
Kap.4 JPEG: Bildkompression - Persönliche...
29
Kap.4 JPEG: Bildkompression Ziel: Gegeben sind Daten y ∈ R N . Bestimme C ∈ R N×N mit C · C T = I , so dass x = C · y dünbesetzt ist. Originalbild y (30Kbt) Komprimiertes Bild z ≈ y (7Kbt)
Transcript of Kap.4 JPEG: Bildkompression - Persönliche...

Kap.4 JPEG: Bildkompression
Ziel: Gegeben sind Daten y ∈ RN . Bestimme C ∈ R
N×N mitC · CT = I, so dass x = C · y dünbesetzt ist.
Originalbild y (30Kbt) Komprimiertes Bild z ≈ y (7Kbt)
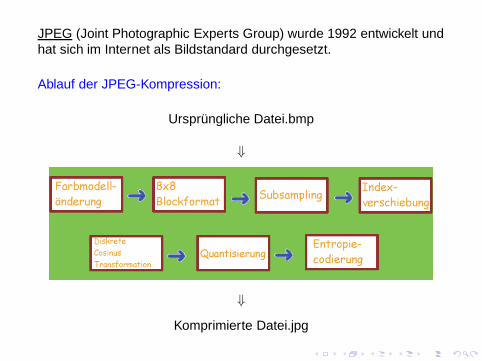
JPEG (Joint Photographic Experts Group) wurde 1992 entwickelt undhat sich im Internet als Bildstandard durchgesetzt.
Ablauf der JPEG-Kompression:
Ursprüngliche Datei.bmp
⇓
⇓
Komprimierte Datei.jpg

4.1 Bildmodelle
Kriterium für die Qualität eines Bildes ist die menschlicheWahrnehmung des Bildes (menschliches Auge):
130 Millionen ’schwarz-weiße’ Rezeptoren, 100 Grautöne
6 Millionen ’farbige’ Rezeptoren: rot, grün, blau.
Definition: Ein Schwarz-Weiß-Bild ist eine N1 × N2 Matrix B = (B[i, j])mit ganzzahligen Einträgen (Pixeln) B[i, j] ∈ 0, . . . , 255.
8−Bit-Farbtiefe:0 → 00000000
. . .
255 → 11111111
Ein 32 × 32 Bild benötigt 1024 · 8Bit =: 1kByte

RGB-Farbraum (Komputermonitoren)
Definition: Ein Farbbild ist eine N1 × N2 × 3 Matrix B = (B[i, j, k ]) mitganzzahligen Einträgen (Pixeln) B[i, j, k ] ∈ 0, . . . , 255.
Pixel[i, j] = Schwarz +B[i, j, 1] ·Rot +B[i, j, 2] ·Grun+B[i, j, 3] ·Blau.

YCbCr-Farbraum (digitales Fernsehen)
Y Luminanz (Helligkeit)
Cb und Cr skalierte Chrominanzen (Farbigkeit)
YCbCr
=
0.299 0.587 0.114−0.169 −0.331 0.500
0.500 −0.419 −0.081
︸ ︷︷ ︸
reguläre Matrix
·
RGB
mit
0 ≤ Y ≤ 255
−127.5 ≤ Cb ≤ 127.5
−127.5 ≤ Cr ≤ 127.5

4.2 JPEG: Farbmodelländerung
︸ ︷︷ ︸
Datei.bmp
gespeichert
als ︸ ︷︷ ︸
RGB–Farbraum
oder
äquivalent ︸ ︷︷ ︸
YCbCr–Farbraum

4.3. JPEG: Blockeinteilung

4.4. JPEG: Subsampling
︸ ︷︷ ︸
Datei.bmp
gespeichert
als ︸ ︷︷ ︸
RGB–Farbraum
oder
äquivalent ︸ ︷︷ ︸
YCbCr–Farbraum
Daten können um einen Faktor 2 reduziert werden (verlustbehaftete Kompression)

4.5. JPEG: Indexverschiebung
RGB
7→
YCbCr
−
12800
∈ −128, . . . , 127
vorzeichenlose Bit 7→ vorzeichenbehaftete Bit
Verlustbehaftet aber keine Kompression.

4.6. JPEG: 2-dim Diskrete Cosinus Transformation
Definition: Die 2-dim DCT ist eine lineare Transformation auf RM×M ,M ∈ N,
B 7→ B, B = C · B · CT , C ∈ RM×M , (1)
die Matrix C = (C[n, ℓ])n,ℓ=0,...,M−1 ist gegeben durch
C[n, ℓ] = d [n] · cosπ(2ℓ + 1)n
2M(2)
mit
d [n] =1√M
1, falls n = 0,√
2, sonst.

Beispiel:
212 212 212 212 212 212 212 212212 212 212 212 212 212 212 21275 75 75 75 75 75 75 7575 75 75 75 75 75 75 7575 75 75 75 75 75 75 7575 75 75 75 75 75 75 7575 75 75 75 75 75 75 7575 75 75 75 75 75 75 75
nach DCT:
874.000 0 0 0 0 0 0 0351.000 0 0 0 0 0 0 0253.143 0 0 0 0 0 0 0123.297 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0−82.384 0 0 0 0 0 0 0−104.855 0 0 0 0 0 0 0−69.842 0 0 0 0 0 0 0

Sei B = (B[n, ℓ])n,ℓ=0,...,M−1. Definiere den Vektor
Bvek =
B[0, 0]...
B[0,M − 1]B[1, 0]
...B[1,M − 1]
...B[M − 1,M − 1]
∈ RM2
und die Matrix
CT⊗ C = (C[ℓ,n]C)ℓ,n=0,...,M−1 , C = (C[n, ℓ])n,ℓ=0,...,M−1 .
Lemma: Es gilt
B = C B CT ⇐⇒ Bvek =(CT ⊗ C
)Bvek .

4.7. JPEG: 2-dim DCT via 1-dim DCT
Die 2-dim DCT ist separabel, d.h. man kann die 2-dim DCT mit Hilfeder 1-dim DCT ausführen.
Definition: Die 1-dim DCT ist eine lineare Transformation auf RM ,M ∈ N,
y 7→ y , y = Cy , C ∈ RM×M . (3)
Die Matrix C = (C[n, ℓ])n,ℓ=0,...,M−1 ist definiert wie in (2).
Eigenschaften der 1-dim DCT:
(i) 1-dim DCT ist nicht symmetrisch, d.h. C 6= CT ;
(ii) 1-dim DCT ist eine orthogonale Transformation, d.h. CCT = I;
(iii) 1-dim DCT ist eine Rotation in RM , d.h. CCT = I und det(C) = 1;
(iv) 1-dim DCT ist eine der Techniken zur Dekorrelation.

4.7 (i) 1-dim DCT ist nicht symmetrisch, denn für N = 8 gilt
C =1√8
1 1 1 1 1 1 1 1a1 b1 c1 d1 −d1 −c1 −b1 −a1
a2 b2 −b2 −a2 −a2 −b2 b2 a2
b1 −d1 −a1 −c1 c1 a1 d1 −b1
1 −1 −1 1 1 −1 −1 1c1 −a1 d1 b1 −b1 −d1 a1 −c1
b2 −a2 a2 −b2 −b2 a2 −a2 b2
d1 −c1 b1 −a1 a1 −b1 c1 −d1
mita1 =
√2 cos π
16 a2 =√
2 cos 2π16 ≈ 1.307
b1 =√
2 cos 3π16 b2 =
√2 cos 6π
16
c1 =√
2 cos 5π16 d1 =
√2 cos 7π
16

4.7 (iii) Energie eines Vektors y ∈ RM ist gegeben durch
‖y‖2 =
√√√√
M∑
j=1
yj .
Lemma: Seien y ∈ RM . Dann gilt
‖C · y‖22 = ‖y‖2
2.
Beweis: Sei y = C · y .
‖C · y‖22 = (Cy)T Cy = yT CT Cy = ‖y‖2
2.
Orthogonale Transformationen ändern die Länge (Energie,Informationsinhalt) eines Vektors (Bildes) nicht.

4.7 (iv) Sei B ein 8 × 8 Block eines Bildes.
Beispiel: Nicht alle B = CBCT sind dünnbesetzt.
B =
0 255 0 255 255 255 0 255255 0 255 0 255 0 255 0
0 255 0 255 255 255 0 255255 0 255 0 255 0 255 0255 255 255 255 255 255 255 255255 0 255 0 255 0 255 0
0 255 0 255 255 255 0 255255 0 255 0 255 0 255 0
nach DCT:
B =
1243.1 −3.4 −124.9 102.2 95.6 −71.9 −51.8 248.2−3.4 −48.2 −41.5 −21.6 31.8 −107.1 −17.2 −154.4
−124.9 −41.5 −54.4 −2.7 41.6 −102 −22.5 −93.2102.2 −21.6 −2.7 −23.2 2.1 −39.6 −1.1 −102.9
95.6 31.8 41.6 2.1 −31.9 78.1 17.3 71.3−71.9 −107.1 −102 −39.6 78.1 −242.8 −42.2 −321.7−51.8 −17.2 −22.5 −1.1 17.3 −42.2 −9.3 −38.6248.2 −154.4 −93.2 −102.9 71.3 −321.7 −38.6 −578.3
Solche Bildblöcke B kommen aber selten vor.Z.z.: B = CBCT ist mit hoher Wahrscheinlichkeit dünnbesetzt.

Definition: Sei X = (X [n])n=0,...,M−1 ein M × 1 Markov, stationäres,stoch. Feld mit E(X [n]) = 0 und cov(X [n]2) = 1, n = 0, . . . ,M − 1,d.h.
cov(X ,X) =
1 ρ ρ2 . . . ρN−1
ρ 1 ρ . . . ρN−2
.... . .
...ρN−2 . . . ρ 1 ρ
ρN−1 . . . ρ2 ρ 1
, ρ = cov(X [0],X [1]).
Die Transformation X = K · X heißt Karhunen-Loeve-Transformationvon X , falls K · cov(X ,X) · K T diagonal ist und die Diagonaleinträgevon K · cov(X ,X) · K T die Eigenwerte von cov(X ,X) sind.
Satz: Unter allen orthogonalen Transformationen X = A · X ,A ∈ R
M×M verteilt die Karhunen-Loeve-Transformation X = K · X ammeisten Energie auf die ersten m + 1 < M Einträge von X .
Satz: Für ρ ≈ 1, gilt K ≈ C.

Die 8 × 8 KLT-Matrix K für ρ = 0.95
0.3383 0.3512 0.3599 0.3642 0.3642 0.3599 0.3512 0.33830.4809 0.4204 0.2860 0.1013 −0.1013 −0.2860 −0.4204 −0.48090.4665 0.2065 −0.1789 −0.4557 −0.4557 −0.1789 0.2065 0.46650.4226 −0.0854 −0.4865 −0.2783 0.2783 0.4865 0.0854 −0.42260.3602 −0.3468 −0.3558 0.3513 0.3513 −0.3558 −0.3468 0.36020.2833 −0.4882 0.0942 0.4154 −0.4154 −0.0942 0.4882 −0.28330.1952 −0.4623 0.4603 −0.1904 −0.1904 0.4603 −0.4623 0.19520.0996 −0.2786 0.4156 −0.4896 0.4896 −0.4156 0.2786 −0.0996
und die 8 × 8 DCT-Matrix C
0.3536 0.3536 0.3536 0.3536 0.3536 0.3536 0.3536 0.35360.4904 0.4157 0.2778 0.0975 −0.0975 −0.2778 −0.4157 −0.49040.4619 0.1913 −0.1913 −0.4619 −0.4619 −0.1913 0.1913 0.46190.4157 −0.0975 −0.4904 −0.2778 0.2778 0.4904 0.0975 −0.41570.3536 −0.3536 −0.3536 0.3536 0.3536 −0.3536 −0.3536 0.35360.2778 −0.4904 0.0975 0.4157 −0.4157 −0.0975 0.4904 −0.27780.1913 −0.4619 0.4619 −0.1913 −0.1913 0.4619 −0.4619 0.19130.0975 −0.2778 0.4157 −0.4904 0.4904 −0.4157 0.2778 −0.0975

4.8. JPEG: Quantisierung mit Q = (3 + 2(i + j))i,j=0,...,7
Bq[i, j] = sgn(B[i, j]) ·⌊
|B[i, j]|Q[i, j]
⌋
, 0 ≤ i, j ≤ 7.

4.8. JPEG: Quantisierung
Zig-Zag-Scan von DCT-Koeffizienten:

4.9. JPEG: Kodierung
Gegeben:
• Info-Quelle (d.h. die ZVe) X : Ω → s1, . . . , sn mit WV
P(X = sj), j = 1, . . . , n.
• Kodealphabet Σ = σ1, . . . , σM
Ziel: Ersetze die Symbole sji in der Nachricht
sj1sj2 . . . sjm , sji ∈ s1, . . . , sn,
durch Kodewörte k(sj) ∈⋃
M>0
ΣM , j = 1, . . . , n, so dass die erwartete
Kodewortlängen∑
j=1
Länge(k(sj)) ·P(X = sj) minimal wird. Falls dieser
Kode eindeutig dekodierbar ist, dann heißt er optimal

Huffman-Kodierung:
1. Erzeuge eine Tabelle mit allen in der Nachricht
sj1sj2 . . . sjm , sji ∈ s1, . . . , sn,
vorhandenen Symbolen sj und deren Wahrscheinlichkeiten.
2. Pflanze den Huffman-Baum und erzeuge daraus eine Kodetabelle
3. Durchlaufe die Nachricht und ersetze jedes Symbol sji mit dementsprechenden Kodewort.
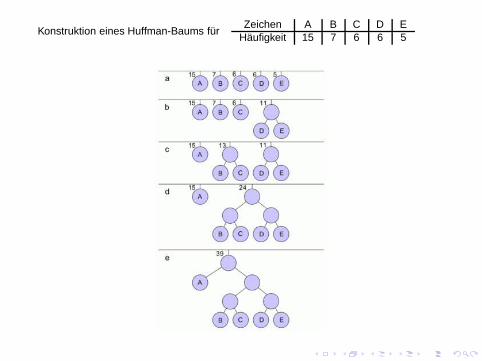
Konstruktion eines Huffman-Baums fürZeichen A B C D E
Häufigkeit 15 7 6 6 5

Huffman-Baum pflanzen:
1. Erzeuge eine nach Wahrscheinlichkeiten sortierte Liste vonBäumen mit jeweils nur einem Knoten (Symbol sj und seineWahrscheinlichkeit).
2. Entferne die letzten beiden Bäume und hänge sie unter einegemeinsame Wurzel, die die Summe der Wahrscheinlichkeiten ihrerKinder speichert. Sortiere die Liste von Bäumen um.
3. Wiederhole Schritt 2., bis nur ein Baum in der Liste enthalten ist.Dieser ist der Huffman-Baum.

Huffman-Kode erzeugen:
1. Von der Wurzel ausgehend, für alle eindeutigen Wege,Kode:=leeres Wort
2. wenn ein linker Teilbaum beschritten wird, schreibe eine 1 hinterden bisherigen Kode
3. wenn ein rechter Teilbaum beschritten wird, schreibe eine 0 hinterden bisherigen Kode
4. Wiederhole Schritt 2. oder 3., bis ein Blatt (Symbol sj) erreicht wird.Schreibe den gefundenen Kode in die Kodetabelle an die Positiondes jeweiligen Symbols sj .

Eigenschaften des Huffman-Kodes
k : s1, . . . , sn → k(s1), . . . k(sn),
oder, äquivalent, des Huffman-Baumes G = (V ,E)
(i) Alle Symbole sj sind Blätter von G.
(ii) Der Baum G ist vollständig und binär.
(iii) Seltene Symbole sj sind tiefer in G als die häufigen Symbole.
(iv) Die zwei seltensten Symbole sind Geschwister, d.h. falls
P(X = si),P(X = sj) < minℓ∈1,...,n\i,j
P(X = sℓ)
dann gilt
k(si) = σj1 . . . σjm 0, k(sj) = σj1 . . . σjm 1, σℓ ∈ 0, 1.
(v) Der Huffman-Kode ist optimal.

Beweis:I.A. X : Ω → s1, s2. Dann ist der Kode k(s1) = 0, k(s2) = 1,optimal, da nur 1Bit pro Symbol benötigt wird.
I.S. Sei k nicht optimal. Dann existiert ein binär, präfixfreier, optimalerKode k mit dem Baum G, so dass
n∑
i=1
Länge(k(si)) · P(X = si) <
n∑
i=1
Länge(k(si)) · P(X = si).
k optimal ⇒ es exitieren sj1 , sj2 ∈ s1, . . . , sn, die Geschwister mitdem Vater v sind, d.h.
k(sj1) = k(v)0 und k(sj2) = k(v)1.

Daraus folgt für D = s1, . . . , sn \ sj1 , sj2
n∑
i=1
Länge(k(si)) · P(X = si) =∑
si∈D
Länge(k(si)) · P(X = si)
+[
Länge(k(v)) + 1]
· [P(X = sj1) + P(X = sj2)]︸ ︷︷ ︸
=:P(X=v)
=
∑
si∈D⋃v
Länge(k(si)) · P(X = si) + P(X = v)I.V .
<
∑
si∈D⋃v
Länge(k(si)) · P(X = si) + P(X = v)
=n∑
i=1
Länge(k(si)) · P(X = si).

Arithmetische Kodierung (ist nicht prüfungsrelevant): wird auch beiJPEG verwendet.
Eingabe: Nachricht
sj1sj2 . . . sjm , sji ∈ s1, . . . , sn.
Initializierung: Ausgangsintervall [0, 1).
Für i = 1, . . . ,m: Ordne jedem Symbol sj , j = 1, . . . , n, der Nachrichtein Subintervall des Ausgangsintervalls zu, dessen Größe derWahrscheinlichkeit P(X = sj) des Symbols sj entspricht. DasSubintervall, das dem Symbol sji der Nachricht entspricht, wird zumneuen Ausgangsintervall.
Ausgabe: Der Kode ist eine beliebige reele Zahl (in der dyadischenDarstellung) aus dem letzten Ausgangsintervall.
Zum Dekodieren: braucht man den Kode und die Anzahl m derSymbole in der kodierten Nachricht.


















