
Mutable Data in Hive's Immutable World
41
Page 1 Mutable Data in Hive’s Immutable World Lester Martin – Hortonworks 2015 Hadoop Summit
-
Upload
lester-martin -
Category
Technology
-
view
358 -
download
2
Transcript of Mutable Data in Hive's Immutable World

Page 1
Mutable Data in Hive’s Immutable WorldLester Martin – Hortonworks
2015 Hadoop Summit

Page 2
Connection before Content
Lester Martin – Hortonworks Professional Services
[email protected] || [email protected]
http://lester.website (links to blog, twitter,
github, LI, FB, etc)

Page 3
“Traditional” Hadoop Data
Time-Series Immutable (TSI) Data – Hive’s sweet spot
Going beyond web logs to more exotic data such as:
Vehicle sensors (ground, air, above/below water – space!)
Patient data (to include the atmosphere around them)
Smart phone/watch (TONS of info)
Clickstream Web & Social
Geolocation Sensor & Machine
Server Logs
Unstructured
SO
UR
CE
S

Page 4
Good TSI Solutions Exist
Hive partitions• Store as much as you want
• Only read the files you need
Hive Streaming Data Ingest from Flume or Storm
Sqoop’s –-incremental mode of append• Use appropriate –-check-column
• “Saved Job” remembering –last-value

Page 5
Use Case for an Active Archive
Evolving Domain Data – Hive likes immutable data
Need exact copy of mutating tables refreshed periodically• Structural replica of multiple RDBMS tables
• The data in these tables are being updated
• Don’t need every change; just “as of” content
Existing Systems
ERP CRM SCM
SO
UR
CE
S
eComm

Page 6
Start With a Full Refresh Strategy
The epitome of the KISS principle• Ingest & load new data
• Drop the existing table
• Rename the newly created table
Surely not elegant, but solves the problem until the reload takes longer than the refresh period

Page 7
Then Evolve to a Merge & Replace Strategy
Typically, deltas are…• Small % of existing data
• Plus, some totally new records
In practice, differences in sizes of circles is often much more pronounced

Page 8
Requirements for Merge & Replace
An immutable unique key• To determine if an addition or a change
• The source table’s (natural or surrogate) PK is perfect
A last-updated timestamp to find the deltas
Leverage Sqoop’s –-incremental mode of lastmodified to identify the deltas• Use appropriate –-check-column
• “Saved Job” remembering –last-value

Page 9
Processing Steps for Merge & Replace
See blog at http://hortonworks.com/blog/four-step-strategy-incremental-updates-hive/, but note that merge can be done in multiple technologies, not just Hive
Ingest – bring over the incremental data
Reconcile – perform the merge
Compact – replace the existing data with the newly merged content
Purge – cleanup & prepare to repeat

Page 10
Full Merge & Replace Will NOT Scale
The “elephant” eventually gets too big and merging it with the “mouse” takes too long!
Example: A Hive structure with 100 billion rows, but only 100,000 delta records

Page 11
What Will? The Classic Hadoop Strategy!

Page 12
But… One Size Does NOT Fit All…
Not everything is “big” – in fact, most operational apps’ tables are NOT too big for a simple Full Refresh
Divide & Conquer requires additional per-table research to ensure the best partitioning strategy is decided upon

Page 13
Criteria for Active Archive Partition Values
Non-nullable & immutable
Ensures sliding scale growth with new records generally creating new partitions
Supports delta records being skewed such that the percentage of partitions needing merge & replace operations is relatively small
Classic value is (still) “Date Created”

Page 14
Work on (FEW!) Partitions in Parallel

Page 15
Partition-Level Merge & Replace Steps
Generate the delta file
Create list of affected partitions
Perform merge & replace operations for affected partitions1. Filter the delta file for the current partition
2. Load the Hive table’s current partition
3. Merge the two datasets
4. Delete the existing partition
5. Recreate the partition with the merged content

Page 16
What Does This Approach Look Like?A Lightning-Fast Review of an Indicative Hybrid Pig-Hive Example

Page 17
One-Time: Create the Table
CREATE TABLE bogus_info(
bogus_id int,
field_one string,
field_two string,
field_three string)
PARTITIONED BY (date_created STRING)
STORED AS ORC
TBLPROPERTIES ("orc.compress"="ZLIB");

Page 18
One-Time: Get Content from the Source
11,2014-09-17,base,base,base
12,2014-09-17,base,base,base
13,2014-09-17,base,base,base
14,2014-09-18,base,base,base
15,2014-09-18,base,base,base
16,2014-09-18,base,base,base
17,2014-09-19,base,base,base
18,2014-09-19,base,base,base
19,2014-09-19,base,base,base

Page 19
One-Time: Read Content from HDFS
as_recd = LOAD '/user/fred/original.txt'
USING PigStorage(',') AS
(
bogus_id:int,
date_created:chararray,
field_one:chararray,
field_two:chararray,
field_three:chararray
);

Page 20
One-Time: Sort and Insert into Hive Table
sorted_as_recd = ORDER as_recd BY
date_created, bogus_id;
STORE sorted_as_recd INTO 'bogus_info'
USING
org.apache.hcatalog.pig.HCatStorer();

Page 21
One-Time: Verify Data are Present
hive> select * from bogus_info;
11 base base base 2014-09-17
12 base base base 2014-09-17
13 base base base 2014-09-17
14 base base base 2014-09-18
15 base base base 2014-09-18
16 base base base 2014-09-18
17 base base base 2014-09-19
18 base base base 2014-09-19
19 base base base 2014-09-19

Page 22
One-Time: Verify Partitions are Present
hdfs dfs -ls /apps/hive/warehouse/bogus_info
Found 3 items
… /apps/hive/warehouse/bogus_info/date_created=2014-09-17
… /apps/hive/warehouse/bogus_info/date_created=2014-09-18
… /apps/hive/warehouse/bogus_info/date_created=2014-09-19

Page 23
Generate the Delta File
20,2014-09-20,base,base,base
21,2014-09-20,base,base,base
22,2014-09-20,base,base,base
12,2014-09-17,base,CHANGED,base
14,2014-09-18,base,CHANGED,base
16,2014-09-18,base,CHANGED,base

Page 24
Read Delta File from HDFS
delta_recd = LOAD '/user/fred/delta1.txt'
USING PigStorage(',') AS
(
bogus_id:int,
date_created:chararray,
field_one:chararray,
field_two:chararray,
field_three:chararray
);

Page 25
Create List of Affected Partitions
by_grp = GROUP delta_recd BY date_created;
part_names = FOREACH by_grp GENERATE group;
srtd_part_names = ORDER part_names BY group;
STORE srtd_part_names INTO '/user/fred/affected_partitions’;

Page 26
Loop/Multithread Through Affected Partitions
Pig doesn’t really help you with this problem
This indicative example could be implemented as:• A simple script that loops through the partitions
• A Java program that multi-threads the partition-aligned processing
Multiple “Control Structures” options exist as described at http://pig.apache.org/docs/r0.14.0/cont.html

Page 27
Loop Step: Filter on the Current Partition
delta_recd = LOAD '/user/fred/delta1.txt'
USING PigStorage(',') AS
( bogus_id:int, date_created:chararray,
field_one:chararray,
field_two:chararray,
field_three:chararray );
deltaP = FILTER delta_recd BY date_created == '$partition_key’;
Page 28
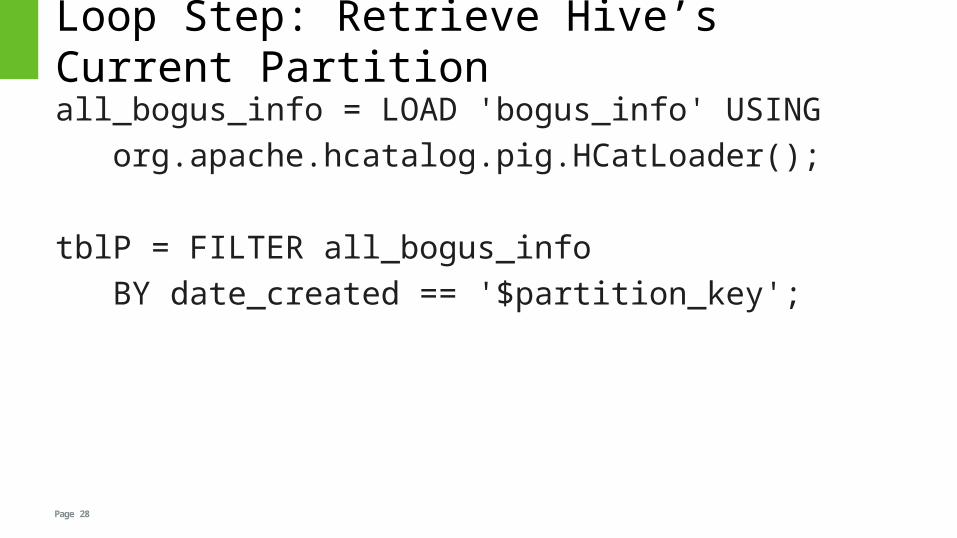
Loop Step: Retrieve Hive’s Current Partition
all_bogus_info = LOAD 'bogus_info' USING
org.apache.hcatalog.pig.HCatLoader();
tblP = FILTER all_bogus_info
BY date_created == '$partition_key';

Page 29
Loop Step: Merge the Datasets
partJ = JOIN tblP BY bogus_id FULL OUTER,
deltaP BY bogus_id;
combined_part = FOREACH partJ GENERATE
((deltaP::bogus_id is not null) ? deltaP::bogus_id: tblP::bogus_id) as bogus_id, /* do for all fields
and end with “;” */
Page 30
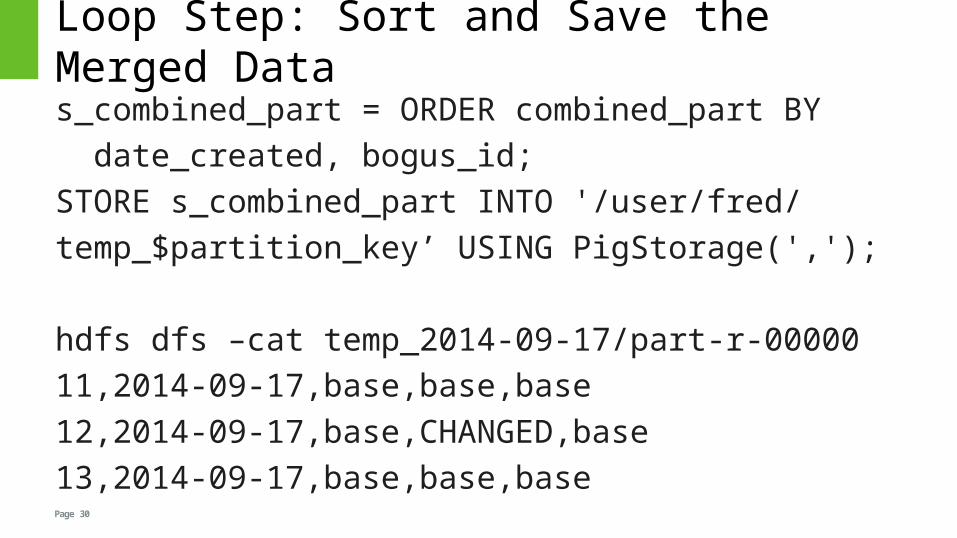
Loop Step: Sort and Save the Merged Data
s_combined_part = ORDER combined_part BY
date_created, bogus_id;
STORE s_combined_part INTO '/user/fred/
temp_$partition_key’ USING PigStorage(',');
hdfs dfs –cat temp_2014-09-17/part-r-00000
11,2014-09-17,base,base,base
12,2014-09-17,base,CHANGED,base
13,2014-09-17,base,base,base

Page 31
Loop Step: Delete the Partition
ALTER TABLE bogus_info DROP IF EXISTS PARTITION (date_created='2014-09-17’);

Page 32
Loop Step: Recreate the Partition
2load = LOAD '/user/fred/
temp_$partition_key'
USING PigStorage(',') AS
( bogus_id:int, date_created:chararray,
field_one:chararray,
field_two:chararray,
field_three:chararray );
STORE 2load INTO 'bogus_info' using
org.apache.hcatalog.pig.HCatStorer();

Page 33
Verify the Loop Step Updates
select * from bogus_info
where date_created = '2014-09-17’;
11 base base base 2014-09-17
12 base CHANGED base 2014-09-17
13 base base base 2014-09-17

Page 34
My Head Hurts, Too!As Promised, We Flew Through That – Take Another Look Later

Page 35
What Does Merge & Replace Miss?
If critical, you have options• Create a delete table sourced by a trigger
• At some wide frequency, start all over with a Full Refresh
Fortunately, ~most~ enterprises don’t delete anything
Marking items “inactive” is popular

Page 36
Hybrid: Partition-Level Refresh
If most of the partition is modified, just replace it entirely
Especially if the changes are only recent (or highly skewed)
Use a configured number of partitions to refresh and assume the rest of the data is static

Page 37
Active Archive Strategy Review
strategy # of rows % of chg
chg skew
handles deletes
complexity
Full Refresh <= millions any any yes simple
Full Merge & Replace
<= millions any any no moderate
Partition-Level Merge & Replace
billions + < 5% < 5% no complex
Partition-Level Refresh
billions + < 5% < 5% yes complex

Page 38
Isn’t There Anything Easier?
HIVE-5317 brought us Insert, Update & Delete• Alan Gates presented Monday
• More tightly-coupled w/o the same “hazard windows”
• “Driver” logic shifts to be delta-only & row-focused
Thoughts & attempts at true DB replication• Some COTS solutions have been tried
• Ideally, an open-source alternative is best such as enhancing the Streaming Data Ingest framework

Page 39
Considerations for HIVE-5317
On performance & scalability; your mileage may vary
Does NOT make Hive a RDBMS
Available in Hive .14 onwards
DDL requirements• Must utilize partitioning & bucketing
• Initially, only supports ORC

Page 40
Recommendations
Take another look at this topic once back at “your desk”
As with all things Hadoop…• Know your data & workloads
• Try several approaches & evaluate results in earnest
• Stick with the KISS principle whenever possible
Share your findings via blogs and local user groups
Expect (even more!) great things from Hive

Page 41
Questions?
Lester Martin – Hortonworks Professional Services
[email protected] || [email protected]
http://lester.website (links to blog, twitter, github, LI, FB, etc)
THANKS FOR YOUR TIME!!

![Riezler - Man; Mutable & Immutable [Excerpts]](https://static.fdocuments.us/doc/165x107/577cc3de1a28aba711976630/riezler-man-mutable-immutable-excerpts.jpg)
















