



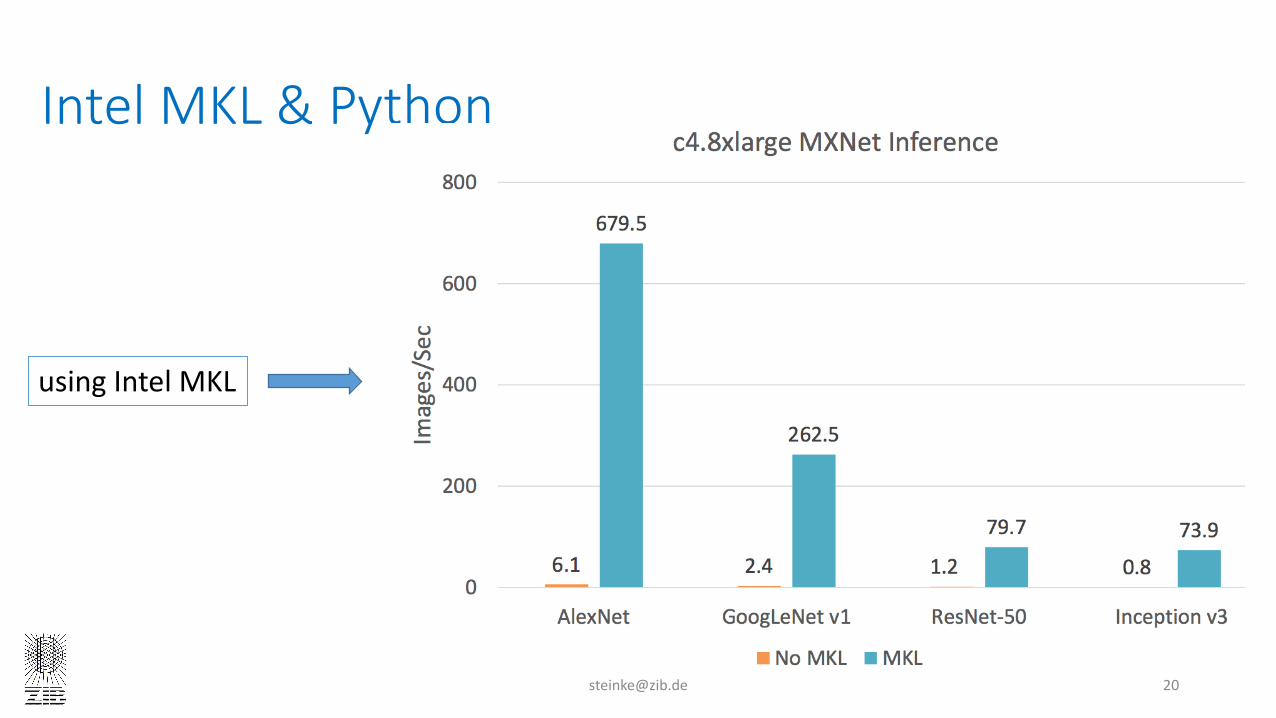







Machine Learning on Accelerated Platforms · Machine Learning on Accelerated Platforms Thomas...
31
ZIB Workshop "Hot Topics in Machine Learning” Machine Learning on Accelerated Platforms Thomas Steinke February 27, 2017
Transcript of Machine Learning on Accelerated Platforms · Machine Learning on Accelerated Platforms Thomas...

ZIBWorkshop"HotTopicsinMachineLearning”
MachineLearningonAcceleratedPlatforms
ThomasSteinke
February27,2017

CPUs&CUDAGPUsandGoogle’sTPU
27.02.17 [email protected] 2
Source:http://www.theverge.com/circuitbreaker/2016/5/19/11716818/google-alphago-hardware-asic-chip-tensor-processor-unit-machine-learning

Outline
§ MachineLearningonAcceleratorsinResearchEnvironmentsv Hardwarev Softwarev Relativeperformancedata
§ Outlookv ProgrammingHeterogeneousPlatformsv FutureDevices
27.02.17 [email protected] 3

DeepLearning:FaceRecognitionTrainingdata:§ 10-100M images
Networkarchitecture:§ 10+layers§ 1B parameters
Learningalgorithm:§ ~30exaflops§ ~30GPUdays
27.02.17 [email protected] 5Source:Nvidia

KeyRequirementsinResearchEnvironments
§ Easyofuse§ Lowbarriersforprogrammability§ Broadspectrumofoptimizedlibrariesandtools§ Affordablehardwareandsoftware§ Sufficientspeed§ ???
27.02.17 [email protected] 6

WhatNeedstobeAccelerated?Buildingblocksinlearningalgorithms:§ Compute:
v Convolutionv Matrix-matrixmultiplyinDeepNeuralNetworks(DNN)
• DonotrequireIEEEfloating-pointops• Weightsmayneedonly3-8bits
§ Accesstodata:v Highmemorybandwidth(lowcomputationalintensity?)
§ Scalability:v Inter-nodecommunication
27.02.17 [email protected] 7
S.Guptaetal.,DeepLearningwithLimitedNumericalPrecision,arXiv,2015J.Paketal.,FPGABasedImplementationofDeepNeuralNetworksUsingOn-chipMemoryonly,arXiv,2016

BasicComputeDevices
§ Multi- andMany-coreCPU§ GraphicsProcessingUnit(GPU)§ FieldProgrammableGateArray(FGPA)
§ Application-SpecificIntegratedCircuit(ASIC)
27.02.17 [email protected] 8
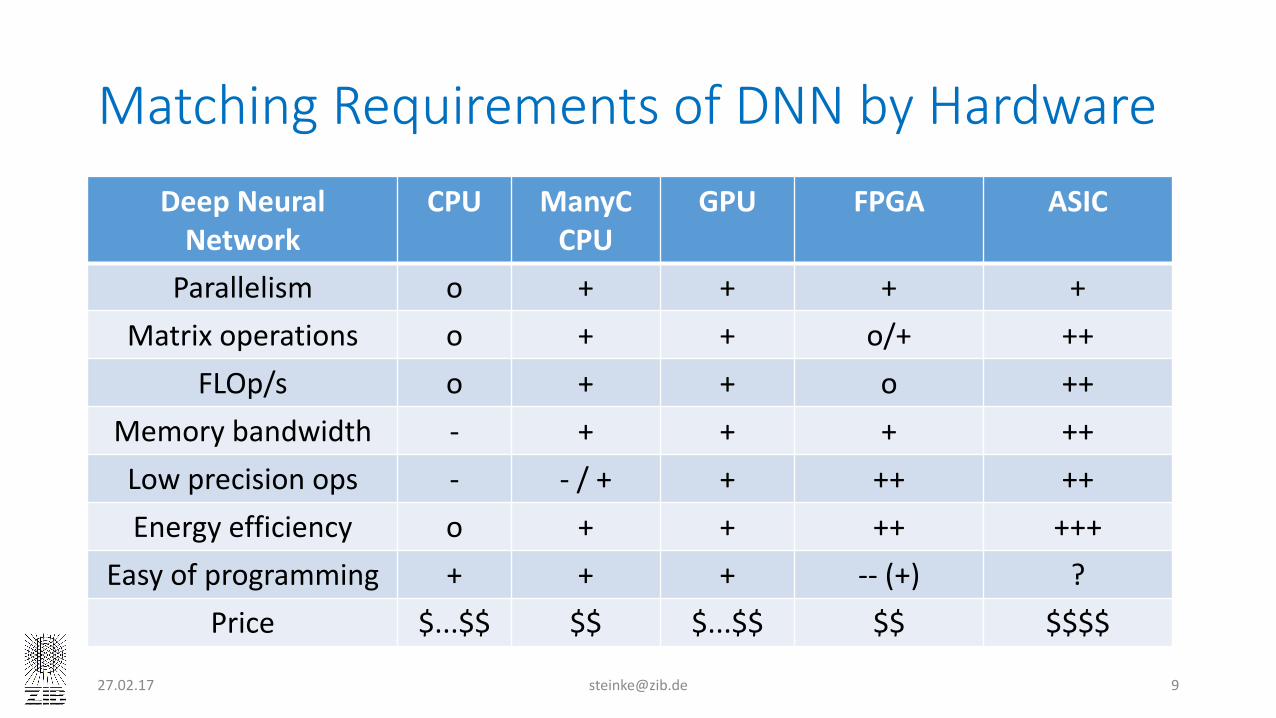
MatchingRequirementsofDNNbyHardwareDeepNeuralNetwork
CPU ManyCCPU
GPU FPGA ASIC
Parallelism o + + + +Matrix operations o + + o/+ ++
FLOp/s o + + o ++Memorybandwidth - + + + ++Low precisionops - - /+ + ++ ++Energyefficiency o + + ++ +++
Easyofprogramming + + + -- (+) ?Price $...$$ $$ $...$$ $$ $$$$
27.02.17 [email protected] 9

ALookatComputePerformance
§ Single-coreCPU: 1§ Multi-coreCPU: 10§ Many-coreCPU: 100§ GPU: 100§ FPGA: 1’000§ ASIC: 10’000…1’000’000
27.02.17 [email protected] 10Source:PhilipJama,TheFutureofMachineLearning Hardwarehttps://hackernoon.com/the-future-of-machine-learning-hardware-c872a0448be8#.x8t8vwae5
DataforMiningCryptocurrencies
§ Computationalcapacity(throughput)§ Energy-efficiency(computationsperJoule)§ Cost-efficiency(throughputper€)

ProcessorsforNNTrainingandInference(I)
§ Nvidia P40(Pascal,2017):v Performance:47INT8TOp/s,12TFlop/s32bitv Configuration:24GBglobalmem,346GB/sbandwidth,250W
§ Nvidia M4(Maxwell,04/2016):v Performance:2.2Tflop/s32bitv Configuration:4GBglobalmem,88GB/sbandwidth,75W
27.02.17 [email protected] 11

12
NVIDIA DGX-1AI supercomputer-appliance-in-a-box
• 8x Tesla P100 (170 TFlop/s 16bit perf)
• NVLink Hybrid Cube Mesh,160 GB/s bi-direct per peer
• Dual Xeon, 512 GB Memory
• 7 TB SSD Deep Learning Cache
• Dual 10GbE, Quad IB 100Gb
• 3RU – 3200W
• Optimized Deep Learning Software across the entire stack
Source: Nvidia

ProcessorsforNNTrainingandInference(II)
§ IntelKnightsMill:3rd genIntelXeonPhi,2017v manycoresv FP16arithmetic,"enhancedvariableprecision"
§ IntelXeonSkylake (AVX512)
§ IntelXeonPhi(KnightsLanding)v Performance:3.5TFlop/s64bit,6+TFlop/s32bitv Configuration:64-72cores,16GBMCDRAM,400+GB/smembandwidth
27.02.17 [email protected] 13

FPGAinImageRecognition
§ FPGAvs.GPU:~5xslower,10xbetterenergyefficiency§ anyprecisionpossible:32float… 8bitfixed
27.02.17 [email protected] 15Source:Intel,2017
Winograd minimalfilteringalgorithm,reducecomputecomplexitybyupto4xw.r.t convolution

UsingFPGAsforNNLearning
§ Fixedpoint:16bit,fractionalpartfrom8to14bits
§ Multiplyandaccumulate(MACC)forinnerproducts
§ Stochasticrounding
27.02.17 [email protected] 16
S.Guptaetal.,DeepLearningwithLimitedNumericalPrecision,arXiv,2015

Nvidia Solutions
27.02.17 [email protected] 19
Nvidia cuDNNDeep Learning Training Performance
Caffe AlexNet
Spee
d-up
of
Imag
es/S
ec v
s K4
0 in
201
3
K40 K80 + cuDN…
M40 + cuDNN4
P100 + cuDNN5
0x
10x
20x
30x
40x
50x
60x
70x
80x
AlexNet training throughput on CPU: 1x E5-2680v3 12 Core 2.5GHz. 128GB System Memory, Ubuntu 14.04M40 bar: 8x M40 GPUs in a node, P100: 8x P100 NVLink-enabled
0
1.000
2.000
3.000
4.000
5.000
6.000
7.000
2 8 128
CPU-OnlyTesla P40 + TensorRT (FP32)Tesla P40 + TensorRT (INT8)
Nvidia TensorRTUp to 36x More Image/sec
Batch SizeGoogLenet, CPU-only vs Tesla P40 + TensorRTCPU: 1 socket E4 2690 v4 @2.6 GHz, HT-onGPU: 2 socket E5-2698 v3 @2.3 GHz, HT off, 1 P40 card in the box
Imag
es/S
econ
d

SYCL- C++Single-SourceHeterogeneousProgrammingforOpenCL§ Cross-platformabstractionlayerbuildonconcept+portabilityofOpenCL§ Enables“single-source”stylestandardC++codeforheterogeneousprocs§ C++templatefunctionswithbothhostanddevicecode§ Open-sourceC++17ParallelSTLforSYCLandOpenCL2.2features§ Targetdevices:CPU,GPU,FPGA(anyOpenCLsupporteddevice)
§ Compiler:v ComputeCpp (Codeplay),freecommunity+commercialversionv triSYCL (Xilinx),open-source(github.com/Xilinx/triSYCL)
27.02.17 [email protected] 23

SYCLinPractice?
§ TensorFlow forOpenCLusingSYCL(Codeplay)§ ParallelSTL(C++extensionsforparallelism)à PartoffutureC++standard
§ BMBFProjectHighPerMeshes (04/2017-03/2020)v ZIB+Paderborn+Erlangen+Fraunhofer ITWM
(M.Weiser,Th.Steinke)
27.02.17 [email protected] 26
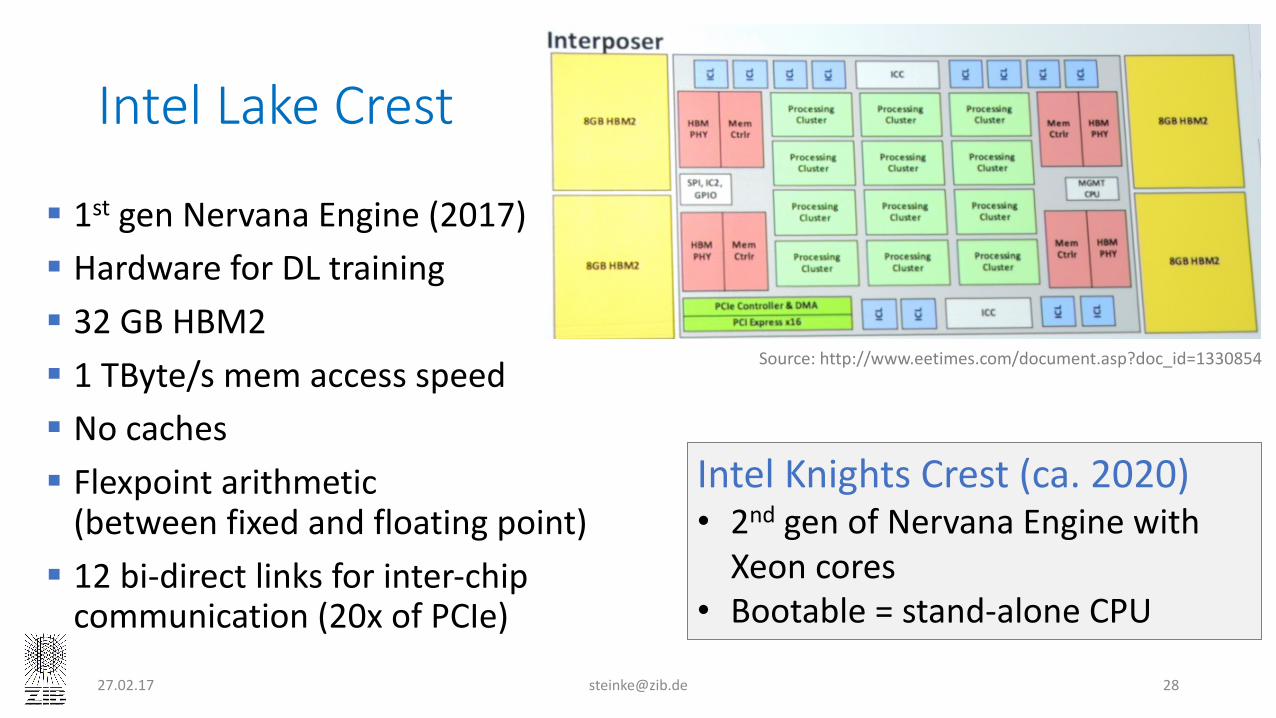
IntelLakeCrest
§ 1st genNervana Engine(2017)§ HardwareforDLtraining§ 32GBHBM2§ 1TByte/smemaccessspeed§ Nocaches§ Flexpoint arithmetic(betweenfixedandfloatingpoint)
§ 12bi-directlinksforinter-chipcommunication(20xofPCIe)
27.02.17 [email protected] 28
Source:http://www.eetimes.com/document.asp?doc_id=1330854
IntelKnightsCrest(ca.2020)• 2nd genofNervana EnginewithXeoncores
• Bootable=stand-aloneCPU

IBMResistiveCross-PointDevices(RPU)
Source:TayfunGokmen,Yurii Vlasov (IBM),AccelerationofDeepNeuralNetworkTrainingwithResistiveCross-PointDevices

MoreInformation
§ Intel:v www.intel.com/ai
• IntelAIDay2017:http://www.inteldevconference.com/ai-day-munich-slides/• IntelAITechnicalWorkshop2017:http://www.inteldevconference.com/intel-ai-workshop-slides
§ Nvidia:v https://developer.nvidia.com/deep-learning-software
27.02.17 [email protected] 30
















![Benchmarking Model-Based Reinforcement Learningtingwuwang/mbrl.pdf · 2019-07-11 · Besides RL, benchmarking platforms have also accelerated areas such as computer vision [13, 31],](https://static.fdocuments.us/doc/165x107/5f647b355ceb3e5fe5762724/benchmarking-model-based-reinforcement-tingwuwangmbrlpdf-2019-07-11-besides.jpg)

