
Next Generation Interconnection for Accelerated...
33
Center for Computational Sciences, Univ. of Tsukuba Next Generation Interconnection for Accelerated Computing Taisuke Boku Deputy Director, Center for Computational Sciences University of Tsukuba 2016/06/23 ExaComm2016@Frankfurt 1
Transcript of Next Generation Interconnection for Accelerated...

Center for Computational Sciences, Univ. of Tsukuba
Next Generation Interconnection for Accelerated Computing
Taisuke BokuDeputy Director, Center for Computational Sciences
University of Tsukuba
2016/06/23ExaComm2016@Frankfurt1

Center for Computational Sciences, Univ. of Tsukuba
FPGA as “glue” for Acceleration andCommunication
2016/06/23ExaComm2016@Frankfurt2

Center for Computational Sciences, Univ. of Tsukuba
Issues on accelerated (GPU) computingn Trading-off: Power vs Dynamism (Flexibility)
n fine grain individual cores consume much power, then ultra-wide SIMD feature to exploit maximum Flops is needed
n Interconnection is a serious issuen current accelerators are hosted by general CPU, and the system is not stand-
alonen current accelerators are connected by some interface bus with CPU then
interconnectionn current accelerators are connected through network interface attached to the
host CPUn Latency is essential (not just bandwidth)
n with the problem of memory capacity, “strong scaling” is required to solve the problems
n “weak scaling” doesn’t work in some case because of time to solution limitn in many algorithms, reduction of just a scalar value over millions of node is
required
2016/06/23ExaComm2016@Frankfurt3
Accelerators must be tightly coupled with each other, meaning “They should be equipped with communication facility of their own”
Center for Computational Sciences, Univ. of Tsukuba
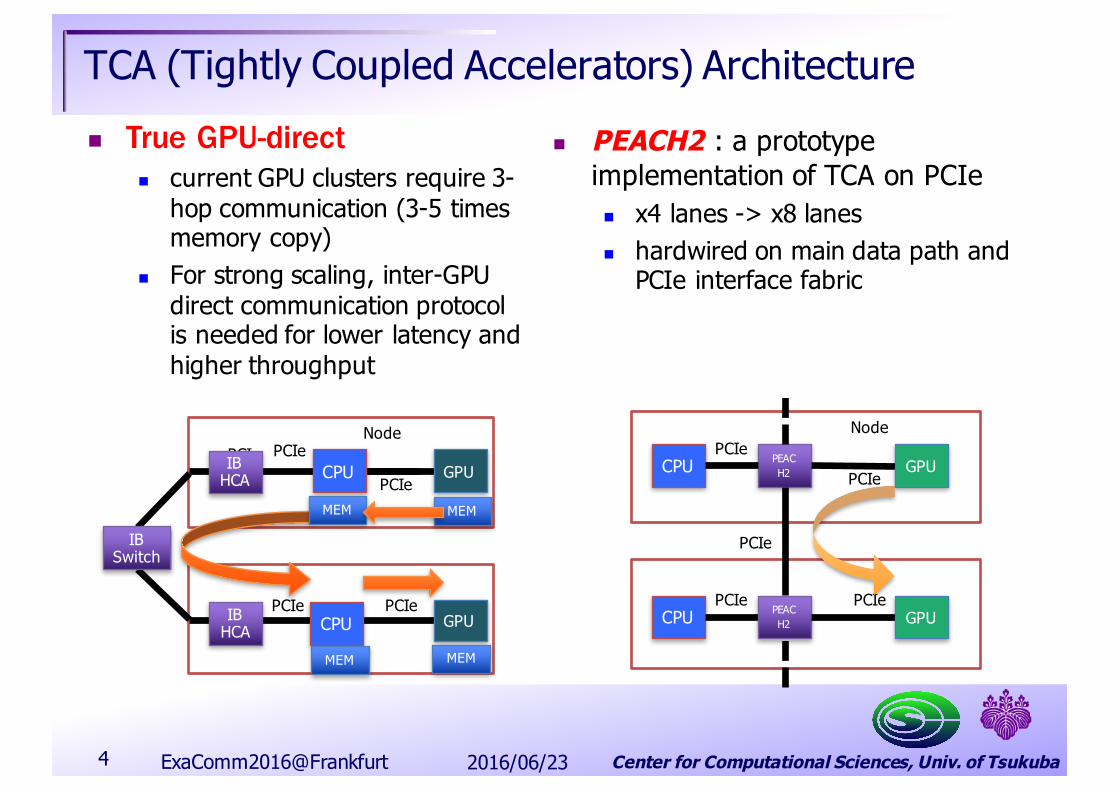
TCA (Tightly Coupled Accelerators) Architecturen PEACH2 : a prototype
implementation of TCA on PCIen x4 lanes -> x8 lanesn hardwired on main data path and
PCIe interface fabric
PEACH2CPU
PCIe
CPUPCIe
Node
PEACH2
PCIe
PCIe
PCIe
GPU
GPU
PCIe
PCIe
Node
PCIe
PCIe
PCIeGPU
GPUCPU
CPU
IB HCA
IB HCA
IBSwitch
n True GPU-directn current GPU clusters require 3-
hop communication (3-5 times memory copy)
n For strong scaling, inter-GPU direct communication protocol is needed for lower latency and higher throughput
MEMMEM
MEM MEM
2016/06/23ExaComm2016@Frankfurt4

Center for Computational Sciences, Univ. of Tsukuba
AC-CREST: Acceleration & Communicationn JST-CREST research projects
n research area “Development of System Software Technologies for post-Peta Scale High Performance Computing” (RS: Dr. M. Sato, RIKEN)
n Research theme: “Research and Development on Unified Environment of Accelerated Computing and Interconnection for Post-Petascale Era” (PI: T. Boku, U. Tsukuba), Oct. 2012 - Mar. 2018, US$3M+ (total)
n My teamn Basic system software and performance evaluation
(by T. Boku, U. Tsukuba)n TCA hardware enhancement
(by H. Amano, Keio U.)n Language: XcalableMP/TCA with OpenACC – XcalbleACC
(by H. Murai, AICS RIKEN)n Application software
(by M. Umemura, U. Tsukuba)
2016/06/23ExaComm2016@Frankfurt5
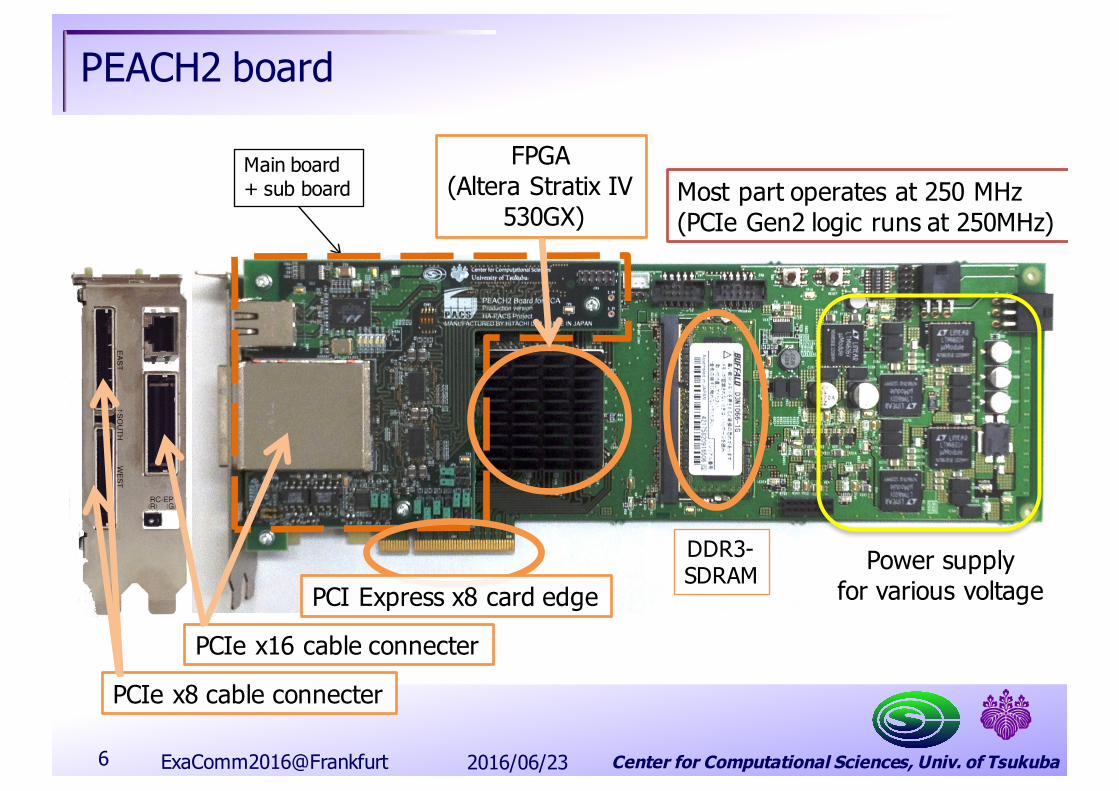
Center for Computational Sciences, Univ. of Tsukuba6
Main board+ sub board Most part operates at 250 MHz
(PCIe Gen2 logic runs at 250MHz)
PCI Express x8 card edgePower supply
for various voltageDDR3-SDRAM
FPGA(Altera Stratix IV
530GX)
PCIe x16 cable connecter
PCIe x8 cable connecter
PEACH2 board
2016/06/23ExaComm2016@Frankfurt
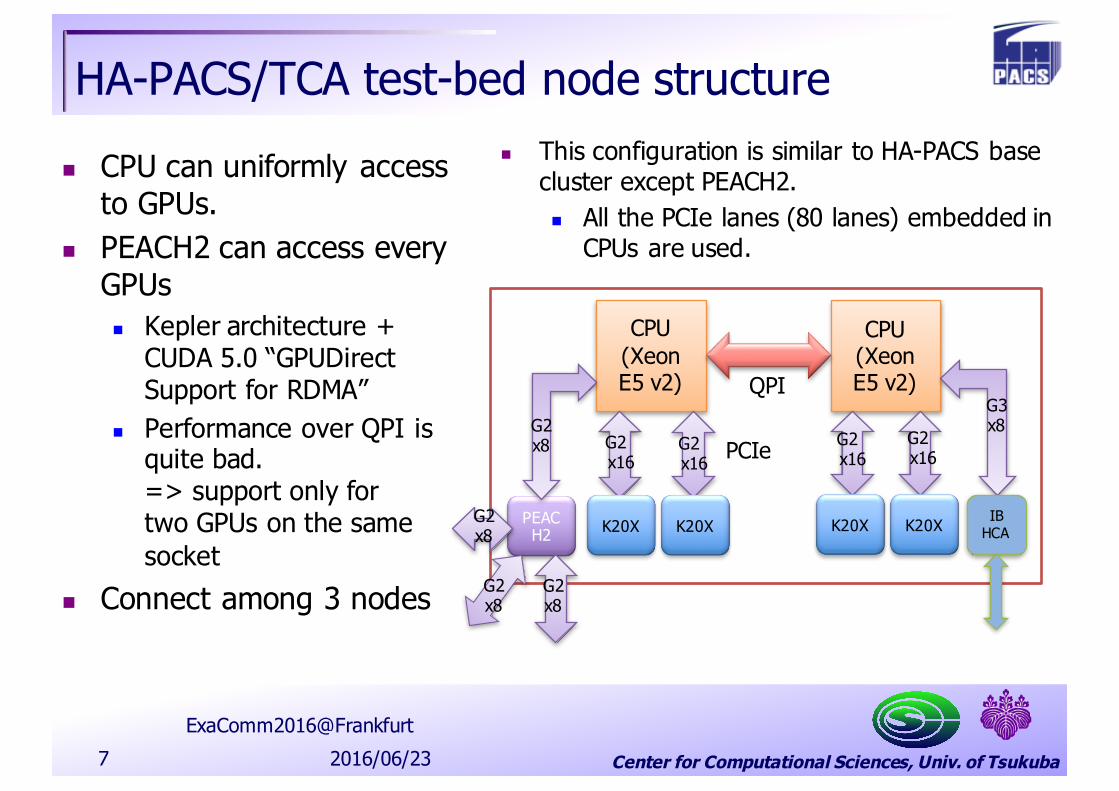
Center for Computational Sciences, Univ. of Tsukuba
HA-PACS/TCA test-bed node structure
n CPU can uniformly access to GPUs.
n PEACH2 can access every GPUsn Kepler architecture +
CUDA 5.0 “GPUDirectSupport for RDMA”
n Performance over QPI is quite bad.=> support only fortwo GPUs on the samesocket
n Connect among 3 nodes
n This configuration is similar to HA-PACS base cluster except PEACH2.n All the PCIe lanes (80 lanes) embedded in
CPUs are used.
CPU(Xeon E5 v2)
CPU(Xeon E5 v2)QPI
PCIe
K20X K20X K20X IBHCA
PEACH2 K20X
G2 x8 G2
x16G2x16
G3x8
G2x16
G2x16
G2 x8
G2 x8
G2 x8
7 2016/06/23ExaComm2016@Frankfurt

Center for Computational Sciences, Univ. of Tsukuba
HA-PACS Base Cluster + TCA(TCA part starts operation on Nov. 1st 2013)
2016/06/23ExaComm2016@Frankfurt8
Base Cluster
TCA
• HA-PACS Base Cluster = 2.99 TFlops x 268 node = 802 TFlops• HA-PACS/TCA = 5.69 TFlops x 64 node = 364 TFlops• TOTAL: 1.166 PFlops• TCA part (individually) ranked as #3 in Green500, Nov. 2013
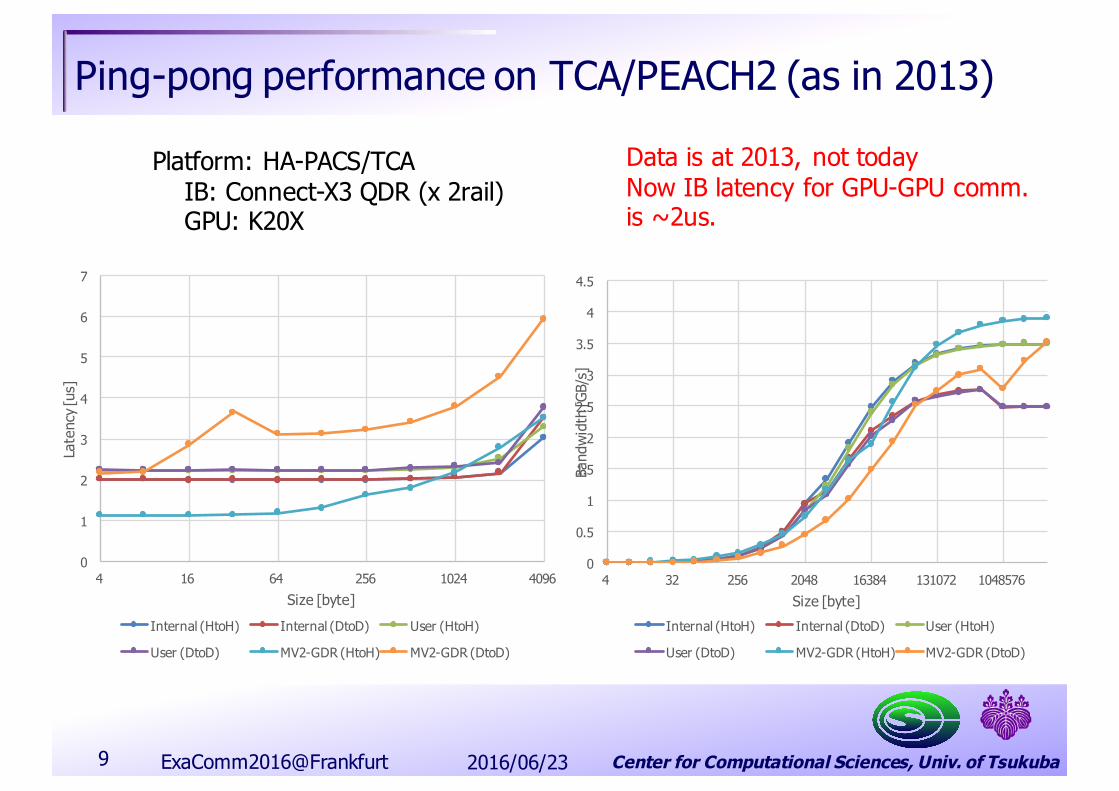
Center for Computational Sciences, Univ. of Tsukuba
Ping-pong performance on TCA/PEACH2 (as in 2013)
2016/06/23ExaComm2016@Frankfurt9
0
1
2
3
4
5
6
7
4 16 64 256 1024 4096
Late
ncy [
us]
Size [byte]Internal (HtoH) Internal (DtoD) User (HtoH)
User (DtoD) MV2-GDR (HtoH) MV2-GDR (DtoD)
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
4 32 256 2048 16384 131072 1048576Ba
ndw
idth
[GB/
s]Size [byte]
Internal (HtoH) Internal (DtoD) User (HtoH)
User (DtoD) MV2-GDR (HtoH) MV2-GDR (DtoD)
Platform: HA-PACS/TCAIB: Connect-X3 QDR (x 2rail)GPU: K20X
Data is at 2013, not todayNow IB latency for GPU-GPU comm.is ~2us.
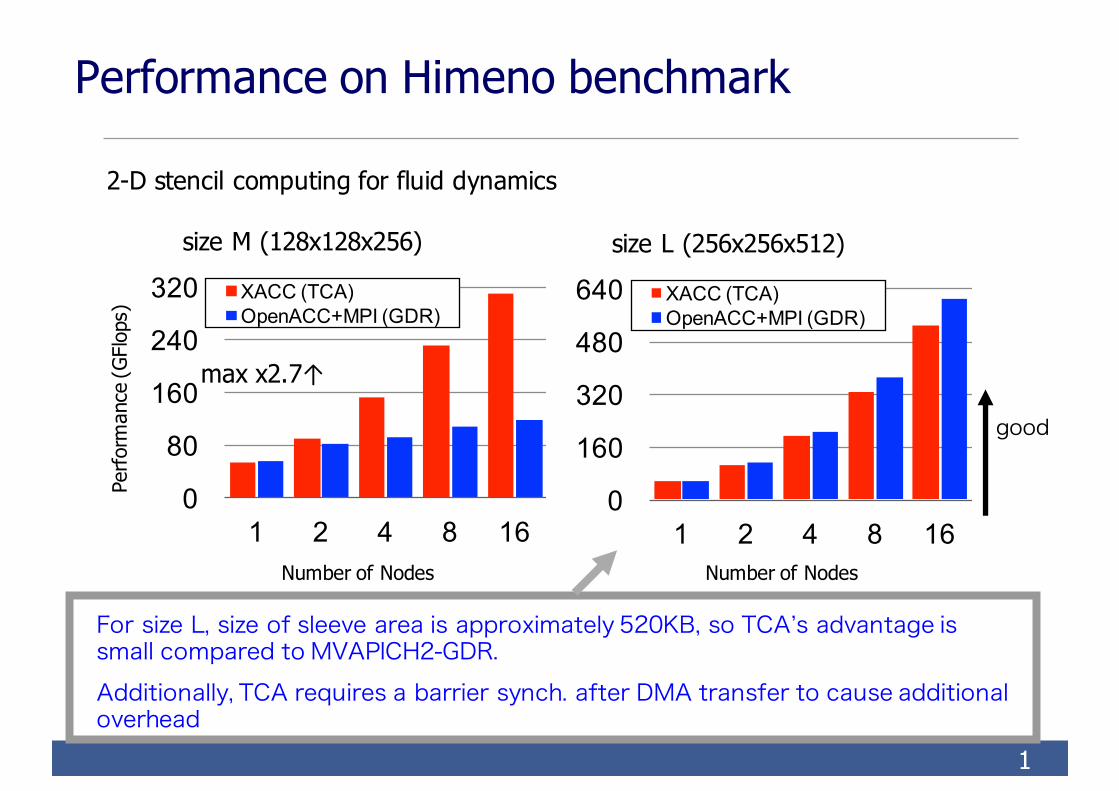
2-D stencil computing for fluid dynamics
10
0
80
160
240
320
1 2 4 8 16
XACC (TCA)OpenACC+MPI (GDR)
Number of Nodes
Perfo
rman
ce (G
Flop
s)
size M (128x128x256)
0
160
320
480
640
1 2 4 8 16
XACC (TCA)OpenACC+MPI (GDR)
size L (256x256x512)
Number of Nodes
max x2.7↑
For size L, size of sleeve area is approximately 520KB, so TCA’s advantage is small compared to MVAPICH2-GDR.Additionally, TCA requires a barrier synch. after DMA transfer to cause additional overhead
good
Performance on Himeno benchmark

Center for Computational Sciences, Univ. of Tsukuba
Bandwidth enhancement: PEACH2 -> PEACH3
E-port、W-portPCI gen3 x8
Altera Stratix V
card edge for hostPCI gen3 x8 Nポート
DDR3 SDRAM
2016/06/23ExaComm2016@Frankfurt11
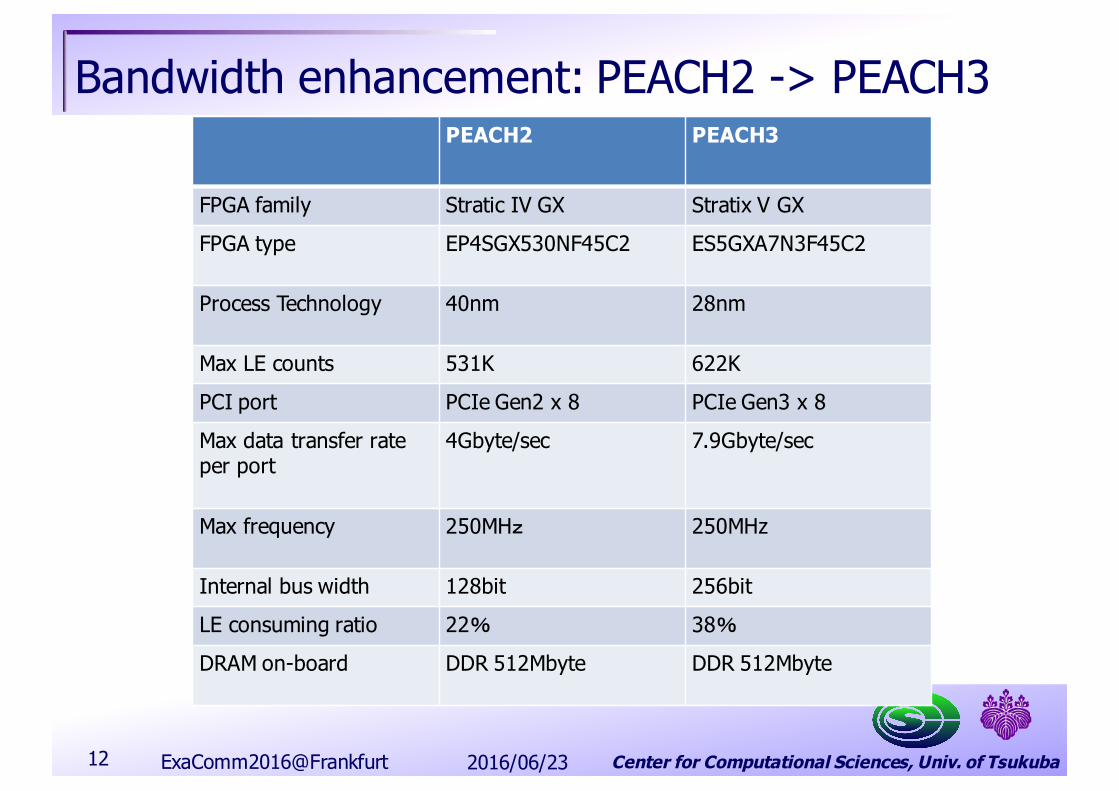
Center for Computational Sciences, Univ. of Tsukuba
Bandwidth enhancement: PEACH2 -> PEACH3PEACH2 PEACH3
FPGA family Stratic IV GX Stratix V GXFPGA type EP4SGX530NF45C2 ES5GXA7N3F45C2
Process Technology 40nm 28nm
Max LE counts 531K 622KPCI port PCIe Gen2 x 8 PCIe Gen3 x 8Max data transfer rate per port
4Gbyte/sec 7.9Gbyte/sec
Max frequency 250MHz 250MHz
Internal bus width 128bit 256bitLE consuming ratio 22% 38%DRAM on-board DDR 512Mbyte DDR 512Mbyte
2016/06/23ExaComm2016@Frankfurt12
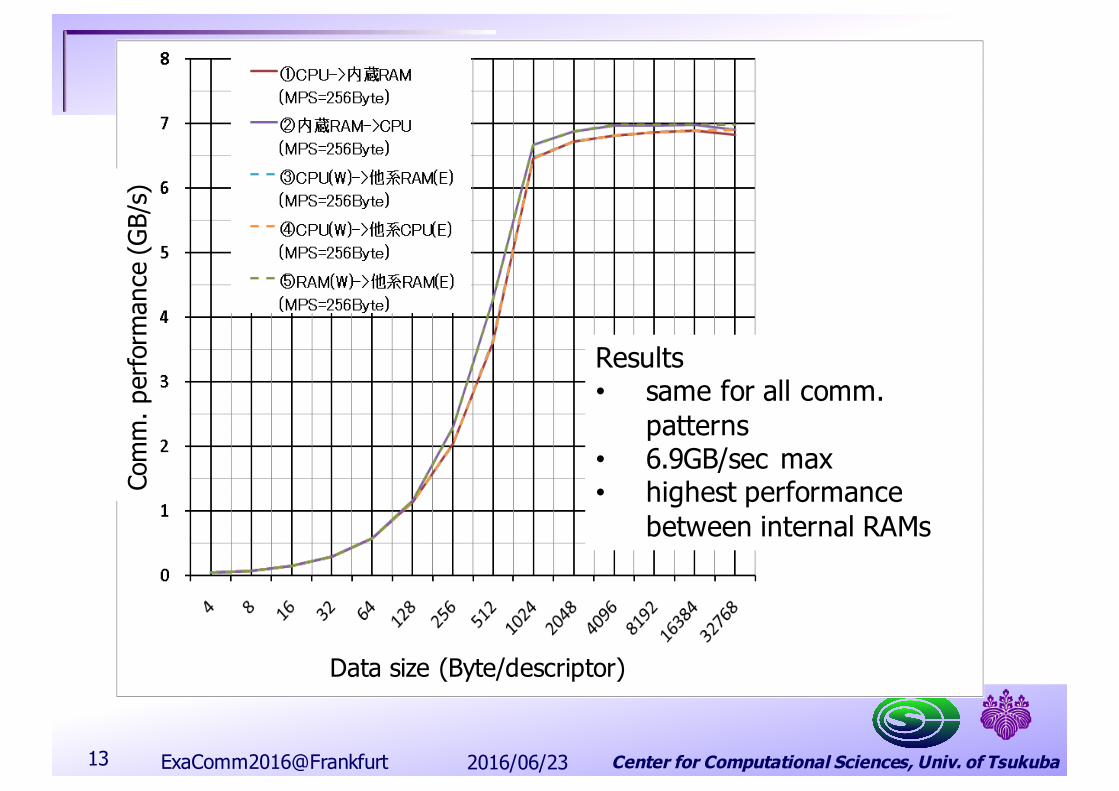
Center for Computational Sciences, Univ. of Tsukuba
Results• same for all comm.
patterns• 6.9GB/sec max• highest performance
between internal RAMs
2016/06/23ExaComm2016@Frankfurt13
Data size (Byte/descriptor)
Com
m. p
erfo
rman
ce (G
B/s)

Center for Computational Sciences, Univ. of Tsukuba
Accelerator in Switch
2016/06/23ExaComm2016@Frankfurt14

Center for Computational Sciences, Univ. of Tsukuba
Is GPU enough for everything ?n GPU is good for:
n coarse grained parallel applicationsn regular pattern of parallel computation without exceptionn applications relying on high memory bandwidth
n In recent HPC applications:n various precision of data is introduced (double, single,
half...)n some computation is strongly related to communication➟ fine ~ mid grained computation not suitable for GPU and too slow by CPU
n complicated algorithm with exception
2016/06/23ExaComm2016@Frankfurt15

Center for Computational Sciences, Univ. of Tsukuba
PEACH2/PEACH3 is based on FPGA
n FPGA for parallel platform for HPCn in general and regular computation, GPU is bettern for something “weird/special” type of computationn (relatively) non bandwidth-aware computation
n PEACH solution on FPGA provides communication and computation on a chipn PEACH2/PEACH3 consumes less than half of LE on FPGAn “partial offloading” of computation in parallel processing can
be implemented on rest of FPGA
2016/06/23ExaComm2016@Frankfurt16
➟ Accelerator in Switch (Network)
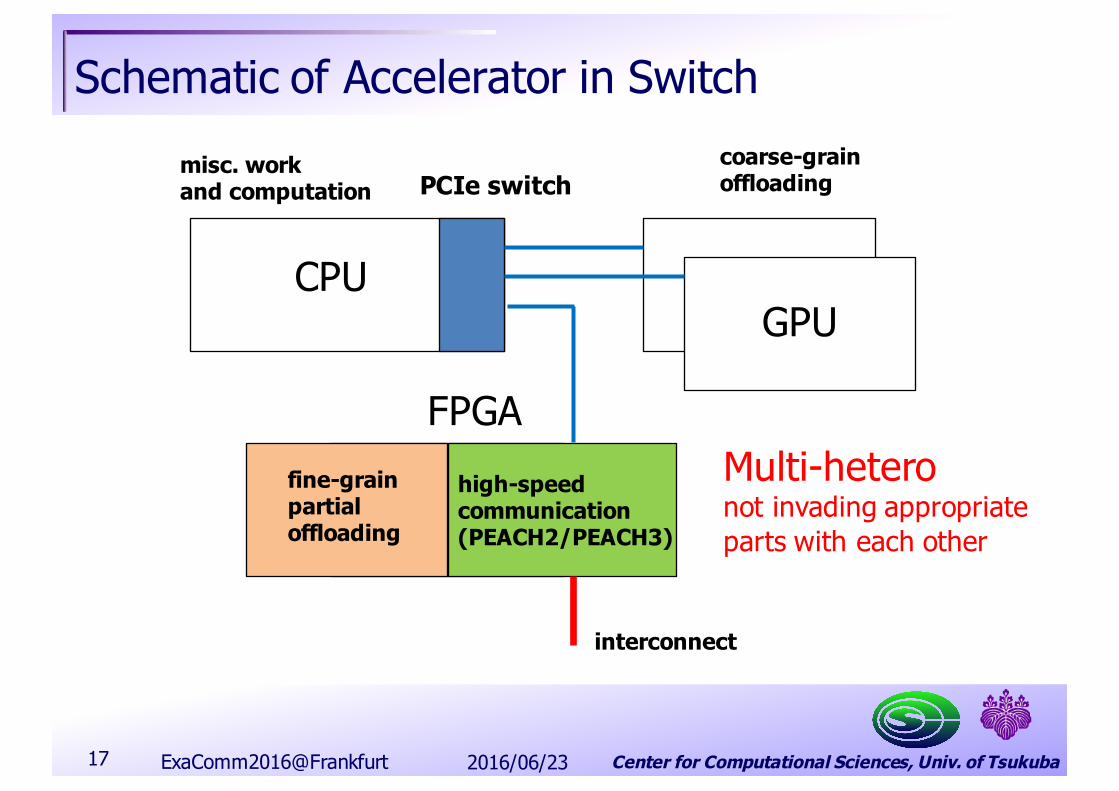
Center for Computational Sciences, Univ. of Tsukuba
Schematic of Accelerator in Switch
2016/06/23ExaComm2016@Frankfurt17
CPUGPU
PCIe switch
FPGAfine-grainpartialoffloading
high-speedcommunication(PEACH2/PEACH3)
coarse-grainoffloading
interconnect
misc. workand computation
Multi-heteronot invading appropriateparts with each other

Center for Computational Sciences, Univ. of Tsukuba
Example of Accelerator in Switch
n Astrophysicsn Gravity calculation in domain decompositionn Tree search is efficientn LET (Locally Essential Tree) is introduced to reduce the
search space in tree structure➟ too complicated to handle in GPU
n CPU is too slow➟ implementing the function on FPGA and combining with PEACH2 communication part
2016/06/23ExaComm2016@Frankfurt18
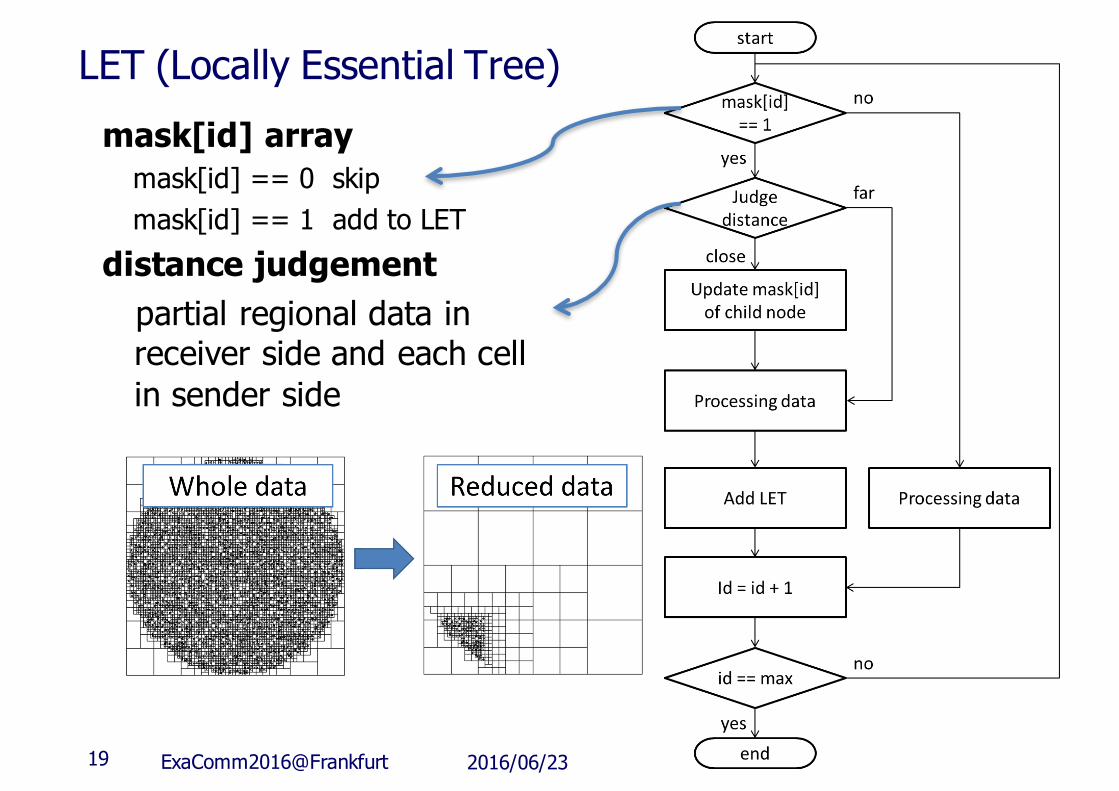
LET (Locally Essential Tree)mask[id] array
mask[id] == 0 skipmask[id] == 1 add to LET
distance judgementpartial regional data inreceiver side and each cellin sender side
19 2016/06/23ExaComm2016@Frankfurt
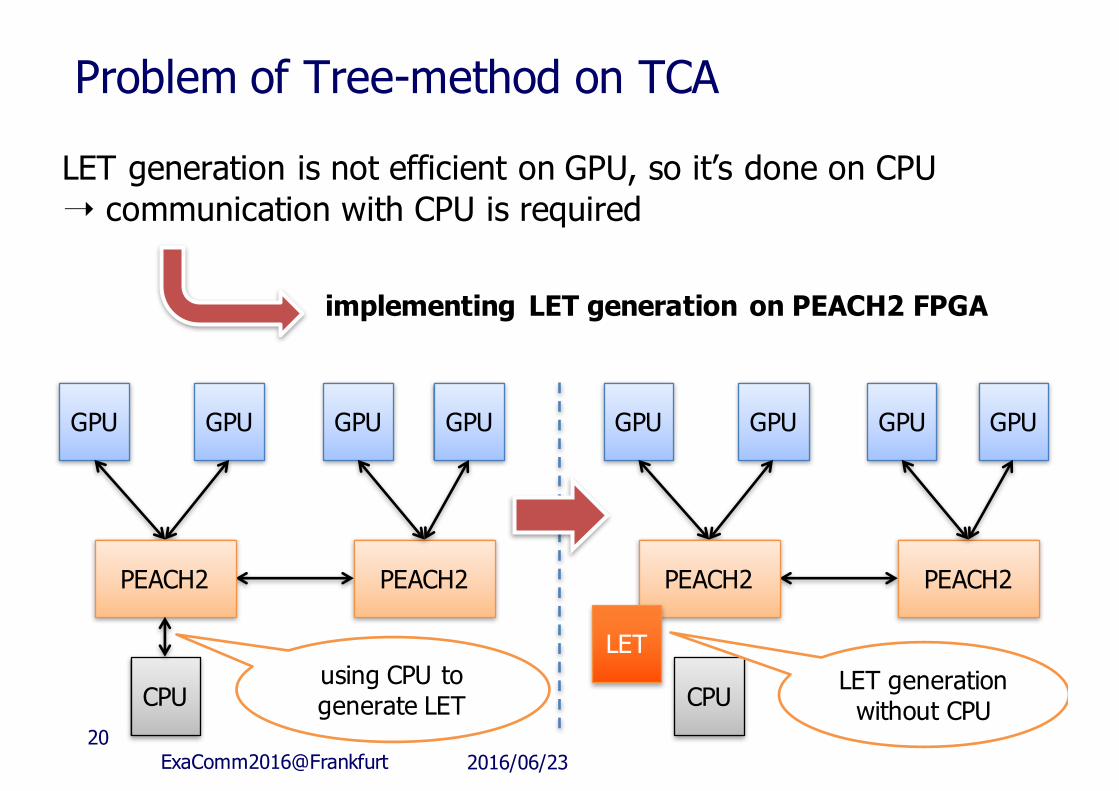
Problem of Tree-method on TCA
LET generation is not efficient on GPU, so it’s done on CPU➝ communication with CPU is required
20
GPU GPU
CPU
GPU GPU
CPU
implementing LET generation on PEACH2 FPGA
PEACH2 PEACH2
GPU GPU
CPU
GPU GPU
CPU
PEACH2 PEACH2
LETusing CPU to generate LET
LET generation without CPU
2016/06/23ExaComm2016@Frankfurt
Center for Computational Sciences, Univ. of Tsukuba2016/06/23ExaComm2016@Frankfurt21
Center for Computational Sciences, Univ. of Tsukuba
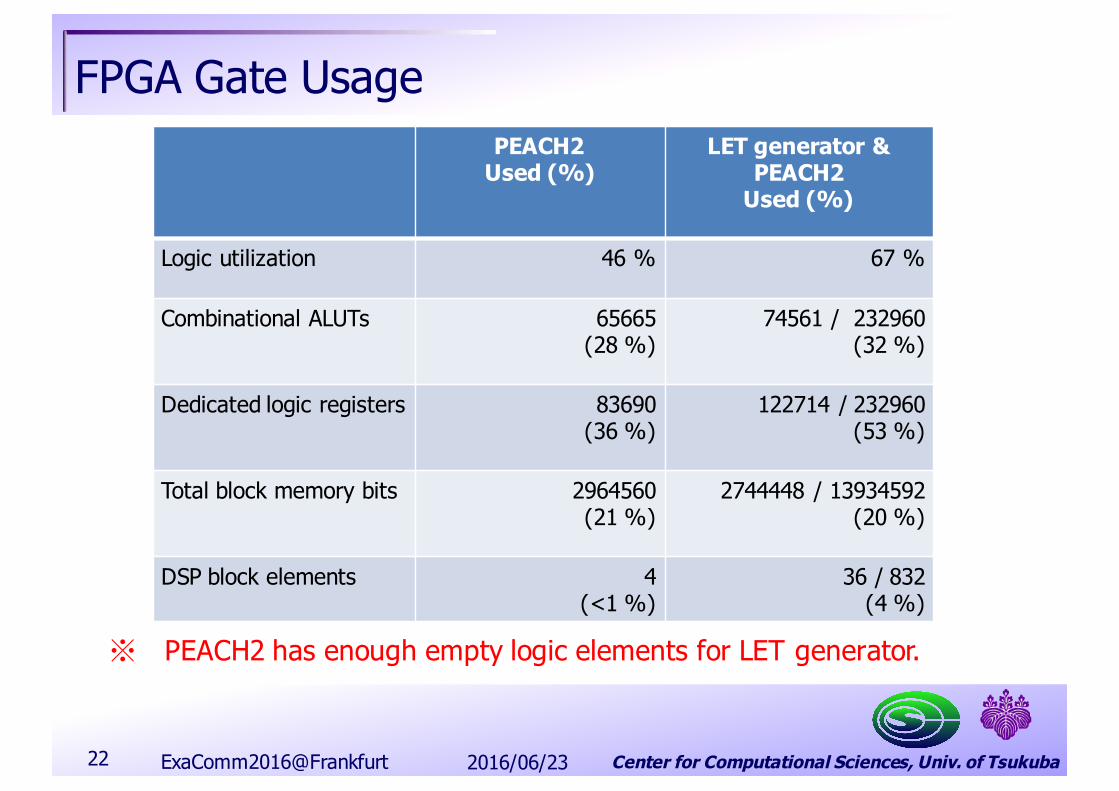
FPGA Gate UsagePEACH2
Used (%)LET generator &
PEACH2Used (%)
Logic utilization 46 % 67 %
Combinational ALUTs 65665 (28 %)
74561 / 232960(32 %)
Dedicated logic registers 83690 (36 %)
122714 / 232960(53 %)
Total block memory bits 2964560 (21 %)
2744448 / 13934592(20 %)
DSP block elements 4 (<1 %)
36 / 832(4 %)
22
※ PEACH2 has enough empty logic elements for LET generator.
2016/06/23ExaComm2016@Frankfurt
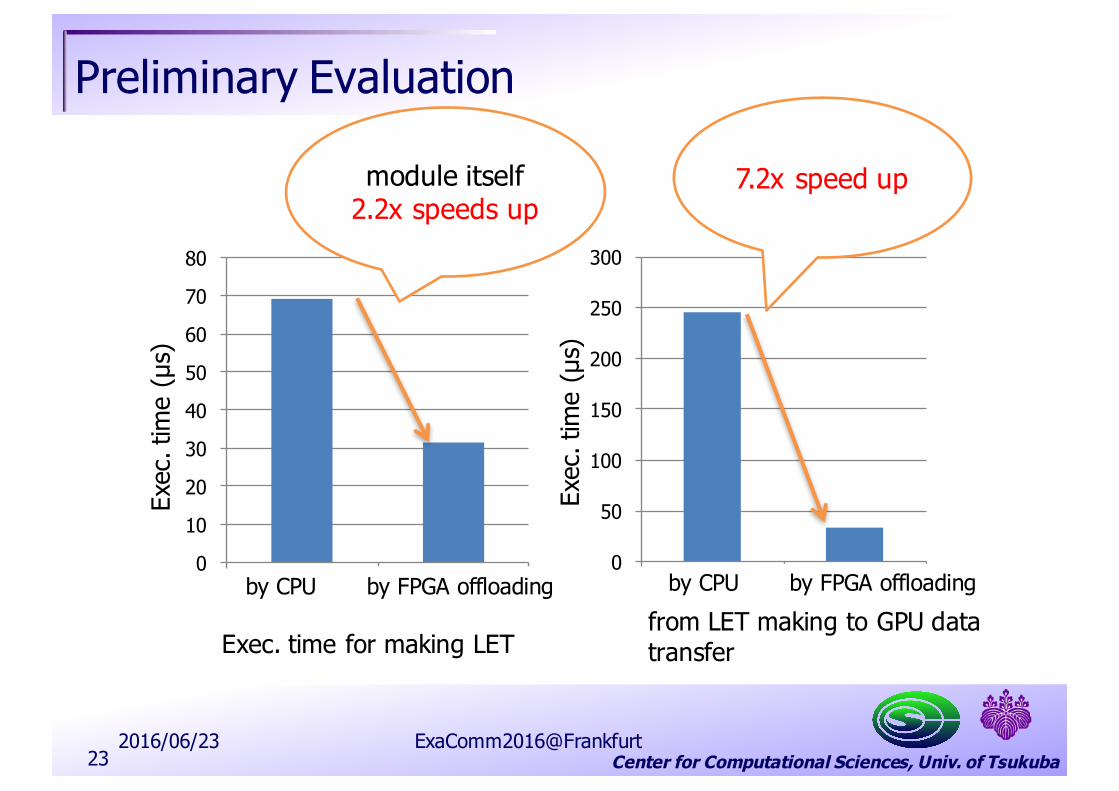
Center for Computational Sciences, Univ. of Tsukuba
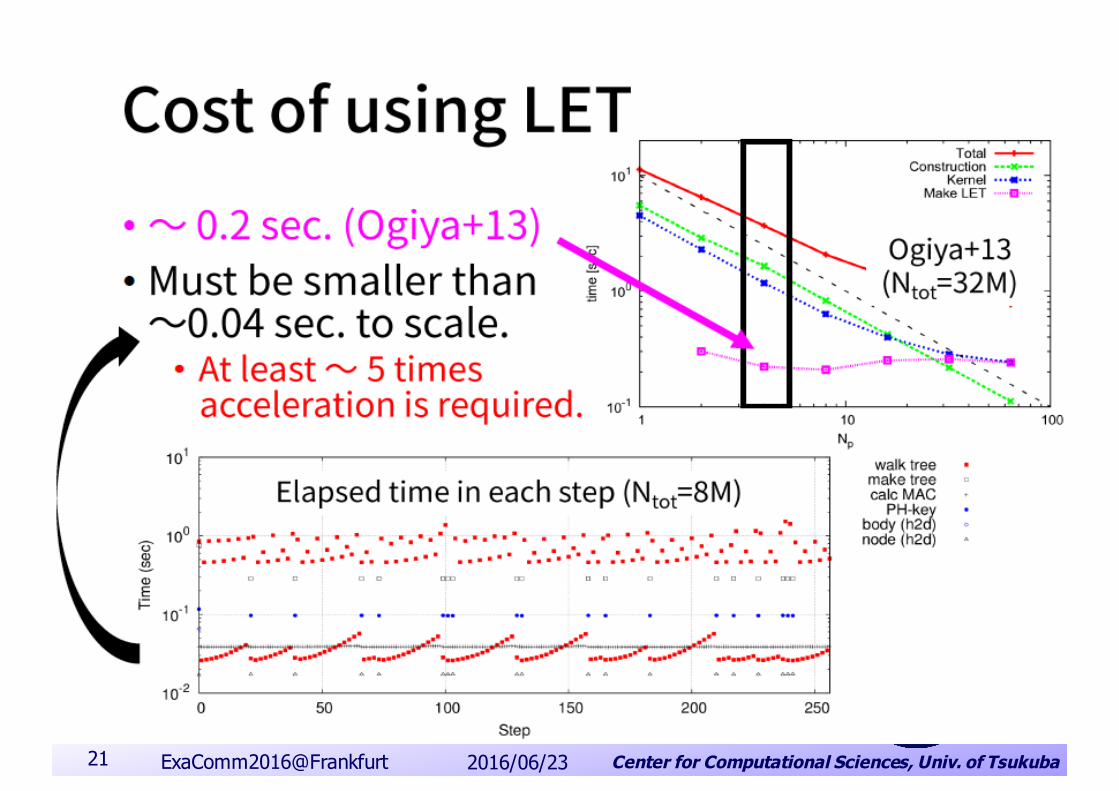
Preliminary Evaluation
0
10
20
30
40
50
60
70
80
CPU実行 オフロード機構
実行時間
( μ s
ec )
23
module itself 2.2x speeds up
0
50
100
150
200
250
300
CPU実行 オフロード機構
実行時間
( μ s
ec )
Exec. time for making LETfrom LET making to GPU data transfer
7.2x speed up
2016/06/23 ExaComm2016@Frankfurt
Exec
. tim
e (μ
s)
Exec
. tim
e (μ
s)by CPU by FPGA offloading by CPU by FPGA offloading

Center for Computational Sciences, Univ. of Tsukuba
Open Issues
n How to program ?n OpenCL may be a key for FPGA computingn How to combine the module on FPGA computation and other framwork
(CPU and GPU)➝ calling special function to invoke FPGA computation from CPU
n XcalableACC -> OpenACC -> OpenCL ?
n How to reconfigure FPGA ?n Partial reconfiguration on FPGA (we have done it)n How to combine multiple modules on FPGA ?n We need to prepare the partially-reconfigurable modules of PEACH2/3
communication part
2016/06/23ExaComm2016@Frankfurt24

Center for Computational Sciences, Univ. of Tsukuba
Inter-FPGA communication link
2016/06/23ExaComm2016@Frankfurt25

Center for Computational Sciences, Univ. of Tsukuba
Performance growth from 2010 to 2016: PCIe on FPGA
2010 2016Virtex 7 (XILINX)Stratix IV (Altera)
UltraScale+ (XILINX)Stratix V (Altera/Intel)
PCI Express Gen2 PCI Express Gen4 ?8 lanes 8 lanes when PCIe Gen4
16 lanes when PCIe Gen34 PCI ports 6 PCI ports256 Gb/s per FPGA 1,536 Gb/s per FPGA
What happens by this performance improvement?
2016/06/23ExaComm2016@Frankfurt26
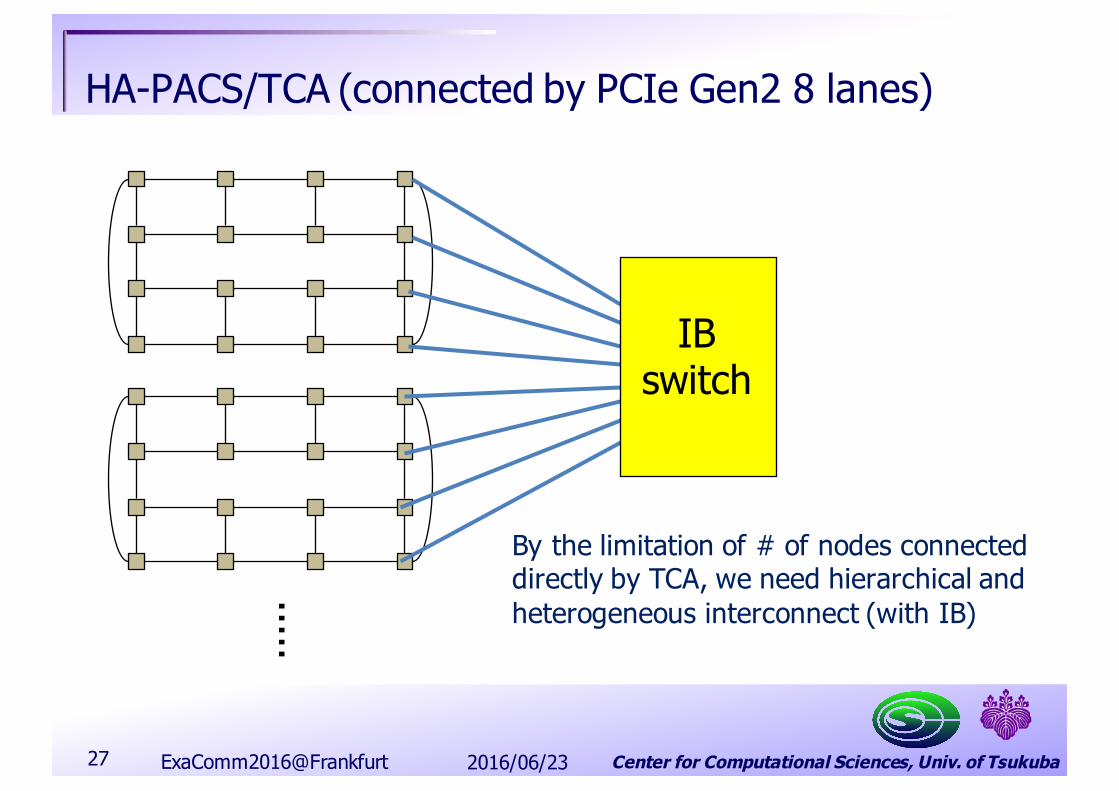
Center for Computational Sciences, Univ. of Tsukuba
HA-PACS/TCA (connected by PCIe Gen2 8 lanes)
.....
IBswitch
By the limitation of # of nodes connecteddirectly by TCA, we need hierarchical andheterogeneous interconnect (with IB)
2016/06/23ExaComm2016@Frankfurt27
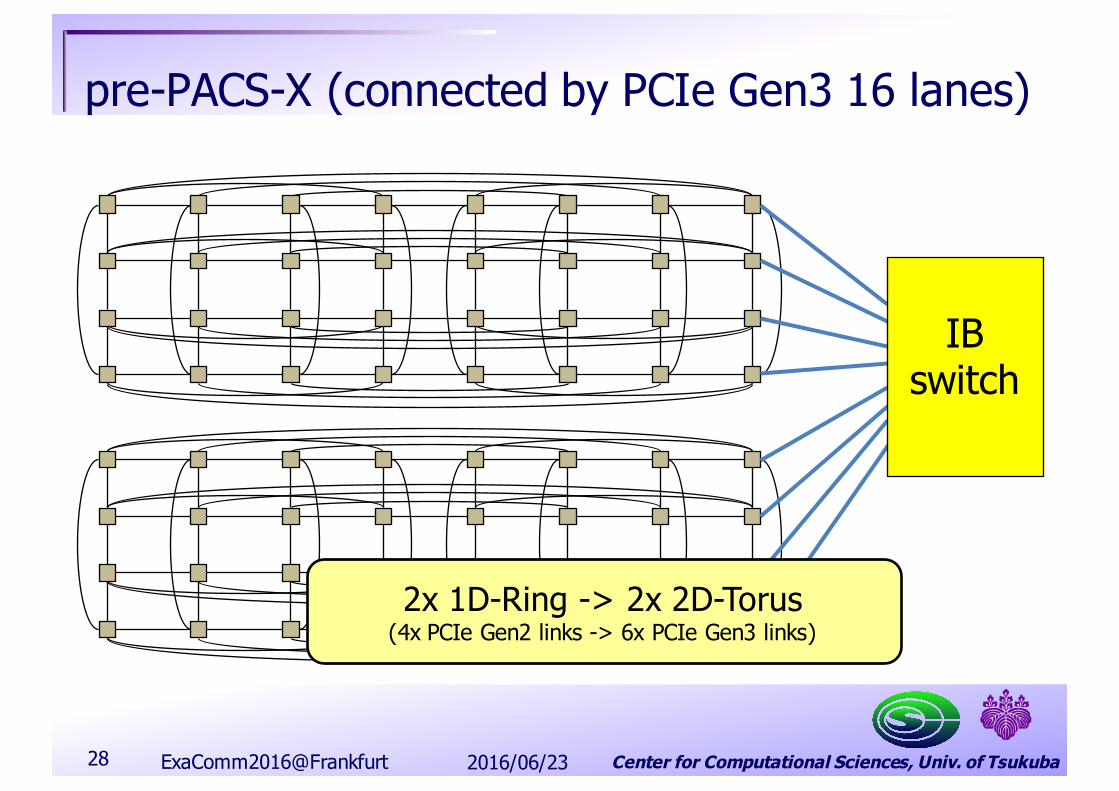
Center for Computational Sciences, Univ. of Tsukuba
pre-PACS-X (connected by PCIe Gen3 16 lanes)
IBswitch
2x 1D-Ring -> 2x 2D-Torus(4x PCIe Gen2 links -> 6x PCIe Gen3 links)
2016/06/23ExaComm2016@Frankfurt28
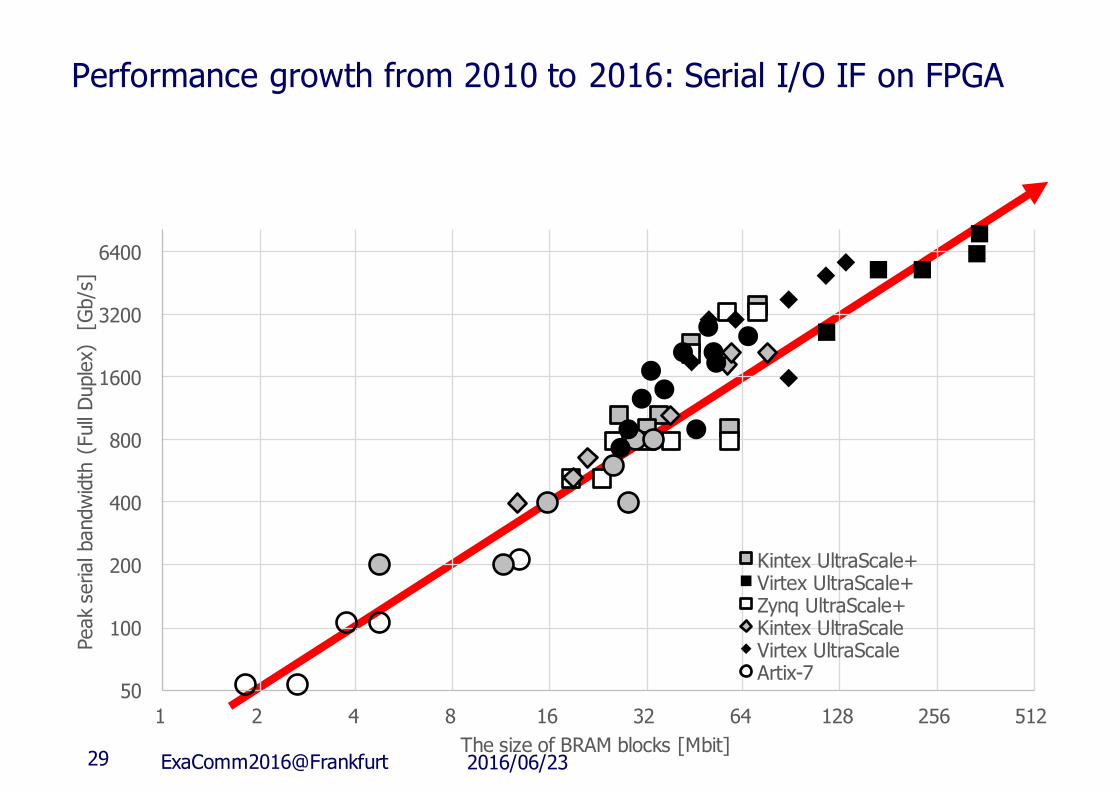
Performance growth from 2010 to 2016: Serial I/O IF on FPGA
50
100
200
400
800
1600
3200
6400
1 2 4 8 16 32 64 128 256 512
Peak
ser
ial b
andw
idth
(Fu
ll Du
plex
) [
Gb/s
]
The size of BRAM blocks [Mbit]
Kintex UltraScale+Virtex UltraScale+Zynq UltraScale+Kintex UltraScaleVirtex UltraScaleArtix-7
2016/06/23ExaComm2016@Frankfurt29
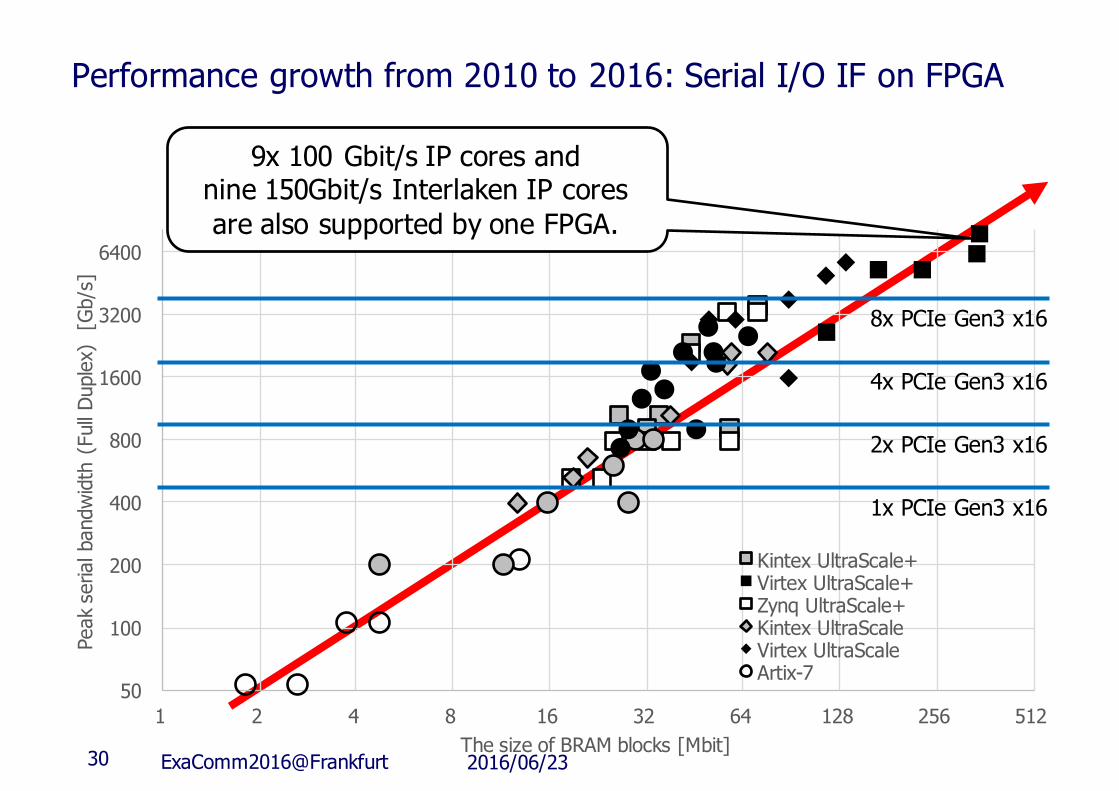
50
100
200
400
800
1600
3200
6400
1 2 4 8 16 32 64 128 256 512
Peak
ser
ial b
andw
idth
(Fu
ll Du
plex
) [
Gb/s
]
The size of BRAM blocks [Mbit]
Kintex UltraScale+Virtex UltraScale+Zynq UltraScale+Kintex UltraScaleVirtex UltraScaleArtix-7
1x PCIe Gen3 x16
2x PCIe Gen3 x16
4x PCIe Gen3 x16
8x PCIe Gen3 x16
9x 100 Gbit/s IP cores andnine 150Gbit/s Interlaken IP coresare also supported by one FPGA.
Performance growth from 2010 to 2016: Serial I/O IF on FPGA
2016/06/23ExaComm2016@Frankfurt30

PACS-X (connected by PCIe & High Speed Serial IO)
2x 2D-Torus -> 2x 5D-Torus6x PCIe Gen3 links+ 6x HS Serial links
2016/06/23ExaComm2016@Frankfurt31
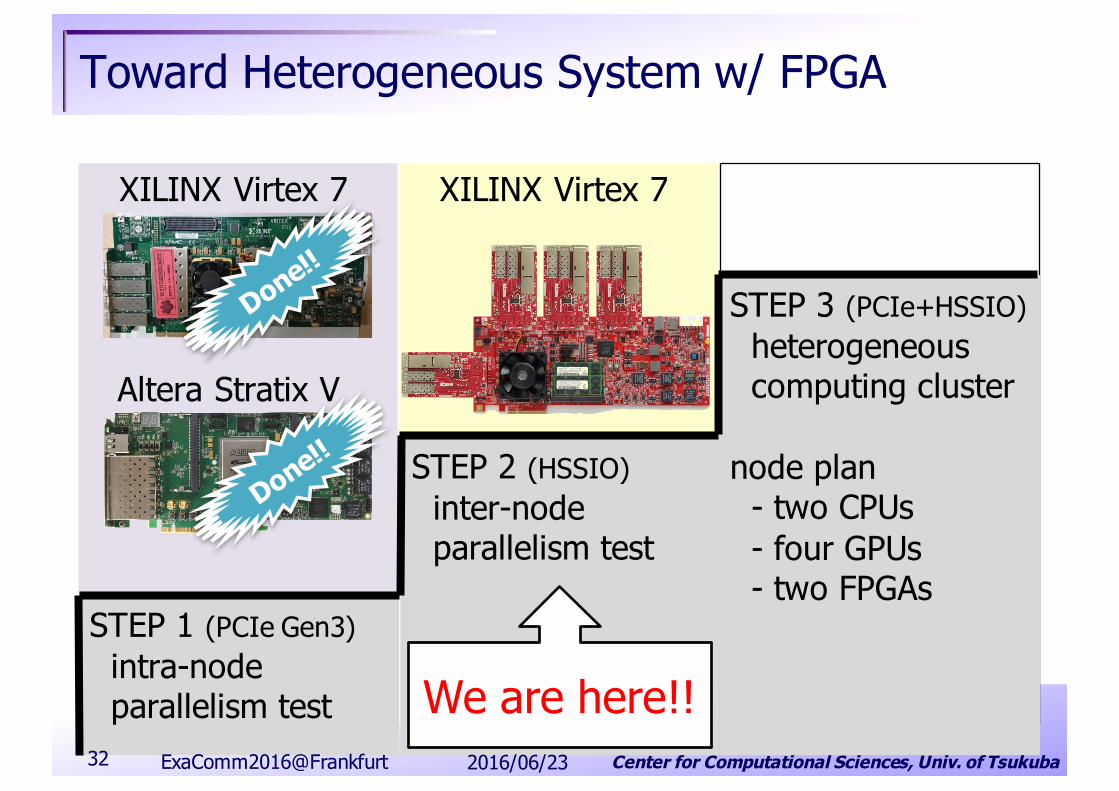
Center for Computational Sciences, Univ. of Tsukuba
Toward Heterogeneous System w/ FPGA
STEP 1 (PCIe Gen3)intra-nodeparallelism test
STEP 2 (HSSIO)inter-nodeparallelism test
STEP 3 (PCIe+HSSIO)heterogeneouscomputing cluster
node plan - two CPUs- four GPUs- two FPGAs
Altera Stratix V
XILINX Virtex 7 XILINX Virtex 7
We are here!!2016/06/23ExaComm2016@Frankfurt32

Center for Computational Sciences, Univ. of Tsukuba
Summaryn Next generation Exa-scale (Flops) system is a challenge to
power consumption (Flops/W)
n Strong scaling is essential, and direct interconnection between accelerators is necessary, within chip and over chips
n TCA is a basic concept on the possibility on direct network between accelerators (GPUs) by current available technology
n FPGA is a very aggressive CoDesign solution, and TCA by PEACH2 on FPGA can handle both partial-offloading and communication based on GPU computation
2016/06/23ExaComm2016@Frankfurt33


















