
PLEXdb Redesign & Implementation Project : Plex Awesomeness Course Involved : CS 461/561 Project...
49
PLEXdb Redesign & Implementation Project : Plex Awesomeness Course Involved : CS 461/561 Project Members : Jesse Walsh Brian Nordland Stephen Mueller Arun Chander
Transcript of PLEXdb Redesign & Implementation Project : Plex Awesomeness Course Involved : CS 461/561 Project...

PLEXdbRedesign & Implementation
Project : Plex Awesomeness
Course Involved : CS 461/561
Project Members : Jesse Walsh Brian Nordland
Stephen Mueller Arun Chander

Introduction to Clients
• John Vanhemert - [email protected]
– John is developing new tools for PLEXdb, and as such is involved in the plex database. John's difficulty understanding the existing database structure and his recognition of its many flaws led him to propose a redesign of the database. John was our primary point of contact, providing us with initial requirements and continuous feedback.
• Sudhansu Dash - [email protected]
– Sudhansu is a curator for PLEXdb. He is the expert on the data and how users access it. He was able to help clarify what data was important and how it was linked together.
• Ethalinda Cannon - [email protected]
– Ethy was one of the original creators of PLEXdb. While she is no longer on the PLEXdb project, she was graciously willing to meet with us and explain some of the considerations that led to the orginal design. She was very helpful in explaining how some of the original tables were meant to join together.
• Julie Dickerson - [email protected]
– Julie is a PI on the PLEXdb project. Julie gave to go-ahead to start our pilot project. She expressed approval with our ER design considerations.

Plant and Plant Pathogen Gene Expression Database
Repository containing microarray gene expression data
MIAME compliant data submission - Minimum Information about A Microarray Experiment
Data from > 200 microarray experiments, > 6000 chips= Experiments from 14 Affymetrix arrays= 13 Species

Requirement Collection
• Clients initial motivation in soliciting our group to work on their project included
– Recognition of existing problems, although the extent of problems had not been assessed.
– Need to store new types of information in PlexDB required updates to the schema.
– Without documentation, knowledge of the database had been lost as its designers moved on. If the database was allowed to grow in size without clear understanding of the tables, the project risks introducing problems later on.
– Clients wanted to start fresh with a clearly documented and properly designed schema

Client Requirements
Expectations from the new database
Remove redundancy and get it normalized.
Better way to store vital information.
Control the overall size of databases.
Schema should support upcoming technologies Eg: nextgen

Expected Deliverables
• Normalized schema design that can replace the experiment and data portions of the existing schema
• Scripts that can populate the new schema
• Intuitive web-based scripts to edit the organism table
• Views that can read from the new schema and present read-only structures similar to existing tables

ISSUES – Table size
PO – 26
Annotation – 105
Blast – 6
Gramenedata – 40
Interpro – 49
Normalization – 229
Ontology – 14
Plexdb – 36
Submission – 12
Table Overgrowth
!

Redundant tables
Creation of new tables that hold the same data
Solution Proposed:
Replace ISAM with InnoDB
Usage of joins
Indexes to match speed
Translate table names to attributes

Improper Storage of Critical Data
Solution proposed:
Translate table names to attributes

Other IssuesImproper typingUndefined relations
Solution Proposed:
Store data using a seperate membership table
RedundancyRepeated text blobs
Solution proposed:Minimize points of storage of such pieces of data using foreign keys

Proposed Improvements
Database Level Complete new schema design Provide JDBC and SQL scripts for data
translation
Weblogic Level Complete view of parent/child relationship for
an organism using the nested set model

Technologies Used
SQL Version 5.0.77Java Version 1.6.0_22PHP Version 5.2.14

ER DIAGRAMJesse Walsh

Background
• Biological data can be complex
• Procedures used and data collected can vary widely
– Require a flexible schema to handle this

ER Diagram
16 Entities

Experimentan example

Experimentan example
Experiment Control
Treatment 1
Treatment 2
Samples

Measurement
Measurement
Measurement
Measurement
Measurement
Measurement
Experimentan example
Experiment Control
Treatment 1
Treatment 2
Measurement
Measurement
Measurement
Measure withMicroarrays

Treatment = Factor + Level
• Time
– 10 hrs
– 20 hrs
• Temperature
– 30 F
– 50 F
• Stress
– Control
– Salinity
– Drought

ER Diagram

What is a MicroArray?

Take home message
• Microarrays measure genes
• The smallest thing measured are probes
• Probes are grouped and summarized into probe sets
• Roughly, probe set = gene
• Microarrays experiment is called a hybridization

ER Diagram

DATABASE DESIGNArun Chander

Relational Schema
Factor(ID,factor_name,factor_order)
Factor_level(ID,factor_id,factor_level,factor_level_order)
Provider(ID,provider,provider_institution,provider_head_of_lab,provider_em
ail,provider_telephone,provider_url)
Users(login_id,first,middle,last,head_of_lab_name,lab,institution,street,state_
province,city,country,zip_code,telephone,fax,email,url,password,activated,
created_time,last_upd_time,lastaccess,job_title)
Groups(name,description,creator,owner,created_date,upd_date)
Experiment(ID,accession_no,experiment_name,experiment_description,login
_id,array_name,quality_control,quality_control_description,visibility,public
_release,curator_visible,reviewer_visible,reviewer_access_code,geo_submi
t,geo_series,import,atlas,finalized,normalized,mark_delete,
sandbox,create,lastmod)
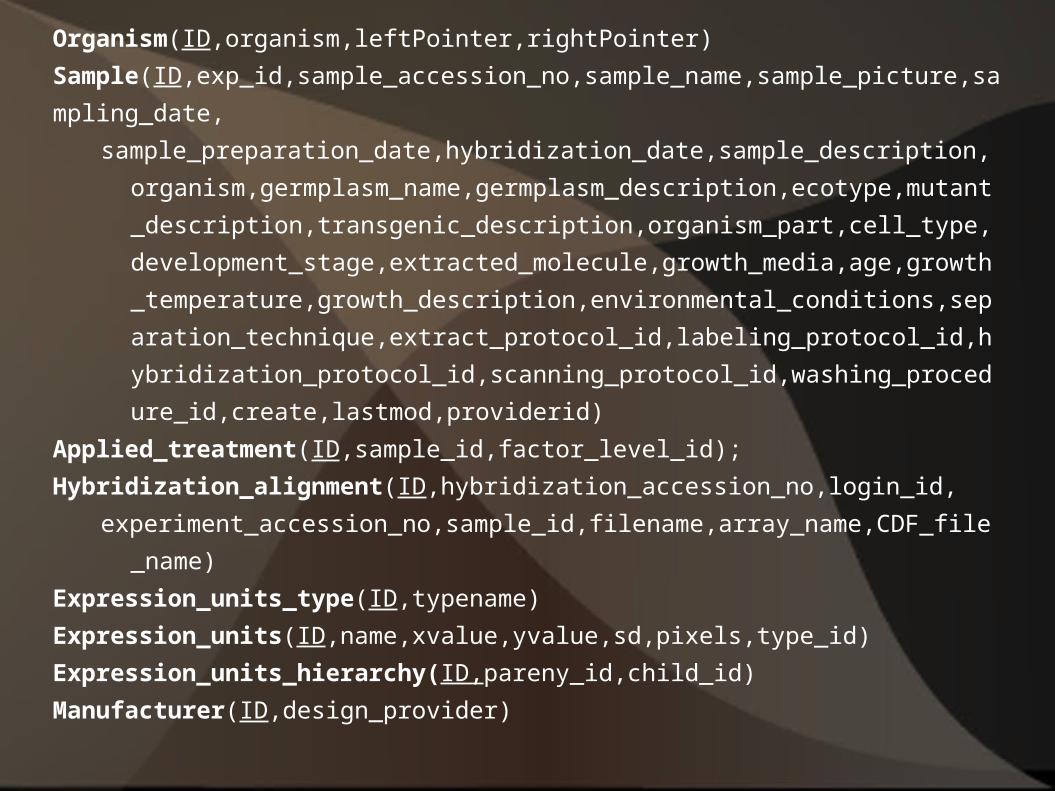
Organism(ID,organism,leftPointer,rightPointer)
Sample(ID,exp_id,sample_accession_no,sample_name,sample_picture,sampli
ng_date,
sample_preparation_date,hybridization_date,sample_description,organis
m,germplasm_name,germplasm_description,ecotype,mutant_descriptio
n,transgenic_description,organism_part,cell_type,development_stage,e
xtracted_molecule,growth_media,age,growth_temperature,growth_des
cription,environmental_conditions,separation_technique,extract_protoc
ol_id,labeling_protocol_id,hybridization_protocol_id,scanning_protocol_
id,washing_procedure_id,create,lastmod,providerid)
Applied_treatment(ID,sample_id,factor_level_id);
Hybridization_alignment(ID,hybridization_accession_no,login_id,
experiment_accession_no,sample_id,filename,array_name,CDF_file_name)
Expression_units_type(ID,typename)
Expression_units(ID,name,xvalue,yvalue,sd,pixels,type_id)
Expression_units_hierarchy(ID,pareny_id,child_id)
Manufacturer(ID,design_provider)

Platforms(ID,array_name,array_name_full,plex_name,geo_platform,data_file
_extn,
number_x,number_y,chip_description,CDF_name,CDF_file_name,CDF_file
_version,CDF_url,number_units,max_units,num_QC_units,design_provi
der_id,info_url,download_url,prefix,default_accession_no,blastdb_name
,mpt_support,exp_support,disable,create,lastmod)
Memberships(login_id,name)
Normalization_methods(ID,method_name,method_description,citation_id,
script_file_name,notes)
Applicable_norm_methods(ID,methodid,array_design_id)
Platform_exprunits(ID,exprid,array_design_id)
Platform_experiment(ID,experiment_id,array_design_id)
Platform_organism(ID,organism_id,array_design_id)
Data_table(ID,expr_id,normmethodid,hybridization_id,intensity)
Statistic(ID,statistic_name,statistic_value double,data_id)

Normalization

DATA MIGRATIONStephen Mueller


Data migration
• Access to VM is slow
• Inconsistencies
• File Names
• Users that don’t exist

State of Release of project
• ER Diagram and Schema Complete

Role of views
• Updating entire database will take place over time
• Views keep website working

Issues Faced & how they were tackled
• Continuous learning
• Continuous requirements gathering
• Complex data
• Data inconsistencies

Issues Faced & how they were tackled
• Getting the data we needed
• Sometimes didn’t know who to ask
• Virtual Machine
• Installing software
• Accessing for data migration

WEB DEVELOPMENTBrian Nordland

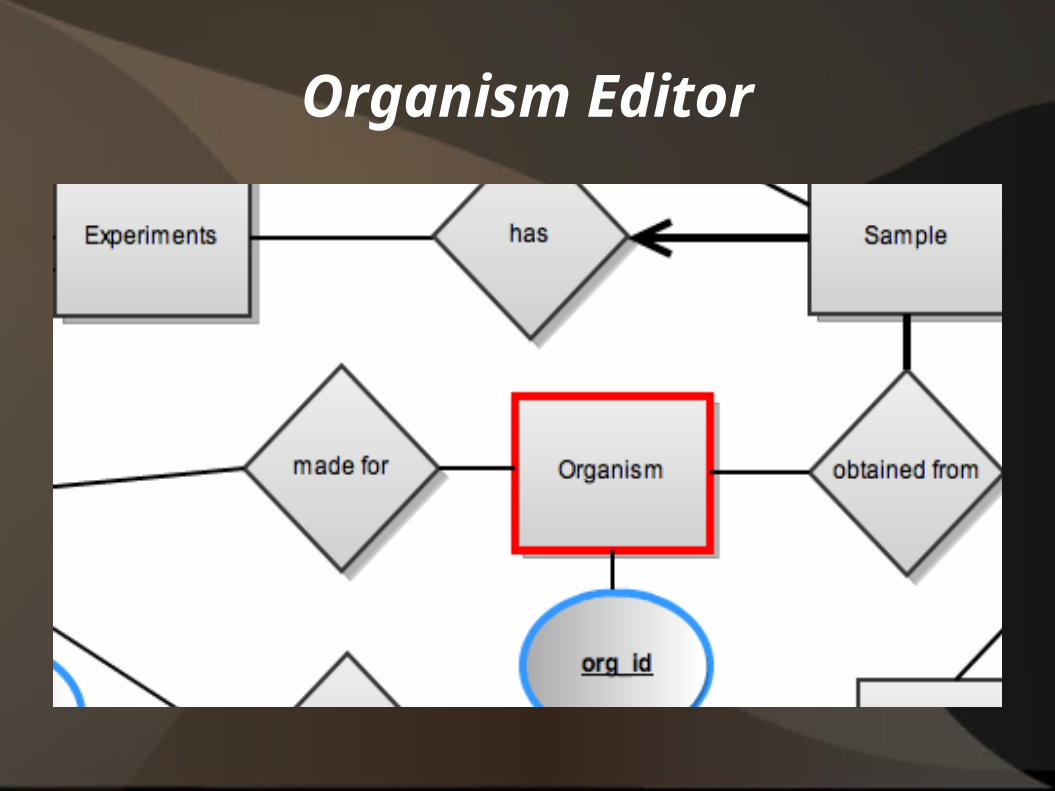
Organism Editor
• Previously the organism was stored with experiment

Organism Editor
Organism Editor

Organism Editor
• Previously the organism was stored with experiment sample
• No sense or hierarchy
• http://cs461-1.cs.iastate.edu/
• Hierarchy adds future ability for more meaningful info

Organism Editor
• Uses a nested set model for hierarchies

Organism Editor
• Uses a nested set model for hierarchies

Organism Editor
• Uses a nested set model for hierarchies
• Makes selecting portion of tree easy

Organism Editor
• Uses a nested set model for hierarchies
• Makes selecting portion of tree easy
• SELECT * FROM tree WHERE lft BETWEEN 2 AND 11

Organism Editor
• Nested Set Model makes retrieval easy
• Changes more complicated, “re-indexing” required

Future Expansion
• Organism Editor
– Ability to move portions of the tree
– Login ability to editor/Integration with PlexDB
• Make PlexDB Use Our Data
– Two-phase process creating views
– Change PlexDB Code to use data directly
• Implement Data Partitioning

Group Member Roles
• Every member was involved in each aspect of the project, but each member also focused their efforts on coordinating certain tasks

Group Member Roles
• Project Manager: Jesse Walsh– Responsible for understanding biology concepts– Focused on ER design
• Web Developer: Brian Nordland– Focused on organism editor
• Java Developer: Stephen Mueller– Focused on data migration
• DBA: Arun Chander– Focused on creation of tables

Questions???


















