
Parallel Sparse Matrix Indexing and Assignmentgilbert/cs240a/old/cs240aSpr2011/slides/...Parallel...
15
1 Parallel Sparse Matrix Indexing and Assignment Aydın Buluç Lawrence Berkeley Na4onal Laboratory John R. Gilbert University of California, Santa Barbara
Transcript of Parallel Sparse Matrix Indexing and Assignmentgilbert/cs240a/old/cs240aSpr2011/slides/...Parallel...

1
Parallel Sparse Matrix Indexing and Assignment
Aydın Buluç Lawrence Berkeley Na4onal Laboratory John R. Gilbert University of California, Santa Barbara
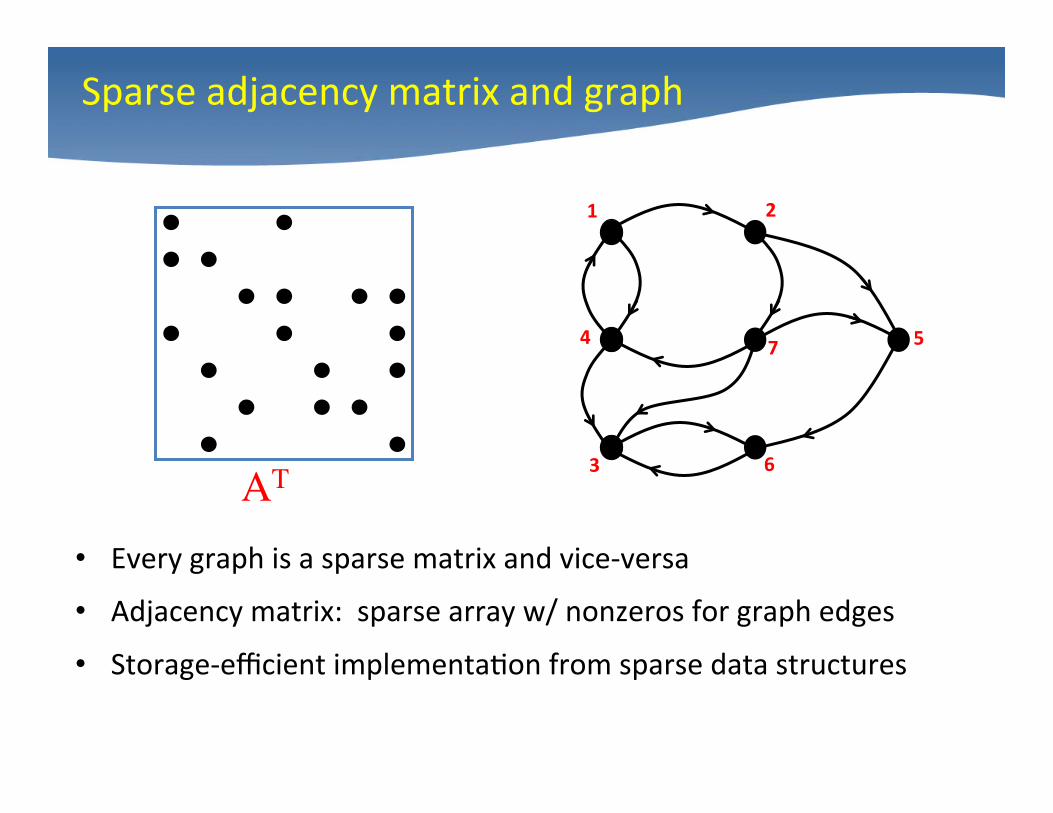
• Every graph is a sparse matrix and vice-‐versa
• Adjacency matrix: sparse array w/ nonzeros for graph edges
• Storage-‐efficient implementa4on from sparse data structures
x
1 2
3
4 7
6
5
AT
à
Sparse adjacency matrix and graph
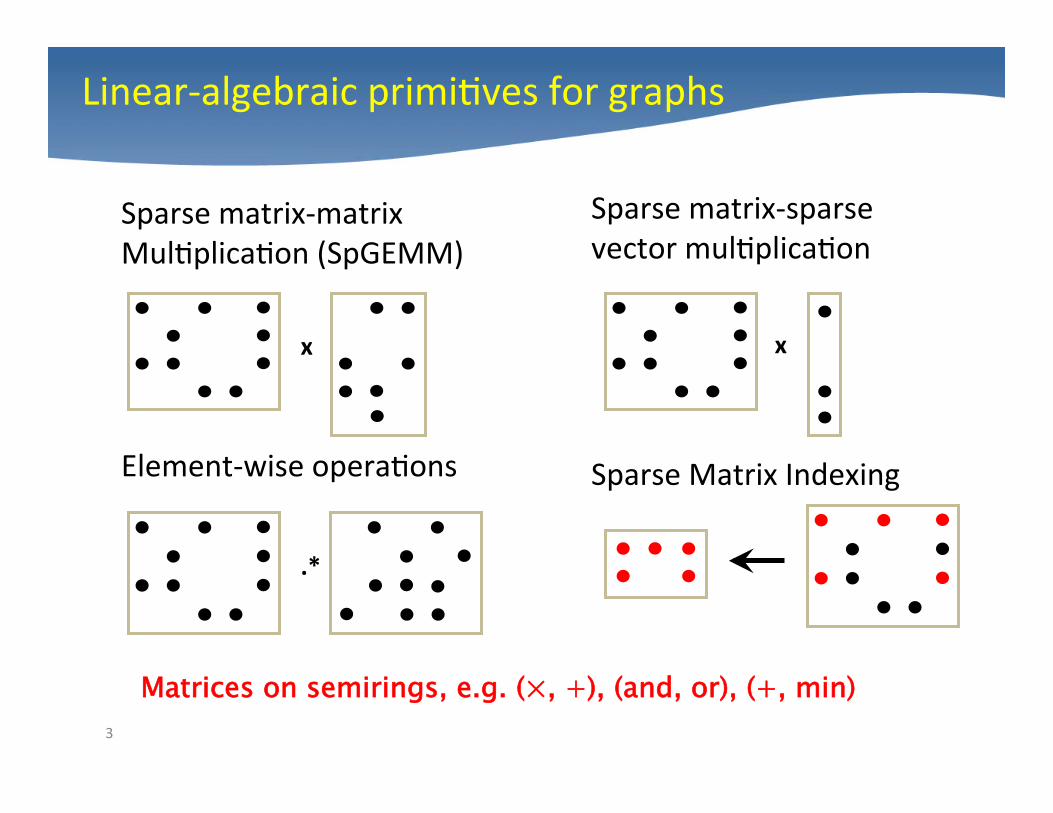
Sparse matrix-‐matrix Mul4plica4on (SpGEMM)
Element-‐wise opera4ons
3
x
Matrices on semirings, e.g. (×, +), (and, or), (+, min)
Sparse matrix-‐sparse vector mul4plica4on
Sparse Matrix Indexing
x
.*
Linear-‐algebraic primi4ves for graphs
4
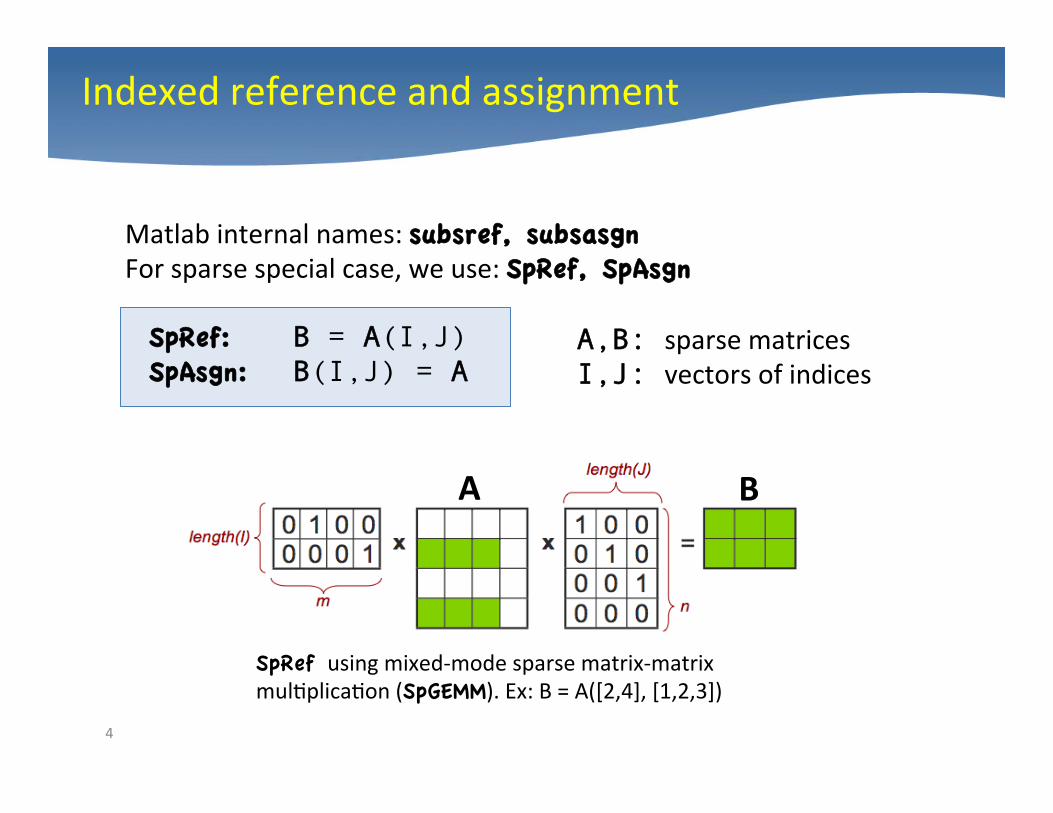
Indexed reference and assignment
Matlab internal names: subsref, subsasgn For sparse special case, we use: SpRef, SpAsgn
SpRef: B = A(I,J) SpAsgn: B(I,J) = A
A,B: sparse matrices I,J: vectors of indices
SpRef using mixed-‐mode sparse matrix-‐matrix mul4plica4on (SpGEMM). Ex: B = A([2,4], [1,2,3])
A B

5
Why are SpRef/SpAsgn important?
Subscrip4ng and colon nota4on: ⇒ Batched and vectorized opera4ons ⇒ High Performance and parallelism.
A=rmat(15) A(r,r) : r random A(r,r) : r=symrcm(A)
− Load balance hard ± Some locality
+ Load balance easy − No locality
− Load balance hard + Good locality
6
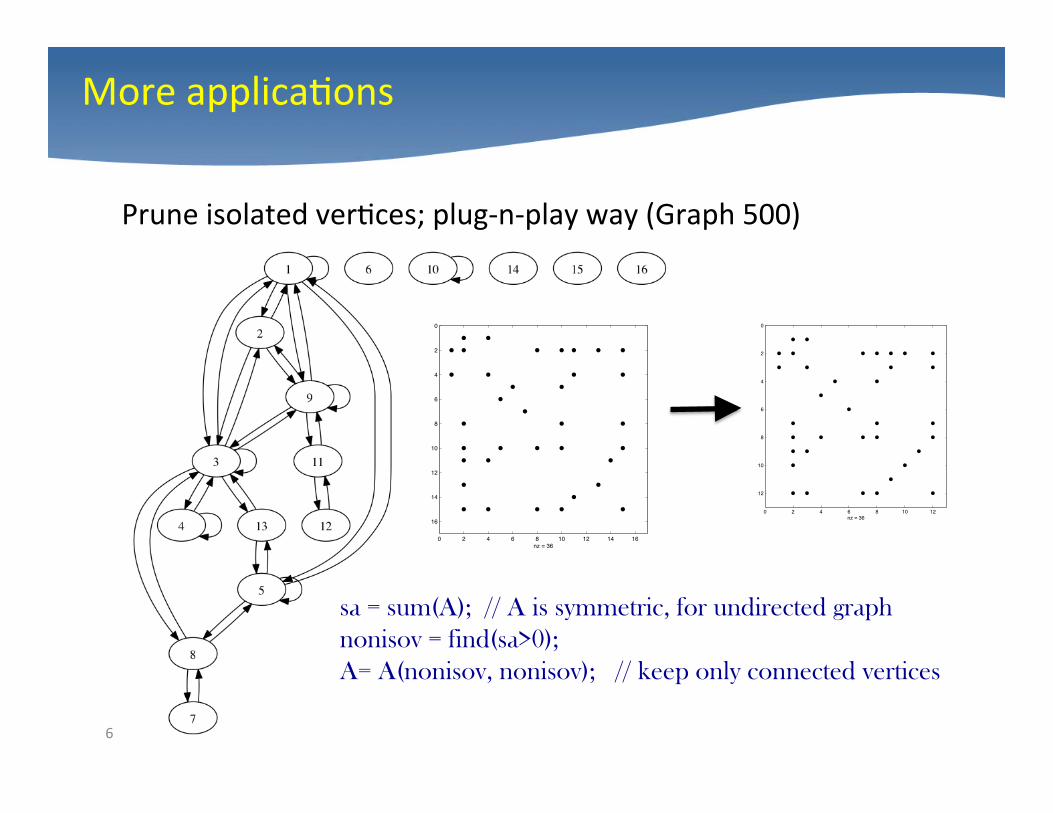
More applica4ons
Prune isolated ver4ces; plug-‐n-‐play way (Graph 500)
0 2 4 6 8 10 12 14 16
0
2
4
6
8
10
12
14
16
nz = 36
0 2 4 6 8 10 12
0
2
4
6
8
10
12
nz = 36
sa = sum(A); // A is symmetric, for undirected graph nonisov = find(sa>0); A= A(nonisov, nonisov); // keep only connected vertices
7
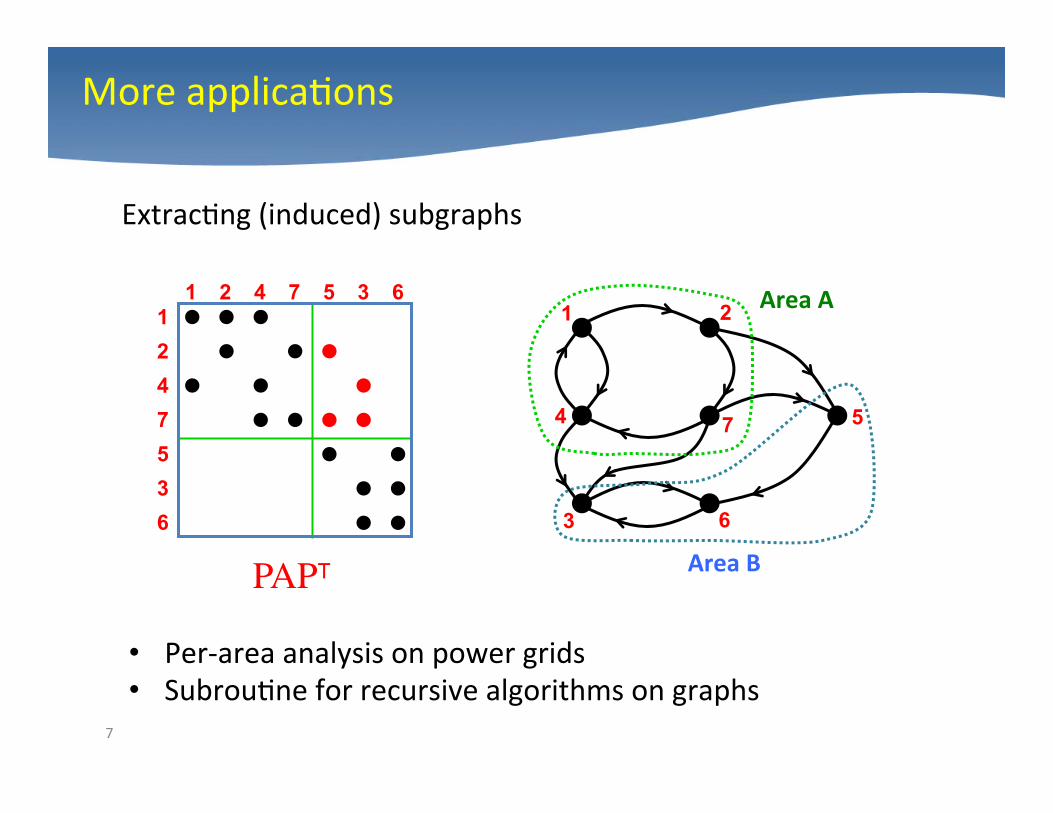
More applica4ons
Extrac4ng (induced) subgraphs
1 2
3
4 7
6
5
1 5 2 4 7 3 6 1
5
2 4 7
3 6
PAPT
Area A
Area B
• Per-‐area analysis on power grids • Subrou4ne for recursive algorithms on graphs

8
Sequen4al algorithms
function B = spref(A,I,J) !R = sparse(1:length(I),I,1,length(I),size(A,1)); !Q = sparse(J,1:length(J),1,size(A,2),length(J)); !B = R*A*Q;!
Tspref = flops(R !A)+ flops(RA !Q) = nnz(R !A)+ nnz(RA !Q) =O(nnz(A))
function C = spasgn(A,I,J,B) ![ma,na] = size(A);![mb,nb] = size(B);!R = sparse(I,1:mb,1,ma,mb);!Q = sparse(1:nb,J,1,nb,na);!S = sparse(I,I,1,ma,ma);!T = sparse(J,J,1,na,na);!C = A + R*B*Q - S*A*T;!
A+0 0 00 B 00 0 0
!
"
###
$
%
&&&'
0 0 00 A(I, J ) 00 0 0
!
"
###
$
%
&&&
Tspasgn =O(nnz(A))
9
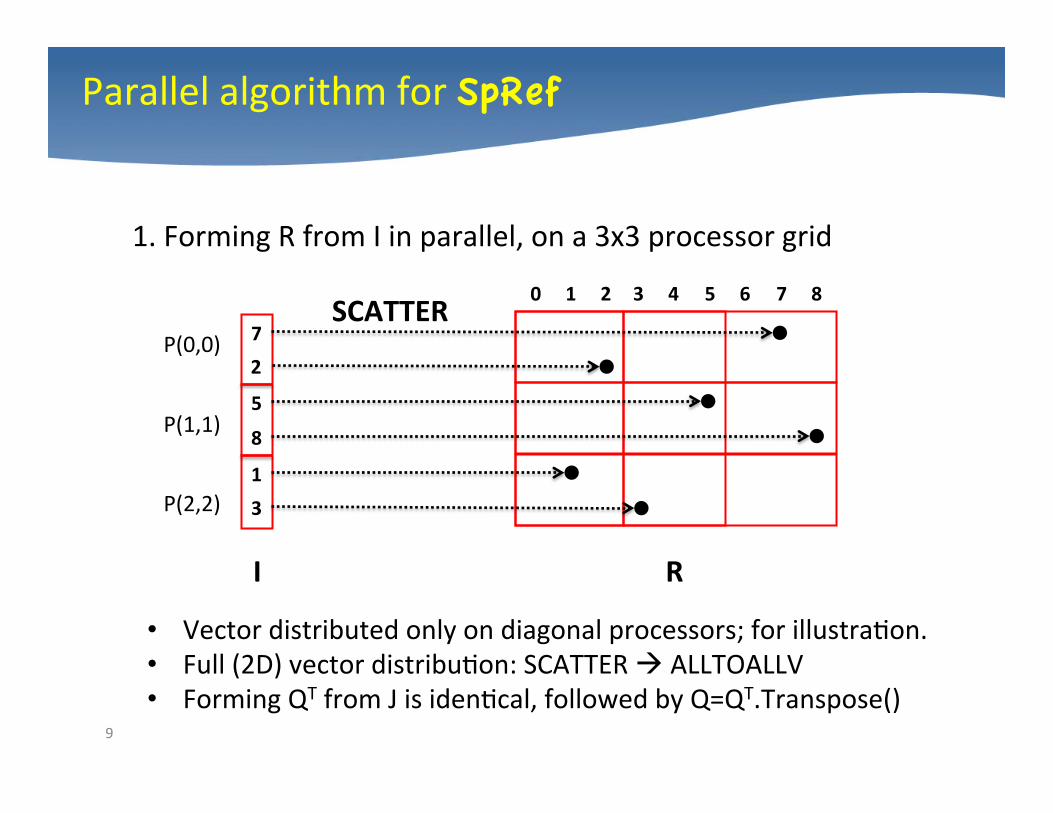
Parallel algorithm for SpRef
1. Forming R from I in parallel, on a 3x3 processor grid
7 2
5
8
1 3
I R
P(0,0)
P(1,1)
P(2,2)
0 2 1 3 5 4 6 8 7 SCATTER
• Vector distributed only on diagonal processors; for illustra4on. • Full (2D) vector distribu4on: SCATTER à ALLTOALLV • Forming QT from J is iden4cal, followed by Q=QT.Transpose()
10
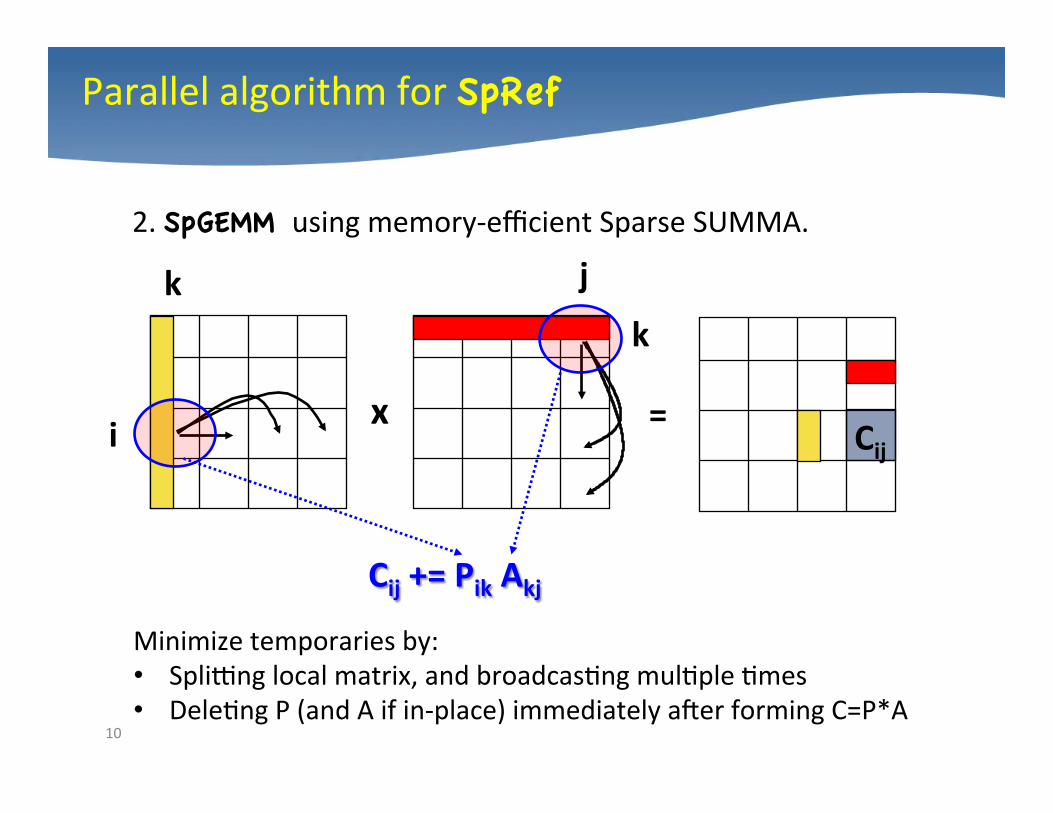
Parallel algorithm for SpRef
2. SpGEMM using memory-‐efficient Sparse SUMMA.
Minimize temporaries by: • Splilng local matrix, and broadcas4ng mul4ple 4mes • Dele4ng P (and A if in-‐place) immediately amer forming C=P*A
j
x = i
k k
Cij
Cij += Pik Akj
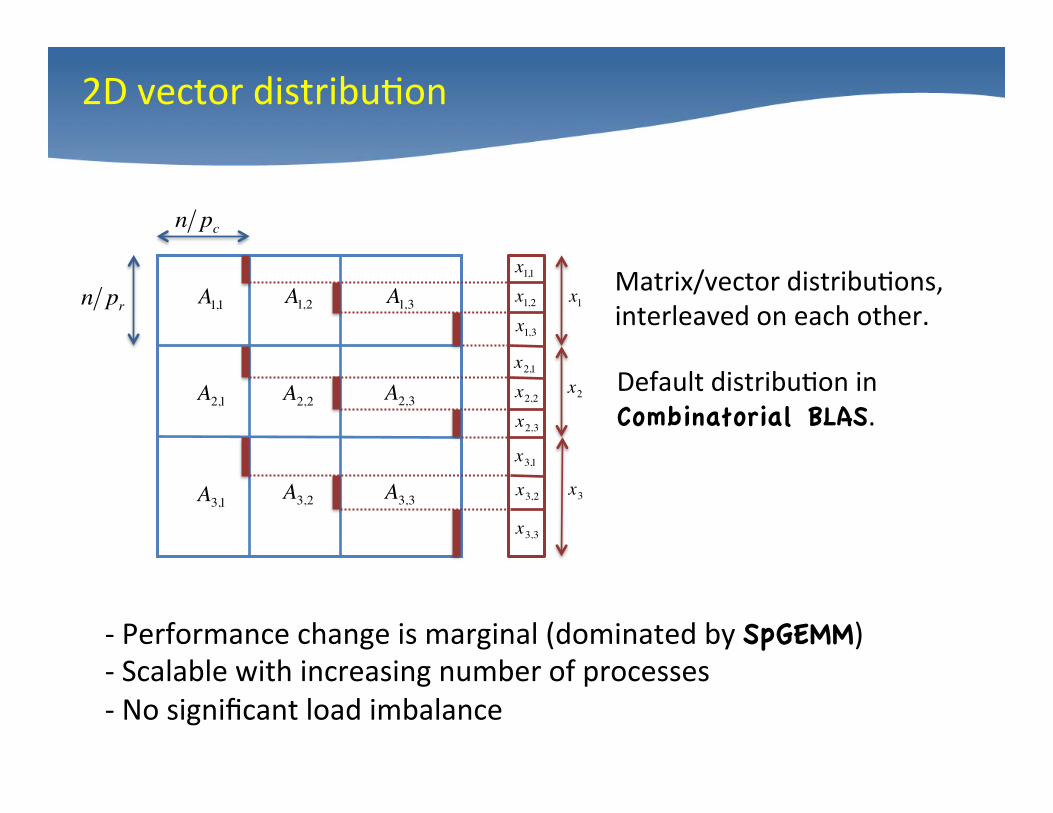
Matrix/vector distribu4ons, interleaved on each other.
5
8
!
x1
!
x1,1
!
x1,2
!
x1,3
!
x2,1
!
x2,2
!
x2,3
!
x3,1
!
x3,2
!
x3,3
!
x2
!
x3
!
A1,1
!
A1,2
!
A1,3
!
A2,1
!
A2,2
!
A2,3
!
A3,1
!
A3,2
!
A3,3
!
n pr!
n pc
2D vector distribu4on
-‐ Performance change is marginal (dominated by SpGEMM) -‐ Scalable with increasing number of processes -‐ No significant load imbalance
Default distribu4on in Combinatorial BLAS.

Complexity analysis
Assump4ons: -‐ The triple product is evaluated from lem to right: B=(R*A)*Q -‐ Nonzeros uniformly distributed to processors (chicken-‐egg?)
Dominated by SpGEMM Bopleneck: bandwidth costs Speedup:
!
" p( )
Tcomp ! "nnz(A)p
# log length(I )p
+length(J )
p+ p
$
%&
'
()
$
%&
'
()
Tcomm =! ! " p +" " nnz(A)p
#
$%%
&
'((
SpGEMM:
Matrix formaDon:
! ! " log(p)+" " length(I )+ length(J )p
#
$%%
&
'((
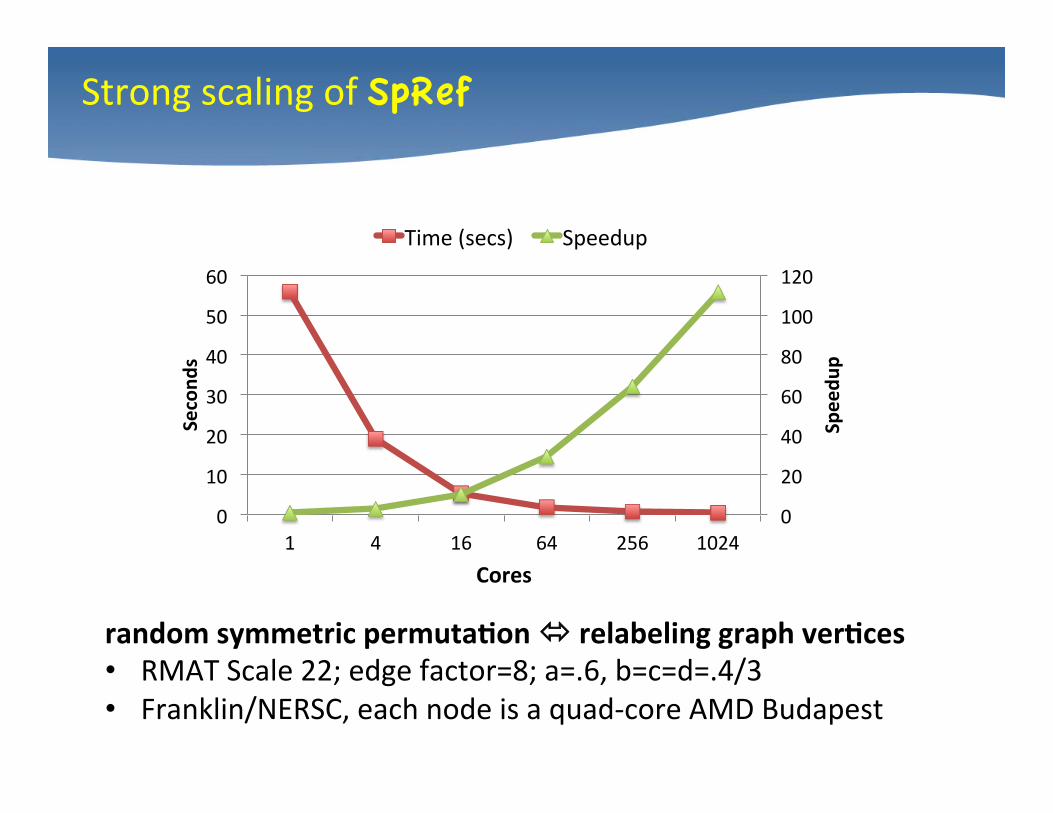
Strong scaling of SpRef
random symmetric permutaDon ó relabeling graph verDces • RMAT Scale 22; edge factor=8; a=.6, b=c=d=.4/3 • Franklin/NERSC, each node is a quad-‐core AMD Budapest
0
20
40
60
80
100
120
0
10
20
30
40
50
60
1 4 16 64 256 1024
Speedu
p
Second
s
Cores
Time (secs) Speedup
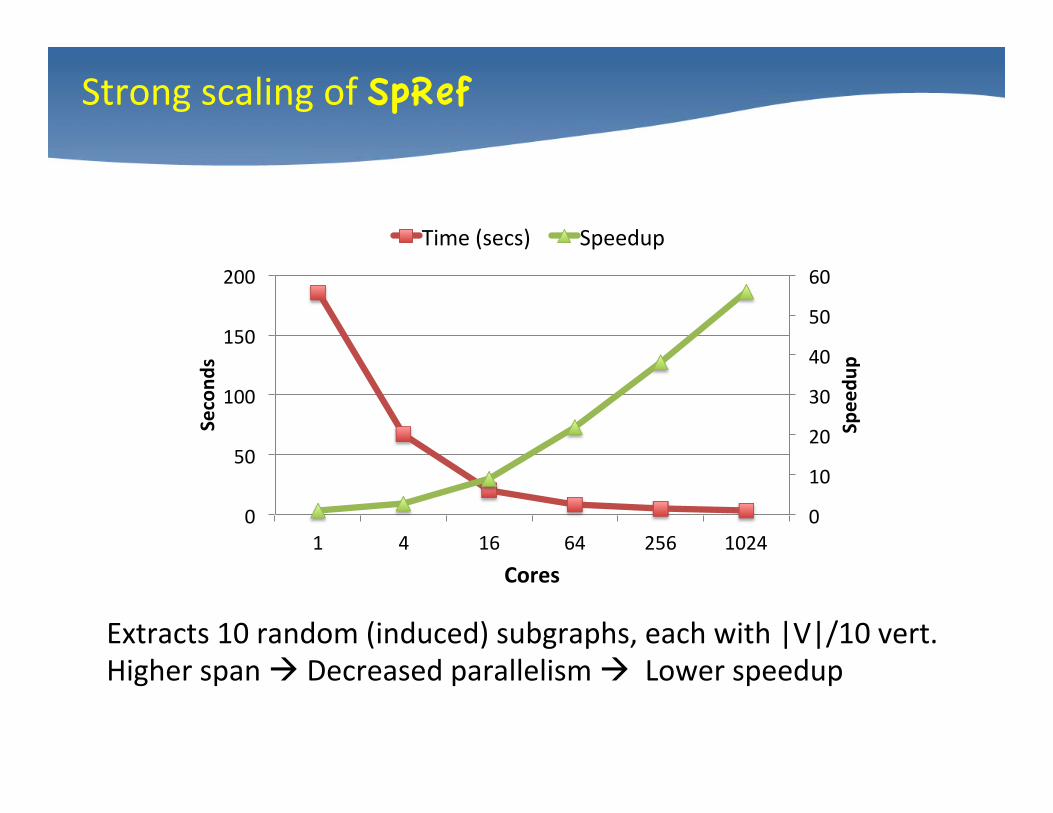
Strong scaling of SpRef
Extracts 10 random (induced) subgraphs, each with |V|/10 vert. Higher span à Decreased parallelism à Lower speedup
0
10
20
30
40
50
60
0
50
100
150
200
1 4 16 64 256 1024
Speedu
p
Second
s
Cores
Time (secs) Speedup

Conclusions
• Parallel algorithms for SpRef and SpAsgn • Systemic algorithm structure imposed by SpGEMM • Analysis made possible for the general case • Good strong scaling for 1000-‐way concurrency • Many applica4ons on sparse matrix and graph world.
Caveat: Avoid load imbalance by indexing non-‐monotonically
I =
134678
!
"
#######
$
%
&&&&&&&
I =
738164
!
"
#######
$
%
&&&&&&&


















![FastQuery: A Parallel Indexing System for Scientific DataMany of the parallel and distributed indexing techniques are derived from the B-Tree [1]. These parallel trees support only](https://static.fdocuments.us/doc/165x107/611e0243a48743664c5e4ce9/fastquery-a-parallel-indexing-system-for-scientiic-data-many-of-the-parallel.jpg)