
Optimizing Terascale Machine Learning Pipelines with Keystone ML
29
OPTIMIZING TERASCALE MACHINE LEARNING PIPELINES WITH Evan R. Sparks, UC Berkeley AMPLab with Shivaram Venkataraman, Tomer Kaftan, Michael Franklin, Benjamin Recht ML Keystone Apache
-
Upload
spark-summit -
Category
Data & Analytics
-
view
395 -
download
1
Transcript of Optimizing Terascale Machine Learning Pipelines with Keystone ML

OPTIMIZING TERASCALE MACHINE LEARNING PIPELINES WITH
Evan R. Sparks, UC Berkeley AMPLab with Shivaram Venkataraman, Tomer Kaftan, Michael Franklin, Benjamin Recht
MLKeystone Apache

WHAT’S A MACHINE LEARNING PIPELINE?

A STANDARD MACHINE LEARNING PIPELINE
Right?
Data TrainClassifier Model

A STANDARD MACHINE LEARNING PIPELINE
That’s more like it!
DataTrainLinear
ClassifierModelFeature
Extraction
Test Data
Predictions

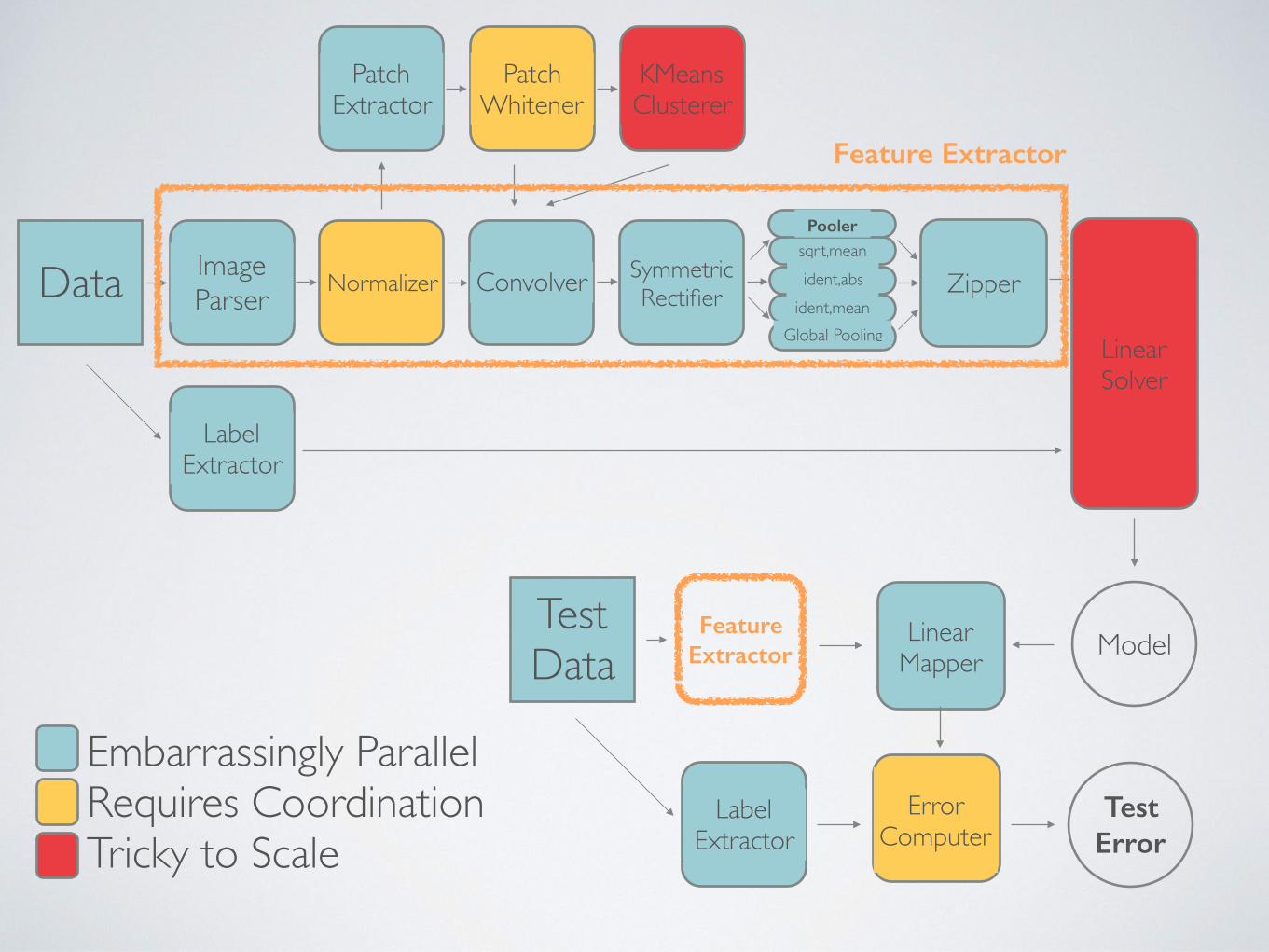
A REAL PIPELINE FOR IMAGE CLASSIFICATION
Inspired by Coates & Ng, 2012
Data ImageParser Normalizer Convolver
sqrt,mean
Zipper
Linear Solver
SymmetricRectifier
ident,absident,mean
Global Pooling
Pooler
PatchExtractor
Patch Whitener
KMeansClusterer
Feature Extractor
LabelExtractor
ModelLinearMapper
TestData
LabelExtractor
Feature Extractor
Test Error
ErrorComputer
Data ImageParser Normalizer Convolver
sqrt,mean
Zipper
Linear Solver
SymmetricRectifier
ident,absident,mean
Global Pooling
Pooler
PatchExtractor
Patch Whitener
KMeansClusterer
Feature Extractor
LabelExtractor
LinearMapper Model
TestData
LabelExtractor
Feature Extractor
Test Error
ErrorComputer
Embarrassingly ParallelRequires CoordinationTricky to Scale

ABOUT KEYSTONEML• Software framework for building scalable end-to-end machine
learning pipelines on Apache Spark.
• Helps us understand what it means to build systems for robust, scalable, end-to-end advanced analytics workloads and the patterns that emerge.
• Example pipelines that achieve state-of-the-art results on large scale datasets in computer vision, NLP, and speech - fast.
• Open source software, available at: http://keystone-ml.org/

SIMPLE EXAMPLE: TEXT CLASSIFICATION
20 Newsgroups.fit( )
Trim
Tokenize
Bigrams
Top Features
Naive Bayes
Max Classifier
Trim
Tokenize
Bigrams
Max Classifier
Top Features Transformer
Naive Bayes Model
Once estimated - apply these steps to your
production data in an online or batch fashion.

NOT SO SIMPLE EXAMPLE: IMAGE CLASSIFICATION
Images(VOC2007).fit( )
Resize
Grayscale
SIFT
PCA
Fisher Vector
MaxClassifier
Linear Regression
Resize
Grayscale
SIFT
MaxClassifier
PCA Map
Fisher Encoder
Linear Model
Achieves performance of Chatfield et. al., 2011
Pleasantly parallelfeaturization and evaluation.
7 minutes on a modest cluster.
5,000 examples, 40,000 features, 20 classes

EVEN LESS SIMPLE: IMAGENETColor Edges
Resize
Grayscale
SIFT
PCA
Fisher Vector
Top 5 Classifier
LCS
PCA
Fisher Vector
Block Linear Solver
<100 SLOC
Upgrading the solverfor higher precision
means changing 1 LOC.Weighted Block Linear Solver
Adding 100,000 moretexture features is easy.
Texture
Gabor
Wavelets
PCA
Fisher Vector
1000 class classification.1,200,000 examples
64,000 features.
90 minutes on 100 nodes.

OPTIMIZING KEYSTONEML PIPELINESHigh-level API enables rich space of optimizations
Automated ML operator selection. Linear Solver
L-BFGS Iterative SGD
Direct Solver
Training Data
Grayscaler SIFT Extractor
ReduceDimensions
Fisher Vector Normalize
Column Sampler
Linear Map
Distributed PCA
Column Sampler
LocalGMM
Least Sq.L-BFGS
Predictions
Training Labels
Auto-caching for iterative workloads.
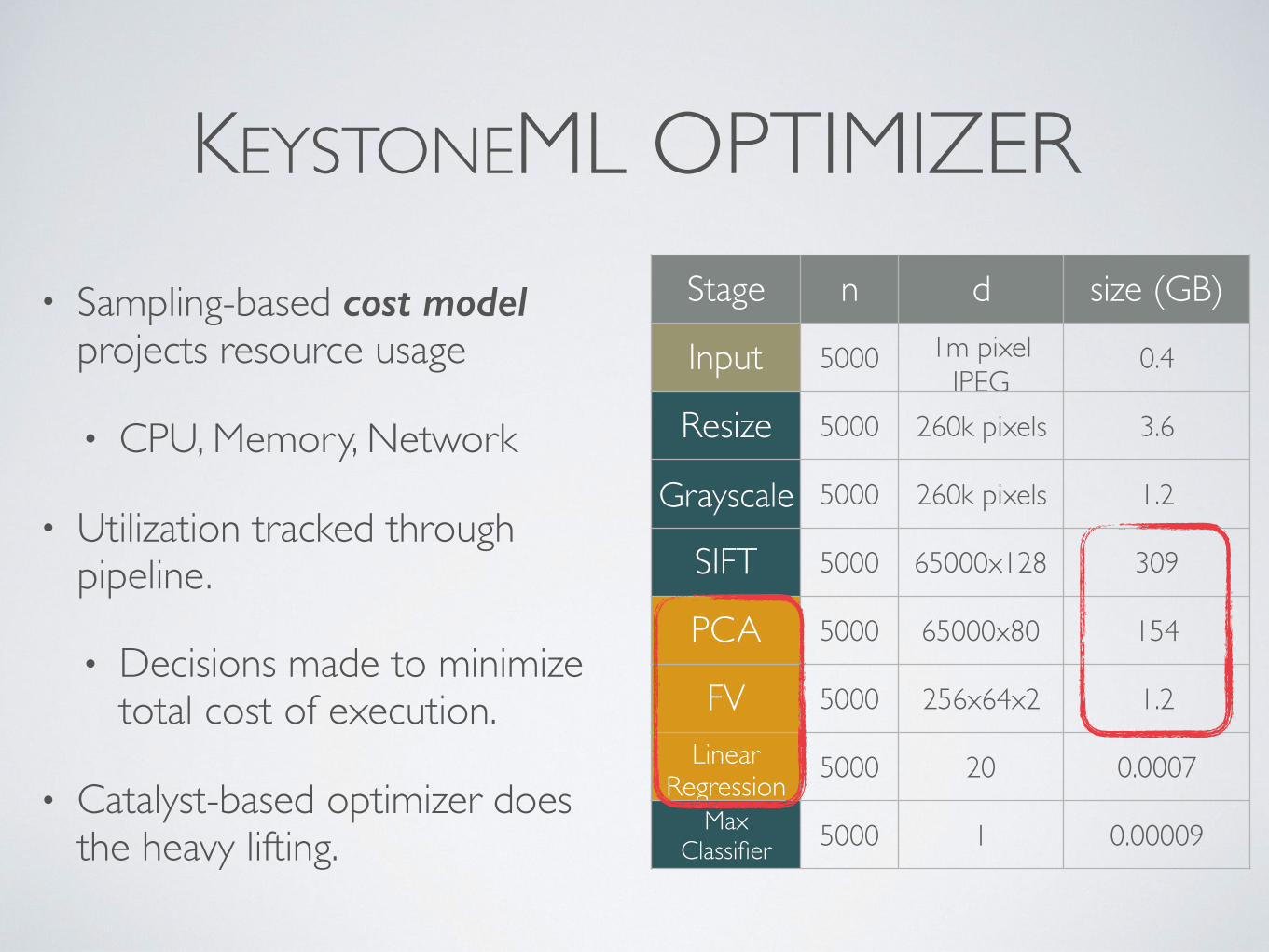
KEYSTONEML OPTIMIZER• Sampling-based cost model
projects resource usage
• CPU, Memory, Network
• Utilization tracked through pipeline.
• Decisions made to minimize total cost of execution.
• Catalyst-based optimizer does the heavy lifting.
Stage n d size (GB)
Input 5000 1m pixel JPEG
0.4
Resize 5000 260k pixels 3.6
Grayscale 5000 260k pixels 1.2
SIFT 5000 65000x128 309
PCA 5000 65000x80 154
FV 5000 256x64x2 1.2
Linear Regression 5000 20 0.0007
Max Classifier 5000 1 0.00009

CHOOSING A SOLVER• Datasets have a number of
interesting degrees of freedom.
• Problem size (n, d, k)
• sparsity (nnz)
• condition number
• Platform has degrees of freedom:
• Memory, CPU, Network, Nodes
• Solvers are predictable!
13
Where:A 2 Rn⇥d
X 2 Rd⇥k
B 2 Rn⇥k
Objective:minX
|AX �B|22 + �|X|22

CHOOSING A SOLVER• Three Solvers
• Exact, Block, LBFGS
• Two datasets
• Amazon - >99% sparse, n=65m
• TIMIT - dense, n=2m
• Exact solve works well for small # features.
• Use LBFGS for sparse problems.
• Block solver scales well to big dense problems.
• Hundreds of thousands of features.
●
●
●
●
●
●
Amazon TIMIT
100
1000
10000
10
100
1000
1024 2048 4096 8192 16384 1024 2048 4096 8192 16384Number of Features
Tim
e (s
)
Solver ● Exact Block Solver LBFGS
14
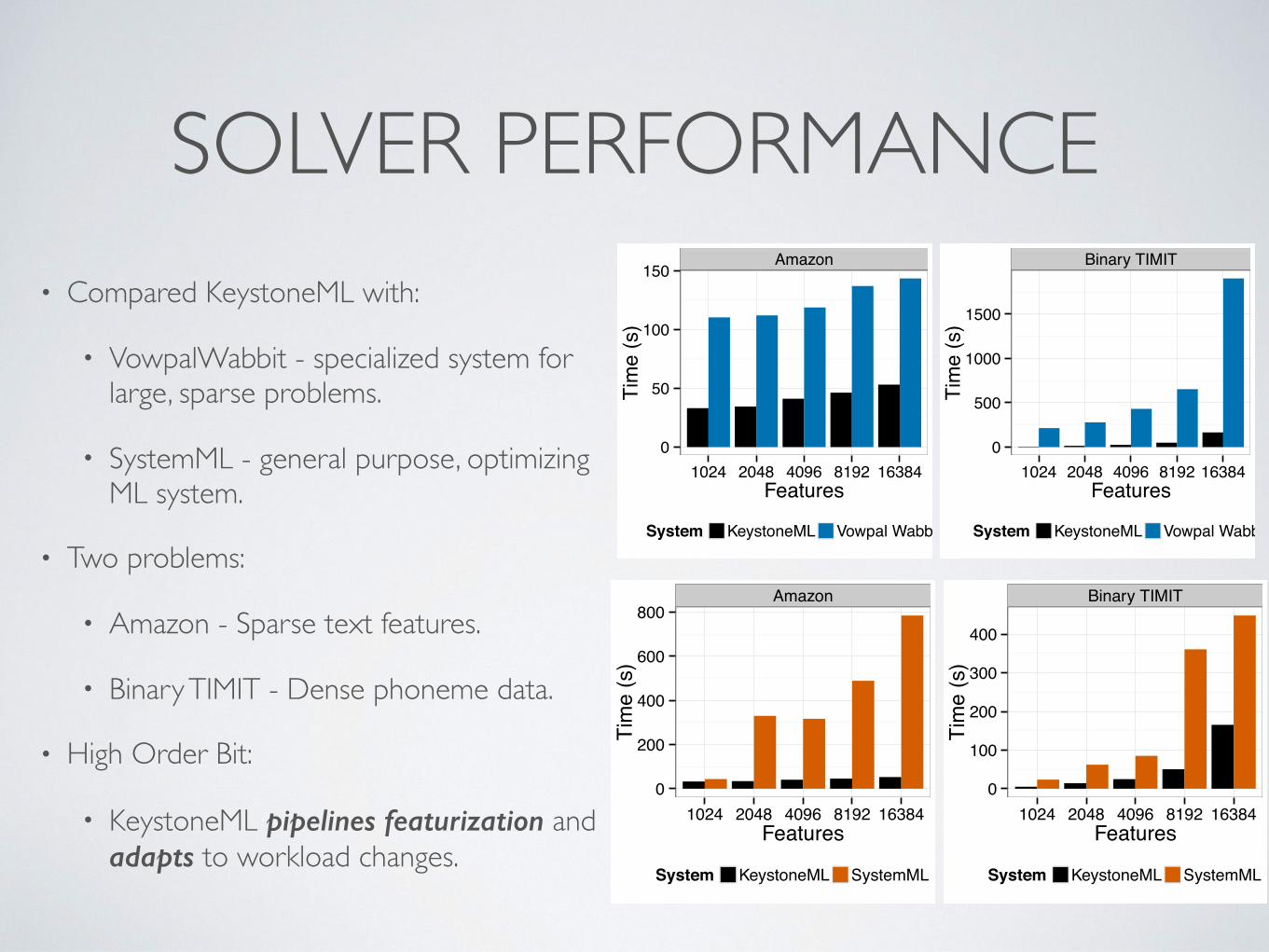
SOLVER PERFORMANCE• Compared KeystoneML with:
• VowpalWabbit - specialized system for large, sparse problems.
• SystemML - general purpose, optimizing ML system.
• Two problems:
• Amazon - Sparse text features.
• Binary TIMIT - Dense phoneme data.
• High Order Bit:
• KeystoneML pipelines featurization and adapts to workload changes.
Amazon
0
200
400
600
800
1024 2048 4096 8192 16384Features
Tim
e (s
)
System KeystoneML SystemML
Binary TIMIT
0
100
200
300
400
1024 2048 4096 8192 16384Features
Tim
e (s
)
System KeystoneML SystemML
Amazon
0
50
100
150
1024 2048 4096 8192 16384Features
Tim
e (s
)
System KeystoneML Vowpal Wabbit
Binary TIMIT
0
500
1000
1500
1024 2048 4096 8192 16384Features
Tim
e (s
)
System KeystoneML Vowpal Wabbit

DECIDING WHAT TO SAVE• Pipelines Generate Lots of
intermediate state.
• E.g. SIFT features blow up a 0.42GB VOC dataset to 300GB.
• Iterative algorithms —> state needed many times.
• How do we determine what to save for later and what to reuse, given fixed resource budget?
• Can we adapt to workload changes?
16
Resize
Grayscale
SIFT
PCA
Fisher Vector
MaxClassifier
Linear Regression

CACHING PROBLEM• Output is computed via depth-
first execution of DAG.
• Caching “truncates” a path after first visit.
• Want to minimize execution time.
• Subject to memory constraints.
• Picking optimal set is hard!17
A B
C
D
E
60s
50g
40s
200g
20s
40g
40g
15s
5s
10g
Output
Cache set Time Memory
ABCDE 140s 340g
B 140s 200g
A 180s 50g
{} 240s 0g

END-TO-END PERFORMANCEDataset Training
Examples Features Raw Size (GB) Feature Size (GB)
Amazon 65 million 100k (sparse) 14 89
TIMIT 2.25 million 528k 7.5 8800
ImageNet 1.28 million 262k 74 2500
VOC 5000 40k 0.43 1.5
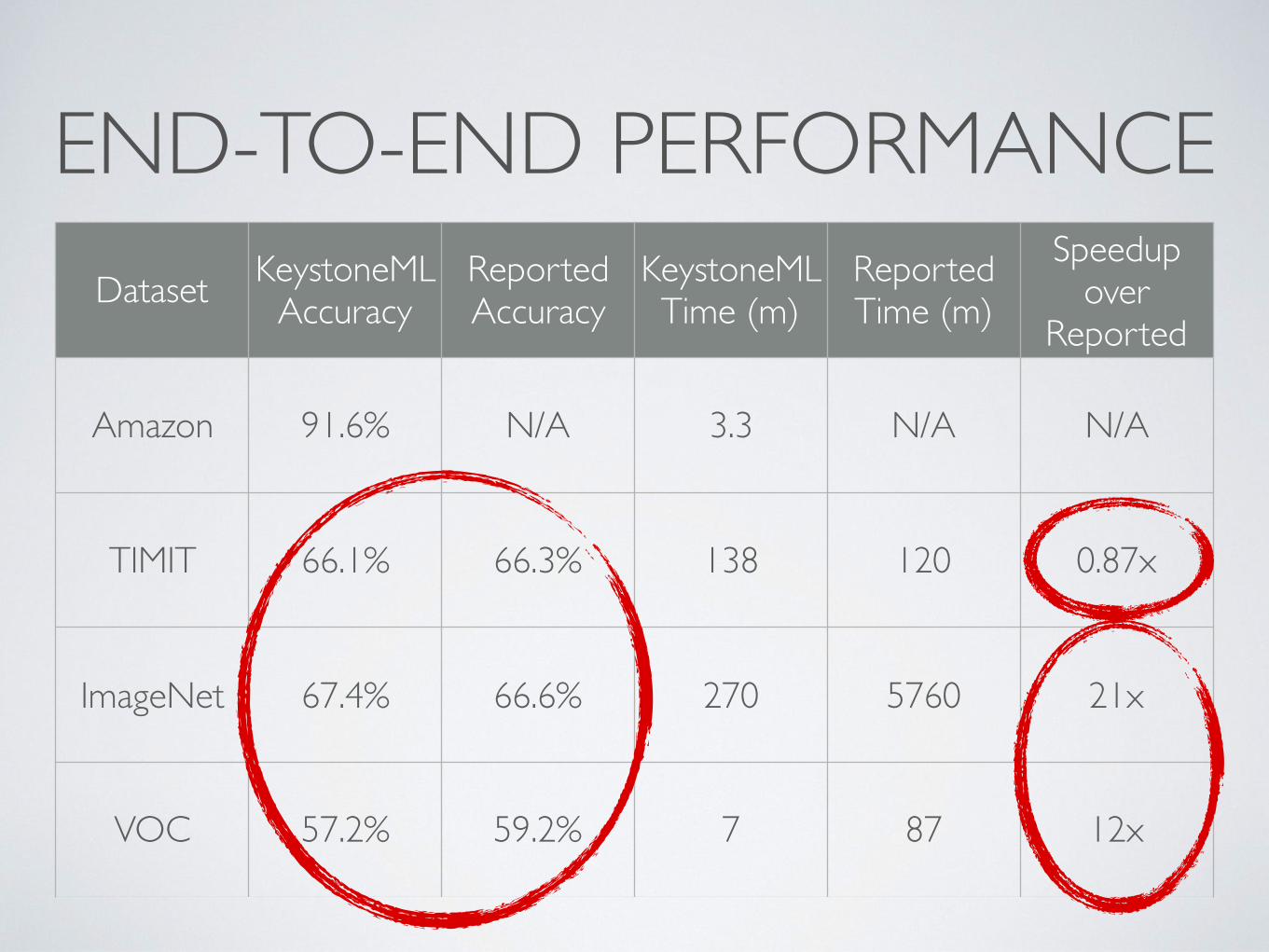
END-TO-END PERFORMANCEDataset KeystoneML
AccuracyReported Accuracy
KeystoneML Time (m)
Reported Time (m)
Speedup over
Reported
Amazon 91.6% N/A 3.3 N/A N/A
TIMIT 66.1% 66.3% 138 120 0.87x
ImageNet 67.4% 66.6% 270 5760 21x
VOC 57.2% 59.2% 7 87 12x

END-TO-END PERFORMANCE
Amazon TIMIT ImageNet
0
5
10
15
0
20
40
60
0
100
200
300
400
500
8 16 32 64 128 8 16 32 64 128 8 16 32 64 128Cluster Size (# of nodes)
Tim
e (m
inut
es)
StageLoading Train Data Featurization Model SolveLoading Test Data Model Eval
●●
●
●
●
●●
●
●
●
●
●
●
●
●
Amazon TIMIT ImageNet
1
2
4
8
16
8 16 32 64 128 8 16 32 64 128 8 16 32 64 128Cluster Size (# of nodes)
Spee
dup
over
8 n
odes
(x)

END-TO-END PERFORMANCE
• Tested three levels of optimization
• None
• Auto-caching only
• Auto-caching and operator-selection.
• 7x to 15x speedup
0
5
10
15
Amazon TIMIT VOCWorkload
Spee
dup
Optimization Level None Whole−Pipeline All

QUESTIONS?
http://keystone-ml.org/Project Page
Code http://github.com/amplab/keystone
Training http://goo.gl/axbkkc

BACKUP SLIDES

SOFTWARE FEATURES• Data Loaders
• CSV, CIFAR, ImageNet, VOC, TIMIT, 20 Newsgroups
• Transformers
• NLP - Tokenization, n-grams, term frequency, NER*, parsing*
• Images - Convolution, Grayscaling, LCS, SIFT*, FisherVector*, Pooling, Windowing, HOG, Daisy
• Speech - MFCCs*
• Stats - Random Features, Normalization, Scaling*, Signed Hellinger Mapping, FFT
• Utility/misc - Caching, Top-K classifier, indicator label mapping, sparse/dense encoding transformers.
• Estimators
• Learning - Block linear models, Linear Discriminant Analysis, PCA, ZCA Whitening, Naive Bayes*, GMM*
• Example Pipelines
• NLP - Amazon Product Review Classification, 20 Newsgroups, Wikipedia Language model
• Images - MNIST, CIFAR, VOC, ImageNet
• Speech - TIMIT
• Evaluation Metrics
• Binary Classification
• Multiclass Classification
• Multilabel Classification
* - Links to external library
Just 11k Lines of Code, 5k of which are Tests or JavaDoc.

KEY API CONCEPTS

TRANSFORMERS
TransformerInput Output
abstract class Transformer[In, Out] {def apply(in: In): Outdef apply(in: RDD[In]): RDD[Out] = in.map(apply)…
}
TYPE SAFETY HELPS ENSURE ROBUSTNESS

ESTIMATORS
EstimatorRDD[Input]
abstract class Estimator[In, Out] {def fit(in: RDD[In]): Transformer[In,Out]…
}
Transformer.fit()

CHAINING
NGrams(2)String Vectorizer VectorBigrams
val featurizer : Transformer[String,Vector] = NGrams(2) then Vectorizer
featurizerString Vector
=

COMPLEX PIPELINES
.fit(data, labels)
pipelineString Prediction
=
val pipeline = (featurizer thenLabelEstimator LinearModel).fit(data, labels)
featurizerString Vector Linear Model Prediction
featurizerString Vector Linear Map Prediction


















