
metafinanz Business & IT Consulting
52
© metafinanz Business & IT Consulting 04.12.2015 Hadoop in a Nutshell
Transcript of metafinanz Business & IT Consulting

©
metafinanz Business & IT Consulting
04.12.2015
Hadoop in a
Nutshell

©
Daten & Fakten
25 Jahre Erfahrung, Qualität & Serviceorientierung
garantieren zufriedene Kunden & konstantes Wachstum
2
220 Umsatz in Mio. EUR
25 Jahre am Markt
Referenzen (Auszug):
Allianz Group | Aioi Nissay Dowa Life Insurance Europe |
ARD.ZDF medienakademie | AXA Versicherungen |
BayWoBau | Bürklin | Commerzbank | COR & FJA | ESPRIT
Europe | Euler Hermes | Frankfurter Fondsbank | Generali |
HSH Nordbank AG | IKEA | KVB| O2 Germany | Ratioform
Verpackungen | R+V Versicherung | Sächsische Aufbaubank
| Swiss Life | Versicherungskammer Bayern u.a.
1400 Berater
1990 Gründung in St.
Georgen/Schwarzwald
1995 Management-Buy-In durch die
Allianz Group – Gründung des
Münchner Standorts
2000 München wird Headquarter
2015 metafinanz feiert
25-jähriges Jubiläum
„Je komplexer die
Prozesse werden, desto
flexibler wird metafinanz.
Die gelieferte Qualität war
hervorragend."
(Kundenstimme im Rahmen der
Zufriedenheitsumfrage 2014)

© 3
Wir fokussieren mit unseren Services die Herausforderungen
des Marktes und verbinden Mensch und IT.
Über metafinanz
metafinanz steht für branchenübergreifendes, ganzheitliches Business & IT
Consulting.
Gemeinsam mit unseren Kunden gestalten wir ihren Weg in eine digitale Welt.
Wir transformieren Geschäftsprozesse und übersetzen strategische Ziele in
effektive IT-Lösungen.
Unsere Kunden schätzen uns seit 25 Jahren als flexiblen und
lösungsorientierten Partner.
Als unabhängiges Unternehmen der Allianz Group sind wir in komplexen Abläufen
und Veränderungsprozessen in Großkonzernen zu Hause.
Insurance
reporting
Analytics
Risk
Enterprise DWH
Themenbereiche
Ihr Kontakt: Mathias Höreth
BI Consultant
• Certified Oracle Developer
• Certified Hadoop Developer
Mail: [email protected]
Phone: +49 89 360531 5416
BI & Risk
• Standard and adhoc
• Reporting
• Dashboarding
• BI office integration
• Mobile BI and in-memory
• SAS trainings for
business analysts
• Predictive models,
data mining
and statistics
• Social media analytics
• Customer intelligence
• Scorecarding
• Fraud and AML
• Data modeling and
integration and ETL
• Architecture:
DWH and data marts
• Hadoop and
Columnar DBs
• Data quality and
data masking
• Solvency II
(Standard & internal
model)
• Regulatory reporting
• Compliance
• Risk management

©
BigData

©
Prognose für die Datenentwicklung
IBM
Jeden Tag erzeugen wir 2,5 Trillionen Bytes an Daten.
90% der heute existierenden Daten wurde allein in den letzten
beiden Jahren erzeugt.
Quelle: http://www-01.ibm.com/software/data/bigdata/what-is-big-data.html
Gartner
Die in Unternehmen gespeicherte Datenmenge wächst innerhalb
der kommenden 5 Jahre um 800%.
80% der Steigerung entfallen auf unstrukturierte Daten. Quelle: http://www.computerwoche.de/hardware/data-center-server/2370509/index2.html
EMC Die weltweit vorhandenen Daten verdoppeln sich alle 2 Jahre
Quelle: http://www.emc.com/leadership/programs/digital-universe.htm
Einführung in Big Data
Die Analysten und großen IT-Firmen sind sich einig:
das Datenwachstum ist ungebremst.
5

©
Prognose für die Datenentwicklung
Einführung in Big Data
130 1.227 2.837
8.591
40.026
0
10.000
20.000
30.000
40.000
50.000
2005 2010 2012 2015 2020
Date
nvo
lum
en
in
Exab
yte
Abbildung: EMC Corporation. n.d. Prognose zum Volumen der jährlich generierten digitalen Datenmenge weltweit in den Jahren 2005 bis 2020 (in Exabyte). Statista. Verfügbar
unter http://de.statista.com/statistik/daten/studie/267974/umfrage/prognose-zum-weltweit-generierten-datenvolumen/ (letzter Zugriff: 27. Juli 2015).
6

©
Big Data wird durch die 4 Dimensionen Volume, Variety, Velocity und Veracity
charakterisiert.
Definition: Die 4 V‘s
Einführung in Big Data
Volume
Velocity
Veracity
Variety
sehr große
Datenmengen nicht einheitlich
strukturiert bzw. die
Struktur ändert sich
schnell erzeugt und
zeitnah benötigt
Verwendbarkeit der
Daten unterschiedlich
7

©
Big Data - Anwendungsfälle
Einführung in Big Data
8
• durch Big Data - Exploration
1. Datenerweiterung
• durch die Erweiterung des DWH mit Big Data - Technologie
2. Erhöhung der Effizienz und Skalierbarkeit der IT
• durch die Auswertung von Maschinendaten
3. Betriebsoptimierung
• durch die verbesserte 360° - Sicht auf den Kunden
4. Verbesserung der Kundeninteraktion
• durch die Anwendung von Regeln
5. Betrugserkennung

©
Apache
Hadoop
04.12.2015

©
Hadoop
Distributed
FileSystem (HDFS)
Skalierbare
Speicherkapazität
Skalierbare Rechenkapazität
Hadoop
MapReduce
1
2
1
2
3
Hadoop Ökosystem
04.12.2
015 Se
ite
10
http://mfwiki.metafinanz.office/confluence/display/BLBIR/Hadoop+Ecosystem
HttpFS
Cascalog
FuseDFS
SequenceFiles Big Data Connectors
Big SQL
Crunch
Kafka
Oryx
ORCFiles

©
Die Apache Software hat sich mittlerweile als Quasi-Standard zur
Speicherung und Verarbeitung von Big Data etabliert.
11
Verwaltung riesiger Datenmengen von strukturierten und unstrukturierten Daten
Linear skarlierbarer Cluster (Speicher & Performance) von Standard-Servern
Performance - Der Code wird zu den Daten auf die entsprechenden Knoten verteilt
Ein großes Ökosystem an Tools rund um Hadoop
Open Source - Kommerzielle Distributionen erhältlich

©
Auch wenn man strukturierte Daten in Hadoop speichern kann –
Hadoop ist keine relationale Datenbank.
Hadoop ist keine Datenbank
12
Verarbeitung un-, teil- oder strukturierter Daten
Schema on Read
Write Once Read Many
Geringe Datenintegrität
Linear erweiterbar
Hadoop
Verarbeitung strukturierter Daten
Schema on Write
Write Read Update Many Times
Hohe Datenintegrität
Nicht linear erweiterbar
Oracle

©
Hardware (Datanode)
64-512 GB Hauptspeicher (ggfs. bis zu 512GB)
2 quad-/hex-/octo-core CPUs, 2-2.5GHz
12–24 1-4TB Festplatten, JBOD-Konfiguration
Bonded Gigabit Ethernet oder
10 Gigabit Ethernet
Ein Hadoop Cluster besteht aus Commodity Servern. Use Case
abhängig sind Hauptspeicher, Festplattenspeicher und Netzwerk
13
Quelle: http://blog.cloudera.com

©
HDFS
04.12.2015

©
Das HDFS ist ein verteiltes Dateisystem und
bildet die Basis für die BigData-Verarbeitung
mit Hadoop.
Definition
• Zuständig für die redundante Speicherung großer
Datenmengen in einem Cluster unter Nutzung von Commodity-
Hardware
• Implementiert in Java auf Grundlage von Google‘s GFS.
• Liegt über einem nativen Dateisystem (wie ext3, ext4 oder xfs)
Hadoop Distributed File System (HDFS)
15

©
HDFS ist für die redundante Speicherung von großen Dateien ausgelegt,
die write-once-read-many Daten enthalten.
• Beste Performance bei der Speicherung von großen Dateien: Besser
weniger große Dateien als viele kleine Dateien!
• Dateien in HDFS sind nicht änderbar (write-once-read-many), d. h. es sind
keine wahlfreien Schreibzugriffe erlaubt.
• Seit Hadoop 2.0 ist es möglich, Daten an Dateien anzuhängen (append).
• HDFS ist optimiert für das sequenzielle Lesen großer Dateien.
• Dateien werden im HDFS in Blöcke aufgeteilt (Default-Blockgröße: 128MB).
• Jeder Block wird redundant im Cluster gespeichert (Default: dreifache
Speicherung).
• Unterschiedliche Blöcke der gleichen Datei werden auf unterschiedlichen
Knoten (und ggf. Racks) gespeichert.
HDFS - Eigenschaften
16

©
Das HDFS besteht aus verschiedenen Systemkomponenten mit
dedizierten Aufgaben.
HDFS - Systemarchitektur
17
HDFS
Client CheckpointNode
/ BackupNode
DataNode DataNode DataNode
Masternodes
Slavenodes
HDFS Cluster
NameNode

©
Das Hadoop Distributed File System (HDFS) speichert große Dateien durch
Aufteilung in Blöcke und verhindert Datenverlust durch Replikation.
Cluster
HDFS - Funktionsweise
18
30
0 M
B
128
MB
128
MB
44MB
$ hdfs dfs –put doc.txt
1 2
3 4 5
6 7 8
3;1;5
3;7;8
6;4;2
Client
x3
x3
x3

©
MapReduce
04.12.2015

©
MapReduce Systemarchitektur
20
Data Node 1
Master Node
Resource
Manager
Node Manager
Job starten
Data Node 2
Node Manager
Scheduler
HDFS
blocks
HDFS
blocks
Client 1
Client 2

©
Shuffle &
Sort Reducer
0 das ist ein beispiel text mit
240 scheinbar unsinnigem inhalt
488 der sich über mehrere zeilen
736 erstreckt und so groß ist
… …
das 1
ist 1
ein 1
beispiel 1
… 1
for (word : line.split("\\s+")) {
write(word, 1);
}
sum = 0;
for (value : values) {
sum = sum + value;
}
write(key, sum);
das [1,1,1,1,1,1,1,1]
ist [1,1,1,1]
ein [1,1,1,1,1,1,1,1,1,1,1,1]
beispiel [1,1]
… […]
das 8
ist 4
ein 12
beispiel 2
… […]
Die Map-Operation liest ein Key-/
Value-Paar ein und gibt beliebig viele
Key-/Value-Paare aus.
Die Reduce-Operation verarbeitet alle
Werte eines Schlüssels und gibt
ebenfalls beliebig viele
Key-/Value-Paare aus.
Mapper
Shuffle & Sort gruppiert alle Werte
nach dem Schlüssel.
Der MapReduce-Algorithmus
21

©
Mapper-Code WordCount
package de.metafinanz.hadoop.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCount {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException,
InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
22

©
package de.metafinanz.hadoop.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
Reducer-Code WordCount
23

©
package de.metafinanz.hadoop.wordcount;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
Driver-Code WordCount
24

©
Hive

©
Apache Hive
Die SQL-"Datenbank" von Hadoop.
04.12.2015
Had
oop
Ecos
yste
m
Seite 26
Factsheet (Stand 25.08.2014)
FAZIT: HiveQL Dialekt bietet gute Kompatibilität mit standard
ANSI-SQL. Problematisch ist die Performanz, welche durch
MapReduce eingeschränkt ist. Als Alternative für die Zukunft ist
SparkSQL vielverprechend, bzw. Hive on Tez, Hive on Spark.
Architektur
Hive Hadoop
HiveQL
(SQL)
CLI
Thrif
t
Driver Job Tracker
metastore
/user/hive/warehous
e
/...
Factsheet (Stand 29.06.2015)
Homepage https://hive.apache.org/
Komponenten HCatalog für Metadaten
Beeswax WebUI in Hue integriert
HiveServer2 und beeline als CLI
Aktuelles Release 1.2.1 vom 27. Juni 2015
Lizenzmodell Apache, OpenSource
Distributionen Cloudera, MapR, Hortonworks, Pivotal,
…
Alleinstellungsmerkmale SQL mit MapReduce
Wettbewerbsprodukte Impala, SparkSQL, HAWQ
Sonstiges

©
Der Beeline Client ist eine simple SQL-Shell, welche es erlaubt HiveQL zu nutzen.
Details hierzu siehe https://hive.apache.org/
Anlegen einer managed-Table
Laden lokaler Daten
Durchführen einer Abfrage
SQL Abfragen mit HIVE
27
> CREATE TABLE EMPLOYEES(
EMPLOYEE_ID INT,
FIRST_NAME STRING,
LAST_NAME STRING )
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
> LOAD DATA LOCAL INPATH 'home/data/employee_data.csv' INTO TABLE EMPLOYEES;
> SELECT * FROM EMPLOYEES;

©
Pig

©
Pig Philosophie (1)
Ein Schwein frisst alles
Pig kann Daten verarbeiten, ob Metadaten vorliegen oder nicht.
Pig kann relationale, verschachtelte oder unstrukturierte Daten
verarbeiten.
Pig kann einfach erweitert werden, um Daten aus anderen Quellen
als Dateien zu verarbeiten (z.B. Datenbanken).
Schweine leben überall:
Pig ist eine Sprache für die parallele Datenverarbeitung.
Es wurde zwar zuerst auf Hadoop implementiert, kann jedoch auch
auf andere Plattformen übertragen werden.

©
Pig Philosophie (2)
Schweine sind Haustiere:
Pig ist so designed, dass es von seinen Anwendern einfach
kontrolliert und geändert werden kann.
Pig erlaubt viele Eingriffsmöglichkeiten und an vielen Stellen die
Verwendung von eigenen Implementierungen.
Schweine fliegen:
Pig verarbeitet Daten schnell.
Es wird ständig daran gearbeitet, die Performanz zu verbessern und
es werden keine Funktionalitäten implementiert, die Pig so
schwergewichtig machen, dass es nicht mehr fliegen kann.

©
Pig-Skript: Wordcount
eingabe = load '/path/to/data/Blaukraut.txt' as (zeile);
woerter = foreach eingabe generate flatten (TOKENIZE(zeile)) as
wort;
gruppe = group woerter by wort;
anzahl = foreach gruppe generate group, COUNT(woerter.wort);
DUMP anzahl;
(und,1)
(bleibt,2)
(Blaukraut,2)
(Brautkleid,2)

©
Apache
Spark

©
• Ursprünglich ein Forschungsprojekt der UC Berkeley in 2009
• Open Source
• Letzte stabile Version: v.1.5.1 (Sept 2015)
• CDH 5.4.2: Version 1.4
• 710.000 Zeilen Code (~ 75% Scala)
• Größter Mitwirker: databricks (~75%)
• Entwickelt von fast 1000 Entwicklern aus über 200 Firmen
Apache Spark
33
Quelle: Brian Clapper (2015): Spark Essentials: Scala, Amsterdam
https://www.openhub.net/p/apache-spark

©
Spark Komponenten
34
Standalone
scheduler YARN
Cluster
Manager
Spark
SQL
Spark
streaming MLib GraphX
Spark Core (API)

©
Resilient distributed dataset (RDD)
35
RDD
Record
Record
●
●
●
Partition 1
HDFS File
Block 1
Block 2
Record
Record
●
●
●
Partition 2
©
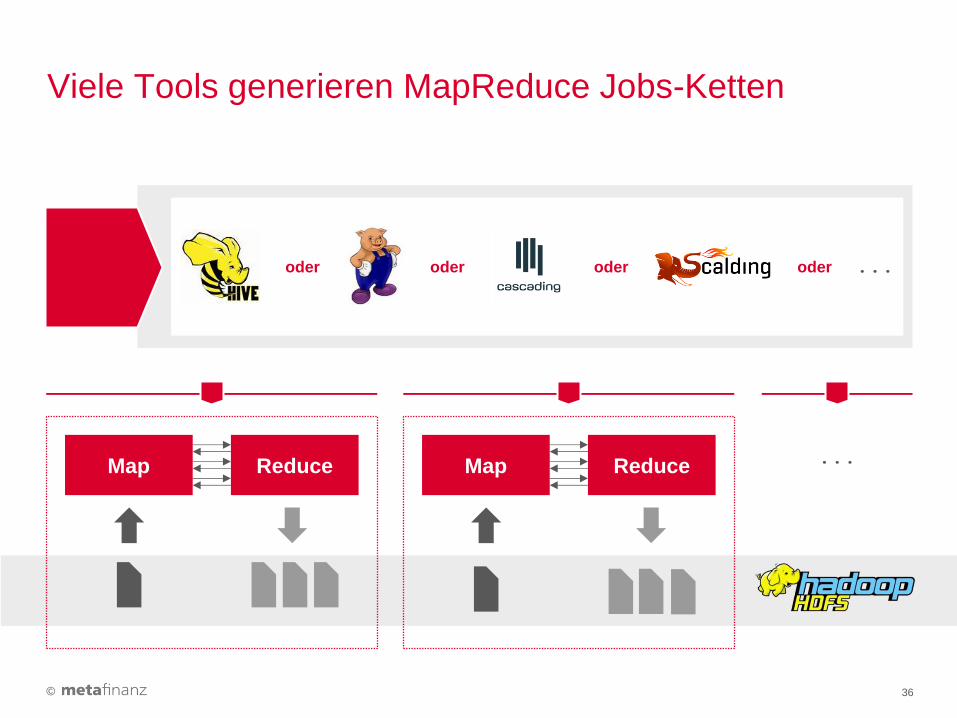
Viele Tools generieren MapReduce Jobs-Ketten
36
Map Reduce Map Reduce ...
... oder oder oder oder

©
Tools wie Impala und Spark reduzieren I/O
37
Impala
Operation Operation Operation ...
... oder oder

©
Grundlegende Unterschiede
Apache Spark
• Viel in-memory Verarbeitung (aber
nicht nur!)
• Reduziertes I/O
• Kompakter Code, einfache API
• Zugriff auf verschiedenste
Datenquellen
• Scala-, Java-, Python-, R- API
38
Hadoop Map Reduce
• Batch-orientiert (lange
Intitierungsphase)
• MapReduce-Job-Ketten mit viel I/O
• Trennung von Logik in Mapper und
Reducer (und mehrere Jobs)
• Viel „Boilerplate“-Code
• Java-API

©
Laden von Daten aus HDFS
39
scala> val fileRDD = sc.textFile("hdfs://...")
Dies ist die erste Textzeile
...
sc = Spark Context = vordefinierte Variable in der Spark Shell

©
Funktionen als Argumente
40
scala> val fileRDD = spark.textFile("hdfs://...")
scala> val resultRDD = fileRDD.flatMap(line =>
line.split(" "))
Dies
ist
die
erste
Textzeile
ParameterName (beliebig) Ausdruck (letztes Ergebnis = Return-Wert)

©
Funktionen als Argumente
41
scala> val fileRDD = spark.textFile("hdfs://...")
scala> val resultRDD = fileRDD.flatMap(line =>
line.split(" "))
.map(word => (word, 1))
Dies, 1
ist, 1
die, 1
erste, 1
Textzeile, 1

©
Spark Wordcount – kompletter Code
42
scala> val fileRDD = spark.textFile("hdfs://...")
scala> val resultRDD = fileRDD.flatMap(line =>
line.split(" "))
.map(word => (word, 1))
.reduceByKey((value1,value2) => value1+value2)
aber, 2
das, 3
...
scala> resultRDD.saveAsTextFile("hdfs://...")

©
DataFrames
& Spark
SQL

©
Spark SQL ermöglicht es…
• Daten aus einer Vielzahl von strukturierten Quellen (JSON, Hive, Parquet) zu laden.
• Daten durch SQL und HiveQL abzufragen
Hierfür bietet Spark ein spezielles RDD an,
das sogenannte DataFrame, welches ein RDD von Row-Objects darstellt.
DataFrames können aus externen Datenquellen, aus dem Ergebnis einer Abfrage oder
aus regulären RDDs erzeugt werden und bieten neue Operationen an.
Mit Spark SQL wird ein Interface zur Verfügung gestellt, um
mit strukturierten, d.h. schemagestützten Daten zu arbeiten.
44
Quelle: Karau et al. 2015: Learning Spark: Lightning-Fast Big Data Analysis
SELECT COUNT(*)
FROM hiveTable
WHERE hive_column = hiveData

©
• DataFrames sind die bevorzugte Abstraktion in Spark
• Dataframes sind immutable sobald konstruiert
• Unterstützen zahlreiche Datenformate und Speichersysteme
• Skalieren von extrem kleinen Datenmengen bis hin zu extrem großen
Datenmengen
• Nutzen den Spark SQL Optimizer Catalyst (CodeGeneration & Optimierung)
• Vereinfachte API für Scala, Python, Java, R
DataFrame Features
45

©
DataFrames API
46
val df = sqlContext.
read.
format(“json“).
option(“samplingRatio“, “0.1“).
load(“/path/to/file“)
df.write.
format(“parquet“).
mode(“append“).
partitionyBy(“columnXY“).
saveAsTable(“outputTBL“)
Spark 1.4

©
DataFrames & Spark SQL
47
df.registerTempTable(“myTable“)
sqlContext.sql(“SELECT COUNT(*) FROM myTable“)
©
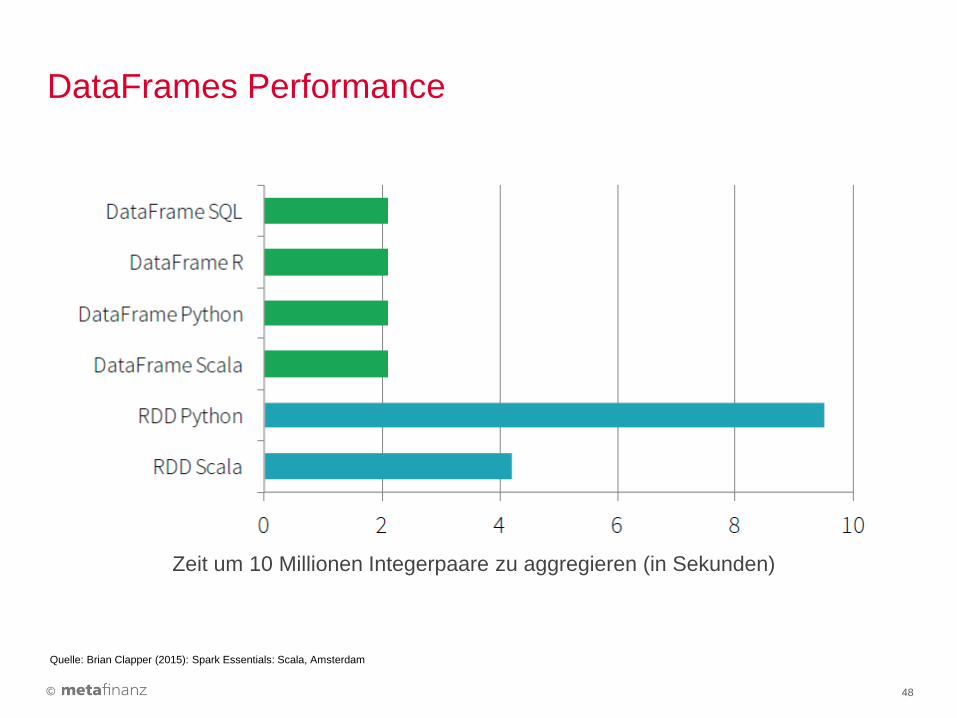
DataFrames Performance
48
Quelle: Brian Clapper (2015): Spark Essentials: Scala, Amsterdam
Zeit um 10 Millionen Integerpaare zu aggregieren (in Sekunden)

©
Optimizer & Execution
49
Quelle: Brian Clapper (2015): Spark Essentials: Scala, Amsterdam

©
Optimizer & Execution
50
joined user.join(events, users.id === events.uid)
filtered = joined.filter(events.date >= „2015-01-01“)
Quelle: Brian Clapper (2015): Spark Essentials: Scala, Amsterdam

©
http://www.metafinanz.de/news/schulungenl
Wir bieten offene Trainings, sowie maßgeschneiderte
Trainings für individuelle Kunden an.
Einführung Apache Spark
Datenverarbeitung in Hadoop
mit Pig und Hive
Oracle SQL Tuning
OWB Skripting mit OMB*Plus
Data Warehousing & Dimensionale Modellierung
Einführung in Oracle: Architektur, SQL und
PL/SQL
Einführung Hadoop (1 Tag)
Hadoop Intensiv-Entwickler
Training (3 Tage)
51

©
Danke! metafinanz
Informationssysteme GmbH
Leopoldstraße 146
D-80804 München
Phone: +49 89 360531 - 0
Fax: +49 89 360531 - 5015
Email: [email protected]
www.metafinanz.de


















