
On Real-Time Twitter Analysis.
26
Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT On Real-Time Twitter Analysis Mikio L. Braun http://blog.mikiobraun.de mikiobraun twimpact UG (haftungsbeschränkt) http://twimpact.com with Matthias Jugel thinkberg Apache Hadoop Get Together, Berlin April 28, 2012
-
Upload
mikio-braun -
Category
Documents
-
view
2.163 -
download
3
description
Slides for the talk given at the Apache Hadoop Get Together in Berlin on April 18, 2012.
Transcript of On Real-Time Twitter Analysis.

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
On Real-Time Twitter Analysis
Mikio L. Braun http://blog.mikiobraun.de mikiobrauntwimpact UG (haftungsbeschränkt) http://twimpact.com
with Matthias Jugel thinkberg
Apache Hadoop Get Together, BerlinApril 28, 2012

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
Big Data and Data Science and Social Media
● There's a lot you can do with social media data
● Trend analysis (“trending topics”)
● Sentiment analysis
● Impact analysis (Klout, Kred, etc.)
● More general studies (diameter of network, distribution patterns, etc.)
● Types of data
● Event treams (Twitter stream)
● Graph data (user relationships, retweet networks)
● Text data (sentiment analysis, word clouds)
● URLs
● …
Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
Social Media Streaming Data
● Examples● Twitter firehose/sprinkler● Click-through data● bit.ly URL resolution requests
● Some numbers:● up to a few thousand events per second● events are small up to a few kilobytes

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
Timestamp
Retweeting User
Retweeted User
Hashtag
Link
User Mention
Keywords
TweetRetweeted Tweet
What's in a Tweet?

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
TWIMPACT - Retweet trends
● Trending by retweet activity● Robust matching of tweets even if shortened,
edited (slightly)● Compute trends for links, hashtags, URLs● Aggregate TWIMPACT score for users

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
How to scale stream processing?

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
History of approaches
● Started in June 2009● Free Twitter stream (capped at 50 tweets/s)
Language Storage backend
Stream mining + in memory
Version 1
Version 2
Version 3

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
Putting it all in a data base
● Insert millions of rows into data base
● Get reports by
● Hardly real-time. Also, data bases will become slower and slower...
SELECT *, COUNT(*) FROM eventsWHERE created_at > … AND created_at < …GROUP BY idORDER BY COUNT(*) DESCLIMIT 100;

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
NoSQL: Cassandra
● Structure: Families → Tables → Rows → Key Value pairs
● Easy clustering (peer-to-peer configuration)● Flexible consistency, read-repair, hinted
handoff, etc.● No locking, (in 0.6.x:) no support for indices,
counters → complete rewrite● Operations profile (about 50:50 read/write)

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
Cassandra: Multithreading
● Multithreading helps (but without locking support?)
1
24
816
32
64
Core i7,4 cores(2 + 2 HT)
Seconds
Tw
eets
per
sec
ond

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
Cassandra: Configuration
Flush
Compaction
Memtables,indexes, etc.
Size of Memtable: 128M, JVM Heap: 3G, #CF: 12

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
Cassandra: Configuration
Compaction
“Big”GC
Tw
eets
per
sec
ond

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
NoSQL/Cassandra - Summary
● Works quite well, faster than PostgreSQL (from 200 to 600 tps)
● Lack of locking/indices require a lot of manual management
● Configuration messy● 4 node cluster vs. single node:
Single node consistently 1.5 – 3 times faster!
● Ultimately, becomes slower and slower● Doesn't handle deletions gracefully
Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
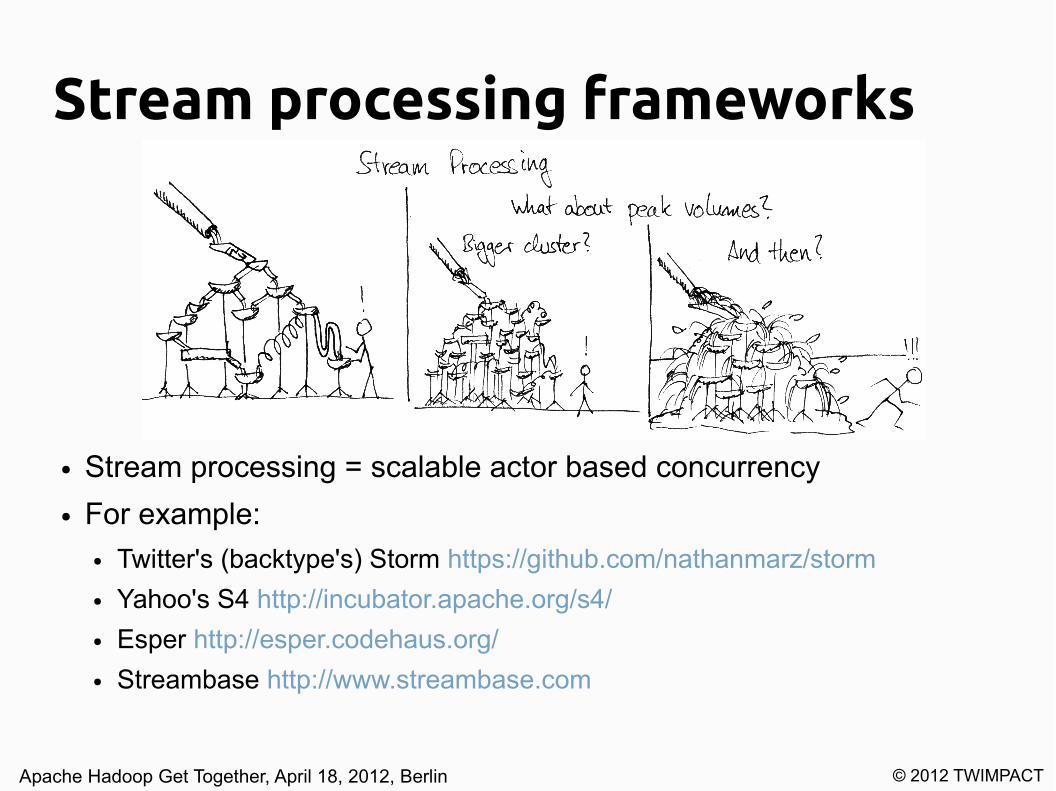
Stream processing frameworks
● Stream processing = scalable actor based concurrency
● For example:● Twitter's (backtype's) Storm https://github.com/nathanmarz/storm
● Yahoo's S4 http://incubator.apache.org/s4/
● Esper http://esper.codehaus.org/
● Streambase http://www.streambase.com

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
Stream processing- some thoughts
● Maximum throughput hard to estimate● Not everything can be parallelized● Scalable storage system still necessary● How to deal with failure/congestion?● Persistent messaging middleware not what you
might want.

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
The DataSift infrastructurehttp://highscalability.com/blog/2011/11/29/datasift-architecture-realtime-datamining-at-120000-tweets-p.html
● C++, PHP, Java/Scala, Ruby
● MySQL on SSDs, HBase (30 nodes, 400TB), memcached, Redis for some queues
● 0MQ, Kafka (LinkedIn)
● 936 CPU cores
● Analyzes 250 million tweets per day
● Peak throughput: 120,000 t/s
● monitoring & accounting
ParseAugmentContent
CustomFilters Delivery
Throughput: 120,000 tweets per second
but: 120,000 / 936 = 128.2 tweets per second per core

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
Principles of Stream Processing
● Keep resource needs constant● Control maximum processing rates● Disks too slow, keep data in RAM

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
Stream mining
asd
fixed number of slots
42
37
25
qwe
13r13t
erqew
erq
fgsa
gwth
5z3
wet
13
20
17
10
7
4
erq
qer
qer 5
● Focus on relevant data, discard the rest
● Provably approximates true counts
● Keep data in memory
Space Saving algorithm (Metwally, Agrawal, Abbadi, “Efficient Computation of Frequent and Top-k Elements in Data Streams”, International Conference on Database Theory, 2005.)
21

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
TWIMPACTReal-time Twitter Retweet Analysis
● Stream mining to keep “hot set” of few hundred thousand most active retweets in memory
● Secondary indices, bipartite graphs, object stores
● Write snapshots to disk for later analysis● Up to several thousand tweets per second
in single threaded operation.
Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
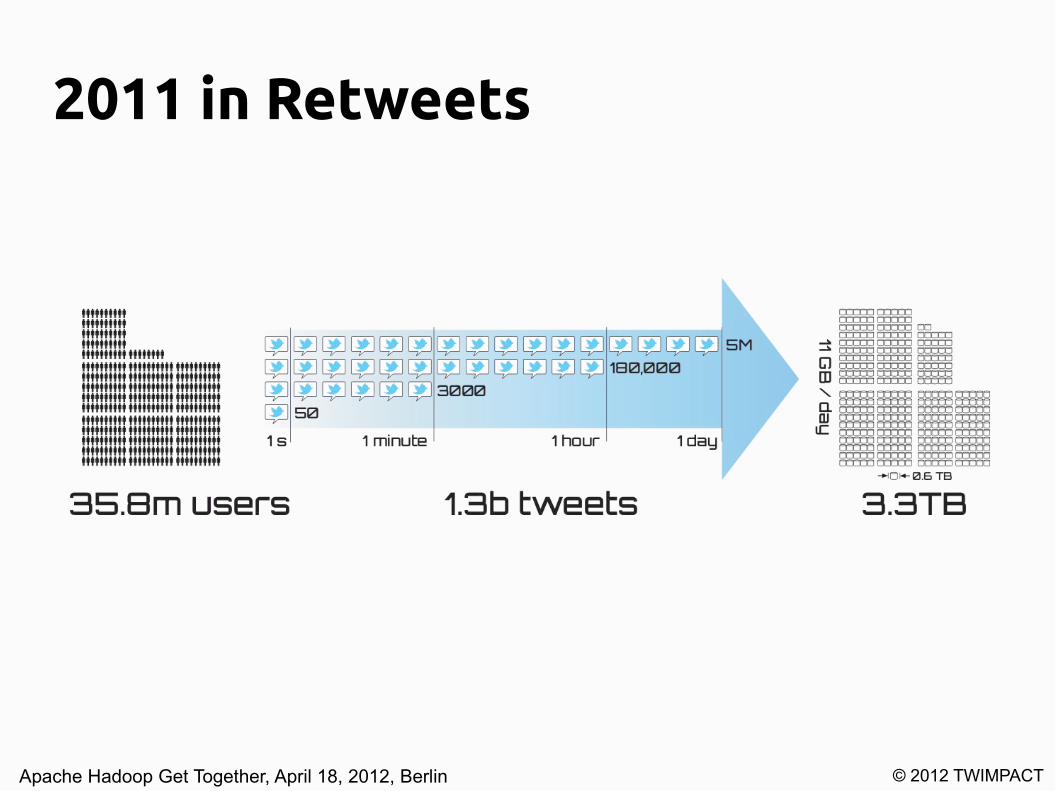
2011 in Retweets

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
2011 in Retweets

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
Our Analysis Pipeline
RetweetMatching
& Retweet TrendsSnapshots
Day 1
Day 2
Day n
Trends
Thread 1
Thread k
Tweets
synchronizedworker threads
single threaded
map reduce like
JSON parsing
Analyzing dependent trends(links/hashtags/etc.)

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
Most retweeted users
Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
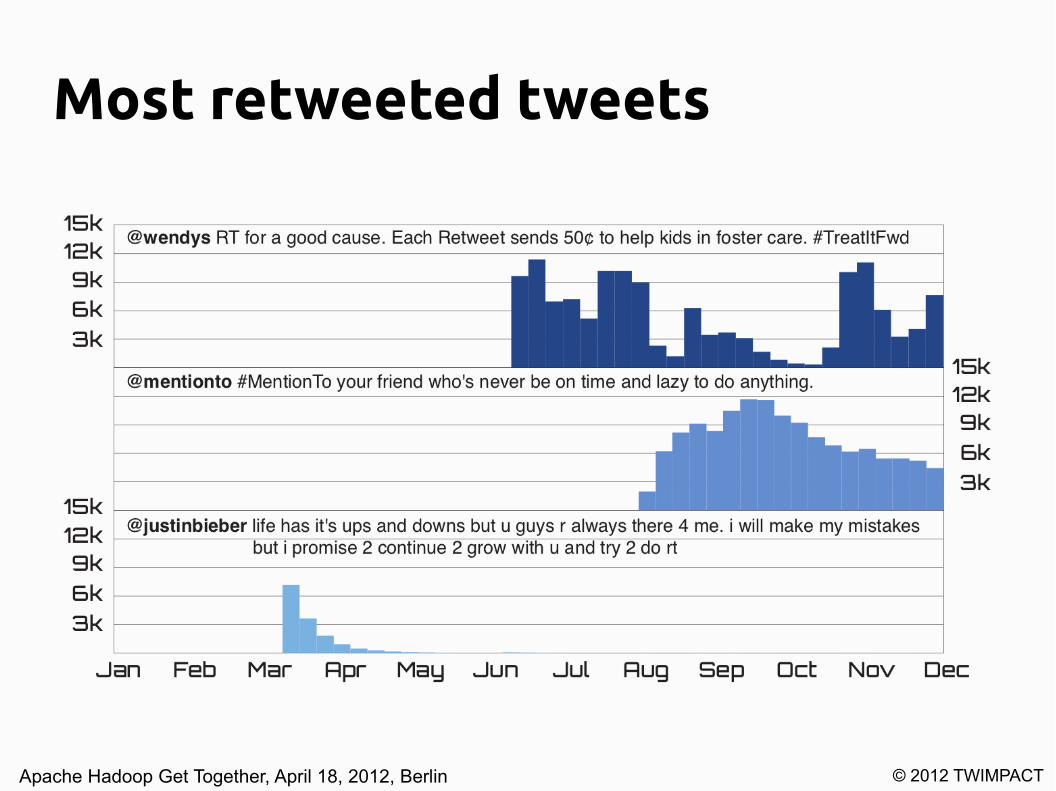
Most retweeted tweets

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
Social network buzz

Apache Hadoop Get Together, April 18, 2012, Berlin © 2012 TWIMPACT
● Many interesting challenges in social media.● Many different data types, including streams.● MapReduce doesn't really fit stream processing● You can't just scale into real-time● Principles of Stream Processing
● Bounded “hot set” of data in memory● Mine stream, discard irrelevant data
● Real world applications often include a mixture of multithreading, stream processing, map reduce and single thread stages.
Summary










![[B1]real time large data at twitter](https://static.fdocuments.us/doc/165x107/54897d26b47959d30c8b5988/b1real-time-large-data-at-twitter.jpg)







