
Pocket Programme Guide British Machine Vision Conference...
54
Pocket Programme Guide British Machine Vision Conference 2018 3rd – 6th September 2018 Northumbria University
Transcript of Pocket Programme Guide British Machine Vision Conference...

Pocket Programme Guide
British Machine Vision Conference 2018
3rd – 6th September 2018
Northumbria University

Platinum Sponsors
Gold Sponsors
Silver Sponsors
Special Support

Points of Interest:

Ground Floor Plan:

First Floor Plan:

Second Floor Plan:

BMVC 2018 Programme Committee
Welcome Message from The General and Programme Chairs
It is our great pleasure to welcome you to Newcastle upon Tyne for the
British Machine Vision Conference (BMVC)! This is the 29th BMVC since
its inception in 1990, and it is the first time at Newcastle upon Tyne. The
conference is hosted by Northumbria University, a research-rich, business-
focused, professional university with a global reputation for academic quality.
The main conference venue is the Student Union building located at the core
of Northumbria University in the city centre. The conference reception,
simple dinner and conference banquet are hosted at the Newcastle Civic
Centre, which was first opened in 1968 with a reputation of rich history and
authentic modernist architecture.
BMVC is one of the top events in the Computer Vision conference
calendar, and a truly international event, with the majority of papers coming
from outside the UK. This year, BMVC attracted a total of 862 full paper
submissions, which is the highest number in the history of BMVC, as well as
a sharp rise over 635 submissions in BMVC 2017 and 365 in BMVC 2016.
This year, despite a very tight schedule bounded by ECCV deadlines from
one side and UK immigration visas from the other, we ran a full reviewing
process. Paper assignment to ACs and reviewers was based on both AC and
reviewer bidding on papers as well as recommendations based on CMT
subject areas and TPMS publication history. There were 426 reviewers and
52 area chairs involved in this process, generously donating their time. Every
paper was handled by two ACs and each paper received just over three
reviews on average. Oral papers were selected based on the reviews, AC
consolidation reports, and suitability of the content for a general audience.
We would like to thank all the reviewers and area chairs for their hard work
and prompt responses! In particular, because of the unexpectedly high
number of submissions, our reviewers and ACs handled more papers than in
previous years. Also, a number of emergency reviewers supported us by
reviewing papers at short notice. We would like to express our sincere
gratitude to them for their invaluable contribution to the conference!
Of the 862 submissions, just 255 were accepted for presentation in
BMVC 2018, which is a 29.5% acceptance rate. Of the accepted papers, 37
were accepted as oral for a podium spot. We also organize spotlight sessions
to promote 19 further outstanding papers. Three paper awards are introduced
including the best paper award, the best student paper award and the best
industrial paper award. The accepted papers represent a truly international
research community, with 13% of the papers from the UK, 21% from Europe
excluding the UK, 23% from North America, 37% from Asia, 3% from
Australia and the rest from elsewhere in the world. As is now standard for
many top conferences, the proceedings are published entirely online.

BMVC 2018 Programme Committee
We have put together an interesting programme and are delighted to
welcome Rama Chellappa, Sven Dickinson and Shaogang (Sean) Gong to the
conference as keynote speakers, Vittorio Ferrari, Ivan Laptev, Abhinav Gupta
and Zeynep Akata as tutorial speakers. BMVC has always had strong links
with industry, and again we are very grateful to our industrial sponsors for
supporting the event. Platinum Sponsors: Scape, Amazon, Microsoft,
NVIDIA, SCAN, Sage, Apple, Facebook, Intel. Gold Sponsors: Disney
Research, IET, Telensa. Silver Sponsors: Gaist, Ocado, Snap Inc. Special
Support: Springer.
Last but not least, we wish to thank all members of the Organizing
Committee, the Area Chairs, reviewers, emergency reviewers, authors, and
the CMT and TPMS teams for the immense amount of hard work and
professionalism that has gone into making BMVC 2018 a first-rate
conference. The conference organization team has made major efforts in
ensuring a smooth and high-quality conference experience. In particular, we
would like to give our special thanks to the organization chairs Edmond S. L.
Ho, Kamlesh Mistry and Ammar Belatreche who have contributed
significantly to the conference. We hope you find BMVC 2018 in Newcastle
upon Tyne both an enjoyable and productive experience, and we hope you
continue to take part in future BMVCs!
Ling Shao, Hubert P. H. Shum, Timothy Hospedales
BMVC 2018 General Chair and Program Chairs

BMVC 2018 Programme Committee
General Chair
Ling Shao
Programme Chair
Hubert P. H. Shum
Timothy Hospedales
Advisory Board
Timothy Cootes
Tae-Kyun Kim
Local Chair
Alan Godfrey
Frederick Li
Kamlesh Mistry
Publicity Chair
He Wang
Bob Fisher
Workshop Chair
Edmond S. L. Ho
Jungong Han
Poster Chair
Longzhi Yang
Sponsorship Chair
Ammar Belatreche
Noura Al Moubayed
Honglei Li
Naveed Anwar
Website Chair
Zheming Zuo
Jie Li
Technical Support Chair Kaveen Perera
Pengpeng Hu
Supporting Organization Chair Jingtian Zhang
Kevin Mccay
Daniel Organisciak
Dimitrios Sakkos

BMVC 2018 Programme Committee
Area Chairs
Adrian Hilton University of Surrey
Antonis Argyros FORTH & University of Crete
Andrea Cavallaro Queen Mary, University of London
Basura Fernando Australian National University
Cees Snoek UVA
Chen-Change Chinese University of Hong Kong
Dahua Lin Chinese University of Hong Kong
Dima Damen University of Bristol
Edmond Boyer INRIA Grenoble Rhone-Alpes
Edwin Hancock University of York
Elisa Ricci University of Perugia
Fabio Cuzzolin Oxford Brookes University
Fei Yan University of Surrey
Francesc Moreno-Noguer UPC
Frederic Jurie University of Caen
Gustavo Carneiro University of Adelaide
Jianguo Zhang University of Dundee
John Collomosse University of Surrey
Majid Mirmehdi University of Bristol
Michel Valstar University of Nottingham
Neill Campbell University of Bath
Nikos Komodakis ENPC
Peter Hall University of Bath
Richard Wilson University of York
Shaogang Gong Queen Mary, University of London
Stefan Leutenegger Imperial College London
Stefanos Zafeiriou Imperial College London
Tae-Kyun Kim Imperial College London
Tim Cootes University of Manchester
Toby Breckon Durham University
Tony Xiang Queen Mary, University of London
Vincent Lepetit TU Graz
Will Smith University of York
Xianghua Xie Swansea University
Yi-Zhe Song Queen Mary, University of London
Yoichi Sato University of Tokyo
Zhao Zhang Soochow University
Sergio Escalera CVC and University of Barcelona
Hakan Bilen University of Edinburgh
Vittorio Murino Istituto Italiano di Tecnologia
Greg Mori Simon Fraser University
Jimei Yang Adobe Research

BMVC 2018 Programme Committee
Efstratios Gavves University of Amste rdam
Michael Brown York University
Ming-Hsuan Yan University of California, Merced
Ming-Yu Liu Nvidia Research
Wei-Shi Zhen Sun Yat-Sen University
Yasuyuki Matsushita Osaka University
Yukun Lai Cardiff University

BMVC 2018 Programme Committee
Technical Committee
Abdelrahman
Abdelhamed
Abdullah
Abuolaim
Abhijith
Punnappurath
Adeline Paiement
Adrian Barbu
Adrian Bors
Adrian Davison
Adrien Bartoli
Akihiro Sugimoto
Akisato Kimura
Alexander
Andreopoulos
ALPER YILMAZ
Amir Ghodrati
Ancong Wu
Andrea Zunino
Andrea
Tagliasacchi
Andrea Prati
Andrea Giachetti
Andrea Torsello
Andrew French
Andrew Gilbert
Angela Yao
Anil Armagan
Ankush Gupta
ANOOP
CHERIAN
Antonio Robles-
Kelly
Antreas Antoniou
Ardhendu Behera
Aria Ahmadi
Armin Mustafa
Arnav Bhavsar
Atsushi Nakazawa
Avinash Kumar
Aykut Erdem
Barbara Caputo
Baris Gecer
Benjamin Kimia
Bin Zhao
Bin Fan
Binod Bhattarai
Bjorn Stenger
Bo Wang
Bob Fisher
Boxin Shi
Boyan Gao
Bruce Maxwell
Bruce Draper
C. Alejandro
Parraga
Cagri Ozcinar
Can Chen
Can Pu
Chao Ma
Chaohui Wang
Chenliang Xu
Christian Wolf
Christian Rauch
Claudia Lindner
Clement Mallet
Conghui Hu
Conrad Sanderson
Corneliu Florea
Da Chen
Daisuke Miyazaki
Damien Muselet
Dan Yang
Daniel Cabrini
Hauagge
David Marshall
David Fouhey
David Bermudez
David Masip
Diego Thomas
Dimitrios
Kosmopoulos
Dingzeyu Li
Dirk Schnieders
Dmitrij
Csetverikov
Domingo Mery
Edmond S. L. Ho
Edward Johns
Edward Kim
Elliot Crowley
Elyor Kodirov
Emanuele Rodolà
Enrique Sánchez-
Lozano
Eraldo Ribeiro
Fahad Shahbaz
Khan
Faisal Qureshi
Fan Zhu
Fatemeh Karimi
Nejadasl
Fatih Porikli
Federico Pernici
Fatih Porikli
Federico Pernici
Foteini
Markatopoulou
Francesco Isgro
Francisco Flórez-
Revuelta
Frank Michel
Frédéric Devernay
Gary Huang
Gary Tam
Gaurav Sharma
Gholamreza
Anbarjafari
Gianfranco
Doretto
Giorgio Patrini
Giorgos Tolias
Giovanni
Farinella
Go Irie
Gregory Rogez
Guillaume-
Alexandre
Bilodeau
Guillermo Garcia-
Hernando
Guillermo
Gallego
Guodong Guo
Guofeng Zhang
Guo-Jun Qi
Guosheng Hu
Gurkirt Singh
Hakki Karaimer
Hang Dong
Han-Pang Chiu
Hansung Kim
He Zhang
Heikki Huttunen
Heydi Mendez-
Vazquez
Hideo Saito
Holger Caesar
Hongyang Li
Hua Wang
Huazhu Fu
Hueihan Jhuang
Hugues Talbot
Hui Zhang
Hwann-Tzong
Chen
HyungJin Chang
HyungJin Chang
Ichiro Ide
Ifeoma Nwogu
Imari Sato
Ioannis Stamos
Irek Defee
Jacopo Cavazza
James Gee
Jan van Gemert
Janusz Konrad
Javier Traver
Javier Lorenzo
Jean-Philippe
Tarel
Jia-Bin Huang
Jiajun Wu
Jianjia Wang
Jiaqi Wang
Jie Yang
Jifei Song
Jing Wu
Jing Yuan
Jingjing Deng
Jinglu Wang
Jinglun Gao
Jinshan Pan
Joachim Dehais
Joachim Denzler
Joao Carreira
John Barron
John Zelek
Jongwoo Lim
Jorge Batista
Ju Yong Chang
Jun Tang
Jun Zhou
Junbin Gao
Junchi Yan
Jungong Han
Junseok Kwon
Kai Zhao
Kai Chen
Kaiyue Pang
KAMAL
NASROLLAHI
Karel Lebeda
Kaustav Kundu
Ke Yu
Keiji Yanai
Kenichi Kanatani
Keshav Seshadri
Abdelrahman

BMVC 2018 Programme Committee
Kihwan Kim
Kinh Tieu
Kun Zhang
Kunkun Pang
Kwang In Kim
Kwang Moo Yi
Kwan-Yee Wong
Kwok-Ping Chan
Kyle Wilson
Lei He
Lei Wang
Leonid Karlinsky
Li Zhang
Li Liu
Liansheng Zhuang
Lin Gao
Lin Chen
Linguang Zhang
Liping Wang
Long Chen
Long Mai
Longyin Wen
Lopamudra
Mukherjee
Luca Cosmo
Lucas Deecke
Mahmoud Afifi
Manohar Paluri
Manolis Lourakis
Marco Paladini
Marcus Magnor
Margret Keuper
Marius Leordeanu
Markus
Oberweger
Martin Hirzer
Martin Fergie
Martin Weinmann
Martin R. Oswald
Mathieu Aubry
Mathieu
Salzmann
Mathieu Bredif
Matt Leotta
Mayank Vatsa
Megha Nawhal
Melih Kandemir
Meng Wang
Mengyao Zhai
Miaomiao Liu
Michael Pound
Michael Breuß
Michael Waechter
Michael Hofmann
Mikhail Sizintsev
Michael Waechter
Michael Hofmann
Mikhail Sizintsev
Min H. Kim
Monica
Hernandez
Muhammad
Awais
Mustafa Ozuysal
Nam Ik Cho
Nick Michiels
Nicolau Werneck
Norimichi Ukita
Ognjen
Arandjelovic
Olaf Kaehler
Onur Hamsici
Oscar Mendez
Pascal Monasse
Pascal Mettes
Paul Gay
Paul Henderson
Peter Roth
peter barnum
Peter O'Connor
Pietro Morerio
Pinar Duygulu
Pol Moreno
Comellas
Pramod Sharma
Praveer SINGH
QI DONG
Qi Wang
Qian Yu
Quanshi Zhang
Radim Tylecek
Rama Chellappa
Ramanathan
Subramanian
Ran Song
Rene Ranftl
Richa Singh
Risheng Liu
Ronald Poppe
Ronald Clark
Rudrasis
Chakraborty
Ruiping Wang
Runze Zhang
Ryo Yonetani
Said Pertuz
Salil Deena
Sam Tsai
Samuel Schulter
Ser-Nam Lim
Sam Tsai
Samuel Schulter
Ser-Nam Lim
Seungkyu Lee
Seungryul Baek
Shai Bagon
Shang-Hong Lai
Shell Hu
Shin'ichi Satoh
Shiro Kumano
Shishir Shah
Shohei Nobuhara
Shuo Chen
Silvio Olivastri
Simone Bianco
Siyu Zhu
Søren Ingvor
Olsen
Srikanth
Muralidharan
Srinath Sridhar
Stavros Tsogkas
Stavros Petridis
Stephan Liwicki
Steve Maybank
Stuart James
Sudipta Sinha
Suman Saha
Suyog Jain
Sven Wachsmuth
Takeshi Oishi
Tak-Wai Hui
Tanmoy
Mukherjee
Tanveer Syeda-
Mahmood
Tatiana Tommasi
Tat-Jen Cham
Tatsuya Harada
Teofilo deCampos
Terrance Boult
Theodore
Tsesmelis
Thibaut Durand
Thierry
BOUWMANS
Tianzhu Zhang
Tim Morris
Tingting Jiang
Tom Runia
Tom Haines
Tomas Simon
Tomasz Trzcinski
Tony Tung
Toru Tamak
Tomasz Trzcinski
Tony Tung
Toru Tamak
Toshihiko
Yamasaki
Tsz-Ho Yu
Tu Bui
Vasileios
Belagiannis
Visesh Chari
Vladimir Kim
Volker Blanz
Wei Yang
Wei-Sheng Lai
Weiyao Lin
Wenwu Wang
Wenyan Yang
Willem Koppen
William Thong
Wonjun Hwang
Xenophon Zabulis
Xi Li
Xianfang Sun
Xiao Bai
Xiaobin Chang
Xiaochun Cao
Xiaoqin Zhang
Xiaoyi Jiang
Xiatian Zhu
Xin Li
Xingang Pan
Xinggang Wang
Xingyu Zeng
Xinlei Chen
Xintao Wang
Xu Chi
Xu Zhang
Xuelong Li
Xun Xu
Yan Tong
Yang Wang
Yang Long
Yang Wu
Yang Xiao
Yann Savoye
Yasushi Makihara
Yebin Liu
Yi Zhu
Yi Wu
Yifan Yang
Yijun Xiao
Yiming Liu
Yiming Wang
YingLi Tian
Yixin Zhu

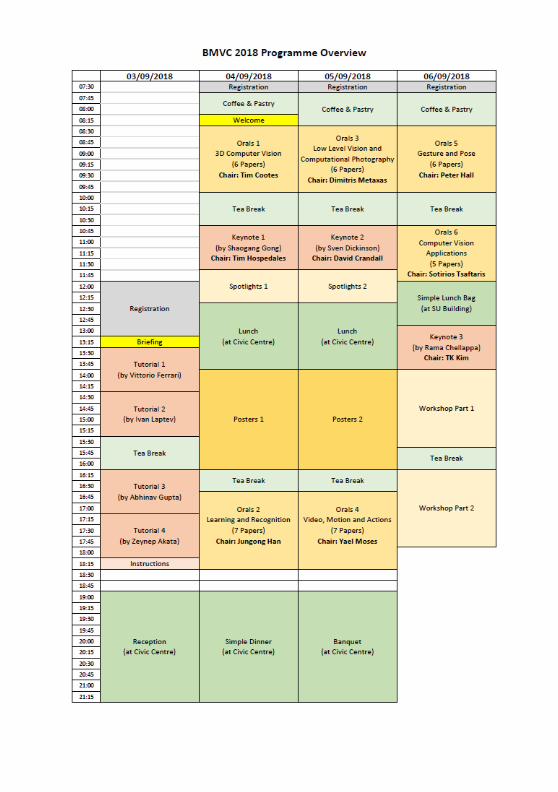
BMVC 2018 Programme
MONDAY 3RD SEPTEMBER
12:00 Registration, Students Union
13:15 - 13:30 Welcome, Students Union
13:30 - 14:30
Tutorial 1, Students Union Knowledge transfer and human-machine collaboration for training visual models. Vittorio Ferrari (University of Edinburgh, Google Research)
14:30 - 15:30
Tutorial 2, Students Union Towards action understanding with less supervision.
Ivan Laptev (INRIA Paris)
15:30 - 16:15 Tea Break, Students Union
16:15 - 17:15
Tutorial 3, Students Union Supersizing and Empowering Visual Learning. Abhinav Gupta (Carnegie Mellon University)
17:15 - 18:15
Tutorial 4, Students Union Explaining and Representing Novel Concepts With Minimal Supervision. Zeynep Akata (University of Amsterdam)
18:15 - 18:30 Instructions, Students Union
19:00 - 21:30 Reception, Civic Centre
TUESDAY 4TH SEPTEMBER
7:30 - 7:45 Registration, Students Union
7:45 - 8:15 Coffee & Pastry, Students Union
8:15 - 8:30 Welcome, Students Union
8:30 - 10:00 Orals 1, Students Union: 3D Computer Vision Chair: Tim Cootes

BMVC 2018 Programme
1. Learning to Generate and Reconstruct 3D Meshes with only 2D Supervision Paul Henderson; Vittorio Ferrari
2.
LieNet: Real-time Monocular Object Instance 6D Pose Estimation Thanh-Toan Do; Trung Pham; Ming Cai; Ian Reid
3.
Scene Coordinate and Correspondence Learning for Image-Based Localization Mai Bui; Shadi Albarqouni; Slobodan Ilic; Nassir Navab
4.
Non-smooth M-estimator for Maximum Consensus Estimation Huu Le; Thanh-Toan Do; Tat-Jun Chin; David Suter
5.
Deep Network for Simultaneous Stereo Matching and Dehazing Taeyong Song; Youngjung Kim; Changjae Oh; Kwanghoon Sohn
6.
SampleAhead: Online Classifier-Sampler Communication for Learning from Synthesized Data Qi Chen,Weichao Qiu; Yi Zhang; Lingxi Xie; Alan Yuille
10:00 - 10:45 Tea Break, Students Union
10:45 - 11:45
Keynote 1, Students Union People Search in Large Scale Videos. Shaogang (Sean) Gong (Queen Mary University of London) Chair: Tim Hospedales
11:45 - 12:30 Spotlights 1, Students Union
7.
Inductive Visual Localisation: Factorised Training for Superior Generalisation
Ankush Gupta; Andrea Vedald; Andrew Zisserman
8.
Equal but Not the Same: Understanding the Implicit Relationship Between Persuasive Images and Text Mingda Zhang; Rebecca Hwa; Adriana Kovashka
9.
Multi-task Mid-level Feature Alignment Network for Unsupervised Cross-Dataset Person Re-Identification Shan Lin; Haoliang Li; Chang-Tsun Li; Alex Kot
10.
EnsembleNet: Improving Grasp Detection using an Ensemble of Convolutional Neural Networks Umar Asif; Jianbin Tang; Stefan Harrer

BMVC 2018 Programme
11. Motion Estimation and Segmentation of Natural Phenomena Da Chen; Wenbin Li; Peter Hall
12.
VSE++: Improving Visual-Semantic Embeddings with Hard Negatives Fartash Faghri; David Fleet; Jamie Kiros; Sanja Fidler
13.
Learning to Doodle with Stroke Demonstrations and Deep Q-Networks Tao Zhou; CHEN FANG; Zhaowen Wang; Jimei Yang; Byungmoon Kim; Zhili Chen; Jonathan Brandt; Demetri Terzopoulos
14.
Propagating Confidences through CNNs for Sparse Data Regression Abdelrahman Eldesokey; Michael Felsberg; Fahad Shahbaz Khan
15.
Recognition self-awareness for active object recognition on depth images Andrea Roberti; Marco Carletti; Francesco Setti; Umberto Castellani; Paolo Fiorini; Marco Cristani
16.
Open Logo Detection Challenge Hang Su; Xiatian Zhu; Shaogang Gong
12:30 - 14:00 Lunch, Civic Centre
14:00 - 16:15 Posters 1, Students Union
17 - 26 Correspond to Tuesday Spotlights 1
17.
Inductive Visual Localisation: Factorised Training for Superior Generalisation Ankush Gupta; Andrea Vedaldi; Andrew Zisserman
18.
Equal But Not The Same: Understanding the Implicit Relationship Between Persuasive Images and Text Mingda Zhang; Rebecca Hwa; Adriana Kovashka
19.
Multi-task Mid-level Feature Alignment Network for Unsupervised Cross-Dataset Person Re-Identification Shan Lin; Haoliang Li; Chang-Tsun Li; Alex Kot
20.
EnsembleNet: Improving Grasp Detection using an Ensemble of Convolutional Neural Networks Umar Asif; Jianbin Tang; Stefan Harrer
21.
Motion Estimation and Segmentation of Natural Phenomena Da Chen; Wenbin Li; Peter Hall

BMVC 2018 Programme
22. VSE++: Improving Visual-Semantic Embeddings with Hard Negatives Fartash Faghri; David Flee; Jamie Kiros; Sanja Fidler
23.
Learning to Doodle with Stroke Demonstrations and Deep Q-Networks Tao Zhou; CHEN FANG; Zhaowen Wang; Jimei Yang; Byungmoon Kim; Zhili Chen; Jonathan Brandt; Demetri Terzopoulos
24.
Propagating Confidences through CNNs for Sparse Data Regression Abdelrahman Eldesokey; Michael Felsberg; Fahad Shahbaz Khan
25.
Recognition self-awareness for active object recognition on depth images Andrea Roberti; Marco Carletti; Francesco Setti; Umberto Castellani; Paolo Fiorini; Marco Cristani
26.
Open Logo Detection Challenge Hang Su; Xiatian Zhu; Shaogang Gong
27 - 32 Correspond to Tuesday Orals 1
27.
Learning to Generate and Reconstruct 3D Meshes with only 2D Supervision Paul Henderson; Vittorio Ferrari
28.
SampleAhead: Online Classifier-Sampler Communication for Learning from Synthesized Data Qi Chen; Weichao Qiu; Yi Zhang; Lingxi Xie; Alan Yuille
29.
Scene Coordinate and Correspondence Learning for Image-Based Localization Mai Bui; Shadi Albarqouni; Slobodan Ilic; Nassir Navab
30.
Non-smooth M-estimator for Maximum Consensus Estimation Huu Minh Le; Anders Eriksson; Michael Milford; Thanh-Toan Do; Tat-Jun Chin; David Suter
31.
LieNet: Real-time Monocular Object Instance 6D Pose Estimation Thanh-Toan Do; Trung Pham; Ming Cai; Ian Reid
32.
Deep Network for Simultaneous Stereo Matching and Dehazing Taeyong Song; Youngjung Kim; Changjae Oh; Kwanghoon Sohn
33 - 39 Correspond to Tuesday Orals 2
33.
BAM: Bottleneck Attention Module Jongchan Park; Sanghyun Woo; Joon-Young Lee; In So Kweon

BMVC 2018 Programme
34. Three for one and one for three: Flow, Segmentation, and Surface Normals Hoang-An Le; Anil S Baslamisli; Thomas Mensink; Theo Gevers
35.
ContextNet: Exploring Context and Detail for Semantic Segmentation in Real-time Rudra P K Poudel; Ujwal Bonde; Stephan Liwicki; Christopher Zach
36.
Efficient Progressive Neural Architecture Search Juan-Manuel Perez-Rua; Moez Baccouche; Stephane Pateux
37.
Learning on the Edge: Explicit Boundary Handling in CNNs Carlo Innamorati; Niloy Mitra
38.
Structured Probabilistic Pruning for Convolutional Neural Network Acceleration Huan Wang; Qiming Zhang; Yuehai Wang; Haoji Hu
39.
RISE: Randomized Input Sampling for Explanation of Black-box Models
Vitali Petsiuk; Abir Das; Kate Saenko
40. Asymmetric Geodesic Distance Propagation for Active Contours Da CHEN; Jack A Spencer; Jean-Marie Mirebeau; Ke Chen; Laurent Cohen
41.
iCAN: Instance-Centric Attention Network for Human-Object Interaction Detection Chen Gao; Yuliang Zou; Jia-Bin Huang
42.
Parallel Separable 3D Convolution for Video and Volumetric Data Understanding Felix Gonda; Donglai Wei; Toufiq Parag; hanspeter pfister
43.
Semantic Embedding for Sketch-Based 3D Shape Retrieval Anran Qi; Yi-Zhe Song; Tao Xiang
44.
Stacked Dense U-Nets with Dual Transformers for Robust Face Alignment Jia Guo; Jiankang Deng; Niannan Xue; Stefanos Zafeiriou
45.
Unconstrained Control of Feature Map Size Using Non-integer Strided Sampling
Donggyu Joo; Junho Yim; Junmo Kim
46. Mass Displacement Networks Natalia Neverova; Iasonas Kokkinos
47.
Efficient Correction for EM Connectomics with Skeletal Representation Konstantin Dimitriev; Toufiq Parag; Brian Matejek; Arie Kaufman; Hanspeter Pfister

BMVC 2018 Programme
48. Deep Association Learning for Unsupervised Video Person Re-identification Yanbei Chen; Xiatian Zhu; Shaogang Gong
49.
Estimating small differences in car-pose from orbits Berkay Kicanaoglu; Ran Tao; Arnold W.M. Smeulders
50.
Weakly-Supervised Video Object Grounding from Text by Loss Weighting and Object Interaction Luowei Zhou; Nathan Louis; Jason J Corso
51.
Improving Image Clustering with Multiple Pretrained CNN Feature Extractors Joris Guerin; Byron Boots
52.
Informed Democracy: Voting-based Novelty Detection for Action Recognition
Alina Roitberg; Ziad Al-Halah; Rainer Stiefelhagen
53.
Pose Flow: Efficient Online Pose Tracking Yuliang Xiu; Jiefeng Li;Haoyu Wang; Yinghong Fang; Cewu Lu
54.
Conditional Kronecker Batch Normalization for Compositional Reasoning Cheng Shi; Chun Yuan; Jiayin Cai; Zhuobin Zheng; Zhihui Lin
55.
3D-LMNet: Latent Embedding Matching for Accurate and Diverse 3D Point Cloud Reconstruction from a Single Image Priyanka Mandikal; Navaneet K L; Mayank Agarwal; Venkatesh Babu RADHAKRISHNAN
56.
Zero-Shot Object Detection by Hybrid Region Embedding
Berkan Demirel; Ramazan Gokberk Cinbis; Nazli Ikizler-Cinbis
57. Story Understanding in Video Advertisements Keren Ye; Kyle Buettner; Adriana Kovashka
58.
Not All Words Are Equal: Video-specific Information Loss for Video Captioning Jiarong Dong; Ke Gao; Xiaokai Chen; junbo guo; Juan Cao; Yongdong Zhang
59.
Tiny-DSOD: Lightweight Object Detection for Resource-Restricted Usages Yuxi Li; Jiuwei Li; Weiyao Lin; Jianguo Li
60.
Incremental Tube Construction for Human Action Detection Harkirat Singh Behl; Michael Sapienza; Gurkirt Singh; Suman Saha; Fabio Cuzzolin; Philip Torr
61. Training Student Networks for Acceleration with Conditional Adversarial Networks

BMVC 2018 Programme
Zheng Xu; Yen-Chang Hsu; Jiawei Huang
62.
Super-resolution of Very Low-Resolution Faces from Videos
Esra Cansizoglu; Michael J Jones
63.
Semi-supervised Skin Lesion Segmentation via Transformation Consistent Self-ensembling Model Xiaomeng Li; Lequan Yu; Hao Chen; Chi-Wing Fu; Pheng-Ann Heng
64.
Metric Learning for Novelty and Anomaly Detection Marc Masana; Idoia Ruiz; Joan Serrat; Joost van de Weijer; Antonio M. Lopez
65.
Adversarial Learning for Semi-supervised Semantic Segmentation Wei-Chih Hung; Yi-Hsuan Tsai; Yan-Ting Liou; Yen-Yu Lin; Ming-Hsuan Yang
66.
Dynamic Super-Rays for Efficient Light Field Video Processing
Matthieu Hog; Neus Sabater; Christine Guillemot
67.
Holistic and Deep Feature Pyramids for Saliency Detection Shizhong Dong; Zhifan Gao; Shanhui Sun; xin wang; ming li); heye zhang; Guang Yang); Huafeng Liu; Shuo Li
68.
Sparse Estimation of Light Transport Matrix under Saturated Condition Naoya Chiba; Koichi Hashimoto
69.
Synthetic View Generation for Absolute Pose Regression and Image Synthesis Pulak Purkait; Cheng Zhao; Christopher Zach
70.
Self-supervised Deep Multiple Choice Learning Network for Blind Image Quality Assessment Kwan-Yee Lin; Guanxiang Wang
71.
Classifier Two Sample Test for Video Anomaly Detections
Yusha Liu; Chun-Liang Li; Barnabas Poczos
72.
A Mixed Classification-Regression Framework for 3D Pose Estimation from 2D Images Siddharth Mahendran; Haider Ali; Rene Vidal
73.
Semantic-aware Grad-GAN for Virtual-to-Real Urban Scene Adaption Peilun Li; XIAODAN LIANG; Daoyuan Jia; Eric Xing
74. Classification-Based Supervised Hashing with Complementary Networks for Image

BMVC 2018 Programme
Search Dong-ju Jeong; Sungkwon Choo; Wonkyo Seo; Nam Ik Cho
75.
Semantic Localisation via Globally Unique Instance Segmentation Ignas Budvytis; Patrick Sauer; Roberto Cipolla
76.
MC-GAN: Multi-conditional Generative Adversarial Network for Image Synthesis Hyojin Park; Youngjoon Yoo; Nojun Kwak
77.
InteriorNet: Mega-scale Multi-sensor Photo-realistic Indoor Scenes Dataset Wenbin Li; Sajad Saeedi; John McCormac; Ronald Clark; Dimos Tzoumanikas; Qing Ye; Yuzhong Huang; Rui Tang; Stefan Leutenegger
78.
In Defense of Single-column Networks for Crowd Counting Ze Wang; Zehao Xiao; Kai Xie; Qiang Qiu; Xiantong Zhen; Xianbin Cao
79.
Few-Shot Semantic Segmentation with Prototype Learning Nanqing Dong; Eric Xing
80.
SymmNet: A Symmetric Convolutional Neural Network for Occlusion Detection
Ang Li; Zejian Yuan
81.
Joint Holistic and Partial CNN for Pedestrian Detection Yun Zhao; Zejian Yuan; Hui Zhang
82.
Think and Tell: Preview Network for Image Captioning Zhihao Zhu; zhan xue; Zejian Yuan
83.
Adaptive Multi-Scale Information Flow for Object Detection Xiaoyu Chen; Wei Li; Qingbo Wu; Fanman Meng
84.
Visual Heart Rate Estimation with Convolutional Neural Network Radim Spetlik; Vojtech Franc; Jan Cech; Jiri Matas
85.
Visually-Driven Semantic Augmentation for Zero-Shot Learning Abhinaba Roy; Jacopo Cavazza; Vittorio Murino
86.
ProFlow: Learning to Predict Optical Flow
Daniel Maurer; Andrés Bruhn
87.
Deep Collaborative Tracking Networks Xiaolong Jiang; Xiantong Zhen; Baochang Zhang; Jian Yang; Xianbin Cao

BMVC 2018 Programme
88.
Adaptive Time-Slice Block-Matching Optical Flow Algorithm for Dynamic Vision Sensors Min Liu; Tobi Delbruck
89.
Crowd Counting by Adaptively Fusing Predictions from an Image Pyramid Di Kang; Antoni Chan
90.
Multi-Task Deep Networks for Depth-Based 6D Object Pose and Joint Registration in Crowd Scenarios Juil Sock; Kwang In Kim; Caner Sahin; Tae-Kyun Kim
91.
Deep active learning for object detection
Soumya Roy; Asim Unmesh; Vinay P Namboodiri
92.
OriNet: A Fully Convolutional Network for 3D Human Pose Estimation Chenxu Luo; Xiao Chu; Alan Yuille
93.
Towards Light-weight Annotations: Fuzzy Interpolative Reasoning for Zero-shot Image Classificaiton Yang Long; Yao Tan; Daniel Organisciak; Longzhi Yang; Ling Shao
94.
Recurrent Multi-frame Single Shot Detector for Video Object Detection Michael J Jones; Alex Broad; Teng-Yok Lee
95.
Persuasive Faces: Generating Faces in Advertisements
Christopher L Thomas; Adriana Kovashka
96.
The Multiscale Bowler-Hat Transform for Vessel Enhancement in 3D Biomedical Images Cigdem Sazak; Carl J. Nelson; Boguslaw Obara
97.
SPG-Net: Segmentation Prediction and Guidance Network for Image Inpainting Yuhang Song; Chao Yang; Yeji Shen; Peng Wang; Qin Huang; C.-C. Jay Kuo
98.
Exemplar-Supported Generative Reproduction for Class Incremental Learning Chen He; Ruiping Wang; Shiguang Shan
99.
GAN-based Semi-supervised Learning on Fewer Labeled Samples
Takumi Kobayashi
100. Generative Adversarial Guided Learning for Domain Adaptation Kai-Ya Wei; Chiou-Ting Hsu

BMVC 2018 Programme
101.
IGCV3: Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks Ke Sun; Mingjie Li; Dong Liu; Jingdong Wang
102.
Self-Supervised Feature Learning for Semantic Segmentation of Overhead Imagery Suriya Singh; Anil Batra; Guan Pang; Lorenzo Torresani; Saikat Basu; Manohar Paluri; C.V. Jawahar
103.
Active Learning for Regression Tasks with Expected Model Output Changes Christoph Käding; Erik Rodner; Alexander Freytag; Oliver Mothes; Björn Barz; Joachim Denzler
104.
A Quantitative Platform for Non-Line-of-Sight Imaging Problems Jonathan Klein; Martin Laurenzis; Dominik Michels; Matthias B Hullin
105.
Few-shot learning of neural networks from scratch by pseudo example optimization Akisato Kimura; Zoubin Ghahramani; Koh Takeuchi; Tomoharu Iwata; Naonori Ueda
106.
Directional Priors for Multi-Frame Optical Flow
Daniel Maurer; Michael Stoll; Andrés Bruhn
107.
Wide Range Depth Estimation from Binocular Light Field Camera feng dai; Xianyu Chen; Yike Ma; Guoqing Jin; Qiang Zhao
108.
CaloriNet: From silhouettes to calorie estimation in private environments Alessandro Masullo; Tilo Burghardt; Dima Damen; Sion Hannung; Víctor Ponce-López; Majid Mirmehdi
109.
Identity Preserving Face Completion for Large Ocular Region Occlusion Yajie Zhao; Weikai Chen; Jun Xing; Xiaoming Li; Zach Bessinger; Fuchang Liu; Wangmeng Zuo; Ruigang Yang
110.
ESTHER: Extremely Simple Image Translation Through Self-Regularization Chao Yang; Taehwan Kim; Ruizhe Wang; Hao Peng; C.-C. Jay Kuo
111.
Multicolumn Networks for Face Recognition Weidi Xie; Andrew Zisserman
112.
Progressive Attention Networks for Visual Attribute Prediction Paul Hongsuck Seo; Zhe Lin; Scott Cohen; Xiaohui Shen; Bohyung Han
113.
Cross-Class Sample Synthesis for Zero-shot Learning
Jinlu Liu; Xirong Li; Gang Yang

BMVC 2018 Programme
114. Shadow Detection Using Robust Texture Learning Tianxiang Pan; Bin Wang; guiguang ding; JunHai Yong
115.
DeepInsight: Multi-Task Multi-Scale Deep Learning for Mental Disorder Diagnosis Mingyu Ding; Yuqi Huo; Jun Hu; Zhiwu Lu
116.
SurReal: enhancing Surgical simulation Realism using style transfer Imanol Luengo; Evangello Flouty; Petros Giataganas; Piyamate Wisanuvej; Jean Nehme; Danail Stoyanov
117.
Guided Upsampling Network for Real-Time Semantic Segmentation Davide Mazzini
118.
Point Attention Network for Gesture Recognition Using Point Cloud Data Cherdsak Kingkan; Joshua Owoyemi; Koichi Hashimoto
119.
A Decomposed Dual-Cross Generative Adversarial Network for Image Rain Removal Xin Jin; Zhibo Chen; Jianxin Lin; Jiale Chen; Wei Zhou; Chaowei Shan
120.
Light-Field Intrinsic Dataset
Sumit Shekhar; Shida Beigpour; Matthias Ziegler; Michał Chwesiuk; Dawid Paleń; Karol Myszkowski; Joachim Keinert; Radosław Mantiuk; Piotr Didyk
121.
CEREALS – Cost-Effective REgion-based Active Learning for Semantic Segmentation Radek J Mackowiak; Philip Lenz; Omair Ghori; Ferran Diego; Oliver Lange; Carsten Rother
122.
Large scale evaluation of local image feature detectors on homography datasets Karel Lenc; Andrea Vedaldi
123.
Error Correction Maximization for Deep Image Hashing Xiang Xu; Xiaofang Wan; Kris Kitani
124.
Learning a Code-Space Predictor by Exploiting Intra-Image-Dependencies Jan P Klopp; Yu-Chiang Frank Wang; Shao-Yi Chien; Liang-Gee Chen
125.
Light-Weight RefineNet for Real-Time Semantic Segmentation
Vladimir Nekrasov; Chunhua Shen); Ian Reid
126.
Accurate Detection and Localization of Checkerboard Corners for Calibration Alexander Duda; Udo Frese

BMVC 2018 Programme
127. 3D Object Structure Recovery via Semi-supervised Learning on Videos Qian He; Desen Zhou; Xuming He
128.
Deep Video Color Propagation Simone Meyer; Victor Cornillere ; Abdelaziz Djelouah; Christopher Schroers; Markus Gross
129.
3D Human Pose Estimation with Relational Networks Sungheon Park; Nojun Kwak
130.
Image-derived generative modeling of pseudo-macromolecular structures -- towards the statistical assessment of Electron CryoTomography template matching Kaiwen Wang; Xiangrui Zeng; Xiaodan Liang; Zhiguang Huo; Eric Xing; Min Xu
131.
Ranking CGANs: Subjective Control over Semantic Image Attributes
Yassir Saquil; Kwang In Kim; Peter M Hall
132.
License Plate Recognition and Super-resolution from Low-Resolution Videos by Convolutional Neural Networks Vojtech Vasek; Vojtech Franc; Martin Urban
133.
End-to-End Speech-Driven Facial Animation with Temporal GANs Konstantinos Vougioukas; Stavros Petridis; Maja Pantic
134.
2sRanking-CNN: A 2-stage ranking-CNN for diagnosis of glaucoma from fundus images using CAM-extracted ROI as an intermediate input
Tae Joon Jun; Dohyeun Kim; Hoang Minh Nguyen; Daeyoung Kim; Youngsub Eom
135.
DeSTNet: Densely Fused Spatial Transformer Networks Roberto Annunziata; Christos Sagonas; Jacques Cali
136.
Fewer is More: Image Segmentation Based Weakly Supervised Object Detection with Partial Aggregation Ce Ge; Jingyu Wang; Qi Qi; Haifeng Sun; Jianxin Liao
137.
Future Semantic Segmentation with Convolutional LSTM Seyed shahabeddin Nabavi; Mrigank Rochan; Yang Wang
138.
Action Completion: A Temporal Model for Moment Detection
Farnoosh Heidarivincheh; Majid Mirmehdi; Dima Damen
139.
Multiple Object Tracking by Learning Feature Representation and Distance Metric Jointly Jun Xiang; Guoshuai Zhang; Nong Sang; Rui Huang; Jianhua Hou

BMVC 2018 Programme
140. Highway Driving Dataset for Semantic Video Segmentation Byungju Kim; Junho Yim; Junmo Kim
141.
The Minimalist Camera Parita Pooj
142.
Localization Guided Learning for Pedestrian Attribute Recognition Pengze Liu; Xihui Liu); Junjie Yan; Jing Shao
143.
Local Point Pair Feature Histogram for Accurate 3D Matching Anders G Buch; Dirk Kraft
144.
Learning Geo-Temporal Image Features Menghua Zhai; Tawfiq Salem; Connor S Greenwell; Scott Workman; Robert Pless; Nathan Jacobs
16:15 - 16:45 Tea Break, Students Union
16:45 - 18:30 Orals 2, Students Union: Learning and Recognition Chair: Jungong Han
145.
Three for one and one for three: Flow, Segmentation, and Surface Normals Hoang-An Le; Anil Baslamisli; Thomas Mensink; Theo Gevers
146.
ContextNet: Exploring Context and Detail for Semantic Segmentation in Real-time Rudra Poudel; Ujwal Bonde; Stephan Liwick; Christopher Zach
147.
BAM: Bottleneck Attention Module
Jongchan Park; Sanghyun Woo; Joon-Young Lee
148. Learning on the Edge: Explicit Boundary Handling in CNNs Carlo Innamorati
149.
Structured Probabilistic Pruning for Convolutional Neural Network Acceleration Huan Wang; Qiming Zhang; Yuehai Wang; Haoji Hu
150.
Efficient Progressive Neural Architecture Search Juan-Manuel Perez-Rua; Moez Baccouche; Stephane Pateux,
151.
RISE: Randomized Input Sampling for Explanation of Black-box Models Vitali Petsiuk; Abir Dasy; Kate Saenko

BMVC 2018 Programme
19:00 - 21:30 Simple Dinner, Civic Centre
WEDNESDAY 5TH SEPTEMBER
7:30 - 7:45 Registration, Students Union
7:45 - 8:30 Coffee & Pastry, Students Union
8:30 - 10:00
Orals 3, Students Union: Low Level Vision and Computational Photography Chair: Dimitris Metaxas
152.
Direct Shot Correspondence Matching Umer Rafi; Bastian Leibe
153.
Gated Fusion Network for Joint Image Deblurring and Super-Resolution Xinyi Zhang; Hang Dong; Zhe Hu; Wei-Sheng Lai; Fei Wang; Ming-Hsuan Yang
154.
Semantic Priors for Intrinsic Image Decomposition Saurabh Saini; P. J. Narayanan
155.
Deep Retinex Decomposition for Low-Light Enhancement
Chen Wei; Wenjing Wang; Wenhan Yan; Jiaying Liu
156. Pixel-level Semantics Guided Image Colorization JIAOJIAO ZHAO; Li Liu; Cees Snoek; Jungong Han; Ling Shao
157.
Automatic Semantic Content Removal by Learning to Neglect Siyang Qin; Jiahui We;; Roberto Manduchi
10:00 - 10:45 Tea Break, Students Union
10:45 - 11:45
Keynote 2, Students Union The Role of Symmetry in Human and Computer Vision.
Sven Dickinson (University of Toronto) Chair: David Crandall
11:45 - 12:30 Spotlights 2, Students Union
158.
CNN-based Action Recognition and Supervised Domain Adaptation on 3D Body Skeletons via Kernel Feature Maps Yusuf Tas; Piotr Koniusz

BMVC 2018 Programme
159. Deep Covariance Descriptors for Facial Expression Recognition Naima OTBERDOUT; Anis Kacem; Mohamed Daoudi; Lahoucine Ballihi; Stefano Berretti
160.
Video Time: Properties, Encoders and Evaluation Amir Ghodrati; Efstratios Gavves; Cees Snoek
161.
Modelling Diffusion Process by Deep Neural Networks for Image Retrieval yan zhao ; Lei Wang; Luping Zhou; Yinghuan Shi; Yang Gao
162.
Memory-efficient Global Refinement of Decision-Tree Ensembles and its Application to Face Alignment Nenad Markus; Ivan Gogić; Igor Pandzic; Jorgen Ahlberg
163.
A Novel Method For Unsupervised Scanner-Invariance Using A Dual-Channel Auto-Encoder Model Andrew D Moyes; Kun Zhang; Liping Wang; Ming Ji; Danny Crookes; Huiyu Zhou
164.
Improved Visual Relocalization by Discovering Anchor Points Soham Saha; Girish Varma; C.V. Jawahar
165.
Bidirectional Long Short-Term Memory Variational Autoencoder
Henglin Shi; Xin Liu); xiaopeng hong; Guoying Zhao
166.
Phase retrieval for Fourier Ptychography under varying amount of measurements Lokesh Boominathan; Mayug Maniparambil; Honey Gupta; Rahul Baburajan; Kaushik Mitra
12:30 - 14:00 Lunch, Civic Centre
14:00 - 16:15 Posters 2, Students Union
167 - 175 Correspond to Wednesday Spotlights 2
167.
CNN-based Action Recognition and Supervised Domain Adaptation on 3D Body Skeletons via Kernel Feature Maps Yusuf Tas; Piotr Koniusz
168.
Deep Covariance Descriptors for Facial Expression Recognition
Naima OTBERDOUT; Anis Kacem; Mohamed Daoudi; Lahoucine Ballihi; Stefano Berretti
169.
Video Time: Properties, Encoders and Evaluation Amir Ghodrati; Efstratios Gavves; Cees Snoek

BMVC 2018 Programme
170. Modelling Diffusion Process by Deep Neural Networks for Image Retrieval yan zhao; Lei Wang; Luping Zhou; Yinghuan Shi; Yang Gao
171.
Memory-efficient Global Refinement of Decision-Tree Ensembles and its Application to Face Alignment Nenad Markus; Ivan Gogić; Igor Pandzic; Jorgen Ahlberg
172.
A Novel Method for Unsupervised Scanner-Invariance Using A Dual-Channel Auto-Encoder Model Andrew D Moyes; Kun Zhang; Liping Wang; Ming Ji; Danny Crookes; Huiyu Zhou
173.
Improved Visual Relocalization by Discovering Anchor Points
Soham Saha; Girish Varma; C.V. Jawahar
174.
Bidirectional Long Short-Term Memory Variational Autoencoder Henglin Shi; Xin Liu; xiaopeng hong; Guoying Zhao
175.
Phase retrieval for Fourier Ptychography under varying amount of measurements Lokesh Boominathan; Mayug Maniparambil; Honey Gupta; Rahul Baburajan; Kaushik Mitra
176 - 181 Correspond to Wednesday Orals 3
176.
Pixel-level Semantics Guided Image Colorization JIAOJIAO ZHAO; Li Liu; Cees Snoek; Jungong Han; Ling Shao
177.
Gated Fusion Network for Joint Image Deblurring and Super-Resolution Xinyi Zhang; Hang Dong; Zhe Hu; Wei-Sheng Lai; Fei Wang; Ming-Hsuan Yang
178.
Direct Shot Correspondence Matching Umer Rafi; Bastian Leibe; Jurgen Gall
179.
Deep Retinex Decomposition for Low-Light Enhancement
Chen Wei; Wenjing Wang; Wenhan Yang; Jiaying Liu
180. Semantic Priors for Intrinsic Image Decomposition Saurabh Saini; P. J. Narayanan
181.
Automatic Semantic Content Removal by Learning to Neglect Siyang Qin; Jiahui Wei; Roberto Manduchi
182 - 188 Correspond to Wednesday Orals 4

BMVC 2018 Programme
182. S3D: Single Shot multi-Span Detector via Fully 3D Convolutional Networks Da Zhang; Xiyang Da; Xin Wang; Yuan-Fang Wang
183.
Budget-Aware Activity Detection with A Recurrent Policy Network Behrooz Mahasseni; Xiaodong Yang; Pavlo Molchanov; Kautz Jan
184.
From Coarse Attention to Fine-Grained Gaze: A Two-stage 3D Fully Convolutional Network for Predicting Eye Gaze in First Person Video Zehua Zhang; Sven Bambach; Chen Yu; David Crandall
185.
LikeNet: A Siamese Motion Estimation Network Trained in an Unsupervised Way
Aria Ahmadi; Marras Ioannis; Ioannis Patras
186.
Learning Human Optical Flow Anurag Ranjan; Javier Romero (MPI-IS); Michael J. Black
187.
Video Summarisation by Classification with Deep Reinforcement Learning Kaiyang Zhou; Tao Xiang; ANDREA CAVALLARO
188.
QuaterNet: A Quaternion-based Recurrent Model for Human Motion Dario Pavllo; David Grangier; Michael Auli
189 - 194 Correspond to Thursday Orals 5
189.
It's all Relative: Monocular 3D Human Pose Estimation from Weakly Supervised Data Matteo Ruggero Ronchi; Oisin Mac Aodha; Robert Eng; Pietro Perona
190.
3D Hand Pose Estimation using Simulation and Partial-Supervision with a Shared Latent Space Masoud Abdi; Ehsan M Abbasnejad; Chee Peng Lim; Saeid Nahavandi
191.
Self-supervised learning of a facial attribute embedding from video Olivia Wiles; A S Koepke; Andrew Zisserman
192.
Face Verification from Depth using Privileged Information Guido Borghi; Stefano Pini; Filippo Grazioli; ROBERTO VEZZANI; Rita Cucchiara
193.
Sign Language Production using Neural Machine Translation and Generative Adversarial Networks Stephanie M Stoll; Necati Cihan Camgoz; Simon Hadfield; Richard Bowden
194. CU-Net: Coupled U-Nets

BMVC 2018 Programme
Zhiqiang Tang; Xi Peng; Shijie Geng; Yizhe Zhu; Dimitris Metaxas
195 - 199 Correspond to Thursday Orals 6
195.
End-to-end Image Captioning Exploits Multimodal Distributional Similarity
Pranava Madhyastha; Josiah Wang; Lucia Special
196.
Boosting up Scene Text Detectors with Guided CNN Xiaoyu Yue; Zhanghui Kuang; Zhaoyang Zhang; Zhenfang Chen; Pan He; Yu Qiao; Wei Zhang
197.
Y-Net: A deep Convolutional Neural Network to Polyp Detection Ahmed Kedir Mohammed; Sule Yildirim-Yayilgan; Marius Pedersen; Ivar Farup; Øistein Hovde
198.
Guitar Music Transcription from Silent Video Shir Goldstein; Yael Moses
199.
Image Retrieval with Mixed Initiative and Multimodal Feedback Nils Murrugarra-Llerena; Adriana Kovashka
200.
Human Activity Recognition with Pose-driven Attention to RGB Fabien Baradel; Christian Wolf; Julien Mille
201.
Generating Photorealistic Facial Expressions in Dyadic Interactions Yuchi Huang; Saad Khan
202.
An Efficient End-to-End Neural Model for Handwritten Text Recognition
Arindam Chowdhury; Lovekesh Vig
203. Online Multi-Object Tracking with Structural Invariance Constraint Xiao Zhou; Peilin Jiang; Zhao Wei; Hang Dong; Fei Wang
204.
Self-attention Learning for Person Re-identification Minyue Jiang; Yuan Yuan; Qi Wang
205.
Improving Fast Segmentation with Teacher-Student Learning Jiafeng Xie; Bing Shuai; Jian-Fang HU; Jingyang Li; WEI-SHI ZHENG
206.
Asymmetric Spatio-Temporal Embeddings for Large-Scale Image-to-Video Retrieval Noa Garcia; George Vogiatzis

BMVC 2018 Programme
207. Adaptive Context-aware Reinforced Agent for Handwritten Text Recognition Liangke Gui; XIAODAN LIANG; Xiaojun Chang; Alexander Hauptmann
208.
Attentional Alignment Networks Lei Yue; Xin Miao; Pengbo Wang; Baochang Zhang; Xiantong Zhen; Xianbin Cao
209.
Regional Attention Based Deep Feature for Image Retrieval Jaeyoon Kim; Sungeui Yoon
210.
Learning and Thinking Strategy for Training Sequence Generation Models Yu Li; Sheng Tang; Min Lin; junbo guo; Jintao Li; Shuicheng Yan
211.
A Deep Framework for Automatic Annotation with Application to Retail Warehouses Kanika Mahajan; ANIMA MAJUMDER; Harika Nanduri; Swagat Kumar
212.
Iteratively Trained Interactive Segmentation
Sabarinath Mahadevan; Paul Voigtlaender; Bastian Leibe
213. Feature Contraction: New ConvNet Regularization in Image Classification Vladimir Li; Atsuto Maki
214.
Deep Attentional Structured Representation Learning for Visual Recognition Krishna Kanth Nakka; Mathieu Salzmann
215.
Ellipse Detection on Images Using Conic Power of Two Points Min Liu; BODI Yuan; Jing Bai
216.
Parsing Pose of People with Interaction Serim Ryou
217.
A Highly Accurate Feature Fusion Network For Vehicle Detection In Surveillance Scenarios
Jianqiang Wang
218.
Structure Aligning Discriminative Latent Embedding for Zero-Shot Learning Omkar Anil Gune; Biplab Banerjee; Subhasis Chaudhuri
219.
ROI-wise Reverse Reweighting Network for Road Marking Detection Xiaoqiang Zhang; Yuan Yuan; Qi Wang
220.
MBLLEN: Low-Light Image/Video Enhancement Using CNNs Feifan Lv; Feng Lu; Jianhua Wu; Chongsoon Lim

BMVC 2018 Programme
221. Hierachical Image Link Selection Scheme for Duplicate Structure Disambiguation Fan Wang; Aditi Nayak; Yogesh Agrawal; Roy Shilkrot
222.
Single Image Super-Resolution via Squeeze and Excitation Network Tao Jiang; yu zhang; Xiaojun Wu; Yuan Rao; Mingquan Zhou
223.
WebCaricature: a benchmark for caricature recognition Jing Huo; Wenbin Li; Yinghuan Shi; Yang Gao; Hujun Yin
224.
Resembled Generative Adversarial Networks: Two Domains with Similar Attributes Duhyeon Bang; Hyunjung Shim
225.
Multispectral Pedestrian Detection via Simultaneous Detection and Segmentation Chengyang Li; Dan Song; Ruofeng Tong; Min Tang
226.
Identity-based Adversarial Training of Deep CNNs for Facial Action Unit Recognition
Zheng Zhang; Shuangfei Zhai; Lijun Yin
227. A Fine-to-Coarse Convolutional Neural Network for 3D Human Action Recognition Thao M. Le; Nakamasa Inoue; Koichi Shinoda
228.
Dense Correspondence of Cone-Beam Computed Tomography Images Using Oblique Clustering Forest Diya Sun; Yuru Pei; Yuke Guo; Gengyu Ma; Tianmin Xu; Hongbin Zha
229.
Attention is All We Need: Nailing Down Object-centric Attention for Egocentric Activity Recognition
Swathikiran Sudhakaran; Oswald Lanz
230. Structure-Aware 3D Shape Synthesis from Single-View Images Xuyang Hu; Fan Zhu; Li Liu; Jin Xie; Jun Tang; Nian Wang; Fumin Shen; Ling Shao
231.
Robust Adversarial Perturbation on Deep Proposal-based Models Yuezun Li; Daniel Tian; Ming-Ching Chang; Xiao Bian; Siwei Lyu
232.
Compact Neural Networks based on the Multiscale Entanglement Renormalization Ansatz Andrew Hallam
233.
Joint Action Unit localisation and intensity estimation through heatmap regression Enrique Sánchez-Lozano; Georgios Tzimiropoulos; Michel Valstar
234. Multiplicative vs. Additive Half-Quadratic Minimization for Robust Cost Optimization

BMVC 2018 Programme
Christopher Zach; Guillaume M Bourmaud
235.
A Differential Approach for Gaze Estimation with Calibration
Gang Liu; Yu Yu; Kenneth Alberto Funes Mora; JEAN-MARC ODOBEZ
236
SAM-RCNN: Scale-Aware Multi-Resolution Multi-Channel Pedestrian Detection Tianrui Liu; Mohamed ElMikaty; Tania Stathaki
237.
Understanding Deep Architectures by Visual Summaries Marco Godi; Marco Carletti; Maya Aghaei; Francesco Giuliari; Marco Cristani
238.
A Hybrid Probabilistic Model for Camera Relocalization Ming Cai; Chunhua Shen; Ian Reid
239.
Action Recognition with the Augmented MoCap Data using Neural Data Translation Shih-Yao Lin; Yen-Yu Lin
240.
StitchAD-GAN for Synthesizing Apparent Diffusion Coefficient Images of Clinically Significant Prostate Cancer Zhiwei Wang; Yi Lin; Chunyuan Liao; Kwang-Ting Cheng; Xin Yang
241.
Long-term object tracking with a moving event camera Bharath Ramesh; Shihao Zhang; Zhi Wei Lee; Zhi Gao; Garrick Orchard; Cheng Xiang
242.
Multi-Scale Recurrent Tracking via Pyramid Recurrent Network and Optical Flow Ding Ma; Wei Bu; XIANGQIAN WU
243.
Strong Baseline for Single Image Dehazing with Deep Features and Instance Normalization Zheng Xu; Xitong Yang; Xue Li; Xiaoshuai Sun
244.
Automatic X-ray Scattering Image Annotation via Double-View Fourier-Bessel Convolutional Networks Ziqiao Guan; Hong Qin; Kevin Yager; Youngwoo Choo; Dantong Yu
246.
Semantics Meet Saliency: Exploring Domain Affinity and Models for Dual-Task Prediction
Md Amirul Islam; Mahmoud Kalash; Neil D. B. Bruce
247. Adaptive Appearance Rendering Mengyao Zhai; Ruizhi Deng; Jiacheng Chen; Lei Chen; Zhiwei Deng; Greg Mori

BMVC 2018 Programme
248. Network Decoupling: From Regular to Depthwise Separable Convolutions Jianbo Guo; Yuxi Li); Weiyao Lin; Yurong Chen; Jianguo Li
249.
BUAA-PRO: A Tracking Dataset with Pixel-Level Annotation Annan Li; Zhiyuan Chen; Yunhong Wang
250.
Reciprocal Attention Fusion for Visual Question Answering Moshiur R Farazi; Salman Khan
251.
Recurrent CNN for 3D Gaze Estimation using Appearance and Shape Cues Cristina Palmero; Javier Selva; Mohammad Ali Bagheri; Sergio Escalera
252.
Active Learning from Noisy Tagged Images
Ehsan M Abbasnejad; Anthony Dick; Qinfeng Shi; Anton Van Den Hengel
253.
STDnet: A ConvNet for Small Target Detection Brais Bosquet; Manuel Mucientes; Victor Brea
254.
Learning Human Poses from Actions Aditya Arun; C.V. Jawahar; M. Pawan Kumar
255.
3D Motion Segmentation of Articulated Rigid Bodies based on RGB-D Data Urbano Miguel G. Nunes
256.
Deep Evolutionary 3D Diffusion Heat Maps for Large-pose Face Alignment Bin Sun; Ming Shao; Siyu Xia; YUN FU
257.
Iterative Deep Learning for Road Topology Extraction Carles Ventura; Jordi Pont-Tuset; Sergi Caelles; Kevis-Kokitsi Maninis; Luc Van Gool
258.
Multi-phase Volume Segmentation with Tetrahedral Mesh
Tuan T Nguyen; Vedrana Andersen Dahl; Andreas Bærentzen
259.
AlphaGAN: Generative adversarial networks for natural image matting Sebastian Lutz; Konstantinos Amplianitis; Aljosa Smolic
260.
Actor-Action Semantic Segmentation with Region Masks Kang Dang; CHUNLUAN ZHOU; Zhigang Tu; Michael Hoy; Justin Dauwels; Junsong Yuan
261.
JointFlow: Temporal Flow Fields for Multi Person Pose Estimation Andreas Doering; Umar Iqbal; Jurgen Gall

BMVC 2018 Programme
262. Learning Short-Cut Connections for Object Counting Daniel Oñoro; Roberto Javier Lopez-Sastre; Mathias Niepert
263.
Convolutional Simplex Projection Network for Weakly Supervised Semantic Segmentation Rania Briq; Michael Moeller; Jürgen Gall
264.
Deep Domain Adaptation in Action Space Arshad Jamal; Vinay P Namboodiri; Dipti Deodhare; K. S. Venkatesh
265.
A New Benchmark and Progress Toward Improved Weakly Supervised Learning Russ Webb; Jason Ramapuram
266.
Recurrent Transformer Network for Remote Sensing Scene Categorisation
Zan Chen; Shidong Wang; Xingsong Hou; Ling Shao
267.
Deep Segmentation and Registration in X-Ray Angiography Video Athanasios Vlontzos; Krystian Mikolajczyk
268.
Instance Segmentation of Fibers from Low Resolution CT Scans via 3D Deep Embedding Learning Tomasz K Konopczynski; Thorben Kröger; Lei Zheng; Jürgen Hesser
269.
Human Motion Parsing by Hierarchical Dynamic Clustering Yan Zhang; Siyu Tang; He Sun; Heiko Neumann
270.
Part-based Graph Convolutional Network for Action Recognition
Kalpit C Thakkar; P. J. Narayanan
271.
Multi-task Learning for Macromolecule Classification, Segmentation and Coarse Structural Recovery in Cryo-Tomography Chang Liu; Xiangrui Zeng; Kaiwen Wang; Qiang Guo; Min Xu
272.
Beef Cattle Instance Segmentation Using Fully Convolutional Neural Network Aram Ter-Sarkisov; John Kelleher; Bernadette Earley; Michael Keane; Robert Ross
273.
Region-Object Relevance-Guided Visual Relationship Detection Yusuke Goutsu
274.
Learning Finer-class Networks for Universal Representations Julien Girard; Youssef Tamaazousti; Herve Le Borgne; Céline Hudelot
275. Mining for meaning: from vision to language through multiple networks consensus

BMVC 2018 Programme
Iulia Duta; Andrei L Nicolicioiu; Simion-Vlad Bogolin; Marius Leordeanu
276.
Self-Paced Learning with Adaptive Deep Visual Embeddings
Vithursan Thangarasa; Graham Taylor
277.
Robust 6D Object Pose Estimation with Stochastic Congruent Sets Chaitanya Mitash; Abdeslam Boularias; Kostas
278.
Neuro-IoU: Learning a Surrogate Loss for Semantic Segmentation Nagendar G; Digvijay Singh; Vineeth N Balasubramanian; C.V. Jawahar
279.
Position-Squeeze and Excitation Block for Facial Attribute Analysis Yan Zhang; Wanxia Shen; Li Sun; Qingli Li
280.
Semantic Iterative Closest Point through Expectation-Maximization Steven Parkison; Lu Gan; Maani Ghaffari Jadidi; Dr.Ryan M Eustice
281.
SF-Net: Learning Scene Flow from RGB-D Images with CNNs Yi-Ling Qiao; Lin Gao; Yukun Lai; Fang-Lue Zhang; Ming-Ze Yuan; Shi-Hong Xia
282.
Functionally Modular and Interpretable Temporal Filtering for Robust Segmentation
Jörg Wagner; Volker Fischer; Michael Herman; Sven Prof. Behnke
283.
Deep Facial Attribute Detection in the Wild: From General to Specific Yuechuan Sun; Jun Yu
284.
Accurate Eye Center Localization via Hierarchical Adaptive Convolution Haibin Cai; Bangli Liu; Zhaojie Ju; Serge Thill; Tony Belpaeme; Bram Vanderborght; Honghai Liu
285.
Pyramid Attention Network for Semantic Segmentation Hanchao Li; pengfei xiong; Jie An; Lingxue Wang
286.
Deep Textured 3D Reconstruction of Human Bodies Abbhinav Venkat; Sai Sagar; Avinash Sharma
287.
Fast-BoW: Scaling Bag-of-Visual-Words Generation Dinesh Singh; Abhijeet Bhure; Sumit Mamtani; C. Krishna Mohan
288.
Query-Conditioned Three-Player Adversarial Network for Video Summarization
Yujia Zhang; Michael C. Kampffmeyer; Xiaodan Liang; Min Tan; Eric Xing

BMVC 2018 Programme
289.
Structure-Aware 3D Hourglass Network for Hand Pose Estimation from Single Depth Image Fuyang Huang; Ailing Zeng; Minhao Liu; Jing Qin; Qiang Xu
290.
Chinese Handwriting Imitation with Hierarchical Generative Adversarial Network Jie Chang; yujun gu; Ya Zhang); Yan-Feng Wang
291.
Deep Learning intra-image and inter-images features for Co-saliency detection min li; Shizhong Dong); kun zhang; Zhifan Gao; Xi Wu; heye zhang; Guang Yang; Shuo Li
292.
Learning Generic Diffusion Processes for Image Restoration Peng Qiao; yong dou; Yunjin Chen; Wensen Feng
16:15 - 16:45 Tea Break, Students Union
16:45 - 18:30 Orals 4, Students Union: Video, Motion and Actions Chair: Yael Moses
293.
S3D: Single Shot multi-Span Detector via Fully 3D Convolutional Networks Da Zhang; Xiyang Dai; Xin Wang; Yuan-Fang Wang
294.
Budget-Aware Activity Detection with A Recurrent Policy Network Behrooz Mahasseni; Xiaodong Yang; Pavlo Molchanov; Kautz Jan
295.
From Coarse Attention to Fine-Grained Gaze: A Two-stage 3D Fully Convolutional Network for Predicting Eye Gaze in First Person Video
Zehua Zhang; David Crandall; Chen Yu; Sven Bambach
296.
LikeNet: A Siamese Motion Estimation Network Trained in an Unsupervised Way Aria Ahmadi; Marras Ioannis; Ioannis Patras
297.
Learning Human Optical Flow Anurag Ranjan; Javier Romero; Michael Black
298.
Video Summarisation by Classification with Deep Reinforcement Learning Kaiyang Zhou; Tao Xiang, Queen Mary; ANDREA CAVALLARO
299.
QuaterNet: A Quaternion-based Recurrent Model for Human Motion Dario Pavll; David Grangie; Michael Auli
19:00 - 21:30 Banquet, Civic Centre

BMVC 2018 Programme
THURSDAY 6TH SEPTEMBER
7:30 - 7:45 Registration, Students Union
7:45 - 8:30 Coffee & Pastry, Students Union
8:30 - 10:00
Orals 5, Students Union: Low Level Vision and Computational Photography Chair: Peter Hall
300.
It's all Relative: Monocular 3D Human Pose Estimation from Weakly Supervised Data Matteo Ronchi; Oisin Mac Aodha, Caltech; Robert Eng; Pietro Perona
301.
3D Hand Pose Estimation using Simulation and Partial-Supervision with a Shared Latent Space Masoud Abdi; Ehsan Abbasnejad; Chee Peng Lim; Saeid Nahavandi
302.
Self-supervised learning of a facial attribute embedding from video A Koepke; Olivia Wiles; Andrew Zisserman
303.
Face Verification from Depth using Privileged Information Guido Borghi; Stefano Pini; Filippo Grazioli; ROBERTO VEZZANI; Rita Cucchiara
304.
Sign Language Production using Neural Machine Translation and Generative Adversarial Networks Stephanie Stoll; Necati Cihan Camgoz; Simon Hadfield; Richard Bowden
305.
CU-Net: Coupled U-Nets Zhiqiang Tang; Xi Peng; Shijie Geng; Yizhe Zhu; Dimitris Metaxas
10:00 - 10:45 Tea Break, Students Union
10:45 - 12:00 Orals 6, Students Union: Computer Vision Applications Chair: Sotirios Tsaftaris
306.
End-to-end Image Captioning Exploits Distributional Similarity in Multimodal Space
Pranava Madhyastha; Josiah Wang; Lucia Specig
307.
Boosting up Scene Text Detectors with Guided CNN Xiaoyu Yue; Zhaoyang Zhang; Zhenfang Chen; Pan He; Yu Qiao, s; Wei Zhang

BMVC 2018 Programme
308.
Y-Net: A deep Convolutional Neural Network for Polyp Detection Ahmed Kedir Mohammed; Sule Yildirim-Yayilgan; Marius Pedersen; Ivar Farup; Øistein Hovde,
309.
Guitar Music Transcription from Silent Video Shir Goldstein; Yael Moses
310.
Image Retrieval with Mixed Initiative and Multimodal Feedback Nils Murrugarra-Llerena; Adriana Kovashka
12:00 - 13:00 Simple Lunch Bag, Students Union
13:00 - 14:00
Keynote 3, Students Union Learning Along the Edge of Deep Networks.
Rama Chellappa (University of Maryland) Chair: TK Kim
14:00 - 15:45 Workshop Part 1, Students Union
15:45 - 16:15 Tea Break, Students Union
16:15 - 18:00 Workshop Part 2, Students Union
WORKSHOPS: THURSDAY 6TH SEPTEMBER
IAHFAR 2018: IMAGE ANALYSIS FOR HUMAN FACIAL AND ACTIVITY
RECOGNITION
Orals:
311.
Graph-based Correlated Topic Model for Motion Patterns Analysis in Crowded Scenes from Tracklets Manal AlGhamdi; Yoshihiko Gotoh
312.
Online Action Recognition based on Skeleton Motion Distribution Bangli Liu; Zhaojie Ju; Naoyuki Kubotay; Honghai Liu
313.
Git Loss for Deep Face Recognition Ignazio Gallo; Shah Nawaz; Alessandro Calefat; Muhammad Kamran Janjua,
314. Bi-stream Region Ensemble Network: Promoting Accuracy in Fingertip

BMVC 2018 Programme
Localization from Stereo Images Cairong Zhang; Guijin Wang; Xinghao Chen; huazhong yang
315.
Practical Action Recognition with Manifold Regularized Sparse Representations Lining Zhang; Rinat Khusainov; John chiverton,
316.
CAKE: a Compact and Accurate K-dimensional representation of Emotion Corentin Kervadec; Valentin Vielzeuf; Stephane Pateux; Alexis Lechervy; Frederic Jurie
Posters:
317.
Feature Selection Mechanism in CNNs for Facial Expression Recognition
Shuwen Zhao, Zhejiang University of Technoogy; Haibin Cai; Honghai Liu; Jianhua Zhang; Shengyong Chen
318.
A Deep Variational Autoencoder Approach for Robust Facial Symmetrization Ting Wang; Shu Zhang; Junyu Dong; Yongquan Liang
319.
Palmprint Recognition System with Double-assistant-point on iOS Mobile Devices Lu Leng
320.
Person Part Segmentation based on Weak Supervision
Yalong Jiang; Zheru Chi
321.
Saliency-Informed Spatio-Temporal Vector of Locally Aggregated Descriptors and Fisher Vectors for Visual Action Recognition Zheming Zuo; Daniel Organisciak; Hubert P. H. Shum; Longzhi Yang
CVPPP 2018: COMPUTER VISION PROBLEMS IN PLANT PHENOTYPING
CVPPP 2018 Editorial
Orals:
322.
A New 4D-RGB Mapping Technique for Field-Based High-Throughput Phenotyping Ali Shafiekhani; Felix B. Fritschi; Guilherme DeSouza

BMVC 2018 Programme
323.
Low-cost vision machine for high-throughput automated monitoring of heterotrophic seedling growth on wet paper support Pejman Rasti; Didier Demilly; Landry Benoit; Etienne Belin; Sylvie DUCOURNAU; Francois CHAPEAU-BLONDEAU; David ROUSSEAU
324.
Data Augmentation using Conditional Generative Adversarial Networks for Leaf Counting in Arabidopsis Plants Yezi Zhu; Marc Aoun; Marcel Krijn; Joaquin Vanschoren
325.
Root Gap Correction with a Deep Inpainting Model Hao Chen; Mario Valerio Giuffrida; Sotirios Tsaftaris; Peter Doerner
326.
Towards Low-Cost Image-based Plant Phenotyping using Reduced-Parameter CNN John Atanbori; Feng Chen; Andrew P French; Tony Pridmore
327.
Deep Leaf Segmentation Using Synthetic Data
Daniel C Ward; Peyman Moghadam; Nicolas Hudson
328.
Leaf counting: Multiple scale regression and detection using deep CNNs Yotam Itzhaky; guy farjon; Faina Khoroshevsky; Alon Shpigler; Aharon Bar-Hillel
Posters:
329.
Instance segmentation for assessment of plant growth dynamics in artificial soilless conditions Dmitrii G; Victor Kulikov; Maxim Fedorov
330.
What’s That Plant? WTPlant is a Deep Learning System to Identify Plants in Natural Images Jonas Krause; Gavin Sugita; Kyungim Baek; Lipyeow Lim
331.
Soybean Leaf Coverage Estimation for Field-Phenotyping Kevin Keller; Raghav Khanna; Norbert Kirchgessner; Roland Siegwrat; Achim Walter; Helge Aasen

BMVC 2018 Keynotes
Learning Along the Edge of Deep Networks
RAMA CHELLAPPA, University of Maryland While Deep Convolutional Neural Networks
(DCNNs) have achieved impressive results on many detection and classification tasks (for example, unconstrained face detection, verification and recognition), it is still unclear why they perform so well and how to properly design them. It is widely recognized that while training deep networks, an abundance of training samples is required. These training samples need to be lossless, perfectly labeled, and spanning various classes in a balanced way.
The generalization performance of designed networks and their robustness to adversarial examples needs to be improved too. In this talk, we analyze each of these individual conditions to understand their effects on the performance of deep networks and present mitigation strategies when the ideal conditions are not met.
First, we investigate the relationship between the performance of a convolutional neural network (CNN), its depth, and the size of its training set and present performance bounds on CNNs with respect to the network parameters and the size of the available training dataset. Next, we consider the task of adaptively finding optimal training subsets which will be iteratively presented to the DCNN. We present convex optimization methods, based on an objective criterion and a quantitative measure of the current performance of the classifier, to efficiently identify informative samples to train on. Then we present Defense-GAN, a new strategy that leverages the expressive capability of generative models to defend DCNNs against adversarial attacks. The Defense-GAN can be used with any classification model and does not modify the classifier structure or training procedure. It can also be used as a defense against any attack as it does not assume knowledge of the process for generating the adversarial examples. An approach for training a DCNN using compressed data will also be presented by employing the GAN framework. Finally, to address generalization to unlabeled test data and robustness to adversarial samples, we propose an approach that leverages unsupervised data to bring the source and target distributions closer in a learned joint feature space. This is accomplished by inducing a symbiotic relationship between the learned embedding and a generative adversarial network. We demonstrate the impact of the analyses discussed above on a variety of reconstruction and classification problems.

BMVC 2018 Keynotes
Prof. Rama Chellappa is a Distinguished University Professor, a Minta Martin Professor of Engineering and Chair of the ECE department at the University of Maryland. His current research interests span many areas in image processing, computer vision, machine learning and pattern recognition. Prof. Chellappa is a recipient of an NSF Presidential Young Investigator Award and four IBM Faculty Development Awards. He received the K.S. Fu Prize from the International Association of Pattern Recognition (IAPR). He is a recipient of the Society, Technical Achievement and Meritorious Service Awards from the IEEE Signal Processing Society. He also received the Technical Achievement and Meritorious Service Awards from the IEEE Computer Society. Recently, he received the inaugural Leadership Award from the IEEE Biometrics Council. At UMD, he received college and university level recognitions for research, teaching, innovation and mentoring of undergraduate students. In 2010, he was recognized as an Outstanding ECE by Purdue University. He received the Distinguished Alumni Award from the Indian Institute of Science in 2016. Prof. Chellappa served as the Editor-in-Chief of PAMI. He is a Golden Core Member of the IEEE Computer Society, served as a Distinguished Lecturer of the IEEE Signal Processing Society and as the President of IEEE Biometrics Council. He is a Fellow of IEEE, IAPR, OSA, AAAS, ACM and AAAI and holds six patents.

BMVC 2018 Keynotes
The Role of Symmetry in Human and
Computer Vision
SVEN DICKINSON, University of Toronto
Symmetry is one of the most ubiquitous regularities in our natural world. For almost 100 years, human vision researchers have studied how the human vision system has evolved to exploit this powerful regularity as a basis for grouping image features and, for almost 50 years, as a basis for how the human vision system might encode the shape of an object. While computer vision is a much younger discipline, the trajectory is similar, with symmetry playing a major role in both
perceptual grouping and object representation. After briefly reviewing some of the milestones in symmetry-based perceptual grouping and object representation/recognition in both human and computer vision, I will articulate some of the research challenges. I will then briefly describe some of our recent efforts to address these challenges, including the detection of symmetry in complex imagery and understanding the role of symmetry in human scene perception.
Dr. Dickinson's research interests revolve around the problem of shape perception in computer vision and, more recently, human vision. Much of his recent work focuses on perceptual grouping and its role in image segmentation and shape recovery. He's introduced numerous qualitative shape representations, and their basis in symmetry provides a focus for his perceptual grouping research. His interest in multiscale, parts-based shape representations, and their common abstraction as hierarchical graphs, has motivated his research in inexact graph indexing and matching -- key problems in object recognition, another broad focus of his research. His research has also explored many problems related to object recognition, including object tracking, vision-based navigation, content-based image retrieval, language-vision integration, and image/model abstraction.

BMVC 2018 Keynotes
People Search in Large Scale Videos
SHAOGANG (SEAN) GONG, Queen Mary University of London
The amount of video data from urban environments is growing exponentially from 24/7 operating infrastructure cameras, online social media sources, self-driving cars, and smart city intelligent transportation systems, with 1.4 trillion hours CCTV video in 2017 and growing to 3.3 trillion hours by 2020. The scale and diversity of these videos make it very difficult to filter and extract useful information in a timely manner.
Finding people and searching for the same individuals against a large population of unknowns in urban spaces pose a significant challenge to computer vision and machine learning. Established techniques such as face recognition, although successful for document verification in controlled environments and on smart phones, is poor for people search in unstructured videos of wide-field views due to low-resolution, motion blur, and a lack of detectable facial imagery in unconstrained scenes. In contrast to face recognition, person re-identification considers pedestrian whole-body appearance matching by exploring clothing characteristics and body-part attributes from arbitrary views. In the past decade, significant progresses have been made on person re-identification for matching people in increasingly larger scale benchmarks. However, such progresses rely heavily on supervised learning with strong assumptions on both model training and testing data being sampled from the same domain, and the availability of pair-wise labelled training data exhaustively sampled for every camera pair in each domain. Such assumptions render most existing techniques unscalable to large scale videos from unknown number of unknown sources. In this talk, I will focus on recent progress in advancing unsupervised person re-identification for people search in large scale videos, addressing the problems of visual attention deep learning, joint attribute-identity domain transfer deep learning, imbalanced attribute deep learning, unsupervised deep learning of space-time correlations, and mutual learning in multi-scale matching.
Gong is Professor of Visual Computation at Queen Mary University of London, elected a Fellow of the Institution of Electrical Engineers, a Fellow of the British Computer Society, a member of the UK Computing Research Committee, and served on the Steering Panel of the UK Government Chief Scientific Advisor's Science Review.

BMVC 2018 Keynotes
Prof. Gong's early interest was in information theory & measurement and received a B.Sc. from the University of Electronic Sciences and Technology of China in 1985. Gong's B.Sc. thesis project was on biomedical image analysis which gave him the opportunity to develop a wider interest in robotics. This led Gong to pursue a doctorate in computer vision under the supervision of Mike Brady at Keble College Oxford and the Oxford Robotics Group in 1986. Brady introduced Gong to differential geometry in computer vision and the work of Ellen Hildreth at the MIT AI Lab on computing optic flow. During that time, Gong met David Murray who was on sabbatical at Oxford from GEC Hirst. Murray introduced Gong to the extensive work by Murray and Bernard Buxton at the GEC Hirst Centre on structure-from-motion for autonomous guided vehicle navigation. Gong received his D.Phil. from Oxford in 1989 with a thesis on computing optic flow by second-order geometrical analysis of Hessian derivatives with wave-diffusion propagation. Gong is a recipient of a Queen's Research Scientist Award in 1987, a Royal Society Research Fellow in 1987 and 1988, and a GEC sponsored Oxford research fellow in 1989.

BMVC 2018 tutorials
s
Knowledge transfer and human-machine collaboration for training visual models
VITTORIO FERRARI, University of Edinburgh, Google Research
Object class detection and segmentation are challenging tasks that typically requires tedious and time-consuming manual annotation for training. In this talk I will present three techniques we recently developed for reducing this effort. In the first part I will explore a knowledge transfer scenario: training object detectors for target classes with only image-level labels, helped by a set of source classes with bounding-box annotations. In the second and third parts I will consider human-machine collaboration scenarios (for annotating bounding-boxes of one object class, and for annotating the class label and
approximate segmentation of every object and background region in an image).
Vittorio Ferrari is a Professor at the School of Informatics of the University
of Edinburgh and a Research Scientist at Google, leading a research group on visual learning in each institution. He received his PhD from ETH Zurich in 2004 and was a post-doctoral researcher at INRIA Grenoble in 2006-2007 and at the University of Oxford in 2007-2008. Between 2008 and 2012 he was Assistant Professor at ETH Zurich, funded by a Swiss National Science Foundation Professorship grant. He received the prestigious ERC Starting Grant, and the best paper award from the European Conference in Computer Vision, both in 2012. He is the author of over 90 technical publications. He regularly serves as an Area Chair for the major computer vision conferences, he will be a Program Chair for ECCV 2018 and a General Chair for ECCV 2020. He is an Associate Editor of IEEE Pattern Analysis and Machine Intelligence. His current research interests are in learning visual models with minimal human supervision, object detection, and semantic segmentation.

BMVC 2018 tutorials
s
Towards action understanding with less supervision
IVAN LAPTEV, INRIA Paris
Next to the impressive progress in static image recognition, action understanding remains a puzzle. The lack of large annotated datasets, the compositional nature of activities and ambiguities of manual supervision are likely obstacles towards a breakthrough. To address these issues, this talk will present alternatives for the fully-supervised approach to action recognition. First I will discuss methods that can efficiently deal with annotation noise. In particular, I will talk about
learning from incomplete and noisy YouTube tags, weakly-supervised action classification from textual descriptions and weakly-supervised action localization using sparse manual annotation. The second half of the talk will discuss the problem of automatically defining appropriate human actions and will draw relations to robotics.
Ivan Laptev is a senior researcher at INRIA Paris, France. He received a PhD degree in Computer Science from the Royal Institute of Technology in
2004 and a Habilitation degree from École Normale Supérieure in 2013.
Ivan's main research interests include visual recognition of human actions, objects and interactions. He has published over 60 papers at international conferences and journals of computer vision and machine learning. He serves as an associate editor of IJCV and TPAMI journals, he will serve as a program
chair for CVPR18, he was an area chair for CVPR’10,’13,’15,’16 ICCV’11,
ECCV’12,’14 and ACCV’14,16, he has co-organized several tutorials, workshops
and challenges at major computer vision conferences. He has also co-organized a series of INRIA summer schools on computer vision and machine learning (2010-2013). He received an ERC Starting Grant in 2012 and was awarded a Helmholtz prize in 2017.

BMVC 2018 tutorials
s
Supersizing and Empowering Visual Learning
ABHINAV GUPTA, Carnegie Mellon University
In the last decade, we have made significant advances in field of computer vision thanks to supervised learning. But this passive supervision of our models has now become our biggest bottleneck. In this talk, I will discuss our efforts towards scaling up and empowering learning. First, I will show how amount of labeled data is still a crucial factor in representation learning. I will then discuss one possible avenue on how we can scale up learning by using self-supervision.
Next, I will discuss how we can scale up semantic learning to 10x and more categories by using visual knowledge and graph-based reasoning. But just scaling on amount of data and categories is not sufficient. We also need to empower our learning algorithms with the ability to control its own supervision. In third part of the talk, I will discuss how we can move from passive to interactive learning in context of VQA. Our agents live in the physical world and need the ability to interact in the physical world. Towards this goal, I will finally present our efforts in large-scale learning of embodied agents in Robotics.
Abhinav Gupta is an Associate Professor at the Robotics Institute, Carnegie Mellon University. Abhinav’s research focuses on scaling up learning by building self-supervised, lifelong and interactive learning systems. Specifically, he is interested in how self-supervised systems can effectively use data to learn visual representation, common sense and representation for actions in robots. Abhinav is a recipient of several awards including ONR Young Investigator Award, PAMI Young Research Award, Sloan Research Fellowship, Okawa Foundation Grant, Bosch Young Faculty Fellowship, YPO Fellowship, IJCAI Early Career Spotlight, ICRA Best Student Paper award, and the ECCV Best Paper Runner-up Award. His research has also been featured in Newsweek, BBC, Wall Street Journal, Wired and Slashdot.

BMVC 2018 tutorials
s
Explaining and Representing Novel Concepts with Minimal Supervision
ZEYNEP AKATA, University of Amsterdam
Clearly explaining a rationale for a classification decision to an end-user can be as important as the decision itself. Existing approaches for deep visual recognition are generally opaque and do not output any justification text; contemporary vision-language models can describe image content but fail to take into account class-discriminative image aspects which justify visual predictions. In this talk, I will present my past and current work on Zero-Shot Learning, Vision and Language for
Generative Modeling and Explainable Artificial Intelligence in that (1) how we can generalize the image classification models to the cases when no visual training data is available, (2) how to generate images and image features using detailed visual descriptions, and (3) how our models focus on discriminating properties of the visible object, jointly predict a class label, explain why the predicted label is appropriate for the image whereas another label is not.
Dr. Zeynep Akata is an Assistant Professor with the University of Amsterdam in the Netherlands, Scientific Manager of the Delta Lab and a Senior Researcher at the Max Planck Institute for Informatics in Germany. She holds a BSc degree from Trakya University (2008), MSc degree from RWTH Aachen (2010) and a PhD degree from University of Grenoble (2014). After completing her PhD at the INRIA Rhone Alpes with Prof. Dr. Cordelia Schmid, she worked as a post-doctoral researcher at the Max Planck Institute for Informatics with Prof. Dr. Bernt Schiele and a visiting researcher with Prof Trevor Darrell at UC Berkeley. She is the recipient of Lise Meitner Award for Excellent Women in Computer Science in 2014. Her research interests include machine learning combined with vision and language for the task of explainable artificial intelligence (XAI).

BMVC2018 Workshops
Workshop Venues Workshop Venue (Northumberland Building)
IAHFAR2018 NBD306 (3rd Floor)
VIBE2018 NBD348 (3rd Floor)
CVPPP2018 NBD442 for presentation NBD449 for poster session (4th
Floor)
CDSA2018 NBD252 (2nd Floor)
Tea Break Arrangement
Tea Break (6th Sept, 15:45-16:15) Room
Northumberland Building 2nd Floor NBD252
Northumberland Building 3rd Floor NBD308
Northumberland Building 4th Floor NBD449

Platinum Sponsors
Gold Sponsors
Silver Sponsors
Special Support


















