
Large Scale Recognition and Retrieval. What does the world look like? High level image statistics...
26
Large Scale Recognition and Retrieval
-
Upload
emory-butler -
Category
Documents
-
view
217 -
download
0
Transcript of Large Scale Recognition and Retrieval. What does the world look like? High level image statistics...

Large Scale Recognition
and Retrieval

What does the world look like?
High level image statisticsObject Recognition for large-scale search
Focus on scaling rather than understanding image
Scaling to billions of images

Content-Based Image Retrieval
• Variety of simple/hand-designed cues:– Color and/or Texture histograms, Shape, PCA, etc.
• Various distance metrics– Earth Movers Distance (Rubner et al. ‘98)
• QBIC from IBM (1999)• Blobworld, Carson et al. 2002

Some vision techniques for large scale recognition
• Efficient matching methods– Pyramid Match Kernel
• Learning to compare images– Metrics for retrieval
• Learning compact descriptors

Some vision techniques for large scale recognition
• Efficient matching methods– Pyramid Match Kernel
• Learning to compare images– Metrics for retrieval
• Learning compact descriptors

Matching features incategory-level recognition

Comparing sets of local features
Previous strategies: • Match features individually,
vote on small sets to verify [Schmid, Lowe, Tuytelaars et al.]
• Explicit search for one-to-one correspondences
[Rubner et al., Belongie et al., Gold & Rangarajan, Wallraven & Caputo, Berg et al., Zhang et al.,…]
• Bag-of-words: Compare frequencies of prototype features
[Csurka et al., Sivic & Zisserman, Lazebnik & Ponce]
Slide credit: Kristen Grauman
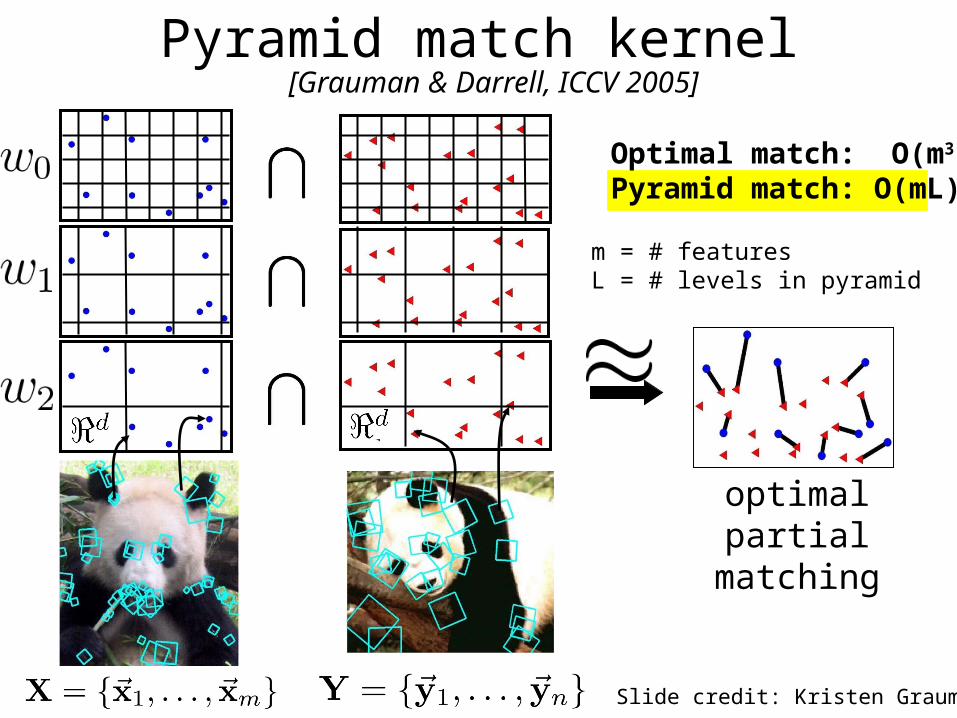
Pyramid match kernel
optimal partial matching
Optimal match: O(m3)Pyramid match: O(mL)
m = # featuresL = # levels in pyramid
[Grauman & Darrell, ICCV 2005]
Slide credit: Kristen Grauman

Pyramid match: main idea
descriptor space
Feature space partitions serve to “match” the local descriptors within successively wider regions.
Slide credit: Kristen Grauman

Pyramid match: main idea
Histogram intersection counts number of possible matches at a given partitioning.
Slide credit: Kristen Grauman

Computing the partial matching
• Earth Mover’s Distance[Rubner, Tomasi, Guibas 1998]
• Hungarian method[Kuhn, 1955]
• Greedy matching
…• Pyramid match
for sets with features of dimension
[Grauman and Darrell, ICCV 2005]

Recognition on the ETH-80R
eco
gn
itio
n a
ccu
racy
(%
)
Test
ing
tim
e (s
)
Mean number of features per set (m) Mean number of features per set (m)
ComplexityKernel
Pyramid match
Match [Wallraven et al.]
Slide credit: Kristen Grauman

wave sit down
Single View Human Action Recognition using Key Pose
Matching, Lv & Nevatia, 2007.
Spatio-temporal Pyramid Matching for Sports
Videos, Choi et al., 2008.
From Omnidirectional Images to Hierarchical
Localization, Murillo et al. 2007.
Pyramid match kernel: examples of extensions and applications by other groups
Action recognition Video indexing Robot localizationSlide : Kristen Grauman

Some vision techniques for large scale recognition
• Efficient matching methods– Pyramid Match Kernel
• Learning to compare images– Metrics for retrieval
• Learning compact descriptors

Learning how to compare images
dissimilar
similar
• Exploit (dis)similarity constraints to construct more useful distance function
• Number of existing techniques for metric learning
[Weinberger et al. 2004, Hertz et al. 2004, Frome et al. 2007, Varma & Ray 2007, Kumar et al. 2007]
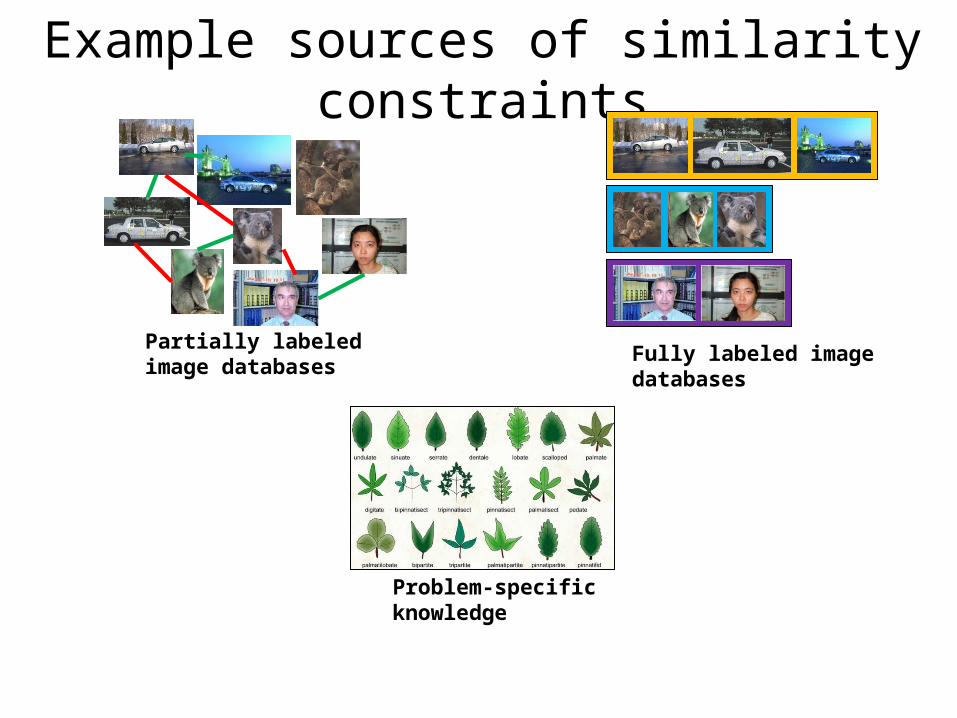
Example sources of similarity constraints
Partially labeled image databases
Fully labeled image databases
Problem-specific knowledge

Locality Sensitive Hashing (LSH)• Gionis, A. & Indyk, P. & Motwani, R. (1999)• Take random projections of data• Quantize each projection with few bits
0
1
0
10
1
101
Descriptor in high D space
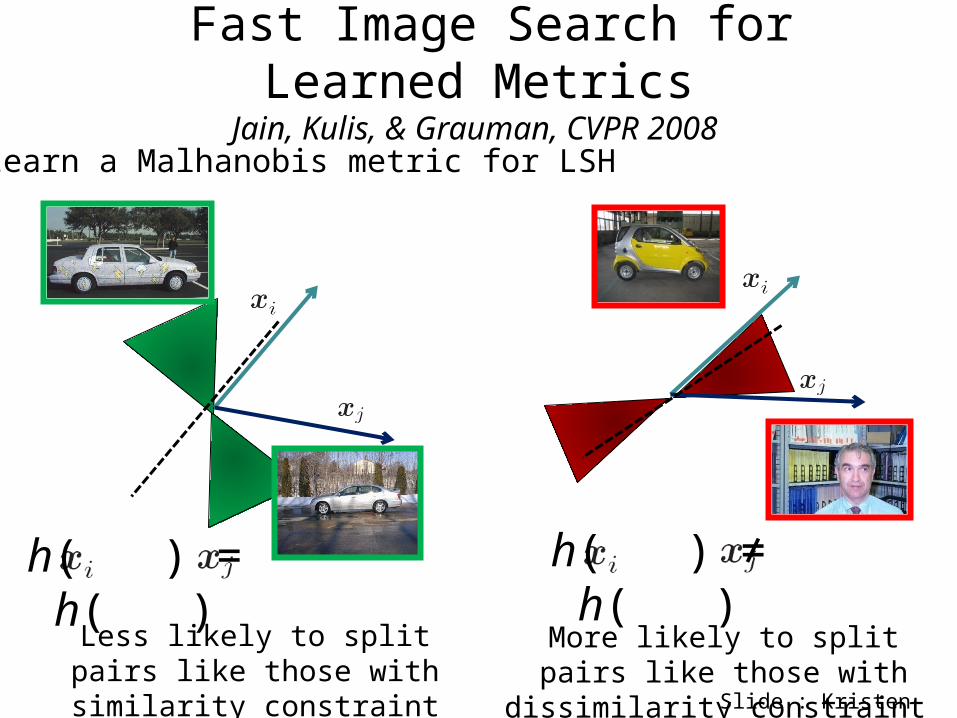
Fast Image Search for Learned MetricsJain, Kulis, & Grauman, CVPR 2008
Less likely to split pairs like those with similarity constraint
More likely to split pairs like those with dissimilarity constraint
h( ) = h( ) h( ) ≠ h( )
Slide : Kristen Grauman
Learn a Malhanobis metric for LSH
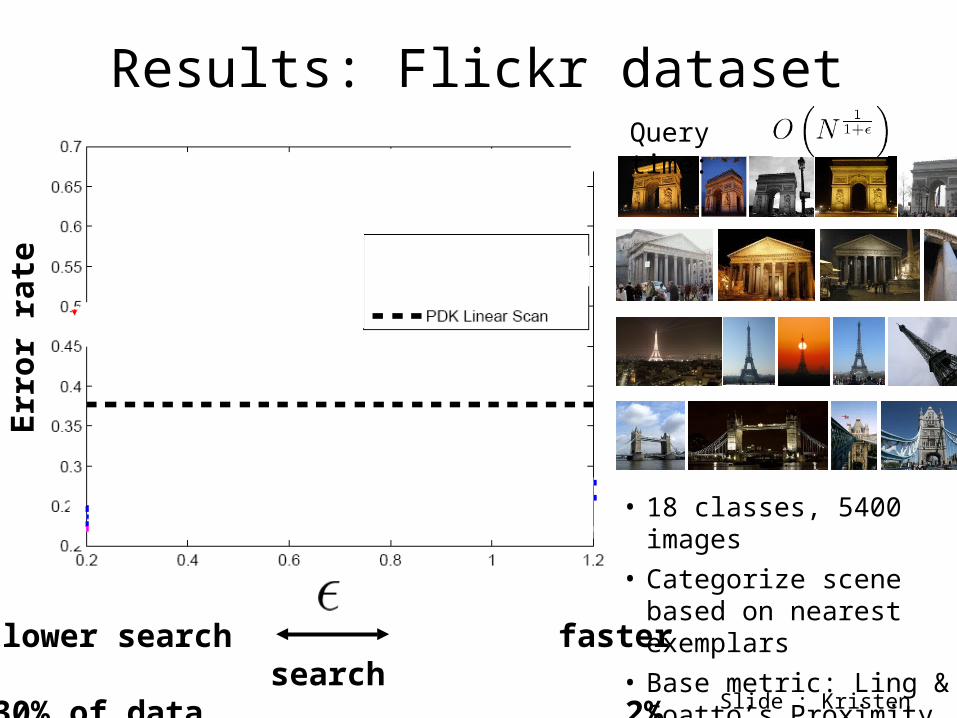
Results: Flickr dataset
slower search faster search30% of data 2% of data
Err
or
rate
• 18 classes, 5400 images
• Categorize scene based on nearest exemplars
• Base metric: Ling & Soatto’s Proximity Distribution Kernel (PDK)
Query time:
Slide : Kristen Grauman

Results: Flickr dataset
slower search faster search30% of data 2% of data
Err
or
rate
• 18 classes, 5400 images
• Categorize scene based on nearest exemplars
• Base metric: Ling & Soatto’s Proximity Distribution Kernel (PDK)
Query time:
Slide : Kristen Grauman

Some vision techniques for large scale recognition
• Efficient matching methods– Pyramid Match Kernel
• Learning to compare images– Metrics for retrieval
• Learning compact descriptors

Semantic Hashing
Address Space
Semantically similar images
Query address
Semantic
HashFunction
Query Image
Binary code
Images in database
[Salakhutdinov & Hinton, 2007] for text documents
Quite differentto a (conventional)randomizing hash

Exploring different choices of semantic hash function
Query Image
3. RBM
Compute Gist
Binary code
Gist descriptor
Image 1
Semantic Hash
Retrieved images <1ms
~1ms (in Matlab)
<10μs
2. BoostSSC1.LSH
Torralba, Fergus, Weiss, CVPR 2008

Learn mapping• Neighborhood Components Analysis [Goldberger et al., 2004] • Adjust model parameters to move:
– Points of SAME class closer
– Points of DIFFERENT class away
Points in code space
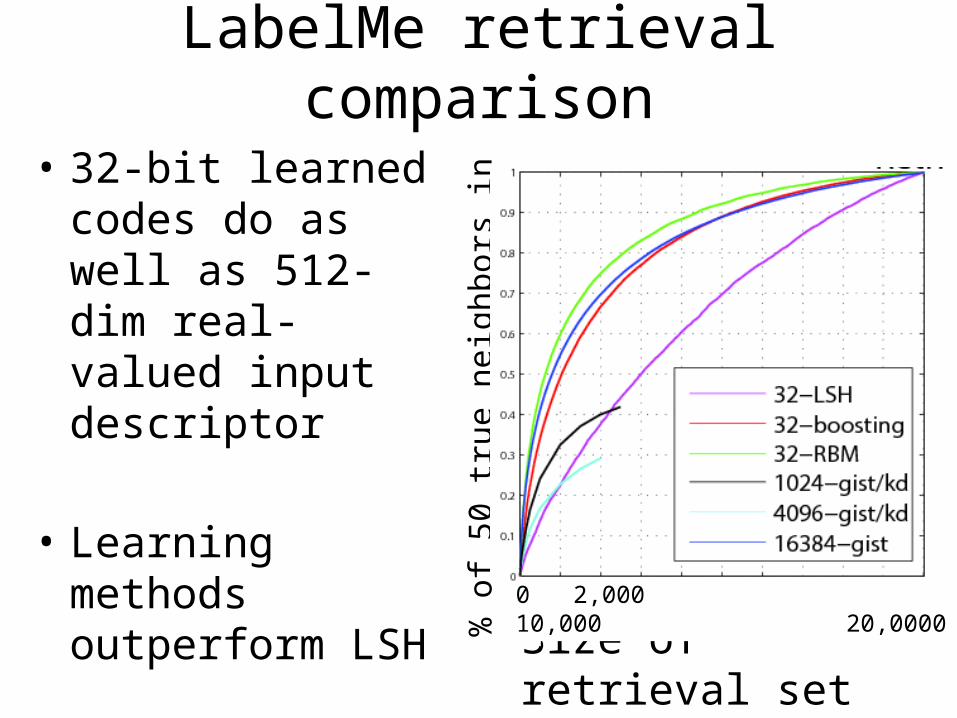
LabelMe retrieval comparison
Size of retrieval set % o
f 50
true
nei
ghbo
rs in
retr
ieva
l set
0 2,000 10,000 20,0000
• 32-bit learned codes do as well as 512-dim real-valued input descriptor
• Learning methods outperform LSH

Review: constructing a good metric from data
• Learn the metric from training data
• Two approaches that do this:• Jain, Kulis, & Grauman, CVPR 2008: Learn Malhanobis distance for LSH.• Torralba, Fergus, Weiss, CVPR 2008: Directly learn mapping from image to
binary code.
• Use Hamming distance (binary codes) for speed• Learning metric really helps over plain LSH• Learning only applied to metric, not representation


















