
More on Disks and FilesCS-502 Fall 20061 More on Disks and File Systems CS-502 Operating Systems...
38
More on Disks and Files CS-502 Fall 2006 1 More on Disks and File Systems CS-502 Operating Systems Fall 2006 (Slides include materials from Operating System Concepts, 7 th ed., by Silbershatz, Galvin, & Gagne and from Modern Operating Systems, 2 nd ed., by Tanenbaum)
-
date post
21-Dec-2015 -
Category
Documents
-
view
214 -
download
0
Transcript of More on Disks and FilesCS-502 Fall 20061 More on Disks and File Systems CS-502 Operating Systems...

More on Disks and FilesCS-502 Fall 2006 1
More on Disks and File Systems
CS-502 Operating SystemsFall 2006
(Slides include materials from Operating System Concepts, 7th ed., by Silbershatz, Galvin, & Gagne and from Modern Operating Systems, 2nd ed., by Tanenbaum)

More on Disks and FilesCS-502 Fall 2006 2
Additional Topics
• Mounting a file system
• Mapping files to virtual memory
• RAID – Redundant Array of Inexpensive Disks
• Stable Storage
• Log Structured File Systems
• Linux Virtual File System

More on Disks and FilesCS-502 Fall 2006 3
Summary of Reading Assignmentsin Silbershatz
• Disks (general) – §12.1 to 12.6
• File systems (general) – Chapter 11• Ignore §11.9, 11.10 for now!
• RAID – §12.7
• Stable Storage – §12.8
• Log-structured File System – §11.8 & §6.9

More on Disks and FilesCS-502 Fall 2006 4
Mounting
mount –t type device pathname
• Attach device (which contains a file system of type type) to the directory at pathname
• File system implementation for type gets loaded and connected to the device
• Anything previously below pathname becomes hidden until the device is un-mounted again
• The root of the file system on device is now accessed as pathname
• E.g.,mount –t iso9660 /dev/cdrom /myCD

More on Disks and FilesCS-502 Fall 2006 5
Mounting (continued)
• OS automatically mount devices in its mount table at initialization time
•/etc/fstab in Linux
• Type may be implicit in device
• Users or applications may mount devices at run time, explicitly or implicitly — e.g.,
• Insert a floppy disk
• Plug in a USB flash drive

More on Disks and FilesCS-502 Fall 2006 6
Linux Virtual File System (VFS)
• A generic file system interface provided by the kernel
• Common object framework– superblock: a specific, mounted file system– i-node object: a specific file in storage– d-entry object: a directory entry– file object: an open file associated with a
process

More on Disks and FilesCS-502 Fall 2006 7
Linux Virtual File System (continued)
• VFS operations– super_operations:
• read_inode, sync_fs, etc.
– inode_operations:• create, link, etc.
– d_entry_operations:• d_compare, d_delete, etc.
– file_operations:• read, write, seek, etc.

More on Disks and FilesCS-502 Fall 2006 8
Linux Virtual File System (continued)
• Individual file system implementations conform to this architecture.
• May be linked to kernel or loaded as modules
• Linux supports over 50 file systems in official kernel
• E.g., minix, ext, ext2, ext3, iso9660, msdos, nfs, smb, …

More on Disks and FilesCS-502 Fall 2006 9
Linux Virtual File System (continued)
• A special file type — proc– Mounted as /proc
– Provides access to kernel internal data structures as if those structures were files!
– E.g., /proc/dmesg
• There are several other special file types– Vary from one version/vendor to another
– See Silbershatz, §11.2.3
– Love, Linux Kernel Development, Chapter 12
– SUSE Linux Administrator Guide, Chapter 20

More on Disks and FilesCS-502 Fall 2006 10
Questions?

More on Disks and FilesCS-502 Fall 2006 11
Mapping files to Virtual Memory
• Instead of “reading” from disk into virtual memory, why not simply use file as the swapping storage for certain VM pages?
• Called mapping
• Page tables in kernel point to disk blocks of the file

More on Disks and FilesCS-502 Fall 2006 12
Memory-Mapped Files
• Memory-mapped file I/O allows file I/O to be treated as routine memory access by mapping a disk block to a page in memory
• A file is initially “read” using demand paging. A page-sized portion of the file is read from the file system into a physical page. Subsequent reads/writes to/from the file are treated as ordinary memory accesses.
• Simplifies file access by allowing application to simple access memory rather than be forced to use read() & write() calls to file system.

More on Disks and FilesCS-502 Fall 2006 13
Memory-Mapped Files (continued)
• A tantalizingly attractive notion, but …
• Cannot use C/C++ pointers within mapped data structure
• Corrupted data structures likely to persist in file• Recovery after a crash is more difficult
• Don’t really save anything in terms of• Programming energy
• Thought processes
• Storage space & efficiency

More on Disks and FilesCS-502 Fall 2006 14
Memory-Mapped Files (continued)
Nevertheless, the idea has its uses1. Simpler implementation of file operations
– read(), write() are memory-to-memory operations
– seek() is simply changing a pointer, etc…
– Called memory-mapped I/O
2. Shared Virtual Memory among processes
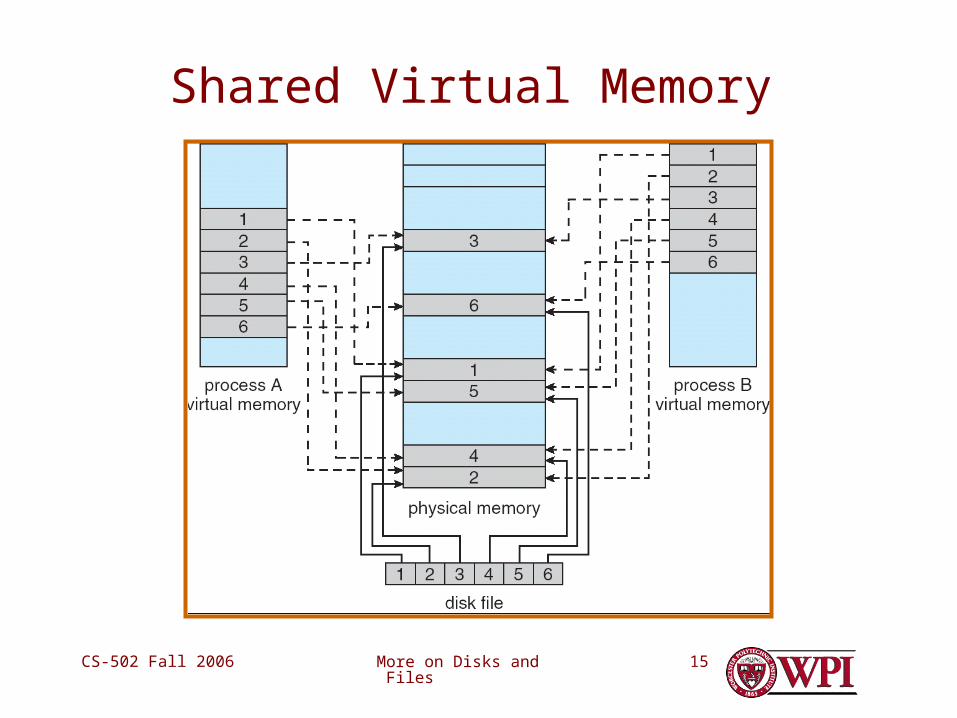
More on Disks and FilesCS-502 Fall 2006 15
Shared Virtual Memory

More on Disks and FilesCS-502 Fall 2006 16
Shared Virtual Memory (continued)
• Supported in – Windows XP– Apollo DOMAIN– Linux??
• Synchronization is the responsibility of the sharing applications– OS retains no knowledge– Few (if any) synchronization primitives
between processes in separate address spaces

More on Disks and FilesCS-502 Fall 2006 17
Questions?

More on Disks and FilesCS-502 Fall 2006 18
Problem
• Question:–– If mean time to failure of a disk drive is 100,000 hours,– and if your system has 100 identical disks,– what is mean time between drive replacement?
• Answer:–– 1000 hours (i.e., 41.67 days 6 weeks)
• I.e.:–– You lose 1% of your data every 6 weeks!
• But don’t worry – you can restore most of it from backup!

More on Disks and FilesCS-502 Fall 2006 19
Can we do better?
• Yes, mirrored– Write every block twice, on two separate disks– Mean time between simultaneous failure of
both disks is 57,000 years
• Can we do even better?– E.g., use fewer extra disks?– E.g., get more performance?

More on Disks and FilesCS-502 Fall 2006 20
RAID – Redundant Array of Inexpensive Disks
• Distribute a file system intelligently across multiple disks to– Maintain high reliability and availability– Enable fast recovery from failure– Increase performance

More on Disks and FilesCS-502 Fall 2006 21
“Levels” of RAID
• Level 0 – non-redundant striping of blocks across disk
• Level 1 – simple mirroring
• Level 2 – striping of bytes or bits with ECC
• Level 3 – Level 2 with parity, not ECC
• Level 4 – Level 0 with parity block
• Level 5 – Level 4 with distributed parity blocks

More on Disks and FilesCS-502 Fall 2006 22
RAID Level 0 – Simple Striping
• Each stripe is one or a group of contiguous blocks
• Block/group i is on disk (i mod n)
• Advantage– Read/write n blocks in parallel; n times bandwidth
• Disadvantage– No redundancy at all. System MBTF is 1/n disk MBTF!
stripe 8stripe 4stripe 0
stripe 9stripe 5stripe 1
stripe 10stripe 6stripe 2
stripe 11stripe 7stripe 3

More on Disks and FilesCS-502 Fall 2006 23
RAID Level 1– Striping and Mirroring
• Each stripe is written twice• Two separate, identical disks
• Block/group i is on disks (i mod 2n) & (i+n mod 2n)• Advantages
– Read/write n blocks in parallel; n times bandwidth– Redundancy: System MBTF = (Disk MBTF)2 at twice the cost– Failed disk can be replaced by copying
• Disadvantage– A lot of extra disks for much more reliability than we need
stripe 8stripe 4stripe 0
stripe 9stripe 5stripe 1
stripe 10stripe 6stripe 2
stripe 11stripe 7stripe 3
stripe 8stripe 4stripe 0
stripe 9stripe 5stripe 1
stripe 10stripe 6stripe 2
stripe 11stripe 7stripe 3

More on Disks and FilesCS-502 Fall 2006 24
RAID Levels 2 & 3
• Bit- or byte-level striping
• Requires synchronized disks• Highly impractical
• Requires fancy electronics • For ECC calculations
• Not used; academic interest only
• See Silbershatz, §12.7.3 (pp. 471-472)

More on Disks and FilesCS-502 Fall 2006 25
Observation
• When a disk or stripe is read incorrectly,
we know which one failed!
• Conclusion:– A simple parity disk can provide very high
reliability• (unlike simple parity in memory)

More on Disks and FilesCS-502 Fall 2006 26
RAID Level 4 – Parity Disk
• parity 0-3 = stripe 0 xor stripe 1 xor stripe 2 xor stripe 3• n stripes plus parity are written/read in parallel• If any disk/stripe fails, it can be reconstructed from others
– E.g., stripe 1 = stripe 0 xor stripe 2 xor stripe 3 xor parity 0-3
• Advantages– n times read bandwidth– System MBTF = (Disk MBTF)2 at 1/n additional cost– Failed disk can be reconstructed “on-the-fly” (hot swap)– Hot expansion: simply add n + 1 disks all initialized to zeros
• However– Writing requires read-modify-write of parity stripe only 1x write
bandwidth.
stripe 8stripe 4stripe 0
stripe 9stripe 5stripe 1
stripe 10stripe 6stripe 2
stripe 11stripe 7stripe 3
parity 8-11parity 4-7parity 0-3

More on Disks and FilesCS-502 Fall 2006 27
RAID Level 5 – Distributed Parity
• Parity calculation is same as RAID Level 4• Advantages & Disadvantages – Same as RAID Level 4• Additional advantages
– avoids beating up on parity disk– Some writes in parallel
• Writing individual stripes (RAID 4 & 5)– Read existing stripe and existing parity– Recompute parity– Write new stripe and new parity
stripe 12stripe 8stripe 4stripe 0
parity 12-15stripe 9stripe 5stripe 1
stripe 13parity 8-11stripe 6stripe 2
stripe 14stripe 10parity 4-7stripe 3
stripe 15stripe 11stripe 7parity 0-3

More on Disks and FilesCS-502 Fall 2006 28
RAID 4 & 5
• Very popular in data centers– Corporate and academic servers
• Built-in support in Windows XP and Linux– Connect a group of disks to fast SCSI port (320
MB/sec bandwidth)– OS RAID support does the rest!

More on Disks and FilesCS-502 Fall 2006 29
New Topic

More on Disks and FilesCS-502 Fall 2006 30
Incomplete Operations
• Problem – how to protect against disk write operations that don’t finish– Power or CPU failure in the middle of a block– Related series of writes interrupted before all
are completed
• Examples:– Database update of charge and credit– RAID 1, 4, 5 failure between redundant writes

More on Disks and FilesCS-502 Fall 2006 31
Solution (part 1) – Stable Storage
• Write everything twice to separate disks• Be sure 1st write does not invalidate previous 2nd
copy
• RAID 1 is okay; RAID 4/5 not okay!
• Read blocks back to validate; then report completion
• Reading both copies• If 1st copy okay, use it – i.e., newest value
• If 2nd copy different, update it with 1st copy
• If 1st copy is bad; use 2nd copy – i.e., old value

More on Disks and FilesCS-502 Fall 2006 32
Stable Storage (continued)
• Crash recovery• Scan disks, compare corresponding blocks• If one is bad, replace with good one• If both good but different, replace 2nd with 1st copy
• Result:–• If 1st block is good, it contains latest value• If not, 2nd block still contains previous value
• An abstraction of an atomic disk write of a single block
• Uninterruptible by power failure, etc.

More on Disks and FilesCS-502 Fall 2006 33
What about more complex disk operations?
• E.g., File create operation involves• Allocating free blocks
• Constructing and writing i-node– Possibly multiple i-node blocks
• Reading and updating directory
• What if system crashes with the sequence only partly completed?
• Answer: inconsistent data structures on disk

More on Disks and FilesCS-502 Fall 2006 34
Solution (Part 2) –Log-Structured File System
• Make changes to cached copies in memory• Collect together all changed blocks
• Including i-nodes and directory blocks
• Write to log file (aka journal file)• A circular buffer on disk• Fast, contiguous write
• Update log file pointer in stable storage
• Offline: Play back log file to actually update directories, i-nodes, free list, etc.
• Update playback pointer in stable storage

More on Disks and FilesCS-502 Fall 2006 35
Transaction Data Base Systems
• Similar techniques– Every transaction is recorded in log before
recording on disk– Stable storage techniques for managing log
pointers– One log exist is confirmed, disk can be updated
in place– After crash, replay log to redo disk operations

More on Disks and FilesCS-502 Fall 2006 36
Berkeley LFS — a slight variation
• Everything is written to log• i-nodes point to updated blocks in log• i-node cache in memory updated whenever i-node is written• Cleaner daemon follows behind to compact log
• Advantages:– LFS is always consistent– LFS performance
• Much better than Unix file system for small writes• At least as good for reads and large writes
• Tanenbaum, §6.3.8, pp. 428-430• Rosenblum & Ousterhout, Log-structured File System (pdf
)
• Note: not same as Linux LFS (large file system)

More on Disks and FilesCS-502 Fall 2006 37
Example
i-node
modified blocksa
b c
Before
old i-node
old blocksa
b c
loga b c
new blocks
new i-node
After

More on Disks and FilesCS-502 Fall 2006 38
Summary of Reading Assignmentsin Silbershatz
• Disks (general) – §12.1 to 12.6
• File systems (general) – Chapter 11• Ignore §11.9, 11.10 for now!
• RAID – §12.7
• Stable Storage – §12.8
• Log-structured File System – §11.8 & §6.9


















