![Fighting latency - events.static.linuxfound.org · L1-dcache-prefetches [Hardware cache event] L1-dcache-prefetch-misses [Hardware cache event] L1-icache-loads [Hardware cache event]](https://static.fdocuments.us/doc/165x107/5f0b8a857e708231d4310611/fighting-latency-l1-dcache-prefetches-hardware-cache-event-l1-dcache-prefetch-misses.jpg)
LATTE-CC: Latency Tolerance Aware Adaptive Cache...
23
LATTE-CC: Latency Tolerance Aware Adaptive Cache Compression Management for Energy Efficient GPUs Akhil Arunkumar , Shin-Ying Lee,Vignesh Soundararajan, Carole-Jean Wu School of Computing, Informatics and Decision Systems Engineering Arizona State University 24th IEEE International Symposium on High-Performance Computer Architecture
Transcript of LATTE-CC: Latency Tolerance Aware Adaptive Cache...

LATTE-CC: Latency Tolerance Aware Adaptive Cache Compression Management for Energy
Efficient GPUs
Akhil Arunkumar, Shin-Ying Lee, Vignesh Soundararajan, Carole-Jean WuSchool of Computing, Informatics and Decision Systems Engineering
Arizona State University
24th IEEE International Symposium on High-Performance Computer Architecture

Accelerate parallel applications• Scientific simulations• Genomics• Artificial intelligence
1/21
GPU Computing is Ubiquitous
SM - NSM - 2
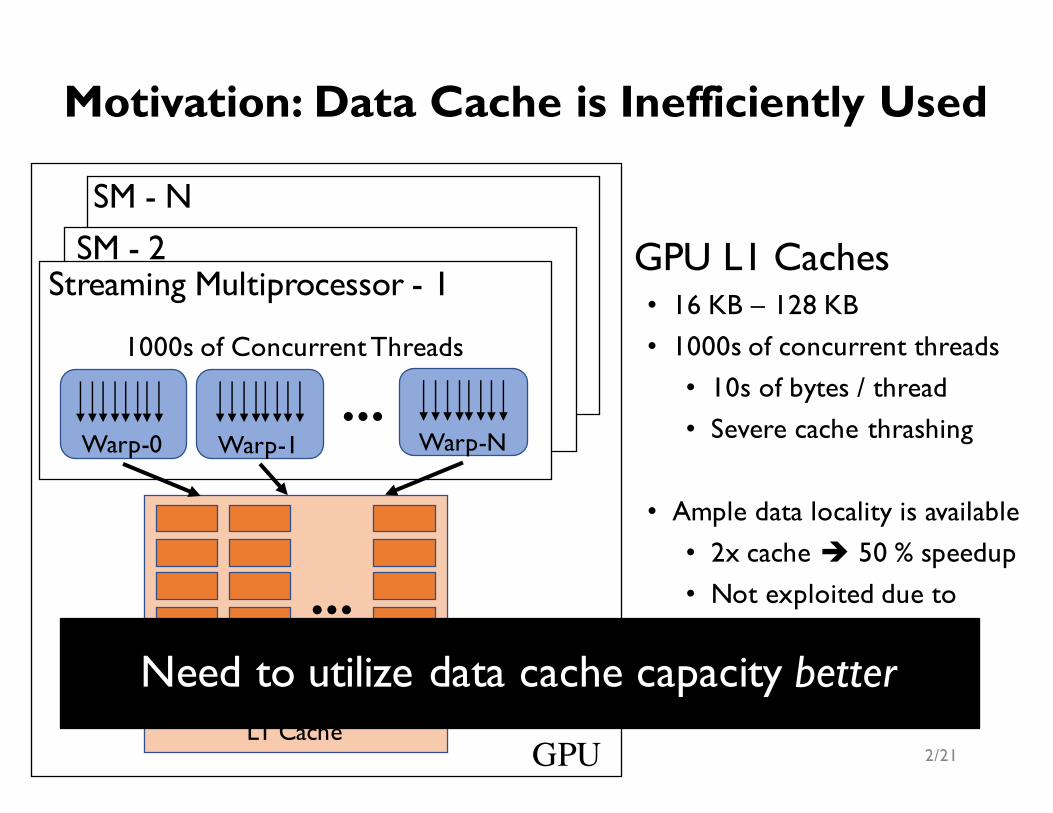
Streaming Multiprocessor - 1GPU L1 Caches• 16 KB – 128 KB• 1000s of concurrent threads • 10s of bytes / thread• Severe cache thrashing
• Ample data locality is available• 2x cache è 50 % speedup• Not exploited due to
thrashing
2/21L1 Cache
...
...Warp-0 Warp-1 Warp-N
Motivation: Data Cache is Inefficiently Used
Need to utilize data cache capacity better
1000s of Concurrent Threads
GPU

• GPU cache bypassing• MRPB [HPCA’14]
• Adaptive bypassing [GPGPU’15]
• PCAL [HPCA’15]
• Ctrl-C [ICCD’16]
• ID-Cache [IISWC’16]
• Others
•Warp scheduling• 2-Level [ISCA’11, MICRO’11]
• CCWS [MICRO’12]
• DAWS [MICRO’13]
• CAWA [ISCA’15]
• Others
3/21
Reduce TLP or hard to recover from inaccuracies
Prior Work

• Data compression• CPUs – DRAMs, interconnect, and last level caches
• GPUs – Interconnect and register files
• Cache compression(+) Increased effective cache capacity
(-) Decompression latency is on the critical path
• GPUs are known to be latency tolerant
4/21
Can Data Compression be Applied to GPU Caches?
DecompressorCompressed Cache
To RequestorDecompressionLatency
Can we exploit GPU latency tolerance for data cache compression?
Hit

• Introduction and Background
• Motivation for L1 cache compression in GPUs
• LATTE-CC: Latency Tolerance Aware Cache Compression Management
• Methodology and Evaluation
• Conclusion
5/21
Outline
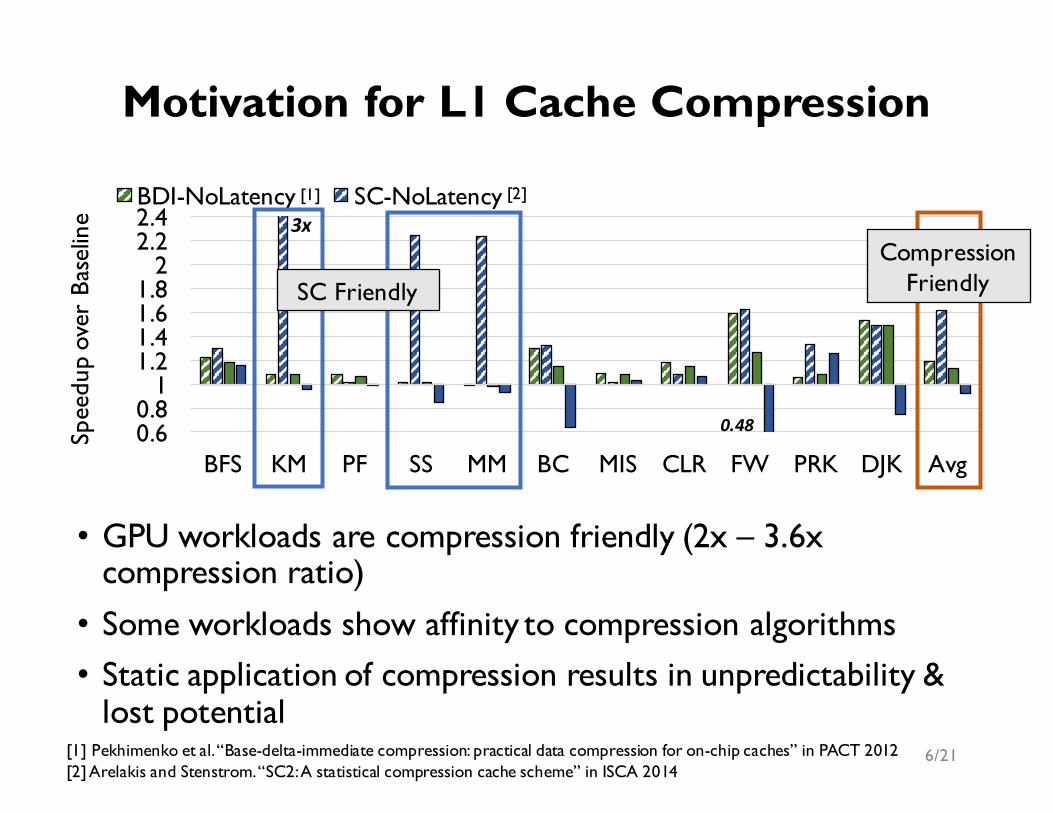
0.60.8
11.21.41.61.8
22.22.4
BFS KM PF SS MM BC MIS CLR FW PRK DJK Avg
Spee
dup
over
Bas
elin
e
BDI-NoLatency SC-NoLatency BDI-WithLatency SC-WithLatency
• GPU workloads are compression friendly (2x – 3.6x compression ratio)• Some workloads show affinity to compression algorithms• Static application of compression results in unpredictability &
lost potential 6/21
[1] [2]
[1] Pekhimenko et al. “Base-delta-immediate compression: practical data compression for on-chip caches” in PACT 2012[2] Arelakis and Stenstrom. “SC2: A statistical compression cache scheme” in ISCA 2014
3x
0.48
[1] [2]
Motivation for L1 Cache Compression
Compression FriendlySC Friendly
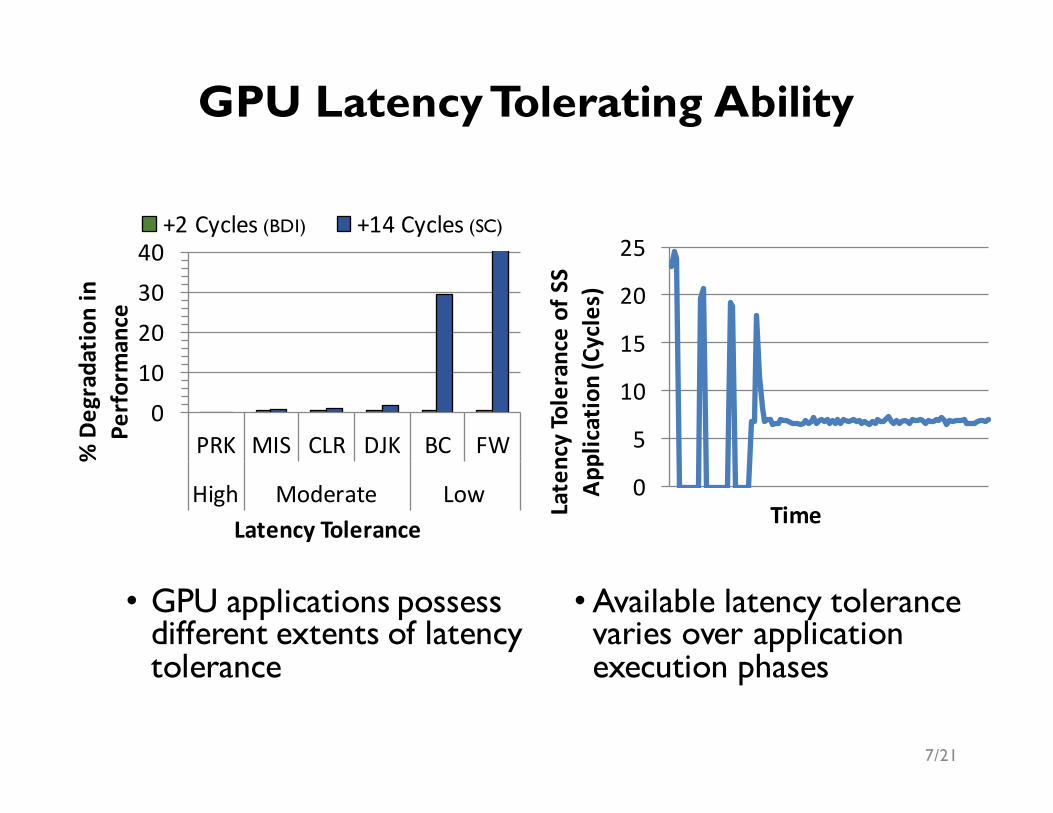
• GPU applications possess different extents of latency tolerance
•Available latency tolerance varies over application execution phases
7/21
010203040
PRK MIS CLR DJK BC FW
High Moderate Low
%Degradatio
nin
Performance
LatencyTolerance
+2Cycles +14Cycles
0
5
10
15
20
25
LatencyToleranceofSS
Application(Cycles)
Time
(BDI) (SC)
GPU Latency Tolerating Ability

• Introduction and Background
• Motivation for L1 cache compression in GPUs
• LATTE-CC: Latency Tolerance Aware Cache Compression Management
• Methodology and Evaluation
• Conclusion
8/21
Outline
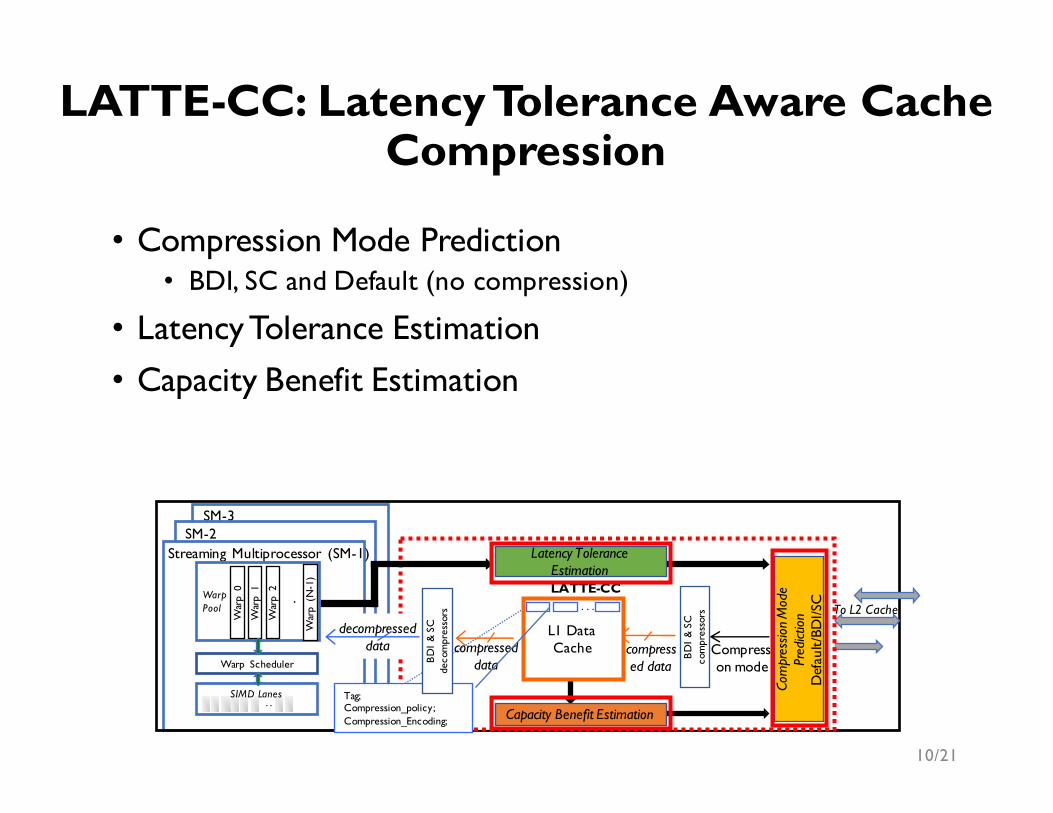
L1 Data CacheL1 Data
Cache
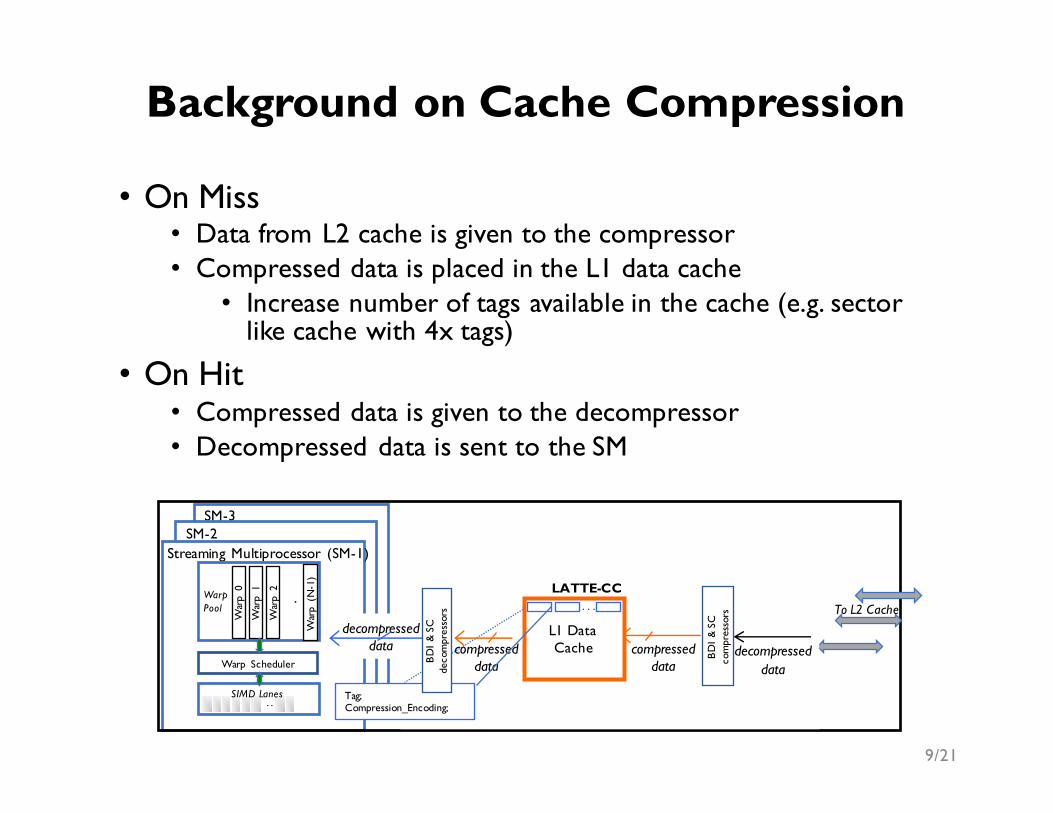
• On Miss• Data from L2 cache is given to the compressor• Compressed data is placed in the L1 data cache
• Increase number of tags available in the cache (e.g. sector like cache with 4x tags)
• On Hit• Compressed data is given to the decompressor• Decompressed data is sent to the SM
SM-3SM-2
Streaming Multiprocessor (SM-1)
To L2 CacheWar
p 0
War
p 1
War
p 2
War
p (N
-1)
WarpPool
.
. . .SIMD Lanes
Warp Scheduler
Com
pres
sion
Mod
e Pr
edic
tion
Def
ault
/BD
I/SC
decompressed data compressed
data
LATTE-CC
compressed data
Tag;Compression_Encoding;
BD
I &
SC
de
com
pres
sors
decompressed data
BD
I &
SC
co
mpr
esso
rs
L1 Data Cache
. . .
Background on Cache Compression
9/21
L1 Data CacheL1 Data
Cache
• Compression Mode Prediction• BDI, SC and Default (no compression)
• Latency Tolerance Estimation• Capacity Benefit Estimation
SM-3SM-2
Streaming Multiprocessor (SM-1)
To L2 CacheWar
p 0
War
p 1
War
p 2
War
p (N
-1)
WarpPool
.
. . .SIMD Lanes
Warp Scheduler
Com
pres
sion
Mod
e Pr
edic
tion
Def
ault
/BD
I/SC
decompressed data compress
ed data
LATTE-CC
compressed data
Tag;Compression_policy;Compression_Encoding;
BD
I &
SC
de
com
pres
sors
Compression mode
Latency Tolerance Estimation
BD
I &
SC
co
mpr
esso
rsCapacity Benefit Estimation
Com
pres
sion
Mod
e Pr
edict
ion
Def
ault/
BDI/S
C
L1 Data Cache
. . .
LATTE-CC: Latency Tolerance Aware Cache Compression
10/21

11/21
Combine latency tolerance, capacity benefit, and decompression latency into one metric èAMAT• Minimize Average Memory Access Time (AMAT)
Accommodate application phases• Divide execution time è multiple experimental phases
(EPs)
• Estimate AMAT of 3 compression modes at each EP
• Choose compression mode with lowest AMAT
LATTE-CC
Decompression Latency
Execution Time
EP-1 EP-m EP-m+1 . . . . . EP-(N)
Compression Mode Selection
12/21
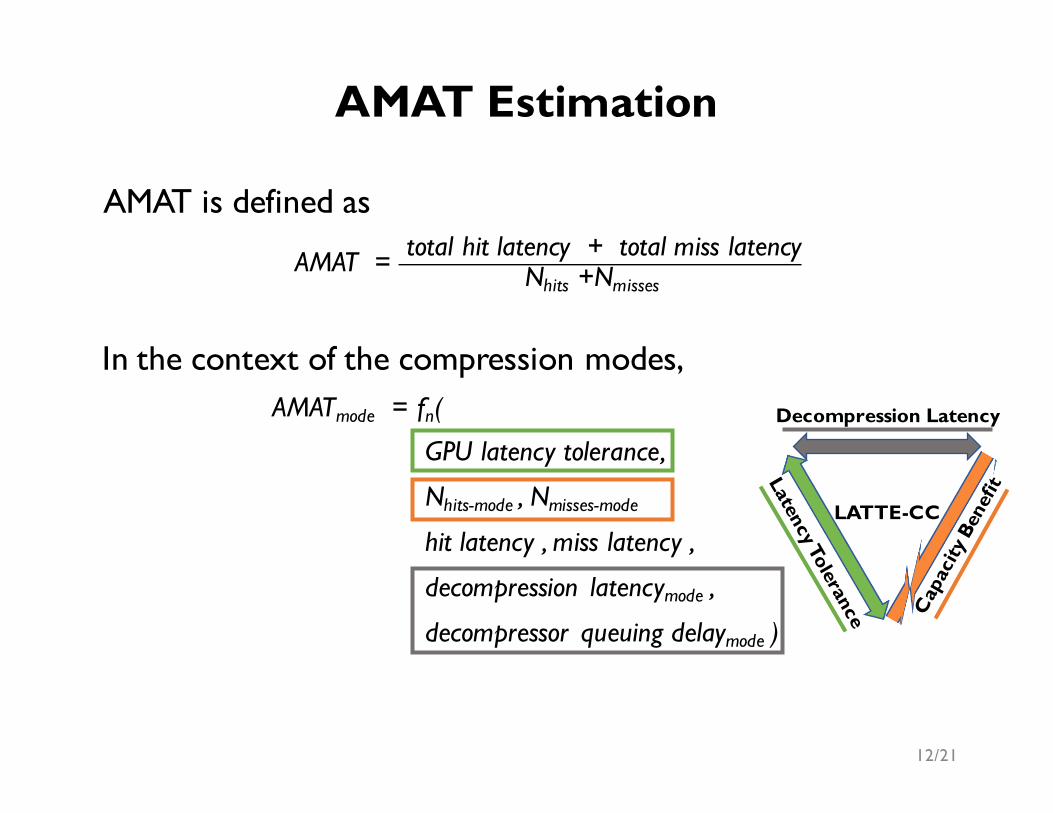
AMAT is defined as
AMAT = total hit latency + total miss latencyNhits +Nmisses
In the context of the compression modes,AMATmode = fn(
GPU latency tolerance,
Nhits-mode , Nmisses-mode
hit latency , miss latency ,
decompression latencymode ,
decompressor queuing delaymode )
LATTE-CC
Decompression Latency
AMAT Estimation
LATTE-CC
Decompression Latency
13/21
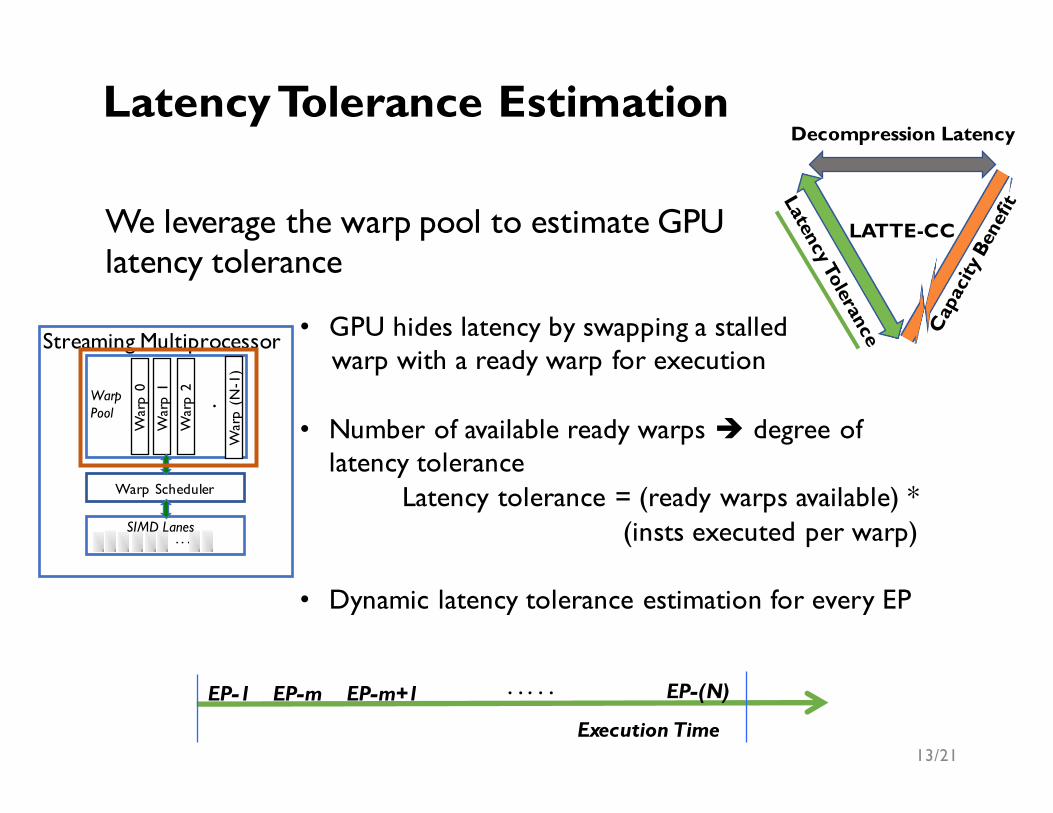
We leverage the warp pool to estimate GPU latency tolerance
Streaming Multiprocessor
War
p 0
War
p 1
War
p 2
War
p (N
-1)
WarpPool
.
. . .SIMD Lanes
Warp Scheduler
• GPU hides latency by swapping a stalled warp with a ready warp for execution
• Number of available ready warps è degree of latency tolerance
Latency tolerance = (ready warps available) * (insts executed per warp)
• Dynamic latency tolerance estimation for every EP
Latency Tolerance Estimation
Execution Time
EP-1 EP-m EP-m+1 . . . . . EP-(N)
LATTE-CC
Decompression Latency
14/21[1] Quereshi et al. “A case for MLP-aware cache replacement” in ISCA 2006
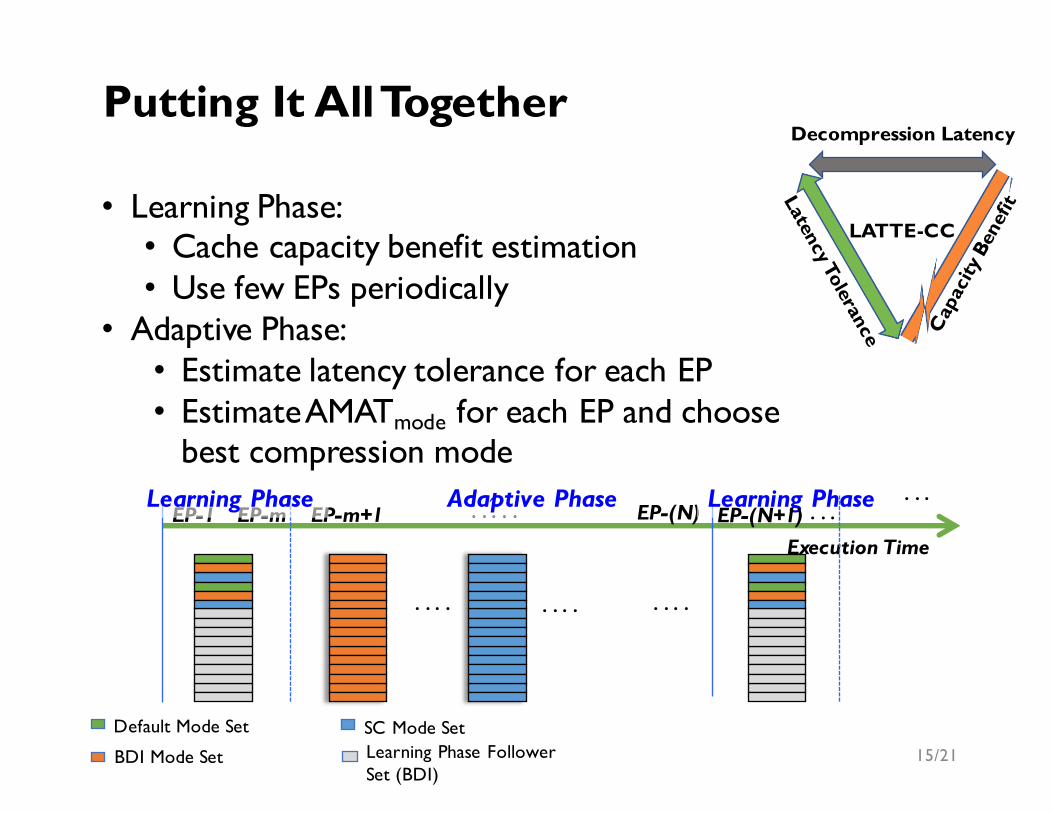
Adaptive Phase
Execution TimeEP-1 EP-m EP-m+1 . . . . . EP-(N)Learning Phase
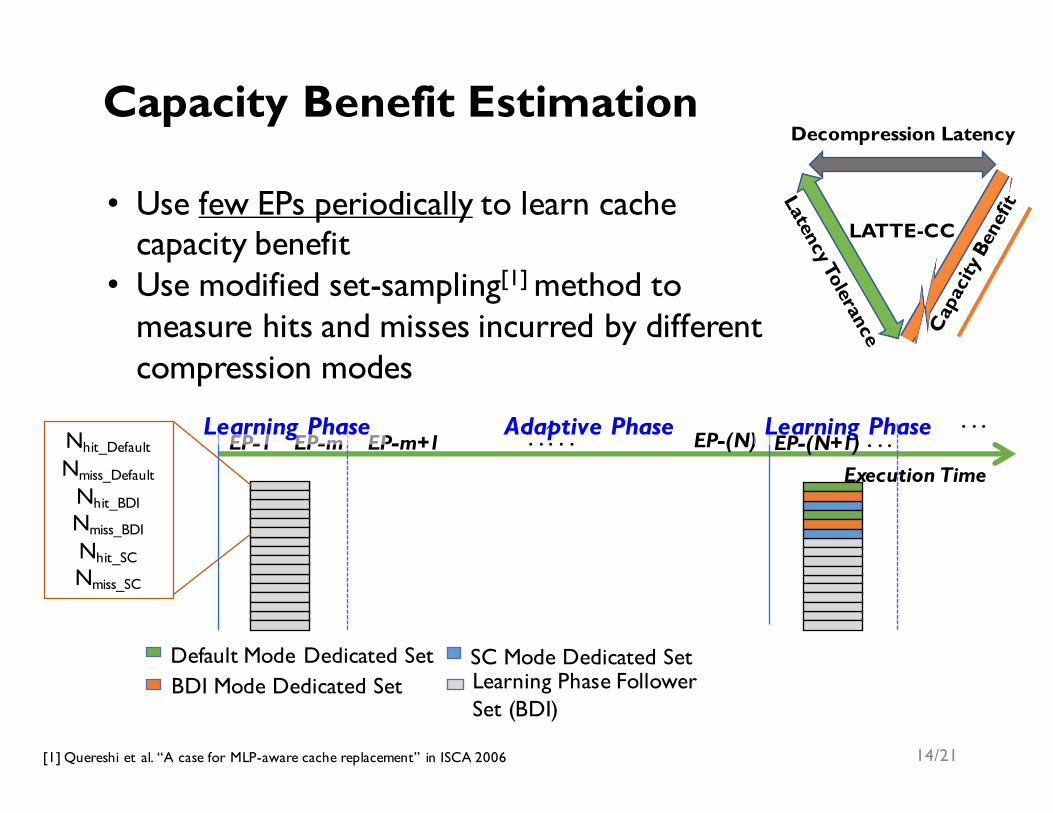
Default Mode Dedicated SetBDI Mode Dedicated Set
SC Mode Dedicated SetLearning Phase Follower Set (BDI)
• Use few EPs periodically to learn cache capacity benefit
• Use modified set-sampling[1] method to measure hits and misses incurred by different compression modes
Learning Phase . . . EP-(N+1) . . . Nhit_Default
Nmiss_Default
Nhit_BDI
Nmiss_BDI
Nhit_SC
Nmiss_SC
Capacity Benefit Estimation
15/21
Execution TimeEP-1 EP-m EP-m+1 . . . . . EP-(N)
. . . . . . . . . . . .
Default Mode Set
BDI Mode Set
SC Mode SetLearning Phase Follower Set (BDI)
Adaptive PhaseLearning Phase Learning Phase . . . EP-(N+1) . . .
• Learning Phase: • Cache capacity benefit estimation• Use few EPs periodically
• Adaptive Phase:• Estimate latency tolerance for each EP• Estimate AMATmode for each EP and choose
best compression mode
Putting It All Together
LATTE-CC
Decompression Latency

• Introduction and Background
• Motivation for L1 cache compression in GPUs
• LATTE-CC: Latency Tolerance Aware Cache Compression Management
• Methodology and Evaluation
• Conclusion
16/21
Outline

17/21
• GPU parameters• 15 SMs• 16 kB L1D cache • 768 kB L2 cache • GTO warp scheduler
[1] Che et al. “Rodinia: A benchmark suite for heterogeneous computing” in IISWC 2009[2] He et al. “Mars: A mapreduce framework on graphics processors” in PACT 2008[3] Che et al. “Pannotia: Understanding irregular GPGPU graph applications” in IISWC 2013[4] NVIDIA, “CUDA C/C++ SDK code samples
Methodology
• LATTE-CC cache parameters• 4x Tags• EP – 256 accesses• Compression & Decompression
Latency• BDI – 2 / 2 Cycles• SC – 6 / 14 Cycles
• GPUWattch• Compression & decompression
energy• BDI – 0.192 / 0.056 nJ• SC – 0.42 / 0.336 nJ
• Benchmarks• 22 benchmarks from Rodinia[1],
Mars[2], Pannotia[3], and CUDA SDK[4]
• 11 cache sensitive (C-Sens) and 11 cache insensitive (C-InSens)
0.6
0.8
1
1.2
1.4
1.6BF
S
KM PF SS
MM BC MIS
CLR FW PRK
DJK
C-Sens
Spee
dup
over
Bas
elin
e
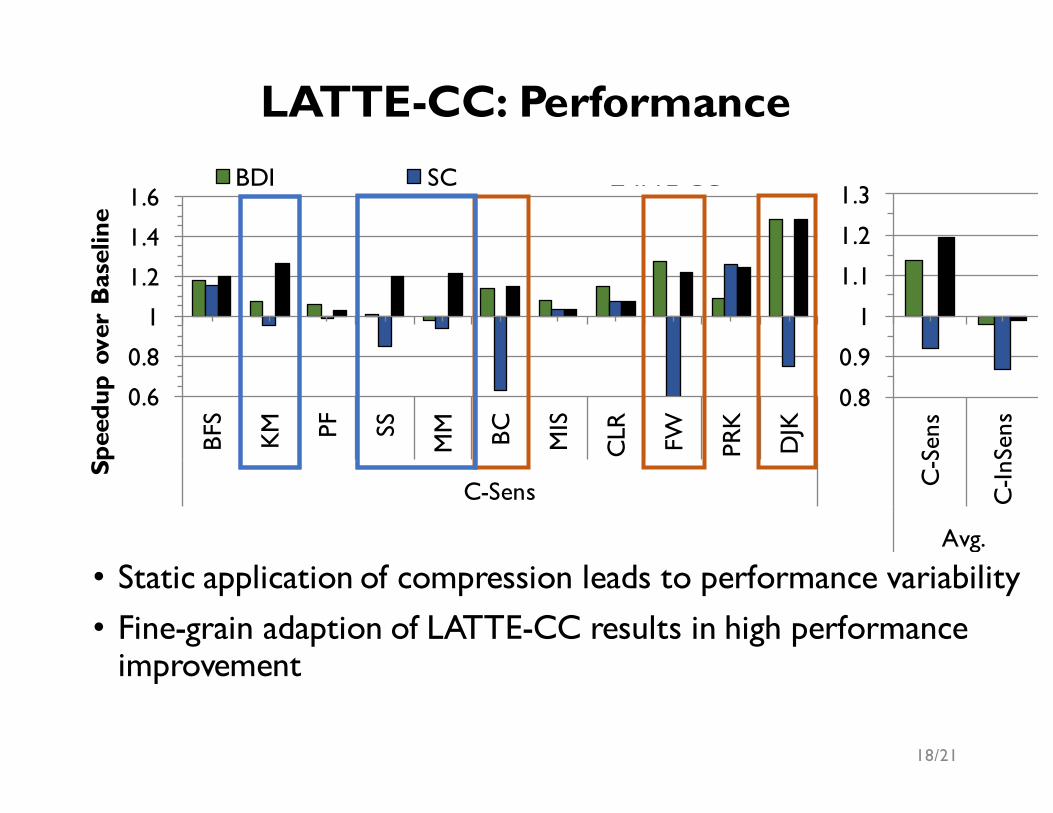
BDI SC LATTE-CC
0.8
0.9
1
1.1
1.2
1.3
C-S
ens
C-In
Sens
Avg.
• Static application of compression leads to performance variability• Fine-grain adaption of LATTE-CC results in high performance
improvement
18/21
LATTE-CC: Performance
0102030
LATT
E-C
C
Ada
ptiv
e-H
it-C
ount
Ada
ptiv
e-C
MP
Reduction in Misses (%)
1
1.1
1.2
LATT
E-C
C
Ada
ptiv
e-H
it-C
ount
Ada
ptiv
e-C
MP
Speedup
Spee
dup
over
Bas
elin
e
MPK
I R
educ
tion
over
Ba
selin
e (%
)
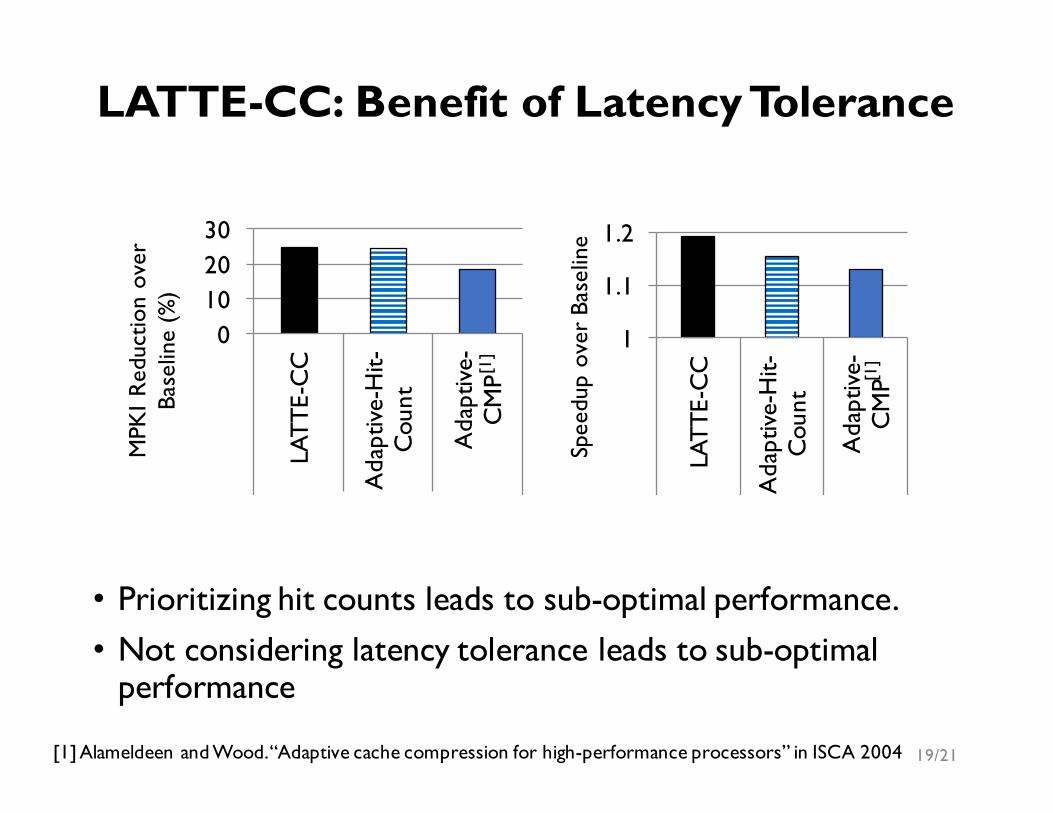
• Prioritizing hit counts leads to sub-optimal performance.• Not considering latency tolerance leads to sub-optimal
performance
19/21[1] Alameldeen and Wood. “Adaptive cache compression for high-performance processors” in ISCA 2004
[1]
[1]
LATTE-CC: Benefit of Latency Tolerance
-5
0
5
10
15
20BF
S
KM PF SS
MM BC MIS
CLR FW PRK
DJK
C-S
ens
C-Sens Avg
LA
TT
E-C
C E
nerg
y R
educ
tion
Com
pare
d to
B
asel
ine
(%)
Data Movement Energy Static EnergyL2 Cache Energy DRAM EnergyOther Energy Compr Energy
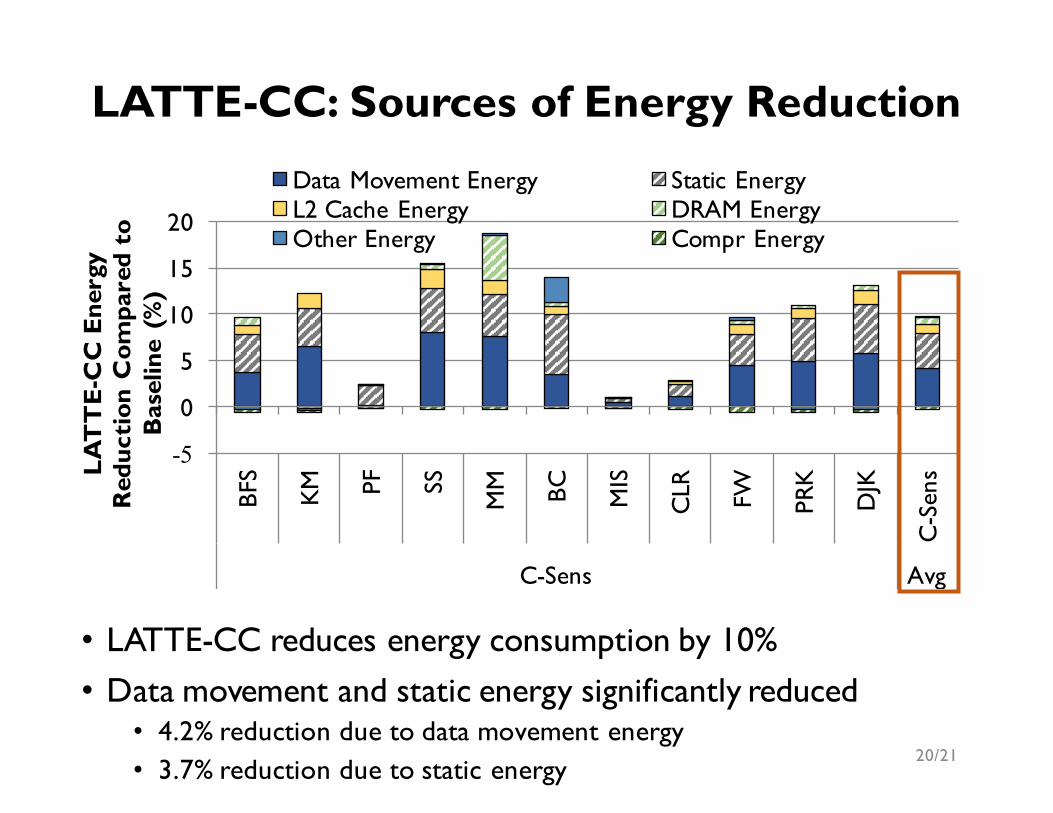
• LATTE-CC reduces energy consumption by 10%• Data movement and static energy significantly reduced
• 4.2% reduction due to data movement energy• 3.7% reduction due to static energy
20/21
LATTE-CC: Sources of Energy Reduction

21/21
• This is the first work to explore cache compression for GPUs• GPU workloads are compression friendly (2x – 3.6x compression ratio)• Decompression latency is hidden by variable extents• To maximize compression benefit, an adaptive compression management
system is needed
• We proposed LATTE-CC to:• Exploit GPU latency tolerance • Perform efficient cache compression on GPU L1 caches
• LATTE-CC achieves • 20% performance improvement• 10% energy reduction
Conclusion

LATTE-CC: Latency Tolerance Aware Adaptive Cache Compression Management for Energy
Efficient GPUs
Akhil Arunkumar, Shin-Ying Lee, Vignesh Soundararajan, Carole-Jean WuSchool of Computing, Informatics and Decision Systems Engineering
Arizona State University
24th IEEE International Symposium on High-Performance Computer Architecture
Thank you


















