
Potential and Challenges of Grid Computing - …gallen/Presentations/MardiGras_GEA_Jan... ·...
70
Potential and Challenges of Grid Computing Gabrielle Allen Department of Computer Science Center for Computation & Technology Louisiana State University http://www.cct.lsu.edu/~gallen
Transcript of Potential and Challenges of Grid Computing - …gallen/Presentations/MardiGras_GEA_Jan... ·...

Potential and Challenges of Grid Computing
Gabrielle Allen
Department of Computer Science
Center for Computation & Technology
Louisiana State University
http://www.cct.lsu.edu/~gallen

Grid Computing Potential
•! Aggregate computational resources across the world –! Compute servers
–! File servers
–! Networks
–! Devices
•! Serve communities
•! Enable new modes of scientific investigation –! Harness multiple sites and
devices
–! Models with new level of complexity and scale, interacting with data
–! New possibilities for collaboration and advanced scenarios

Globus Toolkit (1996-…)
•! Standards and basic middleware for applications in a distributed resource environment …
–!File transfer, Job management, Information, Security, ….
–!Moved through several versions, clients and APIs to grid services and web services
•! Base components of many higher level tools
•! Success stories today: LIGO data, MONTAGE, caBIG, Earth System Grid, …
3

NSF TeraGrid (2001-…)
4
Not just machines, also coordinated support, services.
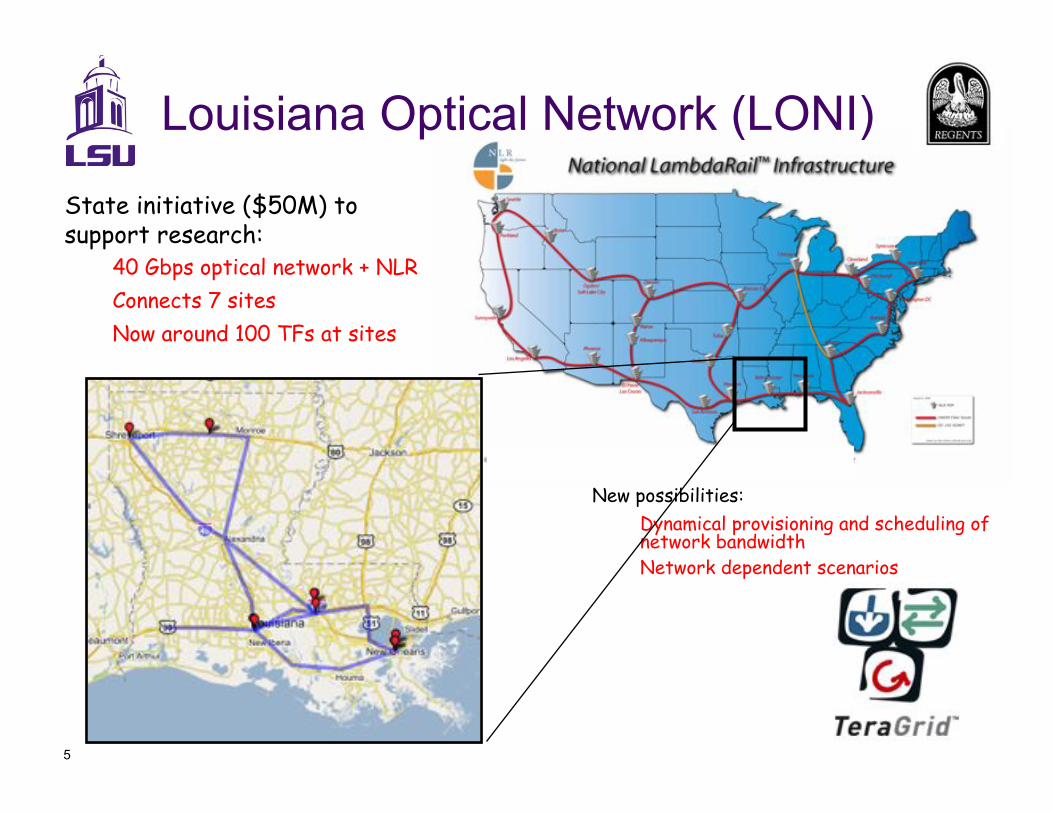
5
State initiative ($50M) to support research:
40 Gbps optical network + NLR
Connects 7 sites
Now around 100 TFs at sites
New possibilities:
Dynamical provisioning and scheduling of network bandwidth Network dependent scenarios
Louisiana Optical Network (LONI)
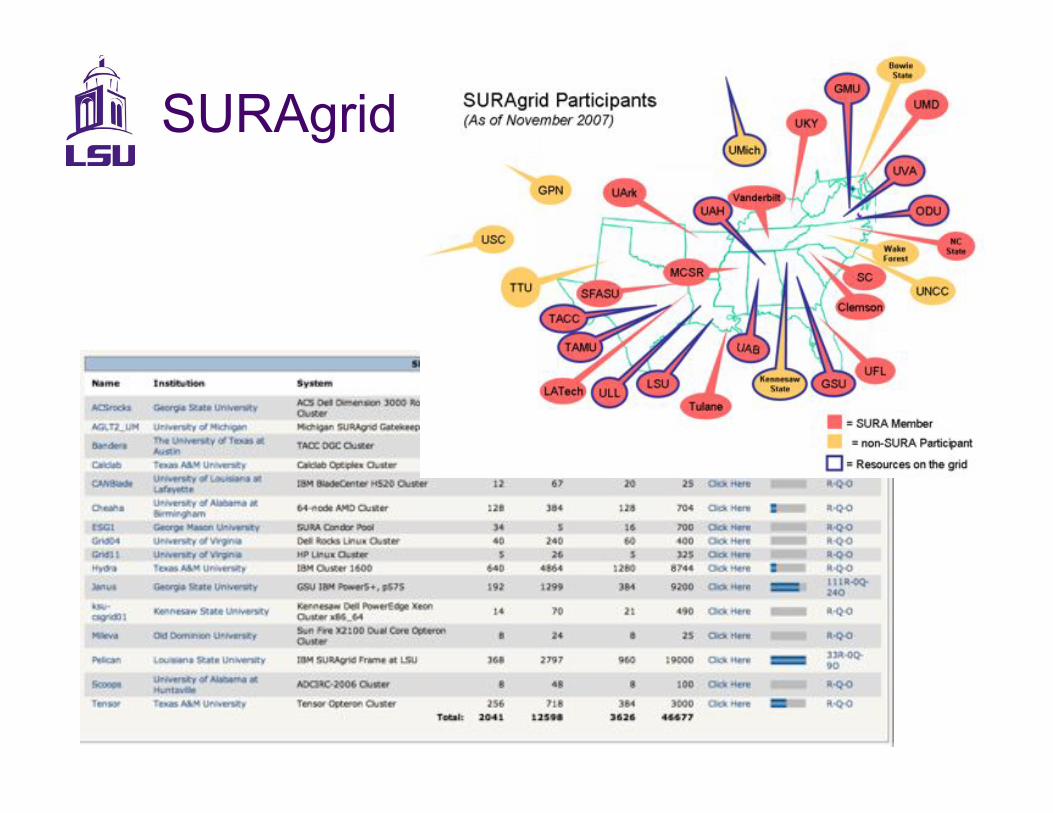
SURAgrid
Gravitational Wave Physics
7
Observations Models
Analysis & Insight
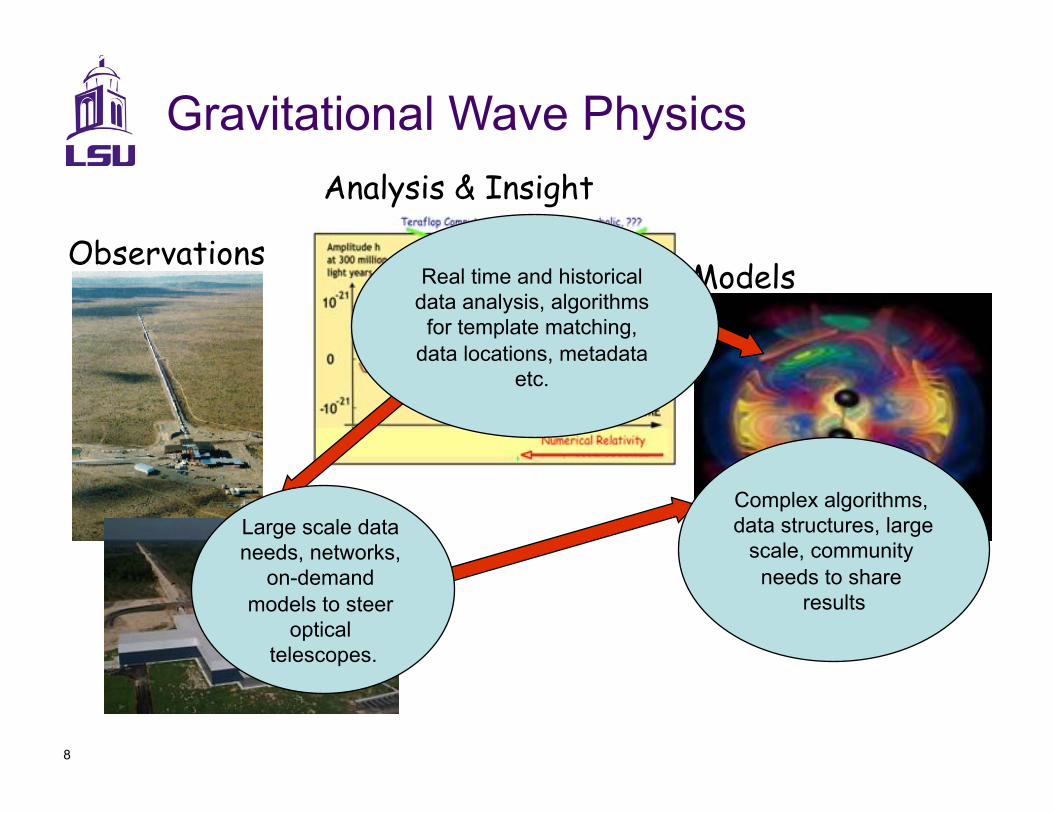
8
Gravitational Wave Physics
Observations Models
Analysis & Insight
Complex algorithms, data structures, large
scale, community
needs to share results
Real time and historical data analysis, algorithms for template matching,
data locations, metadata etc.
Large scale data needs, networks,
on-demand
models to steer optical
telescopes.
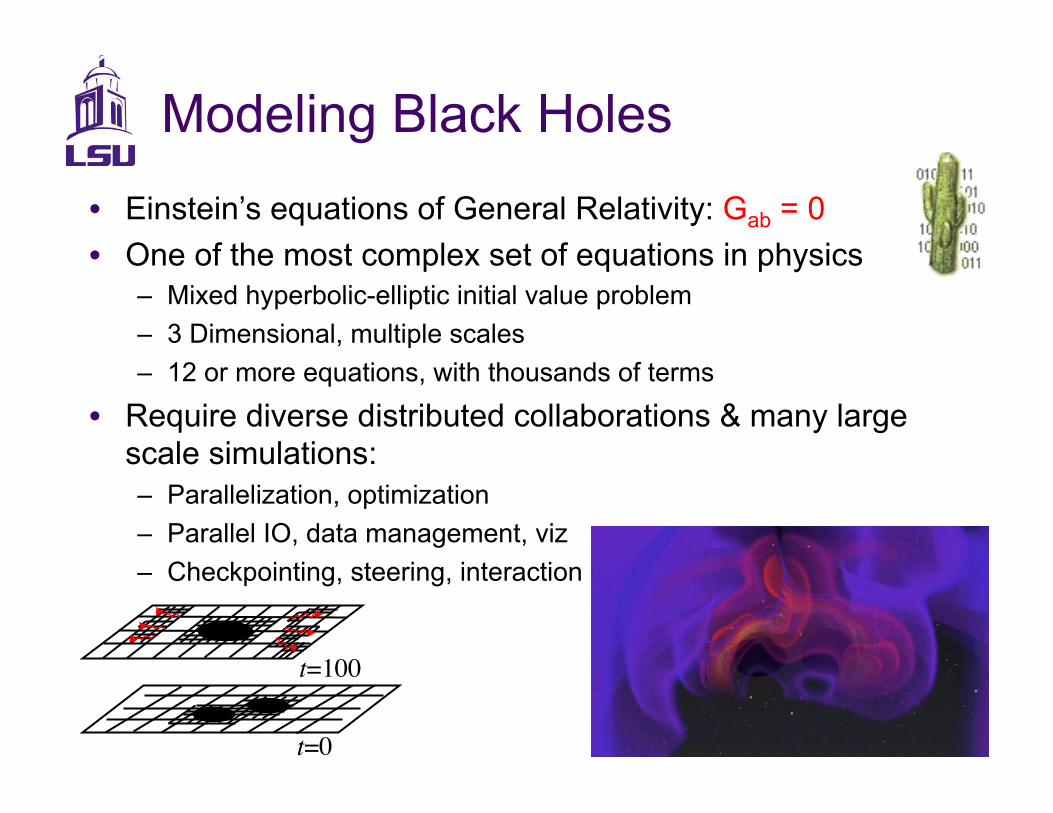
Modeling Black Holes
•! Einstein’s equations of General Relativity: Gab = 0
•! One of the most complex set of equations in physics –! Mixed hyperbolic-elliptic initial value problem
–! 3 Dimensional, multiple scales
–! 12 or more equations, with thousands of terms
•! Require diverse distributed collaborations & many large scale simulations:
–! Parallelization, optimization
–! Parallel IO, data management, viz
–! Checkpointing, steering, interaction
t=100!
t=0!

10
Cactus Framework (1997-…)
•! Freely available, modular, environment for collaboratively developing parallel, high-performance multi-dimensional simulations (Component-based)
•! Developed for Numerical Relativity, but now general framework for parallel computing
•! Science driven design issues
•! Designed with the Grid in mind: –! Checkpoint/restart
–! Portable
–! Steering
–! Well defined components/interfaces
•! Over $10M funding over 10 years

HPC Programming Frameworks
•! Complex apps need software development tools
•! Separate computational physics and from infrastructure and HPC issues:
–! Make system, portability, parallelization, I/O, interpolators, elliptic solvers, check-pointing, optimization, petascale, Grids, new paradigms, …
•! Collaboration, enable code sharing and reuse
•! Community building
•! Leveraging other fields and tools
•! Cactus development team: many discussions about interfaces, module structure, data structures, etc
… Need similar strategy for Grid programming

Grid Application Types
•! Community Driven
–! Distributed communities share resources
–! Video Conferencing
–! Virtual Collaborative Environments
•! Data Driven
–! Remote access of huge data, data mining
–! Eg. Gravitational wave analysis, particle physics, astronomy
•! Process/Simulation Driven
–! Demanding Simulations of Science and Engineering
–! Task farming, resource brokering, distributed computations, workflow
•! Interaction Driven –! Remote visualization, steering and interaction, etc…
•! Often a combination of them all

13
Sit Here & Compute There
Astrophysics Simulation Collaboratory (1999):
•! Early “science gateway”
•! Portlets for parameter file preparing, comparison, managing
•! Simulation staging, managing, monitoring
•! Link to data archives, viz etc.
•! Submit distributed jobs
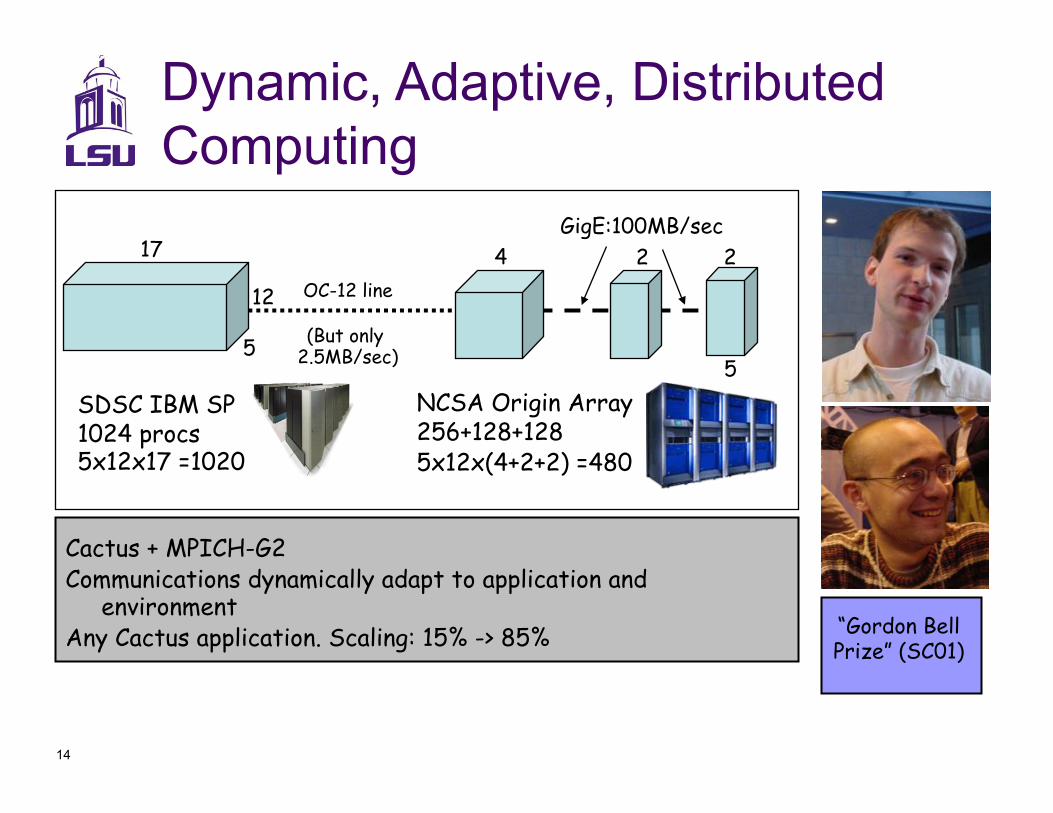
14
SDSC IBM SP 1024 procs 5x12x17 =1020
NCSA Origin Array 256+128+128 5x12x(4+2+2) =480
OC-12 line
(But only 2.5MB/sec)
GigE:100MB/sec 17
12
5
4 2
5
2
Cactus + MPICH-G2 Communications dynamically adapt to application and
environment Any Cactus application. Scaling: 15% -> 85% “Gordon Bell
Prize” (SC01)
Dynamic, Adaptive, Distributed Computing

New Focus for Dynamic Grids
•! Addressing large, complex, multidisciplinary problems with collaborative teams of varied researchers ...
•! Code/User/Infrastructure should be aware of environment
–! Discover and monitor resources available NOW
–! What is my allocation on these resources?
–! What is bandwidth/latency Code/User/Infrastructure should make decisions
–! Slow part of simulation can run independently … spawn it off!
–! New powerful resources just became available … migrate there!
–! Machine went down … reconfigure and recover!
–! Need more memory (or less!), get by adding (dropping) machines!
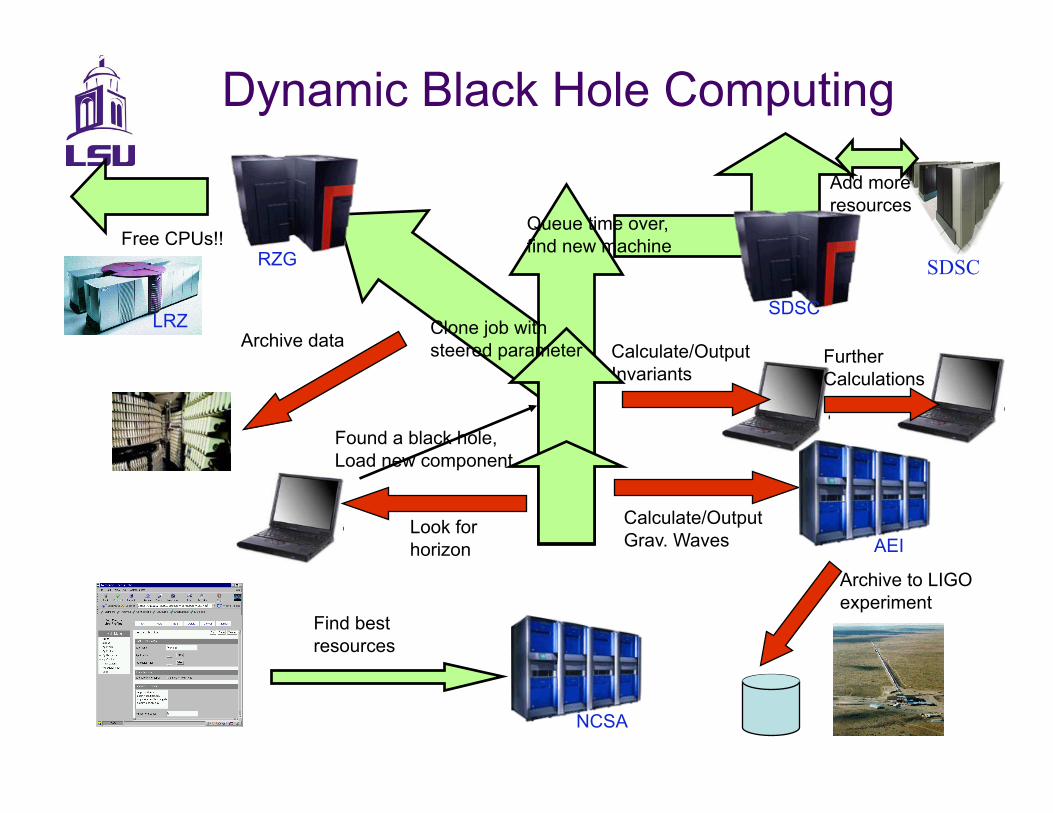
Found a black hole, Load new component
Look for horizon
Calculate/Output Grav. Waves
Calculate/Output Invariants
Find best resources
Free CPUs!!
NCSA
SDSC
RZG
LRZ Archive data
SDSC
Add more resources
Clone job with steered parameter
Queue time over, find new machine
Further Calculations
AEI
Archive to LIGO experiment
Dynamic Black Hole Computing

Migration: Cactus Worm (2000)
•! Cactus simulation starts, launched from portal
•! Migrates itself to another site –! Grid technologies / lots of sticky tape
•! Registers new location
•! User tracks/steers, using HTTP, streaming data, etc…
•! Continues around Europe…

User only has to invoke Cactus “Spawner” thorn…
Appropriate analysis tasks spawned automatically to free resources worldwide
Task Spawning (2001)
Cactus “Spawner” thorn automatically prepares analysis tasks for spawning
Grid technologies find resources, manage tasks, collect data
Intelligence to decide when to spawn
Main Cactus BH simulation starts here

Global Grid Testbed Collaboration
•! 5 continents and over 14 countries.
•! Around 70 machines, 7500+ processors
•! Many hardware types, including PS2, IA32, IA64, MIPS,
•! Many OSs, including Linux, Irix, AIX, OSF, True64, Solaris, Hitachi
•! Many organizations: DOE, NSF, MPG, universities, vendors
•! All ran same Grid infrastructure, and used for different applications
Cactus black hole simulations spawned apparent horizon finding tasks across the grid.
Supercomputing 2001
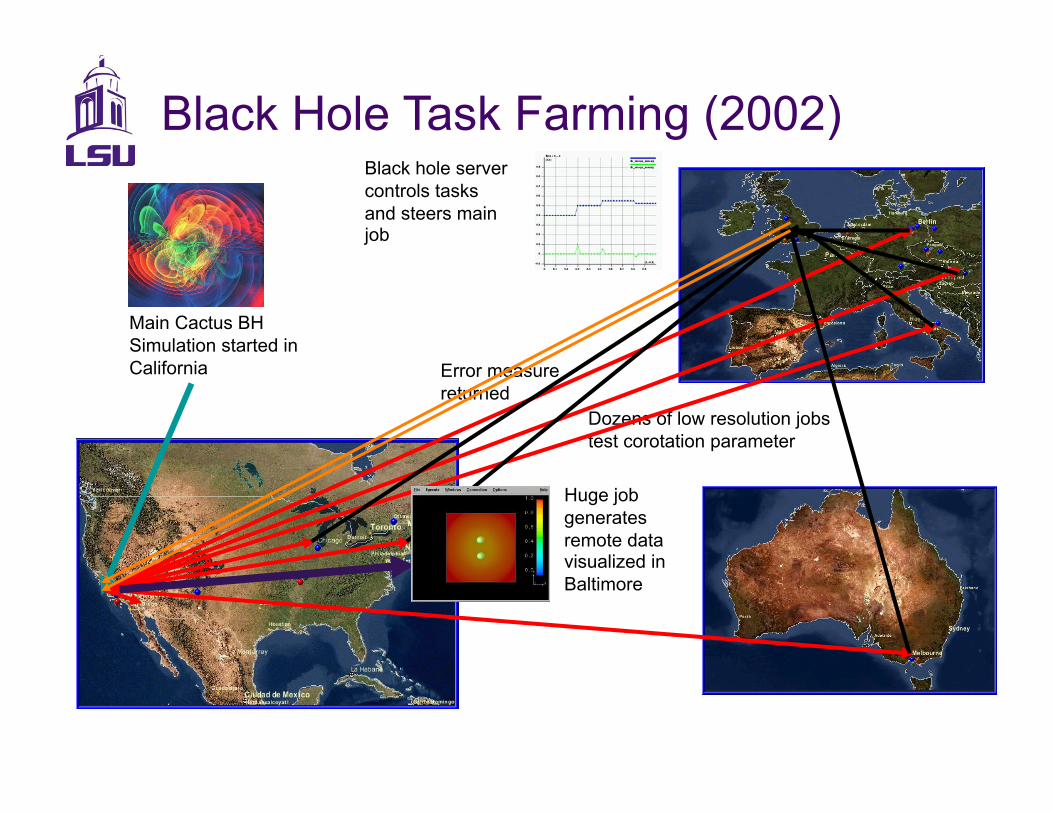
Main Cactus BH Simulation started in California
Dozens of low resolution jobs test corotation parameter
Huge job generates remote data visualized in Baltimore
Error measure returned
Black hole server controls tasks and steers main job
Black Hole Task Farming (2002)
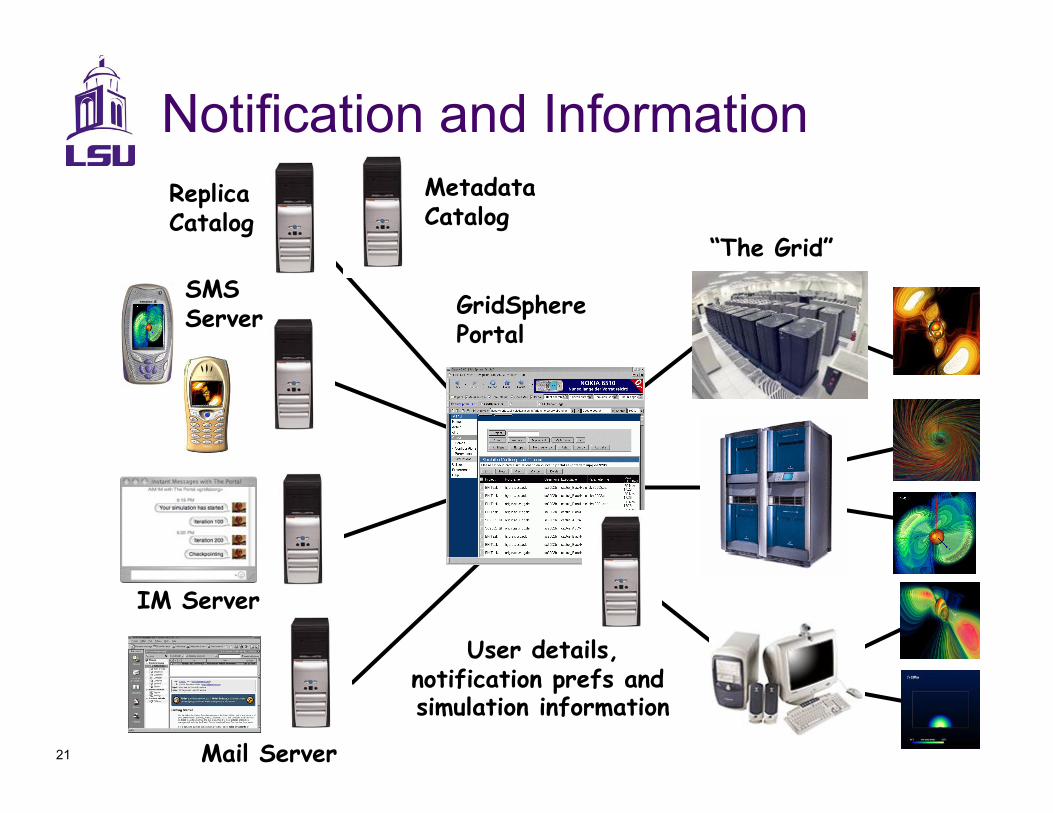
21
GridSphere Portal
SMS Server
Mail Server
“The Grid”
Replica Catalog
User details, notification prefs and simulation information!
IM Server
Notification and Information Metadata Catalog
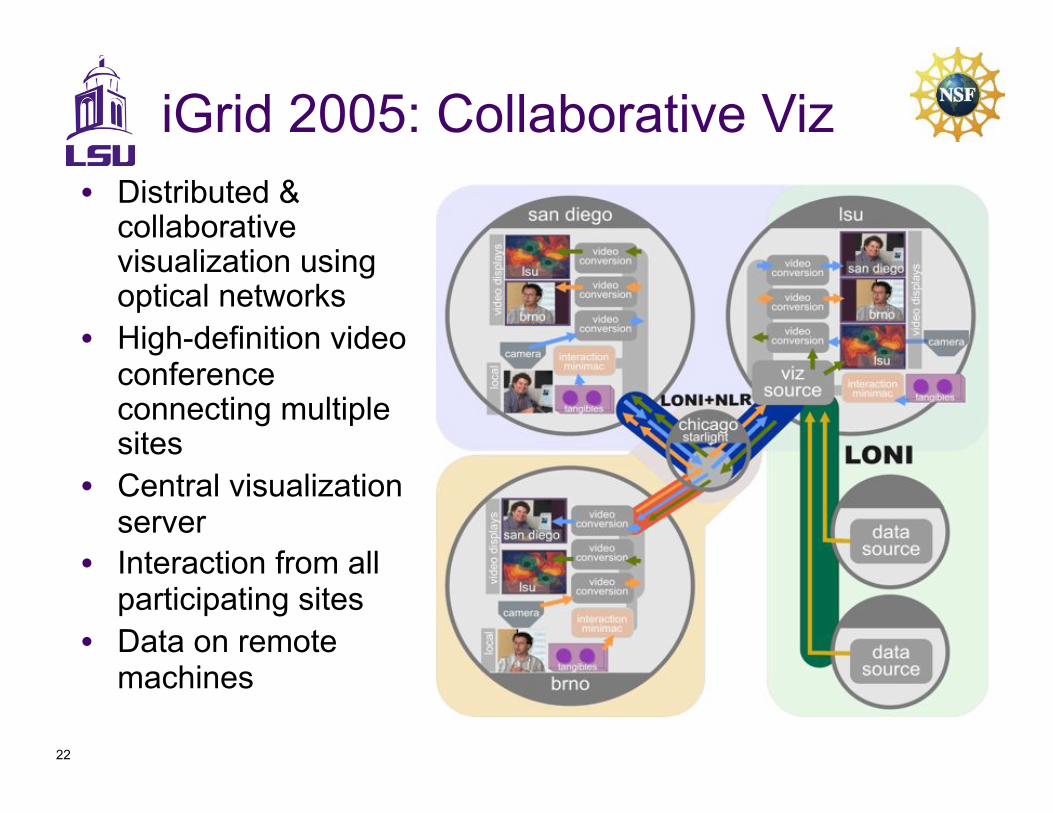
22
iGrid 2005: Collaborative Viz
•! Distributed & collaborative visualization using optical networks
•! High-definition video conference connecting multiple sites
•! Central visualization server
•! Interaction from all participating sites
•! Data on remote machines

Moving on from Demonstations
•! Prototyped new grid scenarios based around numerical relativity driver
–!Where are the production versions of these?
–!Missing services (e.g. co-allocation), immature software, not robust (because not used?)
•!How to go from demo’s to production?
–!Topic of this workshop … real grid applications
23

Application Tools for Grids
•! Application developers need the right kinds of tools and environments to use Grids
–!APIs, toolkits, debuggers, …
•! Focused on the application requirements (MPI, Fortran, legacy, ….)
•! Hide the complexities of the Grid
•! Work in a familiar way (avoid new paradigms)
•! Ideally part of regular work environment
–!Functioning and reliable heterogeneous testbed environments for developing and testing
–!Support new and dynamic application scenarios, as generic as possible.
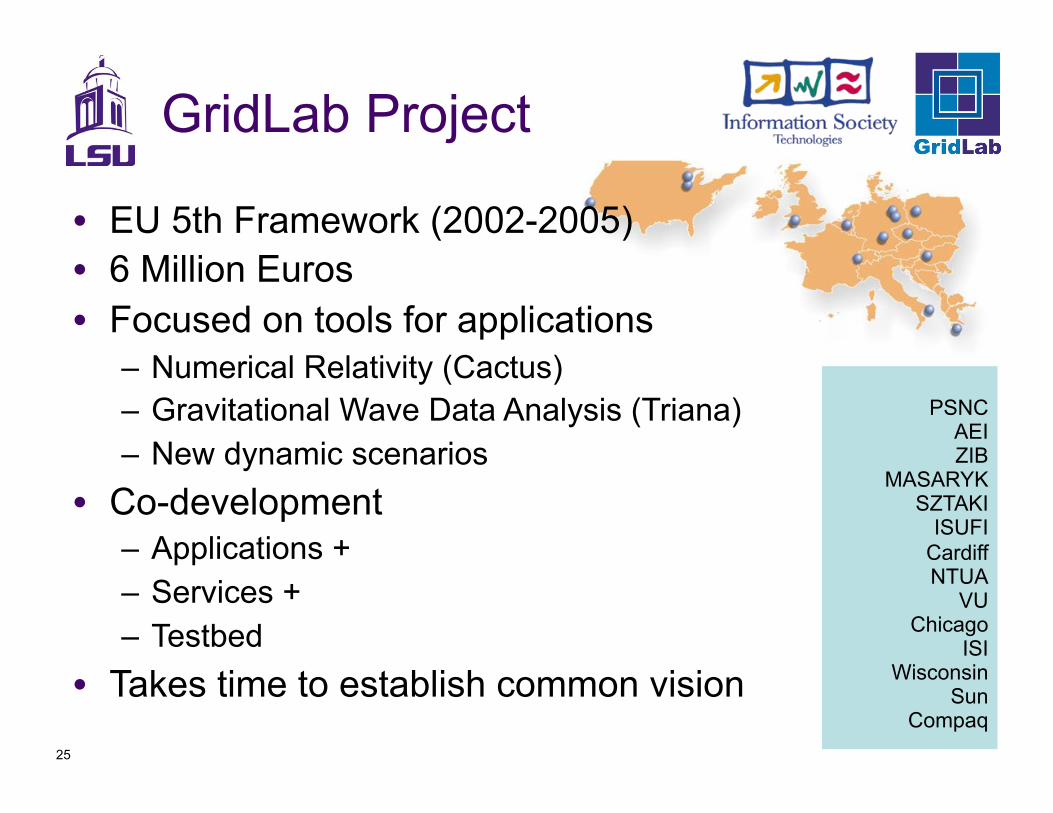
25
GridLab Project
PSNC AEI ZIB
MASARYK SZTAKI
ISUFI Cardiff NTUA
VU Chicago
ISI Wisconsin
Sun Compaq
•! EU 5th Framework (2002-2005)
•! 6 Million Euros
•! Focused on tools for applications –!Numerical Relativity (Cactus)
–!Gravitational Wave Data Analysis (Triana)
–!New dynamic scenarios
•! Co-development –!Applications +
–!Services +
–!Testbed
•! Takes time to establish common vision

26
•! Abstract programming interface between applications and Grid services
•! Designed for applications (move file, run remote task, migrate, write to remote file)
Grid Application Toolkit (GAT)

GridSphere
•! GridSphere portal framework, developed in GridLab at AEI
–! Motivation: Intuitive web-based interface for numerical relativity (Grid, Viz, shared data, …)
–! History: NR Workbench (NCSA 1992), ASC Portal (2001), GridSphere (Sept 2003)
•! Generic JSR 168 compliant portlet container
•! Architecture for “pluggable” web applications
•! Core portlets, Grid Portlets, Cactus Portlets, D-Grid, LSU projects
27

SURA Coastal Ocean Observing and Prediction (SCOOP)
•! Integrating data from regional observing systems for realtime coastal forecasts in SE
•! Coastal modelers working closely with computer scientists to couple models, provide data solutions, deploy ensembles of models on the Grid, assemble realtime results with GIS technologies.
•! Three scenarios: event-driven ensemble prediction, retrospective analysis, 24/7 forecasts

29
SCOOP Models
•! Variety of meshes and included properties.
•! Models are suited for different conditions: e.g. shallow water, deep ocean.
•! Basic variables are water level and current, and wave height, frequency and direction.
•! All require forcing (wind, tides), boundary conditions, initial conditions (“hotstart” or “spin-up”)
•! Model codes are very different …
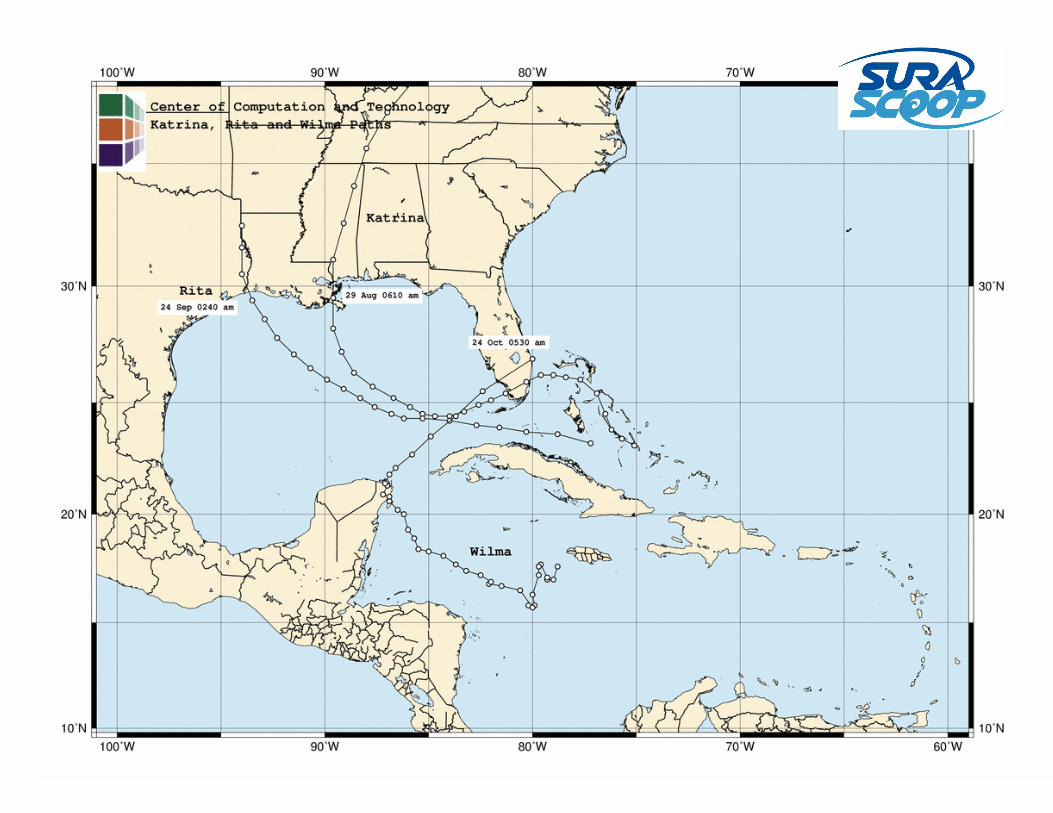
30
Hurricane tracks
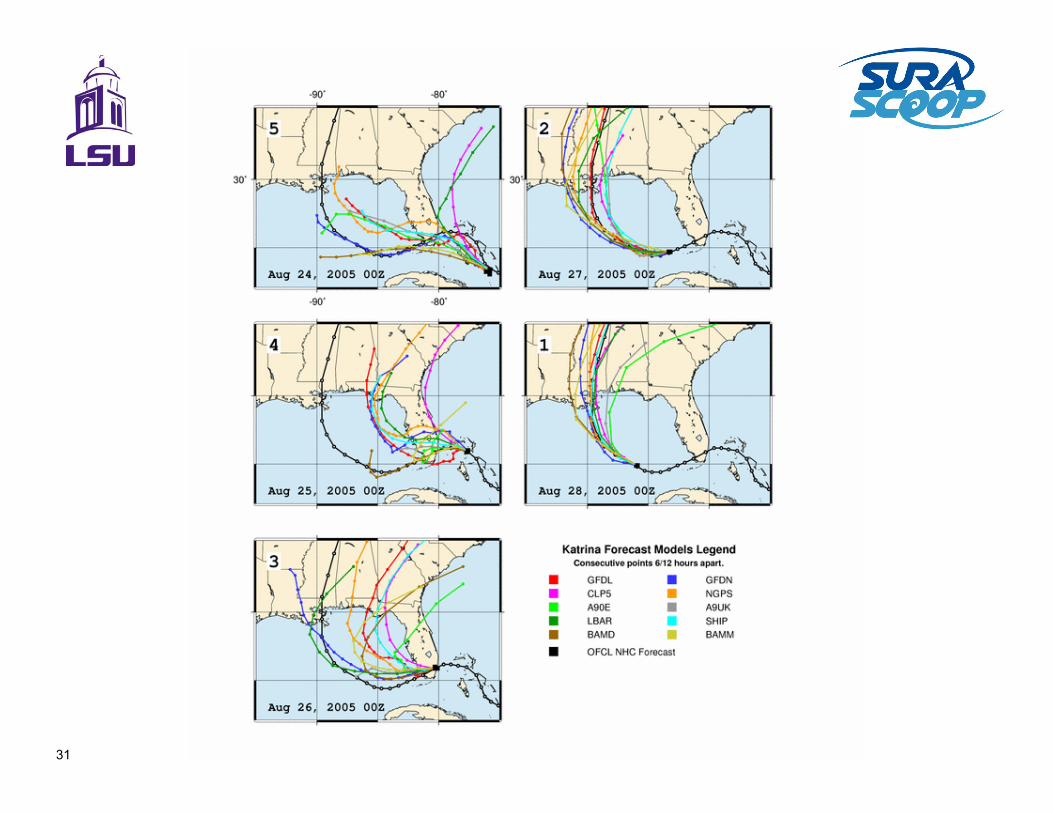
31
32
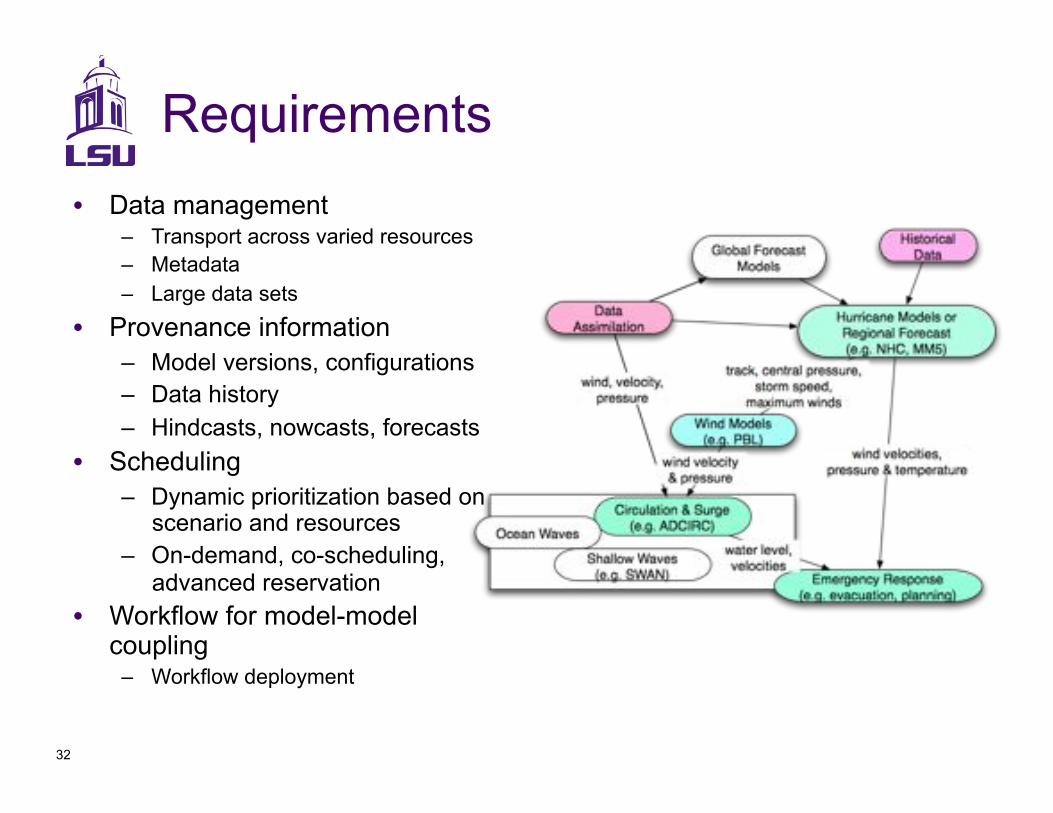
Requirements
•! Data management –! Transport across varied resources
–! Metadata
–! Large data sets
•! Provenance information
–! Model versions, configurations
–! Data history
–! Hindcasts, nowcasts, forecasts
•! Scheduling
–! Dynamic prioritization based on scenario and resources
–! On-demand, co-scheduling, advanced reservation
•! Workflow for model-model coupling
–! Workflow deployment

33
DDDAS New Capabilities
–!dynamically invoke more accurate models and algorithms as hurricane approaches coast,
–!choose appropriate computing resources for needed confidence levels
–!compare model results with observations to feedback into running simulations
–! realtime data assimilation
–!adaptive multi-scale simulations
–!dynamic component recomposition
–!simulation needs steer sensors and data input
Requirements for numerical
libraries, scheduling, policies etc.
www.dddas.org
34
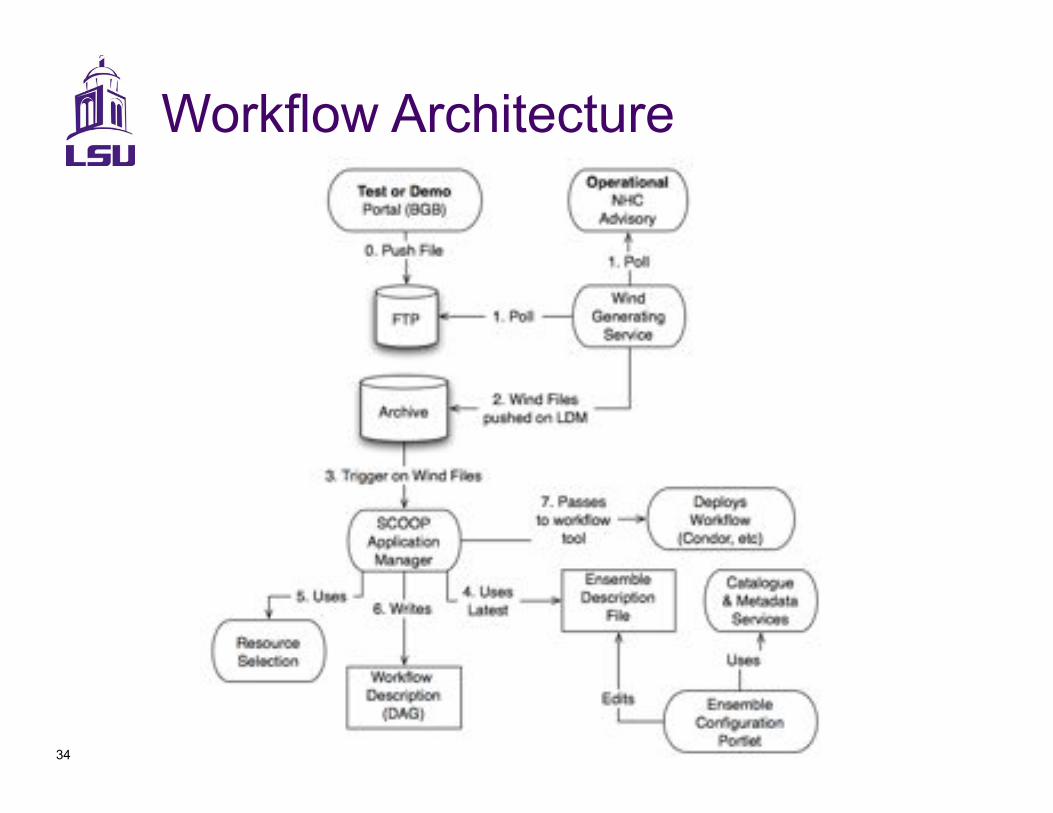
Workflow Architecture
35
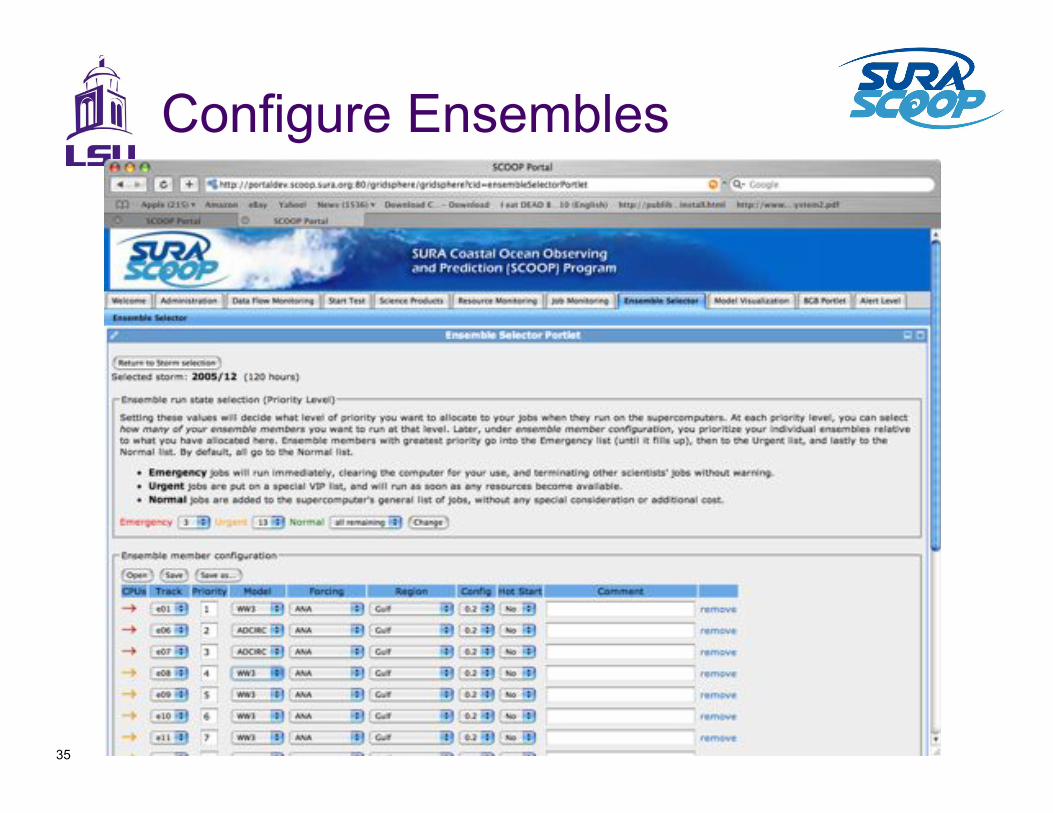
Configure Ensembles

36
Urgency & Priority
•!Urgency Level:
–!Emergency: run on-demand (e.g. preemption)
–!Urgent: run in priority queue (e.g. next to run)
–!Normal: best effort, e.g. guess best queue
•! Priority:
–!Order in which jobs should be completed
37
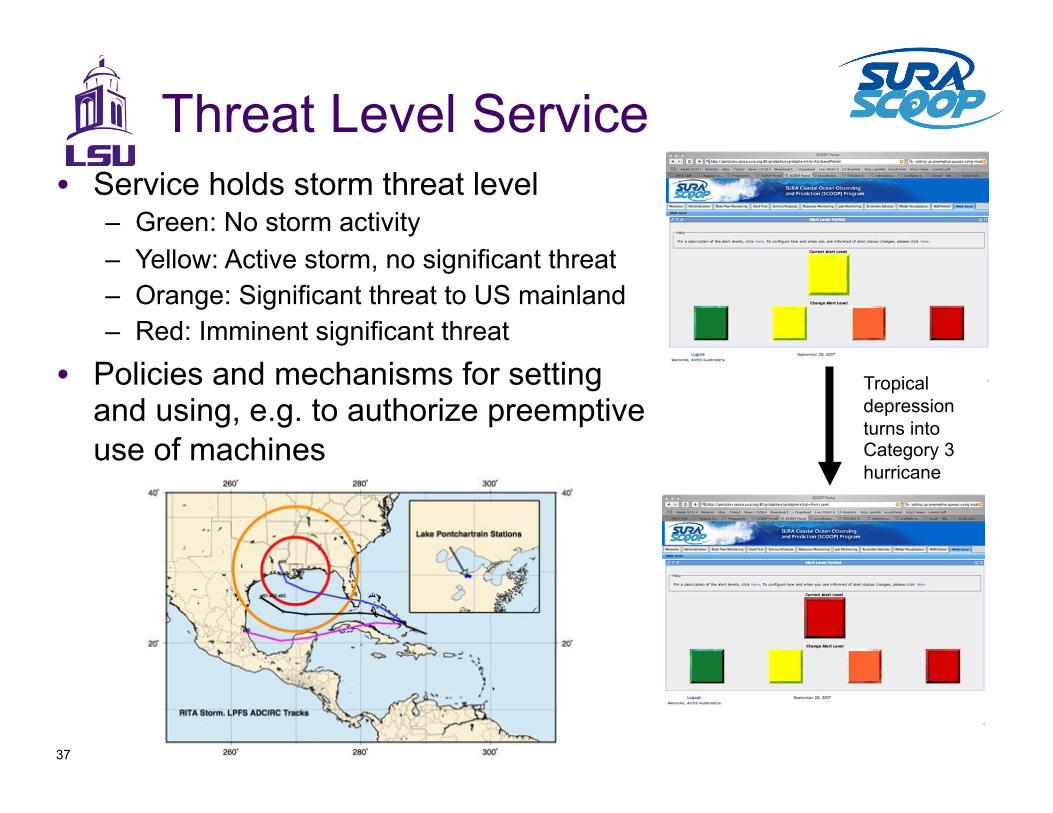
Threat Level Service •! Service holds storm threat level
–! Green: No storm activity
–! Yellow: Active storm, no significant threat
–! Orange: Significant threat to US mainland
–! Red: Imminent significant threat
•! Policies and mechanisms for setting and using, e.g. to authorize preemptive use of machines
Tropical depression turns into Category 3 hurricane
38
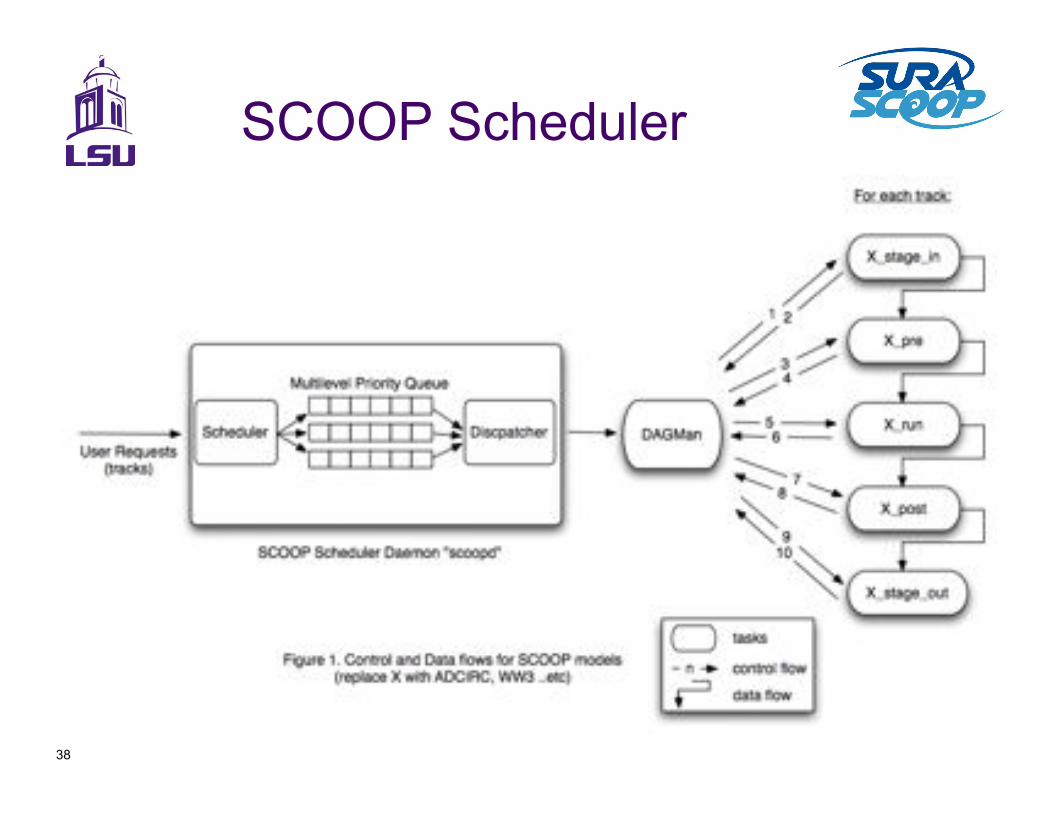
SCOOP Scheduler

39
SCOOP Scheduler
40
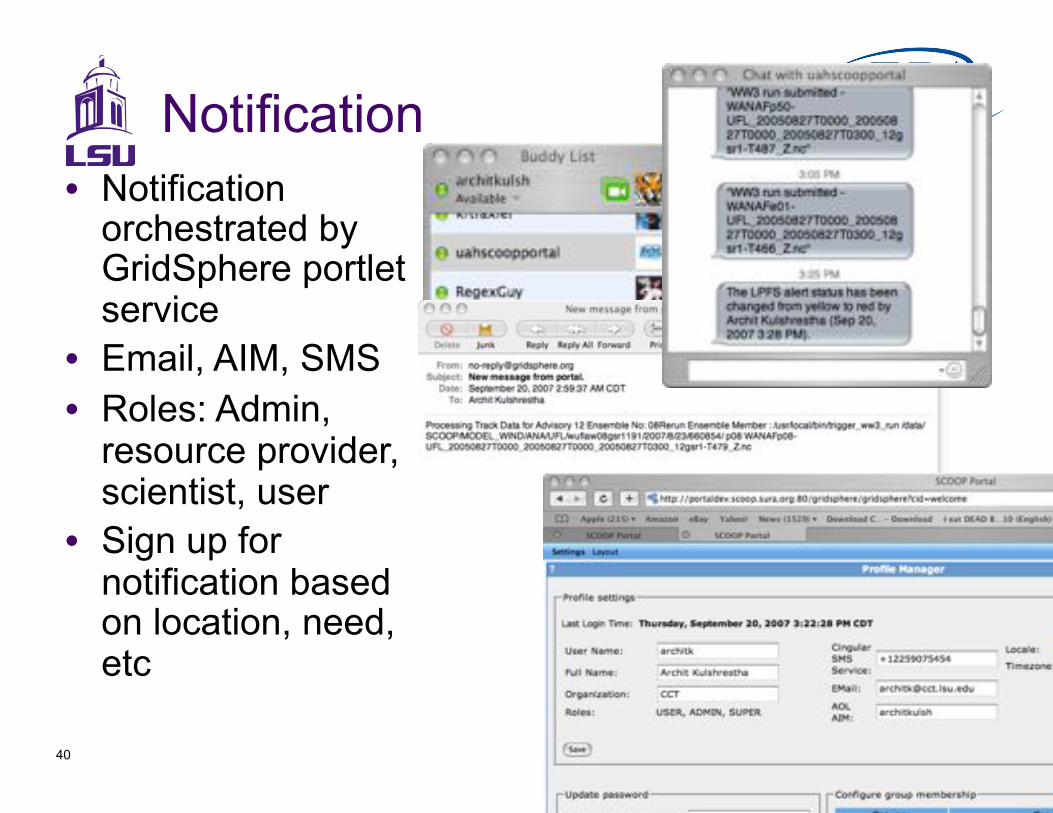
Notification
•! Notification orchestrated by GridSphere portlet service
•! Email, AIM, SMS
•! Roles: Admin, resource provider, scientist, user
•! Sign up for notification based on location, need, etc
“Ubiquitous Computing & Monitoring System for Discovery & Management
of Energy Resources”
•! DOE/BOR EPSCOR Research Infrastructure Project
–!University of Louisiana at Lafayette (ULL), Louisiana State University (LSU), Southern University (SUBR)
•! Research areas: –! Petroleum engineering application scenarios
(reservoir simulations, seismic analysis, well/pipeline surveillance, drilling performance, production recovery)
–! Wireless sensor networks, mesh networks
–! Grid computing, high performance computing
UCoMS

Reservoir Studies
•! Assessments and predictions of oil/gas reservoir performance, depending on
–!Geological heterogeneity
–!Engineering choices
•! Used for development and operational decisions … models assess different production scenarios.
•! Applications:
–!Sensitivity analysis & uncertainty assessment (factorial & experimental design for parameter surveys)
–!History matching (model verification and tuning) (inversion, ensembles)
–!Well placement & performance prediction

Model Inversion using Ensemble Kalman Filters (EnKF)
•! Ensemble Kalman Filters (EnKF): Recursive filter suitable for problems with large numbers of variables. Used for data assimilation for ensemble forecasting
•! Objective: Use dynamic production data and the prior geologic models provides the posterior geomodel parameters and forecast uncertainties.
•! Motivation: Grid computing is attractive because of parallelism between ensemble members.
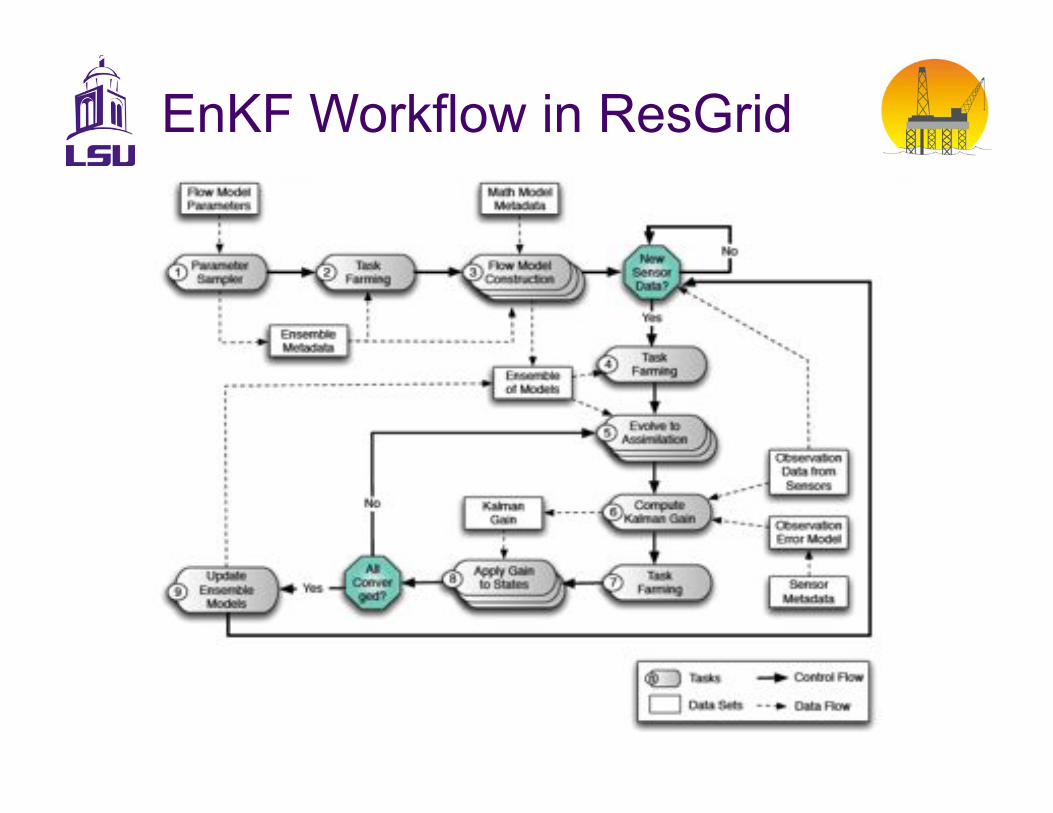
EnKF Workflow in ResGrid

Computational Challenges
•! EnKF is expensive; many simulations
•! Kalman gain calculation is global; synchronize all members at each assimilation step.
–!Members have different run times -> load balancing challenge
–!Large data from members must be transferred to the Kalman gain processor and back to the member processors at each assimilation.
•! Ensembles have ~100 members; each state vector has ~100 reals; ~100 assimilation steps

HIGH LEVEL
PLANNER
DATA
SCHEDULER
COMPUTE
SCHEDULER
BATCH SCHEDULERS
DISTRIBUTED RESOURCES
RESOURCE BROKER
Control Flow
Data Flow
Resource
policies
Job
policies
ABSTRACT
WORKFLOW
WORKFLOW
MANAGER
Workflow Execution (conceptual)

3rd IEEE E-Science and Grid Computing, Bangalore, December 2007
Workflow Middleware Components
•! PEGASUS: takes the abstract workflow and maps it to the available grid resources (creates concrete workflow)
•! DAGMan: executes the concrete workflow
•! Condor-G: schedules tasks to multiple Grid resources via Globus
•! Stork: specialized batch scheduler for data movement and I/O; can optimize data movement between tasks
•! PetaShare: multi-institutional data archival system; enables transparent data handling
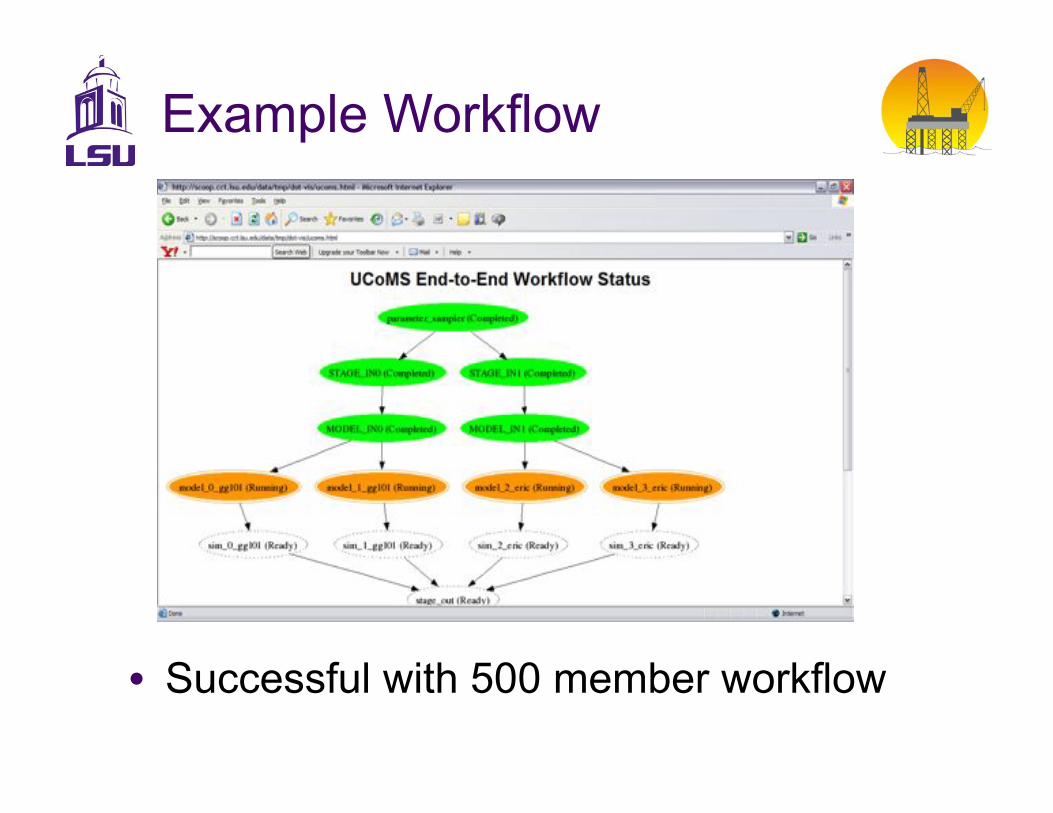
Example Workflow
•! Successful with 500 member workflow
49
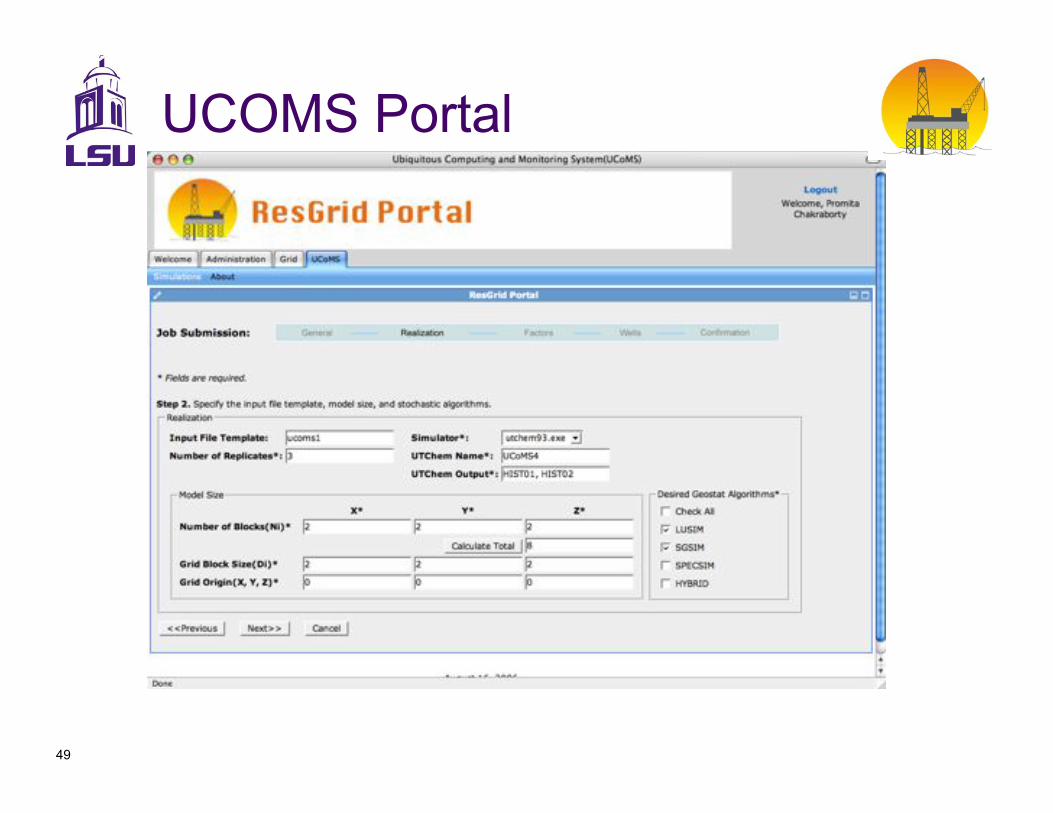
UCOMS Portal

PetaShare – the Genesis •! LONI brings:
•! + fat pipes (40Gb/s) and vast computing resources (100 Tflops)
•! - missing a distributed data management and storage infrastructure
Our Goals:
•! Bring additional storage to LONI
•! Provide a CI for easy and efficient storage, access, and management of data.
“Let scientists focus on their science rather than
dealing with low level data issues. The CI should
take care of that.”

•! Goal: enable domain scientists to focus on their primary research problem, assured that the underlying infrastructure will manage the low-level data handling issues.
•! Novel approach: treat data storage resources and the tasks related to data access as first class entities just like computational resources and compute tasks.
•! Key technologies being developed: data-aware storage systems, data-aware schedulers (i.e. Stork), and cross-domain meta-data scheme.
•! Provides and additional 250TB disk, and 400TB tape storage (and access to national storage facilities)
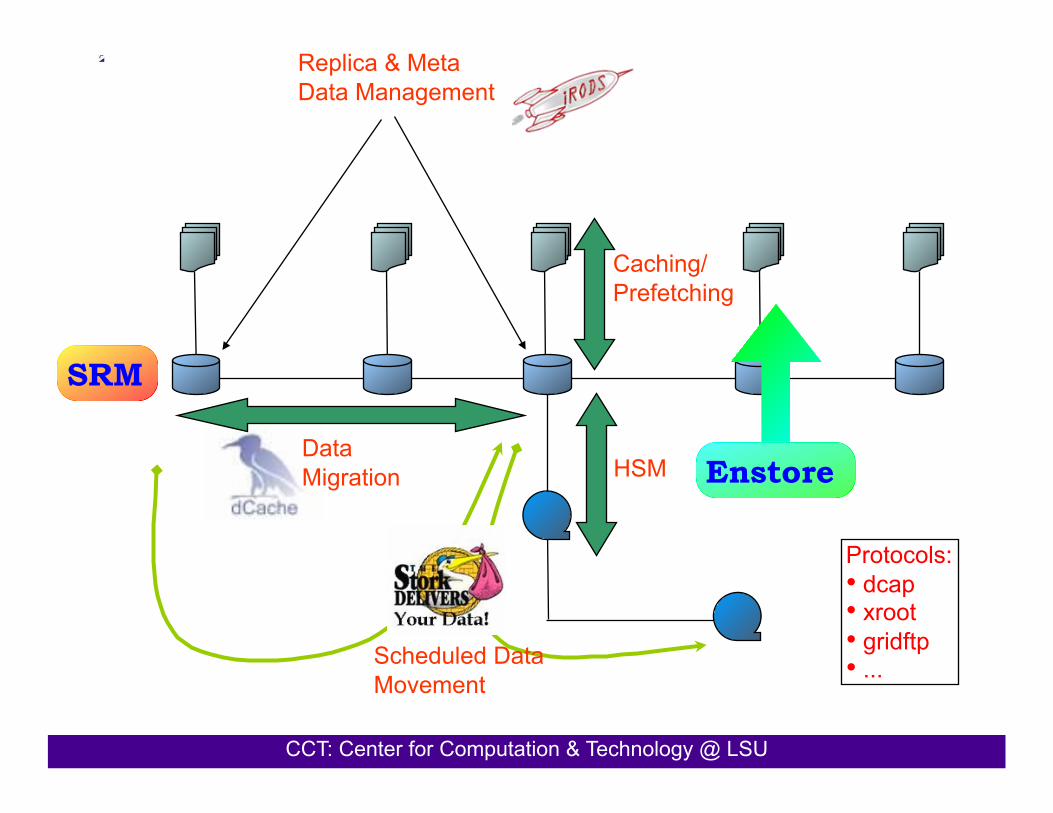
CCT: Center for Computation & Technology @ LSU
HSM
Caching/ Prefetching
Scheduled Data Movement
Replica & Meta Data Management
Data Migration Enstore
SRM
Protocols: •! dcap •! xroot •! gridftp •! ...
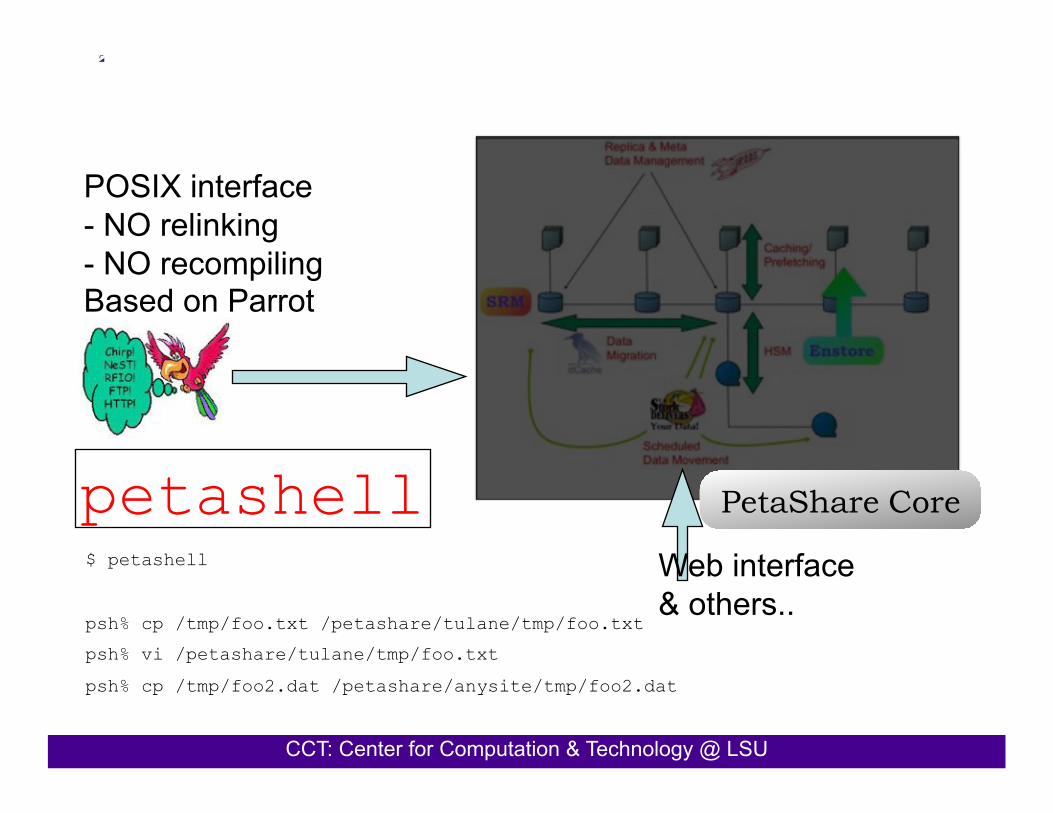
CCT: Center for Computation & Technology @ LSU
PetaShare Core
POSIX interface - NO relinking - NO recompiling Based on Parrot
petashell Web interface & others..
$ petashell
psh% cp /tmp/foo.txt /petashare/tulane/tmp/foo.txt psh% vi /petashare/tulane/tmp/foo.txt
psh% cp /tmp/foo2.dat /petashare/anysite/tmp/foo2.dat

•!Working group of OGF to develop standard (based on GAT, Java COG, ….)
•!Motivation: A lack of:
•! Programming interface that provides common grid functionality with the correct level of abstractions?
•! Ability to hide underlying complexities, varying semantics, heterogenities and changes from application program(er)
•!Simple, integrated, stable, uniform, high-level interface
•!Simplicity: Restricted in scope, 80/20
•!Measure(s) of success:
•! Does SAGA enable quick development of “new” distributed applications?
•! Does it enable greater functionality using less code?
SAGA: Simple API for Grid Applications

SAGA Example: Copy a File High-level, uniform
#include <string>
#include <saga/saga.hpp>
void copy_file(std::string source_url, std::string target_url)
{
try {
saga::file f(source_url);
f.copy(target_url);
}
catch (saga::exception const &e) {
std::cerr << e.what() << std::endl;
}
}
•! Provides the high level abstraction, that application programmers need; will work across different systems
•! Shields gory details of lower-level middle-ware and system issues
•! Like MapReduce – leave details of distribution etc. out
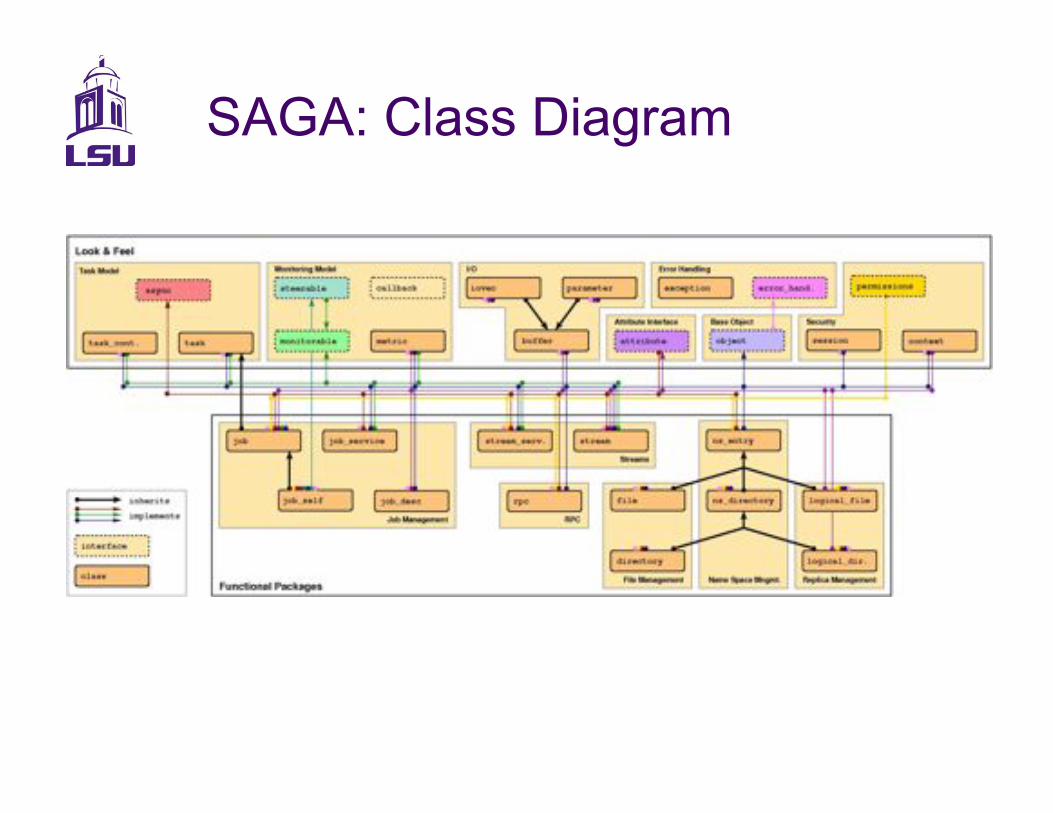
SAGA: Class Diagram

SAGA: Rough Taxonomy of Applications
•! Some applications are Grid-unaware and want to remain so
–! Use tools/environments (e.g, NanoHub, GridChem)
–! May run on Grid-aware/Grid-enabled environments (e.g. Condor) or programming environment (e.g, MPICH-G2)
•! Some applications are explicitly Grid-aware
–! Control, Interact & Exploit distributed systems at the application level

Importance of Standards
•! As SAGA becomes a standard:
–!Increased willingness to support it by middleware developers and RP
–!Development and deployment becomes wider (pervasive) and deeper (more functionality) more application developed and commited
–!Vendor implementations

SAGA Applications
•! SAGA modules directly in Cactus
–!Applications using grid services in the same way as regular HPC applications
•!Used also for developing middleware, e.g. simple task farmer
•!Note
–!SAGA provides a natural language for design patterns for grid computing applications
59

Shrimp Modeling on the Grid (with SAGA)
•! Grid Class project (Ole Weidner and J.C. Bidal)
•! FORTRAN-90 code developed at LSU’s Department of Oceanography
•! Spatially explicit, individual-based model to explore the roll of marsh vegetation and edge habitat in brown shrimp survival
•! Added as Cactus thorn (Elena Caraba)

Shrimp Model
•! Task farming use-case: parameter survey to get a better understanding of the model
•!How does the model react on growth and mortality parameter change:
–!3 mortality parameters - range [0.98-1.02]
–!3 growth parameters - range [0.98-1.02]
–!= 2 x 125 = 250 runs - each ~ 1 - 1 1/2 days = ~ 1 year run-time on a single core system!
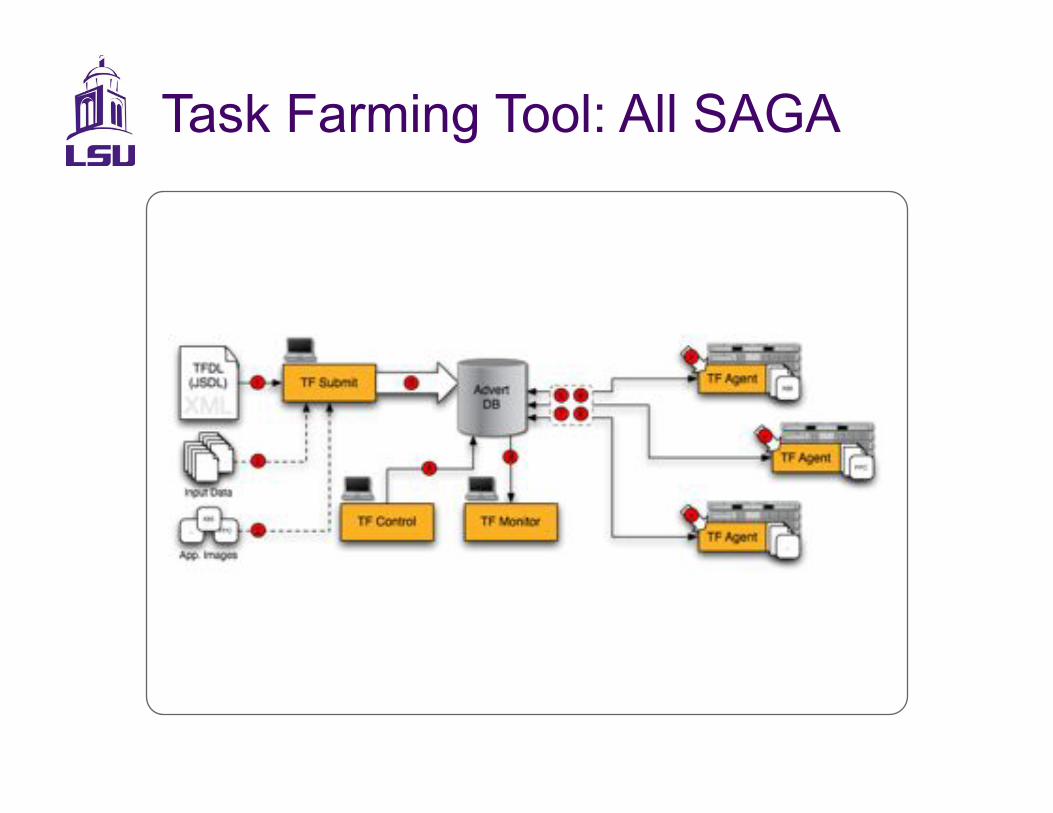
Task Farming Tool: All SAGA

The Workflow
•! Script generates 250 different Cactus parameter files and an XML file which describes the task farming session
•! Task farming manager launches agents on target hosts and creates work-packages (one for each parameter file) in a central DB
•! Task farming agents begin execution and try to complete the work-packages

Preliminary Results
•! Scaling was perfect - as expected
•! BUT: > 25% failed jobs - reasons unknown –! Example: avg. runtime on oliver.loni.org: 19:00h but some
jobs exceeded max. wall-time limit (48:00h). Error in simulation code ?!? Hard to debug !!!!
•! Task farming infrastructure: SAGA + Cactus: very generic, good design pattern.
PBS Job Id: 2925.oliver2!Job Name: ""ShrimpModel!Execution terminated!Exit_status=0!resources_used.cput=19:49:33!resources_used.mem=503152kb!resources_used.vmem=874872kb!resources_used.walltime=19:50:20!
PBS Job Id: 2898.oliver2!Job Name: ""ShrimpModel!Execution terminated!Exit_status=271!resources_used.cput=47:55:02!resources_used.mem=466104kb!resources_used.vmem=874920kb!resources_used.walltime=48:00:28!

Problems and Issues
•! Grids have deep software stacks
–! everything needs to work
–! Hard to figure out problems (error reporting) or who should fix it
–! Need consistent enforced software stack, machines have red/
green for compliance
•! Deploying applications
–! Compile/test on machines a big deal for most apps
–! Confusion on queues, local resource policies
–! Specialized information at sites
–! Virtualization? Improved apps? Better information needed
•! Information services
–! Contain more app information … libraries, queues, disks, scratch space
–! Queryable directly from application middleware
65

Problems and Issues
•! Interfaces to the Grid –! Better portals, clients tools
•! High level common services –! E.g. Everyone wants to collect data, metadata, how do we
do it?
•! People –! Application developers need to know too much about Grids
–! Grid Application developers need to know too much about the applications
–! Difficult to develop in distributed teams, important to have common vision and methodology
–! Need more information (metadata) about applications, their data, and interface to the Grid … needs to be provided by scientists
66

Challenges for Grid Computing
•! Individual services maturing: Now need proven design patterns, best practices
•! Training sys-admins, students, researchers
–!Training in application issues!!
•! Broader range of applications … right now still mainly heroes and innovators
•! Production deployment and support
•! Application oriented interfaces (standards, but not too many)
•! Applications developed to be able to use the Grid … design implications
67

New Petascale Challenges
•! Basic algorithms in place for black holes (recent development)
•! Our codes scale to ~128 procs (AMR), but petascale mahines will have 500K procs.
–!Lots to do with scaling, dynamic load balancing, fault tolerance, software environments, debugging tools
•! Consider novel ways to break up applications
–!Farming off non-parallelizable analysis tasks, viz, coupling of codes, spawning
•! Handling all the data …storing, retrieving, visualizing, analyzing, lambda provisioning
68

Summary
•! Benefit of Grid computing/e-Science clear for science
–! Technologies and tools are maturing, some success stories (mainly data), lots of promise
•! We still have problems using technologies in production, job management hard for real apps.
•! New application complexity: DDDAS, adaptive, event driven
–! Also, petascale computing with 500K cores, new architectures, multicore, accelerators
•! Need:
–! Design patterns, working best practices
–! Improved software (applications, middleware, services)
–! Standard application interfaces (SAGA), grid capabilities direct from application toolkits (e.g. Cactus-SAGA)
–! Higher level services and interfaces designed for applications
–! Training and people …. 69

QUESTIONS?
Thanks for slides and thoughts: Ed Seidel, Archit Kulshrestha, Ole Weidner, Shantenu Jha, Tevfik Kosar, …
70










