
MediaEval 2016 - HUCVL Predicting Interesting Key Frames with Deep Models
16
Göksu Erdoğan, Aykut Erdem, Erkut Erdem HUCVL @ MediaEval 2016: Predicting Interesting Key Frames with Deep Models HACETTEPE UNIVERSITY COMPUTER VISION LAB
-
Upload
multimediaeval -
Category
Science
-
view
52 -
download
1
Transcript of MediaEval 2016 - HUCVL Predicting Interesting Key Frames with Deep Models

Göksu Erdoğan, Aykut Erdem, Erkut Erdem
HUCVL @ MediaEval 2016: PredictingInteresting Key
Frames with Deep Models
HACETTEPE UNIVERSITY COMPUTER VISION LAB

2
Which is more interesting? Why?

3
Deep Learning
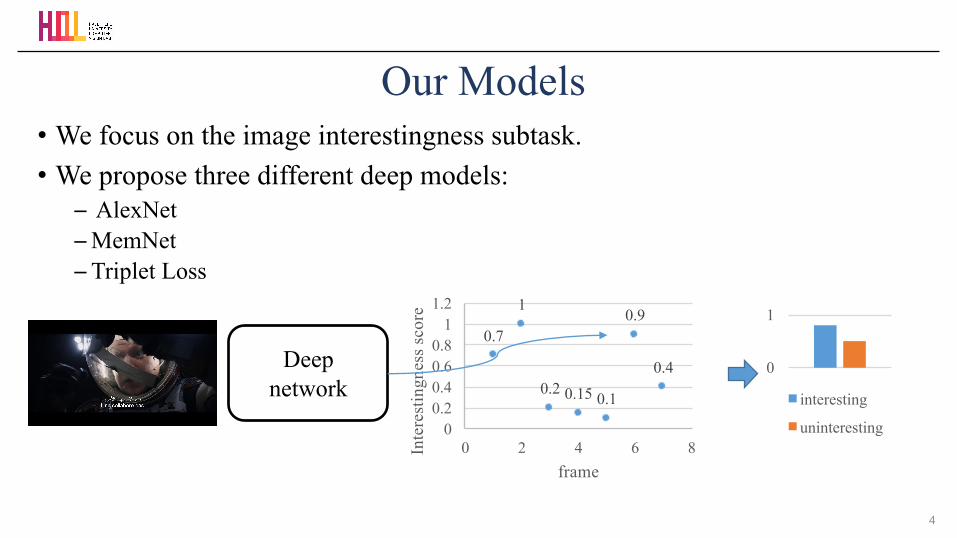
• We focus on the image interestingness subtask.• We propose three different deep models:
− AlexNet−MemNet−Triplet Loss
4
Our Models
Deepnetwork
0.7
1
0.2 0.15 0.1
0.9
0.4
00.20.40.60.8
11.2
0 2 4 6 8Inte
rest
ingn
esss
core
frame
0
1
interesting
uninteresting

• ImageNet dataset• ILSVRC 2012 task• Object classification
interesting
5
AlexNet
A. Krizhevsky, I. Sutskever, G. Hinton, "ImageNet Classification with Deep Convolutional Neural Networks", Advances in Neural Information Processing Systems, pages 1097 - 1105, 2012
conv
1re
lu1
conv
2re
lu2
conv
3re
lu3
conv
4re
lu4
norm
1
pool
1
norm
2
pool
2
conv
5re
lu5
pool
5
fc6
relu
6dr
op6
fc7
relu
7dr
op7
fc8
softm
axlo
ss
labe
l
5 convolutional layers 3 fully connected layers

• Training lasted approximately 2000 epochs.
confidence
6
AlexNet for Interestingness Prediction
A. Krizhevsky, I. Sutskever, G. Hinton, "ImageNet Classification with Deep Convolutional Neural Networks", Advances in Neural Information Processing Systems, pages 1097 - 1105, 2012
conv
1re
lu1
conv
2re
lu2
conv
3re
lu3
conv
4re
lu4
norm
1
pool
1
norm
2
pool
2
conv
5re
lu5
pool
5
fc6
relu
6dr
op6
fc7
relu
7dr
op7
fc8
Eucl
idea
nlo
ss
real
-val
ue
frozen fine-tuned

7
MemNet
A. Khosla, A. Raju, A. Torralba, A. Oliva, "Understanding and predicting image memorability at a large scale", In Proc. International Conference on Computer Vision, pages 2390 - 2398, 2015
Are memorability and interestingness of a image correlated?
Decresing memorability

• Memorability and interestingness are both intrinsic image properties.
confidence
8
MemNet
conv
1re
lu1
conv
2re
lu2
conv
3re
lu3
conv
4re
lu4
pool
1
norm
1
pool
2
norm
2
conv
5re
lu5
pool
5
fc6
relu
6dr
op6
fc7
relu
7dr
op7
fc8
eucl
idea
nlo
ss
real
-val
ue
5 convolutional layers 3 fully connected layers
A. Khosla, A. Raju, A. Torralba, A. Oliva, "Understanding and predicting image memorability at a large scale", In Proc. International Conference on Computer Vision, pages 2390 - 2398, 2015

• Training lasted approximately 3000 epochs.
confidence
9
MemNet for Interestingness Prediction
conv
1re
lu1
conv
2re
lu2
conv
3re
lu3
conv
4re
lu4
pool
1
norm
1
pool
2
norm
2
conv
5re
lu5
pool
5
fc6
relu
6dr
op6
fc7
relu
7dr
op7
fc8
eucl
idea
nlo
ss
real
-val
ue
frozen fine-tuned
A. Khosla, A. Raju, A. Torralba, A. Oliva, "Understanding and predicting image memorability at a large scale", In Proc. International Conference on Computer Vision, pages 2390 - 2398, 2015

𝑥#
𝑥$
𝑥
𝐿 𝑥, 𝑥$, 𝑥# = max 0, 𝐷 𝑥, 𝑥$ − 𝐷 𝑥, 𝑥# + 𝑀
10
Triplet Loss
X. Wang and A. Gupta, "Unsupervised learning of visual representations using videos", In Proc.International Conference on Computer Vision, pages 2794 - 2802, 2015

11
Triplet Loss for Interestingness Prediction
conv
1re
lu1
conv
2re
lu2
conv
3re
lu3
conv
4re
lu4
norm
1
pool
1
norm
2
pool
2
conv
5re
lu5
pool
5
fc6
relu
6dr
op6
fc7
relu
7dr
op7
fc8
tripl
etlo
ss
shared weights
𝑥
𝑥$
𝑥#
X. Wang and A. Gupta, "Unsupervised learning of visual representations using videos", In Proc.International Conference on Computer Vision, pages 2794 - 2802, 2015
Interestingness scorex x+ x-
frozen fine-tuned

• Interestingness scores Class labels
12
Interestingness Classification
Distributions of the confidence values forinteresting/uninteresting frames over the training data (left) anda video sample(right)

Highest %10 interestingRemaining uninteresting
13
Interestingness Classification
frames mean std
interesting 0.11 0.08
uninteresting 0.89 0.08
Statistics for the confidence values for interesting anduninteresting frames over training data
14
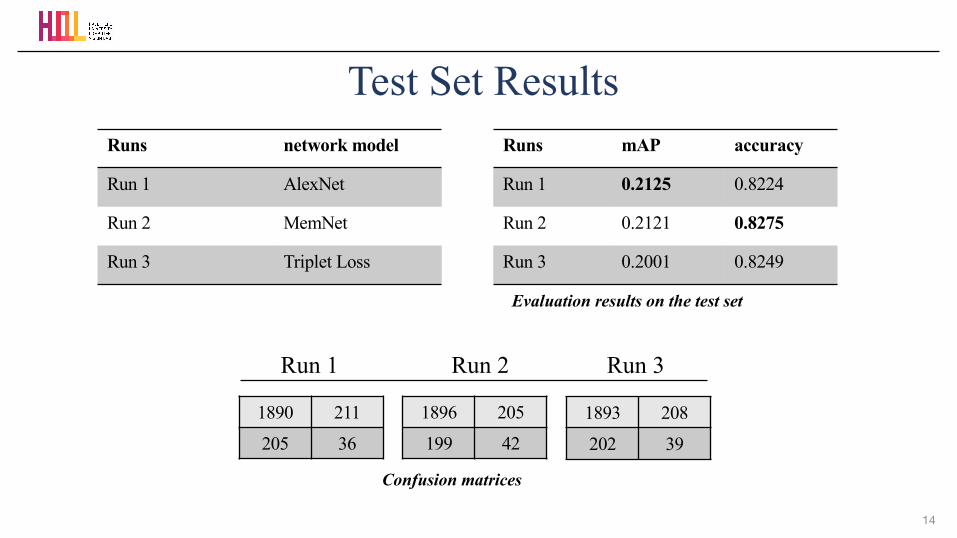
Test Set ResultsRuns network model
Run 1 AlexNet
Run 2 MemNet
Run 3 Triplet Loss
Runs mAP accuracy
Run 1 0.2125 0.8224
Run 2 0.2121 0.8275
Run 3 0.2001 0.8249
1890 211
205 36
1896 205
199 42
1893 208
202 39
Run 1 Run 2 Run 3
Confusion matrices
Evaluation results on the test set

• Imbalanced data makes training process challenging.• Data size is very small to train a deep model.
• Future directions:−Using the context of a local temporal neighborhood or the whole video.−Using a multi-task learning scheme, which jointly performs classification and
regression• Classification for label prediction• Regression for interestingness score prediction
15
Conclusion

Thank you!
16


















