
Modelos clasicos de recuperacion
14
MODELOS CLASICOS DE RECUPERACION
-
Upload
hernanarteaga -
Category
Education
-
view
1.046 -
download
2
Transcript of Modelos clasicos de recuperacion

MODELOS CLASICOS DE
RECUPERACION

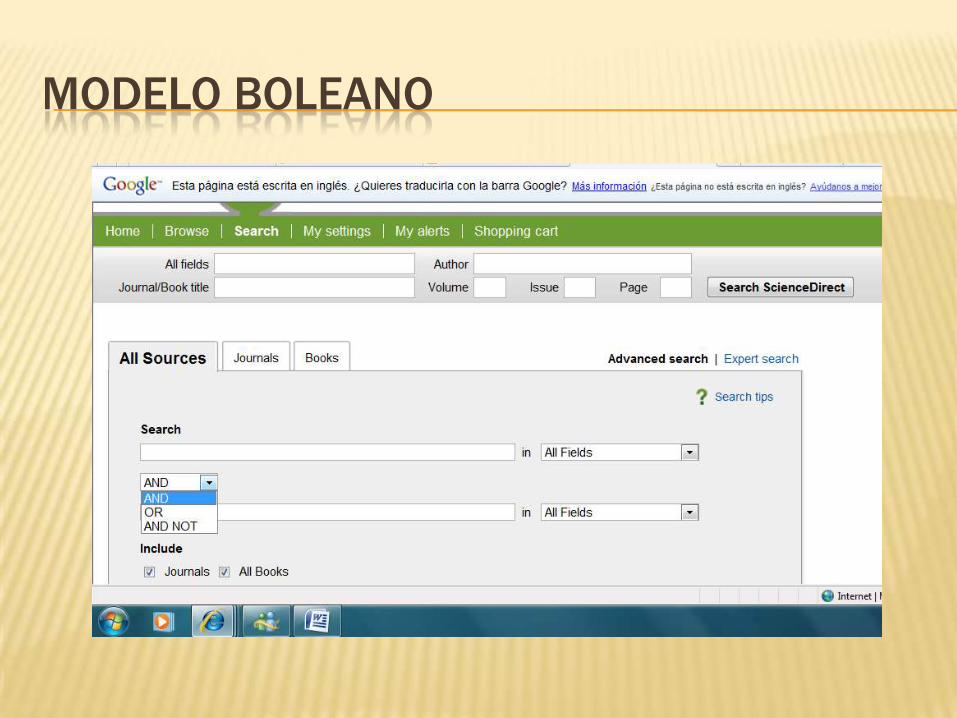
MODELO BOOLEANO
Uno de los modelos mas utilizados en recuperación
de información.
las consultas se dan en operadores lógicos (y, o,
no).
documentos que cumplen con los aspectos lógicos
de la consulta que parecen relevantes para el
usuario.
Está compuesto por el sistema binario (0 y 1).
Conecta términos y hacen que el documento esté o
no esté

MODELO BOLENAO
No tiene en cuenta la semántica del documento.
Lo que está bajo el término lo recupera, pero los que presentan alguna relación no lo recupera.
Es muy sencillo y básico.
Cuando el sistema es tan simple el trabajo preliminar se sobredimensiona y presenta gran falta de semántica.

MODELO BOLEANO
Esta basado en la teoría de conjuntosLa relevancia es binaria: un documento es relevante o no lo es.
Consultas de una palabra: un documento es relevante si contiene
la palabra.
Consultas AND: Los documentos deben contener todas
las palabras.
Consultas OR: Los documentos deben contener alguna palabra.
Consultas A BUTNOT B: Los documentos los documentos deben
ser relevantes para A pero no para B.
Ejemplo: lo mejor de Maradona
Maradona AND Mundial
AND (( México ’86 OR Italia ’90) BUTNOT U.S.A. ’94)
Es el modelo mas primitivo, sin embargo es el mas popular.
MODELO BOLEANO

MODELO VECTORIAL
Es una mejora del sistema booleano.
Utiliza un espacio vectorial, con un
direccionamiento que considera el sistema
es cercano o equivalente al término que
necesita el usuario.
Los términos están relacionados de acuerdo
a dos representaciones de consulta o
búsqueda.
(Indexación semántica latente, redes neuronales y algoritmos genéticos)

MODELO VECTORIAL
Los términos, tanto del documento como del
usuario se equiparan.
por ejemplo las consultas en Google: en los
resultados que aparecen el algoritmo se
muestra con un mayor peso o relevancia
(que en este caso sería el número de veces
que aparece el término dentro del
documento).

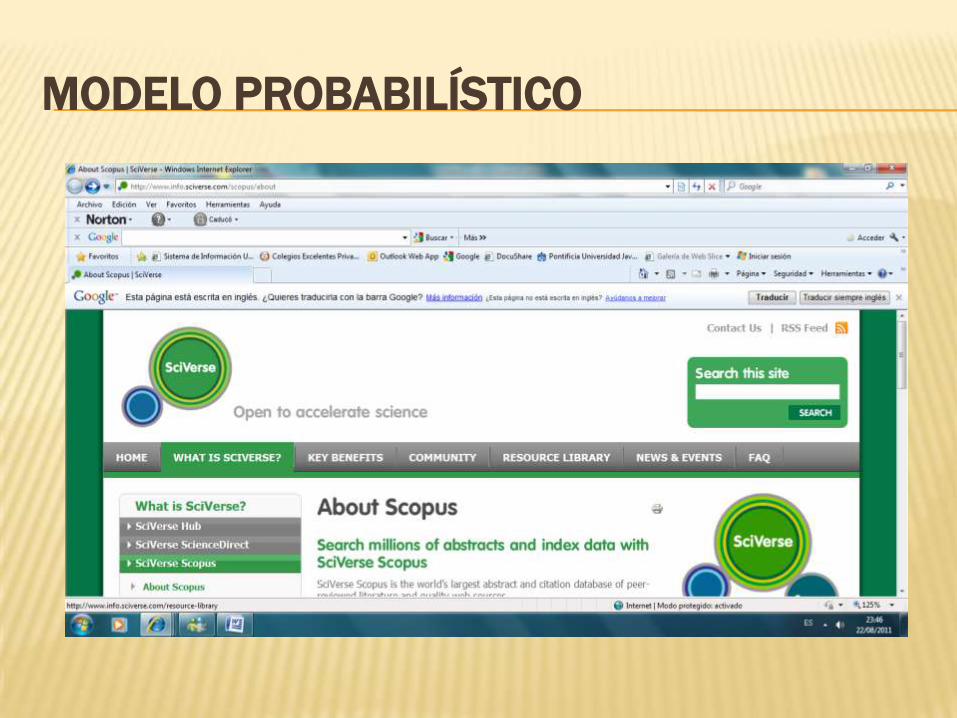
MODELO PROBABILÍSTICO
La evolución de los modelos anteriores.
Estima, un conjunto de documentos que responde a la consulta, lo que hace que en el proceso de recuperación se genere una probabilidad proyectando la información recuperada.
soportado tanto en el sistema como en el usuario.
Interactúa con el usuario.

MODELO PROBABILÍSTICO
El sistema responde a la búsqueda:
usted desea estos o aquellos documentos.
Le da al usuario la posibilidad de escoger.
Tiene en cuenta la semántica (a aunque no
del todo).
Ejemplo Pro.corbis.com: Lengua: que quiere
recuperar Anatomía? O Alimento?
MODELO PROBABILÍSTICO

Scopus muestra los tres modelos anteriores
en una sola herramienta.
se utiliza conectores, muestra rangos
(pesos),el usuario puede tomar decisiones
de como limitar la búsqueda.
Ejemplo utópico del modelo probabilístico es la
web 2.0 y la web semántica.


¿CUÁLES SON LAS DIFERENCIAS DE LOS
MODELOS CLÁSICOS?
cada modelo es mejor a su antecesor.
Los modelos evoluciona y en la medida que las tecnologías y los sistemas
El modelo booleano recupera la información. Los términos están o no.
El Vectorial además de recurar por el sistema binario, adiciona documentos relacionados .
Modelo probabilístico adiciona a lo anterior la interacción con el usuario y lo que considera es relevante a la necesidad del mismo.

BIBLIOGRAFÍA
Salvador olivan, una aproximación al concepto de la recuperación de información le marco de la ciencia de la documentación.
. Juan Antonio Martínez Comeche. Los modelos clásicos de Recuperación de información y su vigencia. RECURSO WEB Disponible en http://eprints.ucm.es/5979/1/Modelos_RI_preprint.pdf consultadoel 19/08/11.
http://www.info.scierce.com/scopus/about.


















