Memory and Cache - csce.uark.educsce.uark.edu/.../lectures/lecture14-memory-cache.pdf · Cache...
92
Memory and Cache Alexander Nelson April 20, 2020 University of Arkansas - Department of Computer Science and Computer Engineering
Transcript of Memory and Cache - csce.uark.educsce.uark.edu/.../lectures/lecture14-memory-cache.pdf · Cache...

Memory and Cache
Alexander Nelson
April 20, 2020
University of Arkansas - Department of Computer Science and Computer Engineering

“Ideally one would deire an indefinitely large
memory capacity such that any particular ...
word would be immediately available. ... We
are ... forced to recognize the possibility of
construction a hierarchy of memories,e ach of
which has greater capacity than the preceding
but which is less quicly accessible” - Burks,
Goldstine, von Neumann (1946)
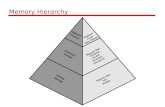
0

Memory
What is memory?
SRAM Cell DRAM Cell
1

Memory
Memory – Safe place to store data
• Includes static & dynamic memory technologies
• Includes magnetic disk storage
Goal – Be able to access data quickly & reliably
May need to access a lot of data
2

Memory
Why a hierarchy of memories?
Type Access Time Cost per GiB
SRAM semiconductor memory 0.5ns - 2.5ns $500 - $1000
DRAM semiconductor memory 50ns - 70ns $10 - $20
Flash semiconductor memory 5,000ns - 50,000ns $0.75 - $1.00
Magnetic disk 5M ns - 20M ns $0.05 - $0.10
(Numbers as of 2012 per our book)
Tradeoff between cost and speed!
3

Goal: Hierarchy of Memories
Why this structure?4

Cache Memory
Use near-CPU memories as cache!
Cache – “A safe place for hiding or storing things”
Copy data from main memory to near memory for quick access
How do we know what will be used?
5

Principle of Temporal Locality
Principle of Temporal Locality
def. “An item that has been referenced is likely to be referenced
again soon”
e.g. Web Browser cache – Store more static aspects of pages
e.g. Variables in a loop
6

Principle of Spatial Locality
Principle of Spatial Locality
def. “An item that is referenced is likely near to items that will be
referenced soon”
e.g. Website pre-fetch – Downloading content before you scroll so
that content shows in real-time
e.g. Sequential instruction access
7

Locality
These two principles of locality enable caches to work well
How do we define working well?
Hit Rate – Fraction of memory accesses found in the upper levels
of cache!
conversely
Miss Rate – Fraction of memory accesses not found in upper
levels of cache
Miss Rate = 1 - Hit Rate
Good cache choices increase hit rate!
8

Taking Advantage of Locality
Cache Strategy:
• Store everything on disk
• Copy recently accessed items
to smaller DRAM memory
• Copy items nearby recent
accesses to smaller DRAM
memory
• Copy most recent accesses
(and nearby) from DRAM to
SRAM
9

Hit Rate & Miss Penalty
Block (a.k.a line) – Minimum addressable unit in memory
If Block present in memory = Hit
If Block not present in memory = Miss
Hit Time = Time required to access a given level of hierarchy if
item is present
Miss Penalty = Time required to fetch a block into a level of
memory hierarchy from a lower level
Hierarchy performance based on improved Hit Time, reduced Miss
Rate & Miss Penalty
10

Memory Technologies

SRAM – Static Random Access Memroy
SRAM – 6-Transistor SRAM cell
Fixed access & write times – typically very close to cycle time
11

DRAM – Dynamic Random Access Memory
DRAM – Uses a capacitor to
store bit
Must be periodically refreshed
To refresh:
• Read value
• Write it back
Charge kept for several
milliseconds
12

DRAM Structure
Uses two-level decode structure – Allows refreshing entire rows at
the same time
13

DRAM Organization
Bits in DRAM organized as rectangular array
• DRAM accesses entire row
• Burst Mode – supply successive words from a row with
reduced latency
Double Data Rate DRAM (DDR DRAM)
• Transfer on rising and falling clock edges
Quad Data Rate (QDR) DRAM
• Separate DDR inputs & outputs
14

DRAM – Cost & Capacity
DRAM – Often organized into DIMM
DIMM = Dual Inline Memory Modules
DIMMs contain 4-16 DRAMs
Cost per bit has dramatically reduced
15

DRAM Performance Factors
Row Buffer
• Allows several words to be read and refreshed in parallel
Synchronous DRAM
• Allow consecutive accesses in bursts without need to send
addresses
• Improves bandwidth
DRAM banking
• Allow simultaneous access to multiple DRAMs
• Improves bandwidth
16

Increasing Memory Bandwidth
17

Flash Storage
Flash – Nonvolatile Semiconductor Storage
• 100x - 1000x faster than disk
• Smaller, lower power, more robust
• More expensive per bit
18

Disk Storage
Disk – Nonvolatile, rotating magnetic storage
19

Disk Sectors and Access
Each sector records
• Sector ID
• Data (512 bytes, 4096 bytes proposed)
• Error correcting code (ECC)
• Used to hide defects and recording errors
• Synchronization fields and gaps
Access to a sector involves – Queuing delay if other accesses are
pending; Seek: move the heads; Rotational latency; Data transfer,
& Controller overhead
20

Cache

Cache Memory
Cache memory – level of memory hierarchy closest to CPU
Cache memory is smaller than lower levels of hierarchy
How do we know if data is in the cache?
Where would we look?
21

Cache Memory
Direct Mapped Cache – Location determined by address
Direct mapped = only one choice!
Cache address = (block address) mod (number of blocks in cache)
# of blocks is a power of 2 22

Cache Memory
How do we know which block in a current location?
23

Cache Memory
How do we know which block in a current location?
Store block address as well as data!
• Only need high order bits
• i.e. (block address) / (number blocks in cache)
• Called the “tag”
What if no data in a location?
24

Cache Memory
How do we know which block in a current location?
Store block address as well as data!
• Only need high order bits
• i.e. (block address) / (number blocks in cache)
• Called the “tag”
What if no data in a location?
Valid bit!
• 1 = present
• 0 = not present
• initialized to 0
25

Cache Example
Consider the following cache:
8 blocks, 1 word/block, direct mapped
Note, all valid bits = 0
26

Cache Example – Initial State
Instruction 1:
lw $s0, $zero, 101102 # Load from 101102 into register
Is this cache hit or miss?
27

Cache Example – Initial State
Instruction 1:
lw $s0, $zero, 101102 # Load from 101102 into register
Is this cache hit or miss?
MISS! – Cache is empty, all valid bits are 0!
Load block from memory into cache, then into register
28

Cache Example – State 1
New state:
Instruction 2:
lw $s1, $zero, 110102 # Load from 110102 into register
Cache hit or miss?
29

Cache Example – State 2
MISS! – Index 010 not valid
Load block from memory, into register. New state:
Instruction 3:
lw $s3, $zero, 101102 # Load from 101102 into register
Cache hit or miss?30

Cache Example – State 3
HIT! – Index 110 valid, and Tag == 10
Load directly from cache into register, no state change
Instruction 4:
lw $s4, $zero, 100002 # Load from 100002 into register
Cache hit or miss?31

Cache Example – State 4
MISS – Index 000 not valid
Load into cache then register
Instruction 5: lw $s5, $zero, 000112 # Load from 000112 into
register
Cache hit or miss?
Instruction 6: lw $s6, $zero, 100002 # Load from 100002 into
register
Cache hit or miss?
32

Cache Example – State 5
Instruction 5: MISS! – index 011 not valid
Instruction 6: HIT! – index 000 valid, tag == 10
New state:
Instruction 7 – lw $s7, $zero, 100102
Cache hit or miss?33

Cache Example – State 6
MISS! – Index 010 valid, but tag != 10
Replace cache with memory, load into register
Final state:
34

Address Subdivision
LSBs determine which cache
block to address
• Less “Byte Offset” = size of
block in words
Compare MSBs to identify if tag
matches
35

Example – Larger Block Size
What if we use a larger block?
64 blocks, 16 bytes/block = 4 words/block
• What block number does address 1200 map to?
36

Example – Larger Block Size
What if we use a larger block?
64 blocks, 16 bytes/block = 4 words/block
• What block number does address 1200 map to?
Block address = (1200/16) = 75
Block Number = 75 mod 64 = 11
37

Block Size Considerations
Larger blocks should reduce miss rate!
• What principle helps us here?
38

Block Size Considerations
Larger blocks should reduce miss rate!
• What principle helps us here?
• Spatial Locality!
But in a fixed-size cache:
• Larger blocks = fewer # of blocks
• More competition = increased miss rate
• Larger blocks leads to pollution
Larger miss penalty!
• Can override benefit of reduced miss rate
• Early restart and critical-word-first addressing can help
39

Cache Miss
On cache hit, CPU loads from cache & proceeds normally
What happens on a cache miss?
40

Cache Miss
On cache hit, CPU loads from cache & proceeds normally
What happens on a cache miss?
On cache miss:
• Stall CPU pipeline
• Fetch block from next level of hierarchy
• Instruction Cache Miss?
• Restart instruction fetch
• Data Cache Miss?
• Complete data access
41

Write-Through Cache
What about cache writing?
42

Write-Through Cache
What about cache writing?
On data write hit, could just update block in cache
• Is this true memory hierarchy?
• No! – Memory & cache inconsistent
Write Through – Also update memory on writes!
What is the drawback of this strategy?
43

Write-Through Cache
What about cache writing?
On data write hit, could just update block in cache
• Is this true memory hierarchy?
• No! – Memory & cache inconsistent
Write Through – Also update memory on writes!
What is the drawback of this strategy?
Writes take longer!
• e.g. Base CPI = 1
• If 10% of instructions are store & write-back takes 100 cycles
• Effective CPI = 1 + 0.1 × 100 = 11!
• Over an order of magnitude slowdown!
44

Write Buffer
How do we solve this problem?
Write Buffer! – Hold onto data waiting to be written to memory
CPU continues immediately, only stalls on write if buffer full
45

Write-Back Cache
Alternate Strategy – Only update memory when cache swapping
Called “Write-Back” cache
Strategy:
• On data-write hit, update in cache
• Keep track of whether a block is “dirty”
• When dirty block replaced – write back to memory
• Can use write buffer to allow replacing block to be read first
46

Write Allocation
What should happen on a write miss?
47

Write Allocation
What should happen on a write miss?
Alternatives for write-through
• Allocate on miss – fetch the block
• Write around – don’t fetch the block
• Programs often write a whole block before reading it
• e.g. Initialization of arrays
For write-back – Usually fetch the block
48

Example – Intrinsity FastMATH
Embedded MIPS processor:
• 12-stage pipeline
• Instruction and data access on each cycle
Split cache – separate Instruction and Data caches
• Each 16KB
• 256 blocks, 16 words/block
• D-cache - write-through or write-back
49

Example – Intrinsity FastMATH
SPEC2000 miss rates:
• I-cache = 0.4%
• D-cache = 11.4%
• Weighted average = 3.2%
50

Example – Intrinsity FastMATH
51

Main Memory Supporting Caches
Use DRAMs for main memory
• Fixed width (e.g. 1 word)
• Connected by fixed-width clocked bus
• Bus clock is typically slower than CPU clock
Example cache block read:
• 1 bus cycle for address transfer
• 15 bus cycles per DRAM access
• 1 bus cycle per data transfer
For 4-word blcok, 1-word-wide DRAM
• Miss penalty = 1 + 4 × 15 + 4 × 1 = 65 cycles
• Bandwidth = 16 bytes / 65 cycles = 0.25 B/cycle
52

Improving Cache Performance

Measuring Cache Performance
Components of CPU time:
• Program execution cycles – includes cache hit time
• Memory stall cycles – mainly cache misses
If we make a few simplifications:
Memory stall cycles = Memory accessesProgram ×Miss rate ×Miss penalty
= InstructionsProgram × Misses
Instruction ×Miss penalty
53

Cache Performance Example
Given:
• I-cache miss rate = 2%
• D-cache miss rate = 4%
• Miss penalty = 100 cycles
• Base CPI (ideal cache) = 2
• Load & stores = 36% of instructions
Then, miss cycles per instruction:
• I-cache = 0.02 × 100 = 2
• D-cache = 0.36 × 0.04 × 100 = 1.44
Therefore, actual CPI:
• 2 (base) + 2 (I-cache) + 1.44 (D-cache) = 5.44
• Ideal: 5.442 = 2.72 times faster
54

Average Access Time
Hit time is also important for performance
Average memory access time (AMAT)
• AMAT = Hit time + Miss rate × Miss penalty
Example:
• CPU with 1ns clock
• Hit time = 1 cycle
• Miss penalty = 20 cycles,
• I-cache miss rate = 0.05 (5%)
AMAT = 1 + 0.05 × 20 = 2ns
(2 cycles per instruction)
55

Performance Summary
When CPU performance increased, miss penalty becomes more
significant!
Decreasing base CPI – greater proportion of time spent on memory
stalls (Amdahl’s law)
Increasing clock rate – memory stalls account for more CPU cycles
Can’t neglect cache behavior when evaluating system performance!
56

Associative Caches
What if we made caches more flexible to improve hit rate?
Associative caches – Blocks have flexibility on where to go
Fully Associative Cache – Allow block to any cache entry
• Requires all entries to be searched at once
• Comparator per entry (expensive!)
n-way set associative – each set contains n entries
• Block number determines which set
• (Block number) mod (#Sets in cache)
• Search all entries in a given set at once
• n comparators (less expensive!)
57

Associative Caches
58

Spectrum of Associativity
For a cache with 8 entries:
59

Associativity Example
Compare 4-block caches:
• Direct mapped, 2-way set associative, fully associative
• Block access sequence: 0, 8, 0, 6, 8
Direct Mapped:
60

Associativity Example
2-way set associative:
Fully associative:
61

How Much Associativity?
Increased associativity decreases miss rate
• With diminishing returns
Simulation of a system with 64KB D-cache, 16-word blocks,
SPEC2000
• 1-way (direct) – 10.3% Miss rate
• 2-way – 8.6% Miss rate
• 4-way – 8.3% Miss rate
• 8-way – 8.1% Miss rate
62

Set Associative Cache Organization
63

Replacement Policy
Direct mapped – no choice!
Set associative:
• Prefer non-valid entry, if exists
• Else, choose among entries in the set
LRU – least recently used:
• Choose the block unused for longest time
• Simple for 2-way, manageable for 4-way, hard beyond that
Random – Approximately same performance as LRU for high
associativity
64

Multilevel Caches
Primary cache attached to CPU – small but fast!
Level-2 cahce services misses from primary cache
• Larger, slower, still faster than main memory
Main memory services L-2 cache misses
Some systems include L-3 cache
L-4 Cache? – Very uncommon
65

Multilevel Cache Example
Given:
• CPU base CPI = 1
• Clock rate = 4 GHz
• Miss rate/instruction = 2%
• Main memory access time = 100ns
With just primary cache:
• Miss penalty = 100ns0.25ns = 400 cycles
• Effective CPI = 1 + 0.02 × 400 = 9
66

Multilevel Cache Example
Now add L-2 cache:
• Access time = 5ns
• Global miss rate to main memory = 0.5%
Primary miss with L-2 hit:
• Penalty = 5ns0.25ns = 20 cycles
Primary miss with L-2 miss:
• Extra penalty = 500 cycles
CPI = 1 + 0.02 × 20 + 0.005 × 400 = 3.4
Performance ratio = 93.4 = 2.6 times faster!
67

Multilevel Cache Considerations
Primary cache – focus on minimal hit time
L-2 cache:
• Focus on low miss-rate to avoid main memory access
• Hit time has less overall impact
Results:
• L-1 cache usually smaller than a single cache
• L-1 block size smaller than L-2 block size
68

Interactions with Advanced CPUs
Out-of-order CPUs can execute instructions during cache miss
• Pending store stays in load/store unit
• Dependent instructions wait in reservation stations
• Independent instructions continue
Effect of miss depends on program data flow
• Much harder to analyze
• Use system simulation
69

Interactions with Software
Misses depend on memory access
patterns
• Algorithm behavior
• Compiler optimization for memory
access
70

Dependable Memory

Dependable Memory
Memory hierarchy needs to hold data
safely, even in failure
Dependability from redundancy!
Two is one, one is none!
71

Defining Failure
How to define failure?
1. Service Accomplishment – Service is delivered as specified
2. Service Interruption – Delivered service is different from
specification
Failure – Transition from state 1 to state 2
Restoration – Transition from state 2 to state 1
Failures can be intermittent or permanent
72

Reliability
Reliability – A measure of continuous service accomplishment
Can be expressed in the amount of time to failure
Mean Time to Failure (MTTF)
–Average amount of time until a failure
Annual Failure Rate (AFR)
– Percentage of devices expected to fail in a year
AFR = 1 − exp(−8766
MTTF) (1)
73

Reliability Example
Example: Assume HD with 1M hours MTTF = 114 years! Assume
server farm with 100k disks. How many disks fail per year?
AFR = 1 − exp( −87661,000,000)
AFR = 1 − exp(−0.008766)
AFR = 1 − 0.99127
AFR = 0.00872 == 0.872%
Failures per year = AFR × #components
Failures per year = 0.00872 × 100, 000
Failures per year = 872.77 Disks/year!
74

Reliability Example
Our book uses an approximation for AFR:
AFR ≈ 8766
MTTF(2)
Using this approximation:
AFR = 87661,000,000 = 0.008766
Failures per year = 0.008766 × 100, 000 = 876.6 disks/year
Fairly close approximation for small AFR!
75

Availability
Service Interruption can be measured in amount of time to repair
Mean Time to Repair (MTTR)
Mean Time Between Failures (MTBF)
– Sum of MTTF + MTTR
Availability – Measure of service accomplishment
Measured with respect to accomplishment and interruption
Therefore:
Availability =MTTF
MTTF + MTTR(3)
76

Availability
Goal – keep availability high!
Shorthand = “nines of availability”
• One nine = 90% = 36.5 days of repair/year
• Two nines = 99% = 3.65 days of repair/year
• Three nines = 99.9% = 526 minutes of repair/year
• Four nines = 99.99% = 52.6 minutes of repair/year
• Five nines = 99.999% = 5.26 minutes of repair/year
Good services can provide four or five nines of availability
77

Increasing Availability
Availability can be improved by:
• Increasing MTTF
• Decreasing MTTR
Fault – Failure of any single component
• May or may not result in system failure
78

Increasing Availability
Three ways to improve MTTF:
• Fault Avoidance – Prevent fault occurrence by construction
• Fault Tolerance – Using redundancy to allow service to
comply with specification despite faults
• Fault Forecasting – Predicting presence and creation of faults,
allowing component to be replaced before it fails
79

Example: Hamming ECC Code
Example of improving dependability:
Goal – Reduce errors as the result of individual bits being incorrect
Hamming Distance – # of bits that are different between two bit
patterns
What is the hamming distance between the following:
0b00110011
0b00100001
80

Example: Hamming ECC Code
Example of improving dependability:
Goal – Reduce errors as the result of individual bits being incorrect
Hamming Distance – # of bits that are different between two bit
patterns
What is the hamming distance between the following:
0b00110011
0b00100001
2!
81

Example: Hamming ECC Code
Minimum Hamming Distance – Minimum allowable difference
between bit patterns
If minimum distance == 2, provide 1-bit error detection
• e.g. Parity codes
If minimum distance == 3, provides singe-bit error correction,
2-bit error detection
82

Example: Hamming ECC Code
Hamming Error Correction Code (ECC) – distance-3 code
Steps:
1. Start number bits from 1 on the left
2. Mark all bit positions that are powers of 2 as parity bits
(positions 1, 2, 4, 8, 16, ...)
3. All other bit positions are used for data bits
4. Position of parity bit determines the sequence of data bits
that it checks
5. Set parity bits to create even parity for each group
83

Example: Hamming ECC Code
For 8 data bits:
• Parity bits at 1, 2, 4, 8
• Data bits at 3, 5, 6, 7, 9, 10, 11, 12
• Bits are checked as follows:
84

Decoding ECC
Value of parity bits indicates which bits are in error!
• Use numbering from encoding procedure
• E.g.:
• Parity bits = 0000 – No Error!
• Parity bits = 1010 – bit 10 was flipped
85

Example Hamming SEC/DED
Did not stop at single ECC
Add an additional parity bit for the whole word (pn)
Makes Hamming Distance == 4
Single Error Correcting, Double Error Detection (SEC/DED)
Decoding: Let H = SEC parity bits
• H even, pn even – No error
• H odd, pn odd – Correctable single bit error
• H even, pn odd – Error in pn bit
• H odd, pn even – Double error occurred
86












