
Constraint Satisfaction Introduction to Artificial Intelligence COS302 Michael L. Littman Fall 2001.
date post
19-Dec-2015Category
view
215download
2
More Probabilistic ModelsMore Probabilistic Models
Introduction toIntroduction toArtificial IntelligenceArtificial Intelligence
COS302COS302
Michael L. LittmanMichael L. Littman
Fall 2001Fall 2001

AdministrationAdministration
2/3, 1/3 split for exams2/3, 1/3 split for exams
Last HW due WednesdayLast HW due Wednesday
Wrap up WednesdayWrap up Wednesday
Sample exam questions later…Sample exam questions later…
Example analogies, share, etc.Example analogies, share, etc.

TopicsTopics
Goal: Try to practice what we know Goal: Try to practice what we know about probabilistic modelsabout probabilistic models
• Segmentation: most likely Segmentation: most likely sequence of wordssequence of words
• EM for segmentationEM for segmentation• Belief net representationBelief net representation• EM for learning probabilitiesEM for learning probabilities

SegmentationSegmentation
Add spaces:Add spaces:
bothearthandsaturnspinbothearthandsaturnspin
Applications:Applications:• no spaces in speechno spaces in speech• no spaces in Chineseno spaces in Chinese• postscript or OCR to textpostscript or OCR to text

So Many Choices…So Many Choices…
Bothearthandsaturnspin.Bothearthandsaturnspin.B O T H E A R T H A N D S A T U R N S P I N.B O T H E A R T H A N D S A T U R N S P I N.
Bo-the-art hands at Urn’s Pin.Bo-the-art hands at Urn’s Pin.
Bot heart? Ha! N D S a turns pi N.Bot heart? Ha! N D S a turns pi N.
Both Earth and Saturn spin.Both Earth and Saturn spin.
……so little time. How to choose?so little time. How to choose?

Probabilistic ApproachProbabilistic Approach
Standard spiel:Standard spiel:
1.1. Choose a generative modelChoose a generative model
2.2. Estimate parametersEstimate parameters
3.3. Find most likely sequenceFind most likely sequence

Generative ModelGenerative Model
Choices:Choices:• unigram unigram Pr(w)Pr(w)• bigram bigram Pr(w|w’)Pr(w|w’)• trigram trigram Pr(w|w’,w’’)Pr(w|w’,w’’)• tag-based HMM tag-based HMM Pr(t|t’,t’’), Pr(w|t)Pr(t|t’,t’’), Pr(w|t)• probabilistic context-free grammar probabilistic context-free grammar
Pr(X Y|Z), Pr(w|Z)Pr(X Y|Z), Pr(w|Z)

Estimate ParametersEstimate Parameters
For English, can count word For English, can count word frequencies in text sample:frequencies in text sample:
Pr(w) = count(w)/sumPr(w) = count(w)/sumw w count(w)count(w)
For Chinese, could get someone to For Chinese, could get someone to segment, or use EM (next).segment, or use EM (next).
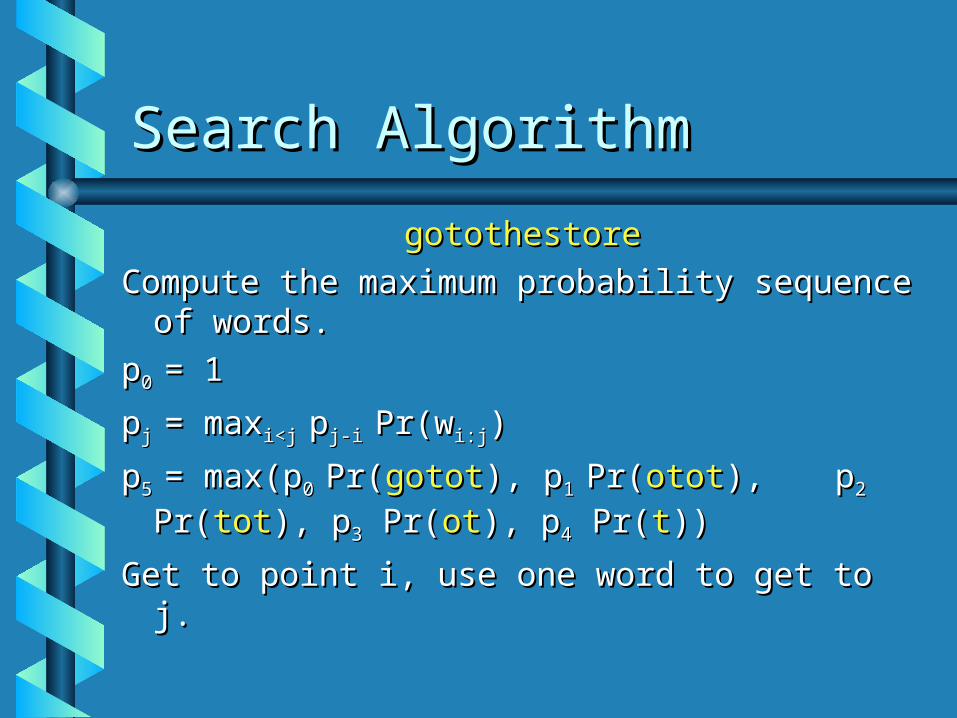
Search AlgorithmSearch Algorithm
gotothestoregotothestore
Compute the maximum probability Compute the maximum probability sequence of words.sequence of words.
pp0 0 = 1= 1
ppj j = max= maxi<j i<j ppj-i j-i Pr(wPr(wi:ji:j))
pp5 5 = max(p= max(p0 0 Pr(Pr(gototgotot), p), p1 1 Pr(Pr(otototot), ), pp22 Pr(Pr(tottot), p), p33 Pr( Pr(otot), p), p44 Pr( Pr(tt))))
Get to point i, use one word to get to j.Get to point i, use one word to get to j.

Unigrams Probs via EMUnigrams Probs via EM
g g 0.010.01 go go 0.780.78 got got 0.210.21 goto goto 0.610.61
o o 0.020.02 t t 0.040.04 to to 0.760.76 tot tot 0.740.74
o o 0.020.02 t t 0.040.04 the the 0.830.83 thes thes 0.040.04
h h 0.030.03 he he 0.220.22 hes hes 0.160.16 hest hest 0.190.19
e e 0.050.05 es es 0.090.09
s s 0.040.04 store store 0.810.81 t t 0.040.04 to to 0.700.70 tore tore 0.070.07
o o 0.020.02 or or 0.650.65 ore ore 0.090.09
r r 0.010.01 re re 0.120.12 e e 0.050.05

EM for SegmentationEM for Segmentation
Pick unigram probabilitiesPick unigram probabilitiesRepeat until probability doesn’t Repeat until probability doesn’t
improve muchimprove much1.1. Fractionally label (like forward-Fractionally label (like forward-
backward)backward)2.2. Use fractional counts to Use fractional counts to
reestimate unigram probabilitiesreestimate unigram probabilities
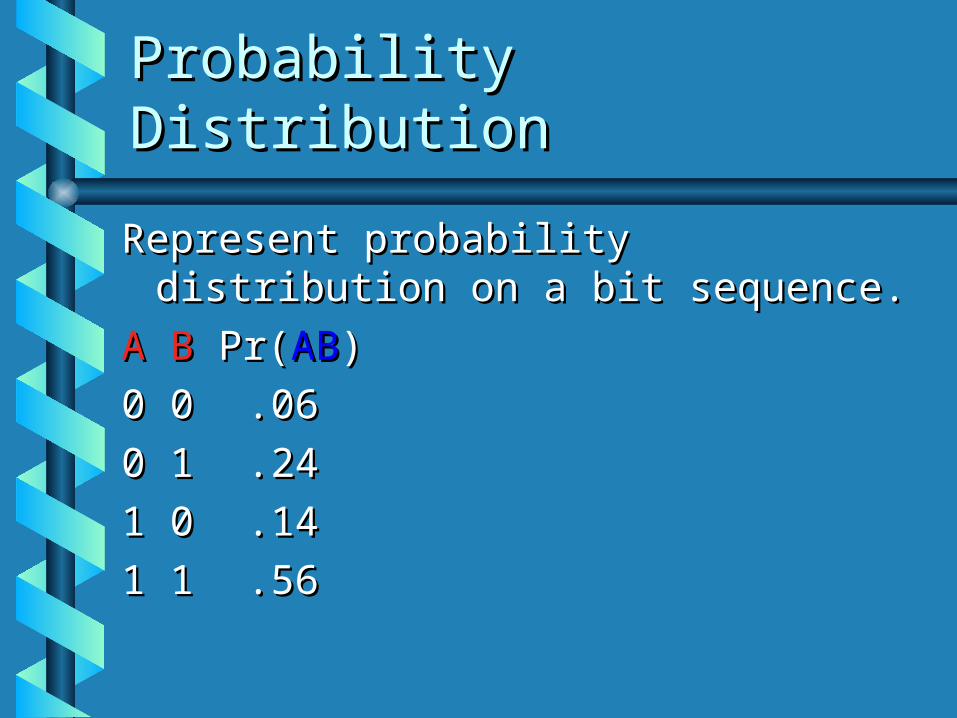
Probability DistributionProbability Distribution
Represent probability distribution on Represent probability distribution on a bit sequence.a bit sequence.
A BA B Pr( Pr(ABAB))
0 00 0 .06.06
0 10 1 .24.24
1 01 0 .14.14
1 11 1 .56.56

Conditional Probs.Conditional Probs.
Pr(Pr(AA||~B~B) = .14/(.14+.06) = .7) = .14/(.14+.06) = .7
Pr(Pr(AA||BB) = .56/(.56+.24) = .7) = .56/(.56+.24) = .7
Pr(Pr(BB||~A~A) = .24/(.24+.06) = .8) = .24/(.24+.06) = .8
Pr(Pr(BB||AA) = .56/(.56+.14) = .8) = .56/(.56+.14) = .8
So, Pr(So, Pr(ABAB)=Pr()=Pr(AA)Pr()Pr(BB))

Graphical ModelGraphical Model
Pick a value for A.Pick a value for A.
Pick a value for B.Pick a value for B.
Independent influence: kind of Independent influence: kind of and/or-ish.and/or-ish.
AA BB.7.7 .8.8
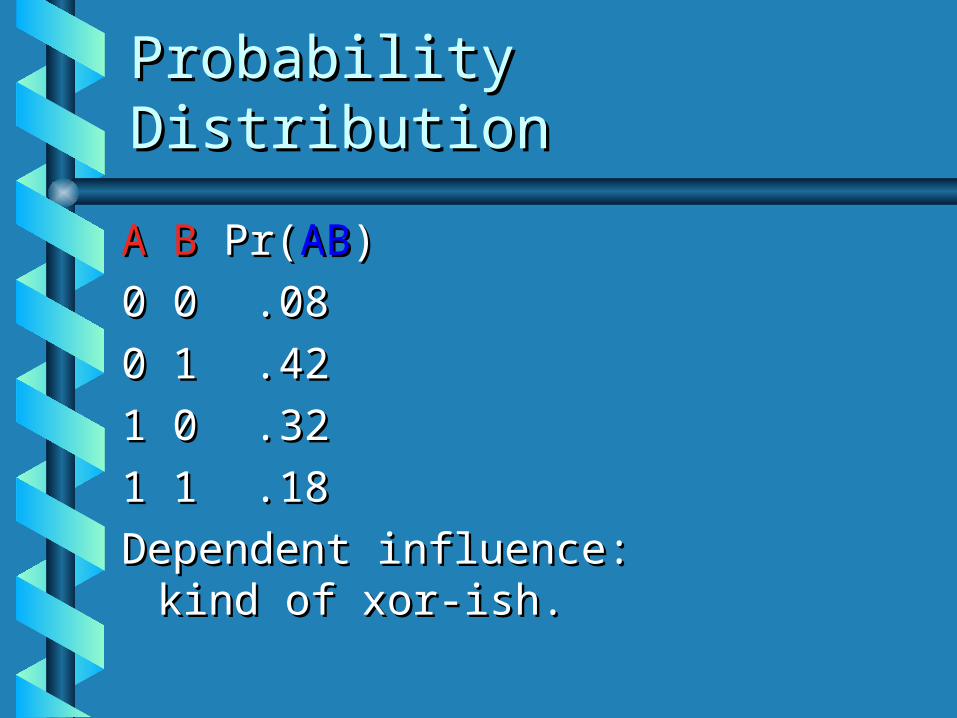
Probability DistributionProbability Distribution
A BA B Pr( Pr(ABAB))
0 00 0 .08.08
0 10 1 .42.42
1 01 0 .32.32
1 11 1 .18.18
Dependent influence: Dependent influence: kind kind of xor-ish.of xor-ish.

Conditional Probs.Conditional Probs.
Pr(Pr(AA||~B~B) = .32/(.32+.08) = .8) = .32/(.32+.08) = .8
Pr(Pr(AA||BB) = .18/(.18+.42) = .3) = .18/(.18+.42) = .3
Pr(Pr(BB||~A~A) = .42/(.42+.08) = .84) = .42/(.42+.08) = .84
Pr(Pr(BB||AA) = .18/(.18+.32) = .36) = .18/(.18+.32) = .36
So, a bit more complex.So, a bit more complex.

Graphical ModelGraphical Model
Pick a value for B.Pick a value for B.
Pick a value for A, based on B.Pick a value for A, based on B.
AA
BB
B Pr(A|B)B Pr(A|B)0 .80 .81 .31 .3
.6.6
CPT: ConditionalCPT: ConditionalProbability TableProbability Table

General FormGeneral Form
Acyclic graph; each node a var.Acyclic graph; each node a var.Node with k in edges; size 2Node with k in edges; size 2kk CPT. CPT.
NN
PP11
PP1 1 PP2 2 … P… Pk k Pr(Pr(NN|P|P11 P P2 2 … P… Pkk))0 0 0 p0 0 0 p00…000…0
… …1 1 1 p1 1 1 p11…111…1
PP22 PPkk……

Belief NetworkBelief Network
Bayesian network, Bayes net, etc.Bayesian network, Bayes net, etc.
Represents a prob. distribution over Represents a prob. distribution over 22n n values with O(2values with O(2kk) entries, where ) entries, where k is the largest indegreek is the largest indegree
Can be applied to variables with Can be applied to variables with values beyond just {0, 1}. Kind of values beyond just {0, 1}. Kind of like a CSP.like a CSP.

What Can You Do?What Can You Do?
Belief net inference: Pr(Belief net inference: Pr(NN||EE11,~E,~E22,E,E33, , ……).).
Polytime algorithms exist if Polytime algorithms exist if undirected version of DAG is undirected version of DAG is acyclic (singly connected)acyclic (singly connected)
NP-hard if multiply connected.NP-hard if multiply connected.

Example BNsExample BNs
EE
BB
CC
DD
AA
EE
BB
CC
DD
AA
singlysinglymultiplymultiply

Popular BNPopular BN
WW
CC
XXVV YY ZZ
Recognize this?Recognize this?

BN ApplicationsBN Applications
Diagnosing diseasesDiagnosing diseases
Decoding noisy messages from deep Decoding noisy messages from deep space probesspace probes
Reasoning about geneticsReasoning about genetics
Understanding consumer purchasing Understanding consumer purchasing patternspatterns
Annoying users of WindowsAnnoying users of Windows

Parameter LearningParameter Learning
A B C D EA B C D E
0 0 1 0 10 0 1 0 1 Pr( Pr(BB||~A~A)?)?
0 0 1 1 10 0 1 1 1
1 1 1 0 11 1 1 0 1
0 1 0 0 10 1 0 0 1
1 0 1 0 11 0 1 0 1
0 0 1 1 00 0 1 1 0
0 0 1 1 10 0 1 1 1
EE
BB
CC
DD
AA
1/51/5

Hidden VariableHidden Variable
A B C D EA B C D E
0 0 1 0 10 0 1 0 1 Pr( Pr(BB||~A~A)?)?
0 0 1 1 10 0 1 1 1
1 1 1 0 11 1 1 0 1
0 1 0 0 10 1 0 0 1
1 0 1 0 11 0 1 0 1
0 0 1 1 00 0 1 1 0
0 0 1 1 10 0 1 1 1
EE
BB
CC
DD
AA

What to LearnWhat to Learn
Segmentation problemSegmentation problemAlgorithm for finding the most likely Algorithm for finding the most likely
segmentationsegmentationHow EM might be used for parameter How EM might be used for parameter
learninglearningBelief network representationBelief network representationHow EM might be used for parameter How EM might be used for parameter
learninglearning


















