

Log Analysis At Scale
67
© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Logging at Scale Alex Smith - @alexjs Solutions Architect April 2016
-
Upload
amazon-web-services -
Category
Technology
-
view
345 -
download
0
Transcript of Log Analysis At Scale

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Logging at Scale
Alex Smith - @alexjs
Solutions Architect
April 2016

Logging is difficult

I thought I knew this
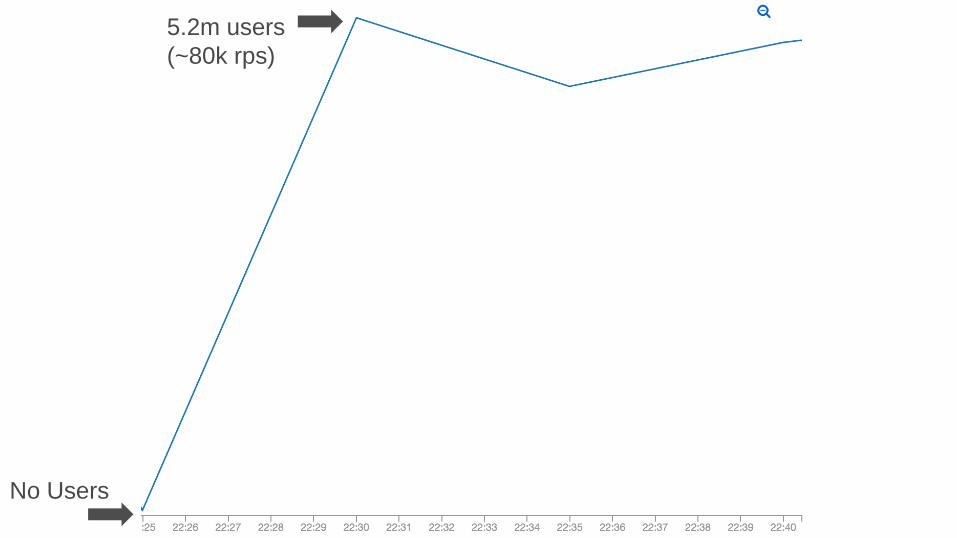
No Users
5.2m users
(~80k rps)

But.
It is really difficult
Problems
• Storage (Temporary)
• Capture
• Storage (Permanent)
• Visualisation

Stealing Content…
‘Your First 10m Users’
ARC301 – re:Invent 2015
http://bitly.com/2015arc301
- Joel Williams
AWS Solutions Architect
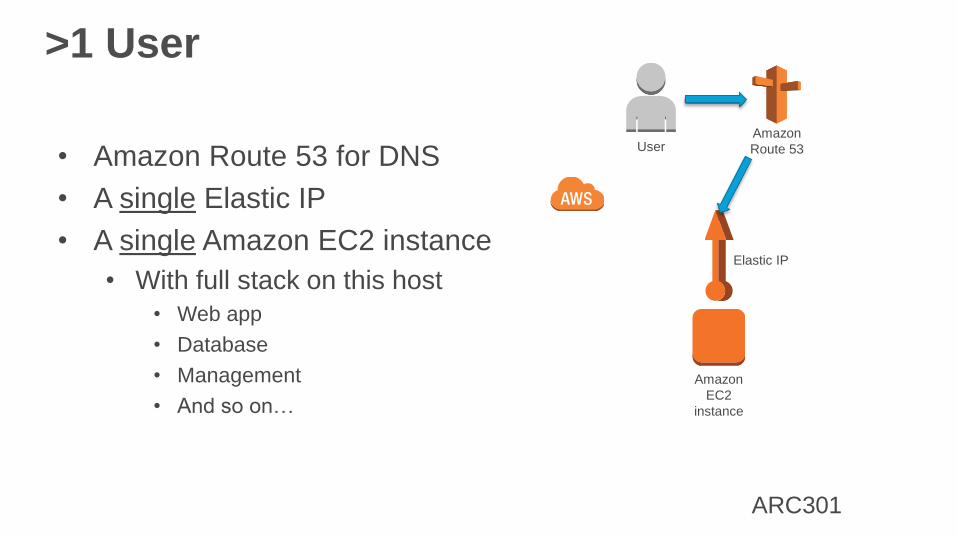
>1 User
• Amazon Route 53 for DNS
• A single Elastic IP
• A single Amazon EC2 instance
• With full stack on this host
• Web app
• Database
• Management
• And so on…
Amazon
EC2
instance
Elastic IP
UserAmazon
Route 53
ARC301
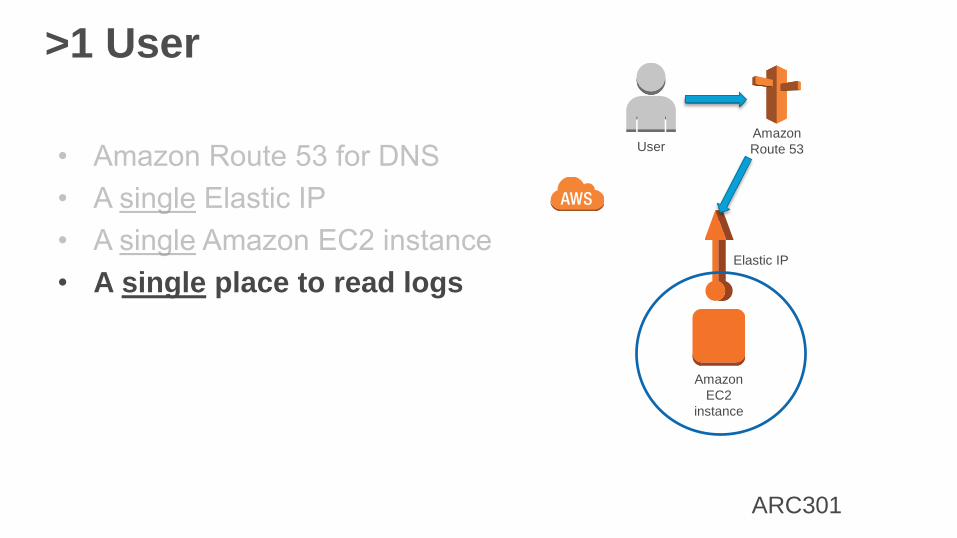
>1 User
• A single place to read logs
Amazon
EC2
instance
Elastic IP
UserAmazon
Route 53
ARC301
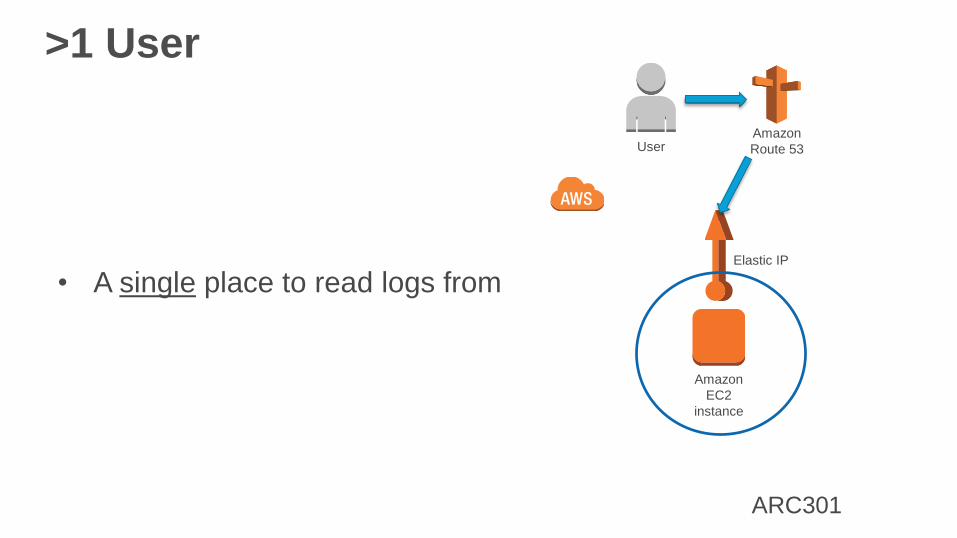
>1 User
• A single place to read logs from
Amazon
EC2
instance
Elastic IP
UserAmazon
Route 53
ARC301

@alexjs hacks – top URLs
# awk -F\" '{print $2'} access_log \
| awk '{print $2}' \
| sort | uniq -c | sort –rn
11208 /
3287 /2016/04/23/welcome

@alexjs hacks – HTTP response codes
# awk '{print $9}' access_log \
| sort | uniq -c | sort –rn
19307 200
1239 404
120 503
1 416

@alexjs hacks - top User-Agents
# awk -F\" '{print $6'} access_log | sort | uniq -c | sort -rn
3774 Mozilla/5.0 (compatible; MSIE 10.0; Windows Phone 8.0; Trident/6.0; IEMobile/10.0; ARM; Touch; Microsoft; Lumia 640 XL)
2949 Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36
2928 Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36
2900 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.5.2171.95 Safari/537.36

@alexjs hacks – requests per second (realtime)
# tail -F access_log \
perl -e 'while (<>) {$l++;if (time > $e) {$e=time;print"$l\n";$l=0}}’
1
1
68
99
912
424
http://bitly.com/bashlps
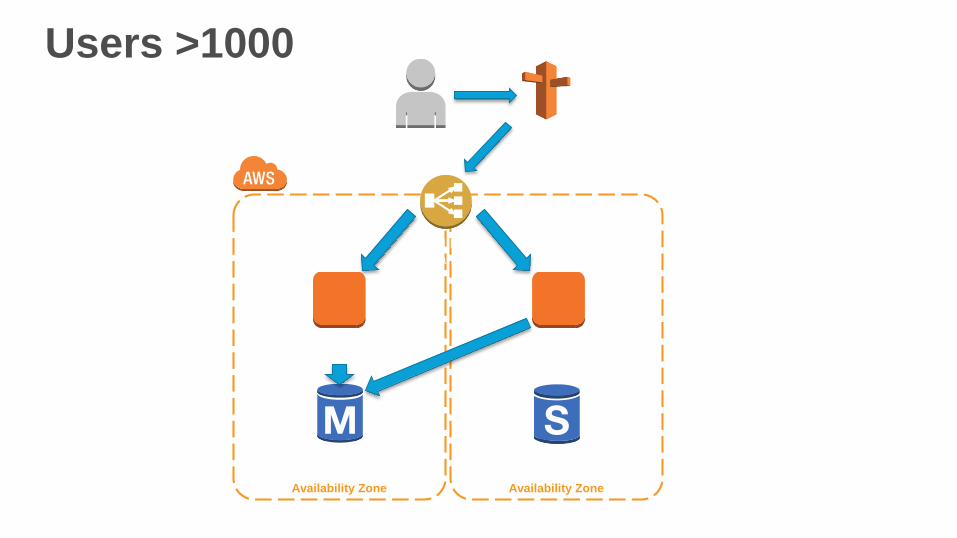
Users >1000
Web
Instance
RDS DB Instance
Active (Multi-AZ)
Availability Zone Availability Zone
Web
Instance
RDS DB Instance
Standby (Multi-AZ)
ELB
Balancer
UserAmazon
Route 53

Real Life
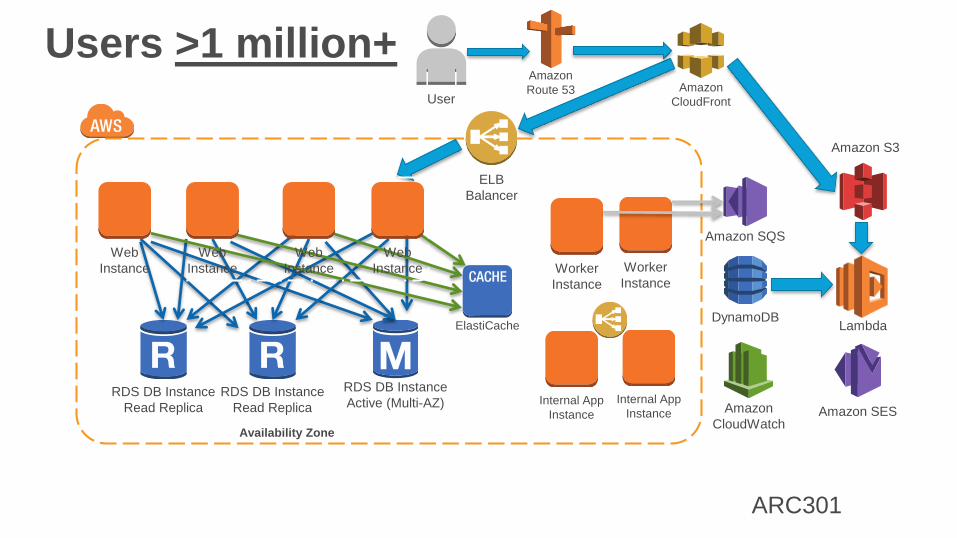
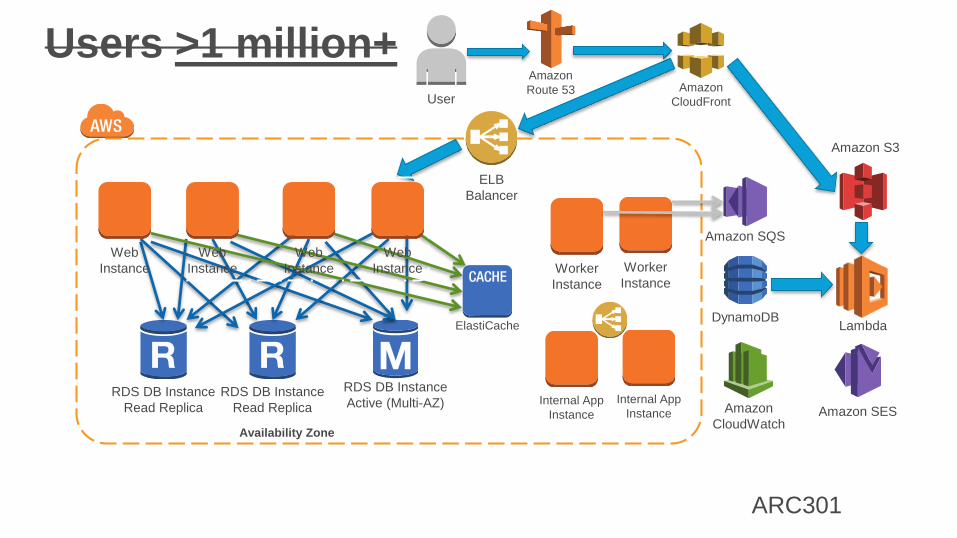
Users >1 million+
RDS DB Instance
Active (Multi-AZ)
Availability Zone
ELB
Balancer
RDS DB Instance
Read Replica
RDS DB Instance
Read Replica
Amazon
Route 53User
Amazon S3
Amazon
CloudFront
DynamoDB
Amazon SQS
ElastiCache
Worker
Instance
Worker
Instance
Amazon
CloudWatch
Internal App
Instance
Internal App
Instance Amazon SES
Lambda
ARC301
Web
Instance
Web
Instance
Web
Instance
Web
Instance
Amazon
EC2
instance
Elastic IP
UserAmazon
Route 53
ARC301
Users >1 million+
RDS DB Instance
Active (Multi-AZ)
Availability Zone
ELB
Balancer
RDS DB Instance
Read Replica
RDS DB Instance
Read Replica
Web
Instance
Amazon
Route 53User
Amazon S3
Amazon
CloudFront
DynamoDB
Amazon SQS
ElastiCache
Worker
Instance
Worker
Instance
Amazon
CloudWatch
Internal App
Instance
Internal App
Instance Amazon SES
Lambda
ARC301
Web
Instance
Web
Instance
Web
Instance
Users >1 million+
RDS DB Instance
Active (Multi-AZ)
Availability Zone
ELB
Balancer
RDS DB Instance
Read Replica
RDS DB Instance
Read Replica
Web
Instance
Amazon
Route 53
Amazon S3
Amazon
CloudFront
DynamoDB
Amazon SQS
ElastiCache
Worker
Instance
Worker
Instance
Amazon
CloudWatch
Internal App
Instance
Internal App
Instance Amazon SES
Lambda
ARC301
Web
Instance
Web
Instance
Web
Instance
Users >1 million+
RDS DB Instance
Active (Multi-AZ)
Availability Zone
ELB
Balancer
RDS DB Instance
Read Replica
RDS DB Instance
Read Replica
Web
Instance
Amazon
Route 53User
Amazon S3
Amazon
CloudFront
DynamoDB
Amazon SQS
ElastiCache
Worker
Instance
Worker
Instance
Amazon
CloudWatch
Internal App
Instance
Internal App
Instance Amazon SES
Lambda
ARC301
Web
Instance
Web
Instance
Web
Instance
Problems
• Storage (Temporary)
• Capture
• Storage (Permanent)
• Visualisation
Problems
• Storage (Temporary)
• Capture
• Storage (Permanent)
• Visualisation
Problems
• Storage (Temporary)
• Capture
• Storage (Permanent)
• Visualisation

When the logs are written (AWS)
• Local memory
• Ephemeral Volumes
• EBS Volumes
• gp2
• st1/sc1
Problems
• Storage (Temporary)
• Capture
• Storage (Permanent)
• Visualisation
• Insight
Problems
• Storage (Temporary)
• Capture
• Storage (Permanent)
• Visualisation
• Insight

Three Problems of Persistence
• Somewhere to stage
• Somewhere to live
• Somewhere to search

To NoSQL, or not to NoSQL?
- Joel

Some folks won’t like this,
but…

Start with SQL databases(even MPP SQL)

Why start with SQL?
• Established and well-worn technology.
• Lots of existing code, communities, books, and tools.
• You aren’t going to break SQL DBs in your first 10 million
users. No, really, you won’t.*
• Clear patterns to scalability (especially in analytics)
*Unless you are doing something SUPER peculiar with the data or you have MASSIVE amounts of it.
…but even then SQL will have a place in your stack.

Ah ha! You said
massive!
- Joel (again)

Why might you need NoSQL?
• Super low-latency applications
• Metadata-driven datasets
• Highly nonrelational data
• Need schema-less data constructs*
• Massive amounts of data (again, in the TB range)
• Rapid ingest of data (thousands of records/sec)
*Need!= “It’s easier to do dev without schemas”

Why might you need NoSQL?
• Super low-latency applications
• Metadata-driven datasets
• Highly nonrelational data
• Need schema-less data constructs*
• Massive amounts of data (again, in the TB range)
• Rapid ingest of data (thousands of records/sec)
*Need!= “It’s easier to do dev without schemas”

Why might you need NoSQL?
• Super low-latency applications
• Metadata-driven datasets
• Highly nonrelational data
• Need schema-less data constructs*
• Massive amounts of data (again, in the TB range)
• Rapid ingest of data (thousands of records/sec)
*Need!= “It’s easier to do dev without schemas”

Three Problems of Persistence
• Somewhere to stage
• Somewhere to live
• Somewhere to search
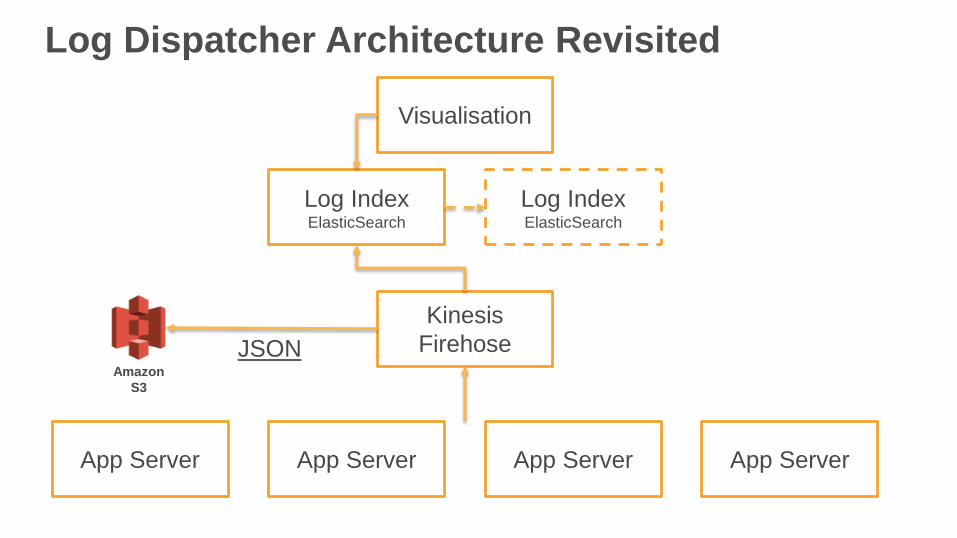
Log Dispatcher Architecture Revisited
App Server App Server App Server App Server
Kinesis
Firehose
Log IndexElasticSearch
Log IndexElasticSearch
Visualisation
Amazon
S3
JSON

Amazon S3
• Simple Storage Service
• Canonical logging target for ELB, CloudFront, etc.
• Virtually unlimited amounts of storage
• Support for Lambda operations
• Very fast – ideal for feeding other services (Redshift,
EMR/Hadoop)
• Data can be automatically pushed here from Amazon
Firehose
Amazon
S3
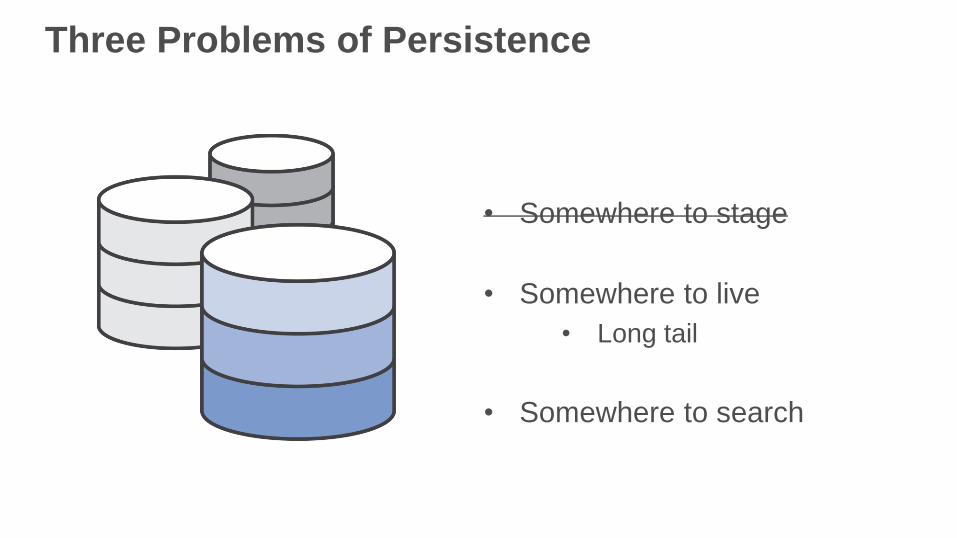
Three Problems of Persistence
• Somewhere to stage
• Somewhere to live
• Long tail
• Somewhere to search
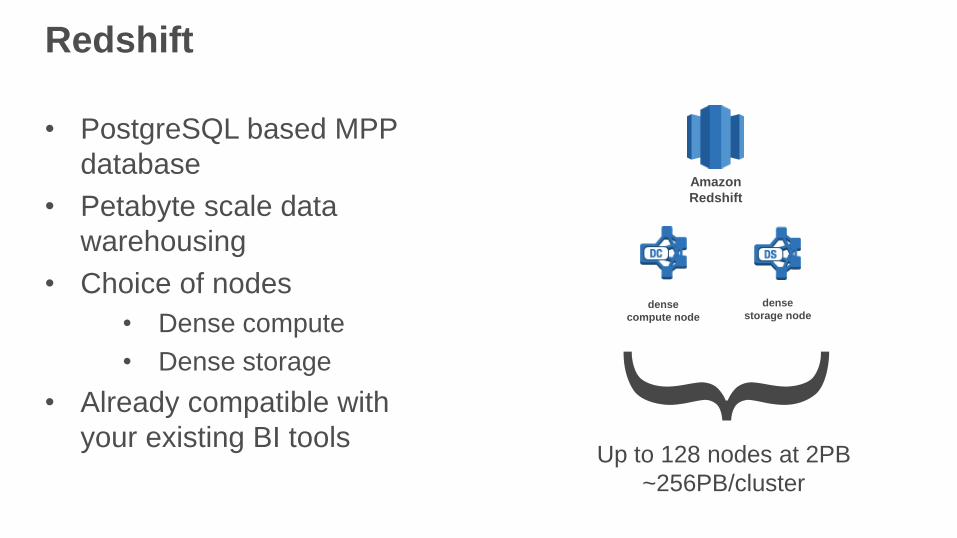
Redshift
• PostgreSQL based MPP
database
• Petabyte scale data
warehousing
• Choice of nodes
• Dense compute
• Dense storage
• Already compatible with
your existing BI tools
dense
compute node
dense
storage node
Amazon
Redshift
Up to 128 nodes at 2PB
~256PB/cluster
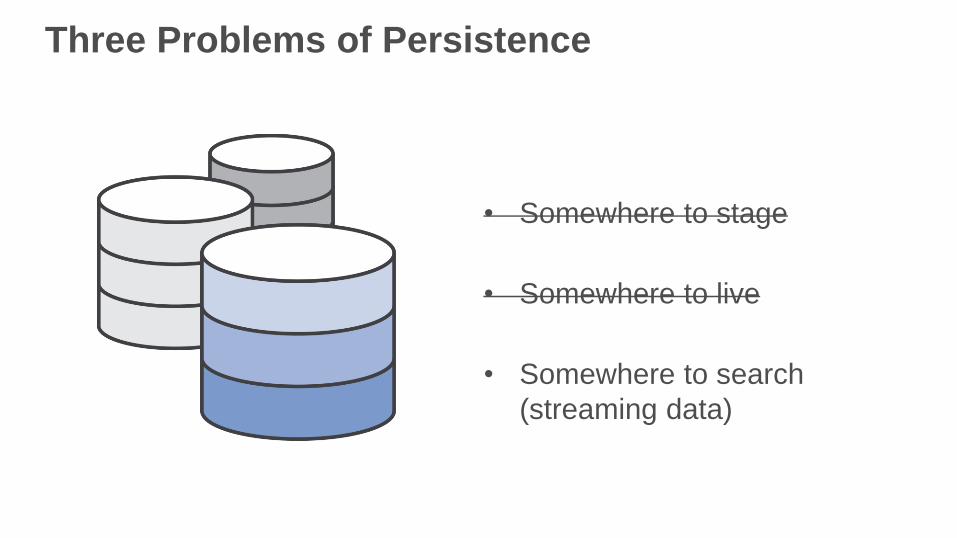
Three Problems of Persistence
• Somewhere to stage
• Somewhere to live
• Somewhere to search
(streaming data)

Amazon ElasticSearch Service
• ElasticSearch
• Popular/Open Source
• Commonly used for log
and clickstream
• Managed Solution
• We prepackage Kibana
• Integrated with IAM,
Firehose, etc
Amazon
Elasticsearch Service
Amazon
Kinesis
Firehose
Three Problems of Persistence
• Somewhere to stage
• Somewhere to live
• Somewhere to search
(streaming data)

Demo: Storage!

ElasticSearch Index Mappingcurl -XPUT 'https://search-loggingatscale-demo-[...].us-east-1.es.amazonaws.com/blog-apache-combined' -d '
{
"mappings": {
"blog-apache-combined": {
"properties": {
"datetime": {
"type": "date",
"format": "dd/MMM/yyyy:HH:mm:ss Z”
},
"agent": {
"type": "string",
"index": "not_analyzed”
}, [...]

ElasticSearch Index Mappingcurl -XPUT 'https://search-loggingatscale-demo-[...].us-east-1.es.amazonaws.com/blog-apache-combined' -d '
{
"mappings": {
"blog-apache-combined": {
"properties": {
"datetime": {
"type": "date",
"format": "dd/MMM/yyyy:HH:mm:ss Z”
},
"agent": {
"type": "string",
"index": "not_analyzed”
}, [...]
Problems
• Storage (Temporary)
• Capture
• Storage (Permanent)
• Visualisation

How do I get my data in anyway?
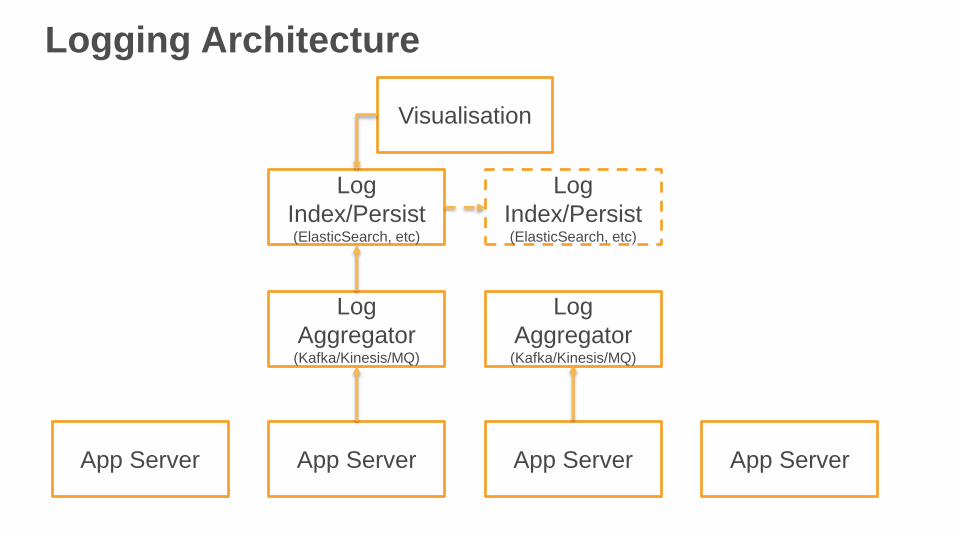
Logging Architecture
App Server App Server App Server App Server
Log
Aggregator(Kafka/Kinesis/MQ)
Log
Aggregator(Kafka/Kinesis/MQ)
Log
Index/Persist(ElasticSearch, etc)
Log
Index/Persist(ElasticSearch, etc)
Visualisation
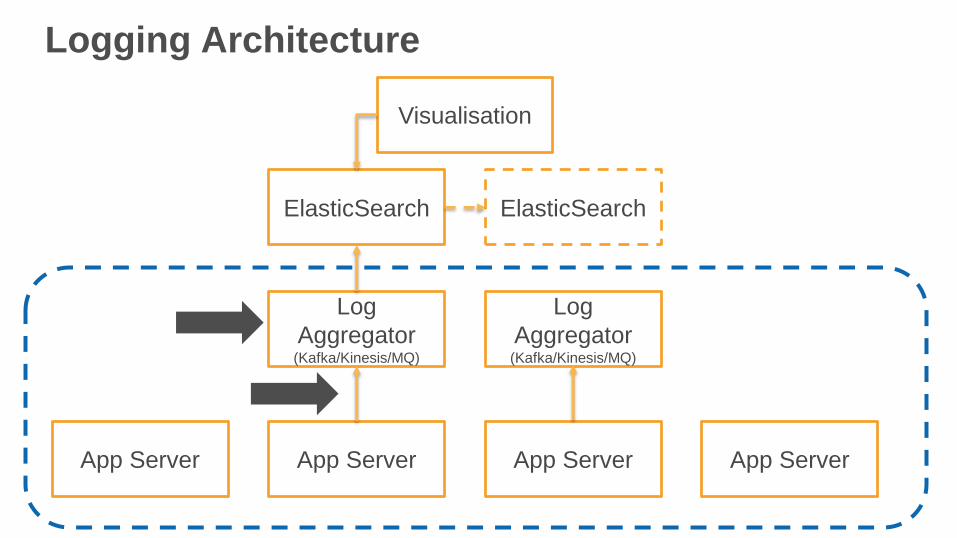
Logging Architecture
App Server App Server App Server App Server
Log
Aggregator(Kafka/Kinesis/MQ)
Log
Aggregator(Kafka/Kinesis/MQ)
ElasticSearch ElasticSearch
Visualisation

Amazon Kinesis
• Firstly, a massively
scalable, low cost way to
send JSON objects to a
’stream’ hosted by AWS
• Users can write applications
(using KCL) to take data
from it and parse/evaluate
• Apps can be written in Java,
Lambda (Node, Python, Java),
etc

Kinesis Streams
• What was previously Kinesis
• Still very customisable, for
innovative stream workloads
• Users still write app to parse
data from the stream
Amazon Kinesis: New Features (re:Invent 2015)
Kinesis Firehose
• Fully managed data ingest
service
• Provision end point
• Send data to end point
• ???
• Data!
• Outputs to S3, Redshift,
ElasticSearch Service
• (And can do two at once)

Amazon Kinesis: New Features (Apr 2016)
Amazon Kinesis Agent
• Standalone Java application from AWS
• Collect and send logs to Kinesis Firehose
• Built-in:
• File rotation
• Failure retries
• Checkpoints
• Integrated with CloudWatch for alerting

Amazon Kinesis Agent
• Multiple input options
• SINGLELINE
• CSVTOJSON
• LOGTOJSON
• LOGTOJSON
• Hoorah!

Demo: Local Capture + Dispatch
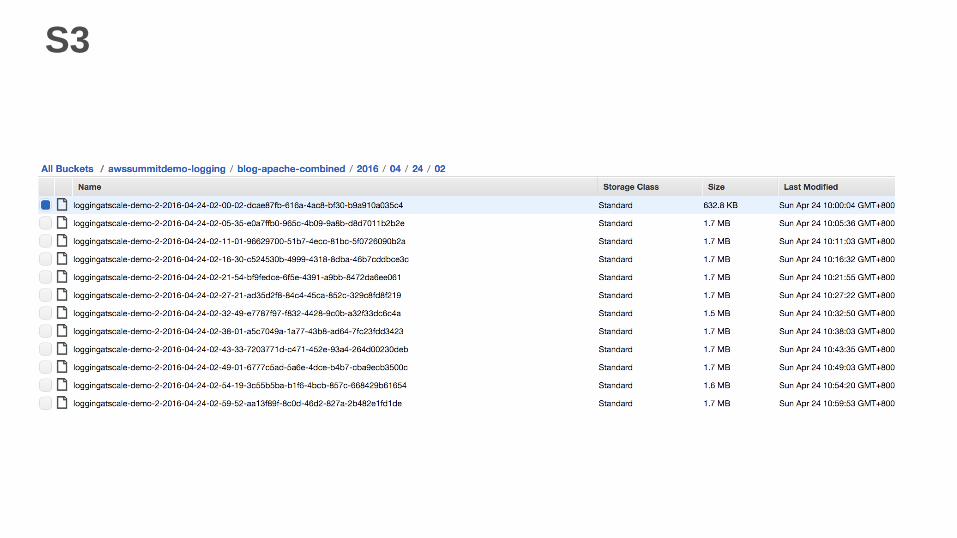
S3
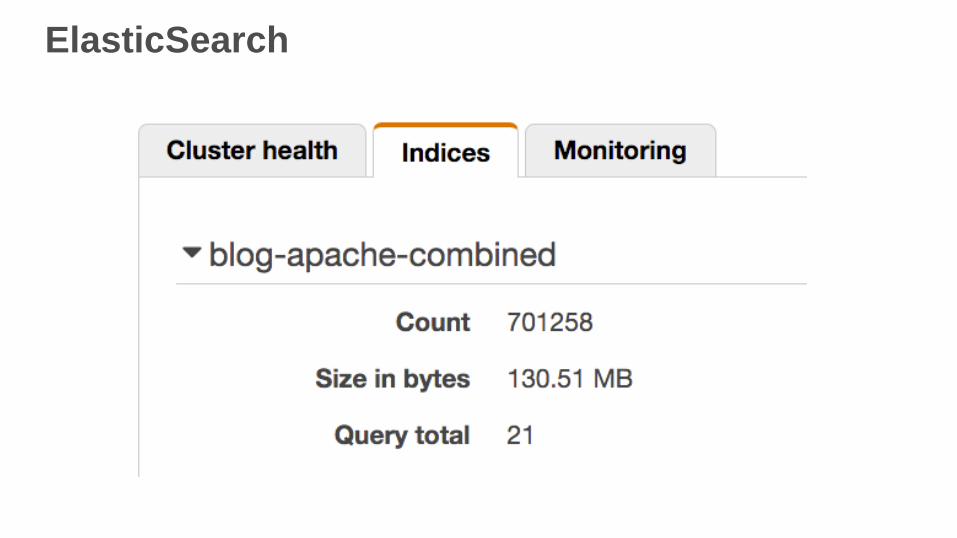
ElasticSearch
Problems
• Storage (Temp)
• Capture
• Storage (Perm)
• Visualisation
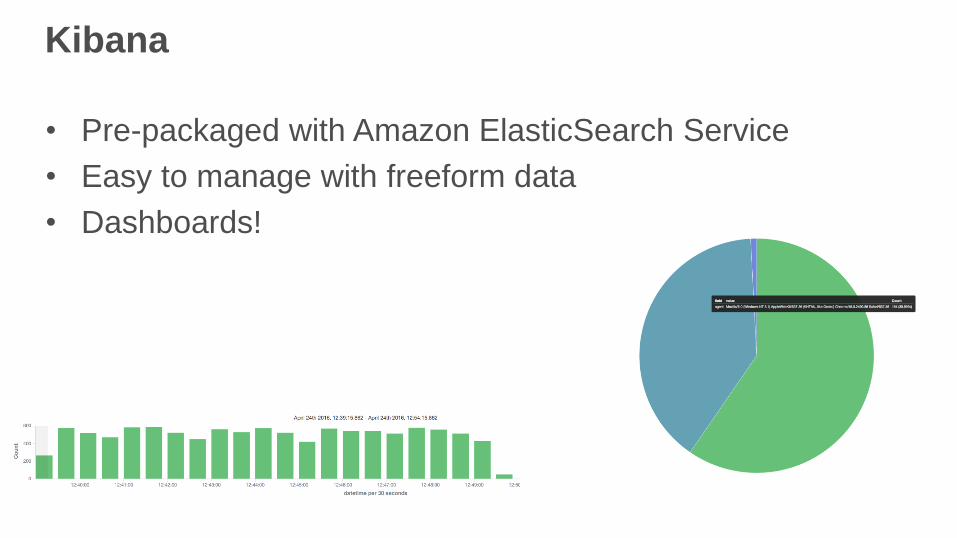
Kibana
• Pre-packaged with Amazon ElasticSearch Service
• Easy to manage with freeform data
• Dashboards!

Your existing BI tools
• As before – your data exists on S3 (JSON)
• S3 -> Redshift
• Commission a Redshift cluster with IAM roles
• Write a manifest of the files to load (JSON)
• Issue a load
• Redshift is PgSQL compatible
• Drivers exist for many tools

Demo: visualisation!(Kibana)
Problems
• Storage (Temporary)
• Capture
• Storage (Permanent)
• Visualisation
• Insight

Recap / Lessons / Next
• Logging is really hard.
• Use tools like AWS Firehose, Kinesis Agent and
ElasticSearch Service to make it easier
• Reuse data, tools and people where possible

Lessons
Don’t be big data dog
Use the right tools at the right
time

Thank You!


















