
Multimedia Systems: Speech/Audio Part 1 -...
102
Origin of human speech Origin of human speech – – Remains as one of the biggest mysteries Remains as one of the biggest mysteries Speech technology development in the past Speech technology development in the past century century – – Telephone, cell phone, speech synthesis, speech Telephone, cell phone, speech synthesis, speech recognition etc. recognition etc. New trend and emerging technologies New trend and emerging technologies – – VoIP VoIP , HCI, Universal Translator etc. , HCI, Universal Translator etc. Unfulfilled dreams ahead Unfulfilled dreams ahead Multimedia Systems: Speech/Audio Part 1
Transcript of Multimedia Systems: Speech/Audio Part 1 -...

Origin of human speechOrigin of human speech–– Remains as one of the biggest mysteriesRemains as one of the biggest mysteries
Speech technology development in the pastSpeech technology development in the pastcenturycentury–– Telephone, cell phone, speech synthesis, speechTelephone, cell phone, speech synthesis, speech
recognition etc.recognition etc.New trend and emerging technologiesNew trend and emerging technologies–– VoIPVoIP, HCI, Universal Translator etc., HCI, Universal Translator etc.
Unfulfilled dreams aheadUnfulfilled dreams ahead
Multimedia Systems: Speech/AudioPart 1

Origin of SpeechOrigin of Speech
““All attempts to shed light on the evolution ofAll attempts to shed light on the evolution ofhuman language havehuman language have failedfailed due to the lack ofdue to the lack ofknowledge regarding the origin ofknowledge regarding the origin of anyanylanguage, and due to the lack of an animal thatlanguage, and due to the lack of an animal thatpossesses anypossesses any ‘‘transitionaltransitional’’ form ofform ofcommunicationcommunication””
http://www.apologeticspress.org/articles/2054
Reference: “Evolution and the Development of Human Speech”by Brad Harrub, Ph.D.

Complexity of Human SpeechComplexity of Human Speech
There are more thanThere are more than 5,000 language5,000 languagess used inused inthe world todaythe world today
““From the beginning, human communication wasFrom the beginning, human communication wasdesigned with a great amount ofdesigned with a great amount of complexity andcomplexity andforethoughtforethought, and has allowed us not only to, and has allowed us not only tocommunicate with one another, but also with our creatorcommunicate with one another, but also with our creator””
In “What is Linguistics?”, by Dr. Suzette Elgin

Development of Human SpeechDevelopment of Human SpeechAt 7 days of age, an infant can distinguish her motherAt 7 days of age, an infant can distinguish her mother’’s voice from another womans voice from another woman’’s voice.s voice.At 2 weeks of age, an infant can distinguish her fatherAt 2 weeks of age, an infant can distinguish her father’’s voice from another mans voice from another man’’s voice.s voice.At 3 months, an infant can make vowel sounds.At 3 months, an infant can make vowel sounds.At 6 to 8 months, the infant has added a few consonant sounds toAt 6 to 8 months, the infant has added a few consonant sounds to the vowel sounds, and maythe vowel sounds, and maysay "dada" or "mama," but does not yet attach them to individualsay "dada" or "mama," but does not yet attach them to individuals.s.At a year, the infant will attach "mama" or "dada" to the rightAt a year, the infant will attach "mama" or "dada" to the right person. The infant can respondperson. The infant can respondto oneto one--step commands ("Give it to me.")step commands ("Give it to me.")At 15 months, the infant continues to string vowel and consonantAt 15 months, the infant continues to string vowel and consonant sounds together (gibberish)sounds together (gibberish)but may imbed real words within the gibberish. The infant may bebut may imbed real words within the gibberish. The infant may be able to say as many as tenable to say as many as tendifferent words.different words.At 18 months, a toddler can say nouns (ball, cup), names of specAt 18 months, a toddler can say nouns (ball, cup), names of special people, and a few actionial people, and a few actionwords/phrases. The infant adds gestures to her speech, and may bwords/phrases. The infant adds gestures to her speech, and may be able to follow a twoe able to follow a two--stepstepcommand ("Go to the bedroom and get the toy.")command ("Go to the bedroom and get the toy.")At 2 years of age, the child can combine words, forming simple sAt 2 years of age, the child can combine words, forming simple sentences like "Daddy go."entences like "Daddy go."At 3 years of age, the child can use sentences twoAt 3 years of age, the child can use sentences two-- to fourto four--words long, follow simplewords long, follow simpleinstructions, and often repeat words he/she overhears in conversinstructions, and often repeat words he/she overhears in conversations.ations.At 4 years of age, the child can understand most sentences, undeAt 4 years of age, the child can understand most sentences, understands physical relationshipsrstands physical relationships(on, in, under), uses sentences that are four(on, in, under), uses sentences that are four-- or fiveor five--words long, can say his/her name, age,words long, can say his/her name, age,and sex, and uses pronouns. Strangers can understand the childand sex, and uses pronouns. Strangers can understand the child’’s spoken language.s spoken language.
Milestones in Speech Development

About Speech LearningAbout Speech Learning
To account for how individualsTo account for how individuals learnlearn oror fail tofail tolearnlearnTo produce and perceive phonetic segmentsTo produce and perceive phonetic segments(vowels, consonants) in a(vowels, consonants) in a second languagesecond language (L2)(L2)Are certain L2 speech soundsAre certain L2 speech sounds not learnablenot learnable??Just learnable byJust learnable by childrenchildren??What causes theWhat causes the different speech learningdifferent speech learningcapabilitiescapabilities among individuals?among individuals?

Relationship to LinguisticsRelationship to Linguistics
What is linguistics?What is linguistics?–– One definition found using Google:One definition found using Google: ““The scientificThe scientific
study of language, which may be undertaken fromstudy of language, which may be undertaken frommany different aspects, for example, soundsmany different aspects, for example, sounds(phonetics) or structures of words (morphology) or(phonetics) or structures of words (morphology) ormeanings (semantics)meanings (semantics)””..

Speech CommunicationSpeech Communication
It was a dream for people to talk to othersIt was a dream for people to talk to othersanywhereanywhere andand anytimeanytimeTwo inventions made the dream come trueTwo inventions made the dream come true–– TeleTelephonephone byby Alexander Graham Bell– Cell phone by Richard H. Frenkiel and Joel S.
Engel

Born of TelephoneBorn of Telephone
Alexander Graham Bell1847 -1922
Bell's first telephone patent was granted on March 7, 1876.Three days later he and Watson, located in different rooms,were about to test the new type of transmitter described inhis patent. Watson heard Bell's voice saying, "Mr. Watson,come here. I want you."
First telephone in the world
http://www.att.com/history/inventing.html

The Born of Cell PhoneThe Born of Cell Phone
Richard H. Frenkiel and Joel S. Engel
They proposed to divide wireless communicationsinto a series of cells, then automatically switchedcallers as they moved so that each cell could bereused
National Medal of Technology’1994

Speech Communication TechnologiesSpeech Communication Technologies
Microphone/speaker (I/O device)Microphone/speaker (I/O device)Digital communicationDigital communication–– A/D conversionA/D conversion–– Coding and decoding of speech signalsCoding and decoding of speech signals–– Error correction coding to fight against channel impairmentError correction coding to fight against channel impairment
Communication networksCommunication networks–– Public Telephone networkPublic Telephone network–– Computer network (Internet)Computer network (Internet)–– Wireless networkingWireless networking

History of Speech SynthesisHistory of Speech Synthesis
Wolfgang vonWolfgang von Kempelen'sKempelen's speaking machinespeaking machine(1791)(1791)

Speaking Machine in the 19Speaking Machine in the 19thth CenturyCentury
Joseph Faber's "Euphonia", as shown in London in 1846.The machine produced not only ordinary and whisperedspeech, but it also sang the anthem "God Save the Queen".

Homer Dudley's VODERHomer Dudley's VODER
A block diagram of VODER and a picture of its demonstration at the World Fair in 1939

Frank Cooper's Pattern PlaybackFrank Cooper's Pattern Playback
“These days ... It's easy to tell ... Four hours ...”
It worked like an inverse of a sound spectrograph

Electrical Models of Speech ProductionElectrical Models of Speech Production
Gunnar Fant, of the Royal Institute of Technology in Stockholm,with his OVE, a formant synthesizer for vowels
Samples: How are you? I love you!
What did you say before that? ...

Speech Synthesis by ComputerSpeech Synthesis by Computer
Closely related to speech analysis used byClosely related to speech analysis used bycompression technologiescompression technologiesMuch more versatileMuch more versatile
http://www.bell-labs.com/project/tts/voices.htmlDemo
Age-transition Woman-to-man man-to-woman

Speech RecognitionSpeech Recognition
To teach a computer to understand humanTo teach a computer to understand humanspeechspeech

Speech Recognition for HCISpeech Recognition for HCIInterface for Human Computer InteractionInterface for Human Computer Interaction–– How much can you tell a computer in one minute byHow much can you tell a computer in one minute by
keyboard typing, mouse clicking or speaking?keyboard typing, mouse clicking or speaking?Imagine, if you can talk to a computer, how will thatImagine, if you can talk to a computer, how will thataffect your life?affect your life?–– You can search web by speaking only (You can search web by speaking only (voiceXMLvoiceXML))–– You can call your friend by just calling the nameYou can call your friend by just calling the name–– You can ask virtual doctors to diagnose your diseaseYou can ask virtual doctors to diagnose your disease–– You can avoid the long wait while calling customer serviceYou can avoid the long wait while calling customer service–– You can talk to your TV, VCR, Garage door opener, roomYou can talk to your TV, VCR, Garage door opener, room
temperature controller, Microwave,temperature controller, Microwave, ……

Brief History of Speech RecognitionBrief History of Speech Recognition
1950s: Bell Labs, RCA Labs, MIT Lincoln Lab1950s: Bell Labs, RCA Labs, MIT Lincoln Lab–– Measure spectral resonance of vowelsMeasure spectral resonance of vowels
1960s:1960s:–– Hardware implementation (Japanese labs)Hardware implementation (Japanese labs)–– Time normalization (Martin at RCA), dynamic timeTime normalization (Martin at RCA), dynamic time
warping (warping (VintsyukVintsyuk in Russia), dynamic tracking ofin Russia), dynamic tracking ofphonemes (Reddy at CMU)phonemes (Reddy at CMU)
1970s1970s–– Use of pattern recognition ideas (Use of pattern recognition ideas (VelichkoVelichko andand ZagoruykoZagoruyko
in Russia)in Russia)–– Successful application of dynamic programming methodsSuccessful application of dynamic programming methods
((SakoeSakoe and Chiba in Japan)and Chiba in Japan)–– Linear predictive coding (Linear predictive coding (ItakuraItakura in USA)in USA)

Brief History of Speech RecognitionBrief History of Speech Recognition((ConCon’’dd))
1970s (1970s (concon’’dd))–– Large vocabulary speech recognition at IBMLarge vocabulary speech recognition at IBM–– Speaker independent recognition at AT&T Bell LabsSpeaker independent recognition at AT&T Bell Labs
1980s1980s–– Focus shifted from isolated word recognition to connectedFocus shifted from isolated word recognition to connected
word recognitionword recognition–– Technology shift from templateTechnology shift from template--based to statisticalbased to statistical
modeling methods (Hidden Markov Model)modeling methods (Hidden Markov Model)–– Culminate in CMUCulminate in CMU’’ss SPHINXSPHINX system (developed by Lee,system (developed by Lee,
Hon and Reddy)Hon and Reddy)1990s1990s--nownow–– Natural language speech recognition, speech recognitionNatural language speech recognition, speech recognition
for other languages, speech recognition with accentfor other languages, speech recognition with accent ……
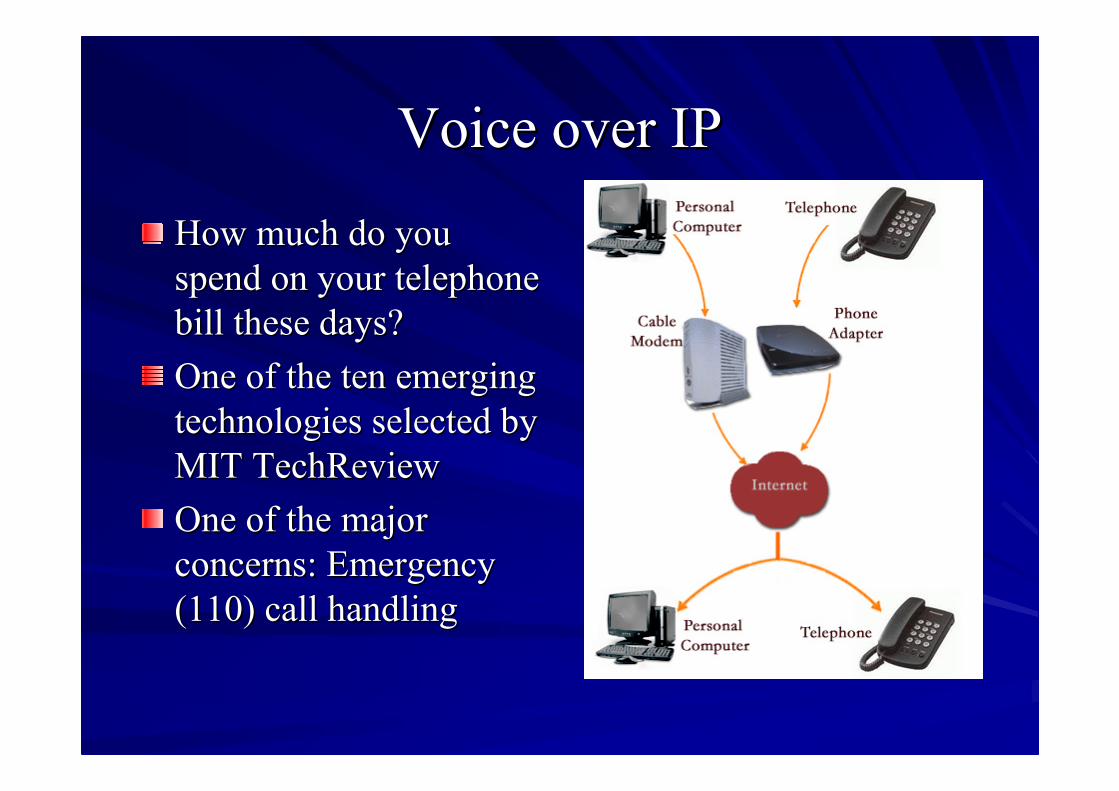
Voice over IPVoice over IP
How much do youHow much do youspend on your telephonespend on your telephonebill these days?bill these days?One of the ten emergingOne of the ten emergingtechnologies selected bytechnologies selected byMITMIT TechReviewTechReviewOne of the majorOne of the majorconcerns: Emergencyconcerns: Emergency(110) call handling(110) call handling

Universal TranslatorUniversal Translator
The ultimate goal is to develop universalThe ultimate goal is to develop universaltranslation software that gleans meaning fromtranslation software that gleans meaning fromphrases in one language and conveys it in anyphrases in one language and conveys it in anyother language, enabling people from differentother language, enabling people from differentcultures to communicate.cultures to communicate.Imagine a world you donImagine a world you don’’t need to learn at need to learn asecondsecond--language anymore (a personal gadgetlanguage anymore (a personal gadgetan be your translator no matter where you go)an be your translator no matter where you go)

Synthetic InterviewsSynthetic Interviews
Today we can use a mobile phone to talk toToday we can use a mobile phone to talk tovirtual agentsvirtual agents–– Interview individuals in a photograph, book,Interview individuals in a photograph, book,
magazine, newspaper, or brochure.magazine, newspaper, or brochure.–– Converse with a World War I airplane pilot whileConverse with a World War I airplane pilot while
examining his airplaneexamining his airplane–– Talk with LeonardoTalk with Leonardo daVincidaVinci while looking at thewhile looking at the
rings of Saturn through a telescoperings of Saturn through a telescope–– Talk with Abraham Lincoln while visiting the logTalk with Abraham Lincoln while visiting the log
cabin in which he was borncabin in which he was born

Speech for Gaming RealismSpeech for Gaming RealismVideo game industry:Video game industry:$30 billion in 2004$30 billion in 2004Speech recognitionSpeech recognitionprovides highprovides high--levellevelcommands to virtualcommands to virtualteammates who respondteammates who respondwith a variety ofwith a variety ofrecorded quipsrecorded quipsMany new opportunitiesMany new opportunitiesin video gamesin video games
High-level commands:“Move out”, Covering fire,” “Grenade,”“Take point,” “Hold position,” “Regroup”

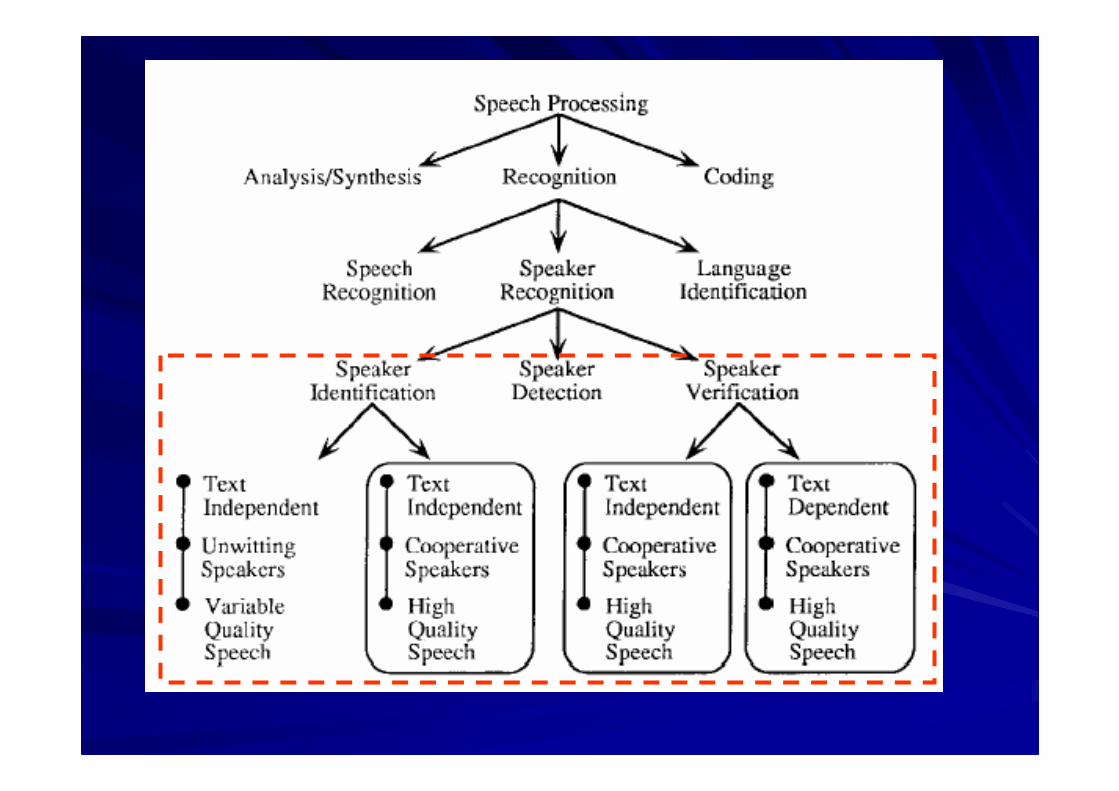
Speaker RecognitionSpeaker Recognition
VoicePrintVoicePrint: a new type of biometrics: a new type of biometricsWhat isWhat is VoicePrintVoicePrint??–– Identify a person by the way he/she talksIdentify a person by the way he/she talks–– Note that speaker recognition is different fromNote that speaker recognition is different from
speech recognition (what you say is less importantspeech recognition (what you say is less importantthan how you say it)than how you say it)
WhyWhy VoicePrintVoicePrint??–– The onlyThe only replaceablereplaceable biometrics so farbiometrics so far

Speech for EducationSpeech for Education
IsnIsn’’t it difficult to learn Italian or Chinese?t it difficult to learn Italian or Chinese?Imagine how you learn a second language withImagine how you learn a second language witha tutora tutorUsing automatic speech recognition, the wholeUsing automatic speech recognition, the wholelearning process can be computerlearning process can be computer--basedbasedExample: FLUENCY project at the LanguageExample: FLUENCY project at the LanguageTechnologies Institute at CMUTechnologies Institute at CMU
http://www.lti.cs.cmu.edu/Research/Fluency/index.html

Speech AnalyticsSpeech Analytics
A new type of data mining applicationA new type of data mining applicationWhat is SA?What is SA?–– Application of speech technologies to the analysis ofApplication of speech technologies to the analysis of
discourse, whether the speech consists of recorded callsdiscourse, whether the speech consists of recorded callsfrom a contact center, wiretap, or some other form of mediafrom a contact center, wiretap, or some other form of media
Why SA?Why SA?–– It help companies reduce churn, improve agent training,It help companies reduce churn, improve agent training,
increase competitive awareness, improve first callincrease competitive awareness, improve first callresolution, and perform root cause analysisresolution, and perform root cause analysis

http://www.speechtechmag.com/
http://www.aaai.org/AITopics/html/speech.html
Internet ResourcesInternet ResourcesLink to speech related to AI research
IEEE Xplore

Look AheadLook Ahead
Imagine you are aImagine you are a SciFiSciFi writer, what kind ofwriter, what kind offancy story about speech technology can youfancy story about speech technology can youcome up with?come up with?–– Can we search and edit speech just like texts?Can we search and edit speech just like texts?–– Can we use speech to help blind people to drive?Can we use speech to help blind people to drive?–– Can we make synthesized speech indistinguishableCan we make synthesized speech indistinguishable
from the natural one?from the natural one?–– Can I wearable a gadget that can automaticallyCan I wearable a gadget that can automatically
correct my accent so my SEI score on speechcorrect my accent so my SEI score on speechclarity can improve?clarity can improve?

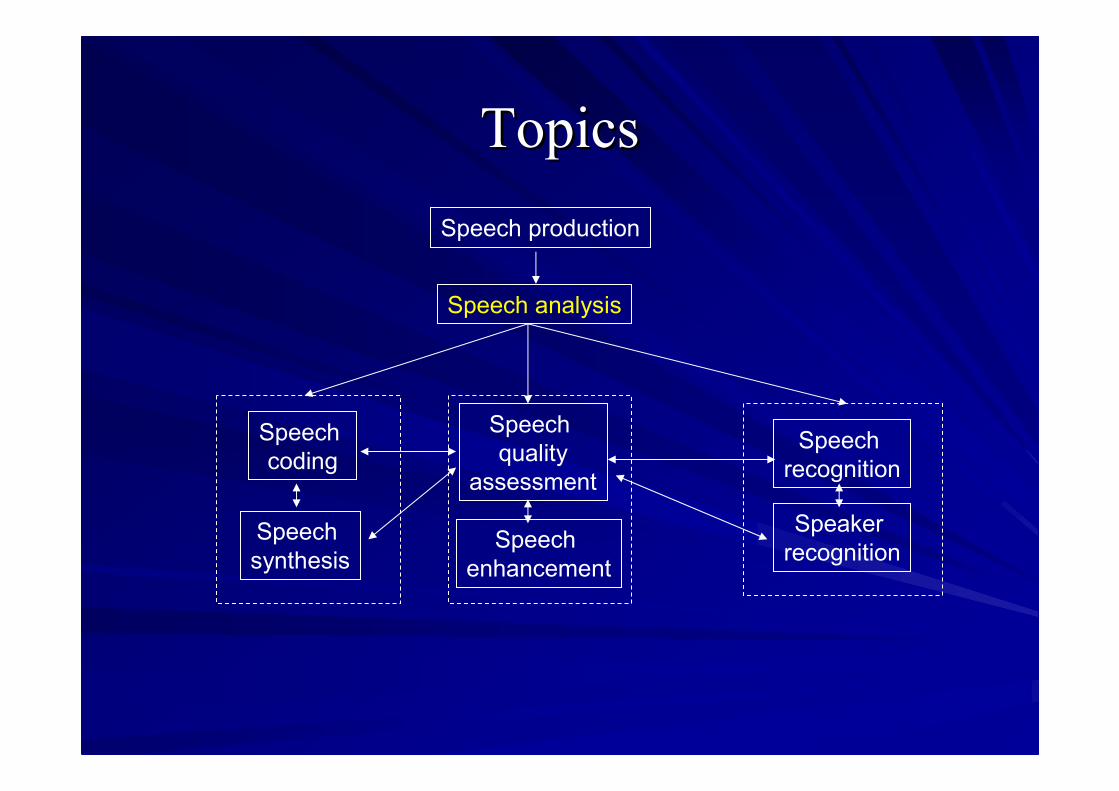
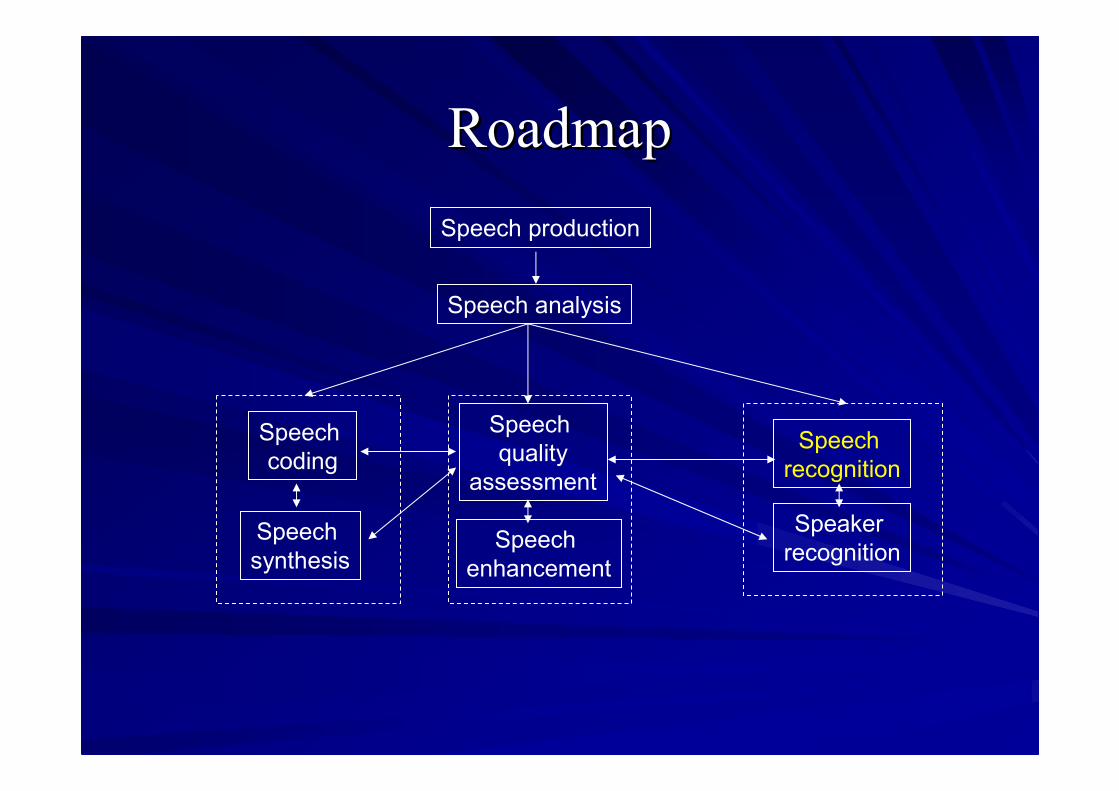
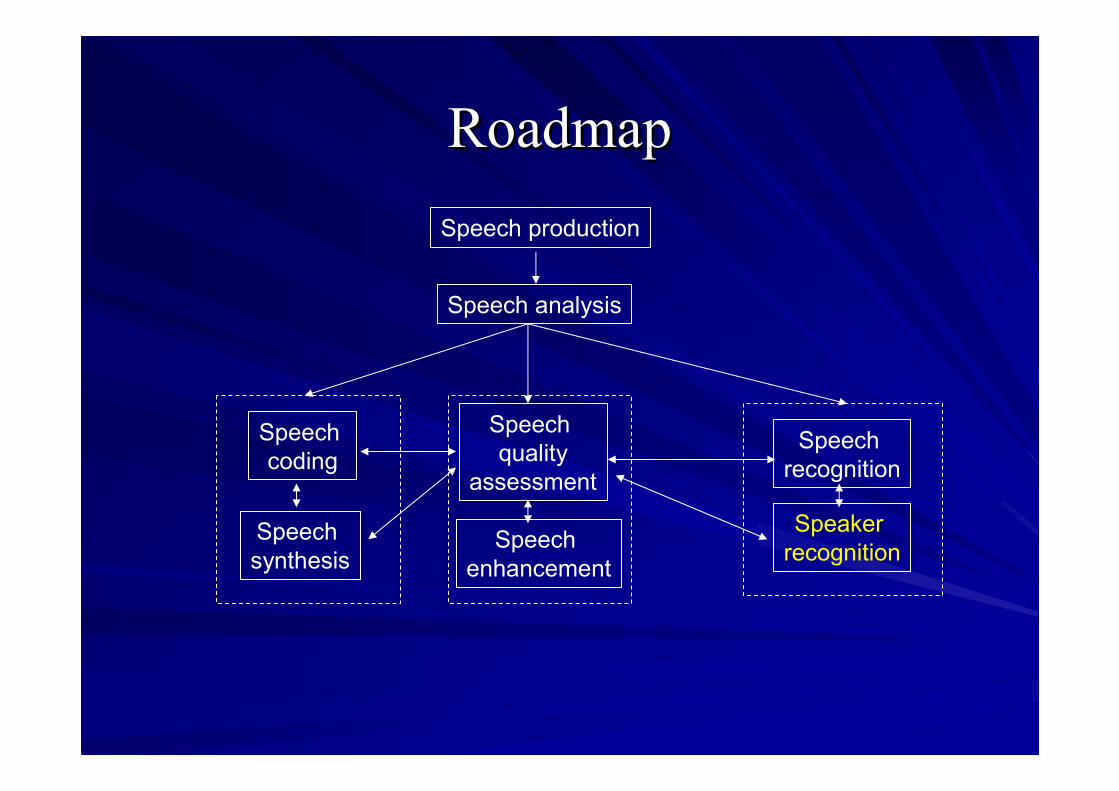
TopicsTopicsSpeech production
Speech analysis
Speechcoding
Speechsynthesis
Speechquality
assessment
Speechrecognition
SpeakerrecognitionSpeech
enhancement

Speech ProductionSpeech Production
Fundamentals of speech scienceFundamentals of speech science–– Linguistics: the scientific study of language andLinguistics: the scientific study of language and
the manner in which languagethe manner in which language--associated rules areassociated rules areused in human communicationused in human communication
–– Phonetics: the science that studies thePhonetics: the science that studies thecharacteristics of human sound production,characteristics of human sound production,especially the description, classification andespecially the description, classification andtranscription of speech.transcription of speech.

PhonemicsPhonemics–– Phoneme is the basic theoretical unit for describingPhoneme is the basic theoretical unit for describing
how speech conveys linguistic meaninghow speech conveys linguistic meaning–– It represents a class of sounds that convey theIt represents a class of sounds that convey the
same meaning (regardless ofsame meaning (regardless of accentaccent,, gendergender, etc.), etc.)
PhoneticsPhonetics–– Study of theStudy of the actual soundsactual sounds of the languageof the language
Phonemics and PhoneticsPhonemics and Phonetics
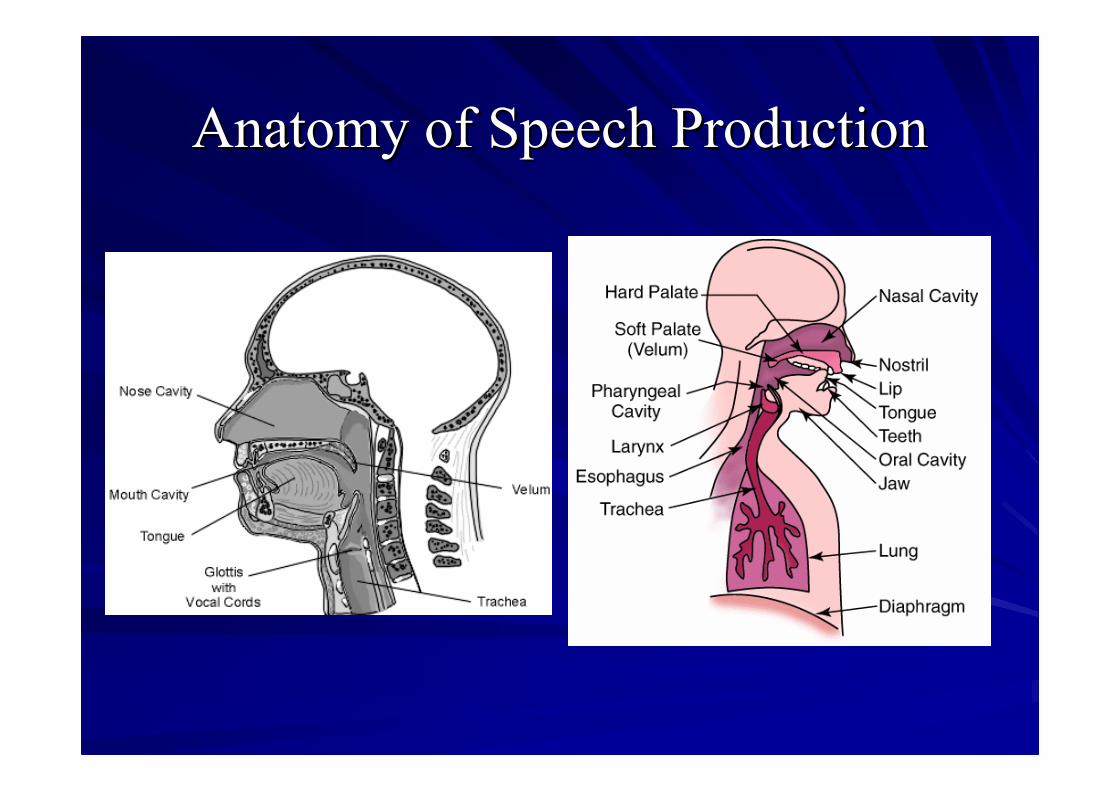
Anatomy of Speech ProductionAnatomy of Speech Production
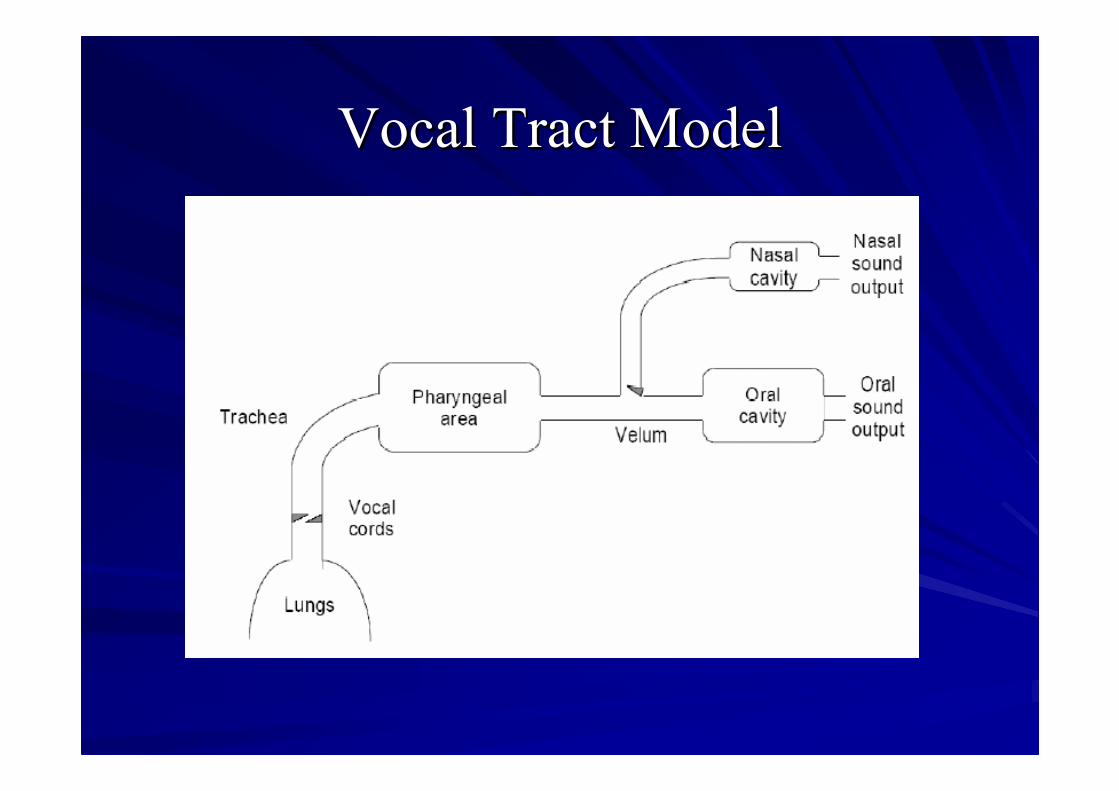
Vocal Tract ModelVocal Tract Model

widely used in speech coding and synthesis
Vocal Tract Model (Vocal Tract Model (concon’’dd))

MultitubeMultitube Lossless ModelLossless Model
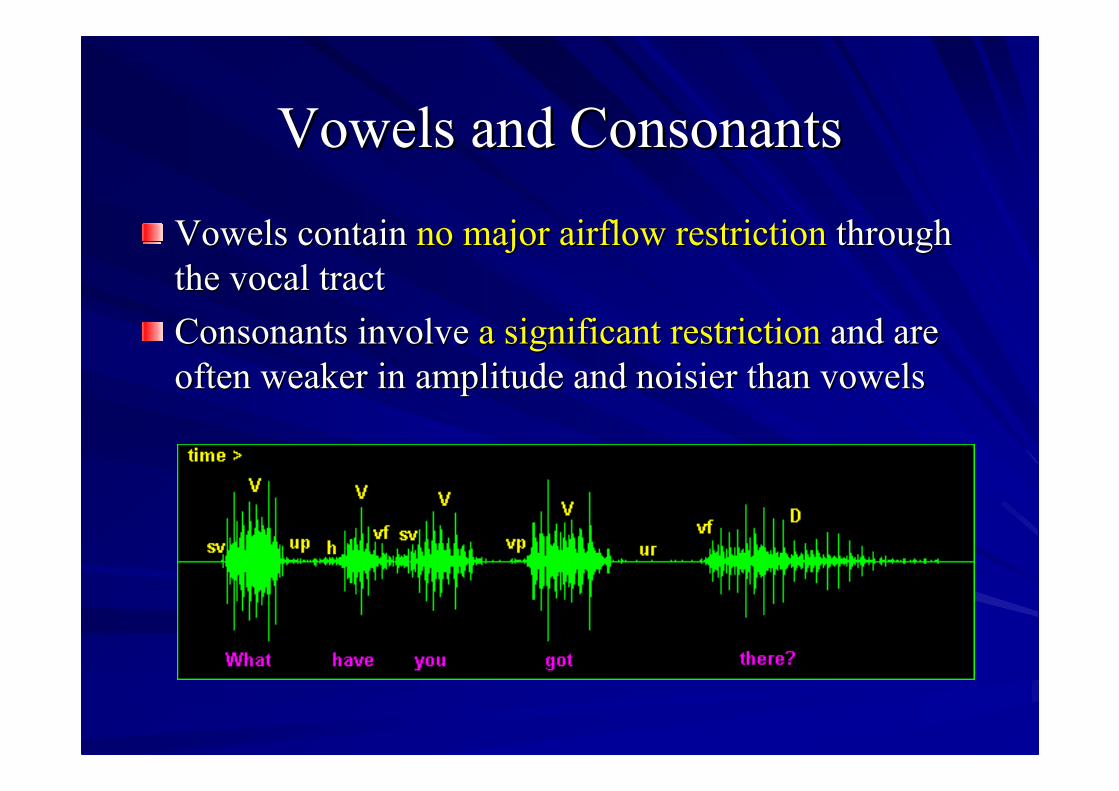
Vowels and ConsonantsVowels and Consonants
Vowels containVowels contain no major airflow restrictionno major airflow restriction throughthroughthe vocal tractthe vocal tractConsonants involveConsonants involve a significant restrictiona significant restriction and areand areoften weaker in amplitude and noisier than vowelsoften weaker in amplitude and noisier than vowels

Speech SpectrographSpeech Spectrograph
“The steward dismissed the girl”
Speech production
Speech analysis
Speechcoding
Speechsynthesis
Speechquality
assessment
Speechrecognition
SpeakerrecognitionSpeech
enhancement
TopicsTopics

What is it?What is it?–– Analysis of speech sounds taking into consideration theirAnalysis of speech sounds taking into consideration their
method of productionmethod of production–– The level of processing between the digitized acousticThe level of processing between the digitized acoustic
waveform and the acoustic feature vectors.waveform and the acoustic feature vectors.–– The extraction of ``The extraction of ``interestinginteresting'' information as an acoustic'' information as an acoustic
vector.vector.How to do it?How to do it?–– ShortShort--time (frametime (frame--based) processingbased) processing–– Linear predictive analysisLinear predictive analysis–– CepstralCepstral analysisanalysis
Speech Analysis OverviewSpeech Analysis Overview
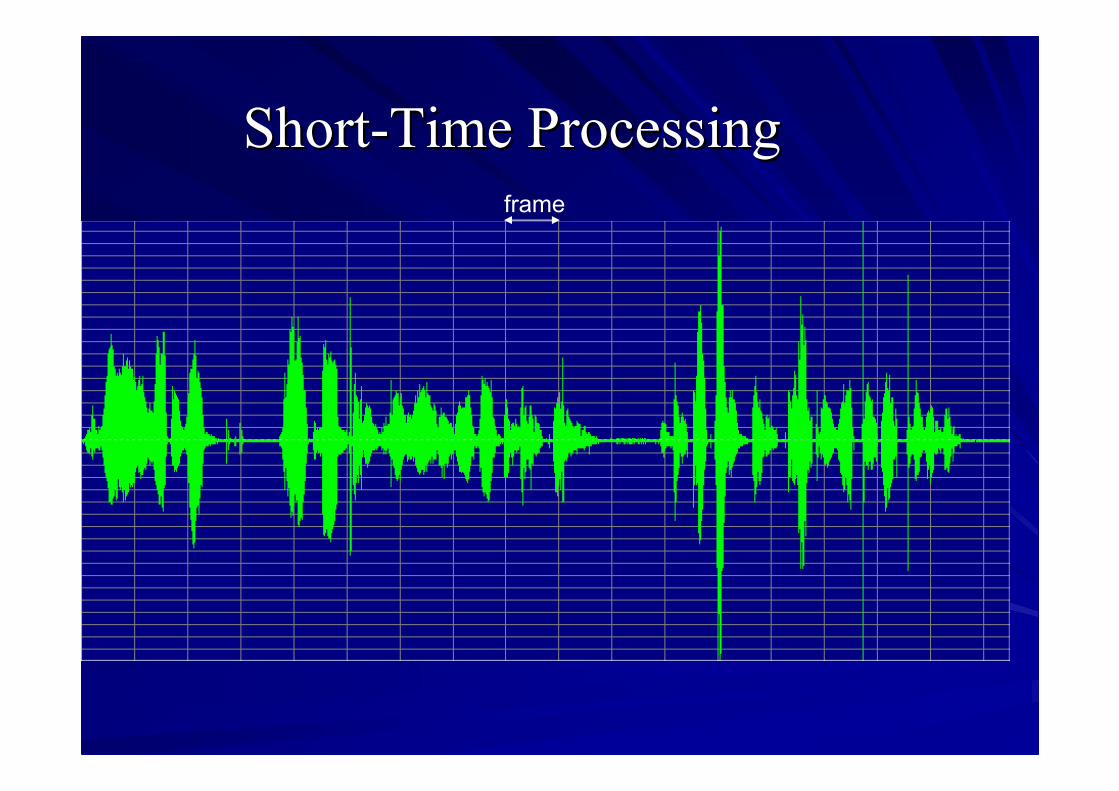
ShortShort--Time ProcessingTime Processingframe

ShortShort--Time Fourier TransformTime Fourier Transform
Why canWhy can’’t we use continuous Fouriert we use continuous Fouriertransforms (e.g., those you learned intransforms (e.g., those you learned inEE327/EE329)EE327/EE329)–– RealReal--world signal is alwaysworld signal is always finitefinite no matter it isno matter it is
speech, audio, image or videospeech, audio, image or video–– Speech isSpeech is dynamicdynamic (time(time--varying)varying)
WindowingWindowing–– Recall the difference between a rectangularRecall the difference between a rectangular
window and a Hamming windowwindow and a Hamming window

Linear Predictive AnalysisLinear Predictive AnalysisLinear prediction (LP) is a widely employedLinear prediction (LP) is a widely employedtechnique beyond speech processingtechnique beyond speech processingThree classes of modelsThree classes of models–– Autoregressive (AR) models: all poleAutoregressive (AR) models: all pole–– Moving average (MA) models: all zeroMoving average (MA) models: all zero–– ARMA models: poleARMA models: pole--zerozero
There are fundamental reasons for the preference ofThere are fundamental reasons for the preference ofAR over ARMA models in speech analysisAR over ARMA models in speech analysis–– Human ear isHuman ear is ““phasephase--deafdeaf””–– AR model is sufficient to preserve theAR model is sufficient to preserve the magnitude spectralmagnitude spectral
dynamicsdynamics (it targets at a minimum(it targets at a minimum--phase system)phase system)

CepstralCepstral AnalysisAnalysisIn one word,In one word, cepstrumcepstrum is FT + logis FT + logWhy do we want to take logarithm?Why do we want to take logarithm?–– Voiced speech is composed of a convolved combination ofVoiced speech is composed of a convolved combination of
the excitation sequencethe excitation sequence e(ne(n) with the vocal system impulse) with the vocal system impulseresponseresponse h(nh(n))
–– In frequency domain, it is the product ofIn frequency domain, it is the product of E(fE(f) and) and H(fH(f))(nonlinear relationship)(nonlinear relationship)
–– Logarithmic operatorLogarithmic operator linearizeslinearizes the relationship betweenthe relationship betweentwo component signalstwo component signals
Useful for separating slowlyUseful for separating slowly--varying from fastvarying from fast--varying componentsvarying components

Critics aboutCritics about CepstrumCepstrum
Limited applicationsLimited applications–– CepstralCepstral coefficients for speech recognitioncoefficients for speech recognition–– Pitch and formant estimationPitch and formant estimation–– Robust watermarking (for copyright protection)Robust watermarking (for copyright protection)
Why?Why?–– Computational complexityComputational complexity–– Mathematical complexityMathematical complexity
Nonlinear logarithmic operation raises many issuesNonlinear logarithmic operation raises many issues

Speech production
Speech analysis
Speechcoding
Speechsynthesis
Speechquality
assessment
Speechrecognition
SpeakerrecognitionSpeech
enhancement
RoadmapRoadmap

Why do we need speech coding?Why do we need speech coding?–– PCM: 8K sampling frequency and 8bits/samplePCM: 8K sampling frequency and 8bits/sample–– Limited communication bandwidthLimited communication bandwidth
Telephone line (32Kbps) or wireless (8Kbps),Telephone line (32Kbps) or wireless (8Kbps),IPIP--based (packetbased (packet--based switching instead of circuitbased switching instead of circuitswitching)switching)
WhyWhy lossylossy compression?compression?–– Human auditory system tolerates the distortion toHuman auditory system tolerates the distortion to
some extent (see Assignment 1)some extent (see Assignment 1)
Speech CodingSpeech Coding

Speech Coding TechniquesSpeech Coding Techniques
Waveform based codersWaveform based coders–– PCM (G.711), DPCM, ADPCM (G.726)PCM (G.711), DPCM, ADPCM (G.726)
Model based codersModel based coders–– LPC10(e) Federal Standard 101LPC10(e) Federal Standard 101–– Mixed Excitation Linear Prediction (MELP)Mixed Excitation Linear Prediction (MELP)
Hybrid codersHybrid coders–– Coded Excitation Linear Prediction (CELP)Coded Excitation Linear Prediction (CELP)–– Vector Sum Excitation Linear Prediction (VSELP)Vector Sum Excitation Linear Prediction (VSELP)
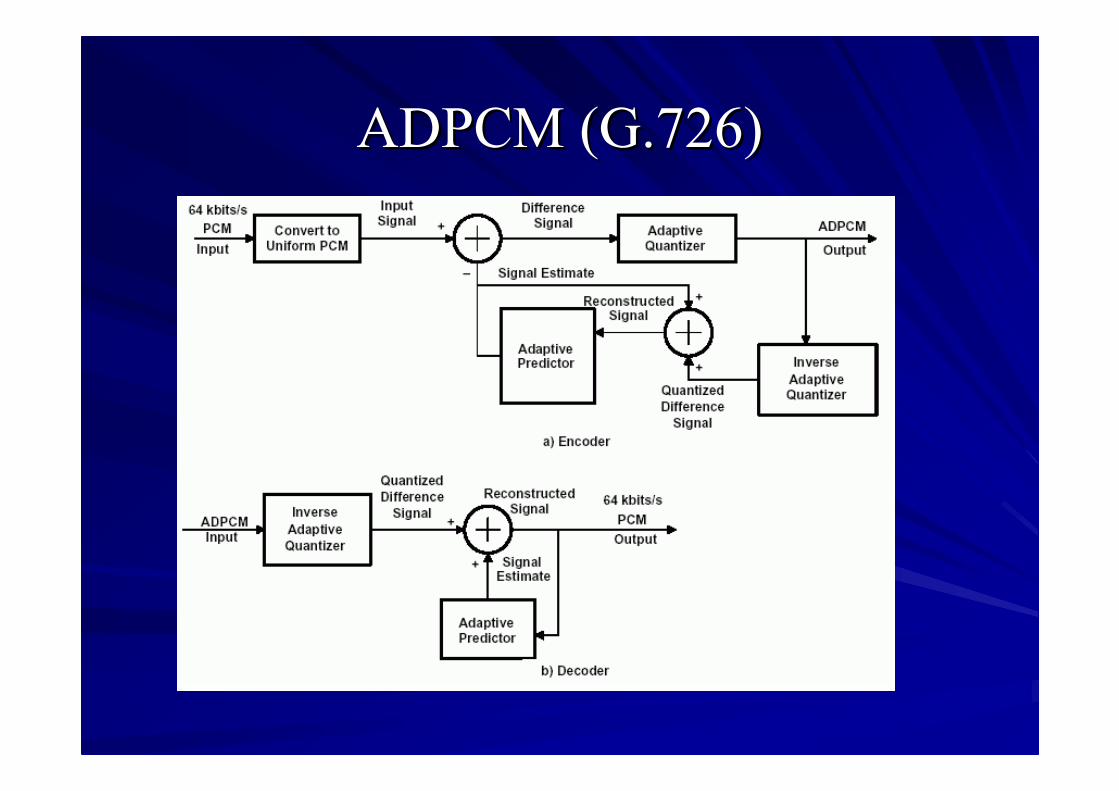
ADPCM (G.726)ADPCM (G.726)
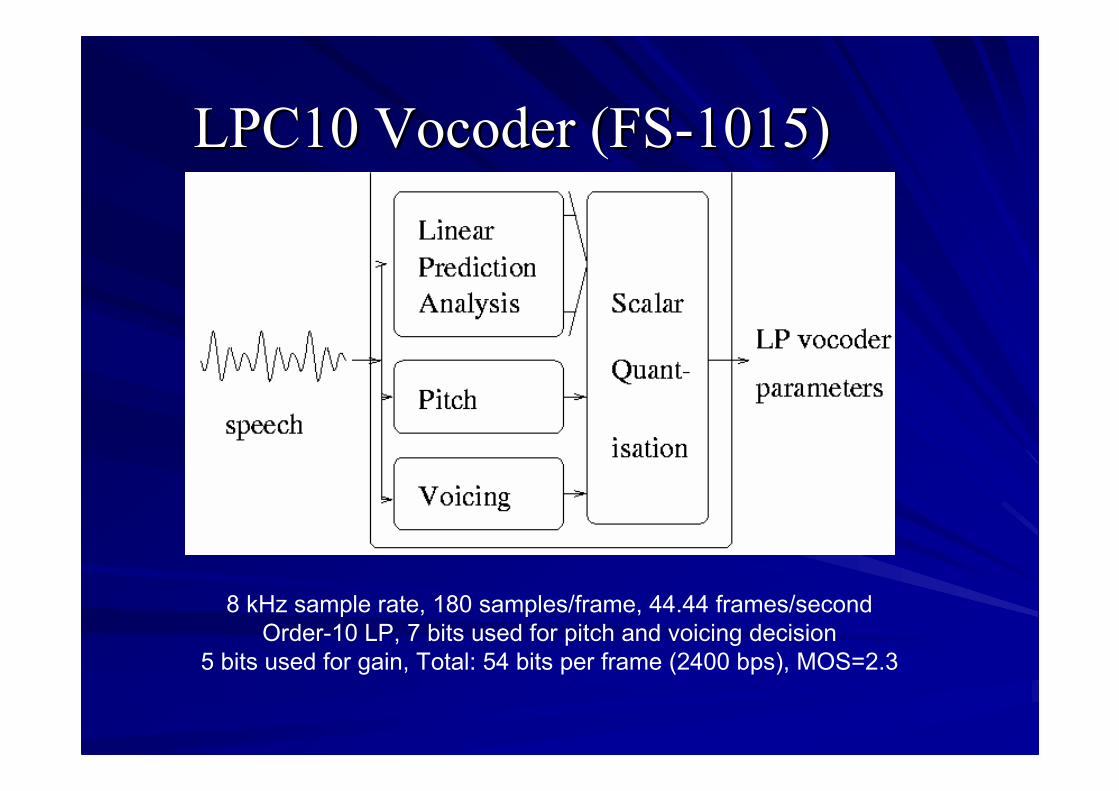
LPC10LPC10 VocoderVocoder (FS(FS--1015)1015)
8 kHz sample rate, 180 samples/frame, 44.44 frames/secondOrder-10 LP, 7 bits used for pitch and voicing decision
5 bits used for gain, Total: 54 bits per frame (2400 bps), MOS=2.3
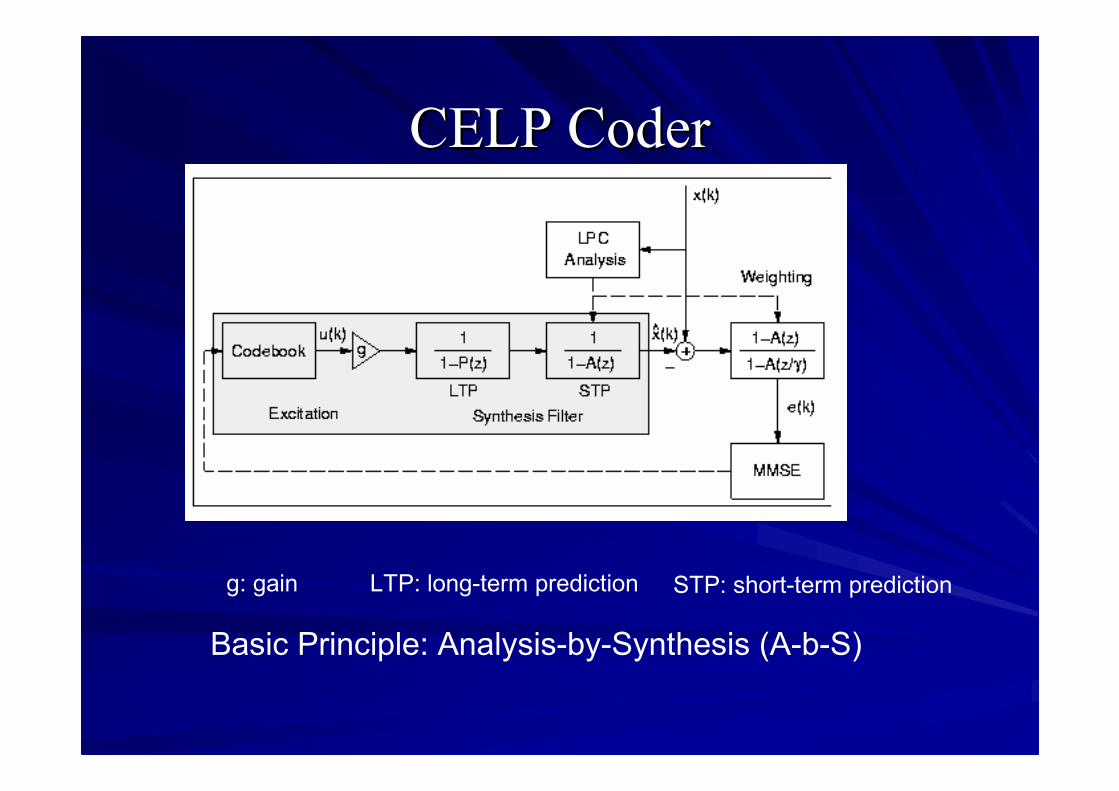
CELP CoderCELP Coder
STP: short-term predictionLTP: long-term predictiong: gain
Basic Principle: Analysis-by-Synthesis (A-b-S)
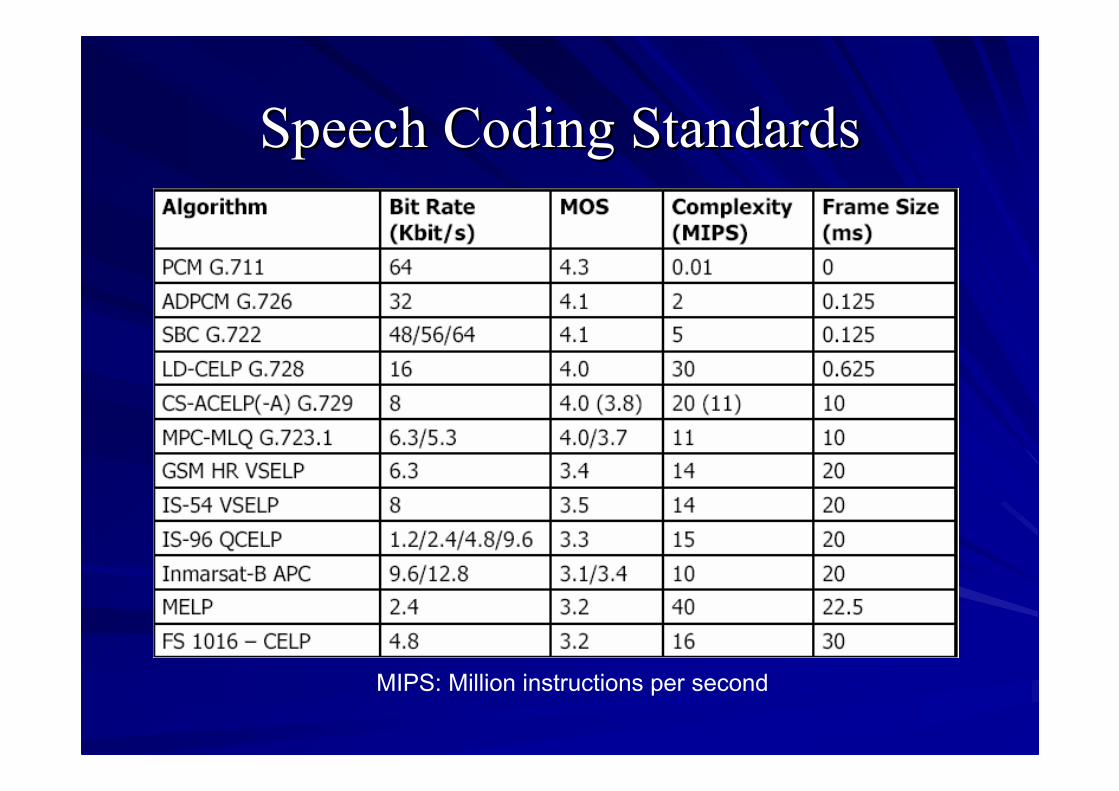
Speech Coding StandardsSpeech Coding Standards
MIPS: Million instructions per second

MPEGMPEG
Moving Picture Experts GroupMoving Picture Experts Group
Part of a multiple standard forPart of a multiple standard for–– Video compressionVideo compression–– Audio compressionAudio compression–– Audio, Video and Data synchronizationAudio, Video and Data synchronizationto an aggregate bit rate of1.5 Mbit/secto an aggregate bit rate of1.5 Mbit/sec

MPEG Audio CompressionMPEG Audio Compression
Physically Lossy compression algorithmPhysically Lossy compression algorithmPerceptually lossless, transparent algorithmPerceptually lossless, transparent algorithmExploits perceptual properties of human earExploits perceptual properties of human earPsychoacoustic modelingPsychoacoustic modelingMPEG Audio Standard ensures interMPEG Audio Standard ensures inter--operability,operability,defines coded bit stream syntax, defines decodingdefines coded bit stream syntax, defines decodingprocess and guarantees decoderprocess and guarantees decoder’’s accuracy.s accuracy.

MPEG Audio FeaturesMPEG Audio Features
No assumptions about the nature of the audio sourceNo assumptions about the nature of the audio sourceExploitation of human auditory system perceptualExploitation of human auditory system perceptuallimitationslimitationsRemoval of perceptually irrelevant parts of audioRemoval of perceptually irrelevant parts of audiosignalsignalIt offers a sampling rate of 32, 44.1 and 48 kHz.It offers a sampling rate of 32, 44.1 and 48 kHz.Offers a choice of three independent layersOffers a choice of three independent layers

MPEG Audio Feautures cont.MPEG Audio Feautures cont.
All three layers allow single chip realAll three layers allow single chip real--time decodertime decoderimplementationimplementationOptional Cyclic Redundancy Check (CRC) errorOptional Cyclic Redundancy Check (CRC) errordetectiondetectionAncillary data may be included in the bit streamAncillary data may be included in the bit streamAlso features such as random access, audio fastAlso features such as random access, audio fastforwarding and audio reverse are possible.forwarding and audio reverse are possible.

OverviewOverview
Quantization, the key to MPEG audio compressionQuantization, the key to MPEG audio compressionTransparent, perceptually lossless compressionTransparent, perceptually lossless compressionNo distinction between original and 6No distinction between original and 6--toto--11compressed audio clipscompressed audio clips


The Polyphase Filter BankThe Polyphase Filter Bank
Key component common to all layersKey component common to all layersDivides the audio signal into 32 equalDivides the audio signal into 32 equal--widthwidthfrequency subbandsfrequency subbandsThe filters provide good time and reasonableThe filters provide good time and reasonablefrequency resolutionfrequency resolutionCritical bands associated with psychoacoustic modelsCritical bands associated with psychoacoustic models

The Psychoacoustic ModelThe Psychoacoustic Model
Analyzes the audio signal and computes the amountAnalyzes the audio signal and computes the amountof noise masking as a function of frequencyof noise masking as a function of frequencyThe encoder decides how best to represent the inputThe encoder decides how best to represent the inputsignal with a minimum number of bitssignal with a minimum number of bits

Basic StepsBasic Steps
Time align audio dataTime align audio dataConvert audio to frequency domain representationConvert audio to frequency domain representationProcess spectral values into tonal and nonProcess spectral values into tonal and non--tonaltonalcomponentscomponentsApply a spreading functionApply a spreading functionSet a lower bound for threshold valuesSet a lower bound for threshold valuesFind the threshold values for each subbandFind the threshold values for each subbandCalculate the signal to mask ratioCalculate the signal to mask ratio

MPEG Audio Layer IMPEG Audio Layer I
Simplest codingSimplest codingSuitable for bit rates above 128 kbits/sec per channelSuitable for bit rates above 128 kbits/sec per channelEach frame contains header, an optional CRC errorEach frame contains header, an optional CRC errorcheck word and possibly ancillary data.check word and possibly ancillary data.Eg. Philips Digital Compact CassetteEg. Philips Digital Compact Cassette

MPEG Audio Layer IIMPEG Audio Layer II
Intermediate complexityIntermediate complexityBit rates around 128 kbits/sec per channelBit rates around 128 kbits/sec per channelDigital Audio Broadcasting (DAB)Digital Audio Broadcasting (DAB)Synchronized Video and Audio on CDSynchronized Video and Audio on CD--ROMROMForms frames of 1152 samples per audio channel.Forms frames of 1152 samples per audio channel.

MPEG Audio Layer IIIMPEG Audio Layer III
Based on Layer I&II filter banksBased on Layer I&II filter banksMost complex codingMost complex codingBest audio qualityBest audio qualityBit rates around 64 kbits/sec per channelBit rates around 64 kbits/sec per channelSuitable for audio transmission over ISDNSuitable for audio transmission over ISDNCompensates filter deficiencies by processing outputsCompensates filter deficiencies by processing outputswith a two different MDCT blocks.with a two different MDCT blocks.
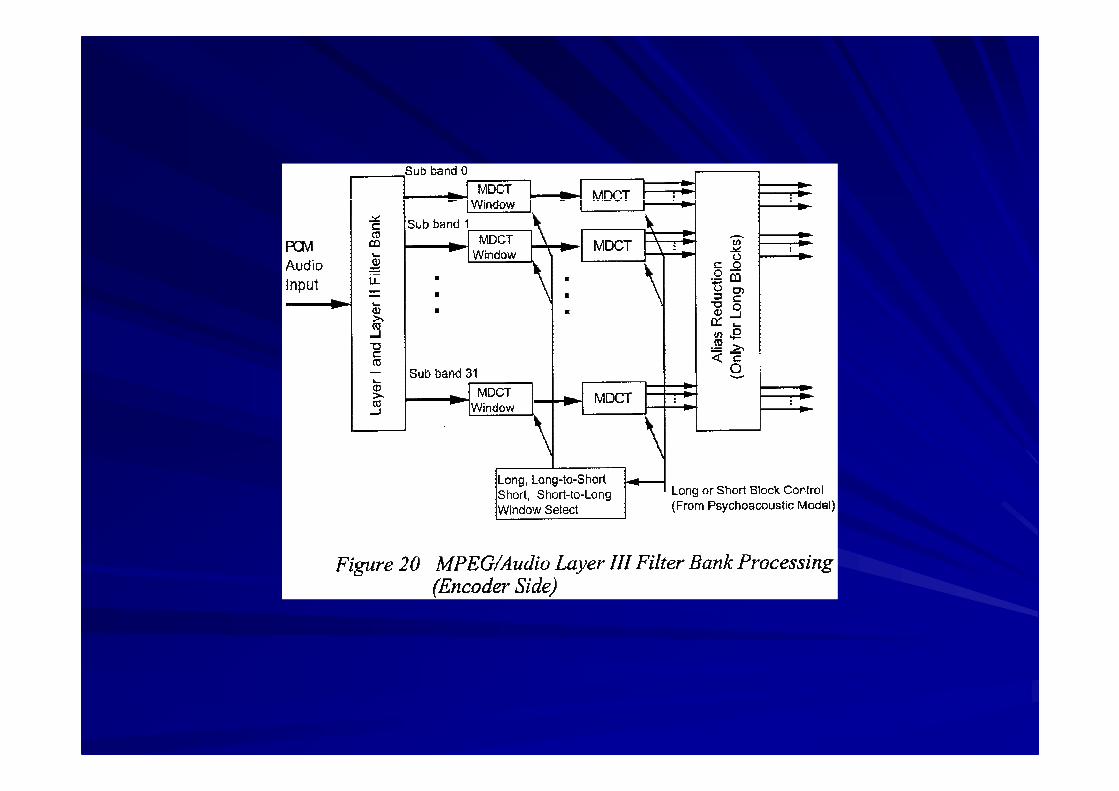

Layer III enhancementsLayer III enhancements
Alias reductionAlias reductionNon uniform quantizationNon uniform quantizationScalefactor bandsScalefactor bandsEntropy coding of data valuesEntropy coding of data valuesUse of aUse of a ““bit reservoirbit reservoir””

MPEG and the Future?MPEG and the Future?
MPEGMPEG--1: Video CD and MP3.1: Video CD and MP3.MPEGMPEG--2: Digital Television set top boxes and DVD2: Digital Television set top boxes and DVDMPEGMPEG--4: Fixed and mobile web4: Fixed and mobile webMPEGMPEG--7: description and search of audio and visual7: description and search of audio and visualcontentcontentMPEGMPEG--21: Multimedia Framework21: Multimedia Framework

Speech Coding DemoSpeech Coding Demo
Original (64kbps PCM)Original (64kbps PCM)ADPCM (32kbps)ADPCM (32kbps)LDLD--CELP (16kbps)CELP (16kbps)CSCS--ACELP (8kbps)ACELP (8kbps)CELP (4.8kbps)CELP (4.8kbps)LPC10(2.4kbps)LPC10(2.4kbps)
http://www.data-compression.com/speech.html#8000bps
Speech production
Speech analysis
Speechcoding
Speechsynthesis
Speechquality
assessment
Speechrecognition
SpeakerrecognitionSpeech
enhancement
RoadmapRoadmap

Speech SynthesisSpeech SynthesisArticulatoryArticulatory Synthesis (only of theoreticalSynthesis (only of theoreticalinterest)interest)Formant SynthesisFormant Synthesis (Probably the most widely(Probably the most widelyused synthesis method during the last decade)used synthesis method during the last decade)ConcatenativeConcatenative Synthesis (ConnectingSynthesis (Connectingprerecorded natural utterances )prerecorded natural utterances )Linear Prediction based MethodsLinear Prediction based MethodsSinusoidal ModelsSinusoidal ModelsHighHigh--Level SynthesisLevel Synthesis

Formant SynthesisFormant Synthesis
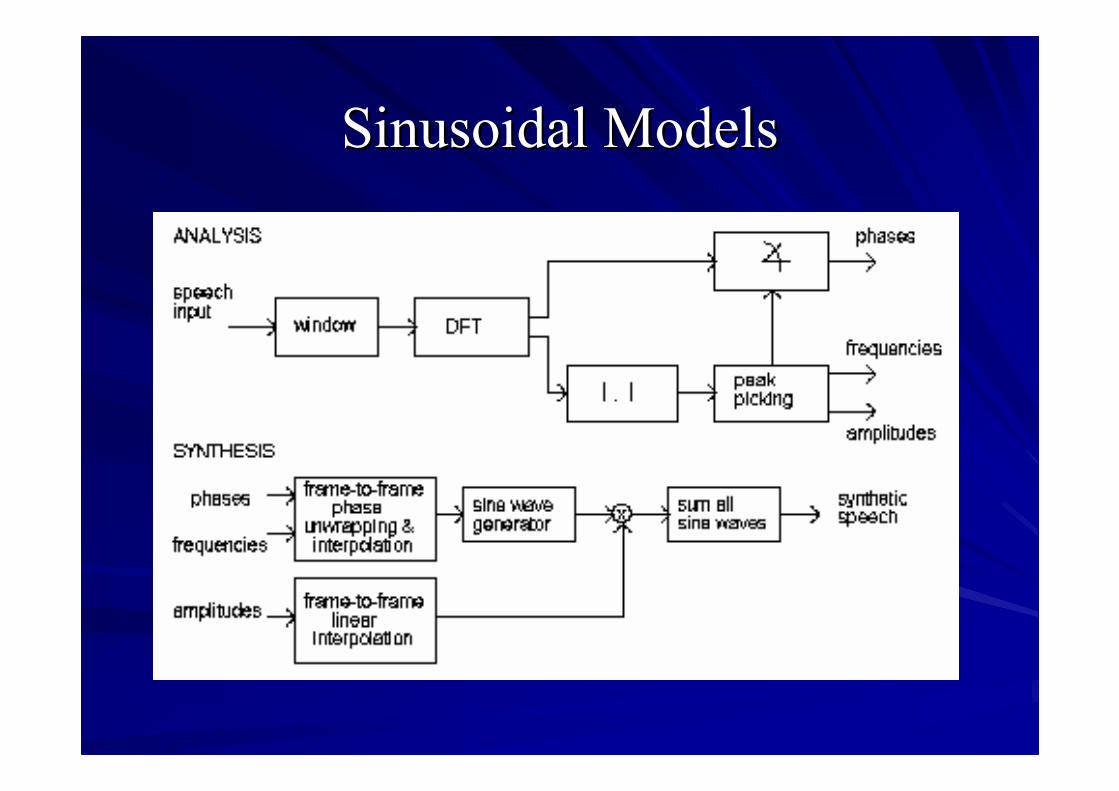
Sinusoidal ModelsSinusoidal Models

Speech Synthesis DemosSpeech Synthesis Demos
http://www.research.att.com/projects/tts/demo.html
http://www.bell-labs.com/project/tts/voices.html
Bell Labs Text-to-Speech Synthesis (TSS) System
AT&T Text-to-Speech Synthesis (TSS) System
Microsoft speech tool (open “speech” under “control panel”)
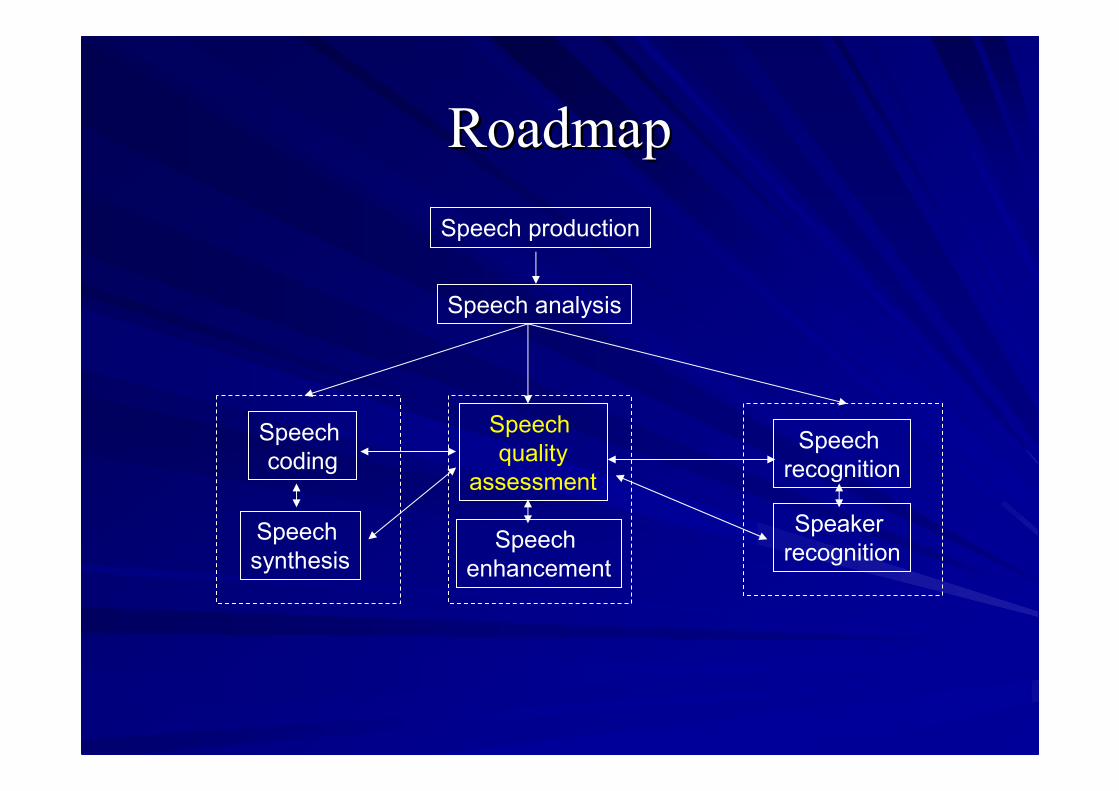
Speech production
Speech analysis
Speechcoding
Speechsynthesis
Speechquality
assessment
Speechrecognition
SpeakerrecognitionSpeech
enhancement
RoadmapRoadmap

Speech Quality AssessmentSpeech Quality AssessmentQuality vs. IntelligibilityQuality vs. Intelligibility–– Unintelligible speech has low quality; but low qualityUnintelligible speech has low quality; but low quality
speech is not necessarily unintelligible (e.g., synthesized)speech is not necessarily unintelligible (e.g., synthesized)SubjectiveSubjective–– MOS (subjective quality)MOS (subjective quality)–– DRT (subjective intelligibility)DRT (subjective intelligibility)–– DAM (overall subjective quality)DAM (overall subjective quality)
ObjectiveObjective–– SNRSNR–– ItakuraItakura loglog--likelihood measurelikelihood measure
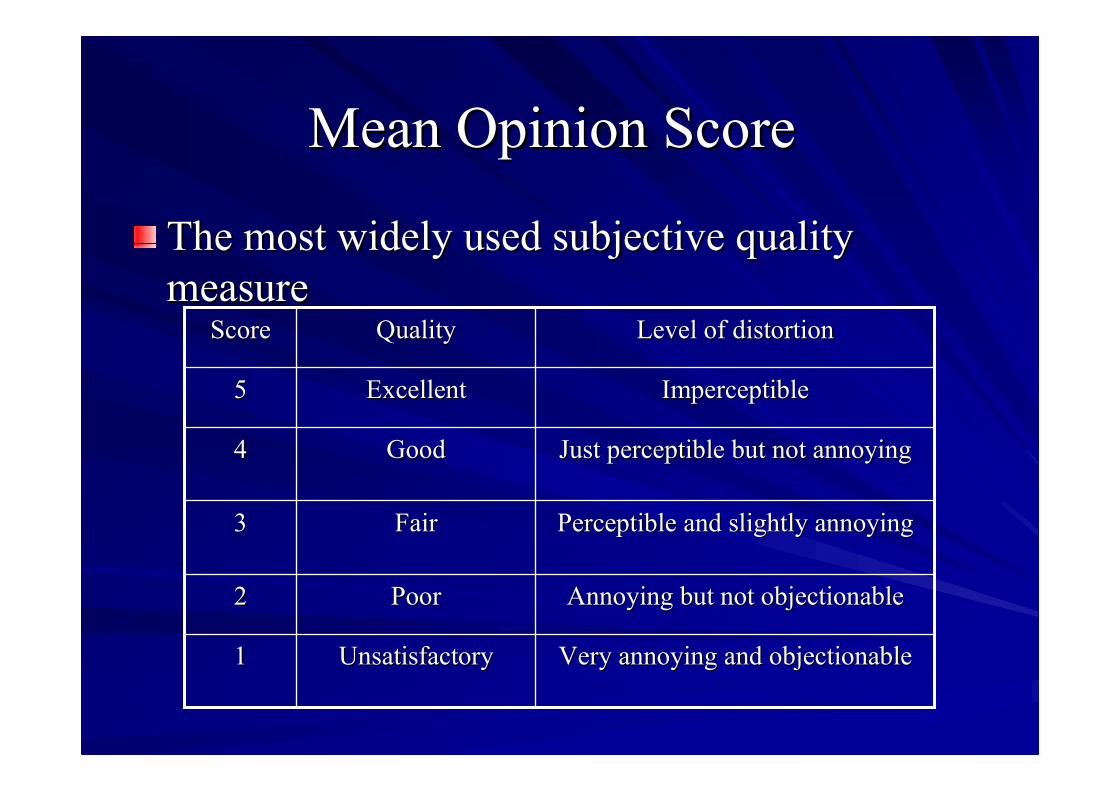
Mean Opinion ScoreMean Opinion Score
The most widely used subjective qualityThe most widely used subjective qualitymeasuremeasure
Very annoying and objectionableVery annoying and objectionableUnsatisfactoryUnsatisfactory11
Annoying but not objectionableAnnoying but not objectionablePoorPoor22
Perceptible and slightly annoyingPerceptible and slightly annoyingFairFair33
Just perceptible but not annoyingJust perceptible but not annoyingGoodGood44
ImperceptibleImperceptibleExcellentExcellent55
Level of distortionLevel of distortionQualityQualityScoreScore

SNRSNR--Based AssessmentBased Assessment
SNRSNR
SNRSNRsegseg
SNRSNRfw_segfw_seg
∑∑
−==
n
n
e
s
nsnsns
EESNR 2
2
1010 )](ˆ)([)(
log10log10
∑ ∑∑−
= ∈
∈
−=
1
02
2
10 )](ˆ)([
)(log101 M
j Sn
Snseg
j
j
nsns
ns
MSNR
∑ ∑∑−
=
=1
0 ,
,
,10,
10
log10log101 M
j k kj
k je
jskj
seg wE
Ew
MSNR

ItakuraItakura MeasureMeasureRecall: human auditory system is insensitive toRecall: human auditory system is insensitive tophase distortionphase distortionWhat is wrong with SNR?What is wrong with SNR?–– Imagine a signal is shifted by several samplesImagine a signal is shifted by several samples–– Perceptually we should hear no difference, thoughPerceptually we should hear no difference, though
a low SNR result is produced due to misalignmenta low SNR result is produced due to misalignmentin the time domainin the time domain
ItakuraItakura measure is based on the dissimilaritymeasure is based on the dissimilaritybetween allbetween all--pole models of original andpole models of original andprocessed speech signalsprocessed speech signals
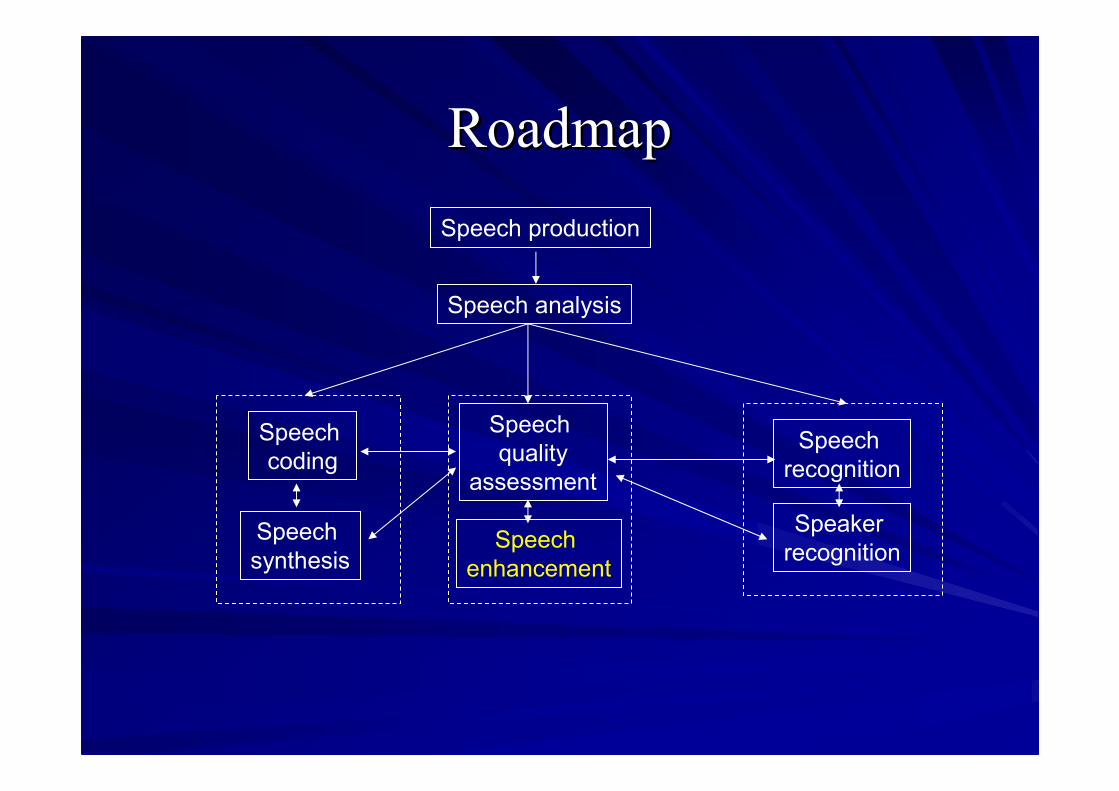
Speech production
Speech analysis
Speechcoding
Speechsynthesis
Speechquality
assessment
Speechrecognition
SpeakerrecognitionSpeech
enhancement
RoadmapRoadmap

Speech EnhancementSpeech Enhancement
Enhancement generally refers to the improvement ofEnhancement generally refers to the improvement ofsubjective quality of a signalsubjective quality of a signal–– It heavily relies on our understanding about humanIt heavily relies on our understanding about human
auditory systemauditory system
Source of quality degradationSource of quality degradation–– Background interferenceBackground interference–– Noisy transmission channelNoisy transmission channel–– Competing speaker in aCompeting speaker in a multispeakermultispeaker settingsetting–– Deficient speech reproduction systemDeficient speech reproduction system–– HearingHearing--impaired listenersimpaired listeners
our focus

Classification of SpeechClassification of SpeechEnhancement TechniquesEnhancement Techniques
Classification based on the number of microphonesClassification based on the number of microphones–– SingleSingle--channel approachchannel approach–– MultiMulti--channel approach (channel approach (microphone arraymicrophone array))
Classification based on technical approachesClassification based on technical approaches–– SingleSingle--channel spectral subtractionchannel spectral subtraction–– Adaptive noise canceling (twoAdaptive noise canceling (two--channel)channel)–– Adaptive comb filtering (suitable for periodic noise)Adaptive comb filtering (suitable for periodic noise)–– ModelModel--based iterative Wiener filteringbased iterative Wiener filtering

Microphone ArrayMicrophone Array
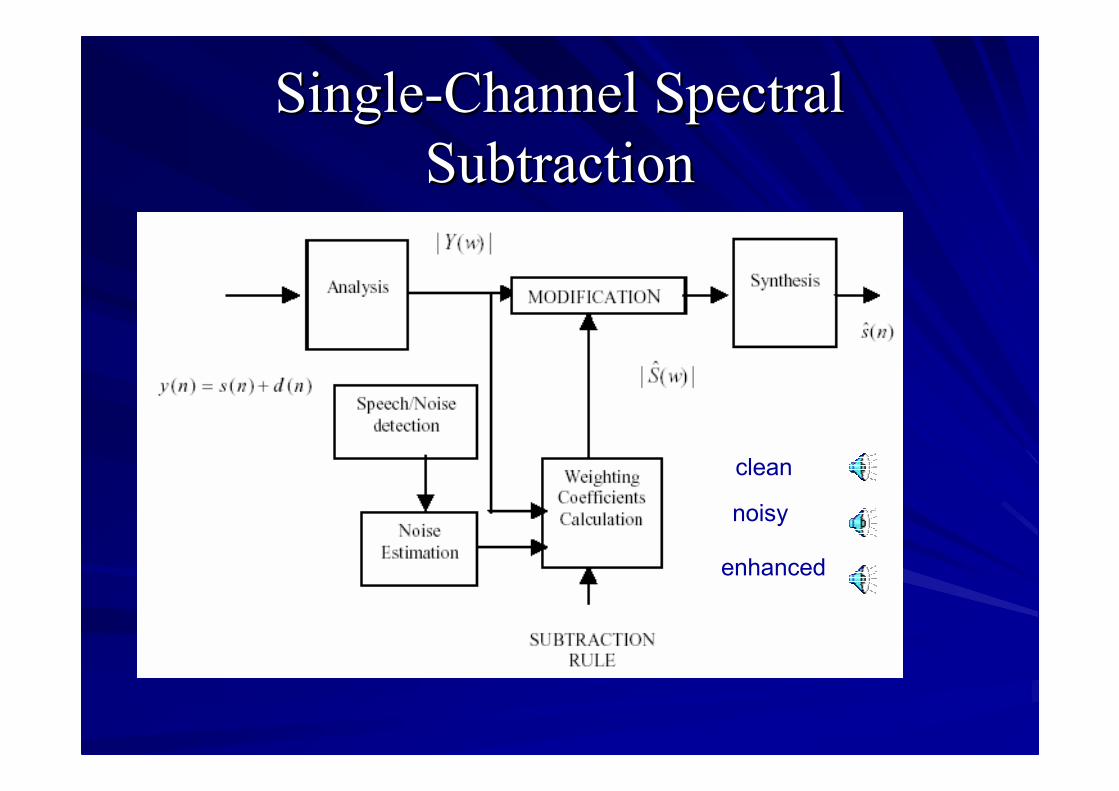
SingleSingle--Channel SpectralChannel SpectralSubtractionSubtraction
clean
noisy
enhanced
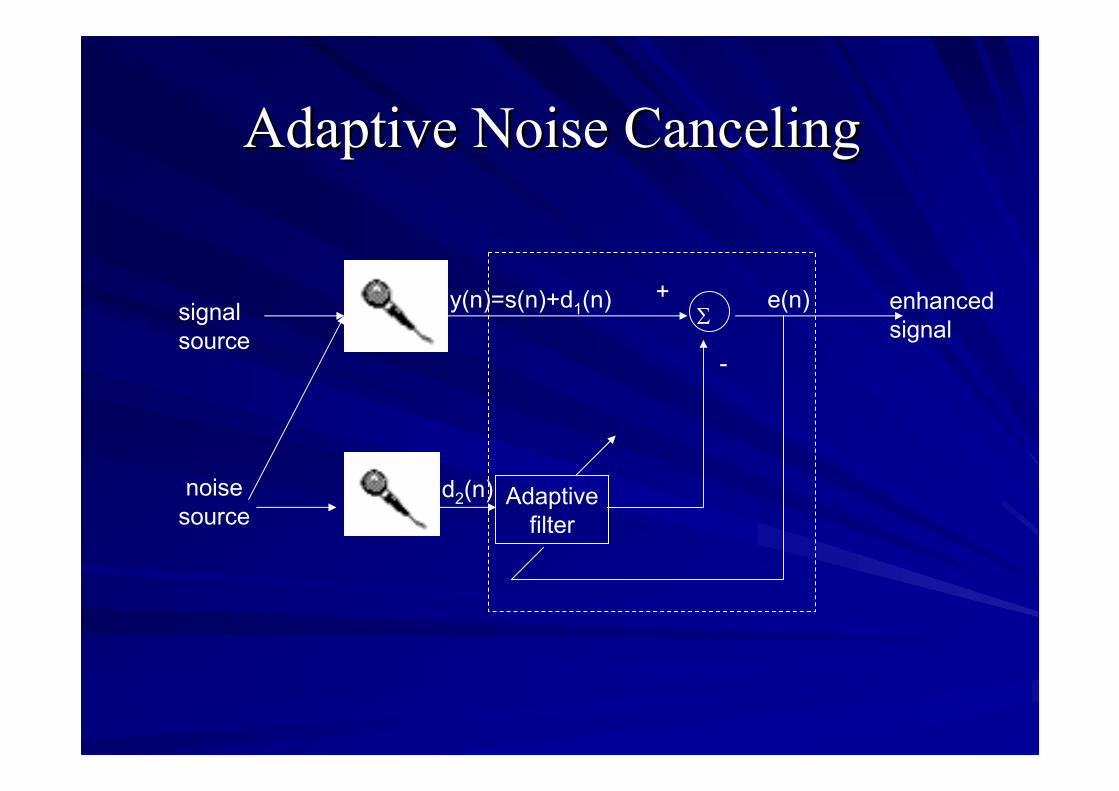
Adaptive Noise CancelingAdaptive Noise Canceling
signalsource
noisesource
Adaptivefilter
Σenhancedsignal
+
-
y(n)=s(n)+d1(n)
d2(n)
e(n)

Adaptive Comb FilteringAdaptive Comb Filtering
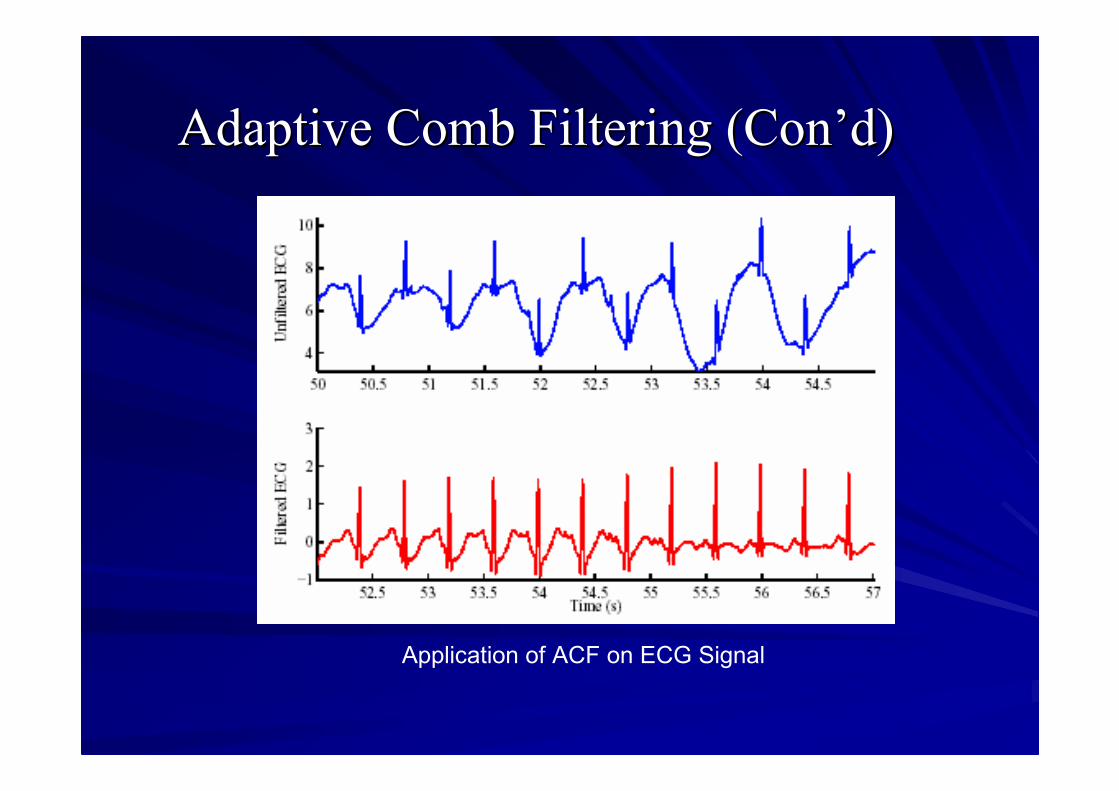
Adaptive Comb Filtering (Adaptive Comb Filtering (ConCon’’dd))
Application of ACF on ECG Signal
Speech production
Speech analysis
Speechcoding
Speechsynthesis
Speechquality
assessment
Speechrecognition
SpeakerrecognitionSpeech
enhancement
RoadmapRoadmap

Speech RecognitionSpeech RecognitionFundamentally speaking, how human auditory systemFundamentally speaking, how human auditory systemworks still largely remains as a mysteryworks still largely remains as a mysteryExisting approachesExisting approaches–– Template matching with dynamic time warping (DTW)Template matching with dynamic time warping (DTW)–– Stochastic recognition based on Hidden Markov ModelStochastic recognition based on Hidden Markov Model
(HMM)(HMM)StateState--ofof--thethe--art in 1990sart in 1990s–– Small vocabularies (<100 words)Small vocabularies (<100 words)–– Large vocabularies (>10000) but spoken in isolationLarge vocabularies (>10000) but spoken in isolation–– Large and continuous but constrained to a certain taskLarge and continuous but constrained to a certain task
domain (e.g., only work for office correspondence at adomain (e.g., only work for office correspondence at aparticular company)particular company)

Known Dimensions of DifficultyKnown Dimensions of Difficulty
SpeakerSpeaker--dependent or speaker independentdependent or speaker independentSize of vocabularySize of vocabularyDiscrete vs. continuousDiscrete vs. continuousThe extent of ambiguity and acousticThe extent of ambiguity and acousticconfusability (e.g.,confusability (e.g., ““knowknow”” vs.vs. ““nono””))Quiet vs. noisy environmentQuiet vs. noisy environmentLinguistic constraints and knowledgeLinguistic constraints and knowledge

Speaker DependencySpeaker Dependency
Speaker dependent recognitionSpeaker dependent recognition–– You will be asked to useYou will be asked to use ““speech toolsspeech tools”” offered byoffered by
Windows XP in a future assignmentWindows XP in a future assignment–– It requires retraining when the system is used by aIt requires retraining when the system is used by a
new usernew userSpeaker independent recognitionSpeaker independent recognition–– Trained for multiple users and used by the sameTrained for multiple users and used by the same
populationpopulation–– Trained for some user but might be used by othersTrained for some user but might be used by others
(outside the training population)(outside the training population)

Vocabulary SizeVocabulary SizeRule of thumbRule of thumb–– Small: 1Small: 1--99 words (e.g., credit card and telephone99 words (e.g., credit card and telephone
number)number)–– Medium: 100Medium: 100--999 words (experimental lab999 words (experimental lab
systems for continuous recognition)systems for continuous recognition)–– Large: >1000 words (commercial products such asLarge: >1000 words (commercial products such as
office correspondence and document retrieval)office correspondence and document retrieval)Relevant to linguistic constraintsRelevant to linguistic constraints–– Those constraints (e.g., grammar) helps reduce theThose constraints (e.g., grammar) helps reduce the
search space when vocabulary size increasessearch space when vocabulary size increases

Isolated vs. ContinuousIsolated vs. Continuous
Isolated Word Recognition (IWR)Isolated Word Recognition (IWR)–– Discrete utterance of each word (minimum pauseDiscrete utterance of each word (minimum pause
of 200ms is required)of 200ms is required)Continuous Speech Recognition (CSR)Continuous Speech Recognition (CSR)–– User utters the message in a relatively (orUser utters the message in a relatively (or
completely) unconstrained mannercompletely) unconstrained manner–– ChallengesChallenges
Deal with unknown temporal boundariesDeal with unknown temporal boundariesHandle crossHandle cross--wordword coarticulationcoarticulation effects and sloppyeffects and sloppyarticulation (e.g., St. Louisarticulation (e.g., St. Louis ZZoo vs. San Diegooo vs. San Diego ZZoo)oo)

Linguistic ConstraintsLinguistic ConstraintsClosely related to natural language processingClosely related to natural language processingWhat are they?What are they?–– Grammatical constraints, lexical constraints, syntacticGrammatical constraints, lexical constraints, syntactic
constraintsconstraintsExamplesExamples–– Colorless paper packages crackle loudlyColorless paper packages crackle loudly–– Colorless yellow ideas sleep furiously (grammaticallyColorless yellow ideas sleep furiously (grammatically
correct, semantically incorrect)correct, semantically incorrect)–– Sleep roses dangerously young colorless ((grammaticallySleep roses dangerously young colorless ((grammatically
incorrect)incorrect)–– BegnBegn bureaburea sferewrtetsferewrtet aweqwrqaweqwrq (lexically incorrect)(lexically incorrect)

Acoustic Ambiguity and ConfusabilityAcoustic Ambiguity and Confusability
AmbiguityAmbiguity–– Acoustically ambiguous words areAcoustically ambiguous words are
indistinguishable in their spoken renditionsindistinguishable in their spoken renditions–– Examples:Examples: ““KnowKnow”” vs.vs. ““NoNo””,, ““TwoTwo”” vs.vs. ““TooToo””
ConfusabilityConfusability–– Refers to the extent to which words can be easilyRefers to the extent to which words can be easily
confused due to partial acoustic similarityconfused due to partial acoustic similarity–– Examples:Examples: ““oneone”” vs.vs. ““ninenine””,, ““BB”” vs.vs. ““DD””

Environmental NoiseEnvironmental Noise
Background noiseBackground noise–– Other speakers, equipment sounds, air conditioners,Other speakers, equipment sounds, air conditioners,
construction noise etc.construction noise etc.
SpeakerSpeaker’’s own actions own action–– Lip smacks, breath noises, coughs, sneezesLip smacks, breath noises, coughs, sneezes
Communication noiseCommunication noise–– Channel errors, quantization noiseChannel errors, quantization noise
Unusual form of noiseUnusual form of noise–– DeepDeep--sea divers breathing hybrid of helium and oxygensea divers breathing hybrid of helium and oxygen
Speech production
Speech analysis
Speechcoding
Speechsynthesis
Speechquality
assessment
Speechrecognition
SpeakerrecognitionSpeech
enhancement
RoadmapRoadmap

Speaker RecognitionSpeaker Recognition
Like handwriting, the way you talk is also oneLike handwriting, the way you talk is also onekind of biometricskind of biometrics
http://www.pixar.com/featurefilms/ts/theater/teaser_480.html

Sources of verification errors

NonNon--speech Signalsspeech Signals
Audio processingAudio processing–– Psychoacoustic maskingPsychoacoustic masking–– MP3 compressionMP3 compression
Music processingMusic processing–– Music representation (pitch, rhythm, timbre etc.)Music representation (pitch, rhythm, timbre etc.)–– Music synthesisMusic synthesis and understandingand understanding
Sound processingSound processing–– Sound effect in movie industrySound effect in movie industry–– Classification of bird soundsClassification of bird sounds for environmental studyfor environmental study

MP3 CompressionMP3 Compression

Music SynthesisMusic SynthesisMusical Instrument Digital Interface (MIDI) protocol has beenMusical Instrument Digital Interface (MIDI) protocol has beenwidely accepted and utilized by musicians and composerswidely accepted and utilized by musicians and composerssince its conception in 1983since its conception in 1983MIDI information is transmitted in "MIDI messages", whichMIDI information is transmitted in "MIDI messages", whichcan be thought of as instructions which tell a music synthesizercan be thought of as instructions which tell a music synthesizerhow to play a piece of musichow to play a piece of music
http://www.midi.org/about-midi/tutorial/tutor.shtml









![[Advanced] Speech & Audio Signal Processing](https://static.fdocuments.us/doc/165x107/56815005550346895dbdd4b4/advanced-speech-audio-signal-processing.jpg)








