
Personal Information Model (PIMO) Ontology Guidenlp.fi.muni.cz/projects/ole/deri/pimo.pdf ·...
32
Integrated Project Priority 2.4.7 Semantic based knowledge systems Personal Information Model (PIMO) Ontology Guide specification draft Version 0.1 01.06.2007 Dissemination level: PU Nature Prototype Due date 31.05.2006 Lead contractor DFKI Start date of project 01.01.2006 Duration 36 months
Transcript of Personal Information Model (PIMO) Ontology Guidenlp.fi.muni.cz/projects/ole/deri/pimo.pdf ·...

Integrated Project
Priority 2.4.7
Semantic based knowledge systems
Personal Information Model (PIMO)Ontology Guide
specification draft
Version 0.101.06.2007Dissemination level: PU
Nature PrototypeDue date 31.05.2006Lead contractor DFKIStart date of project 01.01.2006Duration 36 months

NEPOMUK 20.03.2007
Authors
Leo Sauermann, DFKILudger Van Elst, DFKI
Project Co-ordinator
Dr. Ansgar BernardiGerman Research Center for Artificial Intelligence (DFKI) GmbHTrippstadter Strasse 122D 67663 KaiserslauternGermanyEmail: [email protected], phone: +49 631 205 3582, fax: +49 631 205 4910
Partners
DEUTSCHES FORSCHUNGSZENTRUM F. KUENSTLICHE INTELLIGENZ GMBHIBM IRELAND PRODUCT DISTRIBUTION LIMITEDSAP AGHEWLETT PACKARD GALWAY LTDTHALES S.A.PRC GROUP - THE MANAGEMENT HOUSE S.A.EDGE-IT S.A.R.LCOGNIUM SYSTEMS S.A.NATIONAL UNIVERSITY OF IRELAND, GALWAYECOLE POLYTECHNIQUE FEDERALE DE LAUSANNEFORSCHUNGSZENTRUM INFORMATIK AN DER UNIVERSITAET KARLSRUHEUNIVERSITAET HANNOVERINSTITUTE OF COMMUNICATION AND COMPUTER SYSTEMSKUNGLIGA TEKNISKA HOEGSKOLANUNIVERSITA DELLA SVIZZERA ITALIANAIRION MANAGEMENT CONSULTING GMBH
Copyright: NEPOMUK Consortium 2006Copyright on template: Irion Management Consulting GmbH 2006
Task Force Ontologies Version 0.1 ii

NEPOMUK 20.03.2007
Versions
Version Date Reason0.1 01.06.2007 a template of the document prepared by Antoni Mylka
Explanations of abbreviations on front page
NatureR: ReportP: PrototypeR/P: Report and PrototypeO: Other
Dissemination levelPU: PublicPP: Restricted to other FP6 participantsRE: Restricted to specified groupCO: Confidential, only for NEPOMUK partners
Task Force Ontologies Version 0.1 iii

NEPOMUK 20.03.2007
Table of contents
1 Abstract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 Status of this document . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 Introduction. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 Examples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
4.1 PIMO ontology and namespaces . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35 Creating Personal Information Models. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
5.1 The User and his individual PIMO .. . . . . . . . . . . . . . . . . . . . . . . . 35.2 Things . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45.3 Identification of things . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55.4 Creating things . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85.5 Setting the class of a Thing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95.6 The PIMO-upper ontology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105.7 Classes in PIMO-upper . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105.8 Describing Things with attributes and relations . . . . . . . . . . . 125.9 Generic Properties in PIMO-upper . . . . . . . . . . . . . . . . . . . . . . . . . 125.10 Refined properties in PIMO-upper . . . . . . . . . . . . . . . . . . . . . . . . . . 135.11 Integrating facts about Things . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
6 Using the NRL Views for PIMO closure . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147 Extending PIMO-upper . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158 Rules defined by PIMO .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
8.1 Construction rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 178.2 Validation rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
9 Design Rationale and frequently asked questions about PIMO .. . 199.1 Collections and sort order of items. . . . . . . . . . . . . . . . . . . . . . . . . . 209.2 Sources considered for designing the PIMO Upper ontology 209.3 Using NIE elements in the PIMO .. . . . . . . . . . . . . . . . . . . . . . . . . . 219.4 Why is PIMO a refinement of the NIE Ontology? . . . . . . . . . 239.5 Isn’t reification enough for a personal view? . . . . . . . . . . . . . . . 239.6 Why not use owl:sameAs? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 239.7 Why isn’t skos:Concept used? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
A Open questions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24A.1 Relation between PIMO:Thing and NIE:InformationElement 24A.2 Complex identifiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25A.3 Equivalence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25A.4 pimo:user or pimo:isDefinedBy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25A.5 hasOtherRepresentation, hasOtherConceptualization, ha-
sOtherSlot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26A.6 What classes and instances appear in a user interface? . . . 26A.7 How do we relate to NAO? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26A.8 Semantic Relations and inference, how to untie hasPart,
Collections, and Topics. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26B PIMO Specification. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
Task Force Ontologies Version 0.1 iv

NEPOMUK 20.03.2007
1 Abstract
The PIMO Ontology can be used to express Personal Information Models ofindividuals. It is based on RDF and NRL, the Nepomuk RepresentationalLanguage and other Semantic Web ontologies. This document describes theprinciple elements of the language and how to use them.
2 Status of this document
This section describes the status of this document at the time of its publication.The form used for this status message and document is inspired by the W3Cprocess.This document is a private Working Draft produced by the task-force On-tologies, part of the Nepomuk Project. This DRAFT is accompanied by aRDFS/NRL ontology, which should be read in parallel to learn more aboutPIMO. The task-force intends this document to become a NEPOMUK stan-dard. The editors of this document value feedback from members of the task-force and other NEPOMUK members. Please send comments to the tf-ontmailinglist ([email protected]) with the subject “Commenton PIMO:”.Knud : Is PIMO really a lan-
guage? This document and the PIMO language as such is a continuation and improve-ment of existing work. Other documents may supersede this document. Partsof this document will be published in other documents, such as scientific publi-cations. This document is based on various other publications by the authors,and is a continuation of existing work. Some formulations from the RDFSprimer and SKOS primer documents were reused.This draft must not be published. The next steps are that the editors havereached agreement and after this, the NEPOMUK consortium reviews. This is adraft document and may be updated, replaced or obsoleted by other documentsat any time. It is inappropriate to cite this document as other than work inprogress.
3 Introduction
PIMO is the abbreviation for the Personal Information Model of a user. ThePIMO-Ontology is both an RDF vocabulary to express such a model and anupper ontology defining basic classes and properties to use.Readers of this document should be familiar with the Resource DescriptionFramework on the level described in the RDFS-Primer [1] and the NRL speci-fication [?].The scope of a PIMO is to model data that is within the attention of theuser and needed for knowledge work or private use. The focus is on datathat is accessed through a Semantic Desktop or other personalized SemanticWeb applications. We call this the Personal Knowledge Workspace [7] (or“Personal Information Space” [14]), embracing all data “needed by an individualto perform knowledge work”. It is (1) independent from the way the useraccesses the data, (2) independent from the source, format, and author of thedata. Is Data that is never part of computerized systems is out of scope.Knud : This is a strange sen-
tence. What does “never part ofcomputerized systems” mean?Is “Love” such data?
Today, such data is typically stored in files, in Personal Information Manage-ment (PIM) or in groupware systems. A user has to cope with formats of data,
Knud : What is ERP? such as text documents, contact information, e-mails, appointments, task lists,project plans, or an ERP system. All this information can be represented inRDF, for example using the NEPOMUK Information Element (NIE) ontology
Task Force Ontologies Version 0.1 1

NEPOMUK 20.03.2007
framework [?]. NIE defines classes for various resources found in the Per-sonal Knowledge Workspace, such as e-mails, documents, appointments, andcontacts. The RDF specification does not give a recommendation how to inte-grate this data across applications, matching elements and merging data (alsocalled smushing) is a service on top of RDF.Knud : Why XML TMs? It’s the
model that matters, not the syn-tax, right? PIMO is based on the idea that users have a mental model to categorize their
environment. Similar to XML Topic Maps or SKOS, individual things arerepresented and their relations formalized. Each user gets an individual model,this is described in Section 5.1. For example the user Claudia Stern has a PIMOcalled “Claudia’s Personal Information Model”. For a user, a living person isalways the same individual, independent if the person is mentioned as senderof an e-mail, address book entry, or author of a document. For example, theco-worker “Dirk Hagemann” will be represented once as element of Claudia’sPIMO and then relate to the documents where he is mentioned.To organize and model tasks in knowledge work, the user can now add morethings in this model. For example, create the project “My trip to Belfast” or the“City of Belfast”(see Section 5.2). Things can be described via their relationsto other things or by literal RDF statements. To attach related travellers,documents, e-mails and websites to “My trip to Belfast”, the generic relationsrelated, hasPart, partOf, hasTopic, and isTopicOf are defined see Section 5.8.An important question is the rdf:type of a Thing, which class it belongs to(Section 5.5).Each Thing created this way needs to be identified, so that documents andrelated information can be retrieved. Also, creating duplicate entries can beavoided by proper identification (Section 5.3).PIMO is similar to SKOS or XML Topic Maps in its goal of providing aneasy way of modelling, but different in the way concepts are modelled. RDFSclasses and subclass relations are used to represent the classes of things, in-dividuals are represented using typed RDF resources, in this regard PIMO isKnud : this sounds very weird.
PIMO is similar to OWL be-cause it uses RDFS class andinstances are RDF resource?Then PIMO is first and foremostsimilar to RDFS!
similar to OWL. Data integration is a three-way process: first each element
Knud : really? Each element is apimo:Thing?
in scope is represented as an instance of the class Thing, independent of itscurrent representation. Then, relations to existing representations are added.Finally, existing data is integrated to the thing. The integration is formalizedand can be implemented with NRL inference. In this respect, it is different
Knud : of course sameAs is di-rected! Every arc in an RDFgraph is directed! Also, direct-edness and whether or not re-sources form a graph are notcontradictions, so why do yousay “rather”?
from OWL, where sameAs relations are equivalence relations and generally notdirected but rather form a graph amongst identical resources. In PIMO, Thingsare connected with resources that represent the same concept using directedrelations.It is not the scope of PIMO to create a new ontology scheme representing dataabout all the elements a user can possibly work with. Rather, it representsthe user itself and the fact that he has a personal model. The design rationale(see Section 9) is to keep the PIMO ontology as minimal as possible, and alsothe data needed to create a PIMO for a user as minimal as possible. Insideone PIMO of a user, duplication is avoided. Instances should be representedonce, the same with classes. To reach this goal, the NEPOMUK standards ofthe NRL representational language and the NIE ontology have been reused asmuch as possible. We also provide a description of how to map existing RDFSontologies to be used (Section 7) and reuse data expressed in these ontologieswithout a conversion process but rather using inference and rules (see Sec-tion 5.11). We have experienced that our previous designs of PIMO were notaccepted by users nor developers if all these questions are not solved properly(precise representation, easy adoption, easy to understand by users, extensibil-ity, interoperability, reuse of existing ontologies, data integration). Althoughsome modelling decisions remain a compromise and may not be shared by you,we have designed this ontology with great effort according to our best knowl-edge and known sources. This enables you to create a model of existing datawith the help of existing ontologies so that it forms a consistent and integratedworld-view for the user.
Task Force Ontologies Version 0.1 2

NEPOMUK 20.03.2007
4 Examples
In this document, a scenario is used to explain the ontology elements. A ficti-cious persona, Claudia Stern, working for SAP is organizing a trip to Belfast.For convenience and readability, this specification uses an abbreviated form torepresent URI-References. A name of the form prefix:suffix should be inter-preted as a URI-Reference consisting of the URI-Reference associated with theprefix concatenated with the suffix.RDF graphs are written in N3/Turtle syntax. Examples serialized as RDFappear in this typesetting:Knud : I find the statement
(Claudia user Claudia) very con-fusing. What’s that supposed tomean?
claudia:Claudia a pimo:Person;pimo:user claudia:Claudia;pimo:isDefinedBy claudia:PIMO;nco:hasEmailAddress <mailto:[email protected]> .
4.1 PIMO ontology and namespaces
The ontology described in this document is downloadable from its namespace:
Namespace: (TODO: replace with real one)http://www.semanticdesktop.org/ontologies/2007/03/19/pimo-temp#
Throughout this document, namespaces are not included in the examples, allnamespaces used are listed here:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .@prefix pimo:<http://www.semanticdesktop.org/ontologies/2007/03/19/pimo-temp#> .
@prefix ncal: <http://ont.semanticdesktop.org/2007/04/02/ncal#> .@prefix nco: <http://ont.semanticdesktop.org/2007/03/22/nco#> .@prefix nfo: <http://ont.semanticdesktop.org/2007/03/22/nfo#> .@prefix nie: <http://ont.semanticdesktop.org/2007/01/nie#> .@prefix nrl:<http://www.semanticdesktop.org/ontologies/2006/11/24/nrl#> .
@prefix claudia: <http://www.sap.com/people/claudia#> .
5 Creating Personal Information Models
In this section, all key elements of the ontology are presented.
5.1 The User and his individual PIMO
Users are represented as instances of the class pimo:Person. For each instance,a new URI is generated and a few key facts are represented to identify the user.As a prerequisite, each user has a personal namespace. Often these are XMLnamespaces using the HTTP URI scheme, but any RDF namespace can beused. The example used in this document is claudia:.Knud: In general, I would write
all ontology elements in a differ-ent font. E.g., pimo:Person First, the user is represented. Claudia is an instance of pimo:Person. Addition-
ally, her e-mail address is added. The e-mail address is modelled by reusing theNEPOMUK contact ontology, NCO. There, it is modelled as a second object.Knud: What do you mean by “as
the second object”?
Task Force Ontologies Version 0.1 3

NEPOMUK 20.03.2007
For the sake of simplicity, we used the URL mailto:[email protected] asidentifier for this nco:EmailAddress resource.
claudia:Claudia a pimo:Person;rdfs:label "Claudia Stern";nco:hasEmailAddress mailto:[email protected].
mailto:[email protected] a nco:EmailAddress;nco:emailAddress "[email protected]".
The second entity that needs to be represented is the Personal InformationModel of the User. For Claudia this would mean:
claudia:PIMO a pimo:PersonalInformationModel;pimo:metaOwner claudia:Claudia.
To state the connection between the Person and her Personal InformationModel, the pimo:metaOwner relation has to be set.The last thing is to connect the Person to the PIMO in which it is defined.For this, the pimo:isDefinedBy relation is used. This is mandatory for everydefined Thing (not only Persons), applications have to know what elements arepart of a PIMO-user1.
claudia:Claudia pimo:isDefinedBy claudia:PIMO.
pimo:PersonalInformationModel is a subclass of nrl:Ontology, allowing moremetadata to be added using NRL compliant standards. We further call anindividual PIMO instantiated for an individual a PIMO-user. Claudia’s PIMO-user is claudia:PIMO. As an abbreviation, it is also correct to say that Claudia’sPIMO is claudia:PIMO.
5.2 Things
The PIMO ontology defines a basic class to represent mental concepts, the classThing. Every information element encountered in knowledge work by a user isrepresented as a Thing. Things are used to uniquely represent entities of thereal world within one PIMO-user. On the Personal Knowledge Workspace, anentity can be represented in multiple data sources. One pimo:Thing is createdas an anchor, which is then linking to these representations. For example, theperson “Dirk Hagemann” may be author of an e-mail, described in an addressbook entry, and stored in a accounting tool, all accessible by our exampleuser “Claudia”. In PIMO, there is one Thing representing him, linking to allrepresentations. When an application handles a representation, it is possible tofind the Thing representing the representation. For example, Claudia’s e-mailclient sees the sender of an e-mail (Dirk) and searches for the pimo:Thing thatrepresents Dirk uniquely. Once the right Thing is found, more informationabout Dirk can be queried.To be adequate, a PIMO of a user should contain all nameable entities knownto the user, but to be efficient, this representation should be restricted tothe minimal data needed. Identification is part of this minimal data, andNIE:identifier provides the property for it.
1We intentionally did not only use NRL graphs to model the relation between the model andinstances defined by it. The pimo:isDefinedBy relation is a clear representation needed by manyapplications.
Task Force Ontologies Version 0.1 4

NEPOMUK 20.03.2007
5.3 Identification of things
A thing should be represented and identified once, but can manifest itself inmultiple elements. For example, the person “Dirk Hagemann” is representedonce as an instance of the class pimo:Person, and then linked to documents orother things that mention this person.For example, given a person, the same person can be represented in multipleresources, especially when having multiple non-semantic web applications:
# The canonical Dirkclaudia:DirkHagemann a pimo:Person;pimo:isDefinedBy claudia:PIMO;nco:hasEmailAddress <mailto:[email protected]>.
# An e-mail in which Dirk occurs<imap://[email protected]/INBOX/1> a nmo:Mail;nmo:from <imap://[email protected]/INBOX/1#from>.
# Dirk #2, as email sender<imap://[email protected]/INBOX/1#from> a nco:Contact;nco:hasEmailAddress <mailto:[email protected]>.
<mailto:[email protected]> a nmo:EmailAddress;nco:emailAddress "[email protected]".
# Dirk #3, as address book contact<file://home/claudia/dirk.vcf#dirk> a nco:PersonContact;nco:nameFamily "Hagemann";nco:nameGiven "Dirk";nco:hasEmailAddress <mailto:[email protected]>;nco:photo <http://www.sap.com/people/dirk/photo.jpg>.
In this example, we have seen that the Person Dirk appears three times in thissystem. Once, as the canonical instance of pimo:Person. Second, as senderof an e-mail and third as entry in an address book. Only one instance is thepimo:Thing representation of Dirk, the first one: claudia:Dirk. All others arerepresentations about the same entity.For Things, URI identifiers are needed. These should be generated using thenamespace of the user. Although they can be randomly generated, we recom-mend to use include the label in the URI for readability. When two things havethe same label, and should not be merged, a random element can be added tothe URI. A URI for Claudia Stern could be:
claudia:ClaudiaStern.Knud : can one “use” an as-sumption? To work effectively, PIMO uses the Unique Name Assumption (UNA). Two
individuals with different URIs are different individuals. This is common indesktop applications and intuitive to grasp for users, for example files withdifferent names are different. It is different from other ontology systems, such asKnud : is OWL a system?OWL, where duplicate entries are common and the Unique Name Assumption(UNA) is not used. The difference is based on the fact that the PIMO isdesigned for personal systems, where an application has access to the completemodel and can avoid duplicates before creating them.Thus, creating a new thing is always connected to beforehand examining if athing with a similar name, type, or other identifying properties already exists.Duplication should be avoided. If an existing thing has a different class or labelthan expected, but the same identifying properties, this may be an indicationfor a modelling error or that the facts in the real world have changed. Bothshould be handled by fixing the problem rather then by duplicating the data.
Task Force Ontologies Version 0.1 5

NEPOMUK 20.03.2007
Things can either be created by the user manually or automatically by analysingexisting native resources. The identifying properties are the most importantproperties needed to identify Things, and they should be set. Existing iden-tification schemes should be reused for this purpose (for example the e-mailaddresses to identify people or ISBN numbers for books) by representing themwith pimo:identifier and its sub-properties. If an identifier is found as meta-Knud: you say pimo:identifier
here and nie:identifier in the ex-ample below. Which one is it?
data of a native resource or nie:InformationElement, the value and propertymust be copied to the Thing, to allow others to match and identify. Thiscopying process can be done manually or by inference.
# Copy all identifiers you can find about the Thing.claudia:DirkHagemann a pimo:Person;nie:identifier "[email protected]".
Grounding Occurrence The relation pimo:groundingOccurrence is used tolink a thing to an nie:InformationElement that has this thing as primarytopic. For example, the grounding for a person could be the entry in theaddress book describing the person. A Thing represents the mental concept,the pimo:groundingOccurrence links to existing Information Elements that arehandled by existing applications. This is a key for reusing the features of theseapplications. pimo:groudingOccurrence allows multiple values, this reflects thefact that the same thing can be represented in multiple applications, and de-pendent on the work context, the user may want to open a different application.
# Link to Dirk #3 from example above.claudia:DirkHagemann a pimo:Person;pimo:groundingOccurrence <file://home/claudia/dirk.vcf#dirk>.
Occurrence is the relation connecting pimo:Things with any representationof the same thing that is part of other data. For example, if the person Dirkappears as resource again as sender of the e-mail, then this is an occurrence ofDirk. Not the e-mail as such is the occurrence, but the sender. These links canbe inferred using identification properties or pimo:referencingOccurrence.
# Link to Dirk #2 from example above,# he occurs as sender of an e-mailclaudia:DirkHagemann a pimo:Person;pimo:occurrence <imap://[email protected]/INBOX/1#from>.
Referencing Occurrences TODO: rename to indicatingOccurrence, closerto Topic Maps? Referencing Occurrences are an indirect approach to identi-fication, the pimo:referencingOccurrence annotates a Thing with a documentthat describes the Thing. The following description is an adaption of XTM’ssubject indicators [13, 10]. The referencing occurrence is a kind of proxy forthe Thing. Examples of referencing occurrences are:
claudia:DirkHagemann a pimo:Person;pimo:referencingOccurrence <http://www.sap.com/people/DirkHagemann>.
claudia:SAP a pimo:Organization;pimo:referencingOccurrence <http://www.sap.com/>;pimo:referencingOccurrence <http://en.wikipedia.org/wiki/SAP_AG>.
It should contain a human readable documentation describing the concept.The resource could be a document, ontology, video, audio, anything able todescribe to a human what the concept is about. The resource is a reference tothe concept.A referencing occurrence describes the concept with the purpose of being widelyused by ontologies. Consequently, it is important the the document describes
Task Force Ontologies Version 0.1 6

NEPOMUK 20.03.2007
exactly what concept it is about and what not. Even if the author works asaccurately as possible, different people will never interpret a referencing occur-rence 100% the same way. However, the concept of referencing occurrences isworth using it, because it allows a shallow match of heterogenous informationmodels, and because there is finally no alternative to it (as Holger Rath putit [10]).
Other Representation The pimo:hasOtherRepresentation relation is used toconnect pimo:Things with other representations of the same thing in otherSemantic Web ontologies. A formal RDF description indicates that the referredresource is another representation of the same Thing, but within a differentontology. This can be the case with shared ontologies, such as company whitepage systems or Semantic Social Networking websites.The knowledge modelled should be compatible with the ontologies used by theuser, mappings may be needed. An example for such other representation:2
claudia:DirkHagemann a pimo:Person;pimo:hasOtherRepresentation <http://id.sap.com/person/1650>.
A complete example for all different identification properties can now bemade by combining above annotations.For Claudia, her co-worker Dirk Hagemann can be represented like this, in-cluding descriptions of the information elements in which Dirk occurs.
# The canonical pimo:Person Dirk,# a pimo:Thing from Claudia’s PIMO,# linked to many occurrences.claudia:DirkHagemann a pimo:Person;pimo:isDefinedBy claudia:PIMO;nie:title ’Dirk Hagemann’;nie:identifier "[email protected]";pimo:occurrence <imap://[email protected]/INBOX/1#from>;pimo:groundingOccurrence <file://home/claudia/dirk.vcf#dirk>;pimo:referencingOccurrence <http://www.sap.com/people/DirkHagemann>;pimo:hasOtherRepresentation <http://id.sap.com/person/1650>.
# An e-mail in which Dirk occurs<imap://[email protected]/INBOX/1> a nmo:Mail;nmo:from <imap://[email protected]/INBOX/1#from>.
# Dirk #2, as email sender<imap://[email protected]/INBOX/1#from> a nco:Contact;nco:hasEmailAddress <mailto:[email protected]>.
<mailto:[email protected]> a nmo:EmailAddress;nco:emailAddress ‘‘[email protected]’’.
# Dirk #3, as address book contact<file://home/claudia/dirk.vcf#dirk> a nco:PersonContact;nco:nameFamily ‘‘Hagemann’’;nco:nameGiven ‘‘Dirk’’;nco:hasEmailAddress <mailto:[email protected]>;nco:photo <http://www.sap.com/people/dirk/photo.jpg>.
This description allows the system to do the following:2Using the setup and spirit of the well documented approach by ECS http://id.ecs.soton.
ac.uk/docs/
Task Force Ontologies Version 0.1 7

NEPOMUK 20.03.2007
• identifying the Thing to be found when occurring in documents
• giving a grounding that can be used to see it with a common desktopapplication (in this case Microsoft Outlook)
• referring to a public website about the Thing, to be able to match thisThing with other representations by authors using the same referencingoccurrence.
• using the other representation to integrate data taken from the companieswhite pages.
The pimo:occurrence link is the generic basis, pimo:groundingOccurrence andpimo:hasOtherRepresentation are subproperties of it. This data should be gen-erated unsupervised, or semi-automatically. It is important to gather identifiersfrom the Knowledge Workspace and annotate the Thing with them, so that allpossible identifiers can be retrieved directly. This can be implemented usinginference rules, see Section 8.1.
5.4 Creating things
An algorithm to create things based on InformationElements or external on-tologies should follow these steps:
Start The software agent encounters a resource with URI X and wants toverify if the user already has knowledge about X.
Check GroundingOccurrence Query the PIMO-user for:
SELECT ?thing WHERE {?thing pimo:groundingOccurrence ?X.}
When a Thing is found, finished.
Check identifiers Validate if the InformationElement has an identifier or areferencing occurrence that is also used on an existing Thing. The informationelement is called an occurrence of a Thing when it shares the same identifiers.The correct query is:
SELECT ?thingWHERE {?thing ?p ?o.?X ?p ?o.?p rdfs:subPropertyOf nie:identifier.} UNION {?thing ?p ?o.?X ?p ?o.?p rdfs:subPropertyOf pimo:referencingOccurrence.}
When a thing is found, finished.
Create a new Thing When the last step did not return an existing thing, thiscan be an indicator that the inspected information X is new to the user andshould be modelled as a Thing. To create a new Thing, mint a URI and add thecore identity values from the InformationElement. In the following example,we assume that Claudia’s System has just encountered a new calendar event Xand represents it using the new minted URI claudia:Event42.
Task Force Ontologies Version 0.1 8

NEPOMUK 20.03.2007
• all identifiers are copied (?i, ?io)
• the title is copied for readability and to use it for tagging (?title)
• the original type(s) are copied (?type)
• the pimo:groundingOccurrence relation is added
• a pimo:metaCreationSuppertedBy flag is set to document the act of cre-ating the new Thing based on data extracted from ?X.
• the contentCreated timestamp is set to the current date, and the creator.
• Find possible PIMO:Thing subclasses that can be used for this type.The given query is not perfect, this depends on how your ontologies aremapped.
CONSTRUCT {<claudia:Event42> rdf:type pimo:Thing.<claudia:Event42> ?i ?io.<claudia:Event42> nie:title ?title.<claudia:Event42> rdf:type ?type.<claudia:Event42> pimo:groundingOccurrence ?X.<claudia:Event42> pimo:metaCreationSuppertedBy ?X.<clauida:Event42> nie:contentCreated ‘‘2007-06-30T18:11:00Z’’.<clauida:Event42> nie:creator claudia:Claudia.<claudia:Event42> rdf:type ?pimotype.} WHERE {OPTIONAL (?X ?i ?io. ?i rdfs:subPropertyOf nie:identifier.).OPTIONAL (?X nie:title ?title).OPTIONAL (?X rdf:type ?type).# This example may return wrong results, use as inspiration.OPTIONAL (?X rdf:type ?nietype. ?pimotype rdfs:subClassOf ?nietype).}
A common problem where this system breaks is duplicate entries, when thesame concept is created using two individual Things. Duplications cannot beavoided completely.
5.4.1 Fixing duplicates
When duplicates are found, one of the things (duplicate) can be deleted andmerged into the other (original). In this process, triples containing the dupli-cate are deleted and recreated using the original. In the local setup with onedesktop and all data stored in a single RDF database, this process is without in-formation loss and causes no side-effects. As Semantic Web applications are in adistributed scenario, deleting a duplicate resource can cause dangling links in re-lated databases and other side-effects. For this, the pimo:hasDeprecatedRepresentationproperty is used to relate the original with the (now deleted) duplicate. Notethat the range of this property is not defined, as all data about the duplicateresource (including the type) is deleted.
5.5 Setting the class of a Thing
Things are represented using RDF resources and typed using the rdf:type rela-tion. Possible classes are pimo:Thing and its subclasses. The PIMO ontologyitself defines several subclasses such as pimo:Person or pimo:Organization. If
Task Force Ontologies Version 0.1 9

NEPOMUK 20.03.2007
these are not specific enough, the user can either create new subclasses man-ually, or import ontologies. This is described below, in the section on import-ing 7.As a rule of thumb, the question to be answered by assigning the class is “Whatis this Thing?” and not “What does it mean to me?”. This often leads to mis-understandings, for example the class “important things” does not describe thenature of the thing as such (is it a document, a project) but the interpreta-tion in a context. Such modelling should be done using the Nepomuk TaggingOntology, where ratings can be given, by other attributes like “important - yesor no” or by using part-of relations like “this Thing is part of the group ofimportant things”. For the concrete example of “importance”, we recommendusing the property TODO:lookAtTaggingOntology. To model collections ofthings that share a common property (such as “important things”), the classpimo:Collection is provided, see there.Thus, we recommend to assign Things to only class when modelling. Thewish to add multiple classes is often an indication that some classes can bebetter modelled using relations. Superclasses are inferred implicitly, and arenot affected by this recommendation.
5.6 The PIMO-upper ontology
The PIMO ontology contains an upper ontology for basic concepts for Per-sonal Information Management (PIM): Person, Location, Event, Organization,Topic, Document, Time. They are modelled to answer basic questions about athing:
• Who is associated? Person
• Where is this? Location
• When is it? Time
• What is it about? Topic
The classes defined in this upper ontology are intended to serve as integrationpoint for PIM applications. In the broader perspective of the Semantic Desktop,they can serve as upper classes for many ontologies.
5.7 Classes in PIMO-upper
TODO: list them, give examples how each should be used. The classes havebeen defined based on related ontologies, a user study, and several softwareprototypes that have been evaluated. They capture the most important classesneeded for PIM. For known domains, subclasses should be created, see section 7.
Thing The root class of the upper ontology. Every entity that can be in theattention of the user is a Thing.
Collection A collection of Things, independent of their class. The items inthe collection share a common property. Several usability studies showedthat collections are important for PIM.
Group A group of Persons. They are connected to each other by sharing acommon attribute, for example they all belong to the same organizationor have a common interest.
Location A physical location. Subclasses are modelled for the most commonlocations humans work in: Building, City, Country, Room, State. This
Task Force Ontologies Version 0.1 10

NEPOMUK 20.03.2007
Task Force Ontologies Version 0.1 11

NEPOMUK 20.03.2007
selection is intended to be applicable cross-cultural and cross-domain.City is a prototype that can be further refined for villages, etc.
LogicalMediaType MediaConcepts are logical media types (e.g., a book, acontract, a promotional video, a todo list). The user can create newlogical media types dependent on their domain: a salesman will needMarketingFlyer, Offer, Invoice while a student might create Report, The-sis and Homework.
Organization An administrative and functional structure (as a business or apolitical party).
Person Represents a person. Either living, dead, real or imaginary. In thisregards, similar to foaf:Person.
PhysicalObject An object of interest in the physical world. It can be touched,Knud : if there is a physical ob-ject, how about an abstract ob-ject? Love? Language?
it is concrete and it is of interest to the user. Examples are cars, tables,products and goods of business interest.
ProcessConcept Concepts that relate to a series of actions or operations con-ducing to an end. Subclasses are defined for Event, SocialEvent, Meeting,Project, Task, and Todo.
Topic A topic is the subject of a discussion or document. Topics are distin-guished from Things in their taxonomic nature, examples are scientificareas.
These classes are intentionally kept very generic and without much detail. Morespecialized ontologies should be used for certain domains of application, theclasses of these ontologies are then be mapped to upper ontology classes us-ing subclass relations, same with properties. We expect that this conformsto a common practice in the Semantic Web, namely to reuse multiple smallontologies where needed.
5.8 Describing Things with attributes and relations
Conventional RDF statements are used to describe Things. The predicates usedhave to be defined as rdfs:Properties according to the NRL standard. Alterna-tively, it is also possible to use properties from other modeling languages likeOWL or RDFS although we do not encourage this without a proper mappingof existing ontologies to PIMO (see 7).As part of the minimalistic approach of PIMO, the class nie:InformationElementis defined as a subclass of pimo:Thing. Some annotations from NIE are reusedin PIMO.The property nie:contentCreated indicates the time when the system has cre-ated the Thing, and nie:contentLastModified indicates when the RDF repre-sentation about the resource were modified. Directions how the semantics ofNIE properties are to be understood when used on PIMO:Things are given insection 9.3.
5.9 Generic Properties in PIMO-upper
For generic annotations, the PIMO-upper ontology contains basic relationsbetween Things and a few core attributes for identifying things (describedabove 5.3) and basic descriptions. Relations of things are:
pimo:related is the most generic relation, giving now further indication howthings may be related. Related is a nrl:SymmetricProperty.
Task Force Ontologies Version 0.1 12

NEPOMUK 20.03.2007
pimo:hasPart and pimo:partOf model partitive relations. They are inverse.Neither is transitive, because part-of relations used for modelling in thedomain of Personal Information Management are vague due to the manycontexts of interpretation (a hotel may be part of a trip plan, a trip planpart of a project, but this does not indicate the hotel to be part of theproject).
pimo:hasTopic and pimo:isTopic connect a thing of interest with a thing re-flecting about it. For example, a meeting can have a project as a topic, ora meeting has a document as a topic, when the goal of the meeting is todiscuss the document. After the meeting, the meeting minutes are a newthing that has the meeting as a topic. This is not restricted to meetingsbut also an organization or a person can have a certain technology as atopic to express that they are working on the topic. The relation is nottransitive, not symmetric. It is not asymmetric because a document Amay have document B as topic, and B also A.
Examples for these relations: TODO.Based on these generic relations, there are specializations for special cases be-tween classes in the upper ontology (see below in Section 5.10).Metadata about things, like the timestamp when the resource was created firstto represent this thing (when the URI was minted), the title, or a plaintextdescription of the thing can be stated by using the normal NIE properties.Some NIE properties defined with domain nie:InformationElement should notbe used to describe instances of pimo:Thing, the exact guidelines are givenbelow in Secition 9.3.
5.10 Refined properties in PIMO-upper
Additional to the relations already mentioned above (5.8), only basic relationsare defined to capture semantically important relations of the core classes, espe-cially those who can be used as symmetric or transitive relations for inference.
pimo:narrower and pimo:broader relate Topics to each other. As Topics arean important mean to organize document collections based on a taxon-omy, these two predicates are defined. They are inverse of each other andtransitive.
pimo:hasOrganizationMember and pimo:isOrganizationMemeberOf are re-lations connecting a Person to an Organization.
pimo:hasLocation and [pimo:isLocationOf] relate a Thing with its Location.Note that any thing can have a physical location, further refinements canbe done by the user (such as limiting topics not to have a location, if thisis needed).
5.11 Integrating facts about Things
When an InformationElement is the occurrence of a Thing, then the factsof both can be integrated for this user. This is true for pimo:occurrences,pimo:groundingOccurrence and pimo:hasOtherRepresentation relations. To geta coherent and meaningful view, the class of the InformationElement (or relatedresource) has to be a subclass of the Thing’s class, or they are the same. Thisrequires all ontologies in question to be integrated using subclass relations, asdescribed later 7.NRL named graphs combined with PIMO inference are used to superimposestatements from occurrences as if they were facts stated about the Thing. The
Task Force Ontologies Version 0.1 13

NEPOMUK 20.03.2007
rules for superimposing data can be expressed using this SPARQL constructstatements are given in Section 8.1.Given the capabilities of today’s inference engines, the last level is a challengingproblem to realize, assuming a normal Semantic Desktop has about one milliontriples already in the store, making this closure can create a virtual graph with alot more facts. To handle these options, we define three default NRL Views andNRL ViewSpecifications for the three inference levels. The View Specificationsallow to define a level of inference based on rules. This specification can then beused to create a named graph that contains the instance data and the inferredstatements.
Infer Occurrences: infer all occurrence statements based on nie:identificationand pimo:referencingOccurrence facts. This
Closure on Groundings: add all statements about the grounding Occurrencesand hasOtherRepresentation to the Thing
Closure on all Occurrences: add all statements about all occurrences to theThing
By providing these graphs, we let the user and software agent decide if the fullclosure is needed at all times. When you need no closure, use the plain NRLgraphs, when you need to do queries like “Which e-mails were sent to me byattendees of meetings that I have today”, then the full closure is a good choice.The ability to superimpose data using inference limits the data needed in aPIMO to a necessary minimum: only the identification properties are manda-tory, the grounding and the hasOtherRepresentation properties superimposeexisting data. The user should only add information that was not expressedbefore.From the perspective of the user, facts stated about grounding occurrencesare correct (they have been taken from existing data managed by the user);as are hasOtherRepresentation (they are from formal ontologies imported andaccepted by the user). If this is not the case, the incorrect statements mustnot be integrated, which is interesting but out of the scope of PIMO for now.
6 Using the NRL Views for PIMO closure
The NRL graph views can now be used to create views that include the enclo-sures defined by PIMO. The requirements on RDF frameworks are thus keptlow, until the full closures are needed. The three closure views are defined aspart of the PIMO ontology.They are accessible using these URIs:
pimo:InferOccurrences a view that infers occurrences based on identifiers
pimo:GroundingClosure a view that adds statements to things that comefrom groundings
pimo:OccurrenceClosure a view that adds statements to things that comefrom every occurrence
pimo:FullPimoView a supergraph of all above
For short, you can use the NRL graphs to get a view of all your data in anintegrated view. All facts stated about occurrences of Things are then entailedas facts about the Things as such, in the view pimo:FullPimoView you are ableto ask the SPARQL query for “Which e-mails were sent to me by attendees ofmeetings that I have today”.
Task Force Ontologies Version 0.1 14

NEPOMUK 20.03.2007
7 Extending PIMO-upperKnud: I changed the title, be-cause I think this chapter isnot only about mapping ontolo-gies, but more generally speak-ing about how to extend PIMOfor one’s needs.
The main approach to map ontologies to PIMO-upper is to define new sub-classes of PIMO-upper classes and to subclass InformationElement classes.Existing classes are extended by subclassing them and adding more proper-ties. For example, if your application domain are training courses and yourusers give trainings connected to courses and training material, all of theseitems can be created as subclasses of pimo:Thing. The course would be a sub-class of pimo:ProcessConcept, the training lesson given would be a subclass ofpimo:Meeting, training material a subclass of pimo:Document. Properties canthen use these classes as a domain and further specify them. This approachis a typical example of how to model domain ontologies for certain applicationareas, where users primarily work with Things and finer models are needed.The domain ontologies may be connected with a special application that helpsusers managing their data, for example a Training Course Manager where userscan assign attendees to trainings, etc. This is also a way to integrate new Infor-mation Elements into the PIMO system. Information Elements needs specialadaptions to be used in PIMO.For example a literature ontology based on Bibtex could be integrated to PIMOthe following way:
• Given an ontology for literature (such as Bibtex), with existing classes forArticle, Book, and Author and relations between them like hasAuthor,bookContainsArticle.
• The literature classes are modelled as subclasses of PIMO classes, forexample Article and Book are subclasses of pimo:Document and Authoris a subclass of pimo:Person.
• If a user does not know which is the correct superclass for a newly createdclass, or an ontology engineer cannot decide how to map an existingontology to PIMO-upper, map the class as subclasses of pimo:Thing.By doing this, the ontology can be used and tested in a system. Theexperiences gathered in this way will help to further refine it. Once thecorrect superclass is known, this fact can be added later as a secondsuperclass relation. The other way round, when you first make a decisionfor the wrong superclass, the modelling error will be reflected somewherein the data created using the mapping.
• For document-oriented classes, this requires special care. Documents havetwo types, one is the LogicalMediaType that captures how a documentis interpreted by the user. Logical Media Types can be contracts, in-voices, assignments, invitations, law texts, etc. The other type is theNFO:Document type, how the system interprets the document. For ex-ample, a text interpreted as invoice by the user can be sent either asnfo:PlainTextDocument or as nfo:PaginatedTextDocument. This is thephysical document type as modelled by NIE. Vice-versa, one pyhsicaltype can be used to represent an invitation or an invoice, which are dif-ferent Logical Media Types. Knowing this separation of content fromrepresentation, you can model documents having two rdf:types, one forphysical type, one for logical.
• Properties which have a domain and range of pimo:Thing should bemapped as subproperties of pimo:related, pimo:hasTopic, pimo:isTopicOf,pimo:hasPart, or pimo:partOf.
• Identifying properties that have domain pimo:Thing and a literal rangeshould be mapped as subproperties of nie:identifier.
Knud : I don’t understand this atall • Identifying properties that have resources as range can either be subprop-
erties of pimo:occurrenceRef, if the vocabulary of the possible objects is
Task Force Ontologies Version 0.1 15

NEPOMUK 20.03.2007
not canonical, or subproperties of pimo:hasOtherRepresentation when theobjects are part of a formal ontology.
• If needed, the classes can also be assigned as subclassses of other ontolo-gies, such as other NIE based ontologies or completely different ontologiessuch as Wordnet, SUMO, or Dolce.
For a literature ontology based on the formalization BibTex (which can existbeforehand), the result could be this :
# Example in N3bibtex:Article a rdfs:Class;# interpreted by the user as nie:Documentrdfs:subClassOf pimo:Document;# interpreted by the system as nfo:TextDocumentrdfs:subClassOf nfo:TextDocument.
bibtex:Author a rdfs:Class;# this adds properties like Namerdfs:subClassOf pimo:Person.
bibtex:hasAuthor a rdf:Property;rdfs:subPropertyOf pimo:related;rdfs:subPropertyOf nfo:creator;rdfs:domain bibtex:Article;rdfs:range bibtex:Author.
bibtex:hasLCCN a rdf:Property;rdfs:subPropertyOf nie:identifier; \# add an identifierrdfs:domain bibtex:Article.
Another possibility is extending existing PIMO-upper classes by subclassingthem from external classes. This is discouraged. For example, if the classpimo:Person would have been a subclass of a nco:PersonContact and pimo:Organizationa subclass of nco:OrganizationContact, automatically all occurrences of theseclasses would have been inferred as Things. But then, properties required bythe Thing class are not defined in the knowledge base and the imported datais rendered invalid. Also, when a mapped class X has cardinality restrictionson its properties (such as required properties), adding X as new superclass toan existing PIMO class can render the instances of the PIMO class invalid.The summary to mapping is:
• Make classes subclasses of PIMO-upper classes.
• Make properties subproperties of PIMO-upper properties.
• Relations: Links between things have to be browseable, properties shouldhave inverse relations defined (see [11])
• Extensibility: Users are free to add new relation types and new classes(see [11])
8 Rules defined by PIMO
A few rules are defined in PIMO that cannot be expressed using NRL semantics.These rules are written here using SPARQL construct queries and are also partof the ontology, using NRL:RuleViewSpecification. The rules help to inferadditional statements or validate a model. All rules in this section assume thatat least the subclass and subproperty relations are inferred.
Task Force Ontologies Version 0.1 16

NEPOMUK 20.03.2007
8.1 Construction rules
The first set of rules define new information that is inferred from existing data.They are used to integrating facts about things by blending, see 5.11.Infer Occurrences. These are the rules to infer occurrences based on identifiers.You can use this approach to integrate data from large stores. For example tosee all e-mails written by Dirk, without first creating each e-mail as Thing andlinking it, this query can use Dirk’s identifier to match him with the authorsof e-mails based on the e-mail address as identifier.
CONSTRUCT {?thing ?p ?o} WHERE {?i rdfs:subPropertyOf nie:identifier.?thing ?i ?io.?ie ?i ?io.?ie ?p ?o.?x ?p ?o}
Closure on Groundings. This adds all facts from grounding occurrences andhasOtherRepresentation occurrances to Things.
CONSTRUCT {?thing ?p ?o} WHERE {?thing pimo:groundingOccurrence ?x.?x ?p ?o.}CONSTRUCT {?s ?p ?thing} WHERE {?thing pimo:groundingOccurrence ?x.?s ?p ?x.}CONSTRUCT {?thing ?p ?o} WHERE {?thing pimo:hasOtherRepresentation ?x.?x ?p ?o.}CONSTRUCT {?s ?p ?thing} WHERE {?thing pimo:hasOtherRepresentation ?x.?s ?p ?x.}
Occurrence Closure. This adds all facts of all occurrences to things.
CONSTRUCT {?thing ?p ?o} WHERE {?thing pimo:occurrence ?x.?x ?p ?o.}CONSTRUCT {?s ?p ?thing} WHERE {?thing pimo:occurrence ?x.?s ?p ?x.
Task Force Ontologies Version 0.1 17

NEPOMUK 20.03.2007
}
A broader Topic is also the Topic of a Thing. If a thing X has the topic Aand topic A has a broader topic B, then X has also the topic B. Broader andnarrower are transitive.
CONSTRUCT {?x pimo:hasTopic ?B}WHERE{?x pimo:hasTopic ?A.?A pimo:broader ?B.}
Note that this is not true for the hasPart relation (see open questions).An alternative to the hasTopic rules would have been to represent topics asRDFS classes (instead of having them as instance of type pimo:Topic) and usingrdfs:subClassOf relations instead of broader/narrower. But this has a nastyside-effect that for a topic like “Semantic Web”, having a sub-topic “RDF” theuser would suddenly be able to create instances of it, which would be confusingand we want to avoid that (pun intended, the joke is on us. perhaps we shoulduse another example).
8.2 Validation rules
These rules validate a model. Some assumptions stated in the text can bevalidated using these rules. As a model for validation, we have chosen topick a similar approach as the Jena valditation engine, namely creating errors.Instead of using rules for this, we use construct queries. The class error:Errorand error:Message and is invented for this purpose and not defined any further,we assume Errors can have parameters that are passed back as error:param1,error:param2, etc. The parameters can be referenced in the error message forreadability.The rules are often used to restrict properties defined in the NIE ontologyto be mandatory on pimo:Things, whereas they are optional when used onnie:InformationElement. Such restrictions are possible in OWL but not inNRL.Every Thing must have a nie:title.
CONSTRUCT {_:err a error:Error._:err error:Message ‘‘Thing \%1 does not have a nie:title’’._:err error:param1 ?x.} WHERE {?x rdf:type pimo:Thing.OPTIONAL { ?x nie:title ?title } .FILTER (!bound(?title))}
Every Thing must have nie:contentCreated.
CONSTRUCT {_:err a error:Error._:err error:Message ‘‘Thing \%1 does not have a nie:contentCreated’’._:err error:param1 ?x.} WHERE {?x rdf:type pimo:Thing.OPTIONAL { ?x nie:contentCreated ?created } .FILTER (!bound(?created))}
Task Force Ontologies Version 0.1 18

NEPOMUK 20.03.2007
9 Design Rationale and frequently asked questions about PIMO
The motivation for creating the PIMO is to find a language to name the termsthat are relevant to a knowledge worker and to have ways to express facts aboutthese terms. Once this language is defined and formalized in the ontologicaldescription of the PIMO, it can be used to translate existing resources, and toexpress information about them. The PIMO is a user-centric view on existingdocuments, domain ontologies, and web data sources.While the organization asks for universally applicable and standardized per-sistent structures, processes, and work organizations to achieve and maintainuniversally accessible information archives, the individual knowledge workerrequests individualized structures and flexibility in processes and work organi-zation in order to reach optimal support for the individual activities.The vision is that a Personal Information Model reflects and captures a user’spersonal knowledge, e. g., about people and their roles, about organizations,processes, things, and so forth, by providing the vocabulary (concepts andtheir relationships) for required expressing it as well as concrete instances. Inother words, the domain of a PIMO is meant to be “all things and nativeresources that are in the attention of the user when doing knowledge work”.Though “native” information models and structures are widely used, there isstill much potential for a more effective and efficient exploitation of the un-derlying knowledge. We think that, compared to the cognitive representationshumans build, there are mainly two shortcomings in native structures:
• Richness of models: Current state of cognitive psychology assumes thathumans build very rich models, encoding not only detailed factual as-pects, but also episodic and situational information. Native structuresare mostly taxonomy- or keyword-oriented.
• Coherence of models: Though nowadays (business) life is very fragmentedhumans tend to interpret situations as a coherent whole and have rep-resentations of concepts that are comprehensive across contexts. Nativestructures, on the other hand, often reflect the fragmentation of multiplecontexts. They tend to be redundant (i.e., the same concepts at multipleplaces in multiple native structures). Frequently, inconsistencies are theconsequence.
The PIMO shall mitigate the shortcomings of native structures by providing acomprehensive model on a sound formal basis.When building concrete PIMOs, we now have the problem of two, potentiallyconflicting demands: On the one hand, we want to give the user the opportunityto span his information space largely in the way he wants. The PIMO shouldmodel his mental models. In consequence, we cannot prescribe much of thisstructure. On the other hand, “empty” systems often suffer from the cold startproblem, being not accepted by user when not already equipped with someinitial content. Using a multi-layer approach (see also [12]), we try to find abalance through providing the presentational basis as given, which users canincorporate or extend:A definition of the term PIMO was given in [?]: A PIMO is a PersonalInformation Model of one person. It is a formal representation of parts of theusers Mental Model. Each concept in the Mental Model can be representedusing a Thing or a subclass of this class in RDF. Native Resources found in thePersonal Knowledge Workspace can be categorized, then they are occurrencesof a Thing.
Task Force Ontologies Version 0.1 19

NEPOMUK 20.03.2007
9.1 Collections and sort order of items
TODO:
• collections are unordered
• temporal order is expressed using implizit modelling (the time differenceis implicit and has to be calculated for explizit knowing it for sorting)
• in science, different sorting systems are described: geographical, alpha-betically, by Time, by Categories, by Hierarchy. (Location, Alphabet,Time, Category, and Hierarchy, known as LATCH TODO: cite R. Wur-man, D. Sume, and L. Leifer, Information Anxiety 2, Que, 2000.)
• Latif and Tjoa, 2006 [8] have existing systems are build on LATCH, andadditionally refine it saying that hierarchy is often taxonomic and thatpeople are an important ordering factor, as also does Dengel2006.
• That said, we see that ordering is dependent on the view in the applicationand on the attributes of the elements, there is a reason WHY the elementsare ordered in a way based on their attributes. For PIMO, we do notprovide an explicit sort order (before/after) relations, this can be addedby implementors as extensions. The NEPOMUK Conceptual Elementsmodel, developed by Max Völkel and Heiko Haller defines the standardsfor ordering. On the level of PIMO, ordering of items in a collection isimplizit by the attributes of the items in the collection and handled by theuser interface, by showing the elements in whatever order is appropriate.
• The Collection class can be used to model collections of items that sharea common attribute.
• Members of collection are modelled using hasPart.
9.2 Sources considered for designing the PIMO Upper ontology
A similar approach was used by Huiyong Xiao and Isabel F. Cruz in their pa-per on “A Multi-Ontology Approach for Personal Information Management”,where they differentiate between Application Layer, Domain Layer and Re-source Layer. Alexakos et al. described “A Multilayer Ontology Scheme forIntegrated Searching in Distributed Hypermedia” in [2]. There, the layers con-sist of an upper search ontology layer, domain description ontologies layer, anda semantic metadata layer.PIMO is different from XML Topic Maps (XTM) as it allows to use inferenceand RDFS definitions, also enabling an efficient way to store the data in RDFdatabases (whereas XTM is based on XML). The main difference to RDF isthat Topic Maps Associations are by definition n-ary relations, whereas in RDFthe relations are typically binary. In RDF, a similar approach as to XTM isthe SKOS vocabulary [5]. It represents all Things using the class Concept, thisblocks reusing inference and typed properties of concepts (like the “first name”property of a person cannot be modelled in SKOS).The idea of mapping SKOS, RDF, OWL and topic maps with upper ontologieshas come up repeatedly, but with varying outcome. We value these articlesas very important for our work, because of their excellent research and theexperience of the authors.
• TODO: make this list shine.
• Pepper+2003: “Curing the Web’s Identity Crisis. Subject Indicators forRDF” tries to map the identification approach of XML Topic Maps toRDF, without only theoretical impact but no practical implementation
Task Force Ontologies Version 0.1 20

NEPOMUK 20.03.2007
following. Note that Steve Pepper is one of the key evangelists of TopicMaps and one of the two editors of the XML Topic Maps standard.
• Jack Park and Adam Cheyer mapped Topic Maps to Semantic Desktopsfor Personal Information Management in [9]. “Just For Me: Topic Mapsand Ontologies”. Note that Jack Park was participating member of theXML Topic Maps Authoring Group and is an experienced Semantic Webresearcher. Adam Cheyer is program director of SRIs AI group.
• The Semex approach could have helped, but they do not publish theirontology [4]
• Jerome Euzenat proposed a top-level ontology for PIM in light of FOAF3 Although this is a small, seemingly unimportant footnote, it shows howoften capable people tried to address this problem.
• User Profile Ontology version 1[6], mentioned in [3] from http://oceanis.mm.di.uoa.gr/pened/?category=publications.
• Richard Saul Wurman found: geographical, alphabetically, by Time, byCategories, by Hierarchy. (Location, Alphabet, Time, Category, and Hi-erarchy, known as LATCH TODO: cite R. Wurman, D. Sume, and L.Leifer, Information Anxiety 2, Que, 2000.)
• Latif and Tjoa, 2006 [8] give an overview on a similar approach. Theymap their ontology against other top-level ontologies such as SUMO andDOLCE and use the LATCH approach from Richard Saul Wurman.
• Nejdl’s Beagle stuff.
They key factors that we found in most related work are identifying resourcesunambiguously and modelling the complicated specializations in specialized do-main ontologies while keeping the core clean. So integration of heterogenousdata wins over trying to make a world-embracing super ontology. The PIMOapproach, using the pimo:groundingOccurrence and the pimo:hasOtherRepresentationrelations together with blending data, instead of using owl:sameAs seems (fromour perspectice) the right choice.
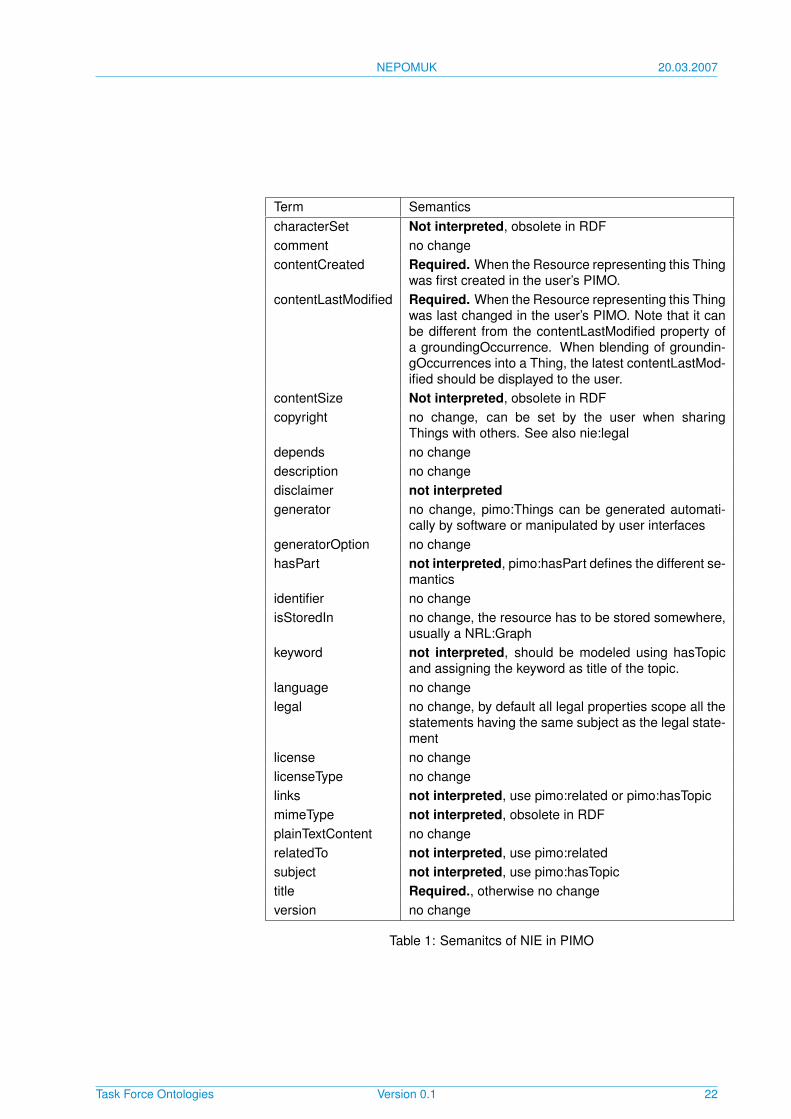
9.3 Using NIE elements in the PIMO
NIE defines several properties with nie:InformationElement as domain, as pimo:Thingis a subclass of nie:InformationElement, this can cause confusion.Based on the assumption that a Thing modeled in PIMO both is both describ-ing a concept from the real world but itself consists of triples stored in a com-puter system, the following semantics are derived and described in Table 1. In-formationElements imported into the PIMO using pimo:groundingOccurrenceor pimo:hasOtherRepresentation are interpreted using the semantics of normalNIE.None of the NIE properties in the domain of nie:InformationElement is re-quired, they are all optional properties. Applied individuals with class pimo:Thing,we have changed the interpretation slightly.The text “no change” means that the interpretation is unchanged from NIE,“not interpreted” means you should avoid using this property. You may noticethat some properties are not interpreted because they have DataObjects orStrings as range, where PIMO has properties modeling the same semanticsbut using other PIMO:Things as range, which is a preciser way of modellingbecause of the UNA. “Required” means that this property is required for allinstances of pimo:Thing and this can be validated using the rules from Section8.2.
3http://www.w3.org/2001/sw/Europe/200210/calendar/SyncLink.html
Task Force Ontologies Version 0.1 21
NEPOMUK 20.03.2007
Term SemanticscharacterSet Not interpreted, obsolete in RDFcomment no changecontentCreated Required. When the Resource representing this Thing
was first created in the user’s PIMO.contentLastModified Required. When the Resource representing this Thing
was last changed in the user’s PIMO. Note that it canbe different from the contentLastModified property ofa groundingOccurrence. When blending of groundin-gOccurrences into a Thing, the latest contentLastMod-ified should be displayed to the user.
contentSize Not interpreted, obsolete in RDFcopyright no change, can be set by the user when sharing
Things with others. See also nie:legaldepends no changedescription no changedisclaimer not interpretedgenerator no change, pimo:Things can be generated automati-
cally by software or manipulated by user interfacesgeneratorOption no changehasPart not interpreted, pimo:hasPart defines the different se-
manticsidentifier no changeisStoredIn no change, the resource has to be stored somewhere,
usually a NRL:Graphkeyword not interpreted, should be modeled using hasTopic
and assigning the keyword as title of the topic.language no changelegal no change, by default all legal properties scope all the
statements having the same subject as the legal state-ment
license no changelicenseType no changelinks not interpreted, use pimo:related or pimo:hasTopicmimeType not interpreted, obsolete in RDFplainTextContent no changerelatedTo not interpreted, use pimo:relatedsubject not interpreted, use pimo:hasTopictitle Required., otherwise no changeversion no change
Table 1: Semanitcs of NIE in PIMO
Task Force Ontologies Version 0.1 22

NEPOMUK 20.03.2007
9.4 Why is PIMO a refinement of the NIE Ontology?
Philosophically speaking, everything encountered in a computer system is anInformation Element, and once seen and understood by a user, the conceptsmentioned within are Things. Technically speaking, making Thing a subclassof Information Element reduces the workload for conceptualization: informa-tion element ontologies already model many properties and relations of possiblethings, when the user agrees with the conceptualizations in these ontologies, theconceptualizations become PIMO. Also, RDF resources (individuals) createdusing the class pimo:Thing are, technically speaking, Information Elements.The annotations nie:contentCreated, nie:title, nie:description are valuable de-scriptions also for pimo:Things.
9.5 Isn’t reification enough for a personal view?
The Semantic Web provides another possibility to express a personal view oninformation elements, namely using normal annotations to the existing ele-ments (by adding triples to them) and then reifying the triples and annotatingthem as “being expressed as personal view”. Using named graphs and NRLis conceptually the same to reification and could also be used for this. Thereasons not to use reification or Named Graphs as primary modelling conceptare both technical and political:
• Data expressed in PIMO should be long-lasting and not be influencedby changes of operating systems, applications or the movement of files.To ensure this, the primary URIs of things are generated in a separatednamespace, tied to the user.
• When Information Elements move, are deleted or are not accessible by theuser anymore, they can be found again based on the identifying propertiesannotated to the stable URIs minted for Things.
• Using annotations on existing URIs would make the decision for the “pri-mary” URI for a Thing ambiguous. The structure of Things impliesthat there is one primary representation, the Thing with its minted URI,pointing to all other representations using relations. This allows imple-mentations to quickly find the focus point (the Thing) from which allother information about it can be found. Although this is typically han-dled by inference engines, the current approach allows to find varioussources of information about a thing in the globally distributed SemanticWeb, where distributed inference is not available.
• Reification is often criticized as being complicated, basing the whole sys-tem on it would direct this critique in the wrong direction.
• From a philosophical point of view, each individual sees and perceives theworld through his or her own eyes and interprets it according to his orher own mental model.
9.6 Why not use owl:sameAs?
OWL’s sameAs is an equivalence relation (transitive, reflexive, symmetric)whereas groundingOccurrence is directed and inverse functional. To expressthat a Thing and an entity from a domain ontology are modelling the same con-cept of the real world, and users have agreed on that, use pimo:hasOtherRepresentation(or pimo:hasOtherConceptualization for classes).Once two things are connected to each other using sameAs, they are modellingthe same entitiy of the real world. As PIMO is subjective, pimo:groundingOccurrence
Task Force Ontologies Version 0.1 23

NEPOMUK 20.03.2007
expresses that from the point of view of the user, they are the same, but notnecessarily for other users. Using sameAs would create n! relations between nsame objects, a fully connected graph. Given an InformationElement as input,querying what Thing has this as a grounding occurrence returns in one step thecorrect single answer, using a simplest query possible. This cannot be done us-ing owl:sameAs, because the answers are possibly many InformationElementsfrom the model, the unique Thing being one of them, only distinguished by itsclass being a subclass of pimo:Thing. So the separation has the semantic rea-son that the view is directed from the user towards his InformationElements,and the technical reason that this allows an efficient realization in possibleimplementations.
9.7 Why isn’t skos:Concept used?
The interested reader may suggest to use skos:Concept instead of pimo:Thing.But then, all resources would have the same rdf:type, namely skos:Concept.Then all domain/range, subclass and subproperty features of RDF are notusable and existing ontologies (such as NRL or NIE) cannot be used to modelThings. This is visible when looking at the skos:narrowerInstantive property,which is a parallel approach to rdf:type. We have tried SKOS in an evaluationand implemented a prototype using it during the EPOS project, coming to thisconclusion.
A Open questions
A.1 Relation between PIMO:Thing and NIE:InformationElement
Background PIMO:Things are unique representations of concepts, such as aperson, a book, a product, a company. For these, often ontologies exist alreadyin NIE, for example nco:PersonContact models people and a bibtex ontology forNIE may be soon available. To identify and distinguish pimo:Thing, an instanceneeds to have all identifying properties of occurrences attached, so for examplea pimo:Event should get the NCAL ncal:uid as a property to match it and apimo:Person should have the nco:contactUID as property. This helps findingthem in the various databases available. So ncal:uid and nco:contactUID shouldbe possible properties for a pimo:Thing (or subclasses). Using a property fromNIE with domain nie:InformationElement on a pimo:Thing infers that the thingis a NIE:InformationElement. Also, the user may want to use the ontologiesdefined in NIE to annotate people and events, for example NIE defines a relationthat a person can attend a meeting, this does not necessarily be remodelledagain in PIMO.
Problem The properties defined in NIE should not be modelled again inPIMO. Sometimes properties from NIE should be usable on PIMO:Things.
Solution pimo:Thing rdfs:isSubClassOf nie:InformationElement This so-lution would allow us to reuse properties from NIE within PIMO without anyproblems. Also, as NIE properties are all optional, Things are not invalid be-cause they miss some properties. For specialized classes, it is possible to makethem subclasses of the specialized NIE classes (pimo:Person rdfs:subClassOfnco:PersonContact). Advantage: we reuse NIE completly for modelling inPIMO. Disadvantage: this would bind the PIMO classes with NIE.
Task Force Ontologies Version 0.1 24

NEPOMUK 20.03.2007
Solution nie:InformationElement rdfs:isSubClassOf pimo:Thing This wasa rather bad idea, that came up when we didn’t want the first solution. Thetrouble here is, that suddenly all InformationElements would be Things, evenif they are only extracted by DataWrapper, and then all data in the store issuddenly invalid because all InformationElements miss the required propertiesof pimo:Thing.
Solution: ? There has to be another way, any ideas?
A.2 Complex identifiers
For identifiers that consist of multiple keys, or that go along more than oneresource, we need some way to capture them.This is tricky, but probably needed.suggestion:
pimo:ComplexIdentifier a rdfs:Class.
pimo:ComplexIdentifierQueryBased a rdfs:Class;rdfs:subClassOf pimo:ComplexIdentifier.
pimo:complexIdentifierTriggerProperty a rdf:Property;rdfs:comment "The object property indicates that the subject Query based complex identifier should be triggered, when a resource has the property set. For the email example, this would be nco:hasEmailAddress".rdfs:domain pimo:ComplexIdentifierQueryBased;rdfs:range rdf:Property.
pimo:complexIdentifierQuery a rdf:Property;rdfs:comment "Defines a query with one parameter, ?x, that is to be filled in. The query selects other variables (?y, ?z, ?a, ?number, etc.) that have to be the same so that twoentities can be considered same. Example for e-mail: SELECT ?x ?mail WHERE {?x nco:hasEmailAddress ?e. ?e nco:emailAddress ?mail.}"rdfs:domain pimo:ComplexIdentifierQueryBased;rdfs:range rdf:Literal.
A.3 Equivalence
When using hasOtherRepresentation and hasOtherConceptualization we didassert equivalence (transitive, reflexive, symmetric). This sounds like it couldcause trouble. Equivalence relations cause many triples to be inferred, if Aand B are equivalent, Statements like (A p o) imply (B p o). Agreement byLeoSauermann, LudgerVanElst, MichaelSintek on 6.7.2007: we need transitiv-ity to benefit from multiple hasOtherRepresentation, to find any hasOtherRepthat is connected to a PIMO Thing. Reflexive/symmetric are open and notdecided as “must have”.
A.4 pimo:user or pimo:isDefinedBy
One of the main ideas of PIMO is to get all things (and their titles and types)of a user with the simplest query possible. We have to clearly decide how wemark which Things are part of a user’s PIMO and which not. One way isto connect things to the PIMO-model, using the pimo:isDefinedBy property.This is similar to rdfs:isDefinedBy (which is discouraged by NRL, but we don’thave to subproperty it). Or we use the property pimo:user, a subproperty ofnco:creator, this has the advantage that automatically a creator is set. Butthe disadvantage that the user is not exactly the creator, but more his system
Task Force Ontologies Version 0.1 25

NEPOMUK 20.03.2007
is. Next disadvantage is that this triple asks for trouble when inserting itand validation is on, because pimo:user has many restrictions (claudia:Claudiapimo:user claudia:Claudia) Both solves the problem, we should decide for one.Agreement by LeoSauermann, LudgerVanElst, MichaelSintek on 6.7.2007: weuse pimo:isDefinedBy and connect Things to the PIMO of the user, and theuser to his/her pimo.
A.5 hasOtherRepresentation, hasOtherConceptualization, hasOtherSlot
These could be subproperties of groudningOccurrence, rdfs:subClassOf andrdfs:subPropertyOf. But other ontologies not conformant to NRL would thencause trouble with our inference engine. So, what to do.
A.6 What classes and instances appear in a user interface?
Assumed that many classes and instances are stored in an available RDF datastore, what classes and instances should be shown to the user? Are all of themof interest? When applying filter rules, should the filter rules be excluding(not wanted classes are filtered out) or including (wanted classes are filteredin). Agreement by LeoSauermann, LudgerVanElst, MichaelSintek on 6.7.2007:This is what NRL views were made for, we can give a recommendation how todo this using NRL.
A.7 How do we relate to NAO?
The identification properties are also in NAO. NAO was started by using thecore properties of the old PIMO, what to do now? Suggestion Leo: we sub-class/subproperty from NAO, once NAO is in a usable state. We wait untilNAO is finished and update PIMO then.
A.8 Semantic Relations and inference, how to untie hasPart, Collections, and Topics.
One thing can both be a Topic of another thing (hasTopic) or part of it (has-Part). A project can be the topic of a document, and the document can be partof the project. The project can also be seen as a collection, namely a collectionof Things that are part of the project or have the project as topic. This wouldbe interesting to somehow represent in a way that would make use of transitiveclosures, for example when searching for “documents that have the topic nepo-muk” users may expect to find documents that have the topic “NRL” which isa part of Nepomuk. But actually, the topic of the NRL document is NRL, andit does not describe facts about Nepomuk. But all these generic terms are -generic - so using them for inference may open a can of worms. Perhaps weshould make hasPart transitive and see what happens. We then also shouldsay that: CONSTRUCT ?x pimo:hasTopic ?B WHERE ?x pimo:hasTopic ?A.?A pimo:partOf ?B.
Task Force Ontologies Version 0.1 26

NEPOMUK 20.03.2007
References
[1] D. Brickley and R.V. Guha. Rdf vocabulary description language 1.0: Rdfschema. w3c recommendation 10 february 2004. http://www.w3.org/TR/rdf-schema/.
[2] K. Votis C. Alexakos, B. Vassiliadis and S. Likothanassis. A MultilayerOntology Scheme for Integrated Searching in Distributed Hypermedia,volume Adaptive and Personalized Semantic Web of Studies in Compu-tational Intelligence. Springer, 2006.
[3] T. Catarci, A. Dix, A. Katifori, G. Lepouras, and A. Poggi. Task-centeredinformation management. In C. Thanos and F. Borri, editors, DELOSConference 2007 on Working Notes, pages 253–263, Tirrenia, Pisa, 13-14February 2007.
[4] Xin Dong and Alon Y. Halevy. A platform for personal information man-agement and integration. In Proc. of the CIDR Conference, pages 119–130,2005.
[5] Alistair Miles (edt). Simple knowledge organisation system (skos). http://www.w3.org/2004/02/skos/, Feb 2004.
[6] M. Golemati, A. Katifori, C. Vassilakis, G. Lepouras,and C. Halatsis. User profile ontology version 1.http://oceanis.mm.di.uoa.gr/pened/?category=publications, 2006.
[7] Harald Holz, Heiko Maus, Ansgar Bernardi, and Oleg Rostanin. FromLightweight, Proactive Information Delivery to Business Process-OrientedKnowledge Management. volume 0, pages 101–127, 2005.
[8] Khalid Latif and A Min Tjoa. Combining context ontology and land-marks for personal information management. In Proceedings of Interna-tional Conference on Computing and Informatics (ICOCI), Kuala Lumpur,Malaysia, June 2006.
[9] Jack Park and Adam Cheyer. Just for me: Topic maps and ontologies.In Lutz Maicher and Jack Park, editors, TMRA Charting the Topic MapsResearch and Applications Landscape, First International Workshop onTopic Maps Research and Applications, volume 3873 of Lecture Notes inComputer Science, pages 145–159. Springer, 2005.
[10] Holger Rath. The topic maps handbook detailed description of the stan-dard and practical guidelines for using it in knowledge management. em-polis white paper, empolis GmbH, 2003.
[11] Jean Rohmer. Lessons for the future of semantic desktops learnt from 10years of experience with the ideliance semantic networks manager. In Ste-fan Decker, Jack Park, Dennis Quan, and Leo Sauermann, editors, Proc.of Semantic Desktop Workshop at the ISWC, Galway, Ireland, November6, volume 175, November 2005.
[12] Leo Sauermann, Gunnar Aastrand Grimnes, Malte Kiesel, ChristiaanFluit, Heiko Maus, Dominik Heim, Danish Nadeem, Benjamin Horak, andAndreas Dengel. Semantic desktop 2.0: The gnowsis experience. In Proc.of the ISWC Conference, pages 887–900, Nov 2006.
[13] Graham Moore (edss). Steve Pepper. Xml topic maps (xtm) 1.0. Specifi-cation, TopicMaps.Org, 2001.
[14] Huiyong Xiao and Isabel F. Cruz. A multi-ontology approach for personalinformation management. In Stefan Decker, Jack Park, Dennis Quan,and Leo Sauermann, editors, Proc. of Semantic Desktop Workshop at theISWC, Galway, Ireland, November 6, volume 175, November 2005.
Task Force Ontologies Version 0.1 27

NEPOMUK 20.03.2007
B PIMO Specification
TODO: include the spec again, its broken at the moment
Task Force Ontologies Version 0.1 28


















