
OPTIMIZED ADAPTIVE FIR FILTER BASED ON ... -...
7
International Journal of Science, Engineering and Technology Research (IJSETR), Volume 3, Issue 4, April 2014 729 ISSN: 2278 – 7798 All Rights Reserved © 2014 IJSETR Abstract— This paper delegates a novel pipelined architecture implementation of adaptive filter based on distributed arithmetic (DA) for low-power, high-throughput, and low-area. The throughput rate of the design is increased by update of parallel lookup table (LUT) and implementation of filtering and weight-update operations concurrently. The conditional signed carry-save accumulation is used in order to reduce the sampling period and area complexity for DA-based inner-product computation. Reduction of power consumption is achieved in the proposed design by utilising a fast bit clock for carry-save accumulation but a much slower clock for all other operations. It consists of multiplexors of same number, LUT of small size, and nearly adders of half number compared to the existing design based on DA. From synthesis results, it is drawn that the proposed design consumes 11% less power and 2% less area than previous DA-based adaptive filter for filter lengths N = 16 and 32 in average. IndexTerms—Adaptivefilter,distributedarithmetic,LMS algorithm,fulladderusingtwohalfadders,circuitoptimization I. INTRODUCTION In signal processing, FIR filter is a filter whose response to finite input is finite , as it comes to zero within a finite time. This is opposite to IIR filters, which have feedback internally and may respond indefinitely . The impulse response of a discrete-time FIR filter of Nth order lasts for N + 1 samples, and then comes to zero. FIR filters can be discrete-time or continuous-time, and digital or analog. Digital filters that have an impulse response that reaches zero in a finite number of steps are called Finite Impulse Response (FIR) filters. An FIR filter can be non-recursively implemented by convolving impulse response of it (which is used to define an FIR filter) with the time data sequence it is called filtering. FIR filters are somewhat simpler than IIR filters, which contain one or more terms of feedback and should be implemented with difference equations or some other recursive technique. DA is a bit-serial operation of computation which allows digital filters to be implemented at high throughput rates, regardless of the filter length. However, it pretence a problem when implementing adaptive digital filters which Manuscript received March, 2014. Jyothirmayi Alahari, M.Tech Vlsi Design,SRM University, Chennai, India, 9791052134 M.Valarmathi, working as Assistant Professor(Sr.G), SRM University, Chennai, SRM University, 9444762782., requires recalculating the contents of LUT’s that store the filter coefficients. In signal processing, a finite impulse response (FIR) filter is a filter whose impulse response (or response to any finite length input) is of finite duration, because it reaches to zero in finite time. Fig. 1 Proposed DA-based structure of LMS adaptive filter of length N = 16 and P = 4. II. DESIGN PARAMETERS Booth’s encoding algorithm is acceptable for 2‟ s complementary and signed number multiplication. Booth’s algorithm also need redundant partial product algorithm also need redundant partial product generations, so-called OPTIMIZED ADAPTIVE FIR FILTER BASED ON DISTRIBUTED ARITHMETIC Jyothirmayi Alahari, M.Valarmathi
Transcript of OPTIMIZED ADAPTIVE FIR FILTER BASED ON ... -...

International Journal of Science, Engineering and Technology Research (IJSETR), Volume 3, Issue 4, April 2014
729
ISSN: 2278 – 7798
All Rights Reserved © 2014 IJSETR
Abstract— This paper delegates a novel pipelined architecture
implementation of adaptive filter based on distributed
arithmetic (DA) for low-power, high-throughput, and
low-area. The throughput rate of the design is increased by
update of parallel lookup table (LUT) and implementation of
filtering and weight-update operations concurrently. The
conditional signed carry-save accumulation is used in order to
reduce the sampling period and area complexity for DA-based
inner-product computation. Reduction of power consumption
is achieved in the proposed design by utilising a fast bit clock
for carry-save accumulation but a much slower clock for all
other operations. It consists of multiplexors of same number,
LUT of small size, and nearly adders of half number compared
to the existing design based on DA. From synthesis results, it is
drawn that the proposed design consumes 11% less power
and 2% less area than previous DA-based adaptive filter for
filter lengths N = 16 and 32 in average.
IndexTerms—Adaptivefilter,distributedarithmetic,LMS
algorithm,fulladderusingtwohalfadders,circuitoptimization
I. INTRODUCTION
In signal processing, FIR filter is a filter whose
response to finite input is finite , as it comes to zero within
a finite time. This is opposite to IIR filters, which have
feedback internally and may respond indefinitely . The
impulse response of a discrete-time FIR filter of Nth order
lasts for
N + 1 samples, and then comes to zero. FIR filters can be
discrete-time or continuous-time, and digital or analog.
Digital filters that have an impulse response that
reaches zero in a finite number of steps are called Finite
Impulse Response (FIR) filters. An FIR filter can be
non-recursively implemented by convolving impulse
response of it (which is used to define an FIR filter) with the
time data sequence it is called filtering. FIR filters are
somewhat simpler than IIR filters, which contain one or
more terms of feedback and should be implemented with
difference equations or some other recursive technique.
DA is a bit-serial operation of computation which allows
digital filters to be implemented at high throughput rates,
regardless of the filter length. However, it pretence a
problem when implementing adaptive digital filters which
Manuscript received March, 2014.
Jyothirmayi Alahari, M.Tech Vlsi Design,SRM University, Chennai,
India, 9791052134
M.Valarmathi, working as Assistant Professor(Sr.G), SRM University,
Chennai, SRM University, 9444762782.,
requires recalculating the contents of LUT’s that store the
filter coefficients. In signal processing, a finite impulse
response (FIR) filter is a filter whose impulse response (or
response to any finite length input) is of finite duration,
because it reaches to zero in finite time.
Fig. 1 Proposed DA-based structure of LMS adaptive filter of length N =
16 and P = 4.
II. DESIGN PARAMETERS
Booth’s encoding algorithm is acceptable for 2‟ s
complementary and signed number multiplication. Booth’s
algorithm also need redundant partial product algorithm
also need redundant partial product generations, so-called
OPTIMIZED ADAPTIVE FIR FILTER
BASED ON DISTRIBUTED ARITHMETIC
Jyothirmayi Alahari, M.Valarmathi

International Journal of Science, Engineering and Technology Research (IJSETR), Volume 3, Issue 4, April 2014
730
All Rights Reserved © 2014 IJSETR
sign-extension. In any multiplication algorithm, the
operation is decayed in a partial product summation. Each
partial product represents a multiple of the multiplicand to
be added to the final result. Nowadays almost all high-speed
multipliers apply a radix-4 recoding multiplication
algorithm. In a radix-2 algorithm, first make a series of
products between the multiplicand, Y, and every bit of the
multiplier, X, generating in this way a set of words called
partial products.
The speed is increased with a wallace reduction tree . in
the conventional wallace tree, multi-input partial product
bits, at the same bit position, are signal and final sum pair
using a series of single-bit full adders ( called 3-2
compressors). At the output, we have two words sum and
carry which have to be added as fast as possible by a
carry-propagate adder (CPA). The Wallace tree structure is a
variety of the carry-save adders (CSA). Radix-4
multiplication obtains an enhancement in the multiplication
algorithm due to less number of partial products moving into
the Wallace tree to be reduced. This can be achieved by the
application of the multiplier recoding, changing from a
2s-complement format to a signed-digit representation from
the set.
An FIR (Finite Impulse Response) filter, oppositely to IIR
filters, has a finite response to impulse signals, which is
described because it does not have feedback. This way, FIR
filters define a version of filter that has only zeros in the
z-transform (the poles are in the origin z=0). In inclusion,
FIR filters have other characteristics that makes these filters
very attractive to many applications, such as phase linearity,
solidity in the frequency response and constant group delay.
Equation below describes an FIR filter of length K:
(1)
Where:
x represent the input and y represent transformed data.
ak is the set of constant coefficients of the filter.
(K-1) is the order of the FIR filter.
An FIR filter can also be specified by its number of
taps (K), which is the order increased by one. The transfer
function A(z) of the FIR filter is conveyed as follows:
(2)
Given equation (2), an FIR filter is also called an
all-zero filter because the frequency response is only
determined by the zeros in the z-transform.
In general, FIR filters are favoured due to its
characteristic of phase linearity and stability. However, IIR
filters can be used in applications that requisite sharp cut-off
or narrow band filters and where there is no requirement of
phase linearity. That is due to FIR filters require much higher
order implementations than IIR filters for a homogeneous
performance.
III. FOUR POINT INNER PRODUCT
Fig. 2 Four Point Inner Product
The LMS adaptive filter, in each cycle, needs to
perform an inner-product computation which accords to the
most of the critical path. For simplicity of presentation, let
the inner product be
Y=
Where wk and xk for 0≤k≤N-1 form N- point vectors
corresponding the current weights and most recent N − 1
input, respectively. The bit slices of vector w are fed one after
the other in the least significant bit to the most significant bit
order to the carry-save accumulator. However, the negative
(two’s complement) of the output of LUT needs to be
occupied in case of MSB slices. Therefore, all the bits of LUT
output are passed through XOR gates with a sign-control
input which is set to one only when the MSB slice appears as
address.
a) DISTRIBUTED ARITHMETIC
.
Fig. 3 Distributed Arithmetic

International Journal of Science, Engineering and Technology Research (IJSETR), Volume 3, Issue 4, April 2014
731
ISSN: 2278 – 7798
All Rights Reserved © 2014 IJSETR
Distributed Arithmetic (DA) is a technique that is
bit-serial in nature. It can therefore appear to be slow. It turns
out when the number of elements in a vector is nearly the
same as the word size, DA is quite fast DA `replaces’ the
explicit multiplications by ROM look-ups an efficient
technique to implement on Field Programmable Gate Arrays
(FPGAs). Area savings from using DA can be up to 80% in
DSP hardware designs.
b) CARRY SAVE ACCUMULATION
The Fig. 4 shows an carry save implementation of shift
accumulation. It reduces the addition of 3 numbers to the
addition of 2 numbers. The propagation delay is 3 gates
regardless of the number of bits. The amount of circuitry is
much less than a carry-look ahead adder.
1)
2) Fig 4: Carry Save Accumulation
The circuit reduces log2K by 0.585 (from 1.585 to 1.0)
for a delay of 3. The overall delay we can expect is therefore
log2K × 3/0.585 = log2K × 5.13. This is better than carry
look ahead for less circuitry. The delay is the same as for a
conventional look ahead-adder tree but uses much less
circuitry. The irregularity of the tree causes a curtailment in
efficiency but this is relatively small (and becomes even
smaller for large K).Inverting alternate stages will speed up
both tree circuits still further but requires more circuitry.
We can modify this block by implementing full adder using
two half adders which reduces number of gates which
results in reduction of area and power. Implementing full
adder using two half adders reduces 1 gate per full adder,
since here there are series of full adder good amount of gates
get reduced.
IV WEIGHT INCREMENT BLOCK
Fig 5: Weight Increment Block
It consists of barrel shifter, adder/substractor, D-Flipflop
and Word Parallel Bit-Serial Converter. It is used to update
the weight of the four point inner product.The 8 bit outputs of
the four point inner product block are given as inputs to this
block.This helps in updating weight of the LUT’s in
distributed arithmetic.
a) Barrel shifter
Fig 6: Barrel Shifter
S2
S1
S0
D7 D6 D5 D4 D3 D2 D1 D0
Z7 Z6 Z5 Z4 Z3 Z2 Z1 Z0
0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1
0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1
0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1
(7,1) (6,1) (5,1) (4,1) (3,1) (2,1) (1,1) (0,1)
(7,2) (6,2) (5,2) (4,2) (3,2) (2,2) (1,2) (0,2)
(7,3) (6,3) (5,3) (4,3) (3,3) (2,3) (1,3) (0,3)
(7,0) (6,0) (5,0) (4,0) (3,0) (2,0) (1,0) (0,0)

International Journal of Science, Engineering and Technology Research (IJSETR), Volume 3, Issue 4, April 2014
732
All Rights Reserved © 2014 IJSETR
Its consists of multiplexers and its serial connections. In
fig 6, different combinations of inputs are given to
multiplexer to perform shifting operation.
a) Word Parallel Bit Serial Converter
Fig 7: Parallel In Serial Out
It consists of D-Flipflop and nand gates.It
is used to find convert parallel bit to serial.
V. DA-BASED LMS ADAPTIVE FILTER OF FILTER LENGTH N =
4
Fig. 6: DA-based LMS adaptive filter of filter length N = 4
The proposed structure of DA-based adaptive filter of length
N = 4.It consists of a inner product block of four point and a
weight-increment block along with additional circuits for the
computation of error value e(n) and control word t for the
barrel shifters. The four-point inner-product block includes a
DA table consisting of a 15 registers array which stores the
partial inner products yl for 0 < l ≤ 15 and a 16: 1 multiplexor
to select the content of one of those registers. Bit slices of
weights A = {w3l w2l w1l w0l} for 0 ≤ l ≤ L − 1 are given to
the MUX as control in LSB-to-MSB order, and the output of
the MUX is given to the carry-save accumulator After L bit
cycles, the carry-save shift accumulator accumulates all the
partial inner products and produces a sum word and a carry
word of size (L + 2) bit each.
a) Control Word Generator
The Control Word Generation for weight increment
block is as follows:
where t is the control word required for the operation of
barrel shifter.
VI DA-based LMS adaptive filter of length N =16 and P
= 4
The figure of this filter is shown in fig1.The inner-product
computation of can be decayed into N/P (assuming that N =
PQ) small adaptive filtering block of filter length P Each of
these P-point inner-product computation blocks will
accordingly have a weight-increment unit to update P
weights. The proposed structure for N = 16 and P = 4. It
consists of four inner-product blocks of length P = 4, which is
shown in Fig. The (L + 2)-bit sums and carry produced by the
four blocks are added by two separate binary adder trees.
Four carry-in bits should be affixed to sum words which are
output of four 4-point inner-product blocks. Since the carry
words are of twice the weight compared to the sum words,
two carry-in bits are set as input carry at the first level binary
adder tree of carry words, which is equivalent to inclusion of
four carry-in bits to the sum words

International Journal of Science, Engineering and Technology Research (IJSETR), Volume 3, Issue 4, April 2014
733
ISSN: 2278 – 7798
All Rights Reserved © 2014 IJSETR
SIMULATION RESULTS
When 8 bit input is 00001110 and 12 bit input is 000000111000 the output is shown below.
Binary output:
When 8 bit input is 00001110 and 12 bit input is 000000111000 the output is shown below.
Unsigned output:
International Journal of Science, Engineering and Technology Research (IJSETR), Volume 3, Issue 4, April 2014
734
All Rights Reserved © 2014 IJSETR
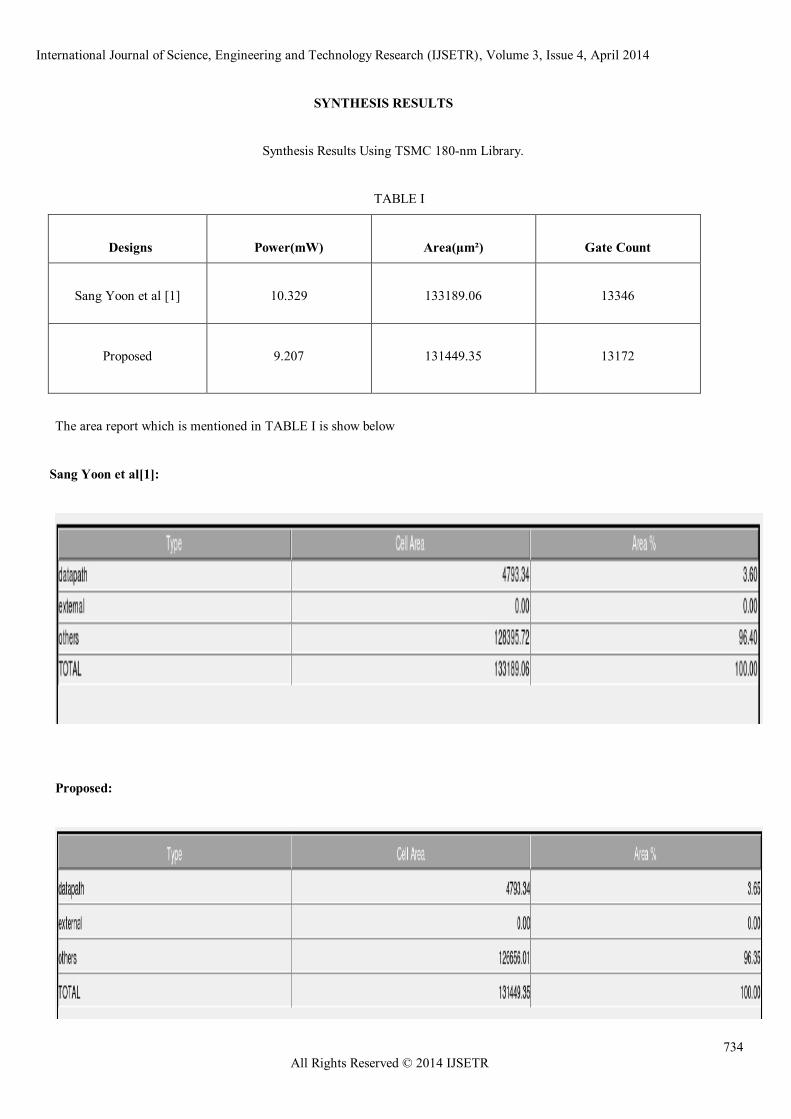
SYNTHESIS RESULTS
Synthesis Results Using TSMC 180-nm Library.
TABLE I
Designs
Power(mW)
Area(µm²)
Gate Count
Sang Yoon et al [1]
10.329
133189.06
13346
Proposed
9.207
131449.35
13172
The area report which is mentioned in TABLE I is show below
Sang Yoon et al[1]:
Proposed:

International Journal of Science, Engineering and Technology Research (IJSETR), Volume 3, Issue 4, April 2014
735
ISSN: 2278 – 7798
All Rights Reserved © 2014 IJSETR
CONCLUSION
An efficient pipelined architecture for low-power,
high-throughput, and low area implementation of
DA-based adaptive filter is presented. Throughput rate is
significantly enhanced by parallel LUT update and
concurrent processing of filtering operation and
weight-update operation. Also proposed a carry-save
accumulation scheme of signed partial inner products for
the computation of filter output. Compared to the best of
other existing designs our proposed design is better for
area and power consumption. Offset binary coding is
popularly used to reduce the LUT size to half for
area-efficient implementation of DA, which can be
applied to our design as well.
REFERENCES
[1] Sang Yoon Park,Pramod Kumar Meher ―Low-Power,
High-Throughput, and Low-Area Adaptive FIR
Filter Based on Distributed Arithmetic‖ IEEE
Transactions On Circuits And Systems—II:
Express Briefs, VOL. 60, NO. 6, JUNE 2013.
[2] S. Haykin and B. Widrow, Least-Mean-Square
Adaptive Filters. Hoboken, NJ, USA: Wiley,2003.
[3] S. A. White, ―Applications of the distributed
arithmetic to digital signal processing: A tutorial
review,‖ IEEE ASSP Mag., vol. 6, no. 3, pp. 4–19,
Jul. 1989.
[4] D. J. Allred, H. Yoo, V. Krishnan, W. Huang, and D.
V. Anderson, ―LMS adaptive filters using
distributed arithmetic for high throughput,‖ IEEE
Trans. Circuits Syst. I, Reg. Papers, vol.52, no. 7,
pp. 1327–1337,Jul. 2005.
[5] R. Guo and L. S. DeBrunner, ―Two
high-performance adaptive filter implementation
schemes using distributed arithmetic,‖ IEEE Trans.
Circuits Syst. II, Exp. Briefs, vol. 58, no. 9, pp.
600–604, Sep. 2011.
[6] R. Guo and L. S. DeBrunner, ―A novel adaptive filter
implementation scheme using distributed
arithmetic,‖ in Proc. Asilomar Conf. Signals, Syst.,
Comput., Nov. 2011, pp.160–164.
[7] P. K. Meher and S. Y. Park, ―High-throughput
pipelined realization of adaptive FIR filter based on
distributed arithmetic,‖ in VLSI Symp. Tech.Dig.,
Oct. 2011, pp. 428–433.
[8] M. D. Meyer and P. Agrawal, ―A modular pipelined
implementation of a delayed LMS transversal
adaptive filter,‖ in Proc. IEEE Int. Symp. Circuits
Syst., May 1990, pp. 1943–1946.
About Author
Jyothirmayi Alahari received B.Tech degree in Electronics
&Communication Engineering from Vignan Institute Of
Technology and Science, Deshmukhi ,Hyderabad, Andhra
Pradesh, India. Currently doing M.Tech in specialization of
VLSI DESIGN in SRM UNIVERSITY, Chennai.
M Valarmathi Currently she is working as Assistant
Professor (Sr.G) at SRM UNIVERSITY, Chennai, Tamil
Nadu.


















