
(PATH ANALYSIS) · (PATH ANALYSIS) ปปญหา ... Parameter estimation to derive the path...
37
การวิเคราะหอิทธิพล นงลักษณ วิรัชชัย ภาควิชาวิจัยการศึกษา คณะครุศาสตร จุฬาลงกรณมหาวิทยาลัย
Transcript of (PATH ANALYSIS) · (PATH ANALYSIS) ปปญหา ... Parameter estimation to derive the path...

การวิเคราะหอิทธิพลนงลักษณ วิรชัชัย
ภาควิชาวิจัยการศึกษา คณะครุศาสตร จฬุาลงกรณมหาวิทยาลัย

การวเิคราะหอิทธิพล
การวเิคราะหเสนทางอิทธิพลการวเคราะหเสนทางอทธพล
(PATH ANALYSIS) (PATH ANALYSIS)

ปญหาในการวเิคราะหถดถอย ปญหาในการวเคราะหถดถอย
- วิเคราะหไดแตคาประมาณอิทธิพลทางตรง ยังไม
สามารถวิเคราะหอิทธิพลทางออมได
- โมเดลการวิเคราะหไมตรงกับโมเดลการวิจัย
ิ โ ิ ิ ไ ไ - วิเคราะหโมเดลอิทธิพลสองทางไมได
ไมสามารถตรวจสอบความตรงของโมเดลได- ไมสามารถตรวจสอบความตรงของโมเดลได
- ขอมลไมสอดคลองกับขอตกลงเบื้องตน ขอมูลไมสอดคลองกบขอตกลงเบองตน

โมเดลการวจิัยโมเดลการวจย
SES SES
IQ GPASTUDYIQ GPA
TIME
ATTATT

โมเดลการวิเคราะหการถดถอยโมเดลการวเคราะหการถดถอย
SES
IQ IQ GPA
ATT
STUDY TIMESTUDY TIME

ขอตกลงเบื้องตนของการวิเคราะหถดถอยขอตกลงเบองตนของการวเคราะหถดถอย
1 ั ั ี 1. ความสมพนธทางเดยว เสนตรงและแบบบวก2 Error มกีารกระจายโคงปกติ มีคาเฉลีย่คงที่2. Error มการกระจายโคงปกต มคาเฉลยคงท
(homoscedasticity)3. Independent error across cases, variables4. Interval measures without measurement
errorerror5. No multicollinearityy

ความเหมาะสมของการวิเคราะหอิทธิพลความเหมาะสมของการวเคราะหอทธพล
ป ิ ิ ไ 1. ประมาณคาอิทธิพลทางออมได
โ ิ ป โ ี ั2. โมเดลการวิเคราะหเปนโมเดลเดียวกับโ ิ ัโมเดลการวจย
ิ ิ ิ ไ 3. วิเคราะหอิทธิพลสองทางได
โ 4. ทดสอบความตรงของโมเดล (สอดคลอง กับขอมลเชิงประจักษ) ทดสอบทฤษฎีได กบขอมูลเชงประจกษ) ทดสอบทฤษฎได

วัตถประสงคของการวิเคราะหอทิธพิลวตถุประสงคของการวเคราะหอทธพล
ื่ ี1. เพอืทดสอบทฤษฎี
ื่ ั2. เพอืพฒันา (develop) และตรวจสอบความตรง
โ ิโมเดลเชิงสาเหตุ (causal model validation)
ื่ ึ ป โ ิ3. เพอืศึกษารูปแบบ โครงสราง ขนาด และทิศทาง
ิ ิ ั้ ื่ ิของอทธพลทงทางตรงและทางออม เพออธบาย
พยากรณ และควบคมปรากฏการณพยากรณ และควบคุมปรากฏการณ

ขั้นตอนการวิเคราะหอิทธิพลปญหาวิจัยปญหาวจย
โมเดลตามทฤษฎี ขอมูลเชิงประจักษ
Computed R matrix Actual R matrix
ไม fit ปรับโมเดล
โมเดล fit กับขอมูล
ขอคนพบจากการวิจัย

SES SES
PASES INCOMEPASES INCOME
SPSES LISATSPSES LISAT
โมเดลความสมัพันธเชิงสาเหตุของความพอใจในชีวิต

SES Endogenous varSES Endogenous var.
PASES INCOMEPASES INCOME
Exogenous var
SPSES LISAT
Exogenous var.
SPSES LISAT
SES, SPSES and INCOME = Mediating VariableSES, SPSES and INCOME Mediating Variable

ขอตกลงเบื้องตนของการวิเคราะหอิทธพิลขอตกลงเบองตนของการวเคราะหอทธพล
1 ั ั ี 1. ความสมพนธทางเดยว เสนตรงและแบบบวก2 Error มกีารกระจายโคงปกติ มีความแปรปรวน2. Error มการกระจายโคงปกต มความแปรปรวนคงที่ (homoscedascity)
3. Independent error across cases, variables4. Interval measures without measurement
errorerror5. No multicollinearityy6. Casual Closure

ทฤษฎีสัมประสิทธอิทธิพลทฤษฎีสัมประสิทธอิทธิพลฤ ฎฤ ฎ(PATH COEFFICIENT THEORY)(PATH COEFFICIENT THEORY)
Y1e1
Y1
e2X1 Y2
DIRECT EFFECT = DEDIRECT EFFECT = DEINDIRECT EFFECT = IEINDIRECT EFFECT = IESPURIOUS CORRELATION = SCSPURIOUS CORRELATION = SCSPURIOUS CORRELATION SCSPURIOUS CORRELATION SCCORRELATION = DE + IE + (SC + UE)CORRELATION = DE + IE + (SC + UE)

Y1z1
GA(1 1)
X1 Y2z2
GA(1,1) BE(2,1)
X1 Y2CA(2,1)
Y1 = GA(1,1)X1 + z1
Y2 = GA(2,1)X1 + BE(2,1)Y1+ z2
r (X1, Y1) = Σ(X1)(Y1) / N
= [Σ(X1) {GA(1,1)X1 + z1}] /N [Σ(X1) {GA(1,1)X1 + z1}] /N
= GA(1,1) {Σ(X1)2}/N = GA(1,1) = DE

Y1z1
GA(1,1)
X1 Y2z2
BE(2,1)
X1 Y2GA(2,1)
r (X1 Y2) = Σ(X1)(Y2) / N r (X1, Y2) = Σ(X1)(Y2) / N
= [Σ(X1) {(GA(2,1)X1 + BE(2,1)Y1+ z2}]/N [ ( ) {( ( , ) ( , ) }]
= GA(2,1){Σ(X1)2}/N + BE(2,1)[ Σ(X1)(Y1) / N]
+ [ Σ(X1)(z2) / N]
= GA(2,1) + BE(2,1)[ GA(1,1)] = DE + IE

กระบวนการวิเคราะหอิทธพิลกระบวนการวเคราะหอทธพล
1 ป ิ 1. การประมาณคาพารามเตอร = การแกสมการชุดsimultaneous linear equations หาคาพารามิเตอรsimultaneous linear equations หาคาพารามเตอร2. การทดสอบทฤษฎี (theory testing) = การ
โฤ ฎ
ทดสอบโดยการเปรียบเทยีบ R matrix จากขอมล กับ R matrix จากโมเดล (ทฤษฎี)ขอมลู กบ R matrix จากโมเดล (ทฤษฎ)
3 การวิเคราะหแยกคาสหสัมพนัธ (Correlation 3. การวเคราะหแยกคาสหสมพนธ (Correlation decomposition) = การวิเคราะหคาสหสัมพนัธ่
pเพือ่ใหไดอิทธพิลทางตรงและทางออม

SES SES
PASES INCOMEPASES INCOME
SPSES LISATSPSES LISAT
โมเดลความสมัพันธเชิงสาเหตุของความพอใจในชีวิต

เมทริกซสหสัมพันธเมทรกซสหสมพนธ
PASES SES SPSES INCOME LISAT PASES 1.00 SES 0 39 1 00 SES 0.39 1.00 SPSES 0.35 0.60 1.00 INCOM 0.18 0.43 0.41 1.00 LISAT 0 10 0 14 0 19 0 24 1 00 LISAT 0.10 0.14 0.19 0.24 1.00 MEAN 50.29 50.21 50.25 7.87 24.35 SD 8.42 8.77 8.81 3.10 3.77

การแปลความหมายเมทริกซสหสัมพันธการแปลความหมายเมทรกซสหสมพนธ
1. แปลความหมายคาสหสัมพนัธ ( r ) ระหวางตัวแปรตนและตัวแปรตาม
2 แปลความหมายคาสหสัมพนัธร หวางตัวแปร2. แปลความหมายคาสหสมพนธระหวางตวแปรตนทั้งหมด เนนเรื่องภาวะรวมเสนตรงพห หรือตนทงหมด เนนเรองภาวะรวมเสนตรงพหุ หรอMulticollinearity3. แปลความหมายคา r รวม 4 ดาน คือ existemce,direction, magnitude, % accounted for

Parameter estimation to derive the path modelRun regression of LISAT on SPSES and INCOMERun - regression of LISAT on SPSES and INCOME
- regression of INCOME on SES and SPSES- regreesion of SPSES on PASES and SES
i f SES SPASES- regression of SES on SPASES
SES .39
.29
PASES INCOME
.39
19
.55PASES
.24.11
.19
14 SPSES LISAT.14

การเปรียบเทียบเมทริกซสหสัมพันธการเปรยบเทยบเมทรกซสหสมพนธ
สมมติฐานในการทดสอบสมมุตฐานในการทดสอบ
H : ρ = ρเกณฑ : 1 คา r ตางกนัไมเกนิ 0 05
H0 : ρComputed ρObserved
เกณฑ : 1. คา r ตางกนไมเกน 0.05
2 คา r ที่ตางกันเกิน 0.05 ตองมีจํานวน2. คา r ทตางกนเกน 0.05 ตองมจานวนไมเกิน 20 % ของจํานวนคา r ทั้งหมด

SES 29
CO
.39.29
.55PASES INCOME
.24 .19
.55
SPSES LISAT.11.14
PASES-SES: DE = 0.39IE = 0.00
r = TE = Total effect = DE + IE = 0 39r = TE = Total effect = DE + IE = 0.39PASES-SPSES: DE = 0.14
IE (0 39) (0 55) 0 21IE = (0.39) (0.55) = 0.21r = TE = 0.14 + 0.21 = 0.35

SES 29
CO
.39.29
.55PASES INCOME
.24 .19
.55
SPSES LISAT.11.14
PASES-INCOME: DE = 0 00PASES-INCOME: DE = 0.00IE via SES = (0.39) (0.29) = 0.11
i S S S (0 14) (0 24) 0 03IE via SPSES = (0.14) (0.24) = 0.03IE via SES, SPSES = (0.39) (0.55) (0.24) = 0.05r = TE = 0.00 + 0.11 + 0.03 + 0.05 = 0.19

ผลการเปรียบเทียบเมทริกซสหสัมพันธผลการเปรยบเทยบเมทรกซสหสมพนธComputed PASES SES SPSES INCOME LISAT Computed
Observed
PASES SES SPSES INCOME LISAT
PASES 1 00 0 39 0 35 0 19 0 07 1.00 0.39 0.35 0.19 0.07 SES 0.39 1.00 0.54 0.42 0.14
SPSES 0.35 0.60 1.00 0.25 0.15 INCOME 0.18 0.43 0.41 1.00 0.29
LISAT 0 10 0 14 0 19 0 24 1 00 LISAT 0.10 0.14 0.19 0.24. 1.00
เกณฑ : 1 คา r ตางกันไมเกิน 0 05 เกณฑ : 1. คา r ตางกนไมเกน 0.05
2. คา r ที่ตางกันเกิน 0.05 ตองมีจํานวนไมเกิน20 %
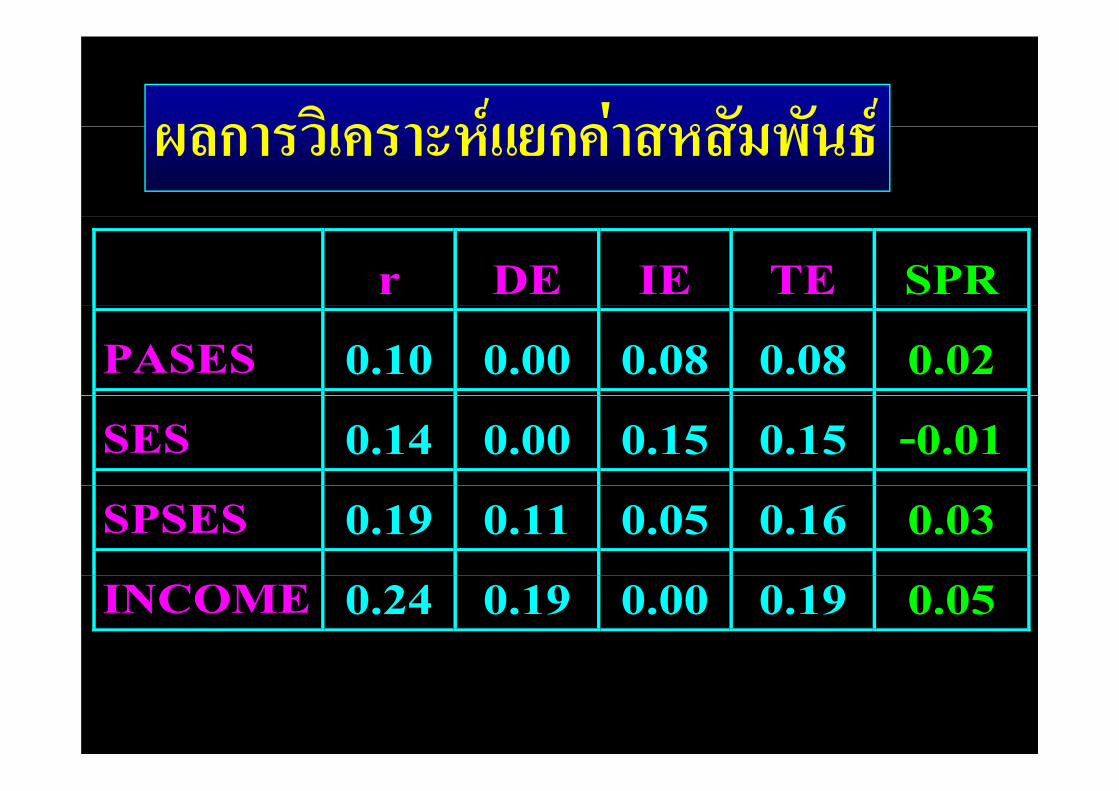
ผลการวิเคราะหแยกคาสหสัมพันธผลการวเคราะหแยกคาสหสมพนธ
r DE IE TE SPR
PASES 0.10 0.00 0.08 0.08 0.02
SES 0.14 0.00 0.15 0.15 -0.01
SPSES 0.19 0.11 0.05 0.16 0.03
INCOME 0.24 0.19 0.00 0.19 0.05

ขอบคุณ

1
การวิเคราะหอิทธิพล (Path Analysis)
นงลกัษณ วิรัชชัย (เอกสารประกอบการบรรยาย/การอภิปราย ในการประชุมปฏิบัคิการ รุนที่ 1 ครั้งที่ 4 เร่ือง ผลงานวิจัยเพื่อเพิ่มพูนจริยธรรม ปญญา และ
สุขภาพจิตตามหลักเศรษฐกิจพอเพียง โดย โครงการพัฒนาหลักสูตรการวิจัยแบบบูรณาการฯ รวมกับ สํานักงานคณะกรรมการวิจัยแหงชาติ
(วช.) วันที่ 10 พฤษภาคม 2550 ณ โรงแรมฮอลิเดยอินน รีสอรท รีเจนท บีช ชะอํา เพชรบุรี)
(ปรับปรุงเปนเอกสารประกอบการบรรยาย ในโครงการ Research Zone เร่ือง การวิเคราะหอิทธิพลและการวิเคราะหโมเดลสมการโครงสราง
จัดโดย สํานักงานคณะกรรมการวิจัยแหงชาติ วันพฤหัสที่ 8 เมษายน 2553 ณ อาคารศูนยการเรียนรูทางการวิจัย ถนนพหลโยธิน สํานักงาน
คณะกรรมการวิจัยแหงชาติ กรุงเทพมหานคร)
การวิเคราะหอิทธิพล (path analysis) เปนสถิติวิเคราะหข้ันสงูที่ไดรับการพัฒนาข้ึนเพื่อศึกษา
ความสัมพันธเชิงสาเหตุ (causal relationship) ระหวางตัวแปรในการวิจัยสํารวจสาเหตุ (causal survey
research) และในการวิจัยทีน่ักวจิัยไมสามารถดําเนินการวิจัยทดลอง (experimental research) ได
เมื่อพิจารณาตามหลกัการวจิัย การวิจัยทดลองนับเปนการวิจัยที่มปีระสิทธิภาพและประสิทธผิล
สูงสุดในการศึกษาความสัมพันธเชิงสาเหตุ เนื่องจากนกัวิจัยสามารถออกแบบการวิจัยทดลองเพือ่ควบคมุ
ตัวแปรแทรกซอนตามเงื่อนไขที่จําเปน (necessary condition) ของการศึกษาความสัมพนัธเชงิสาเหตุ
ระหวาง X กับ Y รวม 3 ประการได คือ ก) X ตองเกิดกอน Y ข) X และ Y ตองแปรผันรวมกนั และ ค) ตอง
ไมมีตัวแปรอื่นใดมาเกี่ยวของหรืออธิบายความแปรปรวนใน Y นอกจาก X ในการออกแบบการวิจัยเชงิ
ทดลองเมื่อนักวิจัยมีสมมุติฐานวิจัยวา ตัวแปร X เปนสาเหตทุําใหเกดิความแตกตางในตวัแปร Y นักวิจยั
สามารถใชกระบวนการสุม (randomization) จัดใหมีกลุมทดลอง (experimental group = E) และกลุม
ควบคุม (control group = C) ที่มีลักษณะเทาเทียม/คลายคลงึกนั ซึ่งนักวิจัยอาจทาํการทดสอบกอน
(pretest) เพือ่ตรวจสอบวาคาเฉลี่ยตัวแปร Y กอนทดลองของกลุม E และ C แตกตางกนัอยางไมมี
นัยสําคัญทางสถิติ จากนัน้นักวจิัยใหตัวแปรจัดกระทํา (treatment X) แกกลุมทดลอง แลวจึงทาํการ
ทดสอบหลงั (posttest) เพื่อตรวจสอบวาคาเฉลีย่ตัวแปร Y ของกลุมทดลองแตกตางจากกลุมควบคุม
อยางมีนยัสําคัญทางสถิติมากนอยเพยีงไร ความแตกตางของคาเฉลีย่ผลการทดสอบหลังดังกลาวเปนการ
พิสูจนถึงอทิธพิลเชิงสาเหตุของตัวแปร X ที่มีตอตัวแปร Y นกัวิจยัใหความสําคญักับการวจิัยทดลองใน
การศึกษาความสัมพนัธเชงิสาเหตุกนัมาก มีการออกแบบการวิจยัทดลองหลายแบบ แบบการวิจยัทดลอง
ที่ใชกนัมากทีสุ่ด คือ แบบการวิจยัชนิดมีกลุมควบคุมการทดสอบกอน-หลัง แบบสุม (randomized
pretest-posttest, control group design) แบบการวิจยัที่ดีที่สุดคือ แบบการวิจัยชนิดสีกลุมของโซโลมอน
(Solomon, four group design) ซึ่งไมเปนที่นยิมใชเพราะใชกลุมตัวอยาง 4 กลุม แทนที่จะใช 2 กลุม
ผลการวิจยัทดลอง แมวาจะไดรับการยอมรับวาสามารถตอบคําถามเกี่ยวกับความสัมพนัธเชงิ
สาเหตุไดดีที่สุด แตในทางปฏิบัติยงัมขีอจํากัดตรงทีส่ถานการณในการทดลองไมเปนไปตามธรรมชาติ
เพราะมกีารศกึษาตัวแปรที่เปนสาเหตุไดไมมากเทาตัวแปรที่เปนสาเหตุจริงซึ่งมหีลากหลาย นกัวิจัยได
พัฒนาสถิติวิเคราะหเพื่อใชในการศึกษาความสัมพนัธเชงิสาเหตุในการวิจัยสํารวจ อันจะชวยใหนักวิจัย

2
สามารถศึกษาสถานการณไดตามที่เปนจริงในธรรมชาติ สถิติวิเคราะหที่ไดรับการพัฒนาขึ้นนี้คือ การ
วิเคราะหอิทธพิล บทความนี้มุงนาํเสนอสาระสําคัญเกีย่วกับการวเิคราะหอิทธพิลรวม 5 ประการ คือ
ความเปนมาของการวิเคราะหอิทธพิล ประเภทของการวิเคราะหอิทธิพล การวิเคราะหอิทธพิลกับการ
วิเคราะหถดถอยพหุคูณ หลกัการวเิคราะหอิทธพิล และวิธีการวิเคราะหอิทธพิล
1. ความเปนมาของการวิเคราะหอิทธพิล
Sewell Wright นักชวีสถิติ ไดรับการยกยองวาเปนผูริเร่ิมใชการวิเคราะหอิทธพิล เมื่อ ค.ศ. 1918
ในการวิจัยเพือ่สรางโมเดลและประมาณคาพารามิเตอรในโมเดลสวนประกอบของกระดูก ตอมาในป ค.ศ.
1921 ไดเขียนบทความแสดงความเกี่ยวของระหวางความสัมพนัธและความสมัพนัธเชงิสาเหตุ ในป ค.ศ.
1925 ไดประยุกตแนวคิดดังกลาวในการวจิัยศึกษาปจจัยเชิงสาเหตุของราคาขาวโพดและสุกร และในป
ค.ศ. 1934 ไดเสนอแนวคิดการวิเคราะหอิทธิพลแสดงขั้นตอนสามขัน้ตอน คือ ข้ันการกําหนดโมเดลแสดง
อิทธิพล (path model) ตามทฤษฎี ข้ันการสรางสมการโครงสราง (structural equations) ในรูปสมการ
ถดถอยแสดงความสัมพันธระหวางตัวแปรในโมเดลแสดงอิทธพิล และขั้นการวิเคราะหแยกอิทธพิลรวม
(total effects) ออกเปนอทิธิพลทางตรง (direct effects) และอิทธิพลทางออม (indirect effects) แตเปน
ที่นาเสียดายทีไ่มมีนักวิจัย นกัสถติิ หรือนกัวิชาการใหความสนใจกับผลงานดังกลาวในชวงป 1925-1955
(Bollen, 1989; Saris and Stronkhorst, 1984; tนงลักษณ วิรัชชัย, 2542)
แนวคิดของ Wright ไดรับการยอมรับและพัฒนา เมื่อ Herbert Simon นักสังคมวทิยาไดพยายาม
ศึกษาความสมัพันธเชงิสาเหตุ โดยการเปรียบเทียบคาสหสัมพนัธแบบงาย (simple correlation) กับคา
สหสัมพนัธพารเชียล (partial correlation) ในป ค.ศ. 1957 และ Hurbert M. Blalock (1961) นักสงัคม
วิทยาไดนาํวิธขีอง Simon มาปรบัปรุงโดยขจัดอิทธิพลจากตัวแปรแทรกซอนอื่นๆ และใชคาสหสมัพันธกึง่
พารเชียล (semi-partial correlation) แทนคาสหสัมพันธพารเชยีล ซึ่งไดผลเชนเดียวกับการใชการ
วิเคราะหถดถอยพหุคูณในการควบคุมตัวแปรแทรกซอนในสมการถดถอยนัน้เอง Blalock เปนคนแรกที่
แสดงใหเหน็ถงึความสําคัญและคุณคาของการวิเคราะหอิทธิพลตามแนวคิดของ Wright นับจากป ค.ศ.
1961 เปนตนมา การวิเคราะหอิทธิพลไดรับความนยิมมากขึ้นเปนลําดับในหมูนักวจิัยสํารวจเพื่อศึกษา
ความสัมพันธเชิงสาเหต ุP.M. Blau, O.D. Duncan, A. Haller and D.R. Heise ไดรับการยกยองวาเปน
นักวจิัยกลุมแรกที่สรางโมเดลแสดงอิทธิพลกรณีที่มีตัวแปรแฝง (latent variables) ผลงานที่สําคัญไดแก
ผลงานของ Duncan (1966); Nygreen (1971) Alwin and Hauser (1975) Pedhazur (1982) แตการ
วิเคราะหอิทธพิลยังมีผูใชไมมากนักเพราะวิธีการวิเคราะหยงัยุงยาก ไมสะดวก ไมมโีปรแกรมคอมพิวเตอร
โดยตรง ตองวเิคราะหดวยการวิเคราะหถดถอยพหุคูณแลวมาคํานวณตอตามสมการในโมเดล
การวิเคราะหอิทธิพลไดรับการพัฒนากาวหนาสงูสุดเมือ่ K.G. Joreskog, J.W. Keesling and
D.E. Wiley ไดพัฒนาโมเดลสมการโครงสราง (structural equation model) ในชวงป ค.ศ. 1972-1973 ซึ่ง
เปนที่รูจกักนัในชื่อ JKW Model ในระยะแรก ตอมาเมือ่ K.G. Jorekog and D. Sorbom พัฒนาโปรแกรม
คอมพิวเตอรข้ึน เรียกวา ACOVS Model (Analysis of Covariance Structure Model) และเปลี่ยนเปน

3
เรียกชื่อวา LISREL Model (Linear Structural Relationship Model) ในระยะหลัง ตอมานกัวิจัยสวน
ใหญเหน็วาชือ่โมเดลลิสเรลไปพองกับชือโปรแกรม ทาํใหนกัวิจยัสวนใหญหนัมาเรยีกชื่อโมเดลวา โมเดล
สมการโครงสราง (Structural Equation Model = SEM) แทน กลาวไดวาโมเดลลิสเรลเปนโมเดลแรกที่มี
ความสมบูรณสูงสุด เปนผลงานบูรณาการของสถิติวิเคราะหที่สําคัญรวมสามวิธ ี คือ การวิเคราะหอิทธพิล
การวิเคราะหองคประกอบ (factor analysis) และการประมาณคาพารามิเตอรตามหลักเศรษฐมิติ
(econometrics) ทําใหเปนโมเดลที่มีโมเดลยอยครอบคลุมสถิติวิเคราะหหลากหลายตั้งแต การวิเคราะห
ความแปรปรวน (ANOVA)การวิเคราะหความแปรปรวนรวม (ANCOVA) การวิเคราะหถดถอยพหุคูณ
(multiple regression analysis = MRA) การวิเคราะหอิทธพิล (path analysis) การวิเคราะหความ
แปรปรวนตัวแปรพหนุาม (MANOVA) การวิเคราะหความแปรปรวนรวมตัวแปรพหนุาม (MANCOVA)การ
วิเคราะหสหสมัพันธคาโนนคิอล (canonical correlation analysis) การวิเคราะหจาํแนกกลุมพห ุ
(multiple discriminant analysis = MDA) การวิเคราะหองคประกอบ (factor analysis) การวเิคราะหโคง
พัฒนาการ (growth curve analysis) การวิเคราะหกลุมพห ุ (multiple-group analysis) การวิเคราะหพหุ
ระดับ (multi-level analysis) การวิเคราะหโมเดลสมการโครงสรางทีม่ีตัวแปรแฝง (SEM with latent
variables) การวิเคราะหขอมูลจัดประเภท (categorical data analysis) และ การวิเคราะหแนวโนม
(trend analysis)
นับต้ังแตป ค.ศ. 1980 เปนตนมา SEM เปนที่สนใจและไดรับการพัฒนามากขึ้น มี
ผูพัฒนาโปรแกรมคอมพิวเตอรสําหรับการวิเคราะห SEM อีกเปนจาํนวนมาก โปรแกรมที่สําคญัที่เปนที่
รูจักและใชกันมาก คือ โปรแกรม EQS ของ Bentler พัฒนาเมื่อป 1980 โปรแกรม LISCOMP ของ
Muthen พัฒนาป 1987 โปรแกรม Mplus ของ Muthen and Muthen พัฒนาป 1995 และ โปรแกรม
AMOS ของ Arbuckle พฒันาป 1995 (Muthen and Muthen, 2003; Bollen, 1989; นงลกัษณ วิรัชชัย,
2542)
2. ประเภทของการวเิคราะหอิทธิพล
การวิเคราะหอิทธิพลจําแนกประเภทตามลักษณะการวเิคราะหไดเปนสองแบบ แบบแรก คือ
การวิเคราะหอิทธิพลแบบดั้งเดิม (classical path analysis) ซึ่งนกัวิจัยใชข้ันตอนวิธ ี (algorithm) การ
วเิคราะหถดถอยโดยการประมาณคาแบบกําลังสองนอยที่สุด (least square estimation) แลวนาํผลการ
วิเคราะหมาคาํนวณหาคาอทิธิพลทางตรงและอิทธิพลทางออม และการวเิคราะหเพื่อทดสอบความตรง
ของทฤษฎี (theroy validation) แบบทีส่อง คือ การวิเคราะหอิทธิพลโดยใชโปรแกรมคอมพิวเตอร
สําหรบัการวเิคราะห SEM ที่สามารถวเิคราะหขอมูลไดอยางสมบูรณ นกัวิจยัยังจําแนกประเภทของการ
วิเคราะหอิทธพิล หรือ การวิเคราะหโมเดลสมการโครงสรางตามลักษณะของโมเดลสมการโครงสรางที่
นักวจิัยสรางขึ้นตามทฤษฎ ีและไดจัดจําแนกลักษณะโมเดลโดยใชเกณฑที่สําคัญ 5 แบบ ดังนี ้
2.1 การจําแนกตามลกัษณะตัวแปร เปน โมเดลมีตัวแปรแฝง (model with latent variables) และ
โมเดลไมมีตัวแปรแฝง (model without latent variables or classical SEM) เปนการวิเคราะหด้ังเดิม

4
2.2 การจาํแนกตามลักษณะความสัมพันธ เปนโมเดลความสัมพนัธทางเดียว (oneway model or
recursive model) และโมเดลความสัมพันธสองทาง (two-way model or non-recursive model)
2.3 การจําแนกตามลกัษณะกลุมประชากร เปน โมเดลกลุมเดียว (single group model) และโมเดล
กลุมพห ุ(multiple group model) เพื่อศึกษาความไมแปรเปลี่ยนของโมเดล (model invariance) ระหวาง
กลุมประชากร
2.4 การจาํแนกตามลกัษณะขอมูล เปน โมเดลภาคตัดขวาง (cross-sectional model) และโมเดลระยะ
ยาว (longitudinal model) เพื่อศึกษาความคงที่ของโมเดล (model consistency) ระหวางชวงเวลา
2.5 การจาํแนกตามลักษณะอิทธพิล เปนโมเดลทีไ่มมทีั้งอทิธพิลกํากับ (moderating effects) และ
อิทธิพลปฏิสัมพันธ (interaction effects) และโมเดลทีม่ีอิทธิพลกํากับ และ/หรืออิทธิพลปฏิสัมพันธ
เมื่อจัดกลุมการจําแนกประเภททั้ง 5 แบบ แบบละ 2 ประเภท จงึไดลักษณะของโมเดลสมการ
โครงสรางที่ใชหลักการวิเคราะหอิทธพิลมรีวมถึง 2X2X2X2X2 = 32 ประเภท แตในทางปฏิบัตินักสถิติ
นิยมจัดจาํแนกประเภทโมเดลสมการโครงสรางออกเปน 2 ประเภท ตามลักษณะตัวแปรเทานั้น คือ โมเดล
สมการโครงสรางแบบไมมีตัวแปรแฝง และโมเดลสมการโครงสรางแบบมีตัวแปรแฝง
การวาดภาพโมเดลแสดงอิทธิพลมีขอตกลงวา ตัวแปรแฝง (latent variables) แทนดวย
สัญลักษณรูปวงกลมหรือวงรี และตัวแปรสังเกตได (observed variables) แทนดวยสัญลักษณรูปส่ีเหลี่ยม
เสนทางอทิธพิลทางตรง (direct effects) ระหวางตัวแปรแทนดวยเสนลูกศร และความแปรปรวนรวมหรือ
ความสัมพันธระหวางตัวแปรแทนดวยลกูศรเสนโคงสองหวั ดังภาพแสดงโมเดลสมการโครงสรางแบบไมมี
ตัวแปรแฝง และแบบมีตัวแปรแฝง ในที่นี้ SEM เปนโมเดลแบบอิทธิพลทางเดียว ประชากรกลุมเดียว
ขอมูลภาคตัดขวาง และไมมีอิทธิพลกํากับและอิทธิพลปฏิสัมพันธ
1ก.โมเดลสมการโครงสราง แบบไมมีตัวแปรแฝง
1ข.โมเดลสมการโครงสราง แบบมีตัวแปรแฝง
ภาพ 1 โมเดลสมการโครงสราง แบบไมมตัีวแปรแฝง และแบบมีตัวแปรแฝง
K1
K2ๅ
E1ๅ
E2ๅ
Y1ๅ
Y2
Y3
Y4
E1
E2
X1ๅ
X5
X2
X3
X4
K1
K2

5
3. การวิเคราะหอิทธิพลกบัการวิเคราะหถดถอยพหคูุณ
การวิเคราะหอิทธิพลเปนสถิติวิเคราะหทีเ่ปนภาคขยาย (extension) ของการวิเคราะหถดถอย
พหุคูณ นักสถติิเห็นขอจํากัดของการวิเคราะหถดถอยพหคูุณในการตอบคําถามวิจัยเกี่ยวกับความสัมพันธ
เชิงสาเหตุ และไดพัฒนาเทคนิคการวิเคราะหขอมูลเพือ่ลดขอจํากัดดังกลาว อันสงผลทาํใหมกีารพัฒนา
เปนการวิเคราะหอิทธิพลในที่สุด ดังจะแสดงใหเหน็ถึงขอจํากัดในการวิเคราะหถดถอยพหุคูณ และผลการ
วิเคราะหจากการวิเคราะหอิทธิพลที่สามารถตอบคําถามการวิจยัไดดีข้ึน ดังนี ้
จากโมเดลความพงึพอใจในชีวิต (life satisfaction model) ในหนังสือของ นงลกัษณ วิรัชชัย
(2542) นักวจิัยสรางโมเดลสมการโครงสรางตามทฤษฎี ไดดังภาพ 2 ตัวแปรในโมเดลประกอบดวย
สถานภาพเศรษฐกิจ-สังคมของพอแม (parental socio-economic status = PASES) สถานภาพ
เศรษฐกิจ-สังคมของตน (socio-economic status = SES) สถานภาพเศรษฐกิจ-สังคมของคูสมรส
(spouse socio-economic status =SPSES) รายได (INCOME) และความพึงพอใจในชวีิต (life
satisfaction = LISAT) อธบิายไดวาคนที่พอแมมีฐานะ (PASES) ดี ยอมมีฐานะ (SES) ดี การมีพอแมมี
ฐานะดีและตนเองมฐีานะดทีําใหมีคูสมรสที่มีฐานะ (SPSES) ดี เมือ่ทั้งตนเองและคูสมรสมีฐานะดียอมมี
รายได (INCOME) สูง ในที่นี้ตัวแปรฐานะขอพอแม (PASES) มีอิทธิพลทางตรงตอตัวแปร SES และตัว
แปร SPSES และมีอิทธพิลทางออมผานตัวแปร SES และ SPSES มาถึงตวัแปรรายได (INCOME) การที่มี
คูสมรสมีฐานะดีและมีรายไดสูงยอมสงมอิีทธิพลทางตรงทําใหมีความพึงพอใจในชวีิตสูง นัน่คือตัวแปร
INCOME และ SPSES มีอิทธิพลทางตรงตอตัวแปร LISAT สวนตัวแปร PASES และ SES มีอิทธพิล
ทางออมผานตัวแปร SPSES และ INCOME ไปถึงตัวแปร LISAT
ภาพ 2 โมเดลความพึงพอใจในชีวิตที่สรางตามทฤษฎ ี
เมื่อนักวิจัยวิเคราะหขอมูลอันประกอบดวยตัวแปรทัง้ 5 ตัว คือ PASES, SES, SPSES, INCOME
และ LISAT โดยใชการวิเคราะหถดถอยพหุคูณ มตัีวแปร LISAT เปนตัวแปรตาม และตัวแปรที่เหลือเปน
ตัวแปรตน ไมวานักวจิัยจะวเิคราะหโดยใชวิธีใสตัวแปรตนทัง้หมด (enter method) หรือวิเคราะหแบบเปน
ข้ันตอน (stepwise method) ดวย SPSS ลักษณะของโมเดลการวิเคราะหจะไมตรงกับโมเดลตามทฤษฎี
ดังภาพ 3 ผลการวิเคราะหถดถอยพหุคูณแบบใสตัวแปรตนทุกตัวจะไดผลการวิเคราะหวา อิทธิพลจากตัว
แปร PASES, SES, SPSES และ INCOME ที่มีตอ LISAT วัดในรูปสัมประสทิธิ์การถดถอยมาตรฐาน
(standardized regression coefficient or beta) มีขนาด 0.03, -0.03, 0.12 และ 0.20 ตามลาํดับเมื่อ
PASES
SES
SPSES
INCOME
LISAT

6
ควบคุมตัวแปรอื่นๆ ในสมการ ดังภาพ 3ก สวนผลการวิเคราะหถดถอยพหุคูณแบบขั้นตอนจะไดผลการ
วิเคราะหข้ันตอนที่สองวา อิทธิพลจากตวัแปร INCOME และ SPSES ที่มีตอ LISAT เทานั้นที่มนีัยสําคัญ
ทางสถิติและมีขนาดอิทธิพล (beta) เทากับ 0.19 และ 0.11 ตามลําดบั ดังภาพ 3ข
LISAT = β1(INCOME)- - - - - - - - - - - - (1)
LISAT = β1(PASES)+β2(SES)+β3(SPSES)+β4(INCOME) LISAT = β2(SPSES)+β3(INCOME) - - (2)
(ตัวแปรทุกตัวอยูในรูปคะแนนมาตรฐาน สมการถดถอยไมมีคาคงที่)
3ก สมการและผลการวเิคราะหแบบ enter 3ข สมการและผลการวเิคราะหแบบ stepwise
ภาพ 3 สมการและผลการวเิคราะหถดถอยพหุคูณโมเดลความพึงพอใจในชีวิต
จะเหน็ไดวาเมือ่นักวจิัยใชการวิเคราะหถดถอยพหุคูณนัน้ นักวิจัยสนใจแตขนาดอิทธิพลทางตรง
(direct effects) และเมื่ออิทธิพลทางตรงไมมีนัยสาํคัญทางสถิติ นกัวิจัยตัดตัวแปรนั้นทิ้งไมนําเสนอเปน
ผลการวิจยั ซึง่ไมตรงตามทฤษฎี ทําใหเกดิเปนขอจํากัดของการวิเคราะหถดถอยพหคูุณ ขอจํากัดดังกลาว
เกิดจากการสรางสมการโครงสรางที่ไมตรงกับโมเดลสมการโครงสรางตามทฤษฎี นักสถิติจึงพฒันาวิธีการ
วิเคราะหอิทธพิลโดยสรางชดุของสมการโครงสรางตามโมเดลที่ไดจากทฤษฎี และแกสมการพรอมกันตาม
หลักการแกสมการ simultaneous linear equation ลักษณะของสมการโครงสรางตามโมเดลในภาพ 2
ประกอบดวยสมการโครงสรางรวม 4 สมการ และมีจาํนวนพารามิเตอรที่ตองประมาณคา 7 คา ดังนี ้ SES = β1(PASES) + e1
SPSES = β2(PASES) + β3(SES) + e2
INCOME= β4(SES) + β5(SPSES) + e3
LISAT = β6(SPSES) + β7(INCOME) + e4
4. หลกัการวเิคราะหอิทธพิล
การวิเคราะหอิทธิพลใชหลกัทฤษฎีสัมประสิทธิ์อิทธพิล (path coefficient theory) ซึ่งกลาววา
สัมประสิทธิ์สหสัมพนัธระหวางตัวแปรแตละคูในโมเดลสมการโครงสราง มีคาเทากับผลรวมของอิทธพิล
ทางตรง (direct effect = DE) อิทธิพลทางออม (indirect effect = IE) ความสมัพันธเทียม (spurious
correlation = SC) และ อิทธิพลรวม (joint effects = JE) ที่ไมเกี่ยวของกับโมเดล ดังสมการ
Correlation = r = DE + IE + (SC + JE)
= (total effect) + (residual)
0.24
0.19
0.11 SPSES
INCOMELISAT
0.20
0.12 - 0.03
PASES
SES
INCOME
SPSES LISAT
0.03 INCOME LISAT

7
หลักการวิเคราะหอิทธพิล จึงเปนการวิเคราะหแยกคาสัมประสิทธิ์สหสัมพันธออกเปนสวนยอยๆ
เพื่อใหไดคาของ DE ละ IE ที่สามารถอธบิายรูปแบบอิทธิพลในโมเดลสมการโครงสรางได วิธีการแยกคา
สัมประสิทธิ์สหสัมพนัธระหวางตัวแปร PASES กับ SES และ คาสัมประสิทธิ์สหสัมพนัธระหวางตัวแปร
PASES กับ SPES แสดงไดดังนี ้
r(PASES,SES)
= {Σ(PASES)(SES)}/n
= [Σ(PASES){ β1(PASES) + e1}]/n (แทนคา SES ลงในสมการ)
= β1{Σ(PASES)2}/n + {Σ(PASES)(e1)}/n
= β1 (1) + (0) = β1 (คา{Σ(PASES)2}/n =1, {Σ(PASES)(e1)}/n =0)
= DE
r(PASES,SPSES)
= {Σ(PASES)(SPSES)}/n
= [Σ(PASES){ β2(PASES) + β3(SES) +e2}]/n (แทนคา SPSES ลงในสมการ)
= β2{Σ(PASES)2}/n + β3{Σ(PASES)(SES)}/n + {Σ(PASES)(e2)}/n
= β2 (1) + (β3){r(PASES,SES)} + (0) (คา{Σ(PASES)2}/n =1, {Σ(PASES)(e2)}/n =0)
= β2 + (β3)( β1)
= DE + IE
จากตัวอยางขางตน จะเห็นไดวา คาอิทธพิลทางออมเกดิจากผลคูณของเสนทางอิทธิพลทางตรง
นั่นเอง ดังนั้น เมื่อนักวิจัยประมาณคาพารามิเตอร β1-β7 อันเปนอิทธิพลทางตรงไดแลว ยอมสามารถ
คํานวณหาอทิธิพลทางออมได ผลการวิเคราะหจงึสามารถอธิบายอทิธพิลไดทั้งทางตรงและทางออม (DE
and IE) ยิ่งไปกวานัน้ นกัวิจัยสามารถคาํนวณคาสัมประสิทธิสหสัมพันธจากคา DE และ IE ไดเปนคา
สัมประสิทธิ์สหสัมพนัธที่คํานวณได (reproduced correlation) และไมมีเทอมความคลาดเคลื่อน เมื่อนาํ
คาสหสัมพันธหรือความแปรปรวนรวม (covariance) มาเขียนเปนเมทริกซ และนําเมทริกซจากขอมูลจริง
(actual matrix) มาเปรียบเทียบกับเมทริกซที่คํานวณได (reproduced matrix) ดังตัวอยางตอไปนี ้
ตาราง 1 การเปรียบเทยีบเมทริกซสหสัมพันธจากขอมลูจริง และจากการคํานวณ ของ LISAT Model
PASES SES SPSES INCOME LISAT
PASES 0.39 0.35 0.19 0.07
SES 0.39 0.54 0.42 0.14
SPSES 0.35 0.60 0.25 0.15
INCOME 0.18 0.43 0.41 0.29
LISAT 0.10 0.14 0.19 0.24
หมายเหตุ ตัวเลขใตแนวทแยงคือสหสัมพันธจากขอมูลจริง ตัวเลขเหนือแนวทแยงคือสหสัมพันธจากการคํานวณ

8
การเปรียบเทยีบเมทรกิซสหสัมพันธจากขอมูลจริง และเมทริกซสหสมัพันธจากการคํานวณ เปน
การทดสอบวาโมเดลตามทฤษฎีสอดคลองกับขอมูลเชิงประจักษหรือไม และเปนการทดสอบความตรงของ
ทฤษฎี (theory validation) ดวย การทดสอบดังกลาวเปนการพิจารณาคาความแตกตางระหวางเมทริกซ
สหสัมพนัธจากขอมูลจริง และเมทริกซสหสัมพันธจากการคํานวณ หรือ คาความคลาดเคลื่อน (residual)
การทดสอบในอดีตใชการตรวจสอบความคลาดเคลื่อน โดยการพิจารณาคาความคลาดเคลื่อนกับเกณฑ
กลาวคือ ถาความคลาดเคลื่อนนอยกวา 0.05 หรือถามีความคลาดเคลื่อนมากกวา 0.05 ตองมีเปนจํานวน
ไมเกินรอยละ 20 ของจํานวนคาสหสัมพนัธ กรณีดังกลาว ถือวาเมทริกซสหสมัพนัธไมแตกตางกัน นัน่คือ
โมเดลตามทฤษฎีสอดคลองกับขอมูลเชิงประจักษ
เมื่อพิจารณาตามเกณฑขางตนจะเหน็วา มีสหสัมพันธ 2 คู ที่มีคาแตกตางกันมากกวา 0.05 ไดแก
สหสัมพนัธระหวาง SPSES-SES และ SPSES-INCOME ในกรณีนีม้ีคาความคลาดเคลื่อนมากกวา 0.05
เพียง 2 คูจากคาสหสัมพันธทั้งหมด 10 คู คิดเปนรอยละ 20 จึงพอสรปุไดวาโมเดลตามทษฎีสอดคลองกับ
ขอมูลเชิงประจักษได
ปจจุบันการทดสอบวาโมเดลตามทฤษฎีสอดคลองกับขอมูลเชิงประจกัษหรือไม หรือการทดสอบ
เพื่อเปรียบเทยีบเมทรกิซสหสัมพันธจากขอมูลจริง และเมทริกซสหสัมพันธจากการคํานวณ ใชการทดสอบ
ไค-สแควร (chi - square test) ในการทดสอบวาเมทรกิซสหสัมพนัธทั้งสองเมทริกซไมแตกตางกนั โดยมี
สมมุติฐานหลกัทางสถิติดังตอไปนี้ H0: Σactual data = Σmodel หากไมปฏิเสธสมมุติฐานหลกั จึงสรุปได
วาโมเดลสอดคลองกับขอมลูเชิงประจักษ และโปรแกรมคอมพิวเตอรสําหรับการวิเคราะห SEM ทุก
โปรแกรมมีการทดสอบไค-สแควร พรอมทัง้คาดัชนีความสอดคลองดี (goodness of fit indices) อีกหลาย
ประเภท
5. วธิีการวิเคราะหอิทธพิล
การวิเคราะหอิทธิพล มีจุดมุงหมายเพื่อพัฒนาโมเดลความสัมพนัธเชงิสาเหตุระหวางตวัแปร
ศึกษาอทิธิพลทางตรง และอิทธิพลทางออม ระหวางตวัแปร และวิเคราะหตรวจสอบความตรงของทฤษฎ ี
หรือทดสอบความสอดคลองระหวางโมเดลที่พัฒนาข้ึนกับขอมูลเชิงประจักษ
วัตถุประสงคของการวิเคราะหอิทธพิลสรุปไดเปน 3 ประการ คือ 1) เพื่อทดสอบทฤษฎี 2) เพื่อ
พัฒนา (develop) และตรวจสอบความตรงของโมเดลเชิงสาเหตุ (causal model validation) และ 3) เพื่อ
ศึกษารูปแบบ โครงสราง ขนาด และทศิทางของอิทธพิลทัง้ทางตรงและทางออม เพื่ออธิบาย พยากรณ
และควบคุมปรากฏการณ
การดําเนินการวิเคราะหขอมูล ดําเนนิการเปนขั้นตอน ดังภาพ 4 โดยตองเริ่มตนจากการสราง
โมเดลตามทฤษฎี ซึ่งตองมีการศึกษาเอกสารที่เกี่ยวของกับการวิจัยอยางเขม การรวบรวมขอมูลเพื่อหา
เมทริกซสหสัมพันธจากขอมลูจริง การสรางสมการโครงสรางตามโมเดลเพื่อหาเมทริกซสหสมัพันธที่
คํานวณไดตามโมเดล การทดสอบเปรียบเทียบความแตกตางระหวางเมทริกซจากขอมูลและเมทริกซที่
คํานวณได หากผลการวิเคราะหพบวามีความแตกตางกนัอยางมีนยัสําคัญทางสถิติ แปลวาโมเดลไม

9
สอดคลองกับขอมูลเชิงประจักษ ตองปรบัเสนอิทธิพลในโมเดลที่เปนการผอนคลายขอตกลงเบื้องตน โดย
ไมควรปรับเสนทางอทิธพิลตามทฤษฎี แลววิเคราะหใหมอีกรอบหนึง่ หากผลการวิเคราะหพบวามีความ
แตกตางกนัอยางไมมีนยัสําคัญทางสถิติ แปลวาโมเดลสอดคลองกับขอมูลเชิงประจักษ ทฤษฎีมคีวามตรง
สามารถศึกษารูปแบบอิทธพิล และแปลความหมายอิทธิพลทางตรง ทางออมตอไป
ภาพ 4 ข้ันตอนการวเิคราะหอิทธพิล หรือการวิเคราะห SEM
ลักษณะขอมลูที่เหมาะสมสําหรับการวิเคราะหอิทธิพล คือ ตัวแปรควรเปนตัวแปรแบบเมตริก
(metric variable) หากเปนตัวแปรจัดประเภท (categorical or non-metric variable) ควรเปลี่ยนรูปเปน
ตัวแปรดัมมี่ หรือใชการวิเคราะห SEM โดยใชสหสัมพนัธที่เหมาะกับระดับการวัดของตัวแปร ในโปรแกรม
LISREL หรือโปรแกรมอื่นๆ นอกจากนี้นกัวิจยัตองตรวจสอบขอตกลงเบื้องตนกอนการวิเคราะหขอมูล
ขอตกลงเบื้องตนที่สําคัญ ไดแก 1) ความสัมพันธทางเดียว แบบเสนตรงและแบบบวก 2) เทอม
ความคลาดเคลื่อน (error) มีการกระจายโคงปกติ มีความแปรปรวนคงที่ (homoscedascity) 3) เทอม
ความคลาดเคลื่อนเปนอิสระระหวางหนวยการวิเคราะห และระหวางตวัแปร (independent error across
cases, and across variables) 4) กรณีการวิเคราะหอิทธพิลแบบไมมีตัวแปรแฝง ตัวแปรทกุตวัตองไมมี
ความคลาดเคลื่อนในการวัด (measurement error) 5) ขอมูลในการวิเคราะหไมมีปญหาภาวะรวม
เสนตรงพห ุ(multicollinearity) และ 6) โมเดลเปนโมเดลเชิงสาเหตุแบบปด (casual closure model)
โดยที่บทความนี้มุงนาํเสนอสารระสําคญัเกี่ยวกับการวิเคราะหอิทธิพล เพื่อเปนพืน้ฐานใน
การศึกษาตอไป ผูเขียนจึงนําเสนอแตหลกัการและวธิีการสําคัญตามขั้นตอนการวิเคราะหเทานั้น มิได
แสดงตัวอยางการวิเคราะหอิทธิพล แตไดนําเสนอตวัอยางการวิเคราะหขอมูลที่ใชการวิเคราะหอิทธิพล
กรณีโมเดลแบบไมมีตัวแปรแฝง ในรูปสไลด power point ไวใชคูกับเอกสารฉบับนี ้ สวนการวิเคราะห
ขอมูลโดยใชโปรแกรม LISREL มีรายละเอียดอีกมาก จึงมิไดนําเสนอในที่นี ้ สําหรับตัวอยางงานวิจัยนั้น
โมเดล fit โมเดลไม fit
โมเดลสมการโครงสราง
การศึกษาทฤษฎีและงานวิจัย
การรวบรวมขอมูล
เมทริกซที่คํานวณได เมทริกซจากขอมูล
สรุป และแปลความหมาย

10
ปจจุบันมีรายงานวิจยัของตางประเทศและรายงานวิจยัของไทยจํานวนมากที่ใชการวิเคราะห SEM ซึ่ง
ผูสนใจสามารถศึกษาติดตามได งานวิจัยของไทยทีเ่ปนโมเดลแบบมีตัวแปรแฝง โมเดลระยะยาว โมเดล
กลุมพหุ โมเดลโคงพัฒนาการ ไดแก งานวิจัยของ งามตา วนนิทานนท (2548) ประสิทธิ์ ไชยกาล (2539)
มนตทวิา ไชยแกว (2542) วรรณี แกมเกตุ (2540) วารณีุ ลัภนโชคด ี(2540) สังวรณ งัดกระโทก (2541)
เปนตน
เอกสารอางอิง งามตา วนนิทานนท. (2548). ปจจัยเชิงเหตุสําคัญของความสาํเร็จในชีวิตสมรส. วารสารจิตพฤติกรรม-
ศาสตร: ระบบพฤติกรรมไทย. 2(1): 8-37.
นงลกัษณ วิรัชชัย. (2533). การวิเคราะหอิทธิพล (Path Analysis) วารสารการวัดผลการศึกษา.
11 (33): 39-50.
นงลกัษณ วิรัชชัย. (2541). ความไมแปรเปลี่ยนของแบบจําลองการเปนสมาชิกดวยใจรักของครูระหวาง
บุคคลากร 2 กลุม: การประยุกต ใชการสรางแบบจําลองสมการโครงสรางชนิดกลยทุธกลุมพห ุ
วารสารสํานักงานคณะกรรมการวจิยัแหงชาติ. 30(1/2): 117-134.
ประสิทธิ์ ไชยกาล. (2539). การเปรียบเทยีบประสิทธิภาพระหวางโมเดลลิสเรล 3 แบบที่ใชในการศึกษา
ตัวแปรที่สัมพนัธกับการเปลีย่นแปลงในระยะยาวของผลสัมฤทธิ์ทางการเรียนวิชาคณิตศาสตร.
วิทยานิพนธปริญญามหาบณัฑิต ภาควิชาวิจัยการศึกษา จฬุาลงกรณมหาวิทยาลยั.
มนตทวิา ไชยแกว. (2542). การเปรียบเทยีบผลการเปลีย่นแปลงระยะยาวโดยใชโมเดลประยุกตโคง
พัฒนาการที่มตัีวแปรแฝงเมือ่มีอัตราการขาดหายของขอมูล ชวงเวลาการวัด และจาํนวนครั้งทีว่ัด
แตกตางกนั. วิทยานิพนธปริญญามหาบณัฑิต ภาควิชาวิจัยการศึกษา จฬุาลงกรณมหาวิทยาลยั.
วรรณี แกมเกตุ. (2540). การพัฒนาตัวบงชี้ประสิทธิภาพการใชครู: การประยุกตใชโมเดลสมการ
โครงสรางกลุมพหุและโมเดลเอ็มทีเอ็มเอม็. วิทยานิพนธปริญญาดุษฏีบัณฑิต ภาควิชาวจิัยการ
ศึกษา จฬุาลงกรณมหาวทิยาลัย
วารุณี ลัภนโชคดี. (2540). การวิเคราะหอิทธิพลปฏิสัมพันธที่มีตัวแปรปรับหนึ่งตวัโดยใชกลยุทธกลุมพห ุ
ในลิสเรล. วทิยานพินธปริญญามหาบัณฑติ ภาควิชาวิจยัการศึกษา จฬุาลงกรณมหาวทิยาลยั.
สังวรณ งัดกระโทก. (2541). การใชโมเดลสมการโครงสรางพหุระดับตรวจสอบ ความตรงของโมเดล
สมการโครงสรางแสดงความสัมพนัธระหวางปจจัยครู ปจจัยโรงเรียน กับความพึงพอใจในการ
ปฏิบัติงานของครู. วิทยานพินธปริญญามหาบัณฑิต ภาควิชาวิจัยการศึกษา จฬุาลงกรณ
มหาวิทยาลยั.
อิทธิพงษ ต้ังสกุลเรืองไล. (2541). การเปรียบเทียบประสิทธิภาพของโมเดลโคงพฒันาการที่มีตัวแปรแฝง
4 รูป ในการศึกษาการเปลี่ยนแปลงระยะยาวของการพฒันาการทางกาย และผลสมัฤทธิ์ทางการ

11
เรียนคณิตศาสตรของนักเรยีนประถมศึกษา. วทิยานพินธปริญญามหาบัณฑิต ภาควิชาวิจัย
การศึกษา จฬุาลงกรณมหาวทิยาลยั.
Blalock, H.M. (1964). Causal Inferences in Nonexperimental Research. Chapel Hill: University of North Carolina Press.
Bollen, K.A. (1989). Structural Equations with Latent Variables. New York: John Wiley & Sons. Duncan, O.D. (1996). Path analysis: sociological examples. American Journal of
Sociology. 72:1-16. Goldstein, H. (1987). Multilevel Models in Educational and Social Research. London:
Oxford University Press. Jaccard, J. and Wan, C.K. (1996). Lisrel Approaches to Interaction Effects in Multiple
Regression Thousand Gaks: Sage Publications. Joreskog, K.G. and Sorbom, D. (1989). LISREL 7 : User’s Reference Guide. Chicago
:Scientific Software, Inc. Joreskog, K.G. and Sorbom, D. (1993). LISREL 8 : User’s Reference Guide. Chicago
:Scientific Software, Inc. Muthen, B. (1987). LISCOMP: Analysis of Linear Structural Equations with a
Comprehensive Measurement Models. Mooresville: Scientific Software, Inc.. Nygreen, G.T. (1971) Interactive Path analysis. American Sociologist. 6:37-43. Pedhazur, E.J. (1982). Multiple Regression in Behavioral Research. New York: Holt,
Rinehart and Winston. Saris, W.E. and Stronkhorst, L.H. (1984). Causal Modeling in Non experimental
Research : An Introduction to the LISREL Approach. Amsterdam: Sociometric Research Foundations.


















