
z/OS UNIX System Services Planning€¦ · z/OS UNIX System Services Planning
Upload
cuneyt-goksuCategory
view
646download
6
© 2017 IBM Corporation
IBM Analytics
A Complete Picture of zAnalytics
DB2, IDAA, & Watson Machine Learning for System z
Cüneyt GöksuzAnalytics Technical Leader, MEA & Turkey
IBM Analytics Platform

© 2017 IBM Corporation2
Topics
zAnalytics Strategy
Introduction to Machine Learning
DB2 for z/OS Update
Integrating the DB2 Analytics Accelerator
Machine Learning for z/OS
© 2017 IBM Corporation3
ETL
pro
cess
Data Replication
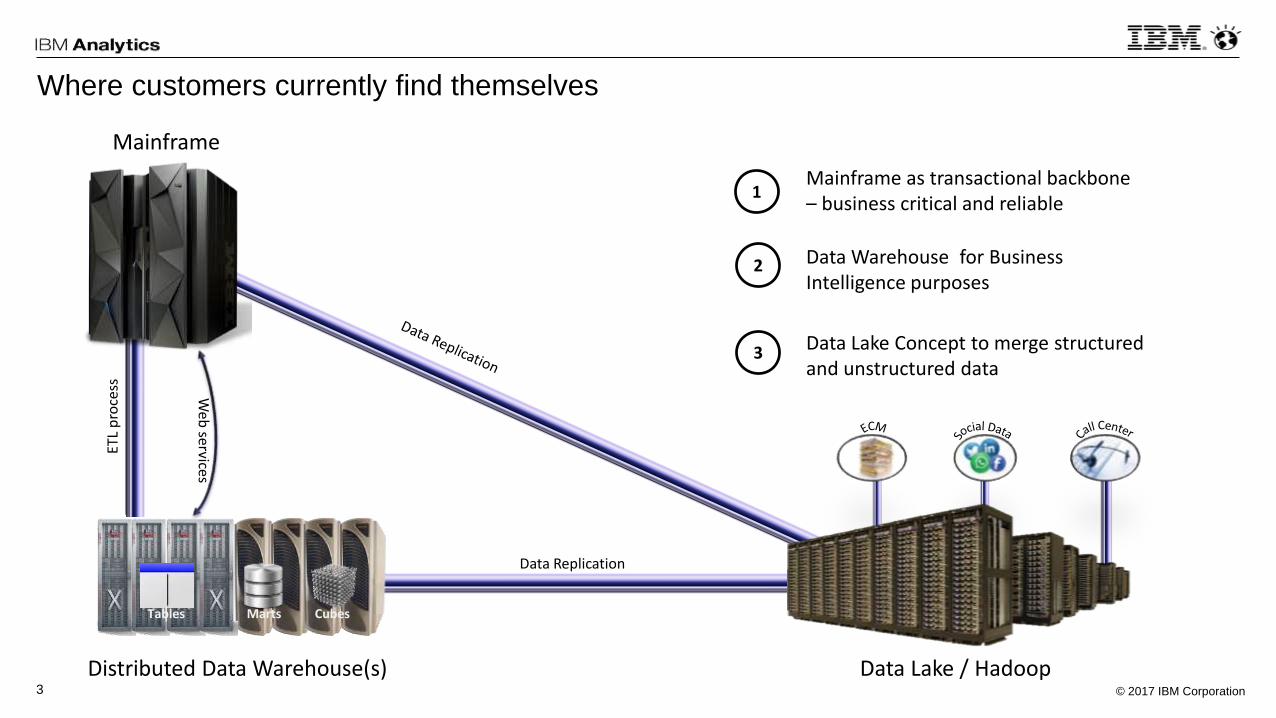
Where customers currently find themselves
Distributed Data Warehouse(s) Data Lake / Hadoop
Mainframe
CubesMartsTables
1Mainframe as transactional backbone– business critical and reliable
Data Warehouse for BusinessIntelligence purposes
Data Lake Concept to merge structuredand unstructured data
2
3
Web
services

© 2017 IBM Corporation4
Data Replication
The challenges of today‘s approaches
Distributed Data Warehouse(s) Data Lake / Hadoop
Mainframe
CubesMartsTables
1Latency caused by an overnight batch and ETL process not acceptable for real-time requirements of business units
Complexity of managing data movement, marts, cubes andsecurity is permanently increasing and no longer manageable
Overall cost to overcome latency and to manage andadminister complexity is exploding
2
3
ETL
pro
cess W
eb services
© 2017 IBM Corporation5
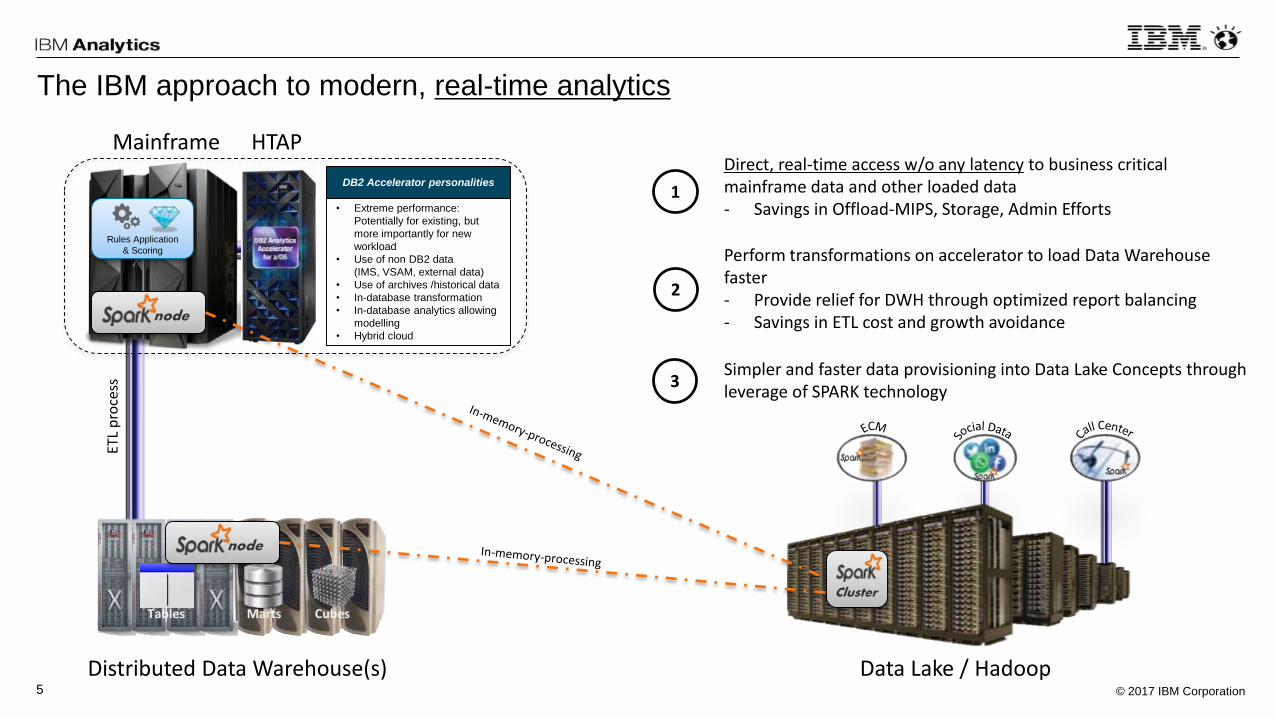
The IBM approach to modern, real-time analytics
Distributed Data Warehouse(s) Data Lake / Hadoop
Mainframe
CubesMartsTables
1
Direct, real-time access w/o any latency to business critical mainframe data and other loaded data- Savings in Offload-MIPS, Storage, Admin Efforts
Perform transformations on accelerator to load Data Warehouse faster- Provide relief for DWH through optimized report balancing- Savings in ETL cost and growth avoidance
Simpler and faster data provisioning into Data Lake Concepts through leverage of SPARK technology
2
3
ETL
pro
cess
Rules Application
& Scoring
HTAP
• Extreme performance:
Potentially for existing, but
more importantly for new
workload
• Use of non DB2 data
(IMS, VSAM, external data)
• Use of archives /historical data
• In-database transformation
• In-database analytics allowing
modelling
• Hybrid cloud
DB2 Accelerator personalities
Cluster
node
node

© 2017 IBM Corporation
IBM Analytics
Introduction to Machine Learning

© 2017 IBM Corporation7
The focus on machine learning
Gartner identifies
Machine Learning as the
Top Trend in IT for 2017 and
at the top of every CIO's
strategy & budget
Source Gartner
Machine learning
segment of the cognitive
computing market forecast to
grow from $6 billion in 2016 to
$52 billion in 2021 with a CAGR
of 53.5% for 2016-2021
Published date: 05/02/2016 Source:
Mindcommerce
Data scientists
are the superheroes and
unicorns of today's business.
But data scientists are only
human, and they are reaching
the limits of productivity with
current processes.
Published date: 02/11/2016 Source:
Forrester

© 2017 IBM Corporation8
“Ability of computers to learn without being explicitly
programmed”
Machine Learning - What and Why?

© 2017 IBM Corporation9
Machine learning is everywhere,
influencing nearly everything we do…
Netflix personalized movie recommendations
7 out of 10 financial customers would take recommendations from a robo advisor
Machine Learning Basics
Identifies patterns in historical data
Builds behavioral models from patterns
Makes recommendations
The data (operational & historical) is used to “train” a model

© 2017 IBM Corporation
IBM Analytics
DB2 for z/OS Update
© 2017 IBM Corporation11
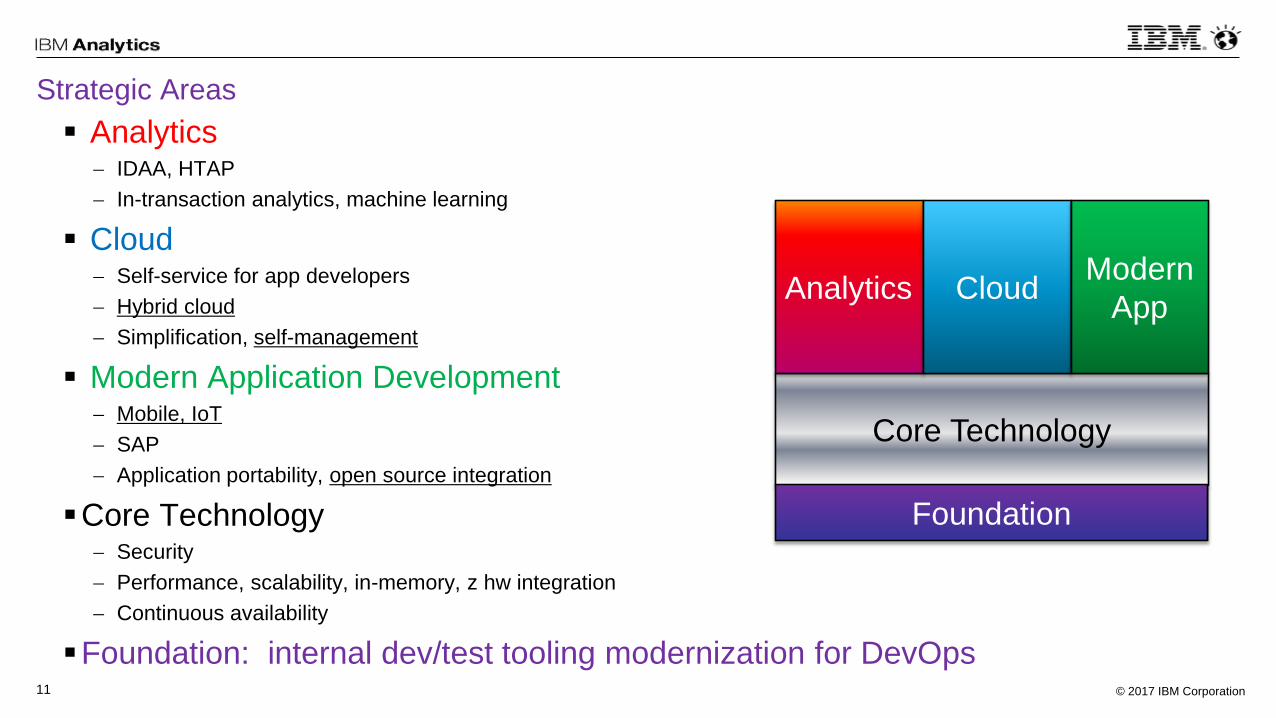
Strategic Areas
Analytics IDAA, HTAP
In-transaction analytics, machine learning
Cloud Self-service for app developers
Hybrid cloud
Simplification, self-management
Modern Application Development Mobile, IoT
SAP
Application portability, open source integration
Core Technology Security
Performance, scalability, in-memory, z hw integration
Continuous availability
Foundation: internal dev/test tooling modernization for DevOps
Core Technology
Analytics
Foundation
CloudModern
App

© 2016 IBM Corporation12
Scale and speed for the next era of mobile applicationsSuper fast ingest rate -- over 11 Million Inserts per second for IOT, Mobile and Cloud*
280 trillion rows in a single DB2 table, with agile partition technology
DB2 12 supports true Enterprise scale next gen apps
In-Memory databaseAdvanced in-memory techniques in DB2 12 mean faster transactions at lowered overhead, up to 20% CPU savings on index
lookups
Deliver analytical insights faster2-10x improvement for modern analytics workloads
Individual modern analytic queries may see up to 100x improvement**
Spark Integration with Enterprise QOS
API Economy - Next Gen application support540 million transactions per hour through RESTful web API
Redefining enterprise IT for digital business and the mobile app economy
DB2 12 for z/OS – Oct, 2016 GA
*: Under dedicated environment using 12 way data sharing on z13, insert against one table (PBR/Member Cluster) from zLinux clients. All partitions were
GBP dependent and logging enabled. Our record is, 11.7 million insert per second without index, 5.3 million insert per second with index defined.
** Modern analytics queries evaluated include SQL constructs such as UNION ALL, outer joins, complex expressions (CASE, CAST, scalar functions etc)

© 2017 IBM Corporation13
DB2 Strategy: Support the Next Wave of
Applications
• Continue as the OLTP leader
• Support Real-time Cognitive Analytics
• Support for mobile and NoSQL apps
• Enable for cloud and hybrid cloud applications
– Cloud services for DB2
• DevOps for modern agile/rapid application development
• Provide new SQL features
4.8M app connections on a single DB2 instance
Unmatched quality of service
Open access to modern apps with data security
Mobile DataCloud
Transparent
Archiving
Real Time Analytics
Location Based
Data
IDAA
Hybrid Transactional/
Analytics Processing

© 2017 IBM Corporation14
What is it? • A major advance in table management in DB2
1. Breaks the existing limitations in terms of table size and partitioning • 280 trillion rows is impressive by anyone's standard• One DB2 12 table can contain every email sent on the entire Earth for 3 years• One DB2 12 table can contain every text message sent on the entire Earth for 32 years
2. A massive improvement in simplifying DB2 table management for our users• Non-disruptive partition size increases for any partition in a table• Ability to insert new partitions in the middle of a table• Much greater partition independence, so if you change table definitions, you do not need to process the entire
table
DB2 12 Agile Partition Technology Table
Partitions
Huge applicability to next generation workloads that require large size and flexibility
Much greater efficiency for administrators, and elimination of application downtime
ATM
Transactions

© 2017 IBM Corporation15
What is it? • Obtaining data for immediate use or storage in a database
Examples:• Tracking clicks on a website• Capturing every text message in a wireless network• Capturing Call Data Records in a mobile network• Tracking events generated by “smart meters” in a monitoring system• Capturing data from hundreds of thousands of mobile application users• Social Media and SaaS applications generate massive amounts of real-time data, as they have matured storing and
analyzing this data has become critically important
DB2 12 Super Fast Ingest RateDB2 clients are creating ever more data at increasing speedsThere are a growing number of consumers of that data — both operations and analytics
Next generation applications demand Ultra high ingest rates with enterprise scale
Qualities of Service only found in DB2 on z/OS,
All while being able to query the data using standard SQL!

© 2017 IBM Corporation16
What is it?• An in-memory database (IMDB) is one that primarily relies on main memory
for data storage (as opposed to disk)
What does this mean? • New workloads (and existing workloads) can benefit tremendously
• Ex. Fast lookup of transactional data from mobile devices• The DB2 Lab has measured up to a 23% reduction in CPU
on existing workloads
• Memory on the z platform is getting larger and cheaper• We expect more growth in future hardware
• DB2 12 exploits large memory for improved performance and CPU reductions• Larger buffer pools to reduce I/O• New memory optimized structures to speed up performance
DB2 12 is an In-Memory Database
In-Memory database means faster transactions and queries with lower CPU overhead

© 2016 IBM Corporation17
DB2 Data as a Service DB2 Cloud/Mobile modernization with RESTful APIs and JSON
Enterprise
Apps
Enterprise
Data
Enterprise
Transaction
Processing
Systems of Record
Cloud APIs
Mobile-Optimized APIs
Cloud-based
ServicesEnterprise
Systems
Integration
z/OS Connect or DB2 native REST
Serving mobile data directly from z/OS is 40% less
expensive than exporting to a system of engagement
CICS,
IMS
Batch,
WAS
• Many modern application developers work with REST services and JSON data formats
• DB2 12 (and DB2 11 APAR PI66828) ship a Native DB2 REST service• Easier DBA management of DB2 RESTful services, means easier adoption
• z/OS Connect Enterprise Edition (zCEE) integration
Native DB2 REST service provider now available

© 2017 IBM Corporation18
DB2 12 Continuous DeliveryEnd of 2015: Reality check for DB2
We deliver most of our new function in a new release ~every 3 years but many are on 4 year cycles, hence
the interest in skip release migrations
Industry and customer trend is to move away from monolithic code delivery towards continuous delivery model
Next Gen apps and workload growth needs to be our focus
Modernize our delivery technique
We changed !!
We dedicated ourselves to going forward with Continuous Delivery
Customers will see a single maintenance stream for DB2 12, with consumable new function
delivered into that
Continuous release cycles : DB2 V12.1, V12.2, V12.3, …. As you order V12, you get what is available
Faster delivery of easily consumable new features. Items delivered when ready, not three years in the
future
Clients will be able to adopt new technology sooner while maintaining complete control
We will pull DB2 customers forward with our exciting new functions
Integrates perfectly with the new DevOps methodologies being adopted by our clients

© 2017 IBM Corporation
IBM Analytics
DB2 Analytics Accelerator Update and
Integrating with Machine Learning
20
IBM Machine Learning for z/OS
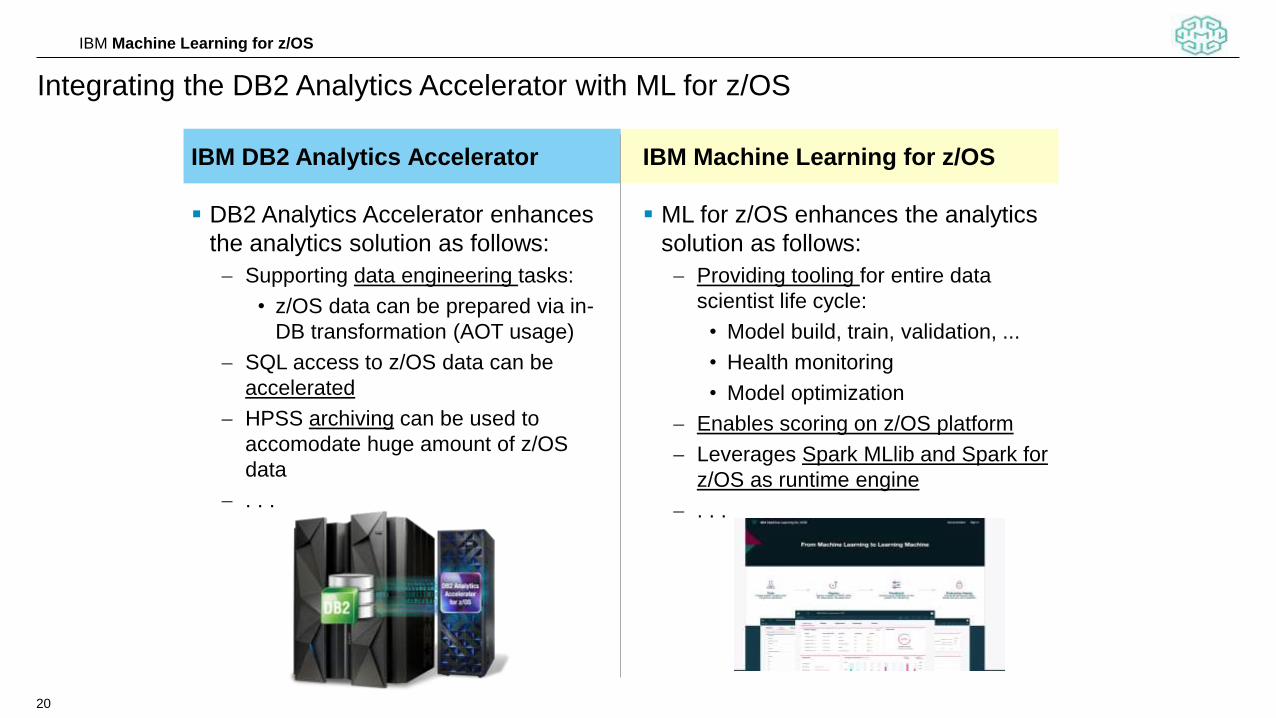
Integrating the DB2 Analytics Accelerator with ML for z/OS
IBM Machine Learning for z/OS
ML for z/OS enhances the analytics
solution as follows:
Providing tooling for entire data
scientist life cycle:
• Model build, train, validation, ...
• Health monitoring
• Model optimization
Enables scoring on z/OS platform
Leverages Spark MLlib and Spark for
z/OS as runtime engine
. . .
IBM DB2 Analytics Accelerator
DB2 Analytics Accelerator enhances
the analytics solution as follows:
Supporting data engineering tasks:
• z/OS data can be prepared via in-
DB transformation (AOT usage)
SQL access to z/OS data can be
accelerated
HPSS archiving can be used to
accomodate huge amount of z/OS
data
. . .
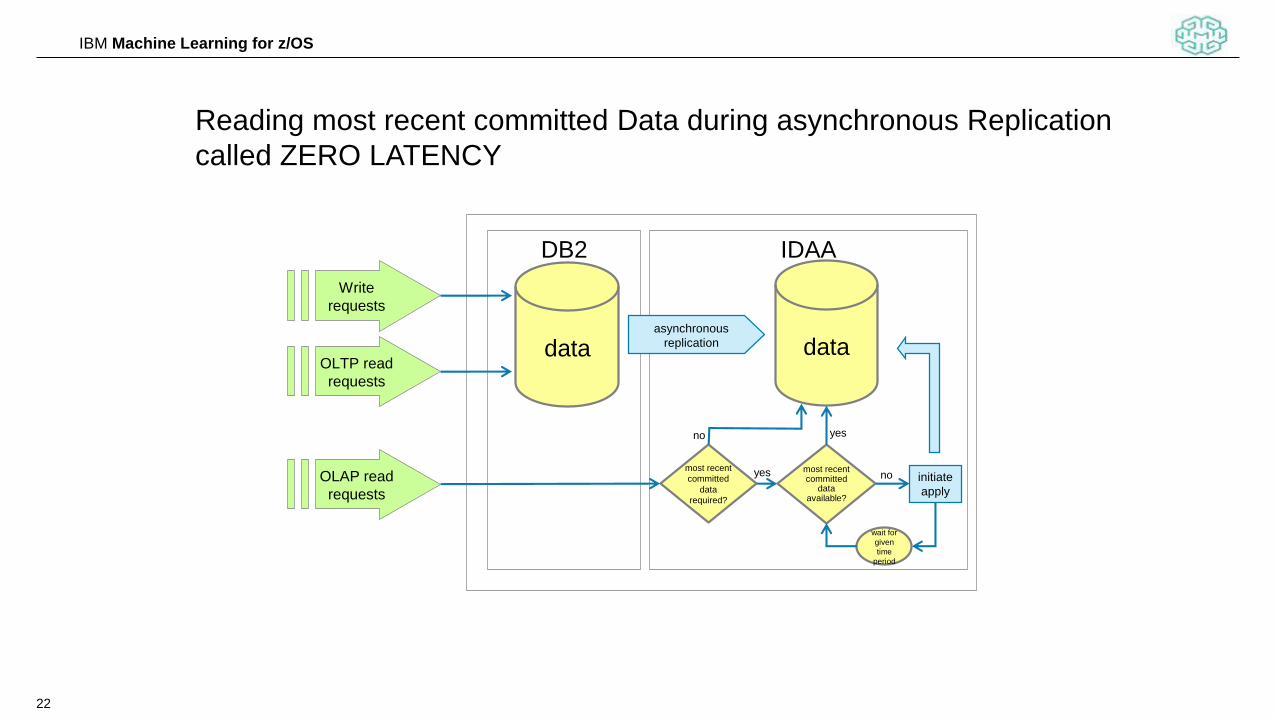
22
IBM Machine Learning for z/OS
DB2 IDAA
data dataasynchronous
replication
most recent committed
data available?
yes
no
Write
requests
OLTP read
requests
OLAP read
requests
wait for
given
time
period
most recent
committed
data
required?
yes
no
initiate
apply
Reading most recent committed Data during asynchronous Replication
called ZERO LATENCY

24
IBM Machine Learning for z/OS
DB2 Analytics Accelerator & ML for z/OS – Complementing Values
Situation #1
Small amount of z/OS
data
zIPP / memory with
sufficient capacity
Scala, Python for data
prep required
Jupyter Notebook of
ML for z/OS used
No SQL skills or SQL
not appropriate
...
ML for z/OS
DB2 Analytics AcceleratorDB2 Analytics AcceleratorDB2 Analytics Accelerator
ML for z/OS ML for z/OS
Situation #2
Large amount of z/OS
data
DataStage (or similar
tool) already used
SQL accepeted for data
prep
Z capacity insufficient
for data prep
ML for z/OS Jupyter
notebook used for
addtl. data prep (similar
to SAS data cube build)
Supporting broader
data lake topologies
Accomodating more
data due to archiving
Need for limited R
support
...
Situation #3
Large amount of z/OS
data
DB2 Analytics
Accelerator already
deployed
Addtl. points similar to
situation #2
Need for limited R
support
...
Situation #3
Large amount of z/OS
data
PMML needed
Batch scoring
SPSS Modeler and
SPSS C&DS already
used (integrates with
the Accelerator)
Interest in in-DB
Analytics
Need for limited R
support
Supporting broader
data lake topologies
...

© 2017 IBM Corporation
IBM Analytics
Machine Learning for z/OS

© 2017 IBM Corporation26
Let’s repeat the ML Concepts
Data is used to “train” a model
The data is historical data and has known outcomes
The model can be tested by a subset of the same data
Usually a percentage of the historical data is held back
A known set of parameters is ”scored” using the model
The result is checked against the actual result from the
historical data
Best practices suggest that the accuracy of the model be
further validated / evaluated by known data
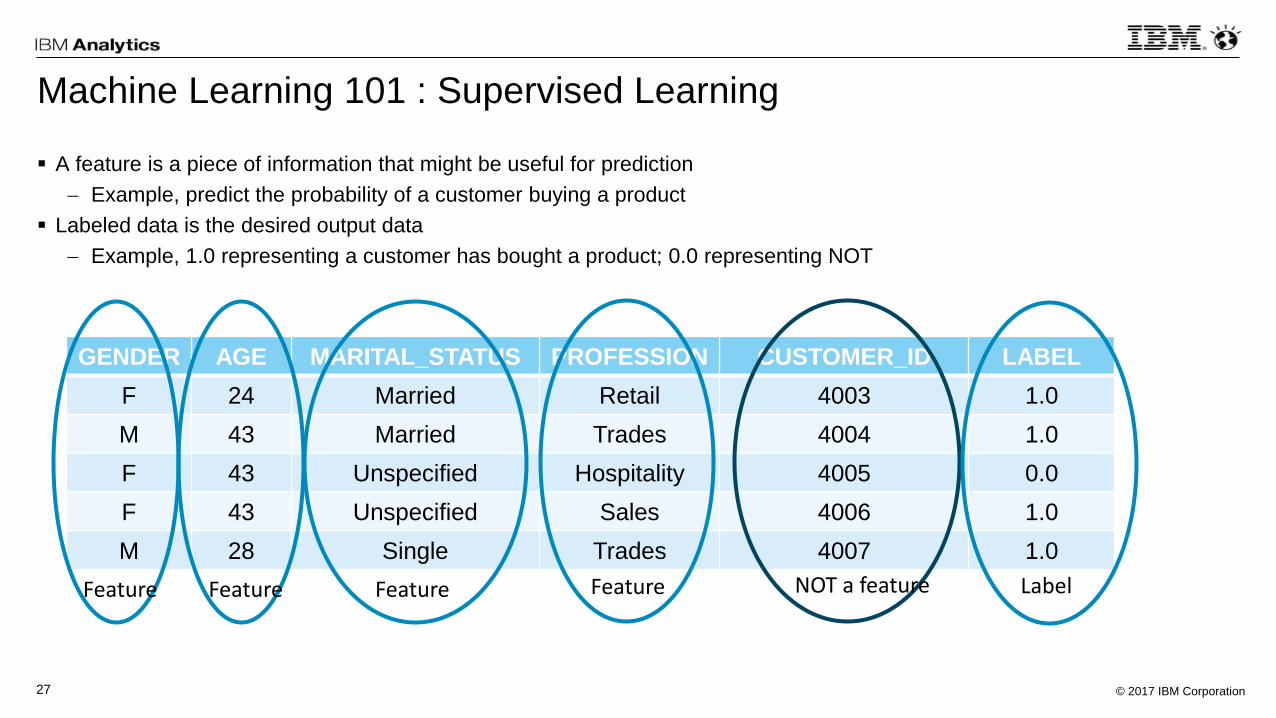
© 2017 IBM Corporation27
A feature is a piece of information that might be useful for prediction
Example, predict the probability of a customer buying a product
Labeled data is the desired output data
Example, 1.0 representing a customer has bought a product; 0.0 representing NOT
Machine Learning 101 : Supervised Learning
GENDER AGE MARITAL_STATUS PROFESSION CUSTOMER_ID LABEL
F 24 Married Retail 4003 1.0
M 43 Married Trades 4004 1.0
F 43 Unspecified Hospitality 4005 0.0
F 43 Unspecified Sales 4006 1.0
M 28 Single Trades 4007 1.0
Feature Feature Feature Feature NOT a feature Label

© 2017 IBM Corporation28
Training a
model
Feature
Engineering
Feature
EngineeringScoring
Labeled examples
Training
Scoring
Newdata
Model
ModelPredicted
data
DeployData Science Experience
Operational system
Dev
Ops
Machine Learning 101 : a TrainOps (DevOps) story

© 2017 IBM Corporation30
IBM Machine Learning for z/OS
Training and scoring on z using Spark for z/OS as the backend data processor
Customers can train models best fit for their business with the data on mainframe
Customers can deploy the ML models and perform online scoring within transaction on mainframe
The machine learning workflow
Online scoring on z – REST API
Training on z
z/OS data – DB2, IMS, VSAM, IDAA etc.
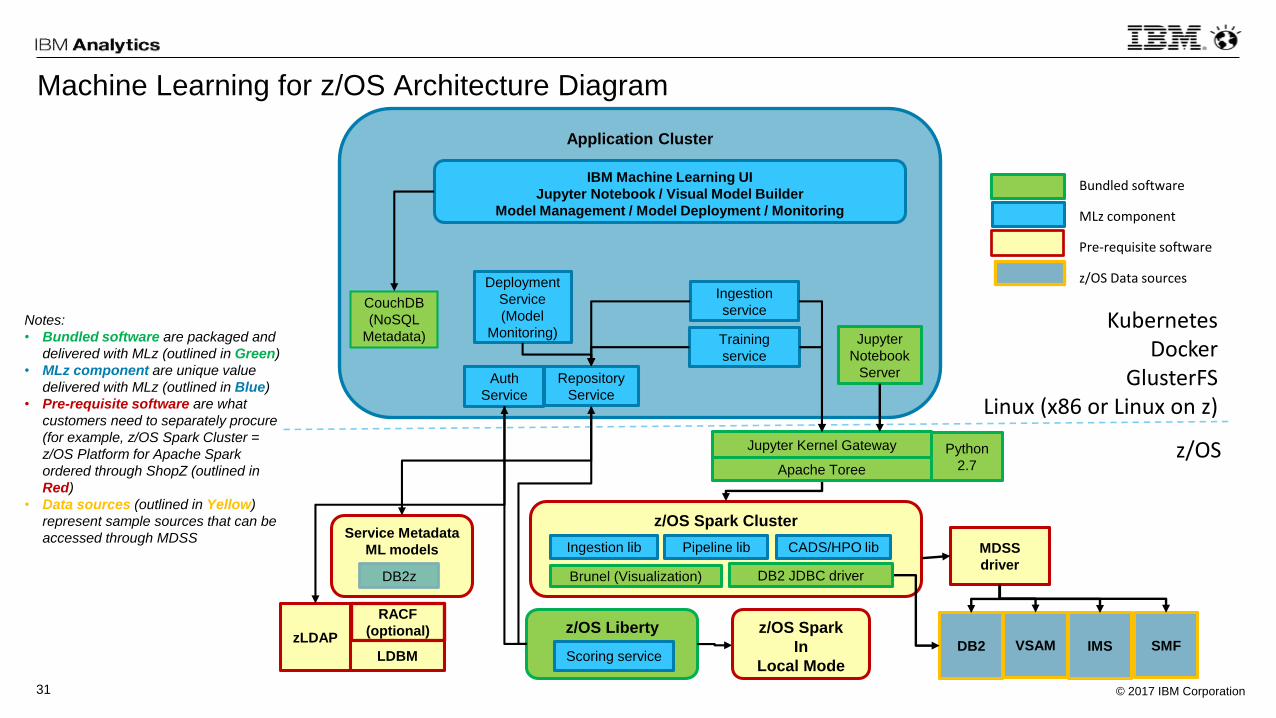
© 2017 IBM Corporation31
Machine Learning for z/OS Architecture Diagram
Notes:
• Bundled software are packaged and
delivered with MLz (outlined in Green)
• MLz component are unique value
delivered with MLz (outlined in Blue)
• Pre-requisite software are what
customers need to separately procure
(for example, z/OS Spark Cluster =
z/OS Platform for Apache Spark
ordered through ShopZ (outlined in
Red)
• Data sources (outlined in Yellow)
represent sample sources that can be
accessed through MDSS
z/OS Liberty
Application Cluster
Ingestion
service
Training
service
z/OS Spark Cluster
Ingestion lib Pipeline libService Metadata
ML models
DB2z
MDSS
driver
IBM Machine Learning UI
Jupyter Notebook / Visual Model Builder
Model Management / Model Deployment / Monitoring
Bundled software
MLz component
Pre-requisite software
z/OS Data sources
zLDAP
RACF
(optional)
Auth
Service
Kubernetes Docker
GlusterFSLinux (x86 or Linux on z)
z/OS
Scoring serviceIMSVSAM
Jupyter Kernel Gateway
Repository
Service
Deployment
Service
(Model
Monitoring)
LDBM
Jupyter
Notebook
Server
DB2 SMF
CouchDB
(NoSQL
Metadata)
Apache Toree
z/OS Spark
In
Local Mode
CADS/HPO lib
DB2 JDBC driver
Python
2.7
Brunel (Visualization)

PHOTO CREDIT: Kyle Harris
Machine Learning is to the 21st century what Industrial Revolution
was to the 18th century.

© 2017 IBM Corporation33


















