


MyHeritage CEO Gilad Japhet's Talk at TechAviv Founders Club - Feb 2013
Upload
ran-levyCategory
view
522download
0
Agenda
• Introduction to MyHeritage
• R&D structure to support scaling
• R&D methodology to support scaling up
• Scaling up technologies and solutions
– Micro-services architecture
– Relational DB scaling out
– Data storing for low latency
– SOLR scaling up
– Queuing services
– File servers
– Caching services
– Statistics services

Family history for Families
Building next generation tools for family history
enthusiasts and their families
Discover Preserve Share

Challenge: Scale
77 million registered users
1.7 billion tree profiles in 27 million trees
6 billion historical records
200 million photos
42 languages
1 million daily emails

R&D structure to support scaling up –
guilds and band
Band Master
Missions
Skill
Gu
ild
s(E
xpert
ise a
nd Q
ualit
y)
Bands (Delivery)
Guild Manager
Product Owner
…
Guild member

R&D Methodology to support scaling up
• Full continuous deployment
– All developers are working on trunk
– Commit triggers flow that ends in production update

R&D Methodology to support scaling up
• Procedure is backed up with:
– Exposure flag (controlled by external UI)
– Code reviews
– Unit/integration tests (over 80% coverage)
– Sensors for each released features.
– Automatic logs and stats scanning

R&D Methodology to support scaling up

R&D Methodology to support scaling up

R&D Methodology to support scaling up

Agenda
Introduction to MyHeritage
R&D structure to support scaling
R&D methodology to support scaling up
• Scaling up technologies and solutions
– Micro-services architecture
– Relational DB scaling out
– Data storing for low latency
– SOLR scaling up
– Queuing services
– File servers
– Caching services
– Statistics services

Micro-services architecture
• Monolithic code can’t scale for long
– Localization of changes
– Concurrency of development
– Limits variety of coding languages
– Scaling up specific services

Micro-services architecture
• Solution:
– Micro-services architecture
• Migration from monolithic code is gradual
– Starting with isolated service
– Gradual replacement of core services

Relational DB scaling out techniques
• Data sharding
• Master – slaves
• Using MySQL 5.5 Percona

Relational DB scaling out techniques –
approaches for data sharding
• Consistent hashing based on key
• Used for MyHeritage Historical Records (6B records)
Func(ABCD)Read(ABCD)

Relational DB scaling out techniques –
approaches for data sharding
• Consistent hashing pros & cons
– Pros:
• Supports high performance lookup
• “Infinite scale”
– Cons:
• Re-sharding is not trivial and requires code change.
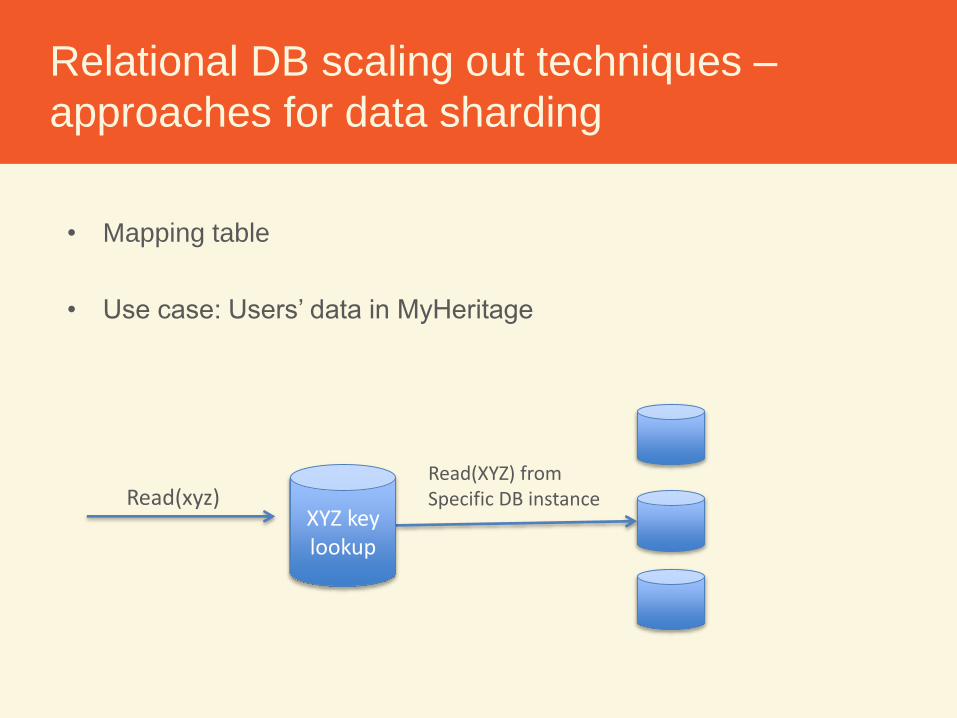
Relational DB scaling out techniques –
approaches for data sharding
• Mapping table
• Use case: Users’ data in MyHeritage
Read(xyz)Read(XYZ) fromSpecific DB instance
XYZ key lookup

Relational DB scaling out techniques –
approaches for data sharding
• Mapping table pros & cons
– Pros:
• Easy re-sharding and scaling up.
– Cons:
• Requires DB lookup prior to data access.
• Limited scalability.

Relational DB scaling out techniques –
Master Slave
Active standby
R/W flow
R/O flow
Master

Data Storing for low latency
• (Berkley DB, MapDB)
• Cassandra
– Account Store
– People Store
– (Counters system, A/B testing data)

Data Storing for low latency – Account Store
• Motivations
– Access account data in sub 1 msec
– High scale (~400M rows)
– Online schema changes
– Reduce OPEX
– Linear Scaling out architecture

Data Storing for low latency – Account Store
• Solution:
– Cassandra
– Apache Cassandra is an open source, distributed, decentralized,
elastically scalable, highly available, fault-tolerant, tuneableconsistent, column-oriented database.

Data Storing for low latency – Account Store
• Cluster main characteristics:
– 5 nodes, 500GB SSD, Replication Factor - 3
– Community Edition 2.0.13 • Very low maintenance (no repair –pr )
• Using counters
• Using secondary indexes
• Using VNodes for easier maintenance
• Using SizeTieredCompactionStrategy compactions (writes optimized)
• Achieved performance
– Avg. local read latency: 0.108 ms
– Avg. local write latency: 0.022 ms

Data Storing for low latency – People Store
(in progress)
• Main Motivations
– Access data rapidly
• Avoiding the need to access multiple partitions
– High scale (scaling to 2B rows)

Search technologies
• Motivations
– Search billion of records in sub 200 msec.
– Cope with differences: languages, spellings, inaccuracies, missing data.
– Ranking of results.

Search technologies
• Solution:
– SOLR
– Solr is highly reliable, scalable and fault tolerant, providing
distributed indexing, replication and load-balanced querying,
automated failover and recovery, centralized configuration and
more.

Search technologies - SOLR
• Solr distributed search allows sharding a big index into smaller chunks
running on multiple hosts. We do not utilize Solr 4’s SolrCloud feature.
• Indexing: Client app is responsible to index each document on a specific shard (using some hashing of document ID)
• Search: Client app sends request to aggregator Solr instance, which in turn queries all shards, and merges the results into one response (sort, paging)
Index Shards:
Application: Indexing
Solr Solr Solr
Indexing
Search
. . .
Search
AggregatorSolr

Search technologies - SOLR
• Indexing hits performance of searching
• Split indexing to separate machines
• Single points of failure: aggregator
Load Balancer(HA Proxy)
Solr SolrSolr Solr. . .
SolrSolr
Indexer Solr Indexer Solr . . .
Searcher Solr Searcher Solr
Rep
licat
ion
Rep
licat
ion
Indexing
Indexer Solr
Searcher SolrR
eplic
atio
n
Search
SolrSolrAggregator Solr
Load Balancer(HA Proxy)
NULLSolrNULLSolrNULL
SolrStaticResp.
Cluster 1 Cluster 2

Queuing services
• (In-house queue implementation)
• (Beanstalkd)
• Kafka
– Kafka is a distributed, partitioned, replicated commit log service.

Queuing System – Kafka High Level
Overview
Broker 1
Family Tree changes Topic
part 1
part 2
part 32
Indexing
Consumers
RecordMatching
Logstash reader
Web
Producers
Daemons
Face recog.
Activity Topic
part 1
part 2
part 32
DRBD replica
Of Broker
2
Broker 2
Family Tree changes Topic
part 1
part 2
part 32 DRBD replica
Of Broker
1
… …
…
…
Notifications sys.Notifications
Topic
Activity Topic
part 1
part 2
part 32
…
Notifications Topic

Kafka @Myheritage – Consumers (Indexing)
EventProcessor
1 Per consumer type, reader per
partition
Broker 2
Broker 1
EventProcessor
EventProcessor
IndexingQueue
IndexingWorkersIndexingWorkers
IndexingWorkers
Fetch work
SOLRUpdate item
KafkaWatermark
Get/update watermark
Add event to queue

File servers
• Traditional – File Servers
– ~30 file servers
– Total storage: 80 TB
– HTTP(s) accessible with REST APIs

File servers
• CEPH
– Use cases:• SEO serving
• OpenStack
– Version in production: FireFly
– Using 40TB
– Lessons learnt:
• Do not use large buckets without index sharding (support from Hammer)
• If you can’t use Hammer shard your buckets (or bad things WILL happen)
• Don’t use the high density nodes

Caching services
• Memcached
• In research: Memcached proxy
• (CDN)

Statistics Services
• In-house MySQL
• Graphite usage for Infrastructure
• In research for app metrics:
– Graphite over InfluxDB
– Cyanite (Graphite over Cassandra)
• Automated Anomaly Detection for infrastructure (Anodot)

Logging Services
• Central logging (including app logging + infrastructure):
in-house in MySQL + ELK stack


















