
Message Proxies for Efficient, Protected Communication ...
12
Message Proxies for Efficient, Protected Communication on SMP Clusters Beng-Hong Lim, Philip Heidelberger, Pratap Pattnaik and Marc Snir IBM T.J. Watson Research Center Yorktown Heights, NY 10598 {bhlim,berger ,pratap, snir}Qwatson. ibm.com Abstract This researchaddresses the problem ofproviding eficient, pro- tected communicationin an SMPcluster without incurring the over- head of system calls or the cost of custom hardware. It anafyzes an approach that uses an idle SMP processor to run a message proxy, a communication process that provides protected access to the nemork. We implement message proxy based communication between a pair of IBM Model G30 SMPs and analyze the resulting overheads. We derive a pevormance model that shows that cache- miss latency within an SMP injluencesmessage proxy performance significantly. Simulations of a suite of ten parallel applications demonstrate that message proxies match the performance of cus- tom hardwarefor three of the ten applications, and are between IO- 30% slowerfor the other seven applications. A direct cache-update mechanism to reduce cache misses improves the pelformance of message proxies on communication-intensiveprograms by 7-25%. We conclude that message proxies provide a viable alternative to custom hardware for protected communication. 1 Introduction Commodity workstation clusters represent a cost-effective platform for scalable, parallel computation. As small-scale symmetric mul- tiprocessors (SMPs) become commonplace as high-performance workstations, we envision that future workstation clusters will be based on SMP nodes. Compared with uniprocessor nodes, SMP nodes provide the economic advantage of packaging multiple pro- cessors together in a single workstation chassis, and the technical advantage of high-speed, tightly-coupled communication between processors within an SMP. This research addresses the question of providing efficient, pro- tected communication between nodes in a cluster of SMPs. Pro- tection is necessary unless strict gang scheduling is used. Previous research on communication in workstation clusters assume unipro- cessor nodes [25, 14, 24, 171. The use of SMP nodes presents new problems as well as solutions. Most important, in an SMP node, multiple processors share a single network interface and may attempt to communicate over that network interface concurrently. Thus, the system has to provide atomic and protected access to the network interface. The traditional OS solution relies on systemcalls and interrupts to provide protection, and locks to ensure atomicity. It requires sys- I S sMp- I --." I I--- I Figure 1: A message proxy provides multiple concurrent user pro- cesses atomic, protected access to the network interface. tem calls and interrupts to be specially optimized to reduce pro- hibitively high overheads [23]. A more expensive solution pro- vides custom hardware support in the network interface for pro- tected communication e.g., Princeton SHRIMP [2] and DEC Mem- ory Channel [7]. SMP nodes enable a third solution: using one of the SMP processors to run a kemel-mode communication process that enforces protection and atomicity. We call such a communica- tion process a message proxy. This paper focuses on the design, implementation and perfor- mance evaluation of message proxies. Figure 1 illustrates how a message proxy provides a protected communication interface to a number of user processes. To communicate, a user process submits communication commands to a message proxy via shared memory queues that are mapped in each user's address space. Because each user has a separate queue to communicate with the message proxy, different users are protected from each other. The message pmxy di- rectly accessesthe network interface, and provides a protected com- munication interface without relying on system calls, intenupts or locks. The amactiveness of message proxies is that it relies solely on commodity parts. To investigate the issues in implementing a message proxy, we designed and implemented a message proxy using the IBM AIX kemel extensioninterface, and measured in detail the resulting com- munication overheads between a pair of IBM Model G30 SWs. We assume a communication model based on remote memory ac- cess and remote queues (see Section 3.) We distill the measure- ments into a performance model for message proxies, parameter- ized by basic machine parameters. It shows that message proxy per- 116 0-8186-7764-3/97 $10.00 0 1997 IEEE
Transcript of Message Proxies for Efficient, Protected Communication ...

Message Proxies for Efficient, Protected Communication on SMP Clusters
Beng-Hong Lim, Philip Heidelberger, Pratap Pattnaik and Marc Snir IBM T.J. Watson Research Center
Yorktown Heights, NY 10598 {bhlim,berger ,pratap, snir}Qwatson. ibm. com
Abstract This research addresses the problem ofproviding eficient, pro-
tected communication in an SMPcluster without incurring the over- head of system calls or the cost of custom hardware. It anafyzes an approach that uses an idle SMP processor to run a message proxy, a communication process that provides protected access to the nemork. We implement message proxy based communication between a pair of IBM Model G30 SMPs and analyze the resulting overheads. We derive a pevormance model that shows that cache- miss latency within an SMP injluencesmessage proxy performance significantly. Simulations of a suite of ten parallel applications demonstrate that message proxies match the performance of cus- tom hardwarefor three of the ten applications, and are between IO- 30% slowerfor the other seven applications. A direct cache-update mechanism to reduce cache misses improves the pelformance of message proxies on communication-intensive programs by 7-25%. We conclude that message proxies provide a viable alternative to custom hardware for protected communication.
1 Introduction Commodity workstation clusters represent a cost-effective platform for scalable, parallel computation. As small-scale symmetric mul- tiprocessors (SMPs) become commonplace as high-performance workstations, we envision that future workstation clusters will be based on SMP nodes. Compared with uniprocessor nodes, SMP nodes provide the economic advantage of packaging multiple pro- cessors together in a single workstation chassis, and the technical advantage of high-speed, tightly-coupled communication between processors within an SMP.
This research addresses the question of providing efficient, pro- tected communication between nodes in a cluster of SMPs. Pro- tection is necessary unless strict gang scheduling is used. Previous research on communication in workstation clusters assume unipro- cessor nodes [25, 14, 24, 171. The use of SMP nodes presents new problems as well as solutions. Most important, in an S M P node, multiple processors share a single network interface and may attempt to communicate over that network interface concurrently. Thus, the system has to provide atomic and protected access to the network interface.
The traditional OS solution relies on systemcalls and interrupts to provide protection, and locks to ensure atomicity. It requires sys-
I S sMp- I
--." I I--- I
Figure 1: A message proxy provides multiple concurrent user pro- cesses atomic, protected access to the network interface.
tem calls and interrupts to be specially optimized to reduce pro- hibitively high overheads [23]. A more expensive solution pro- vides custom hardware support in the network interface for pro- tected communication e.g., Princeton SHRIMP [2] and DEC Mem- ory Channel [7]. SMP nodes enable a third solution: using one of the SMP processors to run a kemel-mode communication process that enforces protection and atomicity. We call such a communica- tion process a message proxy.
This paper focuses on the design, implementation and perfor- mance evaluation of message proxies. Figure 1 illustrates how a message proxy provides a protected communication interface to a number of user processes. To communicate, a user process submits communication commands to a message proxy via shared memory queues that are mapped in each user's address space. Because each user has a separate queue to communicate with the message proxy, different users are protected from each other. The message pmxy di- rectly accessesthe network interface, and provides a protected com- munication interface without relying on system calls, intenupts or locks. The amactiveness of message proxies is that it relies solely on commodity parts.
To investigate the issues in implementing a message proxy, we designed and implemented a message proxy using the IBM AIX kemel extensioninterface, and measured in detail the resulting com- munication overheads between a pair of IBM Model G30 S W s . We assume a communication model based on remote memory ac- cess and remote queues (see Section 3.) We distill the measure- ments into a performance model for message proxies, parameter- ized by basic machine parameters. It shows that message proxy per-
116 0-8186-7764-3/97 $10.00 0 1997 IEEE

formance is heavily influenced by the latency of cache misses within an SMP. The model can be used to predict message proxy perfor- mance on other S M P cluster architectures.
To compare the performance of message proxies with custom hardware and system calls, we built a parallel execution-driven sim- ulator. Measurements of a suite of ten parallel applications written in various programming styles show that message proxies match the performance of custom hardware for three of the ten applica- tions. In the other seven applications, message proxies result in ex- ecution times that are between 10-30% longer than with custom hardware. As an optimization, a cache-update mechanism to avoid cache misses between the user and message proxy processes re- duces the application execution time by 7-25%. Using system calls results in significantly worse performance for fiveof the ten applica- tions, where execution times are 45-1005 longer than with custom hardware.
The concept of using a dedicated S M P processor for commu- nication was introduced in the Intel Paragon [18], but the reported performance measurements were only simple latency-bandwidth curves, and there is no comparison between their system and other design alternatives. The Wisconsin ‘Qphoon prototypes [ 191 ded- icate an SMP processor to execute user-level protocol handlers to improve performance, and rely on gang scheduling for protection. In contrast, our motivation is to provide protected communication without relying on expensive system calls and interrupts, or on gang scheduling. This requires message proxies to be defensive against uncooperative processes, and to be run as a trusted process with kemel-level privileges.
This paper makes the following contributions.
0 It presents the design of an efficient all-software, in-kemel approach to protected communication in an SMP cluster, called message proxies, that leverages commodity hardware and operating systems.
0 It provides an in-depth analysis of the overheads involved in message proxies. It also provides a performance model for message proxies that exposes communication bottlenecks and that can be used to predict performance on different plat- forms.
0 It presents an extensive performance comparison of mes- sage proxies with custom hardware and system call based ap- proaches. The comparison includes application-level perfor- mance numbers as well as micro-benchmark numbers that measure individual latencies, bandwidths, and overheads.
The rest of this paper. is organized as follows. Section 2 dis- cusses the design altematives for providing protected communica- tion SMP clusters. Section 3 describes the communication primi- tives that we use in our investigation. Section 4 describes the imple- mentation and performance measurements of message proxies on a commodity SMP cluster. Section 5 compares the performance of message proxies with other altematives. Finally, Sections 6 and 7 discuss related work and the conclusions drawn from this research.
2 Architectures for Protected Communication This paper explores several architectural alternatives for imple- menting protected communication that are based mainly on com- modity parts and software. The design has to observe several con- straints. First, to leverage advances in commodity processor and
network hardware, we restrict any hardware additions or changes to a network adapter that plugs into the memory or VO bus of a commodity SMP. Second, in the interest of software reuse, the de- sign should not require massive changes to the commodity operat- ing system running on the SMP.
There exists a spectrum of choices on what hardware resources to place in a network adapter. At one extreme is a bare-bones ap- proach where the adapter provides a pair of input and output FIFOs to the network and a DMA engine to transfer data to and from phys- ical memory. At the other extreme, the adapter provides support for virtually-addressed DMA, which includes address translation tables and hardwired protocol engines for implementing communication protocols. An intermediate approach uses a coprocessoron the net- work adapter to perform address translation and execute communi- cation protocols.
With these restrictions, we contrast three possible approaches to implementing protected communication on S M P clusters.
Custom Hardware. In this approach, the network adapter in- cludes hardware to implement protection. The Princeton SHRIMP [2] and DEC Memory Channel [7] designs provide hardware support for virtual-memory-mapped communica- tion, leveraging existing virtual memory protection hardware for protected communication.
System-Level Communication. This approach relies on the op- erating system’s userkemel protection boundary. Outgoing communication is initiated via system calls, and incoming messages are handled by a combination of polling and inter- rupts. In an SMP, or in a preemptible kernel, locks are neces- sary for atomicity.
Message Proxies. This approach relies on using an idle SMP pro- cessor to mediate access to the network interface and to ser- vice incoming messages. In network adapters that contain a coprocessor, such as the Meiko CS-2 [l], and Myricom Myrinet [22], the coprocessormay also be used to run a mes- sage proxy.
Figure 2 illustrates how each of thesedifferent approachesresult in different control and data movements during message input and output. Each approach has to address the following issues:
Minimize Overhead. Overhead refers to cycles spent on compute processors due to communication operations. High-overhead oper- ations, such as memory copies, system calls, locks, and interrupts should be avoided. We subdivide overhead into protocol overhead and protection overhead. Custom hardware relies on virtual ad- dressing to minimize protection overhead. It implements commu- nication protocols directly in hardware to minimize protocol over- head. System-level communication relies on system calls and inter- rupts for protection. Thekkath et al. [24] describe how to streamline system calls and interrupts to reduce protection overhead. The com- pute processors execute the communication protocols and incur the full protocol overhead. Message proxies avoid the protection over- head of system calls and interrupts by multiplexing all communica- tion through a single trusted agent, but incurs the protection over- head of communicating through messagequeues in shared-memory. The message proxy may execute part of the communication proto- col, reducing protocol overhead on the compute processor.
117

Custom Hardware System Calls Message Proxy
Q) 0) m 3 5
I. Read network input packet 2. If large block, setup DMA and transfer 2. If small block, do programmed VO (PIO)
into memoty
.L J 0. +L a % * 2 c D 8 1
1. Submit command to custom hardware 2. If large block. setup DMA and transfer 2'. If small block, PI0 output
E
1. lntem t 2. setup Eemei mode 3. If large block. setup DMA 3'. If small block, PI0 into memory 4. DMA transfer
1. System call 2. If large block, setup DMA 2'. If small block, PI0 output 3. DMA transfer
1. System call 2. If large block, setup DMA 2'. If small block, PI0 output 3. DMA transfer
Figure 2 Contrasting the control and data movements involved in
Atomicity. On SMP clusters, an implementation needs to mediate concurrent communication operations through a single network in- terface. Custom hardware hides the network interface behind mem- ory bus transactions, and relies on memory bus arbitration to or- der concurrent remote memory accesses. System-level communica- tion requires the kemel code to acquire locks and disable interrupts for atomicity. A communication operation may block in the kemel waiting for a lock, preventing the user-level code from overlapping communication with computation. Message proxies hide the net- work interface behind shared-memory message queues in separate address spaces so that user-level code may communicate concur- rently through message proxy without requiring locks.
Forward progress. To guarantee forward progress, an imple- mentation must continuously drain the network and process incom- ing messages. Essentially, an agent should be responsible for listen- ing continuously to the network input FIFO. With custom hardware, a hardware protocol engine continuously consumes messages from the network input and directs it to an appropriate buffer. In system- level communication, interrupts must be forced either by an amv- ing message or a timer interrupt to guarantee that input messages get serviced. Message proxies conunuously poll the network input and do not require interrupts.
Virtual addressing. User-level communication uses virtual ad- dresses that must be translated to physical addresses, and page faults may be encountered during data transfer unless the source and desti- nation buffers are pinned. Custom hardware includes address trans- lation hardware and requires buffers to be permanently pinned at setup time. Both system-level communication and message prox- ies use existing paging hardware in the SMP processors for address translation and can handle page faults. Pages must be dynamically
1. Read network input packet 2. If large block, setup DMA 2'. If small block. PI0 to memory 3. DMA transfer
1. Submit command to shared-memory 2. Read command from shared-memory 3. If large block, setup DMA 3'. If small block, PI0 output 4. DMA transfer
communication in the three approaches to protected communication.
pinned before transferring data via a DMA engine. Since pinning is expensive, we use programmed VO @IO) to transfer small blocks and pinned DMA to transfer large blocks of data.
3 Communication Model We use remote memory access (RMA) and remote queues (RQ) as the lowest-level communication primitives to be implemented by the design altematives described above. RMA allows a process to read from or write to the address space of another process, while RQ allows a process to enqueue and dequeue data in the address space of another process. RMA and RQ provide natural communi- cation primitives that can serve a compiler target for parallel appli- cations as well as improve the performance of distributed operating systems [8,3,24]. They form an efficient and convenient layer for implementing higher-level communication protocols such as Active Messages [25] and MPI [16].
The RMA operations are asynchronous PUT/GET primitives:
PUT(laddr, ruddr, asid, nbytes, fsync, rsync) GET(fuddr, raddr, asid, nbytes, fsync, rsync)
PUT copies nbytes bytes of data starting at local address iuddr to a remote address ruddr. Conversely, GET copies nbytes bytes of data starting at remote address ruddr to local address laddr. The rest of the arguments are described further below.
The RQ operations are asynchronous ENQDEQ primitives:
ENQ(laddr, rq, usid, nbytes, Isync) DEQ(laddr, rq, asid, nbytes, Zsync)
ENQ atomically copies nbytes bytes of data starting at local ad- dress laddr to the tail of remote queue rq. Conversely, DEQ copies
118

Remota A d d m Spacea
W A d d n u Spocs
I
Figure 3 Software view of Remote Memory Access and Remote Queue operations.
I
nbytes bytes of data from the head of remote queue rq to local ad- dress M r . Figure 3 illustrates the software view of these primi- tives.
Local and Remote Addresses Local addresses are relative to the caller's address space. Remote addresses and queues are relative to the address space specified by mid, a logical identifier that maps to a memory segment in some process within the SMP cluster. The mapping between asid and an address space is defined at program initialization time. The system faults a process that tries to access an address space without first getting permission to do so.
Synchronization The RMA and RQ primitives are asynchronous so that the calling program may overlap communication latencies with computation. Completion of an RMC or RQ operation is sig- naled via local and remote synchronization flags. lsync is the ad- dress of a flag within the local address space, while rsync is the ad- dress of a flag within the address space specified by asid.
4 An Implementation of Message Proxies This section provides an analysis and detailed performance mea- surements of message proxy based communication on a cluster of SMPs. The message proxy is implemented as an AIX kernel exten- sion, and does not require any modifications to the base operating system. A real message proxy implementation allows us to deter- mine the factors that contribute to communication latency and over- head, and confirms that existing AIX kemel services are sufficient for implementing a message proxy.
The message proxy runs as an AIX kernel process on a pair of IBM Model G30 SMPs connected via a prototype network switch and adapter designed for the IBM RS/6000 SP2. Figure 4 illus- trates a single SMP node in the set up. Each SMP has four 75 MHz PowerPC 601 processors. The network adapter plugs into the micro channel interface and communicates through an 8-way SP switch. The adapter presents the processors with an input and out- put FIFO interface to the network. The network can be substituted with any other commodity network without significantly affecting our results, since we are interested mainly in the overhead between user code and the network adapter.
In order to communicate with the message proxy, a user pro- cess first allocates a pair of command queues in its address space, and registers those queues with the message proxy via a system call. The message proxy stores a cross-memory descriptor for the address
Message Pmw
7 K c t " e i
adapter to network switch
Figure 4: A message proxy implementation of protected communica- tion between a pair of IBM SMPs. One of the processors in the SMP is dedicated to running a message proxy.
space of the queues. The cross-memory descriptor allows the mes- sage proxy to attach and detach the user's address space and access the command queues at a later time. Since each user allocates mes- sage queues in its own address space, they are protected from each other. This structure is illustrated in Figure 1.
The message proxy executes a loop that polls each registered output command queue and the network input queue in a round robin fashion. Figure 5 presents pseudo-code for the loop. In or- der to submit a remote memory access command, user code calls a library function that writes the opcode of the command and its operands into its output command queue. When the message proxy dequeues a command from that queue, it decodes the command and dispatches to a handler that sends the command and associated data through the network output FWO.
Several properties of the AIX kemel extension interface were essential in our implementation. First, the kernel cross-memory ser- vices allows the message proxy to attach and map user memory safely (using the v m a t t kemel service). Second, the kernel exten- sion interface provides routines to pin and unpin memory buffers. Last, AIX kernel processes are pageable so that page faults are han- dled by the base kernel automatically.
In the case of a PUT command, the message proxy reads the data directly from the source buffer and transmits it through the net- work. Alternatively, if the PUT specifies a large memory transfer, it pins the memory and uses the DMA engine to perform the trans- fer. The message proxy at the remote end decodes the PUT mes- sage and stores it directly to the destination buffer. In the case of a GET command, the message proxy sends a request message to the remote end. The remote message proxy decodes the GET request message, and sends the data directly from the source buffer back to the requester. When the GET data arrives, the message proxy at the requesting end stores the incoming data directly to the destina- tion buffer. ENQ and DEQ are handled similarly, except that queue pointers are also updated.
Several properties of the message proxy implementation are worth mentioning:
It is a strictly polling implementation of communication. The advantage of polling is twofold: i) it avoids the high inter- rupt overheads that threatens to get higher with more deeply pipelined and wider issue processors, and ii) message han-
119

loop forever: for queue in (registered-queues)
qbuf := vm-attcqueue->xdesc.subspace-id,
qitem := q-head(qbuf); if (qitem->valid)
queue->qbuf);
transmitmessage(qitem); qitem->valid := FALSE; advance-head(qbuf) ;
vm-det(qbuf); buf := pol1,netnorkO; if (buf->valid)
receive-messageCbuf) ;
Operation enq command, (read miss, write miss) polling delay vmatt to FIFO queue
Figure 5: The main dispatch loop for the message proxy. The mes- sage proxy altemates between polling the user command queues and the network input.
Latency 2 c P V
Variable 1 Definition I Value I time to service a cache miss 1.0 ps
0.65 ps processor speed, (multiple of 75MHz) polling delay 3.0 ps
set up network packet header
transit time launch packet
polling delay read input packet header, (read miss) decode packet, dispatch to handler compute remote address, check validity vmatt to remote address address and packet size check set up network packet header fill in data, read miss set remote sync. register, (write miss) launch uacket
Table 1: The primitive operations in the critical path of message proxy based communication, and their values on an IBM Model G30 SMP.
U + 0.61s U L P C
0.41s 0.11s
v 0.16
U + 0.71s c + u
C U
dlers are naturally atomic since there are no interrupt-driven handlers that may execute at arbitrary instances.
It is a completely lock-free implementation, even with truly concurrent processes in an SMP. Since the command queues are single-producer, single-consumer queues, the queue syn- chronization can be enforced by a fulVempty flag in each queue entry.
It is a zero-copy implementation since data is transfered di- rectly from the source buffers to the network, and from the network to the destination buffers.
It guarantees fonvard progress in the network since the mes- sage proxy is an active agent that continuously drains the net- work input queues.
0 User overhead consists of inserting a remote memory ac- cess command to the output command queue. All RMA and RQ protocol processing is ofiloaded by the message proxy, thereby minimizing user overhead.
transit time polling delay read input packet header, (read miss) decode packet, dispatch to handler
vmatt to local address space
set local sync. register, (write miss) read local sync. register, (read miss)
find local addr in CCB, check validity
copy data to destination, (write miss)
4.1 Performance Measurement and Analysis The measured one-way latency of a PUT operation is 18.5 + L ps, and the latency of a GET operation is 27.5 + L ps where L is the network latency. In a commodity network, L x 1 - 2ps. To deter- mine the components of the latency, we instrument the critical path
L P C
0.41s 0.31s V
C + U C C
Agent User
Message Proxy (local)
Network Message
(remote) Proxy
Network Message
Proxy (local)
User
dequeue entry, (read miss) decode command, allocate CCB dispatch to send routine
0.51s I C 0.51s
Table 2: Latency components of the critical path of a one-word GET operation. CCB refers to a communication control block that main- tains the state of an outstanding communication.
in a PUT/GET operation and distill the overhead into a number of primitive operations listed in Table 1. Table 2 presents a trace of the latency and overhead involved in a GET operation on a quies- cent system, in terms of the primitives. The fixed numbers in the table, such as OSIS, represent time to execute non-loadstore Pow- erPC instructions that reside in the instruction cache. A PUT opera- tion is similar, except it involves a one-way communication instead of a round trip. From these measurements, we can quantify the over- head imposed by a message proxy, and project the performance of other software approaches.
From the numbers in Table 2 and some extra measurements, we model the latency of a GET of up to a word of data by
(1OC + 6U + 3v + 3.6/S + 3 P + 2L) ps
and the latency of a PUT of up to a word of data by
(7C + 4U + 2V + 2.2 /s + 2 P + L ) ps
These equations allow us to predict the performance of message proxy based communication on other SMP clusters with different processor and memory speeds.
The numbers show that message proxies impose a protection cost of 3C + 3V + 3P zz 14ps for a GET operation, and about
120

3C + 2V + 2P NN 1 0 . 3 ~ s for a PUT operation. In comparison, system-level communicatiori that relies on streamlined system calls and interrupts imposes a protection cost of about 23 ps for a GET operation and I9 ps for a PUT operation [23]. Messageproxies pro- vide lower protection cost without modifying the operating system, but at the price of using a processor to run a message proxy.
Although communication latency is significantly higher than custom hardware, user overhead amounts to only three cache misses to submit the command. This is not significantly more than the over- head in custom hardware that also requires commands to traverse the memory bus. Asynchronous primitives allow user code to over- lap a significant fraction of protocol processing and communica- tion latency with computation. Such protocol offload is not possible with system-level communication.
The following factors affect latency and overhead significantly:
Cache misses and uncached accesses The latency of cache misses and uncached accesses is a significant fraction of the latency of a PUT or GET. Only the three cache misses to read and write the command queue are inherent to message proxies. Cache misses in reading and writing source and destination data buffers will occur in any implementation, and cache misses in setting synchronization flags will also occur whenever the agent setting the flags is on a dif- ferent processor, which is likely to be the case in an SMP.
Polling delay Another significant source of latency is the polling delay, where the message proxy is busy scanning other queues be- fore handling a new command or an arriving message. This may be an issue if the message proxy services a large number of processes within an SMP. We can reduce the polling delay by polling only the queues of scheduled processes. To further accelerate polling, the communicating processes and the message proxy can cooper- atively maintain a shared bit vector that serves as an indication of non-empty command queues. The message proxy can detect the state of a number of command queues in a single probe of the bit vector. In practice, there is a limit to the number of processors that a single network adapter can support so that the number of active command queues should be small.
Virtual addressing The overhead of vm-att and vmdet to at- tach and detach user address spaces lies directly in the critical path of the message proxy loop, and contributes to about 1 . 3 ~ s of la- tency. A 64-bit implementation of the PowerPC architecture [I51 can avoid this overhead by permanently attaching to the address spaces of all communicating user processes. The 32-bit implemen- tation allows at most 16 segment registers, which limits the number of address spaces the message proxy can attach simultaneously. The 64-bit implementation removes this restriction.
5 A Comparative Evaluation of Message Proxies
This section compares the performance of protected communication under message proxies, custom hardware and system-level commu- nication. We use a parallel, execution-driven simulator to model the different architectures at several technological design points. The simulator supports the RMA and RQ communication primitives de- scribed above. We re-target the Split-C [ 5 ] and CRL [9] program- ming model libraries to RMA and RQ primitives. This allows us to run parallel applications written in those languages, as well as micro-benchmarks, for comparing the architectures.
5.1 Simulator Organization We implemented the simulator on an IBM RS/6000 SP2 parallel computer with 66MHz POWER2 processors, 64KB data caches, and 128MB of physical memory. The simulator emulates the RMC and RQ data transport on top of MPI. To time the application, we instrument each RMC and RQ primitive to communicate with an event-driven simulator that maintains the state of the communica- tion adapters and preserves the correct order and timing of the RMC and RQ events. Time progresses in the simulation by sending the time interval in between communication events to the event sirnu- lator along with a description of the event wheneverthe application calls the RMA and RQ primitives. Such an approach works for my application that communicates by using explicit calls to communi- cation operations.
The simulated application runs natively on the SP2, and the interval in between communication events is measured with the POWER2 processor’s real time clock with a resolution of about 100 ns. We use a quiescent SP2 to prevent process switches from inflat- ing the real time intervals. Each application process and the event- driven simulator process maps to a different node of an SP2, thus requiring n + 1 SP2 nodes to simulate an application running on n processors. For safety, we cross check the real time interval with the user time reported by clock () . Using the real time clock im- plies that the simulator models compute processors with the same performance characteristics as the SP2’s POWER2 processors, and equivalent cache and memory organizations.
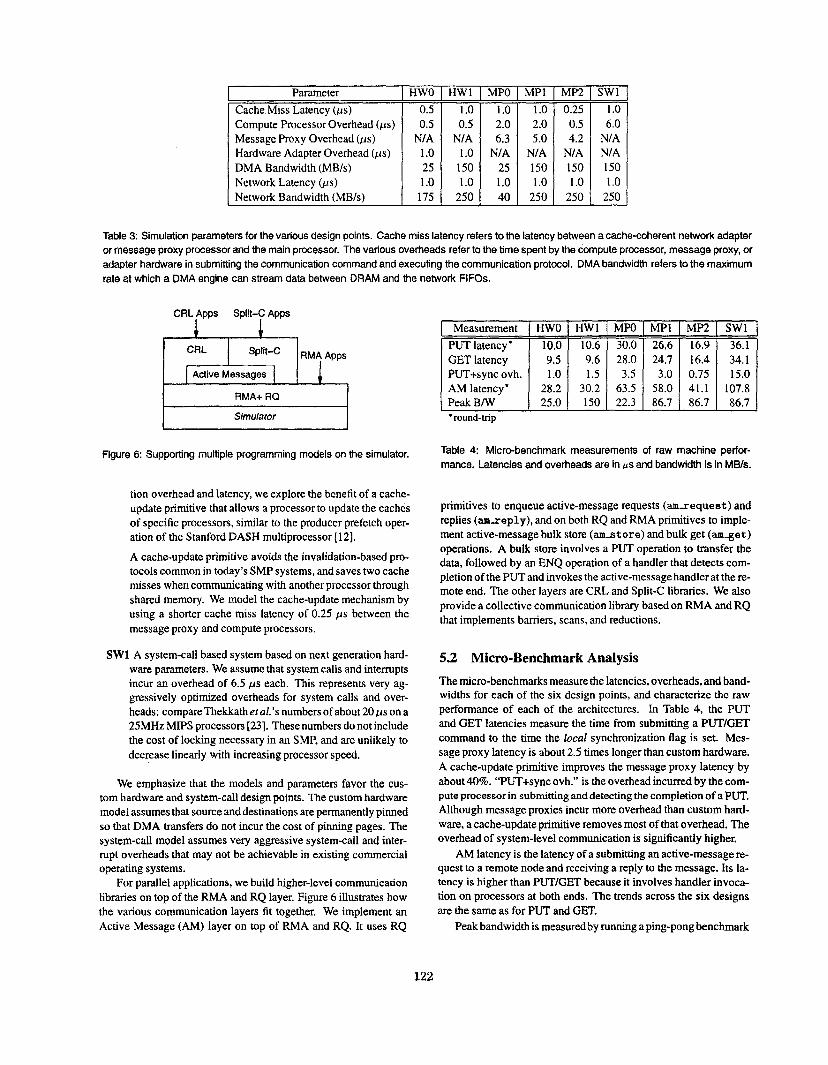
The event simulator implements parameterized models of the three approaches to protected communication, and is written in CSIM [21]. We assume aggressive network interfaces that sit on the memory bus. The models account for contention for hardware resources within a node, such as the processors, the DMA engines, and the network queues. We use the latency model developed in the previous section to model the message proxies, which we as- sume run on dedicated processors. For simplicity and efficiency, the models do not model memory bus and network switch contention. The models’ parameters allow us to experiment with different tech- nological design points. Table 3 summarizes the design points we consider:
HWO A custom hardware based system with uniprocessor nodes based on today’s technology. The Princeton SHRIMP is rep- resentative of such an architecture.
HWl A custom hardware basedsystem with SMP nodes and based on next generation hardware parameters. It has a higher DMA and network bandwidth than HWO. Because of the SMP node, it has a higher cache miss latency than HWO.
MPO A message proxy system based on today’s technology. The message proxy implementation on the IBM G30 SMPs de- scribed in the previous section is representative of such an ar- chitecture.
MP1 A message proxy system based on next generation hardware parameters. Compared with MPO, it has a higher speed mes- sage proxy processor and higher DMA and network band- width. The higher speed processor results in lower message proxy overhead per communication operation.
MP2 Motivated by the analysis in the previous section that shows the significant effect of cache miss latencies on communica-
121
Parameter I HWO I HWI I MPO Cache Miss Latency ( p s ) I 0.5 I 1.0 1 1.0
GET latency PUT+syncovh. AM latency’ I Peaic~/W
Compute Processor Overhead (ps) Message Proxy Overhead (ps) Hardware Adapter Overhead (ps) DMA Bandwidth (MBIs) Network Latency (ps) Network Bandwidth (MBls)
9.5 9.6 28.0 24.7 16.4 34.1 1.0 1.5 3.5 3.0 0.75 15.0
28.2 30.2 63.5 58.0 41.1 107.8 25.0 150 22.3 86.7 86.7 86.7
0.5 NIA
1 .o 25 1 .o 175
”j: N i
250
MPI [ MP2 I SWI I
150
Table 3: Simulation parameters for the various design points. Cache miss latency refers to the latency between a cache-coherent network adapter or message proxy processor and the main processor. The various overheads refer to the time spent by the compute processor, message proxy, or adapter hardware in submitting the communication command and executing the communication protocol. DMA bandwidth refers to the maximum rate at which a DMA engine can stream data between DRAM and the network FIFOs.
CRL Apps Split-C Apps
RMA Apps
RMA+ RQ
I Simulator
Figure 6: Supporting multiple programming models on the simulator.
tion overhead and latency, we explore the benefit of a cache- update primitive that allows a processor to update the caches of specific processors, similar to the producer prefetch oper- ation ofthe Stanford DASH multiprocessor [12].
A cache-update primitive avoids the invalidation-based pro- tocols common in today’s SMP systems, and saves two cache misses when communicating with another processor through shared memory. We model the cache-update mechanism by using a shorter cache miss latency of 0.25 ps between the message proxy and compute processors.
SW1 A system-call based system based on next generation hard- ware parameters. We assume that system calls and interrupts incur an overhead of 6.5 ps each. This represents very ag- gressively optimized overheads for system calls and over- heads: CompareThekkathet al.’s numbers of about 20 ps on a 25MH.z MIPS processors [23]. These numbers do not include the cost of locking necessary in an SMP, and are unlikely to decrease linearly with increasing processor speed.
We emphasize that the models and parameters favor the cus- tom hardware and system-call design points. The custom hardware model assumes that source and destinations are permanently pinned so that DMA transfers do not incur the cost of pinning pages. The system-call model assumes very aggressive system-call and inter- rupt overheads that may not be achievable in existing commercial operating systems.
Far parallel applications, we build higher-level communication libraries on top of the RMA and RQ layer. Figure 6 illustrates how the various communication layers fit together. We implement an Active Message (AM) layer on top of RMA and RQ. It uses RQ
[ Measurement 1 HWO 1 HWl I MPO I MPI 1 MP2 I SWl PUTlatency’ I 10.0 I 10.6 I 30.0 1 26.6 I 16.9 I 36.1
“round-trip
Table 4: Micrc-benchmark measurements of raw machine perfor- mance. Latencies and overheads are in ps and bandwidth is in MBIs.
primitives to enqueue active-message requests (amiequest) and replies (amieply), and on both RQ and RMA primitives to imple- ment active-message bulk store (amstore) and bulk get (amset) operations. A bulk store involves a PUT operation to transfer the data, followed by an ENQ operation of a handler that detects com- pletion of the PUT and invokes the active-message handler at the re- mote end. The other layers are CRL and Split-C libraries. We also provide a collective communication library based on RMA and RQ that implements barriers, scans, and reductions.
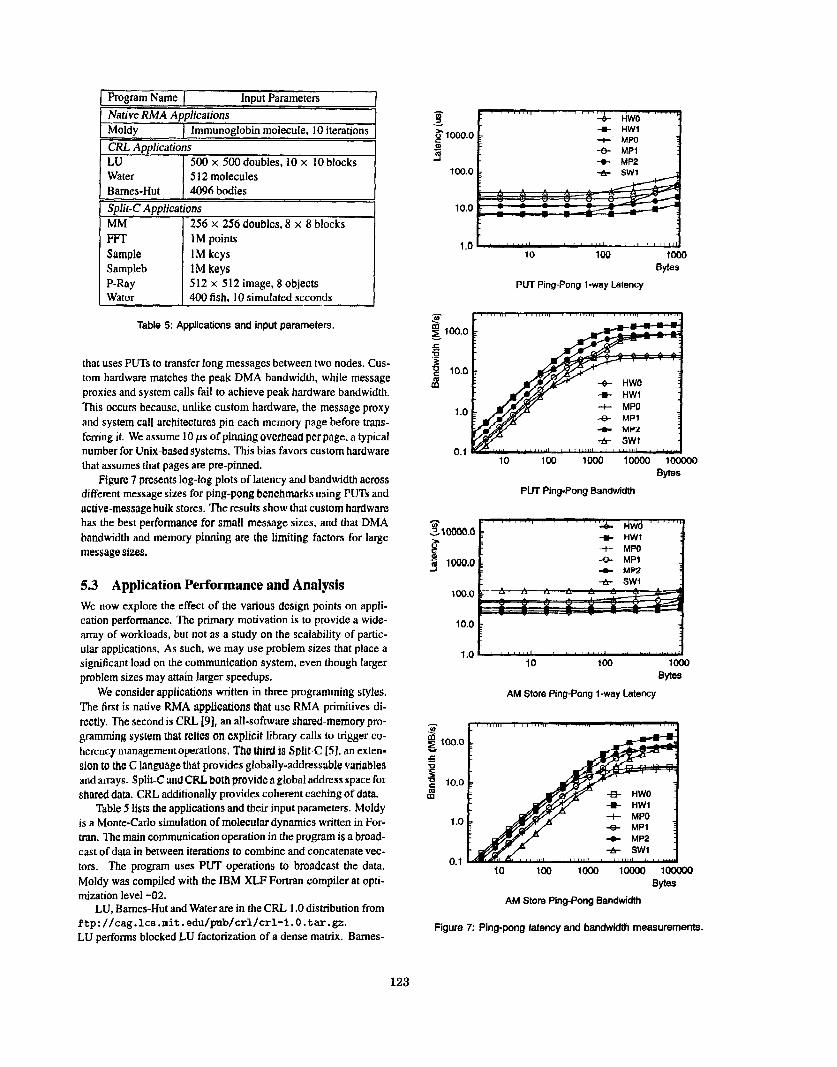
5.2 Micro-Benchmark Analysis The micro-benchmarks measure the latencies, overheads, and band- widths for each of the six design points, and characterize the raw performance of each of the architectures. In Table 4, the PUT and GET latencies measure the time from submitting a PUT/GET command to the time the focd synchronization flag is set. Mes- sage proxy latency is about 2.5 times longer than custom hardware. A cache-update primitive improves the message proxy latency by about 40%. “PUT+sync ovh.” is the overhead incurred by the com- pute processorin submitting and detecting the completion of a PUT. Although message proxies incur more overhead than custom hard- ware, a cache-update primitive removes most of that overhead. The overhead of system-level communication is significantly higher.
AM latency is the latency of a submitting an active-message re- quest to a remote node and receiving a reply to the message. Its la- tency is higher than PUTIGET because it involves handler invoca- tion on processors at both ends. The trends across the six designs are the same as for PUT and GET.
Peak bandwidth is measured by running a ping-pong benchmark
122
ProgramName 1 Input Parameters Native RMA Applications Moldy CRL Applications LU
1000.0 1 lmmunoglobin molecule, 10 iterations
I 500 x 500 doubles, 10 x 10 blocks al
4 MP2 4 Water Barnes-Hut
5 12 molecules 4096 bodies
100.0
10.0 MM m Sample Sampleb P-Ray Wator
1 .o 10 199 1000
Bytes PUT Ping-Pong I-way Latency
256 x 256 doubles, 8 x 8 blocks 1M points 1M keys 1 M keys 512 x 512 image, 8 objects 400 fish, 10 simulated seconds
Table 5: Applications and input parameters.
that uses PUTs to transfer long messages between two nodes. Cus- tom hardware matches the peak DMA bandwidth, while message proxies and system calls fail to achieve peak hardware bandwidth. This occurs because, unlike custom hardware, the message proxy and system call architectures pin each memory page before trans- ferring it. We assume 10 ps of pinning overhead per page, a typical number for Unix-based systems. This bias favors custom hardware that assumes that pages are pre-pinned.
Figure 7 presents log-log plots of latency and bandwidth across different message sizes for ping-pong benchmarks using PUTs and active-message bulk stores. The results show that custom hardware has the best performance for small message sizes, and that DMA bandwidth and memory pinning are the limiting factors for large message sizes.
5.3 Application Performance and Analysis We now explore the effect of the various design points on appli- cation performance. The primary motivation is to provide a wide- array of workloads, but not as a study on the scalability of partic- ular applications. As such, we may use problem sizes that place a significant load on the communication system, even though larger problem sizes may attain larger speedups.
We consider applications written in three programming styles. The first is native RMA applications that use RMA primitives di- rectly. The second is CRL [9], an all-software shared-memory pro- gramming system that relies on explicit library calls to trigger co- herency management operations. The third is Split-C [5], an exten. sion to the C language that provides globally-addressable variables and arrays. Split-C and CRL both provide a global address space for shared data. CRL additionally provides coherent caching of data.
Table 5 lists the applications and their input parameters Moldy is a Monte-Carlo simulation of molecular dynamics written in For- tran. The main communication operation in the program is a broad- cast of data in between iterations to combine and concatenate vec- tors. The program uses PUT operations to broadcast the data. Moldy was compiled with the IBM XLF Fortran compiler at opti-
- .... . 1 .o
-C MP2 -& sw1
Bytes
PUT Ping-Pong Bandwidth
100.0
10.0 [ 1 1 .o
10 100 lo00 Bytes
AM Store Ping-Pong I -way Latency
E 0 3
m 10.0 5
1 .o
01 -. . 100 lo00 loo00 loo000 10
Bvtes AM Store Ping-Pong Bandwidth
Figure 7: Ping-pong latency and bandwidth measurements.
mization level -02. LU, Barnes-Hut and Water are in the CRL 1 .O distribution from
f tp: //cag.lcs.mit . edu/pub/crl/crl-1.0. tar. gz. LU performs blocked LU factorization of a dense matrix. Barnes-
123
- 1 4 r Moldy
Processors
Processors
Barnes-Hut G.
Processors
Sample T(1)=6.06S P w.
8 4 3 2 1 0
(0
1 2 4 8 16 Processors
Sampleb n 12 g IQ
E 8
5 2 U
6
4 6 4 2
2
n 0
i 0) 0)
1 2 4 8 16 Processors
Water a 6 r
" 1 2 4 8 16 Processors
5 - 8 5 $ 4 (I)
3 2 1 0
1 2 4 8 16 Processors
MM P 8r Wator a 61-
Processors
a 5 z 5 a 6 0) n 4
3 4
2 2
1 n 0
v) cn"
1 2 4 8 16 Processors
- 1 2 4 8 16
Processors
Graph Legend: %>>>-%c/e
Figure 8: Application speedups, relative to execution time on a single-processor HW1 configuration, T( 1).
124
Program Archi- Avg. Msg. Avg. Msg. Interface tecture Size Rate Utiliza-
HWI 6456 0.43 2.0% (bytes) (Op/ms) tion
I I I
P-Ray MPI I 29 I 0.88 I 1.9% SWl I 29 I 0.89 I
Moldy I I I
MPI 1 6456 I 0.43 1 4.1% SWI I 6456 I 0.43 I
Table 6: Average application message sizes, rates, and communi- cation interface utilization on 16 processors. Message rate is per- processor. "Interface utilization" refers to the utilization of the mes- sage input and output logic for HW1, and to the utilization of the mes- sage proxy for MPI.
Wator
Hut and Water are adapted from the SPLASH-2 benchmarks [26]. Barnes-Hut uses a hierarchical n-body technique to simulate a sys- tem of bodies under gravitational forces. Water is an "n-squared version of a molecular dynamics application that models a system of water molecules. For Barnes-Hut and Water, we measure the av- erage time for the secondand third iterations. These programs were compiled with the IBM XLC compiler at optimization level -02.
MM, FFT, Sample, Sampleb, P-Ray, and Wator are Split-C ap- plications from the Berkeley Split-C FTP site (f t p : //f t p . cs. berkeley.edu/ucb/projects/CASTLE/Split-C/release/). MM perfoms blocked matrix multiplication. FlT computes a 1 -D Fast Fourier Transform with bulk transfers to exchange data. Sam- ple is a sample son algorithm that uses amieques t / rep ly mes- sages to exchange keys. Sampleb is a version of sample sort that uses bulk transfers. P-Ray is a ray tracing program. Wator is an n- body simulation of fish in a current. These programs were compiled
I
HWI 40 19.00 5.5% MPI 40 14.48 25.7% SWl 40 11.34
with gcc and s p l i t - c c at optimization level -04. Figure 8 presents the self-relative speedups of each of these ap-
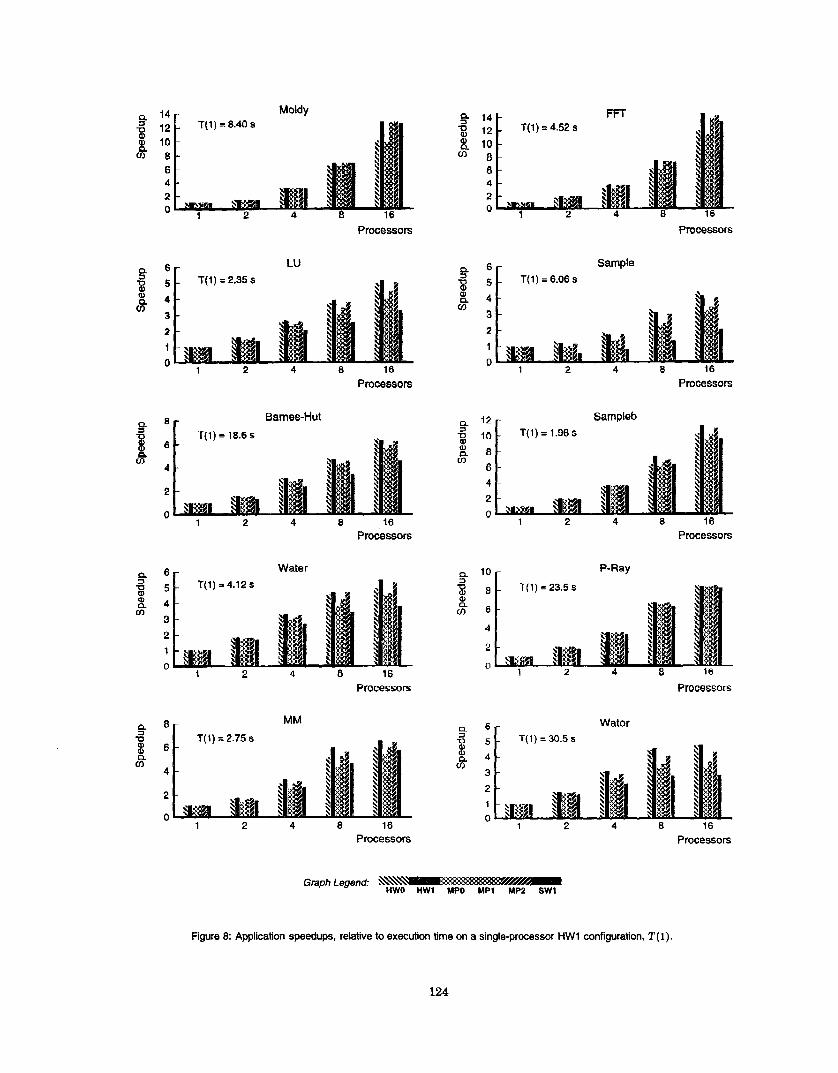
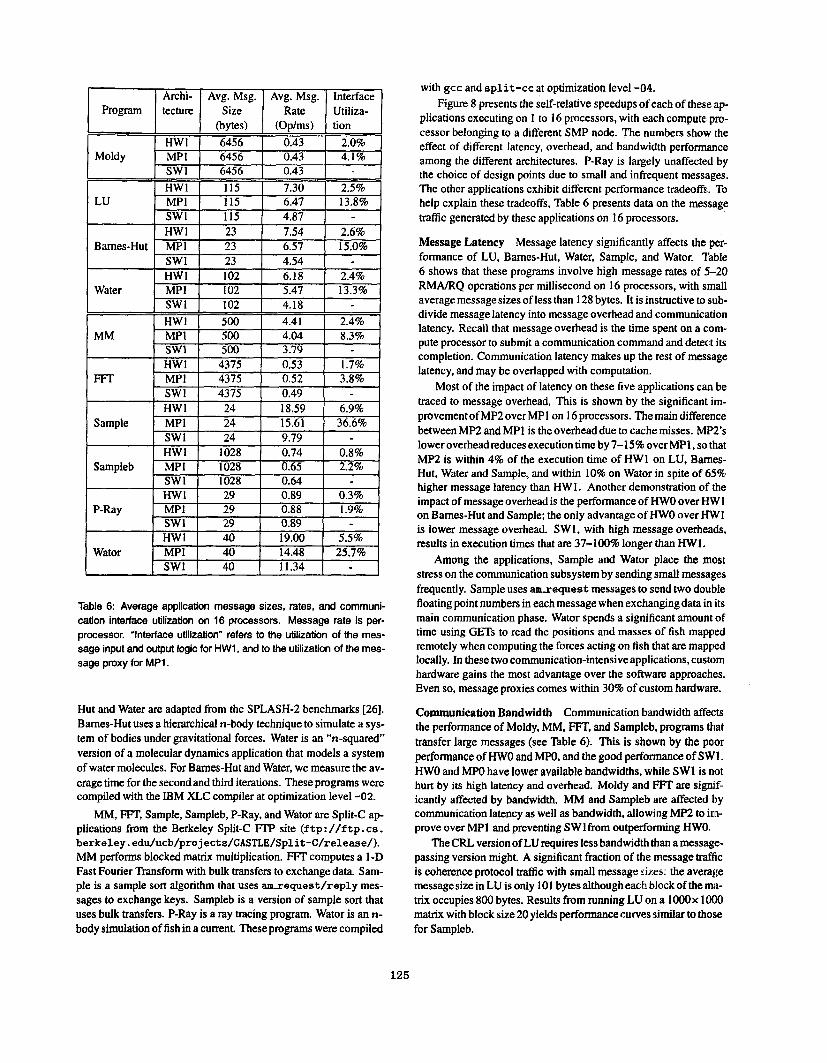
plications executing on 1 to 16 processors, with each compute pro- cessor belonging to a different SMP node. The numbers show the effect of different latency, overhead, and bandwidth performance among the different architectures. P-Ray is largely unaffected by the choice of design points due to small and infrequent messages. The other applications exhibit different performance tradeoffs. To help explain these tradeoffs, Table 6 presents data on the message traffic generated by these applications on 16 processors.
Message Latency Message latency significantly affects the per- formance of LU, Barnes-Hut, Water, Sample, and Wator. Table 6 shows that these programs involve high message rates of 5-20 RMA/RQ operations per millisecond on 16 processors, with small averagemessagesizes of less than 128 bytes. It is instructive to sub- divide message latency into message overhead and communication latency. Recall that message overhead is the time spent on a com- pute processor to submit a communication command and detec:t its completion. Communication latency makes up the rest of message latency, and may be overlapped with computation.
Most of the impact of latency on these five applications can be traced to message overhead. This is shown by the significant im- provement of MP2 over MPI on 16 processors. The main difference between MP2 and MPI is the overhead due to cache misses. MP2's lower overheadreduces execution time by 7-1 5% over MPl, so ithat MP2 is within 4% of the execution time of HWI on LU, Barnes- Hut, Water and Sample, and within 10% on Wator in spite of 65% higher message latency than HW 1. Another demonstration of the impact of message overhead is the performance of HWO over HWI on Bames-Hut and Sample: the only advantage of HWO over HWI is lower message overhead. SWl. with high message overheads, results in execution times that are 37-100% longer than HWl.
Among the applications, Sample and Wator place the most stress on the communication subsystem by sending small messages frequently. Sample uses amieques t messages to send two double floating point numbers in each message when exchangingdata in its main communication phase. Wator spends a significant amount of time using GETS to read the positions and masses of fish mapped remotely when computing the forces acting on fish that are mapped locally. In these two communication-intensive applications, custom hardware gains the most advantage over the software approaches. Even so, message proxies comes within 30% of custom hardware.
Communication Bandwidth Communication bandwidth affects the performance of Moldy, MM, FFT, and Sampleb, programs that transfer large messages (see Table 6). This is shown by the poor performance of H W O and MPO. and the good performance of SWl . HWO and MPO have lower available bandwidths, while SWl is not hurt by its high latency and overhead. Moldy and FIT are signif- icantly affected by bandwidth. MM and Sampleb are affected by communication latency as well as bandwidth, allowing MP2 to inn- prove over MP1 and preventing SWlfrom outperforming H W O .
The CRL version of LU requires less bandwidth than a message- passing version might. A significant fraction of the message traffic is coherence protocol traffic with small message rizes; the average message size in LU is only 101 bytes although each block of the mil-
trix occupies 800 bytes. Results from running LU on a lOOOx 10CO matrix with block size 20 yields performance curves similar to those for Sampleb.
125

Q -//I- 4 6
c n 4
2
n
HW1 MP1 MF'7. SW1 W W 0.
- LU Barnes Water Sample Wator
Figure 9: Speedups of selected applications with significant commu- nication workloads on a configuration of 4 SMP nodes with 4 compute processors per node.
5.4 Other Issues Contention for Message Proxies This section considers the question of how many processors a message proxy can support be- fore contention degrades performance. A simple queuing model analysis indicates that the utilization of a communication agent should be below 50% for stable behavior, but space limitations pre- vent us from deriving this condition here. Using the utilization numbers in Table 6, and assuming each compute processor places an equal load on the messageproxy, we predict that a message proxy can support two compute processors for all the applications, but will be over-utilized for four compute processors in LU, Bames-Hut, Water, Sample and Wator. Although multiple message proxies may help, the memory bus and network interface ultimately place a hard constraint on the number of processors that may be supported.
To see the effect of overloading the message proxy, Figure 9 plots the speedups on a configuration of 4 SMP nodes with 4 com- pute processorsper node for these five applications. Compared with Figure 8, it shows that the performance gap between HW 1 and MPl has increased substantially. However, the degradation is not as large as one might expect because intra-node communication reduces the load on the message proxy. The cache-update primitive in MP2 lowers message proxy utilization and allows MP2 to support four compute processors reasonably well.
To Compute or to Communicate? Since both message proxies and system-level communication are software-based methods, one has a choice between using a processor for a message proxy or for computation. Clearly, one would use additional processors for mes- sage proxies when the application no longer speeds up significantly from more compute processors. However, the tradeoff is not as clear when the application speedup curve has not yet leveled off at the maximum number of available processors. In this case, an al- temative is to use idle processors to run the message proxy instead of dedicating a processor.
If there is insufficient idle cycles so that one has to dedicate a processor to a message proxy, then the choice depends on the application and its load on the message proxy. Since application speedup is almost always sub-linear, in an SMP cluster with P pro- cessor SMPs, one should definitely use a message proxy when- ever it improves performance by more than a factor of P / ( P - 1) over system-level communication. Otherwise, performance may be better if we use the additional processor to compute and incur the higher overhead of system-level communication. Figure 9 predicts that for five-processor SMP nodes, it is better to use MP2 than SW1 for LU, Barnes-Hut, Water, Sample and Wator. However, the choice
is not as clear between MPl and SWI, mainly due to the unrealis- tically low overheads we have assumed for SWl.
6 Related Work This paper focuses on supporting user-level remote memory access and queues for protected communication. Previous work show that remote memory access provides a natural communication primitive for compilers, and can improve the performance of parallel pro- grams, as well as distributed systems [8, 241. Remote queues are essential for supporting message-based communication [20].
A more efficient way to communicate may be to support pro- tected, user-level access to the network interface. The challenge here is to multiplex the network among multiple, possibly uncoop- erative users. A solution is to gang schedule the applications. How- ever, gang scheduling may not always be appropriate. Mackenzie er al. [ 131 rely on a combination of hardware messagetagging, timers, deadlock detection, and OS support to provide protected access to the network without gang scheduling.
Using an SMP processor for communication has been explored previously. Pierce and Regnier dedicate a processor in each node of an Intel Paragon to implement a message passing library [ 181. Wis- consin 'Qphoon-0.1 [ 191 and MIT START-NG [4] dedicate an SMP processor as a protocol processor. Instead of dedicating a processor, Karlsson and Stenstrom use idle SMP processors to accelerate pro- tocol handling for a DVSM system [ IO]. Falsafi and Wood study the tradeoff between using idle processors and dedicated processors for executing communication protocol handlers 161. Krishnamurthy et al. evaluate SplitC on existing machines and conclude that a sep- arate protocol processor improves performance [ 111.
7 Summary and Conclusions This paper describes the design issues and tradeoffs between using custom hardware, system-level communication and message prox- ies for protectedcommunication. We implemented a message proxy based system on a cluster of SMPs that does not require any spe- cial hardware or operating system modifications. Detailed measure- ments of communication cycles yield a latency model that can be used to predict message proxy performance on different SMP plat- forms. The model shows that performance is heavily influenced by the latency of cache misses within an SMP.
We compare message proxies with custom hardware and system-level communication. Micro-benchmarks show that cus- tom hardware has significantly lower communication latencies than message proxies or system calls, but that compute processor over- heads in custom hardware and message proxies are comparable. Re- sults from ten parallel applications written in different programming styles show that both message proxies and system-level communi- cation match the performance of custom hardware for three of the nine applications. Of these three, two are bandwidth limited and the third does not communicate frequently. In the other seven appli- cations, message proxies result in execution times that are between 10-30% longer than with custom hardware. Using system calls re- sults in significantly worse performance - execution times are 37- 100% longer than with custom hardware.
The results also show that a cache-update primitive removes the main bottleneck for message proxy performance and reduces the execution times of communication-intensive programs by 7-25%. With this primitive, message. proxies match the performance of cus-
126

tom hardware for six of the ten applications. In general, cache up- date is useful for producer-consumer or event signaling communi- cation, and we strongly suggest that SMP and processor designs support such a primitive, Custom hardware performance may also be enhanced by this primitive.
In conclusion, message proxies provide an efficient commodity solution to protected communication, even for parallel applications that communicate frequently with small messages. They represent an all-software approach to protected communication that is a viable altemative to custom hardware approaches.
Acknowledgments We would like to acknowledge the contributions of Kattamuri
Ekanadham, Hubertus Franke, Mark Giampapa, and Joefon Jann of IBM Research. Thanks also to Gregorz Czajkowski and Chi-Chao Chang for providing us with Split-C on the SP-2, to Rich Martin for providing us with a suite of Split-C benchmarks, and to Oman Krieger for reviewing the paper.
References [ 11 J. Beecroft, M. Homewood, and M. McLaren. Meiko CS-2 in-
terconnect Elan-Elite design. Parallel Computing, 2 0 1627- 1638,1994.
[2] M. A. Blumrich, K. Li, R. Alpert, C. Dubnicki, E. W. Fel-
I
ten, and J. Sandberg. Virtual Memory Mapped Network In- terface for the SHRIMP Multicomputer. In Proceedings 21st Annual Intemational Symposium on Computer Architecture, pages 142-153, April 1994. E. Brewer, E Chong,L. T. Liu, S . Sharma, and J. Kubiatowicz. Remote Queues: Exposing Message Queues for Optimization and Atomicity. In Proceedingsof the 7th Intemational Sympo- sium on Parallel Algorithms and Architectures. ACM, 1995.
D. Chiou et al. START-NG: Delivering Seamless Parallel Computing. In Proceedings of EURO-PAR '95, Lecture Notes in Computerscience, No. 966, pages 101-1 16,Berlin, August 1995. Springer-Verlag.
D. Culler et al. Parallel Programming in Split-C. In Proceed- ings of Supercomputing '93, pages 262-273, Portland, OR, November 1993. B. Falsafi and D. A. Wood. Scheduling Communication on a SMP Node Parallel Machine. In Proceedings of the 3nd Inter- national Symposium on High-Performance Computer Archi- tecture, San Antonio, TX, February 1997. IEEE.
R. Gillett, M. Collins, and D. Pimm. Overview of Memory Channel Network for PCI. In Proceedingsof the 4lstAnnual IEEE Computer Society Computer Conference (COMPCON), Santa Clara, CA, February 1996. IEEE.
M. Gupta and E. Schonberg. Static analysis to reduce synchro- nization costs in data-parallel programs. In Proceedingsof the 23rd Annual ACM Symposium on Principles of Programming Languages, St. Petersburg Beach, FL, January 1996.
K. L. Johnson, M. E Kaashoek, and D. A. Wallach. CRL: High-Performance All-Software Distributed Shared Memory. In Proceedings of the 15th ACM Symposium on Operating Systems Principles, December 1995.
M. Karlsson and P. Stenstrom. Performance Evaluation of a Cluster-Based Multiprocessor Built from ATM Switches and Bus-Based Multiprocessor Servers. In Proceedings of the 2nd International Symposium on High-Performance Com- puter Architecture, pages 4-13, San Jose, CA, February 1996. IEEE.
[ l l ] A. Krishnamurthy et al. Evaluation of Architectural Sup- port for Global Address-basedCommunication in Large-scale Parallel Machines. In Proceedings of the 7th International Conference on Architectural Support for Programming Lm- guages and Operating Systems, Cambridge, MA, Octoiber 1996. ACM.
[ 121 D. Lenoski, J. Laudon, K. Gharachorloo, W. Weber, A. Gupta, J. Hennessy, M. Horowitz, and M. Lam. The Stanford DASH Multiprocessor. IEEE Computer, 25(3):63-79, March 1992.
[I31 K. Mackenzie, J. Kubiatowicz, M. Frank, W. Lee, A. Agar- wal, and M. F. Kaashoek. UDM: User Direct Message- ing for General-Purpose Multiprocessing. Technical Re- port MITLCSm-556, Massachusetts Institute of Technol- ogy, Cambridge, MA, March 1996.
[ 141 R. P. Martin. HPAM: An Active Message Layer for a Network of HP Workstations. In Proceedings of the IEEE Symposium on Hot Interconnects. IEEE, 1994.
[I51 C. May, E. Silha, R. Simpson, and H. Warren, editors. The PowerPC Architecture: A Specification for a New Family of RISC Processors. Morgan Kaufmann, San Francisco, CA, 2nd edition, May 1994.
[ 161 Message Passinn Interface Forum. Universitv of Tennessee. KnoxGlle. MPI.:A Message-Passing Interface Standard, May 1995.
S. Pakin, A. Chien, and M. Lauria. High Performance Messag- ing on Workstations: Illinois Fast Messages (FM) for Myrinet. In Proceedings of Supercomputing '95, San Diego, CA, De- cember 1995. ACM.
P. Pierce and G. Regnier. The Paragon Implementation of the NX Message Passing Interface. In Proceedings of the Scall- able High-Performance Computing Conference, pages 184C 190, Knoxville, 1994. IEEE. S. K. Reinhardt, R. W. Pfile, and D. A. Wood. Decou- pled Hardware Support for Distributed Shared Memory. In Proceedings of the 23rd Annual lntemational Symposium on Computer Architecture, pages 34-43, Philadelphia, PA, April 1996. ACM.
K. E. Schauser and C. J. Scheiman. Experience with Active Messages on the Meiko CS-2. In Proceedings of the 9th In- ternarional Symposium on Parallel Processing, 1995.
H. Schwetman. CSlM Reference Manual (Rev. 16). Micro- electronics and Computer Technology Corporation (MCC), Austin, TX, June 1992.
C. Seitz. Myrinet - A Gigabit-per-Second Local-Area Net- work. In Proceedings of Hot Interconnects 11, August 1994.
C. A. Thekkath, H. M. Levy, and E. D. Lazowska. Efficienit Support for Multicomputing on ATM Networks. UW-CSE93- 04-03, University of Washington, Seattle, WA, April 1993.
C. A. Thekkath, H. M. Levy, andE. D. Lazowska. Separating Data and Control Transfer in Distributed Operating Systems,. In Proceedings of the 6th International Conference on Archi- tectural Support for Programming Languages and Operatinip Systems, pages 2-1 1, San Jose, CA, October 1994. ACM.
T. von Eicken, A. Basu, and V. Buch. Low-Latency Commu- nication Over ATM Networks Using Active Messages. IEELS Micro, pages 46-53, February 1995.
S. C. Woo, M. Ohara, E. Tome, J. P. Singh, and A. Gupta. The SPLASH-2 Programs: Characterization and Methodological Considerations. In Proceedings of the 22nd Annual Inrema.. tional Symposium on Computer Architecture, pages 24-36, S. Margherita Ligure, Italy, July 1995. ACM.
127


















