
Outline - saahpc.ncsa.illinois.edusaahpc.ncsa.illinois.edu/presentations/chien.pdf · o Sandy...
24
7/11/12 1 Can we Systematically Evaluate and Exploit Heterogeneous Accelerators? A 10x10 Perspective Andrew A. Chien Dept of Computer Science, University of Chicago MCS, Argonne National Laboratory SAAHPC Keynote July 11, 2012 Outline • The Future is Heterogeneous • Accelerators in Perspective • Towards Systematic Accelerator Evalution • 10x10: Systematic Heterogeneous Architecture • Summary and Futures July 11, 2012 © Andrew A. Chien, 2012
Transcript of Outline - saahpc.ncsa.illinois.edusaahpc.ncsa.illinois.edu/presentations/chien.pdf · o Sandy...

7/11/12
1
Can we Systematically Evaluate and Exploit Heterogeneous Accelerators?
A 10x10 Perspective
Andrew A. Chien Dept of Computer Science, University of Chicago
MCS, Argonne National Laboratory
SAAHPC Keynote July 11, 2012
Outline • The Future is Heterogeneous • Accelerators in Perspective • Towards Systematic Accelerator Evalution • 10x10: Systematic Heterogeneous Architecture • Summary and Futures
July 11, 2012 © Andrew A. Chien, 2012

7/11/12
2
The Future is Heterogeneous
July 11, 2012 © Andrew A. Chien, 2012
Heterogeneous Supercomputers • Tianhe-1 (NUDT, Nov
2010) o 5PF o 14,336 Xeons + 7168 Teslas
• Titan (ORNL, fall 2012) o 19K AMD CPU’s + 960 GPU’s o Grow to 20PF in fall? o ~ 20PF/2TF => 10K Nvidia GPU’s
(Kepler?)
• Blue Waters (NCSA, late 2012) o 11.5PF, 1.5PB o 49K AMD CPUS (380K cores) o 3K Nvidia GPU’s (Kepler)
July 11, 2012 © Andrew A. Chien, 2012

7/11/12
3
Heterogeneity Dominates
• Heterogeneity is growing dramatically – on single chips, in systems, and in high volume deployment o Sandy Bridge/Fusion/Denver, Tegra 2/Omap/A5
• Heterogeneous in architecture and implementation is the dominant computing platform of future
July 11, 2012
Smart Phones
Laptops and Tablets
Desktops
Servers Homogeneous
Some Heterogeneity (2x)
Extreme Heterogeneity (10x)
2015
© Andrew A. Chien, 2012
Exploding Diversity
• Highly competitive markets, many without a dominant leader • Smart Phone Market Highly fragmented – and diverse • Laptop and Tablet Market fragmenting?
July 11, 2012
Smart Phones
Laptops and Tablets
2015 Marvell (RIM)
TI Omap
Apple Qualcomm
Mediatek
Intel
AMD
Apple
Nvidia
Qualcomm, TI, …
© Andrew A. Chien, 2012

7/11/12
4
Accelerators in Perspective
July 11, 2012 © Andrew A. Chien, 2012
Accelerators in HPC Systems
• Waning Moore’s Law o Energy-limited, Data Movement
Limited [BorkarChien, CACM May 2011]
• Base vs Base+Acc vs. Ratiod o Performance, Coupling, Capacity
• Cost: compute chips, total energy, compute/cuft, price
• DIFF: Delivery in Whole Compute Chips
July 11, 2012 © Andrew A. Chien, 2012
CPU/APU
CPU/APU
CPU CPU
CPU GPU
PCI
GPU
PCI
GPU
PCI

7/11/12
5
How Accelerators Deliver Performance
• Location: Path-oriented accelerators (flow and offload), NIC offload, PIM
• Special Resources: high performance memory (e.g. GDDR, Convey )
• Customization: specialized logic and dense packaging/coupling
• Assumption: regular, replicated organization • Scaled to thousands or millions
• Challenges: Programming, Specialization, Integration
July 11, 2012 © Andrew A. Chien, 2012
Programming • Porting effort? (software
architecture, algorithms) • Performance attainable? • The Fast road? • ...or the road to nowhere? • ....How long is good
enough?
July 11, 2012 © Andrew A. Chien, 2012

7/11/12
6
Programming
• Critical: Avoiding Disaster!! July 11, 2012 © Andrew A. Chien, 2012
Specialization • “Everyone uses only 10% of the functionality, the only
trouble is its a different 10% for everyone”
• (image, character, graphics, floating point) Embedded, Smartphone, Laptop, Server processors
• (parallel) Multithreaded applications? • (floating point) DOE Scientific applications mini-apps
and PETSc – 20-30% of operation count
• Architect: What to specialize and how to expose? • Software Architect: What abstractions? (datatype,
representation, movement) What interfaces and partitions?
• => see 10x10
July 11, 2012 © Andrew A. Chien, 2012

7/11/12
7
Integration • Future programming is about orchestrating data
movement, not operations. Data Movement dominates energy consumption.
– DARPA Exascale Software report (2009)
• Parallel computing – horizontal, internode • Exascale computing – vertical and horizontal, internode
and intranode (memory and accelerator hierarchy)
• Not just about computing, but the relationship of computing to memory and to each other (and to the network)
July 11, 2012 © Andrew A. Chien, 2012
Accelerator Integration
• Shared Nothing, Asymmetric
• Shared Memory, Symmetric
• Shared Memory, Internal Customization, Symmetric
July 11, 2012 © Andrew A. Chien, 2012
CPU/Acc
CPU/Acc
CPU CPU
CPU Acc
PCI

7/11/12
8
What’s a Programmer to do?
Towards Systematic Accelerator Evalution
July 11, 2012 © Andrew A. Chien, 2012
OmniBench: Systematic Evaluation of Accelerators
• Objective: Neutral evaluation of performance
• Idea: Benchmark with codes Designed for an accelerator...
But not “exactly this” accelerator
• Software complexity is the key driver • “The community can tune for 1, but not for dozens”
July 11, 2012 © Andrew A. Chien, 2012

7/11/12
9
Omnibench Experiment • Challenging Kernel Programs
o SGEMM, SpMV, BFS, FFT
• Standard Interface – OpenCL 1.2 o Simple model: CPU + ACC
• Range of Heterogeneous Platforms o Vary compute capabilities o Vary special resources o Vary integration and memory hierarchy approaches o Range of cost/power levels
July 11, 2012 © Andrew A. Chien, 2012
Heterogeneous CPU-‐‑GPU Systems
• IvyBridge: Intel Core i5 3570K o 4 CPU cores (3.4 GHz) o 64 graphics cores (1.15 GHz) o 6 MB LLC, shared by CPU and integrated graphics o dual-channel, DDR3 Memory, 25.6 GB/s o 77 W, 22 nm, 216 mm^2, 1.4 billion transistors
• APU: AMD A-8 3850 o 4 CPU cores (2.9 GHz) o 400 graphics cores (0.6 GHz) o 4 MB LLC, dedicated to the CPU cores o Dual-channel, DDR3 Memory, 29.9 GB/s o 100 W, 32 nm, 228 mm^2, 1.45 billion transistors
• Tesla: NVIDIA Tesla C2075 o 448 cores = 14 multiprocessors * 32 (1.15 GHz) o 768 KB LLC, 64 KB shared memory/multiprocessor o Private GDDR5 Memory, 144 GB/s o 225 W, 40 nm, 520 mm^2, 3 billion transistors o CPU-GPU link: PCI-Express x16 Gen 2, 8 GB/s
CPU/ACC CPU
CPU GPU
PCI
CPU/acc CPU
7/11/12
10
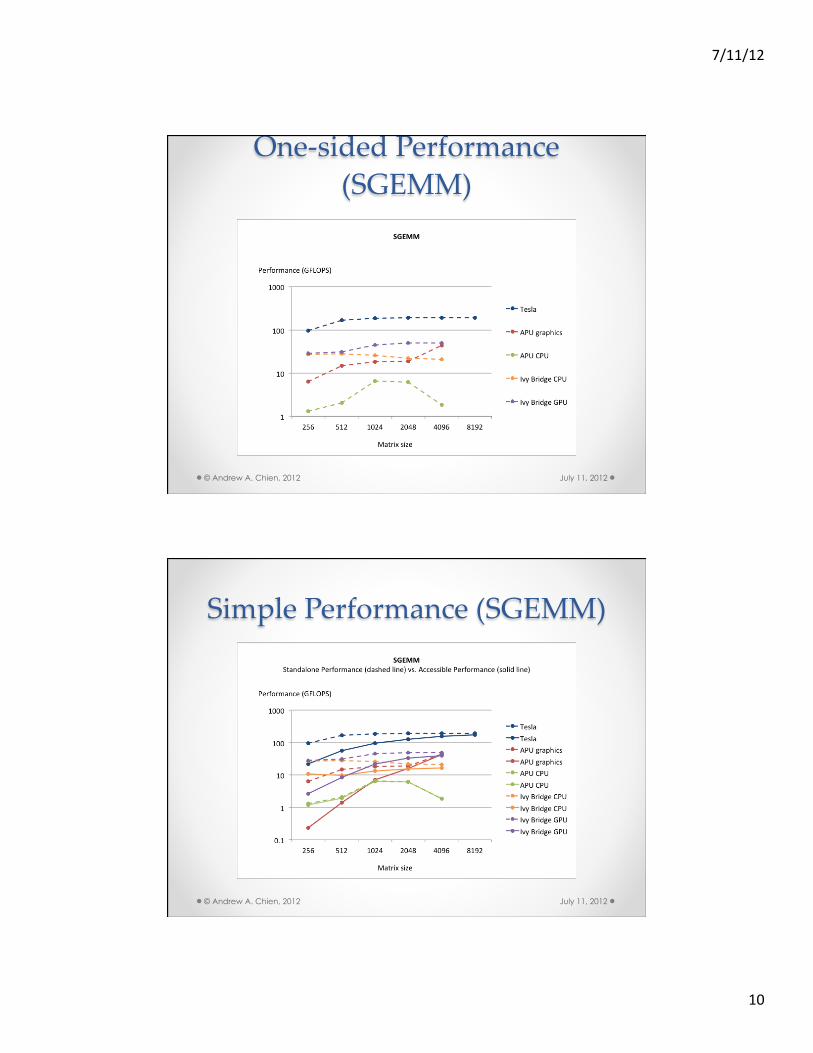
One-‐‑sided Performance (SGEMM)
July 11, 2012 © Andrew A. Chien, 2012
Simple Performance (SGEMM)
July 11, 2012 © Andrew A. Chien, 2012

7/11/12
11
Self-‐‑normalized Accessible Performance (SGEMM)
July 11, 2012 © Andrew A. Chien, 2012 Self-‐‑normalized (integration)
• Integration (data transfer and computation)
• Fraction of “Peak” Performance
• Fraction of Accessible Performance
Relative Accessible Performance (SGEMM)
July 11, 2012 © Andrew A. Chien, 2012
• Same terms • Normalized to
performance of fastest accelerator
7/11/12
12
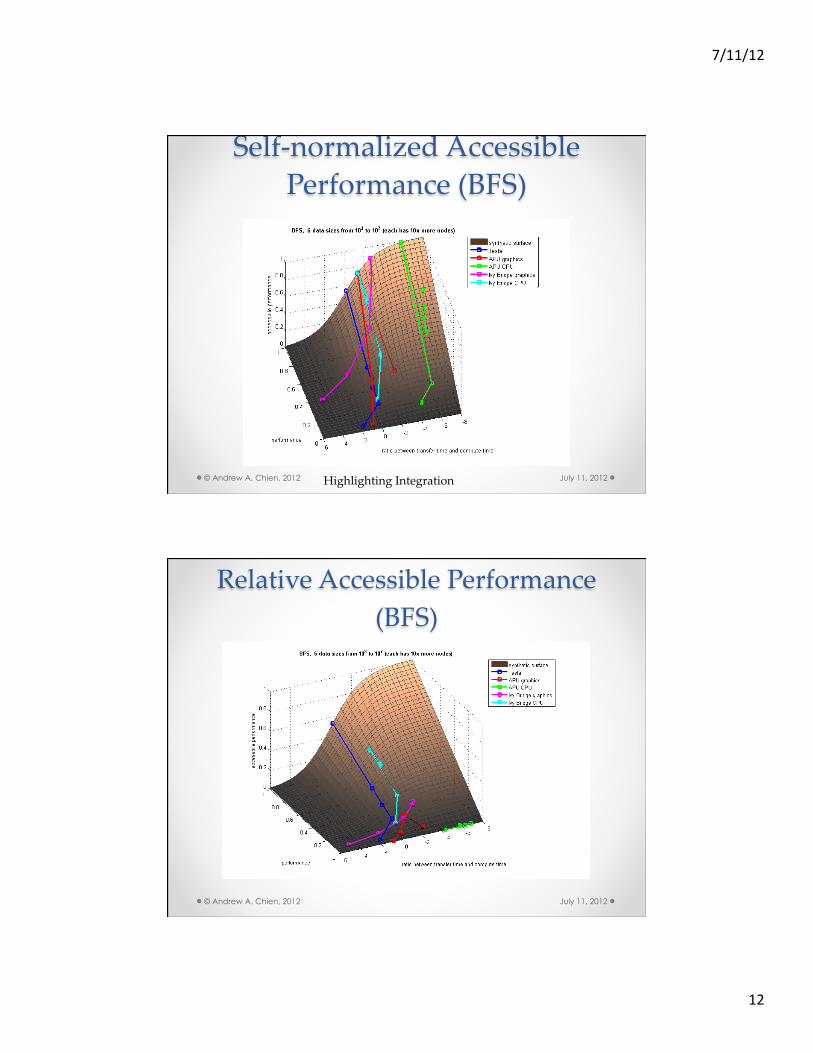
Self-‐‑normalized Accessible Performance (BFS)
July 11, 2012 © Andrew A. Chien, 2012 Highlighting Integration
Relative Accessible Performance (BFS)
July 11, 2012 © Andrew A. Chien, 2012

7/11/12
13
Observations • Data home location has significant impact on
accessible performance, should be captured in benchmarking
• Organizational differences not highlighted by compute-intensive applications, but exposed clearly by memory-intensive
• Data movement management is problematic in current integrated CPU-GPU systems (sw/hw)
• Performance of discrete accelerators dominates on compute-intensive, but not on memory-intensive workloads (even w/o equal chip resources)
July 11, 2012 © Andrew A. Chien, 2012
Related and Future Work • Related Work
o Accelerator Benchmarking: CUDA, OpenCL benchmarks (Rodinia, SHoC, ...)
o Extensive Performance Modeling
• Future Work o Additional Platforms – configs, types, variations o Improved software (always): Drivers, MemHierarcy, Compilers o Higher level software interfaces: Beyond OpenCL? ,Open
ACC, ?? o Larger systems: Larger-nodes (e.g. 2 hybrid vs CPU+GPU), Parallel
(multi-node) systems
July 11, 2012 © Andrew A. Chien, 2012

7/11/12
14
10x10 Systematic Heterogeneity
July 11, 2012 © Andrew A. Chien, 2012
July 11, 2012
Three Paths Forward
Heterogeneous (incl. Hybrid)
Small Core (100’s)
Big Core (10’s)
Dennard Scaling Energy-‐‑limited Scaling
Performan
ce
Time
[Borkar and Chien, “Technology Scaling creates New Landscape for Computer Architecture”, Communications of the ACM, May 2011]
© Andrew A. Chien, 2012

7/11/12
15
Path #3: Customize, Scaleup
• Customize: a collection of custom tools form a core o Designed for a narrow domain, high performance and energy efficient o Tool domains complement each other to cover general-purpose space
• Separation maximizes energy efficiency o Layout density, Isolation o Exercise one/few tools at a time
• Challenges: Programmability, Code Portability, Design Effort, Architecture, Si utilization
July 11, 2012
Customize
© Andrew A. Chien, 2012
Examples: SoC & Integrated GPU
• Apple’s A5
• Nvidia’s Tegra 2 and 3
• Intel Ivy Bridge
• AMD Fusion (Ontario)
July 11, 2012
What’s WRONG with these chips?
Not very programmable...
© Andrew A. Chien, 2012

7/11/12
16
10x10 Framework Enables Systematic Exploitation of Heterogeneity
Tight Clusters Loose Clusters No Clusters (general-‐‑purpose)
Micro-‐‑engine Workload Coverage
Micro-‐‑engine Energy Efficiency
Overall Workload Energy Efficiency
July 11, 2012 © Andrew A. Chien, 2012
10x10 = Federated Heterogeneity
Traditional Core 10x10 Core
July 11, 2012
µengine #6
Basic RISC CPU
µengine #2
µengine #3
µengine #4
µengine #5 <tbd>
I-‐‑Cache
Shared L1 Data Cache
I-‐‑Cache I-‐‑Cache I-‐‑Cache I-‐‑Cache I-‐‑Cache
L1 Inst Cache
L1 Data Cache
© Andrew A. Chien, 2012

7/11/12
17
Traditional Optimization: 90/10 Paradigm
• Workloads: analyze and derive common cases(90%) • Invent arch features, implementation optimizations with broad
impact (90%) • Improve performance by adding optimizations • Aggregation and Efficiency: 8080 80 insts => SB 500+ instructions
Workloads
“ILP” “reuse locality” “linear access” “bit-‐‑field opns” “branch panerns”
“pipelining” “superscalar” “caches & blocks” “mmedia” “branch pred”
Abstracted “common” cases Optimizations
Amdahl’s Law, H&P’s Comp Arch: A Quantitative Approach July 11, 2012 © Andrew A. Chien, 2012
10x10 Optimization Paradigm
• Identify 10 application clusters; compute structures; datatypes (focus on 10 distinct bins)
• Optimize architecture, Optimize implementation of each separately (improve energy-delay product by 10-100x)
• Compose together sharing memory hierarchy and interconnect (preserve the benefits of customization)
7 idiom, 29 SPEC, 13 dwarves, 11NPB “Workload”
Factor into 10 Bins Compose Micro-‐‑engine
per Bin
July 11, 2012 © Andrew A. Chien, 2012

7/11/12
18
The Big Picture: 10x10 • Spectrum of energy efficiency vs. programmability • Asics, soc, gpu, parallel cpu, cpu
• Where are we going? Overlap, dominate? • Answer is deeply a hardware and software question
o Waning days of Moore’s Law, end of Moore’s Law, success of near-threshold and device scaling heroics
o Software translation technology for cross-compilation, transformation and optimization, higher-level programming
July 11, 2012
EE [Ops/J]
@ fixed Process
Programmability/ Portability
Core
GPU
SoC / IP Accel
ASIC
+M-‐‑core
+ features
+GPU+M-‐‑core
Ideal Compute Chip
10x10
© Andrew A. Chien, 2012
10x10 Workload Clustering • Challenges
o How to cluster? (try LOTS of things) o How many for good coverage? o How much benefit?
• Broad Set of Workloads (34 total, varied) o UHPC Challenge Problems (5) “Super”
• Streaming sensor, chess, graph, md, shock hydro • DARPA”Extreme Computing”
o PARSEC (12) “PC” • Data mining, vision, financial, genetic, physics, …
o Embedded Benchmarks (10) “Mobile, IOT” • Image, crypto, coding, signal processing
o Biobench (7) “Data mining” • Alignment, assembly, phylogeny, database search
July 11, 2012 © Andrew A. Chien, 2012

7/11/12
19
What Characteristics Maner?
• Where the time goes o Focus on important sections– >90% coverage from each application
• Architecturally Significant Features o Cluster based on like requirements o Supports sharing of customization
• Two Feature Vectors o Low-resolution: (Datatype x Size) o High Resolution: (Datatype x Operation x Size)
July 11, 2012
Dynamic Profiles
Vector Clustering
Codes, Benchmarks
Loops, Opns
Memory
Clustered Regions
© Andrew A. Chien, 2012
Low Res Clusters (8)
code regions
BR 8B INT 8B REG_XFER 8B INT 4B REG_XFER 4B REG_XFER 16BFLT 8B FLT 16B OTHER 4B FLT 4B OTHER <1B OTHER 2BINT 16B OTHER 8B INT 1B INT 2B REG_XFER 1B REG_XFER 2B
July 11, 2012 © Andrew A. Chien, 2012
• Width is “hot region” count; Ordered by Dynamic Weight • Legend is Operation x Datatype • #1 Integer, #2-‐‑5 FP single, double, vector • Much simpler, cleaner clustering... • 8 clusters (100%)
7/11/12
20
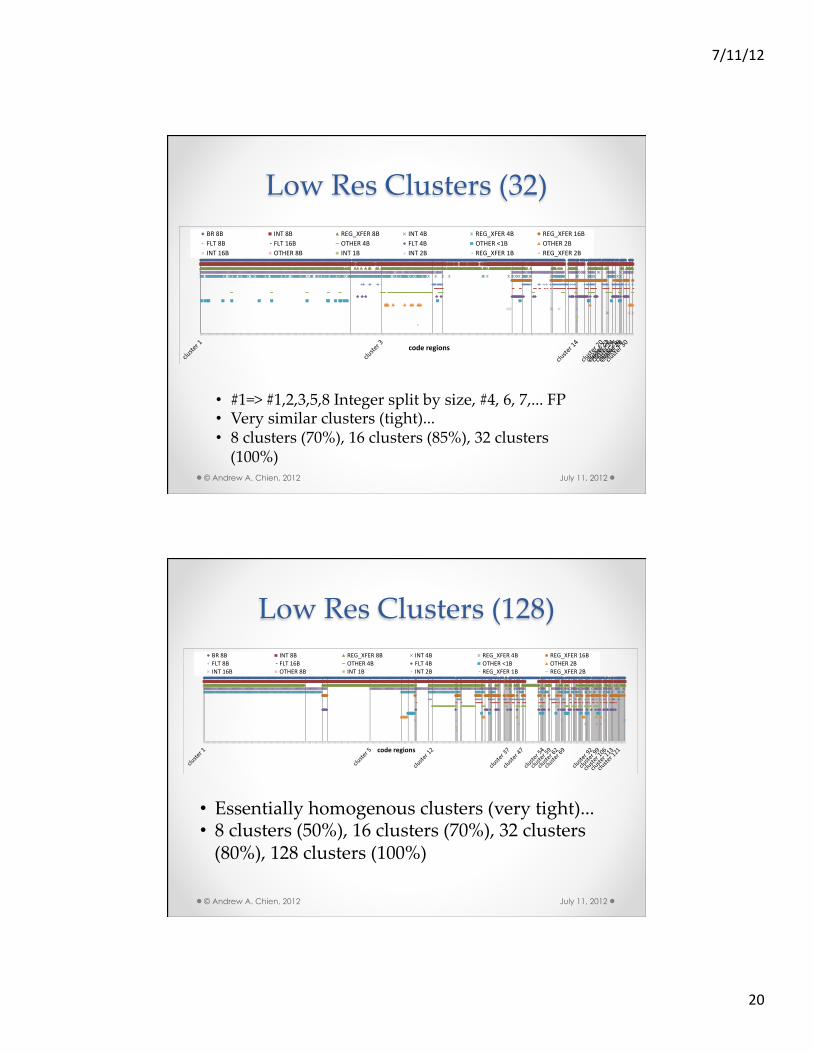
Low Res Clusters (32)
code regions
BR 8B INT 8B REG_XFER 8B INT 4B REG_XFER 4B REG_XFER 16BFLT 8B FLT 16B OTHER 4B FLT 4B OTHER <1B OTHER 2BINT 16B OTHER 8B INT 1B INT 2B REG_XFER 1B REG_XFER 2B
July 11, 2012 © Andrew A. Chien, 2012
• #1=> #1,2,3,5,8 Integer split by size, #4, 6, 7,... FP • Very similar clusters (tight)... • 8 clusters (70%), 16 clusters (85%), 32 clusters (100%)
Low Res Clusters (128)
code regions
BR 8B INT 8B REG_XFER 8B INT 4B REG_XFER 4B REG_XFER 16BFLT 8B FLT 16B OTHER 4B FLT 4B OTHER <1B OTHER 2BINT 16B OTHER 8B INT 1B INT 2B REG_XFER 1B REG_XFER 2B
July 11, 2012 © Andrew A. Chien, 2012
• Essentially homogenous clusters (very tight)... • 8 clusters (50%), 16 clusters (70%), 32 clusters (80%), 128 clusters (100%)
7/11/12
21
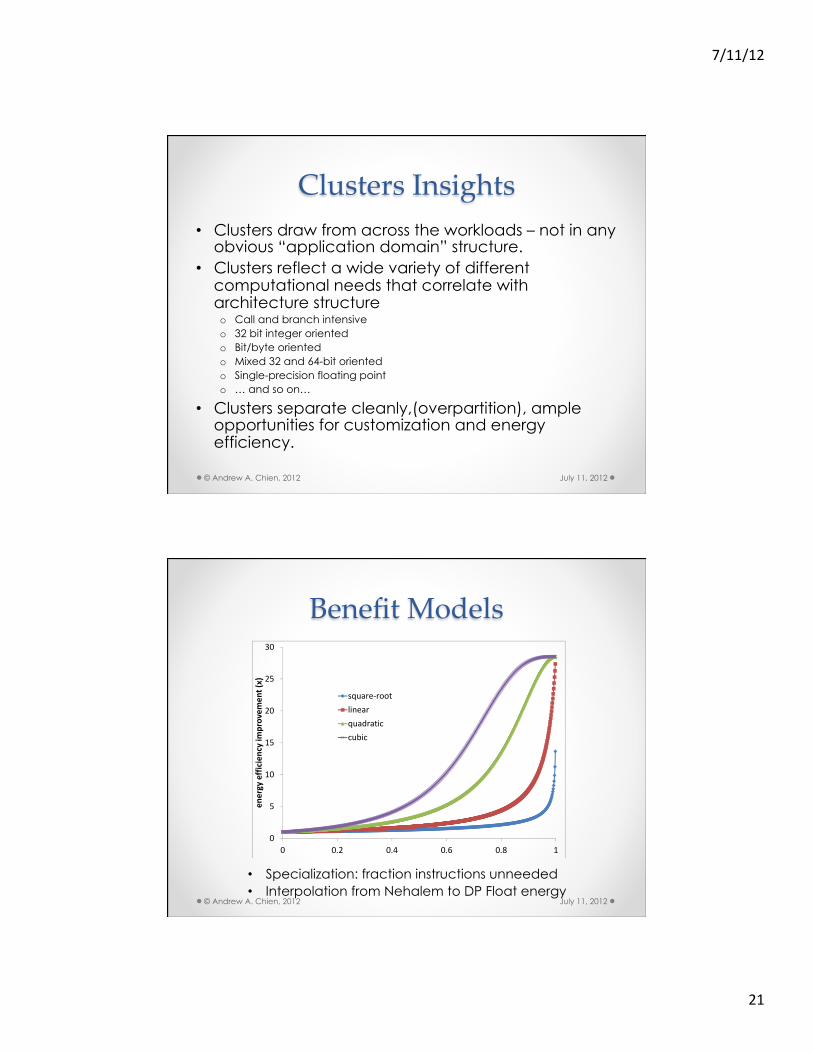
Clusters Insights • Clusters draw from across the workloads – not in any
obvious “application domain” structure. • Clusters reflect a wide variety of different
computational needs that correlate with architecture structure o Call and branch intensive o 32 bit integer oriented o Bit/byte oriented o Mixed 32 and 64-bit oriented o Single-precision floating point o … and so on…
• Clusters separate cleanly,(overpartition), ample opportunities for customization and energy efficiency.
July 11, 2012 © Andrew A. Chien, 2012
Benefit Models
• Specialization: fraction instructions unneeded • Interpolation from Nehalem to DP Float energy
July 11, 2012 © Andrew A. Chien, 2012
0
5
10
15
20
25
30
0 0.2 0.4 0.6 0.8 1
ener
gy e
ffici
ency
impr
ovem
ent (
x)
fraction of unimplemented opcodes
square-rootlinearquadraticcubic

7/11/12
22
Weighted Benefit vs. Benefit Model
0
5
10
15
20
25
30
aver
age
bene
fit (x
)
sq rootlinearquadraticcubic
July 11, 2012 © Andrew A. Chien, 2012
Weighted Benefit (linear) vs. # Cores
0
2
4
6
8
10
12
1 co
res
4 co
res
7 co
res
10 c
ores
13 c
ores
16 c
ores
19 c
ores
22 c
ores
25 c
ores
28 c
ores
31 c
ores
34 c
ores
37 c
ores
40 c
ores
43 c
ores
46 c
ores
49 c
ores
52 c
ores
55 c
ores
58 c
ores
61 c
ores
64 c
ores
wei
ghte
d be
nefit
(x)
linear benefit model
hr8hr16hr32hr64hr128lr8lr16lr32lr64lr128
July 11, 2012 © Andrew A. Chien, 2012

7/11/12
23
Related Work • System on Chip (SoC, SoP, 3D, etc.) [CE products]
o Rapid system integration, not architectural design. Less stable; discontinuous change, partitioned software.
o 6 months to α-silicon, 6 months to product in market
• CPU+Reconfigurable hardware (FPGA’s, LUTS, adders, etc.) o Convey HC-1, Sankaralingam11, Xilinx Zynq [EPP]
o Advantages: flexibility o Disadvantages: lose customized implementation, speed, energy efficiency.
• Hybrid Computing (CPU-GPU, APU, GenX…) o Advantages: Silicon today o Disdvantages: programmability,1-way hetero, cost, energy efficiency.
• Low-level Programmability and Heterogeneity o QSCores/GreenDroid: Super instructions ; Khan11 [Morphing], Wu11 [VM-based, single ISA], o Advantage: Don’t require much software support o Disadvantages: local impact
• Build “Chip Generators”, not Chips o Horowitz; customization and closed systems
o Custom for everything: programmabiliity?
July 11, 2012 © Andrew A. Chien, 2012
Summary and Perspective • Heterogeneity is endemic, and a basic source of
efficiency (local) • We need integrated assessment – programmable,
usable, delivered performance (demand it) • Unibench – uniform, systematic assessment of
accessible performance for a diverse accelerator future
• 10x10 – federated heterogeneous architecture based on systematic optimization of energy efficiency (major benefit)
• Prepare wisely for a Heterogenous future!
July 11, 2012 © Andrew A. Chien, 2012

7/11/12
24
More Information • Papers
o The Future of Microprocessors. Communications of the ACM 54(5): 67-77 (2011), [Borkar & Chien]
o 10x10: A General-purpose Architectural Approach to Heterogeneity and Energy Efficiency. Procedia CS 4: 1987-1996 (2011) [Chien, Snavely, Gahagan]
o 10x10: Taming Heterogeneity for General-purpose Architecture, in 2nd Workshop on New Directions in Computer Architecture, June 2011. Held at ISCA-38. [Chien]
o Systematic Evaluation of Workload Clustering for Designing Heterogeneous, General-Purpose Architectures, UChicago Tech Report 2012, [A. Guha, A. Chien]
o An Empirical Foundation for Heterogeneity: Clustering Applications by Computation and Memory Behavior, UChicago Tech Report 2011, [A. Guha, P. Cicotti, A. Snavely, and A. Chien]
• Acknowledgements o Apala Guha, Yao Zhang, Mark Sinclair o Allan Snavely, Pietro Cicotti, Mark Gahagan o Insightful feedback from Shekhar Borkar (Intel) and Bill Harrod (DARPA) o Supported by the National Science Foundation under NSF Grant OCI-1057921
and DARPA MTO
July 11, 2012 © Andrew A. Chien, 2012
Questions?
July 11, 2012 © Andrew A. Chien, 2012



![Regulation of [H + ] Acid-Base Physiology.. pH vs [H + ]](https://static.fdocuments.us/doc/165x107/56649e955503460f94b99936/regulation-of-h-acid-base-physiology-ph-vs-h-.jpg)














