

New Abstractions For Data Parallel Programming
63
New Abstractions For Data Parallel Programming James C. Brodman Department of Computer Science [email protected] In collaboration with: George Almási, Basilio Fraguela, María Garzarán, David Padua 1
description
New Abstractions For Data Parallel Programming. James C. Brodman Department of Computer Science [email protected] In collaboration with: George Almási , Basilio Fraguela , María Garzarán , David Padua. Outline. Introduction Hierarchically Tiled Arrays - PowerPoint PPT Presentation
Transcript of New Abstractions For Data Parallel Programming

New Abstractions For Data Parallel Programming
James C. BrodmanDepartment of Computer Science
In collaboration with:George Almási, Basilio Fraguela,
María Garzarán, David Padua
1

Outline• Introduction• Hierarchically Tiled Arrays• Additional Abstractions for Data Parallel
Programming• Conclusions
2

1. Introduction
3

Going Beyond Arrays• Parallel programming has been well studied for
numerical programs– Shared/Distributed Memory APIs, Array languages– Hierarchically Tiled Arrays (HTAs)
• However, many important problems today are non numerical
• Examine non-numerical programs and find new abstractions– Data Structures– Parallel Primitives
4

Array Languages• Many numerical programs were written using Array
languages• Popular among scientists and engineers.
– Fortran 90 and successors– MATLAB
• Parallelism not the reason for this notation.
5

Array Languages• Convenient notation for linear algebra and other
algorithms– More compact– Higher level of abstraction
do i=1,n do i=1,n
do j=1,n do j=1,n
C(i,j)= A(i,j)+B(i,j) S = S + A(i,j)
end do end do
end do end do
C = A + B S += sum(A)
6

Data Parallel Programming • Array languages seem a natural fit for parallelism
• Parallel programming with aggregate-based or loop-based languages is data centric, or, data parallel– Phrased in terms of performing the same operation on
multiple pieces of data – Contrast with task parallelism where parallel tasks may
perform completely different operations
• Many reasons to prefer data parallel programming over task parallel approaches
7

Data Parallel Advantages• Data parallel programming is scalable
– Scales with increasing number of processors by increasing the size of the data
• Data parallel programs based on array operations resemble conventional, serial programs.– Parallelism is encapsulated.– Parallelism is structured
• Portable– Can run on any class of machine for which the appropriate
operators are implemented• Shared/Distributed Memory, Vector Intrinsics, GPUs
8
Operations implemented as messages if distributed memoryOperations implemented as messages if distributed memory
Operations implemented as parallel loops in shared memoryOperations implemented as parallel loops in shared memory
Operations implemented with vector intrinsics for SIMDOperations implemented with vector intrinsics for SIMD

Data Parallel Advantages• Data parallel programming can both:
– Enforce determinacy– Encapsulate non-determinacy
• Data parallel programming facilitates autotuning
9

2. Hierarchically Tiled Arrays
10

Numerical Programs and Tiling• Blocking/Tiling is important:
– Data Distribution– Locality– Parallelism
• Who is responsible for tiling:– The Compiler?– The Programmer?
11

Tiling and Compilers (Matrix Multiplication)
12
20x
MFL
OPS
Matrix Size
Intel MKL
icc -O3 -xT
icc -O3
Clearly, the Compiler isn’t doing a good job at tilingClearly, the Compiler isn’t doing a good job at tiling

Tiling and Array Languages• Another option is to leave it up to the programmer
• What does the code look like?– Notation can get complicated
• Additional Dimensions• Arrays of Arrays
– Operators not built to handle tiling
13

• The complexity of the tiling problem directly motivates the Hierarchically Tiled Array (HTA)
• Makes tiles first class objects– Referenced explicitly – Extended array operations to operate with tiles
14
Hierarchically Tiled Arrays

Multicore
Locality
Distributed
Hierarchically Tiled Arrays
15

Higher Level Operations• Many operators part of the library
– Map, reduce, circular shift, replicate, transpose, etc
• Programmers can create new complex parallel operators through the primitives hmap (and MapReduce)– Applies user defined operators to each tile of the HTA
• And corresponding tiles if multiple HTAs are involved
– Operator applied in parallel across tiles
16

User Defined Operationshmap( F(), X, Y)
17
X
F()
Y

HTA Examples• We can handle many basic types of computations
using the HTA library– Cannon’s Matrix Multiplication– Sparse Matrix/Vector Multiplication
• We also support more complicated computations– Recursive parallelism– Dynamic partitioning
18

Cannon's Matrix Multiplication
19
A00
A01
A10
A20
A11
A21
A22
A12
A02 B
01
B10
B20
B11
B21
B22
B12
B02
B00
A00
B00
A01
B11
A02
B22
A12
B21
A11
B10
A10
B02
A22
B20
A20
B01
A21
B12
A00
B00
A01
B11
A02
B22
A12
B21
A11
B10
A10
B02
A22
B20
A20
B01
A21
B12
initial skew
shift-multiply-add

Cannon's Matrix MultiplicationHTA A, B, C
do i = 1:m // initial skewA(i,:) = circ_shift( A(i,:), [ 0, -(i-1)] ) // shift rows leftB(:,i) = circ_shift( B(:,i), [ -(i-1), 0 ] ) // shift rows up
do i = 1:n // main loopC = C + A * B // matrix add. and mult.A = circ_shift( A, [ 0 -1 ] )B = circ_shift( B, [ -1 0 ] )
20

Sparse Matrix/Vector Multiplication
21
* =

Sparse Matrix/Vector Multiplication
22
TransposeTranspose ReplicateReplicate
.* = Reduce(+)Reduce(+)

Sparse Matrix/Vector MultiplicationSparse_HTA AHTA In, Res
Res = transpose( In )Res = replicate( Res, [3 1] ) // replicateRes = map( *, A, Res) // element-by-element
mult.Res = reduce( +, Res, [0 1] ) // row reduction
23

User Defined Operations - MergeMerge(HTA input1, HTA input2, HTA output ) {…
if (output.size() < THRESHOLD)SerialMerge( input1, input2, output )
else {
i = input1.size() / 2input1.addPartition( i )
j = h2.location_first_gt( input1[i] )input2.addPartition(j)
k = i + joutput.addPartition(k)
hmap( Merge(), input1, input2, output )}
…}
24
input1 input2
input1
input2
Merge Merge
Dynamic Partitioning
Dynamic Partitioning

Advantages of tiling as a first class object for optimization
• HTAs have been implemented as C++ and MATLAB libraries.– For shared and distributed memory machines– A GPU version is planned
• Implemented several benchmark suites.• Performance is competitive with OpenMP, MPI, and
TBB counterparts• Furthermore, the HTA notation produces code more
readable than other notations. It significantly reduces number of lines of code.
25

Advantages of tiling as a first class object
26
EP CG MG FT LU
Lines of code
Lines of Code. HTA vs. MPI

Performance Results
27
MG
IS
FT
CG
With basic compiler optimizations, can match Fortran/MPI

3. Additional Abstractions for Data Parallel Programming
28

Extending Data Parallel Programming• Many of today’s programs are amenable to data
parallelism but not with today’s abstractions
• Need to identify new primitives to extend data parallelism to these types of programs– Non numerical– Non deterministic– Traditionally task parallel
29

3.1. Non Numerical Computations
30

New Data Structures for Non Numerical Computations
• Operations on aggregates do not have to be confined to arrays– Trees– Graphs– Sets
31

Sets• Sets are a possible aggregate to consider for data
parallelism– Have been examined before (The Connection Machine –
Hillis)
• What primitives do we need?– Map – apply some function to every element of a set– Reduce – apply reductions across a set or multiple sets
(Union, Intersection, etc)– MapReduce– Scan – perform a prefix operation on sets
32

What problem domains can be solved in parallel using set operations
• We have studied several areas including– Search– Datamining– Mesh Refinement
• In all cases, it was possible to obtain a highly parallel and readable version using set operations
33

Example – Search – 15 Puzzle• 4x4 grid of tiles with a “hole”• Slide tiles to go from a start state to the Goal• States (puzzle configurations) and transitions (moves)
form a graph• Solve using a Best-First Search
34

Example - Search
35

Parallel Search Algorithms• Best-First search uses a heuristic to guide the search to
examine “good” nodes first– If the search space is very large, prefer nodes that are closer to a
solution over nodes less likely to quickly reach the goal– Ex. The 15 puzzle search space size is ~16!
• For the puzzle, the heuristic function takes a state and gives it a score– Better scores are likely to lead to solutions more quickly– Metric is sum of:
• Steps so far• Sum of distances of each tile from its final position
36

Parallel Search Algorithms
37
expandexpand
select
W
Expand
W
select

Parallel Search AlgorithmsSearch( initial_state )
work_list.add( initial_state )
while ( work_list not empty )n = SELECT( work_list )If ( n contains GOAL ) breakwork_list = work_list – nsuccessors = expand( n )update( work_list, successors )
38
The implementation of SELECT determines the type of search:
• ALL Breadth-First• DEEPEST Depth-First• BEST (Heuristic) Best-FirstCode looks sequential
Operators can be parallelCode looks sequentialOperators can be parallel

Parallel Search Algorithms• One way to efficiently implement the parallel
operators is to used tiled sets and use a map primitive (as before we used tiled arrays and HTA’s hmap)
• Want to tile for same reasons as before:– Data distribution– Locality– Parallelism
39

Mapping and Tiled Sets• Cannot create a tiled set as easily as a tiled array• Specifying tiling is trivial for Arrays• A Tiled Set requires two parameters:
– The number of tiles– A mapping function that takes a piece of data from the set and
specifies a destination tile number
40
Tile 1
2
3
4Set

Locality vs Load Balance• Choosing a “good” mapping function is important as it
affects:– Load Balance– Locality
• Load imbalance can occur if data is not evenly mapped to tiles
• One possible solution is Overdecomposition– Compromise between extra overhead and better load balance– Specify more tiles than processors and have a “smart” runtime
(i.e. Cilk’s and Intel TBB’s Task Stealing, CHARM++)
41

Tiled Sets and Locality• The mapping function affects locality
• Ideally, all the red nodes would end up in the original tile– Shared Memory – new nodes in cache for the next iteration– Distributed Memory – minimizes communication for mapping
new nodes• However, this is not always the case
42
select
expand
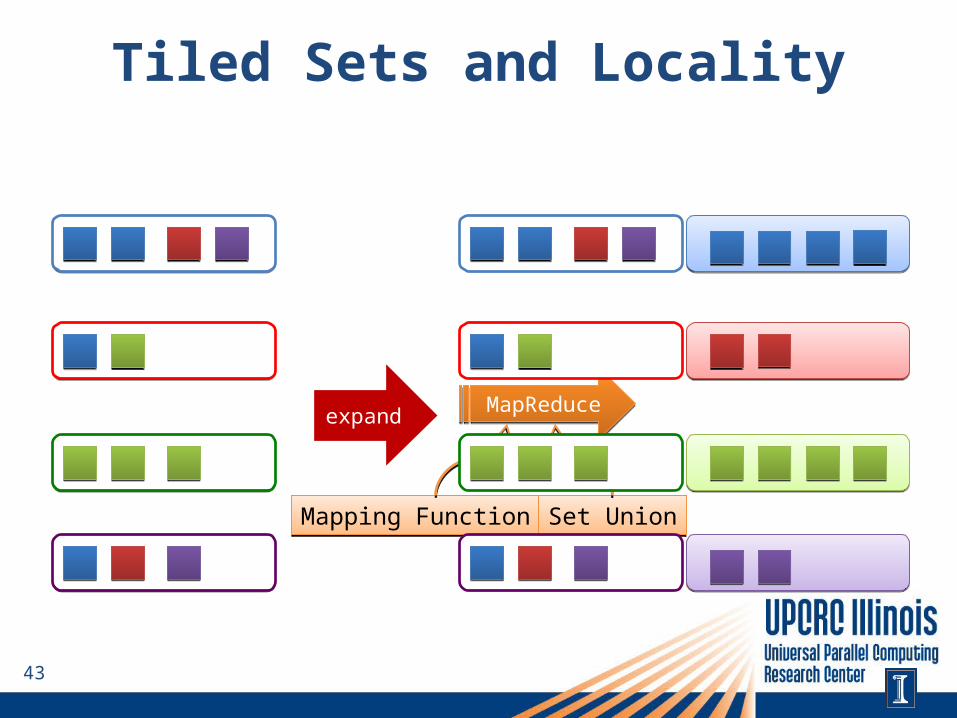
Tiled Sets and Locality
43
expand MapReduceMapReduce
Mapping FunctionMapping Function Set UnionSet Union

15 Puzzle Performance
44

Non Numerical Computations• Many non numerical computations amenable to data
parallelism when it is properly extended– Search, etc
• Tiling can benefit Sets just as it does Arrays when properly extended– Mapping function explicit– “Quality” of mapping important
45

3.2. Non Deterministic Computations
46

Non Deterministic Computations• Many non deterministic problems could be amenable
to data parallelism with the proper extensions
• Need new primitives that can either:– Enforce determinacy– Encapsulate the non determinacy
• Two examples– Vector operations with indirect indices– Delaunay Mesh Refinement
47

Vector Operations with Indirect Indices
• Consider A( X(i) ) += V(i) :– Fully parallel if X does not contain duplicate values– Potential races if duplicates exist
• One possible way to parallelize is to annotate that all updates to A must be atomic
48

Vector Operations with Indirect Indices• A( X(i) ) += V(i) :
– Let A represent the balances of accounts– Let the values of X represent the indices of specific accounts in A– Let V be a series of transactions sorted chronologically
• If the bank imposes penalties for negative balances, the transactions associated with an individual account cannot be reordered
• Can be successfully parallelized if the programmer can specify that updates are not commutative– Allow the parallel update of different accounts,
but serialize updates to the same account– Inspector/Executor
49

Delaunay Mesh Refinement• Given a mesh of triangles, want to refine the mesh such that all
the triangles meet certain properties– The circumcircle of any triangle does not contain points of any other
triangle– The minimum degree of any triangle is at least a certain size
• Can be written as a sequence of data parallel operators– Given a set of triangles, find those that are “bad” – For each bad triangle, calculate the affected neighboring triangles, or
cavity– For each set of triangles, remove the bad triangle and its neighbors and
replace them with new triangles• Might create new bad triangles
– Repeat until the mesh contains no bad triangles
50

Delaunay Mesh Refinement• This problem is non deterministic
– The order in which bad triangles are processed does not matter, as long as a valid refined mesh is produced
– One possibility is to only permit one processor to commit its changes if more than one processor is operating on bad triangles with overlapping cavities, (Lonestar Benchmarks - http://iss.ices.utexas.edu/lonestar/)
– However, could be deterministic by imposing an ordering on the triangles, operating on sets of independent triangles each iteration
51

New Primitives for Non Determinacy• The Indirect Indices and Mesh Refinement examples both
require the same extensions to support data parallelism
• Two new primitives:– atomic_map – a map that can apply some function to all the data
atomically, encapsulating the non determinacy• Pessimistic: Locks• Optimistic: Transactions
– ordered_map – a map that imposes an ordering on the data to enforce determinacy
52

3.3 Traditional task parallel problems
53

Data Parallel Pipeline• Pipelines are traditionally considered a task parallel
problem– Each task performs a stage of the pipeline– Parallelism is limited by the number of stages
• Consider the following example:– A simple 3-stage pipeline that:
• Reads a string from a file• Performs some processing on the strings• Writes the output to a file
54

Data Parallel Pipeline
55
Read File Process Write File
Task Parallel Data Parallel (DoAcross)
P1 P2 P3 P1 P2 P3

Data Parallel Pipeline• The parallelism of a task parallel implementation is limited by
the number of tasks/stages– In this example, one processor per task – reading, processing, writing– Does not benefit from adding processors
• A data parallel implementation requires that the programmer specify an ordering– Encapsulated inside the operator
• In this case, a data parallel implementation could possibly better utilize additional processors
56

Data Parallel Pipeline
57
Read File Process Write File
Task Parallel Data Parallel
P1 P2 P3 P1 P2 P3 P4

4. Conclusions
58

Conclusions• We believe data parallel to be the right paradigm for
parallel programming– Scalable– Portable
• Data parallel has been successful for numerical programs
• Need new abstractions for other types of computations– Non numerical– Non deterministic– Traditionally task parallel
59

Conclusions• Sets are a promising aggregate
– Resulting programs highly readable– Can benefit from tiling when extended appropriately
• How do we help programmers find good mapping functions for irregular data structures?
• Good mappings try to balance locality and load balance
• Non deterministic and task parallel problems need new primitives
• However, we still have many challenges:– Performance– How do we evaluate programmer productivity?
• Lines of Code• Human experiments
– How much compiler support do we need?– More applications
60

Data Parallel Best-First Search with Tiled Sets
TiledSet work_list[ # of Tiles ]TiledSet best_nodes[ # of Tiles ]TiledSet children[ # of Tiles ]TiledSet seen[ # of Tiles ]
BFS( TiledSet work_list, TiledSet children)work_list[0].insert( initial_state )
while ( not done )smap( select_best(), work_list, best_nodes )
if ( GOAL not in best_nodes )smap( mark_seen(), best_nodes, seen )smap( expand(), best_nodes, children )MapReduce( mapping_func(), Union(), children, rearranged_children) smap( update(), rearranged_children, work_list, seen )
62
Tiled SetsPrimitivesOperators

Task Parallel Search
WorkerThread(my_id):
while not done:lock( work_list[ my_id ] )
curr = work_list[ my_id ].front()if (curr)
work_list[ my_id ].pop()else
steal
if (curr != GOAL)lock( seen )seen.insert(curr)
expand(curr)for each child of curr
lock work_list[ my_id ]reader_lock ( seen )
if validadd to WL
63


















