Performance Analysis of OVERFLOW on Sandia Compute Clusters Daniel W. Barnette Sandia National Labs...
28
Performance Analysis of OVERFLOW on Sandia Compute Clusters Daniel W. Barnette Sandia National Labs Albuquerque, New Mexico DOD HPCMO Users Group Conference June 2006 Denver, CO Sandia is a multiprogram laboratory operated by Sandia Corporation, a Lockheed Martin Company, for the United States Department of Energy’s National Nuclear Security Administration under contract DE-AC04-94AL85000.
-
Upload
harold-lindsey -
Category
Documents
-
view
215 -
download
0
Transcript of Performance Analysis of OVERFLOW on Sandia Compute Clusters Daniel W. Barnette Sandia National Labs...

Performance Analysisof OVERFLOW on Sandia Compute Clusters
Daniel W. BarnetteSandia National LabsAlbuquerque, New Mexico
DOD HPCMO Users Group ConferenceJune 2006Denver, CO
Sandia is a multiprogram laboratory operated by Sandia Corporation, a Lockheed Martin Company,for the United States Department of Energy’s National Nuclear Security Administration
under contract DE-AC04-94AL85000.

Introduction… DOD asked DOE to participate … thanks! Sandia has assembled a performance modeling
team I’m a newcomer to performance modeling, but
not to CFD Have been analyzing OVERFLOW for a few
months now Much more needs to be done (as always!) Came to this conference to learn from you!! Certainly can use constructive guidance…
So here goes….
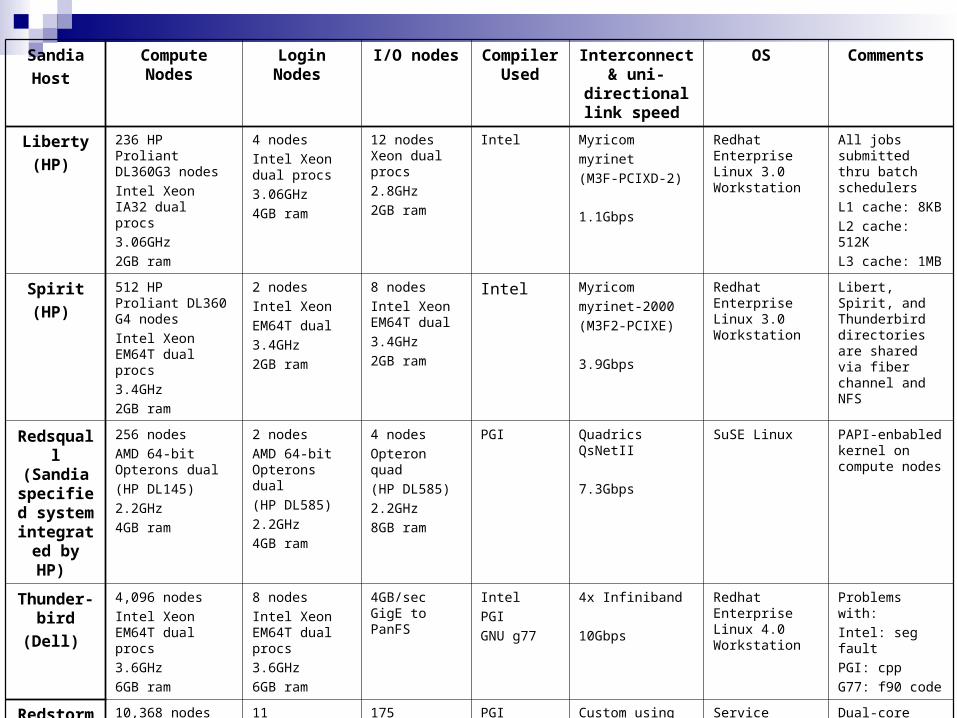
Sandia
Host
Compute Nodes
Login Nodes I/O nodes Compiler Used
Interconnect & uni-directional
link speed
OS Comments
Liberty
(HP)
236 HP Proliant DL360G3 nodes
Intel Xeon IA32 dual procs
3.06GHz
2GB ram
4 nodes
Intel Xeon dual procs
3.06GHz
4GB ram
12 nodes Xeon dual procs
2.8GHz
2GB ram
Intel Myricom
myrinet
(M3F-PCIXD-2)
1.1Gbps
Redhat Enterprise Linux 3.0 Workstation
All jobs submitted thru batch schedulers
L1 cache: 8KB
L2 cache: 512K
L3 cache: 1MB
Spirit
(HP)
512 HP Proliant DL360 G4 nodes
Intel Xeon EM64T dual procs
3.4GHz
2GB ram
2 nodes
Intel Xeon
EM64T dual
3.4GHz
2GB ram
8 nodes
Intel Xeon EM64T dual
3.4GHz
2GB ram
Intel Myricom
myrinet-2000
(M3F2-PCIXE)
3.9Gbps
Redhat Enterprise Linux 3.0 Workstation
Libert, Spirit, and Thunderbird directories are shared via fiber channel and NFS
Redsquall (Sandia
specified system
integrated by HP)
256 nodes
AMD 64-bit Opterons dual
(HP DL145)
2.2GHz
4GB ram
2 nodes
AMD 64-bit Opterons dual
(HP DL585)
2.2GHz
4GB ram
4 nodes
Opteron quad
(HP DL585)
2.2GHz
8GB ram
PGI Quadrics QsNetII
7.3Gbps
SuSE Linux PAPI-enbabled kernel on compute nodes
Thunder-bird
(Dell)
4,096 nodes
Intel Xeon EM64T dual procs
3.6GHz
6GB ram
8 nodes
Intel Xeon EM64T dual procs
3.6GHz
6GB ram
4GB/sec GigE to PanFS
Intel
PGI
GNU g77
4x Infiniband
10Gbps
Redhat Enterprise Linux 4.0 Workstation
Problems with:
Intel: seg fault
PGI: cpp
G77: f90 code
Redstorm
(Cray XT3)
10,368 nodes
AMD 64-bit Opteron procs
(1 proc/node)
2.0GHz
2-to-4 GB ram
11 nodes/side
AMD 64-bit Opteron procs
(1 proc/node)
2.0GHz
6GB ram
175 nodes/side
AMD 64-bit Opteron procs
(1 proc/node)
2.0GHz
6GB ram
PGI Custom using Cray SeaStar NICS;
3-D mesh
6 links/node, with torus in z-direction
9Gbps HyperTran’t
24Gbps/link-dir
Service nodes:
SuSE Linux
Compute Nodes:
Catamount Light-Weight Kernel (LWK)
Dual-core Opterons coming July 06
Has unclassified and classified sides;
L1 cache: 64KB
L2 cache: 1MB

Overflow CFD Code Mature compressible flow code Mostly written and maintained by Pieter Buning,
NASA LaRC Uses overset grid technology, a powerful
method for complex aerodynamic geometries Used heavily in DOD, DOE, NASA, Boeing Lots of flexibility on how to run the code Used to benchmark 5-sphere test case…
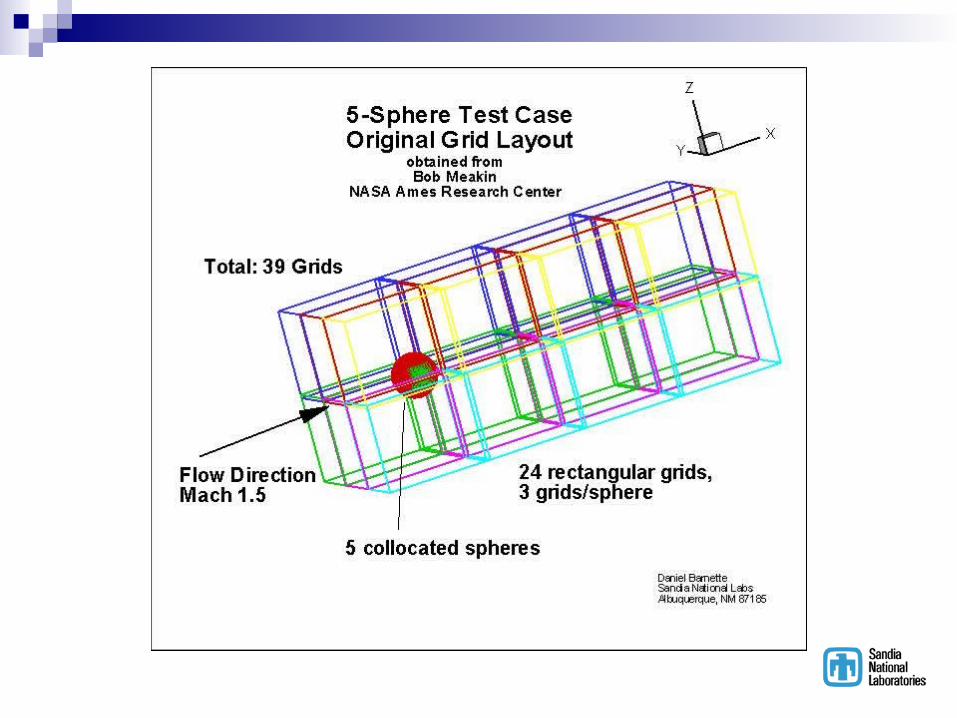
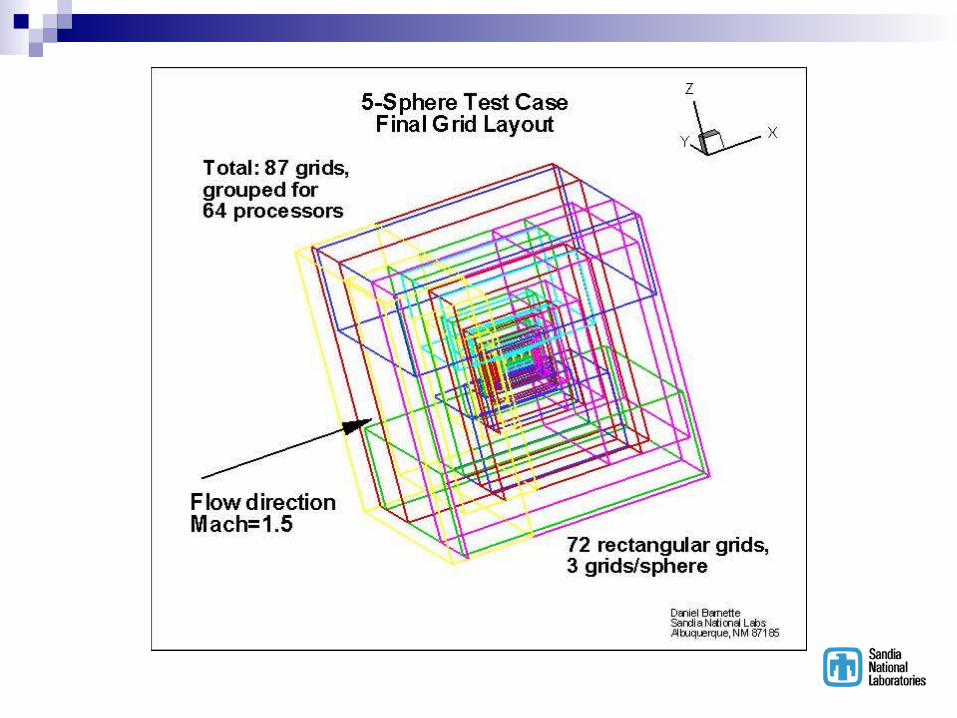
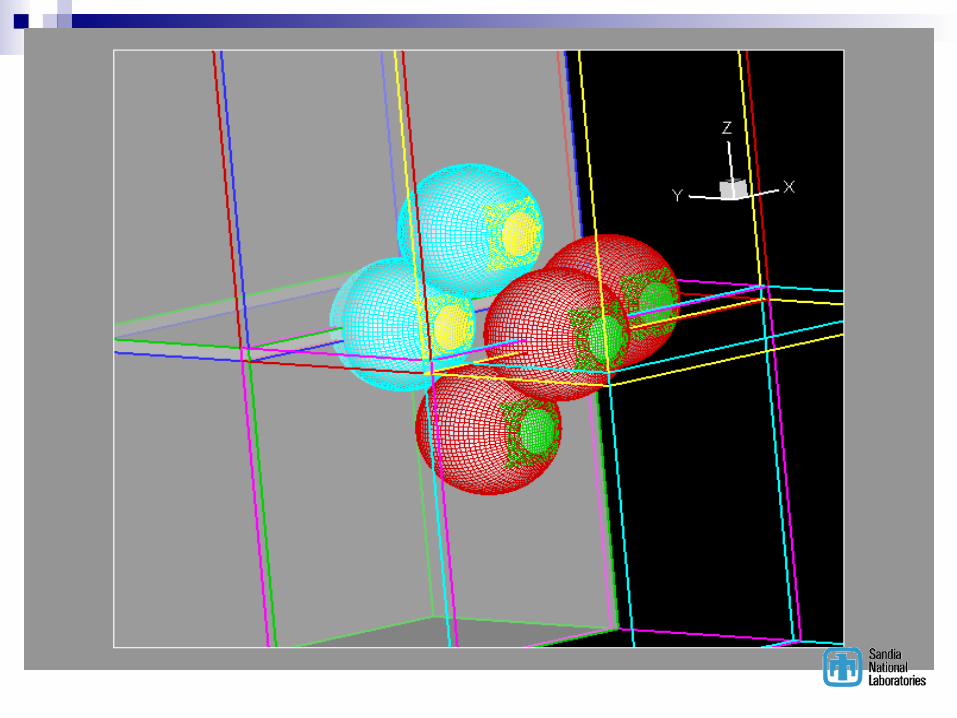
CFD Test Case5 Spheres Mach 1.5 Flow
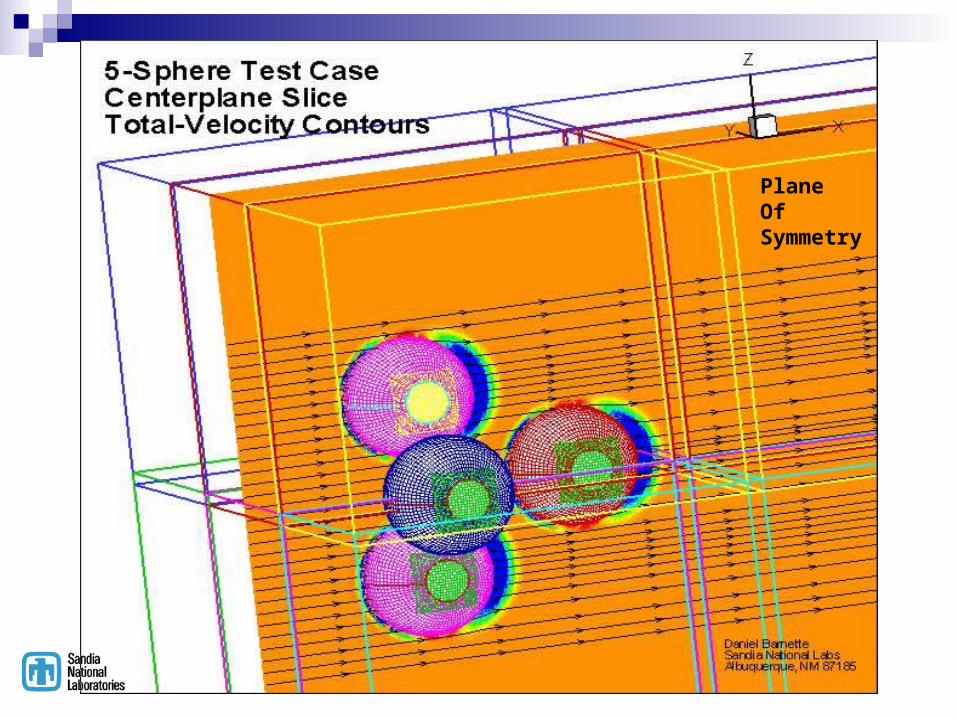
PlaneOfSymmetry
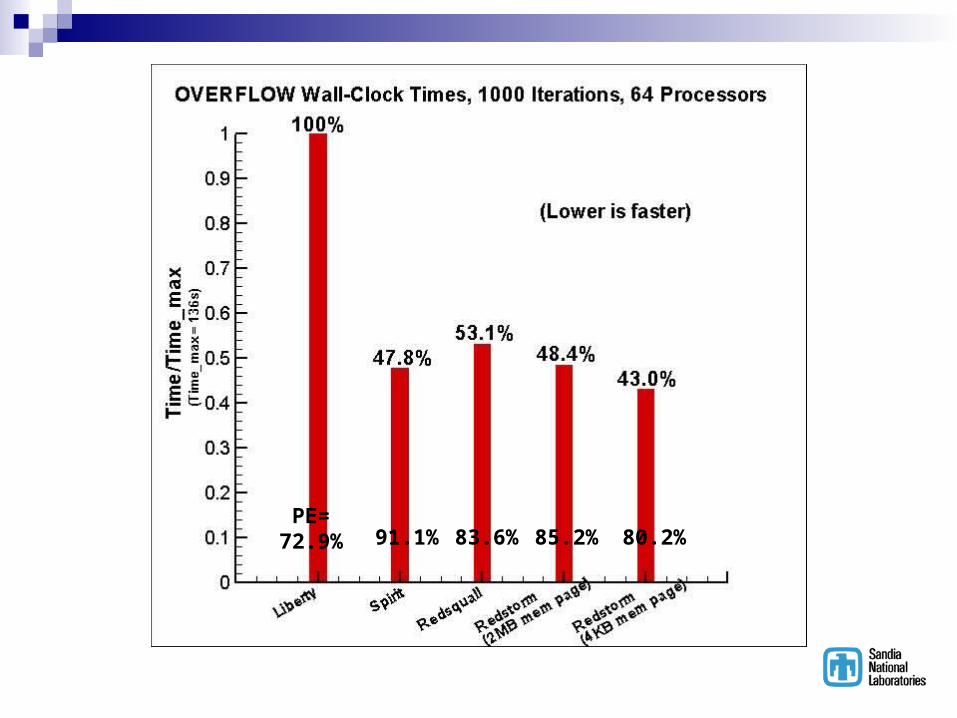
PE=72.9% 91.1% 83.6% 85.2% 80.2%

PerfMod Database Working with Sue Goudy and Ryan D. Scott (BYU summer
intern) to establish format Will store metadata + run characteristics + data for post-
processing Will interface with Python GUI (TBD) in an as-yet-
undetermined form Will provide search & retrieve functionality Sorely needed to help analyze large datasets from multiple
runs for multiple platforms Database will be used to impact
System cost/performance analyses Application performance analyses Determination of app-to-architecture mapping strategies Etc…..

Python GUI
To help with submitting large numbers of jobs for performance modeling analysis
Helps new users to get started running on Sandia’s clusters by utilizing point-and-click methods to compile/run/post-process
Helps to document runs for archive purposes by keeping track of input/output data
Will interface with R. Scott’s database
PerfMod Gui (work in progress)

Future Work Timing studies for fixed-size problem over range
of processors Run on newest Redstorm (dual-core, faster
NICs) Performance Comparison of OVERFLOW with
PREMO, a Sandia CFD code + other codes MPI vs. MPI/SMP - Does it make a difference?-------------------------------- Investigate how the cache is being utilized Run with minimized ratio “t_comm/t_comp” and
compare with non-optimal ratio (a SOFTWARE approach to greater performance??)
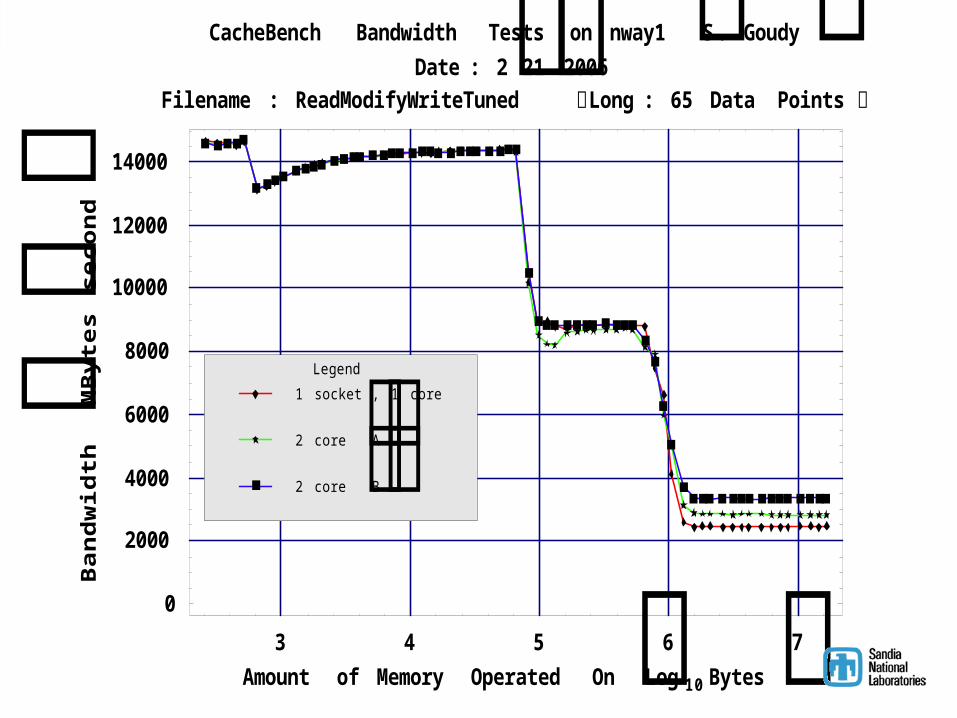
3 4 5 6 7Amount of Memory Operated OnLog 10Bytes0
2000
4000
6000
8000
10000
12000
14000
htdiwdnaB
setyBM
dnoces Filename : ReadModifyWriteTuned Long : 65 Data Points
CacheBench Bandwidth Tests on nway1S. GoudyDate : 2212006
2 coreB2 coreA1 socket , 1 coreLegend

Future Work Timing studies for fixed-size problem over range of
processors Run on newest Redstorm (dual-core, faster NICs) Performance Comparison of OVERFLOW with PREMO,
a Sandia CFD code + other codes MPI vs. MPI/SMP - Does it make a difference?-------------------------------- Investigate how the cache is being utilized Run with minimized ratio “t_comm/t_comp” and
compare with non-optimal ratio (a SOFTWARE approach to greater performance??)

Current OVERFLOW Strategy for Parallelized Overset Grids
Grids are broken up and then grouped to get large # of points on each processor (load-balanced)
Grid-to-grid communication packet sizes are not considered (speed-up is not optimized)
Question needs to be asked: On any one processor, does minimizing overset grid
surfaces (i.e., minimizing grid-to-grid communications), but maximizing overset grid volumes (i.e., maximizing the compute time), have a significant effect on run time?

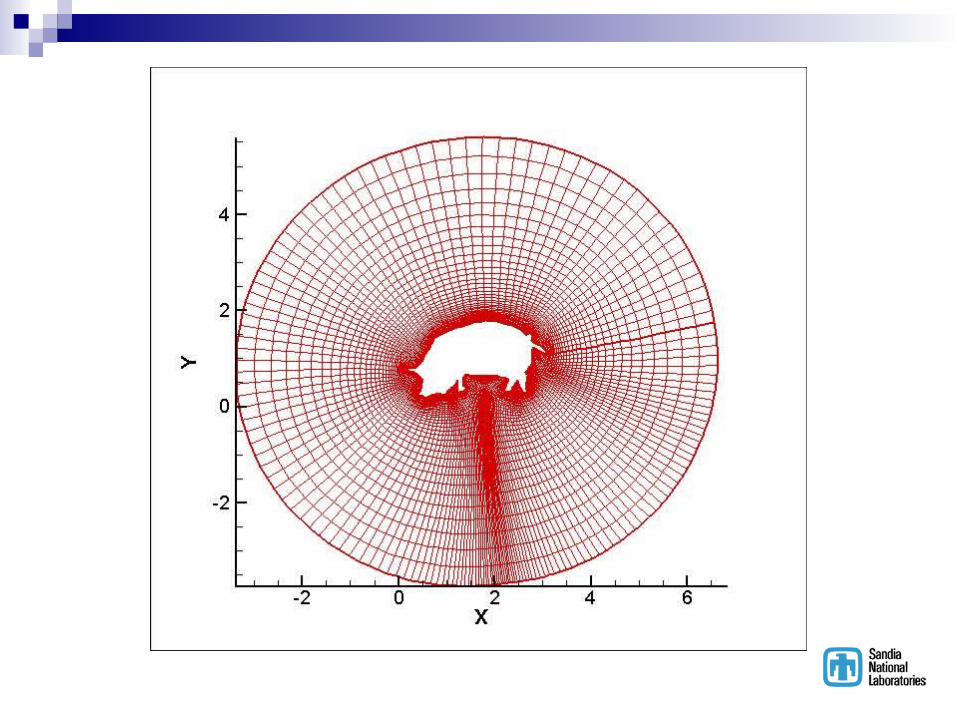
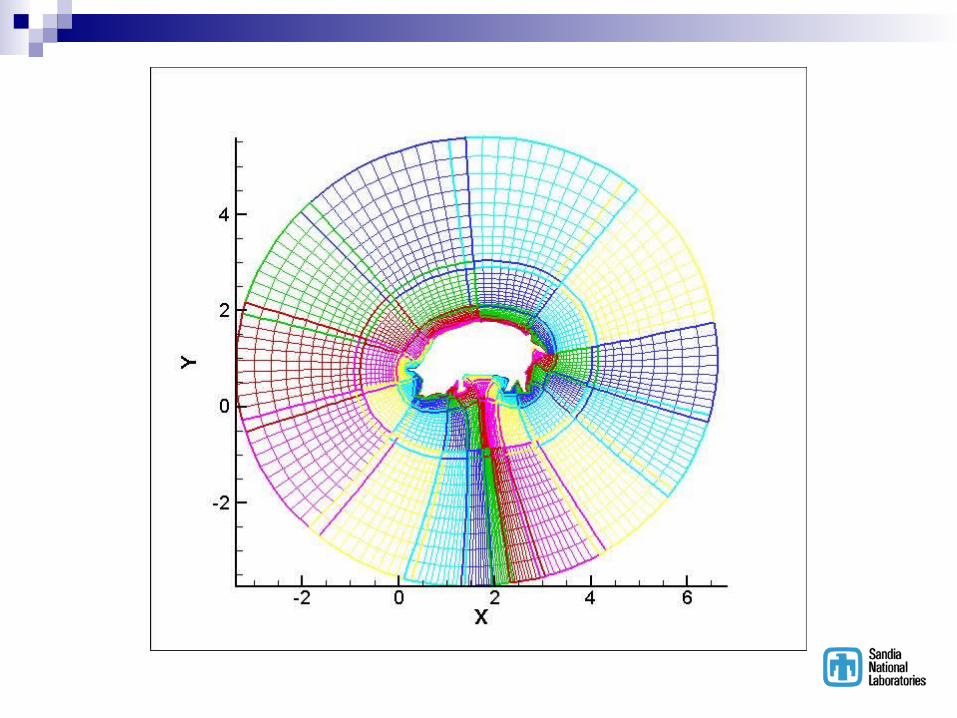
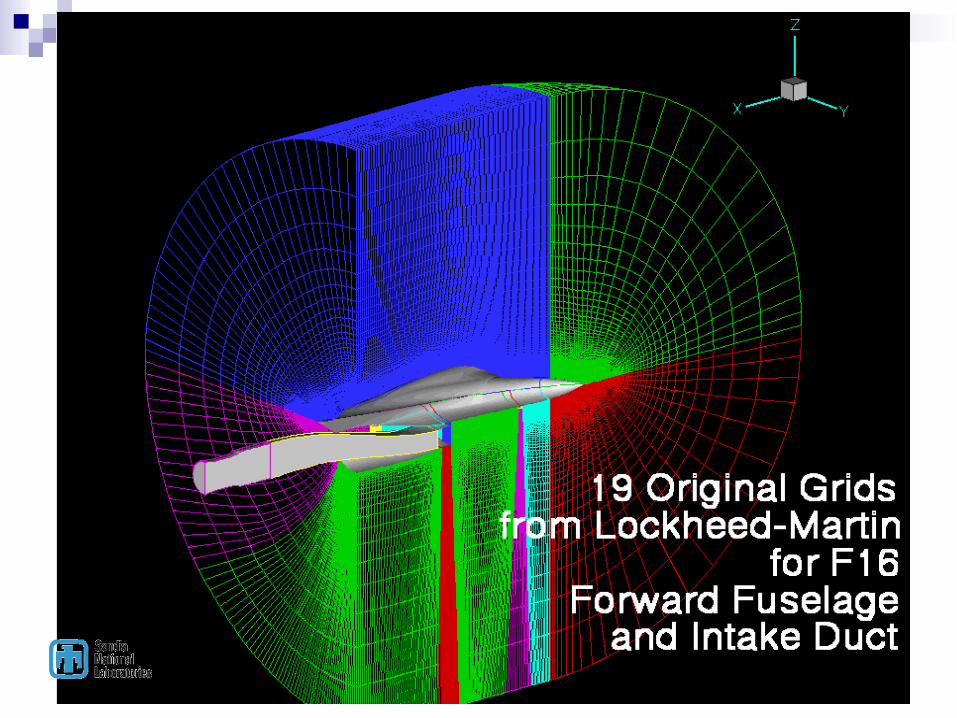
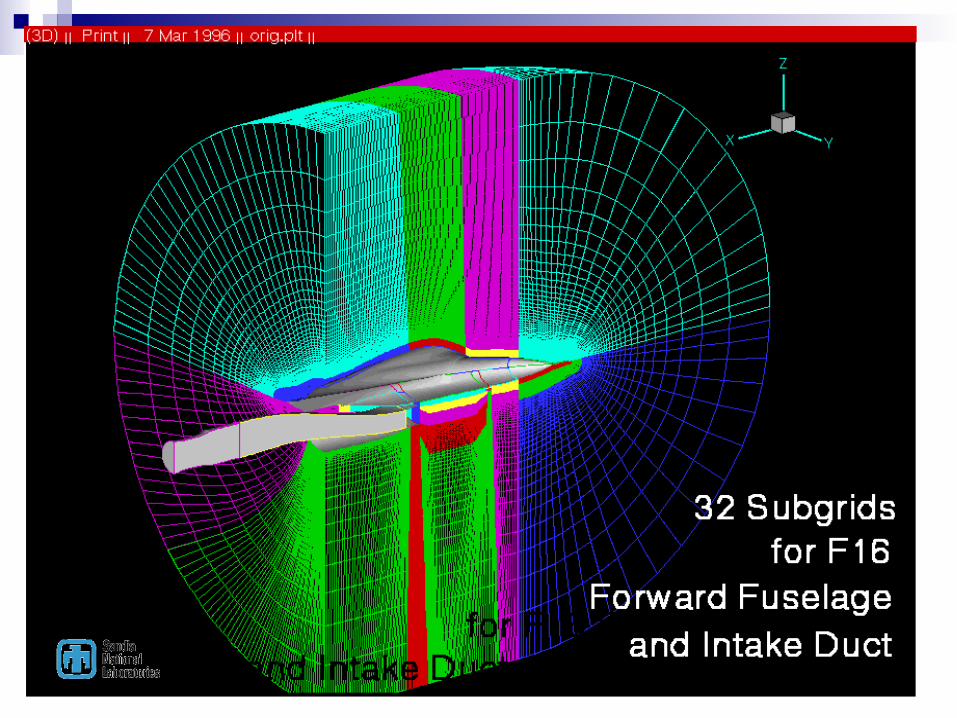
BREAKUP, a pre-processor to OVERFLOW Code written 10 years ago Prepares overset grids for parallel computers
Computes avg number of pts/processor Generates near-uniform distribution of grid
points/processor for ‘sub-grids’ Constructs appropriate connectivity tables Sequences all grid orientation possibilities, choosing
the orientation that minimizes the ratio “t_comm/t_comp”
Examples …….
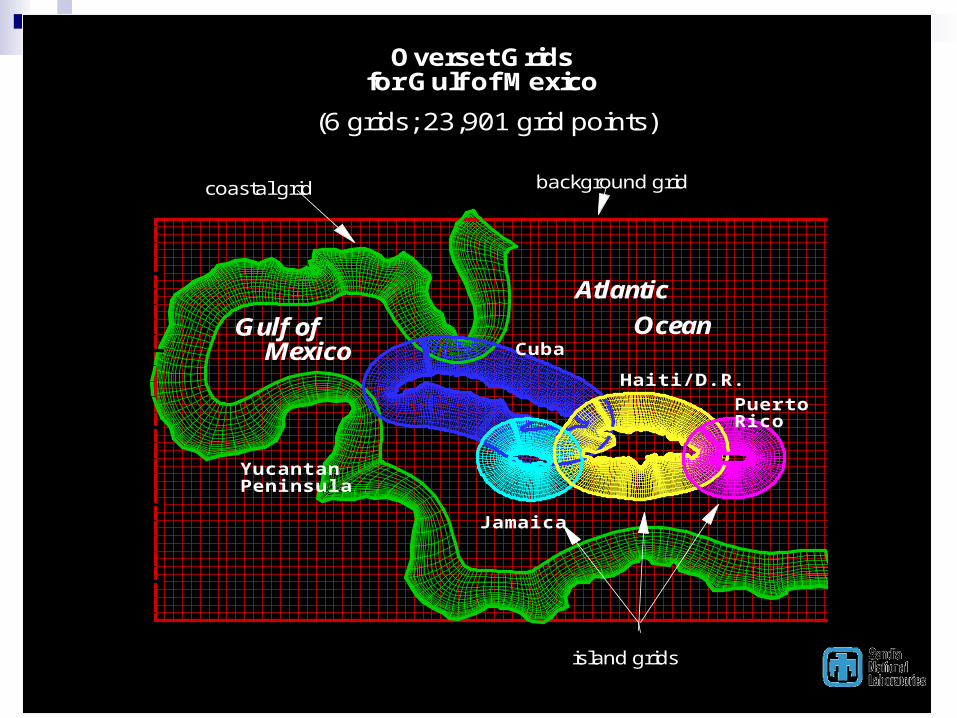
-1 0 1 2X
-1
-0.5
0
0.5
1
1.5
2
Y
Atlantic
Ocean
PuertoRico
Haiti/D.R.
Cuba
Jamaica
YucantanPeninsula
Gulf ofMexico
background gridcoastal grid
island grids
Overset Gridsfor Gulf of Mexico
(6 grids; 23,901 grid points)
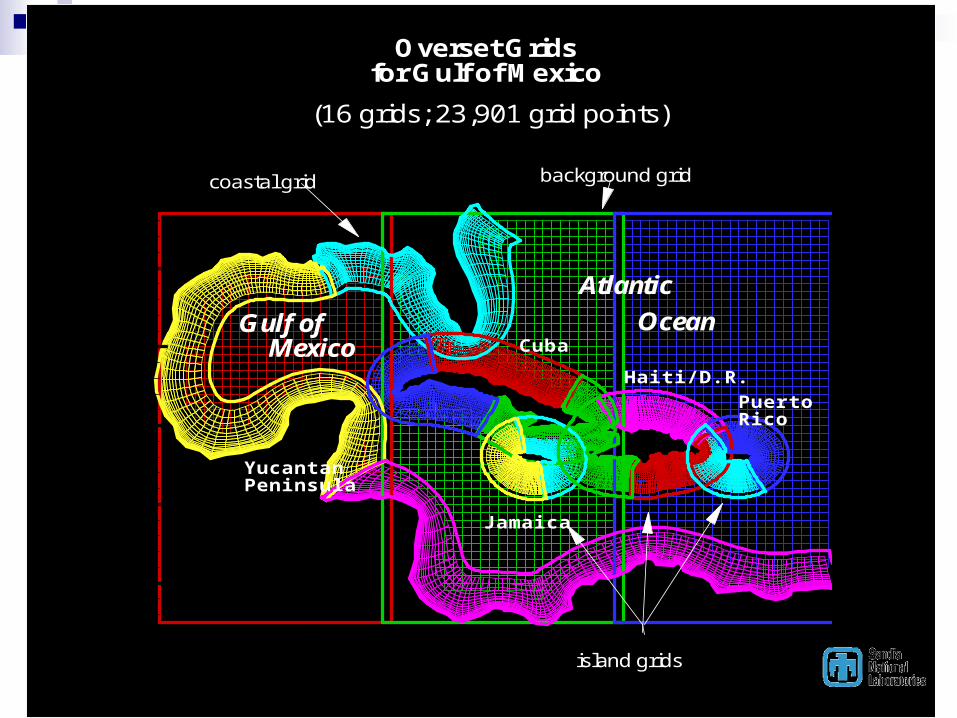
-1 0 1 2X
-1
-0.5
0
0.5
1
1.5
2Y
Atlantic
Ocean
PuertoRico
Haiti/D.R.
Cuba
Jamaica
YucantanPeninsula
Gulf ofMexico
background gridcoastal grid
island grids
Overset Gridsfor Gulf of Mexico
(16 grids; 23,901 grid points)
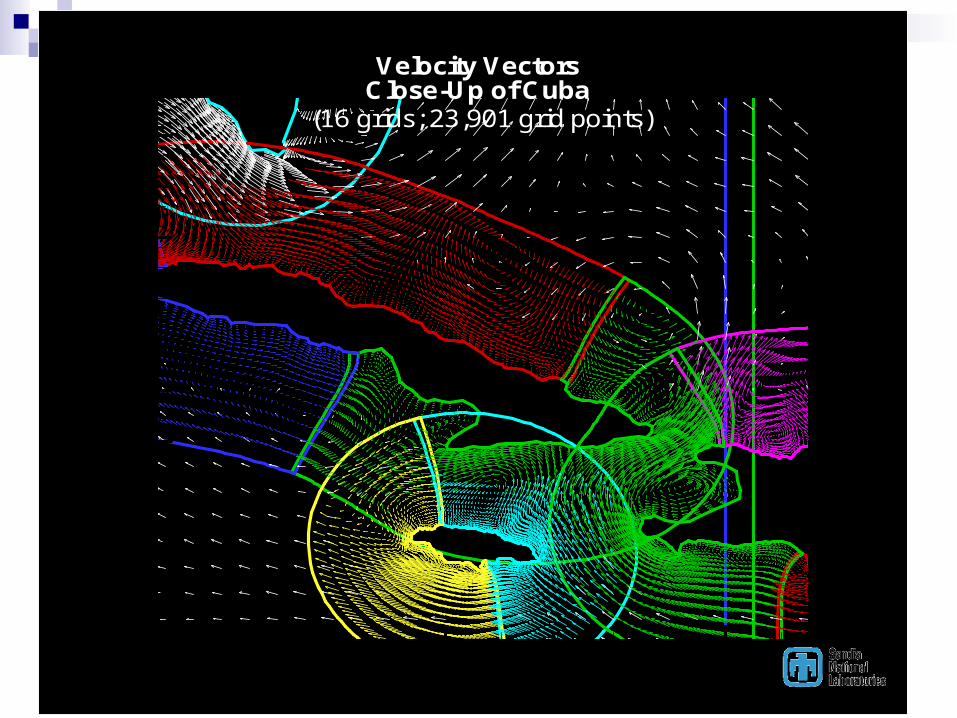
0 0.5 1X
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
YVelocity Vectors
Close-Up of Cuba(16 grids; 23,901 grid points)