
Large-scale Matrix Factorizationkijungs/etc/10-405.pdf · Large-scale Matrix Factorization ......
99
Large-scale Matrix Factorization Kijung Shin Ph.D. Student, CSD
Transcript of Large-scale Matrix Factorizationkijungs/etc/10-405.pdf · Large-scale Matrix Factorization ......

Large-scale Matrix Factorization
Kijung Shin
Ph.D. Student, CSD

Roadmap•Matrix Factorization (review)
•Algorithms◦ Distributed SGD: DSGD
◦ Alternating Least Square: ALS
◦ Cyclic Coordinate Descent: CCD++
• Experiments
• Extension to Tensor Factorization
•Conclusions
Large-scale Matrix Factorization (by Kijung Shin) 2/99

Roadmap•Matrix Factorization (review) <<
•Algorithms◦ Distributed SGD: DSGD
◦ Alternating Least Square: ALS
◦ Cyclic Coordinate Descent: CCD++
• Experiments
• Extension to Tensor Factorization
•Conclusions
Large-scale Matrix Factorization (by Kijung Shin) 3/99

Matrix Factorization: Problem•Given:
◦ 𝑽: 𝑛 by 𝑚 matrix
▪possibly with missing values
◦ 𝑟: target rank (a scalar)
▪usually 𝑟 << 𝑛 and 𝑟 << 𝑚
Large-scale Matrix Factorization (by Kijung Shin) 4/99
𝑚
𝑛
?
?
?
?
𝑽

Matrix Factorization: Problem•Given:
◦ 𝑽: 𝑛 by 𝑚 matrix
▪possibly with missing values
◦ 𝑟: target rank (a scalar)
▪usually 𝑟 << 𝑛 and 𝑟 << 𝑚
• Find:◦ 𝑾: 𝑛 by 𝑟 matrix
◦ 𝑯: 𝑟 by 𝑚 matrix
▪without missing values
Large-scale Matrix Factorization (by Kijung Shin) 5/99
𝑛
𝑟
𝑚
𝑾
𝑯
𝑟

Matrix Factorization: Problem•Goal: 𝑾𝑯 ≈ 𝑽
Large-scale Matrix Factorization (by Kijung Shin) 6/99
𝑾
𝑯
𝑽
≈×?
?
?
?

Loss Function𝐿 𝑉,𝑊,𝐻
= σ 𝑖,𝑗 ∈𝑍 (𝑉𝑖𝑗 − 𝑊𝐻 𝑖𝑗)2 + …
Goal: to make 𝑾𝑯 similar to 𝑽
Large-scale Matrix Factorization (by Kijung Shin) 7/99
Indices ofnon-missing entries
i.e., 𝑖, 𝑗 ∈ 𝑍↔ 𝑉𝑖𝑗 is not missing
(𝑖, 𝑗)-th entry of 𝑊𝐻
(𝑖, 𝑗)-th entry of 𝑉

Loss Function (cont.)𝐿 𝑉,𝑊,𝐻
= σ 𝑖,𝑗 ∈𝑍 (𝑉𝑖𝑗 − 𝑊𝐻 𝑖𝑗)2
+ 𝜆( 𝑊 𝐹2 + 𝐻 𝐹
2)
Goal: to prevent overfitting
(by making the entries of 𝑊 and 𝐻 close to zero)
Large-scale Matrix Factorization (by Kijung Shin) 8/99
Regularization parameter
Frobenius Norm:
𝑊 𝐹2 =
𝑖=1
𝑛
𝑘=1
𝑟
𝑊𝑖𝑘2

Algorithms•How can we minimize this loss function 𝐿?
◦ Stochastic Gradient Descent: SGD (covered in the last lecture)
◦ Alternating Least Square: ALS (covered today)
◦ Cyclic Coordinate Descent: CCD++ (covered today)
•Are these algorithms parallelizable?
• Yes, all of them!
Large-scale Matrix Factorization (by Kijung Shin) 9/99

Roadmap•Matrix Factorization (review)
•Algorithms◦ Distributed SGD: DSGD <<
◦ Alternating Least Square: ALS
◦ Cyclic Coordinate Descent: CCD++
• Experiments
• Extension to Tensor Factorization
•Conclusions
Large-scale Matrix Factorization (by Kijung Shin) 10/99

Distributed SGD (DSGD)
Large-scale matrix factorizationwith distributed
stochastic gradient descent(KDD 2011)
Large-scale Matrix Factorization (by Kijung Shin) 11/99
Rainer Gemulla, Erik Nijkamp, Peter J. Haas, and Yannis Sismanis

Stochastic GD for MF (review)
• Let 𝑊 =
− 𝑊1: −
:− 𝑊𝑛: −
, 𝐻 =
| |𝐻:1 … 𝐻:𝑚| |
•𝐿 𝑉,𝑊,𝐻 : sum of loss for each non-missing entry
𝐿 𝑉,𝑊,𝐻 =
𝑖,𝑗 ∈𝑍
𝐿′ 𝑉𝑖𝑗 ,𝑊𝑖:, 𝐻:𝑗
where loss at each non-missing entry 𝑉𝑖𝑗 is
𝐿′ 𝑉𝑖𝑗 ,𝑊𝑖:, 𝐻:𝑗 ≔ 𝑉𝑖𝑗 −𝑊𝑖:𝐻:𝑗2+ 𝜆
𝑊𝑖:2
𝑁𝑖:+
𝐻:𝑗2
𝑁:𝑗
Large-scale Matrix Factorization (by Kijung Shin) 12/99
= 𝑊𝐻 𝑖𝑗
Number of non-missing entries in the 𝑖-th row of 𝑉

Stochastic GD for MF (cont.)• Stochastic Gradient Descent (SGD) for MF
• repeat until convergence◦ randomly shuffle the non-missing entries of 𝑉
◦ for each non-missing entry:
▪perform an SGD step on it
Large-scale Matrix Factorization (by Kijung Shin) 13/99

Stochastic GD for MF (cont.)•An SGD step on each non-missing entry 𝑉𝑖𝑗:
◦ Read 𝑊𝑖: and 𝐻:𝑗
◦ Compute gradient of 𝐿′ 𝑉𝑖𝑗 ,𝑊𝑖:, 𝐻:𝑗◦ Update 𝑊𝑖: and 𝐻:𝑗▪Detailed update rules were
covered in the last lecture
Large-scale Matrix Factorization (by Kijung Shin) 14/99
𝑽𝑾
𝑯
𝑉𝑖𝑗𝑊𝑖:
𝐻:𝑗

Simple Parallel SGD for MF• Parameter Mixing: MSGD
◦ entries of 𝑉 are distributed across multiple machines
Large-scale Matrix Factorization (by Kijung Shin) 15/99
Machine 1 Machine 2 Machine 3
𝑽 𝑽 𝑽

Simple Parallel SGD for MF (cont.)• Parameter Mixing: MSGD
◦ entries of 𝑉 are distributed across multiple machines
◦ Map step: each machine runs SGD independently on the assigned entries until convergence
Large-scale Matrix Factorization (by Kijung Shin) 16/99
Machine 1 Machine 2 Machine 3
𝑽
𝑾
𝑯
𝑽
𝑾
𝑯
𝑽
𝑾
𝑯

• Parameter Mixing: MSGD◦ Map step: each machine runs
▪an independent instance of SGD on subsets of the data
▪until convergence
◦ Reduce step: average results (i.e., 𝑾 and 𝑯)
• Problem: does not converge to correct solutions◦ no guarantee that “the average” reduces the loss function 𝐿
Large-scale Matrix Factorization (by Kijung Shin) 17/99
Simple Parallel SGD for MF (cont.)
𝑯𝑯 𝑯 𝑯+ +
←
Machine 1 Machine 2 Machine 3
3

Simple Parallel SGD for MF (cont.)• Iterative Parameter Mixing: ISGD
◦ entries of 𝑉 are distributed across multiple machines
◦ Repeat until convergence
▪Map step: each machine runs SGD independently on the assigned entries for some time
▪Reduce step:
◦ average results (i.e., 𝑾 and 𝑯)
◦ broadcast averaged results
• Problem: slow convergence◦ still has the averaging step
Large-scale Matrix Factorization (by Kijung Shin) 18/99

Interchangeability•How can we avoid the averaging step?
◦ let different machines update different entries of W and 𝐻
• Two entries 𝑉𝑖𝑗 and 𝑉𝑘𝑙 of 𝑽 are interchangeable if they share neither row nor column
Large-scale Matrix Factorization (by Kijung Shin) 19/99
𝑽𝑾
𝑯
𝑉𝑖𝑗𝑊𝑖:
𝐻:𝑗
𝑉𝑖𝑙
𝐻:𝑙Not interchangeable!
𝑽𝑾
𝑯
𝑉𝑖𝑗𝑊𝑖:
𝐻:𝑗
𝑉𝑘𝑙
𝐻:𝑙
𝑊𝑘:
Interchangeable!

Interchangeability (cont.)• If 𝑉𝑖𝑗 and 𝑉𝑘𝑙 are interchangeable,
• SGD steps on 𝑉𝑖𝑗 and 𝑉𝑘𝑙 can be parallelized safely
Large-scale Matrix Factorization (by Kijung Shin) 20/99
Read 𝑊𝑖: and 𝐻:𝑗Compute gradient of 𝐿′ 𝑊𝑖:, 𝐻:𝑗Update 𝑊𝑖: and 𝐻:𝑗
Read 𝑊𝑘: and 𝐻:𝑙Compute gradient of 𝐿′ 𝑊𝑙:, 𝐻:𝑙Update 𝑊𝑘: and 𝐻:𝑙
no conflicts!
𝑽𝑾
𝑯
𝑉𝑖𝑗𝑊𝑖:
𝐻:𝑗
𝑉𝑘𝑙
𝐻:𝑙
𝑊𝑘:
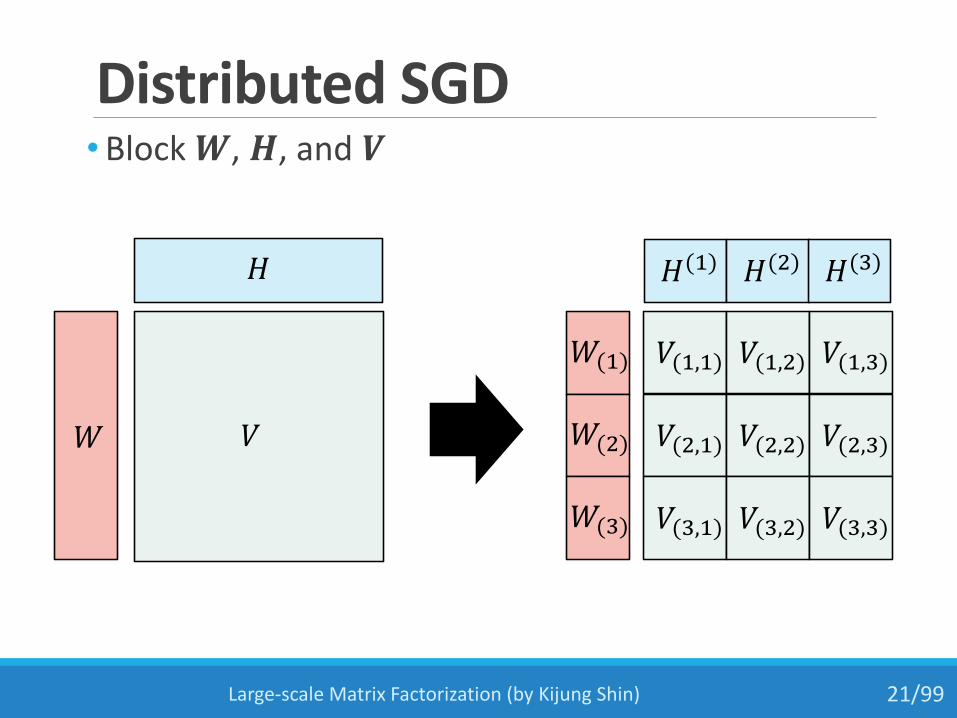
Distributed SGD •Block 𝑾, 𝑯, and 𝑽
Large-scale Matrix Factorization (by Kijung Shin) 21/99
𝑊(1)
𝑊(2)
𝑊(3)
𝐻(1) 𝐻(2) 𝐻(3)
𝑉(1,1) 𝑉(1,2) 𝑉(1,3)
𝑉(2,1) 𝑉(2,2) 𝑉(2,3)
𝑉(3,1) 𝑉(3,2) 𝑉(3,3)
𝑊
𝐻
𝑉

Distributed SGD (cont.) •Block 𝑾, 𝑯, and 𝑽
• repeat until convergence◦ for a set of interchangeable blocks of 𝑉
▪1. run SGD on the blocks in parallel
◦ no conflict between machines
▪2. merge results (i.e., 𝑾 and 𝑯)
◦ averaging is not needed
Large-scale Matrix Factorization (by Kijung Shin) 22/99
𝑊(1)
𝑊(2)
𝑊(3)
𝐻(1) 𝐻(2) 𝐻(3)
𝑉(1,1)
𝑉(2,2)
𝑉(3,3)Blocks on a diagonal are interchangeable!

Interchangeable Blocks• Example of interchangeable blocks
Large-scale Matrix Factorization (by Kijung Shin) 23/99
𝑊(1)
𝑊(2)
𝑊(3)
𝐻(1) 𝐻(2) 𝐻(3)
𝑉(1,1)
𝑉(2,2)
𝑉(3,3)
Machine 1 Machine 2
Machine 3Blocks are interchangeable!
𝑊(1)
𝐻(1)
𝑉(1,1) 𝑊(2)
𝐻(2)
𝑉(2,2)
𝑊(3)
𝐻(3)
𝑉(3,3)

Interchangeable Blocks (cont.)• Example of interchangeable blocks
Large-scale Matrix Factorization (by Kijung Shin) 24/99
𝑊(1)
𝑊(2)
𝑊(3)
𝐻(1) 𝐻(2) 𝐻(3)
𝑉(1,2)
𝑉(2,3)
𝑉(3,1)
𝑊(1)
𝐻(2)
𝑉(1,2) 𝑊(2)
𝐻(3)
𝑉(2,3)
𝑊(3)
𝐻(1)
𝑉(3,1)
Machine 1 Machine 2
Machine 3Blocks are interchangeable!

Interchangeable Blocks (cont.)• Example of interchangeable blocks
Large-scale Matrix Factorization (by Kijung Shin) 25/99
𝑊(1)
𝑊(2)
𝑊(3)
𝐻(1) 𝐻(2) 𝐻(3)
𝑉(1,3)
𝑉(2,1)
𝑉(3,2)
𝑊(1)
𝐻(3)
𝑉(1,3) 𝑊(2)
𝐻(1)
𝑉(2,1)
𝑊(3)
𝐻(2)
𝑉(3,2)
Machine 1 Machine 2
Machine 3Blocks are interchangeable!

Interchangeable Blocks (cont.)•Not interchangeable blocks
◦ Not used in DSGD
Large-scale Matrix Factorization (by Kijung Shin) 26/99
𝑊(1)
𝑊(2)
𝑊(3)
𝐻(1) 𝐻(2) 𝐻(3)
𝑉(1,3)
𝑉(2,3)
𝑉(3,2)
Blocks are not interchangeable!
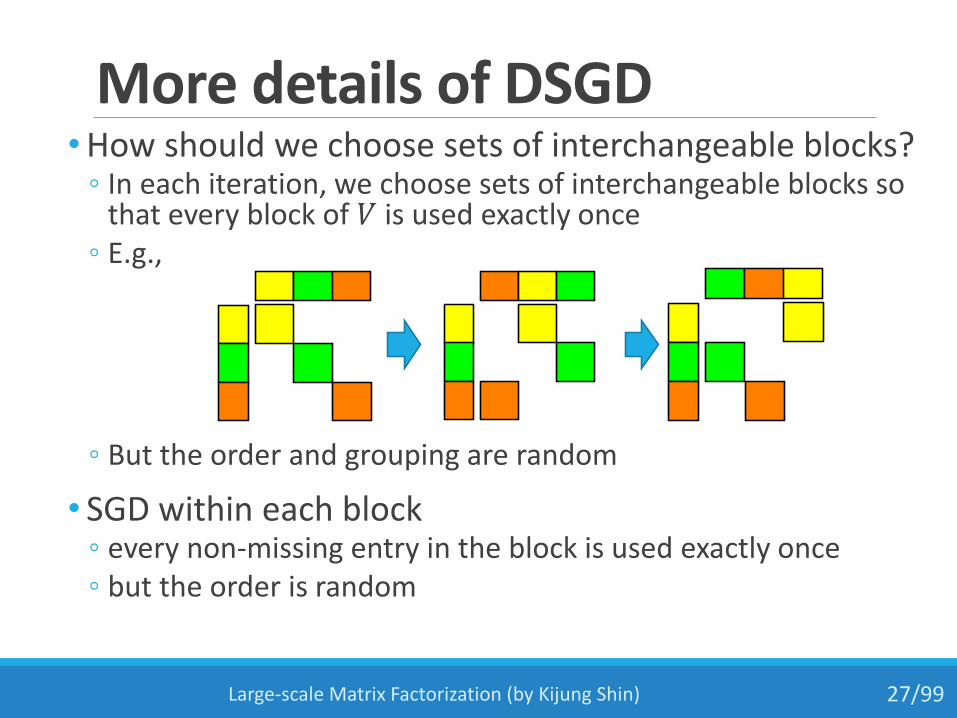
More details of DSGD•How should we choose sets of interchangeable blocks?
◦ In each iteration, we choose sets of interchangeable blocks so that every block of 𝑉 is used exactly once
◦ E.g.,
◦ But the order and grouping are random
• SGD within each block◦ every non-missing entry in the block is used exactly once ◦ but the order is random
Large-scale Matrix Factorization (by Kijung Shin) 27/99

More details of DSGD (cont.)•Use “bold driver” to set step size (or learning rate)
◦ After each iteration,
▪ increase the step size if the loss decreases
▪decrease the step size if the loss increases
• Implemented Hadoop and R/Snowfall◦ Snowfall: package for parallel R programs
◦ https://cran.r-project.org/web/packages/snowfall/index.html
Large-scale Matrix Factorization (by Kijung Shin) 28/99

Pros & Cons of DSGD• Pros:
◦ Faster convergence than MSGD and ISGD▪no averaging step
◦ Memory efficiency: each machine needs to maintain a single block of W and a single block of H in memory
•Cons:◦ Many hyperparameters: step size (𝜖) in addition to
regularization parameter (𝜆) and rank (𝑟)
Large-scale Matrix Factorization (by Kijung Shin) 29/99
𝑊(1)
𝐻(1)
𝑉(1,1) 𝑊(2)
𝐻(2)
𝑉(2,2) 𝑊(3)
𝐻(3)
𝑉(3,3)
Machine 1 Machine 2 Machine 3

Roadmap•Matrix Factorization (review)
•Algorithms◦ Distributed SGD: DSGD
◦ Alternating Least Square: ALS <<
◦ Cyclic Coordinate Descent: CCD++
• Experiments
• Extension to Tensor Factorization
•Conclusions
Large-scale Matrix Factorization (by Kijung Shin) 30/99

Alternating Least Square
Large-scale Parallel Collaborative Filtering for the Netflix Prize
(AAIM 2008)
Large-scale Matrix Factorization (by Kijung Shin) 31/99
Yunhong Zhou, Dennis Wilkinson, Robert Schreiber and Rong Pan

Main Idea behind ALS•How hard is matrix factorization?
◦ i.e., finding argmin𝑾,𝑯
𝐿(𝑉,𝑊,𝐻)
• Solving the entire problem is difficult◦ 𝐿 𝑉,𝑊,𝐻 is a non-convex function of 𝑾 and 𝑯
▪many local optima
◦ finding a global optimum is NP-hard
Large-scale Matrix Factorization (by Kijung Shin) 32/99

Main Idea behind ALS (cont.)•How hard is solving a smaller problem?
◦ Specifically, findingargmin
𝑯𝐿(𝑉,𝑊,𝐻)
while fixing 𝑾 to its current value
•Much easier!◦ 𝐿 𝑉,𝑊,𝐻 is a convex function of 𝑯 (once 𝑾 is fixed)
▪one local optimum, which is also globally optimal
◦ Moreover, there exists the closed-form solution
▪we can direct compute the global optimum
Large-scale Matrix Factorization (by Kijung Shin) 33/99

Updating H• Finding
argmin𝑯
𝐿(𝑉,𝑊,𝐻)
while fixing 𝑾 to its current value
• This problem is solved by the following update rule
◦ derived from 𝜕𝐿
𝜕𝐻𝑘𝑗= 0, ∀𝑘, ∀𝑗 (first-order condition)
Large-scale Matrix Factorization (by Kijung Shin) 34/99
For j = 1…𝑚
𝐻:𝑗 ←
𝑖∈𝑍:𝑗
𝑊𝑖: 𝑊𝑖:𝑇 + 𝜆𝐼𝑘
−1
𝑖∈𝑍:𝑗
𝑉𝑖𝑗𝑊𝑖:
row indices of non-missing entries in the 𝑗-th column of 𝑽
𝑘 by 𝑘 identity matrix

Updating W• Likewise, finding
argmin𝑾
𝐿(𝑉,𝑊,𝐻)
while fixing 𝑯 to its current value
• This problem is solved by the following update rule
◦ derived from 𝜕𝐿
𝜕𝑊𝑖𝑘= 0, ∀𝑖, ∀𝑘 (first-order condition)
Large-scale Matrix Factorization (by Kijung Shin) 35/99
For i = 1…𝑛
𝑊𝑖: ←
𝑖∈𝑍𝑖:
𝐻:𝑗𝑇𝐻:𝑗 + 𝜆𝐼𝑘
−1
𝑗∈𝑍𝑖:
𝑉𝑖𝑗𝐻:𝑗
column indices of non-missing entries in the 𝑖-th row of 𝑽

Alternating Least Square (ALS)randomly Initialize 𝑾 and 𝑯
repeat until convergenceupdate 𝑾 while fixing 𝑯 to its current value
update 𝑯 while fixing 𝑾 to its current value
Large-scale Matrix Factorization (by Kijung Shin) 36/99
• Each step never increases 𝐿 𝑉,𝑊,𝐻◦ 𝑾 is updated to the “best” 𝑾 that minimizes 𝐿 𝑉,𝑊,𝐻
for current 𝑯◦ 𝑯 is updated to the “best” 𝑯 that minimizes 𝐿 𝑉,𝑊,𝐻
for current 𝑾
•𝐿 𝑉,𝑊,𝐻 monotonically decreases until convergence

Parallel ALS: Idea•Recall the update rule for each 𝑗-th column of 𝑯
Large-scale Matrix Factorization (by Kijung Shin) 37/99
𝐻:𝑗 ←
𝑖∈𝑍:𝑗
𝑊𝑖: 𝑊𝑖:𝑇 + 𝜆𝐼𝑘
−1
𝑖∈𝑍:𝑗
𝑉𝑖𝑗𝑊𝑖:
𝑽𝑾
𝑯
𝑉:𝑗
𝐻:𝑗Read Written
𝑽𝑾
𝑯

Parallel ALS: Idea (cont.)• Potentially every entry of 𝑾 needs to be read
• Only the 𝑗-th column of 𝑽 needs to be read
• 𝑯 does not need to be read⇒ can update the columns of 𝑯 independently in parallel
Large-scale Matrix Factorization (by Kijung Shin) 38/99
𝑽𝑾
𝑯
𝑉:𝑗
𝐻:𝑗Read Written
𝑽𝑾
𝑯

Updating H in Parallel•A toy example with 3 machines
• 1. Divide 𝑽 column-wise into 3 pieces
Large-scale Matrix Factorization (by Kijung Shin) 39/99
𝑽(𝟏) 𝑽(𝟐) 𝑽(𝟑)𝑾

Updating H in Parallel (cont.)
Large-scale Matrix Factorization (by Kijung Shin) 40/99
• 2. Distribute the pieces across the machines
• 3. 𝑾 is broadcast to every machine
𝑽(𝟏) 𝑽(𝟐) 𝑽(𝟑)𝑾 𝑾 𝑽(𝟏) 𝑾 𝑽(𝟐) 𝑾 𝑽(𝟑)
Machine 1 Machine 2 Machine 3

Updating H in Parallel (cont.)
Large-scale Matrix Factorization (by Kijung Shin) 41/99
• 4. Compute the corresponding columns of 𝑯 in parallel
𝑽(𝟏) 𝑽(𝟐) 𝑽(𝟑)𝑾 𝑾 𝑽(𝟏) 𝑾 𝑽(𝟐) 𝑾 𝑽(𝟑)
Machine 1 Machine 2 Machine 3
𝑯(𝟏) 𝑯(𝟐) 𝑯(𝟑)New! New! New!

Updating H in Parallel (cont.)
Large-scale Matrix Factorization (by Kijung Shin) 42/99
Machine 1 Machine 2 Machine 3
• 5. Broadcast the part of 𝑯 that each machine computes
𝑾 𝑽(𝟏) 𝑾 𝑽(𝟐) 𝑾 𝑽(𝟑)
𝑯(𝟏) 𝑯(𝟐) 𝑯(𝟑) 𝑯(𝟏) 𝑯(𝟐) 𝑯(𝟑) 𝑯(𝟏) 𝑯(𝟐) 𝑯(𝟑)

Parallel ALS: Idea•Recall the update rule for each row of 𝑾
Large-scale Matrix Factorization (by Kijung Shin) 43/99
𝑊𝑖: ←
𝑖∈𝑍𝑖:
𝐻:𝑗𝑇𝐻:𝑗 + 𝜆𝐼𝑘
−1
𝑗∈𝑍𝑖:
𝑉𝑖𝑗𝐻:𝑗
𝑽𝑾
𝑯
𝑉𝑖:
Read Written
𝑽𝑾
𝑯
𝑊𝑖:

Parallel ALS: Idea (cont.)• Potentially every entry of 𝑯 needs to be read
• Only the 𝑖-th row of 𝑽 needs to be read
•𝑾 does not need to be read⇒ can update the rows of 𝑾 independently in parallel
Large-scale Matrix Factorization (by Kijung Shin) 44/99
𝑽𝑾
𝑯
𝑉𝑖:
Read Written
𝑽𝑾
𝑯
𝑊𝑖:
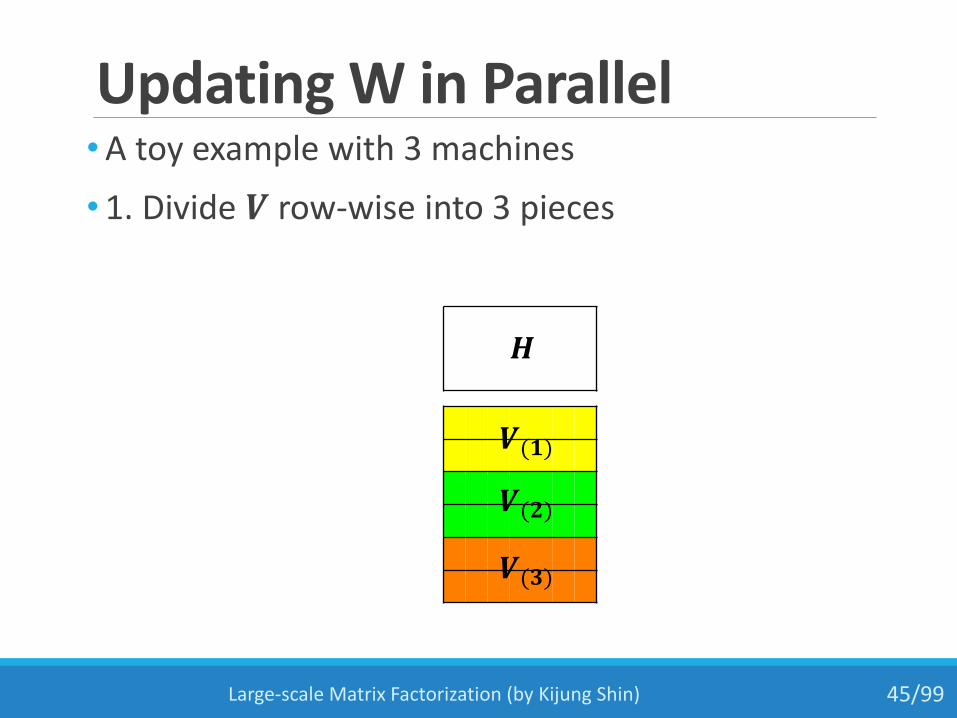
Updating W in Parallel•A toy example with 3 machines
• 1. Divide 𝑽 row-wise into 3 pieces
Large-scale Matrix Factorization (by Kijung Shin) 45/99
𝑽(𝟏)
𝑯
𝑽(𝟐)
𝑽(𝟑)

Updating W in Parallel (cont.)
Large-scale Matrix Factorization (by Kijung Shin) 46/99
Machine 1 Machine 2 Machine 3
• 2. Distribute the pieces across the machines
• 3. 𝑯 is broadcast to every machine
𝑯 𝑯 𝑯
𝑽(𝟏) 𝑽(𝟐) 𝑽(𝟑)
𝑽(𝟏)
𝑯
𝑽(𝟐)
𝑽(𝟑)

Updating W in Parallel (cont.)
Large-scale Matrix Factorization (by Kijung Shin) 47/99
• 4. Compute the corresponding rows of 𝑾 in parallel
Machine 1 Machine 2 Machine 3
𝑯 𝑯 𝑯
𝑽(𝟏) 𝑽(𝟐) 𝑽(𝟑)𝑾(𝟐)𝑾(𝟏) 𝑽(𝟑)
New! New! New!

Updating W in Parallel (cont.)
Large-scale Matrix Factorization (by Kijung Shin) 48/99
Machine 1 Machine 2 Machine 3
• 5. Broadcast the part of 𝑾 that each machine computes
𝑯 𝑯 𝑯
𝑽(𝟏) 𝑽(𝟐) 𝑽(𝟑)
𝑾(𝟏)
𝑾(𝟐)
𝑾(𝟑)
𝑾(𝟏)
𝑾(𝟐)
𝑾(𝟑)
𝑾(𝟏)
𝑾(𝟐)
𝑾(𝟑)

Pros & Cons of ALS• Pros:
◦ Less hyper-parameters: not requiring step size
•Cons:◦ High computational cost: e.g., matrix inversion takes O(𝑟3)
Large-scale Matrix Factorization (by Kijung Shin) 49/99
𝐻:𝑗 ←
𝑖∈𝑍:𝑗
𝑊𝑖: 𝑊𝑖:𝑇 + 𝜆𝐼𝑘
−1
𝑖∈𝑍:𝑗
𝑉𝑖𝑗𝑊𝑖:

Pros & Cons of ALS (cont.)
Large-scale Matrix Factorization (by Kijung Shin) 50/99
𝑾 𝑽(𝟏) 𝑾 𝑽(𝟐) 𝑾 𝑽(𝟑)
Machine 1 Machine 2 Machine 3
•Cons (cont.)◦ High memory requirement:
▪while updating 𝑾(or 𝑯),
▪each machine maintains the entire 𝑯(or 𝑾) in memory

Roadmap•Matrix Factorization (review)
•Algorithms◦ Distributed SGD: DSGD
◦ Alternating Least Square: ALS
◦ Cyclic Coordinate Descent: CCD++ <<
• Experiments
• Extension to Tensor Factorization
•Conclusions
Large-scale Matrix Factorization (by Kijung Shin) 51/99

Cyclic Coordinate Descent
Scalable Coordinate Descent Approaches
to Parallel Matrix Factorization
for Recommender Systems
(ICDM 2012)
Large-scale Matrix Factorization (by Kijung Shin) 52/99
Hsiang-Fu Yu, Cho-Jui Hsieh, Si Si, and Inderjit Dhillon
Best Paper Award

Matrix Factorization: Revisit
Large-scale Matrix Factorization (by Kijung Shin) 53/99
•Goal: 𝑽 is approximated by the product of 𝑾 and 𝑯
𝑾
𝑯
𝑽
≈ ×?
?
?
?
𝑛
𝑟 𝑚
𝑟
𝑛
𝑚

Matrix Factorization: Revisit
Large-scale Matrix Factorization (by Kijung Shin) 54/99
•Goal: 𝑽 is approximated by the product of 𝑾 and 𝑯
𝑾
𝑯
𝑽
≈ ×?
?
?
?
𝑛
𝑟 𝑚
𝑟𝑊𝑖:
𝐻:𝑗
𝑉𝑖𝑗 ≈ 𝑊𝐻 𝑖𝑗
= σ𝑘=1𝑟 𝑊𝑖𝑘𝐻𝑘𝑗 = 𝑊𝑖1𝐻1𝑗 +⋯+𝑊𝑖𝑟𝐻𝑟𝑗
𝑛
𝑚
𝑉𝑖𝑗

Matrix Factorization: Revisit
Large-scale Matrix Factorization (by Kijung Shin) 55/99
• Equivalently, 𝑽 is approximated by the sum of 𝑟 matrices
𝑽
≈ ×?
?
?
?
𝑊:1
𝐻1:
×
𝑊:𝑟
𝐻𝑟:
+⋯+
𝑉𝑖𝑗 ≈ 𝑊:1𝐻1: 𝑖𝑗 +⋯+ 𝑊:𝑟𝐻𝑟: 𝑖𝑗 = 𝑊𝑖1𝐻1𝑗 +⋯+𝑊𝑖𝑟𝐻𝑟𝑗
𝑊:1𝐻1: 𝑖𝑗 = 𝑊𝑖1𝐻1𝑗
𝑊:𝑟𝐻𝑟:
𝑊:𝑟𝐻𝑟: 𝑖𝑗 = 𝑊𝑖𝑟𝐻𝑟𝑗
1st column of 𝑊
1st row of 𝐻
rth column of 𝑊
rth row of 𝐻

Cyclic Coordinate Descent: CCD++• repeat until convergence
◦ for 𝑘 = 1…𝑟
update the 𝑘-th column of 𝑾 and the 𝑘-th row of 𝑯
while fixing the other entries of 𝑾 and 𝑯
Large-scale Matrix Factorization (by Kijung Shin) 56/99
•Consider a toy example with rank 3
𝑽
≈ ×
𝑊:1
+ × + ×
𝐻1:
𝑊:2
𝐻2:
𝑊:3
𝐻3:
Step 1:

Large-scale Matrix Factorization (by Kijung Shin) 57/99
𝑽
≈ ×
𝑊:1
+ × + ×
𝐻1:
𝑊:2
𝐻2:
𝑊:3
𝐻3:
𝑽
≈ ×
𝑊:1
+ × + ×
𝐻1:
𝑊:2
𝐻2:
𝑊:3
𝐻3:
Step 2:
Step 3:
Order of Updates in CCD++

Performing one update• Let 𝑊:1 and 𝐻1: be the updated row and column
Large-scale Matrix Factorization (by Kijung Shin) 58/99
𝑽
≈ ×
𝑊:1
𝐻1:
− × − ×
𝑊:2
𝐻2:
𝑊:3
𝐻3:
residual matrix 𝑹
𝑽
≈ ×
𝑊:1
+ × + ×
𝐻1:
𝑊:2
𝐻2:
𝑊:3
𝐻3:

Performing one update (cont.)
• Updating 𝑊:1 and 𝐻1: equals to factorizing 𝑹 with rank 1
• 𝑹 = 𝑽 −𝑊:2𝐻2: −𝑊:3𝐻:3
= 𝑽 −𝑊:1𝐻1: −𝑊:2𝐻2: −𝑊:3𝐻:3 +𝑊:1𝐻1:
= 𝑽 −𝑾𝑯+𝑊:1𝐻1:
Large-scale Matrix Factorization (by Kijung Shin) 59/99
𝑽
≈ ×
𝑊:1
𝐻1:
− × − ×
𝑊:2
𝐻2:
𝑊:3
𝐻3:
residual matrix 𝑹

Performing one update (cont.)• Factorizing 𝑹 with rank 1 can be performed using ALS
•with the following rules:◦ The updates rules can be derived from those in ALS
Large-scale Matrix Factorization (by Kijung Shin) 60/99
For i = 1…𝑛
𝑊𝑖𝑘 ← ൙σ𝑗∈𝑍𝑖:
𝑅𝑖𝑗𝐻𝑘𝑗
σ𝑗∈𝑍𝑖:𝐻𝑘𝑗
2+ 𝜆
For j = 1…𝑚
𝐻𝑘𝑗 ← ൙σ𝑖∈𝑍:𝑗
𝑅𝑖𝑗𝑊𝑖𝑘
σ𝑖∈𝑍:𝑗𝑊𝑖𝑘
2 + 𝜆

Pseudocode of CCD++
Large-scale Matrix Factorization (by Kijung Shin) 61/99
randomly initialize 𝑾 and 𝑯
repeat until convergencefor 𝑘 = 1…𝑟:𝑹 ← 𝑽 −𝑾𝑯+𝑊:𝑘𝐻𝑘:update 𝑊:𝑘 and 𝐻𝑘:
(rank-1 factorization of 𝑹)
randomly initialize 𝑾 and 𝑯
𝑹 ← 𝑽 −𝑾𝑯
repeat until convergencefor 𝑘 = 1…𝑟:𝑹 ← 𝑹 +𝑊:𝑘𝐻𝑘:update 𝑊:𝑘 and 𝐻𝑘:(rank-1 factorization of 𝑹)
𝑹 ← 𝑹 +𝑊:𝑘𝐻𝑘:Repeated!!
Maintained!!
Pseudocode (Simple) Pseudocode (Detailed)

Parallel CCD++ •Updating 𝐻𝑘: in parallel
◦ 1. divide 𝑹 column-wise
◦ 2. distribute the pieces across the machines
◦ 3. 𝑊:𝑘 is broadcast to every machine
Large-scale Matrix Factorization (by Kijung Shin) 62/99
𝑊:𝑘
𝑹(𝟏) 𝑹(𝟐) 𝑹(𝟑)
Machine 1 Machine 2 Machine 3
𝑊:𝑘 𝑊:𝑘
𝑹(𝟏) 𝑹(𝟐) 𝑹(𝟑)
𝑊𝐾:
𝐻𝑘:

Parallel CCD++ (cont.) •Updating 𝐻𝑘: in parallel (cont.)
◦ 4. compute the corresponding entries of 𝐻𝑘: in parallel
Large-scale Matrix Factorization (by Kijung Shin) 63/99
𝑊:𝑘
𝑹(𝟏) 𝑹(𝟐) 𝑹(𝟑)
Machine 1 Machine 2 Machine 3
𝐻 1𝑘:
New!
𝑊:𝑘 𝑊:𝑘
𝐻 2𝑘:
New!
𝐻 3𝑘:
New!

Parallel CCD++ (cont.) •Updating 𝐻𝑘: in parallel (cont.)
◦ 5. send the computed entries to the other machines.
Large-scale Matrix Factorization (by Kijung Shin) 64/99
𝑊:𝑘
𝑹(𝟏) 𝑹(𝟐) 𝑹(𝟑)
Machine 1 Machine 2 Machine 3
𝑊:𝑘 𝑊:𝑘
𝐻𝑘: 𝐻𝑘: 𝐻𝑘:

Pros & Cons of CCD++• Pros:
◦ Low computational cost
▪update rules do not need matrix inversion
Large-scale Matrix Factorization (by Kijung Shin) 65/99
𝐻𝑘𝑗 ← ൙σ𝑖∈𝑍:𝑗
𝑅𝑖𝑗𝑊𝑖𝑘
σ𝑖∈𝑍:𝑗𝑊𝑖𝑘
2 + 𝜆𝑊𝑖𝑘 ← ൙
σ𝑗∈𝑍𝑖:𝑅𝑖𝑗𝐻𝑘𝑗
σ𝑗∈𝑍𝑖:𝐻𝑘𝑗
2+ 𝜆

Pros & Cons of CCD++• Pros (cont.):
◦ Low memory requirements
▪each machine needs to maintain
▪one row of 𝑯 (or one column of 𝑾) in memory at a time
▪ instead of entire 𝑯 (or𝑾)
Large-scale Matrix Factorization (by Kijung Shin) 66/99
Machine 1 in ALS
𝑾 𝑽(𝟏)
Machine 1 in CCD++
𝑊:𝑘
𝑹(𝟏)

Pros & Cons of CCD++•Cons:
◦ Slow for dense matrices with many non-missing entries
▪To update 𝑹 , every non-missing entry
▪needs to be read and rewritten.
▪This is especially slow if 𝑹 is stored on disk.
Large-scale Matrix Factorization (by Kijung Shin) 67/99

Roadmap• Problem (review)
•Algorithms◦ Distributed SGD: DSGD
◦ Alternating Least Square: ALS
◦ Cyclic Coordinate Descent: CCD++
• Experiments <<
• Extension to Tensor Factorization
•Conclusions
Large-scale Matrix Factorization (by Kijung Shin) 68/99

Experimental Settings•Datasets:
Large-scale Matrix Factorization (by Kijung Shin) 69/99
5 ? 4 3
3 4 1 ?
2 ? 1 ?
5 3 ? 2
Use
rs
Movies (or songs)
Ratings

Experimental Settings (cont.)•Datasets:
Large-scale Matrix Factorization (by Kijung Shin) 70/99
(2.7M users, 18K movies, 100M ratings)
(1M users, 625K songs, 256M ratings)
(71K users, 65K movies, 10M ratings)

Experimental Settings (cont.)• Split of Datasets:
◦ Training set: about 80% of non-missing entries
◦ Test set: about 20% of non-missing entries
• Evaluation Metric:◦ Test RMSE (Root-mean square error)
Large-scale Matrix Factorization (by Kijung Shin) 71/99
𝑅𝑀𝑆𝐸 𝑉,𝑊,𝐻 =1
|𝑍𝑡𝑒𝑠𝑡|
(𝑖,𝑗)∈𝑍𝑡𝑒𝑠𝑡
𝑉𝑖𝑗 − 𝑊𝐻 𝑖𝑗2
index of test entriesEstimated
ratingTrue
rating

Experimental Settings (cont.)•Machines and implementations
◦ Shared-memory setting:
▪8 cores
▪OpenMP in C++
◦ Distributed setting:
▪up to 20 machines
▪MPI in C++
Large-scale Matrix Factorization (by Kijung Shin) 72/99
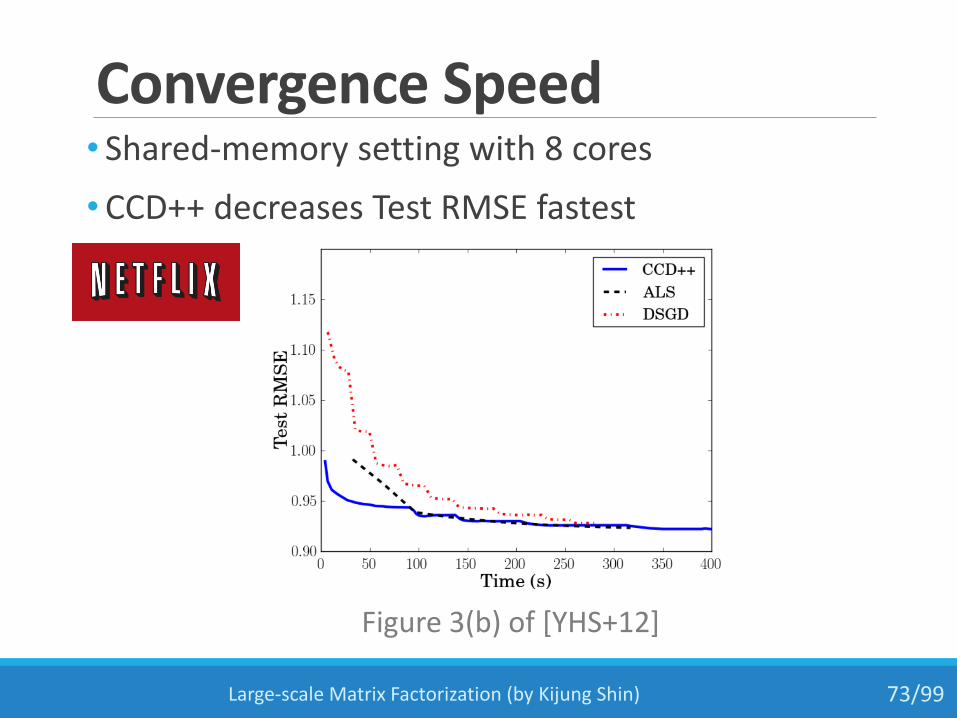
Convergence Speed
Large-scale Matrix Factorization (by Kijung Shin) 73/99
• Shared-memory setting with 8 cores
•CCD++ decreases Test RMSE fastest
Figure 3(b) of [YHS+12]

Convergence Speed (cont.)
Large-scale Matrix Factorization (by Kijung Shin) 74/99
• Shared-memory setting with 8 cores
•CCD++ converges Test RMSE fastest
Figure 3(c) of [YHS+12]

Large-scale Matrix Factorization (by Kijung Shin) 75/99
• Shared-memory setting with 8 cores
•CCD++ converges fastest
Figure 3(a) of [YHS+12]
Convergence Speed (cont.)

Speedup in Shared Memory•CCD++ and ALS show near-linear machine scalability
•DSGD suffers form high cache-miss rates due to its randomness◦ Cache-miss rate increases as more cores are used
Large-scale Matrix Factorization (by Kijung Shin) 76/99
Figure 4 of [YHS+12]

•All algorithms show similar speedups
Large-scale Matrix Factorization (by Kijung Shin) 77/99
Speedup in Distributed Settings
Figure 6(b) of [YHS+12]

Roadmap•Matrix Factorization (review)
•Algorithms◦ Distributed SGD: DSGD
◦ Alternating Least Square: ALS
◦ Cyclic Coordinate Descent: CCD++
• Experiments
• Extension to Tensor Factorization <<
•Conclusions
Large-scale Matrix Factorization (by Kijung Shin) 78/99

Tensors
Large-scale Matrix Factorization (by Kijung Shin) 79/99
•An 𝑁-way tensor is an 𝑁-dimensional array
𝑡11 ⋯ 𝑡1𝐼2⋮ ⋱ ⋮𝑡𝐼11 ⋯ 𝑡𝐼1𝐼2
𝑖1=1,…
,𝐼1
𝑖2 = 1,… , 𝐼2
𝑡1⋮𝑡𝐼1
1-way tensor(= vector)
2-way tensor(= matrix)
3-way tensor

Tensor Factorization: Problem
Large-scale Matrix Factorization (by Kijung Shin) 80/99
•Given: ◦ 𝑿: 𝐼 by 𝐽 by 𝐾 tensor
▪possibly with missing values
◦ 𝑅: target rank (a scalar)
▪usually 𝑅 ≪ 𝐼, 𝐽, 𝐾
𝐼
𝐽
𝐾
?
?
?
?
𝑿

Tensor Factorization: Problem
Large-scale Matrix Factorization (by Kijung Shin) 81/99
•Given: ◦ 𝑿: 𝐼 by 𝐽 by 𝐾 tensor (i.e., 3-dim array)
▪possibly with missing values
◦ 𝑅: target rank (a scalar)
▪usually 𝑅 ≪ 𝐼, 𝐽, 𝐾
• Find:◦ 𝑼: 𝐼 by 𝑅 matrix
◦ 𝑯: 𝐽 by 𝑅 matrix
◦ 𝑾: 𝐾by 𝑅 matrix
▪without missing values
𝐼
𝑅
𝑼
𝐽
𝑯
𝐾
𝑾
𝑅
𝑅

Tensor Factorization: Problem•Goal: 𝑿 ≈ [𝑼𝑯𝑾]
◦ where 𝑼𝑯𝑾 𝑖𝑗𝑘 = σ𝑟=1𝑅 𝑈𝑖𝑟𝐻𝑗𝑟𝑊𝑘𝑟
Large-scale Matrix Factorization (by Kijung Shin) 82/99
?
?
?
?
≈
𝑼
𝑯𝑻
𝑿

Loss Function𝐿 𝑋, 𝑈, 𝐻,𝑊
= σ 𝑖,𝑗,𝑘 ∈𝑍 (𝑋𝑖𝑗𝑘 − 𝑈𝐻𝑊 𝑖𝑗𝑘)2 + …
Goal: to make 𝑿 and 𝑼𝑯𝑾 similar
Large-scale Matrix Factorization (by Kijung Shin) 83/99
Indices ofnon-missing entries
i.e., 𝑖, 𝑗, 𝑘 ∈ 𝑍↔ 𝑋𝑖𝑗𝑘 is not missing
(𝑖, 𝑗, 𝑘)-th entry of [UHW]
(𝑖, 𝑗, 𝑘)-thentry of 𝑋

Loss Function (cont.)𝐿 𝑋, 𝑈, 𝐻,𝑊
= σ 𝑖,𝑗,𝑘 ∈𝑍 (𝑋𝑖𝑗𝑘 − 𝑈𝐻𝑊 𝑖𝑗𝑘)2
+ 𝜆( 𝑈 𝐹2 + 𝐻 𝐹
2 + 𝑊 𝐹2)
Goal: to prevent overfitting
(by making the entries of 𝑈, 𝐻 and 𝑉 close to zero)
Large-scale Matrix Factorization (by Kijung Shin) 84/99
Regularization parameter
Frobenius Norm:
𝑈 𝐹2 =
𝑖=1
𝐼
𝑟=1
𝑅
𝑈𝑖𝑟2

SGD for TF•𝐿 𝑋, 𝑈, 𝐻,𝑊 : sum of loss for each non-missing entry
𝐿 𝑋, 𝑈, 𝐻,𝑊 = σ 𝑖,𝑗,𝑘 ∈𝑍 𝐿′(𝑋𝑖𝑗𝑘 , 𝑈𝑖:𝐻𝑗:𝑊𝑘:)
•An SGD step on each non-missing entry 𝑋𝑖𝑗𝑘:◦ Read 𝑈𝑖: , 𝐻𝑗:, and 𝑊𝑘:
◦ Compute gradient of 𝐿′ 𝑉𝑖𝑗 ,𝑊𝑖:, 𝐻:𝑗 ,𝑊𝑘:
◦ Update 𝑈𝑖: , 𝐻𝑗:, 𝑊𝑘:
Large-scale Matrix Factorization (by Kijung Shin) 85/99
𝑼
𝑯𝑻
𝑾
𝑋𝑖𝑗𝑘
𝑿

Parallel Algorithms for TF• Parallel algorithms for MF are extended to TF
◦ DSGD → FlexiFaCT [BKP+14]
◦ ALS [SPK16]
◦ CCD++ → CDTF [SK17]
Large-scale Matrix Factorization (by Kijung Shin) 86/99
FlexiFaCT [VKP+14]

Applications•Context-aware recommendation [KABO10]
Large-scale Matrix Factorization (by Kijung Shin) 87/99
Use
rs
Ratings
?
5
3
4
2
Movies
𝑋𝑖𝑗𝑘= 𝑈𝐻𝑊 𝑖𝑗𝑘
Missing rating

Applications (cont.)•Context-aware recommendation [KABO10]
Large-scale Matrix Factorization (by Kijung Shin) 88/99
Use
rs
Ratings
?
5
3
4
2
Restaurants
Missing rating𝑋𝑖𝑗𝑘= 𝑈𝐻𝑊 𝑖𝑗𝑘

Applications (cont.)•Video Restoration [LMWY13]
Large-scale Matrix Factorization (by Kijung Shin) 89/99
X-a
xis
Pixels
?
5
3
4
2
Y-Axis
Missing or corrupted pixel𝑋𝑖𝑗𝑘= 𝑈𝐻𝑊 𝑖𝑗𝑘

Applications (cont.)•Video Restoration [LMWY13]
Large-scale Matrix Factorization (by Kijung Shin) 90/99
Corrupted frame Restored frame

Applications (cont.)• Personalized Web Search [SZL+05]
Large-scale Matrix Factorization (by Kijung Shin) 91/99
Use
rs
Preference
?
5
3
4
2
Query keywords
Missing preference
𝑋𝑖𝑗𝑘= 𝑈𝐻𝑊 𝑖𝑗𝑘

Roadmap•Matrix Factorization (review)
•Algorithms◦ Distributed SGD: DSGD
◦ Alternating Least Square: ALS
◦ Cyclic Coordinate Descent: CCD++
• Experiments
• Extension to Tensor Factorization
•Conclusions <<
Large-scale Matrix Factorization (by Kijung Shin) 92/99

Conclusions•Matrix Factorization (MF)
• Parallel algorithms for MF◦ Distributed SGD: DSGD
◦ Alternating Least Square: ALS
◦ Cyclic Coordinate Descent: CCD++
• Tensor Factorization (TF)◦ Extension of MF to tensors
◦ Applications: context-aware recommendation, video restoration, personalized web search, etc.
Large-scale Matrix Factorization (by Kijung Shin) 93/99

Questions?• These slides are available at:
www.cs.cmu.edu/~kijungs/ETC/10-405.pdf
• Email: [email protected]
Large-scale Matrix Factorization (by Kijung Shin) 94/99

References• [SZL+05] Jian-Tao Sun, Hua-Jun Zeng, Huan Liu, Yuchang Lu, and Zheng Chen. "Cubesvd: a novel approach to personalized web search." WWW 2005
• [ZWSP08] Yunhong Zhou, Dennis Wilkinson, Robert Schreiber, and RongPan. "Large-scale parallel collaborative filtering for the netflix prize." AAIM 2008
• [KABO10] Karatzoglou, Alexandros, Xavier Amatriain, Linas Baltrunas, and Nuria Oliver. "Multiverse recommendation: n-dimensional tensor factorization for context-aware collaborative filtering." RecSys 2010.
• [GNHS11] Rainer Gemulla, Erik Nijkamp, Peter J. Haas, and YannisSismanis. "Large-scale matrix factorization with distributed stochastic gradient descent." KDD 2011
• [DKA11] Daniel M. Dunlavy, Tamara G. Kolda, and Evrim Acar. "Temporal link prediction using matrix and tensor factorizations." TKDD 2011
Large-scale Matrix Factorization (by Kijung Shin) 95/99

References (cont.)• [YHSD12] Yu, Hsiang-Fu, Cho-Jui Hsieh, Si Si, and Inderjit Dhillon. "Scalable coordinate descent approaches to parallel matrix factorization for recommender systems." ICDM 2012
• [LMWY13] Ji Liu, Przemyslaw Musialski, Peter Wonka, and Jieping Ye. "Tensor completion for estimating missing values in visual data." TPAMI 2013.
• [BKP+14] Alex Beutel, Abhimanu Kumar, Evangelos E. Papalexakis, Partha Pratim Talukdar, Christos Faloutsos, and Eric P. Xing. "Flexifact: Scalable flexible factorization of coupled tensors on hadoop." SDM 2014
• [SPK16] Shaden Smith, Jongsoo Park, and George Karypis. "An exploration of optimization algorithms for high performance tensor completion." In High Performance Computing, Networking, Storage and Analysis, SC 2016
• [SK17] Kijung Shin and U Kang. “Distributed Methods for High-dimensional and Large-scale Tensor Factorization.” ICDM 2014
Large-scale Matrix Factorization (by Kijung Shin) 96/99

Closed-Form Solution of ALS
• Let 𝑊 =
− 𝑊1: −
:− 𝑊𝑛: −
, 𝐻 =| |𝐻:1 … 𝐻:𝑚| |
Then,
𝐿 𝑉,𝑊,𝐻
= σ 𝑖,𝑗 ∈𝑍 (𝑉𝑖𝑗 −𝑊𝑖:𝐻:𝑗)2 + 𝜆 σ𝑖=1
𝑛 𝑊𝑖: 2 + σ𝑗=1𝑚 𝐻:𝑗 2
= σ 𝑖,𝑗 ∈𝑍 (𝑉𝑖𝑗 −σ𝑘=1𝑟 𝑊𝑖𝑘𝐻𝑘𝑗)
2
+ 𝜆 σ𝑖=1𝑛 σ𝑘=1
𝑟 𝑊𝑖𝑘2 +σ𝑗=1
𝑚 σ𝑘=1𝑟 𝐻𝑘𝑗
2
Large-scale Matrix Factorization (by Kijung Shin) 97/99

Closed-Form Solution of ALS (cont.)1
2
𝜕𝐿
𝜕𝐻𝑘𝑗= 0, ∀𝑘, ∀𝑗 (first-order conditions)
⇒ σ𝑖∈𝑍:𝑗𝑉𝑖𝑗 −𝑊𝑖:𝐻:𝑗 𝑊𝑖𝑘 + 𝜆𝐻𝑘𝑗 = 0, ∀𝑘, ∀𝑗
⇒ σ𝑖∈𝑍:𝑗𝑊𝑖:𝐻:𝑗𝑊𝑖𝑘 + 𝜆𝐻𝑘𝑗 = σ𝑖∈𝑍:𝑗
𝑉𝑖𝑗𝑊𝑖𝑘 , ∀𝑘, ∀𝑗
⇒ σ𝑖∈𝑍:𝑗𝑊𝑖:𝐻:𝑗𝑊𝑖𝑘 + 𝜆𝐻𝑘𝑗 = σ𝑖∈𝑍:𝑗
𝑉𝑖𝑗𝑊𝑖𝑘 , ∀𝑘, ∀𝑗
Large-scale Matrix Factorization (by Kijung Shin) 98/99
rows of non-missing entrys in the 𝑗-th column of 𝑽

(If we stack 𝑟 conditions on 𝐻1𝑗, …., 𝐻𝑟𝑗)
⇒ (σ𝑖∈𝑍:𝑗𝑊𝑖: 𝑊𝑖:
𝑇 + 𝜆𝐼𝑘)𝐻:𝑗 = σ𝑖∈𝑍:𝑗𝑉𝑖𝑗𝑊𝑖: , ∀𝑗
⇒ 𝐻:𝑗 = σ𝑖∈𝑍:𝑗𝑊𝑖: 𝑊𝑖:
𝑇 + 𝜆𝐼𝑘−1
σ𝑖∈𝑍:𝑗𝑉𝑖𝑗𝑊𝑖: , ∀𝑗
Large-scale Matrix Factorization (by Kijung Shin) 99/99
𝑘 by 𝑘 identity matrix
Closed-Form Solution of ALS (cont.)


















