
Libra: Tailoring SIMD Execution using Heterogeneous Hardware and Dynamic Configurability
23
University of Michigan Electrical Engineering and Computer Science 1 Libra:Tailoring SIMD Execution using Heterogeneous Hardware and Dynamic Configurability Yongjun Park 1 , Jason Jong Kyu Park 1 , Hyunchul Park 2 , and Scott Mahlke 1 December 3, 2012 1 University of Michigan, Ann Arbor 2 Programming Systems Lab, Intel Labs, Santa Clara, CA
description
Libra: Tailoring SIMD Execution using Heterogeneous Hardware and Dynamic Configurability. Yongjun Park 1 , Jason Jong Kyu Park 1 , Hyunchul Park 2 , and Scott Mahlke 1. December 3, 2012 1 University of Michigan, Ann Arbor 2 Programming Systems Lab, Intel Labs, Santa Clara, CA. - PowerPoint PPT Presentation
Transcript of Libra: Tailoring SIMD Execution using Heterogeneous Hardware and Dynamic Configurability

University of MichiganElectrical Engineering and Computer Science1
Libra:Tailoring SIMD Execution using Heterogeneous Hardware and Dynamic Configurability
Yongjun Park1, Jason Jong Kyu Park1 , Hyunchul Park2, and Scott Mahlke1
December 3, 2012
1University of Michigan, Ann Arbor2Programming Systems Lab, Intel Labs, Santa Clara, CA
University of MichiganElectrical Engineering and Computer Science
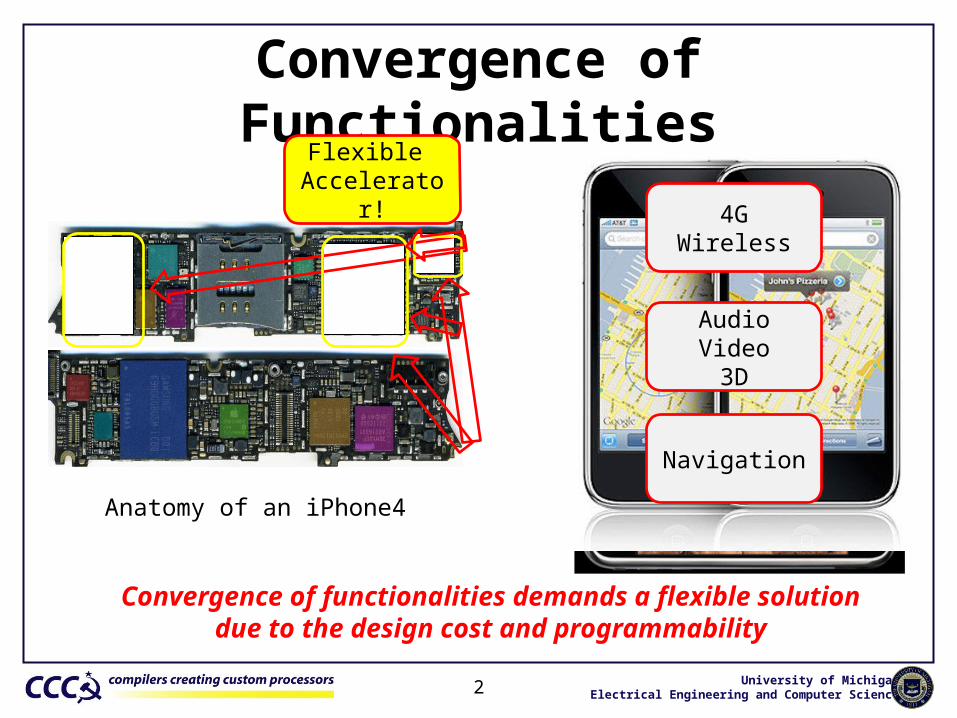
Convergence of Functionalities
2
Convergence of functionalities demands a flexible solution due to the design cost and programmability
Anatomy of an iPhone4
4G Wireless
Navigation
AudioVideo
3D
Flexible Accelerator!
University of MichiganElectrical Engineering and Computer Science
Mixture of ILP/DLP
legacy workloads media processing
web browsing
scientific computingwireless communication
Image processing
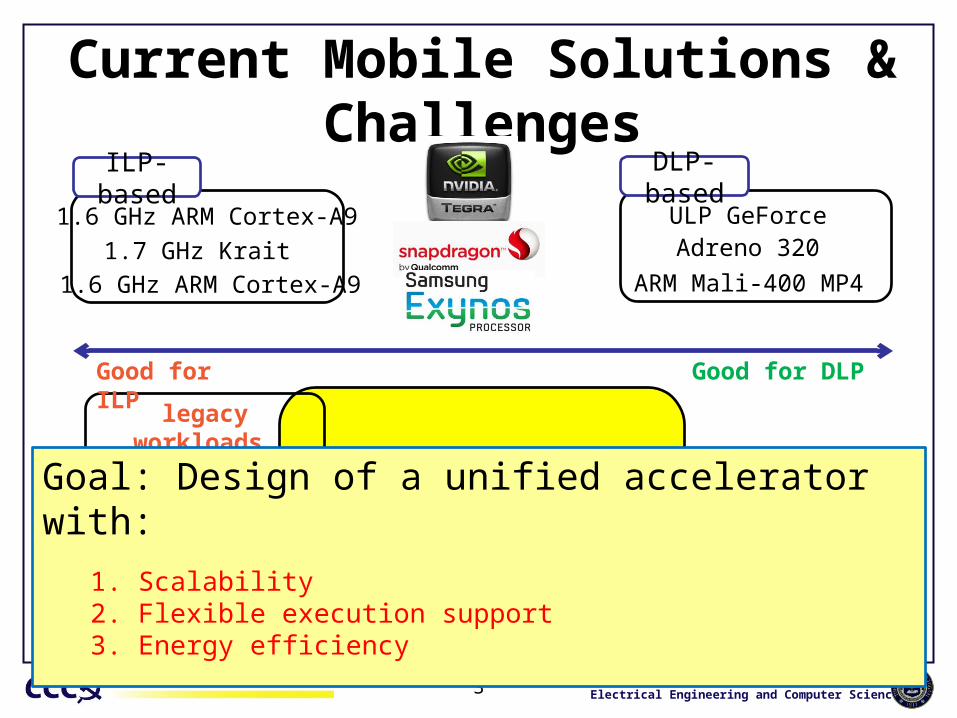
Current Mobile Solutions & Challenges
3
Good for ILP Good for DLP
1.6 GHz ARM Cortex-A9 ULP GeForce1.7 GHz Krait Adreno 320
1.6 GHz ARM Cortex-A9 ARM Mali-400 MP4
ILP-based DLP-based
Goal: Design of a unified accelerator with:1. Scalability2. Flexible execution support3. Energy efficiency
University of MichiganElectrical Engineering and Computer Science
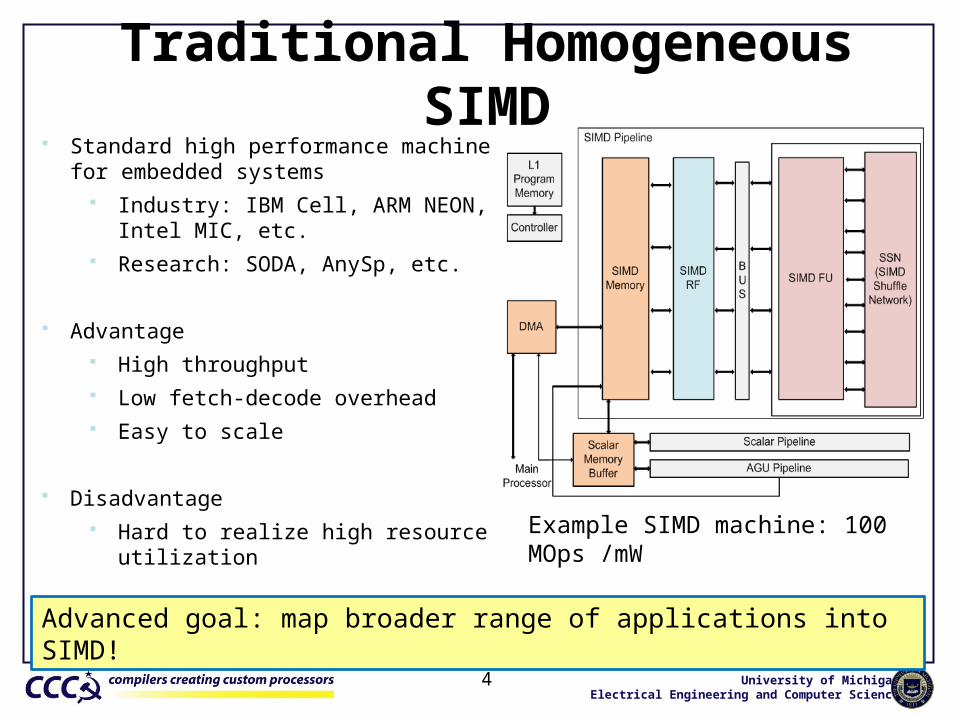
Traditional Homogeneous SIMD
4
Standard high performance machine for embedded systems
Industry: IBM Cell, ARM NEON, Intel MIC, etc. Research: SODA, AnySp, etc.
Advantage High throughput Low fetch-decode overhead Easy to scale
Disadvantage Hard to realize high resource utilization
Example SIMD machine: 100 MOps /mW
Advanced goal: map broader range of applications into SIMD!
University of MichiganElectrical Engineering and Computer Science
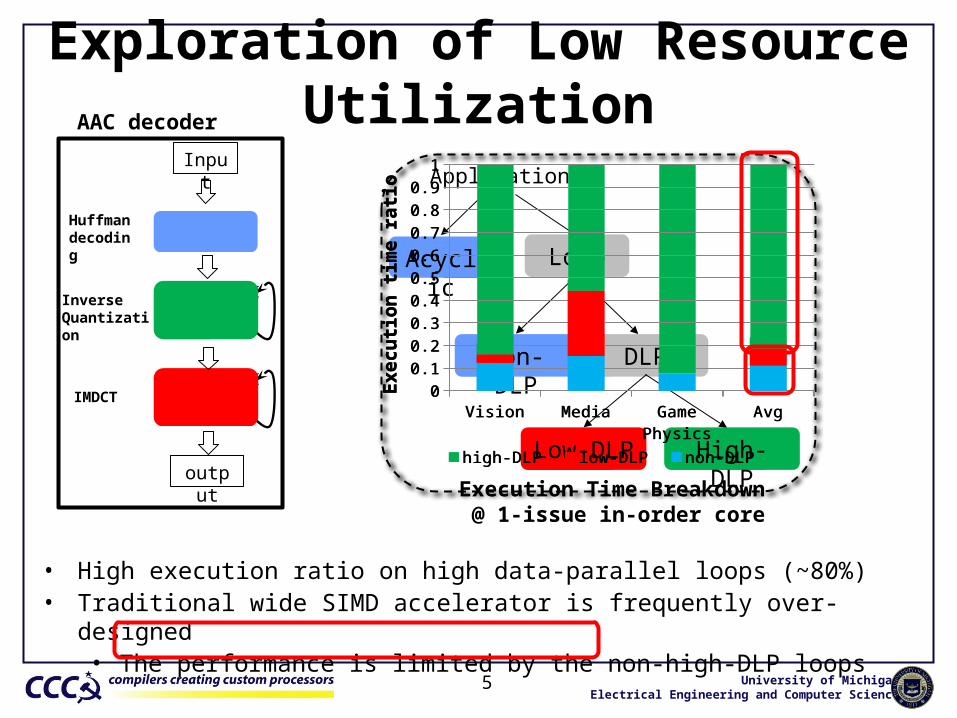
Exploration of Low Resource Utilization
5
AAC decoder
• High execution ratio on high data-parallel loops (~80%)• Traditional wide SIMD accelerator is frequently over-designed
• The performance is limited by the non-high-DLP loops
Input
for ( …… ) {
}
output
for ( …… ) {
}
Huffman decoding
InverseQuantization
IMDCT
Application
Acyclic Loop
Non-DLP DLP
Low-DLP High-DLP
Vision Media Game Physics
Avg0
0.10.20.30.40.50.60.70.80.9
1
high-DLP low-DLP non-DLP
Exec
utio
n tim
e ra
tioVision Media Game
PhysicsAvg
00.10.20.30.40.50.60.70.80.9
1
high-DLP low-DLP non-DLP
Exec
utio
n tim
e ra
tio
Execution Time Breakdown @ 1-issue in-order core
University of MichiganElectrical Engineering and Computer Science
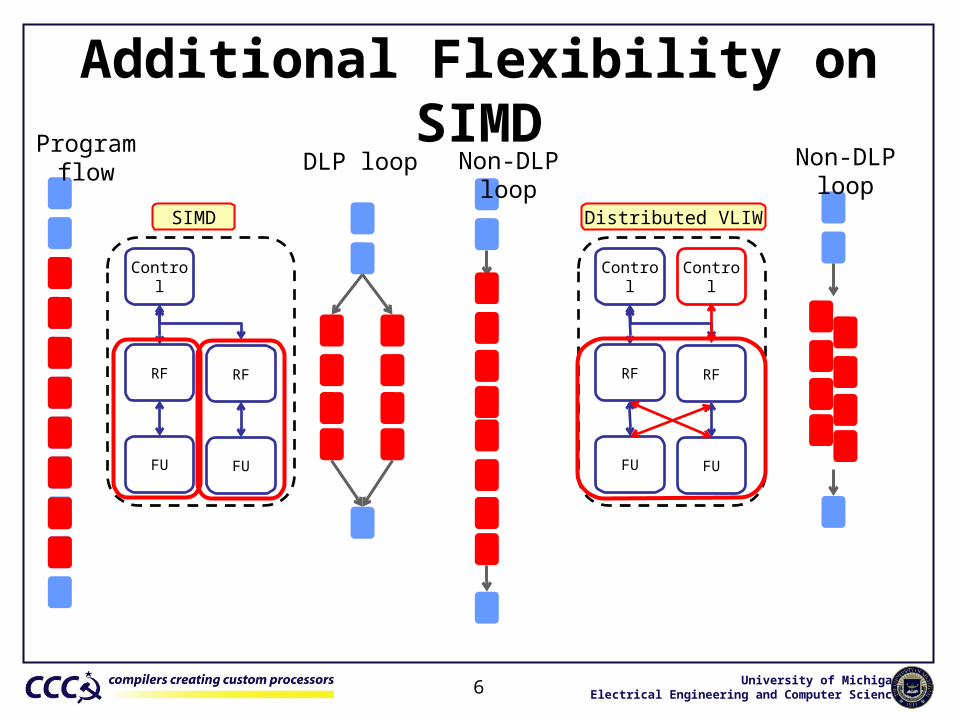
Additional Flexibility on SIMD
6
SIMD
Control
RF RF
FU FU
Distributed VLIW
Control
RF RF
FU FU
Control
DLP loop Non-DLP loopProgram flow Non-DLP loop
University of MichiganElectrical Engineering and Computer Science
89101112
131415
1234
567
0
Libra
89
101112
131415
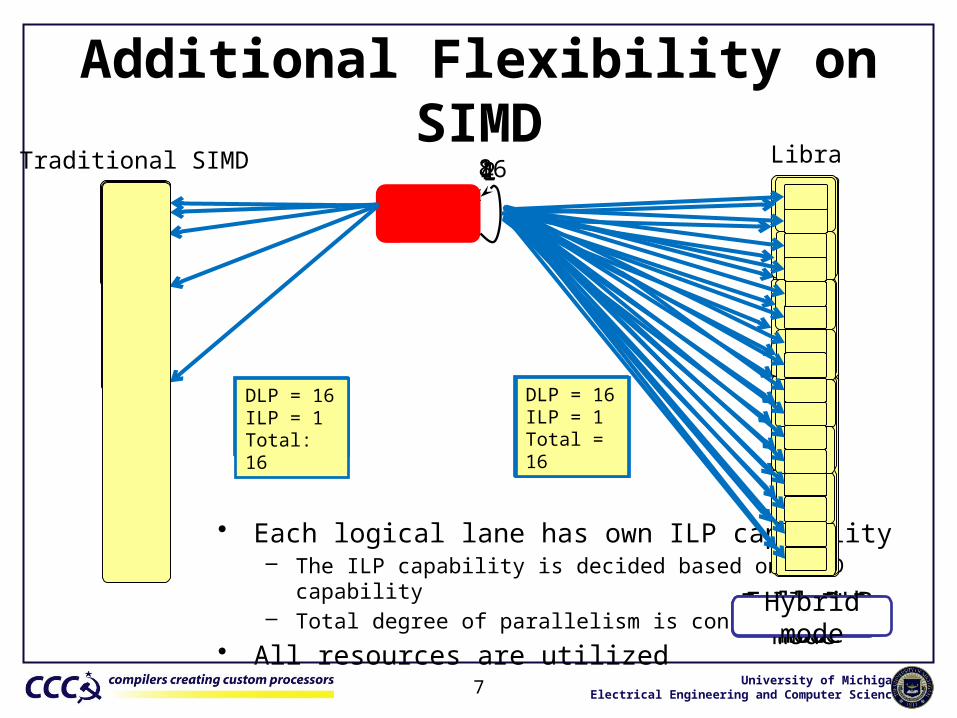
Additional Flexibility on SIMD
• Each logical lane has own ILP capability– The ILP capability is decided based on SIMD capability – Total degree of parallelism is consistent
• All resources are utilized
7
for ( …… ) {
}1234
567
0
Traditional SIMD 1248
DLP = 1ILP = 1Total: 1
DLP = 1ILP = 16Total = 16
16
DLP = 2ILP = 1Total: 2
DLP = 2ILP = 8Total = 16
DLP = 4ILP = 1Total: 4
DLP = 4ILP = 4Total = 16
DLP = 8ILP = 1Total: 8
DLP = 8ILP = 2Total = 16
DLP = 16ILP = 1Total: 16
DLP = 16ILP = 1Total = 16
Full DLP modeFull ILP modeHybrid mode

University of MichiganElectrical Engineering and Computer Science
Looks Good, but Too Expensive!
8
Control
RF RF
FU FU
Control Control
RF RF
FU FU
Control Control
RF RF
FU FU
Control Control
RF RF
FU FU
Control

University of MichiganElectrical Engineering and Computer Science
Opportunity: Resource Utilization
• Resource over-provision: Lane uniformity incurs inefficiency– Each SIMD lane provides the same functionalities– Only 32% (memory) and 16% (multiplication) of total dynamic instructions– More complex design, more static power consumption
• High variation in the resource requirements of loops– Simple sharing leads to performance degradation
9
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.2
0.4
0.6
0.8
1
Memory ratio
Mul
tiply
Rat
io
Loop distribution over static ratio of multiply and memory instructions
for ( …… ) {
}
Small fraction of mul/mem instructions
University of MichiganElectrical Engineering and Computer Science
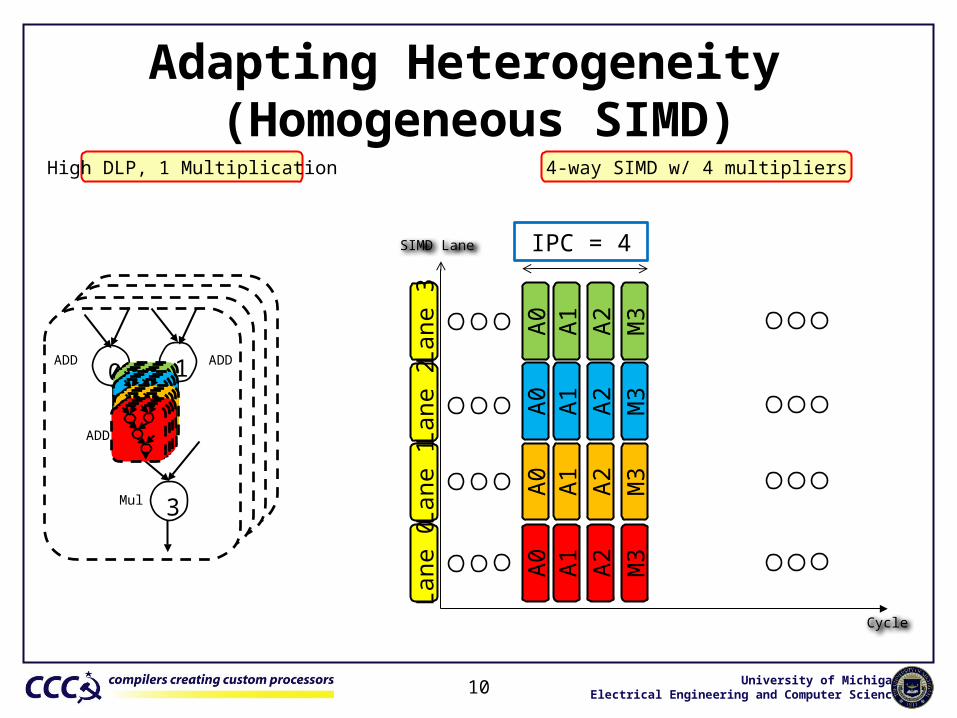
Adapting Heterogeneity (Homogeneous SIMD)
10
High DLP, 1 Multiplication
SIMD Lane
Cycle
0 1
3
2
ADD ADD
ADD
Mul
4-way SIMD w/ 4 multipliers
Lane
0La
ne 1
Lane
2La
ne 3
A0
A0
A0
A0
A1
A1
A1
A1
A2
A2
A2
A2
M3
M3
M3
M3
IPC = 4
University of MichiganElectrical Engineering and Computer Science
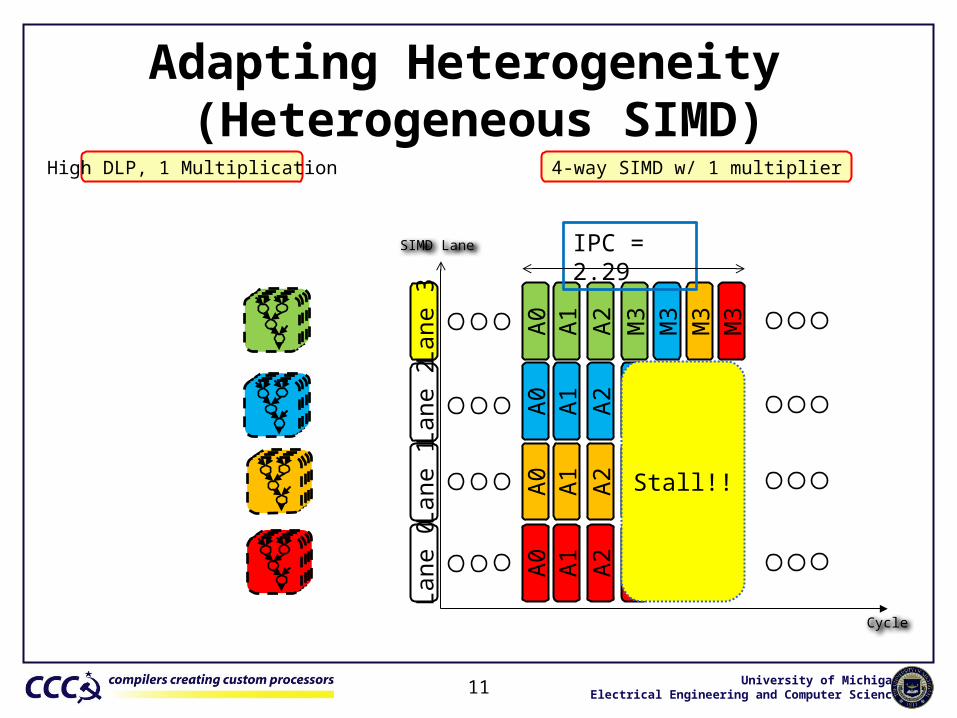
Adapting Heterogeneity (Heterogeneous SIMD)
11
High DLP, 1 Multiplication
SIMD Lane
Cycle
4-way SIMD w/ 1 multiplier
Lane
0La
ne 1
Lane
2La
ne 3
A0
A0
A0
A0
A1
A1
A1
A1
A2
A2
A2
A2
M3
M3
M3
M3
M3
M3
M3
IPC = 2.29
Stall!!
University of MichiganElectrical Engineering and Computer Science
Logi
cal l
ane
0
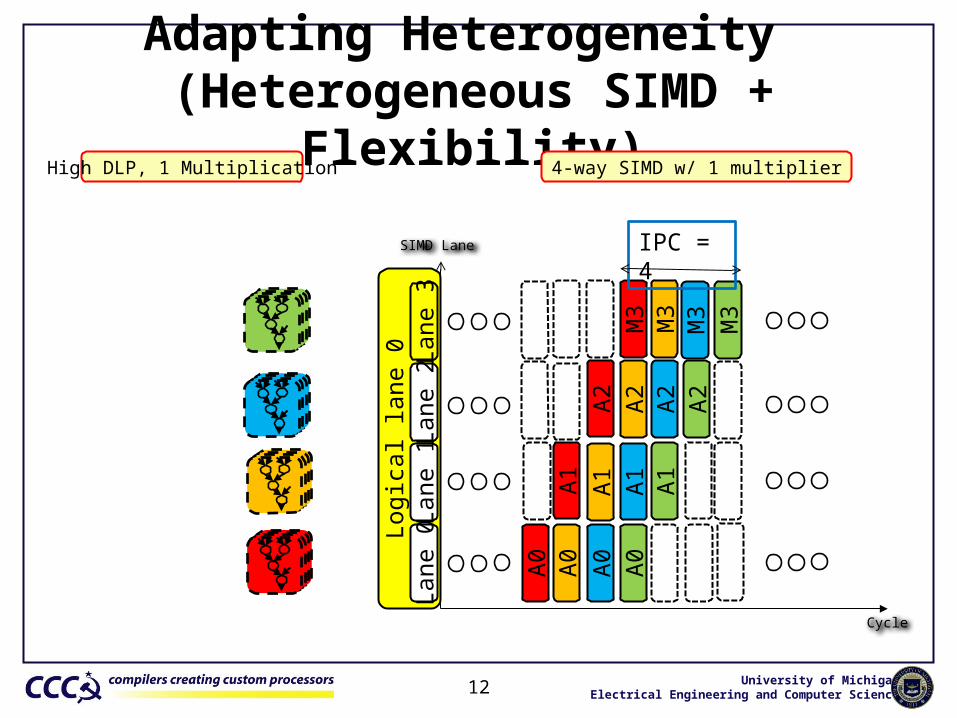
Adapting Heterogeneity (Heterogeneous SIMD + Flexibility)
12
High DLP, 1 Multiplication
SIMD Lane
Cycle
4-way SIMD w/ 1 multiplier
Lane
0La
ne 1
Lane
2La
ne 3
A0
A0
A1
A0
A1
A2
A0
A1
A2
M3
A1
A2
M3
A2
M3
M3
IPC = 4
University of MichiganElectrical Engineering and Computer Science
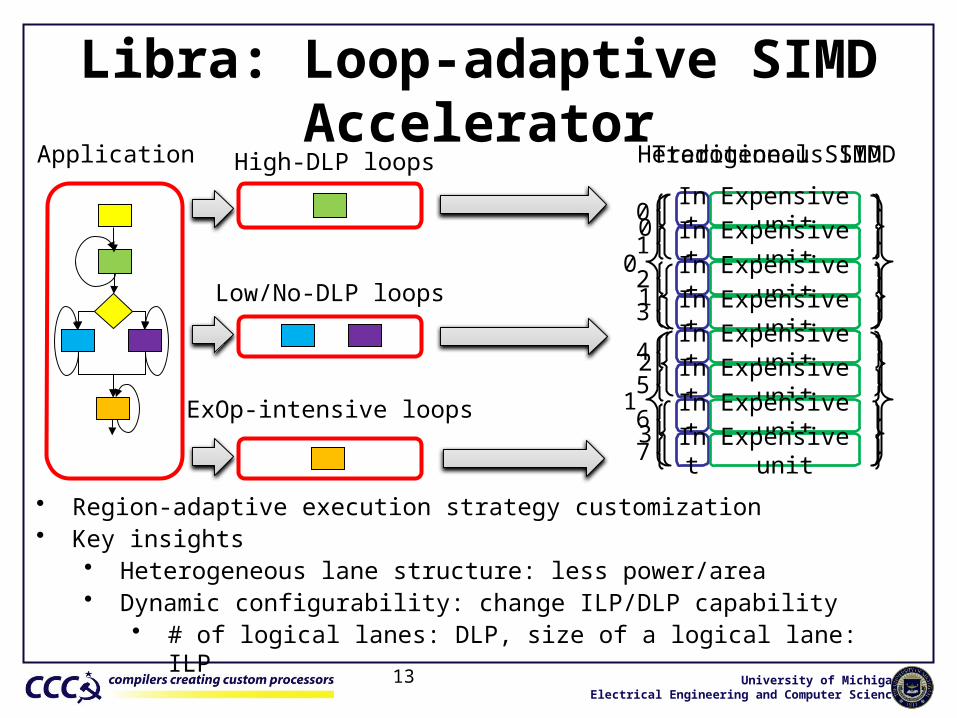
• Region-adaptive execution strategy customization• Key insights
• Heterogeneous lane structure: less power/area• Dynamic configurability: change ILP/DLP capability
• # of logical lanes: DLP, size of a logical lane: ILP
Libra: Loop-adaptive SIMD Accelerator
13
High-DLP loops
Low/No-DLP loops
Application
ExOp-intensive loops
Int Expensive unitInt Expensive unitInt Expensive unitInt Expensive unitInt Expensive unitInt Expensive unitInt Expensive unitInt Expensive unit
Traditional SIMDHeterogeneous SIMD
0123
4567
0
1
2
3
0
1
University of MichiganElectrical Engineering and Computer Science
Loop Configuration buffer
RF0 FU0 Int
RF1 FU1Int+Mem
RF2 FU2Int+Mul
RF3 FU3Int
4x8 Crossbar
(4(n-1))
(4(n+1))
(4(n-1)+1)
(4(n+1)+1)
(4(n-1)+2)
(4(n+1)+2)
(4(n-1)+3)
(4(n+1)+3)
PE Group 9
PE
Intra-group Interconnect
Inter-group Interconnect
Out
Out
Out
Out
SIMD controller
Thread controller
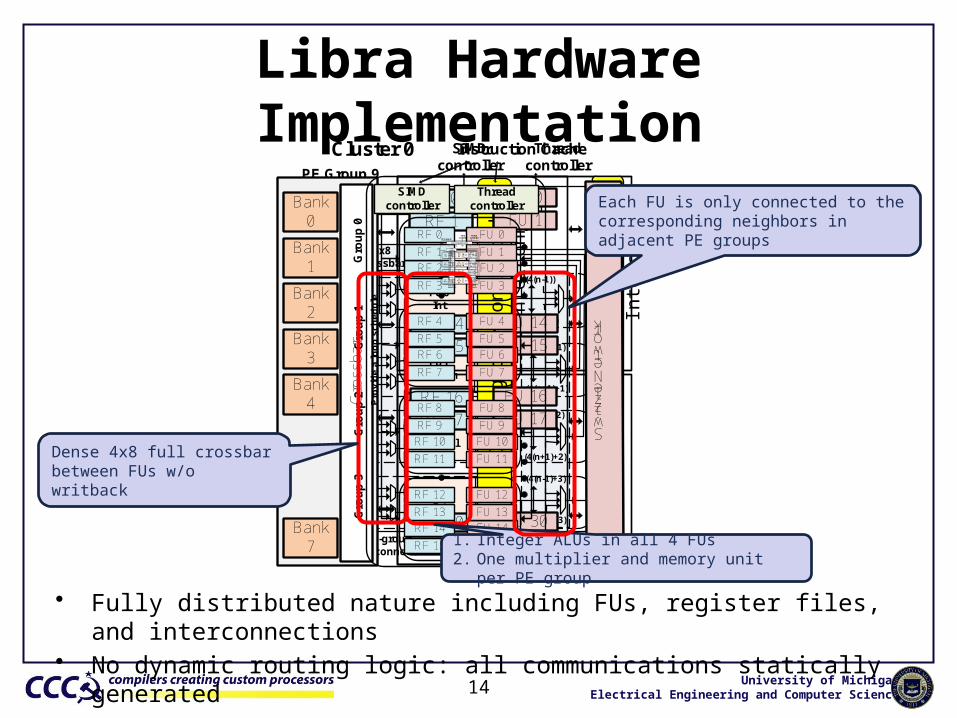
Libra Hardware Implementation
• Fully distributed nature including FUs, register files, and interconnections• No dynamic routing logic: all communications statically generated
14
Intra
-gro
up C
onfig
urab
le In
terc
onne
ct
Inte
r-gr
oup
Con
figur
able
Inte
rcon
nect
Bank7
Bank0
Bank1
Bank2
Bank3
Bank4 C
ross
bar
RF 0
RF 15RF 14
RF 1
RF 16
RF 31RF 30
RF 17
FU 0
FU 15FU 14
FU 1
FU 16
FU 31FU 30
FU 17 Swizzle Network
Cluster 0
SIMD controller
Thread controller
RF 2 FU 2RF 3 FU 3
RF 0 FU 0RF 1 FU 1
RF 6 FU 6RF 7 FU 7
RF 4 FU 4RF 5 FU 5
RF 10 FU 10RF 11 FU 11
RF 8 FU 8RF 9 FU 9
RF 14 FU 14RF 15 FU 15
RF 12 FU 12RF 13 FU 13
Gro
up 0
Gro
up 1
Gro
up 2
Gro
up 3
Prov
ide
a lo
op s
ched
ule
Instruction Cache
Loop Configuration buffer
RF(4n)
FU(4n) Int
RF(4n+1)
FU(4n+1)
Int+Mem
RF(4n+2)
FU(4n+2)
Int+Mul
RF(4n+3)
FU(4n+3)
Int
4x8 Crossbar
(4(n-1))
(4(n+1))
(4(n-1)+1)
(4(n+1)+1)
(4(n-1)+2)
(4(n+1)+2)
(4(n-1)+3)
(4(n+1)+3)
PE Group N
PE (4n)
Intra-group Interconnect
Inter-group Interconnect
Out
Out
Out
Out
SIMD controller
Thread controller
1. Integer ALUs in all 4 FUs2. One multiplier and memory unit per PE group
Dense 4x8 full crossbar between FUs w/o writback
Each FU is only connected to the corresponding neighbors in adjacent PE groups
University of MichiganElectrical Engineering and Computer Science
Logical Lane 0cycle
123456789
10
PE0 PE1 PE2 PE3Logical Lane 1
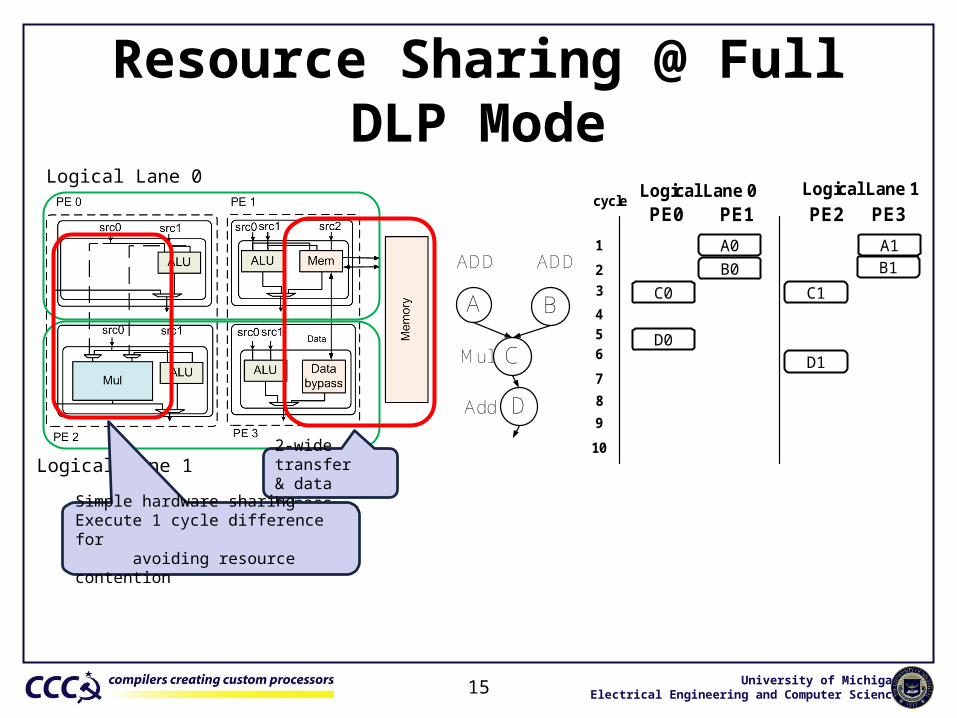
Resource Sharing @ Full DLP Mode
15
Logical Lane 0
Logical Lane 1 2-wide transfer& data bypass
A0B0
C0
D0
A1B1
C1
D1
Simple hardware sharing Execute 1 cycle difference for avoiding resource contention
A B
C
D
ADD ADD
Mul
Add
University of MichiganElectrical Engineering and Computer Science
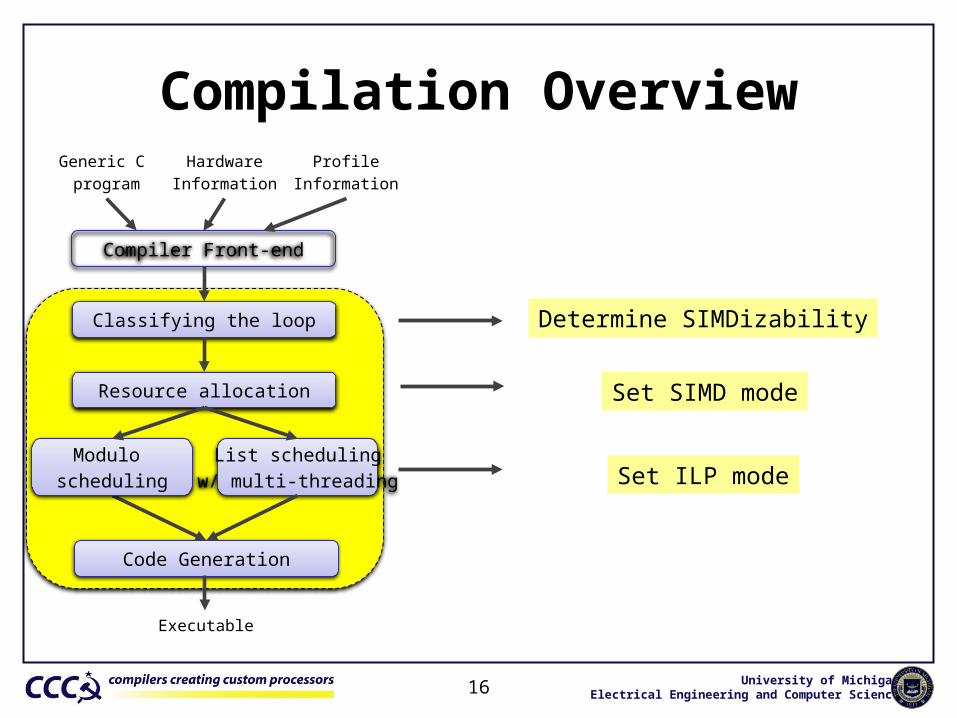
Compilation Overview
16
Compiler Front-end
Classifying the loop
Resource allocation
Code Generation
Generic C program
HardwareInformation
Determine SIMDizability
Set SIMD mode
Set ILP mode
ProfileInformation
Modulo scheduling
List schedulingw/ multi-threading
Executable

University of MichiganElectrical Engineering and Computer Science
Experimental Setup• Target applications
– Vision applications: SD-VBS [Venkata, IISWC '09]– Media benchmark: AAC decoder, H.264 decoder, and 3D rendering– Game physics benchmarks: line of sight, convolution, and conjugate
• Target architecture: SIMD, clustered VLIW, and Libra– 16 ~ 64 heterogeneous/homogeneous resources
• IMPACT frontend compiler + cycle-accurate simulator
• Power measurement– IBM SOI 45nm technology @ 500MHz/0.81V
17
University of MichiganElectrical Engineering and Computer Science
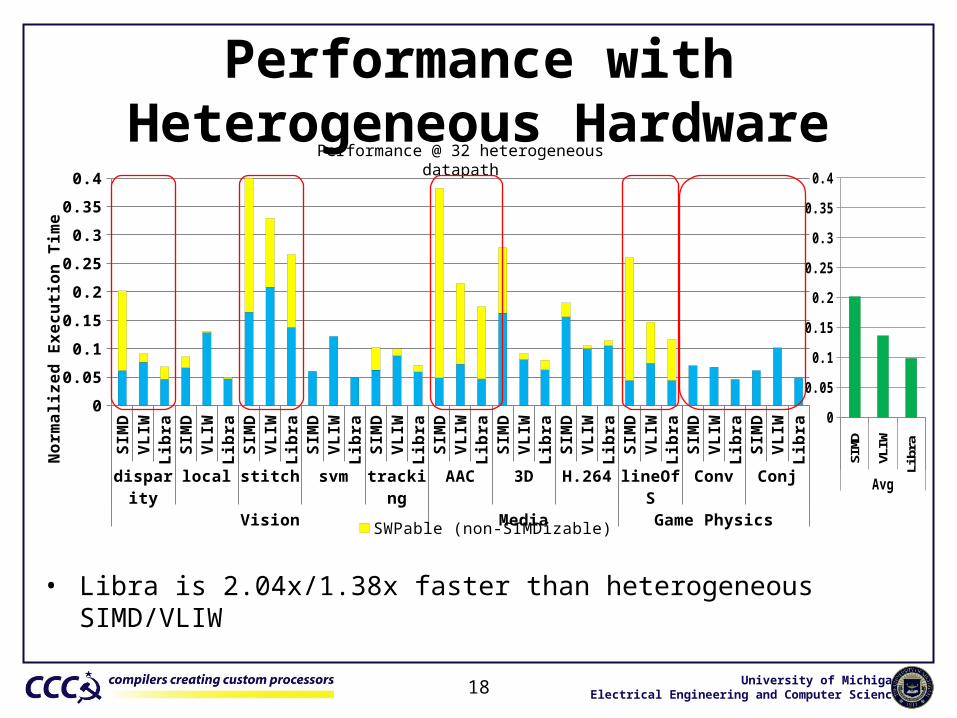
Performance with Heterogeneous Hardware
18
Performance @ 32 heterogeneous datapath
• Libra is 2.04x/1.38x faster than heterogeneous SIMD/VLIW
SIM
DVL
IWLi
bra
SIM
DVL
IWLi
bra
SIM
DVL
IWLi
bra
SIM
DVL
IWLi
bra
SIM
DVL
IWLi
bra
SIM
DVL
IWLi
bra
SIM
DVL
IWLi
bra
SIM
DVL
IWLi
bra
SIM
DVL
IWLi
bra
SIM
DVL
IWLi
bra
SIM
DVL
IWLi
bra
dispar-ity
local stitch svm track-ing
AAC 3D H.264 lineOfS Conv Conj
Vision Media Game Physics
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
SWPable (non-SIMDizable) SIMDizable
Nor
mal
ized
Exe
cutio
n Ti
me
SIM
D
VLIW
Libr
a
Avg
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4

University of MichiganElectrical Engineering and Computer Science
Scalability with Heterogeneous Hardware
19
16 32 64 16 32 64 16 32 64 16 32 64Vision Media Game Average
0
5
10
15
20
25
30
SIMD VLIW Libra
Nor
mal
ized
Perf
orm
ance
• Libra is scalable when having enough total ILP/DLP parallelism
University of MichiganElectrical Engineering and Computer Science
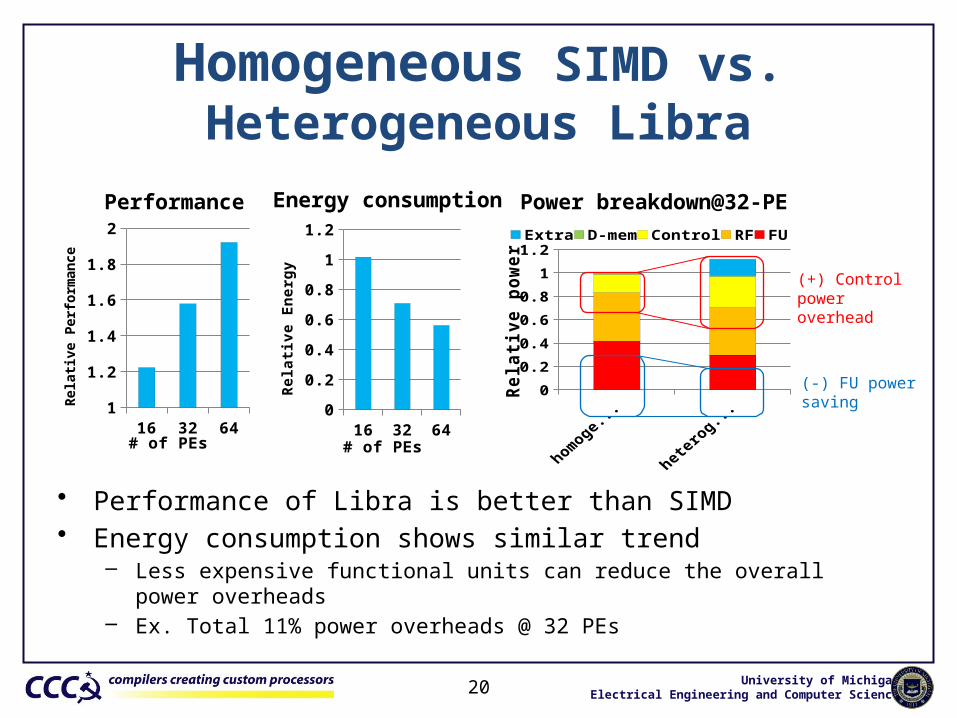
Homogeneous SIMD vs. Heterogeneous Libra
• Performance of Libra is better than SIMD• Energy consumption shows similar trend
– Less expensive functional units can reduce the overall power overheads– Ex. Total 11% power overheads @ 32 PEs
20
16 32 641
1.2
1.4
1.6
1.8
2
# of PEs
Rel
ativ
e Pe
rfor
man
ce
16 32 640
0.2
0.4
0.6
0.8
1
1.2
# of PEs
Rel
ativ
e En
ergy
00.20.40.60.8
11.2Extra D-mem Control RF FU
Rel
ativ
e po
wer
(-) FU power saving
(+) Control power overhead
Power breakdown@32-PE Performance Energy consumption

University of MichiganElectrical Engineering and Computer Science
Mode Selection
• All available modes are used for considerable fraction• The mode is selected based on application characteristics
21
Distribution of loop execution modes
16 32 64 16 32 64 16 32 64 16 32 64Vision Media Game Physics Avg
0%
20%
40%
60%
80%
100%
643216842Ex
ecuti
on ti
me
ratio
Logical lane size

University of MichiganElectrical Engineering and Computer Science
Conclusion
• Mobile applications consist of loops with wide range of different level of ILP and DLP.
• Heterogeneous SIMD lane structure can reduce the power overhead of over-provided resources.
• Dynamic configurability enables broader applicability.
• Libra outperforms traditional SIMD by 1.58x performance improvement with 29% less energy consumption on 32-PE architectures.
22

University of MichiganElectrical Engineering and Computer Science23
Questions?
For more informationhttp://cccp.eecs.umich.edu


















