
RETHINKING REINFORCEMENT: ALLOCATION, INDUCTION, AND CONTINGENCY

On Self-adaptive Resource Allocationthrough Reinforcement Learning
Jacopo Panerati†, Filippo Sironi‡, Matteo Carminati‡, Martina Maggio§,Giovanni Beltrame†, Piotr J. Gmytrasiewicz¶, Donatella Sciuto‡ and Marco D. Santambrogio‡
†Polytechnique Montreal, ‡Politecnico Milano, §Lund University, ¶University of Illinois Chicago
Politecnico di Torino - Turin, 25 June 2013

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Rationale
Methodology
(1) Reinforcement Learning (RL).
Objective
(2) Self-adaptive Computing.
Research Question
Is RL a suitable approach for self-adaptive computing?
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 2/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Rationale
Methodology
(1) Reinforcement Learning (RL).
Objective
(2) Self-adaptive Computing.
Research Question
Is RL a suitable approach for self-adaptive computing?
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 2/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Rationale
Methodology
(1) Reinforcement Learning (RL).
Objective
(2) Self-adaptive Computing.
Research Question
Is RL a suitable approach for self-adaptive computing?
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 2/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Rationale
Methodology
(1) Reinforcement Learning (RL).
Objective
(2) Self-adaptive Computing.
Research Question
Is RL a suitable approach for self-adaptive computing?
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 2/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Rationale
Methodology
(1) Reinforcement Learning (RL).
Objective
(2) Self-adaptive Computing.
Research Question
Is RL a suitable approach for self-adaptive computing?
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 2/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Rationale
Methodology
(1) Reinforcement Learning (RL).
Objective
(2) Self-adaptive Computing.
Research Question
Is RL a suitable approach for self-adaptive computing?
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 2/31 – mistlab.ca
POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
A Typical Machine Learning Problem
Generic (Informal) Steps
• given a (labelled or unlabelled) training set D ⊆ Rd
• pick, from hypotheses set H, a function f ∶ Rd → R (or C )
• such that, given a new data-point X ∈ Rd , f (X ) is the actual label of X
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 3/31 – mistlab.ca
POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
A Typical Machine Learning Problem
Generic (Informal) Steps
• given a (labelled or unlabelled) training set D ⊆ Rd
• pick, from hypotheses set H, a function f ∶ Rd → R (or C )
• such that, given a new data-point X ∈ Rd , f (X ) is the actual label of X
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 3/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
A Typical Machine Learning Problem
Generic (Informal) Steps
• given a (labelled or unlabelled) training set D ⊆ Rd
• pick, from hypotheses set H, a function f ∶ Rd → R (or C )
• such that, given a new data-point X ∈ Rd , f (X ) is the actual label of X
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 3/31 – mistlab.ca
POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
A Typical Machine Learning Problem
Generic (Informal) Steps
• given a (labelled or unlabelled) training set D ⊆ Rd
• pick, from hypotheses set H, a function f ∶ Rd → R (or C )
• such that, given a new data-point X ∈ Rd , f (X ) is the actual label of X
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 3/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
A Typical Machine Learning Problem
Generic (Informal) Steps
• given a (labelled or unlabelled) training set D ⊆ Rd
• pick, from hypotheses set H, a function f ∶ Rd → R (or C )
• such that, given a new data-point X ∈ Rd , f (X ) is the actual label of X
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 3/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Machine Learning Methodologies
Supervised Learning
Classification Algorithms
when labels are known to belong to a finite set C
Regression Algorithms
when labels are known to belong to R
Unsupervised Learning
Clustering Algorithms
when labels are unknown but their cardinality K is assumed be fixed
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 4/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Machine Learning Methodologies
Supervised Learning
Classification Algorithms
when labels are known to belong to a finite set C
Regression Algorithms
when labels are known to belong to R
Unsupervised Learning
Clustering Algorithms
when labels are unknown but their cardinality K is assumed be fixed
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 4/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Machine Learning Methodologies
Supervised Learning
Classification Algorithms
when labels are known to belong to a finite set C
Regression Algorithms
when labels are known to belong to R
Unsupervised Learning
Clustering Algorithms
when labels are unknown but their cardinality K is assumed be fixed
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 4/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Example of Classification Problem
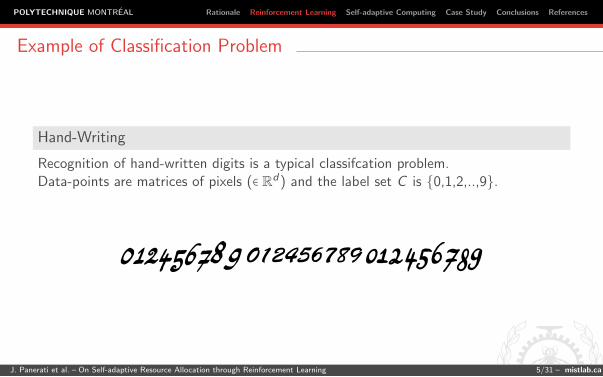
Hand-Writing
Recognition of hand-written digits is a typical classifcation problem.Data-points are matrices of pixels (∈ Rd) and the label set C is {0,1,2,..,9}.
012456789 012456789 012456789
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 5/31 – mistlab.ca
POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Example of Classification Problem
Hand-Writing
Recognition of hand-written digits is a typical classifcation problem.Data-points are matrices of pixels (∈ Rd) and the label set C is {0,1,2,..,9}.
012456789 012456789 012456789
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 5/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Machine Learning Methodologies
Supervised Learning
Classification Algorithms
when labels are known to belong to a finite set C
Regression Algorithms
when labels are known to belong to R
Unsupervised Learning
Clustering Algorithms
when labels are unknown but their cardinality K is assumed be fixed
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 6/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Machine Learning Methodologies
Supervised Learning
Classification Algorithms
when labels are known to belong to a finite set C
Regression Algorithms
when labels are known to belong to R
Unsupervised Learning
Clustering Algorithms
when labels are unknown but their cardinality K is assumed be fixed
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 6/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Machine Learning Methodologies
Supervised Learning
Classification Algorithms
when labels are known to belong to a finite set C
Regression Algorithms
when labels are known to belong to R
Unsupervised Learning
Clustering Algorithms
when labels are unknown but their cardinality K is assumed be fixed
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 6/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Machine Learning Methodologies
Supervised Learning
Classification Algorithms
when labels are known to belong to a finite set C
Regression Algorithms
when labels are known to belong to R
Unsupervised Learning
Clustering Algorithms
when labels are unknown but their cardinality K is assumed be fixed
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 6/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Example of Clustering Problem
Space Exploration
Clustering algorithms can be used to identify patterns in remotely (e.g. in space)sensed data and improve the scientific return by sending to the ground station onlystatistically significant data [1].
1
1http://nssdc.gsfc.nasa.gov/J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 7/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Example of Clustering Problem
Space Exploration
Clustering algorithms can be used to identify patterns in remotely (e.g. in space)sensed data and improve the scientific return by sending to the ground station onlystatistically significant data [1].
1
1http://nssdc.gsfc.nasa.gov/J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 7/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Reinforcements in Behavioural Psychology
Definition
In behavioural psychology, reinforcement consists of the strengthening of a behaviourassociated to a stimulus through its repetition.
Pioneers
B.F. Skinner (1904-1990), together with E. Thorndike (1874-1949), is considered to beone the fathers of current theories on reinforcement and conditioning [2].
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 8/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Reinforcements in Behavioural Psychology
Definition
In behavioural psychology, reinforcement consists of the strengthening of a behaviourassociated to a stimulus through its repetition.
Pioneers
B.F. Skinner (1904-1990), together with E. Thorndike (1874-1949), is considered to beone the fathers of current theories on reinforcement and conditioning [2].
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 8/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Reinforcements in Behavioural Psychology
Definition
In behavioural psychology, reinforcement consists of the strengthening of a behaviourassociated to a stimulus through its repetition.
Pioneers
B.F. Skinner (1904-1990), together with E. Thorndike (1874-1949), is considered to beone the fathers of current theories on reinforcement and conditioning [2].
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 8/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Reinforcements in Behavioural Psychology
Definition
In behavioural psychology, reinforcement consists of the strengthening of a behaviourassociated to a stimulus through its repetition.
Pioneers
B.F. Skinner (1904-1990), together with E. Thorndike (1874-1949), is considered to beone the fathers of current theories on reinforcement and conditioning [2].
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 8/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Reinforcements in Behavioural Psychology
Definition
In behavioural psychology, reinforcement consists of the strengthening of a behaviourassociated to a stimulus through its repetition.
Pioneers
B.F. Skinner (1904-1990), together with E. Thorndike (1874-1949), is considered to beone the fathers of current theories on reinforcement and conditioning [2].
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 8/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Reinforcements in Behavioural Psychology
Definition
In behavioural psychology, reinforcement consists of the strengthening of a behaviourassociated to a stimulus through its repetition.
Pioneers
B.F. Skinner (1904-1990), together with E. Thorndike (1874-1949), is considered to beone the fathers of current theories on reinforcement and conditioning [2].
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 8/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Reinforcements in Behavioural Psychology
Definition
In behavioural psychology, reinforcement consists of the strengthening of a behaviourassociated to a stimulus through its repetition.
Pioneers
B.F. Skinner (1904-1990), together with E. Thorndike (1874-1949), is considered to beone the fathers of current theories on reinforcement and conditioning [2].
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 8/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Reinforcements in Behavioural Psychology
Definition
In behavioural psychology, reinforcement consists of the strengthening of a behaviourassociated to a stimulus through its repetition.
Pioneers
B.F. Skinner (1904-1990), together with E. Thorndike (1874-1949), is considered to beone the fathers of current theories on reinforcement and conditioning [2].
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 8/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Pavlov’s Dog
A precursor of Skinner theories
Ivan Pavlov (1849-1936) made conditioning famous with his experiment of droolingdogs.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 9/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Pavlov’s Dog
A precursor of Skinner theories
Ivan Pavlov (1849-1936) made conditioning famous with his experiment of droolingdogs.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 9/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
reinforcement learning in computer science is something a bit differentboth from supervised/unsupervised learning and reinforcements in behavioural psychology..
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 10/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (I)
Supervised/Unsupervised Machine Learning
data-point → label (or a cluster)
Reinforcements in Behavioural Psychology
stimulus → behaviour
Reinforcement Learning
state of the world → action
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 11/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (I)
Supervised/Unsupervised Machine Learning
data-point → label (or a cluster)
Reinforcements in Behavioural Psychology
stimulus → behaviour
Reinforcement Learning
state of the world → action
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 11/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (I)
Supervised/Unsupervised Machine Learning
data-point → label (or a cluster)
Reinforcements in Behavioural Psychology
stimulus → behaviour
Reinforcement Learning
state of the world → action
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 11/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (I)
Supervised/Unsupervised Machine Learning
data-point → label (or a cluster)
Reinforcements in Behavioural Psychology
stimulus → behaviour
Reinforcement Learning
state of the world → action
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 11/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (I)
Supervised/Unsupervised Machine Learning
data-point → label (or a cluster)
Reinforcements in Behavioural Psychology
stimulus → behaviour
Reinforcement Learning
state of the world → action
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 11/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (I)
Supervised/Unsupervised Machine Learning
data-point → label (or a cluster)
Reinforcements in Behavioural Psychology
stimulus → behaviour
Reinforcement Learning
state of the world → action
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 11/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (I)
Supervised/Unsupervised Machine Learning
data-point → label (or a cluster)
Reinforcements in Behavioural Psychology
stimulus → behaviour
Reinforcement Learning
state of the world → action
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 11/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (I)
Supervised/Unsupervised Machine Learning
data-point → label (or a cluster)
Reinforcements in Behavioural Psychology
stimulus → behaviour
Reinforcement Learning
state of the world → action
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 11/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (I)
Supervised/Unsupervised Machine Learning
data-point → label (or a cluster)
Reinforcements in Behavioural Psychology
stimulus → behaviour
Reinforcement Learning
state of the world → action
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 11/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (I)
Supervised/Unsupervised Machine Learning
data-point → label (or a cluster)
Reinforcements in Behavioural Psychology
stimulus → behaviour
Reinforcement Learning
state of the world → action
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 11/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (II)
Reinforcement Learning
state of the world → action → new state of the world → action → ..
Because the performance metric of RL (i.e., the collected rewardS)
is computed over time, solving a RL problem allows to make
• planning
• complex, sequential decisions
• even counterintuitive decisions
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 12/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (II)
Reinforcement Learning
state of the world → action → new state of the world → action → ..
Because the performance metric of RL (i.e., the collected rewardS)
is computed over time, solving a RL problem allows to make
• planning
• complex, sequential decisions
• even counterintuitive decisions
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 12/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (II)
Reinforcement Learning
state of the world → action → new state of the world → action → ..
Because the performance metric of RL (i.e., the collected rewardS)
is computed over time, solving a RL problem allows to make
• planning
• complex, sequential decisions
• even counterintuitive decisions
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 12/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (II)
Reinforcement Learning
state of the world → action → new state of the world → action → ..
Because the performance metric of RL (i.e., the collected rewardS)
is computed over time, solving a RL problem allows to make
• planning
• complex, sequential decisions
• even counterintuitive decisions
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 12/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (II)
Reinforcement Learning
state of the world → action → new state of the world → action → ..
Because the performance metric of RL (i.e., the collected rewardS)
is computed over time, solving a RL problem allows to make
• planning
• complex, sequential decisions
• even counterintuitive decisions
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 12/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (II)
Reinforcement Learning
state of the world → action → new state of the world → action → ..
Because the performance metric of RL (i.e., the collected rewardS)
is computed over time, solving a RL problem allows to make
• planning
• complex, sequential decisions
• even counterintuitive decisions
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 12/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (II)
Reinforcement Learning
state of the world → action → new state of the world → action → ..
Because the performance metric of RL (i.e., the collected rewardS)
is computed over time, solving a RL problem allows to make
• planning
• complex, sequential decisions
• even counterintuitive decisions
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 12/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (III)
If today was a sunny day
• a classification algorithm would label it as “go to the seaside”
• RL would tell you “you might as well study and enjoy the fact that you did notfail your exams later in the summer”
RL is not an epicurean carpe diem methodology, but a more farsighted and judiciousapproach.
The point is, not how long you live, but how nobly you live.- Lucius Annaeus Seneca
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 13/31 – mistlab.ca
POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (III)
If today was a sunny day
• a classification algorithm would label it as “go to the seaside”
• RL would tell you “you might as well study and enjoy the fact that you did notfail your exams later in the summer”
RL is not an epicurean carpe diem methodology, but a more farsighted and judiciousapproach.
The point is, not how long you live, but how nobly you live.- Lucius Annaeus Seneca
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 13/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (III)
If today was a sunny day
• a classification algorithm would label it as “go to the seaside”
• RL would tell you “you might as well study and enjoy the fact that you did notfail your exams later in the summer”
RL is not an epicurean carpe diem methodology, but a more farsighted and judiciousapproach.
The point is, not how long you live, but how nobly you live.- Lucius Annaeus Seneca
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 13/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (III)
If today was a sunny day
• a classification algorithm would label it as “go to the seaside”
• RL would tell you “you might as well study and enjoy the fact that you did notfail your exams later in the summer”
RL is not an epicurean carpe diem methodology, but a more farsighted and judiciousapproach.
The point is, not how long you live, but how nobly you live.- Lucius Annaeus Seneca
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 13/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (III)
If today was a sunny day
• a classification algorithm would label it as “go to the seaside”
• RL would tell you “you might as well study and enjoy the fact that you did notfail your exams later in the summer”
RL is not an epicurean carpe diem methodology, but a more farsighted and judiciousapproach.
The point is, not how long you live, but how nobly you live.- Lucius Annaeus Seneca
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 13/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Why Reinforcement Learning is Different (III)
If today was a sunny day
• a classification algorithm would label it as “go to the seaside”
• RL would tell you “you might as well study and enjoy the fact that you did notfail your exams later in the summer”
RL is not an epicurean carpe diem methodology, but a more farsighted and judiciousapproach.
The point is, not how long you live, but how nobly you live.- Lucius Annaeus Seneca
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 13/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
moving on to self-adaptive computing..
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 14/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Typical Properties of Self-adaptive Computing
Self-configuration
The system requires limited or no human intervention in order to set-up.
Self-optimization
The system is able to achieve user-defined goals autonomously, without humaninteraction.
Self-healing
The system can detect and recover from faults without human intervention.
Together with self-protection, these are the properties identified in [3] for autonomic system.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 15/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Typical Properties of Self-adaptive Computing
Self-configuration
The system requires limited or no human intervention in order to set-up.
Self-optimization
The system is able to achieve user-defined goals autonomously, without humaninteraction.
Self-healing
The system can detect and recover from faults without human intervention.
Together with self-protection, these are the properties identified in [3] for autonomic system.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 15/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-configuration Example
Multi-platform software
Software that is able to run on different hardware configurations seamlessly is a goodexample of self-configuration.
Hardware
Inst.Tools Software
Detect Config.
Install
Run
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 16/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-configuration Example
Multi-platform software
Software that is able to run on different hardware configurations seamlessly is a goodexample of self-configuration.
Hardware
Inst.Tools Software
Detect Config.
Install
Run
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 16/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Typical Properties of Self-adaptive Computing
Self-configuration
The system requires limited or no human intervention in order to set-up.
Self-optimization
The system is able to achieve user-defined goals autonomously, without humaninteraction.
Self-healing
The system can detect and recover from faults without human intervention.
Together with self-protection, these are the properties identified in [3] for autonomic system.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 17/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Typical Properties of Self-adaptive Computing
Self-configuration
The system requires limited or no human intervention in order to set-up.
Self-optimization
The system is able to achieve user-defined goals autonomously, without humaninteraction.
Self-healing
The system can detect and recover from faults without human intervention.
Together with self-protection, these are the properties identified in [3] for autonomic system.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 17/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-optimization Example
Smart Video Players
Players that can adjust media encoding in order to maintain a certain Quality ofService (QoS) can be considered self-optimizing applications.
Video
Manager Encoder
Detect Quality
Control
Play
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 18/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-optimization Example
Smart Video Players
Players that can adjust media encoding in order to maintain a certain Quality ofService (QoS) can be considered self-optimizing applications.
Video
Manager Encoder
Detect Quality
Control
Play
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 18/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Typical Properties of Self-adaptive Computing
Self-configuration
The system requires limited or no human intervention in order to set-up.
Self-optimization
The system is able to achieve user-defined goals autonomously, without humaninteraction.
Self-healing
The system can detect and recover from faults without human intervention.
Together with self-protection, these are the properties identified in [3] for autonomic system.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 19/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Typical Properties of Self-adaptive Computing
Self-configuration
The system requires limited or no human intervention in order to set-up.
Self-optimization
The system is able to achieve user-defined goals autonomously, without humaninteraction.
Self-healing
The system can detect and recover from faults without human intervention.
Together with self-protection, these are the properties identified in [3] for autonomic system.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 19/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-healing Example
Reconfigurable Logic
FPGAs are a good playground for self-healing implementation. Part of the hardwareresources can be used to verify the correct functioning of the rest of the logic and forcereconfiguration when a fault is detected.
Prog.Logic
Listener µContr.
Detect Fault
Inform
Reconfigure
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 20/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-healing Example
Reconfigurable Logic
FPGAs are a good playground for self-healing implementation. Part of the hardwareresources can be used to verify the correct functioning of the rest of the logic and forcereconfiguration when a fault is detected.
Prog.Logic
Listener µContr.
Detect Fault
Inform
Reconfigure
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 20/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Typical Properties of Self-adaptive Computing
Self-configuration
The system requires limited or no human intervention in order to set-up.
Self-optimization
The system is able to achieve user-defined goals autonomously, without humaninteraction.
Self-healing
The system can detect and recover from faults without human intervention.
Together with self-protection, these are the properties identified in [3] for autonomic system.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 21/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Typical Properties of Self-adaptive Computing
Self-configuration
The system requires limited or no human intervention in order to set-up.
Self-optimization
The system is able to achieve user-defined goals autonomously, without humaninteraction.
Self-healing
The system can detect and recover from faults without human intervention.
Together with self-protection, these are the properties identified in [3] for autonomic system.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 21/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Research Question
Is RL a suitable approach for self-adaptive computing?
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 22/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Case Study
Testing Environment
• Desktop workstation
• Multi-core Intel i7 Processor
• Linux-based operating system
Objective of our Experiments
Enabling self-adaptive properties in applications of the PARSEC[4] benchmark suitethrough reinforcement learning algorithms.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 23/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Case Study
Testing Environment
• Desktop workstation
• Multi-core Intel i7 Processor
• Linux-based operating system
Objective of our Experiments
Enabling self-adaptive properties in applications of the PARSEC[4] benchmark suitethrough reinforcement learning algorithms.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 23/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Case Study
Testing Environment
• Desktop workstation
• Multi-core Intel i7 Processor
• Linux-based operating system
Objective of our Experiments
Enabling self-adaptive properties in applications of the PARSEC[4] benchmark suitethrough reinforcement learning algorithms.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 23/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Tests Set-Up
Reinforcement Learning Framework
• A finite set of states S → heart rate of the PARSEC benchmark applicationmeasured through Heart Rate Monitor (HRM) APIs [5]
• A finite set of actions A → (1) number of cores on which the PARSECbenchmark application is scheduled 2
and (2) CPU frequency 3
• A reward function R(s) ∶ S → R →whether a user-defined target(in heartbeats/s) is met or not
2sched setaffinity system call3cpufrequtils package
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 24/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Tests Set-Up
Reinforcement Learning Framework
• A finite set of states S → heart rate of the PARSEC benchmark applicationmeasured through Heart Rate Monitor (HRM) APIs [5]
• A finite set of actions A → (1) number of cores on which the PARSECbenchmark application is scheduled 2
and (2) CPU frequency 3
• A reward function R(s) ∶ S → R →whether a user-defined target(in heartbeats/s) is met or not
2sched setaffinity system call3cpufrequtils package
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 24/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Tests Set-Up
Reinforcement Learning Framework
• A finite set of states S → heart rate of the PARSEC benchmark applicationmeasured through Heart Rate Monitor (HRM) APIs [5]
• A finite set of actions A → (1) number of cores on which the PARSECbenchmark application is scheduled 2
and (2) CPU frequency 3
• A reward function R(s) ∶ S → R →whether a user-defined target(in heartbeats/s) is met or not
2sched setaffinity system call3cpufrequtils package
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 24/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Tests Set-Up
Reinforcement Learning Framework
• A finite set of states S → heart rate of the PARSEC benchmark applicationmeasured through Heart Rate Monitor (HRM) APIs [5]
• A finite set of actions A → (1) number of cores on which the PARSECbenchmark application is scheduled 2
and (2) CPU frequency 3
• A reward function R(s) ∶ S → R →whether a user-defined target(in heartbeats/s) is met or not
2sched setaffinity system call3cpufrequtils package
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 24/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Tests Set-Up
Reinforcement Learning Framework
• A finite set of states S → heart rate of the PARSEC benchmark applicationmeasured through Heart Rate Monitor (HRM) APIs [5]
• A finite set of actions A → (1) number of cores on which the PARSECbenchmark application is scheduled 2
and (2) CPU frequency 3
• A reward function R(s) ∶ S → R →whether a user-defined target(in heartbeats/s) is met or not
2sched setaffinity system call3cpufrequtils package
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 24/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Tests Set-Up
Reinforcement Learning Framework
• A finite set of states S → heart rate of the PARSEC benchmark applicationmeasured through Heart Rate Monitor (HRM) APIs [5]
• A finite set of actions A → (1) number of cores on which the PARSECbenchmark application is scheduled 2
and (2) CPU frequency 3
• A reward function R(s) ∶ S → R →whether a user-defined target(in heartbeats/s) is met or not
2sched setaffinity system call3cpufrequtils package
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 24/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Tests Set-Up
Reinforcement Learning Framework
• A finite set of states S → heart rate of the PARSEC benchmark applicationmeasured through Heart Rate Monitor (HRM) APIs [5]
• A finite set of actions A → (1) number of cores on which the PARSECbenchmark application is scheduled 2
and (2) CPU frequency 3
• A reward function R(s) ∶ S → R →whether a user-defined target(in heartbeats/s) is met or not
2sched setaffinity system call3cpufrequtils package
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 24/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Tests Set-Up
Reinforcement Learning Framework
• A finite set of states S → heart rate of the PARSEC benchmark applicationmeasured through Heart Rate Monitor (HRM) APIs [5]
• A finite set of actions A → (1) number of cores on which the PARSECbenchmark application is scheduled 2
and (2) CPU frequency 3
• A reward function R(s) ∶ S → R →whether a user-defined target(in heartbeats/s) is met or not
2sched setaffinity system call3cpufrequtils package
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 24/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
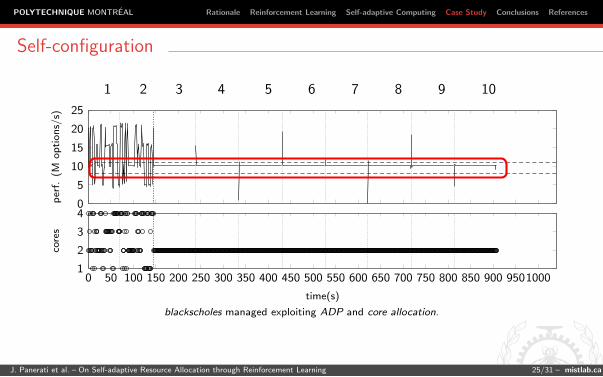
Self-configuration
1 2 3 4 5 6 7 8 9 10
0
5
10
15
20
25
per
f.(M
op
tio
ns/
s)
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 800 850 900 95010001
2
3
4
time(s)
core
s
blackscholes managed exploiting ADP and core allocation.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 25/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-configuration
1 2 3 4 5 6 7 8 9 10
0
5
10
15
20
25
per
f.(M
op
tio
ns/
s)
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 800 850 900 95010001
2
3
4
time(s)
core
s
blackscholes managed exploiting ADP and core allocation.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 25/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-configuration
1 2 3 4 5 6 7 8 9 10
0
5
10
15
20
25
per
f.(M
op
tio
ns/
s)
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 800 850 900 95010001
2
3
4
time(s)
core
s
blackscholes managed exploiting ADP and core allocation.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 25/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-configuration
1 2 3 4 5 6 7 8 9 10
0
5
10
15
20
25
per
f.(M
op
tio
ns/
s)
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 800 850 900 95010001
2
3
4
time(s)
core
s
blackscholes managed exploiting ADP and core allocation .
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 25/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-configuration
1 2 3 4 5 6 7 8 9 10
0
5
10
15
20
25
per
f.(M
op
tio
ns/
s)
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 800 850 900 95010001
2
3
4
time(s)
core
s
blackscholes managed exploiting ADP and core allocation.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 25/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-configuration
1 2 3 4 5 6 7 8 9 10
0
5
10
15
20
25
per
f.(M
op
tio
ns/
s)
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 800 850 900 95010001
2
3
4
time(s)
core
s
blackscholes managed exploiting ADP and core allocation.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 25/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-configuration
1 2 3 4 5 6 7 8 9 10
0
5
10
15
20
25
per
f.(M
op
tio
ns/
s)
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 800 850 900 95010001
2
3
4
time(s)
core
s
blackscholes managed exploiting ADP and core allocation.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 25/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-configuration
1 2 3 4 5 6 7 8 9 10
0
5
10
15
20
25
per
f.(M
op
tio
ns/
s)
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 800 850 900 95010001
2
3
4
time(s)
core
s
blackscholes managed exploiting ADP and core allocation.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 25/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-configuration
1 2 3 4 5 6 7 8 9 10
0
5
10
15
20
25
per
f.(M
op
tio
ns/
s)
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 800 850 900 95010001
2
3
4
time(s)
core
s
blackscholes managed exploiting ADP and core allocation.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 25/31 – mistlab.ca
POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-configuration
1 2 3 4 5 6 7 8 9 10
0
5
10
15
20
25
per
f.(M
op
tio
ns/
s)
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 800 850 900 95010001
2
3
4
time(s)
core
s
blackscholes managed exploiting ADP and core allocation.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 25/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-configuration
1 2 3 4 5 6 7 8 9 10
0
5
10
15
20
25
per
f.(M
op
tio
ns/
s)
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 800 850 900 95010001
2
3
4
time(s)
core
s
blackscholes managed exploiting ADP and core allocation.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 25/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-optimization
1 2 3 4 5 6 7 8 9 10
0
0.5
1
1.5
2
2.5
per
f.(M
exch
an
ges
/s)
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 8001
2
3
4
time (s)
core
s
canneal managed exploiting ADP and core allocation.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 26/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-optimization
1 2 3 4 5 6 7 8 9 10
0
0.5
1
1.5
2
2.5
per
f.(M
exch
an
ges
/s)
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 8001
2
3
4
time (s)
core
s
canneal managed exploiting ADP and core allocation.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 26/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-healing
1 2 3 4 5 6 7 8 9 10
0
0.5
1
1.5
2
2.5
per
f.(M
exch
an
ges
/s)
1
2
3
4
core
s
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 8001
14
time (s)
freq
uen
cy
canneal managed exploiting ADP, core allocation, and frequency scaling.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 27/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-healing
1 2 3 4 5 6 7 8 9 10
0
0.5
1
1.5
2
2.5
per
f.(M
exch
an
ges
/s)
1
2
3
4
core
s
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 8001
14
time (s)
freq
uen
cy
canneal managed exploiting ADP, core allocation, and frequency scaling .
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 27/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-healing
1 2 3 4 5 6 7 8 9 10
0
0.5
1
1.5
2
2.5
per
f.(M
exch
an
ges
/s)
1
2
3
4
core
s
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 8001
14
time (s)
freq
uen
cy
canneal managed exploiting ADP, core allocation, and frequency scaling.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 27/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Self-healing
1 2 3 4 5 6 7 8 9 10
0
0.5
1
1.5
2
2.5
per
f.(M
exch
an
ges
/s)
1
2
3
4
core
s
0 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 8001
14
time (s)
freq
uen
cy
canneal managed exploiting ADP, core allocation, and frequency scaling.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 27/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Conclusions
• Reinforcement learning and its relation with other machine learning methodologiesand behavioural psychology
• Properties of self-adaptive computing
• How to exploit reinforcement learning for self-adaptive computing
• Experimental results showing reinforcement learning enabling self-adaptivecomputing properties
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 28/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Conclusions
• Reinforcement learning and its relation with other machine learning methodologiesand behavioural psychology
• Properties of self-adaptive computing
• How to exploit reinforcement learning for self-adaptive computing
• Experimental results showing reinforcement learning enabling self-adaptivecomputing properties
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 28/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Conclusions
• Reinforcement learning and its relation with other machine learning methodologiesand behavioural psychology
• Properties of self-adaptive computing
• How to exploit reinforcement learning for self-adaptive computing
• Experimental results showing reinforcement learning enabling self-adaptivecomputing properties
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 28/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Conclusions
• Reinforcement learning and its relation with other machine learning methodologiesand behavioural psychology
• Properties of self-adaptive computing
• How to exploit reinforcement learning for self-adaptive computing
• Experimental results showing reinforcement learning enabling self-adaptivecomputing properties
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 28/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Conclusions
• Reinforcement learning and its relation with other machine learning methodologiesand behavioural psychology
• Properties of self-adaptive computing
• How to exploit reinforcement learning for self-adaptive computing
• Experimental results showing reinforcement learning enabling self-adaptivecomputing properties
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 28/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
Q&A
4
4http://www.dilbert.com/J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 29/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
References I
D. S. Hayden, S. Chien, D. R. Thompson, and R. Castano, “Using clustering andmetric learning to improve science return of remote sensed imagery,” ACM Trans.Intell. Syst. Technol., vol. 3, no. 3, pp. 51:1–51:19, May 2012. [Online]. Available:http://doi.acm.org/10.1145/2168752.2168765
B. F. Skinner, Science and human behavior. Free Press, 1965.
J. Kephart and D. Chess, “The vision of autonomic computing,” Computer,vol. 36, no. 1, pp. 41–50, 2003.
C. Bienia, “Benchmarking modern multiprocessors,” Ph.D. dissertation, Princeton,NJ, USA, 2011, aAI3445564.
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 30/31 – mistlab.ca

POLYTECHNIQUE MONTREAL Rationale Reinforcement Learning Self-adaptive Computing Case Study Conclusions References
References II
F. Sironi, D. B. Bartolini, S. Campanoni, F. Cancare, H. Hoffmann, D. Sciuto, andM. D. Santambrogio, “Metronome: operating system level performancemanagement via self-adaptive computing,” in Proceedings of the 49th AnnualDesign Automation Conference, ser. DAC ’12. New York, NY, USA: ACM, 2012,pp. 856–865. [Online]. Available: http://doi.acm.org/10.1145/2228360.2228514
J. Panerati et al. – On Self-adaptive Resource Allocation through Reinforcement Learning 31/31 – mistlab.ca


















