
Max Prin - SMX West 2017 - What to do when Google can't understand your JavaScript
41
#SMX #23A2 @maxxeight SEO Best Practices for JavaScript What To Do When Google Can't Understand Your JavaScript
Transcript of Max Prin - SMX West 2017 - What to do when Google can't understand your JavaScript

#SMX #23A2 @maxxeightSEO Best Practices for JavaScript
What To Do When Google
Can't Understand
Your JavaScript

#SMX #23A2 @maxxeight

#SMX #23A2 @maxxeight
How Search Engines Typically Work

#SMX #23A2 @maxxeight
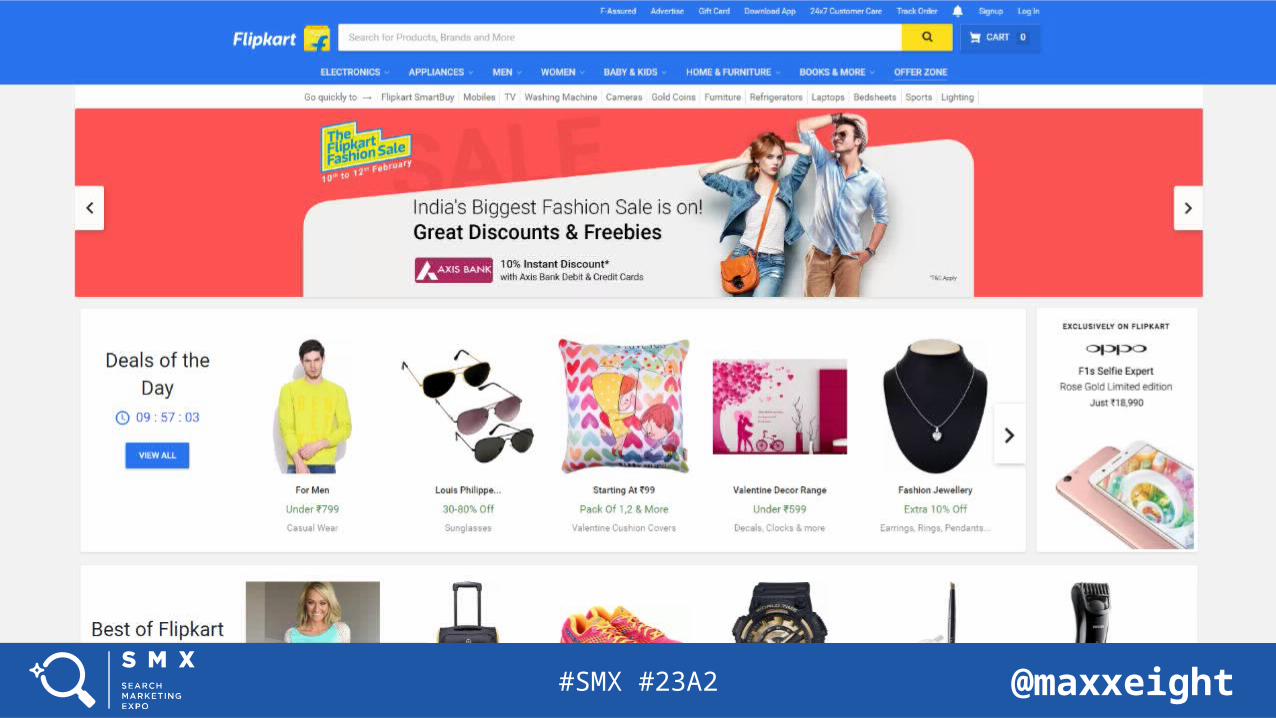
Everything is there!

#SMX #23A2 @maxxeight
#SMX #23A2 @maxxeight

#SMX #23A2 @maxxeight
Web Development Technologies

#SMX #23A2 @maxxeight
Search Engines’ Mission:
Serving the best result

#SMX #23A2 @maxxeight
No page titleNo content
Etc.

#SMX #23A2 @maxxeight
It’s in the DOM!

#SMX #23A2 @maxxeight
How Search Engines Typically Work
Render “Understanding web pages
better”

#SMX #23A2 @maxxeight

#SMX #23A2 @maxxeight
So, what now?

#SMX #23A2 @maxxeight
Crawling– Don’t block resources via robots.txt
How To Make Sure Google Can Understand Your Pages

#SMX #23A2 @maxxeight

#SMX #23A2 @maxxeight

#SMX #23A2 @maxxeight
Crawling– Don’t block resources via robots.txt – onclick + window.location != <a href=”link.html”>
How To Make Sure Google Can Understand Your Pages

#SMX #23A2 @maxxeight

#SMX #23A2 @maxxeight
Crawling– Don’t block resources via robots.txt – onclick + window.location != <a href=”link.html”>– 1 unique “clean” URL per piece of content (and vice-
versa)
How To Make Sure Google Can Understand Your Pages

#SMX #23A2 @maxxeight
URL Structures (with AJAX websites)
Fragment Identifier: example.com/#url– Not supported. Ignored. URL = example.com
Hashbang: example.com/#!url (pretty URL)– Google and Bing will request: example.com/?_escaped_fragment_=url (ugly URL)
– The escaped_fragment URL should return an HTML snapshot
Clean URL: example.com/url– Leveraging the pushState function from the History
API– Must return a 200 status code when loaded directly

#SMX #23A2 @maxxeightHistory API - pushState()

#SMX #23A2 @maxxeight
Crawling– Don’t block resources via robots.txt – onclick + window.location != <a href=”link.html”>– 1 unique “clean” URL per piece of content (and vice-
versa) Rendering– Load content automatically, not based on user
interaction (click, mouseover, scroll)
How To Make Sure Google Can Understand Your Pages

#SMX #23A2 @maxxeight

#SMX #23A2 @maxxeight
Crawling– Don’t block resources via robots.txt – onclick + window.location != <a href=”link.html”>– 1 unique “clean” URL per piece of content (and vice-
versa) Rendering– Load content automatically, not based on user
interaction (click, mouseover, scroll) – the 5-second rule
How To Make Sure Google Can Understand Your Pages

#SMX #23A2 @maxxeight
Google Fetch & Render PageSpeed Insights
The 5-second rule

#SMX #23A2 @maxxeight
Crawling– Don’t block resources via robots.txt – onclick + window.location != <a href=”link.html”>– 1 unique “clean” URL per piece of content (and vice-
versa) Rendering– Load content automatically, not based on user
interaction (click, mouseover, scroll) – the 5-second rule– Avoid JavaScript errors (bots vs. browsers)
How To Make Sure Google Can Understand Your Pages

#SMX #23A2 @maxxeight

#SMX #23A2 @maxxeight
HTML snapshots are only required with uncrawlable URLs (#!)
When used with clean URLs:– 2 URLs requested for each content (crawl
budget!) Served directly to (other) crawlers
(Facebook, Twitter, Linkedin, etc.) Matching the content in the DOM No JavaScript (except JSON-LD markup) Not blocked from crawling
The “Old” AJAX Crawling Scheme And HTML Snapshots
DOMHTML
Snapshot

#SMX #23A2 @maxxeight
HTML snapshots are only required with uncrawlable URLs (#!)
When used with clean URLs:– 2 URLs requested for each content (crawl
budget!) Served directly to (other) crawlers
(Facebook, Twitter, Linkedin, etc.) Matching the content in the DOM No JavaScript (except JSON-LD markup) Not blocked from crawling
The “Old” AJAX Crawling Scheme And HTML Snapshots
DOMHTML
Snapshot

#SMX #23A2 @maxxeight
Crawling– Don’t block resources via robots.txt – onclick + window.location != <a href=”link.html”>– 1 unique “clean” URL per piece of content (and vice-
versa) Rendering– Load content automatically, not based on user
interaction (click, mouseover, scroll) – the 5-second rule– Avoid JavaScript errors (bots vs. browsers)
Indexing– Mind the order of precedence (SEO signals and
content)
How To Make Sure Google Can Understand Your Pages

#SMX #23A2 @maxxeight
HTTP Headers
HTML Source DOM
HTML Snapsh
ot

#SMX #23A2 @maxxeight
Google cache (unless HTML snapshots)
Tools For SEO And JavaScript
#SMX #23A2 @maxxeight

#SMX #23A2 @maxxeight
Google cache (unless HTML snapshots) Google Fetch & Render (Search Console)– limitation in terms of bytes (~200 KBs)– doesn’t show HTML snapshot (DOM)
Tools For SEO And JavaScript

#SMX #23A2 @maxxeight

#SMX #23A2 @maxxeight
Google cache (unless HTML snapshots) Google Fetch & Render (Search Console)– limitation in terms of bytes (~200 KBs)– doesn’t show HTML snapshot (DOM)
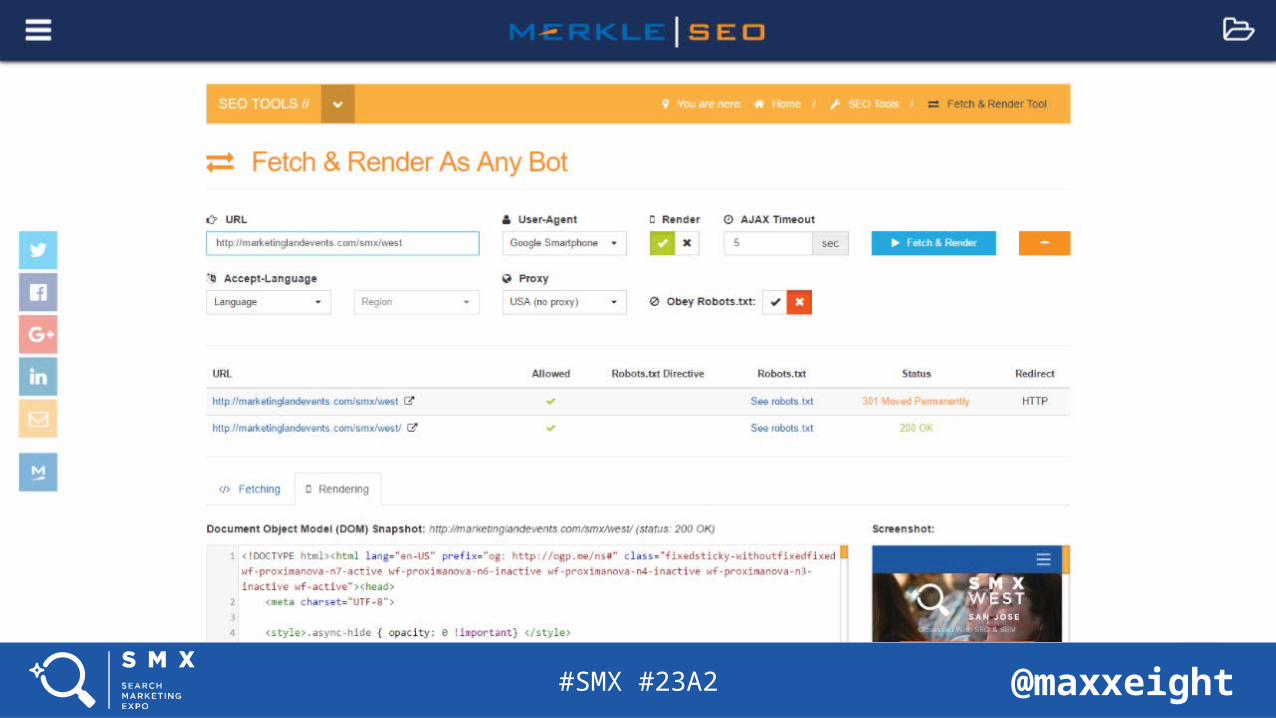
Fetch & Render As Any Bot (TechnicalSEO.com)
Tools For SEO And JavaScript
#SMX #23A2 @maxxeight

#SMX #23A2 @maxxeight
Google cache (unless HTML snapshots) Google Fetch & Render (Search Console)– limitation in terms of bytes (~200 KBs)– doesn’t show HTML snapshot (DOM)
Fetch & Render As Any Bot (TechnicalSEO.com)
Chrome DevTools (JavaScript Console)
Tools For SEO And JavaScript

#SMX #23A2 @maxxeight

#SMX #23A2 @maxxeight
Google cache (unless HTML snapshots) Google Fetch & Render (Search Console)– limitation in terms of bytes (~200 KBs)– doesn’t show HTML snapshot (DOM)
Fetch & Render As Any Bot (TechnicalSEO.com)
Chrome DevTools (JavaScript Console) SEO Crawlers– ScreamingFrog– Botify– Scalpel (Merkle proprietary tool)
Tools For SEO And JavaScript

#SMX #23A2 @maxxeightLEARN MORE: UPCOMING @SMX EVENTS
THANK YOU! SEE YOU AT THE NEXT #SMX


















