
Practical Neural Machine TranslationPractical Neural Machine Translation Rico Sennrich, Barry Haddow...
165
Practical Neural Machine Translation Rico Sennrich, Barry Haddow Institute for Language, Cognition and Computation University of Edinburgh April 4, 2017 (Last Updated: April 28, 2017) Sennrich, Haddow Practical Neural Machine Translation 1 / 109
Transcript of Practical Neural Machine TranslationPractical Neural Machine Translation Rico Sennrich, Barry Haddow...

Practical Neural Machine Translation
Rico Sennrich, Barry Haddow
Institute for Language, Cognition and ComputationUniversity of Edinburgh
April 4, 2017(Last Updated: April 28, 2017)
Sennrich, Haddow Practical Neural Machine Translation 1 / 109

Practical Neural Machine Translation
1 Introduction
2 Neural Networks — Basics
3 Language Models using Neural Networks
4 Attention-based NMT Model
5 Edinburgh’s WMT16 System
6 Analysis: Why does NMT work so well?
7 Building and Improving NMT Systems
8 Resources, Further Reading and Wrap-Up
Sennrich, Haddow Practical Neural Machine Translation 1 / 109

NMT Timeline
1987 Early encoder-decoder, with vocabulary size 30-40 [Allen, 1987]
...
2013 Pure neural MT system presented [Kalchbrenner and Blunsom, 2013]
2014 Competitive encoder-decoder for large-scale MT[Bahdanau et al., 2015, Luong et al., 2014]
2015 NMT systems in shared tasks – perform well in WMT,state-of-the-art at IWSLT
2016 NMT systems top most language pairs in WMT
2016 Commercial deployments of NMT launched
Sennrich, Haddow Practical Neural Machine Translation 2 / 109
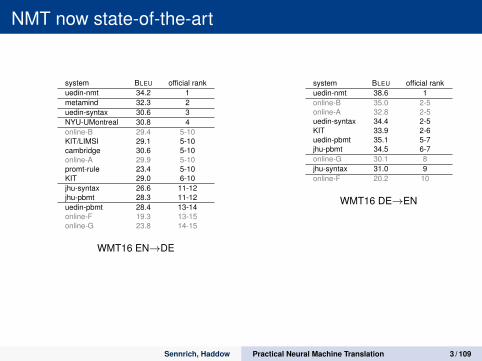
NMT now state-of-the-art
system BLEU official rankuedin-nmt 34.2 1metamind 32.3 2uedin-syntax 30.6 3NYU-UMontreal 30.8 4online-B 29.4 5-10KIT/LIMSI 29.1 5-10cambridge 30.6 5-10online-A 29.9 5-10promt-rule 23.4 5-10KIT 29.0 6-10jhu-syntax 26.6 11-12jhu-pbmt 28.3 11-12uedin-pbmt 28.4 13-14online-F 19.3 13-15online-G 23.8 14-15
WMT16 EN→DE
system BLEU official rankuedin-nmt 38.6 1online-B 35.0 2-5online-A 32.8 2-5uedin-syntax 34.4 2-5KIT 33.9 2-6uedin-pbmt 35.1 5-7jhu-pbmt 34.5 6-7online-G 30.1 8jhu-syntax 31.0 9online-F 20.2 10
WMT16 DE→EN
pure NMT
NMT component
Sennrich, Haddow Practical Neural Machine Translation 3 / 109
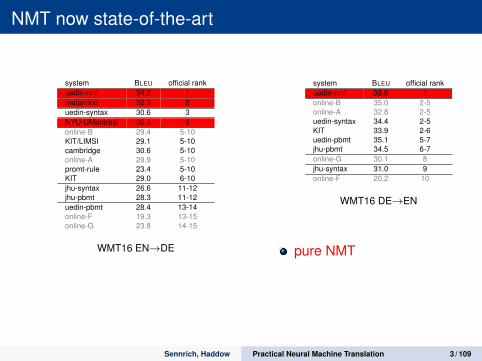
NMT now state-of-the-art
system BLEU official rankuedin-nmt 34.2 1metamind 32.3 2uedin-syntax 30.6 3NYU-UMontreal 30.8 4online-B 29.4 5-10KIT/LIMSI 29.1 5-10cambridge 30.6 5-10online-A 29.9 5-10promt-rule 23.4 5-10KIT 29.0 6-10jhu-syntax 26.6 11-12jhu-pbmt 28.3 11-12uedin-pbmt 28.4 13-14online-F 19.3 13-15online-G 23.8 14-15
WMT16 EN→DE
system BLEU official rankuedin-nmt 38.6 1online-B 35.0 2-5online-A 32.8 2-5uedin-syntax 34.4 2-5KIT 33.9 2-6uedin-pbmt 35.1 5-7jhu-pbmt 34.5 6-7online-G 30.1 8jhu-syntax 31.0 9online-F 20.2 10
WMT16 DE→EN
pure NMT
NMT component
Sennrich, Haddow Practical Neural Machine Translation 3 / 109
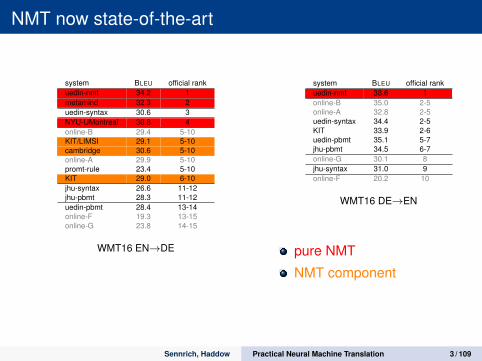
NMT now state-of-the-art
system BLEU official rankuedin-nmt 34.2 1metamind 32.3 2uedin-syntax 30.6 3NYU-UMontreal 30.8 4online-B 29.4 5-10KIT/LIMSI 29.1 5-10cambridge 30.6 5-10online-A 29.9 5-10promt-rule 23.4 5-10KIT 29.0 6-10jhu-syntax 26.6 11-12jhu-pbmt 28.3 11-12uedin-pbmt 28.4 13-14online-F 19.3 13-15online-G 23.8 14-15
WMT16 EN→DE
system BLEU official rankuedin-nmt 38.6 1online-B 35.0 2-5online-A 32.8 2-5uedin-syntax 34.4 2-5KIT 33.9 2-6uedin-pbmt 35.1 5-7jhu-pbmt 34.5 6-7online-G 30.1 8jhu-syntax 31.0 9online-F 20.2 10
WMT16 DE→EN
pure NMT
NMT component
Sennrich, Haddow Practical Neural Machine Translation 3 / 109
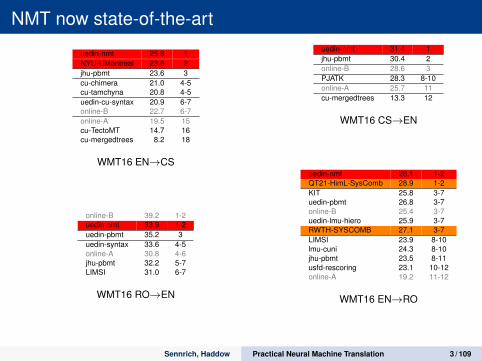
NMT now state-of-the-art
uedin-nmt 25.8 1NYU-UMontreal 23.6 2jhu-pbmt 23.6 3cu-chimera 21.0 4-5cu-tamchyna 20.8 4-5uedin-cu-syntax 20.9 6-7online-B 22.7 6-7online-A 19.5 15cu-TectoMT 14.7 16cu-mergedtrees 8.2 18
WMT16 EN→CS
online-B 39.2 1-2uedin-nmt 33.9 1-2uedin-pbmt 35.2 3uedin-syntax 33.6 4-5online-A 30.8 4-6jhu-pbmt 32.2 5-7LIMSI 31.0 6-7
WMT16 RO→EN
uedin-nmt 31.4 1jhu-pbmt 30.4 2online-B 28.6 3PJATK 28.3 8-10online-A 25.7 11cu-mergedtrees 13.3 12
WMT16 CS→EN
uedin-nmt 28.1 1-2QT21-HimL-SysComb 28.9 1-2KIT 25.8 3-7uedin-pbmt 26.8 3-7online-B 25.4 3-7uedin-lmu-hiero 25.9 3-7RWTH-SYSCOMB 27.1 3-7LIMSI 23.9 8-10lmu-cuni 24.3 8-10jhu-pbmt 23.5 8-11usfd-rescoring 23.1 10-12online-A 19.2 11-12
WMT16 EN→RO
Sennrich, Haddow Practical Neural Machine Translation 3 / 109
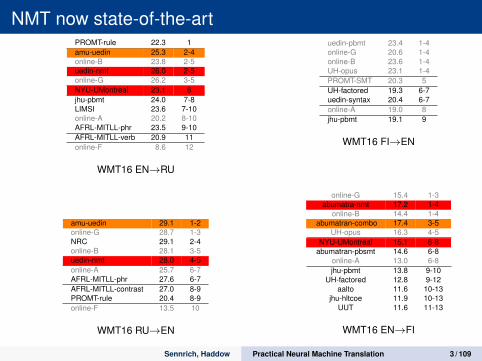
NMT now state-of-the-artPROMT-rule 22.3 1amu-uedin 25.3 2-4online-B 23.8 2-5uedin-nmt 26.0 2-5online-G 26.2 3-5NYU-UMontreal 23.1 6jhu-pbmt 24.0 7-8LIMSI 23.6 7-10online-A 20.2 8-10AFRL-MITLL-phr 23.5 9-10AFRL-MITLL-verb 20.9 11online-F 8.6 12
WMT16 EN→RU
amu-uedin 29.1 1-2online-G 28.7 1-3NRC 29.1 2-4online-B 28.1 3-5uedin-nmt 28.0 4-5online-A 25.7 6-7AFRL-MITLL-phr 27.6 6-7AFRL-MITLL-contrast 27.0 8-9PROMT-rule 20.4 8-9online-F 13.5 10
WMT16 RU→EN
uedin-pbmt 23.4 1-4online-G 20.6 1-4online-B 23.6 1-4UH-opus 23.1 1-4PROMT-SMT 20.3 5UH-factored 19.3 6-7uedin-syntax 20.4 6-7online-A 19.0 8jhu-pbmt 19.1 9
WMT16 FI→EN
online-G 15.4 1-3abumatra-nmt 17.2 1-4
online-B 14.4 1-4abumatran-combo 17.4 3-5
UH-opus 16.3 4-5NYU-UMontreal 15.1 6-8
abumatran-pbsmt 14.6 6-8online-A 13.0 6-8jhu-pbmt 13.8 9-10
UH-factored 12.8 9-12aalto 11.6 10-13
jhu-hltcoe 11.9 10-13UUT 11.6 11-13
WMT16 EN→FI
Sennrich, Haddow Practical Neural Machine Translation 3 / 109
NMT in Production
Sennrich, Haddow Practical Neural Machine Translation 4 / 109
NMT in Production
Sennrich, Haddow Practical Neural Machine Translation 4 / 109
NMT in Production
Sennrich, Haddow Practical Neural Machine Translation 4 / 109
NMT in Production
Sennrich, Haddow Practical Neural Machine Translation 4 / 109
NMT in Production
Sennrich, Haddow Practical Neural Machine Translation 4 / 109
NMT in Production
Sennrich, Haddow Practical Neural Machine Translation 4 / 109

NMT in Production
Sennrich, Haddow Practical Neural Machine Translation 4 / 109

NMT in Production
Sennrich, Haddow Practical Neural Machine Translation 4 / 109

Course Goals
At the end of this tutorial, you will
have a basic theoretical understanding of models/algorithms in NMT
understand strengths and weaknesses of NMT
know techniques that help to build state-of-the-art NMT systemsknow practical tips for various problems you may encounter:
training and decoding efficiencydomain adaptationways to further improve translation quality...
no hands-on coding/training in tutorial, but helpful resources are provided
Sennrich, Haddow Practical Neural Machine Translation 5 / 109

Practical Neural Machine Translation
1 Introduction
2 Neural Networks — Basics
3 Language Models using Neural Networks
4 Attention-based NMT Model
5 Edinburgh’s WMT16 System
6 Analysis: Why does NMT work so well?
7 Building and Improving NMT Systems
8 Resources, Further Reading and Wrap-Up
Sennrich, Haddow Practical Neural Machine Translation 6 / 109

What is a Neural Network?
A complex non-linear function which:is built from simpler units (neurons, nodes, gates, . . . )maps vectors/matrices to vectors/matricesis parameterised by vectors/matrices
Why is this useful?
very expressivecan represent (e.g.) parameterised probability distributionsevaluation and parameter estimation can be built up from components
Sennrich, Haddow Practical Neural Machine Translation 7 / 109

What is a Neural Network?
A complex non-linear function which:is built from simpler units (neurons, nodes, gates, . . . )maps vectors/matrices to vectors/matricesis parameterised by vectors/matrices
Why is this useful?very expressivecan represent (e.g.) parameterised probability distributionsevaluation and parameter estimation can be built up from components
Sennrich, Haddow Practical Neural Machine Translation 7 / 109
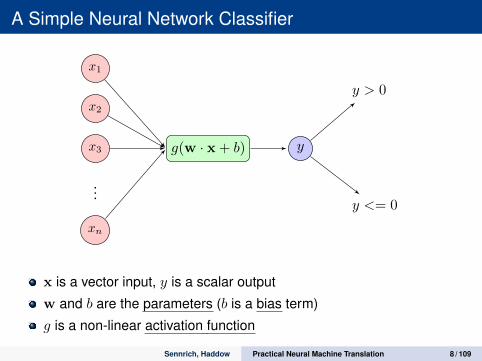
A Simple Neural Network Classifier
x1
x2
x3
...
xn
g(w · x + b) y
y > 0
y <= 0
x is a vector input, y is a scalar output
w and b are the parameters (b is a bias term)
g is a non-linear activation function
Sennrich, Haddow Practical Neural Machine Translation 8 / 109
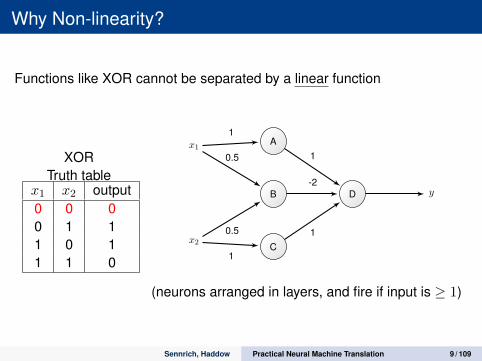
Why Non-linearity?
Functions like XOR cannot be separated by a linear function
XORTruth table
x1 x2 output0 0 00 1 11 0 11 1 0
A
B
C
D
x1
x2
y
1
1
1
-2
1
0.5
0.5
(neurons arranged in layers, and fire if input is ≥ 1)
Sennrich, Haddow Practical Neural Machine Translation 9 / 109
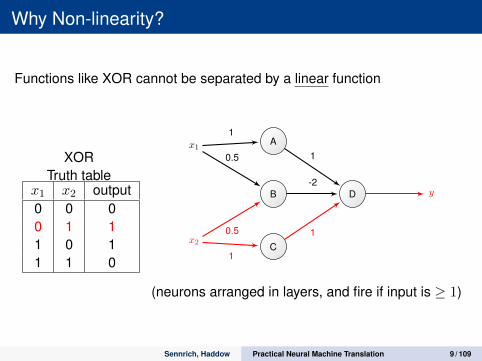
Why Non-linearity?
Functions like XOR cannot be separated by a linear function
XORTruth table
x1 x2 output0 0 00 1 11 0 11 1 0
A
B
C
D
x1
x2
y
1
1
1
-2
1
0.5
0.5
(neurons arranged in layers, and fire if input is ≥ 1)
Sennrich, Haddow Practical Neural Machine Translation 9 / 109
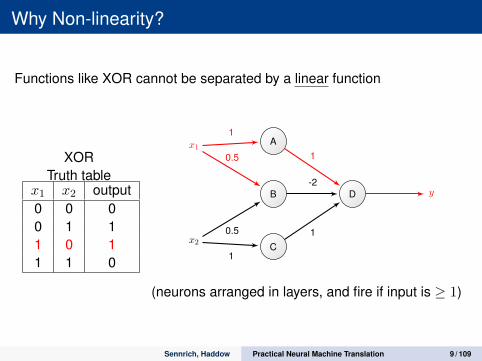
Why Non-linearity?
Functions like XOR cannot be separated by a linear function
XORTruth table
x1 x2 output0 0 00 1 11 0 11 1 0
A
B
C
D
x1
x2
y
1
1
1
-2
1
0.5
0.5
(neurons arranged in layers, and fire if input is ≥ 1)
Sennrich, Haddow Practical Neural Machine Translation 9 / 109
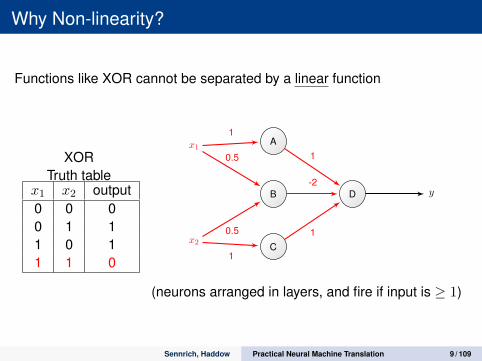
Why Non-linearity?
Functions like XOR cannot be separated by a linear function
XORTruth table
x1 x2 output0 0 00 1 11 0 11 1 0
A
B
C
D
x1
x2
y
1
1
1
-2
1
0.5
0.5
(neurons arranged in layers, and fire if input is ≥ 1)
Sennrich, Haddow Practical Neural Machine Translation 9 / 109
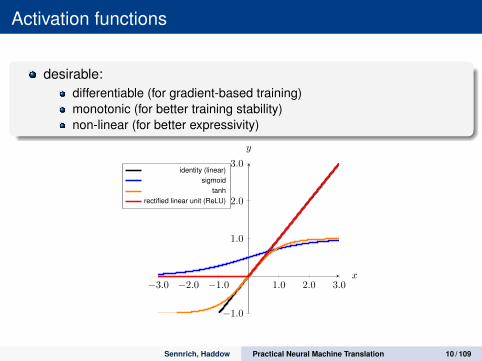
Activation functions
desirable:differentiable (for gradient-based training)monotonic (for better training stability)non-linear (for better expressivity)
−3.0 −2.0 −1.0 1.0 2.0 3.0
−1.0
1.0
2.0
3.0
x
y
identity (linear)sigmoid
tanhrectified linear unit (ReLU)
Sennrich, Haddow Practical Neural Machine Translation 10 / 109
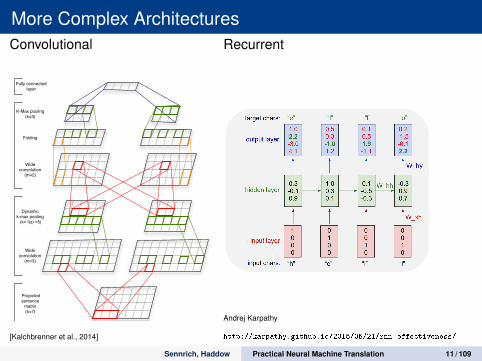
More Complex ArchitecturesConvolutional
tor wi ∈ Rd of a word in the sentence:
s =
w1 . . . ws
(2)
To address the problem of varying sentencelengths, the Max-TDNN takes the maximum ofeach row in the resulting matrix c yielding a vectorof d values:
cmax =
max(c1,:)...
max(cd,:)
(3)
The aim is to capture the most relevant feature, i.e.the one with the highest value, for each of the drows of the resulting matrix c. The fixed-sizedvector cmax is then used as input to a fully con-nected layer for classification.
The Max-TDNN model has many desirableproperties. It is sensitive to the order of the wordsin the sentence and it does not depend on externallanguage-specific features such as dependency orconstituency parse trees. It also gives largely uni-form importance to the signal coming from eachof the words in the sentence, with the exceptionof words at the margins that are considered fewertimes in the computation of the narrow convolu-tion. But the model also has some limiting as-pects. The range of the feature detectors is lim-ited to the span m of the weights. Increasing m orstacking multiple convolutional layers of the nar-row type makes the range of the feature detectorslarger; at the same time it also exacerbates the ne-glect of the margins of the sentence and increasesthe minimum size s of the input sentence requiredby the convolution. For this reason higher-orderand long-range feature detectors cannot be easilyincorporated into the model. The max pooling op-eration has some disadvantages too. It cannot dis-tinguish whether a relevant feature in one of therows occurs just one or multiple times and it for-gets the order in which the features occur. Moregenerally, the pooling factor by which the signalof the matrix is reduced at once corresponds tos−m+1; even for moderate values of s the pool-ing factor can be excessive. The aim of the nextsection is to address these limitations while pre-serving the advantages.
3 Convolutional Neural Networks withDynamic k-Max Pooling
We model sentences using a convolutional archi-tecture that alternates wide convolutional layers
K-Max pooling(k=3)
Fully connected layer
Folding
Wideconvolution
(m=2)
Dynamick-max pooling (k= f(s) =5)
Projectedsentence
matrix(s=7)
Wideconvolution
(m=3)
The cat sat on the red mat
Figure 3: A DCNN for the seven word input sen-tence. Word embeddings have size d = 4. Thenetwork has two convolutional layers with twofeature maps each. The widths of the filters at thetwo layers are respectively 3 and 2. The (dynamic)k-max pooling layers have values k of 5 and 3.
with dynamic pooling layers given by dynamic k-max pooling. In the network the width of a featuremap at an intermediate layer varies depending onthe length of the input sentence; the resulting ar-chitecture is the Dynamic Convolutional NeuralNetwork. Figure 3 represents a DCNN. We pro-ceed to describe the network in detail.
3.1 Wide Convolution
Given an input sentence, to obtain the first layer ofthe DCNN we take the embedding wi ∈ Rd foreach word in the sentence and construct the sen-tence matrix s ∈ Rd×s as in Eq. 2. The valuesin the embeddings wi are parameters that are op-timised during training. A convolutional layer inthe network is obtained by convolving a matrix ofweights m ∈ Rd×m with the matrix of activationsat the layer below. For example, the second layeris obtained by applying a convolution to the sen-tence matrix s itself. Dimension d and filter widthm are hyper-parameters of the network. We let theoperations be wide one-dimensional convolutionsas described in Sect. 2.2. The resulting matrix chas dimensions d× (s + m− 1).
658
[Kalchbrenner et al., 2014]
Recurrent
Andrej Karpathy
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Sennrich, Haddow Practical Neural Machine Translation 11 / 109

Training of Neural Networks
Parameter estimationUse gradient descentRequires labelled training data . . .. . . and differentiable objective function
Network structure enables efficient computationForward pass to compute network outputBackpropogation, i.e. backward pass using chain rule, to calculategradient
Normally train stochastically using mini-batches
Sennrich, Haddow Practical Neural Machine Translation 12 / 109

Practical Considerations
hyperparameters:number and size of layersminibatch sizelearning rate...
initialisation of weight matrices
stopping criterion
regularization (dropout)
bias units (always-on input)
Sennrich, Haddow Practical Neural Machine Translation 13 / 109

Toolkits for Neural Networks
What does a Toolkit ProvideMulti-dimensional matrices (tensors)
Automatic differentiation
Efficient GPU routines for tensor operations
http://torch.ch/
TensorFlow https://www.tensorflow.org/
http://deeplearning.net/software/theano/
There are many more!Sennrich, Haddow Practical Neural Machine Translation 14 / 109

Practical Neural Machine Translation
1 Introduction
2 Neural Networks — Basics
3 Language Models using Neural Networks
4 Attention-based NMT Model
5 Edinburgh’s WMT16 System
6 Analysis: Why does NMT work so well?
7 Building and Improving NMT Systems
8 Resources, Further Reading and Wrap-Up
Sennrich, Haddow Practical Neural Machine Translation 15 / 109

Language model
chain rule and Markov assumptiona sentence T of length n is a sequence w1, . . . , wn
p(T ) = p(w1, . . . , wn)
=
n∏i=1
p(wi|w0, . . . , wi−1) (chain rule)
≈n∏
i=1
p(wi|wi−k, . . . , wi−1) (Markov assumption: n-gram model)
Sennrich, Haddow Practical Neural Machine Translation 16 / 109
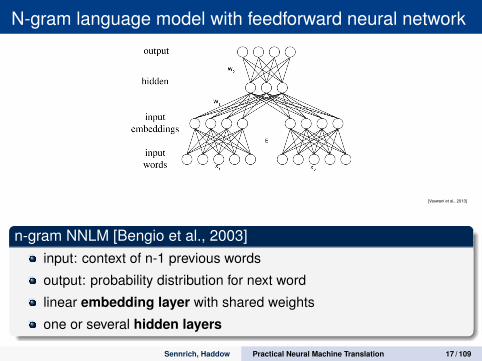
N-gram language model with feedforward neural network
[Vaswani et al., 2013]
n-gram NNLM [Bengio et al., 2003]input: context of n-1 previous words
output: probability distribution for next word
linear embedding layer with shared weights
one or several hidden layers
Sennrich, Haddow Practical Neural Machine Translation 17 / 109

Representing words as vectors
One-hot encodingexample vocabulary: ’man, ’runs’, ’the’, ’.’
input/output for p(runs|the man):
x0 =
0010
x1 =
1000
ytrue =
0100
size of input/output vector: vocabulary sizeembedding layer is lower-dimensional and dense
smaller weight matricesnetwork learns to group similar words to similar point in vector space
Sennrich, Haddow Practical Neural Machine Translation 18 / 109

Softmax activation function
softmax function
p(y = j|x) =exj
∑k e
xk
softmax function normalizes output vector to probability distribution→ computational cost linear to vocabulary size (!)
ideally: probability 1 for correct word; 0 for rest
SGD with softmax output minimizes cross-entropy (and henceperplexity) of neural network
Sennrich, Haddow Practical Neural Machine Translation 19 / 109
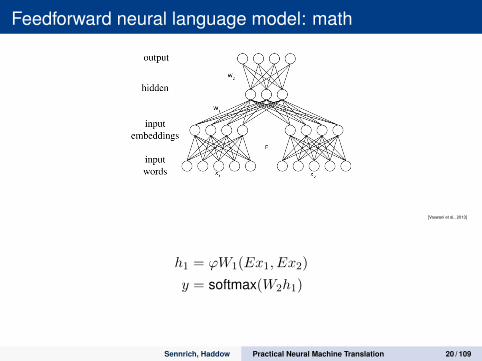
Feedforward neural language model: math
[Vaswani et al., 2013]
h1 = ϕW1(Ex1, Ex2)
y = softmax(W2h1)
Sennrich, Haddow Practical Neural Machine Translation 20 / 109

Feedforward neural language model in SMT
FFNLMcan be integrated as a feature in the log-linear SMT model[Schwenk et al., 2006]
costly due to matrix multiplications and softmaxsolutions:
n-best rerankingvariants of softmax (hierarchical softmax, self-normalization [NCE])shallow networks; premultiplication of hidden layer
scales well to many input words→ models with source context [Devlin et al., 2014]
Sennrich, Haddow Practical Neural Machine Translation 21 / 109

Recurrent neural network language model (RNNLM)
RNNLM [Mikolov et al., 2010]motivation: condition on arbitrarily long context→ no Markov assumption
we read in one word at a time, and update hidden state incrementally
hidden state is initialized as empty vector at time step 0parameters:
embedding matrix Efeedforward matrices W1, W2
recurrent matrix U
hi =
{0, , if i = 0
tanh(W1Exi + Uhi−1) , if i > 0
yi = softmax(W2hi−1)
Sennrich, Haddow Practical Neural Machine Translation 22 / 109
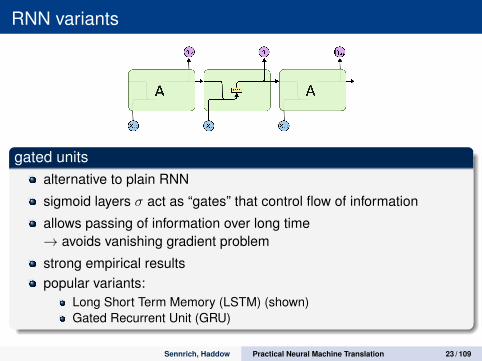
RNN variants
gated unitsalternative to plain RNN
sigmoid layers σ act as “gates” that control flow of information
allows passing of information over long time→ avoids vanishing gradient problem
strong empirical resultspopular variants:
Long Short Term Memory (LSTM) (shown)Gated Recurrent Unit (GRU)
Christopher Olah http://colah.github.io/posts/2015-08-Understanding-LSTMs/Sennrich, Haddow Practical Neural Machine Translation 23 / 109
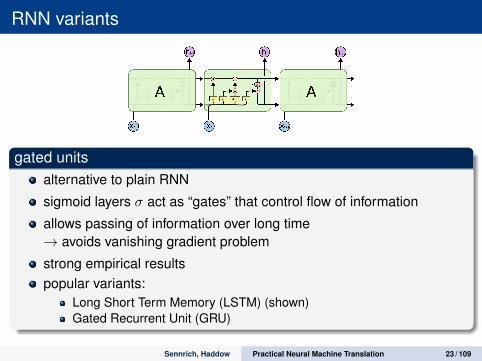
RNN variants
gated unitsalternative to plain RNN
sigmoid layers σ act as “gates” that control flow of information
allows passing of information over long time→ avoids vanishing gradient problem
strong empirical resultspopular variants:
Long Short Term Memory (LSTM) (shown)Gated Recurrent Unit (GRU)
Christopher Olah http://colah.github.io/posts/2015-08-Understanding-LSTMs/Sennrich, Haddow Practical Neural Machine Translation 23 / 109

Practical Neural Machine Translation
1 Introduction
2 Neural Networks — Basics
3 Language Models using Neural Networks
4 Attention-based NMT Model
5 Edinburgh’s WMT16 System
6 Analysis: Why does NMT work so well?
7 Building and Improving NMT Systems
8 Resources, Further Reading and Wrap-Up
Sennrich, Haddow Practical Neural Machine Translation 24 / 109

Modelling Translation
Suppose that we have:a source sentence S of length m (x1, . . . , xm)a target sentence T of length n (y1, . . . , yn)
We can express translation as a probabilistic model
T ∗ = arg maxT
p(T |S)
Expanding using the chain rule gives
p(T |S) = p(y1, . . . , yn|x1, . . . , xm)
=
n∏
i=1
p(yi|y1, . . . , yi−1, x1, . . . , xm)
Sennrich, Haddow Practical Neural Machine Translation 25 / 109

Differences Between Translation and Language Model
Target-side language model:
p(T ) =
n∏
i=1
p(yi|y1, . . . , yi−1)
Translation model:
p(T |S) =
n∏
i=1
p(yi|y1, . . . , yi−1, x1, . . . , xm)
We could just treat sentence pair as one long sequence, but:We do not care about p(S)We may want different vocabulary, network architecture for source text
→ Use separate RNNs for source and target.
Sennrich, Haddow Practical Neural Machine Translation 26 / 109

Differences Between Translation and Language Model
Target-side language model:
p(T ) =
n∏
i=1
p(yi|y1, . . . , yi−1)
Translation model:
p(T |S) =
n∏
i=1
p(yi|y1, . . . , yi−1, x1, . . . , xm)
We could just treat sentence pair as one long sequence, but:We do not care about p(S)We may want different vocabulary, network architecture for source text
→ Use separate RNNs for source and target.
Sennrich, Haddow Practical Neural Machine Translation 26 / 109
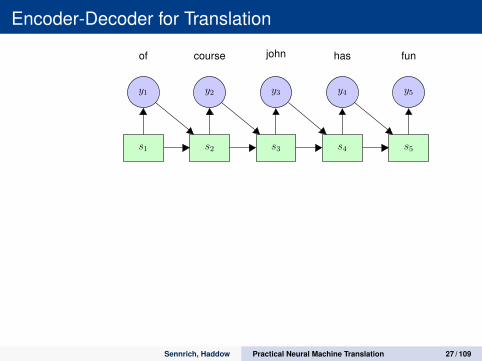
Encoder-Decoder for Translation
s1 s2 s3 s4 s5
y1 y2 y3 y4 y5
of course john has fun
h1 h2 h3 h4
x1 x2 x3 x4
natürlich hat john spaß
Decoder
Encoder
Sennrich, Haddow Practical Neural Machine Translation 27 / 109
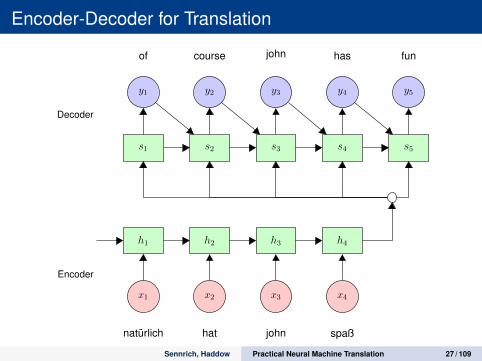
Encoder-Decoder for Translation
s1 s2 s3 s4 s5
y1 y2 y3 y4 y5
of course john has fun
h1 h2 h3 h4
x1 x2 x3 x4
natürlich hat john spaß
Decoder
Encoder
Sennrich, Haddow Practical Neural Machine Translation 27 / 109

Summary vector
Last encoder hidden-state “summarises” source sentence
With multilingual training, we can potentially learnlanguage-independent meaning representation
[Sutskever et al., 2014]
Sennrich, Haddow Practical Neural Machine Translation 28 / 109
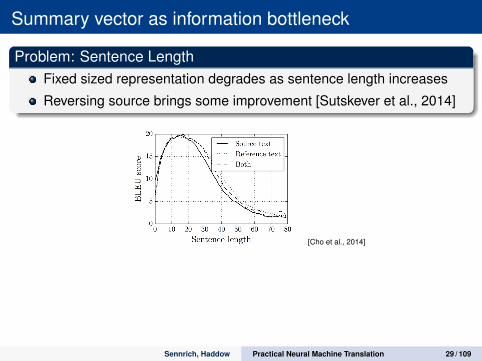
Summary vector as information bottleneck
Problem: Sentence LengthFixed sized representation degrades as sentence length increases
Reversing source brings some improvement [Sutskever et al., 2014]
[Cho et al., 2014]
Solution: AttentionCompute context vector as weighted average of source hidden states
Weights computed by feed-forward network with softmax activation
Sennrich, Haddow Practical Neural Machine Translation 29 / 109
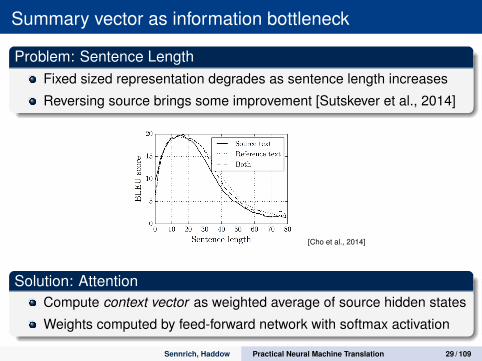
Summary vector as information bottleneck
Problem: Sentence LengthFixed sized representation degrades as sentence length increases
Reversing source brings some improvement [Sutskever et al., 2014]
[Cho et al., 2014]
Solution: AttentionCompute context vector as weighted average of source hidden states
Weights computed by feed-forward network with softmax activation
Sennrich, Haddow Practical Neural Machine Translation 29 / 109
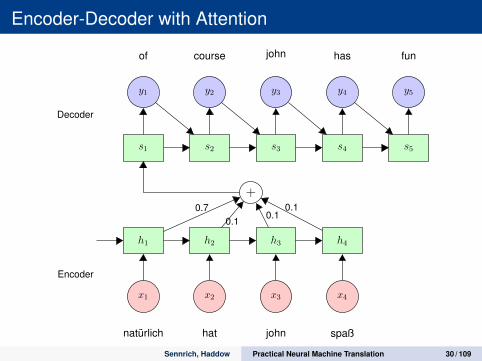
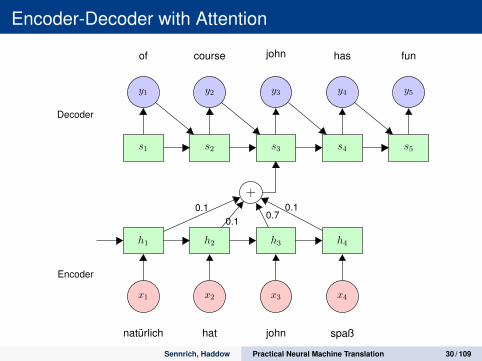
Encoder-Decoder with Attention
h1 h2 h3 h4
x1 x2 x3 x4
natürlich hat john spaß
+
s1 s2 s3 s4 s5
y1 y2 y3 y4 y5
of course john has fun
0.70.1
0.10.1
Decoder
Encoder
Sennrich, Haddow Practical Neural Machine Translation 30 / 109
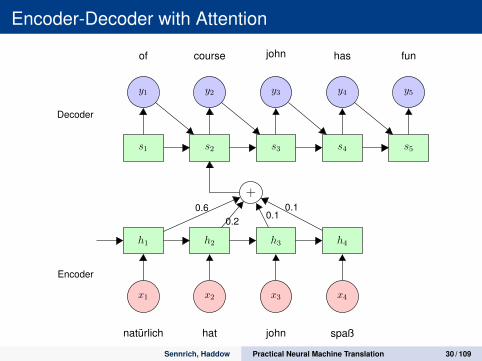
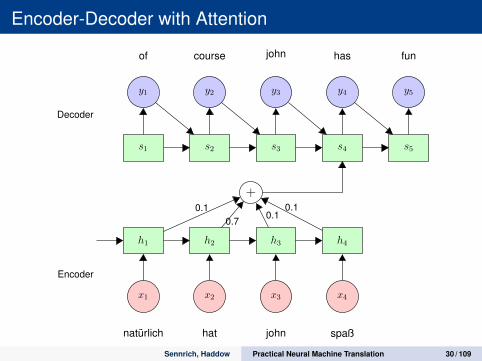
Encoder-Decoder with Attention
h1 h2 h3 h4
x1 x2 x3 x4
natürlich hat john spaß
+
s1 s2 s3 s4 s5
y1 y2 y3 y4 y5
of course john has fun
0.60.2
0.10.1
Decoder
Encoder
Sennrich, Haddow Practical Neural Machine Translation 30 / 109
Encoder-Decoder with Attention
h1 h2 h3 h4
x1 x2 x3 x4
natürlich hat john spaß
+
s1 s2 s3 s4 s5
y1 y2 y3 y4 y5
of course john has fun
0.10.1
0.70.1
Decoder
Encoder
Sennrich, Haddow Practical Neural Machine Translation 30 / 109
Encoder-Decoder with Attention
h1 h2 h3 h4
x1 x2 x3 x4
natürlich hat john spaß
+
s1 s2 s3 s4 s5
y1 y2 y3 y4 y5
of course john has fun
0.10.7
0.10.1
Decoder
Encoder
Sennrich, Haddow Practical Neural Machine Translation 30 / 109
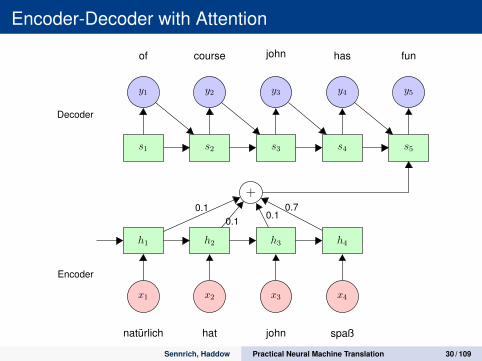
Encoder-Decoder with Attention
h1 h2 h3 h4
x1 x2 x3 x4
natürlich hat john spaß
+
s1 s2 s3 s4 s5
y1 y2 y3 y4 y5
of course john has fun
0.10.1
0.10.7
Decoder
Encoder
Sennrich, Haddow Practical Neural Machine Translation 30 / 109

Attentional encoder-decoder: Maths
simplifications of model by [Bahdanau et al., 2015] (for illustration)plain RNN instead of GRU
simpler output layer
we do not show bias terms
decoder follows Look, Update, Generate strategy [Sennrich et al., 2017]
Details in https://github.com/amunmt/amunmt/blob/master/contrib/notebooks/dl4mt.ipynb
notationW , U , E, C, V are weight matrices (of different dimensionality)
E one-hot to embedding (e.g. 50000 · 512)W embedding to hidden (e.g. 512 · 1024)U hidden to hidden (e.g. 1024 · 1024)C context (2x hidden) to hidden (e.g. 2048 · 1024)Vo hidden to one-hot (e.g. 1024 · 50000)
separate weight matrices for encoder and decoder (e.g. Ex and Ey)
input X of length Tx; output Y of length TySennrich, Haddow Practical Neural Machine Translation 31 / 109

Attentional encoder-decoder: Maths
encoder
−→h j =
{0, , if j = 0
tanh(−→W xExxj +
−→U xhj−1) , if j > 0
←−h j =
{0, , if j = Tx + 1
tanh(←−W xExxj +
←−U xhj+1) , if j ≤ Tx
hj = (−→h j ,←−h j)
Sennrich, Haddow Practical Neural Machine Translation 32 / 109

Attentional encoder-decoder: Maths
decoder
si =
{tanh(Ws
←−h i), , if i = 0
tanh(WyEyyi−1 + Uysi−1 + Cci) , if i > 0
ti = tanh(Uosi +WoEyyi−1 + Coci)
yi = softmax(Voti)
attention model
eij = v>a tanh(Wasi−1 + Uahj)
αij = softmax(eij)
ci =
Tx∑
j=1
αijhj
Sennrich, Haddow Practical Neural Machine Translation 33 / 109

Attention model
attention modelside effect: we obtain alignment between source and target sentence
information can also flow along recurrent connections, so there is noguarantee that attention corresponds to alignmentapplications:
visualisationreplace unknown words with back-off dictionary [Jean et al., 2015]...
Kyunghyun Chohttp://devblogs.nvidia.com/parallelforall/introduction-neural-machine-translation-gpus-part-3/
Sennrich, Haddow Practical Neural Machine Translation 34 / 109

Attention model
attention model also works with images:
[Cho et al., 2015]
Sennrich, Haddow Practical Neural Machine Translation 35 / 109
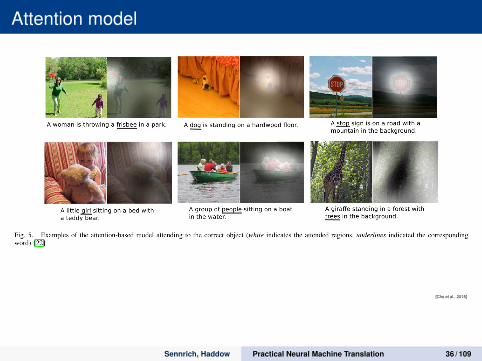
Attention model
[Cho et al., 2015]
Sennrich, Haddow Practical Neural Machine Translation 36 / 109

Application of Encoder-Decoder Model
Scoring (a translation)p(La, croissance, économique, s’est, ralentie, ces, dernières, années, . |Economic, growth, has, slowed, down, in, recent, year, .) = ?
Decoding ( a source sentence)Generate the most probable translation of a source sentence
y∗ = argmaxy p(y|Economic, growth, has, slowed, down, in, recent, year, .)
Sennrich, Haddow Practical Neural Machine Translation 37 / 109

Decoding
exact searchgenerate every possible sentence T in target language
compute score p(T |S) for each
pick best one
intractable: |vocab|N translations for output length N→ we need approximative search strategy
Sennrich, Haddow Practical Neural Machine Translation 38 / 109

Decoding
approximative search/1: greedy searchat each time step, compute probabilitydistribution P (yi|S, y<i)
select yi according to some heuristic:
sampling: sample from P (yi|S, y<i)greedy search: pick argmaxy p(yi|S, y<i)
continue until we generate <eos>
! 0.928
0.175
<eos> 0.999
0.175
hello 0.946
0.056
world 0.957
0.100
0
efficient, but suboptimal
Sennrich, Haddow Practical Neural Machine Translation 39 / 109
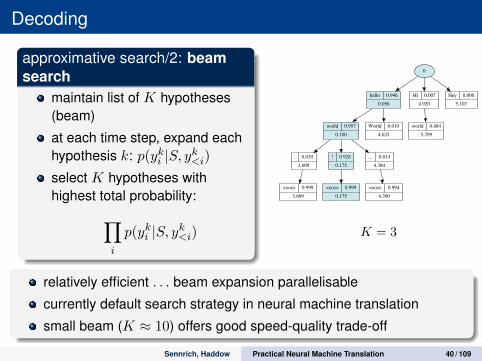
Decoding
approximative search/2: beamsearch
maintain list of K hypotheses(beam)
at each time step, expand eachhypothesis k: p(yki |S, yk<i)
select K hypotheses withhighest total probability:
∏
i
p(yki |S, yk<i)
hello 0.946
0.056
world 0.957
0.100
World 0.010
4.632
. 0.030
3.609
! 0.928
0.175
... 0.014
4.384
<eos> 0.999
3.609
world 0.684
5.299
HI 0.007
4.920
<eos> 0.994
4.390
Hey 0.006
5.107
<eos> 0.999
0.175
0
K = 3
relatively efficient . . . beam expansion parallelisable
currently default search strategy in neural machine translation
small beam (K ≈ 10) offers good speed-quality trade-off
Sennrich, Haddow Practical Neural Machine Translation 40 / 109

Ensembles
at each timestep, combine the probability distribution of M differentensemble components.
combine operator: typically average (log-)probability
logP (yi|S, y<i) =
∑Mm=1 logPm(yi|S, y<i)
M
requirements:same output vocabularysame factorization of Y
internal network architecture may be different
source representations may be different(extreme example: ensemble-like model with different sourcelanguages [Junczys-Dowmunt and Grundkiewicz, 2016])
Sennrich, Haddow Practical Neural Machine Translation 41 / 109

Practical Neural Machine Translation
1 Introduction
2 Neural Networks — Basics
3 Language Models using Neural Networks
4 Attention-based NMT Model
5 Edinburgh’s WMT16 System
6 Analysis: Why does NMT work so well?
7 Building and Improving NMT Systems
8 Resources, Further Reading and Wrap-Up
Sennrich, Haddow Practical Neural Machine Translation 42 / 109

Innovations in Edinburgh’s WMT16 Systems
Basic encoder-decoder-with-attention, plus:
1 Subword models to allow translation of rare/unknown words→ since networks have small, fixed vocabulary
2 Back-translated monolingual data as additional training data→ allows us to make use of extensive monolingual resources
3 Combination of left-to-right and right-to-left models→ Reduces “label-bias” problem
4 Bayesian dropout→ Improves generalisation performance with small training data
Sennrich, Haddow Practical Neural Machine Translation 43 / 109

Subwords for NMT: Motivation
MT is an open-vocabulary problemcompounding and other productive morphological processes
they charge a carry-on bag fee.sie erheben eine Hand|gepäck|gebühr.
names
Obama(English; German)Îáàìà (Russian)オバマ (o-ba-ma) (Japanese)
technical terms, numbers, etc.
... but Neural MT architectures have small and fixed vocabulary
Sennrich, Haddow Practical Neural Machine Translation 44 / 109

Subword units
segmentation algorithms: wishlistopen-vocabulary NMT: encode all words through small vocabulary
encoding generalizes to unseen words
small text size
good translation quality
our experimentsafter preliminary experiments, we use:
character n-grams (with shortlist of unsegmented words)segmentation via byte pair encoding
Sennrich, Haddow Practical Neural Machine Translation 45 / 109

Byte pair encoding for word segmentation
bottom-up character mergingstarting point: character-level representation→ computationally expensive
compress representation based on information theory→ byte pair encoding [Gage, 1994]
repeatedly replace most frequent symbol pair (’A’,’B’) with ’AB’
hyperparameter: when to stop→ controls vocabulary size
word freq’l o w </w>’ 5’l o w e r </w>’ 2’n e w e s t </w>’ 6’w i d e s t </w>’ 3
vocabulary:l o w </w> e r n s t i d
es est est</w> lo low
Sennrich, Haddow Practical Neural Machine Translation 46 / 109

Byte pair encoding for word segmentation
bottom-up character mergingstarting point: character-level representation→ computationally expensive
compress representation based on information theory→ byte pair encoding [Gage, 1994]
repeatedly replace most frequent symbol pair (’A’,’B’) with ’AB’
hyperparameter: when to stop→ controls vocabulary size
word freq’l o w </w>’ 5’l o w e r </w>’ 2’n e w es t </w>’ 6’w i d es t </w>’ 3
vocabulary:l o w </w> e r n s t i des
est est</w> lo low
Sennrich, Haddow Practical Neural Machine Translation 46 / 109

Byte pair encoding for word segmentation
bottom-up character mergingstarting point: character-level representation→ computationally expensive
compress representation based on information theory→ byte pair encoding [Gage, 1994]
repeatedly replace most frequent symbol pair (’A’,’B’) with ’AB’
hyperparameter: when to stop→ controls vocabulary size
word freq’l o w </w>’ 5’l o w e r </w>’ 2’n e w est </w>’ 6’w i d est </w>’ 3
vocabulary:l o w </w> e r n s t i des est
est</w> lo low
Sennrich, Haddow Practical Neural Machine Translation 46 / 109

Byte pair encoding for word segmentation
bottom-up character mergingstarting point: character-level representation→ computationally expensive
compress representation based on information theory→ byte pair encoding [Gage, 1994]
repeatedly replace most frequent symbol pair (’A’,’B’) with ’AB’
hyperparameter: when to stop→ controls vocabulary size
word freq’l o w </w>’ 5’l o w e r </w>’ 2’n e w est</w>’ 6’w i d est</w>’ 3
vocabulary:l o w </w> e r n s t i des est est</w>
lo low
Sennrich, Haddow Practical Neural Machine Translation 46 / 109

Byte pair encoding for word segmentation
bottom-up character mergingstarting point: character-level representation→ computationally expensive
compress representation based on information theory→ byte pair encoding [Gage, 1994]
repeatedly replace most frequent symbol pair (’A’,’B’) with ’AB’
hyperparameter: when to stop→ controls vocabulary size
word freq’lo w </w>’ 5’lo w e r </w>’ 2’n e w est</w>’ 6’w i d est</w>’ 3
vocabulary:l o w </w> e r n s t i des est est</w> lo
low
Sennrich, Haddow Practical Neural Machine Translation 46 / 109

Byte pair encoding for word segmentation
bottom-up character mergingstarting point: character-level representation→ computationally expensive
compress representation based on information theory→ byte pair encoding [Gage, 1994]
repeatedly replace most frequent symbol pair (’A’,’B’) with ’AB’
hyperparameter: when to stop→ controls vocabulary size
word freq’low </w>’ 5’low e r </w>’ 2’n e w est</w>’ 6’w i d est</w>’ 3
vocabulary:l o w </w> e r n s t i des est est</w> lo low
Sennrich, Haddow Practical Neural Machine Translation 46 / 109

Byte pair encoding for word segmentation
why BPE?open-vocabulary:operations learned on training set can be applied to unknown words
compression of frequent character sequences improves efficiency→ trade-off between text length and vocabulary size
’l o w e s t </w>’
e s → eses t → estest </w> → est</w>l o → lolo w → low
Sennrich, Haddow Practical Neural Machine Translation 47 / 109

Byte pair encoding for word segmentation
why BPE?open-vocabulary:operations learned on training set can be applied to unknown words
compression of frequent character sequences improves efficiency→ trade-off between text length and vocabulary size
’l o w es t </w>’
e s → eses t → estest </w> → est</w>l o → lolo w → low
Sennrich, Haddow Practical Neural Machine Translation 47 / 109

Byte pair encoding for word segmentation
why BPE?open-vocabulary:operations learned on training set can be applied to unknown words
compression of frequent character sequences improves efficiency→ trade-off between text length and vocabulary size
’l o w est </w>’
e s → eses t → estest </w> → est</w>l o → lolo w → low
Sennrich, Haddow Practical Neural Machine Translation 47 / 109

Byte pair encoding for word segmentation
why BPE?open-vocabulary:operations learned on training set can be applied to unknown words
compression of frequent character sequences improves efficiency→ trade-off between text length and vocabulary size
’l o w est</w>’
e s → eses t → estest </w> → est</w>l o → lolo w → low
Sennrich, Haddow Practical Neural Machine Translation 47 / 109

Byte pair encoding for word segmentation
why BPE?open-vocabulary:operations learned on training set can be applied to unknown words
compression of frequent character sequences improves efficiency→ trade-off between text length and vocabulary size
’lo w est</w>’
e s → eses t → estest </w> → est</w>l o → lolo w → low
Sennrich, Haddow Practical Neural Machine Translation 47 / 109

Byte pair encoding for word segmentation
why BPE?open-vocabulary:operations learned on training set can be applied to unknown words
compression of frequent character sequences improves efficiency→ trade-off between text length and vocabulary size
’low est</w>’
e s → eses t → estest </w> → est</w>l o → lolo w → low
Sennrich, Haddow Practical Neural Machine Translation 47 / 109

Evaluation: data and methods
dataWMT 15 English→German and English→Russian
modelattentional encoder–decoder neural network
parameters and settings as in [Bahdanau et al, 2014]
Sennrich, Haddow Practical Neural Machine Translation 48 / 109
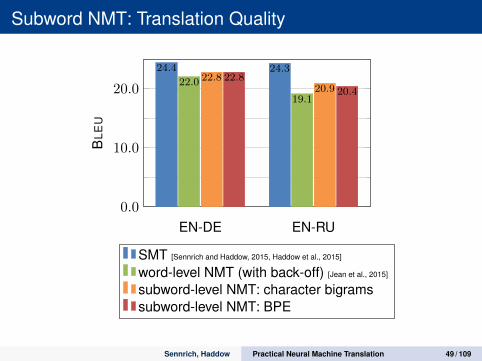
Subword NMT: Translation Quality
EN-DE EN-RU0.0
10.0
20.0
24.4 24.3
22.0
19.1
22.820.9
22.8
20.4B
LEU
SMT [Sennrich and Haddow, 2015, Haddow et al., 2015]
word-level NMT (with back-off) [Jean et al., 2015]
subword-level NMT: character bigramssubword-level NMT: BPE
Sennrich, Haddow Practical Neural Machine Translation 49 / 109
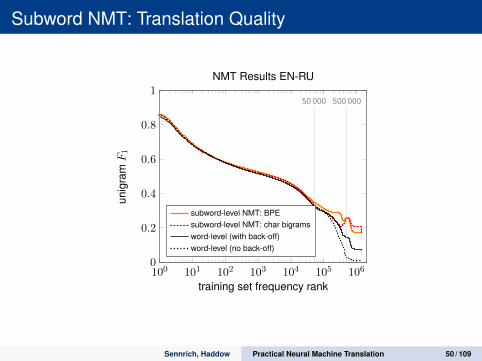
Subword NMT: Translation Quality
100 101 102 103 104 105 1060
0.2
0.4
0.6
0.8
150 000 500 000
training set frequency rank
unig
ramF1
NMT Results EN-RU
subword-level NMT: BPEsubword-level NMT: char bigramsword-level (with back-off)word-level (no back-off)
Sennrich, Haddow Practical Neural Machine Translation 50 / 109

Examples
system sentencesource health research institutesreference Gesundheitsforschungsinstituteword-level (with back-off) Forschungsinstitutecharacter bigrams Fo|rs|ch|un|gs|in|st|it|ut|io|ne|nBPE Gesundheits|forsch|ungsin|stitutesource rakfiskreference ðàêôèñêà (rakfiska)word-level (with back-off) rakfisk → UNK→ rakfiskcharacter bigrams ra|kf|is|k→ ðà|êô|èñ|ê (ra|kf|is|k)BPE rak|f|isk → ðàê|ô|èñêà (rak|f|iska)
Sennrich, Haddow Practical Neural Machine Translation 51 / 109

BPE in WMT16 Systems
Used Joint BPEJust concatenate source and target, then trainNamed-entities are split consistently
Learn 89,500 merge operationsUse ISO-9 transliteration for Russian:
transliterate Russian corpus into Latin scriptlearn BPE operations on concatenation of English and transliteratedRussian corpustransliterate BPE operations into Cyrillicfor Russian, apply both Cyrillic and Latin BPE operations→ concatenate BPE files
Set vocabulary size according to BPE vocabulary
Code available: https://github.com/rsennrich/subword-nmt
Sennrich, Haddow Practical Neural Machine Translation 52 / 109

Monolingual Data in NMT
Why Monolingual Data for Phrase-based SMT?more training data 3
relax independence assumptions 3
more appropriate training data (domain adaptation) 3
Why Monolingual Data for NMT?more training data 3
relax independence assumptions 7
more appropriate training data (domain adaptation) 3
Sennrich, Haddow Practical Neural Machine Translation 53 / 109
Monolingual Data in NMT
encoder-decoder already conditions onprevious target words
no architecture change required to learnfrom monolingual data
Sennrich, Haddow Practical Neural Machine Translation 54 / 109

Monolingual Training Instances
Output predictionp(yi) is a function of hidden state si, previous output yi−1, and sourcecontext vector cionly difference to monolingual RNN: ci
Problemwe have no source context ci for monolingual training instances
Solutionstwo methods to deal with missing source context:
empty/dummy source context ci→ danger of unlearning conditioning on sourceproduce synthetic source sentence via back-translation→ get approximation of ci
Sennrich, Haddow Practical Neural Machine Translation 55 / 109

Monolingual Training Instances
Output predictionp(yi) is a function of hidden state si, previous output yi−1, and sourcecontext vector cionly difference to monolingual RNN: ci
Problemwe have no source context ci for monolingual training instances
Solutionstwo methods to deal with missing source context:
empty/dummy source context ci→ danger of unlearning conditioning on sourceproduce synthetic source sentence via back-translation→ get approximation of ci
Sennrich, Haddow Practical Neural Machine Translation 55 / 109

Monolingual Training Instances
Dummy source1-1 mix of parallel and monolingual training instances
randomly sample from monolingual data each epoch
freeze encoder/attention layers for monolingual training instances
Synthetic source1-1 mix of parallel and monolingual training instances
randomly sample from back-translated data
training does not distinguish between real and synthetic parallel data
Sennrich, Haddow Practical Neural Machine Translation 56 / 109
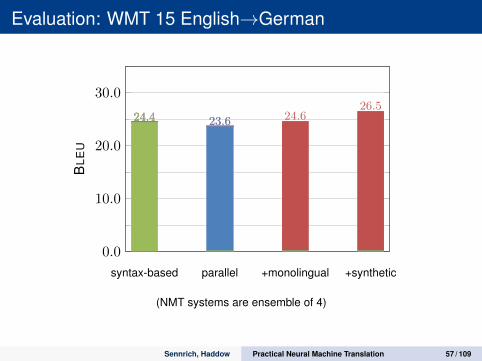
Evaluation: WMT 15 English→German
syntax-based parallel +monolingual +synthetic
0.0
10.0
20.0
30.0
24.4 23.6 24.626.5
24.4 23.624.4
BLE
U
(NMT systems are ensemble of 4)
Sennrich, Haddow Practical Neural Machine Translation 57 / 109
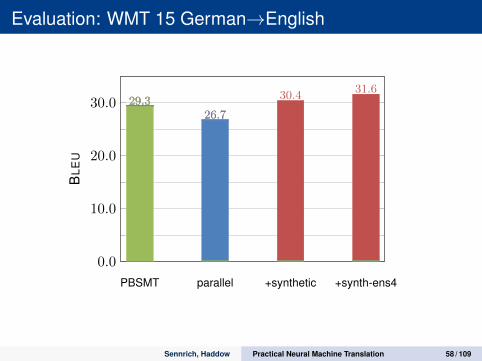
Evaluation: WMT 15 German→English
PBSMT parallel +synthetic +synth-ens4
0.0
10.0
20.0
30.0 29.326.7
30.431.6
29.326.7
29.3
BLE
U
Sennrich, Haddow Practical Neural Machine Translation 58 / 109

Why is monolingual data helpful?
Domain adaptation effect
Reduces over-fitting
Improves fluency
(See [Sennrich et al., 2016] for more analysis.)
Sennrich, Haddow Practical Neural Machine Translation 59 / 109

Left-to-Right / Right-to-Left Reranking
Target history is strong signal for next predictionHistory is reliable at training time, but not at test timeLow-entropy output words lead to poor translationSimilar to label bias problem
Reranking with reverse model can help1 Train two models, one has target reversed2 Generate n-best lists with one model3 Rescore lists with second model4 Rerank using combined scores
Consistent increase (0.5 – 1) in BLEU
Sennrich, Haddow Practical Neural Machine Translation 60 / 109
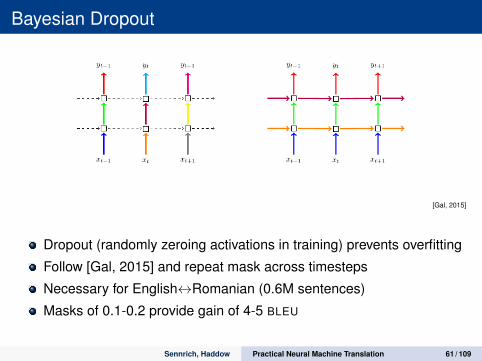
Bayesian Dropout
[Gal, 2015]
Dropout (randomly zeroing activations in training) prevents overfitting
Follow [Gal, 2015] and repeat mask across timesteps
Necessary for English↔Romanian (0.6M sentences)
Masks of 0.1-0.2 provide gain of 4-5 BLEU
Sennrich, Haddow Practical Neural Machine Translation 61 / 109
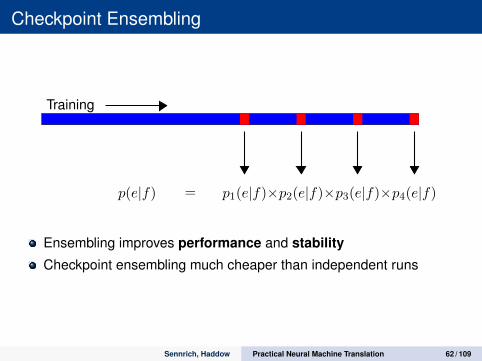
Checkpoint Ensembling
Training
p4(e|f)p3(e|f)p2(e|f)p1(e|f)p(e|f) = × × ×
Ensembling improves performance and stability
Checkpoint ensembling much cheaper than independent runs
Sennrich, Haddow Practical Neural Machine Translation 62 / 109
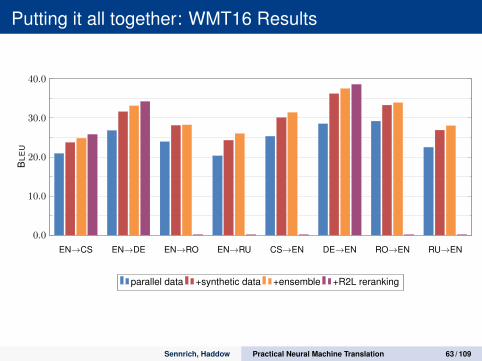
Putting it all together: WMT16 Results
EN→CS EN→DE EN→RO EN→RU CS→EN DE→EN RO→EN RU→EN
0.0
10.0
20.0
30.0
40.0
BLE
U
parallel data +synthetic data +ensemble +R2L reranking
Sennrich, Haddow Practical Neural Machine Translation 63 / 109

Practical Neural Machine Translation
1 Introduction
2 Neural Networks — Basics
3 Language Models using Neural Networks
4 Attention-based NMT Model
5 Edinburgh’s WMT16 System
6 Analysis: Why does NMT work so well?
7 Building and Improving NMT Systems
8 Resources, Further Reading and Wrap-Up
Sennrich, Haddow Practical Neural Machine Translation 64 / 109

Comparison between phrase-based and neural MT
human analysis of NMT (reranking) [Neubig et al., 2015]NMT is more grammatical
word orderinsertion/deletion of function wordsmorphological agreement
minor degradation in lexical choice?
Sennrich, Haddow Practical Neural Machine Translation 65 / 109

Comparison between phrase-based and neural MT
analysis of IWSLT 2015 results [Bentivogli et al., 2016]human-targeted translation error rate (HTER) based on automatictranslation and human post-edit
4 error types: substitution, insertion, deletion, shift
systemHTER (no shift) HTER
word lemma %∆ (shift only)PBSMT [Ha et al., 2015] 28.3 23.2 -18.0 3.5NMT [Luong and Manning, 2015] 21.7 18.7 -13.7 1.5
word-level is closer to lemma-level performance: better atinflection/agreement
improvement on lemma-level: better lexical choice
fewer shift errors: better word order
Sennrich, Haddow Practical Neural Machine Translation 66 / 109

Comparison between phrase-based and neural MT
analysis of IWSLT 2015 results [Bentivogli et al., 2016]human-targeted translation error rate (HTER) based on automatictranslation and human post-edit
4 error types: substitution, insertion, deletion, shift
systemHTER (no shift) HTER
word lemma %∆ (shift only)PBSMT [Ha et al., 2015] 28.3 23.2 -18.0 3.5NMT [Luong and Manning, 2015] 21.7 18.7 -13.7 1.5
word-level is closer to lemma-level performance: better atinflection/agreement
improvement on lemma-level: better lexical choice
fewer shift errors: better word order
Sennrich, Haddow Practical Neural Machine Translation 66 / 109

Comparison between phrase-based and neural MT
analysis of IWSLT 2015 results [Bentivogli et al., 2016]human-targeted translation error rate (HTER) based on automatictranslation and human post-edit
4 error types: substitution, insertion, deletion, shift
systemHTER (no shift) HTER
word lemma %∆ (shift only)PBSMT [Ha et al., 2015] 28.3 23.2 -18.0 3.5NMT [Luong and Manning, 2015] 21.7 18.7 -13.7 1.5
word-level is closer to lemma-level performance: better atinflection/agreement
improvement on lemma-level: better lexical choice
fewer shift errors: better word order
Sennrich, Haddow Practical Neural Machine Translation 66 / 109

Comparison between phrase-based and neural MT
analysis of IWSLT 2015 results [Bentivogli et al., 2016]human-targeted translation error rate (HTER) based on automatictranslation and human post-edit
4 error types: substitution, insertion, deletion, shift
systemHTER (no shift) HTER
word lemma %∆ (shift only)PBSMT [Ha et al., 2015] 28.3 23.2 -18.0 3.5NMT [Luong and Manning, 2015] 21.7 18.7 -13.7 1.5
word-level is closer to lemma-level performance: better atinflection/agreement
improvement on lemma-level: better lexical choice
fewer shift errors: better word order
Sennrich, Haddow Practical Neural Machine Translation 66 / 109
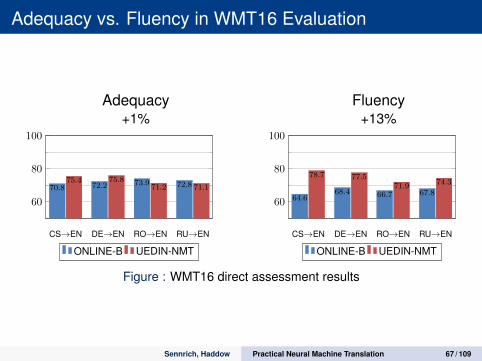
Adequacy vs. Fluency in WMT16 Evaluation
Adequacy Fluency+1% +13%
CS→EN DE→EN RO→EN RU→EN
60
80
100
70.8 72.2 73.9 72.875.4 75.8
71.2 71.1
ONLINE-B UEDIN-NMT
CS→EN DE→EN RO→EN RU→EN
60
80
100
64.668.4 66.7 67.8
78.7 77.571.9 74.3
ONLINE-B UEDIN-NMT
Figure : WMT16 direct assessment results
Sennrich, Haddow Practical Neural Machine Translation 67 / 109
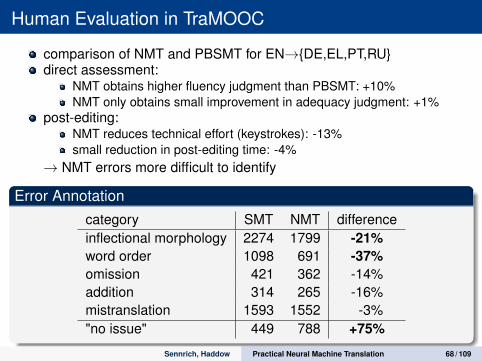
Human Evaluation in TraMOOC
comparison of NMT and PBSMT for EN→{DE,EL,PT,RU}direct assessment:
NMT obtains higher fluency judgment than PBSMT: +10%NMT only obtains small improvement in adequacy judgment: +1%
post-editing:NMT reduces technical effort (keystrokes): -13%small reduction in post-editing time: -4%
→ NMT errors more difficult to identify
Error Annotationcategory SMT NMT differenceinflectional morphology 2274 1799 -21%word order 1098 691 -37%omission 421 362 -14%addition 314 265 -16%mistranslation 1593 1552 -3%"no issue" 449 788 +75%
Sennrich, Haddow Practical Neural Machine Translation 68 / 109

Assessing MT Quality with Contrastive Translation Pairs
Questionshow well does NMT perform for specific linguistic phenomena?
example: is grammaticality affected by choice of subword unit?
Method [Sennrich, 2017]compare probability of human reference translation with contrastivetranslation that introduces a specific type of error→ NMT model should prefer referenceerrors related to:
morphosyntactic agreementdiscontiguous units of meaningpolaritytransliteration
Sennrich, Haddow Practical Neural Machine Translation 69 / 109

Contrastive Translation Pairs: Example
English [...] that the plan will be approvedGerman (correct) [...], dass der Plan verabschiedet wirdGerman (contrastive) * [...], dass der Plan verabschiedet werden
subject-verb agreement
Sennrich, Haddow Practical Neural Machine Translation 70 / 109

Assessing MT Quality with Contrastive Translation Pairs
ResultsWMT16 NMT system detects agreement errors with high accuracy –96.6–98.7%.
character-level system [Lee et al., 2016] better than BPE-to-BPEsystem at transliteration, but worse at morphosyntactic agreement
difference higher for agreement over long distances
0 4 8 12 160.5
0.6
0.7
0.8
0.9
1
≥ 16
distance
accu
racy
(sub
ject
-ver
bag
reem
ent)
BPE-to-BPEchar-to-char
Sennrich, Haddow Practical Neural Machine Translation 71 / 109

NMT vs. PBMT: An extended test [Junczys-Dowmunt et al., 2016a]
Experimental SetupTraining and test drawn from UN corpus
Multi-parallel, 11M linesArabic, Chinese, English, French, Russian, Spanish
Use only parallel data, evaluate with BLEU on 4000 sentences
Sennrich, Haddow Practical Neural Machine Translation 72 / 109

Why is neural MT output more grammatical?
phrase-based SMTlog-linear combination of many “weak” features
data sparsenesss triggers back-off to smaller units
strong independence assumptions
neural MTend-to-end trained model
generalization via continuous space representation
output conditioned on full source text and target history
Sennrich, Haddow Practical Neural Machine Translation 73 / 109

Practical Neural Machine Translation
1 Introduction
2 Neural Networks — Basics
3 Language Models using Neural Networks
4 Attention-based NMT Model
5 Edinburgh’s WMT16 System
6 Analysis: Why does NMT work so well?
7 Building and Improving NMT Systems
8 Resources, Further Reading and Wrap-Up
Sennrich, Haddow Practical Neural Machine Translation 74 / 109

Resource Usage
We all want our experiments to finish faster . . .What influences training speed/memory usage?
Number of model parameters, especially vocabulary sizeSize of training instance (max. length × batch size)Hardware and library versions
Decoding speedLess important for NMT researchersStandard Nematus model→ Use AmuNMT (hand-crafted GPU code)
Sennrich, Haddow Practical Neural Machine Translation 75 / 109
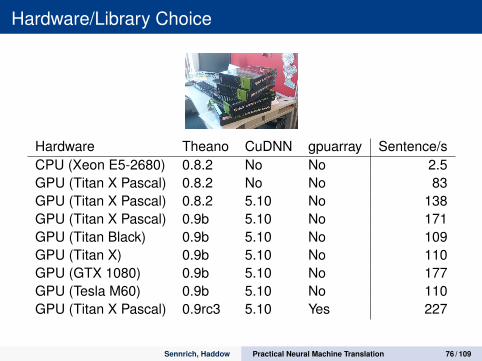
Hardware/Library Choice
Hardware Theano CuDNN gpuarray Sentence/sCPU (Xeon E5-2680) 0.8.2 No No 2.5GPU (Titan X Pascal) 0.8.2 No No 83GPU (Titan X Pascal) 0.8.2 5.10 No 138GPU (Titan X Pascal) 0.9b 5.10 No 171GPU (Titan Black) 0.9b 5.10 No 109GPU (Titan X) 0.9b 5.10 No 110GPU (GTX 1080) 0.9b 5.10 No 177GPU (Tesla M60) 0.9b 5.10 No 110GPU (Titan X Pascal) 0.9rc3 5.10 Yes 227
Sennrich, Haddow Practical Neural Machine Translation 76 / 109
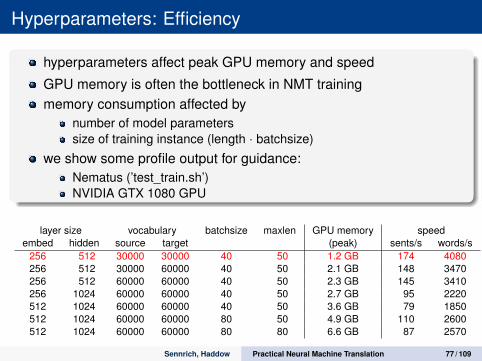
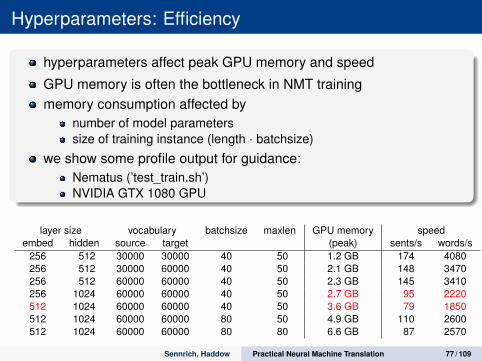
Hyperparameters: Efficiency
hyperparameters affect peak GPU memory and speed
GPU memory is often the bottleneck in NMT trainingmemory consumption affected by
number of model parameterssize of training instance (length · batchsize)
we show some profile output for guidance:Nematus (’test_train.sh’)NVIDIA GTX 1080 GPU
layer size vocabulary batchsize maxlen GPU memory speedembed hidden source target (peak) sents/s words/s
256 512 30000 30000 40 50 1.2 GB 174 4080256 512 30000 60000 40 50 2.1 GB 148 3470256 512 60000 60000 40 50 2.3 GB 145 3410256 1024 60000 60000 40 50 2.7 GB 95 2220512 1024 60000 60000 40 50 3.6 GB 79 1850512 1024 60000 60000 80 50 4.9 GB 110 2600512 1024 60000 60000 80 80 6.6 GB 87 2570
Sennrich, Haddow Practical Neural Machine Translation 77 / 109
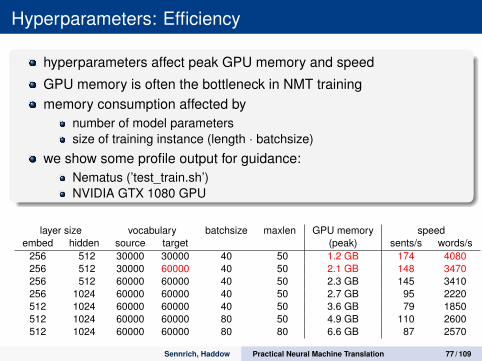
Hyperparameters: Efficiency
hyperparameters affect peak GPU memory and speed
GPU memory is often the bottleneck in NMT trainingmemory consumption affected by
number of model parameterssize of training instance (length · batchsize)
we show some profile output for guidance:Nematus (’test_train.sh’)NVIDIA GTX 1080 GPU
layer size vocabulary batchsize maxlen GPU memory speedembed hidden source target (peak) sents/s words/s
256 512 30000 30000 40 50 1.2 GB 174 4080256 512 30000 60000 40 50 2.1 GB 148 3470256 512 60000 60000 40 50 2.3 GB 145 3410256 1024 60000 60000 40 50 2.7 GB 95 2220512 1024 60000 60000 40 50 3.6 GB 79 1850512 1024 60000 60000 80 50 4.9 GB 110 2600512 1024 60000 60000 80 80 6.6 GB 87 2570
Sennrich, Haddow Practical Neural Machine Translation 77 / 109
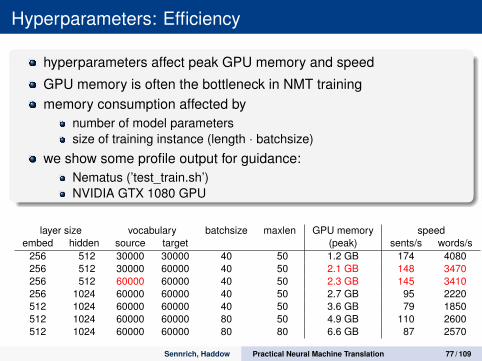
Hyperparameters: Efficiency
hyperparameters affect peak GPU memory and speed
GPU memory is often the bottleneck in NMT trainingmemory consumption affected by
number of model parameterssize of training instance (length · batchsize)
we show some profile output for guidance:Nematus (’test_train.sh’)NVIDIA GTX 1080 GPU
layer size vocabulary batchsize maxlen GPU memory speedembed hidden source target (peak) sents/s words/s
256 512 30000 30000 40 50 1.2 GB 174 4080256 512 30000 60000 40 50 2.1 GB 148 3470256 512 60000 60000 40 50 2.3 GB 145 3410256 1024 60000 60000 40 50 2.7 GB 95 2220512 1024 60000 60000 40 50 3.6 GB 79 1850512 1024 60000 60000 80 50 4.9 GB 110 2600512 1024 60000 60000 80 80 6.6 GB 87 2570
Sennrich, Haddow Practical Neural Machine Translation 77 / 109
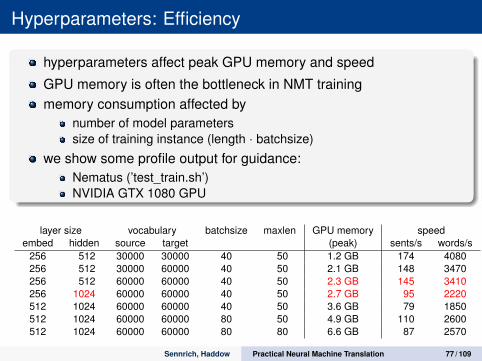
Hyperparameters: Efficiency
hyperparameters affect peak GPU memory and speed
GPU memory is often the bottleneck in NMT trainingmemory consumption affected by
number of model parameterssize of training instance (length · batchsize)
we show some profile output for guidance:Nematus (’test_train.sh’)NVIDIA GTX 1080 GPU
layer size vocabulary batchsize maxlen GPU memory speedembed hidden source target (peak) sents/s words/s
256 512 30000 30000 40 50 1.2 GB 174 4080256 512 30000 60000 40 50 2.1 GB 148 3470256 512 60000 60000 40 50 2.3 GB 145 3410256 1024 60000 60000 40 50 2.7 GB 95 2220512 1024 60000 60000 40 50 3.6 GB 79 1850512 1024 60000 60000 80 50 4.9 GB 110 2600512 1024 60000 60000 80 80 6.6 GB 87 2570
Sennrich, Haddow Practical Neural Machine Translation 77 / 109
Hyperparameters: Efficiency
hyperparameters affect peak GPU memory and speed
GPU memory is often the bottleneck in NMT trainingmemory consumption affected by
number of model parameterssize of training instance (length · batchsize)
we show some profile output for guidance:Nematus (’test_train.sh’)NVIDIA GTX 1080 GPU
layer size vocabulary batchsize maxlen GPU memory speedembed hidden source target (peak) sents/s words/s
256 512 30000 30000 40 50 1.2 GB 174 4080256 512 30000 60000 40 50 2.1 GB 148 3470256 512 60000 60000 40 50 2.3 GB 145 3410256 1024 60000 60000 40 50 2.7 GB 95 2220512 1024 60000 60000 40 50 3.6 GB 79 1850512 1024 60000 60000 80 50 4.9 GB 110 2600512 1024 60000 60000 80 80 6.6 GB 87 2570
Sennrich, Haddow Practical Neural Machine Translation 77 / 109
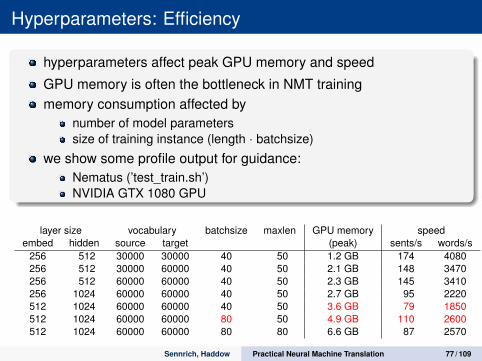
Hyperparameters: Efficiency
hyperparameters affect peak GPU memory and speed
GPU memory is often the bottleneck in NMT trainingmemory consumption affected by
number of model parameterssize of training instance (length · batchsize)
we show some profile output for guidance:Nematus (’test_train.sh’)NVIDIA GTX 1080 GPU
layer size vocabulary batchsize maxlen GPU memory speedembed hidden source target (peak) sents/s words/s
256 512 30000 30000 40 50 1.2 GB 174 4080256 512 30000 60000 40 50 2.1 GB 148 3470256 512 60000 60000 40 50 2.3 GB 145 3410256 1024 60000 60000 40 50 2.7 GB 95 2220512 1024 60000 60000 40 50 3.6 GB 79 1850512 1024 60000 60000 80 50 4.9 GB 110 2600512 1024 60000 60000 80 80 6.6 GB 87 2570
Sennrich, Haddow Practical Neural Machine Translation 77 / 109
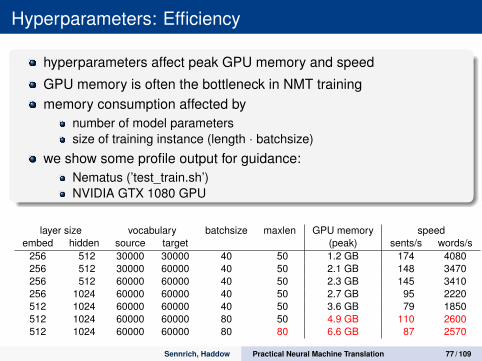
Hyperparameters: Efficiency
hyperparameters affect peak GPU memory and speed
GPU memory is often the bottleneck in NMT trainingmemory consumption affected by
number of model parameterssize of training instance (length · batchsize)
we show some profile output for guidance:Nematus (’test_train.sh’)NVIDIA GTX 1080 GPU
layer size vocabulary batchsize maxlen GPU memory speedembed hidden source target (peak) sents/s words/s
256 512 30000 30000 40 50 1.2 GB 174 4080256 512 30000 60000 40 50 2.1 GB 148 3470256 512 60000 60000 40 50 2.3 GB 145 3410256 1024 60000 60000 40 50 2.7 GB 95 2220512 1024 60000 60000 40 50 3.6 GB 79 1850512 1024 60000 60000 80 50 4.9 GB 110 2600512 1024 60000 60000 80 80 6.6 GB 87 2570
Sennrich, Haddow Practical Neural Machine Translation 77 / 109

Training: Minibatches
Why Minibatches?parallelization (GPUs!) is more efficiently with larger matrices
easy way to increase matrix size: batch up training instances
other advantage: stabilizes updates
how do we deal with difference in sentence length in batch?standard solution: pad sentence with special tokens
layer no. unitsinput alphabet size (X) 300embedding sizes 256char RNN (forward) 400char RNN (backward) 400attention 300char decoder 400target alphabet size (T ) 300
Table 1. Hyperparameter values used for training thechar-to-char model. Where Σsrc and Σtrg represent thenumber of classes in the source and target languages, respec-tively.
layer no. unitsinput alphabet size (X) 300embedding sizes 256char RNN (forward) 400spaces RNN (forward) 400spaces RNN (backward) 400attention 300char decoder 400target alphabet size (T ) 300
Table 2. Hyperparameter values used for training thechar2word-to-charmodel. Where Σsrc and Σtrg repre-sent the number of classes in the source and target languages,respectively.
timesteps, which can result in a lot of wasted resources [Han-nun et al., 2014] (see figure 4). Training translation modelsis further complicated by the fact that source and target sen-tences, while correlated, may have different lengths, and it isnecessary to consider both when constructing batches in orderto utilize computation power and RAM optimally.
To circumvent this issue, we start each epoch by shufflingall samples in the dataset and sorting them with a stable sort-ing algorithm according to both the source and target sentencelengths. This ensures that any two samples in the dataset thathave almost the same source and target sentence lengths arelocated close to each other in the sorted list while the exactorder of samples varies between epochs. To pack a batch wesimply started adding samples from the sorted sample list tothe batch, until we reached the maximal total allowed charac-ter threshold (which we set to 50,000) for the full batch withpadding after which we would start on a new batch. Finallyall the batches are fed in random order to the model for train-ing until all samples have been trained on, and a new epochbegins. Figure 5 illustrates what such dynamic batches mightlook like.
Fig. 4. A regular batch with random samples.
Fig. 5. Our dynamic batches of variable batch size and se-quence length.
5.3. Results
5.3.1. Quantitative
The quantitative results of our models are illustrated in ta-ble 3. Notice that the char2word-to-char model out-performs the char-to-charmodel on all datasets (average1.28 BLEU performance increase). This could be an indica-tion that either having hierarchical, word-like, representationson the encoder or simply the fact that the encoder was signifi-cantly smaller, helps in NMT when using a character decoderwith attention.
[Johansen et al., 2016]
Sennrich, Haddow Practical Neural Machine Translation 78 / 109
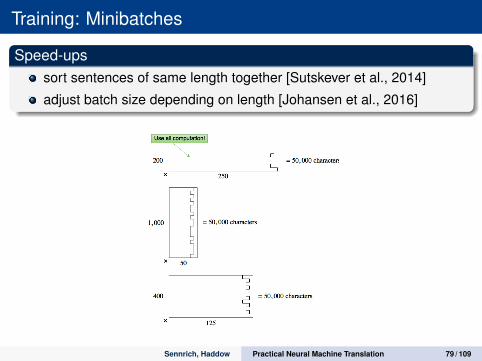
Training: Minibatches
Speed-upssort sentences of same length together [Sutskever et al., 2014]
adjust batch size depending on length [Johansen et al., 2016]
layer no. unitsinput alphabet size (X) 300embedding sizes 256char RNN (forward) 400char RNN (backward) 400attention 300char decoder 400target alphabet size (T ) 300
Table 1. Hyperparameter values used for training thechar-to-char model. Where Σsrc and Σtrg represent thenumber of classes in the source and target languages, respec-tively.
layer no. unitsinput alphabet size (X) 300embedding sizes 256char RNN (forward) 400spaces RNN (forward) 400spaces RNN (backward) 400attention 300char decoder 400target alphabet size (T ) 300
Table 2. Hyperparameter values used for training thechar2word-to-charmodel. Where Σsrc and Σtrg repre-sent the number of classes in the source and target languages,respectively.
timesteps, which can result in a lot of wasted resources [Han-nun et al., 2014] (see figure 4). Training translation modelsis further complicated by the fact that source and target sen-tences, while correlated, may have different lengths, and it isnecessary to consider both when constructing batches in orderto utilize computation power and RAM optimally.
To circumvent this issue, we start each epoch by shufflingall samples in the dataset and sorting them with a stable sort-ing algorithm according to both the source and target sentencelengths. This ensures that any two samples in the dataset thathave almost the same source and target sentence lengths arelocated close to each other in the sorted list while the exactorder of samples varies between epochs. To pack a batch wesimply started adding samples from the sorted sample list tothe batch, until we reached the maximal total allowed charac-ter threshold (which we set to 50,000) for the full batch withpadding after which we would start on a new batch. Finallyall the batches are fed in random order to the model for train-ing until all samples have been trained on, and a new epochbegins. Figure 5 illustrates what such dynamic batches mightlook like.
Fig. 4. A regular batch with random samples.
Fig. 5. Our dynamic batches of variable batch size and se-quence length.
5.3. Results
5.3.1. Quantitative
The quantitative results of our models are illustrated in ta-ble 3. Notice that the char2word-to-char model out-performs the char-to-charmodel on all datasets (average1.28 BLEU performance increase). This could be an indica-tion that either having hierarchical, word-like, representationson the encoder or simply the fact that the encoder was signifi-cantly smaller, helps in NMT when using a character decoderwith attention.
[Johansen et al., 2016]
Sennrich, Haddow Practical Neural Machine Translation 79 / 109

Out-of-memory: what to do
little effect on quality:reduce batch sizeremove long sentences (also in validation!)tie embedding layer and output layer in decoder [Press and Wolf, 2017](’--tie_decoder_embeddings’ in Nematus)model parallelism: different parts of model on different GPU
unknown (or negative) effect on quality:reduce layer sizereduce target vocabulary
Sennrich, Haddow Practical Neural Machine Translation 80 / 109
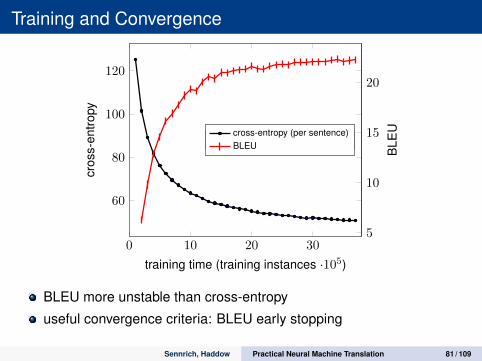
Training and Convergence
0 10 20 30
60
80
100
120
training time (training instances ·105)
cros
s-en
tropy
cross-entropy (per sentence)
5
10
15
20
BLE
Ucross-entropy (per sentence)BLEU
BLEU more unstable than cross-entropy
useful convergence criteria: BLEU early stopping
Sennrich, Haddow Practical Neural Machine Translation 81 / 109

Decoding Efficiency
How to make decoding fast?
Small beam size is often sufficientGreedy decoding can be competitive in quality→ especially with knowledge distillation [Kim and Rush, 2016]
Filter output vocabulary [Jean et al., 2015, L’Hostis et al., 2016]based on which words commonly co-occur with source words
process multiple sentences in batch [Wu et al., 2016]
low-precision arithmetic [Wu et al., 2016](requires suitable hardware)
NB: Amun supports batching, vocabulary filtering
Sennrich, Haddow Practical Neural Machine Translation 82 / 109
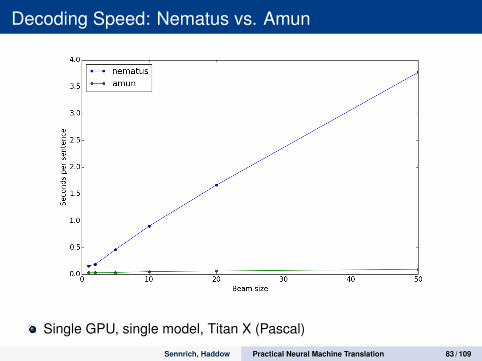
Decoding Speed: Nematus vs. Amun
Single GPU, single model, Titan X (Pascal)
Sennrich, Haddow Practical Neural Machine Translation 83 / 109

Improving Translation Quality
There are many possible ways of improving the basic system1 Improve corpus preparation2 Domain adaptation3 Obtain appropriate synthetic data4 Hybrid of NMT and traditional SMT5 Add extra linguistic information6 Minimum risk training7 Deep models8 Hyperparameter exploration
Sennrich, Haddow Practical Neural Machine Translation 84 / 109
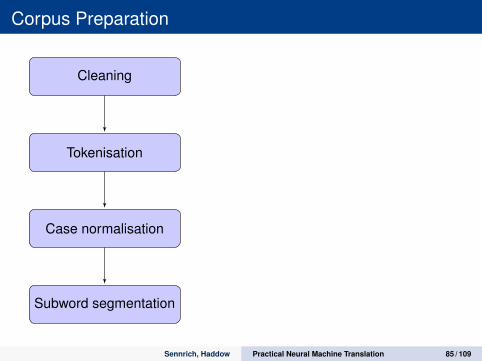
Corpus Preparation
Cleaning
Tokenisation
Case normalisation
Subword segmentation
Punctuation/encoding/spelling normalisation
Language identification
Removing non-parallel segments
Lowercasing
Truecasing (convert to most frequent)
Headlines etc.
Statistical
Linguistically motivated
Sennrich, Haddow Practical Neural Machine Translation 85 / 109
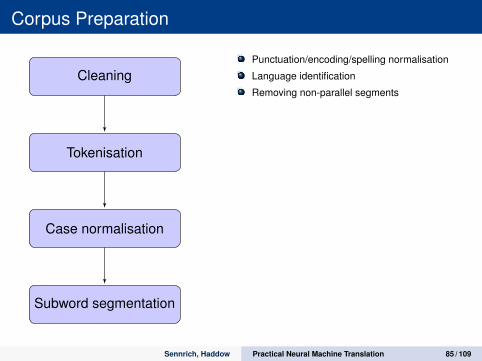
Corpus Preparation
Cleaning
Tokenisation
Case normalisation
Subword segmentation
Punctuation/encoding/spelling normalisation
Language identification
Removing non-parallel segments
Lowercasing
Truecasing (convert to most frequent)
Headlines etc.
Statistical
Linguistically motivated
Sennrich, Haddow Practical Neural Machine Translation 85 / 109
Corpus Preparation
Cleaning
Tokenisation
Case normalisation
Subword segmentation
Punctuation/encoding/spelling normalisation
Language identification
Removing non-parallel segments
Lowercasing
Truecasing (convert to most frequent)
Headlines etc.
Statistical
Linguistically motivated
Sennrich, Haddow Practical Neural Machine Translation 85 / 109
Corpus Preparation
Cleaning
Tokenisation
Case normalisation
Subword segmentation
Punctuation/encoding/spelling normalisation
Language identification
Removing non-parallel segments
Lowercasing
Truecasing (convert to most frequent)
Headlines etc.
Statistical
Linguistically motivated
Sennrich, Haddow Practical Neural Machine Translation 85 / 109
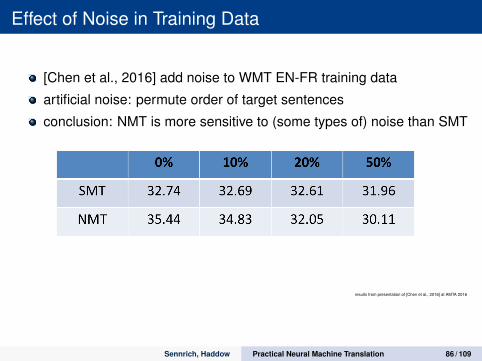
Effect of Noise in Training Data
[Chen et al., 2016] add noise to WMT EN-FR training data
artificial noise: permute order of target sentences
conclusion: NMT is more sensitive to (some types of) noise than SMT
Phrase-based SMT is robust to noise (Goutte et al., 2012)◦ performance is hardly affected when the misalignment rate is
below 30%, and introducing 50% alignment error brings performance down less than 1 BLEU point.
But does this also hold for NMT?◦ No!◦ WMT en2fr task (12M training pairs), on newstest14 test
21
Noise reduction is more important to NMT
results from presentation of [Chen et al., 2016] at AMTA 2016
Sennrich, Haddow Practical Neural Machine Translation 86 / 109
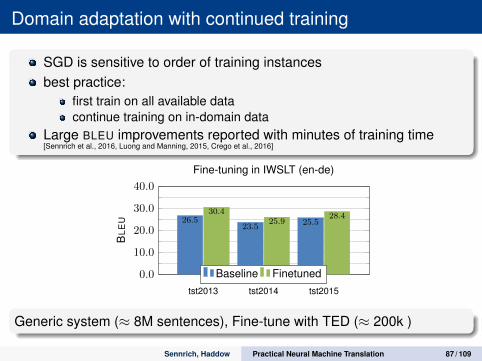
Domain adaptation with continued training
SGD is sensitive to order of training instancesbest practice:
first train on all available datacontinue training on in-domain data
Large BLEU improvements reported with minutes of training time[Sennrich et al., 2016, Luong and Manning, 2015, Crego et al., 2016]
tst2013 tst2014 tst2015
0.0
10.0
20.0
30.0
40.0
26.523.5
25.5
30.425.9
28.4
BLE
U
Fine-tuning in IWSLT (en-de)
Baseline Finetuned
Generic system (≈ 8M sentences), Fine-tune with TED (≈ 200k )
Sennrich, Haddow Practical Neural Machine Translation 87 / 109

Continued training with synthetic data
what if we have monolingual in-domain training data?we compare fine-tuning with:
200 000 sentence pairs in-domain200 000 target-language sentences in-domain, plus automaticback-translation
system BLEU (tst2015)WMT data 25.5fine-tuned on in-domain (parallel) 28.4fine-tuned on in-domain (synthetic) 26.7
English→German translation performance on IWSLT test set (TED talks).
→ parallel in-domain data is better, but domain adaptation withmonolingual data is possible→WMT16 results (using large synthetic news corpora)
[Sennrich et al., 2016]
Sennrich, Haddow Practical Neural Machine Translation 88 / 109

Continued training with synthetic data
ProblemHow to create synthetic data from source-language in-domain data?
Solution1 Gather source-language in-domain data.2 Translate to target language3 Use this translated data to select from CommonCrawl corpus4 Back-translate selected data to create synthetic data
Sennrich, Haddow Practical Neural Machine Translation 89 / 109

Continued training with synthetic data
ProblemHow to create synthetic data from source-language in-domain data?
Solution1 Gather source-language in-domain data.2 Translate to target language3 Use this translated data to select from CommonCrawl corpus4 Back-translate selected data to create synthetic data
Sennrich, Haddow Practical Neural Machine Translation 89 / 109

Continued training with synthetic data
SetupLanguage pairs: English→ Czech, German, Polish and Romanian
Domains: Two healthcare websites (NHS 24 and Cochrane)
Baselines: Data drawn from WMT releases and OPUSFine-tuning:
Use crawls of full websites as selection “seed”Continue training with 50-50 synthetic/parallel mix
en→cs en→de en→plen→ro
0.0
10.0
20.0
30.0
40.0
30.2
37.6
15.5
31.533.4
38.5
19.1
34.4
BLE
U
Cochrane
Baseline Finetuned
en→cs en→de en→plen→ro
0.0
10.0
20.0
30.0
40.0
23.1
31.6
19.5
28.626.7
32.9
24.2
29.7
BLE
U
NHS 24
Baseline Finetuned
Sennrich, Haddow Practical Neural Machine Translation 90 / 109
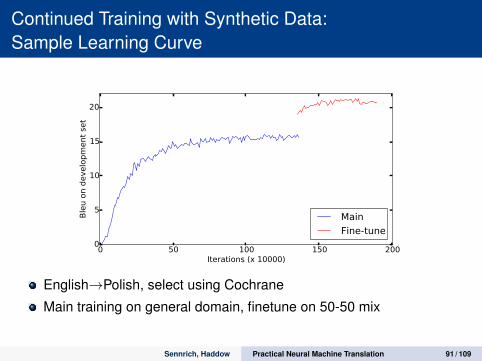
Continued Training with Synthetic Data:Sample Learning Curve
0 50 100 150 200Iterations (x 10000)
0
5
10
15
20
Bleu
on
deve
lopm
ent s
et
MainFine-tune
English→Polish, select using Cochrane
Main training on general domain, finetune on 50-50 mix
Sennrich, Haddow Practical Neural Machine Translation 91 / 109
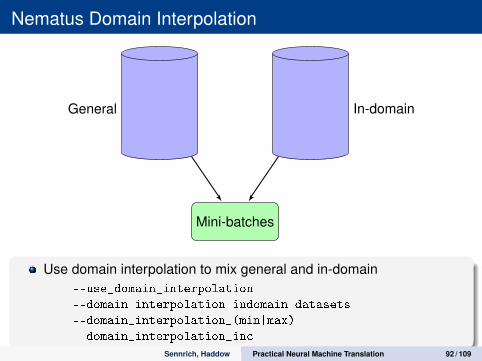
Nematus Domain Interpolation
General In-domain
Mini-batches
Use domain interpolation to mix general and in-domain--use_domain_interpolation
--domain_interpolation_indomain_datasets
--domain_interpolation_(min|max)
--domain_interpolation_inc
Sennrich, Haddow Practical Neural Machine Translation 92 / 109

NMT Hybrid Models
Model combination (ensembling) is well establishedSeveral ways to combine NMT with PBMT / Syntax-based MT:
Re-ranking output of traditional SMT with NMT [Neubig et al., 2015]Incorporating NMT as feature function in PBMT[Junczys-Dowmunt et al., 2016b]Rescoring hiero lattices with NMT [Stahlberg et al., 2016]
Reduces chance of “bizarre” NMT outputs
Sennrich, Haddow Practical Neural Machine Translation 93 / 109
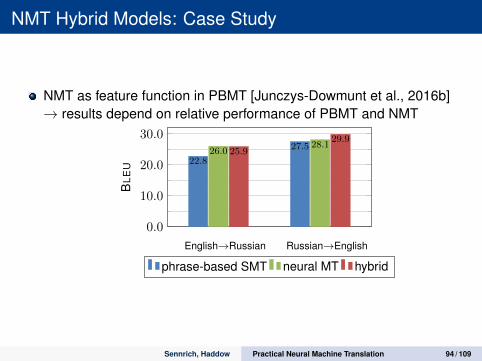
NMT Hybrid Models: Case Study
NMT as feature function in PBMT [Junczys-Dowmunt et al., 2016b]→ results depend on relative performance of PBMT and NMT
English→Russian Russian→English
0.0
10.0
20.0
30.0
22.8
27.526.028.1
25.9
29.9
BLE
U
phrase-based SMT neural MT hybrid
Sennrich, Haddow Practical Neural Machine Translation 94 / 109

Why Linguistic Features?
disambiguate words by POS
English Germancloseverb schließencloseadj nahclosenoun Ende
source We thought a win like this might be closeadj.reference Wir dachten, dass ein solcher Sieg nah sein könnte.baseline NMT *Wir dachten, ein Sieg wie dieser könnte schließen.
Sennrich, Haddow Practical Neural Machine Translation 95 / 109

Why Linguistic Features?
better generalization; combat data sparsity
word form
lemma morph. features
liegen (lie)
liegen (lie) (3.p.pl. present)
liegst (lie)
liegen (lie) (2.p.sg. present)
lag (lay)
liegen (lie) (3.p.sg. past)
läge (lay)
liegen (lie) (3.p.sg. subjunctive II)
Sennrich, Haddow Practical Neural Machine Translation 96 / 109

Why Linguistic Features?
better generalization; combat data sparsity
word form lemma morph. featuresliegen (lie) liegen (lie) (3.p.pl. present)liegst (lie) liegen (lie) (2.p.sg. present)lag (lay) liegen (lie) (3.p.sg. past)läge (lay) liegen (lie) (3.p.sg. subjunctive II)
Sennrich, Haddow Practical Neural Machine Translation 96 / 109

Neural Machine Translation: Multiple Input Features
Use separate embeddings for each feature, then concatenate
baseline: only word feature
E(close) =
0.50.20.30.1
|F | input features
E1(close) =
0.40.10.2
E2(adj) =
[0.1]
E1(close) ‖ E2(adj) =
0.40.10.20.1
Sennrich, Haddow Practical Neural Machine Translation 97 / 109
Experiments
Featureslemmas
morphological features
POS tags
dependency labels
BPE tags
DataWMT16 training/test data
English↔German and English→Romanian
Sennrich, Haddow Practical Neural Machine Translation 98 / 109
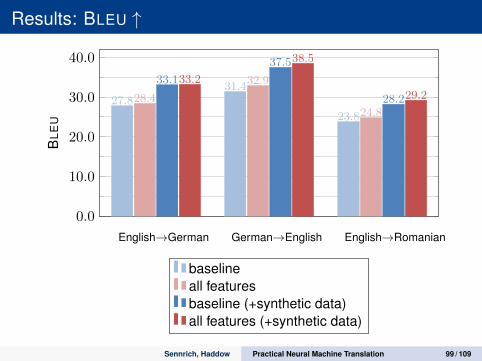
Results: BLEU ↑
English→German German→English English→Romanian
0.0
10.0
20.0
30.0
40.0
27.831.4
23.8
28.4
32.9
24.8
33.1
37.5
28.2
33.2
38.5
29.2
BLE
U
baselineall featuresbaseline (+synthetic data)all features (+synthetic data)
Sennrich, Haddow Practical Neural Machine Translation 99 / 109

Minimum Risk Training [Shen et al., 2016]
The standard NMT training objective is cross-entropy→ maximise probability of training data
In traditional SMT, we usually tune for BLEU
Can train NMT to minimise Expected Loss
S∑
s=1
Ep(y|x(s))
[∆(y, y(s))
]
(Loss function: ∆ ; Training pair: (x(s), y(s)) )
Run MRT after training with cross-entropy loss
Approximate expectation with sum over samples
Sennrich, Haddow Practical Neural Machine Translation 100 / 109

Minimum Risk Training in Nematus
Recipe:Train initial model with standard cross-entropy trainingContinue training with ’--objective MRT’
Sensitive to hyperparameters→ Use small learning rate with SGDmixed results:
Improvements over some baselines (EN→RO parallel)No improvement so far over others (EN→DE with synthetic data)
Sennrich, Haddow Practical Neural Machine Translation 101 / 109
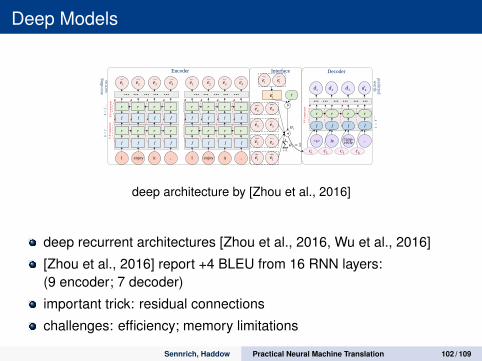
Deep Models
+
I it .
r r r r
it .I
r r r r
r r r r r r r r
… … … … …
k =
2 ..
.en
codi
ng
vect
ors
Je .
r r r
… … … … … …predicted
words
1e
2e
3e
4e
1e
2e
3e
4e
1e
2e
3e
4e
1e
2e
3e
4e
2d 3d 4d
4
1
1ii
a
ia
<s>
r
1d
fc
enjoy enjoy
l'app-récie
ff ff
ff ff
ff ff
ff ff
f f ff
Encoder Interface Decoder
ie
ie
r
F-F
conn
ectio
nF-
F co
nnec
tion
F-F
conn
ectio
n
1c 2c 3c 4c
'ie
k =
1... k =
1
… … … … …
Figure 2: The network. It includes three parts from left to right: encoder part (P-E), interface (P-I) and decoder part(P-D). We only show the topology of Deep-Att as an example. “f” and “r” blocks correspond to the feed-forward partand the subsequent LSTM computation. The F-F connections are denoted by dashed red lines.
connections can accelerate the model convergenceand while improving the performance. A similaridea was also used in (He et al., 2016; Zhou andXu, 2015).Encoder: The LSTM layers are stacked followingEq. 5. We call this type of encoder interleaved bi-directional encoder. In addition, there are two sim-ilar columns (a1 and a2) in the encoder part. Eachcolumn consists of ne stacked LSTM layers. Thereis no connection between the two columns. The firstlayers of the two columns process the word repre-sentations of the source sequence in different direc-tions. At the last LSTM layers, there are two groupsof vectors representing the source sequence. Thegroup size is the same as the length of the input se-quence.Interface: Prior encoder-decoder models and atten-tion models are different in their method of extract-ing the representations of the source sequences. Inour work, as a consequence of the introduced F-Fconnections, we have 4 output vectors (hne
t and fnet
of both columns). The representations are modifiedfor both Deep-ED and Deep-Att.
For Deep-ED, et is static and consists of fourparts. 1: The last time step output hne
m of thefirst column. 2: Max-operation Max(·) of hne
t
at all time steps of the second column, denotedby Max(hne,a2
t ). Max(·) denotes obtaining themaximal value for each dimension over t. 3:Max(fne,a1
t ). 4: Max(fne,a2t ). The max-operation
and last time step state extraction provide compli-
mentary information but do not affect the perfor-mance much. et is used as the final representationct.
For Deep-Att, we do not need the above two op-erations. We only concatenate the 4 output vectorsat each time step to obtain et, and a soft attentionmechanism (Bahdanau et al., 2015) is used to calcu-late the final representation ct from et. et is summa-rized as:
Deep-ED: et
[hne,a1m ,Max(hne,a2
t ),Max(fne,a1t ),Max(fne,a2
t )]
Deep-Att: et
[hne,a1t , hne,a2
t , fne,a1t , fne,a2
t ] (7)
Note that the vector dimensionality of f is four timeslarger than that of h (see Eq. 4). ct is summarized as:
Deep-ED: ct = et, (const)
Deep-Att: ct =
m∑
t′=1
αt,t′Wpet′ (8)
αt,t′ is the normalized attention weight computedby:
αt,t′ =exp(a(Wpet′ , h
1,dect−1 ))
∑t′′ exp(a(Wpet′′ , h
1,dect−1 ))
(9)
h1,dect−1 is the first hidden layer output in the decodingpart. a(·) is an alignment model described in (Bah-danau et al., 2015). For Deep-Att, in order to re-duce the memory cost, we linearly project (withWp)
deep architecture by [Zhou et al., 2016]
deep recurrent architectures [Zhou et al., 2016, Wu et al., 2016]
[Zhou et al., 2016] report +4 BLEU from 16 RNN layers:(9 encoder; 7 decoder)
important trick: residual connections
challenges: efficiency; memory limitations
Sennrich, Haddow Practical Neural Machine Translation 102 / 109

Hyperparameter Exploration
Massive Exploration of Neural Machine Translation Architectures[Britz et al., 2017]
Spent 250,000 hours GPU time exploring hyperparametersConclusions:
Small gain from increasing embedding sizeLSTM better than GRU2-4 Layer Bidirectional encoder better4-layer decoder gives some advantageAdditive better than multiplicative attentionLarge beams not helpful (best = 10)
BLEU variance across runs small (± 0.2-0.3)
Sennrich, Haddow Practical Neural Machine Translation 103 / 109

Practical Neural Machine Translation
1 Introduction
2 Neural Networks — Basics
3 Language Models using Neural Networks
4 Attention-based NMT Model
5 Edinburgh’s WMT16 System
6 Analysis: Why does NMT work so well?
7 Building and Improving NMT Systems
8 Resources, Further Reading and Wrap-Up
Sennrich, Haddow Practical Neural Machine Translation 104 / 109

Getting Started: Do it Yourself
sample files and instructions for training NMT modelhttps://github.com/rsennrich/wmt16-scripts
pre-trained models to test decoding (and for further experiments)http://statmt.org/rsennrich/wmt16_systems/
lab on installing/using Nematus:http://www.statmt.org/eacl2017/practical-nmt-lab.pdf
Sennrich, Haddow Practical Neural Machine Translation 105 / 109
(A small selection of) Resources
NMT toolsNematus (theano) https://github.com/rsennrich/nematus
OpenNMT (torch) https://github.com/OpenNMT/OpenNMT
nmt.matlab https://github.com/lmthang/nmt.matlab
neural monkey (tensorflow) https://github.com/ufal/neuralmonkey
lamtram (DyNet) https://github.com/neubig/lamtram
...and many more https://github.com/jonsafari/nmt-list
Sennrich, Haddow Practical Neural Machine Translation 106 / 109

Further Reading
secondary literaturelecture notes by Kyunghyun Cho: [Cho, 2015]
chapter on Neural Network Models in “Statistical Machine Translation”by Philipp Koehn http://mt-class.org/jhu/assets/papers/neural-network-models.pdf
tutorial on sequence-to-sequence models by Graham Neubighttps://arxiv.org/abs/1703.01619
Sennrich, Haddow Practical Neural Machine Translation 107 / 109

AcknowledgmentsThis project has received funding from the European Union’sHorizon 2020 research and innovation programme undergrant agreements 645452 (QT21) and 644402 (HimL).
Sennrich, Haddow Practical Neural Machine Translation 108 / 109
Questions
Thank you!
Sennrich, Haddow Practical Neural Machine Translation 109 / 109
Bibliography I
Allen, R. (1987).Several Studies on Natural Language and Back-Propagation.In IEEE First International Conference on Neural Networks, pages 335–341, San Diego, California, USA.
Bahdanau, D., Cho, K., and Bengio, Y. (2015).Neural Machine Translation by Jointly Learning to Align and Translate.In Proceedings of the International Conference on Learning Representations (ICLR).
Bengio, Y., Ducharme, R., Vincent, P., and Janvin, C. (2003).A Neural Probabilistic Language Model.J. Mach. Learn. Res., 3:1137–1155.
Bentivogli, L., Bisazza, A., Cettolo, M., and Federico, M. (2016).Neural versus Phrase-Based Machine Translation Quality: a Case Study.In EMNLP 2016.
Britz, D., Goldie, A., Luong, T., and Le, Q. (2017).Massive Exploration of Neural Machine Translation Architectures.ArXiv e-prints.
Chen, B., Kuhn, R., Foster, G., Cherry, C., and Huang, F. (2016).Bilingual Methods for Adaptive Training Data Selection for Machine Translation.In Proceedings of AMTA.
Cho, K. (2015).Natural Language Understanding with Distributed Representation.CoRR, abs/1511.07916.
Sennrich, Haddow Practical Neural Machine Translation 110 / 109

Bibliography II
Cho, K., Courville, A., and Bengio, Y. (2015).Describing Multimedia Content using Attention-based Encoder-Decoder Networks.
Cho, K., van Merrienboer, B., Bahdanau, D., and Bengio, Y. (2014).On the Properties of Neural Machine Translation: Encoder-Decoder Approaches.ArXiv e-prints.
Crego, J., Kim, J., Klein, G., Rebollo, A., Yang, K., Senellart, J., Akhanov, E., Brunelle, P., Coquard, A., Deng, Y., Enoue, S.,Geiss, C., Johanson, J., Khalsa, A., Khiari, R., Ko, B., Kobus, C., Lorieux, J., Martins, L., Nguyen, D.-C., Priori, A., Riccardi, T.,Segal, N., Servan, C., Tiquet, C., Wang, B., Yang, J., Zhang, D., Zhou, J., and Zoldan, P. (2016).SYSTRAN’s Pure Neural Machine Translation Systems.ArXiv e-prints.
Devlin, J., Zbib, R., Huang, Z., Lamar, T., Schwartz, R., and Makhoul, J. (2014).Fast and Robust Neural Network Joint Models for Statistical Machine Translation.In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages1370–1380, Baltimore, Maryland. Association for Computational Linguistics.
Gage, P. (1994).A New Algorithm for Data Compression.C Users J., 12(2):23–38.
Gal, Y. (2015).A Theoretically Grounded Application of Dropout in Recurrent Neural Networks.ArXiv e-prints.
Ha, T.-L., Niehues, J., Cho, E., Mediani, M., and Waibel, A. (2015).The KIT translation systems for IWSLT 2015.In Proceedings of the International Workshop on Spoken Language Translation (IWSLT), pages 62–69.
Sennrich, Haddow Practical Neural Machine Translation 111 / 109

Bibliography III
Haddow, B., Huck, M., Birch, A., Bogoychev, N., and Koehn, P. (2015).The Edinburgh/JHU Phrase-based Machine Translation Systems for WMT 2015.In Proceedings of the Tenth Workshop on Statistical Machine Translation, pages 126–133, Lisbon, Portugal. Association forComputational Linguistics.
Jean, S., Cho, K., Memisevic, R., and Bengio, Y. (2015).On Using Very Large Target Vocabulary for Neural Machine Translation.InProceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers),pages 1–10, Beijing, China. Association for Computational Linguistics.
Johansen, A. R., Hansen, J. M., Obeid, E. K., Sønderby, C. K., and Winther, O. (2016).Neural Machine Translation with Characters and Hierarchical Encoding.CoRR, abs/1610.06550.
Junczys-Dowmunt, M., Dwojak, T., and Hoang, H. (2016a).Is Neural Machine Translation Ready for Deployment? A Case Study on 30 Translation Directions.In Proceedings of IWSLT.
Junczys-Dowmunt, M., Dwojak, T., and Sennrich, R. (2016b).The AMU-UEDIN Submission to the WMT16 News Translation Task: Attention-based NMT Models as Feature Functions inPhrase-based SMT.In Proceedings of the First Conference on Machine Translation, Volume 2: Shared Task Papers, pages 316–322, Berlin,Germany. Association for Computational Linguistics.
Junczys-Dowmunt, M. and Grundkiewicz, R. (2016).Log-linear Combinations of Monolingual and Bilingual Neural Machine Translation Models for Automatic Post-Editing.In Proceedings of the First Conference on Machine Translation, pages 751–758, Berlin, Germany. Association for ComputationalLinguistics.
Sennrich, Haddow Practical Neural Machine Translation 112 / 109
Bibliography IV
Kalchbrenner, N. and Blunsom, P. (2013).Recurrent Continuous Translation Models.In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle. Association forComputational Linguistics.
Kalchbrenner, N., Grefenstette, E., and Blunsom, P. (2014).A Convolutional Neural Network for Modelling Sentences.In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).
Kim, Y. and Rush, A. M. (2016).Sequence-Level Knowledge Distillation.CoRR, abs/1606.07947.
Lee, J., Cho, K., and Hofmann, T. (2016).Fully Character-Level Neural Machine Translation without Explicit Segmentation.ArXiv e-prints.
L’Hostis, G., Grangier, D., and Auli, M. (2016).Vocabulary Selection Strategies for Neural Machine Translation.ArXiv e-prints.
Luong, M.-T. and Manning, C. D. (2015).Stanford Neural Machine Translation Systems for Spoken Language Domains.In Proceedings of the International Workshop on Spoken Language Translation 2015, Da Nang, Vietnam.
Luong, T., Sutskever, I., Le, Q. V., Vinyals, O., and Zaremba, W. (2014).Addressing the Rare Word Problem in Neural Machine Translation.CoRR, abs/1410.8206.
Sennrich, Haddow Practical Neural Machine Translation 113 / 109
Bibliography V
Mikolov, T., Karafiát, M., Burget, L., Cernocký, J., and Khudanpur, S. (2010).Recurrent neural network based language model.InINTERSPEECH 2010, 11th Annual Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, September 26-30, 2010,pages 1045–1048.
Neubig, G., Morishita, M., and Nakamura, S. (2015).Neural Reranking Improves Subjective Quality of Machine Translation: NAIST at WAT2015.In Proceedings of the 2nd Workshop on Asian Translation (WAT2015), pages 35–41, Kyoto, Japan.
Press, O. and Wolf, L. (2017).Using the Output Embedding to Improve Language Models.In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics (EACL),Valencia, Spain.
Schwenk, H., Dechelotte, D., and Gauvain, J.-L. (2006).Continuous Space Language Models for Statistical Machine Translation.In Proceedings of the COLING/ACL 2006 Main Conference Poster Sessions, pages 723–730, Sydney, Australia.
Sennrich, R. (2017).How Grammatical is Character-level Neural Machine Translation? Assessing MT Quality with Contrastive Translation Pairs.In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics (EACL),Valencia, Spain.
Sennrich, R., Firat, O., Cho, K., Birch, A., Haddow, B., Hitschler, J., Junczys-Dowmunt, M., Läubli, S., Barone, A. V. M., andNadejde, M. (2017).Nematus: a Toolkit for Neural Machine Translation.In Proceedings of EACL (Demo Session).
Sennrich, Haddow Practical Neural Machine Translation 114 / 109

Bibliography VI
Sennrich, R. and Haddow, B. (2015).A Joint Dependency Model of Morphological and Syntactic Structure for Statistical Machine Translation.In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 2081–2087, Lisbon,Portugal. Association for Computational Linguistics.
Sennrich, R., Haddow, B., and Birch, A. (2016).Improving Neural Machine Translation Models with Monolingual Data.In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages86–96, Berlin, Germany. Association for Computational Linguistics.
Shen, S., Cheng, Y., He, Z., He, W., Wu, H., Sun, M., and Liu, Y. (2016).Minimum Risk Training for Neural Machine Translation.In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).
Stahlberg, F., Hasler, E., Waite, A., and Byrne, B. (2016).Syntactically Guided Neural Machine Translation.In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages299–305, Berlin, Germany. Association for Computational Linguistics.
Sutskever, I., Vinyals, O., and Le, Q. V. (2014).Sequence to Sequence Learning with Neural Networks.InAdvances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014,pages 3104–3112, Montreal, Quebec, Canada.
Vaswani, A., Zhao, Y., Fossum, V., and Chiang, D. (2013).Decoding with Large-Scale Neural Language Models Improves Translation.In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, EMNLP 2013, pages1387–1392, Seattle, Washington, USA.
Sennrich, Haddow Practical Neural Machine Translation 115 / 109

Bibliography VII
Wu, Y., Schuster, M., Chen, Z., Le, Q. V., Norouzi, M., Macherey, W., Krikun, M., Cao, Y., Gao, Q., Macherey, K., Klingner, J.,Shah, A., Johnson, M., Liu, X., Kaiser, Ł., Gouws, S., Kato, Y., Kudo, T., Kazawa, H., Stevens, K., Kurian, G., Patil, N., Wang, W.,Young, C., Smith, J., Riesa, J., Rudnick, A., Vinyals, O., Corrado, G., Hughes, M., and Dean, J. (2016).Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation.ArXiv e-prints.
Zhou, J., Cao, Y., Wang, X., Li, P., and Xu, W. (2016).Deep Recurrent Models with Fast-Forward Connections for Neural Machine Translation.Transactions of the Association of Computational Linguistics – Volume 4, Issue 1, pages 371–383.
Sennrich, Haddow Practical Neural Machine Translation 116 / 109


















![Machine Translation - 04: Neural Machine Translationhomepages.inf.ed.ac.uk/rsennric/mt18/4.pdf · R. Sennrich MT – 2018 – 04 12/20. Attention model [Cho et al., 2015] R. Sennrich](https://static.fdocuments.us/doc/165x107/603a4d2f2fca99785a286177/machine-translation-04-neural-machine-r-sennrich-mt-a-2018-a-04-1220-attention.jpg)