

MongoDB Schema Design and its Performance Implications
49
Schema Design (and its performance implications) Jay Runkel Principal Solutions Architect j [email protected] @jayrunkel
-
Upload
lewis-lin- -
Category
Software
-
view
35 -
download
4
Transcript of MongoDB Schema Design and its Performance Implications

Schema Design(and its performance implications)
Jay RunkelPrincipal Solutions [email protected]@jayrunkel

2
Agenda
1. Today’s Example
2. MongoDB Schema Design vs. Relational
3. Modeling Relationships
4. Schema Design and Performance

Today’s Example
4
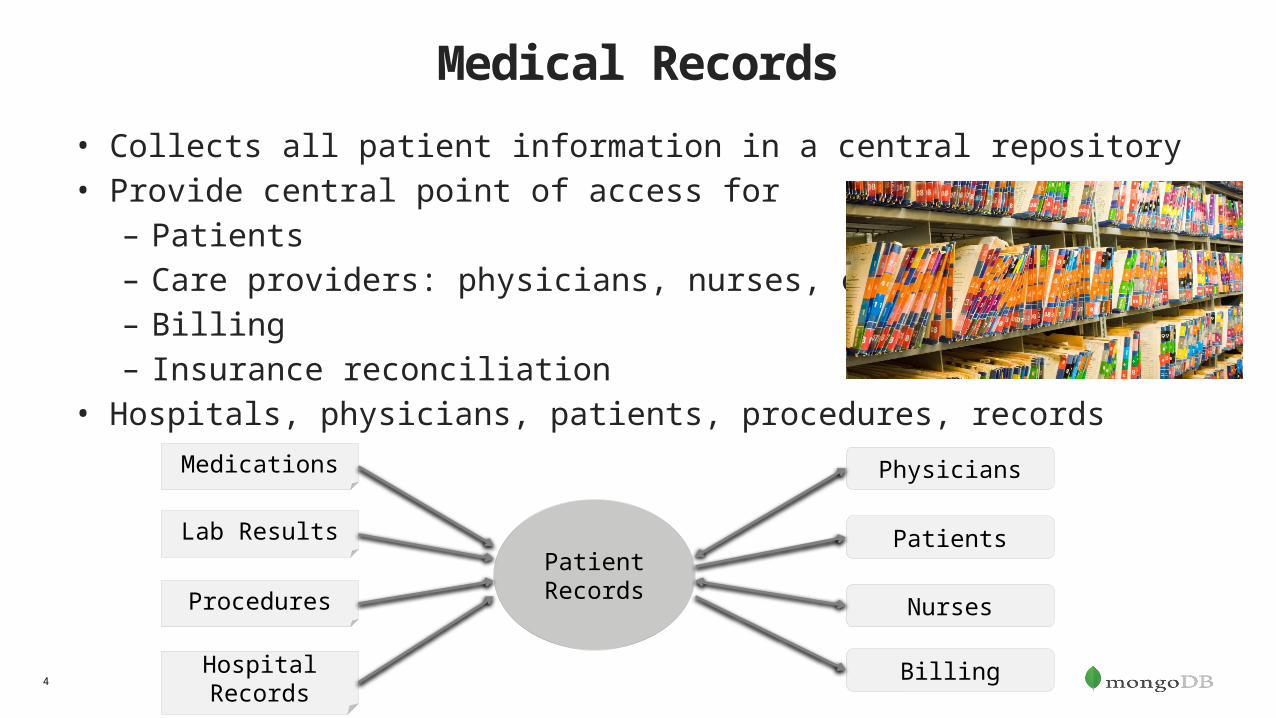
Medical Records• Collects all patient information in a central repository• Provide central point of access for
– Patients– Care providers: physicians, nurses, etc.– Billing– Insurance reconciliation
• Hospitals, physicians, patients, procedures, records
PatientRecords
Medications
Lab Results
Procedures
Hospital Records
Physicians
Patients
Nurses
Billing
5
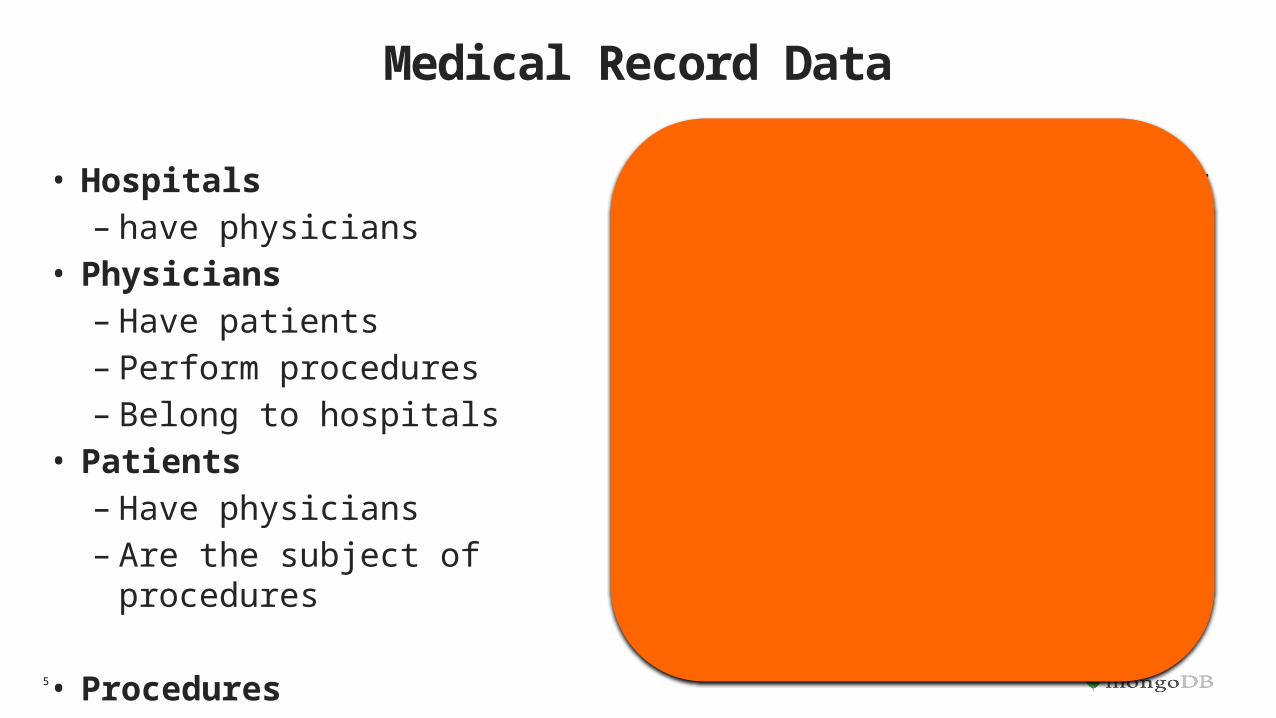
Medical Record Data
• Hospitals – have physicians
• Physicians– Have patients– Perform procedures– Belong to hospitals
• Patients– Have physicians– Are the subject of procedures
• Procedures– Associated with a patient– Associated with a physician– Have a record– Variable meta data
• Records– Associated with a procedure– Binary data– Variable fields

6
Lot of Variability
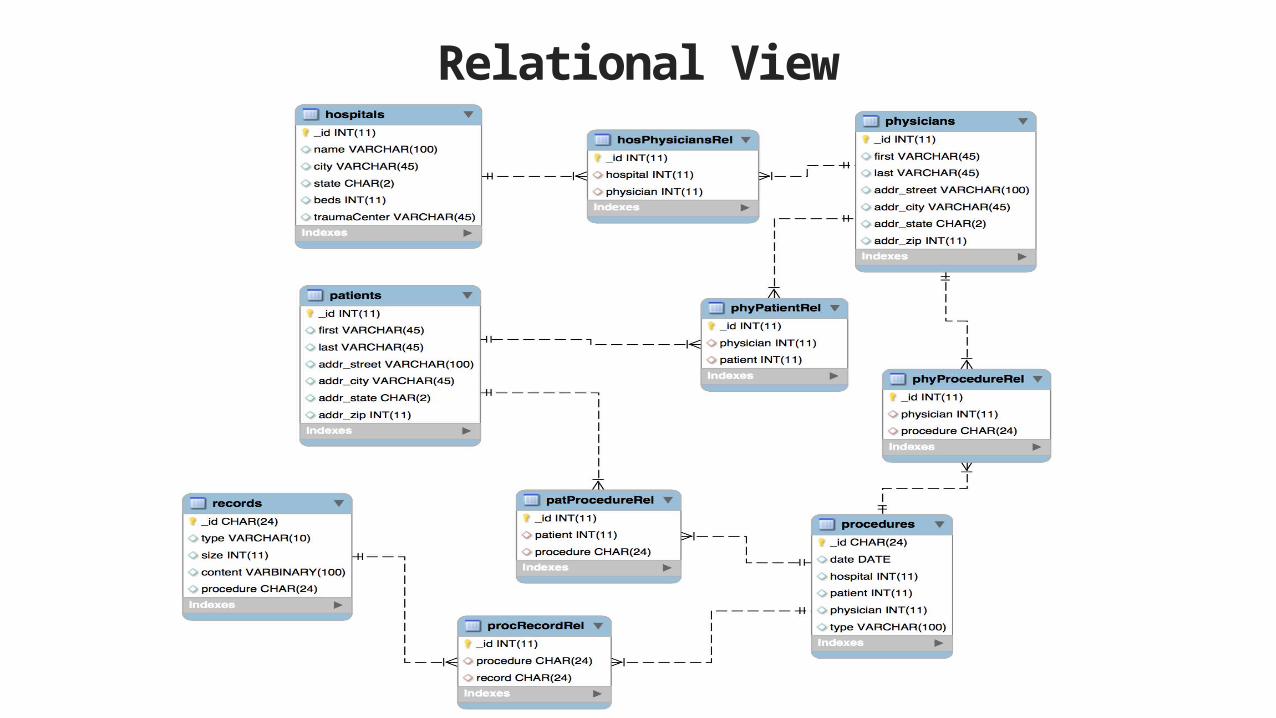
Relational View

Schema Design:
MongoDB vs. Relational

MongoDB Relational
Collections Tables
Documents Rows
Data Use Data Storage
What questions do I have? What answers do I have?
MongoDB versus Relational
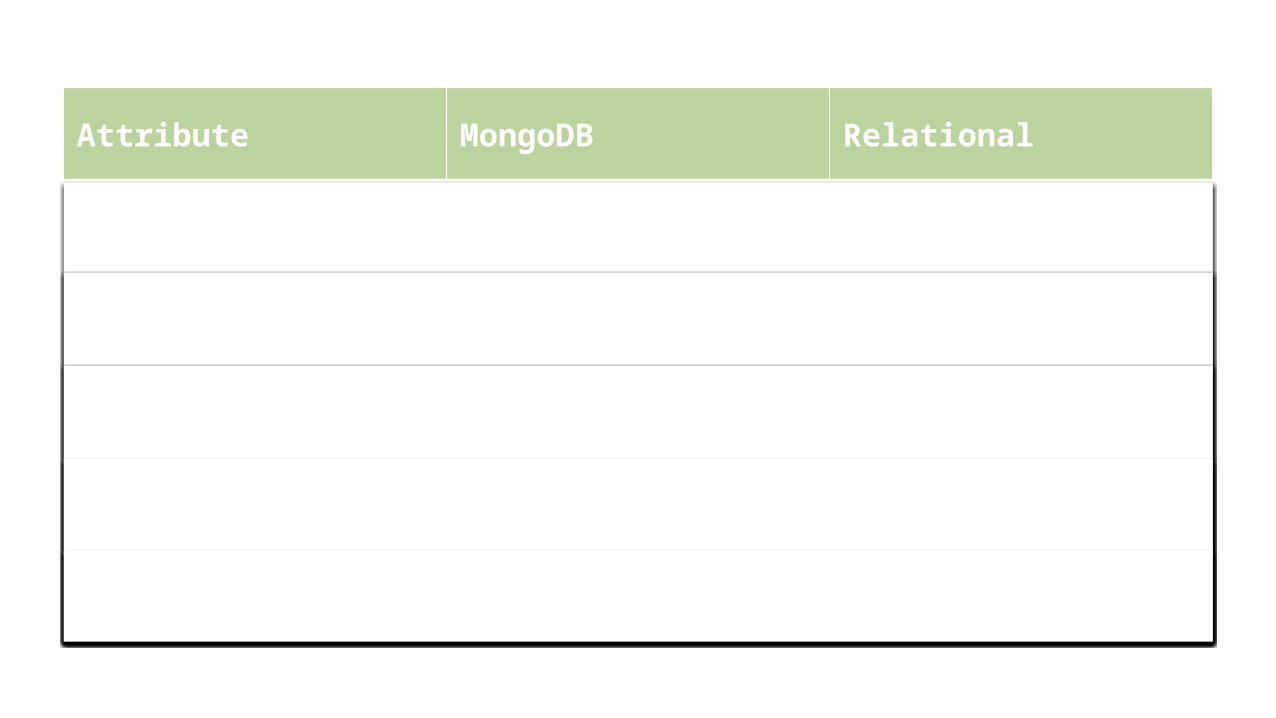
Attribute MongoDB Relational
Storage N-dimensional Two-dimensional
Field Values 0, 1, many, or embed Single value
Query Any field or level Any field
Schema Flexible Very structured

Complex Normalized Schemas

Complex Normalized Schemas

13
Documents are Rich Data Structures{ first_name: ‘Paul’, surname: ‘Miller’, cell: ‘+447557505611’ city: ‘London’, location: [45.123,47.232], Profession: [banking, finance, trader], cars: [ { model: ‘Bentley’, year: 1973, value: 100000, … }, { model: ‘Rolls Royce’, year: 1965, value: 330000, … } ]}
Fields can contain an array of sub-documents
Fields
Typed field values
Fields can contain arrays
String
Number
Geo-Coordinates

Relationships

Modeling One-to-One Relationships

16
Referencing
Procedure• patient• date• type• physician• type
Results• dataType• size• content: {…}
Use two collections with a reference
Similar to relational

17
Procedure• patient• date• type• results
• equipmentId• data1• data2
• physician
• Results• type• size• content: {…}
Embedding
Document Schema
18
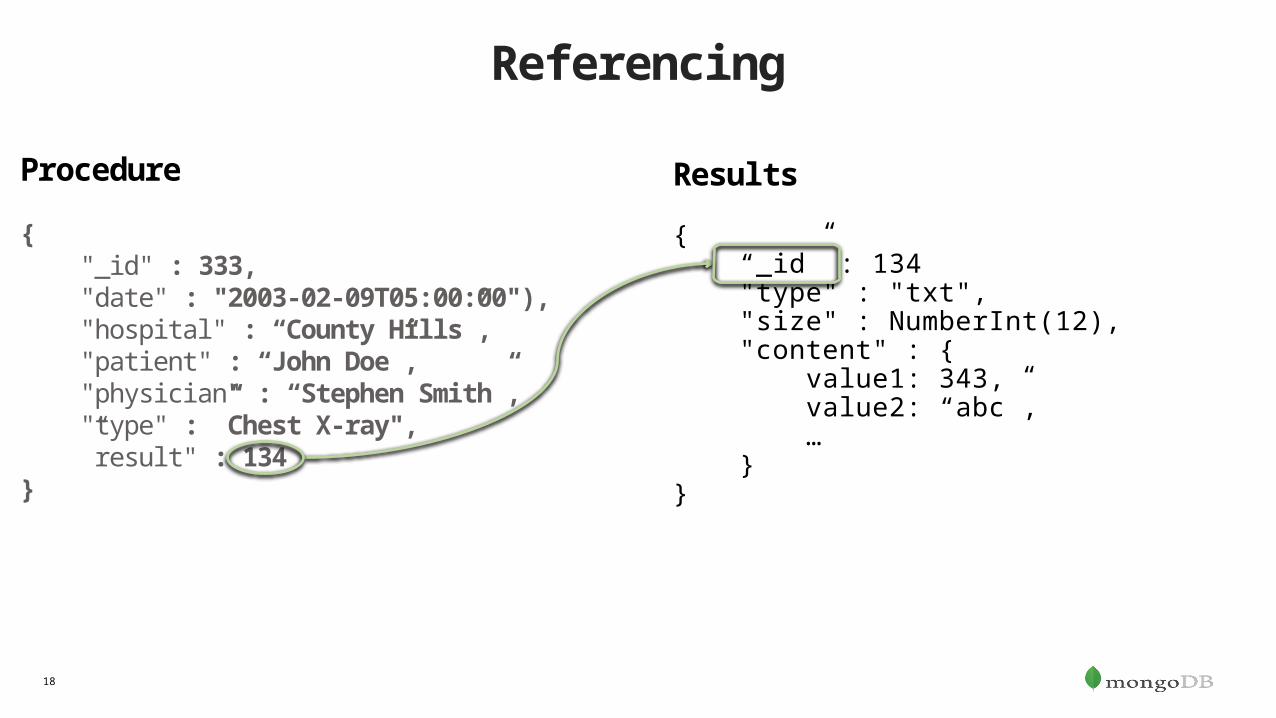
Referencing
Procedure
{ "_id" : 333, "date" : "2003-02-09T05:00:00"), "hospital" : “County Hills”, "patient" : “John Doe”, "physician" : “Stephen Smith”, "type" : ”Chest X-ray", ”result" : 134}
Results
{ “_id” : 134 "type" : "txt", "size" : NumberInt(12), "content" : { value1: 343, value2: “abc”, … } }

19
EmbeddingProcedure{ "_id" : 333, "date" : "2003-02-09T05:00:00"), "hospital" : “County Hills”, "patient" : “John Doe”, "physician" : “Stephen Smith”, "type" : ”Chest X-ray", ”result" : { "type" : "txt", "size" : NumberInt(12), "content" : { value1: 343, value2: “abc”, … } }}

20
Embedding
• Advantages– Retrieve all relevant information in a single query/document– Avoid implementing joins in application code– Update related information as a single atomic operation
• MongoDB doesn’t offer multi-document transactions
• Limitations– Large documents mean more overhead if most fields are not relevant– 16 MB document size limit

21
Atomicity
• Document operations are atomicdb.patients.update({_id: 12345},
{$inc : {numProcedures : 1}, $push : {procedures : “proc123”}, $set : {addr.state : “TX”}})
• No multi-document transactions
db.beginTransaction();db.patients.update({_id: 12345}, …);db.procedure.insert({_id: “proc123”, …});db.records.insert({_id: “rec123”, …});db.endTransaction();

22
Embedding
• Advantages– Retrieve all relevant information in a single query/document– Avoid implementing joins in application code– Update related information as a single atomic operation
• MongoDB doesn’t offer multi-document transactions
• Limitations– Large documents mean more overhead if most fields are not relevant– 16 MB document size limit

23
Referencing
• Advantages– Smaller documents– Less likely to reach 16 MB document limit– Infrequently accessed information not accessed on every query– No duplication of data
• Limitations– Two queries required to retrieve information– Cannot update related information atomically

24
One to One: General Recommendations
• Embed– No additional data duplication– Can query or index on
embedded field• e.g., “result.type”
• Exceptional cases…• Embedding results in large
documents• Set of infrequently access
fields
{ "_id" : 333, "date" : "2003-02-09T05:00:00"), "hospital" : “County Hills”, "patient" : “John Doe”, "physician" : “Stephen Smith”, "type" : ”Chest X-ray", ”result" : { "type" : "txt", "size" : NumberInt(12), "content" : { value1: 343, value2: “abc”, … } }}

Modeling One-to-Many Relationships

26
{ _id: 2, first: “Joe”, last: “Patient”, addr: { …}, procedures: [ { id: 12345, date: 2015-02-15, type: “Cat scan”,
…}, { id: 12346, date: 2015-02-15, type: “blood test”,
…}]}
Pat
ient
s
Embed
One-to-Many RelationshipsModeled in 2 possible ways
{ _id: 2, first: “Joe”, last: “Patient”, addr: { …}, procedures: [12345, 12346]}
{ _id: 12345, date: 2015-02-15, type: “Cat scan”, …} { _id: 12346, date: 2015-02-15, type: “blood test”, …}
Pat
ient
s
Reference
Pro
cedu
res

27
One to Many: General Recommendations
• Embed, when possible– Access all information in a single query– Take advantage of update atomicity– No additional data duplication– Can query or index on any field
• e.g., { “phones.type”: “mobile” }
• Exceptional cases:– 16 MB document size– Large number of infrequently accessed fields
{ _id: 2, first: “Joe”, last: “Patient”, addr: { …}, procedures: [ { id: 12345, date: 2015-02-15, type: “Cat scan”,
…}, { id: 12346, date: 2015-02-15, type: “blood test”,
…}]}

Modeling Many-to-Many Relationships

29
Many to ManyTraditional Relational Association
Join table
Physiciansnamespecialtyphone
Hospitalsname
HosPhysicanRelhospitalIdphysicianIdX
Use arrays instead

30
{ _id: 1, name: “Oak Valley Hospital”, city: “New York”, beds: 131, physicians: [ { id: 12345, name: “Joe Doctor”, address: {…},
…}, { id: 12346, name: “Mary Well”, address: {…},
…}]}
Many-to-Many RelationshipsEmbedding physicians in hospitals collection
{ _id: 2, name: “Plainmont Hospital”, city: “Omaha”, beds: 85, physicians: [ { id: 63633, name: “Harold Green”, address: {…},
…}, { id: 12345, name: “Joe Doctor”, address: {…},
…}]}
Data Duplication

31
{ _id: 1, name: “Oak Valley Hospital”, city: “New York”, beds: 131, physicians: [12345, 12346]}
Many-to-Many RelationshipsReferencing
{ id: 63633, name: “Harold Green”, address: {…}, …}
Hospitals
{ _id: 2, name: “Plainmont Hospital”, city: “Omaha”, beds: 85, physicians: [63633, 12345]}
Physicians
{ id: 12345, name: “Joe Doctor”, address: {…}, …}
{ id: 12346, name: “Mary Well”, address: {…}, …}

32
Many to ManyGeneral Recommendation
• Use case determines whether to reference or embed:1. Data Duplication
• Embedding may result in data duplication
• Duplication may be okay if reads dominate updates
2. Referencing may be required if many related items
3. Hybrid approach• Potentially do both
{ _id: 2, name: “Oak Valley Hospital”, city: “New York”, beds: 131, physicians: [12345, 12346]}
{ _id: 12345, name: “Joe Doctor”, address: {…}, …} { _id: 12346, name: “Mary Well”, address: {…}, …}
Hos
pita
ls
Reference
Phy
sici
ans

What If I Want to Store Large Files in MongoDB?

34
GridFS
Driv
erGridFS APIdoc.jpg(meta data)
doc.jpg(1)doc.jpg
(1)doc.jpg(1)
fs.files fs.chunksdoc.jpg
mongofiles utility provides command line GridFS interface

Schema Design and Performance
Two Examples

Example 1: Hybrid Approach
Embed and Reference

37
Healthcare Example
patients
procedures

Tailor Schema to Queries (cont.)
{ "_id" : 593340651, "first" : "Gregorio", "last" : "Lang", "addr" : { "street" : "623 Flowers Rd", "city" : "Groton", "state" : "NH", "zip" : 3266 }, "physicians" : [10387 33456], "procedures” : ["551ac”, “343fs”]}
{ "_id" : "551ac”, "date" :"2000-04-26”, "hospital" : 161, "patient" : 593340651, "physician" : 10387, "type" : "Chest X-ray", "records" : [ “67bc6”]}
Patient Procedure
Find all patients from NH that have had chest x-rays

Tailor Schema to Queries (cont.)
{ "_id" : 593340651, "first" : "Gregorio", "last" : "Lang", "addr" : { "street" : "623 Flowers Rd", "city" : "Groton", "state" : "NH", "zip" : 3266 }, "physicians" : [10387 33456], "procedures” : [ {id : "551ac”, type : “Chest X-ray”}, {id : “343fs”, type : “Blood Test”}]}
{ "_id" : "551ac”, "date" :"2000-04-26”, "hospital" : 161, "patient" : 593340651, "physician" : 10387, "type" : "Chest X-ray", "records" : [ “67bc6”]}
Patient Procedure
Find all patients from NH that have had chest x-rays

Example 2: Time Series Data
Medical Devices

41
Vital Sign Monitoring Device
Vital Signs Measured:• Blood Pressure• Pulse• Blood Oxygen Levels
Produces data at regular intervals• Once per minute
42
We have a hospital(s) of devices

43
Data From Vital Signs Monitoring Device
{ deviceId: 123456, spO2: 88, pulse: 74, bp: [128, 80], ts: ISODate("2013-10-16T22:07:00.000-0500")}
• One document per minute per device
• Relational approach

44
Document Per Hour (By minute)
{ deviceId: 123456, spO2: { 0: 88, 1: 90, …, 59: 92}, pulse: { 0: 74, 1: 76, …, 59: 72}, bp: { 0: [122, 80], 1: [126, 84], …, 59: [124, 78]}, ts: ISODate("2013-10-16T22:00:00.000-0500")}
• Store per-minute data at the hourly level
• Update-driven workload
• 1 document per device per hour

45
Characterizing Write Differences
• Example: data generated every minute• Recording the data for 1 patient for 1 hour:
Document Per Event60 inserts
Document Per Hour1 insert, 59 updates

46
Characterizing Read Differences
• Want to graph 24 hour of vital signs for a patient:
• Read performance is greatly improved
Document Per Event 1440 reads
Document Per Hour24 reads

47
Characterizing Memory and Storage Differences
Document Per Minute Document Per HourNumber Documents 52.6 B 876 M
Total Index Size 6364 GB 106 GB
_id index 1468 GB 24.5 GB
{ts: 1, deviceId: 1} 4895 GB 81.6 GB
Document Size 92 Bytes 758 Bytes
Database Size 4503 GB 618 GB
• 100K Devices • 1 years worth of data
100000 * 365 * 24 * 60
100000 * 365 * 24
100000 * 365 * 24 * 60 * 130
100000 * 365 * 24 * 130
100000 * 365 * 24 * 60 * 92
100000 * 365 * 24 * 758

48
Summary• Relationships can be modeled by embedding or references
• Decision should be made in context of application data and query workload– Tailor schema to application workload
• It is okay recommended to violate RDBMS schema design principles– No duplication of data– Normalization
• Different schemas may result in dramatically different– Query performance– Hardware requirements


















