
On the Road to Exascale: Lessons from Contemporary ... · ... Full PCIe X16 Datacenter GPFS and TG...
51
On the Road to Exascale: Lessons from Contemporary Scalable GPU Systems Jeffrey Vetter http://ft.ornl.gov [email protected] Presented to ATIP/A*STAR/NSF Workshop on Accelerator Technologies Singapore 8 May 2012
Transcript of On the Road to Exascale: Lessons from Contemporary ... · ... Full PCIe X16 Datacenter GPFS and TG...

On the Road to Exascale: Lessons from Contemporary
Scalable GPU Systems
Jeffrey Vetter
http://ft.ornl.gov [email protected]
Presented to ATIP/A*STAR/NSF Workshop on Accelerator Technologies
Singapore 8 May 2012

Highlights
Today’s HPC landscape is growing more diverse
Projections for Exascale architectures are extreme – Scalability to 1B threads – Move to diverse, heterogeneous architectures – Limited memory capacity and bandwidth
Emerging technologies – GPUs – NVRAM technologies may offer a solution
Lessons from today’s emerging technologies for Exascale
– Software infrastructure plays a pivotal role

HPC Landscape Today 8 May 2012 4

Contemporary Architectures Date System Location Comp Comm Peak
(PF)
Power
(MW)
2009 Jaguar; Cray XT5 ORNL AMD 6c Seastar2 2.3 7.0
2010 Tianhe-1A NSC Tianjin Intel + NVIDIA Proprietary 4.7 4.0
2010 Nebulae NSCS Shenzhen Intel + NVIDIA IB 2.9 2.6
2010 Tsubame 2 TiTech Intel + NVIDIA IB 2.4 1.4
2011 K Computer RIKEN/Kobe SPARC64 VIIIfx Tofu 10.5 12.7
2011 Sunway BlueLight NSC Jinan Shenwei SW-1600 IB 1 1
2012 Titan; Cray XK6 ORNL AMD + NVIDIA Gemini 10-20 7?
2012 Mira; BlueGeneQ ANL SoC Proprietary 10 4-5?
2012 Sequoia; BlueGeneQ LLNL SoC Proprietary 20 8-10?
2012 Blue Waters; Cray NCSA/UIUC AMD + (partial)
NVIDIA
Gemini 10? ?
2013 Stampede TACC Intel + MIC IB 10? 10?

K: #1 in November 2011
10.5 PF (93% of peak) – 12.7 MW
705,024 cores 1.4 PB memory
Source: Riken, Fujitsu

Source: OLCF

Looking Forward to Exascale
8 May 2012 8

Notional Exascale Architecture Targets (From Exascale Arch Report 2009)
System attributes 2001 2010 “2015” “2018”
System peak 10 Tera 2 Peta 200 Petaflop/sec 1 Exaflop/sec
Power ~0.8 MW 6 MW 15 MW 20 MW
System memory 0.006 PB 0.3 PB 5 PB 32-64 PB
Node performance 0.024 TF 0.125 TF 0.5 TF 7 TF 1 TF 10 TF
Node memory BW 25 GB/s 0.1 TB/sec 1 TB/sec 0.4 TB/sec 4 TB/sec
Node concurrency 16 12 O(100) O(1,000) O(1,000) O(10,000)
System size (nodes)
416 18,700 50,000 5,000 1,000,000 100,000
Total Node Interconnect BW
1.5 GB/s 150 GB/sec 1 TB/sec 250 GB/sec 2 TB/sec
MTTI day O(1 day) O(1 day)
http://science.energy.gov/ascr/news-and-resources/workshops-and-conferences/grand-challenges/

Trend #1: Facilities and Power
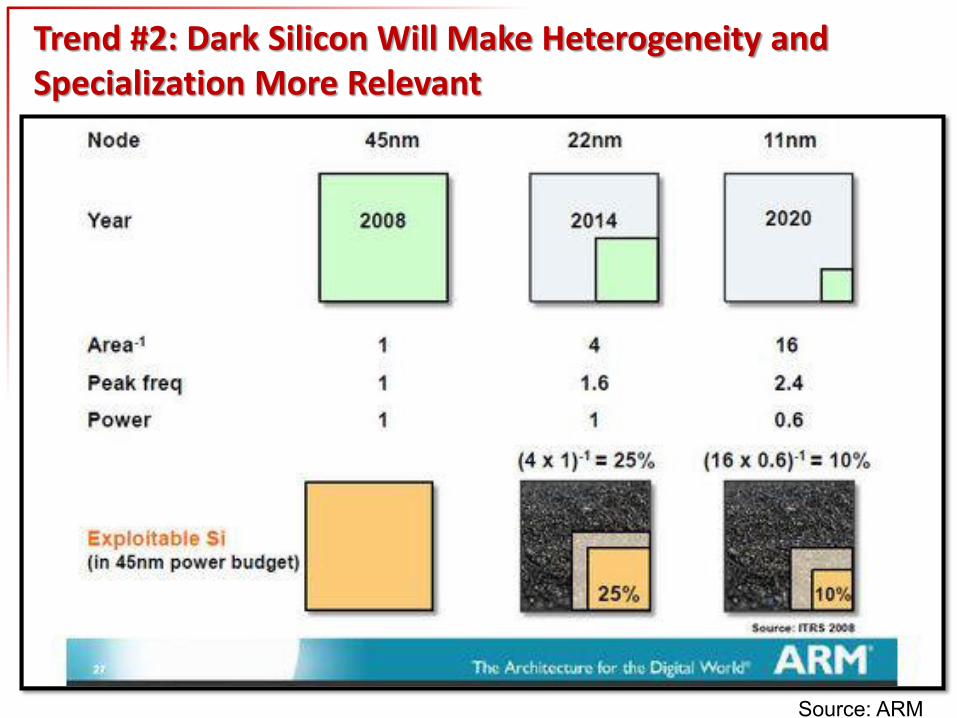
Trend #2: Dark Silicon Will Make Heterogeneity and Specialization More Relevant
Source: ARM

NVIDIA Echelon System Sketch
DARPA Echelon team: NVIDIA, ORNL, Micron, Cray, Georgia Tech, Stanford, UC-Berkeley, U Penn, Utah, Tennessee, Lockheed Martin

Source: Hitchcock, Exascale Research Kickoff Meeting

Current Node Architectures

Keeneland Initial Delivery system procured and installed in Oct 2010
201 TFLOPS in 7 racks (90 sq ft incl service area)
902 MFLOPS per watt on HPL (#12 on Green500)
Upgraded April 2012 to 255 TFLOPS
Final delivery system over 500 TFLOPS coming this summer Keeneland System
(7 Racks)
ProLiant SL390s G7 (2CPUs, 3GPUs)
S6500 Chassis (4 Nodes)
Rack (6 Chassis)
M2070
Xeon 5660
12000-Series Director Switch
Integrated with NICS Datacenter GPFS and TG Full PCIe X16
bandwidth to all GPUs
67 GFLOPS
515 GFLOPS
1679 GFLOPS 24/18 GB
6718 GFLOPS
40306 GFLOPS
201528 GFLOPS
http://keeneland.gatech.edu
J.S. Vetter, R. Glassbrook et al., “Keeneland: Bringing heterogeneous GPU computing to the computational science community,” IEEE Computing in Science and Engineering, 13(5):90-5, 2011, http://dx.doi.org/10.1109/MCSE.2011.83.

Keeneland Full-Scale System
500+ TF Full scale system being built now – Installation scheduled for June
Configuration – 700+ NVIDIA M2090 GPUs – HP ProLiant S250 G8 Nodes
• 2 Sandy Bridge processors
– Mellanox IB FDR
Petabyte+ Lustre fileystem NSF XSEDE Production resource as of Oct 1
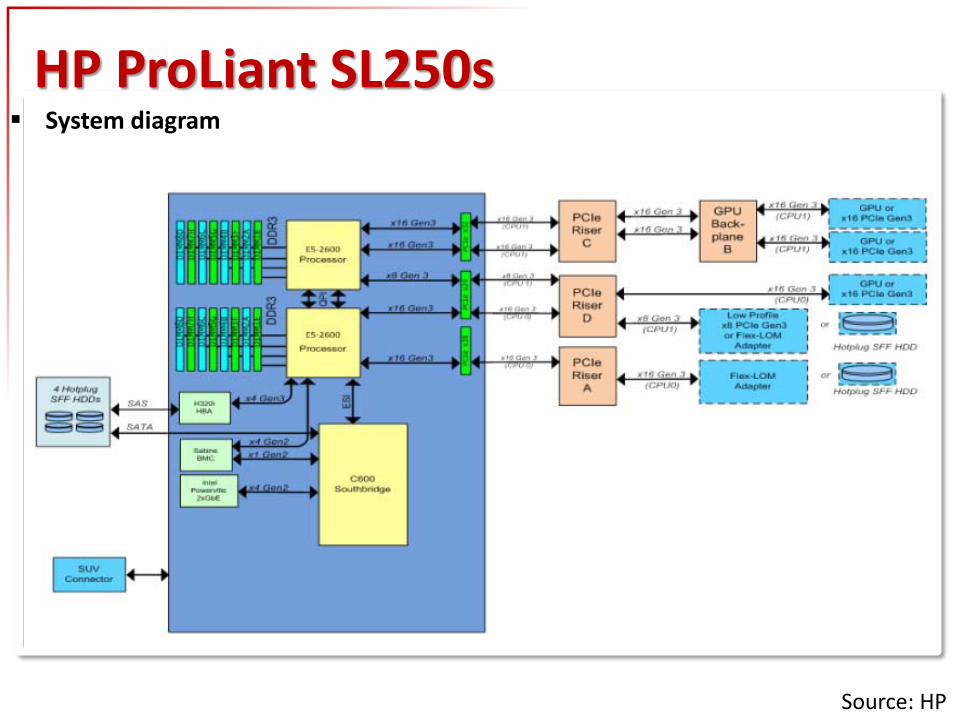
HP ProLiant SL250s System diagram
Source: HP
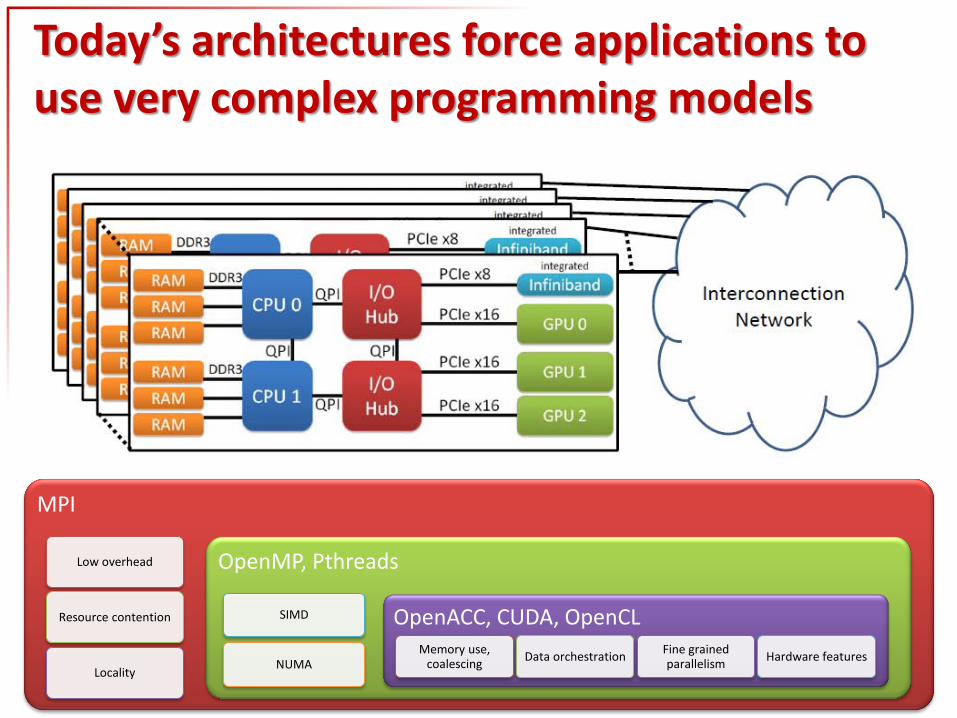
Today’s architectures force applications to use very complex programming models
MPI
Low overhead
Resource contention
Locality
OpenMP, Pthreads
SIMD
NUMA
OpenACC, CUDA, OpenCL Memory use,
coalescing Data orchestration
Fine grained parallelism
Hardware features
19

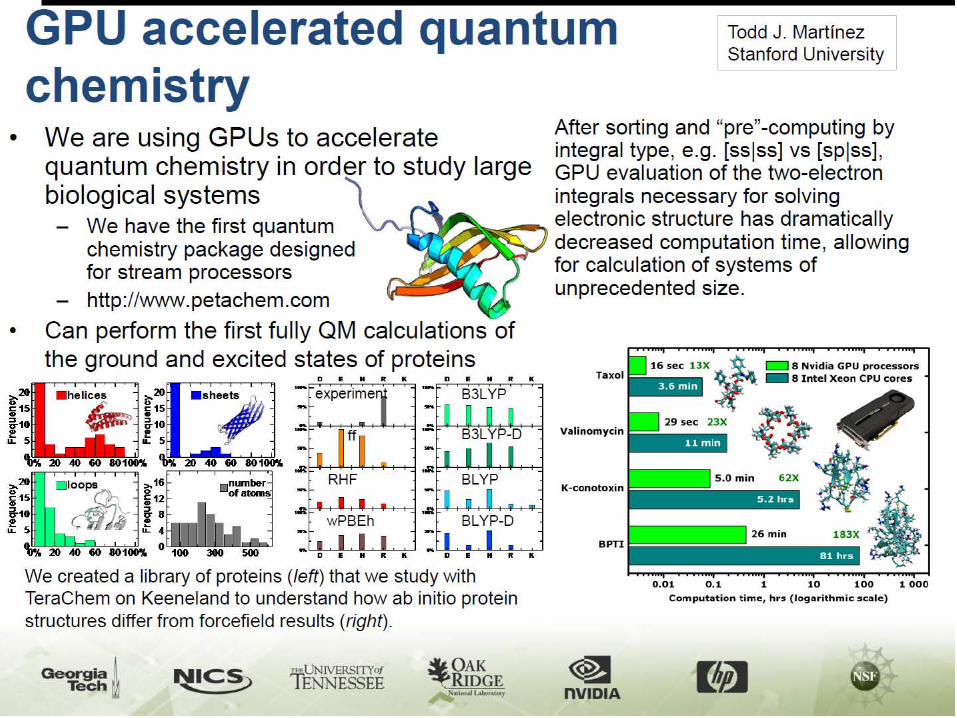

E.M. Aldrich, J. Fernández-Villaverde et al., “Tapping the supercomputer under your desk: Solving dynamic equilibrium models with graphics processors,” Journal of Economic Dynamics and Control, 35(3):386-93, 2011,


What can the Recent Move to GPUs Provide Lessons for
Exascale ??

Observations on GPU HPC Challenges
Lack of hardware features – double precision arithmetic, ECC, etc
Scalability continues unabated Programming complexity
– Reasonable abstractions to program architectures
(Performance) Portability – Functional portability is mandatory
• MPI and OpenMP are functional specifications
– Performance portability is becoming critically important • Though, well-funded experts can always optimize their
applications
– Even GPU systems are usually different • Node architecture, host processors, interconnects, mem
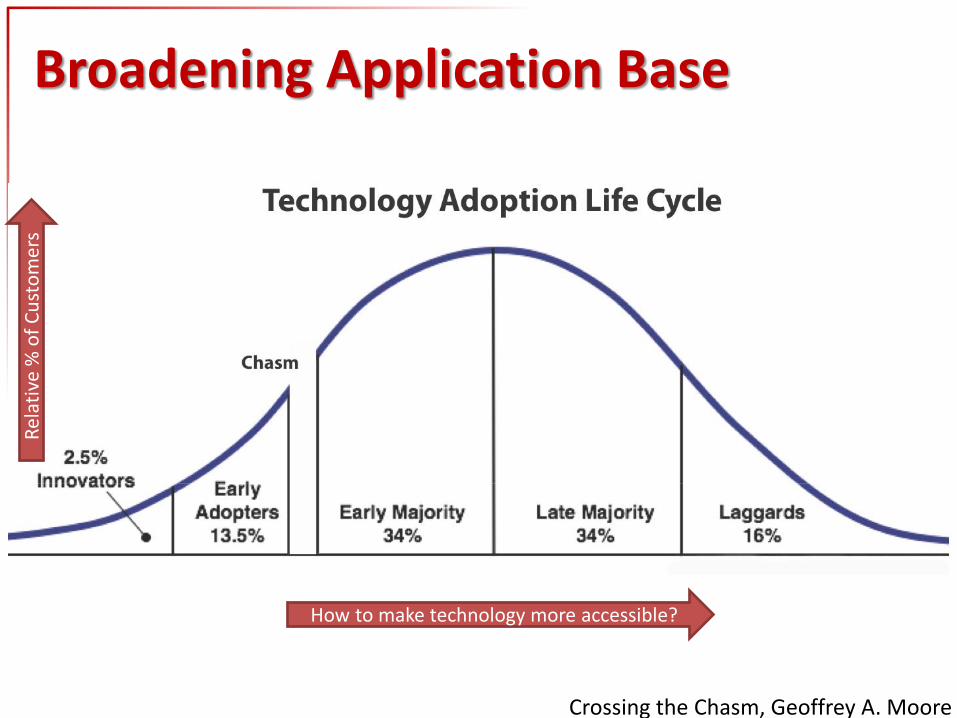
Crossing the Chasm, Geoffrey A. Moore
Rel
ativ
e %
of
Cu
sto
mer
s
How to make technology more accessible?
Broadening Application Base

Application Drivers for Exascale
Town Hall Meetings April-June 2007 Scientific Grand Challenges Workshops
Nov, 2008 – Oct, 2009 – Climate Science (11/08),
– High Energy Physics (12/08),
– Nuclear Physics (1/09),
– Fusion Energy (3/09),
– Nuclear Energy (5/09),
– Biology (8/09),
– Material Science and Chemistry (8/09),
– National Security (10/09)
– Cross-cutting technologies (2/10)
Exascale Steering Committee – Extreme Architecture and Technology
Workshop 12/2009
International Exascale Software Project
MISSION IMPERATIVES
FUNDAMENTAL SCIENCE
http://science.energy.gov/ascr/news-and-resources/workshops-and-conferences/grand-challenges/ http://www.exascale.org/iesp/Main_Page

Codesign View of HPC
Applications
• Materials
• Climate
• Fusion
• National Security
• Combustion
• Nuclear Energy
• Cybersecurity
• Biology
• High Energy Physics
• Energy Storage
• Photovoltaics
• National Competitiveness
• Usage Scenarios
• Ensembles
• UQ
• Visualization
• Analytics
Programming Environment
• Domain specific
• Libraries
• Frameworks
• Templates
• Domain specific languages
• Patterns
• Autotuners
• Platform specific
• Languages
• Compilers
• Interpreters/Scripting
• Performance and Correctness Tools
• Source code control
System Software
• Resource Allocation
• Scheduling
• Security
• Communication
• Synchronization
• Filesystems
• Instrumentation
• Virtualization
Architectures
• Processors
• Multicore
• Graphics Processors
• Vector processors
• FPGA
• DSP
• Memory and Storage
• Shared (cc, scratchpad)
• Distributed
• RAM
• Storage Class Memory
• Disk
• Archival
• Interconnects
• Infiniband
• IBM Torrent
• Cray Gemini, Aires
• BGL/P/Q
• 1/10/100 GigE
Performance, Resilience, Power, Programmability

Impact and Champions Milestones/Dates/Status
Novel Ideas
Principal Investigator: Robert Rosner, ANL March 1, 2012
Scheduled Actual
Kernels, initial codes in repository 1/12 12/11
Formulation of 1st-year calculation 1/12 1/12
NEK data structures in MOAB 1/12 1/12
Initial performance model for NEK 7/12 -
Initial performance analysis for UNIC 7/12 -
Initial uncertainty quant. runs 7/12 -
Complete pin bundle calculations 10/12 -
Custom viz design for NEK/UNIC output 12/12 -
• Develop innovative, scalable algorithms for
neutronics and thermo-hydraulics
computations suitable for exascale computers
• Couple high-fidelity thermo-hydraulics and
neutronics codes for challenging multi-scale,
multi-physics computations
• Drive design decisions for next-generation
programming models and computer
architectures at the exascale
IMD CESAR – Center for Exascale Simulation of Advanced Reactors
Simulating a complete nuclear power system in fine detail will fundamentally change the paradigm of how advanced nuclear reactors are designed, built, tested and operated. • Every step of the nuclear regulatory timeline can be
compressed by guiding expensive experiment efforts. • New designs can be rapidly prototyped, accident
scenarios can be studied in detail, material properties can be discovered, and design margins can be dramatically improved.
• Scientists can analyze problems for a wide range of novel reactor systems.

Impact and Champions Milestones/Dates/Status
Novel Ideas
30 Mar 2012
Scheduled Actual
Kickoff Workshop AUG 2011 AUG 2011
Initial molecular dynamics DEC 2011 DEC 2011
(MD) SPMD proxy app(s)
Initial scale-bridging MPMD MAY 2012
proxy app(s)
Prototype MD DSL SEP 2012
Assessment of data/resource 2013
sharing requirements, both for
scale-bridging and in situ
visualization/analysis
Demonstrate scale-bridging 2015
on 10+ PF-class platform
IMPACT. Our goal is to establish the
interrelationship between hardware, middleware
(software stack), programming models, and
algorithms required to enable a productive
exascale environment for multiphysics simulations
of materials in extreme mechanical and radiation
environments.
The design and development of extreme
environment tolerant advanced materials by
manipulating microstructure and interfaces, at the
grain scale, depends on such predictive
capabilities.
Embedded Scale-Bridging Materials Science
Adaptive physics refinement
Asynchronous task-based approach
Agile Development of Proxy Application Suite
Single-scale apps target node-level issues
Scale-bridging apps target system-level issues
Co-optimization for P3R: Price, Performance, Power,
and Resiliency
ASPEN, SST models & simulators
GREMLIN emulator for stress-testing
IMD Exascale Co-Design Center for Materials in Extreme Environments
Director: Tim Germann (LANL)
Deputy Director: Jim Belak (LLNL)

‘Real’ Performance Bounds
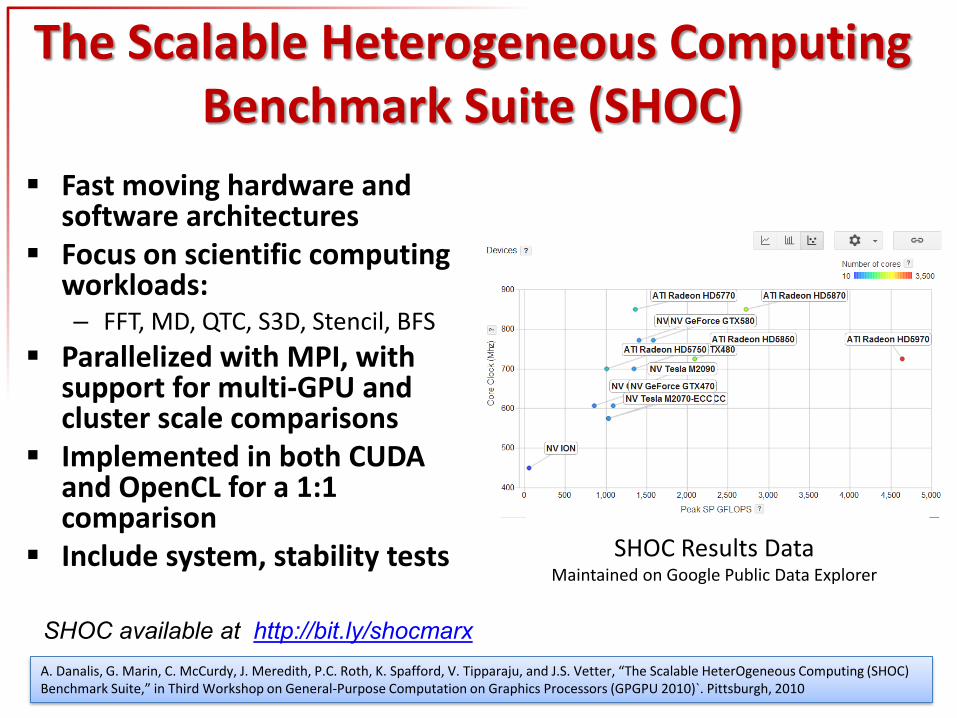
The Scalable Heterogeneous Computing Benchmark Suite (SHOC)
Fast moving hardware and software architectures
Focus on scientific computing workloads: – FFT, MD, QTC, S3D, Stencil, BFS
Parallelized with MPI, with support for multi-GPU and cluster scale comparisons
Implemented in both CUDA and OpenCL for a 1:1 comparison
Include system, stability tests SHOC Results Data Maintained on Google Public Data Explorer
A. Danalis, G. Marin, C. McCurdy, J. Meredith, P.C. Roth, K. Spafford, V. Tipparaju, and J.S. Vetter, “The Scalable HeterOgeneous Computing (SHOC) Benchmark Suite,” in Third Workshop on General-Purpose Computation on Graphics Processors (GPGPU 2010)`. Pittsburgh, 2010
SHOC available at http://bit.ly/shocmarx

Example: Molecular Dynamics
Motivation – Classic nbody pairwise
computation, important to all MD codes such as LAMMPS, AMBER, NAMD, Gromacs, Charmm
Basic design – Computation of the
Lennard Jones potential
– 3D domain, random distribution
– Neighbor list algorithm

Example: S3D Motivation
– Measure performance of important DoE application
– S3D solves Navier-Stokes equations for a regular 3D domain, used to simulate combustion
– Benchmark is the ethylene-air getrates kernel
Basic design – Assign each grid point to a device
thread
– Highly parallel, as grid points are independent
OpenCL/CUDA observations – CUDA performance dominates OpenCL
• Big factor: native transcendentals (sin, cos, tan, etc.)
3D Regular Domain Decomposition – Each thread handles a grid point, blocks handle regions

AMD’s Llano: A-Series APU
Combines – 4 x86 cores
– Array of Radeon cores
– Multimedia accelerators
– Dual channel DDR3
32nm
Up to 29 GB/s memory bandwidth
Up to 500 Gflops SP
45W TDP
Source: AMD
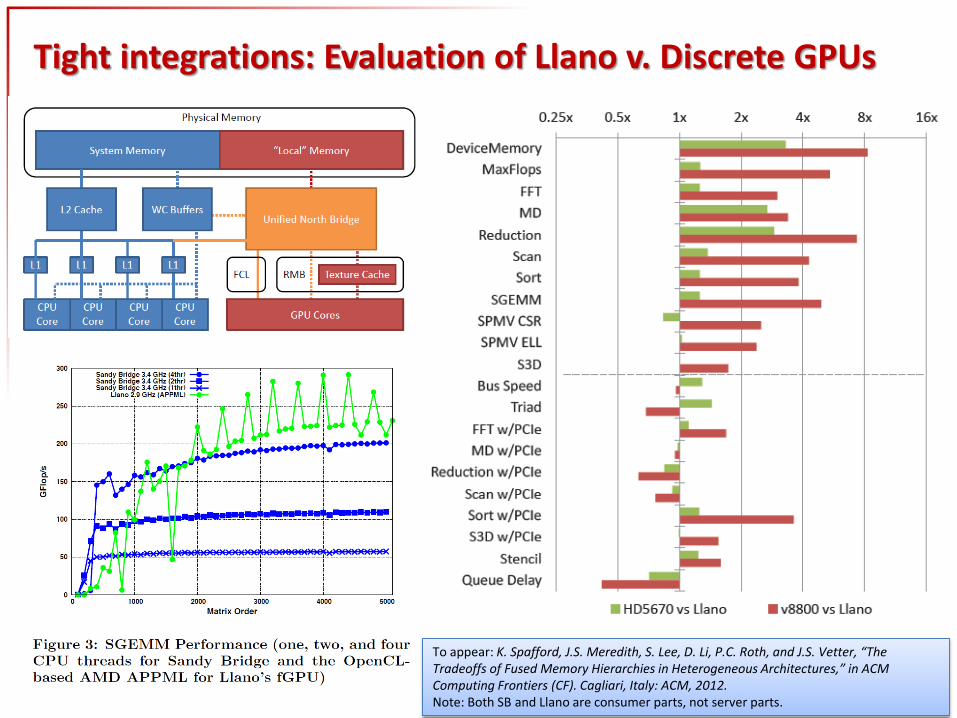
Tight integrations: Evaluation of Llano v. Discrete GPUs
To appear: K. Spafford, J.S. Meredith, S. Lee, D. Li, P.C. Roth, and J.S. Vetter, “The Tradeoffs of Fused Memory Hierarchies in Heterogeneous Architectures,” in ACM Computing Frontiers (CF). Cagliari, Italy: ACM, 2012. Note: Both SB and Llano are consumer parts, not server parts.

CUDA and OpenCL Today’s performance ?
This chart shows the speedup of CUDA over OpenCL on a single Tesla M2070 on KIDS (CUDA 4.0)
39
1.00 1.00 0.99 1.01 1.00 0.94 1.00 1.00 0.99
5.21 6.15
1.49 1.77
1.18 1.67
1.01 1.00 1.01 1.08 1.06 1.00
2.17 1.08 1.01
2.41 1.53
0.93 0.96 0.94 1.11
maxspflops
gmem_readbw
lmem_readbw
tex_readbw
bspeed_readback
fft_dp
dgemm_n
md_dp_bw
reduction_pcie
scan
spmv_csr_scalar_sp
spmv_ellpackr_sp
spmv_csr_vector_dp
stencil
s3d

A second look 40
1.00
1.00
0.99
1.01
1.00
0.94
1.00
1.00
0.99
5.21
6.15
1.49
1.77
1.18
1.67
1.01
1.00
1.01
1.08
1.06
1.00
2.17
1.08
1.01
2.41
1.53
0.93
0.96
0.94
1.11
maxspflops
maxdpflops
gmem_readbw
gmem_writebw
lmem_readbw
lmem_writebw
tex_readbw
bspeed_download
bspeed_readback
fft_sp
fft_dp
sgemm_n
dgemm_n
md_sp_bw
md_dp_bw
reduction
reduction_pcie
reduction_dp
scan
scan_dp
spmv_csr_scalar_sp
spmv_csr_vector_sp
spmv_ellpackr_sp
spmv_csr_scalar_dp
spmv_csr_vector_dp
spmv_ellpackr_dp
stencil
stencil_dp
s3d
s3d_dp
Reliant on texture memory
Dependent on transcendentals

27.4
205.2
300.3
54.8 10.4
165.9
292.9
373.1
72.1
16.4
0
100
200
300
400
FFT MD SGEMM Reduction Scan
OpenCL
CUDA
But this wasn’t always the case…
v3.0 (Feb 2010)
v2.3 (Sept 2009)
Tesla C1060 GPU

Who is using SHOC?
Thousands of hits per month, thousands of downloads
Procurements and acceptance tests – Procurement and acceptance on NSF Keeneland System – Various government agencies
AMD, ARM, IBM, NVIDIA, Intel, etc – Nvcc compiler regression suite – OpenCL compiler regression suite
Scientists are using SHOC for research (55 citations to date) Try SHOC at http://bit.ly/shocmarx

Software Development Environment

Directive-based Compilation and Tuning
PGI Accelerate, HMPP Caps Enterprise, Cray, R-stream
OpenACC (http://www.openacc-standard.org/)
OpenMPC (OpenMP extended for CUDA) – OpenMPC = OpenMP + a new set of
directives and environment variables for CUDA
– OpenMPC provides • A high level abstraction of the CUDA
programming model (Programmability) • An easy tuning environment to generate
CUDA programs in many optimization variants (Tunability)
Seyong Lee et al., OpenMPC: Extended OpenMP Programming and Tuning for GPUs, SC10: Proceedings of the 2010 ACM/IEEE conference on Supercomputing (Best Student Paper Award), November 2010.
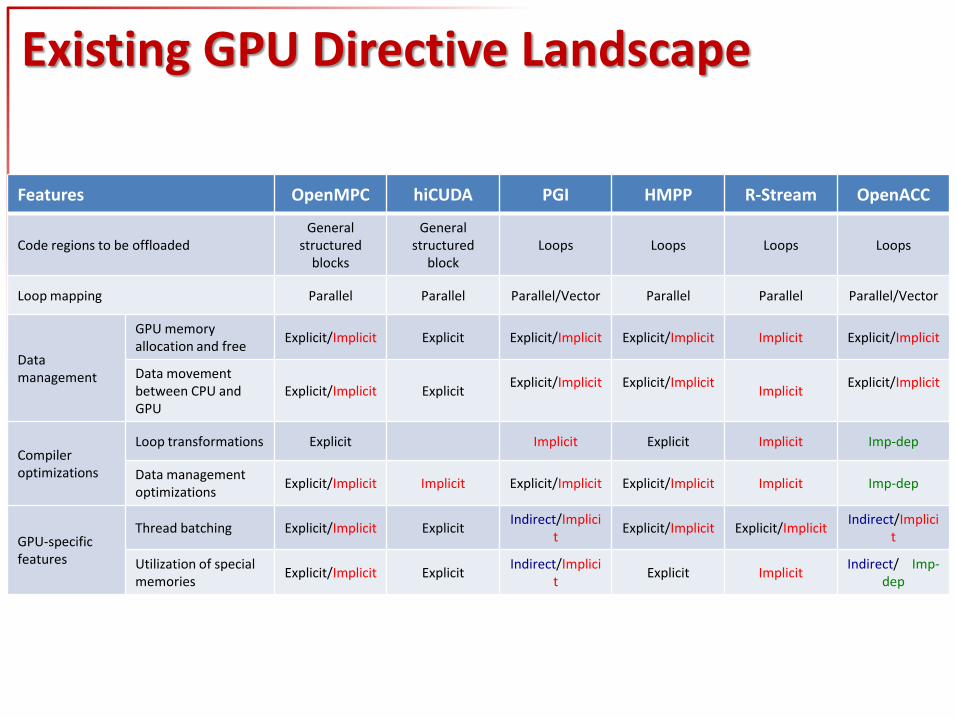
Existing GPU Directive Landscape
Features OpenMPC hiCUDA PGI HMPP R-Stream OpenACC
Code regions to be offloaded General
structured blocks
General structured
block Loops Loops Loops Loops
Loop mapping Parallel Parallel Parallel/Vector Parallel Parallel Parallel/Vector
Data management
GPU memory allocation and free
Explicit/Implicit Explicit Explicit/Implicit Explicit/Implicit Implicit Explicit/Implicit
Data movement between CPU and GPU
Explicit/Implicit Explicit Explicit/Implicit
Explicit/Implicit
Implicit
Explicit/Implicit
Compiler optimizations
Loop transformations Explicit Implicit Explicit Implicit Imp-dep
Data management optimizations
Explicit/Implicit Implicit Explicit/Implicit Explicit/Implicit Implicit Imp-dep
GPU-specific features
Thread batching Explicit/Implicit Explicit Indirect/Implici
t Explicit/Implicit Explicit/Implicit
Indirect/Implicit
Utilization of special memories
Explicit/Implicit Explicit Indirect/Implici
t Explicit Implicit
Indirect/ Imp-dep
46
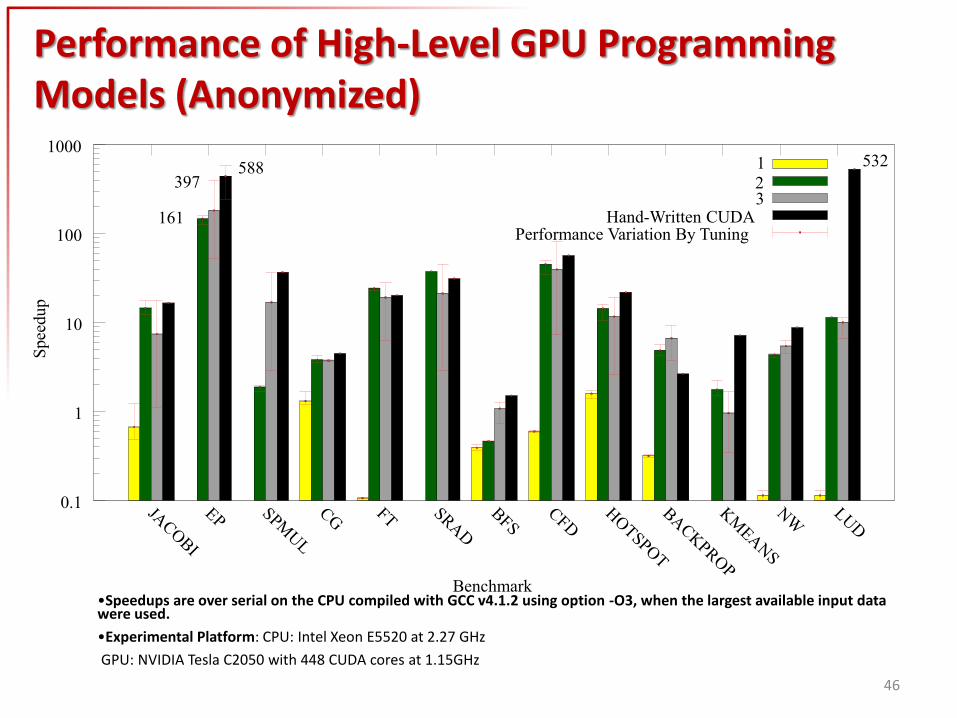
Performance of High-Level GPU Programming Models (Anonymized)
•Speedups are over serial on the CPU compiled with GCC v4.1.2 using option -O3, when the largest available input data were used.
•Experimental Platform: CPU: Intel Xeon E5520 at 2.27 GHz
GPU: NVIDIA Tesla C2050 with 448 CUDA cores at 1.15GHz
0.1
1
10
100
1000
Benchmark
S p e e
d u p
161
397 588 532 1
2 3
Hand-Written CUDA Performance Variation By Tuning
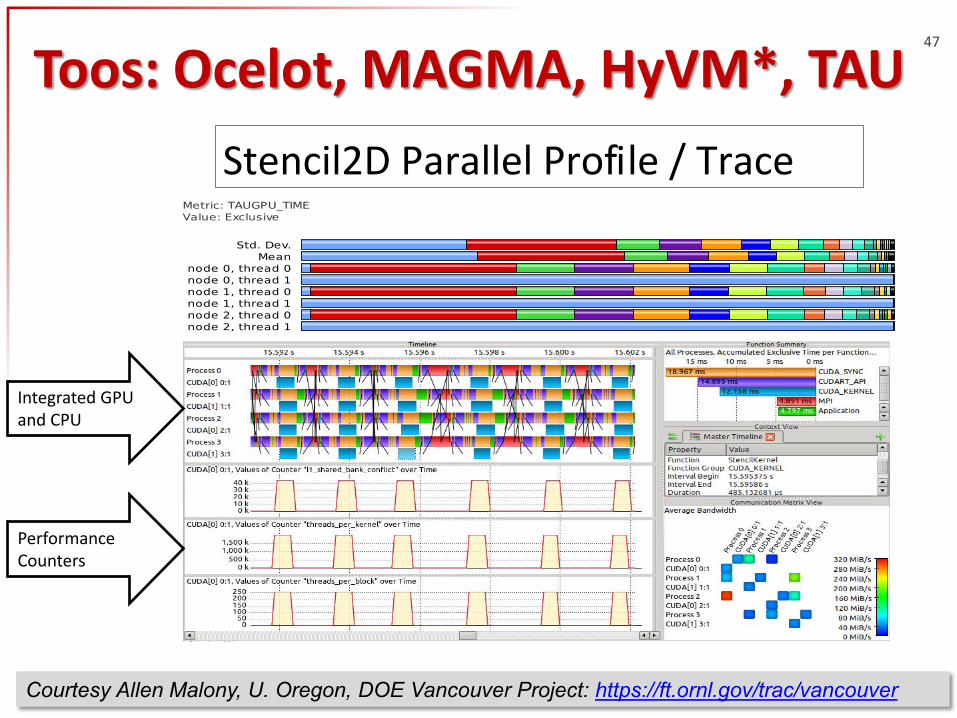
Stencil2DParallelProfile/Trace
Keeneland Tutorial, April 14-15, 2011 43
Toos: Ocelot, MAGMA, HyVM*, TAU 47
Courtesy Allen Malony, U. Oregon, DOE Vancouver Project: https://ft.ornl.gov/trac/vancouver
Integrated GPU and CPU
Performance Counters

Other software activities
Maestro autotuning for OpenCL
GA-GPU – Global Arrays over GPUs
Extending VisIt for in-situ visualization

Memory Bandwidth and Capacity

50
Blackcomb: Hardware-Software Co-design for Non-Volatile Memory in Exascale Systems
Approach Objectives
Rearchitect servers and clusters, using nonvolatile memory (NVM) to overcome resilience, energy, and performance walls in exascale computing:
Ultrafast checkpointing to nearby NVM;
Reoptimize the memory hierarchy for exascale, using new memory technologies;
Replace disk with fast, low-power NVM;
Low power cores inside the data store.
Co-design using proxy applications from Co-des ctrs.
Jeffrey Vetter, ORNL Robert Schreiber, HP Labs
Trevor Mudge, University of Michigan Yuan Xie, Penn State University
Impact
FWP #ERKJU59
A comparison of various memory technologies
Provide memory capacity needed for exascale with outstanding power, cost, and bandwidth
Address energy scalability of future exascale systems; NV memories have zero standby power.
Increase system reliability; MRAM/PCRAM are resilient to soft errors.
Create new programmer’s interfaces to NVM.
Identify and evaluate the most promising (NVM) technologies – STT, PCRAM, memristor.
Explore assembly of NVM and CMOS into a storage + memory stack.
Propose an exascale HPC system architecture that builds on our new memory architecture.
New resilience strategies in software.
Test and simulate, driven by proxy applications.
SRAM DRAM NAND
Flash
PC-RAM STT-
RAM
R-RAM
(Xpoint)
Data Retention N N Y Y Y Y
Memory Cell Factor (F2)
50-200 6 2-5 4-10 6-20 ≤ 4
Read Time (ns) < 1 30 104 10-100 10-40 5-30
Write /Erase Time (ns)
< 1 50 105 100-300 10-40 5-100
Number of Rewrites 1016 1016 104-105 108-1015 1015 106-1012
Power Read/Write Low Low High Low Low Low
Power (other than R/W)
Leakage Current
Refresh Power
None None None None

51
Formal Problem Statement Challenges
Understand and mitigate limitations of NVM as memory: higher write latency, lower endurance than SRAM/DRAM.
Analytical/simulation hybrid model to understand trade-offs between energy efficiency, resilience, and performance.
Evaluate productivity of programming models that exploit NVM to guarantee correctness in face of hw/sw failures.
• Proposes a new distributed architecture in which:
1. Mechanical-disk-based data-stores are completely replaced with energy-efficient non-volatile memories;
2. Compute capacity, comprised of balanced low-power simple cores, is co-located with the data store;
3. Most levels of the hierarchy, including DRAM and last levels of SRAM cache, are completely eliminated.
• Addresses device scalability and energy efficiency of charge-based memories, eliminates the problem of increasing DRAM soft-error rates, revolutionizes storage.
Co-design using proxy applications.
Understand likely failure scenarios and probabilities at exascale.
Simulators, simulations, and tests.
New system architecture at node level.
Programming layer software.
Analyses of NVM technologies; improved low-level architectures that use them.
Research Products/Artifacts Potential NV-RAM DIMM Layout
John Smith, ORNL Jane Doe, University of Tennessee
Jeffrey Vetter, ORNL Robert Schreiber, HP Labs
Trevor Mudge, University of Michigan Yuan Xie, Penn State University
Blackcomb: Hardware-Software Co-design for Non-Volatile Memory in Exascale Systems

Summary
Today’s HPC landscape is growing more diverse
Projections for Exascale architectures are extreme – Scalability to 1B threads
– Move to diverse, heterogeneous architectures
– Limited memory capacity and bandwidth
Emerging technologies – GPUs
– NVRAM technologies may offer a solution
Lessons
– Performance bounds: SHOC Benchmarks
– Software infrastructure plays a pivotal role in Exascale success • Directive based compilation, Tools, GA-GPU

Contributors and Sponsors
Future Technologies Group: http://ft.ornl.gov
US National Science Foundation Keeneland Project: http://keeneland.gatech.edu
US Department of Energy Office of Science
– DOE Vancouver Project: https://ft.ornl.gov/trac/vancouver
– DOE Blackcomb Project: https://ft.ornl.gov/trac/blackcomb
– DOE ExMatEx Codesign Center: http://codesign.lanl.gov
– DOE Cesar Codesign Center: http://cesar.mcs.anl.gov/
– DOE Exascale Efforts: http://science.energy.gov/ascr/research/computer-science/
Scalable Heterogeneous Computing Benchmark team: http://bit.ly/shocmarx
US DARPA NVIDIA Echelon
NVIDIA CUDA Center of Excellence
International Exascale Software Project: http://www.exascale.org/iesp/Main_Page


















