
Linux+ Guide to Linux Certification Chapter Fifteen Linux Networking.

Linux porting and migration, part 1 of 3—a software engineering perspective
HP Services

Table of contents Introduction......................................................................................................................................... 4 Executive summary............................................................................................................................... 4 Versions information ............................................................................................................................ 6 Section 1. Migration process description ................................................................................................ 7
Migration, an overview .................................................................................................................... 7 Investigation and assessment phase................................................................................................ 7 Planning phase ............................................................................................................................ 8 Migration phase........................................................................................................................... 8 Testing and acceptance phase ....................................................................................................... 9 Production rollout phase................................................................................................................ 9
Approaches to migration .................................................................................................................. 9 Source environment emulation ....................................................................................................... 9 Portability wrappers/libraries for platform services ........................................................................... 9 Source code modification ............................................................................................................ 10
Dependency resolution by source code modification .......................................................................... 10 Change..................................................................................................................................... 11 Compile objects ......................................................................................................................... 11 Build binaries............................................................................................................................. 12 Test........................................................................................................................................... 12
Identifying, analyzing, and resolving software package dependencies ................................................. 12 Language and compiler related.................................................................................................... 12 Platform and hardware architecture related ................................................................................... 14 OS run time environment related .................................................................................................. 16 System command set related........................................................................................................ 17 Application programmer interface related ..................................................................................... 18 Software build environment related............................................................................................... 19 GUI support look and feel related................................................................................................. 20 Third-party tools and products related ........................................................................................... 20 External interface related............................................................................................................. 21 Use of tools in the migration process............................................................................................. 22 Debuggers................................................................................................................................. 23
Section 2. Optimizations .................................................................................................................... 23 Comparison of effect of optimizations on target programs .................................................................. 23 Comparisons between compilers...................................................................................................... 24
Section 3. Migrating to Linux on the Intel Itanium Processor Family .......................................................... 26 Key considerations ......................................................................................................................... 26
64-bit readiness ......................................................................................................................... 26 The Intel Itanium Processor Family architectural features for improving performance ........................... 27 Comparative study of compiler optimizations on the Intel Itanium Processor Family and IA-32 ............. 29
Approaches when migrating to the Intel Itanium Processor Family ........................................................ 31 Multi-step approach .................................................................................................................... 31 Direct migration to the Intel Itanium Processor Family ...................................................................... 31
Conclusion........................................................................................................................................ 32 For more information.......................................................................................................................... 32
Additional papers in this three-part series.......................................................................................... 32 References for further reading.......................................................................................................... 32 Web site references for further information........................................................................................ 33
Glossary of terms............................................................................................................................... 34 Appendix 1. Sample programs ........................................................................................................... 35 Appendix 2. Descriptive listing of compiler options................................................................................ 38
2

List of figures Figure 1. Lifecycle for an enterprise application migration ........................................................................ 6 Figure 2. High-level migration steps ....................................................................................................... 8 Figure 3. Migration steps—dependency resolution by source code modification ....................................... 11 Figure 4. Results with the GCC compiler............................................................................................... 24 Figure 5. Results with Intel compiler ..................................................................................................... 24 Figure 6. Comparison of RANPI execution times for binaries using GCC and Intel CC............................... 25 Figure 7. Comparison of Dhrystone execution times for binaries using GCC and Intel CC .......................... 25 Figure 8. Comparison of Whetstone execution times for binaries using GCC and Intel CC ......................... 26 Figure 9. Effect of optimization on execution time of Dhrystone ............................................................... 30 Figure 10. Effect of optimization on execution time of Whetstone ............................................................ 30 Figure 11. Example program 1: Signal handling and threading.............................................................. 35 Figure 12. Example program 2: Word size dependency ........................................................................ 36 Figure 13. Example program 3: Endianness dependency ....................................................................... 36 Figure 14. Endianness dependent code................................................................................................ 37 Figure 15. Example program 4: Change in API calls ............................................................................. 37
List of tables Table 1. Operating systems and platforms .............................................................................................. 7 Table 2. Compilers and tools ................................................................................................................ 7 Table 3. Differences in packaging operations between Solaris and Linux ................................................. 18 Table 4. GNU Make conversion summary ............................................................................................ 19 Table 5. Migration tools ..................................................................................................................... 22 Table 6. Intel C/C++ Compiler options ................................................................................................ 38 Table 7. GCC Compiler options .......................................................................................................... 39
3

Introduction Although Linux was popularized primarily in Web serving and other peripheral functions, the open source operating system has become a viable alternative to the high-end UNIX® offerings and Windows® environments that run enterprise mission-critical services. This is making migration to Linux an increasingly common phenomenon, as it becomes the operating system of choice for many industries—and a key development platform for major software and hardware providers. “Graduating” to the enterprise has made Linux the only operating system to grow in market share in the last 18 months, as an ever-larger number of organizations realize the technical and financial benefits of building IT infrastructure on a robust, highly reliable open source platform.
Many documents discuss migration to the Linux platform in one form or another, but a single reference that covers complete “migration engineering” is notably absent. (Here the term “migration engineering” is intended to mean the engineering that addresses, in sufficient breadth, best practices for migrations to Linux.)
This paper (along with two related successors) is meant to fill this gap, attempting to address broadly all the important engineering considerations that arise during a software migration to the Linux platform. We will deal generally with engineering for migration to Linux, with a specific focus on migration from UNIX variants, such as Solaris, to Linux on the Intel® Itanium® Processor Family (IPF).
The flowchart in “Figure 1. Lifecycle for an enterprise application migration” describes the entire lifecycle of migrating an enterprise application to a new platform—of which migration engineering is only one phase. In this paper, only the migration phase is covered extensively. Related but distinct topics, such as the re-engineering of software for a new platform, are not within its scope.
The information we present is built on HP’s experience in executing migration projects for customers around the globe. It presents a formalized approach to migration based on source code modification. This approach classifies the “areas of dependency” of a software package on the source platform from which it is being migrated. Dependencies are those properties of the application components, such as run time and development environment, that depend on platform characteristics for proper functioning and must be modified to operate successfully on the target platform.
After reading this document, you should be equipped with a good knowledge of the engineering approaches to and the challenges involved in a migration. While there are many compelling arguments, both technical and non-technical, for moving to Linux, this paper is concerned with the time after the decision to migrate to Linux has already been made.
The two subsequent papers in this three-part series will cover “Linux porting and migration—the development environment” and “Linux porting and migration—migration patterns,” respectively.
Executive summary The objective of this paper is to detail the engineering considerations that arise when migrating from UNIX to Linux in general, and from Solaris to Linux in particular. Migration developers, migration solution architects, planners, and all others who need to be educated on “total migration engineering” for migrations to Linux will benefit most from reading this document.
This paper is organized in three major sections.
The first section discusses the migration processes, describes HP’s big picture of the migration landscape, and lists the different phases that comprise the larger activity of migration.
4

There are several high-level approaches to software migration, including:
• Source environment emulation • Porting using wrappers/libraries for platform services • Source code modification
Source code modification is the focus of this paper; it is the most detailed and time-consuming but frequently the most effective solution, because it produces native binaries that run with greater efficiency on the target platform.
A formal process of identifying and overcoming platform migration obstacles is divided into four steps:
• Dependency analysis—determining the dependencies of the software package on the source platform
• Dependency resolution—determining approaches to eliminating dependencies • Test—verifying successful source code modifications • Optimize—tuning the software performance for the target platform
The dependency analysis and resolution steps are applied to the following nine areas of dependency:
• Language and compiler • Platform and hardware architecture • OS run time environment • System command set • Application programmer interface • Software build environment • GUI support look and feel • Third-party tools and products • External interface
The second section discusses optimizing in the build process by using various selected compiler options, which can have a substantial effect on application performance. For example, the GNU Compiler Collection (GCC) version 2.96 and Intel C/C++ Compiler 7.1 are run on an IA-32 and an Itanium-based server running Linux. We find that compiler options must be tuned specifically to each application and that the Intel compiler produces higher compiler scores than GCC at higher optimization levels. The findings are illustrated by benchmark results.
The third and final section gives details on the migration issues specific to moving to a 64-bit computing platform and the Intel Itanium Processor Family in particular. We conclude by finding that migrating one step at a time has the advantage of minimizing risk but can lead to inefficiency, while direct migration is often more effective but entails higher risk.
5

Figure 1. Lifecycle for an enterprise application migration
Versions information The examples in this paper have been tried on respective versions of platforms and software listed in Table 1 and Table 2 shown below.
6

Table 1. Operating systems and platforms
1 Linux OS Kernel 2.4.19 (Debian v3.0) on Intel Itanium 2-based workstation
2 Linux OS Kernel 2.4.X (Red Hat Enterprise Linux, formerly known as Red Hat Linux Advanced Server [AS 2.1]) running on IA-32
3 SunOS 5.8 sun4u running on SPARC SUNW, Ultra-6
4 AIX 4.3.X on IBM PowerPC
Table 2. Compilers and tools
1 GCC version 2.96 for Linux on IA-32
2 GCC version 2.96 for Linux on Intel Itanium Processor Family
3 GCC version 3.0 for AIX on PowerPC
4 Intel C/C++ Compiler 7.1, for IA-32
5 Intel C/C++ Compiler 7.1, for Intel Itanium Processor Family
6 GNU Make version 3.79
Section 1. Migration process description
Migration, an overview The flowchart in “Figure 1. Lifecycle for an enterprise application migration” shows the entire lifecycle for a typical enterprise application migration. It comprises the following key stages:
Investigation and assessment phase Before any further steps are considered, it is important to assess the scope of the migration activity to understand the software package’s architecture and to determine whether the migration being considered is financially viable and technically feasible. In order to establish this, consider the following questions:
• Third-party products: Are all the third-party products required for operation of this software package available on the target platform?
• Tools: Are all the software tools required for operation of this package available on the target platform?
• Languages: Are the compilers/linkers/interpreters for languages/scripts used to build this software product available on the target platform?
• Source platform specific considerations: Are there any specific, unique characteristics of the source platform that are vital for the operation of the software package being migrated, and are those available on the target platform? In particular, look for: – High availability characteristics – Real-time response characteristics – Special hardware devices and device drivers
If you answered in the negative to any of the questions above, then the software package needs to be re-engineered rather than migrated to the target platform. Software re-engineering is a broad topic worthy of a complete white paper of its own and is not covered here.
7

In most cases where migrating the software has been deemed possible, an accurate assessment of the package’s size and complexity must be performed using assessment tools. This is necessary to determine efforts involved in migration, particularly when costly consulting may be needed.
Planning phase In this phase, the planning of the methodology, processes, and environment (tools, infrastructure, etc.) for the migration activity takes place. An offshoot of this phase is the development and customization of migration tools, where necessary. Such tools, if any, are developed for use during the migration.
Prior to the actual migration, there may be an optional pilot migration phase. A pilot migration is a test migration of a selected small portion of the target software package. The pilot migration is done with an eye to verifying the applicability of the selected migration methodology to the software package. Pilots are typically undertaken if the technological risks have been deemed high.
Migration phase This paper’s topic, the “migration” phase of migrating any software package to the target platform (the blue box in “Figure 1. Lifecycle for an enterprise application migration”) is broken down into three main steps, as illustrated in “Figure 2. High-level migration steps”:
• Platform dependency analysis: Identification of software “dependencies” on the source platform. These dependencies translate into “migration impacts.” From this point forward, the dependency of the software package on platform-specific features and consequential migration impact will be referred to simply as the “dependency.”
• Dependency resolution: Determination of an approach for resolving each of the identified dependencies, and the use of these approaches to resolve the dependencies.
• Test: “Whitebox Testing” on the target platform in the development setup. The testing focuses on validation of the migration process. It seldom covers complete functionality of the product. It is constrained by limitations of the development setup.
• Optimization: An optional fourth step during which the application binaries are tuned to run efficiently on the target platform.
Figure 2. High-level migration steps
8

A typical list of the software package components that need to be considered for dependency analysis includes:
• The source code • Scripts and utilities • Packaging utilities (if it is a product) • Documentation for end users and programmers • Interfaces to external systems • Third-party software that forms an integral part of the software package
The types of dependencies that these components can have are discussed later, in the section on “Identifying, analyzing, and resolving software package dependencies.”
Testing and acceptance phase In this phase, the complete product functionality is tested in order to validate the success of the migration project. In most cases, representatives from the application owner are directly involved in the test, and the team that performed the migration is expected to provide support to the test team. Ideally, the acceptance test is carried out on a setup comparable to the production environment.
Production rollout phase In this phase, the migrated software package is deployed on the actual production hardware. The testing and acceptance phase described above establishes whether the migrated software package is ready for production use. In most cases, however, significant work still needs to be done in order to install the software package on the new platform and make everything production-ready.
Approaches to migration Before we delve into the details of migration engineering, it is worthwhile to discuss some differing approaches to software migration.
Source environment emulation This kind of migration involves providing an emulation environment so that binaries generated for the source platform are run directly on the target platform without any code changes. An example of such an emulator is Wine, an open source implementation of the Windows API on top of X, UNIX, and Linux. (See www.winehq.com/ for more details.)
Source environment emulation requires a minimal porting effort, as there is no need to make any change to the software package being migrated. However, emulators are not available for all source and target platforms. In addition, the emulation environment is typically significantly slower than the native environment on the target platform—and it can frequently impose limitations on functionality as well.
This approach is taken where the following conditions exist:
• An emulator with required capabilities is available on the target platform • Work involved in developing an emulator is significantly less than migrating application sources • Source code is not available • Performance requirements are not critical
Portability wrappers/libraries for platform services Portability wrappers/libraries provide an abstraction layer that offers either a “generic platform-independent” or “a specific source platform-like” implementation of system services and interfaces on the target platform. One example of a generic platform-independent portability library that provides a POSIX layer is the Adaptive Communication Environment or ACE. (See
9

www.cs.wustl.edu/~schmidt/ACE.html for details on ACE. Another example, “Building an open-source Solaris compatible threads library” can be seen at http://opensource.hp.com/the_source/linux_papers/scl_solaris.htm.)
Initially, the software package should be programmed to make use of portability libraries on its existing platform. If that can be achieved, then this technique can reduce the task of migration to a mere recompile on the target platform. Also, the porting effort can be significantly reduced if wrappers, which provide a source platform–like interface, are available on the target platform. This is because the need to make modifications to the original source code is minimized. In addition, it ensures that the program can be migrated easily to all those platforms where the wrapper is available. However, in some cases the changes involved in modifying application software to make use of portability libraries might be more complex than the changes involved in migrating to the target platform directly. Hence, this approach is most likely to be beneficial when porting to multiple target platforms.
This approach can prove costly in terms of performance due to the overhead associated with a wrapper and is best used when the following conditions prevail:
• The application already uses the wrappers or permits the use of wrappers with reasonable effort • Portability is highly desirable (e.g., the application will be ported to many platforms) • Suitable wrappers are readily available on the target platform or can be built with reasonable effort • Performance requirements are not critical
Source code modification This approach involves modifying the software package’s source code to remove the source platform dependencies. It is the most demanding in time and effort—but it is also the most effective in terms of performance, as it produces native binaries. In addition, no wrapper libraries or emulators are necessary, and the approach can be applied in all situations where source code is available.
Source code modification is ideal where:
• Application code is available • Performance and functionality constraints warrant the effort of modifying source code
Dependency resolution by source code modification Among the approaches discussed above, source code modification is the approach that this paper is focused on (though most of the considerations are also applicable to portability wrapper development). If we expand the “dependency resolution” step depicted in “Figure 2. High-level migration steps,” it consists of three sub-steps—change, compile objects, and build—as illustrated in Figure 3.
10

Figure 3. Migration steps—dependency resolution by source code modification
Change This step involves carrying out changes to the software package being migrated—by translating bindings to the source platform into bindings to the target platform. It is important to consider all the components of software packages when carrying out these changes. A few examples of the components that may have to be changed are:
• Software packaging • Source code • Test suites • Miscellaneous utility scripts
Once the dependencies have been identified in the dependency analysis phase, then performing the actual changes is a relatively simple job, although it needs to be done with diligence.
The following are important considerations and good practices to apply while performing changes to a software package:
Separating support for source and target platform: If the same source code base is to be used for either platform, then the source code changes need to be guarded by appropriate guard conditions such as “#ifdefs” in C/C++ code. Ideally, unless there are considerations that force the coexistence of supportability for multiple platforms in the same code base, a new branch of code is maintained for the migrated code base. Maintaining two separate code bases is preferable, because where multi-platform support coexists in a single source, then #ifdef-like guard conditions greatly affect code readability and maintainability in the long run.
Localizing migration changes: To minimize effort and for better maintainability, it is advisable to localize changes where possible. This can be achieved to some extent by grouping common migration-impact–related changes in a single place by adopting one or more of the following techniques:
• Group macro re-definitions, structure re-declarations, and changed or new function prototypes in one or more newly created header files.
• Create wrapper functions for missing or changed system calls and API calls and group them in a few newly created source files.
Compile objects In this step, source files are compiled to generate objects. Additional changes may need to be made to remove errors and warnings.
11

During this step it is best to:
• Maintain a log of compiler errors and warnings generated in the iterations of compilations for subsequent reviews.
• For critical code segments, review the warning messages as well as errors.
Build binaries This step involves building the final products of the software package such as program binaries and the libraries by linking objects. After this step, the software package is ready for testing on the target platform.
Test The binaries thus generated are run on the target platform in the development setup itself. A preliminary round of testing is performed to ensure the binaries’ readiness for complete functionality testing.
The four steps listed above—change, compile, and build, followed by a limited form of testing—are typically performed in the migration development environment. As mentioned in the introduction, the environment, including details about tools/processes/methodology, is the subject a future paper in this series.
Identifying, analyzing, and resolving software package dependencies For a successful migration, it is important to take into account the complete spectrum of possible dependencies that the software being migrated can have on the source platform. These dependencies need to be analyzed for each component of the software.
This section discusses the most common categories of dependencies and provides some illustrative examples. Ways to unearth dependencies (i.e., “dependency analysis”) and specific ways, if any, to resolve these dependencies are also discussed.
Below is a list of the most common dependencies. It is not exhaustive by any means, because every migration is unique and may unearth a new kind of dependency.
• Language and compiler • Platform and hardware architecture • OS run time environment • System command set • Application programmer interface • Software build environment • GUI support look and feel • Third-party tools and products • External interface
Each of the above dependencies is discussed in the following subsection. When any of these dependencies is not supported on the target platform, it translates to a “migration impact” that calls for a change.
Language and compiler related Dependency description: Dependencies of the software package being migrated on language-related characteristics of the source platform (or rather, on native tools on the source platform, such as compilers, linkers, etc.)
12

These dependencies include:
• Syntax variations in language implementation • Implementation idiosyncrasies in standard libraries like libc and standard template libraries • Compiler/Linker options
With the advent of language standardization bodies such as ANSI/ISO, syntax variations in language implementations of languages like C are rare but not unheard of.
Similarly, implementation idiosyncrasies in language syntax are rare but relatively more common in newer technologies such as the C++ and the C++ standard template library.
Compiler/Linker option changes are relatively more common, because on any given source platform, a vendor-specific native code compiler is typically used. As an example, the “Sun WorkShop C compiler” from Sun is predominantly used on the Sun platform. On a Linux platform, GCC is the compiler of choice.
The source code build environment has dependencies on the native compiler due to the use of specific compiler options. These dependencies are of varying complexity as illustrated below. Sometimes they are straightforward mappings from one option to another comparable option—for example, to enforce compliance with the ANSI/ISO standard on Sun Solaris, one uses the compiler option $ cc –Xa. On Linux using GCC, it needs to map to $ GCC -ansi.
In other cases, there is no direct mapping available, and indirect means have to be used. For example, the abovementioned Sun compiler provides a compiler option specified as $ cc –xmaxopt. This option is interpreted as follows: In the source compiled by the Sun compiler we can have a #pragma preprocessor directive specified as #pragma opt level (funcname[,funcname]). The value of “level” specifies the optimization level for the “funcname” subprograms and can be assigned a value of 0, 1, 2, 3, 4, or 5.
By use of this compiler option, the actual level of optimization for the function “funcname” listed in the #pragma is reduced to the value of -xmaxopt.
The pragma is ignored when -xmaxopt=off.
Up to version 2.96 of GCC there has been no comparable option; hence when migrating to GCC you need to ensure that the source code does not use these types of pragmas.
Dependency analysis: A keyword scan of sources and build scripts or makefiles can be done to unearth such impacts. For example, build scripts or makefiles can be scanned either manually or by using a scan tool to identify compiler options that need to change when moving to the target platform. Such scanning has the prerequisite that a reference of option differences is available. If such a scan is not possible, it might be necessary to attempt an actual make and let the compiler throw out unrecognized options. To depend on the latter approach might be risky because some options might be recognized, but interpreted incorrectly. The same is true for syntax variation, where a preferred approach is a keyword scan; where scan data is not available, a compile run should to be attempted to identify dependencies.
Dependency resolution: Once the dependencies have been identified, resolving them is simply a matter of proceeding as follows:
For all compiler options and code fragments that have a dependency, generate a mapping for compatible options/code on the target platform. This needs to be done carefully so as not to disturb the semantics of the original options/code. It is preferable to review the mapping because it forms a basis for further changes. Then, make the changes in accordance with the generated mapping, and review the changes.
13

Platform and hardware architecture related Dependency description: Platform and hardware architecture dependencies consist of characteristics such as word size and endianness or byte ordering.
When porting from a 32-bit platform (such as win32) to a 64-bit platform such as Linux on the Intel Itanium Processor Family, you may be faced with many issues that need to be addressed if the application is not “word size neutral.” When porting from a big endian architecture Like Solaris on Sun SPARC to a little endian architecture like Linux on the Intel Itanium architecture, there can be lot of issues that need to be addressed, especially if the application is not “endian neutral.”
Being endian/word size neutral means that the application code is either well-constructed code, so that the byte ordering/word size of a system is transparent, or that the application is geared to handle problems that endian/word size difference can cause wherever there is a dependency.
If the application is not endian/word size neutral, the porting process needs to address this issue and correct the problems caused due to differences.
Word size dependency: Code segments likely to have word size issues are those that use data types of similar size on one platform interchangeably to store values of the other type.
If the code does any of the following, then it may exhibit problems when running on an architecture using a different word size:
• Uses variables of a native data type, such as an integer as a storage space for pointers • Assigns a value held in a variable of the long data type to an integer • Makes any other assignment between mutually incompatible data types simply because they
happen to be the same size on a particular architecture
Consider the code fragment shown in “Appendix 1, Figure 12. Example program 2: Word size dependency.” When we run this code on a 32-bit machine we get following output:
$run32 This works with ELF 32-bit LSB. I got: 10
When we build the same program as a “64-bit LP64 binary” and run this program on a 64-bit machine, it crashes with a segmentation violation.
(Note: 64-bit ELF binaries in the Intel Itanium Processor Family support LP64 Model where long type and all pointer types are 64-bit objects.) More information on the application binary interface of the Intel Itanium Processor Family can be obtained from http://developer.intel.com/design/itanium/downloads/245370.htm.
Endianness dependency: Code segments prone to endianness issues are those that make use of unions, byte arrays, and/or data transfer—especially over a network to a machine with a different architecture without the use network byte order.
14

Look at the code fragment shown in “Figure 13. Example program 3: Endianness dependency.” When this program was run on a sun4u SPARC box running SunOS 5.8 (big endian), the output was as follows:
$test_endian RAW Data = 20300245 Detailed Information ------------------- Registration No : 20 Roll No : 30 Grade : 2 Credits : 45
When the same program was run on a IA-32 box running Linux (little endian), the following was returned:
$ test_endian RAW Data = 20300245 Detailed Information -------------------- Registration No : 45 Roll No : 2 Grade : 30 Credits : 20
For further reference on this topic, Intel offers a very useful online tutorial for porting Solaris applications to the Intel architecture. This tutorial gives some more examples on the endianness problem illustrated with code segments. (See http://cedar.intel.com/media/training/slei_site3/tutorial/index.htm for more details.)
Dependency analysis: These dependencies are difficult to identify using a simple keyword source code scan. Consider the illustration shown in “Figure 12. Example program 2: Word size dependency.” A reasonably good compiler such as GCC will give a warning for such an assignment. Code checking tools like “lint” are useful as well. When this program was checked using a lint variant called “splint” (more information on splint can be obtained from http://www.splint.org/) on a Linux server, it gave the following output:
$splint wordsize.c Splint 3.1.1 --- 28 Apr 2003 wordsize.c: (in function main) wordsize.c:9:2: Assignment of int * to int: b = &a Types are incompatible. (Use -type to inhibit warning)
This assignment happens to be the culprit in rendering the program word size dependent. However, if we introduce an explicit cast such as “b=(int)&a;” in this assignment, then the error remains but lint fails to catch it, nor does the compiler issue a warning!
Endianness impacts are also tough to catch using code scanners, compiler warnings, or code checkers. To determine endianness impact, critical code segments need to be manually reviewed.
Another deceptively easy, but risky option is to build binaries notwithstanding these dependencies and rely on the anomalies that surface in testing to unearth the problems. A debugger like the GNU gdb can be used for pinpointing these dependencies at the code level.
15

Dependency resolution: Provided the dependencies are identified, resolution is a relatively simple step-by-step process. For all identified code fragments that have a dependency, generate a mapping for compatible code on the target platform. This needs to be done carefully in order not to disturb the semantics of the original options/code. It is preferable to review the mapping because it forms a basis for further changes. Apply the changes according to the generated mapping and review the code changes.
For example, the word size dependency illustrated in “Figure 12. Example program 2: Word size dependency” can be removed by using a proper pointer instead of an integer to store an address. This can be done by changing the type of “b” from a pointer to int (i.e., an “int*”).
And for the endianness problem illustrated in “Figure 13. Example program 3: Endianness dependency,” the following is one of the crude ways of resolving this:
Adapt the definition of the structure to the target platform as shown in “Figure 14. Endianness dependent code.” Reversing the order of fields on the target platform nullifies the effect of reversed byte ordering and the end result remains unchanged in this case. This code fragment also illustrates how two platform supports can co-exist using a #ifdef. Of course, it is better to avoid such endianness dependency by writing endian-neutral code in the first place, or rewriting the affected code fragment to be endian neutral.
OS run time environment related Dependency description: Dependencies on specific components of the run time environment.
Some examples of OS run time environments that may differ from source to target platform are:
• Thread model—The Linux thread model (at least up to Kernel 2.4.X) is different from the rest of the UNIX flavors such as Solaris or AIX. This version of Linux, unlike the other UNIX flavors, spawns a new process for every thread created.
• Signals and signal handling—Linux supports most of the signals provided by the signal defined in ANSI, BSD, POSIX, and System-V. However, there are some exceptions. Signals SIGEMT, SIGINFO, and SIGSYS are unsupported. SIGABRT and SIGIOT are identical; SIGIO, SIGPOLL, and SIGURG are identical; and SIGBUS is defined as SIGUNUSED. A comprehensive description of Linux signals is easy to find on the Web. A terse but complete listing may be found on http://ctdp.tripod.com/os/Linux/programming/Linux_pgsignals.html.
Signal handling when coupled with the Linux thread model becomes particularly interesting as signals are individually delivered to the threads (threads being individual processes in Linux). Each thread inherits a signal handler if one was registered by a parent process that spawned the thread.
To make this clear let us illustrate this by example. Consider the small test program in “Appendix 1, Figure 11. Example program 1: Signal handling and threading.” This simple program registers a signal handler to handle SIGUSR1. The signal handler simply prints the process ID (PID) of the process that received that signal. The program spawns three threads after it registers the signal handler and waits on those threads. Each thread simply goes into an infinite loop and does nothing.
We first compile and run this program on an AIX machine, producing the following output:
$ ./threadprog & my pid=32302 my thread id=258 my pid=32302 my thread id=515 my pid=32302 my thread id=772 Now we use a kill command to send SIGUSR1 to the only process (32302). The output is as follows $kill –s SIGUSR1 32302 Inside my SIGNAL HANDLER, PID: 32302
16

Subsequently, we compile and run the same program on a Linux machine.
$ ./threadprog & my pid=9515 my thread id=1026 my pid=9516 my thread id=2051 my pid=9517 my thread id=3076
Now we use a kill command to send SIGUSR1 to the FIRST process out of the three new processes spawned. The output is as follows:
Inside my SIGNAL HANDLER, PID: 9515
One ought to be careful when migrating programs that use signal handling coupled with threads when migrating to Linux—especially if they involve the use of process IDs.
Note that the new features supported in Linux Kernel 2.6 and onwards include improved POSIX threading support, such as the “Native POSIX Thread Library for Linux” (NPTL). With the new threading support, the behavior described above changes significantly. An informative paper on NPTL design can be found at http://people.redhat.com/drepper/nptl-design.pdf.
Dependency analysis: Broadly speaking, a keyword scan can point to suspect code sections or “critical code sections”; however, determination of the actual impact calls for manual code review.
Dependency resolution: Provided the dependencies are identified, the resolution needs to happen via a step-by-step process. For all identified code fragments that have a dependency, rewrite the code fragments to remove the dependency. In some complex cases the rewrite may be significant or the changes spread out (not localized). Rewriting needs to be done carefully in order not to disturb the semantics of the original options/code. It is preferable to review the mapping because it forms the basis for further changes—and, as always, review any code changes that are made.
System command set related Dependency description: Dependencies on system command repertoire and/or behavior
Applications depend on system commands for various tasks; these commands might be part of a given application as utility scripts. The migration impacts for system commands can be of four types:
1. Equivalent exists with same name and same behavior 2. Close equivalent exists—only the name is different 3. Equivalent exists but calls for substantial change 4. Equivalent command does not exist
Most UNIX commands are of the first two varieties, for which the solution is straightforward. Because the Linux command set is rather comprehensive, the fourth case rarely occurs.
Let’s look at an example of case 3, which can occur very often and is significant from the perspective of migration impact. Consider software installation and patch management. On a Sun Solaris system, one uses “pkgadd, pkginfo … pkgxxx” commands for software installation and patch management. On a Red Hat Linux system, we have to use the “rpm” command. There are differences in the way these operate. The table below, “Table 3. Differences in packaging operations between Solaris and Linux,” provides some examples of common packaging operations and commands used on Solaris and on Linux.
17

Table 3. Differences in packaging operations between Solaris and Linux
Operation Solaris Linux
Installing Pkgadd rpm -I
Uninstalling Pkgrm rpm -e
Verifying Pkginfo rpm -q
Package building Pkgmk rpm -ba
The most complex issue is the migration of the package building—specifically, migrating or recreating the packaging specifications. The format of the package specification “template” files used by pkgmk in Solaris is different from the “spec” file used by RPM, and translating packaging information from “template” files into spec files requires a substantial effort. (More information on the RPM Package Manager is available from www.rpm.org/.)
The Web site www.ucgbook.com/ provides a fairly complete listing of commands for all operating systems and some cross mappings as well.
Dependency analysis: These types of dependencies are relatively easy to fish for; a simple keyword scan of shell scripts (that use system commands) can be performed to uncover them.
Dependency resolution: Once the dependencies are identified, resolution proceeds as follows:
• For all identified scripts that have a dependency, generate a mapping for compatible code on the target platform.
• In cases where the mapping is straightforward, execute changes in accordance with the generated mapping.
• In cases where an equivalent command exists but calls for a lot of changes due to differences in the new command’s characteristics (as we saw in the case of replacing pkgxxx commands by rpm), it might be advisable to understand and plan for the changes involved before performing actual modifications. Performing an initial analysis and then outlining an approach can be very helpful.
• In cases where no direct equivalent exists, there might be a need to write wrapper scripts that use a custom program or a collection of commands to achieve similar results.
Application programmer interface related Dependency description: Dependencies on proprietary (non-POSIX) system calls and on non-standard library calls.
This represents one of the largest areas of dependency, and in a typical migration a significant effort is spent here.
Listed below are the broad categories of API differences you may expect to encounter:
• API calls with the same name and similar functionality on either platform, but with a slight difference in attributes such as parameters and return values or side effects (like the setting value of errno). For instance, the sigprocmask call on Solaris and Linux have an argument, sigset_t, which is defined differently on the two systems.
• API calls that are not available on Linux with the same name, but which have a near equivalent on Linux. For example, consider the plock call on Solaris. This call allows the calling process to lock into or unlock from memory its text and/or data segment. Segments thus locked are immune to routine swapping. There is no plock call on Linux, but there is an mlock call that does something similar. In particular, mlock disables paging for the memory in the range starting at addr with length len bytes. All pages that contain a part of the specified memory range are guaranteed to be resident in RAM when the mlock system call returns successfully. For another illustrated example of API calls that are not available on Linux with the same name, but have a near equivalent on Linux
18

see “Figure 15. Example program 4: Change in API calls.” This code fragment illustrates the difference between Solaris-specific and Linux (POSIX compliant) implementations of the regcmp and regex functions. These functions are used for simple regular expression compile and match. When migrating this code from Solaris to Linux, the routines regexp and regcmp on Solaris need to be replaced by the comparable routines, regexec and regcomp on Linux. The ensuing code change is also depicted in Figure 15. This code fragment also illustrates how two platform supports can co-exist using #ifdef. It is worth noting that the POSIX style regex is also available on Solaris.
• API calls that are specific to the source platform and have no equivalent on the target platform, such as the Solaris-specific thread calls thr_suspend or thr_continue()—used to suspend or continue thread execution; these are not available on Linux, nor are there any close equivalents.
Dependency analysis: These kinds of dependencies are relatively easy to fish for—a simple keyword scan of source code can be performed to unearth them.
Dependency resolution: Once the dependencies are identified, resolution proceeds as follows:
1. For all identified API call dependencies, generate a mapping for compatible calls on the target platform (most often, this mapping is straightforward, and scanner tools can be programmed to provide suggestions). Where there are no direct equivalents available, a wrapper-call may have to be implemented on the target platform.
2. Make changes according to the generated mapping. In some cases, the changes are more than a simple one-to-one replacement of the API call because return values and arguments differ and may trigger code changes in surrounding code blocks.
3. Review code changes.
Software build environment related Dependency description: Dependencies on platform-specific characteristics of build utilities such as Make.
We’ll begin by discussing dependencies on build utilities. Consider a build environment that uses the native Make on Solaris. On Linux, the default make environment is GNU Make (gmake). There are differences between makefiles for these two environments.
The following table is reproduced from the HP Developer and Solutions Partner Portal, a source for lots of useful information (www.hp.com/dspp).
Table 4. GNU Make conversion summary
Category Solaris Make construct GNU Make equivalent
Library dependencies libname((symbol)) libname(file.o)
Current target $(targets): [email protected] $(targets): %: %.o
Conditional macro $(targets) := c_flags = -g $(targets) ... : c_flags = -g
Empty rules .c.a: .c.a: ;
~Suffix rules .c~.o: Unnecessary, already built into GNU Make
This table lists the most important dependencies, although there may be some subtle differences that are not listed above but have an impact nevertheless.
For example, there is a small difference between Solaris Make and GNU Make; if you intend to specify a default compiler used in “implicit rules” for object conversion of C++ files, then you need to use a built-in makefile variable. The built-in makefile variable to specify a default compiler in Solaris
19

native Make is “CCC,” while for the GNU Make it is “CXX.” Similarly, the default compiler flag changes from CCFLAGS to CXXFLAGS.
Apart from dependencies on build utilities, there are other dependencies that surface during build time, including the locations of system header files and system run time libraries, which may be in different paths. These are specified in the options to linkers and compilers in makefiles.
Dependency analysis: Makefiles can be manually reviewed to uncover dependencies on the build environment. Keyword-based scanning tools can be used to determine dependencies on header file location.
Another simpler and equally effective technique is to perform a dry run of makefiles and generate an error log. In GNU the make –k –n command will perform a dry run for a complete makefile.
Dependency resolution: For all identified impacts, perform changes according to the conversion summary in “Table 4. GNU Make conversion summary.” Then perform another dry run to ensure that the changes have been successful.
GUI support look and feel related Dependency description: Dependencies on specifics of GUI support behavior
If you are using X Window (called “Xfree86” on Linux) as your GUI, there should be little impact when migrating from any UNIX offering to Linux. Xfree86 used on Linux is an open source implementation of the X Window “X11” system and is supposed to be a direct port of the standard X11R5 system to 80386-based architectures. (More information on Xfree86 can be obtained at www.xfree86.org/; for more information on the X Window GUI, see www.x.org/.)
In the past, one of the few migration impacts of moving to Linux was that the CDE (common desktop environment) Windows manager for Solaris was not available on Linux, as it did not function well under the Xfree86 server. Therefore, if a particular application was dependent on CDE features, that dependency used to constitute a migration impact. However, lately some commercial versions of CDE for Linux have become available, and these need to be tested.
Also note that Xfree86 is yet to mature, so there is a possibility of running into a fair share of bugs/problems.
Dependency analysis: It may be difficult to perform a definitive dependency analysis due to the nature of the information available. If, however, the application uses CDE then this certainly constitutes a dependency. The remaining issues are likely to be bugs, which may be eliminated as the X server on Linux matures.
Dependency resolution: One approach to resolving the CDE dependency is to port required CDE modules to Linux if the sources are available. Otherwise, these modules may have to be rewritten.
Third-party tools and products related Dependency description: Dependencies on third-party enterprise software products and tools that are needed during build time or run-time.
Linux’s development environment is, to say the least, rich. Tools for software development on any given UNIX operating environment are often also available on Linux, if only as a variant. But this wealth of tools can result in incompatibilities among different versions.
In the section below titled “Use of tools in migration,” we include a high-level description of the usefulness and the limitation of migration tools. However, a more detailed discussion on the topic of development environment and migration tools can be found in the second of our series of three white papers on Linux migration.
20

While many tools are available, in the past lack of support has been an issue. However, Linux support for the most common third-party tools and products, including popular middleware, RDBMS, etc., is gradually increasing. Most vendors now certify their products for popular Linux distributions such as Red Hat and SuSE.
Red Hat publishes a list of enterprise software products supported on its respective Linux distributions at www.redhat.com/solutions/partners/software/. Go to www.suse.com/us/partner/search_partners/technology_partners/index.html for a list of SuSE technology partners.
But ultimately, when moving from a UNIX operating environment to a given Linux distribution, you will more than likely encounter some of the following difficulties:
• Product version change—Even though a similar product is available on the Linux distribution of your choice, it may not be same version used on the source platform, implying the need for a version change.
• Maturity of support—For many products, support on Linux distributions is a relatively new addition and often at a level below that of other variants of UNIX. This could mean bugs and teething troubles of one kind or another.
• Linux version complications—Among the suite of products required for moving a solution, some may be supported on one Linux distribution while others are supported on another distribution.
Dependency analysis and resolution: In this case, since the dependencies are largely a function of the product concerned, dependency analysis and resolution require strong product-specific expertise that may differ from version to version. In many cases, product vendors provide tools for carrying out such migrations between product versions.
As an example, if you are moving from a previous version of Oracle® RDBMS to Oracle 9.X on Linux, then you can make use of a tool from Oracle called “migration workbench.” (See http://otn.oracle.com/tech/migration/workbench/content.html for details.) If the product vendor does not provide such tools, a product migration expert will need to analyze and resolve any dependencies manually.
External interface related Dependency description: Dependencies of the software package on interfaces with external systems
A software package being migrated may be part of a larger system in an enterprise, and its interfaces to external systems may be over the network or via protocol layers, or it may use special devices by directly interfacing with the device drivers. Specifically, one must consider the following:
• Interfaces with protocol layers/protocol stacks—Typically, applications interface with protocol stacks using APIs like the socket calls for TCP/IP networking. If the implementations of these APIs differ from the source platform to Linux, then the application interfaces may need to be fine-tuned to suit the new API.
• Interfaces with device drivers—For character as well as block device drivers, the “Device” exists as a special file in the /dev directory. A user-level application interacting with a character/block device driver uses a standard file system interface provided by the OS such as open, ioctl, read, and write. There can be differences in device driver characteristics as well as in the interfaces provided by the OS.
Note that other subtle differences may appear between platforms that will have to be addressed.
21

Dependency analysis: This kind of dependency is typically localized. Analysis should begin by identifying the critical code sections and critical modules that will be affected. Since this type of dependency is very specific in nature, code scanning tools or checking utilities are of little help, and critical code sections need to be manually reviewed for dependencies.
Dependency resolution: Resolution depends on the severity of individual dependency and may involve anything from a simple code change to a complete rewrite of the module.
Use of tools in the migration process As mentioned earlier, a detailed description of development environments and tools isn’t covered here. However, as tools are an important aspect of migration engineering, they merit a brief mention.
The table below gives a few examples of analysis and migration change automation tools available to assist in migrating from Solaris to Linux on the Intel Itanium Processor Family.
Table 5. Migration tools
# Type Examples Description
1 Commercial migration automation tools
Migratec 32Direct, 64 Express Automates the process to a large extent, including analysis of actual code changes
2 Code scanner-based migration tools Homegrown scanners from HPS ISO, the HP Software Transition Kit
These tools act as advisory code scanners that help in pinpointing dependencies that can be determined by a keyword scan
3 Code checkers lint, splint These UNIX code syntax-checking tools can be useful for analysis in some types of dependencies
These tools can ease the task of migration to a significant extent by taking some of the hard work out of code analysis, especially when the code base involved is large. However, each tool has its limitations, and even when using commercial tools that claim to significantly automate the code migration process, it is often necessary to seek the help of professional migration experts.
Some dependencies, for example, do not reveal themselves to simple keyword-based scanning or even code checking, as we saw in the “Platform and hardware architecture related” dependencies section.
In addition, keyword-based code-scanning tools rely on an “information database,” which in its simplest form is a dictionary of keywords that needs to be used during scan. This information is typically drawn from the expertise developed during previous migration cycles, and the following points should be taken into account:
• Any given migration may present unique challenges not posed by previously performed migrations. • A given information database seldom captures 100% of the migration impacts. • Information building is a continuous process, and the information database needs to be expanded
with information gathered from subsequent migration cycles.
There are many more cautionary remarks that could be made here, but these alone make a convincing argument that the services of a team of migration experts are at times indispensable.
22

Debuggers One cannot overestimate the importance of debuggers. Debuggers are as indispensable in a migration project as they are in a development project. Despite all the analysis and code changes, it is likely that a few dependencies will still lurk in the code. These dependencies surface eventually, compelling you to get down to review migrated code at the source level using a debugger. The GNU debugger (GDB) is the classic debugger and is sufficient for most practical purposes.
Before we conclude this section, one thing deserves to be mentioned. The dependencies described above might have bindings to a particular Linux distribution, and there might be subtle differences from one distribution of Linux to other. Already there is an initiative in place to standardize on Linux distributions to ensure mutual compatibility. This effort is called the Linux Standard Base (LSB). If an application migration conforms to LSB standards, then the migrated application is compatible with any distribution of Linux that confirms to LSB. More information on LSB can be found at LSB’s home page www.linuxbase.org/.
Section 2. Optimizations Using the right compiler options can have a substantial effect on the performance of your applications. The effects of compiler options vary from program to program and from compiler to compiler. The degree of optimization achieved is a function of the program in question.
For the study described below, we used results obtained from three different benchmarking programs:
• RANPI is a number-crunching program. It’s floating-point intensive, and it computes pi (π) by probability. The sources were obtained from www.msu.edu/~mrr/mycomp/bench.htm.
• Whetstone is the C variant of an original ALGOL program by H.J. Curnow and B.A. Wichman. The primary aim of this benchmark is to provide a performance measure of both floating-point (FP) and integer arithmetic operations.
• Dhrystone is a short synthetic benchmark program by Reinhold Weicker [email protected], [email protected], intended to measure integers’ performance. It is designed to represent a “typical” application mix of mathematical and other operations.
Comparison of effect of optimizations on target programs All the above benchmark sources were compiled using the GCC version 2.96 compiler and Intel C/C++ Compiler 7.1, IA-32, on an IA-32 server running Linux. Here we should mention that later (and better!) versions of GCC are available; we used 2.96 because it was available as a native compiler on platforms that we worked with and as a cross compiler with the HP NUE IPF Linux simulator environment that we used.
The compiler options used in this study for both Intel and GNU compilers are listed in “Table 6. Intel C/C++ Compiler options” and “Table 7. GCC Compiler options,” respectively. The generated binaries were run on the same Linux server.
The graph in “Figure 4. Results with the GCC compiler” shows normalized results for the three programs compiled with GCC 2.96.
The graph in “Figure 5. Results with Intel compiler” shows normalized results for the same programs compiled with Intel C/C++ Compiler 7.1, IA-32.
The X-axis represents various compiler options, and the Y-axis shows the normalized time used for execution.
23

Figure 4. Results with the GCC compiler
Figure 5. Results with Intel compiler
As the graph indicates, these three programs respond differently to different compiler optimization options. We can, therefore, infer that appropriate compiler options have to be determined based on the nature of the application.
Comparisons between compilers Some compilers appear to score better than others in achieving optimizations.
The three graphs below in Figure 6, Figure 7, and Figure 8 compare results using binaries from the Intel and GCC compilers for these three micro benchmarks at different optimization levels.
24

Figure 6. Comparison of RANPI execution times for binaries using GCC and Intel CC
Figure 7. Comparison of Dhrystone execution times for binaries using GCC and Intel CC
25

Figure 8. Comparison of Whetstone execution times for binaries using GCC and Intel CC
From these results, it seems that our version of the Intel compiler scores higher than GCC at higher optimization levels.
Section 3. Migrating to Linux on the Intel Itanium Processor Family
Key considerations This section discusses some key considerations when migrating to Linux on the Intel Itanium Processor Family.
Migrating to Linux on the Intel Itanium Processor Family is not much different from migrating to Linux on IA-32, and all the considerations discussed above apply. There are, however, a few concerns specific to the Itanium Processor Family. Most important among these are:
• 64-bit readiness • Performance enhancements on the Intel Itanium Processor Family
64-bit readiness The greatest issue here is the word-size change when migrating software from a 32-bit architecture to the Itanium Processor Family’s 64-bit architecture. The impact of 32- to 64-bit migration has already been discussed in the section on “Platform and hardware architecture related” dependencies. If a piece of code has a dependency on word size as illustrated in “Figure 12. Example program 2: Word size dependency,” then it needs to be made word-size neutral or 64-bit ready.
As stated earlier regarding the program in Figure 12, using a proper pointer variable instead of an integer variable to store an address can eliminate the dependency on word size. You can do this by changing the type of “b” to a pointer to int.
Linux on the Intel Itanium Processor Family is little endian, just like Linux on IA-32. This is possible because the Intel Itanium processor is endian neutral, and it supports “big endian” byte ordering as well as “little endian” byte ordering based on the operating system—so the discussion about endianness in the section on “Platform and hardware architecture related” dependencies is applicable
26

as it is written, even if one is migrating software to the Intel Itanium Processor Family from a “big endian” architecture.
The Intel Itanium Processor Family architectural features for improving performance The Itanium Processor Family is based on the EPIC architecture, which comes with a rich set of architectural enhancements for improving performance.
The following is a high-level list of performance enhancing features provided by the Itanium Processor Family:
• Large 64-bit address space—Large memory addressability implies accelerated response time for high-end applications that process large amounts of data.
• Very large set of registers—Supports 128 integer, 128 floating-point, and eight branch registers. This means better performance for code with heavy data manipulation.
• Speculation—Permits the compiler to schedule pre-fetching speculative loads from memory well in advance of the need for the data. This offers better performance for code with heavy branching coupled with memory access. Speculation is further explained in the section titled “A brief look at speculation.” Reference 1 explains this in more specific details, albeit in the context of HP-UX on the Itanium Processor Family.
• Predication—This is the ability to execute both paths of the branch, or “if” statements, in parallel with execution of the branch instruction itself, and to discard the unwanted one after the result is known. More generally, offers the ability to execute multiple paths, in parallel with the branch instruction preceding those paths. These paths themselves may have branch instructions. This results in better performance for code with lots of nested branching based on simple logical conditions). Predication is further explained in the section titled “A brief look at predication.” Reference 1 explains this in more detail, albeit in the context of HP-UX on the Intel Itanium Processor Family.
• Increased instruction parallelism—More instructions per machine cycle results in better application performance. This feature is of particular significance and is made possible by the EPIC (Explicitly Parallel Instruction Computing) architecture of the Intel Itanium Processor Family. Reference 2 is a short paper that deals with this and describes the quest for optimal performance on the Itanium processor via the use of compiler options. This paper looks at the Intel and GNU compilers and their respective options for obtaining peak performance on the Intel Itanium Processor Family. It also stresses the importance of using profiling tools, such as gprof, for identifying bottlenecks and unexpected hot spots.
A brief look at speculation: The two main forms of speculation are control speculation and data speculation.
Control speculation is the execution of a given instruction before the branch condition in the program logic that governs its execution.
Consider the code fragment shown below.
int global_var; extern char *p; int myfunc() { int x,y; /* code … */ if(branch_condition) { x = global_var; y = *p; } }
27

The evaluation of branch_condition governs the execution of two assignment statements. Control speculation is the execution of these two assignments before the result of testing branch_condition is known. There are two types of speculation being made here.
The first assignment, to x, is from a global variable. Since the address of the global variable is known to be valid, this assignment is considered safe. However, the second assignment, to y, is from a pointer. It is not guaranteed that this pointer, p, contained a valid address at the time of assignment, so the assignment is unsafe. The Intel Itanium Processor Family architecture provides support that lets this kind of speculation be handled safely.
Data speculation involves reading data from a particular memory location before all the instructions that might potentially store in that memory location are executed.
Reads from memory are normally slower than the execution times for most other instructions. Execution speeds can be substantially improved if memory reads can be promoted (executed ahead of their position in program sequence). However, it can be risky to do so because if we promoted the read, one of the instructions that precedes the read instruction in the original program sequence might now be executed in parallel with, or later than, the read itself. Because of this, the value read from memory may be invalid. This is possible because the new, valid value (which was supposed to be picked up from memory by the read) was stored in memory only after the read took place.
One form of data speculation is the parallel (simultaneous) execution of a and b, as described below:
a. A sequence of instructions that involves the potential storage (governed by a condition) into a given memory location
b. An instruction that reads from the same memory location
Consider the following example in simplified pseudo machine code:
Instruction cycle Traditional architecture Instruction cycle Data speculation
# Sequence of instructions as programmed
# Instructions that read from memory location and use the value
Sequence of other instructions from original program
1 Instruction1 1 Load from memory location (promoted)
Instruction1
2 Instruction2 2 Use the value Instruction2
3,4… … 3,4… …
N Branch N Branch
N+1 Load from memory location N
N+2 Use the value
The Intel Itanium Processor Family architecture provides support that lets this kind of speculation be handled safely.
Both control and data speculation execution can decrease the overall time for execution because instructions that would have been executed sequentially are now executed in parallel.
A brief look at predication: Predication, or predicated execution, refers to the conditional execution of an instruction based on the setting of a Boolean (true or false) value. The Boolean value is stored in a “predicate register.” The Intel Itanium Processor Family architecture provides 64 predicate registers that can be used to control the execution of nearly all instructions.
28

Consider the following code segment:
if ( a == 0 ) { x = 5; } else { x = *p; }
When executed without predication support, this code needs at least three instruction cycles and two branches. With predication support, both paths can be executed in parallel with the if-statement, and unwanted results are discarded based on results of if-statements (results are stored in the predicate registers). This saves two instructions and at least one execution cycle.
Comparative study of compiler optimizations on the Intel Itanium Processor Family and IA-32 We executed the micro benchmarks that were used on IA-32 and on our Itanium-based server as well. The graphs in Figure 9 and Figure 10 show a plot for Dhrystone and Whetstone programs. They depict variations in execution times with successive optimization levels for Dhrystone and Whetstone, respectively, both on the Itanium Processor Family and IA-32 machines. The execution time is normalized to emphasize the “trend” or variation that successive optimizations give us.
As both figures 9 and 10 show, variations in performance with successive optimization options are more pronounced on the Itanium Processor Family.
Although not shown here, profiler-based optimizations have a very high performance impact on the Itanium Processor Family. Examples are the “prof-gen” and “prof-use” compiler options for the Intel compiler.
We concluded that on the Intel Itanium Processor Family, compiler-based optimizations show a significant performance gain. Hence, it becomes even more important to use the appropriate compiler options for optimal performance.
29
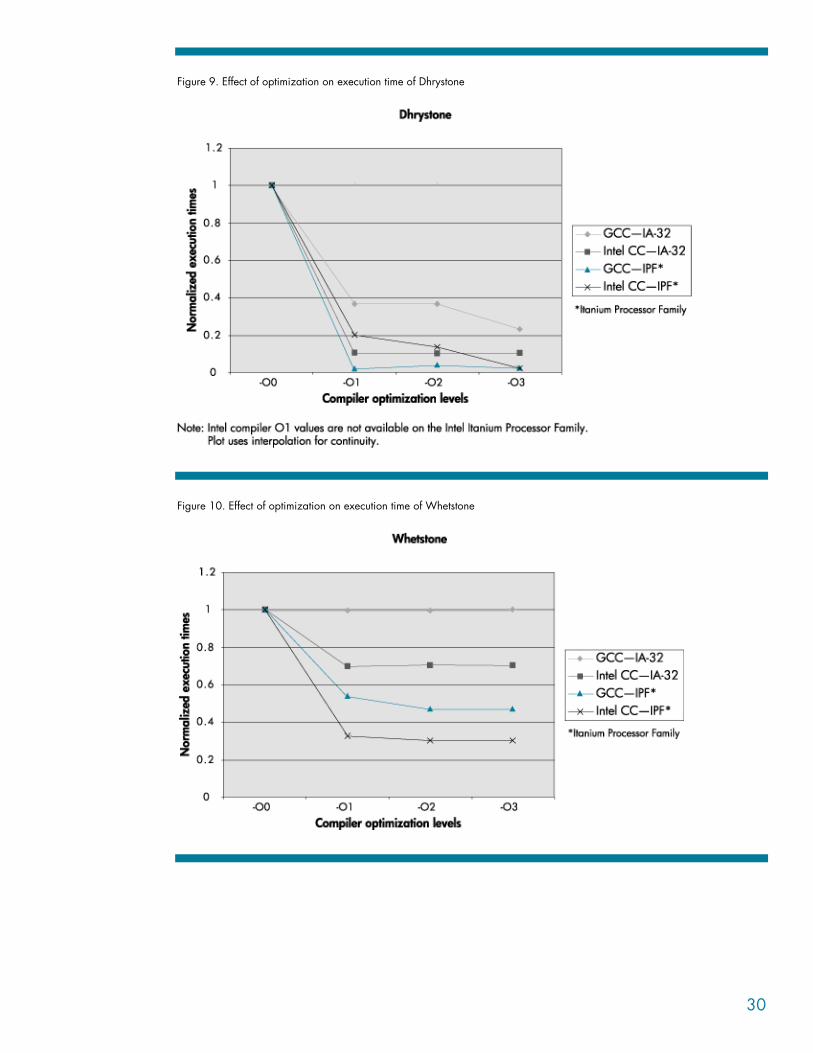
Figure 9. Effect of optimization on execution time of Dhrystone
Figure 10. Effect of optimization on execution time of Whetstone
30

Approaches when migrating to the Intel Itanium Processor Family When migrating to Linux on the Itanium Processor Family, one of the two approaches described below can be followed.
Multi-step approach In this approach, one small and low-risk step towards the target platform is taken at a time. Below are the possible steps. (It may not be necessary to take each step separately—some can be clubbed together.)
• Rebuild the product on the source platform with open source tools available on Linux such as open compilers and open build environments like gnu make, GCC, g++.
• Migrate the product to Linux on IA-32. • Rebuild and test the product for the Intel Itanium Processor Family using the HPNUE IPF Linux
simulator, on IA-32 (see www.software.hp.com/products/LIA64 for further details on the NUE simulator).
• Migrate the product to Linux on the 64-bit Intel Itanium Processor Family.
This approach has the advantage of reducing risk because at any given step, a relatively smaller number of migration impacts needs to be handled. In addition, the migration-related development can be a step ahead of investments to be made in the target hardware and third-party product licenses (i.e., investment in target hardware can be deferred). Or, it can jumpstart development, even if procurement of the target platform has been delayed for some reason.
This approach is also useful if the third-party products and tools needed are currently available on IA-32 and an Intel Itanium Processor Family 64-bit version is expected in the future.
Some disadvantages of this approach are that it consumes more time and resources, which can be expensive and may make it difficult to stay focused on the migration.
This approach is suitable in situations where some or all of following apply:
• Time is not a constraint. • The target hardware is not available immediately. • Some products and tools are not currently available on the Intel Itanium Processor Family platform
but may soon be. • Commitment to migration is not very strong and there is a possibility of future rollback.
Direct migration to the Intel Itanium Processor Family In a direct migration, all the dependencies are resolved in one step as the product is migrated directly from the source platform to the Intel Itanium Processor Family.
Advantages of direct migration:
• Fast and effective • Requires less time and fewer resources
Disadvantages:
• High risk due to technical leap • All dependencies must be fully resolved
This approach is suitable in situations where time constraints are critical and commitment to migration is high—and where all dependencies, including hardware, products, and tools, can be resolved in the near future on the target hardware.
31

Conclusion We opened this paper by looking at a schematic for the entire lifecycle of an enterprise application migration. Although a lot of research needs to be done prior to migrating, it is during the migration phase that the hard work often needs to be accomplished. Although in some cases there are less intensive alternatives, source code modification is frequently the most effective. Above, we have described a process that will allow you to approach systematically the task of identifying and modifying components of a given software application that depend on unique properties of the source platform to function properly.
As we concluded earlier, there are tools to assist in eliminating these dependencies at both the application and source code levels. However, the migration process cannot be fully automated—there will always be some tasks that must be performed manually. Indeed, any one approach is not likely to be suitable for all software migrations, and optimizations (as with the compiler options, for example) will need to be customized for the application and platform in question.
Although there are approaches that allow you to proceed with the migration in a piecemeal way that reduces risk and makes rollback easier if necessary, the fact remains that performing the full migration in one step usually is substantially more efficient and produces better results. This paper has described many of the challenges that need to be addressed when migrating a software package from UNIX to Linux. If you want professional assistance from HP’s team of dedicated migration experts, please contact an HP sales representative in your area.
For more information
Additional papers in this three-part series These papers are expected to be released in the second half of 2003.
• Linux porting and migration, Part 2 of 3—the development environment • Linux porting and migration, Part 3 of 3—migration patterns
References for further reading 1. Thompson, Carol. Developing High-Performance Applications for HP-UX on the Intel Itanium
Processor Family. Hewlett-Packard Company, 2001. 2. Jarp, Sverre. Searching for optimal performance on the Intel Itanium Processor Family/Linux.
HP Labs, 2002.
32

Web site references for further information
URLs Information
http://cedar.intel.com/media/training/slei_site3/tutorial/index.htm Useful online tutorial from Intel for porting Solaris applications to IPF
http://ctdp.tripod.com/os/linux/programming/linux_pgsignals.html A complete description of Linux signals
www.rpm.org/ Information about RPM package manager
www.ucgbook.com/ Listing of commands for all UNIX flavors
www.hp.com/dspp HP developer and solution partner portal. Has a summary of make constructs and lots of other useful information.
www.xfree86.org/ Xfree86 information
www.x.org/ X Window information
www.redhat.com/solutions/partners/software/ List of enterprise software products supported on Red Hat Linux
www.suse.com/us/partner/search_partners/technology_partners/index.html
List of SuSE Linux technology partners
www.winehq.com/ Information on Wine API
www.cs.wustl.edu/~schmidt/ACE.html Adaptive Communication Environment
www.msu.edu/~mrr/mycomp/bench.htm Sources for the RANPI benchmark
www.splint.org/ Information about splint code checker
http://otn.oracle.com/tech/migration/workbench/content.html Details on Oracle migration workbench
http://developer.intel.com/design/itanium/downloads/245370.htm A description of the Intel Itanium processor-specific Application Binary Interface (ABI) can be downloaded from here
www.software.hp.com/products/LIA64 HP’s NUE IPF Linux simulator and other developer tools
http://opensource.hp.com/the_source/linux_papers/scl_solaris.htm Open source Solaris compatible threads library
www.linuxbase.org/spec/ Linux standard base: the specifications for standardization among Linux distributions.
33
Glossary of terms
Term Description
ELF Extended linking format—a format of executable object file supported on the Intel Itanium Processor Family
Endian, endianness The way computers address a specific storage unit—either by the least significant byte (little-endian) or by the most significant byte (big-endian)
HP Hewlett-Packard Company
HPS ISO HP Services, India Software operations—HP’s Indian offshore delivery center for software services
MFLOP 106 floating-point operations, a measure of computing power
NPTL Native POSIX thread library for Linux
NUE Native user environment
POSIX Portable Operating System Interface—a set of standard operating system interfaces based on the UNIX operating system
RHAS Red Hat Advanced Server
34

Appendix 1. Sample programs
Figure 11. Example program 1: Signal handling and threading
/* threadprog.c*/ /* Installs a signal handler for sigusr1 and creates three threads*/ /* Thereafter waits on threads. Threads do nothing */ #include <pthread.h> #include <sched.h> #include <signal.h> void my_handler (int no) { printf("Inside my SIGNAL HANDLER, PID : %d\n", getpid()); return; } void install_handler () { struct sigaction sigusr1; sigusr1.sa_flags = 0; sigusr1.sa_handler = &my_handler; sigemptyset (&sigusr1.sa_mask); sigaction(SIGUSR1,&sigusr1,NULL); } void *threadbare (void *arg) { printf (" my pid=%d my thread id=%d\n",getpid(), *((int*)arg)); while(1); return NULL; } int main (int argc, char *argv[]) { pthread_t thread_id1, thread_id2, thread_id3; int status; install_handler(); pthread_create (&thread_id1, NULL, threadbare, &thread_id1); pthread_create (&thread_id2, NULL, threadbare, &thread_id2); pthread_create (&thread_id3, NULL, threadbare, &thread_id3); pthread_join (thread_id1, NULL); pthread_join (thread_id2, NULL); pthread_join (thread_id3, NULL); return 0; }
35

Figure 12. Example program 2: Word size dependency
Figure 13. Example program 3: Endianness dependency
#include <stdio.h> struct DB_FIELDS{ char studentId; /* Student Registration Number */ char rollno; /* Roll No */ char grade; /* Current Grade */ char credits; /* Total Credits earned */ }DB_FIELDS; /* Union of dissimilar types. A possibility of Endianness impact */ union DB_REC{ int DB_ROW; struct DB_FIELDS _fields; }DB_REC; int main () { union DB_REC _rec; _rec.DB_ROW=0x20300245; int i; printf ("RAW Data = %X\n",_rec.DB_ROW); printf ("Detailed Information\n"); printf ("--------------------\n"); printf ("Registration No : %X\n",_rec._fields.studentId); printf ("Roll No : %X\n",_rec._fields.rollno); printf ("Grade : %X\n",_rec._fields.grade); printf ("Credits : %X\n",_rec._fields.credits); return 0; }
/* Demonstrates word size dependency */ #include <stdio.h> main() { int a,b,c; a=10; b=&a;; /* problem assignment – may work fine on 32-bit */ c=*(int*)b; /* may result in an invalid address on 64-bit! */ printf("This works with ELF 32-bit LSB. I got: %d \n",c); }
36

Figure 14. Endianness dependent code
Figure 15. Example program 4: Change in API calls
/* APIchange.c */ #include <time.h> #include <regex.h> int main (){ char ret0[9]; char *newcursor, *name; #ifdef SOLARIS name = regcmp("[A-Za-z0-9]", (char *)0); newcursor = regex(name, "012Testing345", ret0); printf("Parsed String = %s\n",ret0); #else regex_t preg; int i=0,err; size_t nmatch=5; regmatch_t pmatch[5]; char errbuff[20]; err = regcomp(&preg,"[A-Za-z0-9]",REG_EXTENDED); regerror (err,&preg,errbuff,sizeof(errbuff)); printf("Error: %s\n",errbuff); err = regexec(&preg,"012Testing345",nmatch,pmatch,0); regerror (err,&preg,errbuff,sizeof(errbuff)); printf("Error: %s\n",errbuff); #endif return 0; }
struct DB_FIELDS{ #ifdef LITTLE_ENDIAN /* Reverse the order of fields */ char credits; /* Total Credits earned */ char grade; /* Current Grade */ char rollno; /* Roll No */ char studentId; /* Student Registration Number */ #endif #ifdef BIG_ENDIAN /* Original order of fields*/ char studentId; /* Student Registration Number */ char rollno; /* Roll No */ char grade; /* Current Grade */ char credits; /* Total Credits earned */ #endif }DB_FIELDS;
37
Appendix 2. Descriptive listing of compiler options This section provides a description and listing of compiler options that were used for the optimization study in this paper.
Table 6. Intel C/C++ Compiler options
Compiler switch Description
-O0 Default setting, performs no optimization
-O2 Optimizes for speed, disables inline expansion of library functions
-O3 Builds on -O1 & -O2, performs loop transformations and data pre-fetching
-ip Enables inter-procedural optimizations for single file compilation
-prof_gen Instructs the compiler to produce instrumented code in your object files in preparation for instrumented execution
-prof_use Instructs the compiler to produce a profile-optimized executable and merges available dynamic information (.dyn) files into a pgopti.dpi file. If you perform multiple executions of the instrumented program, -prof_use merges the dynamic information files again and overwrites the previous pgopti.dpi file.
-parallel Enables the auto-parallelizer to generate multithreaded code for loops that can be safely executed in parallel
-tpp6 Optimizes code for Intel Pentium® Pro, Intel Pentium II, and Intel Pentium III processors
38
Table 7. GCC Compiler options
Compiler switch Description
-O0 Default setting, performs no optimization
-O1, -O The compiler tries to reduce code size and execution time without performing any optimizations that take a great deal of compilation time.
-O turns on the following optimization flags:
-fdefer-pop -fmerge-constants -fthread-jumps -floop-optimize -fcrossjumping -fif-conversion -fif-conversion2 -fdelayed-branch -fguess-branch-probability -fcprop-registers
-O also turns on -fomit-frame-pointer on machines where doing so does not interfere with debugging.
-O2 GCC performs nearly all supported optimizations that do not involve a space-speed tradeoff. The compiler does not perform loop unrolling or function inlining when you specify -O2. As compared to -O, this option increases both compilation time and the performance of the generated code.
-O2 turns on all optimization flags specified by -O. It also turns on the following optimization flags:
-fforce-mem -foptimize-sibling-calls -fstrength-reduce -fcse-follow-jumps -fcse-skip-blocks -frerun-cse-after-loop -frerun-loop-opt -fgcse -fgcse-lm -fgcse-sm -fdelete-null-pointer-checks -fexpensive-optimizations -fregmove -fschedule-insns -fschedule-insns2 -fsched-interblock -fsched-spec -fcaller-saves -fpeephole2 -freorder-blocks -freorder-functions -fstrict-aliasing -falign-functions -falign-jumps -falign-loops -falign-labels
-O3 -O3 turns on all optimizations specified by -O2 and also turns on the -finline-functions and -frename-registers options.
-fexpensive-optimizations Perform a number of minor optimizations that are relatively expensive. Enabled at levels -O2, -O3, -Os.
-ffast-math This option causes the preprocessor macro __FAST_MATH__ to be defined. This option should never be turned on by any -O option since it can result in incorrect output for programs which depend on an exact implementation of IEEE or ISO rules/specifications for math functions.
-funroll-all-loops Unroll loops whose number of iterations can be determined at compile time or upon entry to the loop. This option makes code larger, and it may or may not make it run faster.
39

© 2003 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. The only warranties for HP products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. HP shall not be liable for technical or editorial errors or omissions contained herein.
Intel, Itanium, and the Intel Itanium Processor Family are trademarks or registered trademarks of Intel Corporation in the United States and other countries and are used under license. Pentium is a U.S. registered trademark of Intel Corporation. Oracle is a registered U.S. trademark of Oracle Corporation, Redwood City, California. UNIX is a registered trademark of The Open Group. Windows is a U.S. registered trademark of Microsoft Corporation.
5982-1046EN, 08/2003
![Linux 2.4 Implementation of Westwood+ TCP with rate-halving ...in the Internet [14]. To test and compare the Linux 2.4.19 implementations of Westwood+ and New Reno TCP more than 4000](https://static.fdocuments.us/doc/165x107/603f267fae920e61530e50f4/linux-24-implementation-of-westwood-tcp-with-rate-halving-in-the-internet.jpg)

















