
LDA FOR BIG DATA - cs.cmu.edu
65
LDA FOR BIG DATA 1
Transcript of LDA FOR BIG DATA - cs.cmu.edu

LDAFORBIGDATA
1

LDAforBigData- Outline• QuickreviewofLDAmodel
– clusteringwords-in-context• ParallelLDA~=IPM• FastsamplingtricksforLDA
–Sparsified sampler–Aliastable–Fenwicktrees
• LDAfortextà LDA-likemodelsforgraphs
2

Recap:TheLDATopicModel
3
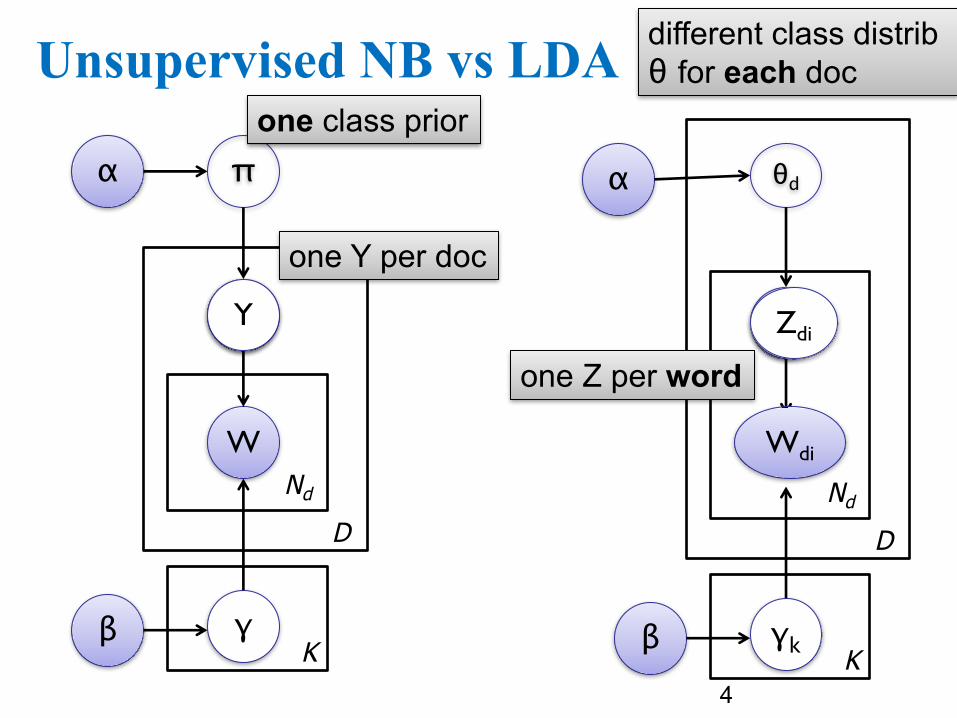
Unsupervised NB vs LDA
Y
NdD
π
W
γK
α
β
Y Y
NdD
θd
γk K
α
β
Zdi
one Y per doc
one Z per word
one class prior
different class distribθ for each doc
Wdi
4
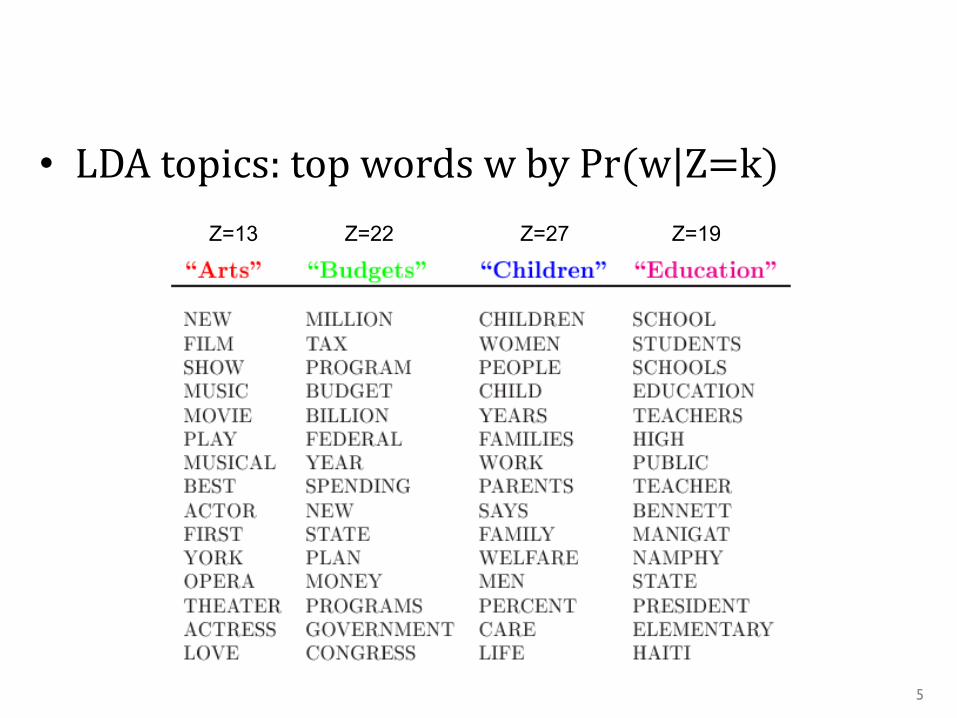
• LDAtopics:topwordswbyPr(w|Z=k)Z=13 Z=22 Z=27 Z=19
5

• LDA’sviewofadocument Mixed membership model
6

LDAand(Collapsed)GibbsSampling• Gibbssampling– worksforanydirectedmodel!- Applicablewhenjointdistributionishardtoevaluatebutconditionaldistributionisknown
- SequenceofsamplescomprisesaMarkovChain- Stationarydistributionofthechainisthejointdistribution
Key capability: estimate distribution of one latent variables given the other latent variables and observed variables.
7
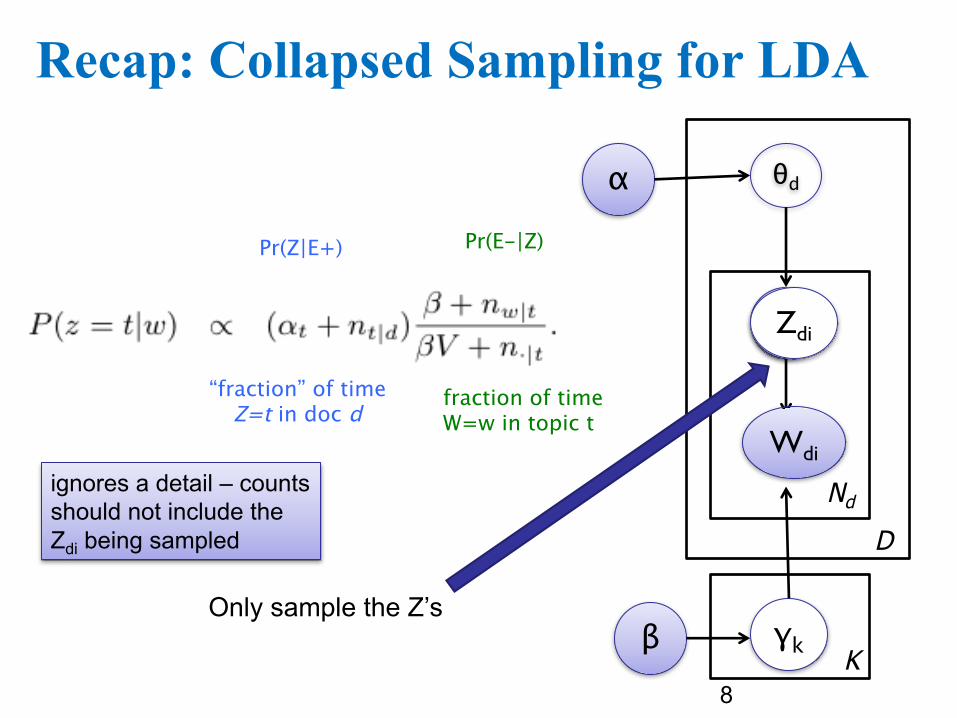
Recap: Collapsed Sampling for LDA
Y
NdD
θd
γk K
α
β
Zdi
Wdi
Pr(Z|E+) Pr(E-|Z)
“fraction” of timeZ=t in doc d
fraction of timeW=w in topic t
8
Only sample the Z’s
ignores a detail – counts should not include the Zdi being sampled

PARALLELLDA
9

JMLR 2009
10

Observation
• Howmuchdoesthechoiceofzdependontheotherz’sinthesamedocument?–quitealot
• Howmuchdoesthechoiceofzdependontheotherz’sinelsewhereinthecorpus?–maybenotsomuch–dependsonPr(w|t)butthatchangesslowly
• CanweparallelizeGibbsandstillgetgoodresults?
11

Question
• CanweparallelizeGibbssampling?– formally,no:everychoiceofzdependsonalltheotherz’s
–Gibbsneedstobesequential• justlikeSGD
12

What if you try and parallelize?Split document/term matrix randomly and distribute to p processors .. then run “Approximate Distributed LDA”
This is iterative parameter mixing
13
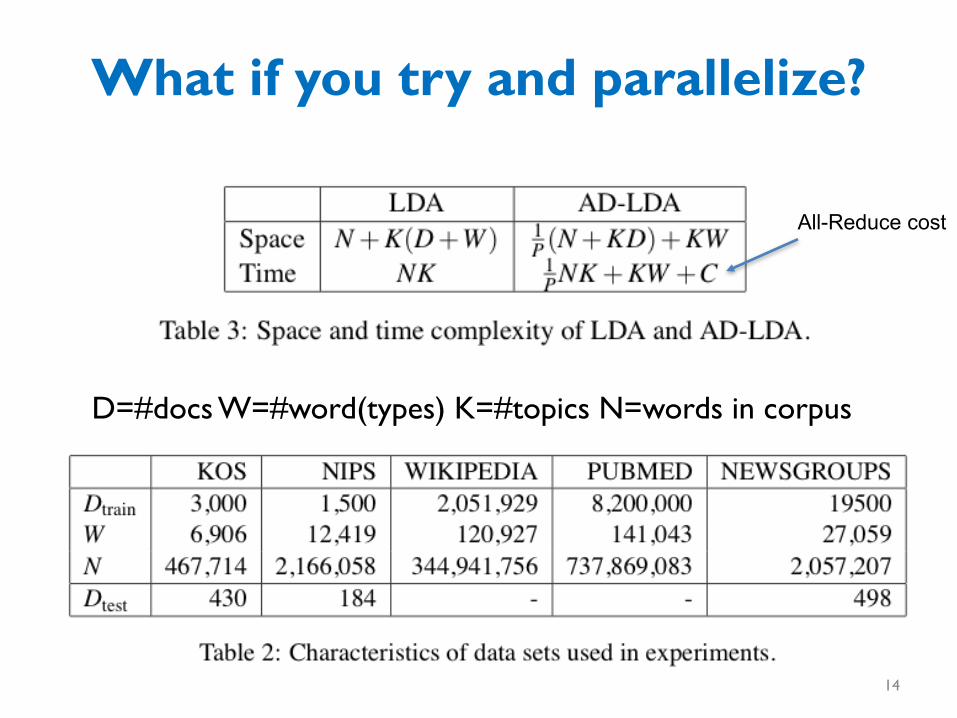
What if you try and parallelize?
D=#docs W=#word(types) K=#topics N=words in corpus
14
All-Reduce cost
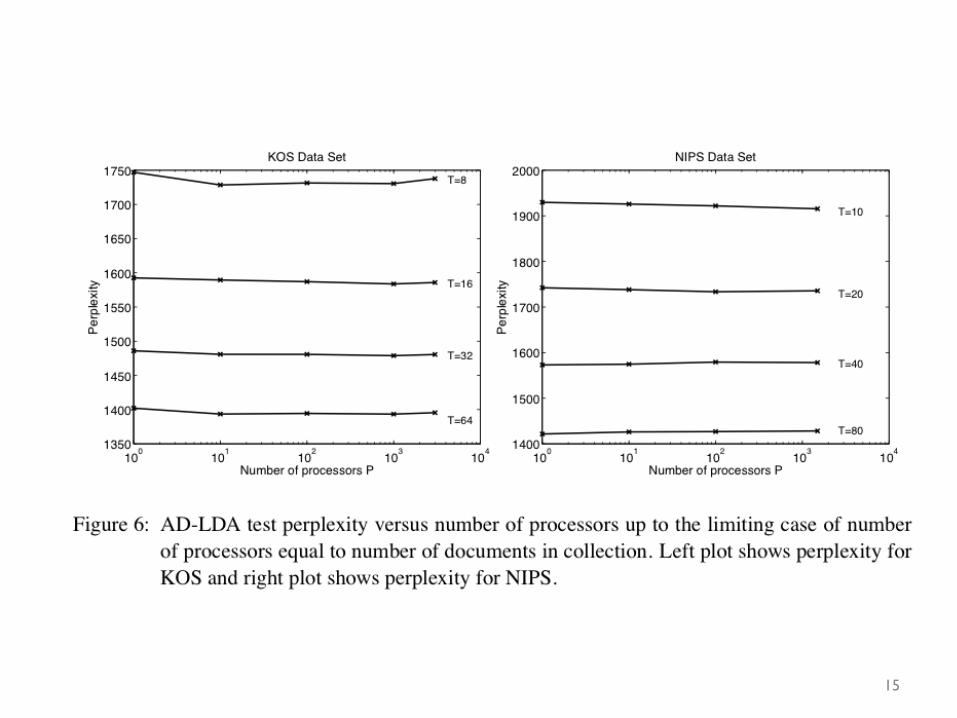
15
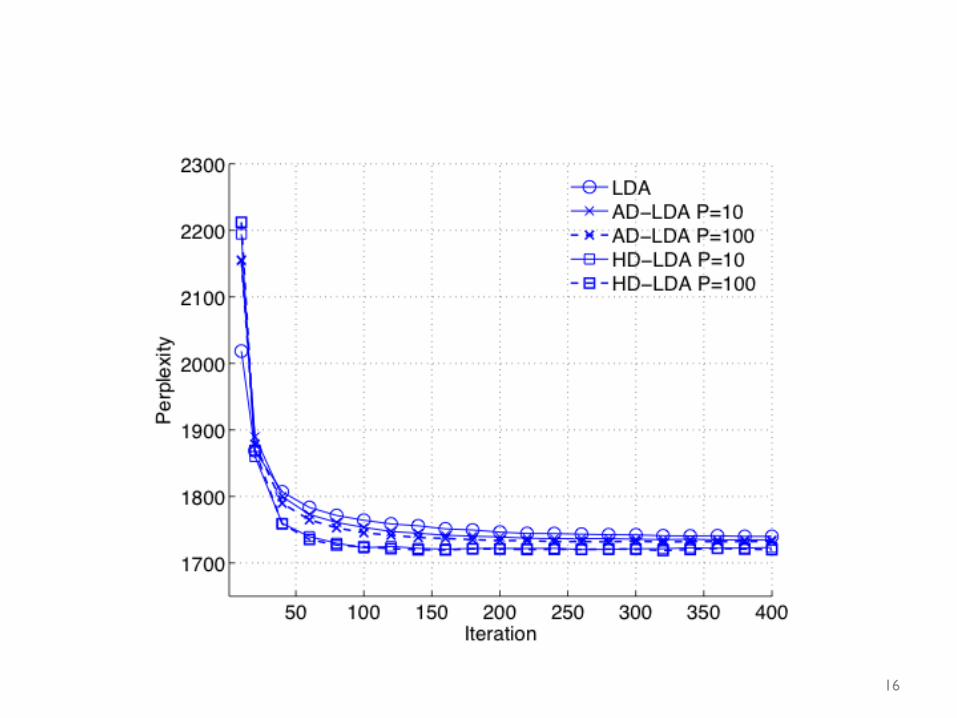
16
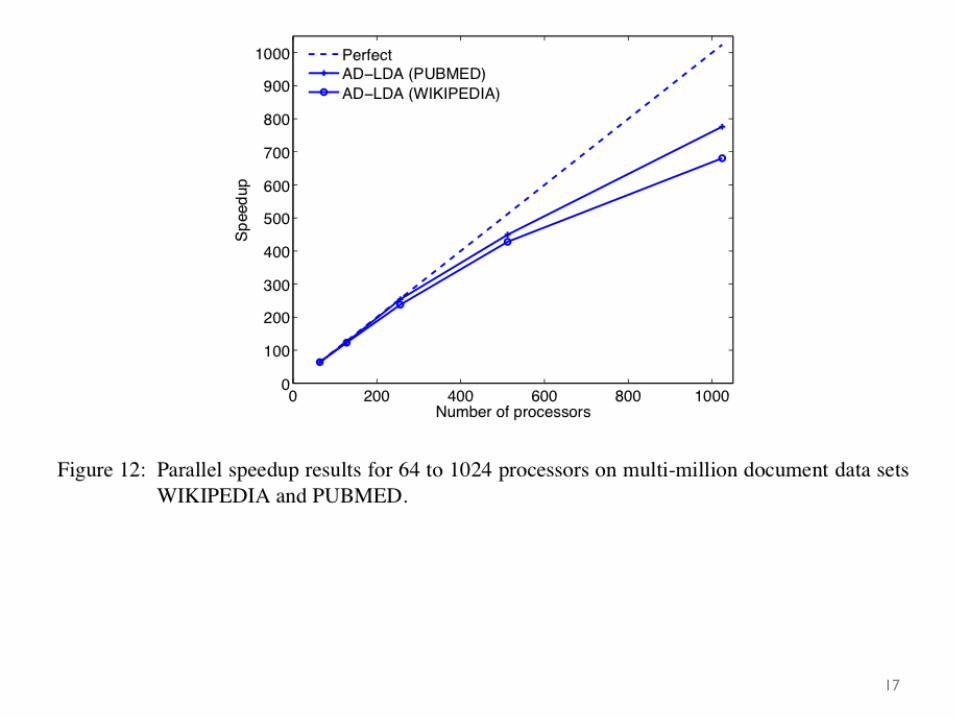
17
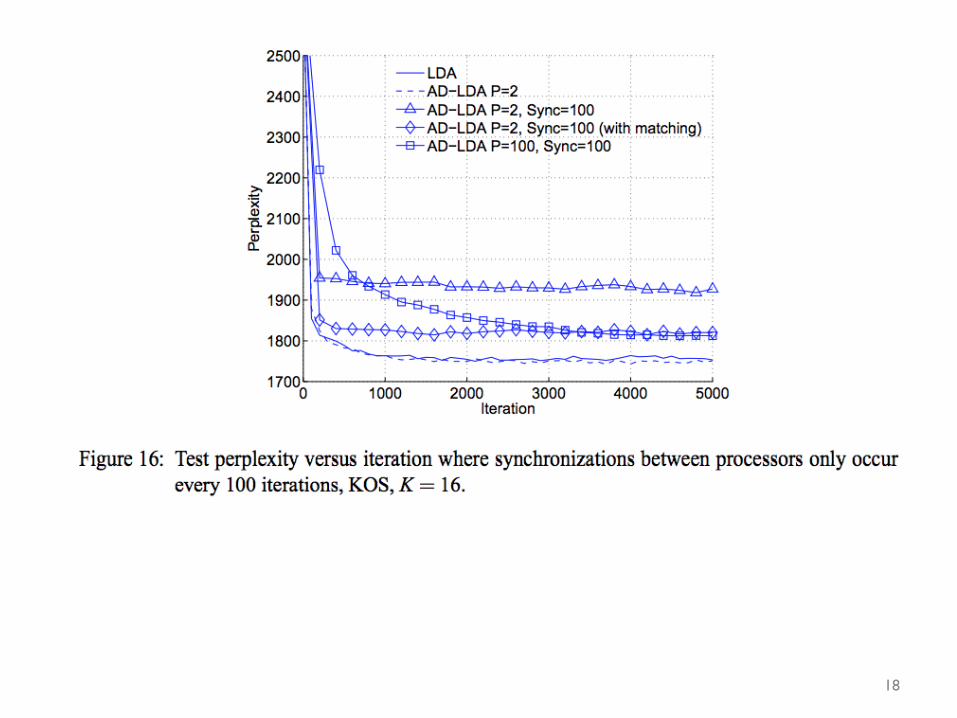
18

Later work….• Algorithms:
– Distributedvariational EM– AsynchronousLDA(AS-LDA)– ApproximateDistributedLDA(AD-LDA)– EnsembleversionsofLDA:HLDA,DCM-LDA
• Implementations:– GitHub Yahoo_LDA
• notHadoop,special-purposecommunicationcodeforsynchronizingtheglobalcounts
• AlexSmola,YahooàCMU– MahoutLDA
• AndySchlaikjer,CMUàTwitter
19

FASTSAMPLING FORLDA
20
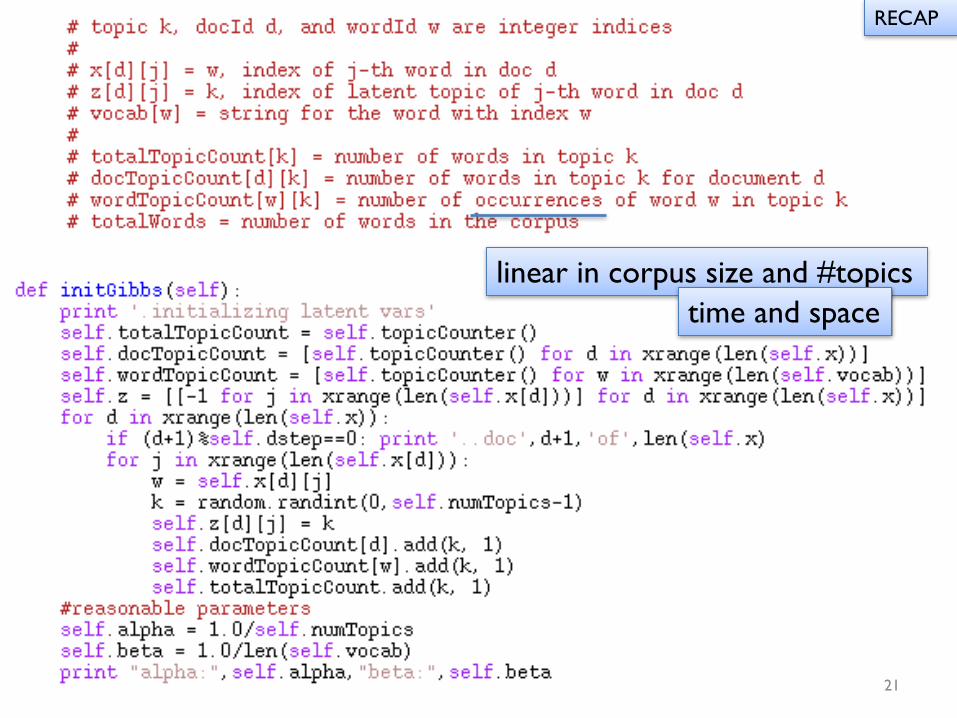
More detailRECAP
linear in corpus size and #topicstime and space
21

RECAP
each iteration: linear in corpus size
most of the time is resampling
resample: linear in #topics
22
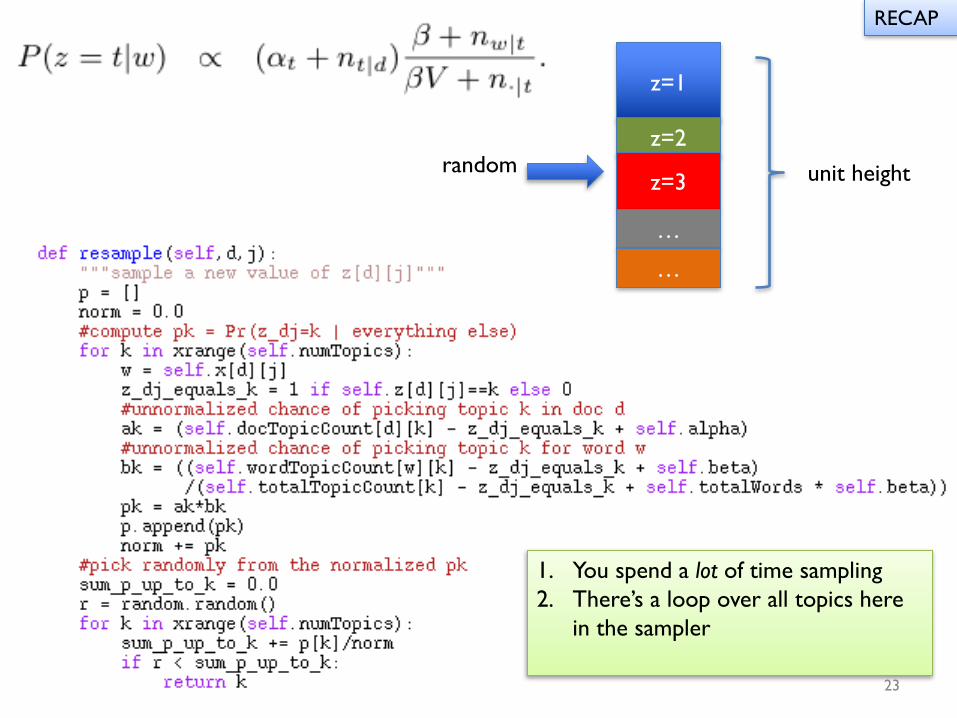
z=1
z=2
z=3
…
…
unit heightrandom
1. You spend a lot of time sampling2. There’s a loop over all topics here
in the sampler
RECAP
23

KDD 09
24
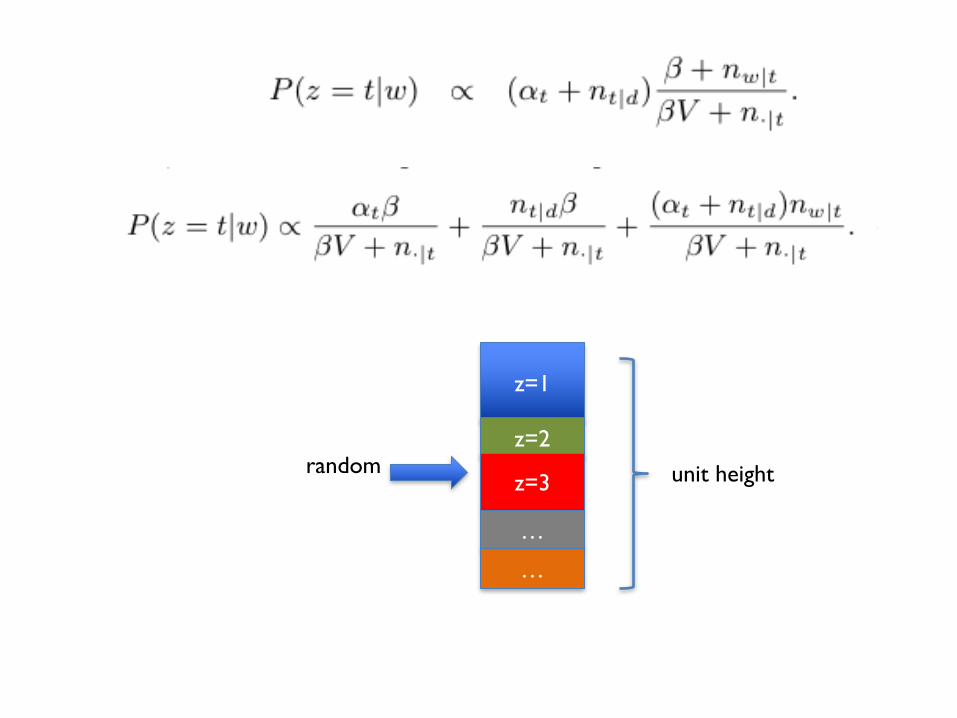
z=1
z=2
z=3
…
…
unit heightrandom
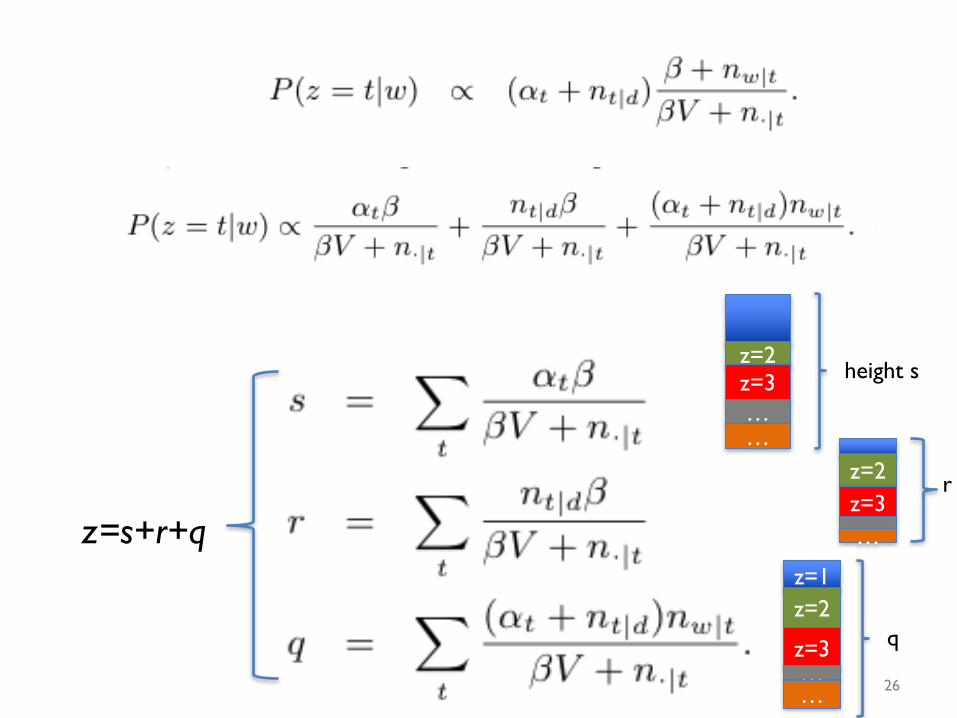
z=s+r+q
26
z=2z=3……
z=2z=3……
z=1z=2
z=3……
height s
q
r
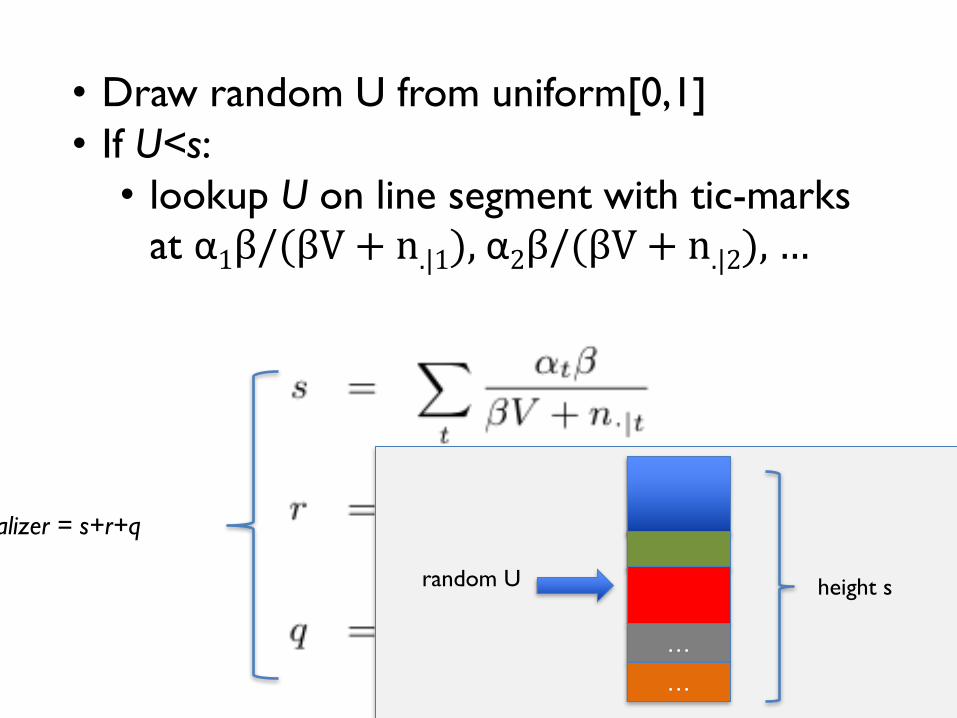
normalizer = s+r+q
• Draw random U from uniform[0,1]• If U<s:
• lookup U on line segment with tic-marks at α1β/(βV+n.|1),α2β/(βV+n.|2),…
27
…
…
height srandom U

z=s+r+q
• If U<s:• lookup U on line segment with tic-marks
at α1β/(βV+n.|1),α2β/(βV+n.|2),…• Ifs<U<r:
• lookupU onlinesegmentforr Only need to check t such that nt|d>0
28

z=s+r+q
• If U<s:• lookup U on line segment with tic-marks
at α1β/(βV+n.|1),α2β/(βV+n.|2),…• Ifs<U<s+r:
• lookupU onlinesegmentforr• Ifs+r<U:
• lookupUonlinesegmentforqOnly need to check t such that nw|t>0
29
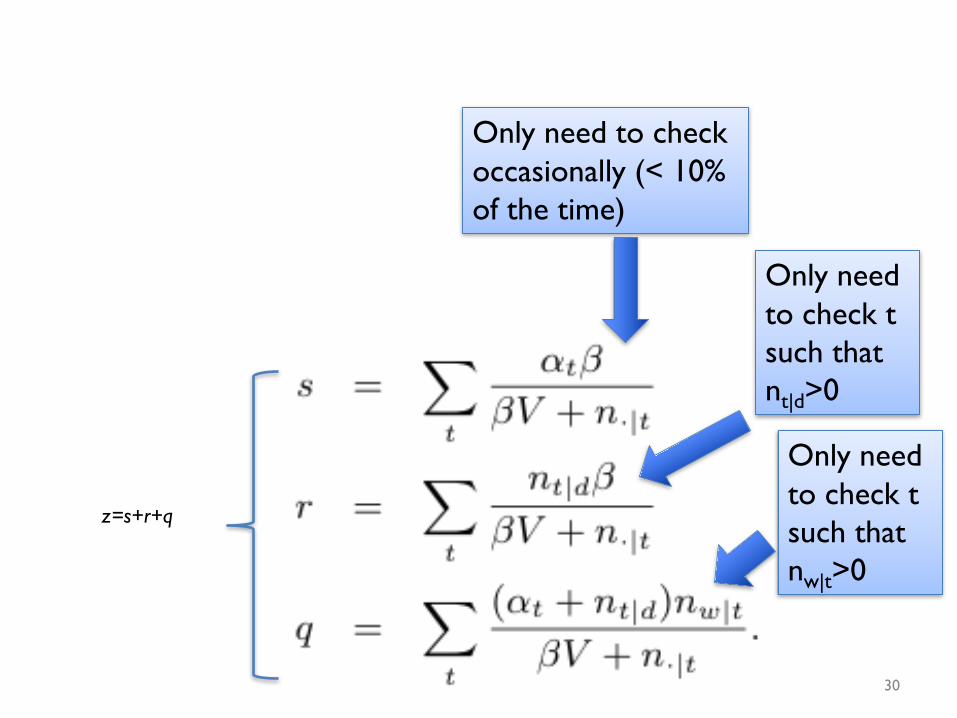
z=s+r+q
Only need to check t such that nw|t>0
Only need to check t such that nt|d>0
Only need to check occasionally (< 10% of the time)
30
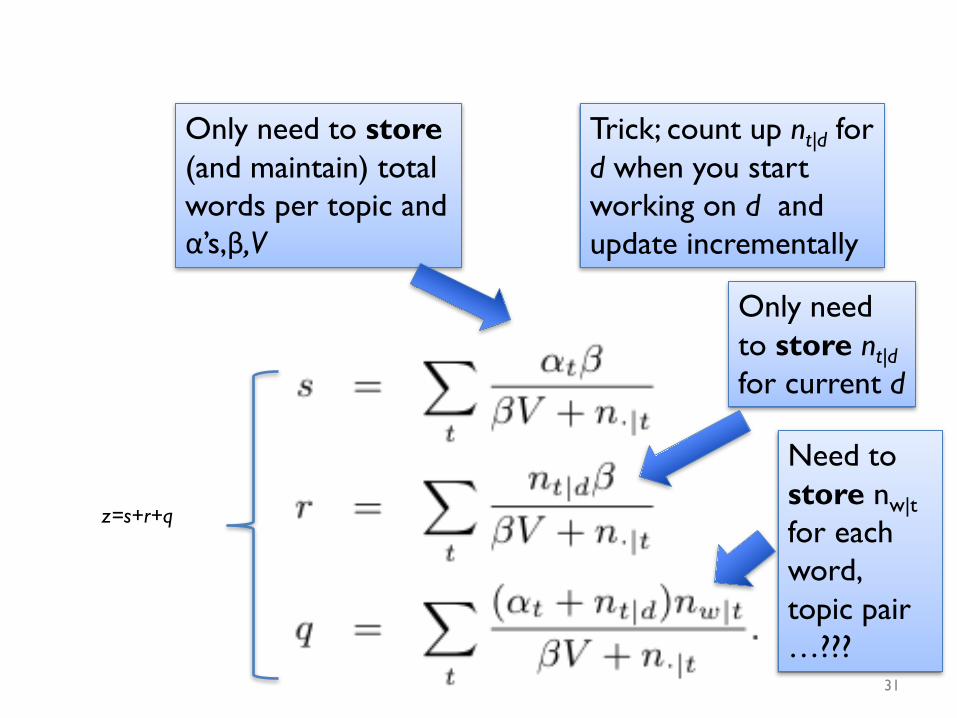
z=s+r+q
Need to store nw|tfor each word, topic pair …???
Only need to store nt|dfor current d
Only need to store(and maintain) total words per topic and α’s,β,V
Trick; count up nt|d for d when you start working on d and update incrementally
31
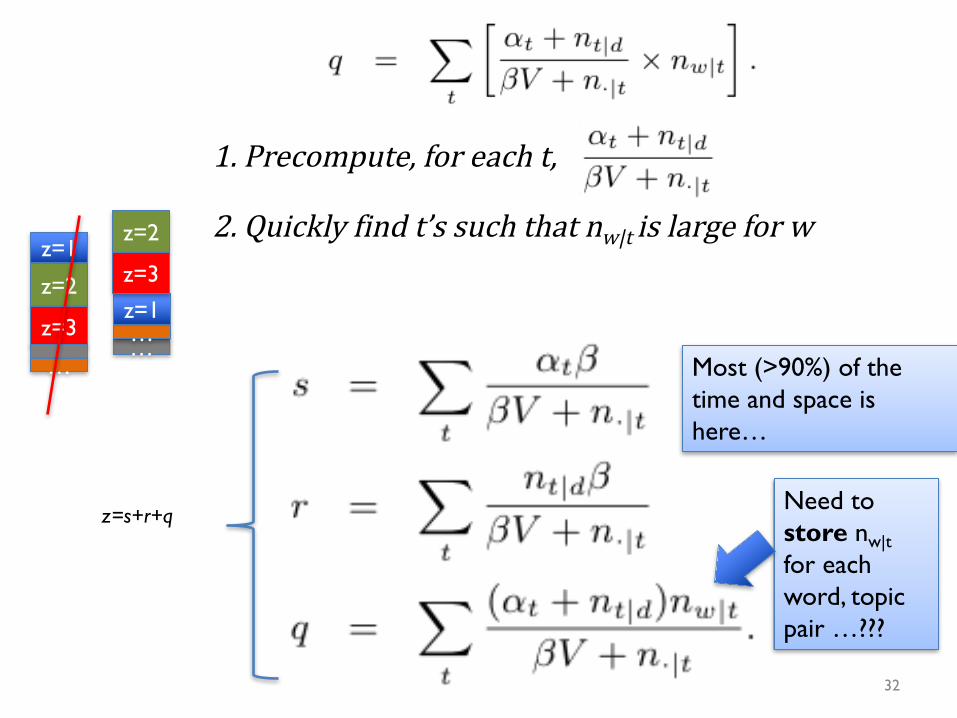
z=s+r+qNeed to store nw|tfor each word, topic pair …???
1.Precompute,foreacht,
Most (>90%) of the time and space is here…
2.Quicklyfindt’ssuchthatnw|t islargeforw
32
z=1
z=2
z=3……
z=1
z=2
z=3
……

Need to storenw|t for each word, topic pair …???
1.Precompute,foreacht,
Most (>90%) of the time and space is here…
2.Quicklyfindt’ssuchthatnw|t islargeforw
• associateeachwwithanint array• nolargerthanfrequencyofw• nolargerthan#topics
• encode (t,n) asabitvector• ninthehigh-orderbits• tinthelow-orderbits
• keepints sortedindescendingorder
33
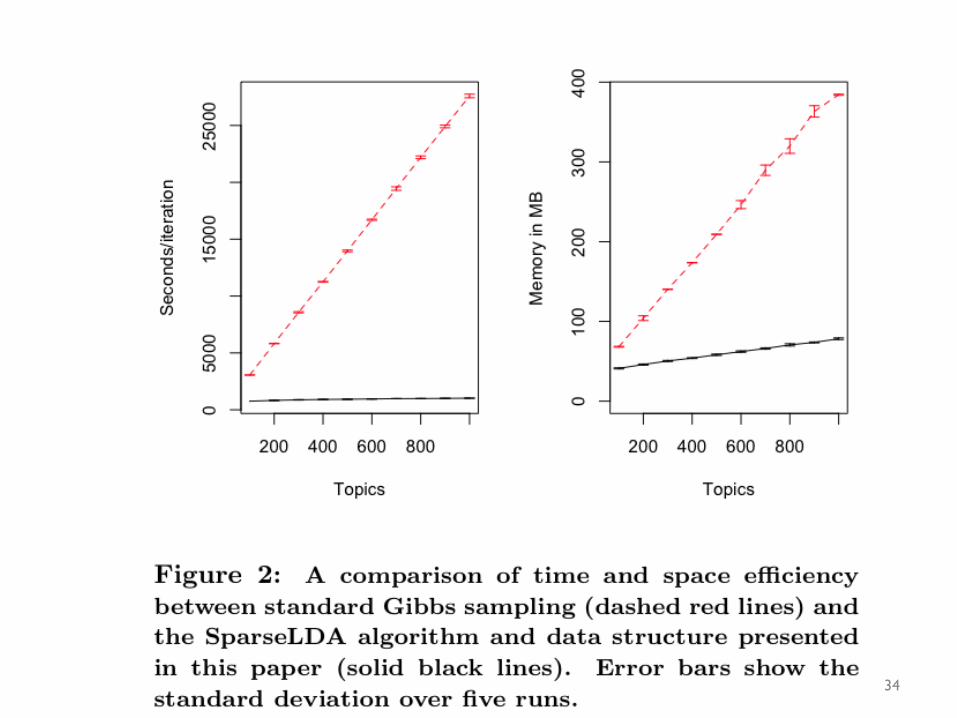
34

OtherFastSamplersforLDA
35
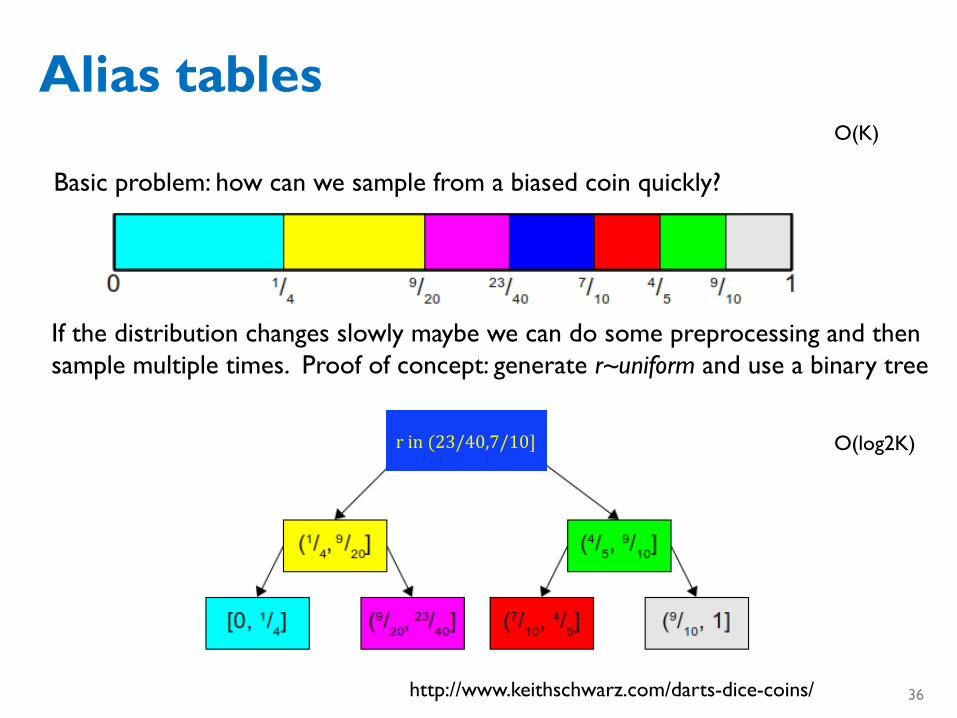
Alias tables
http://www.keithschwarz.com/darts-dice-coins/
Basic problem: how can we sample from a biased coin quickly?
If the distribution changes slowly maybe we can do some preprocessing and then sample multiple times. Proof of concept: generate r~uniform and use a binary tree
rin(23/40,7/10]
O(K)
O(log2K)
36
Alias tables
Basic problem: how can we sample from a biased die quickly?
O(K)
37
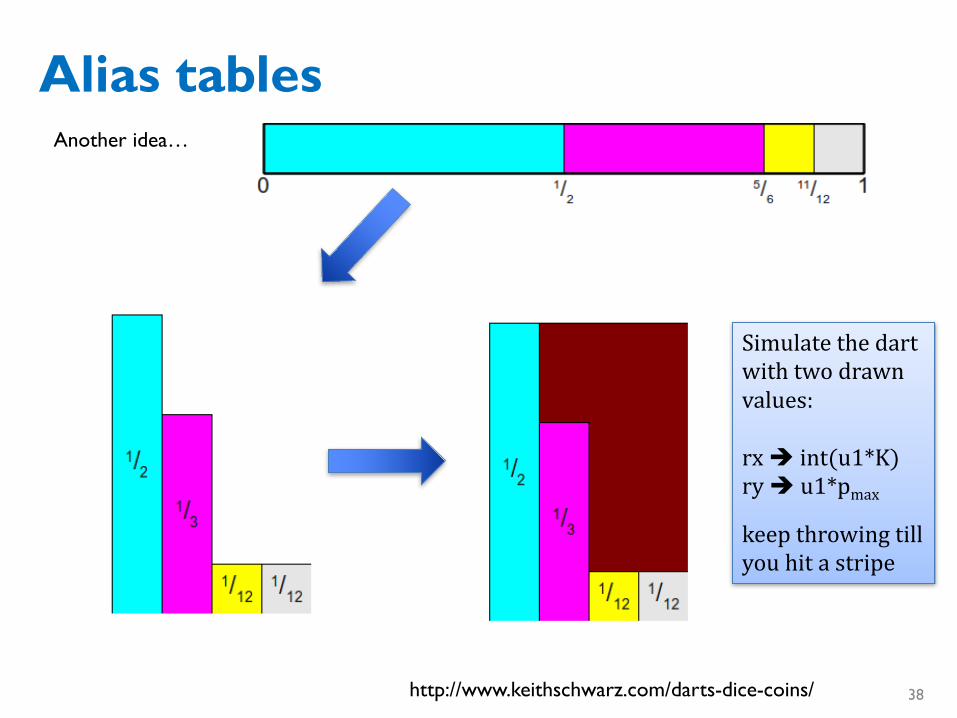
Alias tables
http://www.keithschwarz.com/darts-dice-coins/
Another idea…
Simulatethedartwithtwodrawnvalues:
rxè int(u1*K)ryè u1*pmax
keepthrowingtillyouhitastripe
38
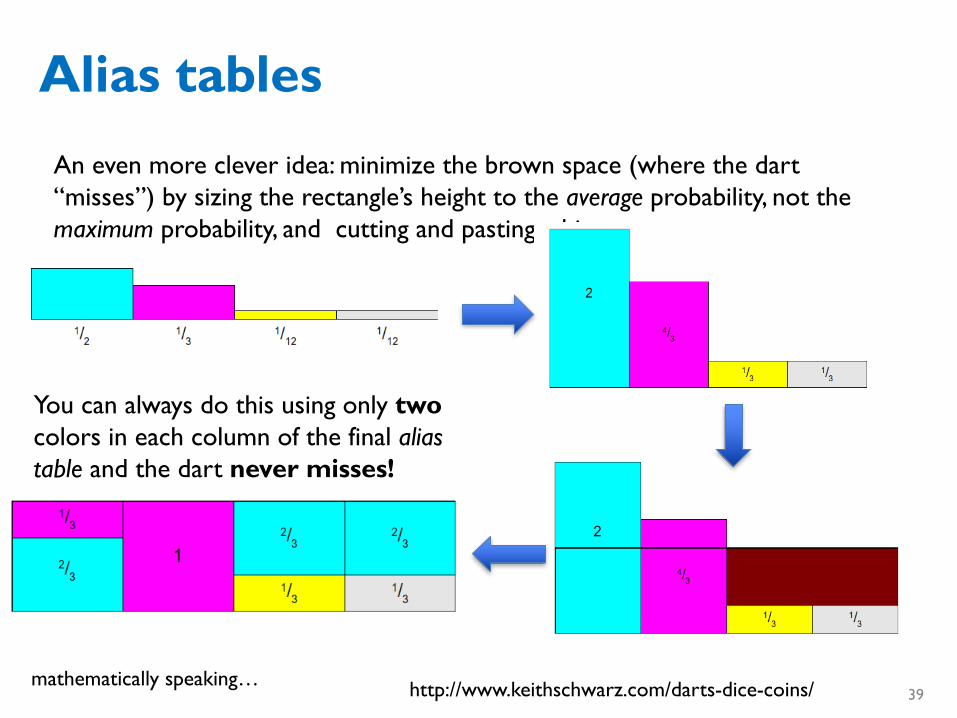
Alias tables
http://www.keithschwarz.com/darts-dice-coins/
An even more clever idea: minimize the brown space (where the dart “misses”) by sizing the rectangle’s height to the average probability, not the maximum probability, and cutting and pasting a bit.
You can always do this using only twocolors in each column of the final alias table and the dart never misses!
mathematically speaking…39

LDAwithAliasSampling
• SampleZ’swithaliassampler• Don’tupdatethesamplerwitheachflip:
– Correctfor“staleness”withMetropolis-Hastingsalgorithm
[KDD 2014]
40
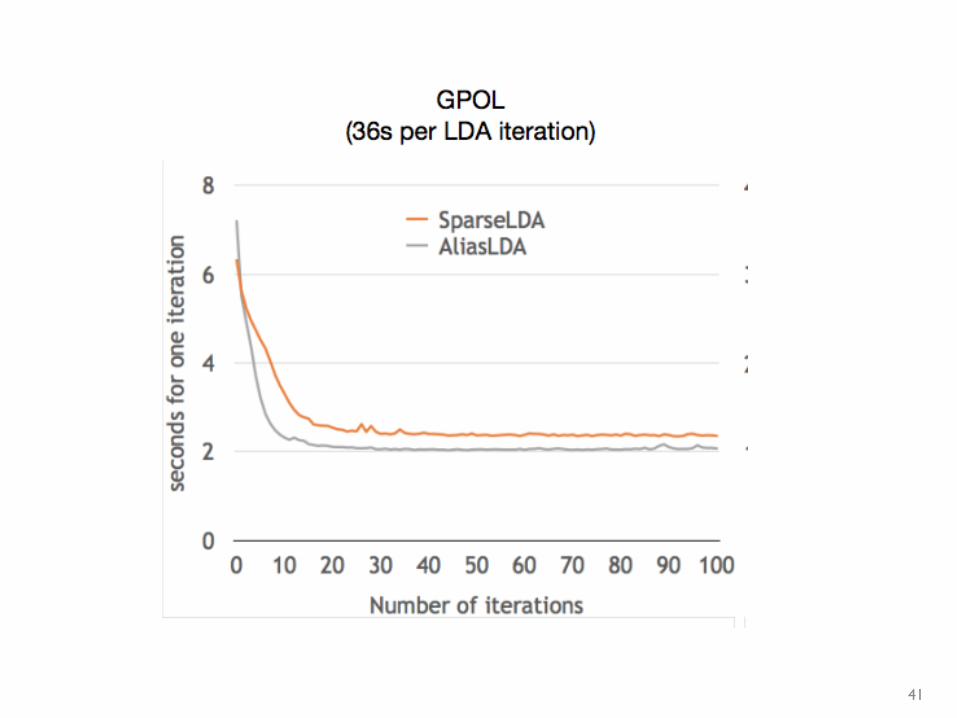
41

YetMoreFastSamplersforLDA
42

WWW 2015
43
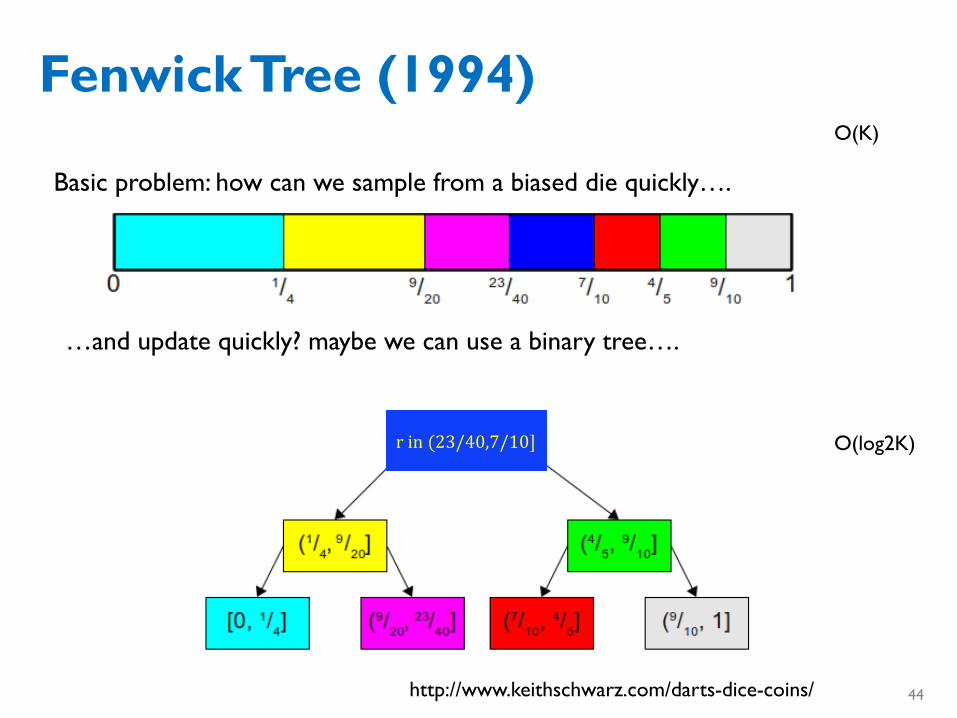
Fenwick Tree (1994)
http://www.keithschwarz.com/darts-dice-coins/
Basic problem: how can we sample from a biased die quickly….
…and update quickly? maybe we can use a binary tree….
rin(23/40,7/10]
O(K)
O(log2K)
44

Datastructuresandalgorithms
LSearch: linear search
45
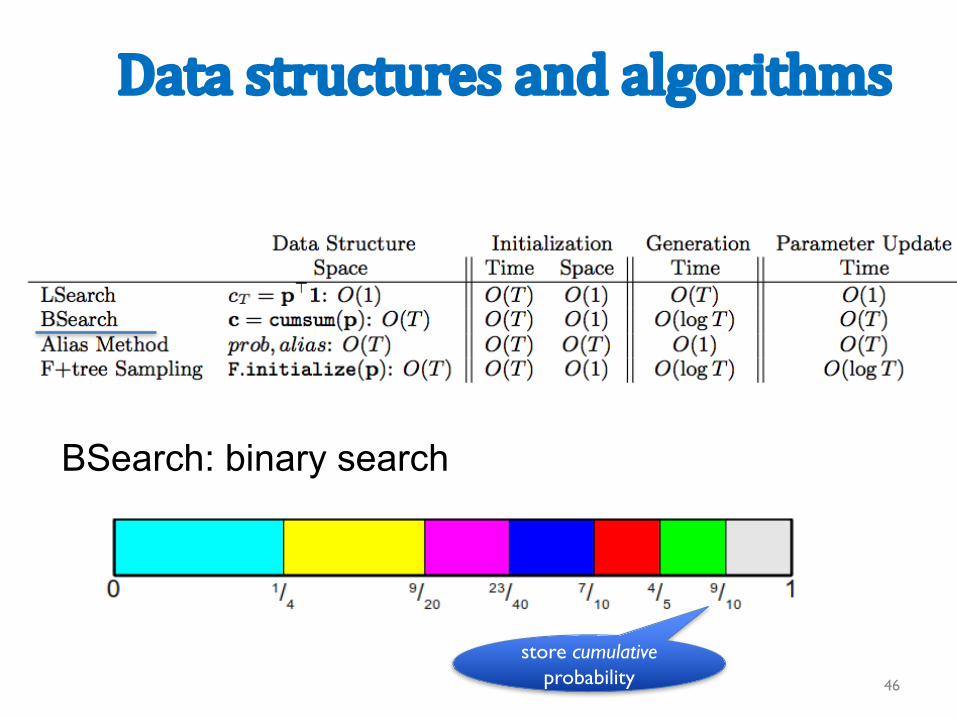
Datastructuresandalgorithms
BSearch: binary search
store cumulativeprobability 46
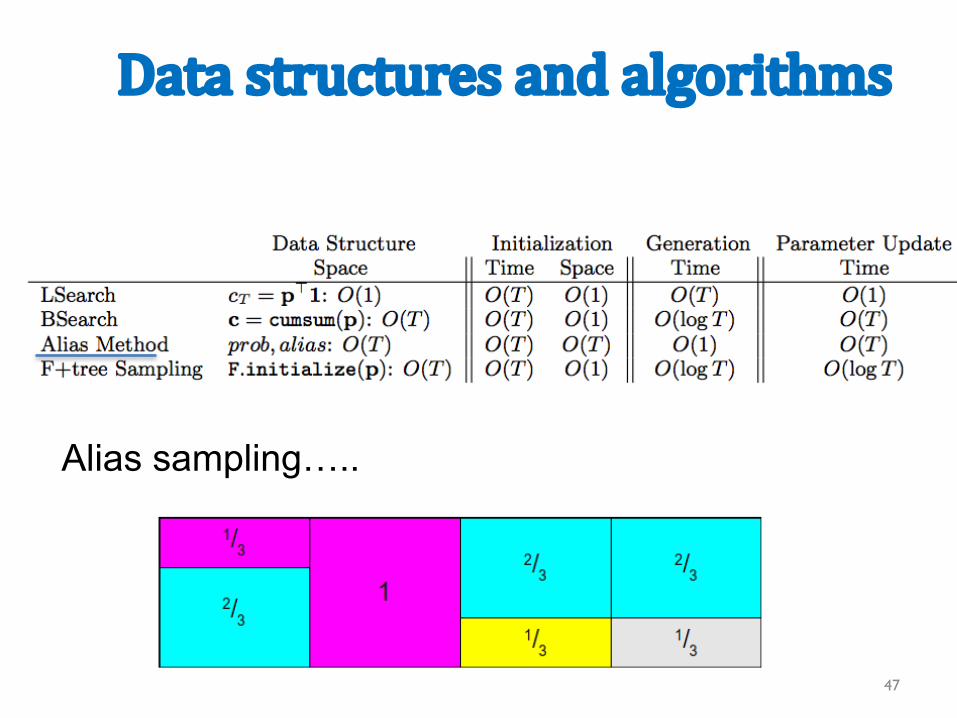
Datastructuresandalgorithms
Alias sampling…..
47
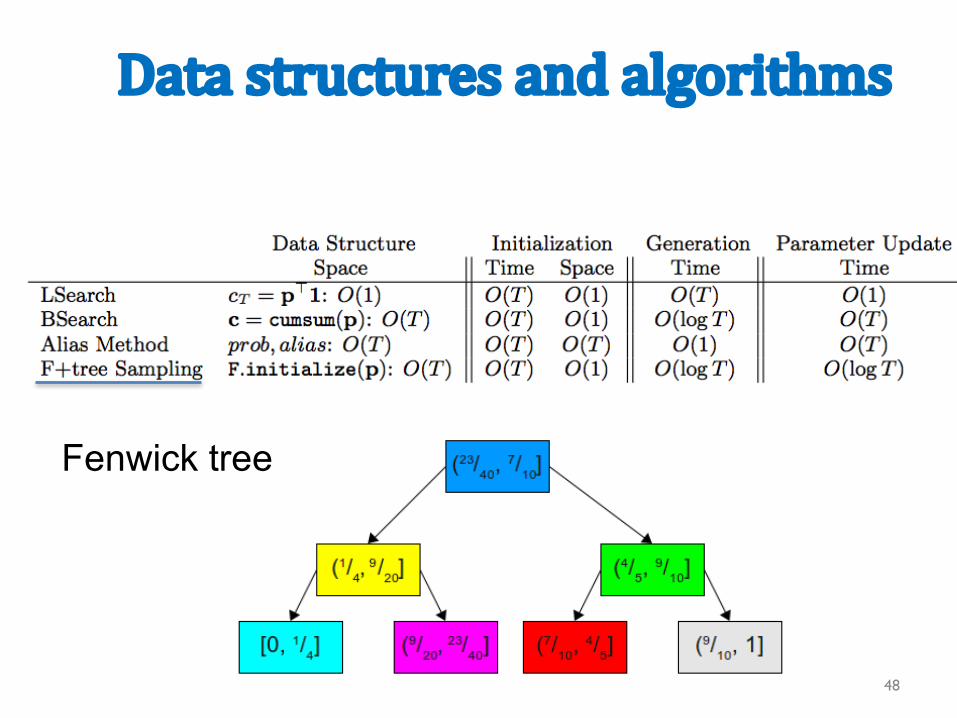
Datastructuresandalgorithms
Fenwick tree
48

Datastructuresandalgorithms
βq: dense, changes slowly, re-used for each word in a document r: sparse, a different one
is needed for each uniqterm in doc
Sampler is:
Fenwick tree
Binary search
49
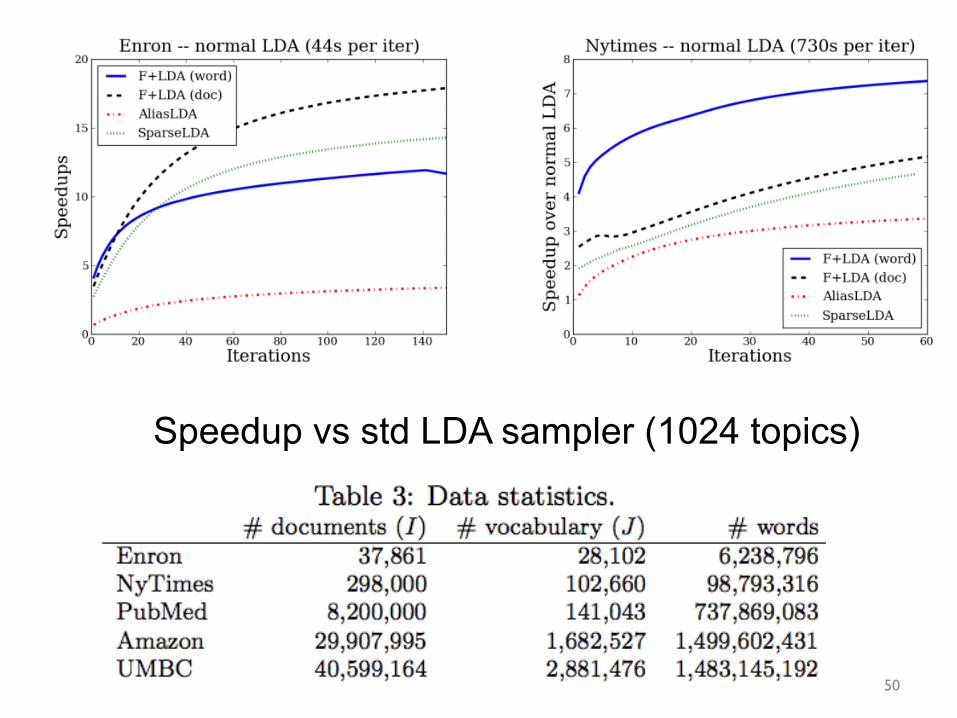
Speedup vs std LDA sampler (1024 topics)
50
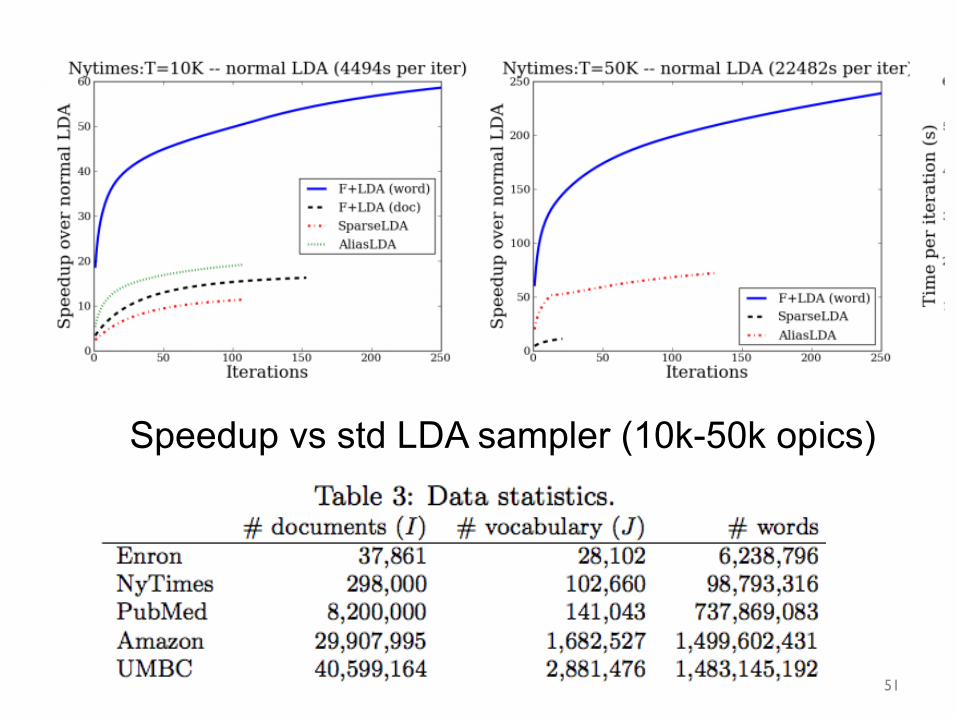
Speedup vs std LDA sampler (10k-50k opics)
51

AndParallelism….
52

Second idea: you can sample document-by-document or word-by-word …. or….
use a MF-like approach to distributing the data. 53
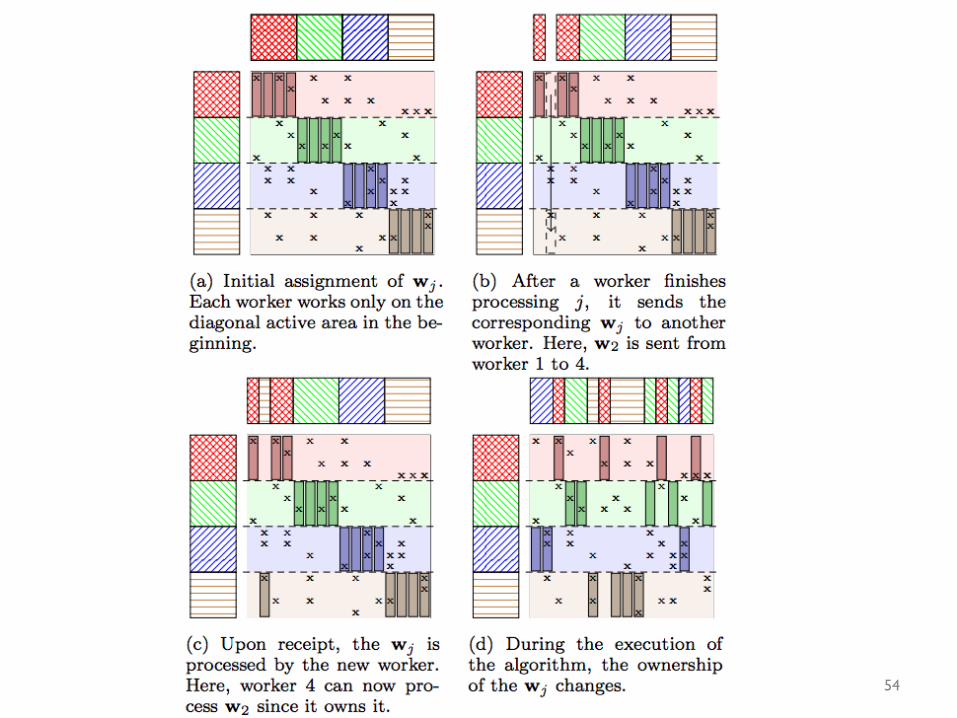
54
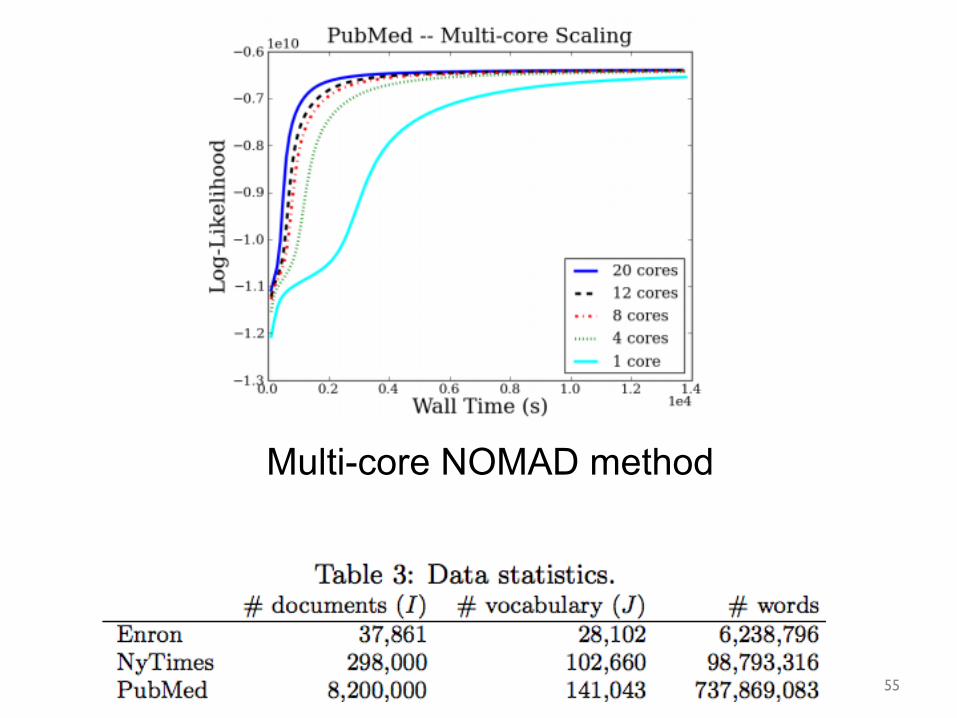
Multi-core NOMAD method
55

LDA-LIKEMODELSFORGRAPHS
56

NetworkDatasets•UBMCBlog•AGBlog•MSPBlog•Cora•Citeseer
57

Motivation• Socialgraphsseemtohave
– someaspectsofrandomness• smalldiameter,giantconnectedcomponents,..
– somestructure• homophily,scale-freedegreedist?
• Howdoyoumodelit?
58

Moreterms• “Stochasticblockmodel”,aka“Block-stochasticmatrix”:–Drawni nodesinblocki–Withprobabilitypij,connectpairs(u,v)whereuisinblocki,visinblockj
– Special,simplecase:pii=qi,andpij=sforalli≠j
• Question:canyoufitthismodeltoagraph?– findeachpij andlatentnodeàblockmapping
59
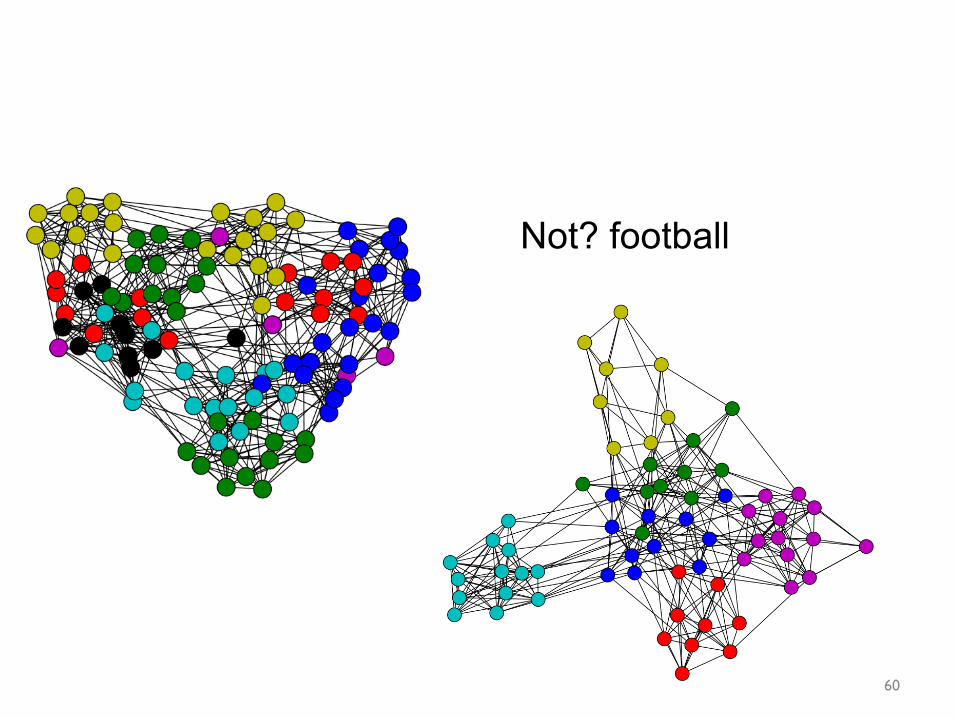
Not? football
60

Not? books
61
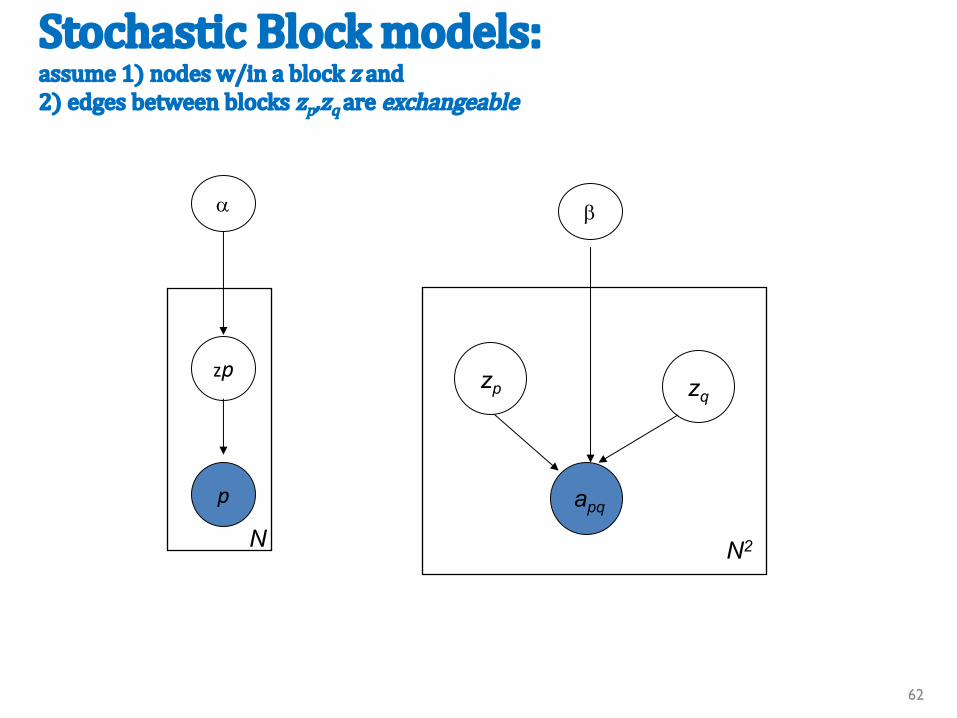
StochasticBlockmodels:assume1)nodesw/inablockz and2)edgesbetweenblockszp,zqareexchangeable
zp zq
apq
N2
zp
N
a
p
b
62
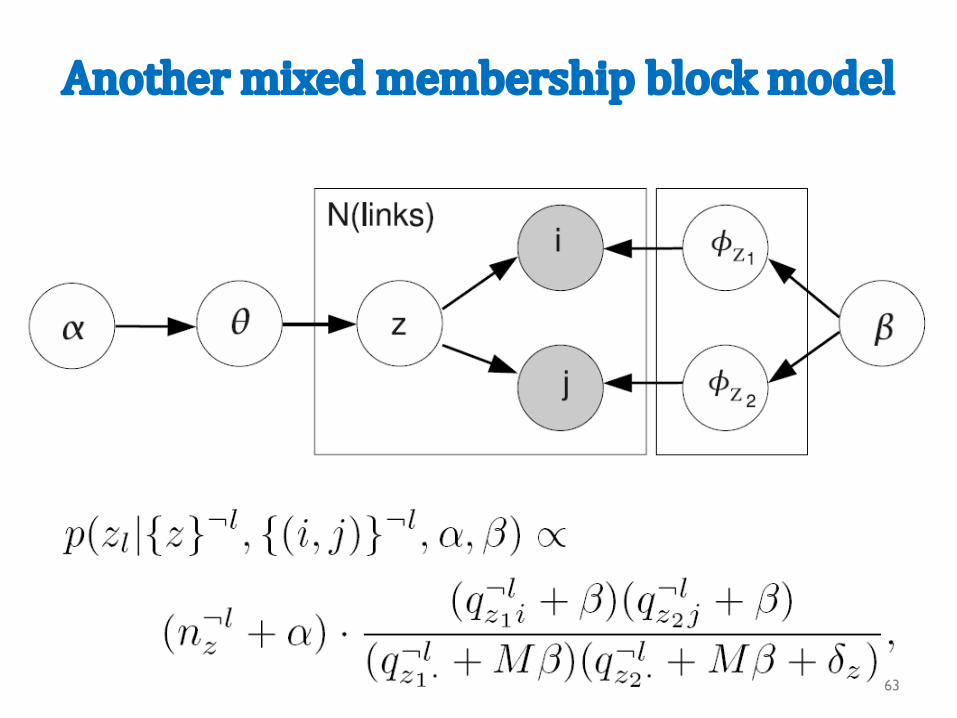
Anothermixedmembershipblockmodel
63

Anothermixedmembershipblockmodel
z=(zi,zj) is a pair of block ids
nz = #pairs z
qz1,i = #links to i from block z1
qz1,. = #outlinks in block z1
δ =indicatorfordiagonal
M=#nodes
64
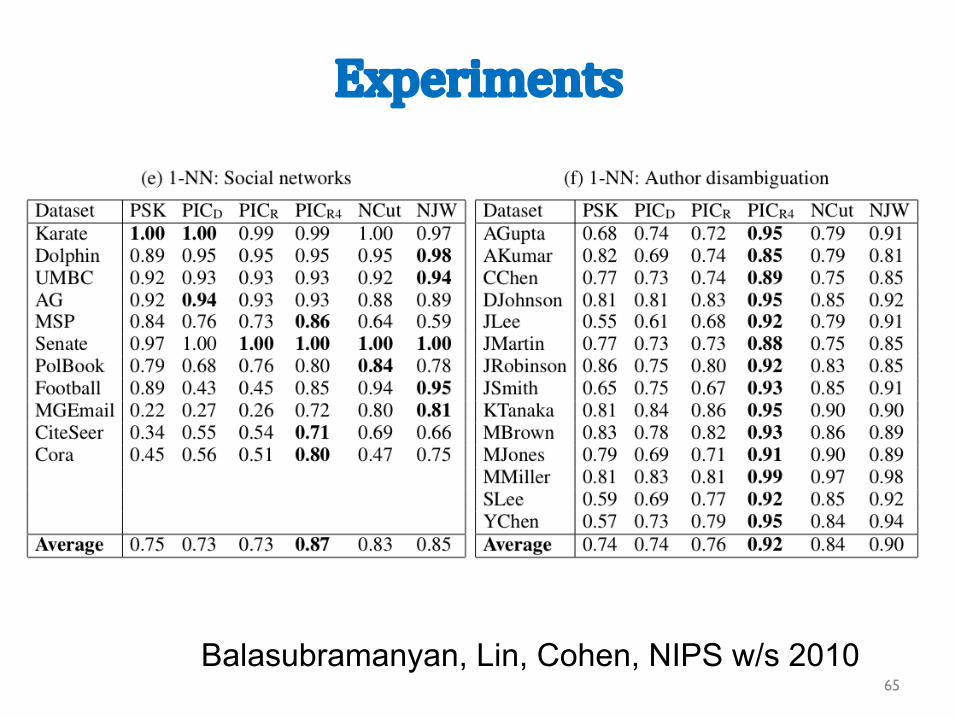
Experiments
Balasubramanyan, Lin, Cohen, NIPS w/s 201065


















