
NLP and the Web
76
NLP for the Web Dr. Matthew Peters @mattthemathman (with thanks to Rutu Mulkar, Erin Renshaw, Dan Lecocq, Chris Whitten, Jay Leary and many others at Moz)
-
Upload
mattthemathman -
Category
Data & Analytics
-
view
821 -
download
1
Transcript of NLP and the Web

NLP for the Web Dr. Matthew Peters @mattthemathman
(with thanks to Rutu Mulkar, Erin Renshaw, Dan Lecocq, Chris Whitten, Jay Leary and many others at Moz)

Moz is a SaaS company that sells SEO and Content Marketing software to professional marketers

We crawl a lot: > 1 Billion pages / day
We’d like to extract structured information from these pages

Author identification

Keyword / topic extraction

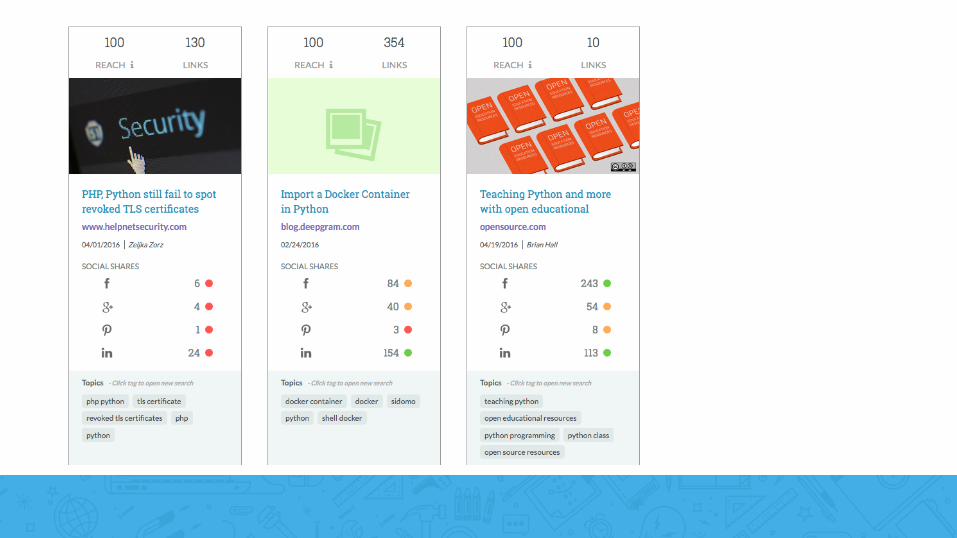
Measure of page’s “Reach”

Measure of page’s “Reach” + structured information à most important topics, associate authors with areas of expertise, etc

Most NLP tasks (parsing, POS tagging, Q&A, sentiment, etc.) focus exclusively on text content.

First two paragraphs
http://www.seattletimes.com/seattle-news/transportation/berthas-delays-prompt-state-to-sue-tunnel-contractor/

POS tagging
Question answering
Language Modeling
Parsing
Sentiment
NLP Web
HTML
XML
Microdata (schema.org)
CSS
Javascript
Interesting problems at intersection

3 extraction tasks

Main article

Keywords Bertha lawsuit Seattle Tunnel Partners STP WSDOT tunnel construction etc.
Author

• Motivation – what are some of the unique challenges and opportunities in doing NLP on the web?
• Main article extraction / page de-chroming • Keyword extraction • Author identification • Conclusion
Outline

Challenges & Opportunities

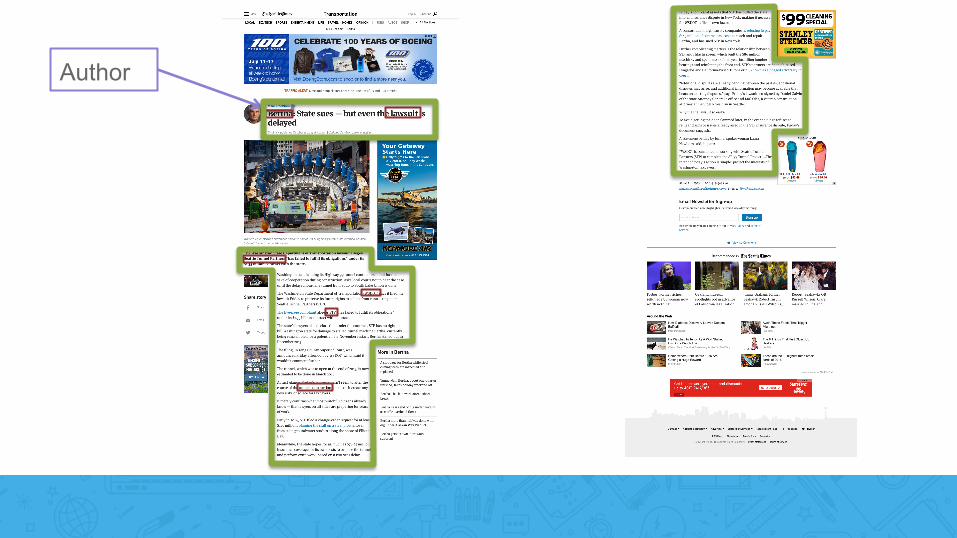
C1: Pages have clutter and unrelated text
Navigation aids Ads
Links to other articles

C2: Text segments can confuse NLP components
Mike Lindblom Bertha: State sues - but even the lawsuit is delayed
Mike Lindblom Bertha State sues NP chunks extracted by our chunker the lawsuit

• Many different standards and only partial adoption • Wide variety of templates and sites • Broken HTML
C3: The web has a lot of cruft

• Web page have attributes other then the visual text: URL string, page title, meta description, etc.
• The HTML/XML has a tree structure we can use
O1: Pages have additional structure

O2: Hyperlinks

O3: CSS
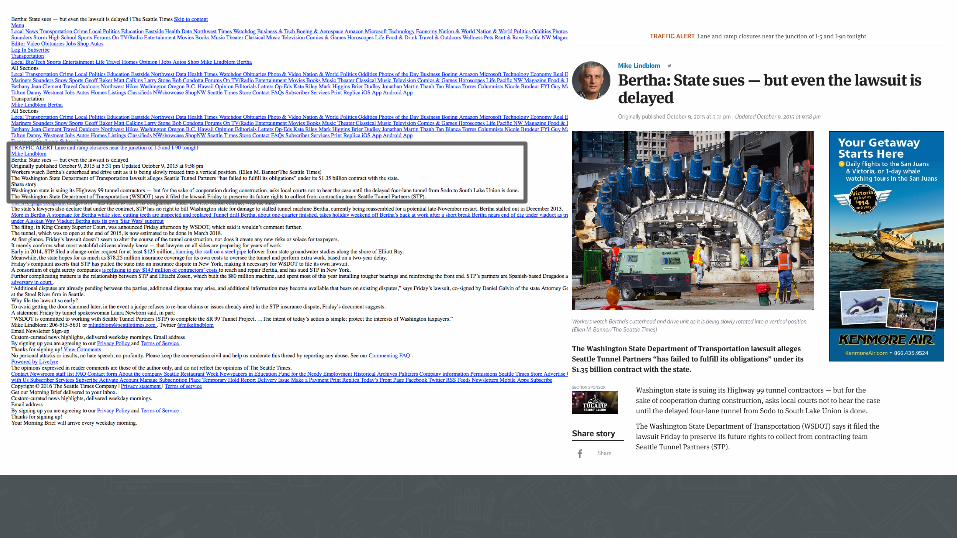
<div class="article-columnist-name vcard"> <a class="author url fn" rel="author" href="/author/mike-lindblom/">Mike Lindblom</a> </div>

General approach 1. Use HTML parser to represent page as a tree 2. Split the tree into small pieces and analyze each piece
separately 3. Run NLP pipelines or other machine learning models on these
small pieces to: - focus attention the important pieces - extract structured information - other task dependent objectives 4. Need algorithms that efficiently process only raw HTML
(without JS, image, CSS, etc.)

Content extraction / Web page de-chroming

Extract main article content (and optionally comments) from a web page
Main article

Dragnet • Combine diverse features with machine learning • Open source: https://github.com/seomoz/dragnet • v1 (2013): link/text density + CETR: blog: https://moz.com/devblog/dragnet-content-extraction-from-diverse-feature-sets/ paper: http://www2013.org/companion/p89.pdf)
• v2: (2015): added Readability blog: https://moz.com/devblog/benchmarking-python-content-extraction-algorithms-dragnet-readability-goose-and-eatiht/

10,000 foot view • Split page into distinct visual elements called “blocks” • Use machine learning to classify each block as content
or no content
Inspired by: Kohlschütter et al, Boilerplate Detection using Shallow Text Features, WSDM ’10 Weninger et al, CETR -- Content Extraction with Tag Ratios, WWW ‘10 Readability: (https://github.com/buriy/python-readability)

Splitting the text into blocks • Use new lines in HTML (\n) (CETR) • Use subtrees (Readability) • Flatten HTML and break on <div>, <p>, <h1>, etc.
(Kohlschütter et al. and us)


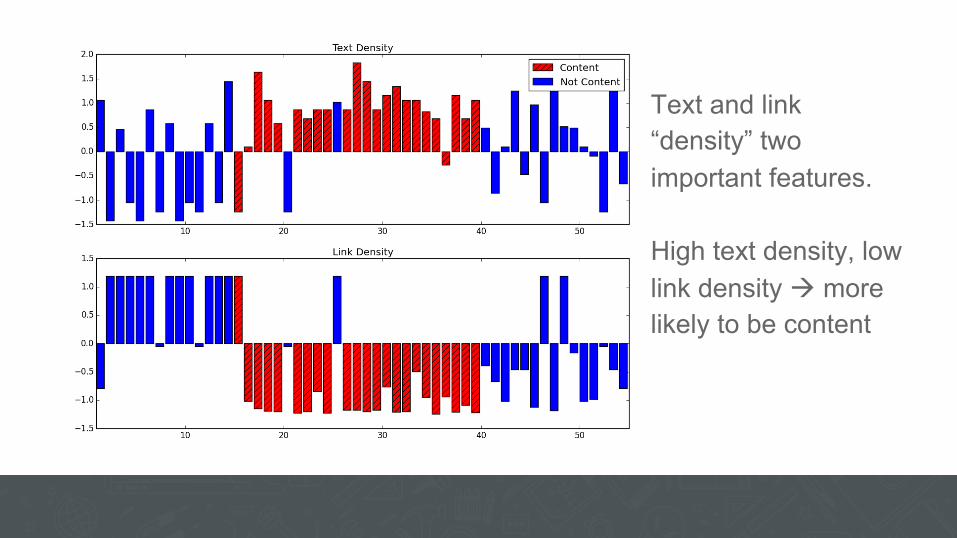
Text and link “density” two important features. High text density, low link density à more likely to be content

Compute “smoothed tag ratio”, ratio of # tags to # chars
Compute “smoothed absolute difference tag ratio”, dTR / dblock. Captures intuition that main content occurs together
Run k-means with 3 clusters on blocks, with one centroid always pinned to (0, 0)
Blocks in (0, 0) cluster are non-content, remainder content
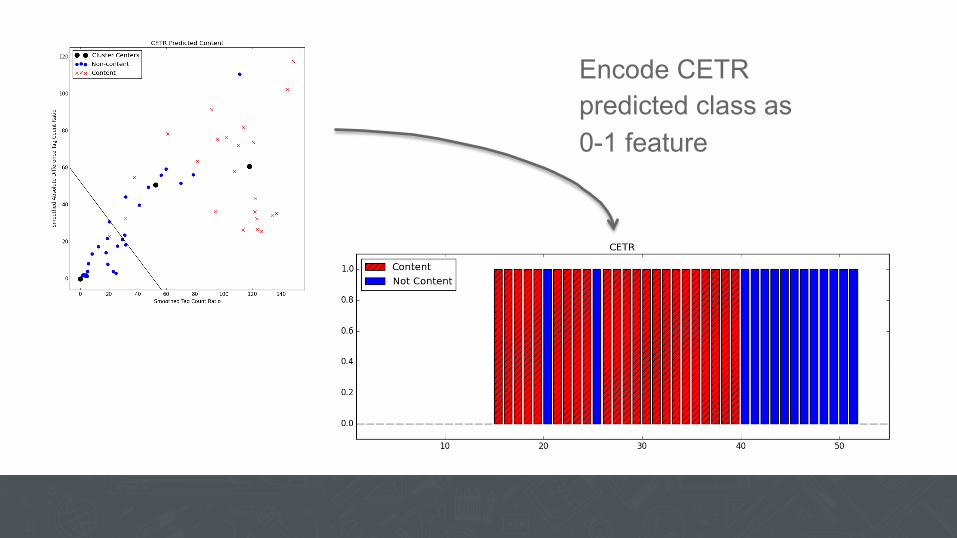
Encode CETR predicted class as 0-1 feature

Use a simplified version of Readability: • Compute score for each subtree using: - parent id/class attributes - length of text • Find subtree with highest score • Block feature = maximum subtree score for all subtrees containing block

Random Forest

Model performance
From 2013 paper (v1) Task: Extract content and comments

Model performance

Model performance

Keyword / topic extraction

Extract a ranked list of keywords from a page with relevancy score (91, 'bertha') (61, 'stp') (59, 'state sues') (44, 'tunnel') (37, 'wsdot') (30, 'tunnel construction') (28, 'the seattle times') (17, 'seattle tunnel partners') (13, 'repair bertha')
(10, 'transportation lawsuit’)

Prior work
Many prior papers on similar task Most use small data sets (hundreds of labeled examples) à unsupervised +
supervised methods Wide range of previous approaches and almost always tailored to specific
type of document (academic papers, etc.) Requirements for “gold standard” are fuzzy Our approach:
Build a web specific algorithm to leverage unique aspects of domain Combine many different features / approaches Overcome data limitations and build complex model by gathering lots of
data automatically

Generate Candidates Rank Candidates
Raw HTML Ranked Topics
CANDIDATES

Main article Run dragnet to extract the main article content. Keep track of individual blocks and process each separately.

This displays as a dash but is the unicode character U+2014
Need to special case @twitter, [email protected], dates, etc.
Text & Token normalization
Include web specific logic in tokenizer / normalizer

Generate Candidates Rank Candidates
Raw HTML Ranked Topics
Parse/ Dechroming
Normalize
Sentence/ word tokenize
CANDIDATES

Processing individual blocks helps NP chunker
Mike Lindblom Bertha: State sues - but even the lawsuit is delayed
Mike Lindblom Bertha NP chunks extracted by our chunker State sues the lawsuit

Wikipedia lookup
Treat “Statue of Liberty” as a single candidate instead of splitting into “Statue” “of Liberty”

Generate Candidates Rank Candidates
Raw HTML Ranked Topics
Parse/ Dechroming
Normalize
Sentence/ word tokenize
POS tag/ Noun phrase chunk
Wikipedia lookup
CANDIDATES

Generate Candidates Rank Candidates
Raw HTML Ranked Topics
Parse/ Dechroming
Normalize
Sentence/ word tokenize
POS tag/ Noun phrase chunk
Wikipedia lookup
Shallow
Occurrence
QDR
POS
URL
CANDIDATES
TF

Ranking model features
Shallow: relative position in document, number of tokens Occurrence: does candidate occur in title, H1, meta description, etc Term frequency: count of occurrences, average token count, sum(in degree),
etc QDR: information retrieval motivated “query-document relevance” ranking
models. TF-IDF (term frequency X inverse document frequency), probabilistic approaches, language models
POS tags: is the keyword a proper noun, etc URL features: does the keyword appear in URL

Generate Candidates Rank Candidates
Raw HTML Ranked Topics
Parse/ Dechroming
Normalize
Sentence/ word tokenize
POS tag/ Noun phrase chunk
Wikipedia lookup
Shallow
Occurrence
QDR
POS
URL
Classifier (probability of relevance)
CANDIDATES
TF
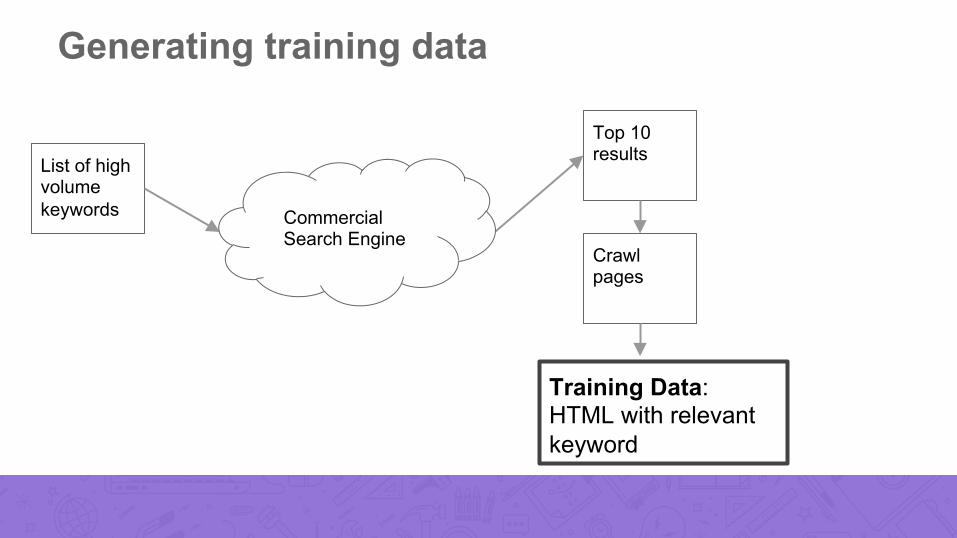
Generating training data
List of high volume keywords
Top 10 results
Crawl pages
Training Data: HTML with relevant keyword
Commercial Search Engine

PU learning
Learning classifiers from only positive and unlabeled data, Elkan and Noto, SIGKDD 2008
● Most ML classifiers have both positive and negative examples in training data
● We only have one keyword per page that is relevant (“positive”) and many others that may or may not be positive
● Use result from this paper applied to our data

Generate Candidates Rank Candidates
Raw HTML Ranked Topics
Parse/ Dechroming
Normalize
Sentence/ word tokenize
POS tag/ Noun phrase chunk
Wikipedia lookup
Shallow
Occurrence
QDR
POS
URL
Classifier (probability of relevance)
CANDIDATES
TF

Keyword extraction review
Resulting algorithm is: ● Robust across different content types – worst case still extracts
reasonable topics ● Reasonably fast, about 25 pages / second end-to-end ● Subjectively outperforms other commercial APIs (e.g. Alchemy, etc). ● In production for a year+, processed many millions of pages

Author extraction

Author
Extract a list of author names (or an empty list if no authors) from a given web page.
See: https://moz.com/devblog/web-page-author-extraction/

Do we need a ML algorithm for this? (why isn’t this trivial?)
Heuristics do an adequate job: ● The microformat rel="author" attribute in link tags (a) is commonly used
to specify the page author ● Some sites specify page authors with a meta author tag. ● Many sites use names like “author” or “byline” for class attributes in their
CSS.

Sometimes heuristics work well
<div class="article-columnist-name vcard"> <a class="author url fn" rel="author" href="/author/mike-lindblom/">Mike Lindblom</a> </div>

But sometimes heuristics fall over
Some pages do not have any special markup for byline...

But sometimes heuristics fall over
Some pages have misleading or wrong markup

But sometimes heuristics fall over
Links to related stories and sidebar bylines look nearly identical to the main byline

Machine learning approach
Use machine learning approach Crowd source labeled data using
Spare5 Approx 9,000 labeled pages

Case study
http://arstechnica.com/science/2016/07/algorithms-used-to-study-brain-activity-may-be-exaggerating-results/

Ranked blocks
Tags for highest ranked block
Dragnet HTML Blockfier
Author chunker
Page HTML
Block representation
Block ranking model

Block ranking model
Combines NLP and web features • Tokens in block text (similar to bag-of-words classification) • Tokens in block HTML tag attributes (e.g. class=“byline”) • The HTML tags in block (e.g. many author names are links) • rel=“author” and other markup inspired features Put all features through Random Forest classifier that predicts probability a block contains author

Block model performance
Overall block model is pretty good – captures intuition that “bylines are easy to spot” Table lists Precision@K whether block actually contains the author’s name.

Author Chunker
Modified IOB tagger similar to NP chunker or POS tagger 3 – class classification problem (Beginning of name, Inside name, Outside) To make predictions at next token:
uni-, bi- and tri-gram tokens from previous/next few tokens uni-, bi- and tri-gram POS tags previous predicted IOB labels HTML tags preceding and following the token rel="author" and other markup inspired features
Overall 85.6% accurate chunking top block.

Author Chunker
<p class="byline”> by <a href="http://arstechnica.com/author/john-timmer/” rel="author”> <span>John Timmer</span> </a> - <span class="date”>Jul 1, 2016 6:55 pm UTC</span> </p>

Author Chunker using HTML features
by John Timmer - Jul 1 IN NNP NNP - NN CD O ??
<p class="byline”> <a rel="author”><span> </span></a>
To make prediction here, we can use tokens, POS tags and HTML structure between tokens

Overall author model performance
Overall accuracy on test set is good, outperforming alternatives.
(heuristics)
(commercial API)
(OS Python library)

Conclusion

POS tagging
Question answering
Language Modeling
Parsing
Sentiment
NLP Web
HTML
XML
Microdata (schema.org)
CSS
Javascript
Conclusion

NLP for the Web
Dr. Matthew Peters @mattthemathman
![[PPT]Deep learning and applications to NLP - University of …people.cs.pitt.edu/.../comps_Deep-learning-for-NLP2.pptx · Web viewDeep learning and applications to NLP Last modified](https://static.fdocuments.us/doc/165x107/5ab021557f8b9aa8438e3852/pptdeep-learning-and-applications-to-nlp-university-of-viewdeep-learning.jpg)








![[PPT]Lecture 36: NLP Tasks and Applications - Department …jason/465/PowerPoint/lect36-tasks.ppt · Web viewTitle Lecture 36: NLP Tasks and Applications Author Jason Eisner Last](https://static.fdocuments.us/doc/165x107/5ab021557f8b9aa8438e3848/pptlecture-36-nlp-tasks-and-applications-department-jason465powerpointlect36-taskspptweb.jpg)








