
Patch-Based Background Initialization in Heavily Cluttered Video
date post
19-Dec-2015Category
view
224download
2
Multimodal Templates for Real-Time Detection of Texture-less Objects in Heavily Cluttered Scenes
Stefan Hinterstoisser, Stefan Holzer, Cedric Cagniart, Slobodan Ilic,Kurt Konolige, Nassir Navab, Vincent Lepetit
Department of Computer Science, CAMP, Technische Universit¨at M¨unchen (TUM), Germany WillowGarage, Menlo Park, CA, USA
IEEE International Conference on Computer Vision (ICCV) 2011

Outline
• Goal & Challenges• Related Work• Modality Extraction– Image Cue– Depth Cue
• Similarity Measure• Efficient Computation• Experiments

Goal

Challenges
• Objects under different poses over heavily cluttered background
• Online learning• Real-time object learning and detection

Related Work
• Solving the problem of multi-view 3D object detection has two main categories:– Learning Based Methods– Template Matching
• Learning Based Methods:– Require a large amount of training data– Require long offline training phase– Expensive learning for new object

Related Work
• Template Matching:– Better adapted to low textured objects than
feature point approaches– Easily update template for new object– Direct matching is inappropriate for real-time.
• Others:– Matching in Range Data : • Construct full 3D CAD model of the object

Outline
• Goal & Challenges• Related Work• Modality Extraction– Image Cue– Depth Cue
• Similarity Measure• Efficient Computation• Experiments

Modality Extraction-Image Cue
• Image Cue:– Image gradients are proved to be discriminant and
robust to illumination change and noise.– Normalized gradients and not their magnitudes
makes the measure robust to contrast changes.– We compute the normalized gradients on each
color channel for input RGB color image.– Input image , gradient map at location x:

– Keep only the gradients whose norms are larger than a threshold.
– Assign to the gradient whose quantized orientation occurs most in a 3 × 3 neighborhood.
• The similarity measurement function fg:
Og(r): the normalized gradient map of thereference image at location r
Ig(t): the normalized gradient map of the input image at location t
Modality Extraction-Image Cue

Modality Extraction-Image Cue
Quantizing the gradient orientations
Gradient image computed on gray image
Gradient image computed with our approach
Input color image

Modality Extraction-Depth Cue
• Depth Cue– We use a standard camera and a aligned depth
sensor to obtain depth map.– Use quantized surface normal computed on a
dense depth field for our template representation.– Consider the first order Taylor expansion of the
depth function D(x):
– Within a patch defined around x, each pixel offset dx yields an equation.

Modality Extraction-Depth Cue
– Estimate an optimal gradient in least-square.– Depth gradient corresponds to a tangent plane
going through three points X, X1 and X2:
vector along the line of sight that goes through pixel x (obtain from parameters of depth sensor)

Modality Extraction-Depth Cue
– The normal to the surface can be estimated as the normalized cross-product of X1 − X and X2 − X.
– Within a patch defined around x, this would not be robust around occluding contours.
– Inspired by bilateral filtering, we ignore the pixels whose depth difference with the central pixel (X) is above a threshold.
D(x) Tangent plane
�⃑��⃑�𝟏�⃑�𝟐
X
Depth sensor Normal of X
+Z

Modality Extraction-Depth Cue
– Quantize the normal directions into n0 bins.– Assign to each location the quantized value that
occurs most often in a 5 × 5 neighborhood.
• The similarity measurement function fD:
OD(r): the normalized surface normal of thereference image at location r
ID(t): the normalized surface normal of the input image at location t

Modality Extraction-Depth CueQuantizing the surface normals
Input image
The correspondingdepth image
Surface normals computed with our approach.
Details are clearly visible and depth discontinuities are well handled.

Outline
• Goal & Challenges• Related Work• Modality Extraction– Image Cue– Depth Cue
• Similarity Measure• Efficient Computation• Experiments

Similarity Measure
• We define a template as T = ({Om} m M∈ , P ).P: a list of pairs (r,m) made of the locations r of a
discriminant feature in modality m. • Each template is created by extracting for each
“m” a set of its most discriminant features (P).
P:(ri, gradients)
P:(rk, surface normals)
r : record the feature location with respect to object center (C).
C

Similarity Measure
• The object measurement energy function :
T: ({Om} m M∈ , P )
c: the detected location (could be object center)R(c+r): [ c+r- , c+r+ ][ c+r- , c+r+ ] , N const.∈
(neighborhood of size N centered on (c+r) in Im)
fm (Om (r), Im (t)) : computes the similarity score for modality m

Efficient Computation
• We first quantize the input data for each modality into a small number of n0.
• Use a lookup table тi,m for energy response:
i: the index of the quantized value of modality m. (also use i to represent the corresponding value)
Lm: list of values of a special modality m appearing in a local neighborhood of a value i from input I.
Lm Lm’
C C’

Efficient Computation
• “Spread” [11] the data around neighborhood to obtain a robust representation Jm instead of Lm.
• For each quantized value of one modality m with index i we can now compute the response at each location c:
тi,m : the precomputed lookup table, Jm as the index
[11] S. Hinterstoisser, C. Cagniart, S. Ilic, P. Sturm, P. Fua, N. Navab, and V. Lepetit. Gradient response maps for realtime detection of texture-less objects. under revision PAMI.

Efficient Computation
• Finally, the similarity measure can be:
• Since the maps Si,m are shared between the templates, matching several templates against the input image can be done very fast once they are computed.

Experiments• LINE-MOD: our approach (intensity & depth)• LINE-2D: introduced in [11] (use only intensity)• LINE-3D: use only the depth map• Hardware:– Performed on one processor of a standard notebook
with an Intel Centrino Processor Core2Duo with 2.4 GHz and 3 GB of RAM.
• Test data:– Six object sequences made of 2000 real images each.– Each sequence presents illumination and large
viewpoint changes over heavy cluttered background.

Experiments• Robustness:
– A threshold (about 80) separates almost all true positives for LINE-MOD.

Experiments• Speed:– Learning new templates only requires extracting and
storing features, which is almost instantaneous.– Templates include: 360 degree tilt rotation, 90
degree inclination rotation and in-plane rotations of ± 80 degrees, scale changes from 1.0 to 2.0.
– Parse a 640×480 image with over 3000 templateswith 126 features at about 10 fps(real-time).
– The runtime of LINE-MOD is only dependent on the number of features and independent of the object/template size.

Experiments• Speed:
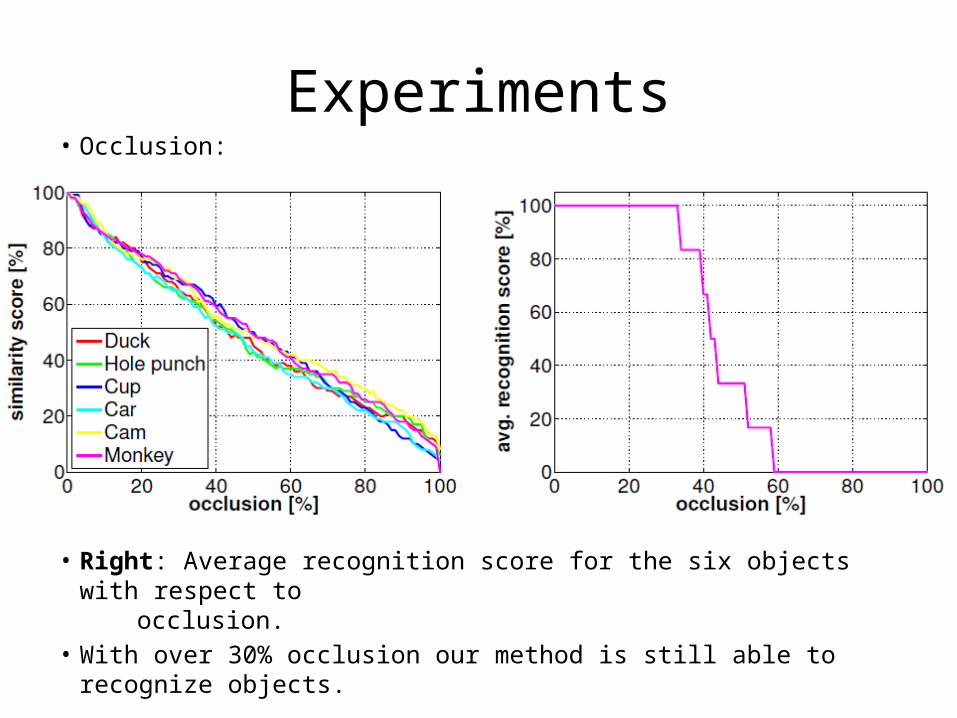
Experiments• Occlusion:
• Right: Average recognition score for the six objects with respect to occlusion.
• With over 30% occlusion our method is still able to recognize objects.
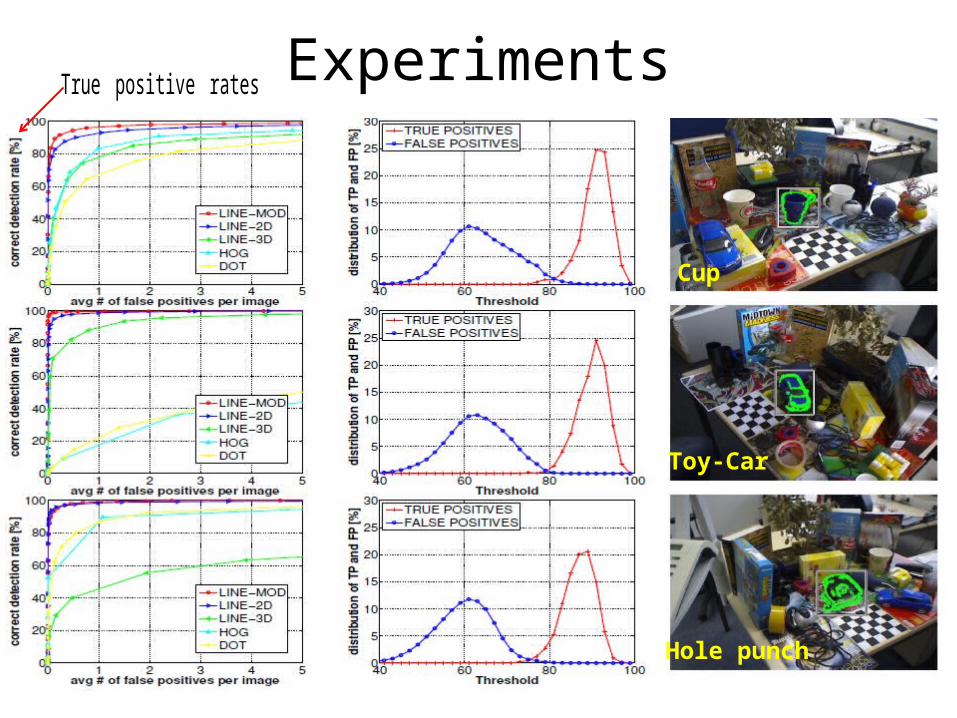
ExperimentsTrue positive rates
Cup
Hole punch
Toy-Car

Experiments
Toy-Monkey
Camera
Toy-Duck

Experiments
True positive rates =
False positive rates =

Experiments


















