
Overview: Efficient Parallel Computing - Virginia...
25
1/30/09 1 Prof. Wu FENG, [email protected], 540-231-1192 Depts. of Computer Science and Electrical & Computer Engineering © W. Feng, January 2009 synergy.cs.vt.edu Overview: Efficient Parallel Computing • Interdisciplinary – Approaches: Experimental, Simulative, and Theoretical – Abstractions: Systems Software, Middleware, Applications • Synergistic Research Sampling – Emerging Chip Multiprocessors: Multicore, GPUs, Cell / PS3 • Performance Analysis & Optimization: Systems & Applications – Automated Process-to-Core Mapping: SyMMer – Mixin Layers & Concurrent Mixin Layers (Tilevich) – Green Supercomputing: EcoDaemon & Green500 – Pairwise Sequence Search: BLAST and Smith-Waterman – Episodic Data Mining (Ramakrishnan, Cao) – Electrostatic Potential (Onufriev) IP2M Award
Transcript of Overview: Efficient Parallel Computing - Virginia...
1/30/09
1
Prof. Wu FENG, [email protected], 540-231-1192 Depts. of Computer Science and Electrical & Computer Engineering
© W. Feng, January 2009
synergy.cs.vt.edu
Overview: Efficient Parallel Computing • Interdisciplinary
– Approaches: Experimental, Simulative, and Theoretical – Abstractions: Systems Software, Middleware, Applications
• Synergistic Research Sampling – Emerging Chip Multiprocessors: Multicore, GPUs, Cell / PS3
• Performance Analysis & Optimization: Systems & Applications – Automated Process-to-Core Mapping: SyMMer – Mixin Layers & Concurrent Mixin Layers (Tilevich) – Green Supercomputing: EcoDaemon & Green500 – Pairwise Sequence Search: BLAST and Smith-Waterman – Episodic Data Mining (Ramakrishnan, Cao) – Electrostatic Potential (Onufriev)
IP2M Award

1/30/09
2
synergy.cs.vt.edu
Overview: Efficient Parallel Computing • Interdisciplinary
– Approaches: Experimental, Simulative, and Theoretical – Abstractions: Systems Software, Middleware, Applications
• Synergistic Research Sampling – Hybrid Circuit- and Packet-Switched Networking
• Application-Awareness in Network Infrastructure: FAATE • Composable Protocols for
High-Performance Networking
synergy.cs.vt.edu
Overview: Efficient Parallel Computing • Interdisciplinary
– Approaches: Experimental, Simulative, and Theoretical – Abstractions: Systems Software, Middleware, Applications
• Synergistic Research Sampling – Large-Scale Bioinformatics
• mpiBLAST: Parallel Sequence Search – “Finding Missing Genes” in Genomes (Setubal)
• ParaMEDIC: Parallel Metadata Environment for Distributed I/O & Computing
www.mpiblast.org
Storage Challenge Award

1/30/09
3
synergy.cs.vt.edu
Overview: Efficient Parallel Computing • Interdisciplinary
– Approaches: Experimental, Simulative, and Theoretical – Abstractions: Systems Software, Middleware, Applications
• Synergistic Research Sampling – Virtual Computing for K-12 Pedagogy & Research (Gardner)
• Characterization & Optimization of Virtual Machines • Cybersecurity & Scalability: Private vs. Public Addresses
Best Undergraduate Student Poster Award
synergy.cs.vt.edu
The Synergy Lab (http://synergy.cs.vt.edu/)
• Ph.D. Students – Jeremy Archuleta – Marwa Elteir – Song Huang – Thomas Scogland – Sushant Sharma – Kumaresh Singh – Shucai Xiao
• M.S. Students – Ashwin Aji – Rajesh Gangam – Ajeet Singh
• B.S. Students – Jacqueline Addesa – William Gomez – Gabriel Martinez
• Faculty Collaborators – Kirk Cameron – Yong Cao – Mark Gardner – Alexey Onufriev – Dimitris Nikolopoulos – Naren Ramakrishnan – Adrian Sandu – João Setubal – Eli Tilevich

1/30/09
4
Prof. Wu FENG, [email protected], 540-231-1192 Depts. of Computer Science and Electrical & Computer Engineering
© W. Feng, January 2009
synergy.cs.vt.edu
Why Green Supercomputing? • Premise
– We need horsepower to compute but horsepower also translates to electrical power consumption.
• Consequences – Electrical power costs $$$$. – “Too much” power affects efficiency, reliability, availability.
• Idea – Autonomic energy and power savings while maintaining
performance in the supercomputer or datacenter. • Low-Power Approach: Power Awareness at Integration Time • Power-Aware Approach: Power Awareness at Run Time Wall Street Journal, January 29, 2007
Green Destiny: Low-Power Supercomputer
Green Destiny “Replica”: Traditional Supercomputer
Only Difference? The Processors
© W. Feng, Mar. 2007

1/30/09
5
synergy.cs.vt.edu
Outline
• Motivation & Background – Where is High-End Computing (HEC)? – The Need for Efficiency, Reliability, and Availability
• Supercomputing in Small Spaces (http://sss.cs.vt.edu/) – Distant Past: Green Destiny (2001-2002) – Recent Past to Present: Evolution of Green Destiny (2003-2007)
• Architectural – MegaScale, Orion Multisystems, IBM Blue Gene/L
• Software-Based – EnergyFit™: Power-Aware Run-Time System (β adaptation)
• Conclusion and Future Work
synergy.cs.vt.edu
Where is High-End Computing?
We have spent decades focusing on performance, performance, performance
(and price/performance).

1/30/09
6
synergy.cs.vt.edu
Where is High-End Computing? TOP500 Supercomputer List
• Benchmark – LINPACK: Solves a (random) dense system of linear
equations in double-precision (64 bits) arithmetic. • Introduced by Prof. Jack Dongarra, U. Tennessee & ORNL
• Evaluation Metric – Performance (i.e., Speed)
• Floating-Operations Per Second (FLOPS)
• Web Site – http://www.top500.org/
synergy.cs.vt.edu
Where is High-End Computing? Gordon Bell Awards at SC
• Metrics for Evaluating Supercomputers (or HEC) – Performance (i.e., Speed)
• Metric: Floating-Operations Per Second (FLOPS) – Price/Performance Cost Efficiency
• Metric: Acquisition Cost / FLOPS • Example: VT System X cluster
• Performance & price/performance are important metrics, but …

1/30/09
7
synergy.cs.vt.edu
Where is High-End Computing?
… more “performance” more horsepower more power consumption
less efficiency, reliability, and availability
synergy.cs.vt.edu
Where is High-End Computing?
… more “performance” more horsepower more power consumption
less efficiency, reliability, and availability

1/30/09
8
synergy.cs.vt.edu
Moore’s Law for Power Consumption?
1
10
100
1000
1.5µ 1µ 0.7µ 0.5µ 0.35µ 0.25µ 0.18µ 0.13µ 0.1µ 0.07µ
I386 I486
Pentium
Pentium Pro Pentium II
Pentium III
Chip Maximum Power in watts/cm2
Surpassed Heating Plate
Surpassed Nuclear Reactor
2004
Pentium 4 (Willamette)
1985 1995 2001
Pentium 4 (Prescott)
Source: Intel
Rocket Nozzle
Year
synergy.cs.vt.edu
Where is High-End Computing?
… more “performance” more horsepower more power consumption
less efficiency, reliability, and availability

1/30/09
9
synergy.cs.vt.edu
Efficiency of HEC Systems • “Performance” and “Price/Performance” Metrics …
– Lower efficiency, reliability, and availability. – Higher operational costs, e.g., admin, maintenance, etc.
• Examples – Computational Efficiency
• Relative to Peak: Actual Performance/Peak Performance • Relative to Space: Performance/Sq. Ft. • Relative to Power: Performance/Watt
– Performance: 10,000-fold increase (since the Cray C90). • Performance/Sq. Ft.: Only 65-fold increase. • Performance/Watt: Only 300-fold increase.
– Massive construction and operational costs associated with powering and cooling.
synergy.cs.vt.edu
Reliability & Availability of HEC Systems
Systems CPUs Reliability & Availability
ASCI Q 8,192 MTBF: 6.5 hrs. 114 unplanned outages/month. – HW outage sources: storage, CPU, memory.
ASCI White
8,192 MTBF: 5 hrs. (2001) and 40 hrs. (2003). – HW outage sources: storage, CPU, 3rd-party
HW. PSC Lemieux
3,016 MTBF: 9.7 hrs. Availability: 98.33%.
Google (projected from 2003)
~450,000 ~550 reboots/day; 2-3% machines replaced/yr. – HW outage sources: storage, memory.
Availabiliity: ~100%.

1/30/09
10
synergy.cs.vt.edu
Ubiquitous Need for Efficiency, Reliability, and Availability • Requirement: Near-100% availability with efficient
and reliable resource usage. – E-commerce, enterprise apps, online services, ISPs, data
and HPC centers supporting R&D. • Problems
– Frequency of Service Outages • 65% of IT managers report that their web sites were
unavailable to customers over a 6-month period. – Cost of Service Outages
• NYC stockbroker: $ 6,500,000 / hour • Amazon.com: $ 1,860,000 / hour • Ebay (22 hours): $ 225,000 / hour • Social Effects: negative press, loss of customers who “click
over” to competitor (e.g., Google vs. Ask Jeeves)
Adapted from David Patterson, IEEE IPDPS 2001
synergy.cs.vt.edu
Outline
• Motivation & Background – Where is High-End Computing (HEC)? – The Need for Efficiency, Reliability, and Availability
• Supercomputing in Small Spaces (http://sss.cs.vt.edu/) – Distant Past: Green Destiny (2001-2002) – Recent Past to Present: Evolution of Green Destiny (2003-2007)
• Architectural – MegaScale, Orion Multisystems, IBM Blue Gene/L
• Software-Based – EnergyFit™: Power-Aware Run-Time System (β adaptation)
• Conclusion and Future Work

1/30/09
11
synergy.cs.vt.edu
Supercomputing in Small Spaces Established 2001 at LANL. Now at Virginia Tech.
• Goals – Improve efficiency, reliability, and availability in large-scale
supercomputing systems (HEC, server farms, distributed systems) • Autonomic energy and power savings while maintaining performance in
a large-scale computing system. – Reduce the total cost of ownership (TCO).
• TCO = Acquisition Cost (“one time”) + Operation Cost (recurring) • Crude Analogy
– Today’s Supercomputer or Datacenter • Formula One Race Car: Wins raw performance but reliability is so poor
that it requires frequent maintenance. Throughput low. – “Supercomputing in Small Spaces” Supercomputer or Datacenter
• Toyota Camry: Loses raw performance but high reliability and efficiency results in high throughput (i.e., miles driven/month answers/month).
http://sss.cs.vt.edu/
synergy.cs.vt.edu
• A 240-Node Cluster in Five Sq. Ft. • Each Node
– 1-GHz Transmeta TM5800 CPU w/ High-Performance Code-Morphing Software running Linux 2.4.x
– 640-MB RAM, 20-GB hard disk, 100-Mb/s Ethernet
• Total – 240 Gflops peak (Linpack: 101 Gflops in March 2002.) – 150 GB of RAM (expandable to 276 GB) – 4.8 TB of storage (expandable to 38.4 TB) – Power Consumption: Only 3.2 kW (diskless)
• Reliability & Availability – No unscheduled downtime in 24-month lifetime.
• Environment: A dusty 85°-90° F warehouse!
Green Destiny Supercomputer (circa December 2001 – February 2002)
Featured in The New York Times, BBC News, and CNN. Now in the Computer History Museum.
2003 WINNER
Equivalent Linpack to a 256-CPU SGI Origin 2000
(On the TOP500 List at the time)
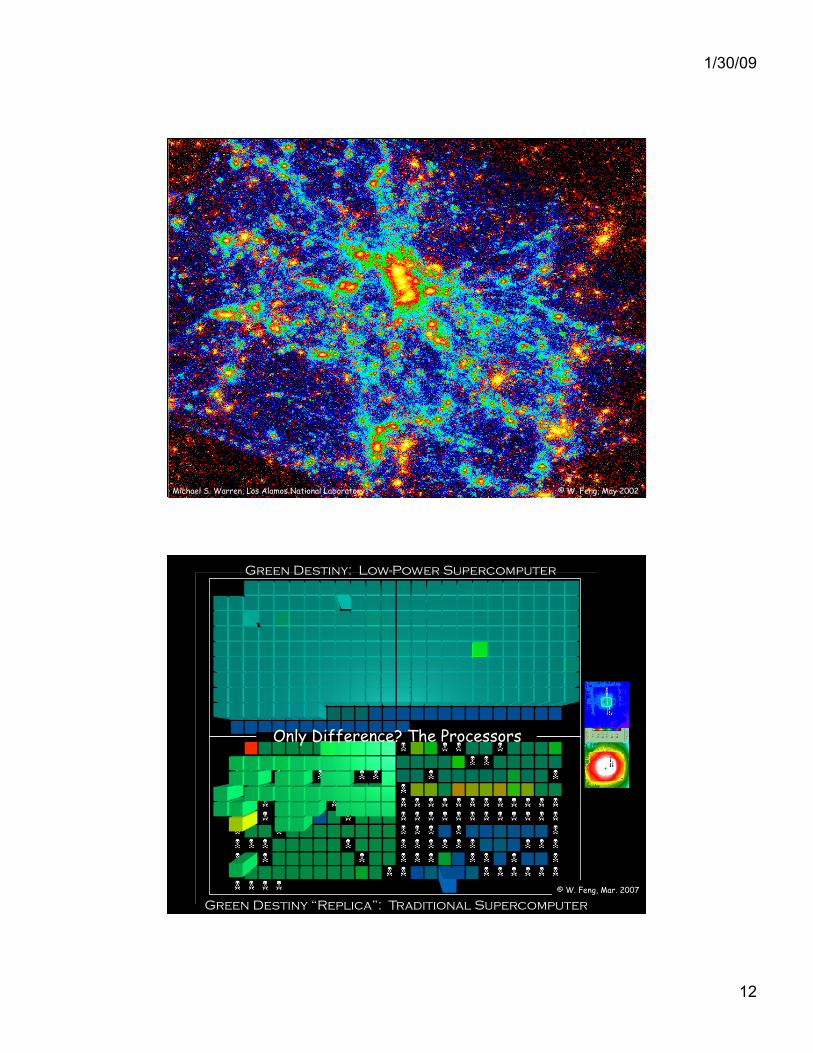
1/30/09
12
synergy.cs.vt.edu Michael S. Warren, Los Alamos National Laboratory © W. Feng, May 2002
Green Destiny: Low-Power Supercomputer
Green Destiny “Replica”: Traditional Supercomputer
Only Difference? The Processors
© W. Feng, Mar. 2007

1/30/09
13
synergy.cs.vt.edu
Machine Avalon Beowulf
ASCI Red
ASCI White
Green Destiny
Year 1996 1996 2000 2002 Performance (Gflops) 18 600 2500 58 Area (ft2) 120 1600 9920 5 Power (kW) 18 1200 2000 5 DRAM (GB) 36 585 6200 150 Disk (TB) 0.4 2.0 160.0 4.8 DRAM density (MB/ft2) 300 366 625 3000 Disk density (GB/ft2) 3.3 1.3 16.1 960.0 Perf/Space (Mflops/ft2) 150 375 252 11600 Perf/Power (Mflops/watt) 1.0 0.5 1.3 11.6
Parallel Computing Platforms Running an N-body Gravitational Code
synergy.cs.vt.edu
Yet in 2002 … • “Green Destiny is so low power that it runs just as fast
when it is unplugged.” • “The slew of expletives and exclamations that followed
Feng’s description of the system …” • “In HPC, no one cares about power & cooling, and no
one ever will …” • “Moore’s Law for Power will stimulate the economy by
creating a new market in cooling technologies.”

1/30/09
14
synergy.cs.vt.edu
Outline
• Motivation & Background – Where is High-End Computing (HEC)? – The Need for Efficiency, Reliability, and Availability
• Supercomputing in Small Spaces (http://sss.cs.vt.edu/) – Distant Past: Green Destiny (2001-2002) – Recent Past to Present: Evolution of Green Destiny (2003-2007)
• Architectural – MegaScale, Orion Multisystems, IBM Blue Gene/L
• Software-Based – EnergyFit™: Power-Aware Run-Time System (β adaptation) – EcoDaemon™: Power-Aware Operating System Daemon
• Conclusion and Future Work
Cluster Technology
Low-Power Systems Design
Linux
But in the form factor of a workstation …
a cluster workstation
© W. Feng, Aug. 2007

1/30/09
15
synergy.cs.vt.edu
• LINPACK Performance – 14 Gflops
• Footprint – 3 sq. ft. (24” x 18”) – 1 cu. ft. (24" x 4" x 18“)
• Power Consumption – 170 watts at load
• How does this compare with a traditional desktop?
synergy.cs.vt.edu Univ. of Tsukuba Booth @ SC2004, Nov. 2004.
Inter-University Project: MegaScale http://www.para.tutics.tut.ac.jp/megascale/

1/30/09
16
synergy.cs.vt.edu
Chip (2 processors)
Compute Card (2 chips, 2x1x1)
Node Card (32 chips, 4x4x2)
16 Compute Cards
System (64 cabinets, 64x32x32)
Cabinet (32 Node boards, 8x8x16)
2.8/5.6 GF/s 4 MB
5.6/11.2 GF/s 0.5 GB DDR
90/180 GF/s 8 GB DDR
2.9/5.7 TF/s 256 GB DDR
180/360 TF/s 16 TB DDR
October 2003 BG/L half rack prototype 500 Mhz 512 nodes/1024 proc. 2 TFlop/s peak 1.4 Tflop/s sustained © 2004 IBM Corporation
IBM Blue Gene/L Now the fastest supercomputer in the world.
synergy.cs.vt.edu
Outline
• Motivation & Background – Where is High-End Computing (HEC)? – The Need for Efficiency, Reliability, and Availability
• Supercomputing in Small Spaces (http://sss.cs.vt.edu/) – Distant Past: Green Destiny (2001-2002) – Recent Past to Present: Evolution of Green Destiny (2003-2007)
• Architectural – MegaScale, Orion Multisystems, IBM Blue Gene/L
• Software-Based – EnergyFit™: Power-Aware Run-Time System (β adaptation) – EcoDaemon™: Power-Aware Operating System Daemon
• Conclusion and Future Work
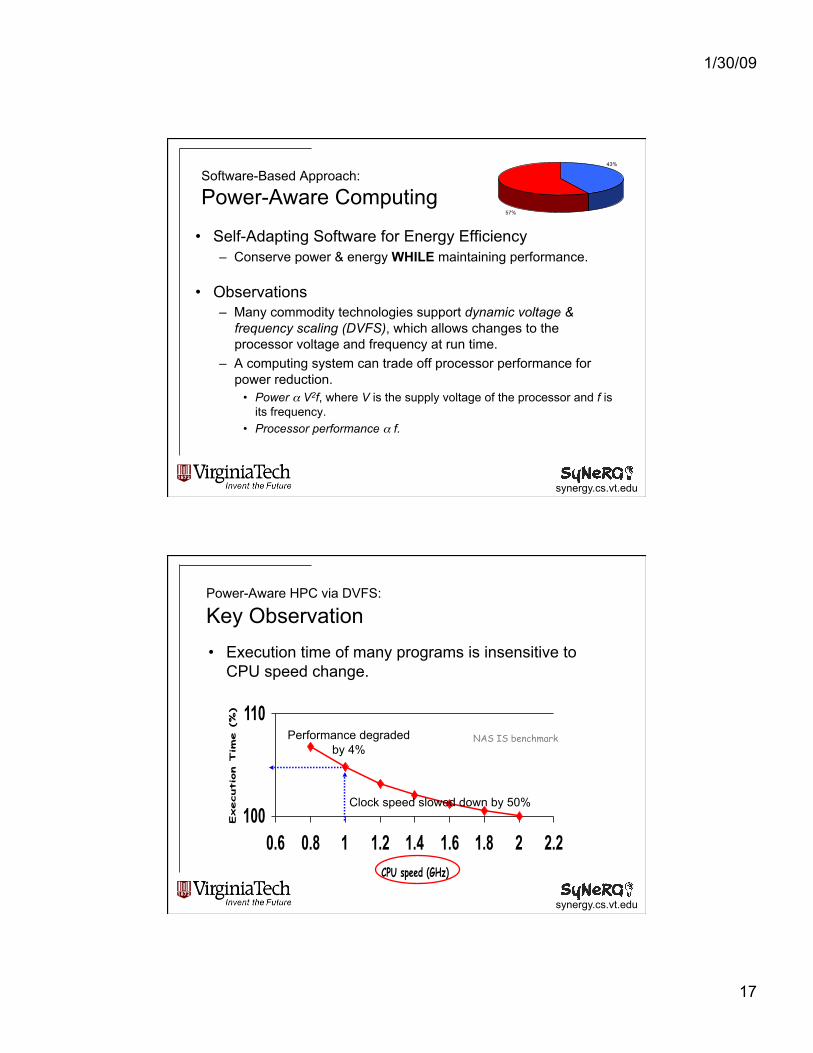
1/30/09
17
synergy.cs.vt.edu
Software-Based Approach:
Power-Aware Computing
• Self-Adapting Software for Energy Efficiency – Conserve power & energy WHILE maintaining performance.
• Observations – Many commodity technologies support dynamic voltage &
frequency scaling (DVFS), which allows changes to the processor voltage and frequency at run time.
– A computing system can trade off processor performance for power reduction.
• Power α V2f, where V is the supply voltage of the processor and f is its frequency.
• Processor performance α f.
57%
43%
synergy.cs.vt.edu
• Execution time of many programs is insensitive to CPU speed change.
Power-Aware HPC via DVFS: Key Observation
100
110
0.6 0.8 1 1.2 1.4 1.6 1.8 2 2.2
CPU speed (GHz)
Execution Tim
e (%)
Clock speed slowed down by 50%
Performance degraded by 4%
NAS IS benchmark
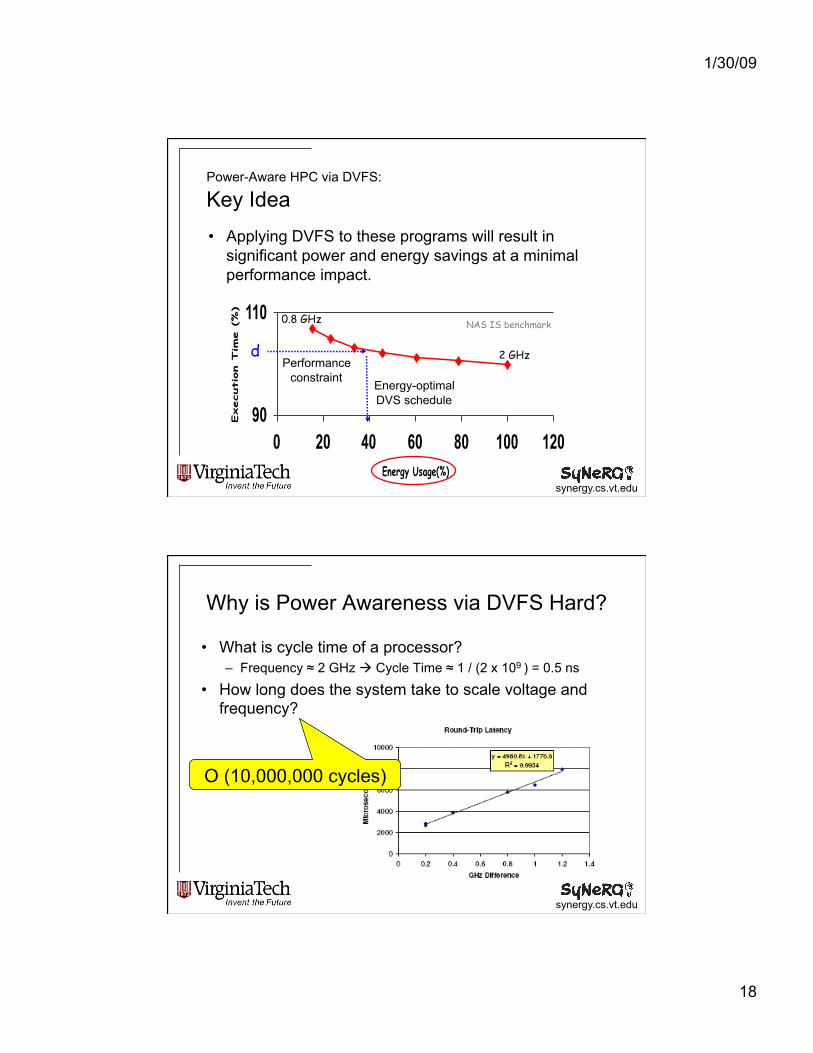
1/30/09
18
synergy.cs.vt.edu
• Applying DVFS to these programs will result in significant power and energy savings at a minimal performance impact.
Power-Aware HPC via DVFS: Key Idea
90
110
0 20 40 60 80 100 120
Energy Usage(%)
Execution Tim
e (%)
Performance constraint
Energy-optimal DVS schedule
d 2 GHz
0.8 GHz NAS IS benchmark
synergy.cs.vt.edu
Why is Power Awareness via DVFS Hard?
• What is cycle time of a processor? – Frequency ≈ 2 GHz Cycle Time ≈ 1 / (2 x 109 ) = 0.5 ns
• How long does the system take to scale voltage and frequency?
O (10,000,000 cycles)

1/30/09
19
synergy.cs.vt.edu
Problem Formulation: LP-Based Energy-Optimal DVFS Schedule
• Definitions – A DVFS system exports n { (fi, Pi ) } settings. – Ti : total execution time of a program running at setting i
• Given a program with deadline D, find a DVS schedule (t1*, …, tn*) such that – If the program is executed for ti seconds at setting i, the total energy
usage E is minimized, the deadline D is met, and the required work is completed.
synergy.cs.vt.edu
Performance Modeling
• Traditional Performance Model – T(f) = (1 / f) * W where T(f) (in seconds) is the execution time of a task running
at f and W (in cycles) is the amount of CPU work to be done.
• Problems? – W needs to be known a priori. Difficult to predict. – W is not always constant across frequencies. – It predicts that the execution time will double if the CPU speed
is cut in half. (Not so for memory & I/O-bound.)

1/30/09
20
synergy.cs.vt.edu
Single-Coefficient β Performance Model
• Our Formulation – Define the relative performance slowdown δ as T(f) / T(fMAX) – 1 – Re-formulate two-coefficient model
as a single-coefficient model:
– The coefficient β is computed at run-time using a regression method on the past MIPS rates reported from the built-in PMU.
C. Hsu and W. Feng. “A Power-Aware Run-Time System for High-Performance Computing,” SC|05, Nov. 2005.
synergy.cs.vt.edu
Current DVFS Scheduling Algorithms
• 2step (i.e., CPUSPEED via SpeedStep): – Using a dual-speed CPU, monitor CPU utilization periodically. – If utilization > pre-defined upper threshold, set CPU to fastest; if utilization <
pre-defined lower threshold, set CPU to slowest. • nqPID: A refinement of the 2step algorithm.
– Recognize the similarity of DVFS scheduling and a classical control-systems problem Modify a PID controller (Proportional-Integral-Derivative) to suit DVFS scheduling problem.
• freq: Reclaims the slack time between the actual processing time and the worst-case execution time.
– Track the amount of remaining CPU work Wleft and the amount of remaining time before the deadline Tleft.
– Set desired CPU frequency at each interval to fnew = Wleft / Tleft. – The algorithm assumes that the total amount of work in CPU cycles is known a
priori, which, in practice, is often unpredictable and not always a constant across frequencies.
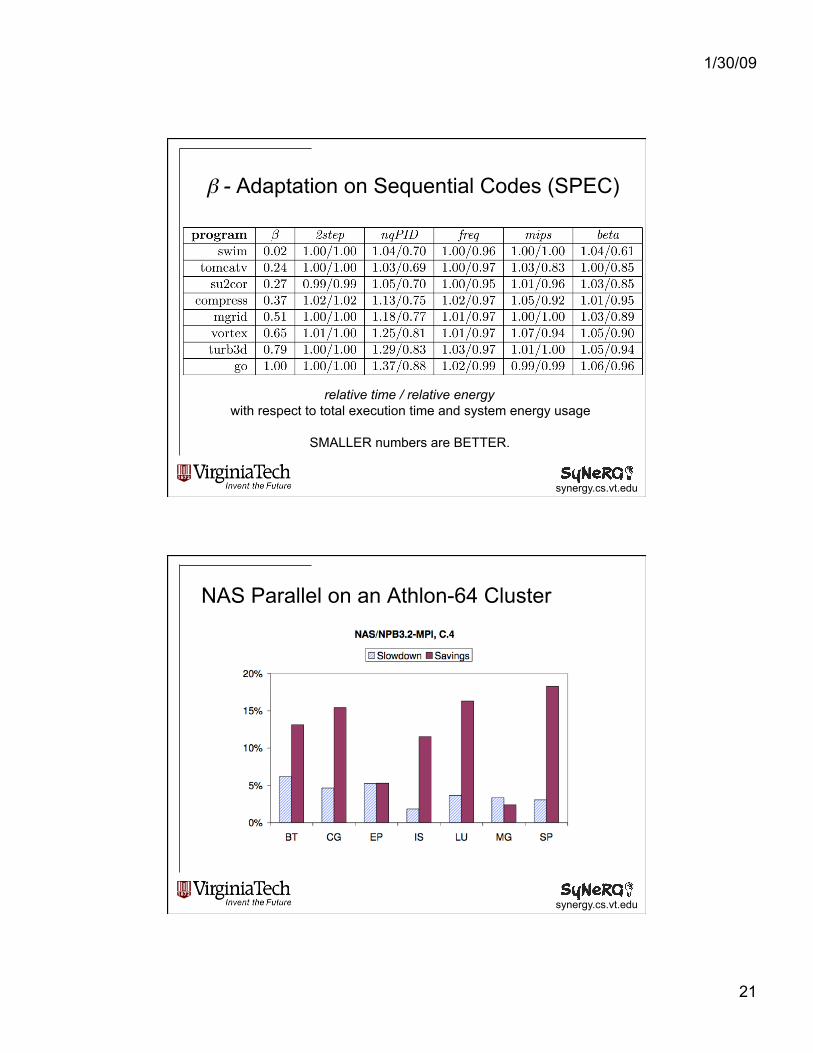
1/30/09
21
synergy.cs.vt.edu
β - Adaptation on Sequential Codes (SPEC)
relative time / relative energy with respect to total execution time and system energy usage
SMALLER numbers are BETTER.
synergy.cs.vt.edu
NAS Parallel on an Athlon-64 Cluster

1/30/09
22
synergy.cs.vt.edu
NAS Parallel on an Opteron Cluster
synergy.cs.vt.edu
Outline
• Motivation & Background – Where is High-End Computing (HEC)? – The Need for Efficiency, Reliability, and Availability
• Supercomputing in Small Spaces (http://sss.cs.vt.edu/) – Distant Past: Green Destiny (2001-2002) – Recent Past to Present: Evolution of Green Destiny (2003-2007)
• Architectural – MegaScale, Orion Multisystems, IBM Blue Gene/L
• Software-Based – EnergyFit™: Power-Aware Run-Time System (β adaptation)
• Conclusion and Future Work

1/30/09
23
synergy.cs.vt.edu
Opportunities Galore!
• Component Level – CPU, e.g., β
(Library vs. OS) – Memory – Disk – System
• Resource Co-scheduling – Across Systems, e.g., Job
Scheduling
• Abstraction Level – Application Transparent
• Compiler: βcompile-time • Library: βrun-time • OS: EnergyFit, EcoDaemon
– Application Modified (Too intrusive)
– Parallel Library Modified (e.g., P. Raghavan & B. Norris, IPDPS’05)
• Directed Monitoring – Hardware performance
counters 57%
43%
synergy.cs.vt.edu
Selected References: Available at http://sss.cs.vt.edu/ Green Supercomputing • “Green Supercomputing Comes of Age,” IT Professional, Jan.-Feb. 2008. • “The Green500 List: Encouraging Sustainable Supercomputing,” IEEE
Computer, Dec. 2007. • “Green Supercomputing in a Desktop Box,” IEEE Workshop on High-
Performance, Power-Aware Computing at IEEE IPDPS, Mar. 2007. • “Making a Case for a Green500 List,” IEEE Workshop on High-Performance,
Power-Aware Computing at IEEE IPDPS, Apr. 2006. • “A Power-Aware Run-Time System for High-Performance Computing,” SC|05,
Nov. 2005. • “The Importance of Being Low Power in High-Performance Computing,”
Cyberinfrastructure Technology Watch (NSF), Aug. 2005. • “Green Destiny & Its Evolving Parts,” International Supercomputer Conf
Innovative Supercomputer Architecture Award,., Apr. 2004. • “Making a Case for Efficient Supercomputing,” ACM Queue, Oct. 2003. • “Green Destiny + mpiBLAST = Bioinfomagic,” 10th Int’l Conf. on Parallel
Computing (ParCo’03), Sept. 2003. • “Honey, I Shrunk the Beowulf!,” Int’l Conf. on Parallel Processing, Aug. 2002.

1/30/09
24
synergy.cs.vt.edu
Conclusion • Recall that …
– We need horsepower to compute but horsepower also translates to electrical power consumption.
• Consequences – Electrical power costs $$$$. – “Too much” power affects efficiency, reliability, availability.
• Solution – Autonomic energy and power savings while maintaining
performance in the supercomputer and datacenter. • Low-Power Architectural Approach • Power-Aware Commodity Approach
synergy.cs.vt.edu
Acknowledgments
• Contributions – Jeremy S. Archuleta (LANL & VT) Former LANL Intern, now PhD – Chung-hsing Hsu (LANL) Former LANL Postdoc – Michael S. Warren (LANL) Former LANL Colleague – Eric H. Weigle (UCSD) Former LANL Colleague
• Sponsorship & Funding (Past) – AMD – DOE Los Alamos Computer Science Institute – LANL Information Architecture Project – Virginia Tech

1/30/09
25
Wu FENG [email protected]
http://sss.cs.vt.edu/
http://synergy.cs.vt.edu/ Laboratory
http://www.green500.org/
http://www.mpiblast.org/
http://www.chrec.org/


















