
Visual Dialog Presentation - University of Torontofidler/slides/2017/CSC2539/Sayyed_slides.pdfbot...
38
Dialog Systems and Visual Dialog Sayyed Nezhadi CSC2539 Feb 2017
Transcript of Visual Dialog Presentation - University of Torontofidler/slides/2017/CSC2539/Sayyed_slides.pdfbot...

DialogSystemsand
VisualDialogSayyedNezhadi
CSC2539Feb2017

WhatisaDialogSystem?• Adialogsystemisamachine(computersystem)withthegoalofconversingwithhumanwithalogicalstructure.
• Thecommunicationwithmachinecanbedonethroughtext,speech,gesture andsoon.
• ANaturalDialogSystemisaformofdialogsystemthattriestoimproveusabilityandusersatisfactionbyimitatinghumanbehaviour.(Berg,2014)
• Turingtest:amachine'sabilityto exhibitintelligentbehaviour equivalentto,orindistinguishablefrom,thatofahuman.
DialogSystem(Chatbot)
Voice
Text

TypesofDialogSystem• Goal-orientedagents: itneedstounderstandtheuserinputandcompletearelatedtaskwithacleargoalwithinalimitednumberofdialogturns.
• Finite-State:Restaurantreservation,airlinebooking,…
• ActiveOntalogy/FrameBased:Personalassistsant,SIRI,Alexa,GoogleNow
• Chatbots:generalconversationwithawidescope
• Chit-chatting• Entertainment• Examples:ELISA,ALICE,APRRY,…
Goal-orientedAgent
KnowledgeBase
ExternalSystems
APICalls

Finite-StateDialog• Aseriesofquestionstobeansweredbyuser
• Fullcontroloftheconversationbythesystem
• Ignoringanyunrelatedanswers
• Simpletobuildandgoodforsimpletasks
• Onlyoneinformationatatime
• Verypracticalbutnotanaturaldialog
From:DanJurafsky slides

ShowmeallChinese
restaurantsinToronto.
ActiveOntology/FrameBased• Morenaturalconversationwithmixed-initiative(Conversationinitiativeshiftsbetweentheuserandthesystem)
• Usercanaskmultiplequestionsorgivemultipleinformationinonesentence
• UsingFrameandSlots:onceallmandatoryslotsinaframearefilled,itwillgeneratequerytoaknowledgebaseorexternalsystems.
• UsingNaturalLanguageUnderstandingtoextractslotsfromsentences(MLcanbeused).
Iwanttobookaflight
fromTorontotoLondon
onTuesdayMorning
LIST
LISTTYPE
CUISINE
LOCATION
BOOKING TYPE
FROM TO
DATE TIME
Sometextsfrom:DanJurafsky slides

ActiveOntology/FrameBased- continued
Voice Synthesis
Voice Synthesis
VoiceRecognition
DialogManagement
ActionSelection
LanguageUnderstanding
SessionContext
KnowledgeBase
Complete?VoiceInput
ClarifyingQuestion
BestOutcome
TextInput
Yes
No
SemanticInterpretation
MissingSlots
InferredUserInput
Basedonafigure fromJeromeBellegarda

Example:AmazonAlexa
AmazonEcho
AmazonAlexaservice
Voice
Utterances
CustomSkillService
AmazonDeveloperPortal
AmazonEchoAppMarket
RegisterSkill
SampleUtterances
IntentSchema
Skills
SlotsandSlotTypes
DB
ExternalSystems

Example:AmazonAlexa• Skills arevoiceenabledapps• ForeveryIntent wedefineasmanyaspossiblesampleutterances
• Sampleutterancescanhaveslots inthem
• Slotsarecategorizedbyslottypes
• Therearebuilt-inintentstostart orstop askilloraskforhelp.
SlotType“FAACODES”:AAC,AAF,AAHAAI,…
IntentSchema:{“intent”:“airportInfoIntent”,”slots”:[{“name”:“AIRPORTCODE”,“type”:“FAACODES”
}]}
SampleUtterances:airportInfoIntent {AIRPORTCODE}airportInfoIntent airportinto{AIRPORTCODE}airportInfoIntent flightdelay{AIRPORTCODE}airportInfoIntent info{AIRPORTCODE}airportInfoIntent flightstatus{AIRPORTCODE}airportInfoIntent airport{AIRPORTCODE}airportInfoIntent flightinfo{AIRPORTCODE}…

GeneralChatbotsRule-based:• Basedonpatternmatching(AIML,ChatScript,Regex,…)
• Usingmentalmodels• Threedifferentmemory:
• Utterance• Session• Global
Corpus-based:• Largecorpusdata• Deepneuralnetworks• Informationretrieval(mine
conversationsandretrievesimilarresponses)
<pattern>HELLO</pattern><random><li>Howdoyoudo.Pleasestateyourproblem..</li><li>Hi.Whatseemstobeyourproblem?.</li></random>
SamplePatterns(ELIZA)
<pattern>YOUARE*</pattern><random><li>WhatmakesyouthinkIam<star/>?.</li><li>DoesitpleaseyoutobelieveIam<star/>?.</li><li>Doyousometimeswishyouwere<star/>?.</li><li>Perhapsyouwould liketobe<star/>..</li></random>
Sometextsfrom:DanJurafsky slides

ANeuralConversationModel(O.Vinyals,Q.V.Le2015)• Sequencetosequence(Seq2seq)mappingusingrecurrentneuralnetworks(readstheinputsequenceonetokenatatime,andpredictstheoutputsequence,alsoonetokenatatime)
• Duringtraining,thetrueoutputsequenceisgiventothemodel
• Themodelistrainedtomaximizethecrossentropyofthecorrectsequencegivenitscontext
• Duringinference,thetrueoutputsequenceisnotobserved,simplyfeedthepredictedoutputtokenasinputtopredictthenextoutput (“greedy”inference)orusebeamsearch,andfeedseveralcandidatesattheprevioussteptothenextstep.Selectionbasedontheprobabilityofthesequence

ANeuralConversationModel– sampleoutput
Describeyourproblem:IforgotmypasswordMachine:hi,thisis<NAME>fromhelpdeskconnect,whatcani helpyouwithtoday?Human:hi,i forgotmypasswordMachine: okgreatHuman: canyoutellmehowi canrecoverit?Machine: i ’ll needtoverifywhoitisatthatmachineMachine: canwedoahangoutMachine: ?
Human:yesMachine: <anonymizedhangoutinstructionsandverifications>Human:cool,i amgoodnowMachine:how’sthislookinggood?Machine:i ’ll goaheadandclosethischat.Machine: takecare.:)Human:byeMachine: bye
• TrainedonITHelpdeskTroubleshootingdataset(Training:30Mtokens,Validation:3Mtokens)
• TrainedasinglelayerLSTMwith1024memorycellsusingstochasticgradientdescentwithgradientclipping.Thevocabularyconsistsofthemostcommon20Kwords,whichincludesspecialtokensindicatingturntakingandactor.

IsNeuralModelGood?J

End-To-EndDialogSystemsUsingGenerativeHierarchicalNeuralNetworkModels(I.V.Serban et.al.2016)
• ThreeRNNmodules• EncoderRNN(encodingeachsub-sequenceintoavector)
• ContextRNN(encodesallprevioussub-sequencesintoavector)
• DecoderRNN(generatesthenextsub-sequence) * The randomness injected by the variable z corresponds to higher-level
decisions, like topic or sentiment of the sentence.
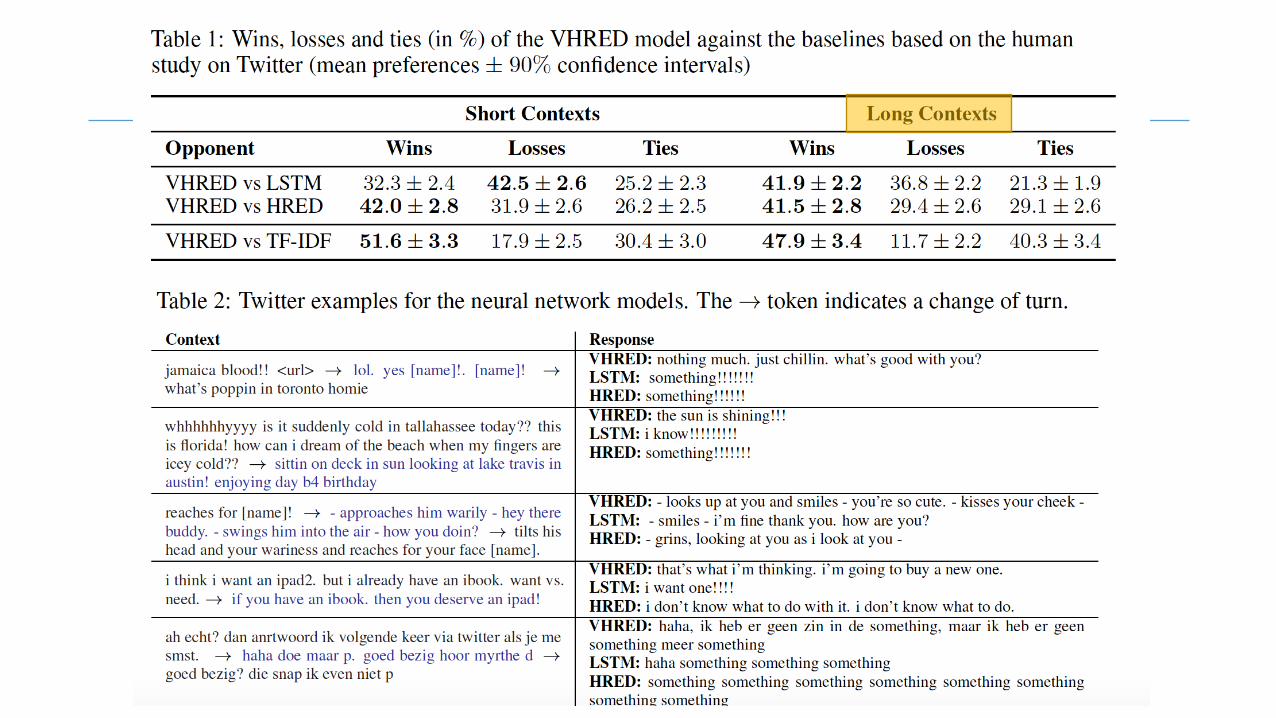

End-to-EndGoal-OrientedDialog(A.Bordes et.al2017)• Theworkhorseoftraditionaldialogsystemsisslot-filling• End-to-enddialogsystems,usuallybasedonneuralnetworks,shownpromisingperformanceinnongoal-orientedchit-chatsettings,wheretheyweretrainedtopredictthenextutteranceinsocialmediaandforumthreads
• Conductinggoal-orienteddialogrequiresskillsthatgobeyondlanguagemodeling,e.g.,askingquestionstoclearlydefineauserrequest,queryingKnowledgeBases(KBs),interpretingresultsfromqueries todisplayoptionstousersorcompletingatransaction
• Thepapershows:end-to-enddialogsystembasedonMemoryNetworkscanreachpromising,yetimperfect,performanceandlearntoperformnon-trivialoperations

End-to-EndGoal-OrientedDialog
Goal-orienteddialogtasks:• Auser(ingreen)chatswithabot(inblue)tobookatableatarestaurant.ModelsmustpredictbotutterancesandAPIcalls(indarkred).Task1teststhecapacityofinterpretingarequestandaskingtherightquestionstoissueanAPIcall.
• Task2checkstheabilitytomodifyanAPIcall.
• Task3and4testthecapacityofusingoutputsfromanAPIcall(inlightred)toproposeoptions(sortedbyrating)andtoprovideextra-information.
• Task5combineseverything.

End-to-endMemoryNetwork(S.Sukhabaatar 2015)
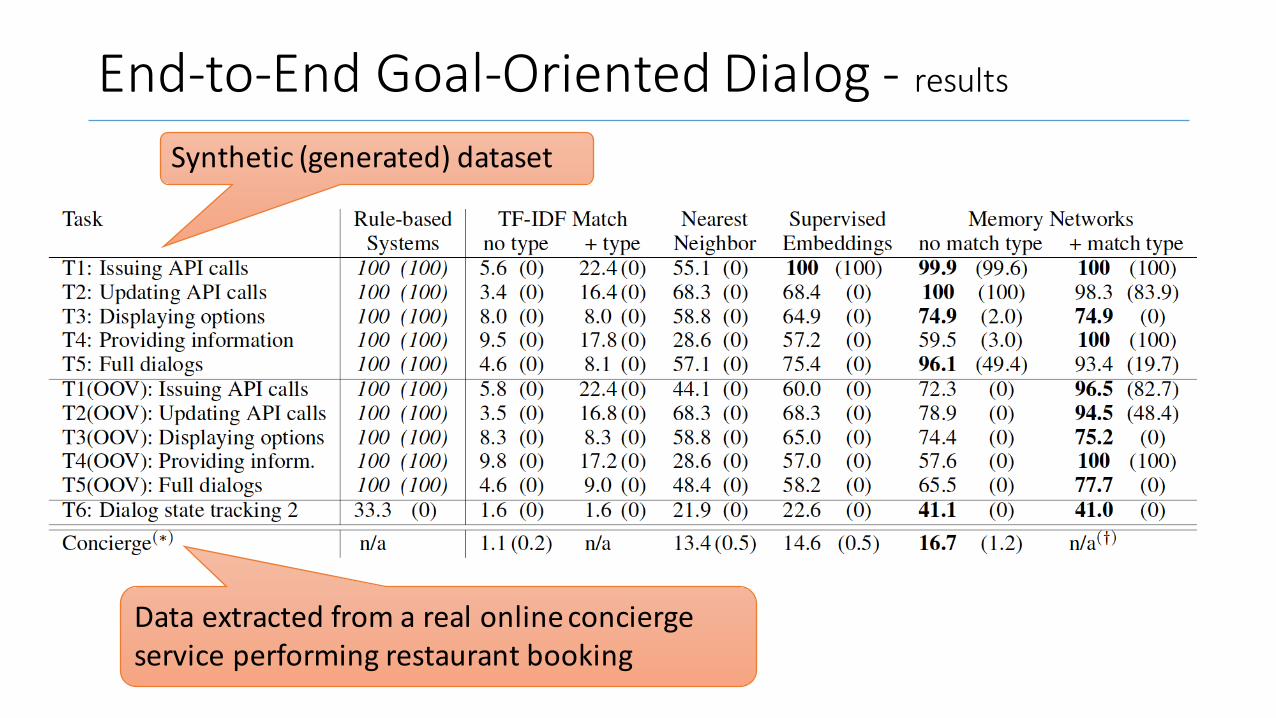
End-to-EndGoal-OrientedDialog- results
Dataextractedfromarealonlineconciergeserviceperformingrestaurantbooking
Synthetic(generated)dataset

VisualDialog(A.Daset.al.2016)ComputerVisionandArtificialIntelligenceTrends:• Imageclassification• Scenerecognition• Objectdetection• Learningtoplayvideogames• ImageandvideoQA
What’sNext?• VisualDialog:Abilitytoholdameaningfuldialogwithhumansinnaturallanguageaboutvisualcontent

VisualDialog– PotentialApplications• AidingvisuallyimpairedusersinunderstandingtheirsurroundingsorsocialmediacontentAI:‘JohnjustuploadedapicturefromhisvacationinHawaii’,Human:‘Great,isheatthebeach?’,AI:‘No,onamountain’
• AidinganalystsinmakingdecisionsbasedonlargequantitiesofsurveillancedataHuman:‘Didanyoneenterthisroomlastweek?’,AI:‘Yes,27instancesloggedoncamera’,Human:‘Wereanyofthemcarryingablackbag?’
• InteractingwithanAIassistantHuman:‘Alexa– canyouseethebabyinthebabymonitor?’,AI:‘Yes,Ican’,Human:‘Ishesleepingorplaying?’
• Roboticsapplications(e.g.searchandrescuemission)Human:‘Istheresmokeinanyroomaroundyou?’,AI:‘Yes,inoneroom’,Human:‘Gothereandlookforpeople’

VisualDialogvs.DialogSystem• VisualDialogTask (visualanalogueoftheTuringTest): givenanimageI,ahistoryofadialogconsistingofasequenceofquestion-answerpairs,andanaturallanguagefollow-upquestion,thetaskforthemachineistoanswerthequestioninfree-formnaturallanguage.
• VisualDialogismorespecificthanageneralchatbot becausethedialogisaboutaspecificimage.
• VisualDialogisnot gearedtowardaspecificgoal(similartogoal-drivendialogsystems).Thereforeslot-fillingmethodswon’twork.

VisualDialogvs.VQA
SessionVariables

VisualDialogDataset– DataCollection• Gooddataforthistaskshouldincludedialogsthathave:
• Temporalcontinuity• Groundingintheimage• Mimicnatural‘conversational’exchanges
• CollectedvisualdialogdataonimagesfromtheCommonObjectsinContext(COCO)dataset,whichcontainsmultipleobjectsineverydayscenes.
• Freeform,open-ended naturallanguagequestionscollectedviatwoworkers chattingonAmazonMechanicalTurk(AMT)real-time
• The‘questioner’seesonlyasinglelineoftextdescribinganimage(captionfromCOCO);theimageremainshiddentothequestioner.
• Theirtaskistoaskquestionsaboutthishiddenimagesoasto‘imaginethescenebetter’
• The‘answerer’seestheimageandthecaption.Theirtaskistoanswerthequestionsaskedbytheirchatpartner.

VisualDialogDataset– DataCollection

VisualDialogDataset– Analysis• One dialog(10 question-answerpairs)on68k imagesfromCOCO(58k trainand10k val ),oratotalof680,000 QApairs
• Morenatural conversationcomparingtootherimageQAdatasetsbecausethequestionerdoesn’tseetheimage(novisualprimingbias)
• Highermean-lengthofanswers(3.1words)andlessbinaryanswers(e.g.‘Yes’,‘No’)
• Coreference indialog: 38%ofquestions,22%ofanswers,andnearlyall(99%)dialogscontainatleastonepronoun
• TemporalContinuityinDialogTopics: basedonhumanevaluationonsmaples,across10rounds,VisDial questionhave4:55+- 0:17topicsonaverage,confirmingthatthesearenotindependentquestions

VisualDialogDataset– Analysis
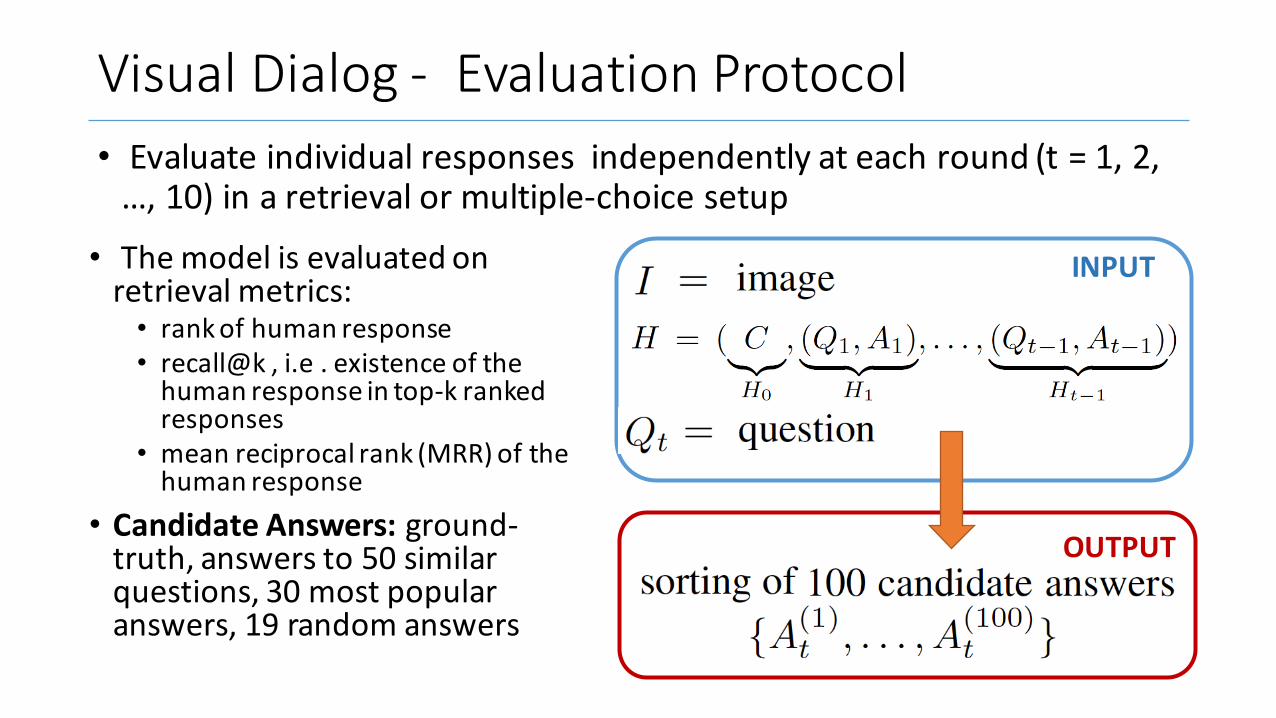
VisualDialog- EvaluationProtocol• Evaluateindividualresponsesindependentlyateachround(t=1,2,…,10)inaretrievalormultiple-choicesetup
INPUT
OUTPUT
• Themodelisevaluatedonretrievalmetrics:
• rankofhumanresponse• recall@k ,i.e .existenceofthehumanresponseintop-krankedresponses
• meanreciprocalrank(MRR)ofthehumanresponse
• CandidateAnswers:ground-truth,answersto50similarquestions,30mostpopularanswers,19randomanswers

NeuralVisualDialogModels• Experimentedwiththeencoder-decodercombinations
• Encoders:convertinputs(I,H,Qt)intoajointrepresentation• Inallcases,werepresentIviathel2-normalizedactivationsfromthepenultimatelayerofVGG-16
• ForeachencoderE,weexperimentwithallpossibleablatedversions:E(Qt),E(Qt,I),E(Qt,H),E(Qt,I,H)
• Decoders:rank candidateanswers based on the jointrepresentationfromencoders
• Generative (LSTM)and Discriminative (Softmax)

VisualDialog- Encoders• LateFusion(LF)Encoder:
• TreatHasalongstringwiththeentirehistory(H0,…,Ht-1)concatenated.• Qt andHareseparatelyencodedwith2differentLSTMs• individualrepresentationsofparticipatinginputs(I,H,Qt)areconcatenatedandlinearlytransformedtoadesiredsizeofjointrepresentation.
• HierarchicalRecurrentEncoder(HRE):• Similararchitectureas‘HierarchicalLatentVariableEncoder-DecoderModel’
• MemoryNetwork(MN)Encoder:• EncodeQt withanLSTMtogeta512-dvector• encodeeachpreviousroundofhistory(H0,…,Ht-1)withanotherLSTMtogetatx512matrix.
• Computeinnerproductofquestionvectorwitheachhistoryvectortogetscoresoverpreviousrounds,whicharefedtoasoftmax togetattention-over-historyprobabilities.

VisualDialog– LateFusionEncoder
Afully-connectedlayerandtanh nonlinearity

VisualDialog– HierarchicalRecurrentEncoder
EachQA-pairindialoghistoryisindependentlyencodedbyanotherLSTMwithsharedweights
Theimage-questionrepresentation,computedforeveryroundfrom1throught,isconcatenatedwithhistoryrepresentationfromthepreviousroundandconstitutesasequenceofquestion-historyvectors

VisualDialog– MemoryNetwork Afully-connectedlayerandtanhnonlinearity
computeattentionoverthetfactsbyinnerproduct

VisualDialog- Decoders• Generative(LSTM):
• EncodedvectorissetastheinitialstateoftheLSTMlanguagemodel• Maximizesthelog-likelihoodofthegroundtruthanswersequencegivenitscorrespondingencodedrepresentation(trainedend-to-end)
• Usesthemodel’sloglikelihood scoresandrankcandidateanswers
• Discriminative(softmax):• ComputesdotproductsimilaritybetweentheinputencodingandanLSTMencodingofeachoftheansweroptions
• Thedotproductsarefedintoasoftmax tocomputetheposteriorprobabilityovertheoptions
• Maximizesthelogliklihoodofthecorrectoptionsandoptionsaresimplyrankedbasedontheirposteriorprobabilities.
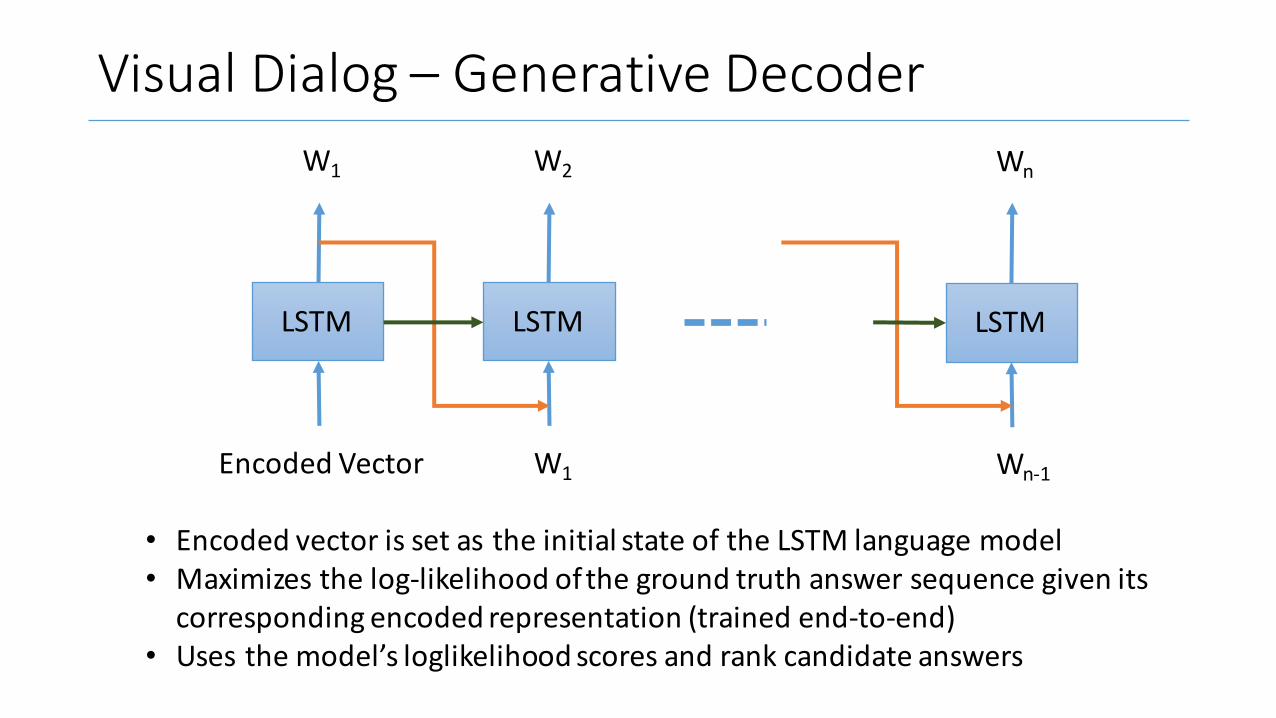
VisualDialog– GenerativeDecoder
LSTM
EncodedVector
W1
LSTM
W2
W1
LSTM
Wn
Wn-1
• EncodedvectorissetastheinitialstateoftheLSTMlanguagemodel• Maximizesthelog-likelihoodofthegroundtruthanswersequencegivenitscorrespondingencodedrepresentation(trainedend-to-end)
• Usesthemodel’sloglikelihood scoresandrankcandidateanswers
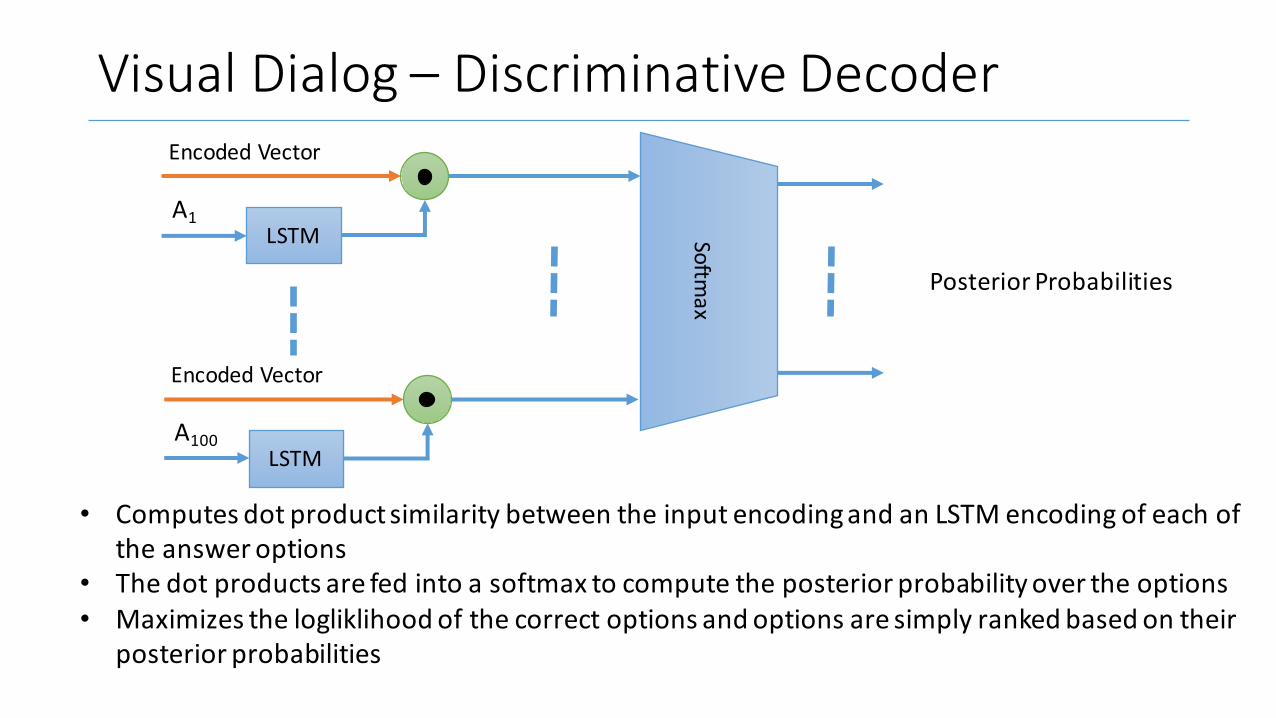
VisualDialog– DiscriminativeDecoder
• ComputesdotproductsimilaritybetweentheinputencodingandanLSTMencodingofeachoftheansweroptions
• Thedotproductsarefedintoasoftmax tocomputetheposteriorprobabilityovertheoptions• Maximizesthelogliklihood ofthecorrectoptionsandoptionsaresimplyrankedbasedontheir
posteriorprobabilities
LSTM
EncodedVector
A1
LSTM
EncodedVector
A100
Softmax
PosteriorProbabilities

VisualDialog– ExperimentResults• Dialogs:50Ktrain,8Kvalidation,10Ktest
HigherBetter LowerBetter

VisualDialog- Conclusions• Demonstratedthefirstvisualchatbot.• Theresultsandanalysisindicatesthatthereissignificantscopeforimprovement,theauthorsbelievethistaskcanserveasatestbed formeasuringprogresstowardsvisualintelligence.
PotentialImprovements:• Usingamodeltogenerateresponsesratherthanrankingcandidateanswers
• Includelanguagefeatures(e.g.part-of-speech)astheinputs• Extendittovideos

THANKS


















