
Personalized Analysis and Recommendation of Aesthetic ...
15
Research Article Personalized Analysis and Recommendation of Aesthetic Evaluation Index of Dance Music Based on Intelligent Algorithm Jun Geng School of Art, Shandong University of Finance and Economics, Jinan 250014, China Correspondence should be addressed to Jun Geng; [email protected] Received 20 August 2021; Accepted 18 September 2021; Published 11 October 2021 Academic Editor: Muhammad Javaid Copyright © 2021 Jun Geng. is is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. In the era of Industry 4.0 and 5G, various dance music websites provide thousands of dances and songs, which meet people’s needs for dance music and bring great convenience to people. However, the rapid development of dance music has caused the overload of dance music information. Faced with a large number of dances and songs, it is difficult for people to quickly find dance music that conforms to their own interests. e emergence of dance music recommendation system can recommend dance music that users may like and help users quickly discover or find their favorite dances and songs. is kind of recommendation service can provide users with a good experience and bring commercial benefits, so the field of dance music recommendation has become the research direction of industry and scholars. According to different groups of individual aesthetic standards of dance music, this paper introduces the idea of relation learning into dance music recommendation system and applies the relation model to dance music recommendation. In the experiment, the accuracy and recall rate are used to verify the effectiveness of the model in the direction of dance music recommendation. 1. Introduction At present, human society has entered the 5G era and In- dustry 4.0. With the continuous development of big data, artificial intelligence, and other technologies, the amount of data will expand rapidly, and the phenomenon of data overload will become more significant. e 46th Statistical Report on Internet Development in China released by China Internet Network Information Center shows that the total number of Internet users in China will reach 940 million in 2020. Affected by the novel coronavirus pneumonia epi- demic, the user scale of online video, online music, short video, and other applications has increased significantly. Users cannot compare and analyze a lot of information in the face of massive data, and information overload has become a potential challenge today [1]. In order to alleviate the problem of information overload, researchers put forward two solutions: search engine and recommendation system. Search systems tend to have a clear purpose for users, when users know what they need more accurately, they can easily get relevant content through search engine channels. However, for some exploratory content, such as watching dance and listening to music, users need to explore according to their interests, so search engines cannot ac- curately meet users’ needs [2]. Recommendation system tends to use data mining and exploration, which is an in- telligent system applying machine learning and data mining technology. It uses users’ historical scores or project content to recommend related content to users. For users, the personalized content provided by the recommendation system will improve the user experience, thus saving them a lot of time. For service providers, recommendation system can help their customers find interesting products in real time so that more consumers are willing to buy products on the service platform and become loyal customers [3]. In recent years, recommendation system has been widely used in online shopping, news portal, music platform, short video, and other fields. Dance music is regarded as the most creative work of human beings, which expresses thoughts and emotions through melody and sound. In recent years, dance music streaming media has become the main way for users to Hindawi Complexity Volume 2021, Article ID 1026341, 15 pages https://doi.org/10.1155/2021/1026341
Transcript of Personalized Analysis and Recommendation of Aesthetic ...

Research ArticlePersonalized Analysis and Recommendation of AestheticEvaluation Index of Dance Music Based on Intelligent Algorithm
Jun Geng
School of Art Shandong University of Finance and Economics Jinan 250014 China
Correspondence should be addressed to Jun Geng 20040293sdufeeducn
Received 20 August 2021 Accepted 18 September 2021 Published 11 October 2021
Academic Editor Muhammad Javaid
Copyright copy 2021 Jun Geng )is is an open access article distributed under the Creative Commons Attribution License whichpermits unrestricted use distribution and reproduction in any medium provided the original work is properly cited
In the era of Industry 40 and 5G various dance music websites provide thousands of dances and songs whichmeet peoplersquos needsfor dance music and bring great convenience to people However the rapid development of dance music has caused the overloadof dance music information Faced with a large number of dances and songs it is difficult for people to quickly find dance musicthat conforms to their own interests )e emergence of dance music recommendation system can recommend dance music thatusers may like and help users quickly discover or find their favorite dances and songs )is kind of recommendation service canprovide users with a good experience and bring commercial benefits so the field of dance music recommendation has become theresearch direction of industry and scholars According to different groups of individual aesthetic standards of dance music thispaper introduces the idea of relation learning into dance music recommendation system and applies the relation model to dancemusic recommendation In the experiment the accuracy and recall rate are used to verify the effectiveness of the model in thedirection of dance music recommendation
1 Introduction
At present human society has entered the 5G era and In-dustry 40 With the continuous development of big dataartificial intelligence and other technologies the amount ofdata will expand rapidly and the phenomenon of dataoverload will become more significant )e 46th StatisticalReport on Internet Development in China released by ChinaInternet Network Information Center shows that the totalnumber of Internet users in China will reach 940 million in2020 Affected by the novel coronavirus pneumonia epi-demic the user scale of online video online music shortvideo and other applications has increased significantlyUsers cannot compare and analyze a lot of information in theface of massive data and information overload has become apotential challenge today [1] In order to alleviate theproblem of information overload researchers put forwardtwo solutions search engine and recommendation system
Search systems tend to have a clear purpose for userswhen users know what they need more accurately they caneasily get relevant content through search engine channels
However for some exploratory content such as watchingdance and listening to music users need to exploreaccording to their interests so search engines cannot ac-curately meet usersrsquo needs [2] Recommendation systemtends to use data mining and exploration which is an in-telligent system applying machine learning and data miningtechnology It uses usersrsquo historical scores or project contentto recommend related content to users For users thepersonalized content provided by the recommendationsystem will improve the user experience thus saving them alot of time For service providers recommendation systemcan help their customers find interesting products in realtime so that more consumers are willing to buy products onthe service platform and become loyal customers [3] Inrecent years recommendation system has been widely usedin online shopping news portal music platform shortvideo and other fields
Dance music is regarded as the most creative work ofhuman beings which expresses thoughts and emotionsthrough melody and sound In recent years dance musicstreaming media has become the main way for users to
HindawiComplexityVolume 2021 Article ID 1026341 15 pageshttpsdoiorg10115520211026341
consume dance music and the main source of income in thedance music industry By 2019 the number of online dancemusic users in China has reached 608 million and the dancemusic income has reached 103 billion yuan [4] Recom-mendation systems are revolutionizing the dance musicindustry in many ways Listeners can improve their taste ofdance music by using them to constantly discover new dancemusic )e challenge of recommendation system is to realizea system that can accurately provide interesting dance musicfor users so as to understand usersrsquo preference for dancemusic For example Spotify can continue to play songs thatit thinks are similar to those in the list after playing all thesongs in that list but the recommended results are based onsimple dance music genre labels which make users feel dullafter a while)is requires that the dance music personalizedrecommendation system should accurately and effectivelyreflect usersrsquo personal preferences and need to be adjusted toachieve personalized recommendation for different usersPersonalized recommendation system is more complex thantraditional dance music recommendation system whichneeds to comprehensively consider various behaviors ofusers and combine dance music feature recognition andaudio processing technology to extract dance music featuresso as to realize personalized recommendation of dancemusic [5]
Dance evaluation theory is based on the philosophicalcontent discrimination of dance criticism objects Philos-ophy allows us to understand the artistic form of dance sothat it can be appreciated and practiced and the humanbody is a tool to express its artistic form )e definition ofldquodancerdquo by many dancers and philosophers is not enoughto explain and distinguish the necessary conditions ofdance from other human nonart forms [6] In fact the bestunderstanding of dance should be the concept of the mainmedia of human body and music movement and thesecondary media of clothing scenery and lighting visualdimension )e ldquoremnantsrdquo refer to those ceremonialperformances that are still being performed but have losttheir original purpose As long as performers and audiencesrecognize and accept the way they have changed suchperformances can still be appreciated and can still play arole in promoting social cohesion and identity LadyNigeriarsquos Girinya dance originally a war dance is a case inpoint In the aesthetics of Tiv dance menrsquos dance should beas energetic as Girinya dance but in the past dance wasabout what warriors should behave in battle and now it isabout continuity and renewal I try to describe and evaluatethis aesthetics and its adaptation to the changing culture ofTiv people in a way with new meanings [7] According tothe case study of a primary school music education projectin Madeira Portugal 30 years ago we analyzed all childrenand their activities and made statistics in the form ofquestionnaires [8] )e results revealed that all respondentsshowed a strong sense of ownership and leadership )econdition of art critics is to observe artistic experiencewhich praises them for observing value but there is notmuch talk about executive value so we should discusswhether ideal aesthetic judges should practice and createthe artistic form they judge Researchers put forward that
practicing dance can better observe some aesthetic qualitiesof dance and dance training can promote kinestheticexperience It is precisely because of these experiences thatthe aesthetic aspects of dance performance can be reflected[9]
With the rapid development of science and technologyrobots have gradually entered peoplersquos lives )is paperproposes a way for robot to dance with music rhythm whichis a humanoid robot formed by synchronizing music to formdance Firstly the audio features are extracted and then thedance is generated through the action formed by the model)is method forms an artificial creation system whichmakes choreographers pay more attention to and excludedance movements )rough the test on Aldebaran NAOhuman form and real-life dance experiment it is evaluatedin the aspects of movement rhythm accuracy and aes-thetics and the effect is satisfactory and accepted [10] Fi-nally the robustness and flexibility of the system enable us toembed it into the artificial creation system in thefuture work
2 Individualized Analysis andRecommendation Technology ofDance Music
)e recommendation engine uses different algorithms tofilter data and recommend the most relevant items to usersIt first captures the customerrsquos past behavior collect personalpreferences calculate the user model on this basis and thencombine the user model with the recommendation algo-rithm model to generate a recommendation algorithmcalculate the scoring level between the user and the targetitem recommend the items with higher scores to the targetuser and recommend the products that the user may buy)e general model of the recommendation system is shownin Figure 1
21 Analysis of Dance Music Evaluation Index On the basisof literature research this study proposes that dance musicrecommendation system includes 10 dimensions contentfunctionality page design response speed perceived us-ability perceived usefulness satisfaction confidence per-ceived experience and potential risk )e interview resultsshow that due to the upgrade of media equipment and theimprovement of network speed the dimension of ldquoresponsespeedrdquo is of little significance and should be deleted Inaddition some items in the dimensions of ldquosatisfactionrdquo andldquopotential riskrdquo have semantic intersection with items inother dimensions which cannot accurately reflect themeasurement intention and should be deleted Consideringthat the personalized recommendation evaluation indexdoes not point to specific fields some items are not dif-ferentiated and cannot fully summarize the use psychologyof dance music users )is study adds the characteristicsrepeatedly mentioned by many respondents and incorpo-rates them into the index system such as ldquosurprise degreerdquoldquoconsistency of browsing habitsrdquo and ldquopotential risksrdquo
2 Complexity
ldquoSurpriserdquo comes from the userrsquos expectation of dancemusic recommendation function Different from other types ofrecommendation systems dance music is a perceptual artisticproduct and users are more likely to accept the recommendedcontent thus generating emotional expectations At presentthe personalized recommendation function of most dancemusic apps in China is on the homepage and occupies animportant layout Users take the consistency of page design andbrowsing habits as a consideration index which reflects theneeds of users for web page interactive experience in the In-ternet age In addition many interviewees expressed theirconcerns about the quality of recommendation includingldquouneven quality of recommendationrdquo ldquofrequent recommen-dation of similar songs that they are not interested inrdquo andldquointerest-related but dislikerdquo
According to the qualitative research results this papergenerated the evaluation scale of dancemusic recommendationsystem which consists of 8 dimensions and 30 items contentfunctionality page design perceived ease of use perceived
usefulness confidence perceived experience and potentialrisk See Table 1 for measurement indexes and their sources
22 Collaborative Filtering RecommendationCollaborative filtering is a method for personalized rec-ommendation according to the ratings and usage behaviorsof system users )e idea behind its approach is that if agroup of users have similar views on one topic they may alsohave similar interests on another topic [11] Collaborativefiltering algorithm does not need to analyze the projectcontent but mainly pays attention to the userrsquos scoring dataof the project )e system will collect the interaction databetween users and projects establish a scoring matrix thenuse the interaction matrix to calculate the similarity betweenusers and recommend related projects according to similarusers Users can obtain recommendations for items thathave not been previously discovered but which have beenpositively evaluated by neighboring users Collaborative
Obtaining user preference according to dance music evaluation index
User model
Recommendation algorithm
modelRecommendation algorithm
Provide recommendations
Seek recommendations
Provide personal preferences
Collect personal preferences
Calculation
Figure 1 Dance music recommendation system model
Table 1 Summary of original evaluation index system of music recommendation system users
Second-order index First-order index Second-order index First-order index
Content
Accuracy Perceived ease of use Convenience of useFamiliarity Feedback convenienceNovelty
Perceived usefulnessTime-consuming
Diversity EfficiencySurprise degree Preference influenceSufficiency
Confidence
Quality confidenceUpdate of speed Recommendation confidence
Requirement considerations Taste confidence
Functionality
Diagnostic ability of perceptual information Dependence on confidencePreference correction
Perceptual experienceCaring for each other
Explanatory power InteractivityCommunication ability Human touch
Page design
Being clear and understandable
Potential risk RiskAdequacy of repertoireInformation richnessStyle consistency
Consistency of browsing habits
Complexity 3
filtering algorithms are mainly divided into two categoriesmemory-based collaborative filtering and model-basedcollaborative filtering
221 Collaborative Filtering Based on Nearest Neighbors
(1) Collaborative Filtering Based on Users Resnick firstproposed a collaborative filtering algorithm based on usersin 1994 By using the scoring matrix R (U I) to model thepreferences of users U about goods I it is considered thatusersrsquo preferences generally do not change with time andmay have similar behavioral preferences for a long time)erefore users with similar preferences in user history dataare grouped to recommend products to those users
In the music and dance recommendation system thehistorical data used are the operation data such as userslistening to songs whether they like or collect songs and thescores of dances For example both user 1 and user 2 oftenlisten to popular music and user 3 likes to listen to Englishmusic )rough similarity calculation it can be concludedthat user 1 and user 2 are the same kind of users and user 2 isrecommended by using the music listened by user 1 )eprinciple of user-based collaborative filtering algorithm isshown in Figure 2
In order to make recommendations to users it is nec-essary to collect usersrsquo historical behavior records and es-tablish a user-item matrix Rmlowastn where m represents thenumber of active users and n represents the number of itemsBy collecting the explicit scores of users on the project theuserrsquos interest in the project is generally indicated by a scorelevel of 0 to 5 )e higher the score the more interested theuser is in the project and the score of 0 indicates that theuser dislikes the project at all In addition you can use userimplicit ratings to represent user ratings Use the user tolisten to a certain music times or praise collect commentand other behaviors use 1 to indicate that there are relatedbehaviors and 0 to indicate that there is no browsing be-havior After weighting the above behaviors the implicitevaluation matrix of the user on the project is obtained [12]
It is difficult to find the similarity degree for such abstractconcepts as users so it is usually to find the similarity degreeof usersrsquo scoring on specific items and compare the similaritydegree of scoring behavior between two users by analyzingthe similarity degree of scoring results of two users on thecontent that they jointly evaluated excessively In this waythe problem is transformed into a problem of solving thesimilarity between vectors Ri and Rj are defined as thecontent set evaluated by two users and Vi and Vj are definedas the scoring vectors of the content by two users in Ri and RjGenerally the method of calculating the similarity betweenthe two vectors is defined as follows
Jaccard coefficient method the similarity is obtained bycalculating the ratio of intersection and union of two usersrsquoscores in the user history behavior set )e larger the ratiothe higher the similarity Generally Jaccard coefficient issuitable for implicit user behavior similarity calculation )eJaccard coefficient is calculated as shown in
Jaccard(i j) Ri cap
Rj
11138681113868111386811138681113868
11138681113868111386811138681113868
Ri cupRj
11138681113868111386811138681113868
11138681113868111386811138681113868 (1)
Cosine similarity method the cosine value of the anglebetween two user rating vectors in space is used to expressthe similarity between them)e closer the cosine value is to1 the more similar the two vectors are )e calculationprocess is shown in
cos(i j) 1113936kvikvjk
1113936kv2ik
1113969 1113936kv
2jk
1113969 (2)
Pearson correlation coefficient method decentralizationof cosine similarity data is an improvement of cosinesimilarity method In the recommendation system theremay bemissing evaluation of a certain item by users Pearsoncorrelation coefficient method automatically fills the missingvalue as 0 and then uses other dimensions to reduce thedimension average of missing vectors to satisfy cosinesimilarity algorithm Pearson correlation coefficient is cal-culated as shown in
Pearson(i j) 1113936k vik minus vi( 1113857 vjk minus vj1113872 1113873
1113936k vik minus vi( 11138572
1113969
1113936k vjk minus vj1113872 11138732
1113969 (3)
Finally according to similar users traversing all positivefeedback items weighted summation is carried out theinterest scores of user I for all items are calculated and thescore prediction is made for each item)e score calculationis shown in
Pis 1113936jisinS(uk)sim(i j) times ris
1113936jisinS(uk)|sim(i j)| (4)
where S(u k) is a user browsing item set similar to user i risis user irsquos interest in item S and sim(i j) is the similaritybetween user i and j
(2) Collaborative Filtering Based on Project Project-based collaborative filtering method mainly focuses onidentifying the similarity of projects However project-basedcollaborative filtering looks for users who have used twoprojects for similar evaluations If both items Music 1 andMusic 2 receive similar ratings throughout the rating dataset it can be assumed that users who like Music 1 may alsolike Music 2 and vice versa )e principle of project-basedcollaborative filtering is shown in Figure 3
Similar to the user-based collaborative filtering methodthe item-based collaborative filtering method uses the userrsquosrating of other content to predict the rating of unevaluatedcontent Similarly ω(i j) needs to be defined between thecontent that has been evaluated and the content that has notbeen evaluated indicating the degree of similarity betweenRi and Rj )e formula is shown in
ω(i j) 1113944k
vik times vjk
1113936riisinRiv2ik
1113969 1113936jisinRj
v2jk
1113969 (5)
4 Complexity
After that the unknown scores can be estimated indifferent ways such as weighted sum Here C (U K) is asimilar set of items in the user evaluation data set and rui i isthe interest of user u in item i )e calculation is shown in
1113958Pis 1113936jisinC(uk)ω(i j) times rus
1113936jisinC(uk)|ω(i j)| (6)
Although the user-based collaborative filtering algo-rithm is logically simple it may take a lot of time to deal withbig data )e project-based collaborative filtering methodsolves the problem of complex user matrix By using asignificantly smaller number of items large-scale matrixoperations in the user-item scoring matrix can be avoidedand project-based collaborative filtering is more time-cost-effective to implement
Item-based collaborative filtering depends to a greatextent on the number of times songs appear in the data setBecause it is impossible to determine whether songs exist inthe user playlist the item-based collaborative filtering sys-tem designates those songs that appear in many playlists inthe data set as more valuable data in this way acting as thebasic processing for item-based collaborative filtering Firstmatch each song in the playlist with a similar song in thesong data set and record it the system records it as ldquosimilar
tracksrdquo and the playlist obtains the most frequentlyappearing songs from the ldquosimilar tracksrdquo matrix com-prehensively considers the userrsquos preference information forsongs and then recommends music to other users who aresimilar to the userrsquos preferences and often listen to them Inthe music recommendation system although the number ofsongs is less than the number of hundreds of millions ofusers it is also very large Each user playlist may containmore than 50 to 100 songs so it is muchmore difficult to findthe similarity of songs in the database of tens of millions ofsongs so the performance advantage of item-based col-laborative filtering is lost [13]
222 Model-Based Collaborative Filtering Model-basedcollaborative filtering is obviously different from the othertwo collaborative filtering methods user-based and content-based methods estimate the unknown item scores directlyaccording to the statistical historical data but model-basedmethods first use the original data to train and generate aspecific model which can quickly predict user preferencesaccording to the generated model )erefore when there area large number of users and projects the model-basedrecommendation algorithm has a high degree of scalabilityand rapidity Common models are as follows
Recommend
UserA
UserB
UserC
Dance Music 1
Dance Music 2
Dance Music 3
Dance Music 4
Dance Music 5
Similarity
Figure 3 Schematic diagram of project-based collaborative filtering
User A
User B
User C
Dance Music 1
Dance Music 2
Dance Music 3
Recommend
Dance Music 4
Dance Music 5
Similarity
Figure 2 Schematic diagram of user-based collaborative filtering
Complexity 5
(1) Bayesian Model Bayesian prediction model is a kind ofprediction using Bayesian statistics Bayesian statistics isdifferent from general statistical methods which does notuse model information and data information but uses priorinformation )rough the method of empirical analysis theprediction results of Bayesian prediction model are com-pared with those of ordinary regression prediction modeland the results show that Bayesian prediction model hasobvious advantages
Bayesian model revolves around giving evidence (E) andobtaining hypothesis (H) which involves two conceptshypothesis probability P(H) before obtaining evidence andhypothesis probability P(HE) after obtaining evidence )emodel is continuously learned by training data and the dataare verified to evaluate the model and make new predictions
In practical applications Naive Bayesian classifier andcollaborative filtering are generally used to implementrecommendation system which can filter new informationand predict whether users need given resources However itis almost impossible to obtain a completely independent setof data in practice Moreover when the number of itemsjointly evaluated is small this direct calculation may distortthe obtained probability
(2) Matrix Decomposition Model Matrix decompositionmodel is a commonly used technology to build recom-mendation system In 2006 Netflix held Netflix PrizeChallenge and matrix decomposition technology was firstproposed In order to decompose the scoring matrix featuresinto low-dimensional spaces the matrix decompositiontechnology learns potential space vectors for each user andeach item which are divided into user feature vectors p anditem feature vectors q )e specific representation of thescoring matrix is shown in
R pi times qTj (7)
Here R represents the training score matrix and i and jrepresent users and projects respectively By learning theminimized objective function (formula (8)) in the knownscores the potential space vectors P and q can be obtained
Yij FLFM
pi qj1113872 1113873 pTi qj (8)
)e algorithms commonly used in matrix factorizationmodel include nonnegative matrix factorization (NMF)algorithm and singular value decomposition (SVD) algo-rithm )e nonnegative matrix factorization algorithm usesproject content to construct the potential space of the projectand then uses user information such as known scores tolearn the potential space of users So as to overcome the coldstart problem in collaborative filtering 28 Singular valuedecomposition (SVD) algorithmmaps users and items to thepotential factor space of f-dimension and the model con-structs users and items as interaction problems within thespace
In addition model-based collaborative filtering algo-rithms also include graph-based walking method SimRankalgorithm and clustering-based collaborative algorithmCollaborative filtering algorithm can recommend variousfavorite contents to users according to historical data but
the recommendation results may not be satisfactory whenthe scoring data are sparse large-scale matrix operation maybe needed when the data volume is huge and the timeconsumption will increase linearly with the data scale soreal-time recommendation cannot be achieved
23 Content-Based Recommendation )e content-basedrecommendation algorithm takes into account the items ofinterest that users have previously shown through ratingsand then constructs user profiles that match the userrsquos in-terest in such items Once the user clearly shows interest inan item the algorithm will analyze the characteristics of theitem and then recommend similar items to the user )econtent descriptor of a project can have many differentforms which can usually be described by tags or projectcontents for example user tags and tags related to projectattributes and related types are generally classified bymanual or machine learning algorithms When a user listensto a popular song about campus the content-based algo-rithm will recommend another type of campus song to theuser
Early content-based recommendation algorithms mostlydeal with text content so early content-based recommen-dation systems mainly use text retrieval technology Vectorspace model (VSM) can match documents according tokeywords and transform song names and singer names intovectors by using word frequency-inverse document fre-quency (TF-IDF) technology TF is the number of wordsappearing and IDF represents the information of words If aword appears more frequently in lyrics or song titles it mayplay a key role in lyrics )e TF-IDF definition is shown in
TF minus IDF tk dj1113872 1113873 TF tk dj1113872 1113873logN
nK (9)
)eTF-IDF algorithm is used to calculate the words withgreater weight in the data and the cosine similarity algo-rithm mentioned above is used to find other songs similar tothis song and recommend them to users
3 Research on Recommendation ModelBased onUser Behavior andMusic andDance
Referring to the correlation model of image classificationthis paper introduces the model of Relationship-Learninginto the field of music recommendation In this model deepneural network and automatic encoder are used to combinethe characteristics of user behavior and music audio andinput them into Music Encoder to realize personalizedcoding in the coding stage to ensure the personalization ofrecommendation By calculating the similarity of userrsquosinterest preference and the similarity of song feature theprediction score of userrsquos music to be selected is obtainedafter averaging them
31 Model Introduction )rough reading the literature weknow that the cold start problem in the recommendationsystem is mainly divided into two subproblems completecold start and incomplete cold start and there are some
6 Complexity
differences in the solutions of these two problems At thesame time the processing process of image classificationdirection in small sample data can be used for reference byrecommendation system For example the classificationproblem of some pictures that have not been seen at all isZero-Shot while the classification problem of some picturesthat appear less frequently is Few-Shot Among these twoproblems the Zero-Shot problem can correspond to thecomplete cold start problem in the recommendationproblem while the Few-Shot problem can correspond to theincomplete cold start problem in the recommendationproblem For the Few-Shot problem and Zero-Shot problema similar solution to the cold start problem in the recom-mendation system is given
For the cold start problem one of the existing methods isto use user information and article information If effectiveinformation can be collected certain clustering operationscan be carried out on this basis and other similar usersrsquofavorite music can be used to recommend the user In ad-dition the structure of Auto Encoder can be used to extractfeatures At this time for the cold-start user the AutoEncoder encodes first and then decodes and the finallydecoded value includes the value inferred from the usercharacteristics [14]
In this paper we pay more attention to the problem ofincomplete cold start when designing the model and use thelimited scoring information as efficiently as possible toanalyze the scoring habits of users more accurately At thesame time it draws lessons from the idea of relationshiplearning in the field of computer vision hoping that therecommendation system can learn how to compare simi-larity in a more accurate way On this basis we investigatethe application of metric learning in recommendationsystem and find that although these methods have the idea ofmaking recommendation system learn distance informationto infer similarity the distance that defines similarity is low-order linear similarity Although this method can give acertain distance description it is difficult to fully capture andutilize the high-order features extracted by neural network)is paper hopes to calculate the similarity between picturesin relation learning and apply it to the recommendationsystem to calculate the similarity between people music andmusic user and music
32 Metric-Learning Model In 2018 Sung and Flood pro-posed a relation network model based on the metric-learning method to solve the classification problem of asmall number of labeled sample data in the field of computervision in deep learning as shown in Figure 4 )e authorproposes a relational network which compares the inputimages in the test set with a small number of known labeledsample images and calculates the correlation scores so as toclassify them )e relation network consists of two modulesan embedded module and a relational module Firstly theembedding module extracts the relevant feature informa-tion and then the relational module compares these em-bedding and obtains the relation score to determine whetherthey belong to the same class
Each block has 64 3times 3 convolution kernels a batchspecification layer and ReLU nonlinear function In addi-tion convolution blocks 1 and 3 have a 2times 2 maximumpooling layer )e author uses four convolution blocks toextract rich feature information between samples with fewerparameters )e network structure is shown in Figure 5
In the relation module you need to combine featuresfirst )e feature combination S recombines the featureinformation of the samples in the training set and the sampleinformation in the test set so that the relational encoder Gcan learn better from the combined features First thefeature mappings of the same class are summarized asshown in
fφ Li( 1113857 1113944K
J1Lij (10)
where Lij(i 1 i 2 j 1 j 2 K) denotes thetraining set features extracted from the embedded moduleand fφ(Li) denotes the mapping of feature information)emapping of combined features can be obtained by summingthe mapped feature sets )e formula is shown in (11)
Si fφ Li( 1113857 + fφ Qn( 1113857 (11)
Si represents the feature formed by the feature mappingof the training data set and the recombination of the testsamples and fφ(Qn) represents the feature from the testsamples )e model does not use conventional Euclideandistance or cosine distance instead we use nonlinear metriclearning In this part two convolution blocks and two fullyconnected layers are used to compare the two samples Eachconvolution block has 64 3times 3 convolution kernels a batchspecification layer a ReLU nonlinear activation layer and a2times 2 maximum pooling layer Finally through two fullyconnected layers the similarity relation score isin[0 1] be-tween the test samples and the training samples is finallyobtained by using the activation functions ReLU and sig-moid )e relation score is shown in
Relation score gϕ S fφ Lij1113872 1113873 fφ Qn( 11138571113872 11138731113872 1113873 (12)
)e detailed structure of the module is shown inFigure 6
33 Construction of Relation Model )e basic idea of thismodel is determined as a hybrid recommendation modellearning the similarity of user ratings by using the idea ofRelationship-Learning and then estimating the rating valuethrough collaborative filtering)emodel structure is shownin Figure 7
)is model mainly deals with two problems in recom-mendation system Firstly timeliness in the current era ofinformation explosion a large amount of data is uploaded tothe Internet every day It is difficult to obtain enough ratingdata at the beginning of these newly uploaded data whichcan be used in the recommendation system for target usersMusic recommendation system often encounters some newsongs which need to be recommended to users for audition
Complexity 7
)erefore through the cold start mechanism of the modelthe problem of new content recommendation can be solvedand the recommendation system can cope with the problemsbrought by timeliness and new content
Secondly personalization when users evaluate songseven if two people give favorable comments on the samesong their motives may be different for example oneperson likes the singer so they like this song and the otherperson likes the song style and likes this song )erefore themodel carries out more personalized processing for songrecommendation according to music characteristics anduser characteristics
331 Enter Data )e input of the model mainly consists oftwo parts one part is the feature information which includesthe personal feature information of the target user thefeature information of the scored n songs and the featureinformation of the target songs )e other part is the scoringinformation which contains the scoring values of the targetusers for n songs that have been scored In the third chapterthe related features have been extracted Formally the re-lated features are expressed as follows
Users U fieldu1 fieldu
2 fieldun1113864 1113865 represents the userrsquos
gender age and other related characteristic informationMusiccharacteristics M fieldM
1 fieldM2 fieldM
t1113966 1113967 representsthe relevant characteristic information of music Dance fea-tures D fieldD
1 fieldD2 fieldD
j1113966 1113967Historical interaction data of user U H
M1 M2 Mk1113864 1113865 user Ursquos comprehensive user score formusicM is Scorei and userUrsquos comprehensive user score fordance D is Scorej
332 Embedding According to the previous feature ex-traction work several user and audio features can be ob-tained Firstly the features are encoded through linear layeror embedding layer to obtain a series of vector represen-tations of features then according to these vectors the userand music are encoded )e user below represents severalcharacteristics of the target user which are represented byvectors Taking it as input the encoding vector of userfeatures is obtained through the User Encoder For usercoding because only text type features such as gender andage are used Auto Encoder model can be directly used tocomplete feature extraction In order to be similar to Music
64 33 convolutionkernels
Batch Normalization
Relu function
33 max-pooling
64 33 convolutionkernels
Batch Normalization
Relu function
64 33 convolutionkernels
Batch Normalization
Relu function
64 33 convolutionkernels
Batch Normalization
Relu function
33 max-pooling
fϕ
Figure 5 Embedding module
FC1Relu function
FC2Sigmoid function
SiRelation score
64 33 convolutionkernels
Batch Normalization
Relu function
22 max-pooling
64 33 convolutionkernels
Batch Normalization
Relu function
22 max-pooling
Figure 6 Relation module
Test sample 1
Test sample 2
Test sample 3
Test sample 4
Test sample 5
Test sample
Embedded module Relationship module
Feature concatenation
Relation score
fφ gϕ
Figure 4 Relation network model
8 Complexity
Encoder feature structure AutoInt model l is used to extractuser features here )e encoding structure of the user part isshown in Figure 8
Next for some music evaluated by users because theyknow their characteristics and scores they can combine theircharacteristics with userrsquos feature vectors and input theminto Music Encoder for coding respectively )is processcan combine usersrsquo personalized information for music sothat the same music can be coded differently by MusicEncoder for different users For unevaluatedmusic althoughthere is only the eigenvalue of music it can still obtain itseigenvector through Music Encoder like the music that hasbeen evaluated which is the coding layer Embedding Layerof music )e music feature coding structure is shown inFigure 9
As can be seen from Figure 9 the main structure ofencoder is multihead attention module and its essence is toperformmultiple self-attention calculations to formmultiplesubspaces so that the model can learn different features ofinformation from different angles and finally merge themTake the Music Encoder as an example and its structure isshown in Figure 10
In the multihead attention the feature matrixF f1 f2 ft1113864 1113865 needs to be transformed linearly tocompare the dimension of the feature vector that is QW
Qi
Perform k self-attention calculations as shown in
hlowast
Attention(Q K V) softmaxQK
T
dk
1113888 1113889V (13)
Splice and linearly map the result hlowast using
h concat hlowast1 hlowast2 h
lowastn( 1113857otimesW
o (14)
)e number of music selections has also been adjusted tosome extent When entering you need to have a series ofknown characteristics of the score and its final scoreHowever there will be many historical records of a personAnd the quantity is different and the model structure doesnot support the dynamic adjustment of the input quantityso this paper chooses the sampling method During eachtraining five historical evaluated songs are selected from thehistorical music of user interaction for input After severalrounds of training all the evaluated songs can be basicallyused in the training Although this method is inefficient inusing data sets it can greatly reduce the training time costand the complexity of the model )erefore after trade-offwe chose the method of randomly selecting five data
333 Interest Matching Module )e information aboutusers andmusic in the data set is processed and the obtainedhigh-order nonlinear eigenvector is taken as the output In
User data
Dance Music 1
Dance Music 2
Dance Music m New project
S M R
P
input
Embedding Module
Feature Vector
Combined Vector
Relation Module
Relation Score Ration
Predicted Ration
Figure 7 Model structure
Complexity 9
Max-Pooling
Multi-Head Attention
Field1 Field2 Field3
y1
Figure 8 User encoder model structure
Max-Pooling
Multi-Head Attention
Field1 Fieldt
y2
User feature vector y1
Characteristics of dance music
Figure 9 Music encoder model structure
10 Complexity
the model of this section we hope to give the similarity ofusers about different music scores through feature vectors
Firstly the characteristics of the scored songs and thecharacteristics of the target unscored songs are combined bythe user )en the similarity gφ between the two songs isgiven by comparing the similarity module and relationmodule its size is limited between 0 and 1 by normalizationfunction and finally a k-dimensional numerical vector re-lation score is obtained )e similarity gφmodel is shown in
gφ q1 q2( 1113857 Sigmoid qT1 Wq21113872 1113873 (15)
)e Interest Matching Relation module constructed inthis paper is not complex and the parameter to be trained isonly a matrix W In the experiment we also use a deeperstructure to replace this structure It is found that this willnot only increase the training time and parameter scale butalso reduce the accuracy )erefore we finally choose thevalue between [0 1] obtained by sigmoid after we get theinner product of two vectors about W as the similarityAccording to the similarity degree the related features of theknown graded music are constructed to predict the featuresof the music )e method is weighted average and theweight of each item is the score multiplied by the similaritydegree )e more similar the music and the higher the scorethe more obvious the influence on the prediction resultsFinally an estimated value of the eigenvector is obtained
Finally there is an output layer which synthesizes thetwo scoring results given before and gives the final con-clusion In the first part of the conclusion Y from theprevious user coding music-to-be-predicted estimationfeatures and music-to-be-predicted coding through a linearlayer this part reflects the idea of collaborative filteringbased on similarity and score to get the target score Anotherpart of the result x is obtained by using a Max Pooling layer
to select the value with the greatest correlation )e strategyembodied in this part is that when the songs to be predictedhave a high similarity with the previous historical songs itcan be considered that users are likely to have a certaininterest in the songs to be evaluated so the results have alarge similarity value at this time Finally the two scores areaveraged to get the final output)is is a value between [0 1]to indicate the degree of interest that users may be interestedin
4 Implementation ofPersonalized Recommendation
Traditional models do not use the information of users whointeract with them in the coding process of known music)is leads to the lack of user personality in the recom-mended content Even for two different users the coding ofthe same content is the same which cannot deal with thepersonalized problem well In addition in the actual in-teractive process content and users have different interactivebehaviors and different interactive behaviors often repre-sent different preferences of users However the previousmodels have not been distinguished to this extent resultingin different information brought by different interactivebehaviors not being used For example for praise andcollection collection means that users are more interestedthan praise because collection means that users are likely tolisten to this song repeatedly later while the probability oflistening to praise will be smaller later
In this paper firstly different behavior scores of users aredistinguished and the scores are divided into 1ndash5 pointsaccording to the listening times 6 points for collectionbehavior and 4 points for praise behavior In addition themultihead attention mechanism is introduced When
Linear
Concat
Self-attention
Linear LinearLinear
User feature vector (V)
Music feature vector (M)
Dance feature vector (D)
K
Output
Figure 10 Multihead attention module
Complexity 11
encoding music features in Music Encoder the user featuresand music features are combined and the user personalizedmusic coding is realized in the encoding layer which ensuresthat even if different users operate the same music the finalrecommendation results are still different because of dif-ferent personal characteristics thus realizing the personal-ized music recommendation
41 Model Training and Experimental Results Beforetraining the model it is necessary to divide the positive andnegative classes and determine the training set and test setused by the model For music recommendation label 0means dislike and label 1 means like which is defined as abinary classification problem According to the scoringprocessing of user behavior characteristics in Chapter 3music with a score higher than 5 is recorded as a positiveclass that is if the user listens to music many times or musicwith a little praise or collection behavior is recorded as apositive class Music with a score below 2 is recorded as anegative example indicating that although the user has someinteraction they have not shown interest Negative caseswith the same number of positive classes are randomlyselected from music with scores lower than 2 to ensure thatthe distribution is as balanced as possible After dividingpositive and negative classes the first 80 of the data set isused as the training set and the last 20 as the test set
42 Super Parameter Adjustment )e hyperparameter ad-justment process aims to optimize the performance of themodel First select the super parameters that can be adjusted)en determine whether they will be fixed or variable and ifthe parameters are changeable set them to different values todetermine in which range they will change
Hidden_size the original model is set to 50 and featuresare represented using the model by setting the number ofhidden layers)e hidden layer is set to 32 64 18 and 256 inthe implementation process and the best parameters aredetermined by experiments in TP100 data set in Figure 11
According to Figure 11 when the hidden layer is set to32 the model is in an underfitting state and cannot becharacterized With the increase of the hidden layer theaccuracy rate and recall rate are continuously improved butwhen the hidden layer is set to 256 both indicators decreaseslightly )erefore in the subsequent experiment the hid-den_size is set to 128
Learning_rate it depends on the Adam optimizer in themodel )e learning rate of each parameter is adapted bymaking smaller updates to frequent parameters and largerupdates to infrequent parameters )e learning rate of theoriginal model is set to 0001 In this experiment thelearning rates are set to 0001 001 01 and 05 respectivelyAccording to Figure 12 when the learning rates are 0001and 001 the accuracy is better In the subsequent experi-ment the learning_rate is set to 001
Batch_size when smaller batches are used a period oftraining is more detailed which usually leads to a decrease inthe number of convergent iterations but the training time islong On the other hand the more the batches the slower theconvergence speed which reduces the risk of overfitting andreduces the training time )e effect of batch_size on ac-curacy is shown in Figure 13
Try to use the batch size training model from 100 to 1000in the whole process As can be seen from Figure 13 andTable 2 using a smaller batch size the training time is longerUsing a large batch size (when it exceeds 700) a memoryerror was encountered
)erefore in the follow-up experiment the batch size isset to 600 for model training which not only meets thetraining time but also does not overflow the memory
43 Experimental Results )e whole training process Loss-Epochs is shown in Figure 14 During each training fivesongs with historical evaluation are selected from the his-torical music interacted by users for input After severalrounds of training all the evaluated songs can basically beused in training and the training loss is basically stable after1024 iterations
0002004006008
01012014016018
02
32 64 128 256Ev
alua
tion
inde
x
hidden_size
RecallPrecision
Figure 11 Impact of hidden size on evaluation indicators
12 Complexity
In order to verify the effectiveness of the model thispaper implements Neural Network Based CollaborativeFiltering (NCF) model and SVDmodel by Python which areverified in TP100 and TP500 data sets respectively )eaccuracy and recall rate are used to evaluate the accuracy ofdifferent recommendation lengths )e accuracy results ofdifferent recommendation lengths are shown in Figure 15
It can be seen from Figure 15 that the accuracy of thedeep learning recommendation model based on Relation-ship-Learning is obviously higher than that of the traditionalSVD recommendation algorithm in two data sets about 3higher than that of the collaborative filtering algorithm
based on neural network in TP100 data set and similar inTP500 data set with lower sparsity both of which are higherthan SVD algorithm
As can be seen from Figure 16 this model has obviousadvantages in both data sets With the increasing number ofrecommendations the recall rate gradually increases whichis about 10 higher than the traditional SVD algorithm InTP500 data sets with dense data the recall rate reaches about03 To sum up the deep learning recommendation modelbased on relationship learning implemented in this papercan accurately predict usersrsquo music preferences and finallycan accurately recommend music lists for users
07
075
08
085
09
095
0001001011A
ccur
acy
learning_rate
Figure 12 Impact of learning rate on accuracy
0
01
02
03
04
05
06
07
08
09
1
0 100 200 300 400 500 600 700 800
Acc
urac
y
batch_size
Figure 13 Effect of batch_size on accuracy
Table 2 Average running time per Epoch
batch_size 100 200 400 600 700Runtime (s) 67 39 20 9 8
Complexity 13
0 128 256 512 102400
02
04
06
08
10
12
14
16
18 Cross entropy loss of model training
Loss
Epochs
Figure 14 Model training loss
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
SVDNCFRelation-Learning
(a)
SVDNCFRelation-Learning
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
(b)
Figure 15 Accuracy of two data sets (a) TP100 data set (b) TP500 data set
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(a)
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(b)
Figure 16 Recall rate of two data sets (a) TP100 data set (b) TP500 data set
14 Complexity
5 Conclusion
Faced with a large number of dances and songs it is difficultfor people to quickly find dance music that meets theirinterests )e emergence of dance music recommendationsystem can recommend dance music that users may like andhelp users quickly discover or find their favorite dances andsongs )is kind of recommendation service can provideusers with a good experience and bring commercial benefitsso the field of dance music recommendation has become theresearch direction of industry and scholars In this paperrelation learning is introduced into dance music recom-mendation system and the relation model is applied todance music recommendation In the experiment the ac-curacy and recall rate are used to verify the effectiveness ofthe model in the direction of dance music recommendation
Data Availability
)e experimental data used to support the findings of thisstudy are available from the corresponding author uponrequest
Conflicts of Interest
)e author declares that no conflicts of interest regardingthis work
References
[1] Y Han Z Han J Wu et al ldquoArtificial intelligence recom-mendation system of cancer rehabilitation scheme based onIoT technologyrdquo IEEE Access vol 8 pp 44924ndash44935 2020
[2] A Rw M A Xiao and J A Chi ldquoHeterogeneous informationnetwork-based music recommendation system in mobilenetworksrdquo Computer Communications vol 150 pp 429ndash4372020
[3] X Wen ldquoUsing deep learning approach and IoT architectureto build the intelligent music recommendation systemrdquo SoftComputing vol 25 no 1 pp 1ndash10 2020
[4] H-G Kim G Y Kim and J Y Kim ldquoMusic recommendationsystem using human activity recognition from accelerometerdatardquo IEEE Transactions on Consumer Electronics vol 65no 3 pp 349ndash358 2019
[5] M S Fathollahi and F Razzazi ldquoMusic similarity measure-ment and recommendation system using convolutional neuralnetworksrdquo International Journal of Multimedia InformationRetrieval vol 5 pp 1ndash11 2021
[6] G Sun YWong and Z Cheng ldquoDeepDance music-to-dancemotion choreography with adversarial learningrdquo IEEETransactions on Multimedia vol 99 p 1 2020
[7] J M Agaku ldquo)e Girinya dance theatre of the Tiv people ofNigeria an aesthetic evaluationrdquo International Journal ofIntangible Heritage vol 3 no 6 pp 29ndash41 2008
[8] G Mota and L Abreu ldquo)irty years of music and dramaeducation in the Madeira Island facing future challengesrdquoInternational Journal of Music Education vol 32 no 3pp 360ndash374 2014
[9] B Montero ldquoPractice makes perfect the effect of dancetraining on the aesthetic judgerdquo Phenomenology and theCognitive Sciences vol 11 no 1 pp 59ndash68 2012
[10] A Manfre I Infantino F Vella and S Gaglio ldquoAn automaticsystem for humanoid dance creationrdquo Biologically InspiredCognitive Architectures vol 15 pp 1ndash9 2016
[11] D Aledo B Carrion Schafer and F Moreno ldquoVHDL vsSystemC design of highly parameterizable artificial neuralnetworksrdquo IEICE - Transactions on Info and Systemsvol E102D no 3 pp 512ndash521 2019
[12] B Sheng and G Sun ldquoMatrix factorization recommendationalgorithm based on multiple social relationshipsrdquo Mathe-matical Problems in Engineering vol 2021 Article ID6610645 8 pages 2021
[13] L Jiang Y Cheng L Yang J Li H Yan and X Wang ldquoAtrust-based collaborative filtering algorithm for E-commercerecommendation systemrdquo Journal of ambient intelligence andhumanized computing vol 10 no 8 pp 3023ndash3034 2019
[14] A Dm A Xl and A Qd ldquoHumming-query and reinforce-ment-learning based modeling approach for personalizedmusic recommendationrdquo Procedia Computer Science vol 176pp 2154ndash2163 2020
Complexity 15

consume dance music and the main source of income in thedance music industry By 2019 the number of online dancemusic users in China has reached 608 million and the dancemusic income has reached 103 billion yuan [4] Recom-mendation systems are revolutionizing the dance musicindustry in many ways Listeners can improve their taste ofdance music by using them to constantly discover new dancemusic )e challenge of recommendation system is to realizea system that can accurately provide interesting dance musicfor users so as to understand usersrsquo preference for dancemusic For example Spotify can continue to play songs thatit thinks are similar to those in the list after playing all thesongs in that list but the recommended results are based onsimple dance music genre labels which make users feel dullafter a while)is requires that the dance music personalizedrecommendation system should accurately and effectivelyreflect usersrsquo personal preferences and need to be adjusted toachieve personalized recommendation for different usersPersonalized recommendation system is more complex thantraditional dance music recommendation system whichneeds to comprehensively consider various behaviors ofusers and combine dance music feature recognition andaudio processing technology to extract dance music featuresso as to realize personalized recommendation of dancemusic [5]
Dance evaluation theory is based on the philosophicalcontent discrimination of dance criticism objects Philos-ophy allows us to understand the artistic form of dance sothat it can be appreciated and practiced and the humanbody is a tool to express its artistic form )e definition ofldquodancerdquo by many dancers and philosophers is not enoughto explain and distinguish the necessary conditions ofdance from other human nonart forms [6] In fact the bestunderstanding of dance should be the concept of the mainmedia of human body and music movement and thesecondary media of clothing scenery and lighting visualdimension )e ldquoremnantsrdquo refer to those ceremonialperformances that are still being performed but have losttheir original purpose As long as performers and audiencesrecognize and accept the way they have changed suchperformances can still be appreciated and can still play arole in promoting social cohesion and identity LadyNigeriarsquos Girinya dance originally a war dance is a case inpoint In the aesthetics of Tiv dance menrsquos dance should beas energetic as Girinya dance but in the past dance wasabout what warriors should behave in battle and now it isabout continuity and renewal I try to describe and evaluatethis aesthetics and its adaptation to the changing culture ofTiv people in a way with new meanings [7] According tothe case study of a primary school music education projectin Madeira Portugal 30 years ago we analyzed all childrenand their activities and made statistics in the form ofquestionnaires [8] )e results revealed that all respondentsshowed a strong sense of ownership and leadership )econdition of art critics is to observe artistic experiencewhich praises them for observing value but there is notmuch talk about executive value so we should discusswhether ideal aesthetic judges should practice and createthe artistic form they judge Researchers put forward that
practicing dance can better observe some aesthetic qualitiesof dance and dance training can promote kinestheticexperience It is precisely because of these experiences thatthe aesthetic aspects of dance performance can be reflected[9]
With the rapid development of science and technologyrobots have gradually entered peoplersquos lives )is paperproposes a way for robot to dance with music rhythm whichis a humanoid robot formed by synchronizing music to formdance Firstly the audio features are extracted and then thedance is generated through the action formed by the model)is method forms an artificial creation system whichmakes choreographers pay more attention to and excludedance movements )rough the test on Aldebaran NAOhuman form and real-life dance experiment it is evaluatedin the aspects of movement rhythm accuracy and aes-thetics and the effect is satisfactory and accepted [10] Fi-nally the robustness and flexibility of the system enable us toembed it into the artificial creation system in thefuture work
2 Individualized Analysis andRecommendation Technology ofDance Music
)e recommendation engine uses different algorithms tofilter data and recommend the most relevant items to usersIt first captures the customerrsquos past behavior collect personalpreferences calculate the user model on this basis and thencombine the user model with the recommendation algo-rithm model to generate a recommendation algorithmcalculate the scoring level between the user and the targetitem recommend the items with higher scores to the targetuser and recommend the products that the user may buy)e general model of the recommendation system is shownin Figure 1
21 Analysis of Dance Music Evaluation Index On the basisof literature research this study proposes that dance musicrecommendation system includes 10 dimensions contentfunctionality page design response speed perceived us-ability perceived usefulness satisfaction confidence per-ceived experience and potential risk )e interview resultsshow that due to the upgrade of media equipment and theimprovement of network speed the dimension of ldquoresponsespeedrdquo is of little significance and should be deleted Inaddition some items in the dimensions of ldquosatisfactionrdquo andldquopotential riskrdquo have semantic intersection with items inother dimensions which cannot accurately reflect themeasurement intention and should be deleted Consideringthat the personalized recommendation evaluation indexdoes not point to specific fields some items are not dif-ferentiated and cannot fully summarize the use psychologyof dance music users )is study adds the characteristicsrepeatedly mentioned by many respondents and incorpo-rates them into the index system such as ldquosurprise degreerdquoldquoconsistency of browsing habitsrdquo and ldquopotential risksrdquo
2 Complexity
ldquoSurpriserdquo comes from the userrsquos expectation of dancemusic recommendation function Different from other types ofrecommendation systems dance music is a perceptual artisticproduct and users are more likely to accept the recommendedcontent thus generating emotional expectations At presentthe personalized recommendation function of most dancemusic apps in China is on the homepage and occupies animportant layout Users take the consistency of page design andbrowsing habits as a consideration index which reflects theneeds of users for web page interactive experience in the In-ternet age In addition many interviewees expressed theirconcerns about the quality of recommendation includingldquouneven quality of recommendationrdquo ldquofrequent recommen-dation of similar songs that they are not interested inrdquo andldquointerest-related but dislikerdquo
According to the qualitative research results this papergenerated the evaluation scale of dancemusic recommendationsystem which consists of 8 dimensions and 30 items contentfunctionality page design perceived ease of use perceived
usefulness confidence perceived experience and potentialrisk See Table 1 for measurement indexes and their sources
22 Collaborative Filtering RecommendationCollaborative filtering is a method for personalized rec-ommendation according to the ratings and usage behaviorsof system users )e idea behind its approach is that if agroup of users have similar views on one topic they may alsohave similar interests on another topic [11] Collaborativefiltering algorithm does not need to analyze the projectcontent but mainly pays attention to the userrsquos scoring dataof the project )e system will collect the interaction databetween users and projects establish a scoring matrix thenuse the interaction matrix to calculate the similarity betweenusers and recommend related projects according to similarusers Users can obtain recommendations for items thathave not been previously discovered but which have beenpositively evaluated by neighboring users Collaborative
Obtaining user preference according to dance music evaluation index
User model
Recommendation algorithm
modelRecommendation algorithm
Provide recommendations
Seek recommendations
Provide personal preferences
Collect personal preferences
Calculation
Figure 1 Dance music recommendation system model
Table 1 Summary of original evaluation index system of music recommendation system users
Second-order index First-order index Second-order index First-order index
Content
Accuracy Perceived ease of use Convenience of useFamiliarity Feedback convenienceNovelty
Perceived usefulnessTime-consuming
Diversity EfficiencySurprise degree Preference influenceSufficiency
Confidence
Quality confidenceUpdate of speed Recommendation confidence
Requirement considerations Taste confidence
Functionality
Diagnostic ability of perceptual information Dependence on confidencePreference correction
Perceptual experienceCaring for each other
Explanatory power InteractivityCommunication ability Human touch
Page design
Being clear and understandable
Potential risk RiskAdequacy of repertoireInformation richnessStyle consistency
Consistency of browsing habits
Complexity 3
filtering algorithms are mainly divided into two categoriesmemory-based collaborative filtering and model-basedcollaborative filtering
221 Collaborative Filtering Based on Nearest Neighbors
(1) Collaborative Filtering Based on Users Resnick firstproposed a collaborative filtering algorithm based on usersin 1994 By using the scoring matrix R (U I) to model thepreferences of users U about goods I it is considered thatusersrsquo preferences generally do not change with time andmay have similar behavioral preferences for a long time)erefore users with similar preferences in user history dataare grouped to recommend products to those users
In the music and dance recommendation system thehistorical data used are the operation data such as userslistening to songs whether they like or collect songs and thescores of dances For example both user 1 and user 2 oftenlisten to popular music and user 3 likes to listen to Englishmusic )rough similarity calculation it can be concludedthat user 1 and user 2 are the same kind of users and user 2 isrecommended by using the music listened by user 1 )eprinciple of user-based collaborative filtering algorithm isshown in Figure 2
In order to make recommendations to users it is nec-essary to collect usersrsquo historical behavior records and es-tablish a user-item matrix Rmlowastn where m represents thenumber of active users and n represents the number of itemsBy collecting the explicit scores of users on the project theuserrsquos interest in the project is generally indicated by a scorelevel of 0 to 5 )e higher the score the more interested theuser is in the project and the score of 0 indicates that theuser dislikes the project at all In addition you can use userimplicit ratings to represent user ratings Use the user tolisten to a certain music times or praise collect commentand other behaviors use 1 to indicate that there are relatedbehaviors and 0 to indicate that there is no browsing be-havior After weighting the above behaviors the implicitevaluation matrix of the user on the project is obtained [12]
It is difficult to find the similarity degree for such abstractconcepts as users so it is usually to find the similarity degreeof usersrsquo scoring on specific items and compare the similaritydegree of scoring behavior between two users by analyzingthe similarity degree of scoring results of two users on thecontent that they jointly evaluated excessively In this waythe problem is transformed into a problem of solving thesimilarity between vectors Ri and Rj are defined as thecontent set evaluated by two users and Vi and Vj are definedas the scoring vectors of the content by two users in Ri and RjGenerally the method of calculating the similarity betweenthe two vectors is defined as follows
Jaccard coefficient method the similarity is obtained bycalculating the ratio of intersection and union of two usersrsquoscores in the user history behavior set )e larger the ratiothe higher the similarity Generally Jaccard coefficient issuitable for implicit user behavior similarity calculation )eJaccard coefficient is calculated as shown in
Jaccard(i j) Ri cap
Rj
11138681113868111386811138681113868
11138681113868111386811138681113868
Ri cupRj
11138681113868111386811138681113868
11138681113868111386811138681113868 (1)
Cosine similarity method the cosine value of the anglebetween two user rating vectors in space is used to expressthe similarity between them)e closer the cosine value is to1 the more similar the two vectors are )e calculationprocess is shown in
cos(i j) 1113936kvikvjk
1113936kv2ik
1113969 1113936kv
2jk
1113969 (2)
Pearson correlation coefficient method decentralizationof cosine similarity data is an improvement of cosinesimilarity method In the recommendation system theremay bemissing evaluation of a certain item by users Pearsoncorrelation coefficient method automatically fills the missingvalue as 0 and then uses other dimensions to reduce thedimension average of missing vectors to satisfy cosinesimilarity algorithm Pearson correlation coefficient is cal-culated as shown in
Pearson(i j) 1113936k vik minus vi( 1113857 vjk minus vj1113872 1113873
1113936k vik minus vi( 11138572
1113969
1113936k vjk minus vj1113872 11138732
1113969 (3)
Finally according to similar users traversing all positivefeedback items weighted summation is carried out theinterest scores of user I for all items are calculated and thescore prediction is made for each item)e score calculationis shown in
Pis 1113936jisinS(uk)sim(i j) times ris
1113936jisinS(uk)|sim(i j)| (4)
where S(u k) is a user browsing item set similar to user i risis user irsquos interest in item S and sim(i j) is the similaritybetween user i and j
(2) Collaborative Filtering Based on Project Project-based collaborative filtering method mainly focuses onidentifying the similarity of projects However project-basedcollaborative filtering looks for users who have used twoprojects for similar evaluations If both items Music 1 andMusic 2 receive similar ratings throughout the rating dataset it can be assumed that users who like Music 1 may alsolike Music 2 and vice versa )e principle of project-basedcollaborative filtering is shown in Figure 3
Similar to the user-based collaborative filtering methodthe item-based collaborative filtering method uses the userrsquosrating of other content to predict the rating of unevaluatedcontent Similarly ω(i j) needs to be defined between thecontent that has been evaluated and the content that has notbeen evaluated indicating the degree of similarity betweenRi and Rj )e formula is shown in
ω(i j) 1113944k
vik times vjk
1113936riisinRiv2ik
1113969 1113936jisinRj
v2jk
1113969 (5)
4 Complexity
After that the unknown scores can be estimated indifferent ways such as weighted sum Here C (U K) is asimilar set of items in the user evaluation data set and rui i isthe interest of user u in item i )e calculation is shown in
1113958Pis 1113936jisinC(uk)ω(i j) times rus
1113936jisinC(uk)|ω(i j)| (6)
Although the user-based collaborative filtering algo-rithm is logically simple it may take a lot of time to deal withbig data )e project-based collaborative filtering methodsolves the problem of complex user matrix By using asignificantly smaller number of items large-scale matrixoperations in the user-item scoring matrix can be avoidedand project-based collaborative filtering is more time-cost-effective to implement
Item-based collaborative filtering depends to a greatextent on the number of times songs appear in the data setBecause it is impossible to determine whether songs exist inthe user playlist the item-based collaborative filtering sys-tem designates those songs that appear in many playlists inthe data set as more valuable data in this way acting as thebasic processing for item-based collaborative filtering Firstmatch each song in the playlist with a similar song in thesong data set and record it the system records it as ldquosimilar
tracksrdquo and the playlist obtains the most frequentlyappearing songs from the ldquosimilar tracksrdquo matrix com-prehensively considers the userrsquos preference information forsongs and then recommends music to other users who aresimilar to the userrsquos preferences and often listen to them Inthe music recommendation system although the number ofsongs is less than the number of hundreds of millions ofusers it is also very large Each user playlist may containmore than 50 to 100 songs so it is muchmore difficult to findthe similarity of songs in the database of tens of millions ofsongs so the performance advantage of item-based col-laborative filtering is lost [13]
222 Model-Based Collaborative Filtering Model-basedcollaborative filtering is obviously different from the othertwo collaborative filtering methods user-based and content-based methods estimate the unknown item scores directlyaccording to the statistical historical data but model-basedmethods first use the original data to train and generate aspecific model which can quickly predict user preferencesaccording to the generated model )erefore when there area large number of users and projects the model-basedrecommendation algorithm has a high degree of scalabilityand rapidity Common models are as follows
Recommend
UserA
UserB
UserC
Dance Music 1
Dance Music 2
Dance Music 3
Dance Music 4
Dance Music 5
Similarity
Figure 3 Schematic diagram of project-based collaborative filtering
User A
User B
User C
Dance Music 1
Dance Music 2
Dance Music 3
Recommend
Dance Music 4
Dance Music 5
Similarity
Figure 2 Schematic diagram of user-based collaborative filtering
Complexity 5
(1) Bayesian Model Bayesian prediction model is a kind ofprediction using Bayesian statistics Bayesian statistics isdifferent from general statistical methods which does notuse model information and data information but uses priorinformation )rough the method of empirical analysis theprediction results of Bayesian prediction model are com-pared with those of ordinary regression prediction modeland the results show that Bayesian prediction model hasobvious advantages
Bayesian model revolves around giving evidence (E) andobtaining hypothesis (H) which involves two conceptshypothesis probability P(H) before obtaining evidence andhypothesis probability P(HE) after obtaining evidence )emodel is continuously learned by training data and the dataare verified to evaluate the model and make new predictions
In practical applications Naive Bayesian classifier andcollaborative filtering are generally used to implementrecommendation system which can filter new informationand predict whether users need given resources However itis almost impossible to obtain a completely independent setof data in practice Moreover when the number of itemsjointly evaluated is small this direct calculation may distortthe obtained probability
(2) Matrix Decomposition Model Matrix decompositionmodel is a commonly used technology to build recom-mendation system In 2006 Netflix held Netflix PrizeChallenge and matrix decomposition technology was firstproposed In order to decompose the scoring matrix featuresinto low-dimensional spaces the matrix decompositiontechnology learns potential space vectors for each user andeach item which are divided into user feature vectors p anditem feature vectors q )e specific representation of thescoring matrix is shown in
R pi times qTj (7)
Here R represents the training score matrix and i and jrepresent users and projects respectively By learning theminimized objective function (formula (8)) in the knownscores the potential space vectors P and q can be obtained
Yij FLFM
pi qj1113872 1113873 pTi qj (8)
)e algorithms commonly used in matrix factorizationmodel include nonnegative matrix factorization (NMF)algorithm and singular value decomposition (SVD) algo-rithm )e nonnegative matrix factorization algorithm usesproject content to construct the potential space of the projectand then uses user information such as known scores tolearn the potential space of users So as to overcome the coldstart problem in collaborative filtering 28 Singular valuedecomposition (SVD) algorithmmaps users and items to thepotential factor space of f-dimension and the model con-structs users and items as interaction problems within thespace
In addition model-based collaborative filtering algo-rithms also include graph-based walking method SimRankalgorithm and clustering-based collaborative algorithmCollaborative filtering algorithm can recommend variousfavorite contents to users according to historical data but
the recommendation results may not be satisfactory whenthe scoring data are sparse large-scale matrix operation maybe needed when the data volume is huge and the timeconsumption will increase linearly with the data scale soreal-time recommendation cannot be achieved
23 Content-Based Recommendation )e content-basedrecommendation algorithm takes into account the items ofinterest that users have previously shown through ratingsand then constructs user profiles that match the userrsquos in-terest in such items Once the user clearly shows interest inan item the algorithm will analyze the characteristics of theitem and then recommend similar items to the user )econtent descriptor of a project can have many differentforms which can usually be described by tags or projectcontents for example user tags and tags related to projectattributes and related types are generally classified bymanual or machine learning algorithms When a user listensto a popular song about campus the content-based algo-rithm will recommend another type of campus song to theuser
Early content-based recommendation algorithms mostlydeal with text content so early content-based recommen-dation systems mainly use text retrieval technology Vectorspace model (VSM) can match documents according tokeywords and transform song names and singer names intovectors by using word frequency-inverse document fre-quency (TF-IDF) technology TF is the number of wordsappearing and IDF represents the information of words If aword appears more frequently in lyrics or song titles it mayplay a key role in lyrics )e TF-IDF definition is shown in
TF minus IDF tk dj1113872 1113873 TF tk dj1113872 1113873logN
nK (9)
)eTF-IDF algorithm is used to calculate the words withgreater weight in the data and the cosine similarity algo-rithm mentioned above is used to find other songs similar tothis song and recommend them to users
3 Research on Recommendation ModelBased onUser Behavior andMusic andDance
Referring to the correlation model of image classificationthis paper introduces the model of Relationship-Learninginto the field of music recommendation In this model deepneural network and automatic encoder are used to combinethe characteristics of user behavior and music audio andinput them into Music Encoder to realize personalizedcoding in the coding stage to ensure the personalization ofrecommendation By calculating the similarity of userrsquosinterest preference and the similarity of song feature theprediction score of userrsquos music to be selected is obtainedafter averaging them
31 Model Introduction )rough reading the literature weknow that the cold start problem in the recommendationsystem is mainly divided into two subproblems completecold start and incomplete cold start and there are some
6 Complexity
differences in the solutions of these two problems At thesame time the processing process of image classificationdirection in small sample data can be used for reference byrecommendation system For example the classificationproblem of some pictures that have not been seen at all isZero-Shot while the classification problem of some picturesthat appear less frequently is Few-Shot Among these twoproblems the Zero-Shot problem can correspond to thecomplete cold start problem in the recommendationproblem while the Few-Shot problem can correspond to theincomplete cold start problem in the recommendationproblem For the Few-Shot problem and Zero-Shot problema similar solution to the cold start problem in the recom-mendation system is given
For the cold start problem one of the existing methods isto use user information and article information If effectiveinformation can be collected certain clustering operationscan be carried out on this basis and other similar usersrsquofavorite music can be used to recommend the user In ad-dition the structure of Auto Encoder can be used to extractfeatures At this time for the cold-start user the AutoEncoder encodes first and then decodes and the finallydecoded value includes the value inferred from the usercharacteristics [14]
In this paper we pay more attention to the problem ofincomplete cold start when designing the model and use thelimited scoring information as efficiently as possible toanalyze the scoring habits of users more accurately At thesame time it draws lessons from the idea of relationshiplearning in the field of computer vision hoping that therecommendation system can learn how to compare simi-larity in a more accurate way On this basis we investigatethe application of metric learning in recommendationsystem and find that although these methods have the idea ofmaking recommendation system learn distance informationto infer similarity the distance that defines similarity is low-order linear similarity Although this method can give acertain distance description it is difficult to fully capture andutilize the high-order features extracted by neural network)is paper hopes to calculate the similarity between picturesin relation learning and apply it to the recommendationsystem to calculate the similarity between people music andmusic user and music
32 Metric-Learning Model In 2018 Sung and Flood pro-posed a relation network model based on the metric-learning method to solve the classification problem of asmall number of labeled sample data in the field of computervision in deep learning as shown in Figure 4 )e authorproposes a relational network which compares the inputimages in the test set with a small number of known labeledsample images and calculates the correlation scores so as toclassify them )e relation network consists of two modulesan embedded module and a relational module Firstly theembedding module extracts the relevant feature informa-tion and then the relational module compares these em-bedding and obtains the relation score to determine whetherthey belong to the same class
Each block has 64 3times 3 convolution kernels a batchspecification layer and ReLU nonlinear function In addi-tion convolution blocks 1 and 3 have a 2times 2 maximumpooling layer )e author uses four convolution blocks toextract rich feature information between samples with fewerparameters )e network structure is shown in Figure 5
In the relation module you need to combine featuresfirst )e feature combination S recombines the featureinformation of the samples in the training set and the sampleinformation in the test set so that the relational encoder Gcan learn better from the combined features First thefeature mappings of the same class are summarized asshown in
fφ Li( 1113857 1113944K
J1Lij (10)
where Lij(i 1 i 2 j 1 j 2 K) denotes thetraining set features extracted from the embedded moduleand fφ(Li) denotes the mapping of feature information)emapping of combined features can be obtained by summingthe mapped feature sets )e formula is shown in (11)
Si fφ Li( 1113857 + fφ Qn( 1113857 (11)
Si represents the feature formed by the feature mappingof the training data set and the recombination of the testsamples and fφ(Qn) represents the feature from the testsamples )e model does not use conventional Euclideandistance or cosine distance instead we use nonlinear metriclearning In this part two convolution blocks and two fullyconnected layers are used to compare the two samples Eachconvolution block has 64 3times 3 convolution kernels a batchspecification layer a ReLU nonlinear activation layer and a2times 2 maximum pooling layer Finally through two fullyconnected layers the similarity relation score isin[0 1] be-tween the test samples and the training samples is finallyobtained by using the activation functions ReLU and sig-moid )e relation score is shown in
Relation score gϕ S fφ Lij1113872 1113873 fφ Qn( 11138571113872 11138731113872 1113873 (12)
)e detailed structure of the module is shown inFigure 6
33 Construction of Relation Model )e basic idea of thismodel is determined as a hybrid recommendation modellearning the similarity of user ratings by using the idea ofRelationship-Learning and then estimating the rating valuethrough collaborative filtering)emodel structure is shownin Figure 7
)is model mainly deals with two problems in recom-mendation system Firstly timeliness in the current era ofinformation explosion a large amount of data is uploaded tothe Internet every day It is difficult to obtain enough ratingdata at the beginning of these newly uploaded data whichcan be used in the recommendation system for target usersMusic recommendation system often encounters some newsongs which need to be recommended to users for audition
Complexity 7
)erefore through the cold start mechanism of the modelthe problem of new content recommendation can be solvedand the recommendation system can cope with the problemsbrought by timeliness and new content
Secondly personalization when users evaluate songseven if two people give favorable comments on the samesong their motives may be different for example oneperson likes the singer so they like this song and the otherperson likes the song style and likes this song )erefore themodel carries out more personalized processing for songrecommendation according to music characteristics anduser characteristics
331 Enter Data )e input of the model mainly consists oftwo parts one part is the feature information which includesthe personal feature information of the target user thefeature information of the scored n songs and the featureinformation of the target songs )e other part is the scoringinformation which contains the scoring values of the targetusers for n songs that have been scored In the third chapterthe related features have been extracted Formally the re-lated features are expressed as follows
Users U fieldu1 fieldu
2 fieldun1113864 1113865 represents the userrsquos
gender age and other related characteristic informationMusiccharacteristics M fieldM
1 fieldM2 fieldM
t1113966 1113967 representsthe relevant characteristic information of music Dance fea-tures D fieldD
1 fieldD2 fieldD
j1113966 1113967Historical interaction data of user U H
M1 M2 Mk1113864 1113865 user Ursquos comprehensive user score formusicM is Scorei and userUrsquos comprehensive user score fordance D is Scorej
332 Embedding According to the previous feature ex-traction work several user and audio features can be ob-tained Firstly the features are encoded through linear layeror embedding layer to obtain a series of vector represen-tations of features then according to these vectors the userand music are encoded )e user below represents severalcharacteristics of the target user which are represented byvectors Taking it as input the encoding vector of userfeatures is obtained through the User Encoder For usercoding because only text type features such as gender andage are used Auto Encoder model can be directly used tocomplete feature extraction In order to be similar to Music
64 33 convolutionkernels
Batch Normalization
Relu function
33 max-pooling
64 33 convolutionkernels
Batch Normalization
Relu function
64 33 convolutionkernels
Batch Normalization
Relu function
64 33 convolutionkernels
Batch Normalization
Relu function
33 max-pooling
fϕ
Figure 5 Embedding module
FC1Relu function
FC2Sigmoid function
SiRelation score
64 33 convolutionkernels
Batch Normalization
Relu function
22 max-pooling
64 33 convolutionkernels
Batch Normalization
Relu function
22 max-pooling
Figure 6 Relation module
Test sample 1
Test sample 2
Test sample 3
Test sample 4
Test sample 5
Test sample
Embedded module Relationship module
Feature concatenation
Relation score
fφ gϕ
Figure 4 Relation network model
8 Complexity
Encoder feature structure AutoInt model l is used to extractuser features here )e encoding structure of the user part isshown in Figure 8
Next for some music evaluated by users because theyknow their characteristics and scores they can combine theircharacteristics with userrsquos feature vectors and input theminto Music Encoder for coding respectively )is processcan combine usersrsquo personalized information for music sothat the same music can be coded differently by MusicEncoder for different users For unevaluatedmusic althoughthere is only the eigenvalue of music it can still obtain itseigenvector through Music Encoder like the music that hasbeen evaluated which is the coding layer Embedding Layerof music )e music feature coding structure is shown inFigure 9
As can be seen from Figure 9 the main structure ofencoder is multihead attention module and its essence is toperformmultiple self-attention calculations to formmultiplesubspaces so that the model can learn different features ofinformation from different angles and finally merge themTake the Music Encoder as an example and its structure isshown in Figure 10
In the multihead attention the feature matrixF f1 f2 ft1113864 1113865 needs to be transformed linearly tocompare the dimension of the feature vector that is QW
Qi
Perform k self-attention calculations as shown in
hlowast
Attention(Q K V) softmaxQK
T
dk
1113888 1113889V (13)
Splice and linearly map the result hlowast using
h concat hlowast1 hlowast2 h
lowastn( 1113857otimesW
o (14)
)e number of music selections has also been adjusted tosome extent When entering you need to have a series ofknown characteristics of the score and its final scoreHowever there will be many historical records of a personAnd the quantity is different and the model structure doesnot support the dynamic adjustment of the input quantityso this paper chooses the sampling method During eachtraining five historical evaluated songs are selected from thehistorical music of user interaction for input After severalrounds of training all the evaluated songs can be basicallyused in the training Although this method is inefficient inusing data sets it can greatly reduce the training time costand the complexity of the model )erefore after trade-offwe chose the method of randomly selecting five data
333 Interest Matching Module )e information aboutusers andmusic in the data set is processed and the obtainedhigh-order nonlinear eigenvector is taken as the output In
User data
Dance Music 1
Dance Music 2
Dance Music m New project
S M R
P
input
Embedding Module
Feature Vector
Combined Vector
Relation Module
Relation Score Ration
Predicted Ration
Figure 7 Model structure
Complexity 9
Max-Pooling
Multi-Head Attention
Field1 Field2 Field3
y1
Figure 8 User encoder model structure
Max-Pooling
Multi-Head Attention
Field1 Fieldt
y2
User feature vector y1
Characteristics of dance music
Figure 9 Music encoder model structure
10 Complexity
the model of this section we hope to give the similarity ofusers about different music scores through feature vectors
Firstly the characteristics of the scored songs and thecharacteristics of the target unscored songs are combined bythe user )en the similarity gφ between the two songs isgiven by comparing the similarity module and relationmodule its size is limited between 0 and 1 by normalizationfunction and finally a k-dimensional numerical vector re-lation score is obtained )e similarity gφmodel is shown in
gφ q1 q2( 1113857 Sigmoid qT1 Wq21113872 1113873 (15)
)e Interest Matching Relation module constructed inthis paper is not complex and the parameter to be trained isonly a matrix W In the experiment we also use a deeperstructure to replace this structure It is found that this willnot only increase the training time and parameter scale butalso reduce the accuracy )erefore we finally choose thevalue between [0 1] obtained by sigmoid after we get theinner product of two vectors about W as the similarityAccording to the similarity degree the related features of theknown graded music are constructed to predict the featuresof the music )e method is weighted average and theweight of each item is the score multiplied by the similaritydegree )e more similar the music and the higher the scorethe more obvious the influence on the prediction resultsFinally an estimated value of the eigenvector is obtained
Finally there is an output layer which synthesizes thetwo scoring results given before and gives the final con-clusion In the first part of the conclusion Y from theprevious user coding music-to-be-predicted estimationfeatures and music-to-be-predicted coding through a linearlayer this part reflects the idea of collaborative filteringbased on similarity and score to get the target score Anotherpart of the result x is obtained by using a Max Pooling layer
to select the value with the greatest correlation )e strategyembodied in this part is that when the songs to be predictedhave a high similarity with the previous historical songs itcan be considered that users are likely to have a certaininterest in the songs to be evaluated so the results have alarge similarity value at this time Finally the two scores areaveraged to get the final output)is is a value between [0 1]to indicate the degree of interest that users may be interestedin
4 Implementation ofPersonalized Recommendation
Traditional models do not use the information of users whointeract with them in the coding process of known music)is leads to the lack of user personality in the recom-mended content Even for two different users the coding ofthe same content is the same which cannot deal with thepersonalized problem well In addition in the actual in-teractive process content and users have different interactivebehaviors and different interactive behaviors often repre-sent different preferences of users However the previousmodels have not been distinguished to this extent resultingin different information brought by different interactivebehaviors not being used For example for praise andcollection collection means that users are more interestedthan praise because collection means that users are likely tolisten to this song repeatedly later while the probability oflistening to praise will be smaller later
In this paper firstly different behavior scores of users aredistinguished and the scores are divided into 1ndash5 pointsaccording to the listening times 6 points for collectionbehavior and 4 points for praise behavior In addition themultihead attention mechanism is introduced When
Linear
Concat
Self-attention
Linear LinearLinear
User feature vector (V)
Music feature vector (M)
Dance feature vector (D)
K
Output
Figure 10 Multihead attention module
Complexity 11
encoding music features in Music Encoder the user featuresand music features are combined and the user personalizedmusic coding is realized in the encoding layer which ensuresthat even if different users operate the same music the finalrecommendation results are still different because of dif-ferent personal characteristics thus realizing the personal-ized music recommendation
41 Model Training and Experimental Results Beforetraining the model it is necessary to divide the positive andnegative classes and determine the training set and test setused by the model For music recommendation label 0means dislike and label 1 means like which is defined as abinary classification problem According to the scoringprocessing of user behavior characteristics in Chapter 3music with a score higher than 5 is recorded as a positiveclass that is if the user listens to music many times or musicwith a little praise or collection behavior is recorded as apositive class Music with a score below 2 is recorded as anegative example indicating that although the user has someinteraction they have not shown interest Negative caseswith the same number of positive classes are randomlyselected from music with scores lower than 2 to ensure thatthe distribution is as balanced as possible After dividingpositive and negative classes the first 80 of the data set isused as the training set and the last 20 as the test set
42 Super Parameter Adjustment )e hyperparameter ad-justment process aims to optimize the performance of themodel First select the super parameters that can be adjusted)en determine whether they will be fixed or variable and ifthe parameters are changeable set them to different values todetermine in which range they will change
Hidden_size the original model is set to 50 and featuresare represented using the model by setting the number ofhidden layers)e hidden layer is set to 32 64 18 and 256 inthe implementation process and the best parameters aredetermined by experiments in TP100 data set in Figure 11
According to Figure 11 when the hidden layer is set to32 the model is in an underfitting state and cannot becharacterized With the increase of the hidden layer theaccuracy rate and recall rate are continuously improved butwhen the hidden layer is set to 256 both indicators decreaseslightly )erefore in the subsequent experiment the hid-den_size is set to 128
Learning_rate it depends on the Adam optimizer in themodel )e learning rate of each parameter is adapted bymaking smaller updates to frequent parameters and largerupdates to infrequent parameters )e learning rate of theoriginal model is set to 0001 In this experiment thelearning rates are set to 0001 001 01 and 05 respectivelyAccording to Figure 12 when the learning rates are 0001and 001 the accuracy is better In the subsequent experi-ment the learning_rate is set to 001
Batch_size when smaller batches are used a period oftraining is more detailed which usually leads to a decrease inthe number of convergent iterations but the training time islong On the other hand the more the batches the slower theconvergence speed which reduces the risk of overfitting andreduces the training time )e effect of batch_size on ac-curacy is shown in Figure 13
Try to use the batch size training model from 100 to 1000in the whole process As can be seen from Figure 13 andTable 2 using a smaller batch size the training time is longerUsing a large batch size (when it exceeds 700) a memoryerror was encountered
)erefore in the follow-up experiment the batch size isset to 600 for model training which not only meets thetraining time but also does not overflow the memory
43 Experimental Results )e whole training process Loss-Epochs is shown in Figure 14 During each training fivesongs with historical evaluation are selected from the his-torical music interacted by users for input After severalrounds of training all the evaluated songs can basically beused in training and the training loss is basically stable after1024 iterations
0002004006008
01012014016018
02
32 64 128 256Ev
alua
tion
inde
x
hidden_size
RecallPrecision
Figure 11 Impact of hidden size on evaluation indicators
12 Complexity
In order to verify the effectiveness of the model thispaper implements Neural Network Based CollaborativeFiltering (NCF) model and SVDmodel by Python which areverified in TP100 and TP500 data sets respectively )eaccuracy and recall rate are used to evaluate the accuracy ofdifferent recommendation lengths )e accuracy results ofdifferent recommendation lengths are shown in Figure 15
It can be seen from Figure 15 that the accuracy of thedeep learning recommendation model based on Relation-ship-Learning is obviously higher than that of the traditionalSVD recommendation algorithm in two data sets about 3higher than that of the collaborative filtering algorithm
based on neural network in TP100 data set and similar inTP500 data set with lower sparsity both of which are higherthan SVD algorithm
As can be seen from Figure 16 this model has obviousadvantages in both data sets With the increasing number ofrecommendations the recall rate gradually increases whichis about 10 higher than the traditional SVD algorithm InTP500 data sets with dense data the recall rate reaches about03 To sum up the deep learning recommendation modelbased on relationship learning implemented in this papercan accurately predict usersrsquo music preferences and finallycan accurately recommend music lists for users
07
075
08
085
09
095
0001001011A
ccur
acy
learning_rate
Figure 12 Impact of learning rate on accuracy
0
01
02
03
04
05
06
07
08
09
1
0 100 200 300 400 500 600 700 800
Acc
urac
y
batch_size
Figure 13 Effect of batch_size on accuracy
Table 2 Average running time per Epoch
batch_size 100 200 400 600 700Runtime (s) 67 39 20 9 8
Complexity 13
0 128 256 512 102400
02
04
06
08
10
12
14
16
18 Cross entropy loss of model training
Loss
Epochs
Figure 14 Model training loss
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
SVDNCFRelation-Learning
(a)
SVDNCFRelation-Learning
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
(b)
Figure 15 Accuracy of two data sets (a) TP100 data set (b) TP500 data set
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(a)
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(b)
Figure 16 Recall rate of two data sets (a) TP100 data set (b) TP500 data set
14 Complexity
5 Conclusion
Faced with a large number of dances and songs it is difficultfor people to quickly find dance music that meets theirinterests )e emergence of dance music recommendationsystem can recommend dance music that users may like andhelp users quickly discover or find their favorite dances andsongs )is kind of recommendation service can provideusers with a good experience and bring commercial benefitsso the field of dance music recommendation has become theresearch direction of industry and scholars In this paperrelation learning is introduced into dance music recom-mendation system and the relation model is applied todance music recommendation In the experiment the ac-curacy and recall rate are used to verify the effectiveness ofthe model in the direction of dance music recommendation
Data Availability
)e experimental data used to support the findings of thisstudy are available from the corresponding author uponrequest
Conflicts of Interest
)e author declares that no conflicts of interest regardingthis work
References
[1] Y Han Z Han J Wu et al ldquoArtificial intelligence recom-mendation system of cancer rehabilitation scheme based onIoT technologyrdquo IEEE Access vol 8 pp 44924ndash44935 2020
[2] A Rw M A Xiao and J A Chi ldquoHeterogeneous informationnetwork-based music recommendation system in mobilenetworksrdquo Computer Communications vol 150 pp 429ndash4372020
[3] X Wen ldquoUsing deep learning approach and IoT architectureto build the intelligent music recommendation systemrdquo SoftComputing vol 25 no 1 pp 1ndash10 2020
[4] H-G Kim G Y Kim and J Y Kim ldquoMusic recommendationsystem using human activity recognition from accelerometerdatardquo IEEE Transactions on Consumer Electronics vol 65no 3 pp 349ndash358 2019
[5] M S Fathollahi and F Razzazi ldquoMusic similarity measure-ment and recommendation system using convolutional neuralnetworksrdquo International Journal of Multimedia InformationRetrieval vol 5 pp 1ndash11 2021
[6] G Sun YWong and Z Cheng ldquoDeepDance music-to-dancemotion choreography with adversarial learningrdquo IEEETransactions on Multimedia vol 99 p 1 2020
[7] J M Agaku ldquo)e Girinya dance theatre of the Tiv people ofNigeria an aesthetic evaluationrdquo International Journal ofIntangible Heritage vol 3 no 6 pp 29ndash41 2008
[8] G Mota and L Abreu ldquo)irty years of music and dramaeducation in the Madeira Island facing future challengesrdquoInternational Journal of Music Education vol 32 no 3pp 360ndash374 2014
[9] B Montero ldquoPractice makes perfect the effect of dancetraining on the aesthetic judgerdquo Phenomenology and theCognitive Sciences vol 11 no 1 pp 59ndash68 2012
[10] A Manfre I Infantino F Vella and S Gaglio ldquoAn automaticsystem for humanoid dance creationrdquo Biologically InspiredCognitive Architectures vol 15 pp 1ndash9 2016
[11] D Aledo B Carrion Schafer and F Moreno ldquoVHDL vsSystemC design of highly parameterizable artificial neuralnetworksrdquo IEICE - Transactions on Info and Systemsvol E102D no 3 pp 512ndash521 2019
[12] B Sheng and G Sun ldquoMatrix factorization recommendationalgorithm based on multiple social relationshipsrdquo Mathe-matical Problems in Engineering vol 2021 Article ID6610645 8 pages 2021
[13] L Jiang Y Cheng L Yang J Li H Yan and X Wang ldquoAtrust-based collaborative filtering algorithm for E-commercerecommendation systemrdquo Journal of ambient intelligence andhumanized computing vol 10 no 8 pp 3023ndash3034 2019
[14] A Dm A Xl and A Qd ldquoHumming-query and reinforce-ment-learning based modeling approach for personalizedmusic recommendationrdquo Procedia Computer Science vol 176pp 2154ndash2163 2020
Complexity 15

ldquoSurpriserdquo comes from the userrsquos expectation of dancemusic recommendation function Different from other types ofrecommendation systems dance music is a perceptual artisticproduct and users are more likely to accept the recommendedcontent thus generating emotional expectations At presentthe personalized recommendation function of most dancemusic apps in China is on the homepage and occupies animportant layout Users take the consistency of page design andbrowsing habits as a consideration index which reflects theneeds of users for web page interactive experience in the In-ternet age In addition many interviewees expressed theirconcerns about the quality of recommendation includingldquouneven quality of recommendationrdquo ldquofrequent recommen-dation of similar songs that they are not interested inrdquo andldquointerest-related but dislikerdquo
According to the qualitative research results this papergenerated the evaluation scale of dancemusic recommendationsystem which consists of 8 dimensions and 30 items contentfunctionality page design perceived ease of use perceived
usefulness confidence perceived experience and potentialrisk See Table 1 for measurement indexes and their sources
22 Collaborative Filtering RecommendationCollaborative filtering is a method for personalized rec-ommendation according to the ratings and usage behaviorsof system users )e idea behind its approach is that if agroup of users have similar views on one topic they may alsohave similar interests on another topic [11] Collaborativefiltering algorithm does not need to analyze the projectcontent but mainly pays attention to the userrsquos scoring dataof the project )e system will collect the interaction databetween users and projects establish a scoring matrix thenuse the interaction matrix to calculate the similarity betweenusers and recommend related projects according to similarusers Users can obtain recommendations for items thathave not been previously discovered but which have beenpositively evaluated by neighboring users Collaborative
Obtaining user preference according to dance music evaluation index
User model
Recommendation algorithm
modelRecommendation algorithm
Provide recommendations
Seek recommendations
Provide personal preferences
Collect personal preferences
Calculation
Figure 1 Dance music recommendation system model
Table 1 Summary of original evaluation index system of music recommendation system users
Second-order index First-order index Second-order index First-order index
Content
Accuracy Perceived ease of use Convenience of useFamiliarity Feedback convenienceNovelty
Perceived usefulnessTime-consuming
Diversity EfficiencySurprise degree Preference influenceSufficiency
Confidence
Quality confidenceUpdate of speed Recommendation confidence
Requirement considerations Taste confidence
Functionality
Diagnostic ability of perceptual information Dependence on confidencePreference correction
Perceptual experienceCaring for each other
Explanatory power InteractivityCommunication ability Human touch
Page design
Being clear and understandable
Potential risk RiskAdequacy of repertoireInformation richnessStyle consistency
Consistency of browsing habits
Complexity 3
filtering algorithms are mainly divided into two categoriesmemory-based collaborative filtering and model-basedcollaborative filtering
221 Collaborative Filtering Based on Nearest Neighbors
(1) Collaborative Filtering Based on Users Resnick firstproposed a collaborative filtering algorithm based on usersin 1994 By using the scoring matrix R (U I) to model thepreferences of users U about goods I it is considered thatusersrsquo preferences generally do not change with time andmay have similar behavioral preferences for a long time)erefore users with similar preferences in user history dataare grouped to recommend products to those users
In the music and dance recommendation system thehistorical data used are the operation data such as userslistening to songs whether they like or collect songs and thescores of dances For example both user 1 and user 2 oftenlisten to popular music and user 3 likes to listen to Englishmusic )rough similarity calculation it can be concludedthat user 1 and user 2 are the same kind of users and user 2 isrecommended by using the music listened by user 1 )eprinciple of user-based collaborative filtering algorithm isshown in Figure 2
In order to make recommendations to users it is nec-essary to collect usersrsquo historical behavior records and es-tablish a user-item matrix Rmlowastn where m represents thenumber of active users and n represents the number of itemsBy collecting the explicit scores of users on the project theuserrsquos interest in the project is generally indicated by a scorelevel of 0 to 5 )e higher the score the more interested theuser is in the project and the score of 0 indicates that theuser dislikes the project at all In addition you can use userimplicit ratings to represent user ratings Use the user tolisten to a certain music times or praise collect commentand other behaviors use 1 to indicate that there are relatedbehaviors and 0 to indicate that there is no browsing be-havior After weighting the above behaviors the implicitevaluation matrix of the user on the project is obtained [12]
It is difficult to find the similarity degree for such abstractconcepts as users so it is usually to find the similarity degreeof usersrsquo scoring on specific items and compare the similaritydegree of scoring behavior between two users by analyzingthe similarity degree of scoring results of two users on thecontent that they jointly evaluated excessively In this waythe problem is transformed into a problem of solving thesimilarity between vectors Ri and Rj are defined as thecontent set evaluated by two users and Vi and Vj are definedas the scoring vectors of the content by two users in Ri and RjGenerally the method of calculating the similarity betweenthe two vectors is defined as follows
Jaccard coefficient method the similarity is obtained bycalculating the ratio of intersection and union of two usersrsquoscores in the user history behavior set )e larger the ratiothe higher the similarity Generally Jaccard coefficient issuitable for implicit user behavior similarity calculation )eJaccard coefficient is calculated as shown in
Jaccard(i j) Ri cap
Rj
11138681113868111386811138681113868
11138681113868111386811138681113868
Ri cupRj
11138681113868111386811138681113868
11138681113868111386811138681113868 (1)
Cosine similarity method the cosine value of the anglebetween two user rating vectors in space is used to expressthe similarity between them)e closer the cosine value is to1 the more similar the two vectors are )e calculationprocess is shown in
cos(i j) 1113936kvikvjk
1113936kv2ik
1113969 1113936kv
2jk
1113969 (2)
Pearson correlation coefficient method decentralizationof cosine similarity data is an improvement of cosinesimilarity method In the recommendation system theremay bemissing evaluation of a certain item by users Pearsoncorrelation coefficient method automatically fills the missingvalue as 0 and then uses other dimensions to reduce thedimension average of missing vectors to satisfy cosinesimilarity algorithm Pearson correlation coefficient is cal-culated as shown in
Pearson(i j) 1113936k vik minus vi( 1113857 vjk minus vj1113872 1113873
1113936k vik minus vi( 11138572
1113969
1113936k vjk minus vj1113872 11138732
1113969 (3)
Finally according to similar users traversing all positivefeedback items weighted summation is carried out theinterest scores of user I for all items are calculated and thescore prediction is made for each item)e score calculationis shown in
Pis 1113936jisinS(uk)sim(i j) times ris
1113936jisinS(uk)|sim(i j)| (4)
where S(u k) is a user browsing item set similar to user i risis user irsquos interest in item S and sim(i j) is the similaritybetween user i and j
(2) Collaborative Filtering Based on Project Project-based collaborative filtering method mainly focuses onidentifying the similarity of projects However project-basedcollaborative filtering looks for users who have used twoprojects for similar evaluations If both items Music 1 andMusic 2 receive similar ratings throughout the rating dataset it can be assumed that users who like Music 1 may alsolike Music 2 and vice versa )e principle of project-basedcollaborative filtering is shown in Figure 3
Similar to the user-based collaborative filtering methodthe item-based collaborative filtering method uses the userrsquosrating of other content to predict the rating of unevaluatedcontent Similarly ω(i j) needs to be defined between thecontent that has been evaluated and the content that has notbeen evaluated indicating the degree of similarity betweenRi and Rj )e formula is shown in
ω(i j) 1113944k
vik times vjk
1113936riisinRiv2ik
1113969 1113936jisinRj
v2jk
1113969 (5)
4 Complexity
After that the unknown scores can be estimated indifferent ways such as weighted sum Here C (U K) is asimilar set of items in the user evaluation data set and rui i isthe interest of user u in item i )e calculation is shown in
1113958Pis 1113936jisinC(uk)ω(i j) times rus
1113936jisinC(uk)|ω(i j)| (6)
Although the user-based collaborative filtering algo-rithm is logically simple it may take a lot of time to deal withbig data )e project-based collaborative filtering methodsolves the problem of complex user matrix By using asignificantly smaller number of items large-scale matrixoperations in the user-item scoring matrix can be avoidedand project-based collaborative filtering is more time-cost-effective to implement
Item-based collaborative filtering depends to a greatextent on the number of times songs appear in the data setBecause it is impossible to determine whether songs exist inthe user playlist the item-based collaborative filtering sys-tem designates those songs that appear in many playlists inthe data set as more valuable data in this way acting as thebasic processing for item-based collaborative filtering Firstmatch each song in the playlist with a similar song in thesong data set and record it the system records it as ldquosimilar
tracksrdquo and the playlist obtains the most frequentlyappearing songs from the ldquosimilar tracksrdquo matrix com-prehensively considers the userrsquos preference information forsongs and then recommends music to other users who aresimilar to the userrsquos preferences and often listen to them Inthe music recommendation system although the number ofsongs is less than the number of hundreds of millions ofusers it is also very large Each user playlist may containmore than 50 to 100 songs so it is muchmore difficult to findthe similarity of songs in the database of tens of millions ofsongs so the performance advantage of item-based col-laborative filtering is lost [13]
222 Model-Based Collaborative Filtering Model-basedcollaborative filtering is obviously different from the othertwo collaborative filtering methods user-based and content-based methods estimate the unknown item scores directlyaccording to the statistical historical data but model-basedmethods first use the original data to train and generate aspecific model which can quickly predict user preferencesaccording to the generated model )erefore when there area large number of users and projects the model-basedrecommendation algorithm has a high degree of scalabilityand rapidity Common models are as follows
Recommend
UserA
UserB
UserC
Dance Music 1
Dance Music 2
Dance Music 3
Dance Music 4
Dance Music 5
Similarity
Figure 3 Schematic diagram of project-based collaborative filtering
User A
User B
User C
Dance Music 1
Dance Music 2
Dance Music 3
Recommend
Dance Music 4
Dance Music 5
Similarity
Figure 2 Schematic diagram of user-based collaborative filtering
Complexity 5
(1) Bayesian Model Bayesian prediction model is a kind ofprediction using Bayesian statistics Bayesian statistics isdifferent from general statistical methods which does notuse model information and data information but uses priorinformation )rough the method of empirical analysis theprediction results of Bayesian prediction model are com-pared with those of ordinary regression prediction modeland the results show that Bayesian prediction model hasobvious advantages
Bayesian model revolves around giving evidence (E) andobtaining hypothesis (H) which involves two conceptshypothesis probability P(H) before obtaining evidence andhypothesis probability P(HE) after obtaining evidence )emodel is continuously learned by training data and the dataare verified to evaluate the model and make new predictions
In practical applications Naive Bayesian classifier andcollaborative filtering are generally used to implementrecommendation system which can filter new informationand predict whether users need given resources However itis almost impossible to obtain a completely independent setof data in practice Moreover when the number of itemsjointly evaluated is small this direct calculation may distortthe obtained probability
(2) Matrix Decomposition Model Matrix decompositionmodel is a commonly used technology to build recom-mendation system In 2006 Netflix held Netflix PrizeChallenge and matrix decomposition technology was firstproposed In order to decompose the scoring matrix featuresinto low-dimensional spaces the matrix decompositiontechnology learns potential space vectors for each user andeach item which are divided into user feature vectors p anditem feature vectors q )e specific representation of thescoring matrix is shown in
R pi times qTj (7)
Here R represents the training score matrix and i and jrepresent users and projects respectively By learning theminimized objective function (formula (8)) in the knownscores the potential space vectors P and q can be obtained
Yij FLFM
pi qj1113872 1113873 pTi qj (8)
)e algorithms commonly used in matrix factorizationmodel include nonnegative matrix factorization (NMF)algorithm and singular value decomposition (SVD) algo-rithm )e nonnegative matrix factorization algorithm usesproject content to construct the potential space of the projectand then uses user information such as known scores tolearn the potential space of users So as to overcome the coldstart problem in collaborative filtering 28 Singular valuedecomposition (SVD) algorithmmaps users and items to thepotential factor space of f-dimension and the model con-structs users and items as interaction problems within thespace
In addition model-based collaborative filtering algo-rithms also include graph-based walking method SimRankalgorithm and clustering-based collaborative algorithmCollaborative filtering algorithm can recommend variousfavorite contents to users according to historical data but
the recommendation results may not be satisfactory whenthe scoring data are sparse large-scale matrix operation maybe needed when the data volume is huge and the timeconsumption will increase linearly with the data scale soreal-time recommendation cannot be achieved
23 Content-Based Recommendation )e content-basedrecommendation algorithm takes into account the items ofinterest that users have previously shown through ratingsand then constructs user profiles that match the userrsquos in-terest in such items Once the user clearly shows interest inan item the algorithm will analyze the characteristics of theitem and then recommend similar items to the user )econtent descriptor of a project can have many differentforms which can usually be described by tags or projectcontents for example user tags and tags related to projectattributes and related types are generally classified bymanual or machine learning algorithms When a user listensto a popular song about campus the content-based algo-rithm will recommend another type of campus song to theuser
Early content-based recommendation algorithms mostlydeal with text content so early content-based recommen-dation systems mainly use text retrieval technology Vectorspace model (VSM) can match documents according tokeywords and transform song names and singer names intovectors by using word frequency-inverse document fre-quency (TF-IDF) technology TF is the number of wordsappearing and IDF represents the information of words If aword appears more frequently in lyrics or song titles it mayplay a key role in lyrics )e TF-IDF definition is shown in
TF minus IDF tk dj1113872 1113873 TF tk dj1113872 1113873logN
nK (9)
)eTF-IDF algorithm is used to calculate the words withgreater weight in the data and the cosine similarity algo-rithm mentioned above is used to find other songs similar tothis song and recommend them to users
3 Research on Recommendation ModelBased onUser Behavior andMusic andDance
Referring to the correlation model of image classificationthis paper introduces the model of Relationship-Learninginto the field of music recommendation In this model deepneural network and automatic encoder are used to combinethe characteristics of user behavior and music audio andinput them into Music Encoder to realize personalizedcoding in the coding stage to ensure the personalization ofrecommendation By calculating the similarity of userrsquosinterest preference and the similarity of song feature theprediction score of userrsquos music to be selected is obtainedafter averaging them
31 Model Introduction )rough reading the literature weknow that the cold start problem in the recommendationsystem is mainly divided into two subproblems completecold start and incomplete cold start and there are some
6 Complexity
differences in the solutions of these two problems At thesame time the processing process of image classificationdirection in small sample data can be used for reference byrecommendation system For example the classificationproblem of some pictures that have not been seen at all isZero-Shot while the classification problem of some picturesthat appear less frequently is Few-Shot Among these twoproblems the Zero-Shot problem can correspond to thecomplete cold start problem in the recommendationproblem while the Few-Shot problem can correspond to theincomplete cold start problem in the recommendationproblem For the Few-Shot problem and Zero-Shot problema similar solution to the cold start problem in the recom-mendation system is given
For the cold start problem one of the existing methods isto use user information and article information If effectiveinformation can be collected certain clustering operationscan be carried out on this basis and other similar usersrsquofavorite music can be used to recommend the user In ad-dition the structure of Auto Encoder can be used to extractfeatures At this time for the cold-start user the AutoEncoder encodes first and then decodes and the finallydecoded value includes the value inferred from the usercharacteristics [14]
In this paper we pay more attention to the problem ofincomplete cold start when designing the model and use thelimited scoring information as efficiently as possible toanalyze the scoring habits of users more accurately At thesame time it draws lessons from the idea of relationshiplearning in the field of computer vision hoping that therecommendation system can learn how to compare simi-larity in a more accurate way On this basis we investigatethe application of metric learning in recommendationsystem and find that although these methods have the idea ofmaking recommendation system learn distance informationto infer similarity the distance that defines similarity is low-order linear similarity Although this method can give acertain distance description it is difficult to fully capture andutilize the high-order features extracted by neural network)is paper hopes to calculate the similarity between picturesin relation learning and apply it to the recommendationsystem to calculate the similarity between people music andmusic user and music
32 Metric-Learning Model In 2018 Sung and Flood pro-posed a relation network model based on the metric-learning method to solve the classification problem of asmall number of labeled sample data in the field of computervision in deep learning as shown in Figure 4 )e authorproposes a relational network which compares the inputimages in the test set with a small number of known labeledsample images and calculates the correlation scores so as toclassify them )e relation network consists of two modulesan embedded module and a relational module Firstly theembedding module extracts the relevant feature informa-tion and then the relational module compares these em-bedding and obtains the relation score to determine whetherthey belong to the same class
Each block has 64 3times 3 convolution kernels a batchspecification layer and ReLU nonlinear function In addi-tion convolution blocks 1 and 3 have a 2times 2 maximumpooling layer )e author uses four convolution blocks toextract rich feature information between samples with fewerparameters )e network structure is shown in Figure 5
In the relation module you need to combine featuresfirst )e feature combination S recombines the featureinformation of the samples in the training set and the sampleinformation in the test set so that the relational encoder Gcan learn better from the combined features First thefeature mappings of the same class are summarized asshown in
fφ Li( 1113857 1113944K
J1Lij (10)
where Lij(i 1 i 2 j 1 j 2 K) denotes thetraining set features extracted from the embedded moduleand fφ(Li) denotes the mapping of feature information)emapping of combined features can be obtained by summingthe mapped feature sets )e formula is shown in (11)
Si fφ Li( 1113857 + fφ Qn( 1113857 (11)
Si represents the feature formed by the feature mappingof the training data set and the recombination of the testsamples and fφ(Qn) represents the feature from the testsamples )e model does not use conventional Euclideandistance or cosine distance instead we use nonlinear metriclearning In this part two convolution blocks and two fullyconnected layers are used to compare the two samples Eachconvolution block has 64 3times 3 convolution kernels a batchspecification layer a ReLU nonlinear activation layer and a2times 2 maximum pooling layer Finally through two fullyconnected layers the similarity relation score isin[0 1] be-tween the test samples and the training samples is finallyobtained by using the activation functions ReLU and sig-moid )e relation score is shown in
Relation score gϕ S fφ Lij1113872 1113873 fφ Qn( 11138571113872 11138731113872 1113873 (12)
)e detailed structure of the module is shown inFigure 6
33 Construction of Relation Model )e basic idea of thismodel is determined as a hybrid recommendation modellearning the similarity of user ratings by using the idea ofRelationship-Learning and then estimating the rating valuethrough collaborative filtering)emodel structure is shownin Figure 7
)is model mainly deals with two problems in recom-mendation system Firstly timeliness in the current era ofinformation explosion a large amount of data is uploaded tothe Internet every day It is difficult to obtain enough ratingdata at the beginning of these newly uploaded data whichcan be used in the recommendation system for target usersMusic recommendation system often encounters some newsongs which need to be recommended to users for audition
Complexity 7
)erefore through the cold start mechanism of the modelthe problem of new content recommendation can be solvedand the recommendation system can cope with the problemsbrought by timeliness and new content
Secondly personalization when users evaluate songseven if two people give favorable comments on the samesong their motives may be different for example oneperson likes the singer so they like this song and the otherperson likes the song style and likes this song )erefore themodel carries out more personalized processing for songrecommendation according to music characteristics anduser characteristics
331 Enter Data )e input of the model mainly consists oftwo parts one part is the feature information which includesthe personal feature information of the target user thefeature information of the scored n songs and the featureinformation of the target songs )e other part is the scoringinformation which contains the scoring values of the targetusers for n songs that have been scored In the third chapterthe related features have been extracted Formally the re-lated features are expressed as follows
Users U fieldu1 fieldu
2 fieldun1113864 1113865 represents the userrsquos
gender age and other related characteristic informationMusiccharacteristics M fieldM
1 fieldM2 fieldM
t1113966 1113967 representsthe relevant characteristic information of music Dance fea-tures D fieldD
1 fieldD2 fieldD
j1113966 1113967Historical interaction data of user U H
M1 M2 Mk1113864 1113865 user Ursquos comprehensive user score formusicM is Scorei and userUrsquos comprehensive user score fordance D is Scorej
332 Embedding According to the previous feature ex-traction work several user and audio features can be ob-tained Firstly the features are encoded through linear layeror embedding layer to obtain a series of vector represen-tations of features then according to these vectors the userand music are encoded )e user below represents severalcharacteristics of the target user which are represented byvectors Taking it as input the encoding vector of userfeatures is obtained through the User Encoder For usercoding because only text type features such as gender andage are used Auto Encoder model can be directly used tocomplete feature extraction In order to be similar to Music
64 33 convolutionkernels
Batch Normalization
Relu function
33 max-pooling
64 33 convolutionkernels
Batch Normalization
Relu function
64 33 convolutionkernels
Batch Normalization
Relu function
64 33 convolutionkernels
Batch Normalization
Relu function
33 max-pooling
fϕ
Figure 5 Embedding module
FC1Relu function
FC2Sigmoid function
SiRelation score
64 33 convolutionkernels
Batch Normalization
Relu function
22 max-pooling
64 33 convolutionkernels
Batch Normalization
Relu function
22 max-pooling
Figure 6 Relation module
Test sample 1
Test sample 2
Test sample 3
Test sample 4
Test sample 5
Test sample
Embedded module Relationship module
Feature concatenation
Relation score
fφ gϕ
Figure 4 Relation network model
8 Complexity
Encoder feature structure AutoInt model l is used to extractuser features here )e encoding structure of the user part isshown in Figure 8
Next for some music evaluated by users because theyknow their characteristics and scores they can combine theircharacteristics with userrsquos feature vectors and input theminto Music Encoder for coding respectively )is processcan combine usersrsquo personalized information for music sothat the same music can be coded differently by MusicEncoder for different users For unevaluatedmusic althoughthere is only the eigenvalue of music it can still obtain itseigenvector through Music Encoder like the music that hasbeen evaluated which is the coding layer Embedding Layerof music )e music feature coding structure is shown inFigure 9
As can be seen from Figure 9 the main structure ofencoder is multihead attention module and its essence is toperformmultiple self-attention calculations to formmultiplesubspaces so that the model can learn different features ofinformation from different angles and finally merge themTake the Music Encoder as an example and its structure isshown in Figure 10
In the multihead attention the feature matrixF f1 f2 ft1113864 1113865 needs to be transformed linearly tocompare the dimension of the feature vector that is QW
Qi
Perform k self-attention calculations as shown in
hlowast
Attention(Q K V) softmaxQK
T
dk
1113888 1113889V (13)
Splice and linearly map the result hlowast using
h concat hlowast1 hlowast2 h
lowastn( 1113857otimesW
o (14)
)e number of music selections has also been adjusted tosome extent When entering you need to have a series ofknown characteristics of the score and its final scoreHowever there will be many historical records of a personAnd the quantity is different and the model structure doesnot support the dynamic adjustment of the input quantityso this paper chooses the sampling method During eachtraining five historical evaluated songs are selected from thehistorical music of user interaction for input After severalrounds of training all the evaluated songs can be basicallyused in the training Although this method is inefficient inusing data sets it can greatly reduce the training time costand the complexity of the model )erefore after trade-offwe chose the method of randomly selecting five data
333 Interest Matching Module )e information aboutusers andmusic in the data set is processed and the obtainedhigh-order nonlinear eigenvector is taken as the output In
User data
Dance Music 1
Dance Music 2
Dance Music m New project
S M R
P
input
Embedding Module
Feature Vector
Combined Vector
Relation Module
Relation Score Ration
Predicted Ration
Figure 7 Model structure
Complexity 9
Max-Pooling
Multi-Head Attention
Field1 Field2 Field3
y1
Figure 8 User encoder model structure
Max-Pooling
Multi-Head Attention
Field1 Fieldt
y2
User feature vector y1
Characteristics of dance music
Figure 9 Music encoder model structure
10 Complexity
the model of this section we hope to give the similarity ofusers about different music scores through feature vectors
Firstly the characteristics of the scored songs and thecharacteristics of the target unscored songs are combined bythe user )en the similarity gφ between the two songs isgiven by comparing the similarity module and relationmodule its size is limited between 0 and 1 by normalizationfunction and finally a k-dimensional numerical vector re-lation score is obtained )e similarity gφmodel is shown in
gφ q1 q2( 1113857 Sigmoid qT1 Wq21113872 1113873 (15)
)e Interest Matching Relation module constructed inthis paper is not complex and the parameter to be trained isonly a matrix W In the experiment we also use a deeperstructure to replace this structure It is found that this willnot only increase the training time and parameter scale butalso reduce the accuracy )erefore we finally choose thevalue between [0 1] obtained by sigmoid after we get theinner product of two vectors about W as the similarityAccording to the similarity degree the related features of theknown graded music are constructed to predict the featuresof the music )e method is weighted average and theweight of each item is the score multiplied by the similaritydegree )e more similar the music and the higher the scorethe more obvious the influence on the prediction resultsFinally an estimated value of the eigenvector is obtained
Finally there is an output layer which synthesizes thetwo scoring results given before and gives the final con-clusion In the first part of the conclusion Y from theprevious user coding music-to-be-predicted estimationfeatures and music-to-be-predicted coding through a linearlayer this part reflects the idea of collaborative filteringbased on similarity and score to get the target score Anotherpart of the result x is obtained by using a Max Pooling layer
to select the value with the greatest correlation )e strategyembodied in this part is that when the songs to be predictedhave a high similarity with the previous historical songs itcan be considered that users are likely to have a certaininterest in the songs to be evaluated so the results have alarge similarity value at this time Finally the two scores areaveraged to get the final output)is is a value between [0 1]to indicate the degree of interest that users may be interestedin
4 Implementation ofPersonalized Recommendation
Traditional models do not use the information of users whointeract with them in the coding process of known music)is leads to the lack of user personality in the recom-mended content Even for two different users the coding ofthe same content is the same which cannot deal with thepersonalized problem well In addition in the actual in-teractive process content and users have different interactivebehaviors and different interactive behaviors often repre-sent different preferences of users However the previousmodels have not been distinguished to this extent resultingin different information brought by different interactivebehaviors not being used For example for praise andcollection collection means that users are more interestedthan praise because collection means that users are likely tolisten to this song repeatedly later while the probability oflistening to praise will be smaller later
In this paper firstly different behavior scores of users aredistinguished and the scores are divided into 1ndash5 pointsaccording to the listening times 6 points for collectionbehavior and 4 points for praise behavior In addition themultihead attention mechanism is introduced When
Linear
Concat
Self-attention
Linear LinearLinear
User feature vector (V)
Music feature vector (M)
Dance feature vector (D)
K
Output
Figure 10 Multihead attention module
Complexity 11
encoding music features in Music Encoder the user featuresand music features are combined and the user personalizedmusic coding is realized in the encoding layer which ensuresthat even if different users operate the same music the finalrecommendation results are still different because of dif-ferent personal characteristics thus realizing the personal-ized music recommendation
41 Model Training and Experimental Results Beforetraining the model it is necessary to divide the positive andnegative classes and determine the training set and test setused by the model For music recommendation label 0means dislike and label 1 means like which is defined as abinary classification problem According to the scoringprocessing of user behavior characteristics in Chapter 3music with a score higher than 5 is recorded as a positiveclass that is if the user listens to music many times or musicwith a little praise or collection behavior is recorded as apositive class Music with a score below 2 is recorded as anegative example indicating that although the user has someinteraction they have not shown interest Negative caseswith the same number of positive classes are randomlyselected from music with scores lower than 2 to ensure thatthe distribution is as balanced as possible After dividingpositive and negative classes the first 80 of the data set isused as the training set and the last 20 as the test set
42 Super Parameter Adjustment )e hyperparameter ad-justment process aims to optimize the performance of themodel First select the super parameters that can be adjusted)en determine whether they will be fixed or variable and ifthe parameters are changeable set them to different values todetermine in which range they will change
Hidden_size the original model is set to 50 and featuresare represented using the model by setting the number ofhidden layers)e hidden layer is set to 32 64 18 and 256 inthe implementation process and the best parameters aredetermined by experiments in TP100 data set in Figure 11
According to Figure 11 when the hidden layer is set to32 the model is in an underfitting state and cannot becharacterized With the increase of the hidden layer theaccuracy rate and recall rate are continuously improved butwhen the hidden layer is set to 256 both indicators decreaseslightly )erefore in the subsequent experiment the hid-den_size is set to 128
Learning_rate it depends on the Adam optimizer in themodel )e learning rate of each parameter is adapted bymaking smaller updates to frequent parameters and largerupdates to infrequent parameters )e learning rate of theoriginal model is set to 0001 In this experiment thelearning rates are set to 0001 001 01 and 05 respectivelyAccording to Figure 12 when the learning rates are 0001and 001 the accuracy is better In the subsequent experi-ment the learning_rate is set to 001
Batch_size when smaller batches are used a period oftraining is more detailed which usually leads to a decrease inthe number of convergent iterations but the training time islong On the other hand the more the batches the slower theconvergence speed which reduces the risk of overfitting andreduces the training time )e effect of batch_size on ac-curacy is shown in Figure 13
Try to use the batch size training model from 100 to 1000in the whole process As can be seen from Figure 13 andTable 2 using a smaller batch size the training time is longerUsing a large batch size (when it exceeds 700) a memoryerror was encountered
)erefore in the follow-up experiment the batch size isset to 600 for model training which not only meets thetraining time but also does not overflow the memory
43 Experimental Results )e whole training process Loss-Epochs is shown in Figure 14 During each training fivesongs with historical evaluation are selected from the his-torical music interacted by users for input After severalrounds of training all the evaluated songs can basically beused in training and the training loss is basically stable after1024 iterations
0002004006008
01012014016018
02
32 64 128 256Ev
alua
tion
inde
x
hidden_size
RecallPrecision
Figure 11 Impact of hidden size on evaluation indicators
12 Complexity
In order to verify the effectiveness of the model thispaper implements Neural Network Based CollaborativeFiltering (NCF) model and SVDmodel by Python which areverified in TP100 and TP500 data sets respectively )eaccuracy and recall rate are used to evaluate the accuracy ofdifferent recommendation lengths )e accuracy results ofdifferent recommendation lengths are shown in Figure 15
It can be seen from Figure 15 that the accuracy of thedeep learning recommendation model based on Relation-ship-Learning is obviously higher than that of the traditionalSVD recommendation algorithm in two data sets about 3higher than that of the collaborative filtering algorithm
based on neural network in TP100 data set and similar inTP500 data set with lower sparsity both of which are higherthan SVD algorithm
As can be seen from Figure 16 this model has obviousadvantages in both data sets With the increasing number ofrecommendations the recall rate gradually increases whichis about 10 higher than the traditional SVD algorithm InTP500 data sets with dense data the recall rate reaches about03 To sum up the deep learning recommendation modelbased on relationship learning implemented in this papercan accurately predict usersrsquo music preferences and finallycan accurately recommend music lists for users
07
075
08
085
09
095
0001001011A
ccur
acy
learning_rate
Figure 12 Impact of learning rate on accuracy
0
01
02
03
04
05
06
07
08
09
1
0 100 200 300 400 500 600 700 800
Acc
urac
y
batch_size
Figure 13 Effect of batch_size on accuracy
Table 2 Average running time per Epoch
batch_size 100 200 400 600 700Runtime (s) 67 39 20 9 8
Complexity 13
0 128 256 512 102400
02
04
06
08
10
12
14
16
18 Cross entropy loss of model training
Loss
Epochs
Figure 14 Model training loss
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
SVDNCFRelation-Learning
(a)
SVDNCFRelation-Learning
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
(b)
Figure 15 Accuracy of two data sets (a) TP100 data set (b) TP500 data set
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(a)
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(b)
Figure 16 Recall rate of two data sets (a) TP100 data set (b) TP500 data set
14 Complexity
5 Conclusion
Faced with a large number of dances and songs it is difficultfor people to quickly find dance music that meets theirinterests )e emergence of dance music recommendationsystem can recommend dance music that users may like andhelp users quickly discover or find their favorite dances andsongs )is kind of recommendation service can provideusers with a good experience and bring commercial benefitsso the field of dance music recommendation has become theresearch direction of industry and scholars In this paperrelation learning is introduced into dance music recom-mendation system and the relation model is applied todance music recommendation In the experiment the ac-curacy and recall rate are used to verify the effectiveness ofthe model in the direction of dance music recommendation
Data Availability
)e experimental data used to support the findings of thisstudy are available from the corresponding author uponrequest
Conflicts of Interest
)e author declares that no conflicts of interest regardingthis work
References
[1] Y Han Z Han J Wu et al ldquoArtificial intelligence recom-mendation system of cancer rehabilitation scheme based onIoT technologyrdquo IEEE Access vol 8 pp 44924ndash44935 2020
[2] A Rw M A Xiao and J A Chi ldquoHeterogeneous informationnetwork-based music recommendation system in mobilenetworksrdquo Computer Communications vol 150 pp 429ndash4372020
[3] X Wen ldquoUsing deep learning approach and IoT architectureto build the intelligent music recommendation systemrdquo SoftComputing vol 25 no 1 pp 1ndash10 2020
[4] H-G Kim G Y Kim and J Y Kim ldquoMusic recommendationsystem using human activity recognition from accelerometerdatardquo IEEE Transactions on Consumer Electronics vol 65no 3 pp 349ndash358 2019
[5] M S Fathollahi and F Razzazi ldquoMusic similarity measure-ment and recommendation system using convolutional neuralnetworksrdquo International Journal of Multimedia InformationRetrieval vol 5 pp 1ndash11 2021
[6] G Sun YWong and Z Cheng ldquoDeepDance music-to-dancemotion choreography with adversarial learningrdquo IEEETransactions on Multimedia vol 99 p 1 2020
[7] J M Agaku ldquo)e Girinya dance theatre of the Tiv people ofNigeria an aesthetic evaluationrdquo International Journal ofIntangible Heritage vol 3 no 6 pp 29ndash41 2008
[8] G Mota and L Abreu ldquo)irty years of music and dramaeducation in the Madeira Island facing future challengesrdquoInternational Journal of Music Education vol 32 no 3pp 360ndash374 2014
[9] B Montero ldquoPractice makes perfect the effect of dancetraining on the aesthetic judgerdquo Phenomenology and theCognitive Sciences vol 11 no 1 pp 59ndash68 2012
[10] A Manfre I Infantino F Vella and S Gaglio ldquoAn automaticsystem for humanoid dance creationrdquo Biologically InspiredCognitive Architectures vol 15 pp 1ndash9 2016
[11] D Aledo B Carrion Schafer and F Moreno ldquoVHDL vsSystemC design of highly parameterizable artificial neuralnetworksrdquo IEICE - Transactions on Info and Systemsvol E102D no 3 pp 512ndash521 2019
[12] B Sheng and G Sun ldquoMatrix factorization recommendationalgorithm based on multiple social relationshipsrdquo Mathe-matical Problems in Engineering vol 2021 Article ID6610645 8 pages 2021
[13] L Jiang Y Cheng L Yang J Li H Yan and X Wang ldquoAtrust-based collaborative filtering algorithm for E-commercerecommendation systemrdquo Journal of ambient intelligence andhumanized computing vol 10 no 8 pp 3023ndash3034 2019
[14] A Dm A Xl and A Qd ldquoHumming-query and reinforce-ment-learning based modeling approach for personalizedmusic recommendationrdquo Procedia Computer Science vol 176pp 2154ndash2163 2020
Complexity 15

filtering algorithms are mainly divided into two categoriesmemory-based collaborative filtering and model-basedcollaborative filtering
221 Collaborative Filtering Based on Nearest Neighbors
(1) Collaborative Filtering Based on Users Resnick firstproposed a collaborative filtering algorithm based on usersin 1994 By using the scoring matrix R (U I) to model thepreferences of users U about goods I it is considered thatusersrsquo preferences generally do not change with time andmay have similar behavioral preferences for a long time)erefore users with similar preferences in user history dataare grouped to recommend products to those users
In the music and dance recommendation system thehistorical data used are the operation data such as userslistening to songs whether they like or collect songs and thescores of dances For example both user 1 and user 2 oftenlisten to popular music and user 3 likes to listen to Englishmusic )rough similarity calculation it can be concludedthat user 1 and user 2 are the same kind of users and user 2 isrecommended by using the music listened by user 1 )eprinciple of user-based collaborative filtering algorithm isshown in Figure 2
In order to make recommendations to users it is nec-essary to collect usersrsquo historical behavior records and es-tablish a user-item matrix Rmlowastn where m represents thenumber of active users and n represents the number of itemsBy collecting the explicit scores of users on the project theuserrsquos interest in the project is generally indicated by a scorelevel of 0 to 5 )e higher the score the more interested theuser is in the project and the score of 0 indicates that theuser dislikes the project at all In addition you can use userimplicit ratings to represent user ratings Use the user tolisten to a certain music times or praise collect commentand other behaviors use 1 to indicate that there are relatedbehaviors and 0 to indicate that there is no browsing be-havior After weighting the above behaviors the implicitevaluation matrix of the user on the project is obtained [12]
It is difficult to find the similarity degree for such abstractconcepts as users so it is usually to find the similarity degreeof usersrsquo scoring on specific items and compare the similaritydegree of scoring behavior between two users by analyzingthe similarity degree of scoring results of two users on thecontent that they jointly evaluated excessively In this waythe problem is transformed into a problem of solving thesimilarity between vectors Ri and Rj are defined as thecontent set evaluated by two users and Vi and Vj are definedas the scoring vectors of the content by two users in Ri and RjGenerally the method of calculating the similarity betweenthe two vectors is defined as follows
Jaccard coefficient method the similarity is obtained bycalculating the ratio of intersection and union of two usersrsquoscores in the user history behavior set )e larger the ratiothe higher the similarity Generally Jaccard coefficient issuitable for implicit user behavior similarity calculation )eJaccard coefficient is calculated as shown in
Jaccard(i j) Ri cap
Rj
11138681113868111386811138681113868
11138681113868111386811138681113868
Ri cupRj
11138681113868111386811138681113868
11138681113868111386811138681113868 (1)
Cosine similarity method the cosine value of the anglebetween two user rating vectors in space is used to expressthe similarity between them)e closer the cosine value is to1 the more similar the two vectors are )e calculationprocess is shown in
cos(i j) 1113936kvikvjk
1113936kv2ik
1113969 1113936kv
2jk
1113969 (2)
Pearson correlation coefficient method decentralizationof cosine similarity data is an improvement of cosinesimilarity method In the recommendation system theremay bemissing evaluation of a certain item by users Pearsoncorrelation coefficient method automatically fills the missingvalue as 0 and then uses other dimensions to reduce thedimension average of missing vectors to satisfy cosinesimilarity algorithm Pearson correlation coefficient is cal-culated as shown in
Pearson(i j) 1113936k vik minus vi( 1113857 vjk minus vj1113872 1113873
1113936k vik minus vi( 11138572
1113969
1113936k vjk minus vj1113872 11138732
1113969 (3)
Finally according to similar users traversing all positivefeedback items weighted summation is carried out theinterest scores of user I for all items are calculated and thescore prediction is made for each item)e score calculationis shown in
Pis 1113936jisinS(uk)sim(i j) times ris
1113936jisinS(uk)|sim(i j)| (4)
where S(u k) is a user browsing item set similar to user i risis user irsquos interest in item S and sim(i j) is the similaritybetween user i and j
(2) Collaborative Filtering Based on Project Project-based collaborative filtering method mainly focuses onidentifying the similarity of projects However project-basedcollaborative filtering looks for users who have used twoprojects for similar evaluations If both items Music 1 andMusic 2 receive similar ratings throughout the rating dataset it can be assumed that users who like Music 1 may alsolike Music 2 and vice versa )e principle of project-basedcollaborative filtering is shown in Figure 3
Similar to the user-based collaborative filtering methodthe item-based collaborative filtering method uses the userrsquosrating of other content to predict the rating of unevaluatedcontent Similarly ω(i j) needs to be defined between thecontent that has been evaluated and the content that has notbeen evaluated indicating the degree of similarity betweenRi and Rj )e formula is shown in
ω(i j) 1113944k
vik times vjk
1113936riisinRiv2ik
1113969 1113936jisinRj
v2jk
1113969 (5)
4 Complexity
After that the unknown scores can be estimated indifferent ways such as weighted sum Here C (U K) is asimilar set of items in the user evaluation data set and rui i isthe interest of user u in item i )e calculation is shown in
1113958Pis 1113936jisinC(uk)ω(i j) times rus
1113936jisinC(uk)|ω(i j)| (6)
Although the user-based collaborative filtering algo-rithm is logically simple it may take a lot of time to deal withbig data )e project-based collaborative filtering methodsolves the problem of complex user matrix By using asignificantly smaller number of items large-scale matrixoperations in the user-item scoring matrix can be avoidedand project-based collaborative filtering is more time-cost-effective to implement
Item-based collaborative filtering depends to a greatextent on the number of times songs appear in the data setBecause it is impossible to determine whether songs exist inthe user playlist the item-based collaborative filtering sys-tem designates those songs that appear in many playlists inthe data set as more valuable data in this way acting as thebasic processing for item-based collaborative filtering Firstmatch each song in the playlist with a similar song in thesong data set and record it the system records it as ldquosimilar
tracksrdquo and the playlist obtains the most frequentlyappearing songs from the ldquosimilar tracksrdquo matrix com-prehensively considers the userrsquos preference information forsongs and then recommends music to other users who aresimilar to the userrsquos preferences and often listen to them Inthe music recommendation system although the number ofsongs is less than the number of hundreds of millions ofusers it is also very large Each user playlist may containmore than 50 to 100 songs so it is muchmore difficult to findthe similarity of songs in the database of tens of millions ofsongs so the performance advantage of item-based col-laborative filtering is lost [13]
222 Model-Based Collaborative Filtering Model-basedcollaborative filtering is obviously different from the othertwo collaborative filtering methods user-based and content-based methods estimate the unknown item scores directlyaccording to the statistical historical data but model-basedmethods first use the original data to train and generate aspecific model which can quickly predict user preferencesaccording to the generated model )erefore when there area large number of users and projects the model-basedrecommendation algorithm has a high degree of scalabilityand rapidity Common models are as follows
Recommend
UserA
UserB
UserC
Dance Music 1
Dance Music 2
Dance Music 3
Dance Music 4
Dance Music 5
Similarity
Figure 3 Schematic diagram of project-based collaborative filtering
User A
User B
User C
Dance Music 1
Dance Music 2
Dance Music 3
Recommend
Dance Music 4
Dance Music 5
Similarity
Figure 2 Schematic diagram of user-based collaborative filtering
Complexity 5
(1) Bayesian Model Bayesian prediction model is a kind ofprediction using Bayesian statistics Bayesian statistics isdifferent from general statistical methods which does notuse model information and data information but uses priorinformation )rough the method of empirical analysis theprediction results of Bayesian prediction model are com-pared with those of ordinary regression prediction modeland the results show that Bayesian prediction model hasobvious advantages
Bayesian model revolves around giving evidence (E) andobtaining hypothesis (H) which involves two conceptshypothesis probability P(H) before obtaining evidence andhypothesis probability P(HE) after obtaining evidence )emodel is continuously learned by training data and the dataare verified to evaluate the model and make new predictions
In practical applications Naive Bayesian classifier andcollaborative filtering are generally used to implementrecommendation system which can filter new informationand predict whether users need given resources However itis almost impossible to obtain a completely independent setof data in practice Moreover when the number of itemsjointly evaluated is small this direct calculation may distortthe obtained probability
(2) Matrix Decomposition Model Matrix decompositionmodel is a commonly used technology to build recom-mendation system In 2006 Netflix held Netflix PrizeChallenge and matrix decomposition technology was firstproposed In order to decompose the scoring matrix featuresinto low-dimensional spaces the matrix decompositiontechnology learns potential space vectors for each user andeach item which are divided into user feature vectors p anditem feature vectors q )e specific representation of thescoring matrix is shown in
R pi times qTj (7)
Here R represents the training score matrix and i and jrepresent users and projects respectively By learning theminimized objective function (formula (8)) in the knownscores the potential space vectors P and q can be obtained
Yij FLFM
pi qj1113872 1113873 pTi qj (8)
)e algorithms commonly used in matrix factorizationmodel include nonnegative matrix factorization (NMF)algorithm and singular value decomposition (SVD) algo-rithm )e nonnegative matrix factorization algorithm usesproject content to construct the potential space of the projectand then uses user information such as known scores tolearn the potential space of users So as to overcome the coldstart problem in collaborative filtering 28 Singular valuedecomposition (SVD) algorithmmaps users and items to thepotential factor space of f-dimension and the model con-structs users and items as interaction problems within thespace
In addition model-based collaborative filtering algo-rithms also include graph-based walking method SimRankalgorithm and clustering-based collaborative algorithmCollaborative filtering algorithm can recommend variousfavorite contents to users according to historical data but
the recommendation results may not be satisfactory whenthe scoring data are sparse large-scale matrix operation maybe needed when the data volume is huge and the timeconsumption will increase linearly with the data scale soreal-time recommendation cannot be achieved
23 Content-Based Recommendation )e content-basedrecommendation algorithm takes into account the items ofinterest that users have previously shown through ratingsand then constructs user profiles that match the userrsquos in-terest in such items Once the user clearly shows interest inan item the algorithm will analyze the characteristics of theitem and then recommend similar items to the user )econtent descriptor of a project can have many differentforms which can usually be described by tags or projectcontents for example user tags and tags related to projectattributes and related types are generally classified bymanual or machine learning algorithms When a user listensto a popular song about campus the content-based algo-rithm will recommend another type of campus song to theuser
Early content-based recommendation algorithms mostlydeal with text content so early content-based recommen-dation systems mainly use text retrieval technology Vectorspace model (VSM) can match documents according tokeywords and transform song names and singer names intovectors by using word frequency-inverse document fre-quency (TF-IDF) technology TF is the number of wordsappearing and IDF represents the information of words If aword appears more frequently in lyrics or song titles it mayplay a key role in lyrics )e TF-IDF definition is shown in
TF minus IDF tk dj1113872 1113873 TF tk dj1113872 1113873logN
nK (9)
)eTF-IDF algorithm is used to calculate the words withgreater weight in the data and the cosine similarity algo-rithm mentioned above is used to find other songs similar tothis song and recommend them to users
3 Research on Recommendation ModelBased onUser Behavior andMusic andDance
Referring to the correlation model of image classificationthis paper introduces the model of Relationship-Learninginto the field of music recommendation In this model deepneural network and automatic encoder are used to combinethe characteristics of user behavior and music audio andinput them into Music Encoder to realize personalizedcoding in the coding stage to ensure the personalization ofrecommendation By calculating the similarity of userrsquosinterest preference and the similarity of song feature theprediction score of userrsquos music to be selected is obtainedafter averaging them
31 Model Introduction )rough reading the literature weknow that the cold start problem in the recommendationsystem is mainly divided into two subproblems completecold start and incomplete cold start and there are some
6 Complexity
differences in the solutions of these two problems At thesame time the processing process of image classificationdirection in small sample data can be used for reference byrecommendation system For example the classificationproblem of some pictures that have not been seen at all isZero-Shot while the classification problem of some picturesthat appear less frequently is Few-Shot Among these twoproblems the Zero-Shot problem can correspond to thecomplete cold start problem in the recommendationproblem while the Few-Shot problem can correspond to theincomplete cold start problem in the recommendationproblem For the Few-Shot problem and Zero-Shot problema similar solution to the cold start problem in the recom-mendation system is given
For the cold start problem one of the existing methods isto use user information and article information If effectiveinformation can be collected certain clustering operationscan be carried out on this basis and other similar usersrsquofavorite music can be used to recommend the user In ad-dition the structure of Auto Encoder can be used to extractfeatures At this time for the cold-start user the AutoEncoder encodes first and then decodes and the finallydecoded value includes the value inferred from the usercharacteristics [14]
In this paper we pay more attention to the problem ofincomplete cold start when designing the model and use thelimited scoring information as efficiently as possible toanalyze the scoring habits of users more accurately At thesame time it draws lessons from the idea of relationshiplearning in the field of computer vision hoping that therecommendation system can learn how to compare simi-larity in a more accurate way On this basis we investigatethe application of metric learning in recommendationsystem and find that although these methods have the idea ofmaking recommendation system learn distance informationto infer similarity the distance that defines similarity is low-order linear similarity Although this method can give acertain distance description it is difficult to fully capture andutilize the high-order features extracted by neural network)is paper hopes to calculate the similarity between picturesin relation learning and apply it to the recommendationsystem to calculate the similarity between people music andmusic user and music
32 Metric-Learning Model In 2018 Sung and Flood pro-posed a relation network model based on the metric-learning method to solve the classification problem of asmall number of labeled sample data in the field of computervision in deep learning as shown in Figure 4 )e authorproposes a relational network which compares the inputimages in the test set with a small number of known labeledsample images and calculates the correlation scores so as toclassify them )e relation network consists of two modulesan embedded module and a relational module Firstly theembedding module extracts the relevant feature informa-tion and then the relational module compares these em-bedding and obtains the relation score to determine whetherthey belong to the same class
Each block has 64 3times 3 convolution kernels a batchspecification layer and ReLU nonlinear function In addi-tion convolution blocks 1 and 3 have a 2times 2 maximumpooling layer )e author uses four convolution blocks toextract rich feature information between samples with fewerparameters )e network structure is shown in Figure 5
In the relation module you need to combine featuresfirst )e feature combination S recombines the featureinformation of the samples in the training set and the sampleinformation in the test set so that the relational encoder Gcan learn better from the combined features First thefeature mappings of the same class are summarized asshown in
fφ Li( 1113857 1113944K
J1Lij (10)
where Lij(i 1 i 2 j 1 j 2 K) denotes thetraining set features extracted from the embedded moduleand fφ(Li) denotes the mapping of feature information)emapping of combined features can be obtained by summingthe mapped feature sets )e formula is shown in (11)
Si fφ Li( 1113857 + fφ Qn( 1113857 (11)
Si represents the feature formed by the feature mappingof the training data set and the recombination of the testsamples and fφ(Qn) represents the feature from the testsamples )e model does not use conventional Euclideandistance or cosine distance instead we use nonlinear metriclearning In this part two convolution blocks and two fullyconnected layers are used to compare the two samples Eachconvolution block has 64 3times 3 convolution kernels a batchspecification layer a ReLU nonlinear activation layer and a2times 2 maximum pooling layer Finally through two fullyconnected layers the similarity relation score isin[0 1] be-tween the test samples and the training samples is finallyobtained by using the activation functions ReLU and sig-moid )e relation score is shown in
Relation score gϕ S fφ Lij1113872 1113873 fφ Qn( 11138571113872 11138731113872 1113873 (12)
)e detailed structure of the module is shown inFigure 6
33 Construction of Relation Model )e basic idea of thismodel is determined as a hybrid recommendation modellearning the similarity of user ratings by using the idea ofRelationship-Learning and then estimating the rating valuethrough collaborative filtering)emodel structure is shownin Figure 7
)is model mainly deals with two problems in recom-mendation system Firstly timeliness in the current era ofinformation explosion a large amount of data is uploaded tothe Internet every day It is difficult to obtain enough ratingdata at the beginning of these newly uploaded data whichcan be used in the recommendation system for target usersMusic recommendation system often encounters some newsongs which need to be recommended to users for audition
Complexity 7
)erefore through the cold start mechanism of the modelthe problem of new content recommendation can be solvedand the recommendation system can cope with the problemsbrought by timeliness and new content
Secondly personalization when users evaluate songseven if two people give favorable comments on the samesong their motives may be different for example oneperson likes the singer so they like this song and the otherperson likes the song style and likes this song )erefore themodel carries out more personalized processing for songrecommendation according to music characteristics anduser characteristics
331 Enter Data )e input of the model mainly consists oftwo parts one part is the feature information which includesthe personal feature information of the target user thefeature information of the scored n songs and the featureinformation of the target songs )e other part is the scoringinformation which contains the scoring values of the targetusers for n songs that have been scored In the third chapterthe related features have been extracted Formally the re-lated features are expressed as follows
Users U fieldu1 fieldu
2 fieldun1113864 1113865 represents the userrsquos
gender age and other related characteristic informationMusiccharacteristics M fieldM
1 fieldM2 fieldM
t1113966 1113967 representsthe relevant characteristic information of music Dance fea-tures D fieldD
1 fieldD2 fieldD
j1113966 1113967Historical interaction data of user U H
M1 M2 Mk1113864 1113865 user Ursquos comprehensive user score formusicM is Scorei and userUrsquos comprehensive user score fordance D is Scorej
332 Embedding According to the previous feature ex-traction work several user and audio features can be ob-tained Firstly the features are encoded through linear layeror embedding layer to obtain a series of vector represen-tations of features then according to these vectors the userand music are encoded )e user below represents severalcharacteristics of the target user which are represented byvectors Taking it as input the encoding vector of userfeatures is obtained through the User Encoder For usercoding because only text type features such as gender andage are used Auto Encoder model can be directly used tocomplete feature extraction In order to be similar to Music
64 33 convolutionkernels
Batch Normalization
Relu function
33 max-pooling
64 33 convolutionkernels
Batch Normalization
Relu function
64 33 convolutionkernels
Batch Normalization
Relu function
64 33 convolutionkernels
Batch Normalization
Relu function
33 max-pooling
fϕ
Figure 5 Embedding module
FC1Relu function
FC2Sigmoid function
SiRelation score
64 33 convolutionkernels
Batch Normalization
Relu function
22 max-pooling
64 33 convolutionkernels
Batch Normalization
Relu function
22 max-pooling
Figure 6 Relation module
Test sample 1
Test sample 2
Test sample 3
Test sample 4
Test sample 5
Test sample
Embedded module Relationship module
Feature concatenation
Relation score
fφ gϕ
Figure 4 Relation network model
8 Complexity
Encoder feature structure AutoInt model l is used to extractuser features here )e encoding structure of the user part isshown in Figure 8
Next for some music evaluated by users because theyknow their characteristics and scores they can combine theircharacteristics with userrsquos feature vectors and input theminto Music Encoder for coding respectively )is processcan combine usersrsquo personalized information for music sothat the same music can be coded differently by MusicEncoder for different users For unevaluatedmusic althoughthere is only the eigenvalue of music it can still obtain itseigenvector through Music Encoder like the music that hasbeen evaluated which is the coding layer Embedding Layerof music )e music feature coding structure is shown inFigure 9
As can be seen from Figure 9 the main structure ofencoder is multihead attention module and its essence is toperformmultiple self-attention calculations to formmultiplesubspaces so that the model can learn different features ofinformation from different angles and finally merge themTake the Music Encoder as an example and its structure isshown in Figure 10
In the multihead attention the feature matrixF f1 f2 ft1113864 1113865 needs to be transformed linearly tocompare the dimension of the feature vector that is QW
Qi
Perform k self-attention calculations as shown in
hlowast
Attention(Q K V) softmaxQK
T
dk
1113888 1113889V (13)
Splice and linearly map the result hlowast using
h concat hlowast1 hlowast2 h
lowastn( 1113857otimesW
o (14)
)e number of music selections has also been adjusted tosome extent When entering you need to have a series ofknown characteristics of the score and its final scoreHowever there will be many historical records of a personAnd the quantity is different and the model structure doesnot support the dynamic adjustment of the input quantityso this paper chooses the sampling method During eachtraining five historical evaluated songs are selected from thehistorical music of user interaction for input After severalrounds of training all the evaluated songs can be basicallyused in the training Although this method is inefficient inusing data sets it can greatly reduce the training time costand the complexity of the model )erefore after trade-offwe chose the method of randomly selecting five data
333 Interest Matching Module )e information aboutusers andmusic in the data set is processed and the obtainedhigh-order nonlinear eigenvector is taken as the output In
User data
Dance Music 1
Dance Music 2
Dance Music m New project
S M R
P
input
Embedding Module
Feature Vector
Combined Vector
Relation Module
Relation Score Ration
Predicted Ration
Figure 7 Model structure
Complexity 9
Max-Pooling
Multi-Head Attention
Field1 Field2 Field3
y1
Figure 8 User encoder model structure
Max-Pooling
Multi-Head Attention
Field1 Fieldt
y2
User feature vector y1
Characteristics of dance music
Figure 9 Music encoder model structure
10 Complexity
the model of this section we hope to give the similarity ofusers about different music scores through feature vectors
Firstly the characteristics of the scored songs and thecharacteristics of the target unscored songs are combined bythe user )en the similarity gφ between the two songs isgiven by comparing the similarity module and relationmodule its size is limited between 0 and 1 by normalizationfunction and finally a k-dimensional numerical vector re-lation score is obtained )e similarity gφmodel is shown in
gφ q1 q2( 1113857 Sigmoid qT1 Wq21113872 1113873 (15)
)e Interest Matching Relation module constructed inthis paper is not complex and the parameter to be trained isonly a matrix W In the experiment we also use a deeperstructure to replace this structure It is found that this willnot only increase the training time and parameter scale butalso reduce the accuracy )erefore we finally choose thevalue between [0 1] obtained by sigmoid after we get theinner product of two vectors about W as the similarityAccording to the similarity degree the related features of theknown graded music are constructed to predict the featuresof the music )e method is weighted average and theweight of each item is the score multiplied by the similaritydegree )e more similar the music and the higher the scorethe more obvious the influence on the prediction resultsFinally an estimated value of the eigenvector is obtained
Finally there is an output layer which synthesizes thetwo scoring results given before and gives the final con-clusion In the first part of the conclusion Y from theprevious user coding music-to-be-predicted estimationfeatures and music-to-be-predicted coding through a linearlayer this part reflects the idea of collaborative filteringbased on similarity and score to get the target score Anotherpart of the result x is obtained by using a Max Pooling layer
to select the value with the greatest correlation )e strategyembodied in this part is that when the songs to be predictedhave a high similarity with the previous historical songs itcan be considered that users are likely to have a certaininterest in the songs to be evaluated so the results have alarge similarity value at this time Finally the two scores areaveraged to get the final output)is is a value between [0 1]to indicate the degree of interest that users may be interestedin
4 Implementation ofPersonalized Recommendation
Traditional models do not use the information of users whointeract with them in the coding process of known music)is leads to the lack of user personality in the recom-mended content Even for two different users the coding ofthe same content is the same which cannot deal with thepersonalized problem well In addition in the actual in-teractive process content and users have different interactivebehaviors and different interactive behaviors often repre-sent different preferences of users However the previousmodels have not been distinguished to this extent resultingin different information brought by different interactivebehaviors not being used For example for praise andcollection collection means that users are more interestedthan praise because collection means that users are likely tolisten to this song repeatedly later while the probability oflistening to praise will be smaller later
In this paper firstly different behavior scores of users aredistinguished and the scores are divided into 1ndash5 pointsaccording to the listening times 6 points for collectionbehavior and 4 points for praise behavior In addition themultihead attention mechanism is introduced When
Linear
Concat
Self-attention
Linear LinearLinear
User feature vector (V)
Music feature vector (M)
Dance feature vector (D)
K
Output
Figure 10 Multihead attention module
Complexity 11
encoding music features in Music Encoder the user featuresand music features are combined and the user personalizedmusic coding is realized in the encoding layer which ensuresthat even if different users operate the same music the finalrecommendation results are still different because of dif-ferent personal characteristics thus realizing the personal-ized music recommendation
41 Model Training and Experimental Results Beforetraining the model it is necessary to divide the positive andnegative classes and determine the training set and test setused by the model For music recommendation label 0means dislike and label 1 means like which is defined as abinary classification problem According to the scoringprocessing of user behavior characteristics in Chapter 3music with a score higher than 5 is recorded as a positiveclass that is if the user listens to music many times or musicwith a little praise or collection behavior is recorded as apositive class Music with a score below 2 is recorded as anegative example indicating that although the user has someinteraction they have not shown interest Negative caseswith the same number of positive classes are randomlyselected from music with scores lower than 2 to ensure thatthe distribution is as balanced as possible After dividingpositive and negative classes the first 80 of the data set isused as the training set and the last 20 as the test set
42 Super Parameter Adjustment )e hyperparameter ad-justment process aims to optimize the performance of themodel First select the super parameters that can be adjusted)en determine whether they will be fixed or variable and ifthe parameters are changeable set them to different values todetermine in which range they will change
Hidden_size the original model is set to 50 and featuresare represented using the model by setting the number ofhidden layers)e hidden layer is set to 32 64 18 and 256 inthe implementation process and the best parameters aredetermined by experiments in TP100 data set in Figure 11
According to Figure 11 when the hidden layer is set to32 the model is in an underfitting state and cannot becharacterized With the increase of the hidden layer theaccuracy rate and recall rate are continuously improved butwhen the hidden layer is set to 256 both indicators decreaseslightly )erefore in the subsequent experiment the hid-den_size is set to 128
Learning_rate it depends on the Adam optimizer in themodel )e learning rate of each parameter is adapted bymaking smaller updates to frequent parameters and largerupdates to infrequent parameters )e learning rate of theoriginal model is set to 0001 In this experiment thelearning rates are set to 0001 001 01 and 05 respectivelyAccording to Figure 12 when the learning rates are 0001and 001 the accuracy is better In the subsequent experi-ment the learning_rate is set to 001
Batch_size when smaller batches are used a period oftraining is more detailed which usually leads to a decrease inthe number of convergent iterations but the training time islong On the other hand the more the batches the slower theconvergence speed which reduces the risk of overfitting andreduces the training time )e effect of batch_size on ac-curacy is shown in Figure 13
Try to use the batch size training model from 100 to 1000in the whole process As can be seen from Figure 13 andTable 2 using a smaller batch size the training time is longerUsing a large batch size (when it exceeds 700) a memoryerror was encountered
)erefore in the follow-up experiment the batch size isset to 600 for model training which not only meets thetraining time but also does not overflow the memory
43 Experimental Results )e whole training process Loss-Epochs is shown in Figure 14 During each training fivesongs with historical evaluation are selected from the his-torical music interacted by users for input After severalrounds of training all the evaluated songs can basically beused in training and the training loss is basically stable after1024 iterations
0002004006008
01012014016018
02
32 64 128 256Ev
alua
tion
inde
x
hidden_size
RecallPrecision
Figure 11 Impact of hidden size on evaluation indicators
12 Complexity
In order to verify the effectiveness of the model thispaper implements Neural Network Based CollaborativeFiltering (NCF) model and SVDmodel by Python which areverified in TP100 and TP500 data sets respectively )eaccuracy and recall rate are used to evaluate the accuracy ofdifferent recommendation lengths )e accuracy results ofdifferent recommendation lengths are shown in Figure 15
It can be seen from Figure 15 that the accuracy of thedeep learning recommendation model based on Relation-ship-Learning is obviously higher than that of the traditionalSVD recommendation algorithm in two data sets about 3higher than that of the collaborative filtering algorithm
based on neural network in TP100 data set and similar inTP500 data set with lower sparsity both of which are higherthan SVD algorithm
As can be seen from Figure 16 this model has obviousadvantages in both data sets With the increasing number ofrecommendations the recall rate gradually increases whichis about 10 higher than the traditional SVD algorithm InTP500 data sets with dense data the recall rate reaches about03 To sum up the deep learning recommendation modelbased on relationship learning implemented in this papercan accurately predict usersrsquo music preferences and finallycan accurately recommend music lists for users
07
075
08
085
09
095
0001001011A
ccur
acy
learning_rate
Figure 12 Impact of learning rate on accuracy
0
01
02
03
04
05
06
07
08
09
1
0 100 200 300 400 500 600 700 800
Acc
urac
y
batch_size
Figure 13 Effect of batch_size on accuracy
Table 2 Average running time per Epoch
batch_size 100 200 400 600 700Runtime (s) 67 39 20 9 8
Complexity 13
0 128 256 512 102400
02
04
06
08
10
12
14
16
18 Cross entropy loss of model training
Loss
Epochs
Figure 14 Model training loss
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
SVDNCFRelation-Learning
(a)
SVDNCFRelation-Learning
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
(b)
Figure 15 Accuracy of two data sets (a) TP100 data set (b) TP500 data set
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(a)
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(b)
Figure 16 Recall rate of two data sets (a) TP100 data set (b) TP500 data set
14 Complexity
5 Conclusion
Faced with a large number of dances and songs it is difficultfor people to quickly find dance music that meets theirinterests )e emergence of dance music recommendationsystem can recommend dance music that users may like andhelp users quickly discover or find their favorite dances andsongs )is kind of recommendation service can provideusers with a good experience and bring commercial benefitsso the field of dance music recommendation has become theresearch direction of industry and scholars In this paperrelation learning is introduced into dance music recom-mendation system and the relation model is applied todance music recommendation In the experiment the ac-curacy and recall rate are used to verify the effectiveness ofthe model in the direction of dance music recommendation
Data Availability
)e experimental data used to support the findings of thisstudy are available from the corresponding author uponrequest
Conflicts of Interest
)e author declares that no conflicts of interest regardingthis work
References
[1] Y Han Z Han J Wu et al ldquoArtificial intelligence recom-mendation system of cancer rehabilitation scheme based onIoT technologyrdquo IEEE Access vol 8 pp 44924ndash44935 2020
[2] A Rw M A Xiao and J A Chi ldquoHeterogeneous informationnetwork-based music recommendation system in mobilenetworksrdquo Computer Communications vol 150 pp 429ndash4372020
[3] X Wen ldquoUsing deep learning approach and IoT architectureto build the intelligent music recommendation systemrdquo SoftComputing vol 25 no 1 pp 1ndash10 2020
[4] H-G Kim G Y Kim and J Y Kim ldquoMusic recommendationsystem using human activity recognition from accelerometerdatardquo IEEE Transactions on Consumer Electronics vol 65no 3 pp 349ndash358 2019
[5] M S Fathollahi and F Razzazi ldquoMusic similarity measure-ment and recommendation system using convolutional neuralnetworksrdquo International Journal of Multimedia InformationRetrieval vol 5 pp 1ndash11 2021
[6] G Sun YWong and Z Cheng ldquoDeepDance music-to-dancemotion choreography with adversarial learningrdquo IEEETransactions on Multimedia vol 99 p 1 2020
[7] J M Agaku ldquo)e Girinya dance theatre of the Tiv people ofNigeria an aesthetic evaluationrdquo International Journal ofIntangible Heritage vol 3 no 6 pp 29ndash41 2008
[8] G Mota and L Abreu ldquo)irty years of music and dramaeducation in the Madeira Island facing future challengesrdquoInternational Journal of Music Education vol 32 no 3pp 360ndash374 2014
[9] B Montero ldquoPractice makes perfect the effect of dancetraining on the aesthetic judgerdquo Phenomenology and theCognitive Sciences vol 11 no 1 pp 59ndash68 2012
[10] A Manfre I Infantino F Vella and S Gaglio ldquoAn automaticsystem for humanoid dance creationrdquo Biologically InspiredCognitive Architectures vol 15 pp 1ndash9 2016
[11] D Aledo B Carrion Schafer and F Moreno ldquoVHDL vsSystemC design of highly parameterizable artificial neuralnetworksrdquo IEICE - Transactions on Info and Systemsvol E102D no 3 pp 512ndash521 2019
[12] B Sheng and G Sun ldquoMatrix factorization recommendationalgorithm based on multiple social relationshipsrdquo Mathe-matical Problems in Engineering vol 2021 Article ID6610645 8 pages 2021
[13] L Jiang Y Cheng L Yang J Li H Yan and X Wang ldquoAtrust-based collaborative filtering algorithm for E-commercerecommendation systemrdquo Journal of ambient intelligence andhumanized computing vol 10 no 8 pp 3023ndash3034 2019
[14] A Dm A Xl and A Qd ldquoHumming-query and reinforce-ment-learning based modeling approach for personalizedmusic recommendationrdquo Procedia Computer Science vol 176pp 2154ndash2163 2020
Complexity 15

After that the unknown scores can be estimated indifferent ways such as weighted sum Here C (U K) is asimilar set of items in the user evaluation data set and rui i isthe interest of user u in item i )e calculation is shown in
1113958Pis 1113936jisinC(uk)ω(i j) times rus
1113936jisinC(uk)|ω(i j)| (6)
Although the user-based collaborative filtering algo-rithm is logically simple it may take a lot of time to deal withbig data )e project-based collaborative filtering methodsolves the problem of complex user matrix By using asignificantly smaller number of items large-scale matrixoperations in the user-item scoring matrix can be avoidedand project-based collaborative filtering is more time-cost-effective to implement
Item-based collaborative filtering depends to a greatextent on the number of times songs appear in the data setBecause it is impossible to determine whether songs exist inthe user playlist the item-based collaborative filtering sys-tem designates those songs that appear in many playlists inthe data set as more valuable data in this way acting as thebasic processing for item-based collaborative filtering Firstmatch each song in the playlist with a similar song in thesong data set and record it the system records it as ldquosimilar
tracksrdquo and the playlist obtains the most frequentlyappearing songs from the ldquosimilar tracksrdquo matrix com-prehensively considers the userrsquos preference information forsongs and then recommends music to other users who aresimilar to the userrsquos preferences and often listen to them Inthe music recommendation system although the number ofsongs is less than the number of hundreds of millions ofusers it is also very large Each user playlist may containmore than 50 to 100 songs so it is muchmore difficult to findthe similarity of songs in the database of tens of millions ofsongs so the performance advantage of item-based col-laborative filtering is lost [13]
222 Model-Based Collaborative Filtering Model-basedcollaborative filtering is obviously different from the othertwo collaborative filtering methods user-based and content-based methods estimate the unknown item scores directlyaccording to the statistical historical data but model-basedmethods first use the original data to train and generate aspecific model which can quickly predict user preferencesaccording to the generated model )erefore when there area large number of users and projects the model-basedrecommendation algorithm has a high degree of scalabilityand rapidity Common models are as follows
Recommend
UserA
UserB
UserC
Dance Music 1
Dance Music 2
Dance Music 3
Dance Music 4
Dance Music 5
Similarity
Figure 3 Schematic diagram of project-based collaborative filtering
User A
User B
User C
Dance Music 1
Dance Music 2
Dance Music 3
Recommend
Dance Music 4
Dance Music 5
Similarity
Figure 2 Schematic diagram of user-based collaborative filtering
Complexity 5
(1) Bayesian Model Bayesian prediction model is a kind ofprediction using Bayesian statistics Bayesian statistics isdifferent from general statistical methods which does notuse model information and data information but uses priorinformation )rough the method of empirical analysis theprediction results of Bayesian prediction model are com-pared with those of ordinary regression prediction modeland the results show that Bayesian prediction model hasobvious advantages
Bayesian model revolves around giving evidence (E) andobtaining hypothesis (H) which involves two conceptshypothesis probability P(H) before obtaining evidence andhypothesis probability P(HE) after obtaining evidence )emodel is continuously learned by training data and the dataare verified to evaluate the model and make new predictions
In practical applications Naive Bayesian classifier andcollaborative filtering are generally used to implementrecommendation system which can filter new informationand predict whether users need given resources However itis almost impossible to obtain a completely independent setof data in practice Moreover when the number of itemsjointly evaluated is small this direct calculation may distortthe obtained probability
(2) Matrix Decomposition Model Matrix decompositionmodel is a commonly used technology to build recom-mendation system In 2006 Netflix held Netflix PrizeChallenge and matrix decomposition technology was firstproposed In order to decompose the scoring matrix featuresinto low-dimensional spaces the matrix decompositiontechnology learns potential space vectors for each user andeach item which are divided into user feature vectors p anditem feature vectors q )e specific representation of thescoring matrix is shown in
R pi times qTj (7)
Here R represents the training score matrix and i and jrepresent users and projects respectively By learning theminimized objective function (formula (8)) in the knownscores the potential space vectors P and q can be obtained
Yij FLFM
pi qj1113872 1113873 pTi qj (8)
)e algorithms commonly used in matrix factorizationmodel include nonnegative matrix factorization (NMF)algorithm and singular value decomposition (SVD) algo-rithm )e nonnegative matrix factorization algorithm usesproject content to construct the potential space of the projectand then uses user information such as known scores tolearn the potential space of users So as to overcome the coldstart problem in collaborative filtering 28 Singular valuedecomposition (SVD) algorithmmaps users and items to thepotential factor space of f-dimension and the model con-structs users and items as interaction problems within thespace
In addition model-based collaborative filtering algo-rithms also include graph-based walking method SimRankalgorithm and clustering-based collaborative algorithmCollaborative filtering algorithm can recommend variousfavorite contents to users according to historical data but
the recommendation results may not be satisfactory whenthe scoring data are sparse large-scale matrix operation maybe needed when the data volume is huge and the timeconsumption will increase linearly with the data scale soreal-time recommendation cannot be achieved
23 Content-Based Recommendation )e content-basedrecommendation algorithm takes into account the items ofinterest that users have previously shown through ratingsand then constructs user profiles that match the userrsquos in-terest in such items Once the user clearly shows interest inan item the algorithm will analyze the characteristics of theitem and then recommend similar items to the user )econtent descriptor of a project can have many differentforms which can usually be described by tags or projectcontents for example user tags and tags related to projectattributes and related types are generally classified bymanual or machine learning algorithms When a user listensto a popular song about campus the content-based algo-rithm will recommend another type of campus song to theuser
Early content-based recommendation algorithms mostlydeal with text content so early content-based recommen-dation systems mainly use text retrieval technology Vectorspace model (VSM) can match documents according tokeywords and transform song names and singer names intovectors by using word frequency-inverse document fre-quency (TF-IDF) technology TF is the number of wordsappearing and IDF represents the information of words If aword appears more frequently in lyrics or song titles it mayplay a key role in lyrics )e TF-IDF definition is shown in
TF minus IDF tk dj1113872 1113873 TF tk dj1113872 1113873logN
nK (9)
)eTF-IDF algorithm is used to calculate the words withgreater weight in the data and the cosine similarity algo-rithm mentioned above is used to find other songs similar tothis song and recommend them to users
3 Research on Recommendation ModelBased onUser Behavior andMusic andDance
Referring to the correlation model of image classificationthis paper introduces the model of Relationship-Learninginto the field of music recommendation In this model deepneural network and automatic encoder are used to combinethe characteristics of user behavior and music audio andinput them into Music Encoder to realize personalizedcoding in the coding stage to ensure the personalization ofrecommendation By calculating the similarity of userrsquosinterest preference and the similarity of song feature theprediction score of userrsquos music to be selected is obtainedafter averaging them
31 Model Introduction )rough reading the literature weknow that the cold start problem in the recommendationsystem is mainly divided into two subproblems completecold start and incomplete cold start and there are some
6 Complexity
differences in the solutions of these two problems At thesame time the processing process of image classificationdirection in small sample data can be used for reference byrecommendation system For example the classificationproblem of some pictures that have not been seen at all isZero-Shot while the classification problem of some picturesthat appear less frequently is Few-Shot Among these twoproblems the Zero-Shot problem can correspond to thecomplete cold start problem in the recommendationproblem while the Few-Shot problem can correspond to theincomplete cold start problem in the recommendationproblem For the Few-Shot problem and Zero-Shot problema similar solution to the cold start problem in the recom-mendation system is given
For the cold start problem one of the existing methods isto use user information and article information If effectiveinformation can be collected certain clustering operationscan be carried out on this basis and other similar usersrsquofavorite music can be used to recommend the user In ad-dition the structure of Auto Encoder can be used to extractfeatures At this time for the cold-start user the AutoEncoder encodes first and then decodes and the finallydecoded value includes the value inferred from the usercharacteristics [14]
In this paper we pay more attention to the problem ofincomplete cold start when designing the model and use thelimited scoring information as efficiently as possible toanalyze the scoring habits of users more accurately At thesame time it draws lessons from the idea of relationshiplearning in the field of computer vision hoping that therecommendation system can learn how to compare simi-larity in a more accurate way On this basis we investigatethe application of metric learning in recommendationsystem and find that although these methods have the idea ofmaking recommendation system learn distance informationto infer similarity the distance that defines similarity is low-order linear similarity Although this method can give acertain distance description it is difficult to fully capture andutilize the high-order features extracted by neural network)is paper hopes to calculate the similarity between picturesin relation learning and apply it to the recommendationsystem to calculate the similarity between people music andmusic user and music
32 Metric-Learning Model In 2018 Sung and Flood pro-posed a relation network model based on the metric-learning method to solve the classification problem of asmall number of labeled sample data in the field of computervision in deep learning as shown in Figure 4 )e authorproposes a relational network which compares the inputimages in the test set with a small number of known labeledsample images and calculates the correlation scores so as toclassify them )e relation network consists of two modulesan embedded module and a relational module Firstly theembedding module extracts the relevant feature informa-tion and then the relational module compares these em-bedding and obtains the relation score to determine whetherthey belong to the same class
Each block has 64 3times 3 convolution kernels a batchspecification layer and ReLU nonlinear function In addi-tion convolution blocks 1 and 3 have a 2times 2 maximumpooling layer )e author uses four convolution blocks toextract rich feature information between samples with fewerparameters )e network structure is shown in Figure 5
In the relation module you need to combine featuresfirst )e feature combination S recombines the featureinformation of the samples in the training set and the sampleinformation in the test set so that the relational encoder Gcan learn better from the combined features First thefeature mappings of the same class are summarized asshown in
fφ Li( 1113857 1113944K
J1Lij (10)
where Lij(i 1 i 2 j 1 j 2 K) denotes thetraining set features extracted from the embedded moduleand fφ(Li) denotes the mapping of feature information)emapping of combined features can be obtained by summingthe mapped feature sets )e formula is shown in (11)
Si fφ Li( 1113857 + fφ Qn( 1113857 (11)
Si represents the feature formed by the feature mappingof the training data set and the recombination of the testsamples and fφ(Qn) represents the feature from the testsamples )e model does not use conventional Euclideandistance or cosine distance instead we use nonlinear metriclearning In this part two convolution blocks and two fullyconnected layers are used to compare the two samples Eachconvolution block has 64 3times 3 convolution kernels a batchspecification layer a ReLU nonlinear activation layer and a2times 2 maximum pooling layer Finally through two fullyconnected layers the similarity relation score isin[0 1] be-tween the test samples and the training samples is finallyobtained by using the activation functions ReLU and sig-moid )e relation score is shown in
Relation score gϕ S fφ Lij1113872 1113873 fφ Qn( 11138571113872 11138731113872 1113873 (12)
)e detailed structure of the module is shown inFigure 6
33 Construction of Relation Model )e basic idea of thismodel is determined as a hybrid recommendation modellearning the similarity of user ratings by using the idea ofRelationship-Learning and then estimating the rating valuethrough collaborative filtering)emodel structure is shownin Figure 7
)is model mainly deals with two problems in recom-mendation system Firstly timeliness in the current era ofinformation explosion a large amount of data is uploaded tothe Internet every day It is difficult to obtain enough ratingdata at the beginning of these newly uploaded data whichcan be used in the recommendation system for target usersMusic recommendation system often encounters some newsongs which need to be recommended to users for audition
Complexity 7
)erefore through the cold start mechanism of the modelthe problem of new content recommendation can be solvedand the recommendation system can cope with the problemsbrought by timeliness and new content
Secondly personalization when users evaluate songseven if two people give favorable comments on the samesong their motives may be different for example oneperson likes the singer so they like this song and the otherperson likes the song style and likes this song )erefore themodel carries out more personalized processing for songrecommendation according to music characteristics anduser characteristics
331 Enter Data )e input of the model mainly consists oftwo parts one part is the feature information which includesthe personal feature information of the target user thefeature information of the scored n songs and the featureinformation of the target songs )e other part is the scoringinformation which contains the scoring values of the targetusers for n songs that have been scored In the third chapterthe related features have been extracted Formally the re-lated features are expressed as follows
Users U fieldu1 fieldu
2 fieldun1113864 1113865 represents the userrsquos
gender age and other related characteristic informationMusiccharacteristics M fieldM
1 fieldM2 fieldM
t1113966 1113967 representsthe relevant characteristic information of music Dance fea-tures D fieldD
1 fieldD2 fieldD
j1113966 1113967Historical interaction data of user U H
M1 M2 Mk1113864 1113865 user Ursquos comprehensive user score formusicM is Scorei and userUrsquos comprehensive user score fordance D is Scorej
332 Embedding According to the previous feature ex-traction work several user and audio features can be ob-tained Firstly the features are encoded through linear layeror embedding layer to obtain a series of vector represen-tations of features then according to these vectors the userand music are encoded )e user below represents severalcharacteristics of the target user which are represented byvectors Taking it as input the encoding vector of userfeatures is obtained through the User Encoder For usercoding because only text type features such as gender andage are used Auto Encoder model can be directly used tocomplete feature extraction In order to be similar to Music
64 33 convolutionkernels
Batch Normalization
Relu function
33 max-pooling
64 33 convolutionkernels
Batch Normalization
Relu function
64 33 convolutionkernels
Batch Normalization
Relu function
64 33 convolutionkernels
Batch Normalization
Relu function
33 max-pooling
fϕ
Figure 5 Embedding module
FC1Relu function
FC2Sigmoid function
SiRelation score
64 33 convolutionkernels
Batch Normalization
Relu function
22 max-pooling
64 33 convolutionkernels
Batch Normalization
Relu function
22 max-pooling
Figure 6 Relation module
Test sample 1
Test sample 2
Test sample 3
Test sample 4
Test sample 5
Test sample
Embedded module Relationship module
Feature concatenation
Relation score
fφ gϕ
Figure 4 Relation network model
8 Complexity
Encoder feature structure AutoInt model l is used to extractuser features here )e encoding structure of the user part isshown in Figure 8
Next for some music evaluated by users because theyknow their characteristics and scores they can combine theircharacteristics with userrsquos feature vectors and input theminto Music Encoder for coding respectively )is processcan combine usersrsquo personalized information for music sothat the same music can be coded differently by MusicEncoder for different users For unevaluatedmusic althoughthere is only the eigenvalue of music it can still obtain itseigenvector through Music Encoder like the music that hasbeen evaluated which is the coding layer Embedding Layerof music )e music feature coding structure is shown inFigure 9
As can be seen from Figure 9 the main structure ofencoder is multihead attention module and its essence is toperformmultiple self-attention calculations to formmultiplesubspaces so that the model can learn different features ofinformation from different angles and finally merge themTake the Music Encoder as an example and its structure isshown in Figure 10
In the multihead attention the feature matrixF f1 f2 ft1113864 1113865 needs to be transformed linearly tocompare the dimension of the feature vector that is QW
Qi
Perform k self-attention calculations as shown in
hlowast
Attention(Q K V) softmaxQK
T
dk
1113888 1113889V (13)
Splice and linearly map the result hlowast using
h concat hlowast1 hlowast2 h
lowastn( 1113857otimesW
o (14)
)e number of music selections has also been adjusted tosome extent When entering you need to have a series ofknown characteristics of the score and its final scoreHowever there will be many historical records of a personAnd the quantity is different and the model structure doesnot support the dynamic adjustment of the input quantityso this paper chooses the sampling method During eachtraining five historical evaluated songs are selected from thehistorical music of user interaction for input After severalrounds of training all the evaluated songs can be basicallyused in the training Although this method is inefficient inusing data sets it can greatly reduce the training time costand the complexity of the model )erefore after trade-offwe chose the method of randomly selecting five data
333 Interest Matching Module )e information aboutusers andmusic in the data set is processed and the obtainedhigh-order nonlinear eigenvector is taken as the output In
User data
Dance Music 1
Dance Music 2
Dance Music m New project
S M R
P
input
Embedding Module
Feature Vector
Combined Vector
Relation Module
Relation Score Ration
Predicted Ration
Figure 7 Model structure
Complexity 9
Max-Pooling
Multi-Head Attention
Field1 Field2 Field3
y1
Figure 8 User encoder model structure
Max-Pooling
Multi-Head Attention
Field1 Fieldt
y2
User feature vector y1
Characteristics of dance music
Figure 9 Music encoder model structure
10 Complexity
the model of this section we hope to give the similarity ofusers about different music scores through feature vectors
Firstly the characteristics of the scored songs and thecharacteristics of the target unscored songs are combined bythe user )en the similarity gφ between the two songs isgiven by comparing the similarity module and relationmodule its size is limited between 0 and 1 by normalizationfunction and finally a k-dimensional numerical vector re-lation score is obtained )e similarity gφmodel is shown in
gφ q1 q2( 1113857 Sigmoid qT1 Wq21113872 1113873 (15)
)e Interest Matching Relation module constructed inthis paper is not complex and the parameter to be trained isonly a matrix W In the experiment we also use a deeperstructure to replace this structure It is found that this willnot only increase the training time and parameter scale butalso reduce the accuracy )erefore we finally choose thevalue between [0 1] obtained by sigmoid after we get theinner product of two vectors about W as the similarityAccording to the similarity degree the related features of theknown graded music are constructed to predict the featuresof the music )e method is weighted average and theweight of each item is the score multiplied by the similaritydegree )e more similar the music and the higher the scorethe more obvious the influence on the prediction resultsFinally an estimated value of the eigenvector is obtained
Finally there is an output layer which synthesizes thetwo scoring results given before and gives the final con-clusion In the first part of the conclusion Y from theprevious user coding music-to-be-predicted estimationfeatures and music-to-be-predicted coding through a linearlayer this part reflects the idea of collaborative filteringbased on similarity and score to get the target score Anotherpart of the result x is obtained by using a Max Pooling layer
to select the value with the greatest correlation )e strategyembodied in this part is that when the songs to be predictedhave a high similarity with the previous historical songs itcan be considered that users are likely to have a certaininterest in the songs to be evaluated so the results have alarge similarity value at this time Finally the two scores areaveraged to get the final output)is is a value between [0 1]to indicate the degree of interest that users may be interestedin
4 Implementation ofPersonalized Recommendation
Traditional models do not use the information of users whointeract with them in the coding process of known music)is leads to the lack of user personality in the recom-mended content Even for two different users the coding ofthe same content is the same which cannot deal with thepersonalized problem well In addition in the actual in-teractive process content and users have different interactivebehaviors and different interactive behaviors often repre-sent different preferences of users However the previousmodels have not been distinguished to this extent resultingin different information brought by different interactivebehaviors not being used For example for praise andcollection collection means that users are more interestedthan praise because collection means that users are likely tolisten to this song repeatedly later while the probability oflistening to praise will be smaller later
In this paper firstly different behavior scores of users aredistinguished and the scores are divided into 1ndash5 pointsaccording to the listening times 6 points for collectionbehavior and 4 points for praise behavior In addition themultihead attention mechanism is introduced When
Linear
Concat
Self-attention
Linear LinearLinear
User feature vector (V)
Music feature vector (M)
Dance feature vector (D)
K
Output
Figure 10 Multihead attention module
Complexity 11
encoding music features in Music Encoder the user featuresand music features are combined and the user personalizedmusic coding is realized in the encoding layer which ensuresthat even if different users operate the same music the finalrecommendation results are still different because of dif-ferent personal characteristics thus realizing the personal-ized music recommendation
41 Model Training and Experimental Results Beforetraining the model it is necessary to divide the positive andnegative classes and determine the training set and test setused by the model For music recommendation label 0means dislike and label 1 means like which is defined as abinary classification problem According to the scoringprocessing of user behavior characteristics in Chapter 3music with a score higher than 5 is recorded as a positiveclass that is if the user listens to music many times or musicwith a little praise or collection behavior is recorded as apositive class Music with a score below 2 is recorded as anegative example indicating that although the user has someinteraction they have not shown interest Negative caseswith the same number of positive classes are randomlyselected from music with scores lower than 2 to ensure thatthe distribution is as balanced as possible After dividingpositive and negative classes the first 80 of the data set isused as the training set and the last 20 as the test set
42 Super Parameter Adjustment )e hyperparameter ad-justment process aims to optimize the performance of themodel First select the super parameters that can be adjusted)en determine whether they will be fixed or variable and ifthe parameters are changeable set them to different values todetermine in which range they will change
Hidden_size the original model is set to 50 and featuresare represented using the model by setting the number ofhidden layers)e hidden layer is set to 32 64 18 and 256 inthe implementation process and the best parameters aredetermined by experiments in TP100 data set in Figure 11
According to Figure 11 when the hidden layer is set to32 the model is in an underfitting state and cannot becharacterized With the increase of the hidden layer theaccuracy rate and recall rate are continuously improved butwhen the hidden layer is set to 256 both indicators decreaseslightly )erefore in the subsequent experiment the hid-den_size is set to 128
Learning_rate it depends on the Adam optimizer in themodel )e learning rate of each parameter is adapted bymaking smaller updates to frequent parameters and largerupdates to infrequent parameters )e learning rate of theoriginal model is set to 0001 In this experiment thelearning rates are set to 0001 001 01 and 05 respectivelyAccording to Figure 12 when the learning rates are 0001and 001 the accuracy is better In the subsequent experi-ment the learning_rate is set to 001
Batch_size when smaller batches are used a period oftraining is more detailed which usually leads to a decrease inthe number of convergent iterations but the training time islong On the other hand the more the batches the slower theconvergence speed which reduces the risk of overfitting andreduces the training time )e effect of batch_size on ac-curacy is shown in Figure 13
Try to use the batch size training model from 100 to 1000in the whole process As can be seen from Figure 13 andTable 2 using a smaller batch size the training time is longerUsing a large batch size (when it exceeds 700) a memoryerror was encountered
)erefore in the follow-up experiment the batch size isset to 600 for model training which not only meets thetraining time but also does not overflow the memory
43 Experimental Results )e whole training process Loss-Epochs is shown in Figure 14 During each training fivesongs with historical evaluation are selected from the his-torical music interacted by users for input After severalrounds of training all the evaluated songs can basically beused in training and the training loss is basically stable after1024 iterations
0002004006008
01012014016018
02
32 64 128 256Ev
alua
tion
inde
x
hidden_size
RecallPrecision
Figure 11 Impact of hidden size on evaluation indicators
12 Complexity
In order to verify the effectiveness of the model thispaper implements Neural Network Based CollaborativeFiltering (NCF) model and SVDmodel by Python which areverified in TP100 and TP500 data sets respectively )eaccuracy and recall rate are used to evaluate the accuracy ofdifferent recommendation lengths )e accuracy results ofdifferent recommendation lengths are shown in Figure 15
It can be seen from Figure 15 that the accuracy of thedeep learning recommendation model based on Relation-ship-Learning is obviously higher than that of the traditionalSVD recommendation algorithm in two data sets about 3higher than that of the collaborative filtering algorithm
based on neural network in TP100 data set and similar inTP500 data set with lower sparsity both of which are higherthan SVD algorithm
As can be seen from Figure 16 this model has obviousadvantages in both data sets With the increasing number ofrecommendations the recall rate gradually increases whichis about 10 higher than the traditional SVD algorithm InTP500 data sets with dense data the recall rate reaches about03 To sum up the deep learning recommendation modelbased on relationship learning implemented in this papercan accurately predict usersrsquo music preferences and finallycan accurately recommend music lists for users
07
075
08
085
09
095
0001001011A
ccur
acy
learning_rate
Figure 12 Impact of learning rate on accuracy
0
01
02
03
04
05
06
07
08
09
1
0 100 200 300 400 500 600 700 800
Acc
urac
y
batch_size
Figure 13 Effect of batch_size on accuracy
Table 2 Average running time per Epoch
batch_size 100 200 400 600 700Runtime (s) 67 39 20 9 8
Complexity 13
0 128 256 512 102400
02
04
06
08
10
12
14
16
18 Cross entropy loss of model training
Loss
Epochs
Figure 14 Model training loss
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
SVDNCFRelation-Learning
(a)
SVDNCFRelation-Learning
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
(b)
Figure 15 Accuracy of two data sets (a) TP100 data set (b) TP500 data set
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(a)
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(b)
Figure 16 Recall rate of two data sets (a) TP100 data set (b) TP500 data set
14 Complexity
5 Conclusion
Faced with a large number of dances and songs it is difficultfor people to quickly find dance music that meets theirinterests )e emergence of dance music recommendationsystem can recommend dance music that users may like andhelp users quickly discover or find their favorite dances andsongs )is kind of recommendation service can provideusers with a good experience and bring commercial benefitsso the field of dance music recommendation has become theresearch direction of industry and scholars In this paperrelation learning is introduced into dance music recom-mendation system and the relation model is applied todance music recommendation In the experiment the ac-curacy and recall rate are used to verify the effectiveness ofthe model in the direction of dance music recommendation
Data Availability
)e experimental data used to support the findings of thisstudy are available from the corresponding author uponrequest
Conflicts of Interest
)e author declares that no conflicts of interest regardingthis work
References
[1] Y Han Z Han J Wu et al ldquoArtificial intelligence recom-mendation system of cancer rehabilitation scheme based onIoT technologyrdquo IEEE Access vol 8 pp 44924ndash44935 2020
[2] A Rw M A Xiao and J A Chi ldquoHeterogeneous informationnetwork-based music recommendation system in mobilenetworksrdquo Computer Communications vol 150 pp 429ndash4372020
[3] X Wen ldquoUsing deep learning approach and IoT architectureto build the intelligent music recommendation systemrdquo SoftComputing vol 25 no 1 pp 1ndash10 2020
[4] H-G Kim G Y Kim and J Y Kim ldquoMusic recommendationsystem using human activity recognition from accelerometerdatardquo IEEE Transactions on Consumer Electronics vol 65no 3 pp 349ndash358 2019
[5] M S Fathollahi and F Razzazi ldquoMusic similarity measure-ment and recommendation system using convolutional neuralnetworksrdquo International Journal of Multimedia InformationRetrieval vol 5 pp 1ndash11 2021
[6] G Sun YWong and Z Cheng ldquoDeepDance music-to-dancemotion choreography with adversarial learningrdquo IEEETransactions on Multimedia vol 99 p 1 2020
[7] J M Agaku ldquo)e Girinya dance theatre of the Tiv people ofNigeria an aesthetic evaluationrdquo International Journal ofIntangible Heritage vol 3 no 6 pp 29ndash41 2008
[8] G Mota and L Abreu ldquo)irty years of music and dramaeducation in the Madeira Island facing future challengesrdquoInternational Journal of Music Education vol 32 no 3pp 360ndash374 2014
[9] B Montero ldquoPractice makes perfect the effect of dancetraining on the aesthetic judgerdquo Phenomenology and theCognitive Sciences vol 11 no 1 pp 59ndash68 2012
[10] A Manfre I Infantino F Vella and S Gaglio ldquoAn automaticsystem for humanoid dance creationrdquo Biologically InspiredCognitive Architectures vol 15 pp 1ndash9 2016
[11] D Aledo B Carrion Schafer and F Moreno ldquoVHDL vsSystemC design of highly parameterizable artificial neuralnetworksrdquo IEICE - Transactions on Info and Systemsvol E102D no 3 pp 512ndash521 2019
[12] B Sheng and G Sun ldquoMatrix factorization recommendationalgorithm based on multiple social relationshipsrdquo Mathe-matical Problems in Engineering vol 2021 Article ID6610645 8 pages 2021
[13] L Jiang Y Cheng L Yang J Li H Yan and X Wang ldquoAtrust-based collaborative filtering algorithm for E-commercerecommendation systemrdquo Journal of ambient intelligence andhumanized computing vol 10 no 8 pp 3023ndash3034 2019
[14] A Dm A Xl and A Qd ldquoHumming-query and reinforce-ment-learning based modeling approach for personalizedmusic recommendationrdquo Procedia Computer Science vol 176pp 2154ndash2163 2020
Complexity 15

(1) Bayesian Model Bayesian prediction model is a kind ofprediction using Bayesian statistics Bayesian statistics isdifferent from general statistical methods which does notuse model information and data information but uses priorinformation )rough the method of empirical analysis theprediction results of Bayesian prediction model are com-pared with those of ordinary regression prediction modeland the results show that Bayesian prediction model hasobvious advantages
Bayesian model revolves around giving evidence (E) andobtaining hypothesis (H) which involves two conceptshypothesis probability P(H) before obtaining evidence andhypothesis probability P(HE) after obtaining evidence )emodel is continuously learned by training data and the dataare verified to evaluate the model and make new predictions
In practical applications Naive Bayesian classifier andcollaborative filtering are generally used to implementrecommendation system which can filter new informationand predict whether users need given resources However itis almost impossible to obtain a completely independent setof data in practice Moreover when the number of itemsjointly evaluated is small this direct calculation may distortthe obtained probability
(2) Matrix Decomposition Model Matrix decompositionmodel is a commonly used technology to build recom-mendation system In 2006 Netflix held Netflix PrizeChallenge and matrix decomposition technology was firstproposed In order to decompose the scoring matrix featuresinto low-dimensional spaces the matrix decompositiontechnology learns potential space vectors for each user andeach item which are divided into user feature vectors p anditem feature vectors q )e specific representation of thescoring matrix is shown in
R pi times qTj (7)
Here R represents the training score matrix and i and jrepresent users and projects respectively By learning theminimized objective function (formula (8)) in the knownscores the potential space vectors P and q can be obtained
Yij FLFM
pi qj1113872 1113873 pTi qj (8)
)e algorithms commonly used in matrix factorizationmodel include nonnegative matrix factorization (NMF)algorithm and singular value decomposition (SVD) algo-rithm )e nonnegative matrix factorization algorithm usesproject content to construct the potential space of the projectand then uses user information such as known scores tolearn the potential space of users So as to overcome the coldstart problem in collaborative filtering 28 Singular valuedecomposition (SVD) algorithmmaps users and items to thepotential factor space of f-dimension and the model con-structs users and items as interaction problems within thespace
In addition model-based collaborative filtering algo-rithms also include graph-based walking method SimRankalgorithm and clustering-based collaborative algorithmCollaborative filtering algorithm can recommend variousfavorite contents to users according to historical data but
the recommendation results may not be satisfactory whenthe scoring data are sparse large-scale matrix operation maybe needed when the data volume is huge and the timeconsumption will increase linearly with the data scale soreal-time recommendation cannot be achieved
23 Content-Based Recommendation )e content-basedrecommendation algorithm takes into account the items ofinterest that users have previously shown through ratingsand then constructs user profiles that match the userrsquos in-terest in such items Once the user clearly shows interest inan item the algorithm will analyze the characteristics of theitem and then recommend similar items to the user )econtent descriptor of a project can have many differentforms which can usually be described by tags or projectcontents for example user tags and tags related to projectattributes and related types are generally classified bymanual or machine learning algorithms When a user listensto a popular song about campus the content-based algo-rithm will recommend another type of campus song to theuser
Early content-based recommendation algorithms mostlydeal with text content so early content-based recommen-dation systems mainly use text retrieval technology Vectorspace model (VSM) can match documents according tokeywords and transform song names and singer names intovectors by using word frequency-inverse document fre-quency (TF-IDF) technology TF is the number of wordsappearing and IDF represents the information of words If aword appears more frequently in lyrics or song titles it mayplay a key role in lyrics )e TF-IDF definition is shown in
TF minus IDF tk dj1113872 1113873 TF tk dj1113872 1113873logN
nK (9)
)eTF-IDF algorithm is used to calculate the words withgreater weight in the data and the cosine similarity algo-rithm mentioned above is used to find other songs similar tothis song and recommend them to users
3 Research on Recommendation ModelBased onUser Behavior andMusic andDance
Referring to the correlation model of image classificationthis paper introduces the model of Relationship-Learninginto the field of music recommendation In this model deepneural network and automatic encoder are used to combinethe characteristics of user behavior and music audio andinput them into Music Encoder to realize personalizedcoding in the coding stage to ensure the personalization ofrecommendation By calculating the similarity of userrsquosinterest preference and the similarity of song feature theprediction score of userrsquos music to be selected is obtainedafter averaging them
31 Model Introduction )rough reading the literature weknow that the cold start problem in the recommendationsystem is mainly divided into two subproblems completecold start and incomplete cold start and there are some
6 Complexity
differences in the solutions of these two problems At thesame time the processing process of image classificationdirection in small sample data can be used for reference byrecommendation system For example the classificationproblem of some pictures that have not been seen at all isZero-Shot while the classification problem of some picturesthat appear less frequently is Few-Shot Among these twoproblems the Zero-Shot problem can correspond to thecomplete cold start problem in the recommendationproblem while the Few-Shot problem can correspond to theincomplete cold start problem in the recommendationproblem For the Few-Shot problem and Zero-Shot problema similar solution to the cold start problem in the recom-mendation system is given
For the cold start problem one of the existing methods isto use user information and article information If effectiveinformation can be collected certain clustering operationscan be carried out on this basis and other similar usersrsquofavorite music can be used to recommend the user In ad-dition the structure of Auto Encoder can be used to extractfeatures At this time for the cold-start user the AutoEncoder encodes first and then decodes and the finallydecoded value includes the value inferred from the usercharacteristics [14]
In this paper we pay more attention to the problem ofincomplete cold start when designing the model and use thelimited scoring information as efficiently as possible toanalyze the scoring habits of users more accurately At thesame time it draws lessons from the idea of relationshiplearning in the field of computer vision hoping that therecommendation system can learn how to compare simi-larity in a more accurate way On this basis we investigatethe application of metric learning in recommendationsystem and find that although these methods have the idea ofmaking recommendation system learn distance informationto infer similarity the distance that defines similarity is low-order linear similarity Although this method can give acertain distance description it is difficult to fully capture andutilize the high-order features extracted by neural network)is paper hopes to calculate the similarity between picturesin relation learning and apply it to the recommendationsystem to calculate the similarity between people music andmusic user and music
32 Metric-Learning Model In 2018 Sung and Flood pro-posed a relation network model based on the metric-learning method to solve the classification problem of asmall number of labeled sample data in the field of computervision in deep learning as shown in Figure 4 )e authorproposes a relational network which compares the inputimages in the test set with a small number of known labeledsample images and calculates the correlation scores so as toclassify them )e relation network consists of two modulesan embedded module and a relational module Firstly theembedding module extracts the relevant feature informa-tion and then the relational module compares these em-bedding and obtains the relation score to determine whetherthey belong to the same class
Each block has 64 3times 3 convolution kernels a batchspecification layer and ReLU nonlinear function In addi-tion convolution blocks 1 and 3 have a 2times 2 maximumpooling layer )e author uses four convolution blocks toextract rich feature information between samples with fewerparameters )e network structure is shown in Figure 5
In the relation module you need to combine featuresfirst )e feature combination S recombines the featureinformation of the samples in the training set and the sampleinformation in the test set so that the relational encoder Gcan learn better from the combined features First thefeature mappings of the same class are summarized asshown in
fφ Li( 1113857 1113944K
J1Lij (10)
where Lij(i 1 i 2 j 1 j 2 K) denotes thetraining set features extracted from the embedded moduleand fφ(Li) denotes the mapping of feature information)emapping of combined features can be obtained by summingthe mapped feature sets )e formula is shown in (11)
Si fφ Li( 1113857 + fφ Qn( 1113857 (11)
Si represents the feature formed by the feature mappingof the training data set and the recombination of the testsamples and fφ(Qn) represents the feature from the testsamples )e model does not use conventional Euclideandistance or cosine distance instead we use nonlinear metriclearning In this part two convolution blocks and two fullyconnected layers are used to compare the two samples Eachconvolution block has 64 3times 3 convolution kernels a batchspecification layer a ReLU nonlinear activation layer and a2times 2 maximum pooling layer Finally through two fullyconnected layers the similarity relation score isin[0 1] be-tween the test samples and the training samples is finallyobtained by using the activation functions ReLU and sig-moid )e relation score is shown in
Relation score gϕ S fφ Lij1113872 1113873 fφ Qn( 11138571113872 11138731113872 1113873 (12)
)e detailed structure of the module is shown inFigure 6
33 Construction of Relation Model )e basic idea of thismodel is determined as a hybrid recommendation modellearning the similarity of user ratings by using the idea ofRelationship-Learning and then estimating the rating valuethrough collaborative filtering)emodel structure is shownin Figure 7
)is model mainly deals with two problems in recom-mendation system Firstly timeliness in the current era ofinformation explosion a large amount of data is uploaded tothe Internet every day It is difficult to obtain enough ratingdata at the beginning of these newly uploaded data whichcan be used in the recommendation system for target usersMusic recommendation system often encounters some newsongs which need to be recommended to users for audition
Complexity 7
)erefore through the cold start mechanism of the modelthe problem of new content recommendation can be solvedand the recommendation system can cope with the problemsbrought by timeliness and new content
Secondly personalization when users evaluate songseven if two people give favorable comments on the samesong their motives may be different for example oneperson likes the singer so they like this song and the otherperson likes the song style and likes this song )erefore themodel carries out more personalized processing for songrecommendation according to music characteristics anduser characteristics
331 Enter Data )e input of the model mainly consists oftwo parts one part is the feature information which includesthe personal feature information of the target user thefeature information of the scored n songs and the featureinformation of the target songs )e other part is the scoringinformation which contains the scoring values of the targetusers for n songs that have been scored In the third chapterthe related features have been extracted Formally the re-lated features are expressed as follows
Users U fieldu1 fieldu
2 fieldun1113864 1113865 represents the userrsquos
gender age and other related characteristic informationMusiccharacteristics M fieldM
1 fieldM2 fieldM
t1113966 1113967 representsthe relevant characteristic information of music Dance fea-tures D fieldD
1 fieldD2 fieldD
j1113966 1113967Historical interaction data of user U H
M1 M2 Mk1113864 1113865 user Ursquos comprehensive user score formusicM is Scorei and userUrsquos comprehensive user score fordance D is Scorej
332 Embedding According to the previous feature ex-traction work several user and audio features can be ob-tained Firstly the features are encoded through linear layeror embedding layer to obtain a series of vector represen-tations of features then according to these vectors the userand music are encoded )e user below represents severalcharacteristics of the target user which are represented byvectors Taking it as input the encoding vector of userfeatures is obtained through the User Encoder For usercoding because only text type features such as gender andage are used Auto Encoder model can be directly used tocomplete feature extraction In order to be similar to Music
64 33 convolutionkernels
Batch Normalization
Relu function
33 max-pooling
64 33 convolutionkernels
Batch Normalization
Relu function
64 33 convolutionkernels
Batch Normalization
Relu function
64 33 convolutionkernels
Batch Normalization
Relu function
33 max-pooling
fϕ
Figure 5 Embedding module
FC1Relu function
FC2Sigmoid function
SiRelation score
64 33 convolutionkernels
Batch Normalization
Relu function
22 max-pooling
64 33 convolutionkernels
Batch Normalization
Relu function
22 max-pooling
Figure 6 Relation module
Test sample 1
Test sample 2
Test sample 3
Test sample 4
Test sample 5
Test sample
Embedded module Relationship module
Feature concatenation
Relation score
fφ gϕ
Figure 4 Relation network model
8 Complexity
Encoder feature structure AutoInt model l is used to extractuser features here )e encoding structure of the user part isshown in Figure 8
Next for some music evaluated by users because theyknow their characteristics and scores they can combine theircharacteristics with userrsquos feature vectors and input theminto Music Encoder for coding respectively )is processcan combine usersrsquo personalized information for music sothat the same music can be coded differently by MusicEncoder for different users For unevaluatedmusic althoughthere is only the eigenvalue of music it can still obtain itseigenvector through Music Encoder like the music that hasbeen evaluated which is the coding layer Embedding Layerof music )e music feature coding structure is shown inFigure 9
As can be seen from Figure 9 the main structure ofencoder is multihead attention module and its essence is toperformmultiple self-attention calculations to formmultiplesubspaces so that the model can learn different features ofinformation from different angles and finally merge themTake the Music Encoder as an example and its structure isshown in Figure 10
In the multihead attention the feature matrixF f1 f2 ft1113864 1113865 needs to be transformed linearly tocompare the dimension of the feature vector that is QW
Qi
Perform k self-attention calculations as shown in
hlowast
Attention(Q K V) softmaxQK
T
dk
1113888 1113889V (13)
Splice and linearly map the result hlowast using
h concat hlowast1 hlowast2 h
lowastn( 1113857otimesW
o (14)
)e number of music selections has also been adjusted tosome extent When entering you need to have a series ofknown characteristics of the score and its final scoreHowever there will be many historical records of a personAnd the quantity is different and the model structure doesnot support the dynamic adjustment of the input quantityso this paper chooses the sampling method During eachtraining five historical evaluated songs are selected from thehistorical music of user interaction for input After severalrounds of training all the evaluated songs can be basicallyused in the training Although this method is inefficient inusing data sets it can greatly reduce the training time costand the complexity of the model )erefore after trade-offwe chose the method of randomly selecting five data
333 Interest Matching Module )e information aboutusers andmusic in the data set is processed and the obtainedhigh-order nonlinear eigenvector is taken as the output In
User data
Dance Music 1
Dance Music 2
Dance Music m New project
S M R
P
input
Embedding Module
Feature Vector
Combined Vector
Relation Module
Relation Score Ration
Predicted Ration
Figure 7 Model structure
Complexity 9
Max-Pooling
Multi-Head Attention
Field1 Field2 Field3
y1
Figure 8 User encoder model structure
Max-Pooling
Multi-Head Attention
Field1 Fieldt
y2
User feature vector y1
Characteristics of dance music
Figure 9 Music encoder model structure
10 Complexity
the model of this section we hope to give the similarity ofusers about different music scores through feature vectors
Firstly the characteristics of the scored songs and thecharacteristics of the target unscored songs are combined bythe user )en the similarity gφ between the two songs isgiven by comparing the similarity module and relationmodule its size is limited between 0 and 1 by normalizationfunction and finally a k-dimensional numerical vector re-lation score is obtained )e similarity gφmodel is shown in
gφ q1 q2( 1113857 Sigmoid qT1 Wq21113872 1113873 (15)
)e Interest Matching Relation module constructed inthis paper is not complex and the parameter to be trained isonly a matrix W In the experiment we also use a deeperstructure to replace this structure It is found that this willnot only increase the training time and parameter scale butalso reduce the accuracy )erefore we finally choose thevalue between [0 1] obtained by sigmoid after we get theinner product of two vectors about W as the similarityAccording to the similarity degree the related features of theknown graded music are constructed to predict the featuresof the music )e method is weighted average and theweight of each item is the score multiplied by the similaritydegree )e more similar the music and the higher the scorethe more obvious the influence on the prediction resultsFinally an estimated value of the eigenvector is obtained
Finally there is an output layer which synthesizes thetwo scoring results given before and gives the final con-clusion In the first part of the conclusion Y from theprevious user coding music-to-be-predicted estimationfeatures and music-to-be-predicted coding through a linearlayer this part reflects the idea of collaborative filteringbased on similarity and score to get the target score Anotherpart of the result x is obtained by using a Max Pooling layer
to select the value with the greatest correlation )e strategyembodied in this part is that when the songs to be predictedhave a high similarity with the previous historical songs itcan be considered that users are likely to have a certaininterest in the songs to be evaluated so the results have alarge similarity value at this time Finally the two scores areaveraged to get the final output)is is a value between [0 1]to indicate the degree of interest that users may be interestedin
4 Implementation ofPersonalized Recommendation
Traditional models do not use the information of users whointeract with them in the coding process of known music)is leads to the lack of user personality in the recom-mended content Even for two different users the coding ofthe same content is the same which cannot deal with thepersonalized problem well In addition in the actual in-teractive process content and users have different interactivebehaviors and different interactive behaviors often repre-sent different preferences of users However the previousmodels have not been distinguished to this extent resultingin different information brought by different interactivebehaviors not being used For example for praise andcollection collection means that users are more interestedthan praise because collection means that users are likely tolisten to this song repeatedly later while the probability oflistening to praise will be smaller later
In this paper firstly different behavior scores of users aredistinguished and the scores are divided into 1ndash5 pointsaccording to the listening times 6 points for collectionbehavior and 4 points for praise behavior In addition themultihead attention mechanism is introduced When
Linear
Concat
Self-attention
Linear LinearLinear
User feature vector (V)
Music feature vector (M)
Dance feature vector (D)
K
Output
Figure 10 Multihead attention module
Complexity 11
encoding music features in Music Encoder the user featuresand music features are combined and the user personalizedmusic coding is realized in the encoding layer which ensuresthat even if different users operate the same music the finalrecommendation results are still different because of dif-ferent personal characteristics thus realizing the personal-ized music recommendation
41 Model Training and Experimental Results Beforetraining the model it is necessary to divide the positive andnegative classes and determine the training set and test setused by the model For music recommendation label 0means dislike and label 1 means like which is defined as abinary classification problem According to the scoringprocessing of user behavior characteristics in Chapter 3music with a score higher than 5 is recorded as a positiveclass that is if the user listens to music many times or musicwith a little praise or collection behavior is recorded as apositive class Music with a score below 2 is recorded as anegative example indicating that although the user has someinteraction they have not shown interest Negative caseswith the same number of positive classes are randomlyselected from music with scores lower than 2 to ensure thatthe distribution is as balanced as possible After dividingpositive and negative classes the first 80 of the data set isused as the training set and the last 20 as the test set
42 Super Parameter Adjustment )e hyperparameter ad-justment process aims to optimize the performance of themodel First select the super parameters that can be adjusted)en determine whether they will be fixed or variable and ifthe parameters are changeable set them to different values todetermine in which range they will change
Hidden_size the original model is set to 50 and featuresare represented using the model by setting the number ofhidden layers)e hidden layer is set to 32 64 18 and 256 inthe implementation process and the best parameters aredetermined by experiments in TP100 data set in Figure 11
According to Figure 11 when the hidden layer is set to32 the model is in an underfitting state and cannot becharacterized With the increase of the hidden layer theaccuracy rate and recall rate are continuously improved butwhen the hidden layer is set to 256 both indicators decreaseslightly )erefore in the subsequent experiment the hid-den_size is set to 128
Learning_rate it depends on the Adam optimizer in themodel )e learning rate of each parameter is adapted bymaking smaller updates to frequent parameters and largerupdates to infrequent parameters )e learning rate of theoriginal model is set to 0001 In this experiment thelearning rates are set to 0001 001 01 and 05 respectivelyAccording to Figure 12 when the learning rates are 0001and 001 the accuracy is better In the subsequent experi-ment the learning_rate is set to 001
Batch_size when smaller batches are used a period oftraining is more detailed which usually leads to a decrease inthe number of convergent iterations but the training time islong On the other hand the more the batches the slower theconvergence speed which reduces the risk of overfitting andreduces the training time )e effect of batch_size on ac-curacy is shown in Figure 13
Try to use the batch size training model from 100 to 1000in the whole process As can be seen from Figure 13 andTable 2 using a smaller batch size the training time is longerUsing a large batch size (when it exceeds 700) a memoryerror was encountered
)erefore in the follow-up experiment the batch size isset to 600 for model training which not only meets thetraining time but also does not overflow the memory
43 Experimental Results )e whole training process Loss-Epochs is shown in Figure 14 During each training fivesongs with historical evaluation are selected from the his-torical music interacted by users for input After severalrounds of training all the evaluated songs can basically beused in training and the training loss is basically stable after1024 iterations
0002004006008
01012014016018
02
32 64 128 256Ev
alua
tion
inde
x
hidden_size
RecallPrecision
Figure 11 Impact of hidden size on evaluation indicators
12 Complexity
In order to verify the effectiveness of the model thispaper implements Neural Network Based CollaborativeFiltering (NCF) model and SVDmodel by Python which areverified in TP100 and TP500 data sets respectively )eaccuracy and recall rate are used to evaluate the accuracy ofdifferent recommendation lengths )e accuracy results ofdifferent recommendation lengths are shown in Figure 15
It can be seen from Figure 15 that the accuracy of thedeep learning recommendation model based on Relation-ship-Learning is obviously higher than that of the traditionalSVD recommendation algorithm in two data sets about 3higher than that of the collaborative filtering algorithm
based on neural network in TP100 data set and similar inTP500 data set with lower sparsity both of which are higherthan SVD algorithm
As can be seen from Figure 16 this model has obviousadvantages in both data sets With the increasing number ofrecommendations the recall rate gradually increases whichis about 10 higher than the traditional SVD algorithm InTP500 data sets with dense data the recall rate reaches about03 To sum up the deep learning recommendation modelbased on relationship learning implemented in this papercan accurately predict usersrsquo music preferences and finallycan accurately recommend music lists for users
07
075
08
085
09
095
0001001011A
ccur
acy
learning_rate
Figure 12 Impact of learning rate on accuracy
0
01
02
03
04
05
06
07
08
09
1
0 100 200 300 400 500 600 700 800
Acc
urac
y
batch_size
Figure 13 Effect of batch_size on accuracy
Table 2 Average running time per Epoch
batch_size 100 200 400 600 700Runtime (s) 67 39 20 9 8
Complexity 13
0 128 256 512 102400
02
04
06
08
10
12
14
16
18 Cross entropy loss of model training
Loss
Epochs
Figure 14 Model training loss
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
SVDNCFRelation-Learning
(a)
SVDNCFRelation-Learning
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
(b)
Figure 15 Accuracy of two data sets (a) TP100 data set (b) TP500 data set
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(a)
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(b)
Figure 16 Recall rate of two data sets (a) TP100 data set (b) TP500 data set
14 Complexity
5 Conclusion
Faced with a large number of dances and songs it is difficultfor people to quickly find dance music that meets theirinterests )e emergence of dance music recommendationsystem can recommend dance music that users may like andhelp users quickly discover or find their favorite dances andsongs )is kind of recommendation service can provideusers with a good experience and bring commercial benefitsso the field of dance music recommendation has become theresearch direction of industry and scholars In this paperrelation learning is introduced into dance music recom-mendation system and the relation model is applied todance music recommendation In the experiment the ac-curacy and recall rate are used to verify the effectiveness ofthe model in the direction of dance music recommendation
Data Availability
)e experimental data used to support the findings of thisstudy are available from the corresponding author uponrequest
Conflicts of Interest
)e author declares that no conflicts of interest regardingthis work
References
[1] Y Han Z Han J Wu et al ldquoArtificial intelligence recom-mendation system of cancer rehabilitation scheme based onIoT technologyrdquo IEEE Access vol 8 pp 44924ndash44935 2020
[2] A Rw M A Xiao and J A Chi ldquoHeterogeneous informationnetwork-based music recommendation system in mobilenetworksrdquo Computer Communications vol 150 pp 429ndash4372020
[3] X Wen ldquoUsing deep learning approach and IoT architectureto build the intelligent music recommendation systemrdquo SoftComputing vol 25 no 1 pp 1ndash10 2020
[4] H-G Kim G Y Kim and J Y Kim ldquoMusic recommendationsystem using human activity recognition from accelerometerdatardquo IEEE Transactions on Consumer Electronics vol 65no 3 pp 349ndash358 2019
[5] M S Fathollahi and F Razzazi ldquoMusic similarity measure-ment and recommendation system using convolutional neuralnetworksrdquo International Journal of Multimedia InformationRetrieval vol 5 pp 1ndash11 2021
[6] G Sun YWong and Z Cheng ldquoDeepDance music-to-dancemotion choreography with adversarial learningrdquo IEEETransactions on Multimedia vol 99 p 1 2020
[7] J M Agaku ldquo)e Girinya dance theatre of the Tiv people ofNigeria an aesthetic evaluationrdquo International Journal ofIntangible Heritage vol 3 no 6 pp 29ndash41 2008
[8] G Mota and L Abreu ldquo)irty years of music and dramaeducation in the Madeira Island facing future challengesrdquoInternational Journal of Music Education vol 32 no 3pp 360ndash374 2014
[9] B Montero ldquoPractice makes perfect the effect of dancetraining on the aesthetic judgerdquo Phenomenology and theCognitive Sciences vol 11 no 1 pp 59ndash68 2012
[10] A Manfre I Infantino F Vella and S Gaglio ldquoAn automaticsystem for humanoid dance creationrdquo Biologically InspiredCognitive Architectures vol 15 pp 1ndash9 2016
[11] D Aledo B Carrion Schafer and F Moreno ldquoVHDL vsSystemC design of highly parameterizable artificial neuralnetworksrdquo IEICE - Transactions on Info and Systemsvol E102D no 3 pp 512ndash521 2019
[12] B Sheng and G Sun ldquoMatrix factorization recommendationalgorithm based on multiple social relationshipsrdquo Mathe-matical Problems in Engineering vol 2021 Article ID6610645 8 pages 2021
[13] L Jiang Y Cheng L Yang J Li H Yan and X Wang ldquoAtrust-based collaborative filtering algorithm for E-commercerecommendation systemrdquo Journal of ambient intelligence andhumanized computing vol 10 no 8 pp 3023ndash3034 2019
[14] A Dm A Xl and A Qd ldquoHumming-query and reinforce-ment-learning based modeling approach for personalizedmusic recommendationrdquo Procedia Computer Science vol 176pp 2154ndash2163 2020
Complexity 15

differences in the solutions of these two problems At thesame time the processing process of image classificationdirection in small sample data can be used for reference byrecommendation system For example the classificationproblem of some pictures that have not been seen at all isZero-Shot while the classification problem of some picturesthat appear less frequently is Few-Shot Among these twoproblems the Zero-Shot problem can correspond to thecomplete cold start problem in the recommendationproblem while the Few-Shot problem can correspond to theincomplete cold start problem in the recommendationproblem For the Few-Shot problem and Zero-Shot problema similar solution to the cold start problem in the recom-mendation system is given
For the cold start problem one of the existing methods isto use user information and article information If effectiveinformation can be collected certain clustering operationscan be carried out on this basis and other similar usersrsquofavorite music can be used to recommend the user In ad-dition the structure of Auto Encoder can be used to extractfeatures At this time for the cold-start user the AutoEncoder encodes first and then decodes and the finallydecoded value includes the value inferred from the usercharacteristics [14]
In this paper we pay more attention to the problem ofincomplete cold start when designing the model and use thelimited scoring information as efficiently as possible toanalyze the scoring habits of users more accurately At thesame time it draws lessons from the idea of relationshiplearning in the field of computer vision hoping that therecommendation system can learn how to compare simi-larity in a more accurate way On this basis we investigatethe application of metric learning in recommendationsystem and find that although these methods have the idea ofmaking recommendation system learn distance informationto infer similarity the distance that defines similarity is low-order linear similarity Although this method can give acertain distance description it is difficult to fully capture andutilize the high-order features extracted by neural network)is paper hopes to calculate the similarity between picturesin relation learning and apply it to the recommendationsystem to calculate the similarity between people music andmusic user and music
32 Metric-Learning Model In 2018 Sung and Flood pro-posed a relation network model based on the metric-learning method to solve the classification problem of asmall number of labeled sample data in the field of computervision in deep learning as shown in Figure 4 )e authorproposes a relational network which compares the inputimages in the test set with a small number of known labeledsample images and calculates the correlation scores so as toclassify them )e relation network consists of two modulesan embedded module and a relational module Firstly theembedding module extracts the relevant feature informa-tion and then the relational module compares these em-bedding and obtains the relation score to determine whetherthey belong to the same class
Each block has 64 3times 3 convolution kernels a batchspecification layer and ReLU nonlinear function In addi-tion convolution blocks 1 and 3 have a 2times 2 maximumpooling layer )e author uses four convolution blocks toextract rich feature information between samples with fewerparameters )e network structure is shown in Figure 5
In the relation module you need to combine featuresfirst )e feature combination S recombines the featureinformation of the samples in the training set and the sampleinformation in the test set so that the relational encoder Gcan learn better from the combined features First thefeature mappings of the same class are summarized asshown in
fφ Li( 1113857 1113944K
J1Lij (10)
where Lij(i 1 i 2 j 1 j 2 K) denotes thetraining set features extracted from the embedded moduleand fφ(Li) denotes the mapping of feature information)emapping of combined features can be obtained by summingthe mapped feature sets )e formula is shown in (11)
Si fφ Li( 1113857 + fφ Qn( 1113857 (11)
Si represents the feature formed by the feature mappingof the training data set and the recombination of the testsamples and fφ(Qn) represents the feature from the testsamples )e model does not use conventional Euclideandistance or cosine distance instead we use nonlinear metriclearning In this part two convolution blocks and two fullyconnected layers are used to compare the two samples Eachconvolution block has 64 3times 3 convolution kernels a batchspecification layer a ReLU nonlinear activation layer and a2times 2 maximum pooling layer Finally through two fullyconnected layers the similarity relation score isin[0 1] be-tween the test samples and the training samples is finallyobtained by using the activation functions ReLU and sig-moid )e relation score is shown in
Relation score gϕ S fφ Lij1113872 1113873 fφ Qn( 11138571113872 11138731113872 1113873 (12)
)e detailed structure of the module is shown inFigure 6
33 Construction of Relation Model )e basic idea of thismodel is determined as a hybrid recommendation modellearning the similarity of user ratings by using the idea ofRelationship-Learning and then estimating the rating valuethrough collaborative filtering)emodel structure is shownin Figure 7
)is model mainly deals with two problems in recom-mendation system Firstly timeliness in the current era ofinformation explosion a large amount of data is uploaded tothe Internet every day It is difficult to obtain enough ratingdata at the beginning of these newly uploaded data whichcan be used in the recommendation system for target usersMusic recommendation system often encounters some newsongs which need to be recommended to users for audition
Complexity 7
)erefore through the cold start mechanism of the modelthe problem of new content recommendation can be solvedand the recommendation system can cope with the problemsbrought by timeliness and new content
Secondly personalization when users evaluate songseven if two people give favorable comments on the samesong their motives may be different for example oneperson likes the singer so they like this song and the otherperson likes the song style and likes this song )erefore themodel carries out more personalized processing for songrecommendation according to music characteristics anduser characteristics
331 Enter Data )e input of the model mainly consists oftwo parts one part is the feature information which includesthe personal feature information of the target user thefeature information of the scored n songs and the featureinformation of the target songs )e other part is the scoringinformation which contains the scoring values of the targetusers for n songs that have been scored In the third chapterthe related features have been extracted Formally the re-lated features are expressed as follows
Users U fieldu1 fieldu
2 fieldun1113864 1113865 represents the userrsquos
gender age and other related characteristic informationMusiccharacteristics M fieldM
1 fieldM2 fieldM
t1113966 1113967 representsthe relevant characteristic information of music Dance fea-tures D fieldD
1 fieldD2 fieldD
j1113966 1113967Historical interaction data of user U H
M1 M2 Mk1113864 1113865 user Ursquos comprehensive user score formusicM is Scorei and userUrsquos comprehensive user score fordance D is Scorej
332 Embedding According to the previous feature ex-traction work several user and audio features can be ob-tained Firstly the features are encoded through linear layeror embedding layer to obtain a series of vector represen-tations of features then according to these vectors the userand music are encoded )e user below represents severalcharacteristics of the target user which are represented byvectors Taking it as input the encoding vector of userfeatures is obtained through the User Encoder For usercoding because only text type features such as gender andage are used Auto Encoder model can be directly used tocomplete feature extraction In order to be similar to Music
64 33 convolutionkernels
Batch Normalization
Relu function
33 max-pooling
64 33 convolutionkernels
Batch Normalization
Relu function
64 33 convolutionkernels
Batch Normalization
Relu function
64 33 convolutionkernels
Batch Normalization
Relu function
33 max-pooling
fϕ
Figure 5 Embedding module
FC1Relu function
FC2Sigmoid function
SiRelation score
64 33 convolutionkernels
Batch Normalization
Relu function
22 max-pooling
64 33 convolutionkernels
Batch Normalization
Relu function
22 max-pooling
Figure 6 Relation module
Test sample 1
Test sample 2
Test sample 3
Test sample 4
Test sample 5
Test sample
Embedded module Relationship module
Feature concatenation
Relation score
fφ gϕ
Figure 4 Relation network model
8 Complexity
Encoder feature structure AutoInt model l is used to extractuser features here )e encoding structure of the user part isshown in Figure 8
Next for some music evaluated by users because theyknow their characteristics and scores they can combine theircharacteristics with userrsquos feature vectors and input theminto Music Encoder for coding respectively )is processcan combine usersrsquo personalized information for music sothat the same music can be coded differently by MusicEncoder for different users For unevaluatedmusic althoughthere is only the eigenvalue of music it can still obtain itseigenvector through Music Encoder like the music that hasbeen evaluated which is the coding layer Embedding Layerof music )e music feature coding structure is shown inFigure 9
As can be seen from Figure 9 the main structure ofencoder is multihead attention module and its essence is toperformmultiple self-attention calculations to formmultiplesubspaces so that the model can learn different features ofinformation from different angles and finally merge themTake the Music Encoder as an example and its structure isshown in Figure 10
In the multihead attention the feature matrixF f1 f2 ft1113864 1113865 needs to be transformed linearly tocompare the dimension of the feature vector that is QW
Qi
Perform k self-attention calculations as shown in
hlowast
Attention(Q K V) softmaxQK
T
dk
1113888 1113889V (13)
Splice and linearly map the result hlowast using
h concat hlowast1 hlowast2 h
lowastn( 1113857otimesW
o (14)
)e number of music selections has also been adjusted tosome extent When entering you need to have a series ofknown characteristics of the score and its final scoreHowever there will be many historical records of a personAnd the quantity is different and the model structure doesnot support the dynamic adjustment of the input quantityso this paper chooses the sampling method During eachtraining five historical evaluated songs are selected from thehistorical music of user interaction for input After severalrounds of training all the evaluated songs can be basicallyused in the training Although this method is inefficient inusing data sets it can greatly reduce the training time costand the complexity of the model )erefore after trade-offwe chose the method of randomly selecting five data
333 Interest Matching Module )e information aboutusers andmusic in the data set is processed and the obtainedhigh-order nonlinear eigenvector is taken as the output In
User data
Dance Music 1
Dance Music 2
Dance Music m New project
S M R
P
input
Embedding Module
Feature Vector
Combined Vector
Relation Module
Relation Score Ration
Predicted Ration
Figure 7 Model structure
Complexity 9
Max-Pooling
Multi-Head Attention
Field1 Field2 Field3
y1
Figure 8 User encoder model structure
Max-Pooling
Multi-Head Attention
Field1 Fieldt
y2
User feature vector y1
Characteristics of dance music
Figure 9 Music encoder model structure
10 Complexity
the model of this section we hope to give the similarity ofusers about different music scores through feature vectors
Firstly the characteristics of the scored songs and thecharacteristics of the target unscored songs are combined bythe user )en the similarity gφ between the two songs isgiven by comparing the similarity module and relationmodule its size is limited between 0 and 1 by normalizationfunction and finally a k-dimensional numerical vector re-lation score is obtained )e similarity gφmodel is shown in
gφ q1 q2( 1113857 Sigmoid qT1 Wq21113872 1113873 (15)
)e Interest Matching Relation module constructed inthis paper is not complex and the parameter to be trained isonly a matrix W In the experiment we also use a deeperstructure to replace this structure It is found that this willnot only increase the training time and parameter scale butalso reduce the accuracy )erefore we finally choose thevalue between [0 1] obtained by sigmoid after we get theinner product of two vectors about W as the similarityAccording to the similarity degree the related features of theknown graded music are constructed to predict the featuresof the music )e method is weighted average and theweight of each item is the score multiplied by the similaritydegree )e more similar the music and the higher the scorethe more obvious the influence on the prediction resultsFinally an estimated value of the eigenvector is obtained
Finally there is an output layer which synthesizes thetwo scoring results given before and gives the final con-clusion In the first part of the conclusion Y from theprevious user coding music-to-be-predicted estimationfeatures and music-to-be-predicted coding through a linearlayer this part reflects the idea of collaborative filteringbased on similarity and score to get the target score Anotherpart of the result x is obtained by using a Max Pooling layer
to select the value with the greatest correlation )e strategyembodied in this part is that when the songs to be predictedhave a high similarity with the previous historical songs itcan be considered that users are likely to have a certaininterest in the songs to be evaluated so the results have alarge similarity value at this time Finally the two scores areaveraged to get the final output)is is a value between [0 1]to indicate the degree of interest that users may be interestedin
4 Implementation ofPersonalized Recommendation
Traditional models do not use the information of users whointeract with them in the coding process of known music)is leads to the lack of user personality in the recom-mended content Even for two different users the coding ofthe same content is the same which cannot deal with thepersonalized problem well In addition in the actual in-teractive process content and users have different interactivebehaviors and different interactive behaviors often repre-sent different preferences of users However the previousmodels have not been distinguished to this extent resultingin different information brought by different interactivebehaviors not being used For example for praise andcollection collection means that users are more interestedthan praise because collection means that users are likely tolisten to this song repeatedly later while the probability oflistening to praise will be smaller later
In this paper firstly different behavior scores of users aredistinguished and the scores are divided into 1ndash5 pointsaccording to the listening times 6 points for collectionbehavior and 4 points for praise behavior In addition themultihead attention mechanism is introduced When
Linear
Concat
Self-attention
Linear LinearLinear
User feature vector (V)
Music feature vector (M)
Dance feature vector (D)
K
Output
Figure 10 Multihead attention module
Complexity 11
encoding music features in Music Encoder the user featuresand music features are combined and the user personalizedmusic coding is realized in the encoding layer which ensuresthat even if different users operate the same music the finalrecommendation results are still different because of dif-ferent personal characteristics thus realizing the personal-ized music recommendation
41 Model Training and Experimental Results Beforetraining the model it is necessary to divide the positive andnegative classes and determine the training set and test setused by the model For music recommendation label 0means dislike and label 1 means like which is defined as abinary classification problem According to the scoringprocessing of user behavior characteristics in Chapter 3music with a score higher than 5 is recorded as a positiveclass that is if the user listens to music many times or musicwith a little praise or collection behavior is recorded as apositive class Music with a score below 2 is recorded as anegative example indicating that although the user has someinteraction they have not shown interest Negative caseswith the same number of positive classes are randomlyselected from music with scores lower than 2 to ensure thatthe distribution is as balanced as possible After dividingpositive and negative classes the first 80 of the data set isused as the training set and the last 20 as the test set
42 Super Parameter Adjustment )e hyperparameter ad-justment process aims to optimize the performance of themodel First select the super parameters that can be adjusted)en determine whether they will be fixed or variable and ifthe parameters are changeable set them to different values todetermine in which range they will change
Hidden_size the original model is set to 50 and featuresare represented using the model by setting the number ofhidden layers)e hidden layer is set to 32 64 18 and 256 inthe implementation process and the best parameters aredetermined by experiments in TP100 data set in Figure 11
According to Figure 11 when the hidden layer is set to32 the model is in an underfitting state and cannot becharacterized With the increase of the hidden layer theaccuracy rate and recall rate are continuously improved butwhen the hidden layer is set to 256 both indicators decreaseslightly )erefore in the subsequent experiment the hid-den_size is set to 128
Learning_rate it depends on the Adam optimizer in themodel )e learning rate of each parameter is adapted bymaking smaller updates to frequent parameters and largerupdates to infrequent parameters )e learning rate of theoriginal model is set to 0001 In this experiment thelearning rates are set to 0001 001 01 and 05 respectivelyAccording to Figure 12 when the learning rates are 0001and 001 the accuracy is better In the subsequent experi-ment the learning_rate is set to 001
Batch_size when smaller batches are used a period oftraining is more detailed which usually leads to a decrease inthe number of convergent iterations but the training time islong On the other hand the more the batches the slower theconvergence speed which reduces the risk of overfitting andreduces the training time )e effect of batch_size on ac-curacy is shown in Figure 13
Try to use the batch size training model from 100 to 1000in the whole process As can be seen from Figure 13 andTable 2 using a smaller batch size the training time is longerUsing a large batch size (when it exceeds 700) a memoryerror was encountered
)erefore in the follow-up experiment the batch size isset to 600 for model training which not only meets thetraining time but also does not overflow the memory
43 Experimental Results )e whole training process Loss-Epochs is shown in Figure 14 During each training fivesongs with historical evaluation are selected from the his-torical music interacted by users for input After severalrounds of training all the evaluated songs can basically beused in training and the training loss is basically stable after1024 iterations
0002004006008
01012014016018
02
32 64 128 256Ev
alua
tion
inde
x
hidden_size
RecallPrecision
Figure 11 Impact of hidden size on evaluation indicators
12 Complexity
In order to verify the effectiveness of the model thispaper implements Neural Network Based CollaborativeFiltering (NCF) model and SVDmodel by Python which areverified in TP100 and TP500 data sets respectively )eaccuracy and recall rate are used to evaluate the accuracy ofdifferent recommendation lengths )e accuracy results ofdifferent recommendation lengths are shown in Figure 15
It can be seen from Figure 15 that the accuracy of thedeep learning recommendation model based on Relation-ship-Learning is obviously higher than that of the traditionalSVD recommendation algorithm in two data sets about 3higher than that of the collaborative filtering algorithm
based on neural network in TP100 data set and similar inTP500 data set with lower sparsity both of which are higherthan SVD algorithm
As can be seen from Figure 16 this model has obviousadvantages in both data sets With the increasing number ofrecommendations the recall rate gradually increases whichis about 10 higher than the traditional SVD algorithm InTP500 data sets with dense data the recall rate reaches about03 To sum up the deep learning recommendation modelbased on relationship learning implemented in this papercan accurately predict usersrsquo music preferences and finallycan accurately recommend music lists for users
07
075
08
085
09
095
0001001011A
ccur
acy
learning_rate
Figure 12 Impact of learning rate on accuracy
0
01
02
03
04
05
06
07
08
09
1
0 100 200 300 400 500 600 700 800
Acc
urac
y
batch_size
Figure 13 Effect of batch_size on accuracy
Table 2 Average running time per Epoch
batch_size 100 200 400 600 700Runtime (s) 67 39 20 9 8
Complexity 13
0 128 256 512 102400
02
04
06
08
10
12
14
16
18 Cross entropy loss of model training
Loss
Epochs
Figure 14 Model training loss
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
SVDNCFRelation-Learning
(a)
SVDNCFRelation-Learning
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
(b)
Figure 15 Accuracy of two data sets (a) TP100 data set (b) TP500 data set
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(a)
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(b)
Figure 16 Recall rate of two data sets (a) TP100 data set (b) TP500 data set
14 Complexity
5 Conclusion
Faced with a large number of dances and songs it is difficultfor people to quickly find dance music that meets theirinterests )e emergence of dance music recommendationsystem can recommend dance music that users may like andhelp users quickly discover or find their favorite dances andsongs )is kind of recommendation service can provideusers with a good experience and bring commercial benefitsso the field of dance music recommendation has become theresearch direction of industry and scholars In this paperrelation learning is introduced into dance music recom-mendation system and the relation model is applied todance music recommendation In the experiment the ac-curacy and recall rate are used to verify the effectiveness ofthe model in the direction of dance music recommendation
Data Availability
)e experimental data used to support the findings of thisstudy are available from the corresponding author uponrequest
Conflicts of Interest
)e author declares that no conflicts of interest regardingthis work
References
[1] Y Han Z Han J Wu et al ldquoArtificial intelligence recom-mendation system of cancer rehabilitation scheme based onIoT technologyrdquo IEEE Access vol 8 pp 44924ndash44935 2020
[2] A Rw M A Xiao and J A Chi ldquoHeterogeneous informationnetwork-based music recommendation system in mobilenetworksrdquo Computer Communications vol 150 pp 429ndash4372020
[3] X Wen ldquoUsing deep learning approach and IoT architectureto build the intelligent music recommendation systemrdquo SoftComputing vol 25 no 1 pp 1ndash10 2020
[4] H-G Kim G Y Kim and J Y Kim ldquoMusic recommendationsystem using human activity recognition from accelerometerdatardquo IEEE Transactions on Consumer Electronics vol 65no 3 pp 349ndash358 2019
[5] M S Fathollahi and F Razzazi ldquoMusic similarity measure-ment and recommendation system using convolutional neuralnetworksrdquo International Journal of Multimedia InformationRetrieval vol 5 pp 1ndash11 2021
[6] G Sun YWong and Z Cheng ldquoDeepDance music-to-dancemotion choreography with adversarial learningrdquo IEEETransactions on Multimedia vol 99 p 1 2020
[7] J M Agaku ldquo)e Girinya dance theatre of the Tiv people ofNigeria an aesthetic evaluationrdquo International Journal ofIntangible Heritage vol 3 no 6 pp 29ndash41 2008
[8] G Mota and L Abreu ldquo)irty years of music and dramaeducation in the Madeira Island facing future challengesrdquoInternational Journal of Music Education vol 32 no 3pp 360ndash374 2014
[9] B Montero ldquoPractice makes perfect the effect of dancetraining on the aesthetic judgerdquo Phenomenology and theCognitive Sciences vol 11 no 1 pp 59ndash68 2012
[10] A Manfre I Infantino F Vella and S Gaglio ldquoAn automaticsystem for humanoid dance creationrdquo Biologically InspiredCognitive Architectures vol 15 pp 1ndash9 2016
[11] D Aledo B Carrion Schafer and F Moreno ldquoVHDL vsSystemC design of highly parameterizable artificial neuralnetworksrdquo IEICE - Transactions on Info and Systemsvol E102D no 3 pp 512ndash521 2019
[12] B Sheng and G Sun ldquoMatrix factorization recommendationalgorithm based on multiple social relationshipsrdquo Mathe-matical Problems in Engineering vol 2021 Article ID6610645 8 pages 2021
[13] L Jiang Y Cheng L Yang J Li H Yan and X Wang ldquoAtrust-based collaborative filtering algorithm for E-commercerecommendation systemrdquo Journal of ambient intelligence andhumanized computing vol 10 no 8 pp 3023ndash3034 2019
[14] A Dm A Xl and A Qd ldquoHumming-query and reinforce-ment-learning based modeling approach for personalizedmusic recommendationrdquo Procedia Computer Science vol 176pp 2154ndash2163 2020
Complexity 15

)erefore through the cold start mechanism of the modelthe problem of new content recommendation can be solvedand the recommendation system can cope with the problemsbrought by timeliness and new content
Secondly personalization when users evaluate songseven if two people give favorable comments on the samesong their motives may be different for example oneperson likes the singer so they like this song and the otherperson likes the song style and likes this song )erefore themodel carries out more personalized processing for songrecommendation according to music characteristics anduser characteristics
331 Enter Data )e input of the model mainly consists oftwo parts one part is the feature information which includesthe personal feature information of the target user thefeature information of the scored n songs and the featureinformation of the target songs )e other part is the scoringinformation which contains the scoring values of the targetusers for n songs that have been scored In the third chapterthe related features have been extracted Formally the re-lated features are expressed as follows
Users U fieldu1 fieldu
2 fieldun1113864 1113865 represents the userrsquos
gender age and other related characteristic informationMusiccharacteristics M fieldM
1 fieldM2 fieldM
t1113966 1113967 representsthe relevant characteristic information of music Dance fea-tures D fieldD
1 fieldD2 fieldD
j1113966 1113967Historical interaction data of user U H
M1 M2 Mk1113864 1113865 user Ursquos comprehensive user score formusicM is Scorei and userUrsquos comprehensive user score fordance D is Scorej
332 Embedding According to the previous feature ex-traction work several user and audio features can be ob-tained Firstly the features are encoded through linear layeror embedding layer to obtain a series of vector represen-tations of features then according to these vectors the userand music are encoded )e user below represents severalcharacteristics of the target user which are represented byvectors Taking it as input the encoding vector of userfeatures is obtained through the User Encoder For usercoding because only text type features such as gender andage are used Auto Encoder model can be directly used tocomplete feature extraction In order to be similar to Music
64 33 convolutionkernels
Batch Normalization
Relu function
33 max-pooling
64 33 convolutionkernels
Batch Normalization
Relu function
64 33 convolutionkernels
Batch Normalization
Relu function
64 33 convolutionkernels
Batch Normalization
Relu function
33 max-pooling
fϕ
Figure 5 Embedding module
FC1Relu function
FC2Sigmoid function
SiRelation score
64 33 convolutionkernels
Batch Normalization
Relu function
22 max-pooling
64 33 convolutionkernels
Batch Normalization
Relu function
22 max-pooling
Figure 6 Relation module
Test sample 1
Test sample 2
Test sample 3
Test sample 4
Test sample 5
Test sample
Embedded module Relationship module
Feature concatenation
Relation score
fφ gϕ
Figure 4 Relation network model
8 Complexity
Encoder feature structure AutoInt model l is used to extractuser features here )e encoding structure of the user part isshown in Figure 8
Next for some music evaluated by users because theyknow their characteristics and scores they can combine theircharacteristics with userrsquos feature vectors and input theminto Music Encoder for coding respectively )is processcan combine usersrsquo personalized information for music sothat the same music can be coded differently by MusicEncoder for different users For unevaluatedmusic althoughthere is only the eigenvalue of music it can still obtain itseigenvector through Music Encoder like the music that hasbeen evaluated which is the coding layer Embedding Layerof music )e music feature coding structure is shown inFigure 9
As can be seen from Figure 9 the main structure ofencoder is multihead attention module and its essence is toperformmultiple self-attention calculations to formmultiplesubspaces so that the model can learn different features ofinformation from different angles and finally merge themTake the Music Encoder as an example and its structure isshown in Figure 10
In the multihead attention the feature matrixF f1 f2 ft1113864 1113865 needs to be transformed linearly tocompare the dimension of the feature vector that is QW
Qi
Perform k self-attention calculations as shown in
hlowast
Attention(Q K V) softmaxQK
T
dk
1113888 1113889V (13)
Splice and linearly map the result hlowast using
h concat hlowast1 hlowast2 h
lowastn( 1113857otimesW
o (14)
)e number of music selections has also been adjusted tosome extent When entering you need to have a series ofknown characteristics of the score and its final scoreHowever there will be many historical records of a personAnd the quantity is different and the model structure doesnot support the dynamic adjustment of the input quantityso this paper chooses the sampling method During eachtraining five historical evaluated songs are selected from thehistorical music of user interaction for input After severalrounds of training all the evaluated songs can be basicallyused in the training Although this method is inefficient inusing data sets it can greatly reduce the training time costand the complexity of the model )erefore after trade-offwe chose the method of randomly selecting five data
333 Interest Matching Module )e information aboutusers andmusic in the data set is processed and the obtainedhigh-order nonlinear eigenvector is taken as the output In
User data
Dance Music 1
Dance Music 2
Dance Music m New project
S M R
P
input
Embedding Module
Feature Vector
Combined Vector
Relation Module
Relation Score Ration
Predicted Ration
Figure 7 Model structure
Complexity 9
Max-Pooling
Multi-Head Attention
Field1 Field2 Field3
y1
Figure 8 User encoder model structure
Max-Pooling
Multi-Head Attention
Field1 Fieldt
y2
User feature vector y1
Characteristics of dance music
Figure 9 Music encoder model structure
10 Complexity
the model of this section we hope to give the similarity ofusers about different music scores through feature vectors
Firstly the characteristics of the scored songs and thecharacteristics of the target unscored songs are combined bythe user )en the similarity gφ between the two songs isgiven by comparing the similarity module and relationmodule its size is limited between 0 and 1 by normalizationfunction and finally a k-dimensional numerical vector re-lation score is obtained )e similarity gφmodel is shown in
gφ q1 q2( 1113857 Sigmoid qT1 Wq21113872 1113873 (15)
)e Interest Matching Relation module constructed inthis paper is not complex and the parameter to be trained isonly a matrix W In the experiment we also use a deeperstructure to replace this structure It is found that this willnot only increase the training time and parameter scale butalso reduce the accuracy )erefore we finally choose thevalue between [0 1] obtained by sigmoid after we get theinner product of two vectors about W as the similarityAccording to the similarity degree the related features of theknown graded music are constructed to predict the featuresof the music )e method is weighted average and theweight of each item is the score multiplied by the similaritydegree )e more similar the music and the higher the scorethe more obvious the influence on the prediction resultsFinally an estimated value of the eigenvector is obtained
Finally there is an output layer which synthesizes thetwo scoring results given before and gives the final con-clusion In the first part of the conclusion Y from theprevious user coding music-to-be-predicted estimationfeatures and music-to-be-predicted coding through a linearlayer this part reflects the idea of collaborative filteringbased on similarity and score to get the target score Anotherpart of the result x is obtained by using a Max Pooling layer
to select the value with the greatest correlation )e strategyembodied in this part is that when the songs to be predictedhave a high similarity with the previous historical songs itcan be considered that users are likely to have a certaininterest in the songs to be evaluated so the results have alarge similarity value at this time Finally the two scores areaveraged to get the final output)is is a value between [0 1]to indicate the degree of interest that users may be interestedin
4 Implementation ofPersonalized Recommendation
Traditional models do not use the information of users whointeract with them in the coding process of known music)is leads to the lack of user personality in the recom-mended content Even for two different users the coding ofthe same content is the same which cannot deal with thepersonalized problem well In addition in the actual in-teractive process content and users have different interactivebehaviors and different interactive behaviors often repre-sent different preferences of users However the previousmodels have not been distinguished to this extent resultingin different information brought by different interactivebehaviors not being used For example for praise andcollection collection means that users are more interestedthan praise because collection means that users are likely tolisten to this song repeatedly later while the probability oflistening to praise will be smaller later
In this paper firstly different behavior scores of users aredistinguished and the scores are divided into 1ndash5 pointsaccording to the listening times 6 points for collectionbehavior and 4 points for praise behavior In addition themultihead attention mechanism is introduced When
Linear
Concat
Self-attention
Linear LinearLinear
User feature vector (V)
Music feature vector (M)
Dance feature vector (D)
K
Output
Figure 10 Multihead attention module
Complexity 11
encoding music features in Music Encoder the user featuresand music features are combined and the user personalizedmusic coding is realized in the encoding layer which ensuresthat even if different users operate the same music the finalrecommendation results are still different because of dif-ferent personal characteristics thus realizing the personal-ized music recommendation
41 Model Training and Experimental Results Beforetraining the model it is necessary to divide the positive andnegative classes and determine the training set and test setused by the model For music recommendation label 0means dislike and label 1 means like which is defined as abinary classification problem According to the scoringprocessing of user behavior characteristics in Chapter 3music with a score higher than 5 is recorded as a positiveclass that is if the user listens to music many times or musicwith a little praise or collection behavior is recorded as apositive class Music with a score below 2 is recorded as anegative example indicating that although the user has someinteraction they have not shown interest Negative caseswith the same number of positive classes are randomlyselected from music with scores lower than 2 to ensure thatthe distribution is as balanced as possible After dividingpositive and negative classes the first 80 of the data set isused as the training set and the last 20 as the test set
42 Super Parameter Adjustment )e hyperparameter ad-justment process aims to optimize the performance of themodel First select the super parameters that can be adjusted)en determine whether they will be fixed or variable and ifthe parameters are changeable set them to different values todetermine in which range they will change
Hidden_size the original model is set to 50 and featuresare represented using the model by setting the number ofhidden layers)e hidden layer is set to 32 64 18 and 256 inthe implementation process and the best parameters aredetermined by experiments in TP100 data set in Figure 11
According to Figure 11 when the hidden layer is set to32 the model is in an underfitting state and cannot becharacterized With the increase of the hidden layer theaccuracy rate and recall rate are continuously improved butwhen the hidden layer is set to 256 both indicators decreaseslightly )erefore in the subsequent experiment the hid-den_size is set to 128
Learning_rate it depends on the Adam optimizer in themodel )e learning rate of each parameter is adapted bymaking smaller updates to frequent parameters and largerupdates to infrequent parameters )e learning rate of theoriginal model is set to 0001 In this experiment thelearning rates are set to 0001 001 01 and 05 respectivelyAccording to Figure 12 when the learning rates are 0001and 001 the accuracy is better In the subsequent experi-ment the learning_rate is set to 001
Batch_size when smaller batches are used a period oftraining is more detailed which usually leads to a decrease inthe number of convergent iterations but the training time islong On the other hand the more the batches the slower theconvergence speed which reduces the risk of overfitting andreduces the training time )e effect of batch_size on ac-curacy is shown in Figure 13
Try to use the batch size training model from 100 to 1000in the whole process As can be seen from Figure 13 andTable 2 using a smaller batch size the training time is longerUsing a large batch size (when it exceeds 700) a memoryerror was encountered
)erefore in the follow-up experiment the batch size isset to 600 for model training which not only meets thetraining time but also does not overflow the memory
43 Experimental Results )e whole training process Loss-Epochs is shown in Figure 14 During each training fivesongs with historical evaluation are selected from the his-torical music interacted by users for input After severalrounds of training all the evaluated songs can basically beused in training and the training loss is basically stable after1024 iterations
0002004006008
01012014016018
02
32 64 128 256Ev
alua
tion
inde
x
hidden_size
RecallPrecision
Figure 11 Impact of hidden size on evaluation indicators
12 Complexity
In order to verify the effectiveness of the model thispaper implements Neural Network Based CollaborativeFiltering (NCF) model and SVDmodel by Python which areverified in TP100 and TP500 data sets respectively )eaccuracy and recall rate are used to evaluate the accuracy ofdifferent recommendation lengths )e accuracy results ofdifferent recommendation lengths are shown in Figure 15
It can be seen from Figure 15 that the accuracy of thedeep learning recommendation model based on Relation-ship-Learning is obviously higher than that of the traditionalSVD recommendation algorithm in two data sets about 3higher than that of the collaborative filtering algorithm
based on neural network in TP100 data set and similar inTP500 data set with lower sparsity both of which are higherthan SVD algorithm
As can be seen from Figure 16 this model has obviousadvantages in both data sets With the increasing number ofrecommendations the recall rate gradually increases whichis about 10 higher than the traditional SVD algorithm InTP500 data sets with dense data the recall rate reaches about03 To sum up the deep learning recommendation modelbased on relationship learning implemented in this papercan accurately predict usersrsquo music preferences and finallycan accurately recommend music lists for users
07
075
08
085
09
095
0001001011A
ccur
acy
learning_rate
Figure 12 Impact of learning rate on accuracy
0
01
02
03
04
05
06
07
08
09
1
0 100 200 300 400 500 600 700 800
Acc
urac
y
batch_size
Figure 13 Effect of batch_size on accuracy
Table 2 Average running time per Epoch
batch_size 100 200 400 600 700Runtime (s) 67 39 20 9 8
Complexity 13
0 128 256 512 102400
02
04
06
08
10
12
14
16
18 Cross entropy loss of model training
Loss
Epochs
Figure 14 Model training loss
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
SVDNCFRelation-Learning
(a)
SVDNCFRelation-Learning
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
(b)
Figure 15 Accuracy of two data sets (a) TP100 data set (b) TP500 data set
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(a)
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(b)
Figure 16 Recall rate of two data sets (a) TP100 data set (b) TP500 data set
14 Complexity
5 Conclusion
Faced with a large number of dances and songs it is difficultfor people to quickly find dance music that meets theirinterests )e emergence of dance music recommendationsystem can recommend dance music that users may like andhelp users quickly discover or find their favorite dances andsongs )is kind of recommendation service can provideusers with a good experience and bring commercial benefitsso the field of dance music recommendation has become theresearch direction of industry and scholars In this paperrelation learning is introduced into dance music recom-mendation system and the relation model is applied todance music recommendation In the experiment the ac-curacy and recall rate are used to verify the effectiveness ofthe model in the direction of dance music recommendation
Data Availability
)e experimental data used to support the findings of thisstudy are available from the corresponding author uponrequest
Conflicts of Interest
)e author declares that no conflicts of interest regardingthis work
References
[1] Y Han Z Han J Wu et al ldquoArtificial intelligence recom-mendation system of cancer rehabilitation scheme based onIoT technologyrdquo IEEE Access vol 8 pp 44924ndash44935 2020
[2] A Rw M A Xiao and J A Chi ldquoHeterogeneous informationnetwork-based music recommendation system in mobilenetworksrdquo Computer Communications vol 150 pp 429ndash4372020
[3] X Wen ldquoUsing deep learning approach and IoT architectureto build the intelligent music recommendation systemrdquo SoftComputing vol 25 no 1 pp 1ndash10 2020
[4] H-G Kim G Y Kim and J Y Kim ldquoMusic recommendationsystem using human activity recognition from accelerometerdatardquo IEEE Transactions on Consumer Electronics vol 65no 3 pp 349ndash358 2019
[5] M S Fathollahi and F Razzazi ldquoMusic similarity measure-ment and recommendation system using convolutional neuralnetworksrdquo International Journal of Multimedia InformationRetrieval vol 5 pp 1ndash11 2021
[6] G Sun YWong and Z Cheng ldquoDeepDance music-to-dancemotion choreography with adversarial learningrdquo IEEETransactions on Multimedia vol 99 p 1 2020
[7] J M Agaku ldquo)e Girinya dance theatre of the Tiv people ofNigeria an aesthetic evaluationrdquo International Journal ofIntangible Heritage vol 3 no 6 pp 29ndash41 2008
[8] G Mota and L Abreu ldquo)irty years of music and dramaeducation in the Madeira Island facing future challengesrdquoInternational Journal of Music Education vol 32 no 3pp 360ndash374 2014
[9] B Montero ldquoPractice makes perfect the effect of dancetraining on the aesthetic judgerdquo Phenomenology and theCognitive Sciences vol 11 no 1 pp 59ndash68 2012
[10] A Manfre I Infantino F Vella and S Gaglio ldquoAn automaticsystem for humanoid dance creationrdquo Biologically InspiredCognitive Architectures vol 15 pp 1ndash9 2016
[11] D Aledo B Carrion Schafer and F Moreno ldquoVHDL vsSystemC design of highly parameterizable artificial neuralnetworksrdquo IEICE - Transactions on Info and Systemsvol E102D no 3 pp 512ndash521 2019
[12] B Sheng and G Sun ldquoMatrix factorization recommendationalgorithm based on multiple social relationshipsrdquo Mathe-matical Problems in Engineering vol 2021 Article ID6610645 8 pages 2021
[13] L Jiang Y Cheng L Yang J Li H Yan and X Wang ldquoAtrust-based collaborative filtering algorithm for E-commercerecommendation systemrdquo Journal of ambient intelligence andhumanized computing vol 10 no 8 pp 3023ndash3034 2019
[14] A Dm A Xl and A Qd ldquoHumming-query and reinforce-ment-learning based modeling approach for personalizedmusic recommendationrdquo Procedia Computer Science vol 176pp 2154ndash2163 2020
Complexity 15

Encoder feature structure AutoInt model l is used to extractuser features here )e encoding structure of the user part isshown in Figure 8
Next for some music evaluated by users because theyknow their characteristics and scores they can combine theircharacteristics with userrsquos feature vectors and input theminto Music Encoder for coding respectively )is processcan combine usersrsquo personalized information for music sothat the same music can be coded differently by MusicEncoder for different users For unevaluatedmusic althoughthere is only the eigenvalue of music it can still obtain itseigenvector through Music Encoder like the music that hasbeen evaluated which is the coding layer Embedding Layerof music )e music feature coding structure is shown inFigure 9
As can be seen from Figure 9 the main structure ofencoder is multihead attention module and its essence is toperformmultiple self-attention calculations to formmultiplesubspaces so that the model can learn different features ofinformation from different angles and finally merge themTake the Music Encoder as an example and its structure isshown in Figure 10
In the multihead attention the feature matrixF f1 f2 ft1113864 1113865 needs to be transformed linearly tocompare the dimension of the feature vector that is QW
Qi
Perform k self-attention calculations as shown in
hlowast
Attention(Q K V) softmaxQK
T
dk
1113888 1113889V (13)
Splice and linearly map the result hlowast using
h concat hlowast1 hlowast2 h
lowastn( 1113857otimesW
o (14)
)e number of music selections has also been adjusted tosome extent When entering you need to have a series ofknown characteristics of the score and its final scoreHowever there will be many historical records of a personAnd the quantity is different and the model structure doesnot support the dynamic adjustment of the input quantityso this paper chooses the sampling method During eachtraining five historical evaluated songs are selected from thehistorical music of user interaction for input After severalrounds of training all the evaluated songs can be basicallyused in the training Although this method is inefficient inusing data sets it can greatly reduce the training time costand the complexity of the model )erefore after trade-offwe chose the method of randomly selecting five data
333 Interest Matching Module )e information aboutusers andmusic in the data set is processed and the obtainedhigh-order nonlinear eigenvector is taken as the output In
User data
Dance Music 1
Dance Music 2
Dance Music m New project
S M R
P
input
Embedding Module
Feature Vector
Combined Vector
Relation Module
Relation Score Ration
Predicted Ration
Figure 7 Model structure
Complexity 9
Max-Pooling
Multi-Head Attention
Field1 Field2 Field3
y1
Figure 8 User encoder model structure
Max-Pooling
Multi-Head Attention
Field1 Fieldt
y2
User feature vector y1
Characteristics of dance music
Figure 9 Music encoder model structure
10 Complexity
the model of this section we hope to give the similarity ofusers about different music scores through feature vectors
Firstly the characteristics of the scored songs and thecharacteristics of the target unscored songs are combined bythe user )en the similarity gφ between the two songs isgiven by comparing the similarity module and relationmodule its size is limited between 0 and 1 by normalizationfunction and finally a k-dimensional numerical vector re-lation score is obtained )e similarity gφmodel is shown in
gφ q1 q2( 1113857 Sigmoid qT1 Wq21113872 1113873 (15)
)e Interest Matching Relation module constructed inthis paper is not complex and the parameter to be trained isonly a matrix W In the experiment we also use a deeperstructure to replace this structure It is found that this willnot only increase the training time and parameter scale butalso reduce the accuracy )erefore we finally choose thevalue between [0 1] obtained by sigmoid after we get theinner product of two vectors about W as the similarityAccording to the similarity degree the related features of theknown graded music are constructed to predict the featuresof the music )e method is weighted average and theweight of each item is the score multiplied by the similaritydegree )e more similar the music and the higher the scorethe more obvious the influence on the prediction resultsFinally an estimated value of the eigenvector is obtained
Finally there is an output layer which synthesizes thetwo scoring results given before and gives the final con-clusion In the first part of the conclusion Y from theprevious user coding music-to-be-predicted estimationfeatures and music-to-be-predicted coding through a linearlayer this part reflects the idea of collaborative filteringbased on similarity and score to get the target score Anotherpart of the result x is obtained by using a Max Pooling layer
to select the value with the greatest correlation )e strategyembodied in this part is that when the songs to be predictedhave a high similarity with the previous historical songs itcan be considered that users are likely to have a certaininterest in the songs to be evaluated so the results have alarge similarity value at this time Finally the two scores areaveraged to get the final output)is is a value between [0 1]to indicate the degree of interest that users may be interestedin
4 Implementation ofPersonalized Recommendation
Traditional models do not use the information of users whointeract with them in the coding process of known music)is leads to the lack of user personality in the recom-mended content Even for two different users the coding ofthe same content is the same which cannot deal with thepersonalized problem well In addition in the actual in-teractive process content and users have different interactivebehaviors and different interactive behaviors often repre-sent different preferences of users However the previousmodels have not been distinguished to this extent resultingin different information brought by different interactivebehaviors not being used For example for praise andcollection collection means that users are more interestedthan praise because collection means that users are likely tolisten to this song repeatedly later while the probability oflistening to praise will be smaller later
In this paper firstly different behavior scores of users aredistinguished and the scores are divided into 1ndash5 pointsaccording to the listening times 6 points for collectionbehavior and 4 points for praise behavior In addition themultihead attention mechanism is introduced When
Linear
Concat
Self-attention
Linear LinearLinear
User feature vector (V)
Music feature vector (M)
Dance feature vector (D)
K
Output
Figure 10 Multihead attention module
Complexity 11
encoding music features in Music Encoder the user featuresand music features are combined and the user personalizedmusic coding is realized in the encoding layer which ensuresthat even if different users operate the same music the finalrecommendation results are still different because of dif-ferent personal characteristics thus realizing the personal-ized music recommendation
41 Model Training and Experimental Results Beforetraining the model it is necessary to divide the positive andnegative classes and determine the training set and test setused by the model For music recommendation label 0means dislike and label 1 means like which is defined as abinary classification problem According to the scoringprocessing of user behavior characteristics in Chapter 3music with a score higher than 5 is recorded as a positiveclass that is if the user listens to music many times or musicwith a little praise or collection behavior is recorded as apositive class Music with a score below 2 is recorded as anegative example indicating that although the user has someinteraction they have not shown interest Negative caseswith the same number of positive classes are randomlyselected from music with scores lower than 2 to ensure thatthe distribution is as balanced as possible After dividingpositive and negative classes the first 80 of the data set isused as the training set and the last 20 as the test set
42 Super Parameter Adjustment )e hyperparameter ad-justment process aims to optimize the performance of themodel First select the super parameters that can be adjusted)en determine whether they will be fixed or variable and ifthe parameters are changeable set them to different values todetermine in which range they will change
Hidden_size the original model is set to 50 and featuresare represented using the model by setting the number ofhidden layers)e hidden layer is set to 32 64 18 and 256 inthe implementation process and the best parameters aredetermined by experiments in TP100 data set in Figure 11
According to Figure 11 when the hidden layer is set to32 the model is in an underfitting state and cannot becharacterized With the increase of the hidden layer theaccuracy rate and recall rate are continuously improved butwhen the hidden layer is set to 256 both indicators decreaseslightly )erefore in the subsequent experiment the hid-den_size is set to 128
Learning_rate it depends on the Adam optimizer in themodel )e learning rate of each parameter is adapted bymaking smaller updates to frequent parameters and largerupdates to infrequent parameters )e learning rate of theoriginal model is set to 0001 In this experiment thelearning rates are set to 0001 001 01 and 05 respectivelyAccording to Figure 12 when the learning rates are 0001and 001 the accuracy is better In the subsequent experi-ment the learning_rate is set to 001
Batch_size when smaller batches are used a period oftraining is more detailed which usually leads to a decrease inthe number of convergent iterations but the training time islong On the other hand the more the batches the slower theconvergence speed which reduces the risk of overfitting andreduces the training time )e effect of batch_size on ac-curacy is shown in Figure 13
Try to use the batch size training model from 100 to 1000in the whole process As can be seen from Figure 13 andTable 2 using a smaller batch size the training time is longerUsing a large batch size (when it exceeds 700) a memoryerror was encountered
)erefore in the follow-up experiment the batch size isset to 600 for model training which not only meets thetraining time but also does not overflow the memory
43 Experimental Results )e whole training process Loss-Epochs is shown in Figure 14 During each training fivesongs with historical evaluation are selected from the his-torical music interacted by users for input After severalrounds of training all the evaluated songs can basically beused in training and the training loss is basically stable after1024 iterations
0002004006008
01012014016018
02
32 64 128 256Ev
alua
tion
inde
x
hidden_size
RecallPrecision
Figure 11 Impact of hidden size on evaluation indicators
12 Complexity
In order to verify the effectiveness of the model thispaper implements Neural Network Based CollaborativeFiltering (NCF) model and SVDmodel by Python which areverified in TP100 and TP500 data sets respectively )eaccuracy and recall rate are used to evaluate the accuracy ofdifferent recommendation lengths )e accuracy results ofdifferent recommendation lengths are shown in Figure 15
It can be seen from Figure 15 that the accuracy of thedeep learning recommendation model based on Relation-ship-Learning is obviously higher than that of the traditionalSVD recommendation algorithm in two data sets about 3higher than that of the collaborative filtering algorithm
based on neural network in TP100 data set and similar inTP500 data set with lower sparsity both of which are higherthan SVD algorithm
As can be seen from Figure 16 this model has obviousadvantages in both data sets With the increasing number ofrecommendations the recall rate gradually increases whichis about 10 higher than the traditional SVD algorithm InTP500 data sets with dense data the recall rate reaches about03 To sum up the deep learning recommendation modelbased on relationship learning implemented in this papercan accurately predict usersrsquo music preferences and finallycan accurately recommend music lists for users
07
075
08
085
09
095
0001001011A
ccur
acy
learning_rate
Figure 12 Impact of learning rate on accuracy
0
01
02
03
04
05
06
07
08
09
1
0 100 200 300 400 500 600 700 800
Acc
urac
y
batch_size
Figure 13 Effect of batch_size on accuracy
Table 2 Average running time per Epoch
batch_size 100 200 400 600 700Runtime (s) 67 39 20 9 8
Complexity 13
0 128 256 512 102400
02
04
06
08
10
12
14
16
18 Cross entropy loss of model training
Loss
Epochs
Figure 14 Model training loss
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
SVDNCFRelation-Learning
(a)
SVDNCFRelation-Learning
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
(b)
Figure 15 Accuracy of two data sets (a) TP100 data set (b) TP500 data set
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(a)
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(b)
Figure 16 Recall rate of two data sets (a) TP100 data set (b) TP500 data set
14 Complexity
5 Conclusion
Faced with a large number of dances and songs it is difficultfor people to quickly find dance music that meets theirinterests )e emergence of dance music recommendationsystem can recommend dance music that users may like andhelp users quickly discover or find their favorite dances andsongs )is kind of recommendation service can provideusers with a good experience and bring commercial benefitsso the field of dance music recommendation has become theresearch direction of industry and scholars In this paperrelation learning is introduced into dance music recom-mendation system and the relation model is applied todance music recommendation In the experiment the ac-curacy and recall rate are used to verify the effectiveness ofthe model in the direction of dance music recommendation
Data Availability
)e experimental data used to support the findings of thisstudy are available from the corresponding author uponrequest
Conflicts of Interest
)e author declares that no conflicts of interest regardingthis work
References
[1] Y Han Z Han J Wu et al ldquoArtificial intelligence recom-mendation system of cancer rehabilitation scheme based onIoT technologyrdquo IEEE Access vol 8 pp 44924ndash44935 2020
[2] A Rw M A Xiao and J A Chi ldquoHeterogeneous informationnetwork-based music recommendation system in mobilenetworksrdquo Computer Communications vol 150 pp 429ndash4372020
[3] X Wen ldquoUsing deep learning approach and IoT architectureto build the intelligent music recommendation systemrdquo SoftComputing vol 25 no 1 pp 1ndash10 2020
[4] H-G Kim G Y Kim and J Y Kim ldquoMusic recommendationsystem using human activity recognition from accelerometerdatardquo IEEE Transactions on Consumer Electronics vol 65no 3 pp 349ndash358 2019
[5] M S Fathollahi and F Razzazi ldquoMusic similarity measure-ment and recommendation system using convolutional neuralnetworksrdquo International Journal of Multimedia InformationRetrieval vol 5 pp 1ndash11 2021
[6] G Sun YWong and Z Cheng ldquoDeepDance music-to-dancemotion choreography with adversarial learningrdquo IEEETransactions on Multimedia vol 99 p 1 2020
[7] J M Agaku ldquo)e Girinya dance theatre of the Tiv people ofNigeria an aesthetic evaluationrdquo International Journal ofIntangible Heritage vol 3 no 6 pp 29ndash41 2008
[8] G Mota and L Abreu ldquo)irty years of music and dramaeducation in the Madeira Island facing future challengesrdquoInternational Journal of Music Education vol 32 no 3pp 360ndash374 2014
[9] B Montero ldquoPractice makes perfect the effect of dancetraining on the aesthetic judgerdquo Phenomenology and theCognitive Sciences vol 11 no 1 pp 59ndash68 2012
[10] A Manfre I Infantino F Vella and S Gaglio ldquoAn automaticsystem for humanoid dance creationrdquo Biologically InspiredCognitive Architectures vol 15 pp 1ndash9 2016
[11] D Aledo B Carrion Schafer and F Moreno ldquoVHDL vsSystemC design of highly parameterizable artificial neuralnetworksrdquo IEICE - Transactions on Info and Systemsvol E102D no 3 pp 512ndash521 2019
[12] B Sheng and G Sun ldquoMatrix factorization recommendationalgorithm based on multiple social relationshipsrdquo Mathe-matical Problems in Engineering vol 2021 Article ID6610645 8 pages 2021
[13] L Jiang Y Cheng L Yang J Li H Yan and X Wang ldquoAtrust-based collaborative filtering algorithm for E-commercerecommendation systemrdquo Journal of ambient intelligence andhumanized computing vol 10 no 8 pp 3023ndash3034 2019
[14] A Dm A Xl and A Qd ldquoHumming-query and reinforce-ment-learning based modeling approach for personalizedmusic recommendationrdquo Procedia Computer Science vol 176pp 2154ndash2163 2020
Complexity 15

Max-Pooling
Multi-Head Attention
Field1 Field2 Field3
y1
Figure 8 User encoder model structure
Max-Pooling
Multi-Head Attention
Field1 Fieldt
y2
User feature vector y1
Characteristics of dance music
Figure 9 Music encoder model structure
10 Complexity
the model of this section we hope to give the similarity ofusers about different music scores through feature vectors
Firstly the characteristics of the scored songs and thecharacteristics of the target unscored songs are combined bythe user )en the similarity gφ between the two songs isgiven by comparing the similarity module and relationmodule its size is limited between 0 and 1 by normalizationfunction and finally a k-dimensional numerical vector re-lation score is obtained )e similarity gφmodel is shown in
gφ q1 q2( 1113857 Sigmoid qT1 Wq21113872 1113873 (15)
)e Interest Matching Relation module constructed inthis paper is not complex and the parameter to be trained isonly a matrix W In the experiment we also use a deeperstructure to replace this structure It is found that this willnot only increase the training time and parameter scale butalso reduce the accuracy )erefore we finally choose thevalue between [0 1] obtained by sigmoid after we get theinner product of two vectors about W as the similarityAccording to the similarity degree the related features of theknown graded music are constructed to predict the featuresof the music )e method is weighted average and theweight of each item is the score multiplied by the similaritydegree )e more similar the music and the higher the scorethe more obvious the influence on the prediction resultsFinally an estimated value of the eigenvector is obtained
Finally there is an output layer which synthesizes thetwo scoring results given before and gives the final con-clusion In the first part of the conclusion Y from theprevious user coding music-to-be-predicted estimationfeatures and music-to-be-predicted coding through a linearlayer this part reflects the idea of collaborative filteringbased on similarity and score to get the target score Anotherpart of the result x is obtained by using a Max Pooling layer
to select the value with the greatest correlation )e strategyembodied in this part is that when the songs to be predictedhave a high similarity with the previous historical songs itcan be considered that users are likely to have a certaininterest in the songs to be evaluated so the results have alarge similarity value at this time Finally the two scores areaveraged to get the final output)is is a value between [0 1]to indicate the degree of interest that users may be interestedin
4 Implementation ofPersonalized Recommendation
Traditional models do not use the information of users whointeract with them in the coding process of known music)is leads to the lack of user personality in the recom-mended content Even for two different users the coding ofthe same content is the same which cannot deal with thepersonalized problem well In addition in the actual in-teractive process content and users have different interactivebehaviors and different interactive behaviors often repre-sent different preferences of users However the previousmodels have not been distinguished to this extent resultingin different information brought by different interactivebehaviors not being used For example for praise andcollection collection means that users are more interestedthan praise because collection means that users are likely tolisten to this song repeatedly later while the probability oflistening to praise will be smaller later
In this paper firstly different behavior scores of users aredistinguished and the scores are divided into 1ndash5 pointsaccording to the listening times 6 points for collectionbehavior and 4 points for praise behavior In addition themultihead attention mechanism is introduced When
Linear
Concat
Self-attention
Linear LinearLinear
User feature vector (V)
Music feature vector (M)
Dance feature vector (D)
K
Output
Figure 10 Multihead attention module
Complexity 11
encoding music features in Music Encoder the user featuresand music features are combined and the user personalizedmusic coding is realized in the encoding layer which ensuresthat even if different users operate the same music the finalrecommendation results are still different because of dif-ferent personal characteristics thus realizing the personal-ized music recommendation
41 Model Training and Experimental Results Beforetraining the model it is necessary to divide the positive andnegative classes and determine the training set and test setused by the model For music recommendation label 0means dislike and label 1 means like which is defined as abinary classification problem According to the scoringprocessing of user behavior characteristics in Chapter 3music with a score higher than 5 is recorded as a positiveclass that is if the user listens to music many times or musicwith a little praise or collection behavior is recorded as apositive class Music with a score below 2 is recorded as anegative example indicating that although the user has someinteraction they have not shown interest Negative caseswith the same number of positive classes are randomlyselected from music with scores lower than 2 to ensure thatthe distribution is as balanced as possible After dividingpositive and negative classes the first 80 of the data set isused as the training set and the last 20 as the test set
42 Super Parameter Adjustment )e hyperparameter ad-justment process aims to optimize the performance of themodel First select the super parameters that can be adjusted)en determine whether they will be fixed or variable and ifthe parameters are changeable set them to different values todetermine in which range they will change
Hidden_size the original model is set to 50 and featuresare represented using the model by setting the number ofhidden layers)e hidden layer is set to 32 64 18 and 256 inthe implementation process and the best parameters aredetermined by experiments in TP100 data set in Figure 11
According to Figure 11 when the hidden layer is set to32 the model is in an underfitting state and cannot becharacterized With the increase of the hidden layer theaccuracy rate and recall rate are continuously improved butwhen the hidden layer is set to 256 both indicators decreaseslightly )erefore in the subsequent experiment the hid-den_size is set to 128
Learning_rate it depends on the Adam optimizer in themodel )e learning rate of each parameter is adapted bymaking smaller updates to frequent parameters and largerupdates to infrequent parameters )e learning rate of theoriginal model is set to 0001 In this experiment thelearning rates are set to 0001 001 01 and 05 respectivelyAccording to Figure 12 when the learning rates are 0001and 001 the accuracy is better In the subsequent experi-ment the learning_rate is set to 001
Batch_size when smaller batches are used a period oftraining is more detailed which usually leads to a decrease inthe number of convergent iterations but the training time islong On the other hand the more the batches the slower theconvergence speed which reduces the risk of overfitting andreduces the training time )e effect of batch_size on ac-curacy is shown in Figure 13
Try to use the batch size training model from 100 to 1000in the whole process As can be seen from Figure 13 andTable 2 using a smaller batch size the training time is longerUsing a large batch size (when it exceeds 700) a memoryerror was encountered
)erefore in the follow-up experiment the batch size isset to 600 for model training which not only meets thetraining time but also does not overflow the memory
43 Experimental Results )e whole training process Loss-Epochs is shown in Figure 14 During each training fivesongs with historical evaluation are selected from the his-torical music interacted by users for input After severalrounds of training all the evaluated songs can basically beused in training and the training loss is basically stable after1024 iterations
0002004006008
01012014016018
02
32 64 128 256Ev
alua
tion
inde
x
hidden_size
RecallPrecision
Figure 11 Impact of hidden size on evaluation indicators
12 Complexity
In order to verify the effectiveness of the model thispaper implements Neural Network Based CollaborativeFiltering (NCF) model and SVDmodel by Python which areverified in TP100 and TP500 data sets respectively )eaccuracy and recall rate are used to evaluate the accuracy ofdifferent recommendation lengths )e accuracy results ofdifferent recommendation lengths are shown in Figure 15
It can be seen from Figure 15 that the accuracy of thedeep learning recommendation model based on Relation-ship-Learning is obviously higher than that of the traditionalSVD recommendation algorithm in two data sets about 3higher than that of the collaborative filtering algorithm
based on neural network in TP100 data set and similar inTP500 data set with lower sparsity both of which are higherthan SVD algorithm
As can be seen from Figure 16 this model has obviousadvantages in both data sets With the increasing number ofrecommendations the recall rate gradually increases whichis about 10 higher than the traditional SVD algorithm InTP500 data sets with dense data the recall rate reaches about03 To sum up the deep learning recommendation modelbased on relationship learning implemented in this papercan accurately predict usersrsquo music preferences and finallycan accurately recommend music lists for users
07
075
08
085
09
095
0001001011A
ccur
acy
learning_rate
Figure 12 Impact of learning rate on accuracy
0
01
02
03
04
05
06
07
08
09
1
0 100 200 300 400 500 600 700 800
Acc
urac
y
batch_size
Figure 13 Effect of batch_size on accuracy
Table 2 Average running time per Epoch
batch_size 100 200 400 600 700Runtime (s) 67 39 20 9 8
Complexity 13
0 128 256 512 102400
02
04
06
08
10
12
14
16
18 Cross entropy loss of model training
Loss
Epochs
Figure 14 Model training loss
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
SVDNCFRelation-Learning
(a)
SVDNCFRelation-Learning
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
(b)
Figure 15 Accuracy of two data sets (a) TP100 data set (b) TP500 data set
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(a)
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(b)
Figure 16 Recall rate of two data sets (a) TP100 data set (b) TP500 data set
14 Complexity
5 Conclusion
Faced with a large number of dances and songs it is difficultfor people to quickly find dance music that meets theirinterests )e emergence of dance music recommendationsystem can recommend dance music that users may like andhelp users quickly discover or find their favorite dances andsongs )is kind of recommendation service can provideusers with a good experience and bring commercial benefitsso the field of dance music recommendation has become theresearch direction of industry and scholars In this paperrelation learning is introduced into dance music recom-mendation system and the relation model is applied todance music recommendation In the experiment the ac-curacy and recall rate are used to verify the effectiveness ofthe model in the direction of dance music recommendation
Data Availability
)e experimental data used to support the findings of thisstudy are available from the corresponding author uponrequest
Conflicts of Interest
)e author declares that no conflicts of interest regardingthis work
References
[1] Y Han Z Han J Wu et al ldquoArtificial intelligence recom-mendation system of cancer rehabilitation scheme based onIoT technologyrdquo IEEE Access vol 8 pp 44924ndash44935 2020
[2] A Rw M A Xiao and J A Chi ldquoHeterogeneous informationnetwork-based music recommendation system in mobilenetworksrdquo Computer Communications vol 150 pp 429ndash4372020
[3] X Wen ldquoUsing deep learning approach and IoT architectureto build the intelligent music recommendation systemrdquo SoftComputing vol 25 no 1 pp 1ndash10 2020
[4] H-G Kim G Y Kim and J Y Kim ldquoMusic recommendationsystem using human activity recognition from accelerometerdatardquo IEEE Transactions on Consumer Electronics vol 65no 3 pp 349ndash358 2019
[5] M S Fathollahi and F Razzazi ldquoMusic similarity measure-ment and recommendation system using convolutional neuralnetworksrdquo International Journal of Multimedia InformationRetrieval vol 5 pp 1ndash11 2021
[6] G Sun YWong and Z Cheng ldquoDeepDance music-to-dancemotion choreography with adversarial learningrdquo IEEETransactions on Multimedia vol 99 p 1 2020
[7] J M Agaku ldquo)e Girinya dance theatre of the Tiv people ofNigeria an aesthetic evaluationrdquo International Journal ofIntangible Heritage vol 3 no 6 pp 29ndash41 2008
[8] G Mota and L Abreu ldquo)irty years of music and dramaeducation in the Madeira Island facing future challengesrdquoInternational Journal of Music Education vol 32 no 3pp 360ndash374 2014
[9] B Montero ldquoPractice makes perfect the effect of dancetraining on the aesthetic judgerdquo Phenomenology and theCognitive Sciences vol 11 no 1 pp 59ndash68 2012
[10] A Manfre I Infantino F Vella and S Gaglio ldquoAn automaticsystem for humanoid dance creationrdquo Biologically InspiredCognitive Architectures vol 15 pp 1ndash9 2016
[11] D Aledo B Carrion Schafer and F Moreno ldquoVHDL vsSystemC design of highly parameterizable artificial neuralnetworksrdquo IEICE - Transactions on Info and Systemsvol E102D no 3 pp 512ndash521 2019
[12] B Sheng and G Sun ldquoMatrix factorization recommendationalgorithm based on multiple social relationshipsrdquo Mathe-matical Problems in Engineering vol 2021 Article ID6610645 8 pages 2021
[13] L Jiang Y Cheng L Yang J Li H Yan and X Wang ldquoAtrust-based collaborative filtering algorithm for E-commercerecommendation systemrdquo Journal of ambient intelligence andhumanized computing vol 10 no 8 pp 3023ndash3034 2019
[14] A Dm A Xl and A Qd ldquoHumming-query and reinforce-ment-learning based modeling approach for personalizedmusic recommendationrdquo Procedia Computer Science vol 176pp 2154ndash2163 2020
Complexity 15

the model of this section we hope to give the similarity ofusers about different music scores through feature vectors
Firstly the characteristics of the scored songs and thecharacteristics of the target unscored songs are combined bythe user )en the similarity gφ between the two songs isgiven by comparing the similarity module and relationmodule its size is limited between 0 and 1 by normalizationfunction and finally a k-dimensional numerical vector re-lation score is obtained )e similarity gφmodel is shown in
gφ q1 q2( 1113857 Sigmoid qT1 Wq21113872 1113873 (15)
)e Interest Matching Relation module constructed inthis paper is not complex and the parameter to be trained isonly a matrix W In the experiment we also use a deeperstructure to replace this structure It is found that this willnot only increase the training time and parameter scale butalso reduce the accuracy )erefore we finally choose thevalue between [0 1] obtained by sigmoid after we get theinner product of two vectors about W as the similarityAccording to the similarity degree the related features of theknown graded music are constructed to predict the featuresof the music )e method is weighted average and theweight of each item is the score multiplied by the similaritydegree )e more similar the music and the higher the scorethe more obvious the influence on the prediction resultsFinally an estimated value of the eigenvector is obtained
Finally there is an output layer which synthesizes thetwo scoring results given before and gives the final con-clusion In the first part of the conclusion Y from theprevious user coding music-to-be-predicted estimationfeatures and music-to-be-predicted coding through a linearlayer this part reflects the idea of collaborative filteringbased on similarity and score to get the target score Anotherpart of the result x is obtained by using a Max Pooling layer
to select the value with the greatest correlation )e strategyembodied in this part is that when the songs to be predictedhave a high similarity with the previous historical songs itcan be considered that users are likely to have a certaininterest in the songs to be evaluated so the results have alarge similarity value at this time Finally the two scores areaveraged to get the final output)is is a value between [0 1]to indicate the degree of interest that users may be interestedin
4 Implementation ofPersonalized Recommendation
Traditional models do not use the information of users whointeract with them in the coding process of known music)is leads to the lack of user personality in the recom-mended content Even for two different users the coding ofthe same content is the same which cannot deal with thepersonalized problem well In addition in the actual in-teractive process content and users have different interactivebehaviors and different interactive behaviors often repre-sent different preferences of users However the previousmodels have not been distinguished to this extent resultingin different information brought by different interactivebehaviors not being used For example for praise andcollection collection means that users are more interestedthan praise because collection means that users are likely tolisten to this song repeatedly later while the probability oflistening to praise will be smaller later
In this paper firstly different behavior scores of users aredistinguished and the scores are divided into 1ndash5 pointsaccording to the listening times 6 points for collectionbehavior and 4 points for praise behavior In addition themultihead attention mechanism is introduced When
Linear
Concat
Self-attention
Linear LinearLinear
User feature vector (V)
Music feature vector (M)
Dance feature vector (D)
K
Output
Figure 10 Multihead attention module
Complexity 11
encoding music features in Music Encoder the user featuresand music features are combined and the user personalizedmusic coding is realized in the encoding layer which ensuresthat even if different users operate the same music the finalrecommendation results are still different because of dif-ferent personal characteristics thus realizing the personal-ized music recommendation
41 Model Training and Experimental Results Beforetraining the model it is necessary to divide the positive andnegative classes and determine the training set and test setused by the model For music recommendation label 0means dislike and label 1 means like which is defined as abinary classification problem According to the scoringprocessing of user behavior characteristics in Chapter 3music with a score higher than 5 is recorded as a positiveclass that is if the user listens to music many times or musicwith a little praise or collection behavior is recorded as apositive class Music with a score below 2 is recorded as anegative example indicating that although the user has someinteraction they have not shown interest Negative caseswith the same number of positive classes are randomlyselected from music with scores lower than 2 to ensure thatthe distribution is as balanced as possible After dividingpositive and negative classes the first 80 of the data set isused as the training set and the last 20 as the test set
42 Super Parameter Adjustment )e hyperparameter ad-justment process aims to optimize the performance of themodel First select the super parameters that can be adjusted)en determine whether they will be fixed or variable and ifthe parameters are changeable set them to different values todetermine in which range they will change
Hidden_size the original model is set to 50 and featuresare represented using the model by setting the number ofhidden layers)e hidden layer is set to 32 64 18 and 256 inthe implementation process and the best parameters aredetermined by experiments in TP100 data set in Figure 11
According to Figure 11 when the hidden layer is set to32 the model is in an underfitting state and cannot becharacterized With the increase of the hidden layer theaccuracy rate and recall rate are continuously improved butwhen the hidden layer is set to 256 both indicators decreaseslightly )erefore in the subsequent experiment the hid-den_size is set to 128
Learning_rate it depends on the Adam optimizer in themodel )e learning rate of each parameter is adapted bymaking smaller updates to frequent parameters and largerupdates to infrequent parameters )e learning rate of theoriginal model is set to 0001 In this experiment thelearning rates are set to 0001 001 01 and 05 respectivelyAccording to Figure 12 when the learning rates are 0001and 001 the accuracy is better In the subsequent experi-ment the learning_rate is set to 001
Batch_size when smaller batches are used a period oftraining is more detailed which usually leads to a decrease inthe number of convergent iterations but the training time islong On the other hand the more the batches the slower theconvergence speed which reduces the risk of overfitting andreduces the training time )e effect of batch_size on ac-curacy is shown in Figure 13
Try to use the batch size training model from 100 to 1000in the whole process As can be seen from Figure 13 andTable 2 using a smaller batch size the training time is longerUsing a large batch size (when it exceeds 700) a memoryerror was encountered
)erefore in the follow-up experiment the batch size isset to 600 for model training which not only meets thetraining time but also does not overflow the memory
43 Experimental Results )e whole training process Loss-Epochs is shown in Figure 14 During each training fivesongs with historical evaluation are selected from the his-torical music interacted by users for input After severalrounds of training all the evaluated songs can basically beused in training and the training loss is basically stable after1024 iterations
0002004006008
01012014016018
02
32 64 128 256Ev
alua
tion
inde
x
hidden_size
RecallPrecision
Figure 11 Impact of hidden size on evaluation indicators
12 Complexity
In order to verify the effectiveness of the model thispaper implements Neural Network Based CollaborativeFiltering (NCF) model and SVDmodel by Python which areverified in TP100 and TP500 data sets respectively )eaccuracy and recall rate are used to evaluate the accuracy ofdifferent recommendation lengths )e accuracy results ofdifferent recommendation lengths are shown in Figure 15
It can be seen from Figure 15 that the accuracy of thedeep learning recommendation model based on Relation-ship-Learning is obviously higher than that of the traditionalSVD recommendation algorithm in two data sets about 3higher than that of the collaborative filtering algorithm
based on neural network in TP100 data set and similar inTP500 data set with lower sparsity both of which are higherthan SVD algorithm
As can be seen from Figure 16 this model has obviousadvantages in both data sets With the increasing number ofrecommendations the recall rate gradually increases whichis about 10 higher than the traditional SVD algorithm InTP500 data sets with dense data the recall rate reaches about03 To sum up the deep learning recommendation modelbased on relationship learning implemented in this papercan accurately predict usersrsquo music preferences and finallycan accurately recommend music lists for users
07
075
08
085
09
095
0001001011A
ccur
acy
learning_rate
Figure 12 Impact of learning rate on accuracy
0
01
02
03
04
05
06
07
08
09
1
0 100 200 300 400 500 600 700 800
Acc
urac
y
batch_size
Figure 13 Effect of batch_size on accuracy
Table 2 Average running time per Epoch
batch_size 100 200 400 600 700Runtime (s) 67 39 20 9 8
Complexity 13
0 128 256 512 102400
02
04
06
08
10
12
14
16
18 Cross entropy loss of model training
Loss
Epochs
Figure 14 Model training loss
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
SVDNCFRelation-Learning
(a)
SVDNCFRelation-Learning
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
(b)
Figure 15 Accuracy of two data sets (a) TP100 data set (b) TP500 data set
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(a)
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(b)
Figure 16 Recall rate of two data sets (a) TP100 data set (b) TP500 data set
14 Complexity
5 Conclusion
Faced with a large number of dances and songs it is difficultfor people to quickly find dance music that meets theirinterests )e emergence of dance music recommendationsystem can recommend dance music that users may like andhelp users quickly discover or find their favorite dances andsongs )is kind of recommendation service can provideusers with a good experience and bring commercial benefitsso the field of dance music recommendation has become theresearch direction of industry and scholars In this paperrelation learning is introduced into dance music recom-mendation system and the relation model is applied todance music recommendation In the experiment the ac-curacy and recall rate are used to verify the effectiveness ofthe model in the direction of dance music recommendation
Data Availability
)e experimental data used to support the findings of thisstudy are available from the corresponding author uponrequest
Conflicts of Interest
)e author declares that no conflicts of interest regardingthis work
References
[1] Y Han Z Han J Wu et al ldquoArtificial intelligence recom-mendation system of cancer rehabilitation scheme based onIoT technologyrdquo IEEE Access vol 8 pp 44924ndash44935 2020
[2] A Rw M A Xiao and J A Chi ldquoHeterogeneous informationnetwork-based music recommendation system in mobilenetworksrdquo Computer Communications vol 150 pp 429ndash4372020
[3] X Wen ldquoUsing deep learning approach and IoT architectureto build the intelligent music recommendation systemrdquo SoftComputing vol 25 no 1 pp 1ndash10 2020
[4] H-G Kim G Y Kim and J Y Kim ldquoMusic recommendationsystem using human activity recognition from accelerometerdatardquo IEEE Transactions on Consumer Electronics vol 65no 3 pp 349ndash358 2019
[5] M S Fathollahi and F Razzazi ldquoMusic similarity measure-ment and recommendation system using convolutional neuralnetworksrdquo International Journal of Multimedia InformationRetrieval vol 5 pp 1ndash11 2021
[6] G Sun YWong and Z Cheng ldquoDeepDance music-to-dancemotion choreography with adversarial learningrdquo IEEETransactions on Multimedia vol 99 p 1 2020
[7] J M Agaku ldquo)e Girinya dance theatre of the Tiv people ofNigeria an aesthetic evaluationrdquo International Journal ofIntangible Heritage vol 3 no 6 pp 29ndash41 2008
[8] G Mota and L Abreu ldquo)irty years of music and dramaeducation in the Madeira Island facing future challengesrdquoInternational Journal of Music Education vol 32 no 3pp 360ndash374 2014
[9] B Montero ldquoPractice makes perfect the effect of dancetraining on the aesthetic judgerdquo Phenomenology and theCognitive Sciences vol 11 no 1 pp 59ndash68 2012
[10] A Manfre I Infantino F Vella and S Gaglio ldquoAn automaticsystem for humanoid dance creationrdquo Biologically InspiredCognitive Architectures vol 15 pp 1ndash9 2016
[11] D Aledo B Carrion Schafer and F Moreno ldquoVHDL vsSystemC design of highly parameterizable artificial neuralnetworksrdquo IEICE - Transactions on Info and Systemsvol E102D no 3 pp 512ndash521 2019
[12] B Sheng and G Sun ldquoMatrix factorization recommendationalgorithm based on multiple social relationshipsrdquo Mathe-matical Problems in Engineering vol 2021 Article ID6610645 8 pages 2021
[13] L Jiang Y Cheng L Yang J Li H Yan and X Wang ldquoAtrust-based collaborative filtering algorithm for E-commercerecommendation systemrdquo Journal of ambient intelligence andhumanized computing vol 10 no 8 pp 3023ndash3034 2019
[14] A Dm A Xl and A Qd ldquoHumming-query and reinforce-ment-learning based modeling approach for personalizedmusic recommendationrdquo Procedia Computer Science vol 176pp 2154ndash2163 2020
Complexity 15

encoding music features in Music Encoder the user featuresand music features are combined and the user personalizedmusic coding is realized in the encoding layer which ensuresthat even if different users operate the same music the finalrecommendation results are still different because of dif-ferent personal characteristics thus realizing the personal-ized music recommendation
41 Model Training and Experimental Results Beforetraining the model it is necessary to divide the positive andnegative classes and determine the training set and test setused by the model For music recommendation label 0means dislike and label 1 means like which is defined as abinary classification problem According to the scoringprocessing of user behavior characteristics in Chapter 3music with a score higher than 5 is recorded as a positiveclass that is if the user listens to music many times or musicwith a little praise or collection behavior is recorded as apositive class Music with a score below 2 is recorded as anegative example indicating that although the user has someinteraction they have not shown interest Negative caseswith the same number of positive classes are randomlyselected from music with scores lower than 2 to ensure thatthe distribution is as balanced as possible After dividingpositive and negative classes the first 80 of the data set isused as the training set and the last 20 as the test set
42 Super Parameter Adjustment )e hyperparameter ad-justment process aims to optimize the performance of themodel First select the super parameters that can be adjusted)en determine whether they will be fixed or variable and ifthe parameters are changeable set them to different values todetermine in which range they will change
Hidden_size the original model is set to 50 and featuresare represented using the model by setting the number ofhidden layers)e hidden layer is set to 32 64 18 and 256 inthe implementation process and the best parameters aredetermined by experiments in TP100 data set in Figure 11
According to Figure 11 when the hidden layer is set to32 the model is in an underfitting state and cannot becharacterized With the increase of the hidden layer theaccuracy rate and recall rate are continuously improved butwhen the hidden layer is set to 256 both indicators decreaseslightly )erefore in the subsequent experiment the hid-den_size is set to 128
Learning_rate it depends on the Adam optimizer in themodel )e learning rate of each parameter is adapted bymaking smaller updates to frequent parameters and largerupdates to infrequent parameters )e learning rate of theoriginal model is set to 0001 In this experiment thelearning rates are set to 0001 001 01 and 05 respectivelyAccording to Figure 12 when the learning rates are 0001and 001 the accuracy is better In the subsequent experi-ment the learning_rate is set to 001
Batch_size when smaller batches are used a period oftraining is more detailed which usually leads to a decrease inthe number of convergent iterations but the training time islong On the other hand the more the batches the slower theconvergence speed which reduces the risk of overfitting andreduces the training time )e effect of batch_size on ac-curacy is shown in Figure 13
Try to use the batch size training model from 100 to 1000in the whole process As can be seen from Figure 13 andTable 2 using a smaller batch size the training time is longerUsing a large batch size (when it exceeds 700) a memoryerror was encountered
)erefore in the follow-up experiment the batch size isset to 600 for model training which not only meets thetraining time but also does not overflow the memory
43 Experimental Results )e whole training process Loss-Epochs is shown in Figure 14 During each training fivesongs with historical evaluation are selected from the his-torical music interacted by users for input After severalrounds of training all the evaluated songs can basically beused in training and the training loss is basically stable after1024 iterations
0002004006008
01012014016018
02
32 64 128 256Ev
alua
tion
inde
x
hidden_size
RecallPrecision
Figure 11 Impact of hidden size on evaluation indicators
12 Complexity
In order to verify the effectiveness of the model thispaper implements Neural Network Based CollaborativeFiltering (NCF) model and SVDmodel by Python which areverified in TP100 and TP500 data sets respectively )eaccuracy and recall rate are used to evaluate the accuracy ofdifferent recommendation lengths )e accuracy results ofdifferent recommendation lengths are shown in Figure 15
It can be seen from Figure 15 that the accuracy of thedeep learning recommendation model based on Relation-ship-Learning is obviously higher than that of the traditionalSVD recommendation algorithm in two data sets about 3higher than that of the collaborative filtering algorithm
based on neural network in TP100 data set and similar inTP500 data set with lower sparsity both of which are higherthan SVD algorithm
As can be seen from Figure 16 this model has obviousadvantages in both data sets With the increasing number ofrecommendations the recall rate gradually increases whichis about 10 higher than the traditional SVD algorithm InTP500 data sets with dense data the recall rate reaches about03 To sum up the deep learning recommendation modelbased on relationship learning implemented in this papercan accurately predict usersrsquo music preferences and finallycan accurately recommend music lists for users
07
075
08
085
09
095
0001001011A
ccur
acy
learning_rate
Figure 12 Impact of learning rate on accuracy
0
01
02
03
04
05
06
07
08
09
1
0 100 200 300 400 500 600 700 800
Acc
urac
y
batch_size
Figure 13 Effect of batch_size on accuracy
Table 2 Average running time per Epoch
batch_size 100 200 400 600 700Runtime (s) 67 39 20 9 8
Complexity 13
0 128 256 512 102400
02
04
06
08
10
12
14
16
18 Cross entropy loss of model training
Loss
Epochs
Figure 14 Model training loss
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
SVDNCFRelation-Learning
(a)
SVDNCFRelation-Learning
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
(b)
Figure 15 Accuracy of two data sets (a) TP100 data set (b) TP500 data set
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(a)
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(b)
Figure 16 Recall rate of two data sets (a) TP100 data set (b) TP500 data set
14 Complexity
5 Conclusion
Faced with a large number of dances and songs it is difficultfor people to quickly find dance music that meets theirinterests )e emergence of dance music recommendationsystem can recommend dance music that users may like andhelp users quickly discover or find their favorite dances andsongs )is kind of recommendation service can provideusers with a good experience and bring commercial benefitsso the field of dance music recommendation has become theresearch direction of industry and scholars In this paperrelation learning is introduced into dance music recom-mendation system and the relation model is applied todance music recommendation In the experiment the ac-curacy and recall rate are used to verify the effectiveness ofthe model in the direction of dance music recommendation
Data Availability
)e experimental data used to support the findings of thisstudy are available from the corresponding author uponrequest
Conflicts of Interest
)e author declares that no conflicts of interest regardingthis work
References
[1] Y Han Z Han J Wu et al ldquoArtificial intelligence recom-mendation system of cancer rehabilitation scheme based onIoT technologyrdquo IEEE Access vol 8 pp 44924ndash44935 2020
[2] A Rw M A Xiao and J A Chi ldquoHeterogeneous informationnetwork-based music recommendation system in mobilenetworksrdquo Computer Communications vol 150 pp 429ndash4372020
[3] X Wen ldquoUsing deep learning approach and IoT architectureto build the intelligent music recommendation systemrdquo SoftComputing vol 25 no 1 pp 1ndash10 2020
[4] H-G Kim G Y Kim and J Y Kim ldquoMusic recommendationsystem using human activity recognition from accelerometerdatardquo IEEE Transactions on Consumer Electronics vol 65no 3 pp 349ndash358 2019
[5] M S Fathollahi and F Razzazi ldquoMusic similarity measure-ment and recommendation system using convolutional neuralnetworksrdquo International Journal of Multimedia InformationRetrieval vol 5 pp 1ndash11 2021
[6] G Sun YWong and Z Cheng ldquoDeepDance music-to-dancemotion choreography with adversarial learningrdquo IEEETransactions on Multimedia vol 99 p 1 2020
[7] J M Agaku ldquo)e Girinya dance theatre of the Tiv people ofNigeria an aesthetic evaluationrdquo International Journal ofIntangible Heritage vol 3 no 6 pp 29ndash41 2008
[8] G Mota and L Abreu ldquo)irty years of music and dramaeducation in the Madeira Island facing future challengesrdquoInternational Journal of Music Education vol 32 no 3pp 360ndash374 2014
[9] B Montero ldquoPractice makes perfect the effect of dancetraining on the aesthetic judgerdquo Phenomenology and theCognitive Sciences vol 11 no 1 pp 59ndash68 2012
[10] A Manfre I Infantino F Vella and S Gaglio ldquoAn automaticsystem for humanoid dance creationrdquo Biologically InspiredCognitive Architectures vol 15 pp 1ndash9 2016
[11] D Aledo B Carrion Schafer and F Moreno ldquoVHDL vsSystemC design of highly parameterizable artificial neuralnetworksrdquo IEICE - Transactions on Info and Systemsvol E102D no 3 pp 512ndash521 2019
[12] B Sheng and G Sun ldquoMatrix factorization recommendationalgorithm based on multiple social relationshipsrdquo Mathe-matical Problems in Engineering vol 2021 Article ID6610645 8 pages 2021
[13] L Jiang Y Cheng L Yang J Li H Yan and X Wang ldquoAtrust-based collaborative filtering algorithm for E-commercerecommendation systemrdquo Journal of ambient intelligence andhumanized computing vol 10 no 8 pp 3023ndash3034 2019
[14] A Dm A Xl and A Qd ldquoHumming-query and reinforce-ment-learning based modeling approach for personalizedmusic recommendationrdquo Procedia Computer Science vol 176pp 2154ndash2163 2020
Complexity 15
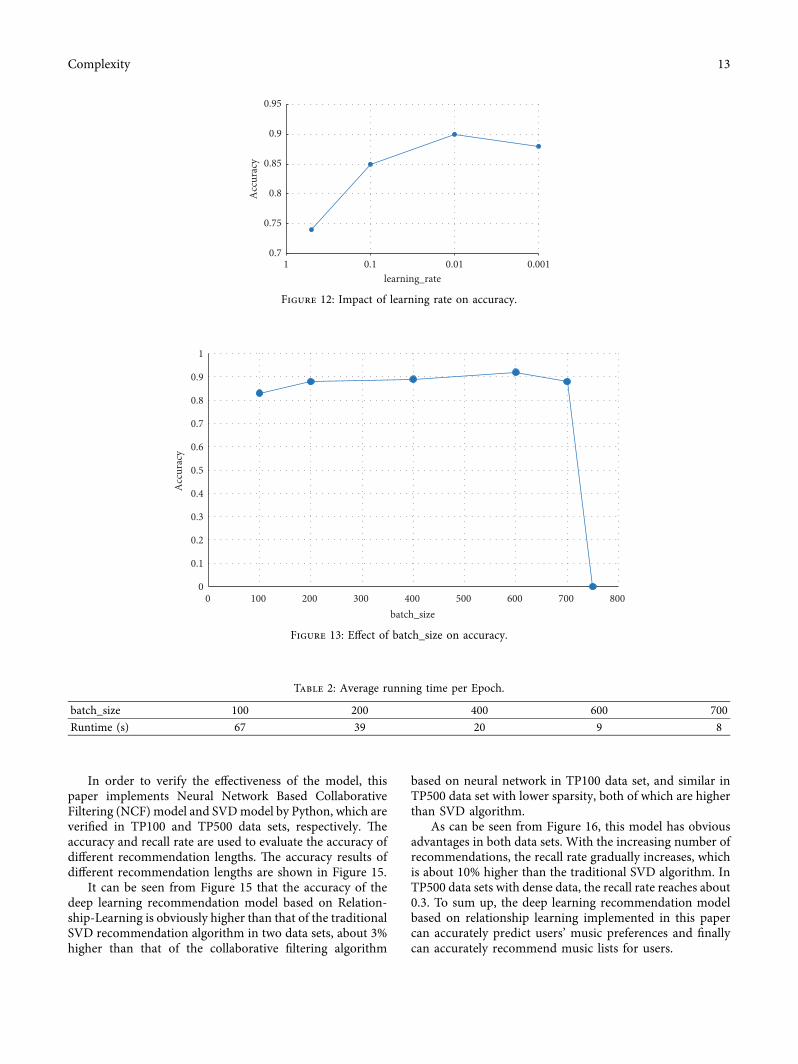
In order to verify the effectiveness of the model thispaper implements Neural Network Based CollaborativeFiltering (NCF) model and SVDmodel by Python which areverified in TP100 and TP500 data sets respectively )eaccuracy and recall rate are used to evaluate the accuracy ofdifferent recommendation lengths )e accuracy results ofdifferent recommendation lengths are shown in Figure 15
It can be seen from Figure 15 that the accuracy of thedeep learning recommendation model based on Relation-ship-Learning is obviously higher than that of the traditionalSVD recommendation algorithm in two data sets about 3higher than that of the collaborative filtering algorithm
based on neural network in TP100 data set and similar inTP500 data set with lower sparsity both of which are higherthan SVD algorithm
As can be seen from Figure 16 this model has obviousadvantages in both data sets With the increasing number ofrecommendations the recall rate gradually increases whichis about 10 higher than the traditional SVD algorithm InTP500 data sets with dense data the recall rate reaches about03 To sum up the deep learning recommendation modelbased on relationship learning implemented in this papercan accurately predict usersrsquo music preferences and finallycan accurately recommend music lists for users
07
075
08
085
09
095
0001001011A
ccur
acy
learning_rate
Figure 12 Impact of learning rate on accuracy
0
01
02
03
04
05
06
07
08
09
1
0 100 200 300 400 500 600 700 800
Acc
urac
y
batch_size
Figure 13 Effect of batch_size on accuracy
Table 2 Average running time per Epoch
batch_size 100 200 400 600 700Runtime (s) 67 39 20 9 8
Complexity 13
0 128 256 512 102400
02
04
06
08
10
12
14
16
18 Cross entropy loss of model training
Loss
Epochs
Figure 14 Model training loss
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
SVDNCFRelation-Learning
(a)
SVDNCFRelation-Learning
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
(b)
Figure 15 Accuracy of two data sets (a) TP100 data set (b) TP500 data set
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(a)
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(b)
Figure 16 Recall rate of two data sets (a) TP100 data set (b) TP500 data set
14 Complexity
5 Conclusion
Faced with a large number of dances and songs it is difficultfor people to quickly find dance music that meets theirinterests )e emergence of dance music recommendationsystem can recommend dance music that users may like andhelp users quickly discover or find their favorite dances andsongs )is kind of recommendation service can provideusers with a good experience and bring commercial benefitsso the field of dance music recommendation has become theresearch direction of industry and scholars In this paperrelation learning is introduced into dance music recom-mendation system and the relation model is applied todance music recommendation In the experiment the ac-curacy and recall rate are used to verify the effectiveness ofthe model in the direction of dance music recommendation
Data Availability
)e experimental data used to support the findings of thisstudy are available from the corresponding author uponrequest
Conflicts of Interest
)e author declares that no conflicts of interest regardingthis work
References
[1] Y Han Z Han J Wu et al ldquoArtificial intelligence recom-mendation system of cancer rehabilitation scheme based onIoT technologyrdquo IEEE Access vol 8 pp 44924ndash44935 2020
[2] A Rw M A Xiao and J A Chi ldquoHeterogeneous informationnetwork-based music recommendation system in mobilenetworksrdquo Computer Communications vol 150 pp 429ndash4372020
[3] X Wen ldquoUsing deep learning approach and IoT architectureto build the intelligent music recommendation systemrdquo SoftComputing vol 25 no 1 pp 1ndash10 2020
[4] H-G Kim G Y Kim and J Y Kim ldquoMusic recommendationsystem using human activity recognition from accelerometerdatardquo IEEE Transactions on Consumer Electronics vol 65no 3 pp 349ndash358 2019
[5] M S Fathollahi and F Razzazi ldquoMusic similarity measure-ment and recommendation system using convolutional neuralnetworksrdquo International Journal of Multimedia InformationRetrieval vol 5 pp 1ndash11 2021
[6] G Sun YWong and Z Cheng ldquoDeepDance music-to-dancemotion choreography with adversarial learningrdquo IEEETransactions on Multimedia vol 99 p 1 2020
[7] J M Agaku ldquo)e Girinya dance theatre of the Tiv people ofNigeria an aesthetic evaluationrdquo International Journal ofIntangible Heritage vol 3 no 6 pp 29ndash41 2008
[8] G Mota and L Abreu ldquo)irty years of music and dramaeducation in the Madeira Island facing future challengesrdquoInternational Journal of Music Education vol 32 no 3pp 360ndash374 2014
[9] B Montero ldquoPractice makes perfect the effect of dancetraining on the aesthetic judgerdquo Phenomenology and theCognitive Sciences vol 11 no 1 pp 59ndash68 2012
[10] A Manfre I Infantino F Vella and S Gaglio ldquoAn automaticsystem for humanoid dance creationrdquo Biologically InspiredCognitive Architectures vol 15 pp 1ndash9 2016
[11] D Aledo B Carrion Schafer and F Moreno ldquoVHDL vsSystemC design of highly parameterizable artificial neuralnetworksrdquo IEICE - Transactions on Info and Systemsvol E102D no 3 pp 512ndash521 2019
[12] B Sheng and G Sun ldquoMatrix factorization recommendationalgorithm based on multiple social relationshipsrdquo Mathe-matical Problems in Engineering vol 2021 Article ID6610645 8 pages 2021
[13] L Jiang Y Cheng L Yang J Li H Yan and X Wang ldquoAtrust-based collaborative filtering algorithm for E-commercerecommendation systemrdquo Journal of ambient intelligence andhumanized computing vol 10 no 8 pp 3023ndash3034 2019
[14] A Dm A Xl and A Qd ldquoHumming-query and reinforce-ment-learning based modeling approach for personalizedmusic recommendationrdquo Procedia Computer Science vol 176pp 2154ndash2163 2020
Complexity 15
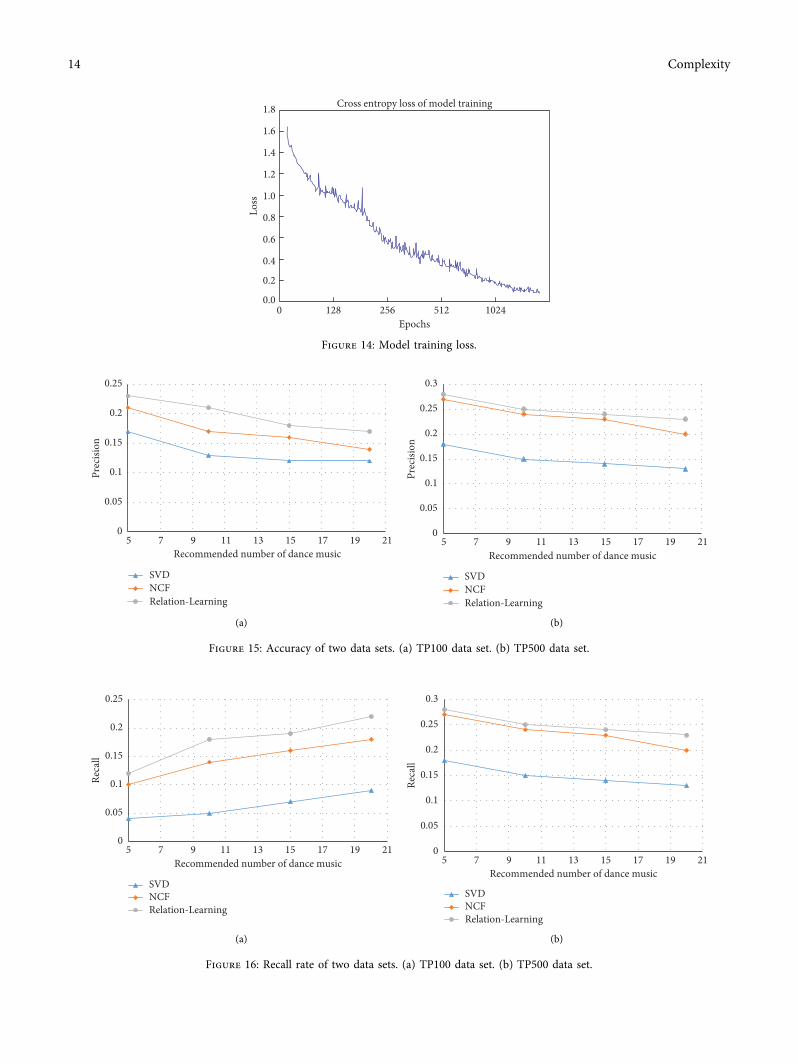
0 128 256 512 102400
02
04
06
08
10
12
14
16
18 Cross entropy loss of model training
Loss
Epochs
Figure 14 Model training loss
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
SVDNCFRelation-Learning
(a)
SVDNCFRelation-Learning
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Prec
ision
Recommended number of dance music
(b)
Figure 15 Accuracy of two data sets (a) TP100 data set (b) TP500 data set
0
005
01
015
02
025
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(a)
0
005
01
015
02
025
03
5 7 9 11 13 15 17 19 21
Reca
ll
Recommended number of dance music
SVDNCFRelation-Learning
(b)
Figure 16 Recall rate of two data sets (a) TP100 data set (b) TP500 data set
14 Complexity
5 Conclusion
Faced with a large number of dances and songs it is difficultfor people to quickly find dance music that meets theirinterests )e emergence of dance music recommendationsystem can recommend dance music that users may like andhelp users quickly discover or find their favorite dances andsongs )is kind of recommendation service can provideusers with a good experience and bring commercial benefitsso the field of dance music recommendation has become theresearch direction of industry and scholars In this paperrelation learning is introduced into dance music recom-mendation system and the relation model is applied todance music recommendation In the experiment the ac-curacy and recall rate are used to verify the effectiveness ofthe model in the direction of dance music recommendation
Data Availability
)e experimental data used to support the findings of thisstudy are available from the corresponding author uponrequest
Conflicts of Interest
)e author declares that no conflicts of interest regardingthis work
References
[1] Y Han Z Han J Wu et al ldquoArtificial intelligence recom-mendation system of cancer rehabilitation scheme based onIoT technologyrdquo IEEE Access vol 8 pp 44924ndash44935 2020
[2] A Rw M A Xiao and J A Chi ldquoHeterogeneous informationnetwork-based music recommendation system in mobilenetworksrdquo Computer Communications vol 150 pp 429ndash4372020
[3] X Wen ldquoUsing deep learning approach and IoT architectureto build the intelligent music recommendation systemrdquo SoftComputing vol 25 no 1 pp 1ndash10 2020
[4] H-G Kim G Y Kim and J Y Kim ldquoMusic recommendationsystem using human activity recognition from accelerometerdatardquo IEEE Transactions on Consumer Electronics vol 65no 3 pp 349ndash358 2019
[5] M S Fathollahi and F Razzazi ldquoMusic similarity measure-ment and recommendation system using convolutional neuralnetworksrdquo International Journal of Multimedia InformationRetrieval vol 5 pp 1ndash11 2021
[6] G Sun YWong and Z Cheng ldquoDeepDance music-to-dancemotion choreography with adversarial learningrdquo IEEETransactions on Multimedia vol 99 p 1 2020
[7] J M Agaku ldquo)e Girinya dance theatre of the Tiv people ofNigeria an aesthetic evaluationrdquo International Journal ofIntangible Heritage vol 3 no 6 pp 29ndash41 2008
[8] G Mota and L Abreu ldquo)irty years of music and dramaeducation in the Madeira Island facing future challengesrdquoInternational Journal of Music Education vol 32 no 3pp 360ndash374 2014
[9] B Montero ldquoPractice makes perfect the effect of dancetraining on the aesthetic judgerdquo Phenomenology and theCognitive Sciences vol 11 no 1 pp 59ndash68 2012
[10] A Manfre I Infantino F Vella and S Gaglio ldquoAn automaticsystem for humanoid dance creationrdquo Biologically InspiredCognitive Architectures vol 15 pp 1ndash9 2016
[11] D Aledo B Carrion Schafer and F Moreno ldquoVHDL vsSystemC design of highly parameterizable artificial neuralnetworksrdquo IEICE - Transactions on Info and Systemsvol E102D no 3 pp 512ndash521 2019
[12] B Sheng and G Sun ldquoMatrix factorization recommendationalgorithm based on multiple social relationshipsrdquo Mathe-matical Problems in Engineering vol 2021 Article ID6610645 8 pages 2021
[13] L Jiang Y Cheng L Yang J Li H Yan and X Wang ldquoAtrust-based collaborative filtering algorithm for E-commercerecommendation systemrdquo Journal of ambient intelligence andhumanized computing vol 10 no 8 pp 3023ndash3034 2019
[14] A Dm A Xl and A Qd ldquoHumming-query and reinforce-ment-learning based modeling approach for personalizedmusic recommendationrdquo Procedia Computer Science vol 176pp 2154ndash2163 2020
Complexity 15

5 Conclusion
Faced with a large number of dances and songs it is difficultfor people to quickly find dance music that meets theirinterests )e emergence of dance music recommendationsystem can recommend dance music that users may like andhelp users quickly discover or find their favorite dances andsongs )is kind of recommendation service can provideusers with a good experience and bring commercial benefitsso the field of dance music recommendation has become theresearch direction of industry and scholars In this paperrelation learning is introduced into dance music recom-mendation system and the relation model is applied todance music recommendation In the experiment the ac-curacy and recall rate are used to verify the effectiveness ofthe model in the direction of dance music recommendation
Data Availability
)e experimental data used to support the findings of thisstudy are available from the corresponding author uponrequest
Conflicts of Interest
)e author declares that no conflicts of interest regardingthis work
References
[1] Y Han Z Han J Wu et al ldquoArtificial intelligence recom-mendation system of cancer rehabilitation scheme based onIoT technologyrdquo IEEE Access vol 8 pp 44924ndash44935 2020
[2] A Rw M A Xiao and J A Chi ldquoHeterogeneous informationnetwork-based music recommendation system in mobilenetworksrdquo Computer Communications vol 150 pp 429ndash4372020
[3] X Wen ldquoUsing deep learning approach and IoT architectureto build the intelligent music recommendation systemrdquo SoftComputing vol 25 no 1 pp 1ndash10 2020
[4] H-G Kim G Y Kim and J Y Kim ldquoMusic recommendationsystem using human activity recognition from accelerometerdatardquo IEEE Transactions on Consumer Electronics vol 65no 3 pp 349ndash358 2019
[5] M S Fathollahi and F Razzazi ldquoMusic similarity measure-ment and recommendation system using convolutional neuralnetworksrdquo International Journal of Multimedia InformationRetrieval vol 5 pp 1ndash11 2021
[6] G Sun YWong and Z Cheng ldquoDeepDance music-to-dancemotion choreography with adversarial learningrdquo IEEETransactions on Multimedia vol 99 p 1 2020
[7] J M Agaku ldquo)e Girinya dance theatre of the Tiv people ofNigeria an aesthetic evaluationrdquo International Journal ofIntangible Heritage vol 3 no 6 pp 29ndash41 2008
[8] G Mota and L Abreu ldquo)irty years of music and dramaeducation in the Madeira Island facing future challengesrdquoInternational Journal of Music Education vol 32 no 3pp 360ndash374 2014
[9] B Montero ldquoPractice makes perfect the effect of dancetraining on the aesthetic judgerdquo Phenomenology and theCognitive Sciences vol 11 no 1 pp 59ndash68 2012
[10] A Manfre I Infantino F Vella and S Gaglio ldquoAn automaticsystem for humanoid dance creationrdquo Biologically InspiredCognitive Architectures vol 15 pp 1ndash9 2016
[11] D Aledo B Carrion Schafer and F Moreno ldquoVHDL vsSystemC design of highly parameterizable artificial neuralnetworksrdquo IEICE - Transactions on Info and Systemsvol E102D no 3 pp 512ndash521 2019
[12] B Sheng and G Sun ldquoMatrix factorization recommendationalgorithm based on multiple social relationshipsrdquo Mathe-matical Problems in Engineering vol 2021 Article ID6610645 8 pages 2021
[13] L Jiang Y Cheng L Yang J Li H Yan and X Wang ldquoAtrust-based collaborative filtering algorithm for E-commercerecommendation systemrdquo Journal of ambient intelligence andhumanized computing vol 10 no 8 pp 3023ndash3034 2019
[14] A Dm A Xl and A Qd ldquoHumming-query and reinforce-ment-learning based modeling approach for personalizedmusic recommendationrdquo Procedia Computer Science vol 176pp 2154ndash2163 2020
Complexity 15


















