.075 0.439 0.477
47

Chapitre 4. Résultats et discussions 4.1. Résultats obtenus pour quatre neurones dans les couches cachées
TABLEAU 4.7 – Résultats pour quatre neurones dans les couches cachées - Epoques = 200 &Taille du lot = 3
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.9655 0.0486 0.033 0.208 0.260
Temps moyen d’attente du canal 0.975 82.034 39.836 0.122 0.220Temps d’attente moyen des entrées 0.987 37.328 26.738 0.137 0.162
Latence moyenne du réseau 0.970 272.034 194.973 0.215 0.241Utilisation moyenne du canal 0.949 0.065 0.0507 0.298 0.314
TABLEAU 4.8 – Résultats pour quatre neurones dans les couches cachées - Epoques = 200 &Taille du lot = 5
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.954 0.056 0.037 0.236 0.300
Temps moyen d’attente du canal 0.974 84.419 45.323 0.139 0.226Temps d’attente moyen des entrées 0.985 39.724 27.979 0.144 0.172
Latence moyenne du réseau 0.969 276.039 196.115 0.216 0.245Utilisation moyenne du canal 0.945 0.0672 0.0507 0.298 0.327
TABLEAU 4.9 – Résultats pour quatre neurones dans les couches cachées - Epoques = 200 &Taille du lot = 6
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.954 0.071 0.0500 0.245 0.298
Temps moyen d’attente du canal 0.975 82.225 38.261 0.117 0.220Temps d’attente moyen des entrées 0.986 38.662 28.419 0.146 0.167
Latence moyenne du réseau 0.970 275.279 196.017 0.216 0.244Utilisation moyenne du canal 0.944 0.068 0.0501 0.295 0.329
48

Chapitre 4. Résultats et discussions 4.1. Résultats obtenus pour quatre neurones dans les couches cachées
TABLEAU 4.10 – Résultats pour quatre neurones dans les couches cachées - Epoques = 500 &Taille du lot = 3
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.979 0.0376 0.0304 0.192 0.201
Temps moyen d’attente du canal 0.977 79.674 32.184 0.099 0.2136Temps d’attente moyen des entrées 0.989 34.291 26.236 0.135 0.148
Latence moyenne du réseau 0.967 286.796 209.145 0.230 0.255Utilisation moyenne du canal 0.979 0.042 0.032 0.188 0.203
TABLEAU 4.11 – Résultats pour quatre neurones dans les couches cachées - Epoques = 500 &Taille du lot = 5
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.970 0.045 0.034 0.217 0.243
Temps moyen d’attente du canal 0.976 80.973 31.962 0.098 0.217Temps d’attente moyen des entrées 0.988 35.705 27.552 0.141 0.155
Latence moyenne du réseau 0.970 271.375 196.288 0.216 0.241Utilisation moyenne du canal 0.979 0.042 0.032 0.186 0.205
TABLEAU 4.12 – Résultats pour quatre neurones dans les couches cachées - Epoques = 500 &Taille du lot = 6
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.969 0.046 0.034 0.216 0.246
Temps moyen d’attente du canal 0.976 81.881 33.881 0.104 0.219Temps d’attente moyen des entrées 0.989 34.372 24.782 0.127 0.1489
Latence moyenne du réseau 0.969 275.863 198.368 0.218 0.245Utilisation moyenne du canal 0.978 0.043 0.033 0.194 0.207
On note à partir des tableaux 4.1 à 4.12 que plus le nombre d’époques augmente plus bassedevient l’erreur jusqu’à converger dans la plupart des cas. De même, en faisant varier la tailledu lot on obtient des résultats différents qui en fonction de la mesure de performance sontgénéralement meilleurs avec la taille du lot la plus basse.
49

Chapitre 4. Résultats et discussions 4.2. Résultats obtenus pour six neurones dans les couches cachées
4.2 Résultats obtenus pour six neurones dans les couches ca-chées
Les tableaux 4.13 à 4.24 présentent les résultats obtenus en calculant les différentes mé-triques entre les valeurs exactes et les valeurs prédites sur l’ensemble de validation en utilisantle modèle de réseau de neurones avec six neurones par couche cachée :
TABLEAU 4.13 – Résultats pour six neurones dans les couches cachées - Epoques = 50 & Tailledu lot = 3
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.945 0.0612 0.041 0.259 0.328
Temps moyen d’attente du canal 0.976 81.599 39.704 0.122 0.219Temps d’attente moyen des entrées 0.978 47.742 35.115 0.1803 0.207
Latence moyenne du réseau 0.935 399.312 296.375 0.326 0.354Utilisation moyenne du canal 0.911 0.0845 0.0632 0.371 0.412
TABLEAU 4.14 – Résultats pour six neurones dans les couches cachées - Epoques = 50 & Tailledu lot = 5
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.944 0.0617 0.042 0.262 0.330
Temps moyen d’attente du canal 0.975 82.756 42.889 0.132 0.222Temps d’attente moyen des entrées 0.971 55.287 40.953 0.210 0.239
Latence moyenne du réseau 0.933 405.699 294.705 0.324 0.360Utilisation moyenne du canal 0.896 0.0912 0.0682 0.401 0.444
50

Chapitre 4. Résultats et discussions 4.2. Résultats obtenus pour six neurones dans les couches cachées
TABLEAU 4.15 – Résultats pour six neurones dans les couches cachées - Epoques = 50 & Tailledu lot = 6
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.940 0.0640 0.044 0.278 0.343
Temps moyen d’attente du canal 0.974 84.804 46.214 0.142 0.227Temps d’attente moyen des entrées 0.967 59.204 43.686 0.224 0.256
Latence moyenne du réseau 0.930 416.616 301.644 0.332 0.370Utilisation moyenne du canal 0.886 0.0951 0.072 0.421 0.463
TABLEAU 4.16 – Résultats pour six neurones dans les couches cachées - Epoques = 100 & Tailledu lot = 3
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.971 0.044 0.0337 0.213 0.237
Temps moyen d’attente du canal 0.976 81.440 35.557 0.109 0.218Temps d’attente moyen des entrées 0.985 39.473 29.737 0.153 0.171
Latence moyenne du réseau 0.941 379.479 289.740 0.319 0.337Utilisation moyenne du canal 0.965 0.0538 0.040 0.236 0.262
TABLEAU 4.17 – Résultats pour six neurones dans les couches cachées - Epoques = 100 & Tailledu lot = 5
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.972 0.045 0.033 0.211 0.233
Temps moyen d’attente du canal 0.977 80.225 36.927 0.113 0.215Temps d’attente moyen des entrées 0.984 40.944 29.992 0.154 0.177
Latence moyenne du réseau 0.940 387.524 296.358 0.326 0.344Utilisation moyenne du canal 0.948 0.065 0.048 0.284 0.318
51

Chapitre 4. Résultats et discussions 4.2. Résultats obtenus pour six neurones dans les couches cachées
TABLEAU 4.18 – Résultats pour six neurones dans les couches cachées - Epoques = 100 & Tailledu lot = 6
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.971 0.045 0.034 0.214 0.239
Temps moyen d’attente du canal 0.976 80.556 38.272 0.117 0.216Temps d’attente moyen des entrées 0.983 42.320 30.664 0.157 0.183
Latence moyenne du réseau 0.938 390.214 299.443 0.330 0.346Utilisation moyenne du canal 0.942 0.068 0.050 0.296 0.333
TABLEAU 4.19 – Résultats pour six neurones dans les couches cachées - Epoques = 200 & Tailledu lot = 3
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.983 0.034 0.028 0.176 0.184
Temps moyen d’attente du canal 0.977 79.814 32.699 0.100 0.214Temps d’attente moyen des entrées 0.987 37.024 27.765 0.143 0.160
Latence moyenne du réseau 0.955 332.973 246.803 0.272 0.296Utilisation moyenne du canal 0.982 0.039 0.029 0.170 0.188
TABLEAU 4.20 – Résultats pour six neurones dans les couches cachées - Epoques = 200 & Tailledu lot = 5
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.974 0.042 0.032 0.203 0.226
Temps moyen d’attente du canal 0.976 81.471 35.611 0.109 0.218Temps d’attente moyen des entrées 0.987 37.231 28.337 0.145 0.161
Latence moyenne du réseau 0.954 339.190 256.834 0.283 0.301Utilisation moyenne du canal 0.979 0.042 0.032 0.190 0.205
52
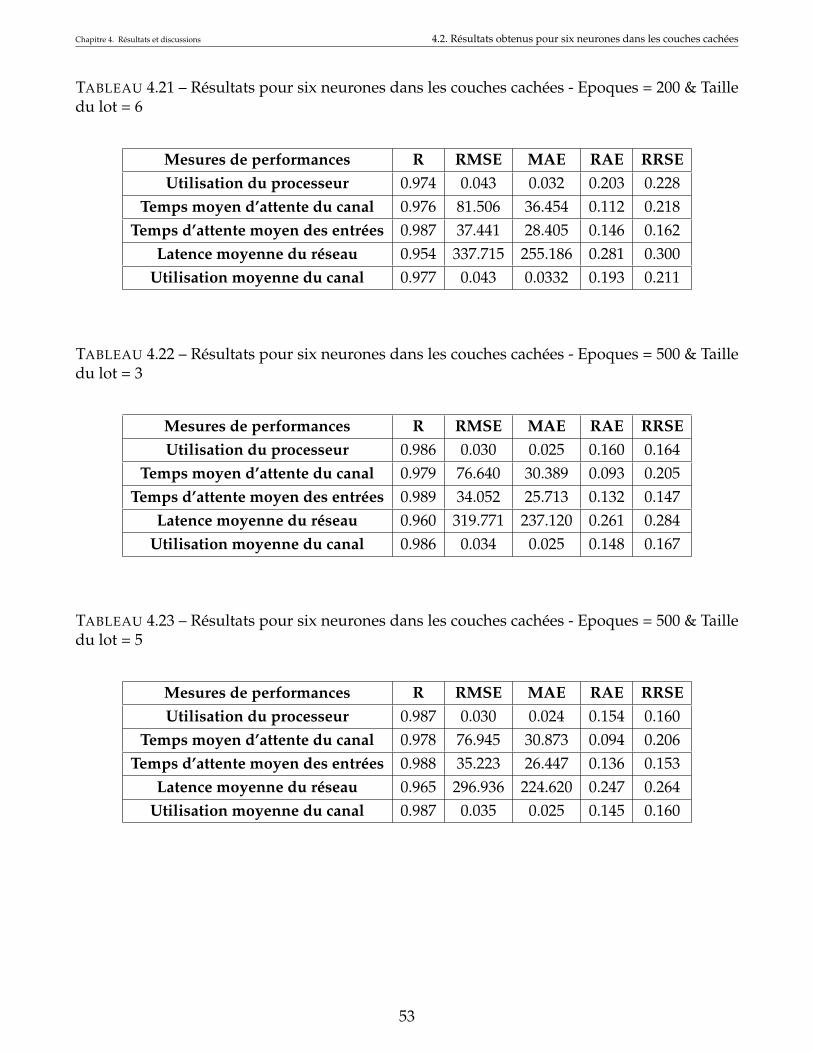
Chapitre 4. Résultats et discussions 4.2. Résultats obtenus pour six neurones dans les couches cachées
TABLEAU 4.21 – Résultats pour six neurones dans les couches cachées - Epoques = 200 & Tailledu lot = 6
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.974 0.043 0.032 0.203 0.228
Temps moyen d’attente du canal 0.976 81.506 36.454 0.112 0.218Temps d’attente moyen des entrées 0.987 37.441 28.405 0.146 0.162
Latence moyenne du réseau 0.954 337.715 255.186 0.281 0.300Utilisation moyenne du canal 0.977 0.043 0.0332 0.193 0.211
TABLEAU 4.22 – Résultats pour six neurones dans les couches cachées - Epoques = 500 & Tailledu lot = 3
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.986 0.030 0.025 0.160 0.164
Temps moyen d’attente du canal 0.979 76.640 30.389 0.093 0.205Temps d’attente moyen des entrées 0.989 34.052 25.713 0.132 0.147
Latence moyenne du réseau 0.960 319.771 237.120 0.261 0.284Utilisation moyenne du canal 0.986 0.034 0.025 0.148 0.167
TABLEAU 4.23 – Résultats pour six neurones dans les couches cachées - Epoques = 500 & Tailledu lot = 5
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.987 0.030 0.024 0.154 0.160
Temps moyen d’attente du canal 0.978 76.945 30.873 0.094 0.206Temps d’attente moyen des entrées 0.988 35.223 26.447 0.136 0.153
Latence moyenne du réseau 0.965 296.936 224.620 0.247 0.264Utilisation moyenne du canal 0.987 0.035 0.025 0.145 0.160
53

Chapitre 4. Résultats et discussions 4.3. Discussion
TABLEAU 4.24 – Résultats pour six neurones dans les couches cachées - Epoques = 500 & Tailledu lot = 6
Mesures de performances R RMSE MAE RAE RRSEUtilisation du processeur 0.987 0.030 0.024 0.151 0.159
Temps moyen d’attente du canal 0.979 76.654 29.814 0.092 0.205Temps d’attente moyen des entrées 0.988 35.954 26.887 0.138 0.156
Latence moyenne du réseau 0.965 296.256 218.030 0.240 0.263Utilisation moyenne du canal 0.984 0.036 0.027 0.160 0.176
L’un des premiers constats à faire est que le modèle de réseaux de neurones à six neuronesdans les couches cachées donne de meilleurs résultats que celui à quatre neurones dans lescouches cachées. Ensuite, à travers les tableaux 4.13 à 4.24, on remarque que les modèlesentrainés avec une taille de lot égale à trois donnent de meilleurs résultats sauf dans le cas dela latence moyenne du réseau où les fluctuations sont fortes.
4.3 Discussion
Des résultats présentés dans la section précédente, nous pouvons tirer plusieurs conclu-sions. Tout d’abord le modèle de réseau de neurones à six neurones dans les couches cachéesoffre de meilleurs résultats avec des erreurs moyennes quadratiques plus faibles et des cœf-ficients de corrélation multiple plus élevés. Ce qui veut dire que les prédictions faites avec lemodèle à six neurones sont plus proches des données de validation et qu’il s’agit ainsi de l’ar-chitecture ayant donné les meilleurs résultats.
Les figures 4.1a à 4.1e présentent les courbes d’entraînement du modèle pour l’obtentiondes mesures de performances. Ainsi, sur chaque figure nous présentons l’évolution du RMSE
en fonction du nombre d’époques et nous le faisons pour chaque taille de lot (batch).
54
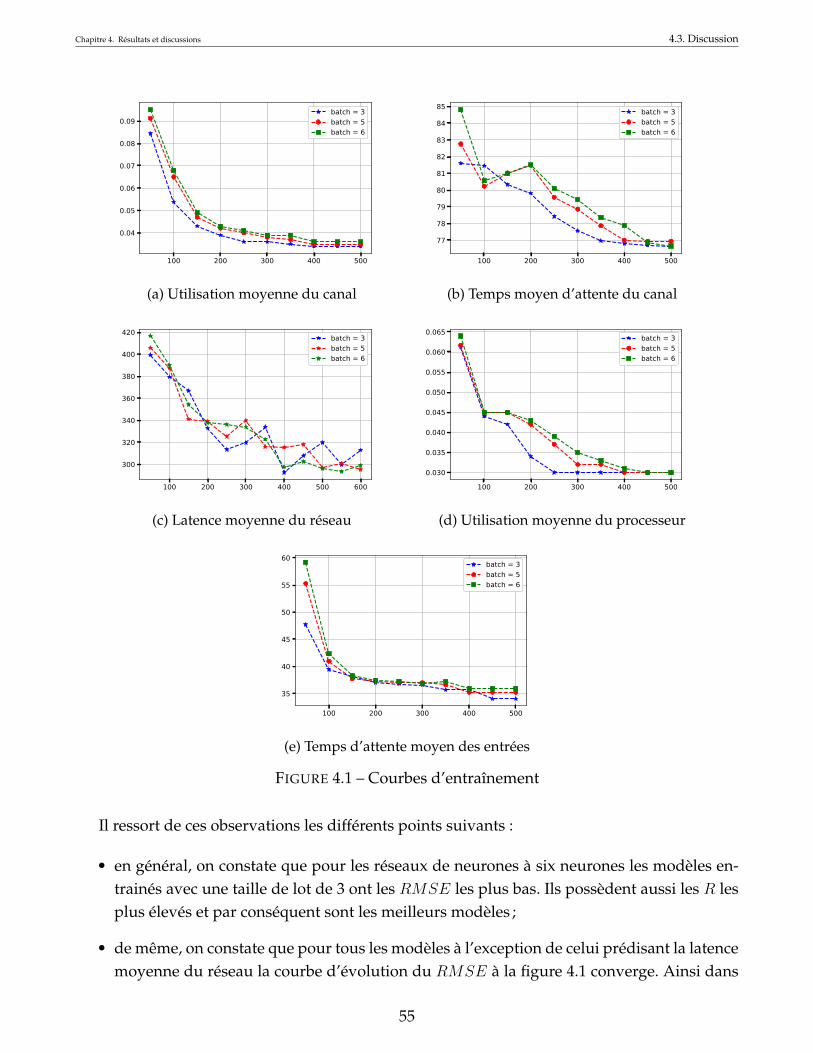
Chapitre 4. Résultats et discussions 4.3. Discussion
100 200 300 400 500
0.04
0.05
0.06
0.07
0.08
0.09batch = 3batch = 5batch = 6
(a) Utilisation moyenne du canal
100 200 300 400 500
77
78
79
80
81
82
83
84
85 batch = 3batch = 5batch = 6
(b) Temps moyen d’attente du canal
100 200 300 400 500 600
300
320
340
360
380
400
420 batch = 3batch = 5batch = 6
(c) Latence moyenne du réseau
100 200 300 400 5000.030
0.035
0.040
0.045
0.050
0.055
0.060
0.065batch = 3batch = 5batch = 6
(d) Utilisation moyenne du processeur
100 200 300 400 500
35
40
45
50
55
60batch = 3batch = 5batch = 6
(e) Temps d’attente moyen des entrées
FIGURE 4.1 – Courbes d’entraînement
Il ressort de ces observations les différents points suivants :
• en général, on constate que pour les réseaux de neurones à six neurones les modèles en-trainés avec une taille de lot de 3 ont les RMSE les plus bas. Ils possèdent aussi les R lesplus élevés et par conséquent sont les meilleurs modèles ;
• de même, on constate que pour tous les modèles à l’exception de celui prédisant la latencemoyenne du réseau la courbe d’évolution du RMSE à la figure 4.1 converge. Ainsi dans
55

Chapitre 4. Résultats et discussions 4.3. Discussion
la plupart des cas le RMSE décroit avec l’augmentation du nombre d’époques jusqu’àdevenir constant ;
– pour l’utilisation moyenne du canal, le temps moyen d’attente du canal 400 époquessuffisent donc pour atteindre un modèle satisfaisant ;
– pour le temps d’attente moyen des entrées il en faut 450 et pour l’utilisation moyennedu processeur il en faut 250.
Il faut aussi noter en ce qui concerne la latence moyenne du réseau, que les courbes d’en-traînement pour les tailles du lot égales à 3 et 5 tout d’abord décroissantes jusqu’au nombred’époques égal à 200 présentent, par le suite une évolution en dents de scie. Ceci peut être dû àla nature des données dans l’ensemble d’entraînement. En effet, avec le trop grand écart entreles valeurs de latence dans l’ensemble de données le modèle n’arrive pas à trouver un relationforte entre les variables de prédiction et la mesure de performance.
De même, pour la taille du lot égale à 6, la courbe suit une allure décroissante bien quene convergeant pas encore. Nous avons donc poursuivi l’entraînement du modèle pour cettemesure de performance jusqu’à atteindre la convergence à 800 époques. Nous présentons lesrésultats dans le tableau 4.27.
En outre, en comparant notre modèle à ceux de [11] on obtient les tableaux 4.25 à 4.29
TABLEAU 4.25 – Résultat pour la prédiction de l’utilisation moyenne du canal.
Mesures de performances R MAE RMSE RAE (%) RRSE (%)Notre Modèle 0.98 0.02 0.03 16.00 16.40SVR-RBF [11] 0.92 0.05 0.07 37.12 37.44MFANN [11] 0.90 0.06 0.08 40.66 43.87
TABLEAU 4.26 – Résultats pour la prédiction du temps d’attente moyen du canal.
Mesures de performances R MAE RMSE RAE (%) RRSE (%)Notre Modèle 0.98 30.38 76.64 9.30 20.5SVR-RBF [11] 0.97 42.73 82.62 13.04 21.63MFANN [11] 0.96 58.88 96.99 17.97 25.39
TABLEAU 4.27 – Résultats pour la prédiction de la latence moyenne du réseau.
Mesures de performances R MAE RMSE RAE (%) RRSE (%)Notre Modèle 0.97 211.764 278.441 23.31 24.72SVR-RBF [11] 0.97 184.60 277.96 19.76 23.31MFANN [11] 0.96 245.09 331.83 26.24 27.83
56
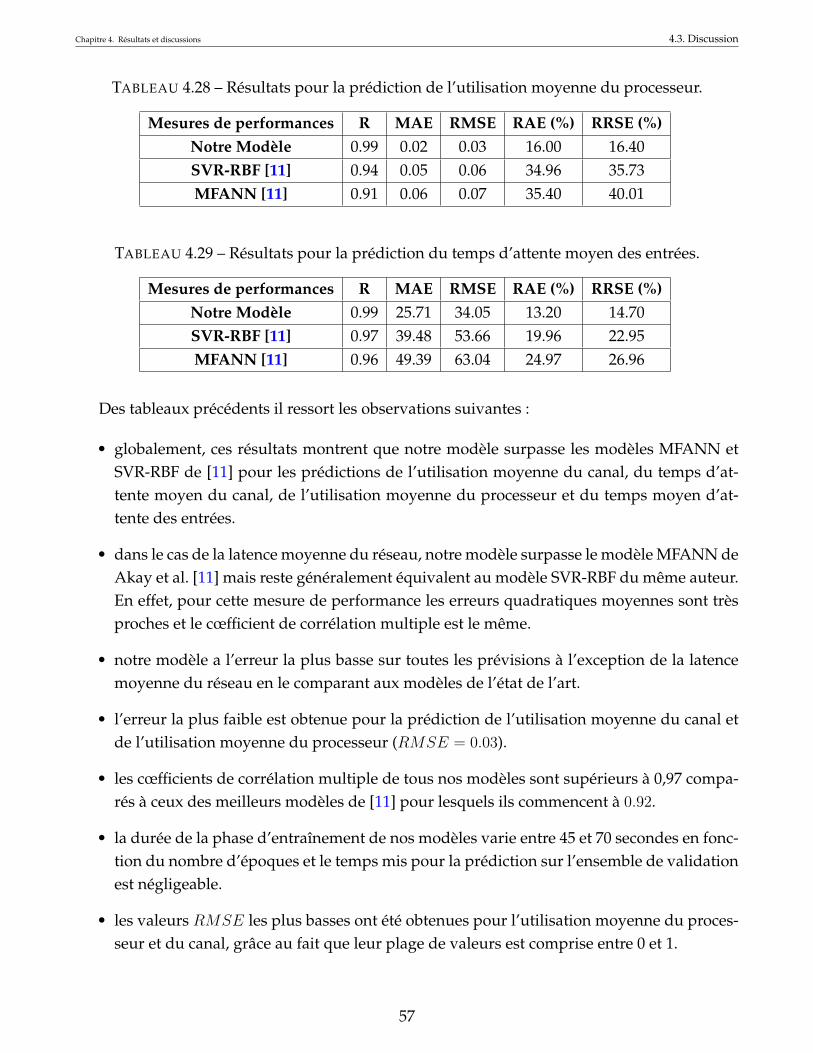
Chapitre 4. Résultats et discussions 4.3. Discussion
TABLEAU 4.28 – Résultats pour la prédiction de l’utilisation moyenne du processeur.
Mesures de performances R MAE RMSE RAE (%) RRSE (%)Notre Modèle 0.99 0.02 0.03 16.00 16.40SVR-RBF [11] 0.94 0.05 0.06 34.96 35.73MFANN [11] 0.91 0.06 0.07 35.40 40.01
TABLEAU 4.29 – Résultats pour la prédiction du temps d’attente moyen des entrées.
Mesures de performances R MAE RMSE RAE (%) RRSE (%)Notre Modèle 0.99 25.71 34.05 13.20 14.70SVR-RBF [11] 0.97 39.48 53.66 19.96 22.95MFANN [11] 0.96 49.39 63.04 24.97 26.96
Des tableaux précédents il ressort les observations suivantes :
• globalement, ces résultats montrent que notre modèle surpasse les modèles MFANN etSVR-RBF de [11] pour les prédictions de l’utilisation moyenne du canal, du temps d’at-tente moyen du canal, de l’utilisation moyenne du processeur et du temps moyen d’at-tente des entrées.
• dans le cas de la latence moyenne du réseau, notre modèle surpasse le modèle MFANN deAkay et al. [11] mais reste généralement équivalent au modèle SVR-RBF du même auteur.En effet, pour cette mesure de performance les erreurs quadratiques moyennes sont trèsproches et le cœfficient de corrélation multiple est le même.
• notre modèle a l’erreur la plus basse sur toutes les prévisions à l’exception de la latencemoyenne du réseau en le comparant aux modèles de l’état de l’art.
• l’erreur la plus faible est obtenue pour la prédiction de l’utilisation moyenne du canal etde l’utilisation moyenne du processeur (RMSE = 0.03).
• les cœfficients de corrélation multiple de tous nos modèles sont supérieurs à 0,97 compa-rés à ceux des meilleurs modèles de [11] pour lesquels ils commencent à 0.92.
• la durée de la phase d’entraînement de nos modèles varie entre 45 et 70 secondes en fonc-tion du nombre d’époques et le temps mis pour la prédiction sur l’ensemble de validationest négligeable.
• les valeurs RMSE les plus basses ont été obtenues pour l’utilisation moyenne du proces-seur et du canal, grâce au fait que leur plage de valeurs est comprise entre 0 et 1.
57

• leRMSE le plus élevé a été obtenu pour la latence réseau moyenne car l’écart entre les va-leurs minimale et maximale de cette mesure de performance est le plus élevé par rapportà celui des autres mesures de performance.
4.4 Conclusion
Ce chapitre a fait la synthèse des résultats de notre étude. Nous avons dans un premiertemps présenté les résultats obtenus en variant le nombre de neurones dans les couches cachéesdes réseaux et nous avons ensuite ressorti les meilleurs modèles obtenus. Les résultats de cesmodèles comparés à ceux de l’état de l’art sont globalement meilleurs.
58

Conclusion et perspectives
Le 2-dimensional Simultaneous Optical Multiprocessor Exchange Bus (2D SOME-Bus) avecsa bande passante élevée et sa faible latence devient un élément de choix réaliste pour fournirune puissance de calcul élevée. Pour s’assurer de son efficacité il est nécessaire d’en évaluerles performances. En effet, il faut pour une telle architecture, évaluer fiablement différents in-dicateurs tels que l’utilisation moyenne du canal, le temps moyen d’attente du canal, la latencemoyenne du réseau, l’utilisation moyenne du processeur et le temps d’attente moyen des en-trées. Cette évaluation est généralement faite analytiquement ou statistiquement et présentedes insuffisances comme le coût relativement élevé en temps.
Dans ce document, nous utilisons les méthodes d’intelligence artificielle plus précisémentl’apprentissage profond (deep learning) en nous basant sur un ensemble de données conte-nant des mesures de performance obtenues grâce à des variables de prédiction comme le rap-port entre le temps de transfert du message et le temps de traitement, le nombre de nœuds,le nombre de threads, les distributions spatiales et temporelles pour construire des modèlescapables d’évaluer ces mesures de performance. Nos modèles montrent de bons résultats surl’ensemble de données et nos résultats sont meilleurs que ceux obtenus dans l’état de l’art. Celamontre que les réseaux de neurones en particulier et l’intelligence artificielle en général peuventreprésenter une alternative intéressante dans la prédiction des mesures de performance des ar-chitectures multi-processeurs.
Des perspectives intéressantes sont envisagées. Il serait intéressant d’appliquer d’autres mé-thodes d’intelligence artificielle au problème afin d’améliorer les modèles de prédiction. Aussi,tester la prédiction des mesures de performance en utilisant des données réelles et appliquerles techniques à d’autres types d’architecture multiprocesseurs sont des perspectives intéres-santes.
59

English Part
60

Introduction
It is important to build computers running on the petaflops-scale with regards to the in-creasing demand for computing power. These computers must offer low latency and operateat high speeds to be qualified as effective. Many applications, operating on parallel computers,outperform the possibilities offered by conventional computing techniques. Among the dif-ferent programming techniques of parallel computers, message passing environments are themost popular because they are flexible, easy to understand, portable. Users of these parallelcomputers want them to be as efficient as possible. Performance is therefore an important con-sideration when bulding parallel computers. Essentially there are two methods to evaluate theperformance of these systems: Analytic performance modeling and Simulation performancemodeling. Analytic performance modeling is the use of mathematical techniques to solve sys-tems of equations that express the steady-state behavior of computer systems. The analyticalmodel has the disadvantage of becoming useless when the dynamics of the multiprocessor isconsidered. Simulation modeling uses programs called simulators that reflect the behavior ofthe modeled system. It is more fexible than analytic modeling because the model is representedby a computer program rather than a system of equations but it has the disadvantage of beingtime-consuming [4]. Reducing this time would be an important advantage when designingmultiprocessor architectures. In this work, we propose some neural network models that haveshown good results in the prediction of performance metrics of SOME-Bus 2D multiprocessorarchitectures. Thanks to our architecture and the different parameters used, our models givebetter results than the different models of the state-of-the-art on most of the prediction. Thiswork corroborates the hypothesis that artificial intelligence can be used in this domain.
4.5 The SOME-bus architecture
Processors in a multiprocessor architecture must communicate with each other using aninterconnect network. This network can be a bottleneck if it cannot support simultaneous com-munication between arbitrary processor pairs. There are several ways to interconnect theseprocessors. We present below two SOME-Bus architectures (the 1D SOME-Bus and the 2-DSOME-Bus) and the difference between them as described in [11].
4.5.1 The 1D SOME-bus architecture
The simultaneous optical multiprocessor exchange bus (SOME-Bus) incorporates opto-electronicdevices into a high-performance processing architecture. It is a low-latency, high-bandwidthfiber optic interconnection network that connects each node directly to all others nodes with-out contention. One of its main features is that each of the N nodes has a dedicated broadcastchannel operating at 20−30GB/s, realized by a group of wavelengths in a specific fiber, and an
61

input channel interface based on a receiver network that simultaneously monitors all N chan-nels, resulting in a fully connected network. The receiver network does not need to performrouting and, as a result, its hardware complexity (including detector, logic, and packet mem-ory storage) is low. This organization eliminates the need for global arbitration and providesbandwidth that scales directly with the number of nodes in the system. No node is ever pre-vented from transmitting by another transmitter or because of a shared switching logic conflict.A queue is associated with each input channel, allowing messages from any number of proces-sors to arrive and be buffered simultaneously until the local processor is ready for them.[3].
4.5.2 The 2D SOME-bus architecture
The 2D SOME-Bus contains N2 nodes with N horizontal and N vertical networks of 1DSOME-Bus. Each node is connected to a 1D horizontal SOME bus and a 1D vertical SOME-Bus.At each node, an electro-optical converter composed of a dual receiver and transmitter pairmakes it possible to forward and broadcast (in cut through manner) the messages broadcast ona bus in the other dimension[3]. Figure 4.2 presents an example of a two dimensional SOME-Bus with 16 nodes.
Figure 4.2 – Example of two dimensional SOME-Bus with 16 Nodes [11]
As explained in [11], if a node Nij (connected to the vertical bus Vi and the horizontal busHj) sends a message to the nodeNmn and i = m or j = n, then a single bus (respectively verticalor horizontal) is used. The header of the message includes the identification of the destination
62

node and the message is broadcast on the appropriate bus. On the other hand, if i 6= m andj 6= n, then the message is first broadcast on the horizontal bus Hj to the node Nmj with theheader containing an indication that the node Nmj broadcasts the message on the vertical busVm so that it can be delivered to its final destination, node Nmn. By symmetry, the source nodemay choose to first broadcast the message on the vertical bus Vi to the intermediate node Nin
for rebroadcasting on the horizontal bus Hn [3].
4.6 Related Works
Artificial intelligence methods have already been applied to predict the performance mea-sures of a multiprocessor architecture (for example [9, 8, 10]). In [10], Akay and Abasikeles havepredicted the performance measures of a multiprocessor architecture employing the distributedshared-memory programming model on the 1-dimensional Simultaneous Optical Multiproces-sor Exchange Bus (1D SOME-Bus) architecture. The authors have generated a dataset based ona statistical simulation of the architecture with the following input variables: ratio of the meanmessage channel transfer time to the mean thread run time (T/R), probability that a block canbe found in modified state, probability that a data message is due to a write miss, probabil-ity that a cache is full and probability of having an upgrade ownership request. They predictaverage network latency, average channel waiting time and average processor utilization byusing Support Vector Regression (SVR) and obtain relatively good performances. In [9], Za-yid and Akay use Multi-layer Feed-forward Artificial Neural Network (MFANN) to predictthe performance measures of the 1D SOME-Bus architecture employing the message passingprogramming model. The authors have used OPNET Modeler [20] to statistically simulate themessage passing in the architecture. The input variables of the prediction model include T/R,node number, thread number and traffic pattern while the output variables of the predictionmodel include average channel waiting time, average channel utilization, average network la-tency, average processor utilization and average input waiting time. In that work, MFANNbased prediction model provides relatively good performance.
Further Akay et al. [11] use SVR, MFANN and Multiple Linear Regression (MLR) to predictthe performance measures of the 2D SOME-Bus multiprocessor architecture using the messagepassing programming model. OPNET Modeler was used to simulate the message passing 2DSOME-Bus multiprocessor architecture and to create the training and testing datasets. Theobtained dataset has five input variables (T/R, node number, thread number, spatial distribu-tion of traffic and traffic mode) and five output variables (average channel utilization, averagechannel waiting time, average network latency, average processor utilization and average inputwaiting time). The authors concluded that SVR using the radial basis function kernel performsbetter than the two other approaches on their dataset.
In this wprk, artificial neural networks have been employed to predict the performancemeasures of the 2-D SOME-Bus multiprocessor architecture using the message passing pro-
63

gramming model. We use the dataset of [11] to conduct our experiments and show that ANNcan have good performances on this problem.
4.7 Primer on Artificial Neural Network
Artificial neural networks, one of the main tools of machine learning, are architectures de-signed to mimic the behavior of a biological neural network. Simulating the behavior of bi-ological neurons, an artificial neural network consists of an input layer, one or more hiddenlayers and an output layer. The input layer receives the data and passes it to the hidden layersthat process it and transform it before sending it to the output layer. The basic element of anartificial neural network is the artificial neuron. Like the biological one, it consists of inputs(dendrites) and output (axon). The neuron receives data at its inputs, then performs operationson these data and passes the result of these operations to other neurons via its output. In ar-tificial neurons, these different operations are done with an activation function. An artificialneural network is composed of several neurons connected by links and interacting with eachother. Each link is associated with a weight that is associated with the data from this link. Thereare two types of topologies in the constitution of an artificial neural network: feed-forward andfeedback. In the first the flow of information is unidirectional. A neuron sends information toanother neuron (on the next layer) from which it receives no information. This type of networkshas fixed inputs and outputs. In the second type, feedback loops are allowed. Information canbe transmitted from an upper layer to a lower layer. This can be used when one needs to keepthis information in mind. ANN learns through a training phase. This training allows the net-work to find and memorize patterns in the data submitted to it. A well trained artificial neuralnetwork has weights that amplify the signal and attenuate the noise. Larger weight meansa closer correlation between a signal and the result of the network. Entries associated withhigher weights will affect the network’s interpretation of the data more than the entries associ-ated with lower weights. Actually, the learning process for a learning algorithm using weightsis the process of adjusting weights and biases.
4.8 Technical choices
Here we synthesize the various tools, both hardware and software that we used throughoutour study.
The Dataset For the experiments, we have used the dataset Optical Interconnection NetworkData Set 1. This dataset was generated by the simulation environment OPNET Modeler [20]and used for the experiments of [11]. It includes 640 samples and is available online from
1http://archive.ics.uci.edu/ml/datasets/Optical+Interconnection+Network+
64

[21]. It contains data such as time distribution and spatial distribution of traffic on the bus. Insimulations, client-server (i.e. a server node sends packets to respond to the reception of packetsfrom clients) and asynchronous traffic modes where used as temporal distributions. For spatialdistributions a set of well-known distributions was used: bit reverse (BR), perfect shuffle (PS),uniform (UN) and hot region (HR). The processing time (R) is assumed to be exponentiallydistributed with a mean of 100 clock cycles. The message transfer time (T ) is assumed to beuniformly distributed with mean in range from 5 to 100 clock cycles. The other parameters ofthe simulation are the number of nodes in the system (selected as 16 and 64), the initial numberof threads run by each processor (selected as 4, 6, 8 and 10). The outputs of the simulationare average channel utilization (i.e. percent of time that the channel server is busy), averagechannel waiting time (i.e. average waiting time of a packet in the channel queue until it istransmitted on the link), average network latency (i.e. the time between a request message isenqueued at the output channel and the corresponding data message is received in the inputqueue), average processor utilization (i.e. percent of time that threads are run by a processor)and average input waiting time (i.e. waiting time of a packet in the input queue until it isserviced by the processor).
Experimental setup The implementations and tests have been realized with python and ana-conda distribution packages [23, 24]. We also use keras [26] with tensorflow [25] as backend tobuild the neural network. All experiments were conducted on a 2.8 GHz Intel core i7 processorusing Ubuntu 18.04 LTS [22].
4.9 Our solution
We describe in this section the experimental setups put in place to obtain prediction models.We also detail the different parameters involved in the training and construction of these mod-els. Carrying out the different experiments in order to obtain the best prediction model requiresusing the dataset in the best way and following the best associated method.
Division and standardization of the dataset In the process of obtaining the prediction modelthere is the training step. To do the training we use data present in the dataset available to us. Sofor the training of the model we use 80% of the data and 20% for the test. Then the available databeing in different formats, it is necessary to make a standardization. It’s all about getting all thedata at the same scale: if the scales of the different variables in the dataset are very different, itmay have a bad effect on the training. Ensuring that the variables in the dataset are normalizedimplicitly allows the neural network to consider them equally. Their representation is the same.During this normalization we assign numerical values to the qualitative data. Thus, for all thevalues of the dataset are found between 0 and 1 to reach faster and better the convergence.
65

Training of the neural network During this phase we proceed to train the network. Train-ing in which different parameters such as neuron weights, bias are varied to obtain an effectivemodel on the training set. But in order to obtain the best possible parameters we need to choosehyperparameters efficiently (that is to say the parameters that we can modify namely, the num-ber of epochs, the size of the batches, the activation functions, optimization algorithms). Testingseveral hyperparameters to find the perfect combination is expensive in time and computingpower There are different algorithms among which Grid Search, Random Search ... We usedthe grid Search because it is a simple method and allows to test all combinations of addedhyperparameters. It consists in setting up a grid of values of these hyperparameters and, foreach combination, forming a model and testing the model on validation data. To evaluate eachcombination of hyperparameter values, we must evaluate them on a validation set. Hyperpa-rameters can not be tested on test data. We can only use the test data once when we evaluatethe final model. The test data is meant to be used to estimate the performance of the modelwhen deployed on real data. Therefore, we do not want to optimize our model against testdata as this will not give us a fair estimate of actual performance. The right approach is to usea validation set. However, instead of splitting the training data into a separate set of trainingand validation, we use cross-validation textit k-fold. In addition to preserving the trainingdata, this should give us a better estimate of the generalization performance on the test set thanusing a single validation set.
Cross validation Suppose you have a model with one or more unknown parameters, anda set of training data on which you can train the model. The learning process optimizes themodel’s parameters so that it fits the data as best as possible. If we then take an independentvalidation sample from the same training population, it will generally prove that the modeldoes not react as well to validation as during training: we sometimes talk about over-learning.Cross validation is a way of predicting the effectiveness of a model on a hypothetical validationset when an independent and explicit validation set is not available. In Kfold cross validationwe divide the original sample into k samples, then we select one of the k samples as the vali-dation set and the k − 1 other samples will constitute the learning set. The performance scoreis calculated and then repeated by selecting another validation sample from the k − 1 samplesthat have not yet been used for model validation. The operation is then repeated k times foreach subsample to be used exactly once as a validation set. The average of k mean squarederrors is finally calculated to estimate the prediction error. Thus with the help of Grid searchand cross-validation textit k-fold with k = 10 we test several hyperparameters to bring out thebest prediction models.
Architecture of our neural networks The final neural network and its various related param-eters were obtained with the trial and errors method. We have therefore tried different modelsof neural networks and change the number of layers or neurons according to the results ob-
66

tained. In this optics of tests and corrections we modify the hyperparameters and the structureof the network with each tests but some details remained unchanged namely:
• Number of neurons in the input layer: our data set has six inputs but our network 7. In-deed after the preprocessing and a normalization of the variables the number goes from6 to 7. Indeed, the variables of predictions such as spatial distribution and temporal dis-tribution are qualitative variables and contain respectively 4 and 2 categories. These cat-egories are converted to digital form in standardization. And in this last one avoids tolist the categories in ordinal way (1, 2, 3) to avoid that the model does not grant morevalues to one category than to another. This is where the concept of bogus variables usingOne-hot encoding comes in.
One-hot encoding is a representation method that takes each category value and convertsit to a size binary vector | i | (number of values of category i) where all columns are zeroin addition to the category column. When using this encoding in our case we obtain forthe spatial distribution 4 and the temporal distribution 2. But the first variables in thisencoding are references to the category so we eliminate them so we go respectively to 3and 1. What we return to a total of 7 variables;
• Number of neurons in the output layer: a single neuron corresponding to the perfor-mance measure to be predicted in the output layer;
• Number of hidden layers: here after several tests the most interesting results were achievedwith two hidden layers whose number of neurons we vary;
• Activation functions: being in a regression case because predicting numerical values inthe output layer we use the linear activation function. In the hidden layer we performedtests using the softmax and relu activation function;
• Training function: for the training function we have tested several such as sgd, rmspropand adam which are all variants of the algorithm of the descent of the gradient. We retainafter all the tests adam.
We present the results of two different models of neural networks. One with 4 neurons perhidden layer and the other 6. The results are presented according to the number of epochs andthe size of the batches in the data set. So we vary:
• the number of epochs between 50 and 500 with an epoch that corresponds to the passageof the entire data set across the neural network only once;
• batch size (3, 4, 5): When training, weights are assigned to the neurons and we calculate aloss or accuracy. The entire dataset is divided into batches. Thus in order to minimize theloss or increase the accuracy after an evaluation at each batch the neural network modifiesthe weights accordingly.
67

Evaluation metrics In order to compare our models with the state-of-the-art machine learningmodels from [11], we use the following metrics to evaluate the different models: R (4.1),RMSE
(4.2), MAE (4.3), RAE (4.4), and RRSE (4.5):
R =
√√√√√√1−
∑ni=1
(Y − Y ′
)2∑n
i=1
(Y − Y
)2 (4.1)
RMSE =
√√√√ 1
n
n∑i=1
(Y − Y ′
)2(4.2)
MAE =1
n
n∑i=1
| Y − Y ′ | (4.3)
RAE =
∑ni=1 | Y − Y ′ |∑ni=1 | Y − Y |
(4.4)
RRSE =
√√√√√√∑n
i=1
(Y − Y ′
)2∑n
i=1
(Y − Y
)2 (4.5)
In equations 3.1 to 3.5, Y represents the present value to be predicted, Y ′ the value that waspredicted, Y the mean of the current values and n the size of the test set. We describe beloweach metric.
• The multiple correlation coefficient (R, 4.1) is a metric closely related to the RMSE (Equa-tion 4.2), but has the advantage of being scale-free. A good model will have an R close to1.
• The RMSE (Equation 4.2) measures the root mean squared error of our predictions. Toobtain the root mean squared error, for each point, we compute the square root of thesquare difference between the predictions and the target, and then average these values.Higher this value is, worse the model is.
• The mean absolute error (MAE, 4.3) is the average of absolute differences between targetvalues and predictions. The MAE is a linear score, which means that all individual dif-ferences are weighted equally in the mean. For example, the difference between 10 and 0will be twice the difference between 5 and 0.
• The relative absolute error (RAE, 4.4) is related to a predictor, which is only the average ofthe actual values Y . In this case, however, the error only corresponds to the total absoluteerror. Thus, the relative absolute error takes the total absolute error and normalizes it by
68

dividing it by the absolute error of the simple predictor. For a perfect model, the error iszero.
• the relative squared error (RRSE, 4.5) is related to what it would have been if a simplepredictor had been used. More precisely, this simple predictor is the average of the realvalues. Thus, the relative quadratic error takes the total squared error and normalizes itby dividing it by the total squared error of the simple predictor. For a perfect model, theerror is zero.
4.10 Result and discussions
We compare the results obtained with the MFANN neural network and the SVR-RBF modelof [11]. These two models represent the best models they have obtained. Table 4.30, Table 4.31,Table 4.32, Table 4.33, and Table 4.34 summarize the performance of our models and those of[11] respectively for the prediction of the average channel utilization, average channel waitingtime, average network latency, average processor utilization and average input waiting time,with regard to R, RMSE, MAE, RAE(%), RRSE(%).
Table 4.30 – Results for prediction of average channel utilization.
Mesures de performances R MAE RMSE RAE (%) RRSE (%)Notre Modèle 0.98 0.02 0.03 16.00 16.40SVR-RBF [11] 0.92 0.05 0.07 37.12 37.44MFANN [11] 0.90 0.06 0.08 40.66 43.87
Table 4.31 – Results for prediction of average channel waiting time.
Mesures de performances R MAE RMSE RAE (%) RRSE (%)Notre Modèle 0.98 30.38 76.64 9.30 20.5SVR-RBF [11] 0.97 42.73 82.62 13.04 21.63MFANN [11] 0.96 58.88 96.99 17.97 25.39
Table 4.32 – Results for prediction of average network latency.
Mesures de performances R MAE RMSE RAE (%) RRSE (%)Notre Modèle 0.97 211.764 278.441 23.31 24.72SVR-RBF [11] 0.97 184.60 277.96 19.76 23.31MFANN [11] 0.96 245.09 331.83 26.24 27.83
69

Table 4.33 – Results for prediction of average processor utilization.
Mesures de performances R MAE RMSE RAE (%) RRSE (%)Notre Modèle 0.99 0.02 0.03 16.00 16.40SVR-RBF [11] 0.94 0.05 0.06 34.96 35.73MFANN [11] 0.91 0.06 0.07 35.40 40.01
Table 4.34 – Results for prediction of average input waiting time.
Mesures de performances R MAE RMSE RAE (%) RRSE (%)Notre Modèle 0.99 25.71 34.05 13.20 14.70SVR-RBF [11] 0.97 39.48 53.66 19.96 22.95MFANN [11] 0.96 49.39 63.04 24.97 26.96
The results of the different prediction models have given decreasing RMSE as the number ofepochs increases and the batch size is changed. These results are referenced on the convergencecurves of Figure 4.3a, Figure 4.3b, Figure 4.3c, Figure 4.3d, and Figure 4.3e.
70

100 200 300 400 500
0.04
0.05
0.06
0.07
0.08
0.09batch = 3batch = 5batch = 6
(a) Convergence curve of Channel Utilization
100 200 300 400 500
77
78
79
80
81
82
83
84
85 batch = 3batch = 5batch = 6
(b) Convergence curve of Channel WaitingTime
100 200 300 400 500 600
300
320
340
360
380
400
420 batch = 3batch = 5batch = 6
(c) Convergence curve of Network ResponseLatency
100 200 300 400 5000.030
0.035
0.040
0.045
0.050
0.055
0.060
0.065batch = 3batch = 5batch = 6
(d) Convergence curve of Processor Utilization
100 200 300 400 500
35
40
45
50
55
60batch = 3batch = 5batch = 6
(e) Convergence curve of Input Waiting Time
Figure 4.3 – Courbes d’entraînement
It comes out from the results obtained the following observations:
• Overall, these results show that our model outperforms the models MFANN and SVR-RBF of [11] for predicting the average channel utilization, average channel waiting time,average processor utilization, and average input waiting time.
• In the case of the average network latency our model surpasses the MFANN model of [11]
71

but remains generally equivalent to the SVR-RBF model of the same author. Indeed, forthis performance measure, the root mean squared errors are very close and the multiplecorrelation coefficient is the same.
• Our ANN model has the lowest error on all predictions compared to other models.
• The lowest error is obtained for the prediction of the average channel utilization and av-erage processor utilization (RMSE = 0.03).
• The R for all our models is ≥ 0.97 while the best models of [11] starts from 0.92.
• The training phase duration of our models varies between 45 and 70 seconds and theirexecution time on the test set is negligible.
• The lowest RMSE was obtained for of average processor utilization and average channelutilization thanks to the fact that their values range is between 0 and 1.
• The highest RMSE was obtained for average network latency because the gap betweenthe minimum and maximum values of the average network latency is the highest com-pared to that of the other performance measures.
Conclusion
The 2-dimensional Simultaneous Optical Multiprocessor Exchange Bus (2D SOME-Bus) withits high bandwidth and low latency becomes a realistic choice element to provide high comput-ing power. To ensure its effectiveness, it is necessary to evaluate its performance. Speaking ofperformance it is necessary for such an architecture to reliably evaluate different metrics suchas average channel utilization, average channel latency, average network latency, average CPUusage and average latency of inputs . This assessment is usually done analytically or statisti-cally and has shortcomings such as the relatively high cost in time.In this document, we use artificial intelligence methods, specifically deep learning, based on aset of data made available to us and containing performance measures obtained using predic-tion variables such as the report. between the message transfer time and the processing time,the number of nodes, the number of threads, the spatial and temporal distributions to buildmodels able to evaluate these performance measures. Our models show good results on thedata set and our results are better than those obtained in the state of the art while being in-expensive in time. This shows that neural networks in particular and artificial intelligence ingeneral can represent an interesting alternative in the prediction of performance measurementsof multiprocessor architectures. Interesting perspectives are being considered, such as applyingother artificial intelligence methods to the problem, testing the prediction of performance mea-sures using real data, and applying the techniques to other types of multi-media architectures.processors.
72

Bibliographie
[1] SCHMIDHUBER J., Deep learning in neural networks : An overview. The Swiss AI Lab IDSIA.2014.
[2] GABELI F. Algorithms and Parallel Computing. First Ed., Wiley, New York, 2011.
[3] KATSINIS C., NABET B. A Scalable Interconnection Network Architecture forPetaflops Computing. The Journal of Supercomputing. 2004, 27(2), pp. 103–128,DOI :10.1023/B :SUPE.0000009318.91562.b0.
[4] YORAM E. Methods for Performance Evaluation of Parallel Computer Systems. Tech. rep.Columbia University Academic Commons, 1986, DOI :10.7916/D8959RKP.
[5] KURIAN J. L., Performance Evaluation : Techniques, Tools and Benchmarks. The University ofTexas at Austin. 2004.
[6] LAXMI N., BHUYAN, XIODONG Z., Tutorial on Multiprocessor Performance Measurement andEvaluation. 1994.
[7] AKAY M. F., C. Katsinis. Performance Evaluation of a Broadcast-based Distributed Shared Me-mory Multiprocessor by OPNET Modeler. 2013.
[8] GENBRUGGE D., EECKHOUT L. Statistical simulation of chip multiprocessors runningmulti-program workloads. In : Proceedings of 25th International Conference on Computer De-sign, IEEE, 2007, 10 pp. 464– 471.
[9] ZAYID E.I.M., AKAY M.F. Predicting the performance measures of a message-passing mul-tiprocessor architecture using artificial neural networks. Neural Computing and Applications,2012, 23(7-8), pp. 2481– 2491, DOI :10.1007/s00521-012-1267-9.
[10] AKAY M.F., ABASIKELES¸ I. Predicting the performance measures of an optical distribu-ted shared memory multiprocessor by using support vector regression. Expert Systems withApplications. 2010, 37(9), pp. 6293–6301, DOI : 10.1016/j.eswa.2010.02.092.
73

[11] AKAY M.F., ACI C.I, ABUT F. Predicting the performance measures of a 2-dimensionalmessage passing multiprocessor architecture by using machine learning methods. NeuralNetwork World. 2015, pp 241–265 DOI : 10.14311/NNW.2015.25.013.
[12] ACI C.I., AKAY M.F. A new congestion control algorithm for improving the performanceof a broadcast-based multiprocessor architecture. Journal of Parallel and Distributed Compu-ting. 2010, 70(9) pp. 930–940 DOI : 10.1016/j.jpdc.2010.06.003.
[13] PATTERSON J., GIBSON A. Deep Learning A Practitioner’s Approach. O’REILLY, First Ed.,2017.
[14] BUDUMA N. Fundamentals of Deep Learning Designing Next-Generation Machine IntelligenceAlgorithms. O’REILLY, First Ed., 2017.
[15] KIRK M. Thoughtful Machine Learning with Python. O’REILLY, First Ed., 2017.
[16] KONSTANTINOS T., KOTAS S., Dimitrios S., Axel J. Designing 2D and 3D Network-on-ChipArchitectures. Springer, First Ed., 2014.
[17] MUHAMMAD Q., STEPHEN J. Multicore Technology : Architecture, Recon
guration, and Modeling. CRC Press., 2014.
[18] DALLY W.J., TOWLES B. Principles and Practices of Interconnection Networks. Morgan Kauf-mann Publishers Inc., 2004.
[19] ADIGA N.R., BLUMRICH M.A., CHEN D., COTEUS P., GARA A., GIAMPAPA M.E., HEI-DELBERGER P., SINGH S., STEINMACHER-BUROW B.D., TAKKEN T., TSAO M., VRA-NAS P. Blue Gene/L torus interconnection network. IBM Journal of Research and Development.2005, 49(2.3), pp. 265–276, DOI : 10.1147/rd.492.0265.
74

Webographie
[20] OPNET Modeler. OPNET Technologies. Disponible depuis : www.opnet.com. Consultéle 18 Septembre 2018.
[21] UCI Machine Learning Repository. Disponible depuis : http://archive.ics.uci.edu. Consulté le 18 Septembre 2018.
[22] Ubuntu. Canonical Group. Disponible depuis : https://www.ubuntu.com/. Consultéle 18 Septembre 2018.
[23] Python. Python Software Fundation. Disponible depuis : https://www.python.org/.Consulté le 19 Septembre 2018.
[24] Anconda. Anaconda Distribution. Disponible depuis : https://www.anaconda.com/.Consulté le 19 Septembre 2018.
[25] Tensorflow. Google. Disponible depuis : https://www.tensorflow.org/. Consulté le19 Septembre 2018.
[26] Keras. Python package. Disponible depuis : https://keras.io/. Consulté le 19 Sep-tembre 2018.
[27] Scikit-learn. Python package. Disponible depuis : https://scikit-learn.org/.Consulté le 19 Septembre 2018.
[28] KDNuggets. Disponible depuis : https://www.kdnuggets.com/2018/05/poll-
tools-analytics-data-science-machine-learning-results.html/. Consultéle 28 Septembre 2018.
75



















