
Learning to Optimize
23
Learning to Optimize - Pramit Choudhary
-
Upload
pramit-choudhary -
Category
Data & Analytics
-
view
35 -
download
0
Transcript of Learning to Optimize

Learning to Optimize - Pramit Choudhary

Introduction
• What is a Machine Learning Model ? • What is Hyper-parameter Optimization ? • HPO pipeline • Questions

Machine Learning Model
• A mathematical function representing the relationship between aspects of the data
• Simplest Model: Linear Regression Model –WtX=Y, where
• X: Vector representing features of the data • Y: Scalar variable representing the target • W: weight vector , that specifies the slope of the equation.
This is a model parameter learned during Model Training.
• Loss Function: Capture the quality of the model based on prediction and ground truth
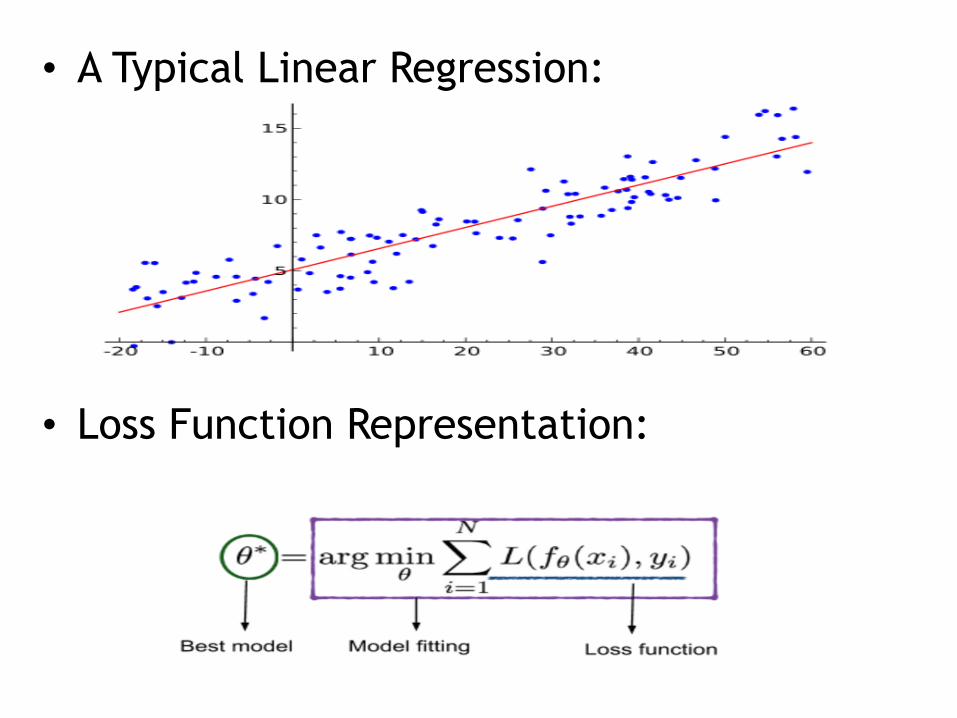
• A Typical Linear Regression:
• Loss Function Representation:
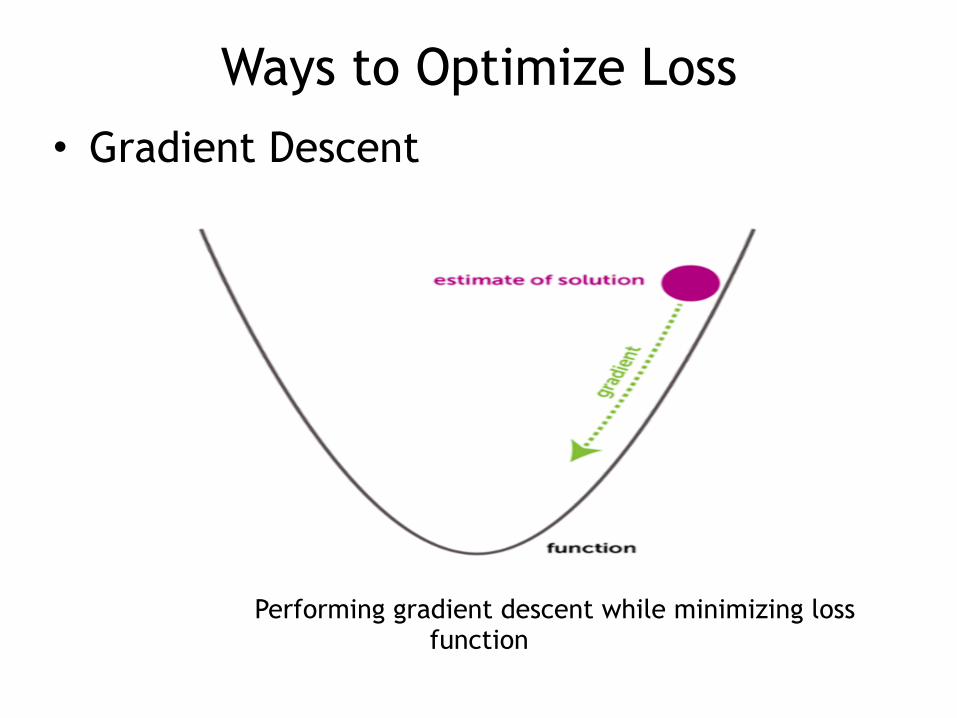
Ways to Optimize Loss• Gradient Descent
Performing gradient descent while minimizing loss function
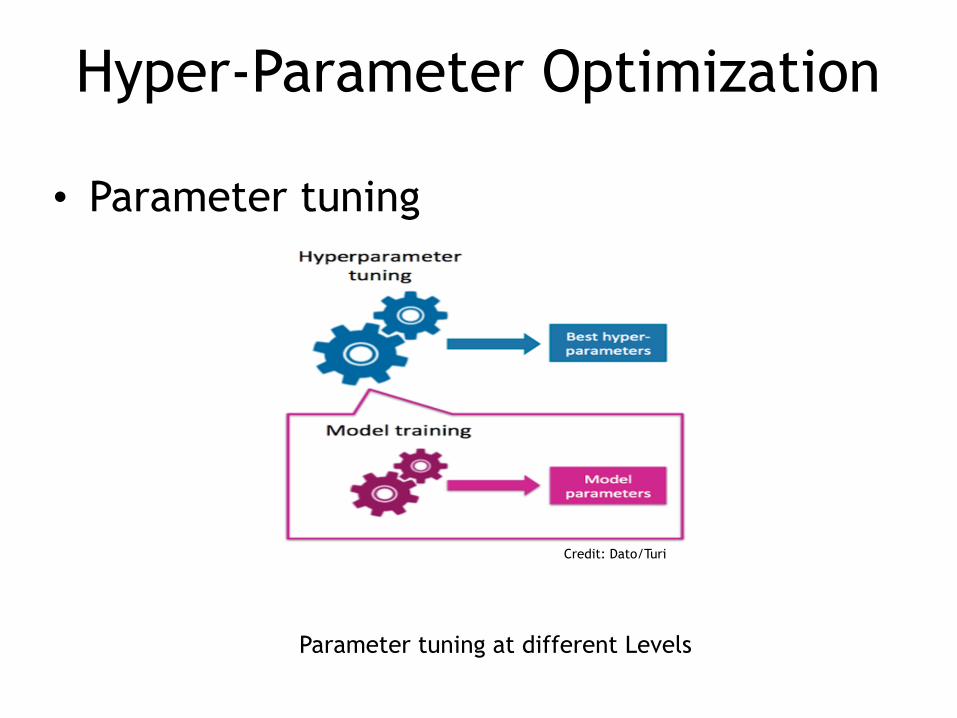
Hyper-Parameter Optimization
• Parameter tuning
Parameter tuning at different Levels
Credit: Dato/Turi

• What is hyper-parameter ? – Also known as nuisance parameters. – Are values specified outside of the training process
E.g. • Linear Regression
– Ridge Regression/LASSO: Weight for regularized term • Logistic Regression
– Regularization parameters • Decision Tree
– Desired Depth, split criteria • SVM
– Penalty factor – Kernel parameters, e.g. width for Radial Basic Function, degree for
polynomial function • Optimizing Loss for Linear learners
– Learning rate, Decay Rate

Why is it important ?
• Determines how rigid the derived model is(how feature dependent the model is).
• Proper tuning helps in reducing over- fitting( generalizing the model)
• Helps in improving the accuracy of the trained model.

Why is it a difficult task?
• Selecting an algorithm for Data Discovery – Selecting the right algorithm is very important
• Post deciding on an algorithm, the process of parameter selection is time consuming
• Parameter values can not be defined as a closed form formula, result of a Black box.
• There is only so much you can do at one point in time restricted by hardware.

Algorithms for Parameter tuning
• Grid Search – Exhaustive parameter sweep over the hyper-
parameter space – E.g. SVM with some kernel – Train on the Cartesian product of constant(c), kernel
parameter(Y) – Suffers from Curse of Dimensionality i.e. the space
to search the parameter value grows exponentially, data becomes sparse and difficult to search on
• Random Search( Implemented ) – Similar to Grid Search – Randomized selection of the parameter values

• Gradient Based Optimization – Specialized algorithm for minimizing the
generalization error in SVM
• Bayesian Optimization(Future) – Sequential design for finding global optimization of a
black box function – Based on developing a statistical model mapping a
function from hyper-parameter values -> objective evaluated.
– Initially placing a prior on the random function and then updating to form a posterior distribution which determines the next query point.
– Reference: http://papers.nips.cc/paper/4522-practical-bayesian-optimization-of-machine-learning-algorithms.pdf

Apache Spark HPOspark-submit --driver-memory 8g --executor-memory 8g --num-executors 2 --executor-cores 4 –class ../modellearner.ExecutionManager --master local[*] model-learner-0.0.1-jar-with-dependencies.jar --help
Experimental Model Learner. For usage see below:
-a, --aloha-spec-file <arg> Specify the aloha spec file name with path -c, --config-file <arg> Specify the config file name with path -n, --negative-downSampling <arg> Specify negative down-sampling needed as a percentage (default = 0.0) -q, --query_data <arg> Specify false if there is no need query for data(useful if data has been queried earlier) (default = true) -s, --seed-value <arg> Specify seed value (default = 0) -t, --top-n-values <arg> Specify the number for top n loss values (default = 10) --help Show help message
*Currently supports only vw, can be extended to include others.

Config Formatproperties: framework: 'vw' cmdPath: 'vw' vwBasic: 'vw --noop -k --cache_file' bitPrecision: ’22' updatePolicies: loss_function:logistic;learning_rate: #0.01,0.02#;l1:#0.001,0.9#;l2:#0.0001,0.00#' manipulationPolicies: '-q JY -q JW -q IY -q IW -q YW -q JI' trainSplitPercentage: '0.8' iteration: '1' errorMetric: 'average loss' generateCache: 'true' sharedDir: ‘<xxxx>' dateRange: '2015-01-03 2015-01-04' region: ’yyy' matchType: ’<match_type>' hdfsBaseDir: ‘<hdfs_path>' hdfsOutputDir: ‘<output_path>' learnerOutputHdfs: ’<learner_output_path>'

Fun with Math
Random or Grid or any other Bayesian method, how can one prepare the infrastructure for optimizing the learner ? i.e Number of iterations ? Lets see • Assume, chance = 0.05 and Guarantee: 0.95 • Probability of missing the optimum in ‘n’ iterations: (1-0.05)^n • Then Probability of success = 1 – (1 – 0.05)^n >=0.95 • Guess ?

Future
• Extend it to support other frameworks such as – R – Lib-SVM – Generalized vw implementation
• Support feature exploration • Other forms of Adaptive Search instead of
Random Search • Gradient based HyperParameter – Reversible
Learning – Reference: http://arxiv.org/pdf/
1502.03492v3.pdf

Other Frameworks
• vw- hypersearch https://github.com/JohnLangford/vowpal_wabbit/wiki/Using-vw-hypersearch
• Python based Hyperopt – No interaction or learning from previous runs – Can’t pause and resume – Parallelization is dependent on MongoDB( opens up
another bag of worms ) • Auto Weka: on top of Weka( Difficult to customize
and support other frameworks) • Spearmint: Only supports Bayesian Optimization
– Difficult to customize to support other machine learning framework.

Example using HyperOpt

Introducing VW
• Is a efficient scalable online Machine Learning framework
• Also supports importance weighting, multiple loss functions and other optimization algorithms.
• Supports dynamic generation of feature interaction
• Test set hold-out and early termination on multiple passes

VW Scalability
• Out of core learning, no need to load all the data in memory at once
• Applies feature hashing to convert feature identities to a weight index using mumurHash3.
For curious mind: https://gist.github.com/cartazio/2903178
• Effective use of the multi-cores • Written in c++, avoids nuances of jvm

Demo of vw
• vw file format [Label] [Importance] [Tag]|Namespace Features |Namespace Features ... |Namespace Features • Label: is the real number that we are trying to predict for this example • Importance: (importance weight) is a non-negative real number indicating
the relative importance of this example over the others. • Tag: is a string that serves as an identifier for the example • Namespace: is an identifier of a source of information for the example • Features: is a sequence of whitespace separated strings, each of which is
optionally followed by a float
• Note: ** vertical bar, colon, space, and newline

Loss Functions

• Stackover flow multiclass prediction problem
Link to the problem: https://www.kaggle.com/c/predict-closed-questions-on-stack-overflow
• Steps followed: – pre-process CSV data – convert it into VW format – run learning and prediction – Evaluate the model
• Has a bunch of features, but for this demo the following features are used: – title, body, tags
• Algorithm: OAA( One Against All )

References
• Random Search for Hyper-parameter optimization: http://www.jmlr.org/papers/volume13/bergstra12a/bergstra12a.pdf
• Practical Bayesian Optimization of ML Algorithms: https://dash.harvard.edu/handle/1/11708816


















