
Kantanfest: Laura Casanellas
16
1 Quality Evaluation Laura Casanellas
-
Upload
kantanmt -
Category
Technology
-
view
43 -
download
3
Transcript of Kantanfest: Laura Casanellas

1
Quality Evaluation
Laura Casanellas

Machine Translation vs Traditional Translation?
The conversation has moved on
PBSMT vs NMT

Quality evaluation in Production
Initial indicators – the engine is likely to produce good quality output when…
Rule of Thumb
F-Measure: 70% or more
BLEU: 60% or more
TER: 40% of less

Initial indicators – the engine is likely to produce good quality output when…
Rule of Thumb
Perplexity: Below 3
Epochs: Between 5 and 9 (depending on Perplexity score)
Quality evaluation in Production - Neural

Quality evaluation – Human validation
• At the final stages of engine creation or re-training and customisation
• To validate automatic scores and improve the engine further• Iterative process: each iteration adds to the quality improvement
of an engine
•Engine meets automatic quality indicators (BLEU, TER, F-Measure, Perplexity…)
#1 Iteration
• Adequacy
• Fluency
• Overall Quality
• Error Classification (MQM)
Linguistic Feedback
Linguistic feedback is included, engine is re-trained
#2 Iteration…
Different set of skills – Linguists of the “now”
Linguists who understand related concepts but also who know how the
different MT technologies work.
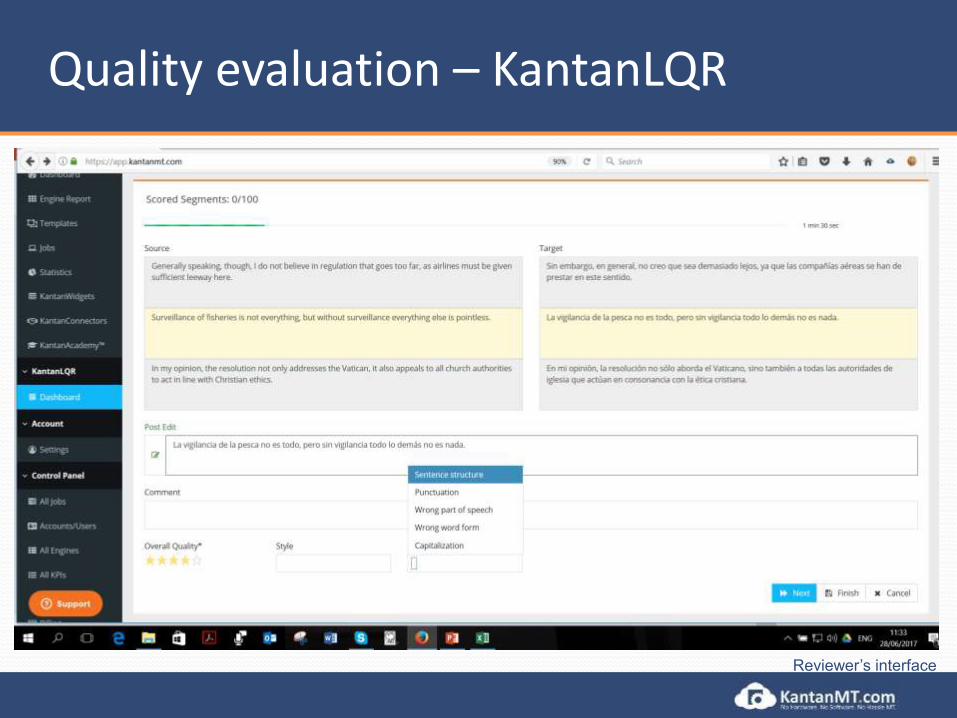
Human Evaluation with KantanLQR • KantanLQR helps automate the process of harvesting linguistic
feedback• Goal: improving engine performance• Ranking – A/B Testing• Quality Evaluation
• KPIs can be used to implement MQM Industry Standards• Adequacy / Fluency / Overall Quality• Error Classification• Customisable KPIs; e.g.: Is this translation fit for publication?
• Post-editing• Productivity
Reviewer’s interface
Quality evaluation – KantanLQR
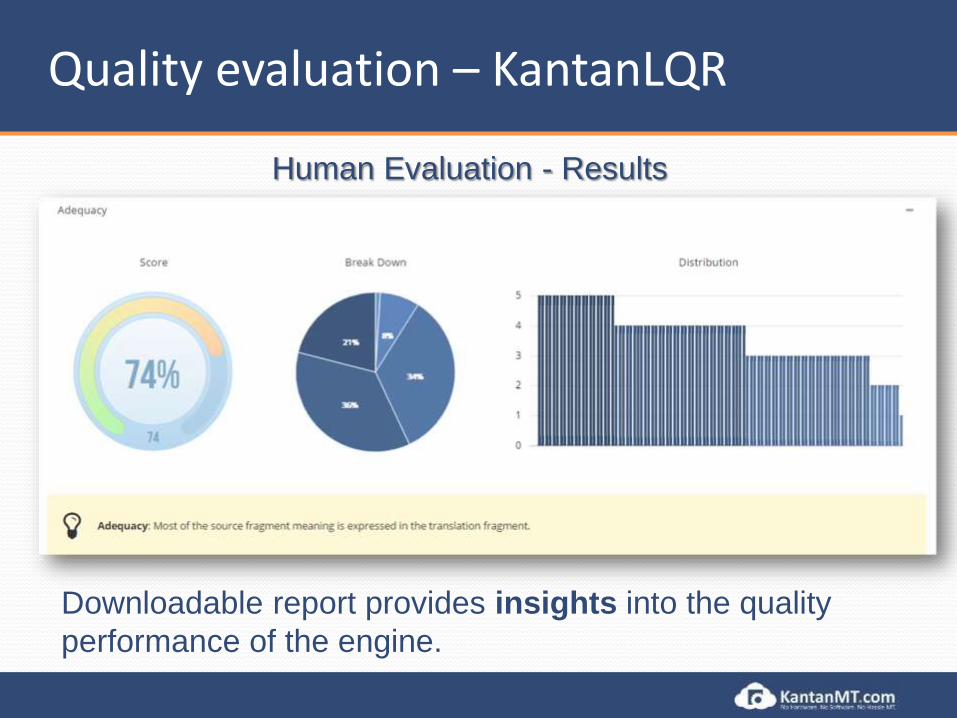
Quality evaluation – KantanLQR
Human Evaluation - Results
Downloadable report provides insights into the quality
performance of the engine.

Quality evaluation – Post-editing
Target segment appears in the Post Edit box to be reviewed or post-edited.
Pro
ductiv
ity !!!

Quality evaluation – Productivity
# seconds per segment
Evaluation Report
Row no Source Target Translation Comment Reviewer Email Processed time(s)
1 We believe that women & girls can reach their full potential when systems are designedto include their experiences and voices, andexisting patriarchal systems are disabled.
We believe que las mujeres & girls pueden dirigirse a la totalidad de los sistemas de posibles cuando estén concebidos para incluir sus experiencias y voices, y existentes patriarchal sistemas se discapacidad.
Creemos que las mujeres y las niñas pueden alcanzar su potencial cuando los sistemas están concebidos para incluir sus experiencias y voc es, y cuando los sistemas patriarcales existentes han sido desabilitados.
KantanMT - Carlos [email protected] 137
2 We believe that the identity of marginalizedcommunities must be safeguarded.
We believe que la identidad de marginalizedComunidades Europeas deben ofrecer prot
ección jurídica.
Creemos que se debe salvaguardar la identidad de comunidades europeas marginadas.
KantanMT - Laura [email protected] 51
3 Ensuring equal dignity for minorities helps to ensure just and equitable systems.
Garantizar la igualdad de respeto de las minorías ello garantizar justo y equitativa sistemas.
Garantizar el respeto a las minorías ayuda a afianzar sistemas justos y equitativos.
KantanMT - Laura [email protected] 147
4 We train law students and civil society on law as an invaluable advocacy tool.
We tren derecho los estudiantes y de la sociedad civil en la Ley invaluable promoción como herramienta.
Formamos a estudiantes de derecho y a la sociedad civil acerca de la ley como herramienta de defensa de un valor incalculable .
KantanMT - Laura [email protected] 138
5 A powerful story of how people can change,why we all must be willing to get to know our fellow human beings, and why echo chambers are so harmful.
Un potentes story de modalidades de personas puede cambio, el motivo por el cual wetodas deben estar dispuesto de la infraestructuras para acordar A conocer mi fellow la trata de personas, y motivo por el cual echo salas son nocivos.
Un potentes story de modalidades de personas puede cambio, el motivo por el cual we todas deben estar dispuesto de la infraestructuras para acordar A conocer mi fellow la trata de personas, y motivo por el cual echo salas son nocivos.
KantanMT - Carlos [email protected] 12

Quality evaluation – KantanLQR
Ranking Translations – A/B Testing
Reviewer’s interface

Quality evaluation – KantanLQR
A/B Testing - Results
We use these results to generate detailed insights such as our recent study on
Neural Industry Trials

Quality evaluation – Neural
A/B Test• 5 language pairs• 200 segments• 3 reviewers per language
37
21
13
24
10
2124
21
34
19
2825.2
37
5853
5662
53.2
ENGLISH->CHINESE ENGLISH->JAPANESE ENGLISH->GERMAN ENGLISH->ITALIAN ENGLISH->SPANISH ALL
Average Scores from A/B Testing
Same SMT NMT

Evaluators SMT Adequacy SMT Fluency NMT Adequacy NMT Fluency
Evaluator 1 - IT 3.78 3.76 3.66 4.14
Evaluator 2 - IT 3.96 4.02 4.24 4.52
Evaluator 3 - ES 3.94 3.64 4.2 4.26
Evaluator 4 - ES 4.16 3.98 4.48 4.38
3.76 4.023.64 3.984.14
4.52 4.26 4.38
EVALUATOR 1 -IT
EVALUATOR 2 -IT
EVALUATOR 3 -ES
EVALUATOR 4 -ES
Fluency
SMT Fluency NMT Fluency
3.78 3.96 3.94 4.163.66
4.24 4.2 4.48
EVALUATOR 1 - IT
EVALUATOR 2 - IT
EVALUATOR 3 - ES
EVALUATOR 4 - ES
Adequacy
SMT Adequacy NMT Adequacy
Quality evaluation – Neural
Adequacy and Fluency – Ongoing test• 2 language pairs (ES and IT)• 50 segments (from the same test set)• 2 reviewers per language (in-house)
Fluency and Adequacy scores are higher for Neural

Quality evaluation – Neural
Productivity test– ongoing test• 2 language pairs (ES and IT)• 150 segments (from the same test set)• 2 reviewers per language
560 576 323 882985
3404
12691708
1367
3743
14271784
EVALUATOR 1 -IT
EVALUATOR 2 -IT
EVALUATOR 3 -ES
EVALUATOR 4 -ES
Translation Rate (words/hour) SMT PE Rate (words/hour)
NMT PE Rate (words/hour)
39% 10% 13% 4%
Average increase from SMT to NMT
17%
Average increase from translation to NMT
196%

Quality evaluation – Looking for the gap
What is the gap between SMT and NMT output?
Ongoing evaluations
Error classificationWhat types of errors can be found in the NMT segments that are more fluent than SMT? Is this language dependent?
ProductivityWhen SMT and NMT output are considered equal in quality, is there one more productive than the other? If so, by how much? Is this language dependent?
TerminologyWhat is NMT behaviour around terminology? Is there a pattern?
Which type of productivity increase can we expect in complex languages (DE. ZH, JP)?
Stay tuned, we will publish the results!

16
Thanks and let’s move to today’s challenge!
Laura Casanellas, KantanMT Product Management


















