
Naïve Bayes Classifier. Bayes Classifier l A probabilistic framework for classification problems l...
26
Naïve Bayes Classifier
-
Upload
garey-jones -
Category
Documents
-
view
223 -
download
0
Transcript of Naïve Bayes Classifier. Bayes Classifier l A probabilistic framework for classification problems l...

Naïve Bayes Classifier

Bayes Classifier
A probabilistic framework for classification problems Often appropriate because the world is noisy and also
some relationships are probabilistic in nature– Is predicting who will win a baseball game probabilistic
in nature? Before getting the heart of the matter, we will go over some
basic probability.– Stop me if you have questions!!!!

Conditional Probability
The conditional probability of an event C given that event A has occurred is denoted P(C|A)
Here are some practice questions that you should be able to answer (e.g., if you took CISC 1100/1400)
Given a standard six-sided die:
– What is P(roll a 1|roll an odd number)?
– What is P(roll a 1|roll an even number)?
– What is P(roll a number >2)?
– What is P(roll a number >2|roll a number > 1)?Given a standard deck of cards:
– What is P(pick an Ace|pick a red card)?
– What is P(pick a red card|pick an Ace)?
– What is P(pick ace of clubs|pick an Ace)?

Conditional Probability Continued
P(A,C) is the probability that A and C both occur– What is P(pick an Ace, pick a red card) = ???
Note that this is the same a the probability of picking a red ace
Two events are independent if one occurring does not impact the occurrence or non-occurrence of the other one
Please give me some examples of independent events In the example from above, are A and C independent
events? If two events A and B are independent, then:
– P(A, B) = P(A) x P(B)– Note that this helps us answer the P(A,C) above,
although most of you probably solved it directly.

Conditional Probability Continued
C AA C
How does the Venn Diagram show these equations to be true?
The following are true:
P(C|A) = P(A,C)/P(A) and
P(A|C) = P(A,C)/P(C)

An Example
Let’s use the example from before, where:
– A = “pick and Ace” and
– C = “pick a red card” Using the previous equation:
– P(C|A) = P(A,C)/P(A) We now get:
– P(red card|Ace) = P(red ace)/P(Ace)
– P(red card|Ace) = (2/52)/(4/52) = 2/4 = .5 Hopefully this makes sense, just like the Venn
Diagram should

Bayes Theorem
Bayes Theorem states that:
– P(C|A) =[ P(A|C) P(C)] / P(A) Prove this equation using the two equations we informally
showed to be true using the Venn Diagrams: P(C|A) = P(A,C)/P(A) and P(A|C) = P(A,C)/P(C)
Start with P(C|A) = P(A,C)/P(A)
– Then notice that we are part way there and only need to replace P(A,C)
– By rearranging the second equation (after the “and”) to isolate P(A,C), we can substitute in P(A|C)P(C) for P(A,C) and the proof is done!

Some more terminology
The Prior Probability is the probability assuming no specific information.
– Thus we would refer to P(A) as the prior probability of even A occurring
– We would not say that P(A|C) is the prior probability of A occurring
The Posterior probability is the probability given that we know something
– We would say that P(A|C) is the posterior probability of A (given that C occurs)

Example of Bayes Theorem
Given: – A doctor knows that meningitis causes stiff neck 50% of the
time
– Prior probability of any patient having meningitis is 1/50,000
– Prior probability of any patient having stiff neck is 1/20
If a patient has stiff neck, what’s the probability he/she has meningitis?
0002.020/150000/15.0
)()()|(
)|( SP
MPMSPSMP

Bayesian Classifiers
Given a record with attributes (A1, A2,…,An) – The goal is to predict class C– Actually, we want to find the value of C that maximizes
P(C| A1, A2,…,An ) Can we estimate P(C| A1, A2,…,An ) directly (w/o Bayes)?
– Yes, we simply need to count up the number of times we see A1, A2,…,An and then see what fraction belongs to each class
– For example, if n=3 and the feature vector “4,3,2” occurs 10 times and 4 of these belong to C1 and 6 to C2, then:What is P(C1|”4,3,2”)?What is P(C2|”4,3,2”)?
Unfortunately, this is generally not feasible since not every feature vector will be found in the training set.– If it did, we would not need to generalize, only memorize

Bayesian Classifiers
Indirect Approach: Use Bayes Theorem– compute the posterior probability P(C | A1, A2, …, An) for
all values of C using the Bayes theorem
– Choose value of C that maximizes P(C | A1, A2, …, An)
– Equivalent to choosing value of C that maximizes P(A1, A2, …, An|C) P(C)Since the denominator is the same for all values of C
)()()|(
)|(21
21
21
n
n
n AAAPCPCAAAP
AAACP

Naïve Bayes Classifier
How can we estimate P(A1, A2, …, An |C)?
– We can measure it directly, but only if the training set samples every feature vector. Not practical!
So, we must assume independence among attributes Ai when class is given:
– P(A1, A2, …, An |C) = P(A1| Cj) P(A2| Cj)… P(An| Cj)
– Then we can estimate P(Ai| Cj) for all Ai and Cj from training dataThis is reasonable because now we are looking only at one feature at a time. We can expect to see each feature value represented in the training data.
New point is classified to Cj if P(Cj) P(Ai| Cj) is maximal.

How to Estimate Probabilities from Data?
Class: P(C) = Nc/N– e.g., P(No) = 7/10,
P(Yes) = 3/10
For discrete attributes:
P(Ai | Ck) = |Aik|/ Nc
– where |Aik| is number of instances having attribute Ai and belongs to class Ck
– Examples:P(Status=Married|No) = 4/7P(Refund=Yes|Yes)=0

How to Estimate Probabilities from Data?
For continuous attributes: – Discretize the range into bins – Two-way split: (A < v) or (A > v)
choose only one of the two splits as new attributeCreates a binary feature
– Probability density estimation: Assume attribute follows a normal distribution and use the data to fit this distributionOnce probability distribution is known, can use it to estimate the conditional probability P(Ai|c)
We will not deal with continuous values on HW or exam– Just understand the general ideas above– For the example tax cheating example, we will assume that
“Taxable Income” is discreteEach of the 10 values will therefore have a prior probability of 1/10
k

Example of Naïve Bayes
We start with a test example and want to know its class. Does this individual evade their taxes: Yes or No?
– Here is the feature vector:Refund = No, Married, Income = 120K
– Now what do we do? First try writing out the thing we want to measure

Example of Naïve Bayes
We start with a test example and want to know its class. Does this individual evade their taxes: Yes or No?
– Here is the feature vector:Refund = No, Married, Income = 120K
– Now what do we do? First try writing out the thing we want to measureP(Evade|[No, Married, Income=120K])
– Next, what do we need to maximize?

Example of Naïve Bayes
We start with a test example and want to know its class. Does this individual evade their taxes: Yes or No?
– Here is the feature vector:Refund = No, Married, Income = 120K
– Now what do we do? First try writing out the thing we want to measureP(Evade|[No, Married, Income=120K])
– Next, what do we need to maximize?P(Cj) P(Ai| Cj)

Example of Naïve Bayes
Since we want to maximize P(Cj) P(Ai| Cj)
– What quantities do we need to calculate in order to use this equation?
– Recall that we have three attributes:– Refund: Yes, No
– Marital Status: Single, Married, Divorced
– Taxable Income: 10 different “discrete” valuesWhile we could compute every P(Ai| Cj) for all Ai, we only need to do it for the attribute values in the test example
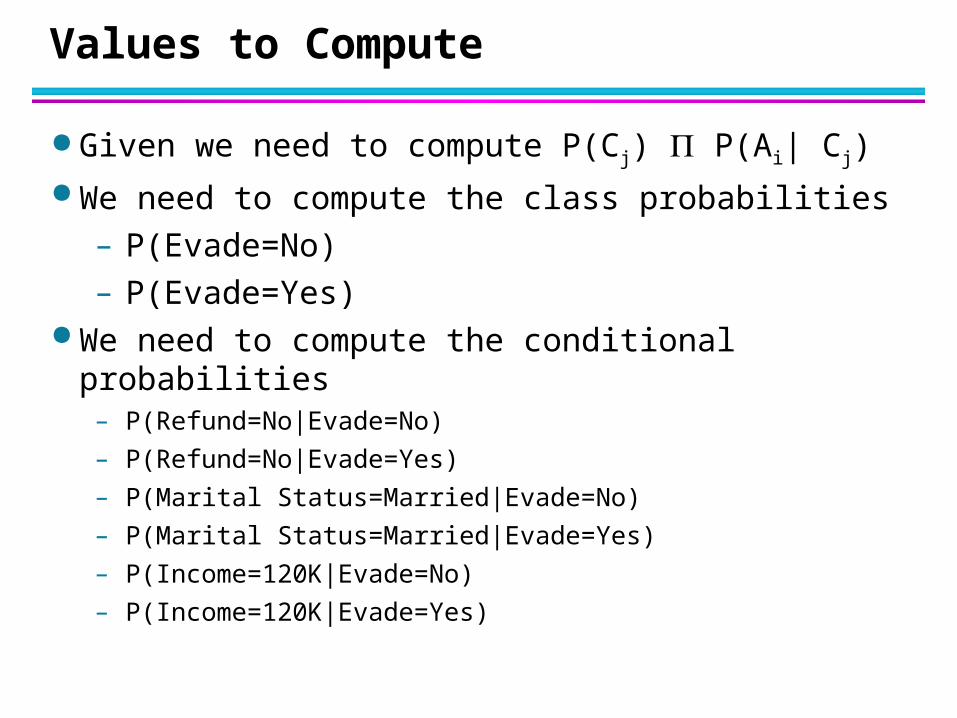
Values to Compute
Given we need to compute P(Cj) P(Ai| Cj)
We need to compute the class probabilities
– P(Evade=No)
– P(Evade=Yes) We need to compute the conditional probabilities
– P(Refund=No|Evade=No)
– P(Refund=No|Evade=Yes)
– P(Marital Status=Married|Evade=No)
– P(Marital Status=Married|Evade=Yes)
– P(Income=120K|Evade=No)
– P(Income=120K|Evade=Yes)

Computed Values
Given we need to compute P(Cj) P(Ai| Cj)
We need to compute the class probabilities
– P(Evade=No) = 7/10 = .7
– P(Evade=Yes) = 3/10 = .3 We need to compute the conditional probabilities
– P(Refund=No|Evade=No) = 4/7
– P(Refund=No|Evade=Yes) 3/3 = 1.0
– P(Marital Status=Married|Evade=No) = 4/7
– P(Marital Status=Married|Evade=Yes) =0/3 = 0
– P(Income=120K|Evade=No) = 1/7
– P(Income=120K|Evade=Yes) = 0/7 = 0

Finding the Class
Now compute P(Cj) P(Ai| Cj) for both classes for the test example [No, Married, Income = 120K]
– For Class Evade=No we get:.7 x 4/7 x 4/7 x 1/7 = 0.032
– For Class Evade=Yes we get:.3 x 1 x 0 x 0 = 0
– Which one is best?Clearly we would select “No” for the class valueNote that these are not the actual probabilities of each class, since we did not divide by P([No, Married, Income = 120K])

Naïve Bayes Classifier
If one of the conditional probability is zero, then the entire expression becomes zero– This is not ideal, especially since probability estimates
may not be very precise for rarely occurring values
– We use the Laplace estimate to improve things. Without a lot of observations, the Laplace estimate moves the probability towards the value assuming all classes equally likely
Examples:1 class A and 5 class BP(A) = 1/6 but with Laplace = 2/7
0 class A and 2 class BP(A) = 0/10 = 0 with Laplace = 1/4

Naïve Bayes (Summary)
Robust to isolated noise points
Robust to irrelevant attributes
Independence assumption may not hold for some attributes
– But works surprisingly well in practice for many problems

Play-tennis example: estimate P(xi|C)
Outlook Temperature Humidity Windy Classsunny hot high false Nsunny hot high true Novercast hot high false Prain mild high false Prain cool normal false Prain cool normal true Novercast cool normal true Psunny mild high false Nsunny cool normal false Prain mild normal false Psunny mild normal true Povercast mild high true Povercast hot normal false Prain mild high true N
outlookP(sunny|p) = 2/9 P(sunny|n) = 3/5
P(overcast|p) = 4/9 P(overcast|n) = 0
P(rain|p) = 3/9 P(rain|n) = 2/5
Temperature
P(hot|p) = 2/9 P(hot|n) = 2/5
P(mild|p) = 4/9 P(mild|n) = 2/5
P(cool|p) = 3/9 P(cool|n) = 1/5
Humidity
P(high|p) = 3/9 P(high|n) = 4/5
P(normal|p) = 6/9 P(normal|n) = 2/5
windy
P(true|p) = 3/9 P(true|n) = 3/5
P(false|p) = 6/9 P(false|n) = 2/5
P(p) = 9/14
P(n) = 5/14

Play-tennis example: classifying X
An unseen sample X = <rain, hot, high, false>
P(X|p)·P(p) = P(rain|p)·P(hot|p)·P(high|p)·P(false|p)·P(p) = 3/9·2/9·3/9·6/9·9/14 = 0.010582
P(X|n)·P(n) = P(rain|n)·P(hot|n)·P(high|n)·P(false|n)·P(n) = 2/5·2/5·4/5·2/5·5/14 = 0.018286
Sample X is classified in class n (don’t play)

Example of Naïve Bayes Classifier
Name Give Birth Can Fly Live in Water Have Legs Class
human yes no no yes mammalspython no no no no non-mammalssalmon no no yes no non-mammalswhale yes no yes no mammalsfrog no no sometimes yes non-mammalskomodo no no no yes non-mammalsbat yes yes no yes mammalspigeon no yes no yes non-mammalscat yes no no yes mammalsleopard shark yes no yes no non-mammalsturtle no no sometimes yes non-mammalspenguin no no sometimes yes non-mammalsporcupine yes no no yes mammalseel no no yes no non-mammalssalamander no no sometimes yes non-mammalsgila monster no no no yes non-mammalsplatypus no no no yes mammalsowl no yes no yes non-mammalsdolphin yes no yes no mammalseagle no yes no yes non-mammals
Give Birth Can Fly Live in Water Have Legs Class
yes no yes no ?
0027.02013
004.0)()|(
021.0207
06.0)()|(
0042.0134
133
1310
131
)|(
06.072
72
76
76
)|(
NPNAP
MPMAP
NAP
MAP
A: attributes
M: mammals
N: non-mammals
P(A|M)P(M) > P(A|N)P(N)
=> Mammals


















