
Pillars of Heterogeneous HDFS Storage
17
1
-
Upload
pete-kisich -
Category
Software
-
view
33 -
download
0
Transcript of Pillars of Heterogeneous HDFS Storage

1

2
Storage Policies & Disk Types (Hadoop 2.6 and up)
Disk Type à Flexible, can assign to any local filesystem
Disk Policy à Set on file or inherited from parent directory
Hadoop HDFS Tiering Support aka – Hetrogenous Storage
Storage Policy Name Disk Type (n replicas)
Lasy_Persist RAM_DISK: 1, DISK: n-1
All_SSD SSD: n
One_SSD SSD: 1, DISK: n-1
Hot (default) DISK: n
Warm DISK: 1, ARCHIVE: n-1
Cold ARCHIVE: n

3
Hadoop HDFS Tiering Support aka – Hetrogenous Storage
/data/results/query2.csv
Hot Nodes
Storage Policy default is Hot Storage Type default is DISK
Archive Nodes
Storage Policy: HOT Storage Type: DISK

4
Hadoop HDFS Tiering Support aka – Hetrogenous Storage
Hot Nodes
Storage Policy is changed File remains on same storage type until mover is run
Archive Nodes
Storage Policy: Cold Storage Type: DISK
/data/results/query2.csv

5
Hadoop HDFS Tiering Support aka – Hetrogenous Storage
Storage Policy: Cold Storage Type: ARCHIVE
Hot Nodes Archive Nodes
After mover is run, all replicas move to storage type Archive. Note: file has not logically moved in HDFS
/data/results/query2.csv

6
WHY TIER HADOOP STORAGE? ISN’T IT ALREADY COMMODITY STORAGE? (aka – The cheapest stuff on the planet)

7
Lower Disk Capacity to Compute
Compute
Disk
Better job scalability, performance, and consistent results
5x to 10x more expensive per GB

8
Much Denser Disk to Compute
Compute
Disk
Much less $ per GB
Could impact performance and produce inconsistent results

9
Cold Goes to Archive. Hot Gets More Resources
Compute
Disk
Much less $ per GB
More resources are free to process jobs.
Compute
Disk
Better Performance & Lower Infrastructure Costs

10
SO à How do I utilize archive storage to lower my storage costs without performance impact? Answer: Intelligent Tiering

11
Access frequency of data is the most important metric for effective tiering
Age is easiest to determine. CAUTION: Some data is long-term active so this cannot be the only criteria.
Zero and small files should be archived differently in tiering Hadoop. Large cold files should have priority for archive
Knowing how long data is accessed once ingested can provide better capacity planning for your tiers.

12
Installed on a server or VM outside your existing Hadoop cluster without inserting any proprietary technology on the cluster or in the data path.
Report data usage (heat), small files, user activity, replication, and HDFS tier utilization. Customize rules and queries to properly utilize infrastructure and plan better for future scale.
Automatically archive, promote, or change the replication factor of data based on usage patterns and user defined rules.
Tier Hadoop HDFS By Heat, Age, Size & Usage In Three Easy Steps
01/INSTALL WITHOUT CHANGES TO CLUSTER
02/VISUALIZE & REPORT
03/AUTOMATE OPTIMIZATION

13
Completely out of the data path FactorData HDFSplus sits outside the Hadoop cluster and collects only metadata information from the Hadoop cluster
No software to install on the existing Hadoop cluster Because HDFSplus leverages only existing Hadoop APIs and features, there is no software to install on the cluster.
Provides a highly scalable solution in a small foot-print HDFS visibility and automation for thousands of Hadoop nodes on a single node, VM or server
HDFSplus
Namenodes
Communicates with Existing Hadoop API
VM or Physical Machine 32GB RAM
4 CPU or vCPU500GB Free Disk

14
Simplify and Automate Archive and Tiering in Hadoop Today • Move seldom accessed data to storage dense archive nodes • Lower software licensing with less infrastructure • Free resources on existing namenodes and datanodes
Who or what application is creating all these small files in the cluster?
How can we move data not accessed for 90 days to archive nodes?
How can we better plan for future scale with real Hadoop storage metrics?
Result: Better Performance, Lower Hardware Costs, Lower Software Costs
Plus: Get Necessary Storage Visibility To Answer These Questions & More with FactorData HDFSplus

15

16
17
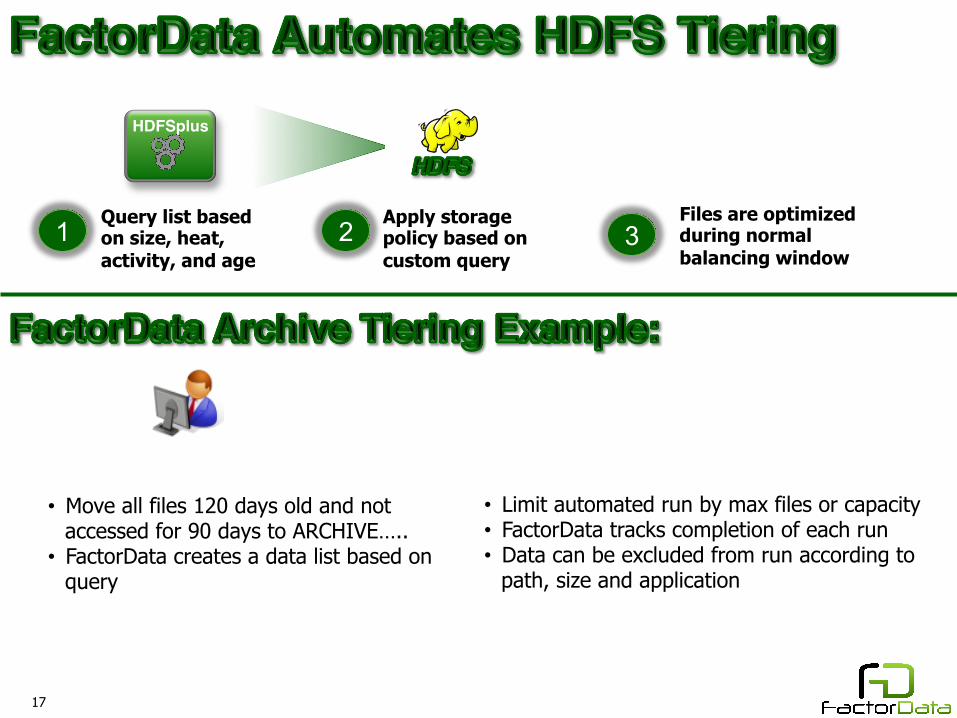
HDFSplus
Apply storage policy based on custom query
Files are optimized during normal balancing window
Query list based on size, heat, activity, and age
1 2 3
• Move all files 120 days old and not accessed for 90 days to ARCHIVE…..
• FactorData creates a data list based on query
• Limit automated run by max files or capacity • FactorData tracks completion of each run • Data can be excluded from run according to
path, size and application
Custom Query Example: Automated Tiering:


















