Pipelining Enhancing Performance. Datapath as Designed in Ch. 5 Consider execution of: lw...
16
Pipelining Enhancing Performance
-
Upload
abraham-miles -
Category
Documents
-
view
213 -
download
0
Transcript of Pipelining Enhancing Performance. Datapath as Designed in Ch. 5 Consider execution of: lw...

Pipelining
Enhancing Performance

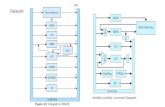
Datapath as Designed in Ch. 5
Consider execution of:lw $t1,100($t0)lw $t2,200($t0)lw $t3,300($t0)
Datapath segments 5 segments Instruction Fetch (IF) Register Read (ID) ALU Operation (EX) Data Access (MEM) Register Write (WB)

Timing
Timing for each segment
Note ms 10-3, s 10-6 (micro), ns 10-9, ps 10-12
Instruction Class IF ID EX MEM WB Total
load word (lw) 200ps 100ps 200ps 200ps 100ps 800ps
store word (sw) 200ps 100ps 200ps 200ps 700ps
R-Format 200ps 100ps 200ps 100ps 600ps
Branch 200ps 100ps 200ps 500ps

Sequential Instruction Execution
Clock Cycle must be 800 ps (lw)
Sequential Execution

Pipelined Execution
Use separate segments on different instructions Each stage will take 200 ps

Analysis Non-pipelined desing
3 x 800 ps = 2400 ps Pipelined design
2 x 200 ps = 600 ps Timing
Timenon-pipelined
Timepipelined = --------------------Num. segments
Expected speedup is: 5 Actual speedup is (5 ins): 4000/1800 = 2.22 Will not get theoretical value because of a variety of
imperfect use of pipeline (see previous diagram)

Pipeline Hazards
Hazards are events that prevent the next instruction from being executed in the next clock cycle.
Three types Structural hazards Data hazards Control hazards

Structural Hazard
Hardware cannot support the combination of instructions
What if we had single memory? Every instruction fetch must read memory Some instructions must write to memory Cannot fetch one instruction from memory while
another is trying to use the memory

Data Hazards
Consider:add $s0,$t0,$t1
sub $t2,$s0,$t3
Solution: Forwarding (bypassing)

Data Hazards (2)
Pipeline stall
Rearranging instructions is one solution Rearranging not always possible More complex solutions are often needed

Control Hazards
Need to make decision in one instruction based upon execution of another instruction.
Consider:add $t4,$t5,$t6
beq $t1,$t2,40
other instructions including branch target
Two sloutions Stall Predict

Stall on Branch

Predict on Branch
Predict Branch Not Taken

The Pipelined Datapath

A Word On Control
Two approaches to control Finite state machine Microprogramming
Finite state machine Hardwired Complex controller is expensive to implement
Microprogramming Break instruction down into micro-instructions Micro-instruction tells how to set control lines

IA-32 Architecture
Complex instruction set Simple instructions require 3 or 4 clock cycles Complex instructions requiring 100s clock cycles
Control for simple instructions is hardwired Control for complex instructions uses
microprogramming All instructions are translated into a series of
RISC like micro-instructions Micro-instructions are queued and executed